

Dhad—A Children’s Handwritten Arabic Characters Dataset for Automated Recognition
 , ,
, ,
Abstract
1. Introduction
- Introduction of the new “Dhad” dataset to facilitate the training of deep learning models for children’s handwritten Arabic characters.
- Investigation of the potential of pre-trained powerful CNN models for children’s handwritten Arabic character classification.
- Examination of the performance of a simple CNN model trained from scratch for children’s handwritten Arabic character classification.
- Exploration of the classification performance on CNN-extracted features using conventional machine learning models including SVM and Random Forest (RF).
- Discussion of the practical use-case of the trained classification model, emphasizing the potential utility of children’s handwritten Arabic characters recognition.
2. Background to Deep Learning Models
2.1. ResNet50
2.2. MobileNet
2.3. DenseNet121
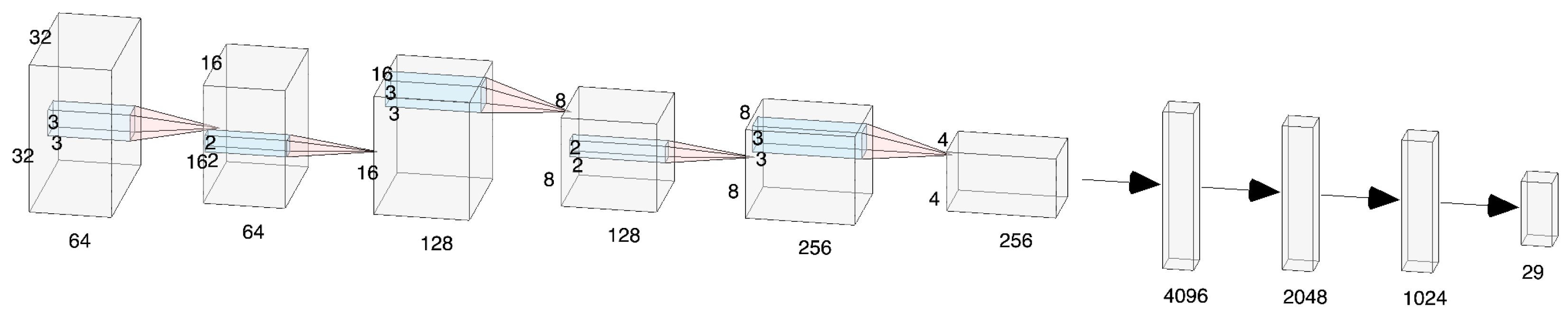
2.4. Custom CNN
3. Related Work
3.1. Children’s Handwriting Classification
3.2. Deep Learning-Based Classification of Children’s Arabic Handwriting
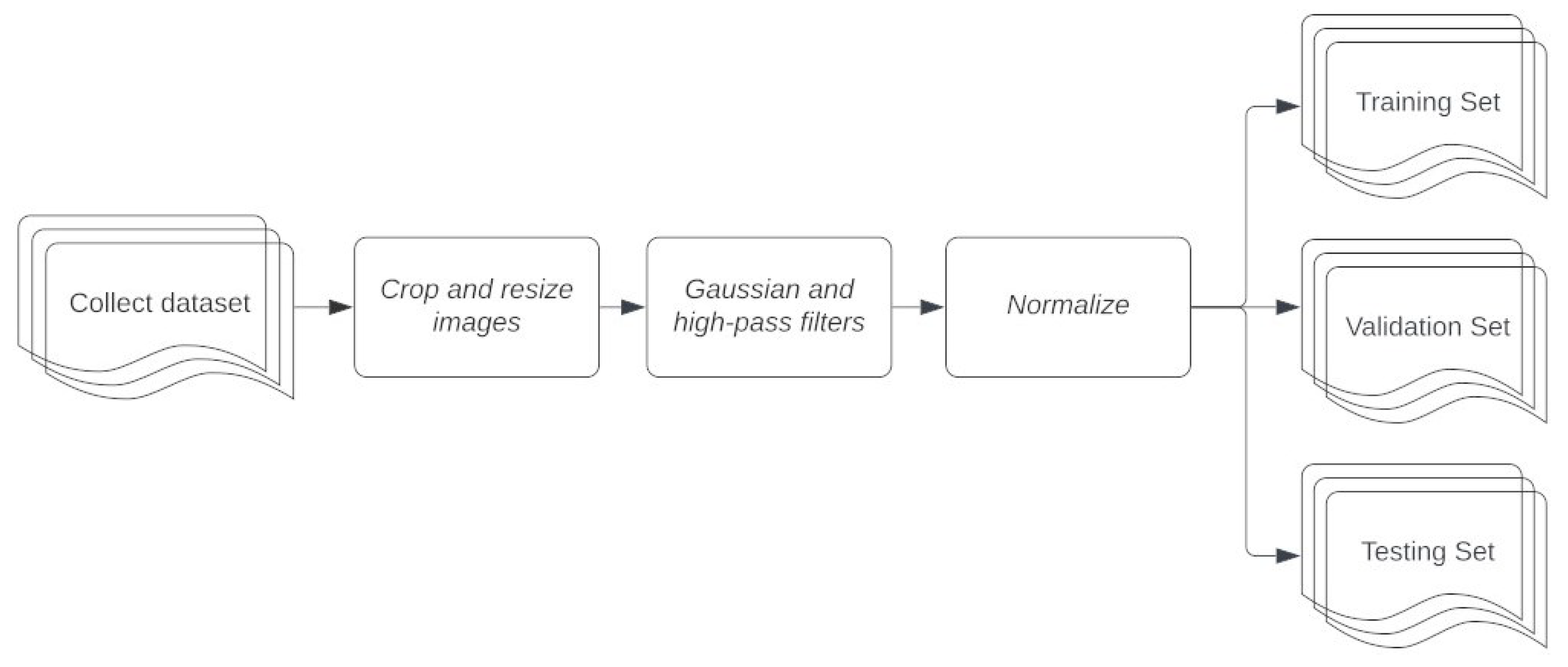
4. Dhad Dataset Formation
5. Experimental Design
- Experiment One—Pre-Trained Models: The first experiment was designed to explore the potential of existing pre-trained powerful CNN models in classifying children’s written Arabic characters. The literature suggests that well-established CNN models pre-trained with large image datasets like that of ImageNet perform superior in comparison to training from scratch. In this context, the ResNet50, MobileNet, and DenseNet121 models are implemented for both the Hijja and Dhad datasets.
- Experiment Two—Custom CNN Model: The second experiment was designed to investigate the performance of a simpler custom CNN model for this problem. The development of custom CNN models has already been reported in the literature; however, varied performances are reported each time. In this experiment, we developed a simple CNN model inspired from the literature and implemented it for both the Hijja and Dhad datasets.
- Experiment Three—Classification on Deep Visual Features: The third experiment was designed to study the performance of classical classification models including SVM, RF, and MLP trained on deep visual features extracted by a deep learning CNN model (i.e., MobileNet trained over ImageNet and MobileNet trained in Experiment One).
6. Experimental Protocols and Evaluation Measures
7. Results
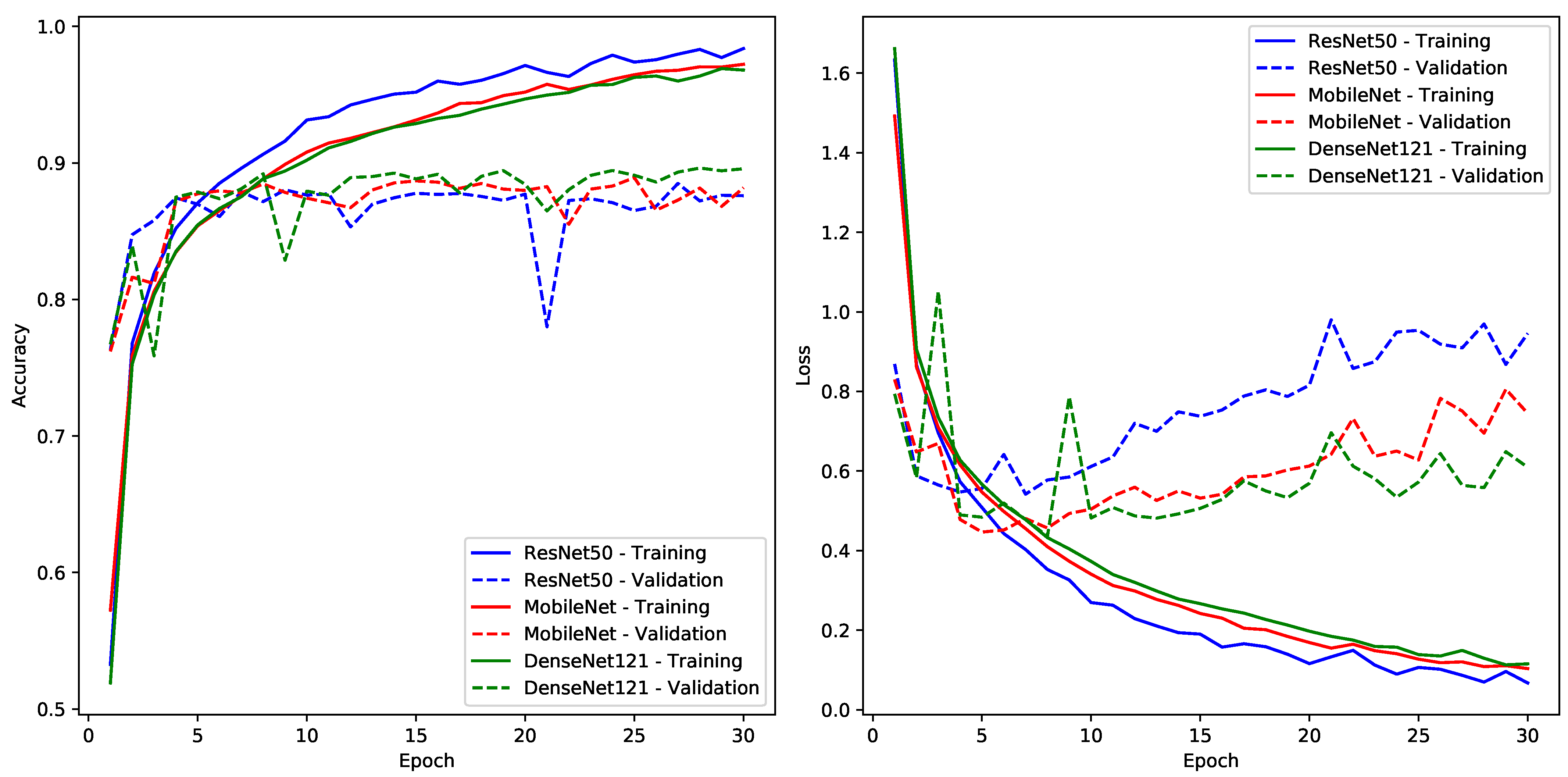
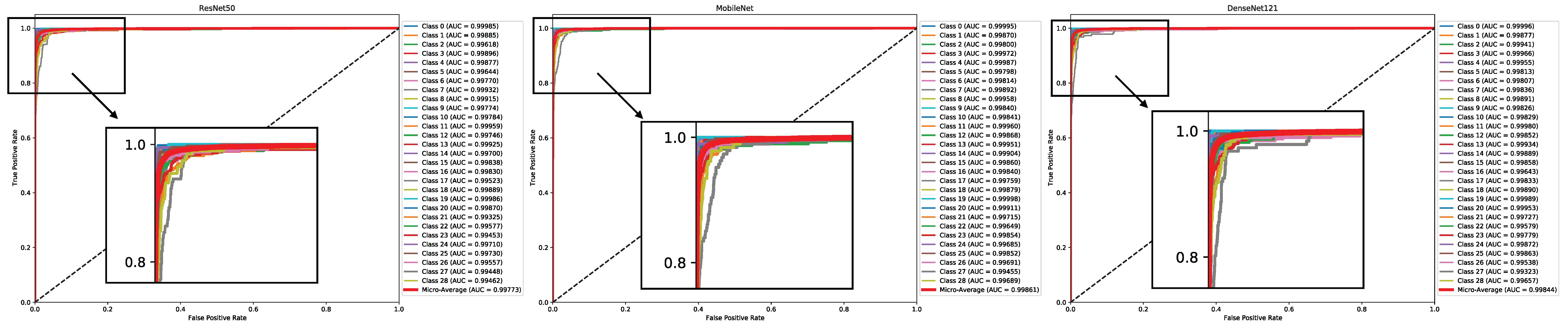
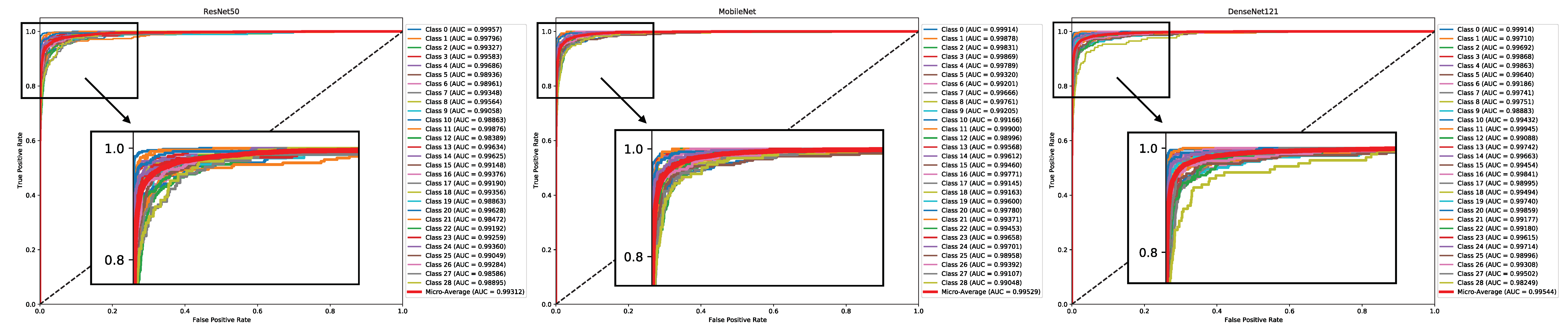
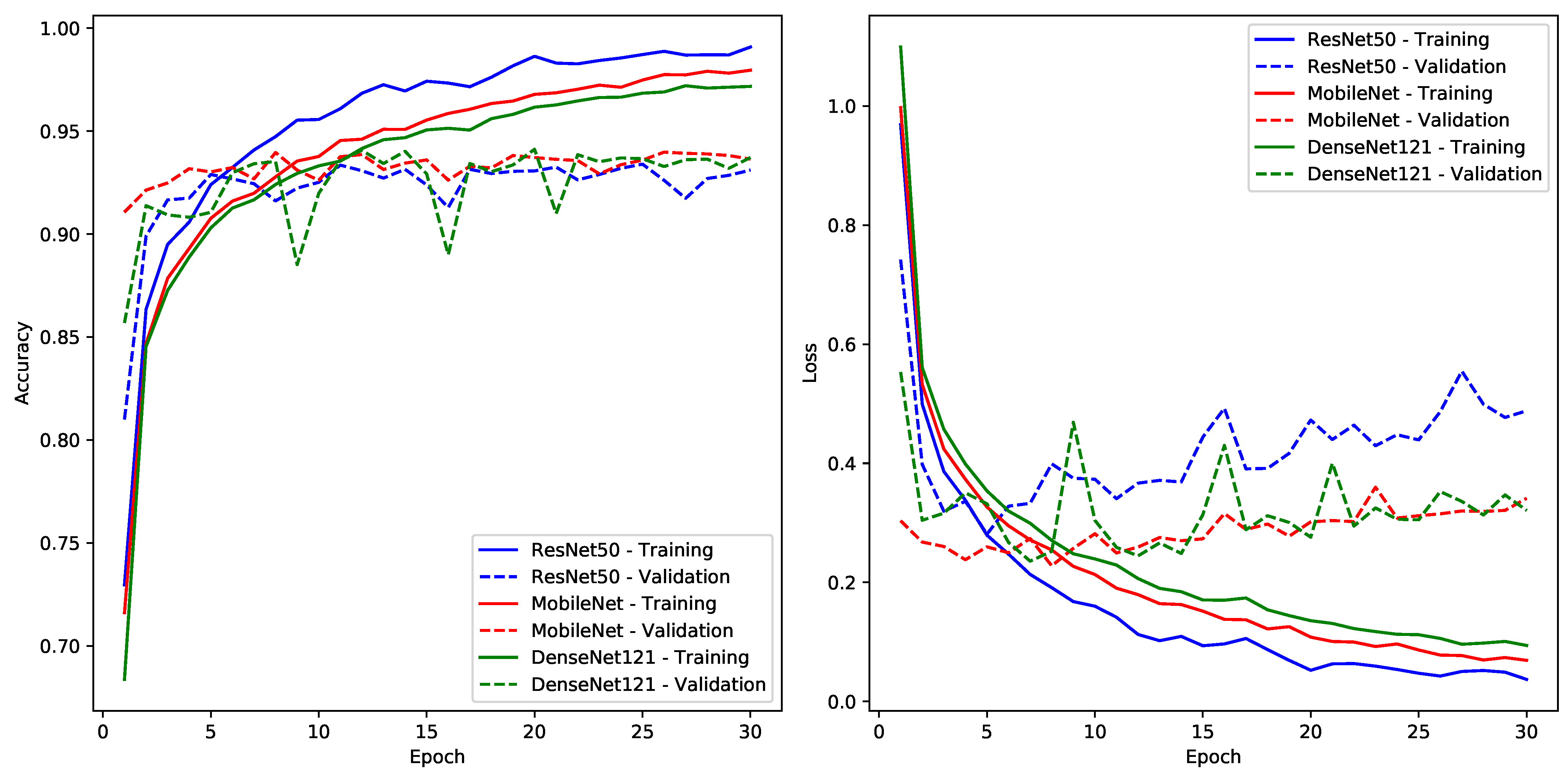
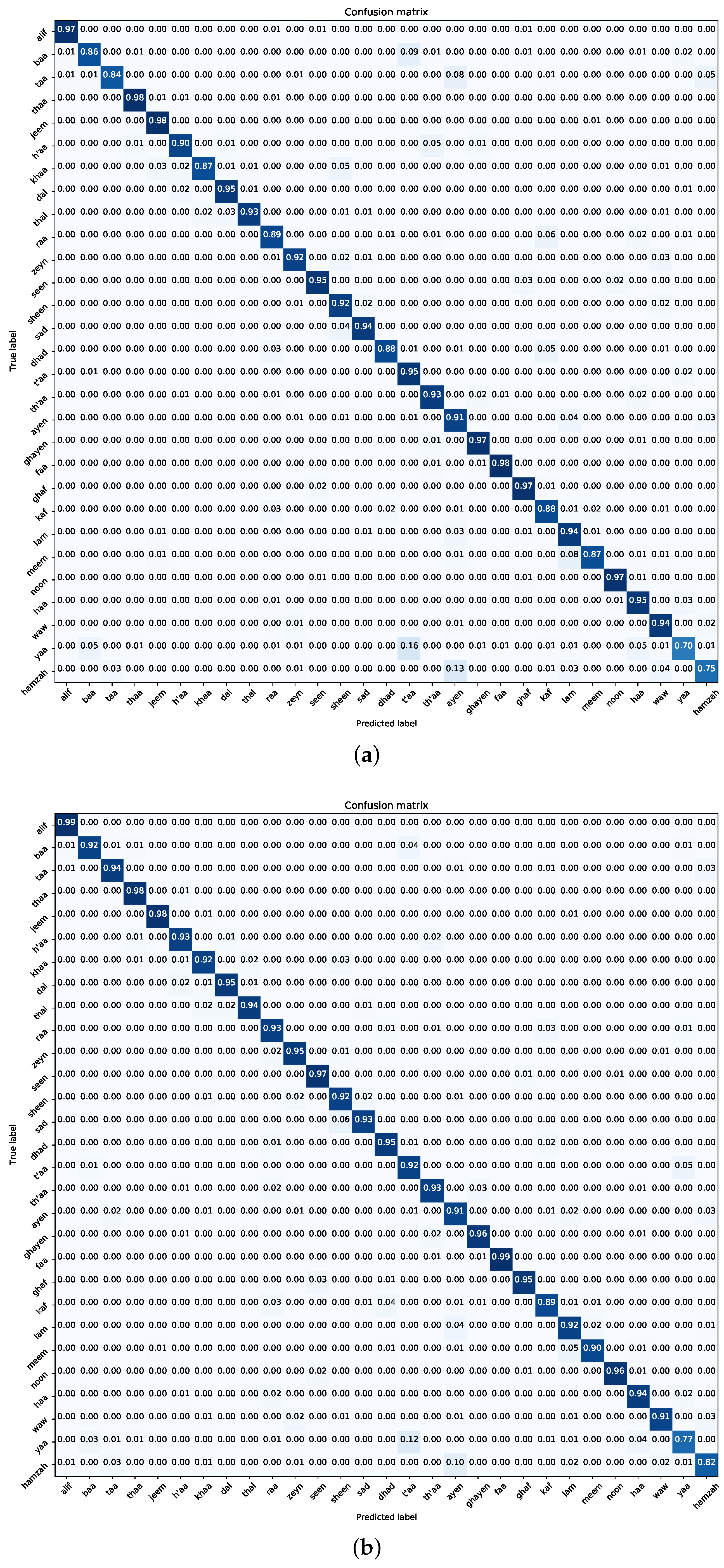
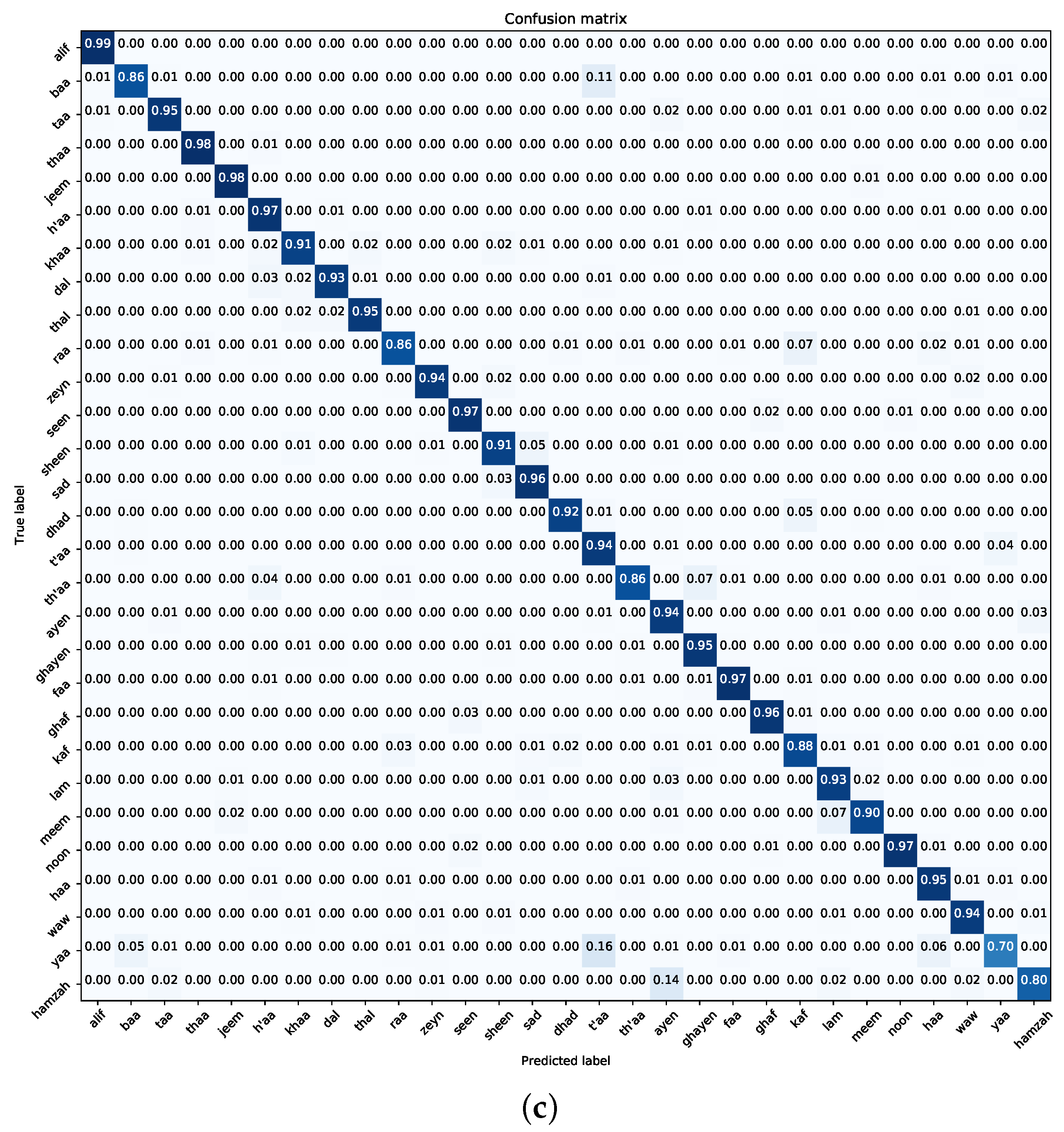
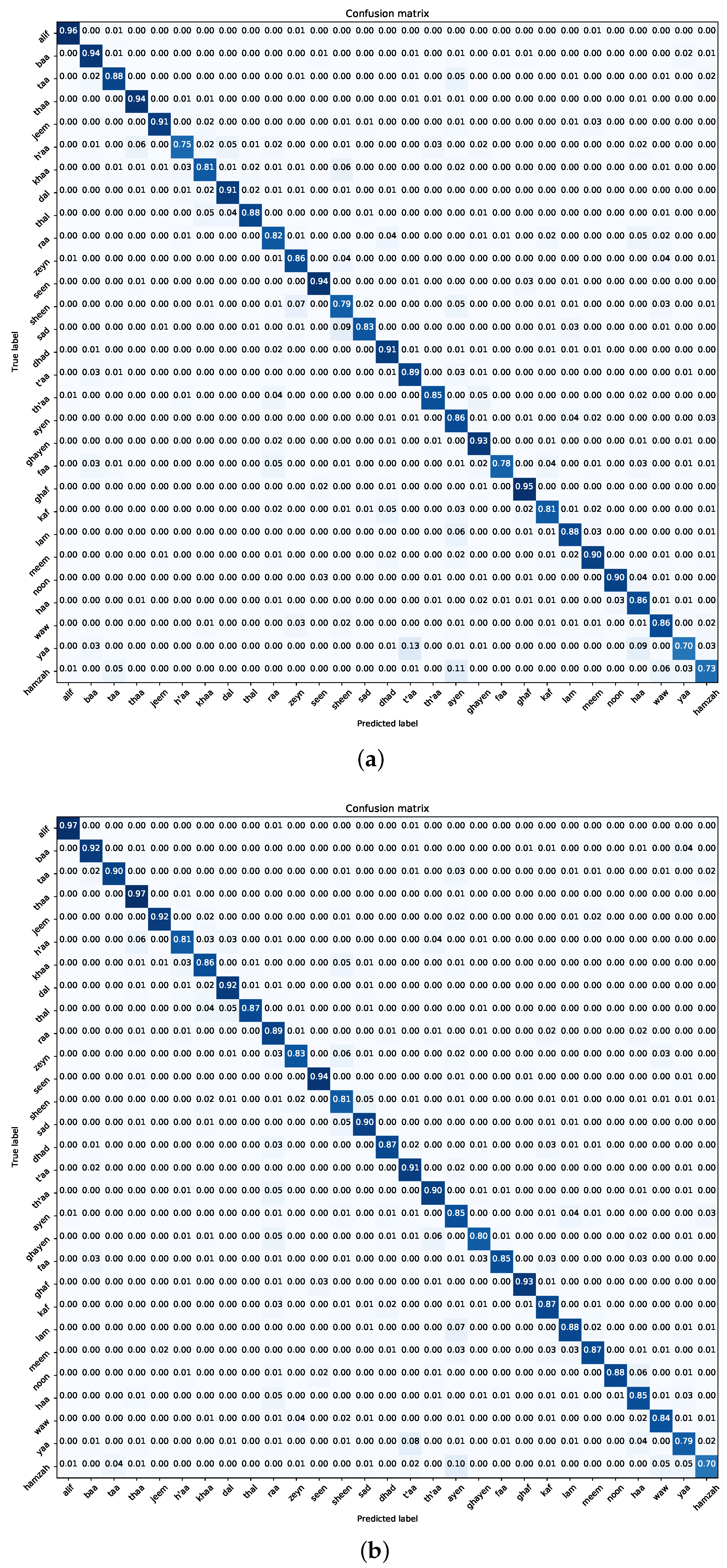
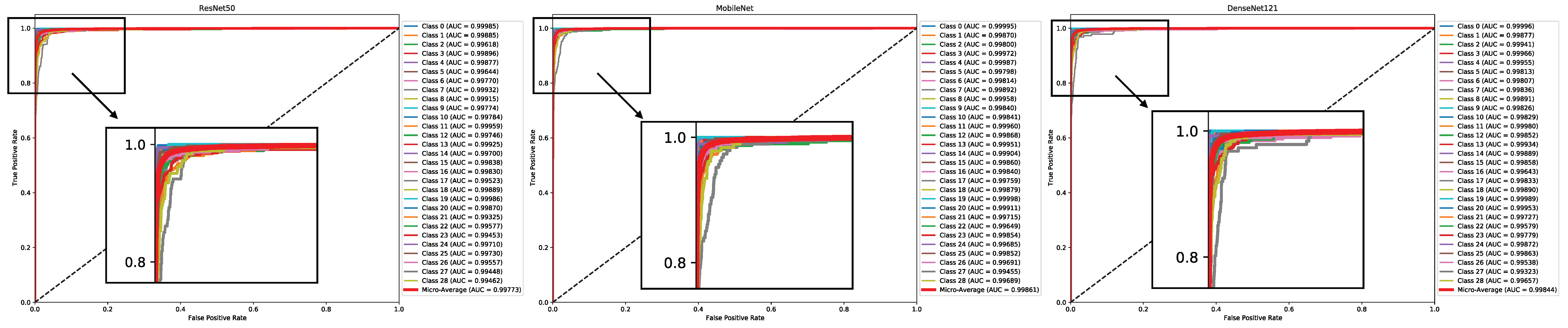
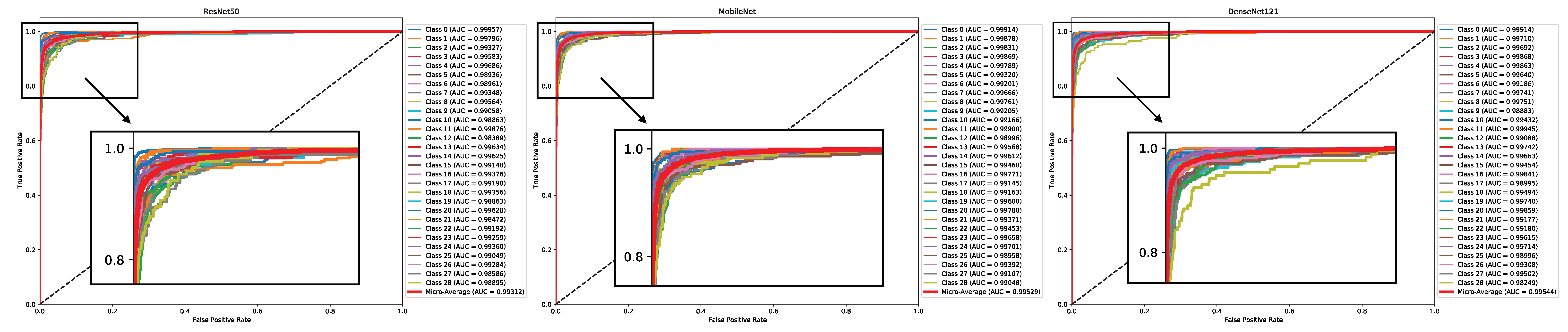
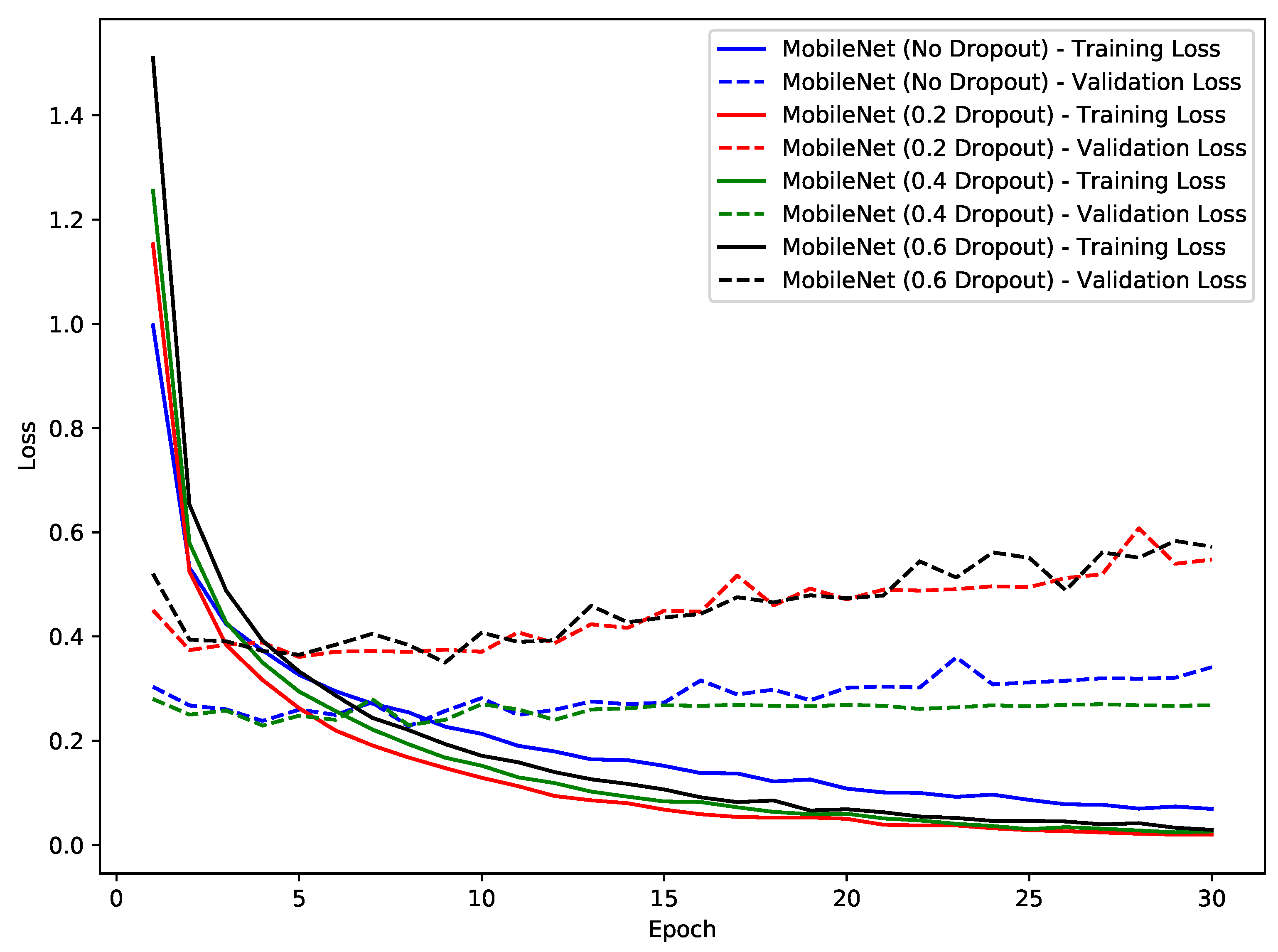
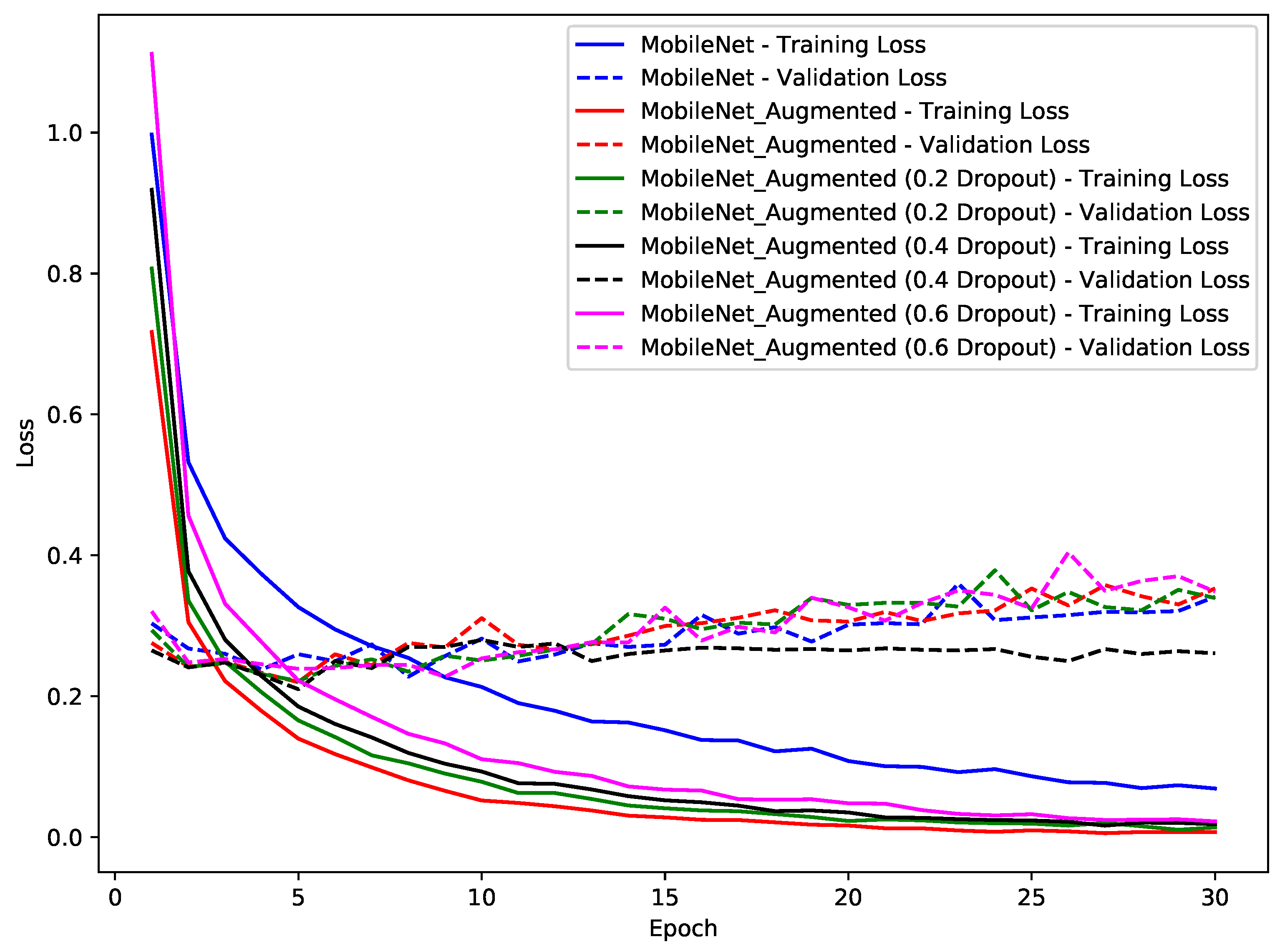
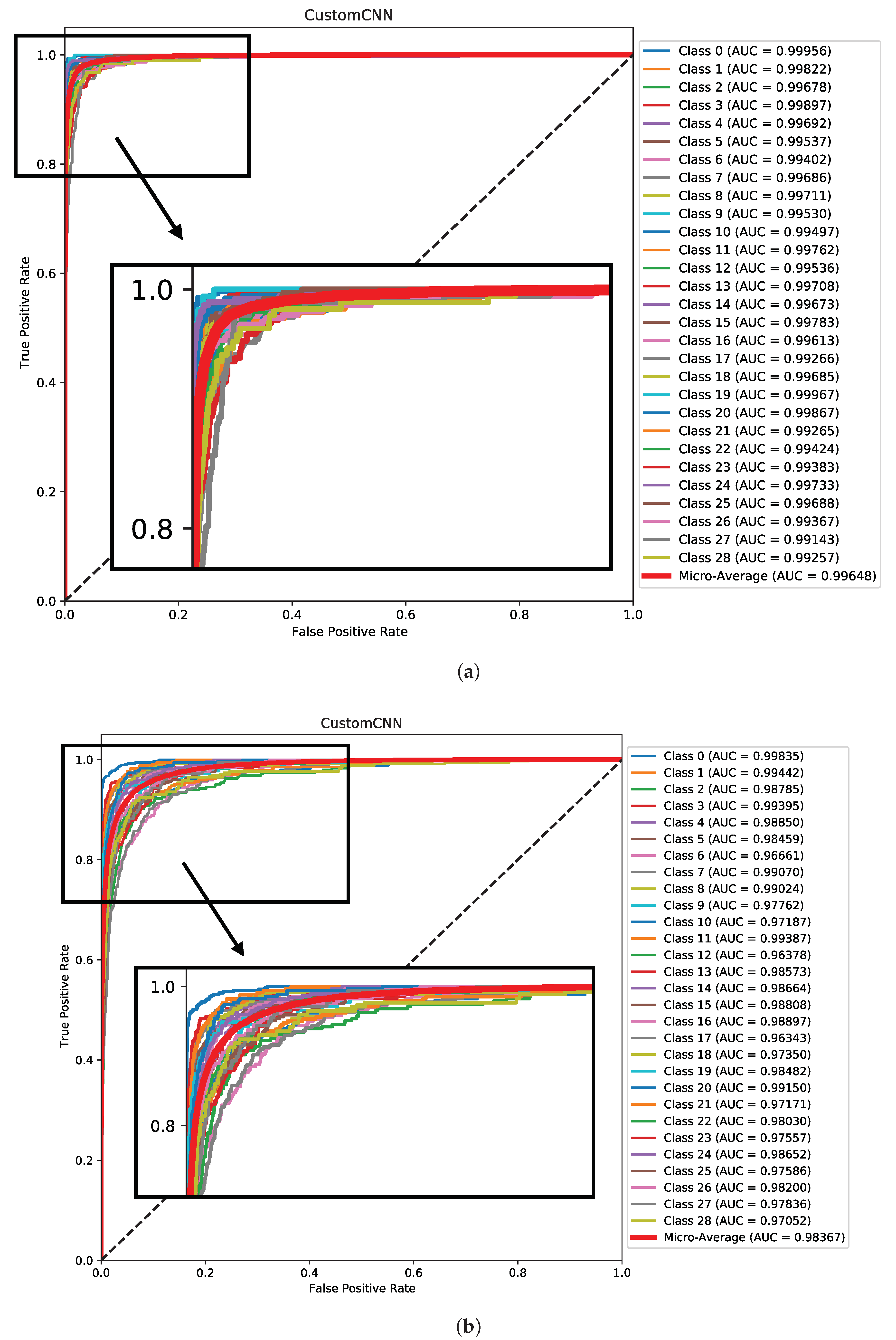
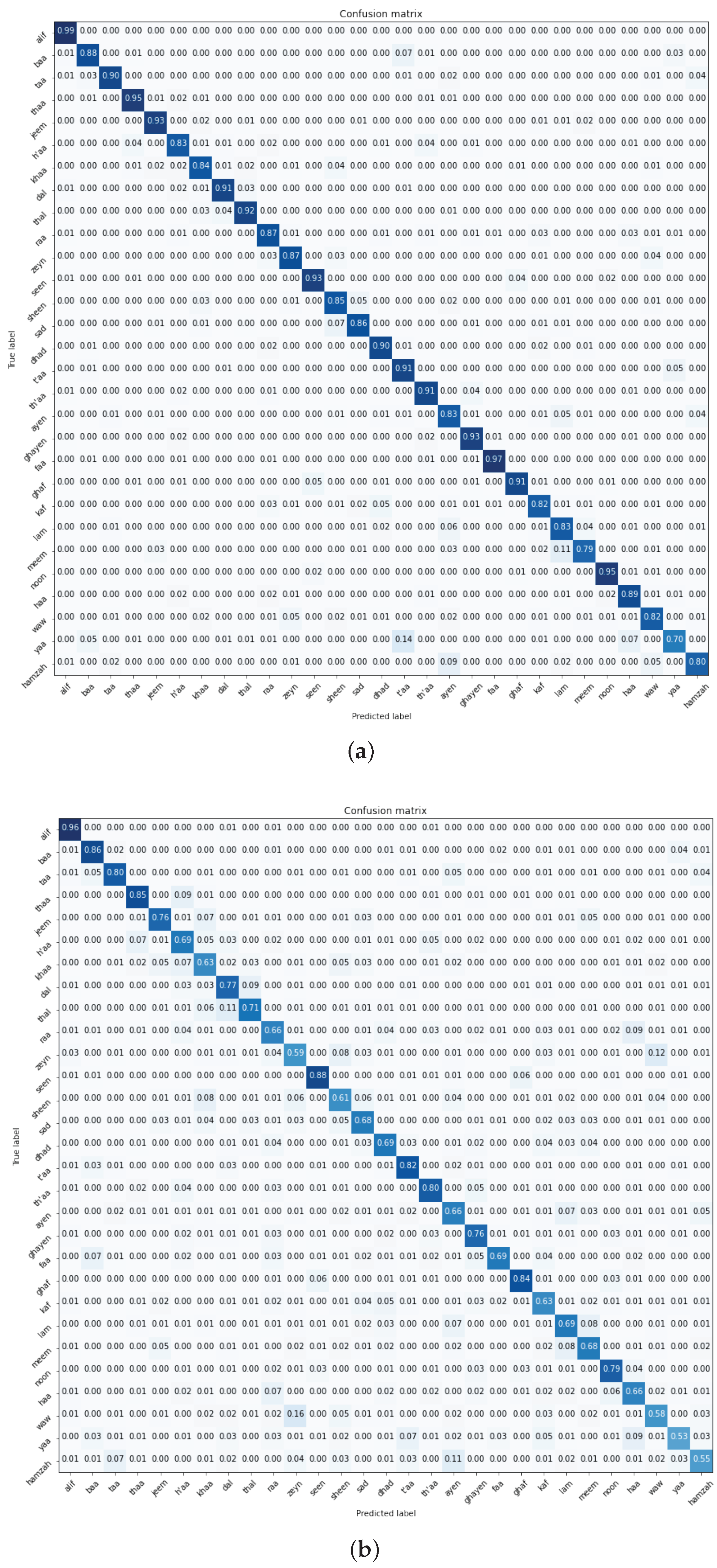
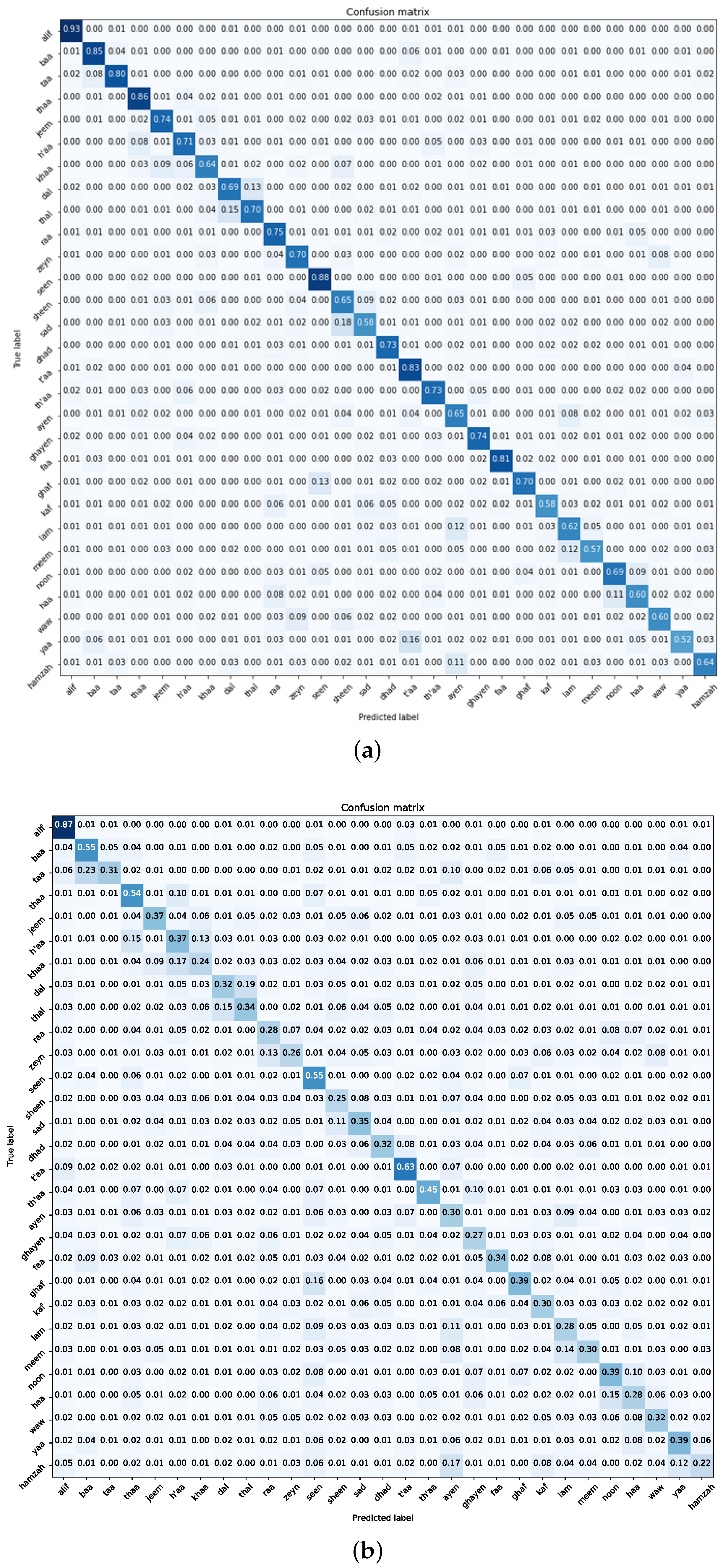
7.1. Experiment One—Pre-Trained CNN Models
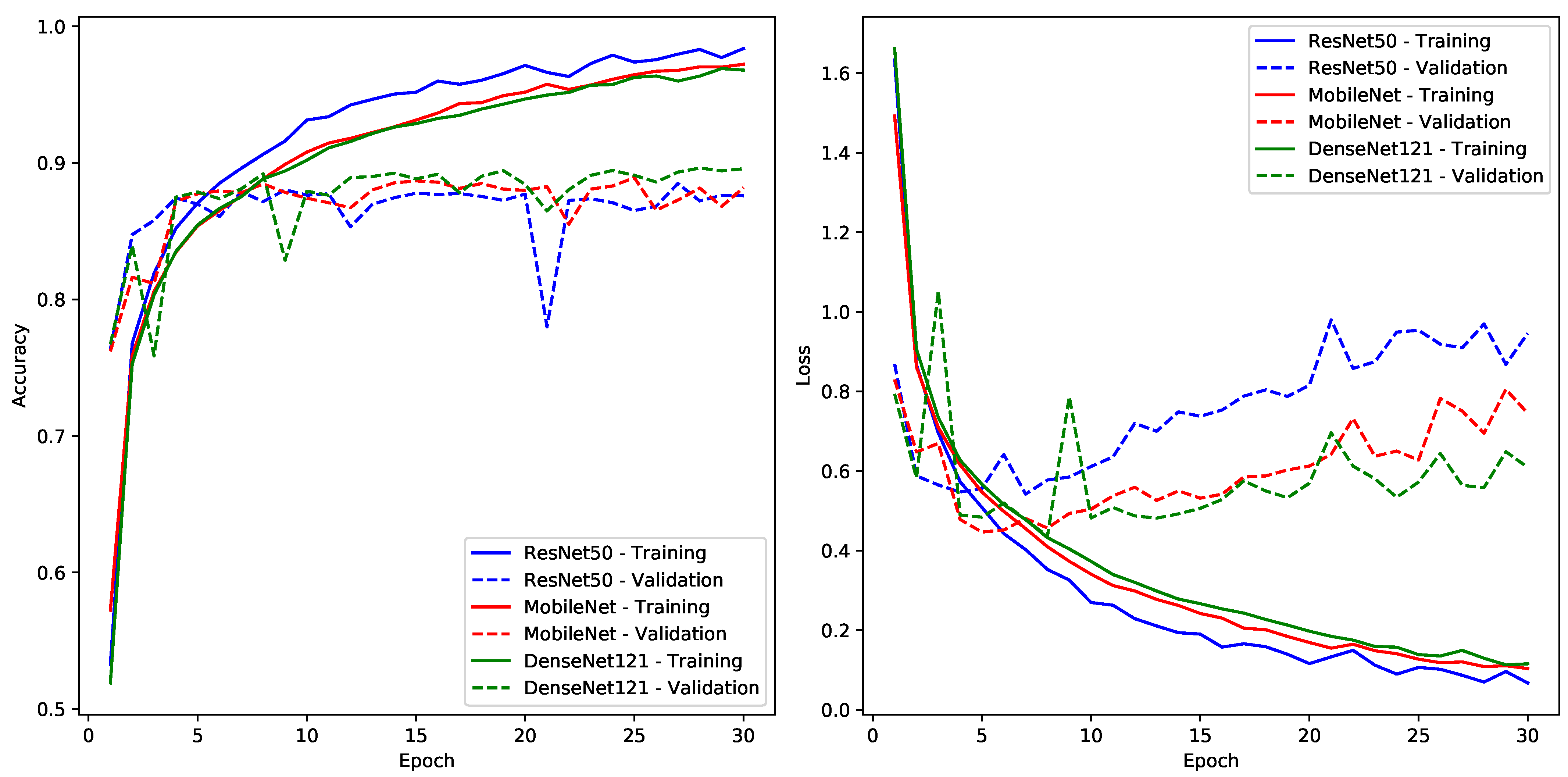
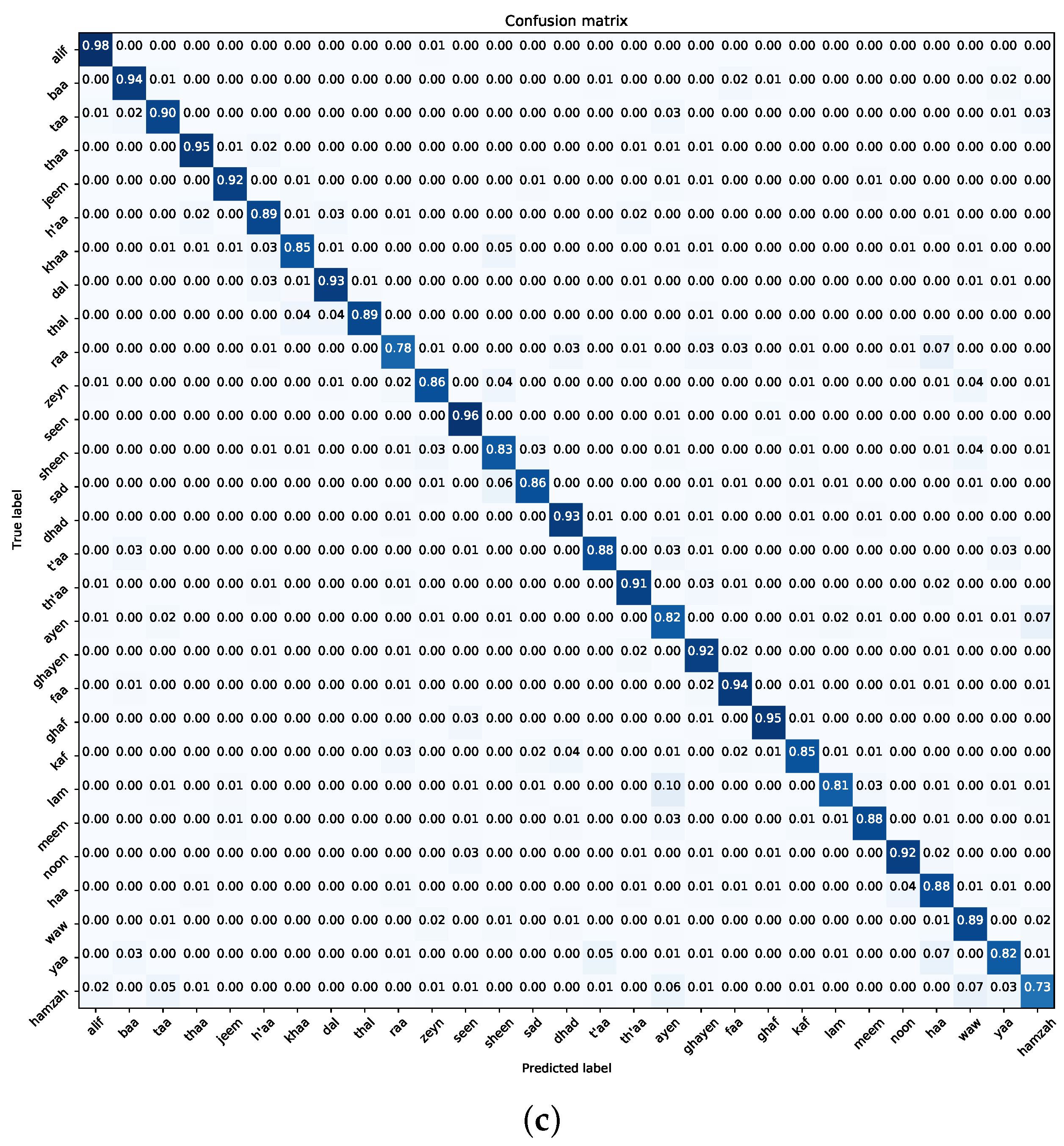
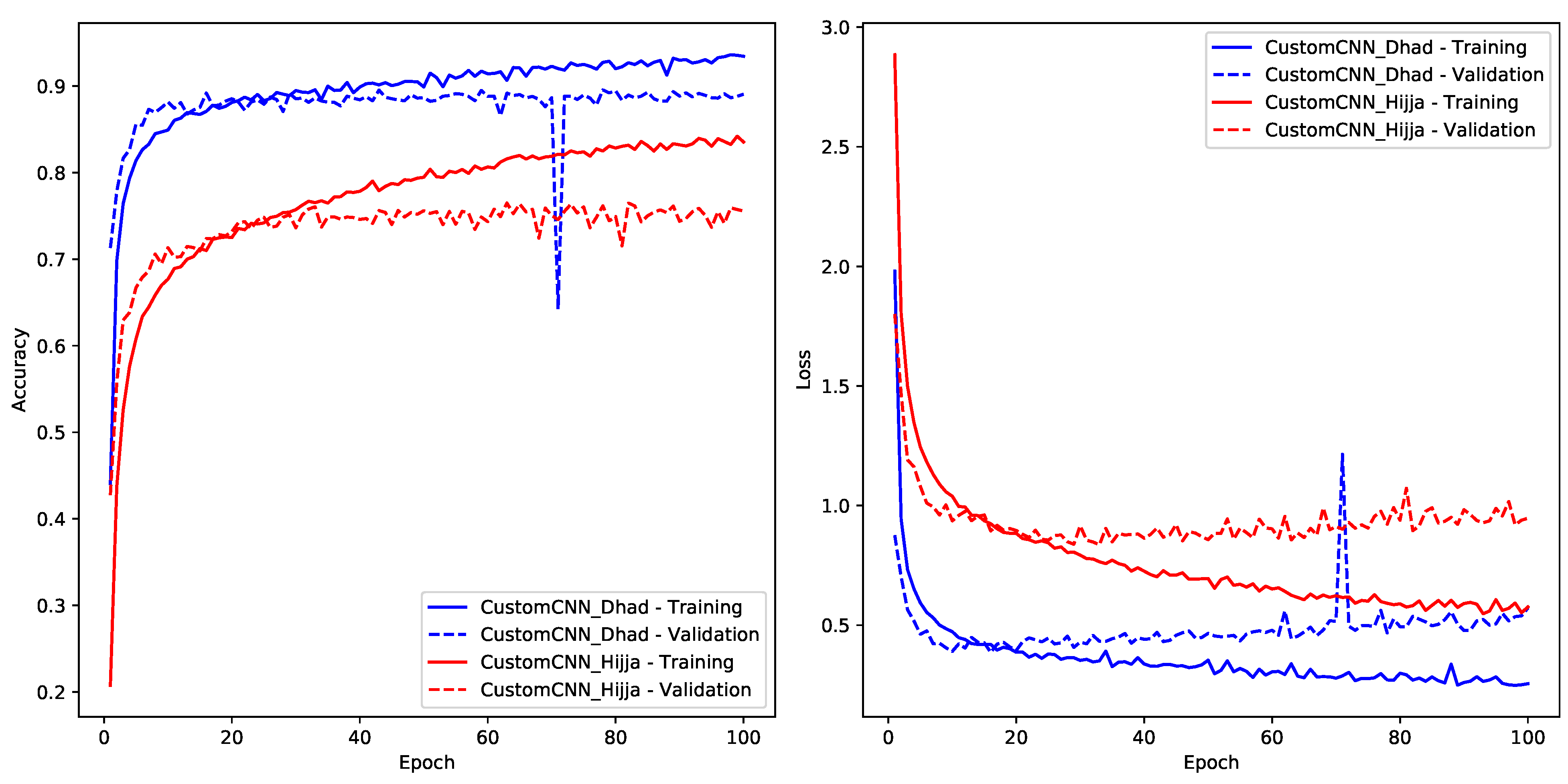
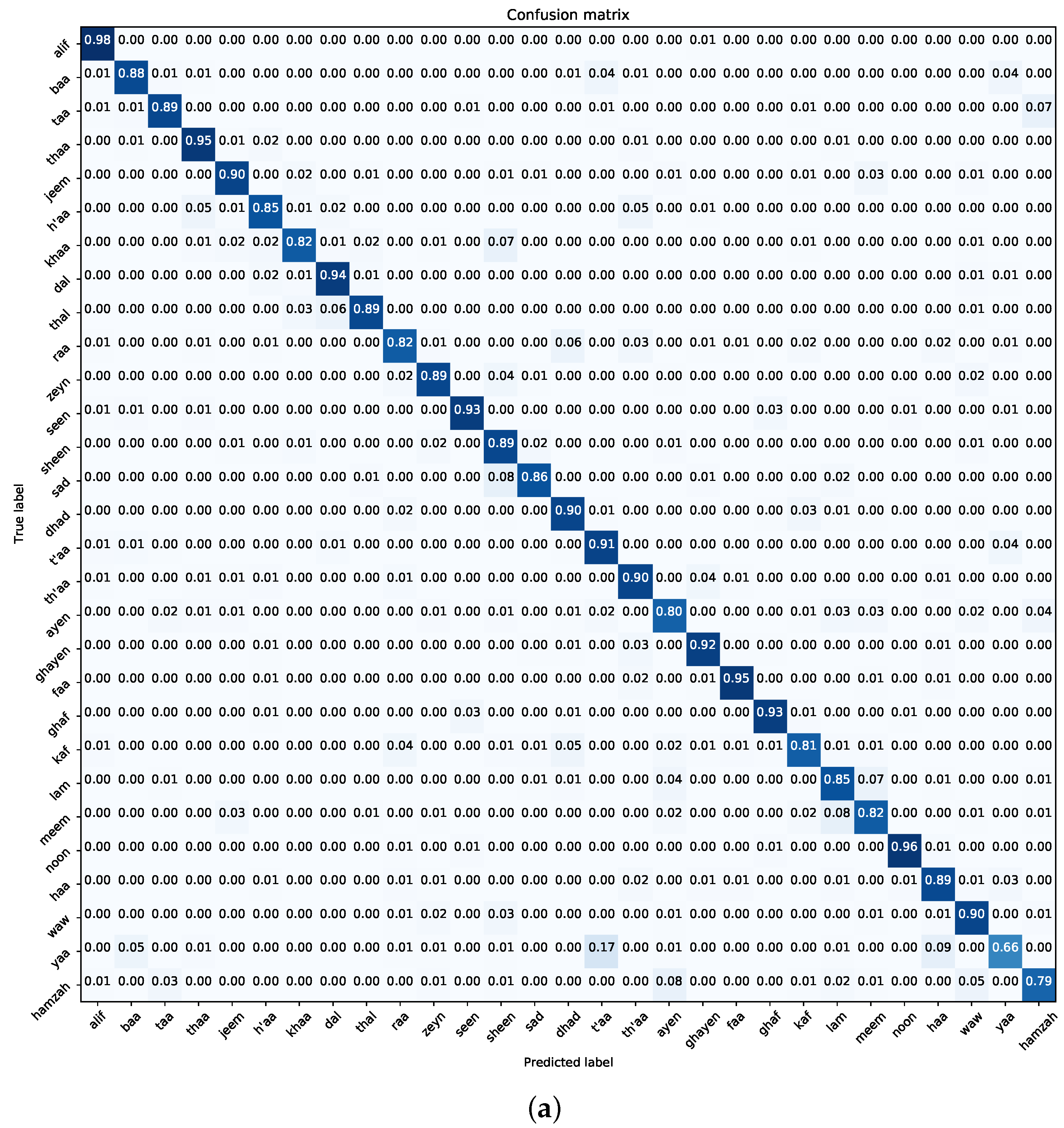
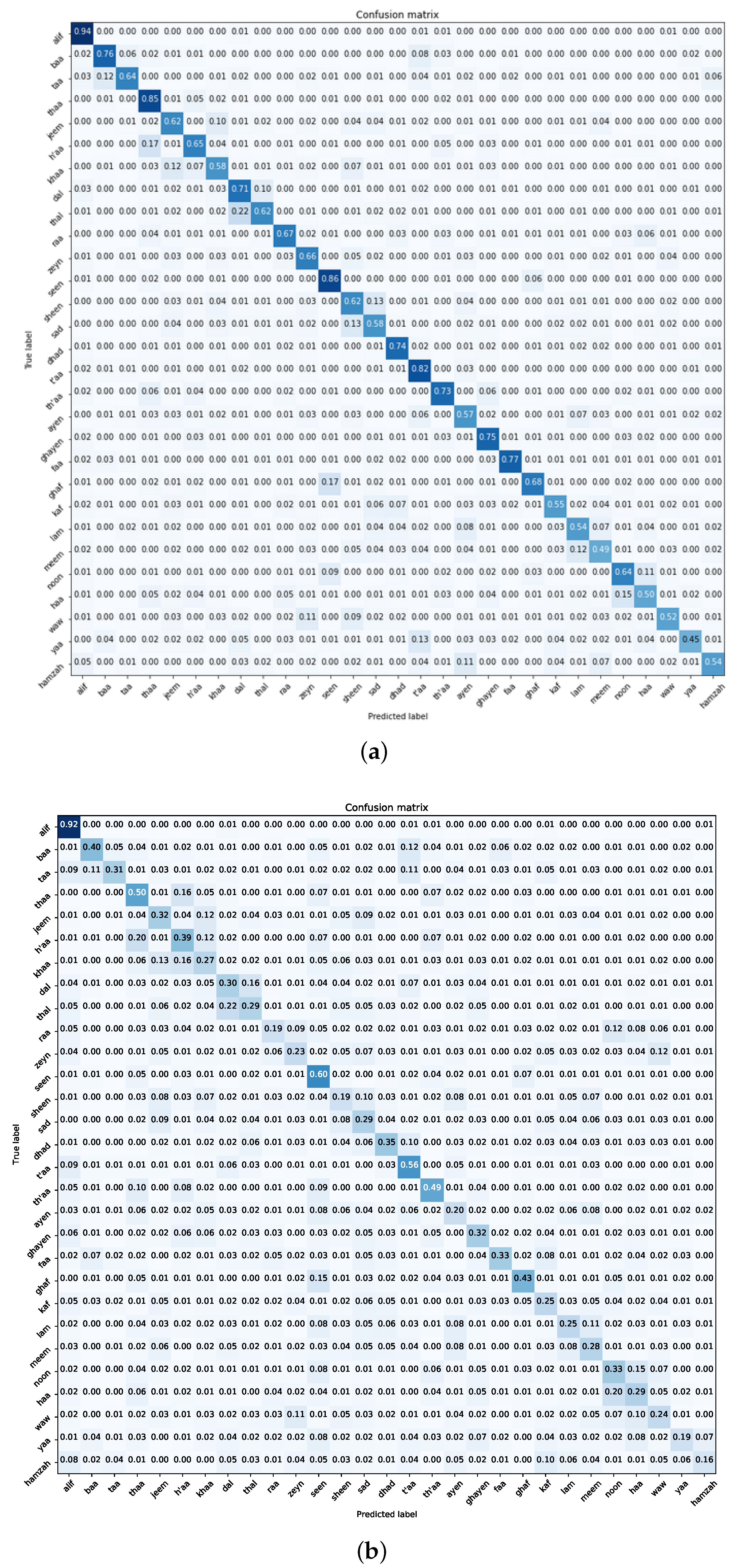
7.2. Experiment Two—Custom CNN Model
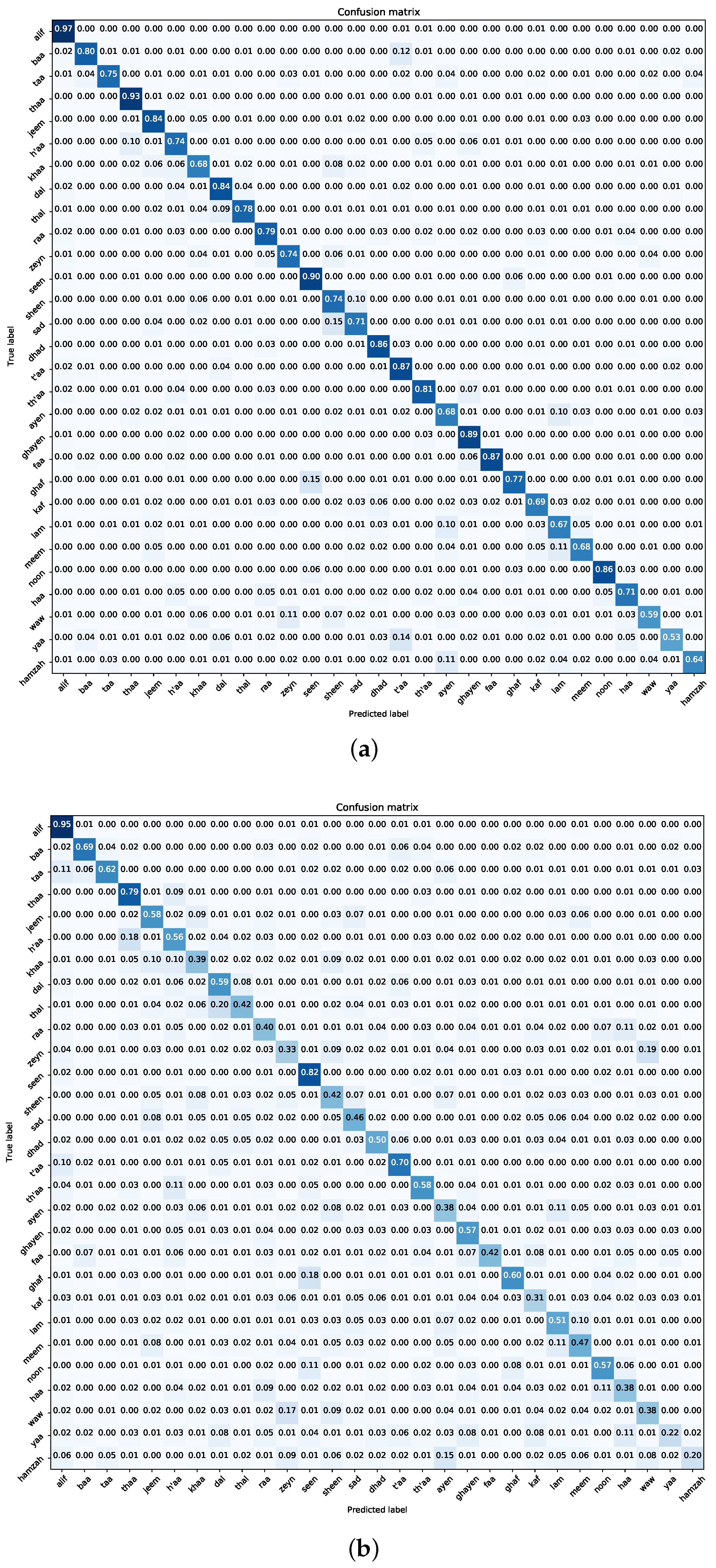
7.3. Experiment Three—Classification of Deep Visual Features
8. Discussion
- Fine-tuning of Existing Models: An important insight from the performed experiments is the unparalleled efficacy of fine-tuning existing deep learning architectures. This approach resonates with the existing literature [29,30,31], highlighting the potential of harnessing pre-trained models fine-tuned for application-specific tasks. The flexibility of fine-tuning, which combines using general features with adjusting to specific dataset details, highlights its essential importance. Especially in situations with limited computing power, its ability to achieve impressive results quickly becomes clearly noticeable.
- Custom CNN Model: In comparison to the established deep architectures, our simpler custom CNN achieved good results in classification. However, the performance did not exceed the fine-tuned pre-trained models. These findings align with what is commonly discussed in current research [32,33], emphasizing that simpler models can be easily affected by minor changes. This highlights the need for cautious interpretations and emphasizes the extra computing work needed when starting from scratch with new models.
- Two-stage Pipeline with Conventional Classifiers: Our exploration of a two-part process, combining deep visual feature extraction with traditional classification methods, resulted in less-than-ideal results. These results are consistent with existing research, highlighting the importance of end-to-end deep learning models trained effectively at once. The shortcomings arising from separate feature extraction and classification emphasize the need for unified model training, bringing together all elements to better achieve the main goal.
- Dataset Dynamics: At the heart of the model’s performance variations lies the quality of the dataset. Our studies highlight the superiority of the Dhad dataset when compared to the Hijja one, likely due to clearer pixels and reduced interference. These insights highlight the crucial importance of careful dataset preparation, underscoring its fundamental role in shaping the best possible model results.
- Navigating Class Confounders: A recurring pattern throughout our experimental journey centres on the differentiation between certain class pairs, particularly “t’aa–yaa” and “ayen–hamzah”. The blending of visual similarities among these classes leads to frequent misclassifications, highlighting the need for future efforts to develop more detailed training samples. Tackling this challenge requires a focused effort to enhance the dataset with diverse class examples, enhancing the model’s ability to accurately distinguish categories.
- Enhanced dataset curation, incorporating diverse writing styles, variations, and real-world noise simulations.
- Comparative evaluations encompassing a broader spectrum of architectures, optimization techniques, and data augmentation strategies.
- Exploration of ensemble methodologies, blending the strengths of multiple models to foster enhanced recognition capabilities.
9. Al-Khatta—An Early Intervention Tool for Arabic Handwriting Improvement
10. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eberhard, D.M.; Simons, G.F.; Fennig, C.D. Ethnologue: Languages of the World; SIL International: Dallas, TX, USA, 2023. [Google Scholar]
- Nahar, K.M.; Alsmadi, I.; Al Mamlook, R.E.; Nasayreh, A.; Gharaibeh, H.; Almuflih, A.S.; Alasim, F. Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques. Sensors 2023, 23, 9475. [Google Scholar] [CrossRef]
- Kasem, M.S.; Mahmoud, M.; Kang, H.S. Advancements and Challenges in Arabic Optical Character Recognition: A Comprehensive Survey. arXiv 2023, arXiv:2312.11812. [Google Scholar]
- Altwaijry, N.; Al-Turaiki, I. Arabic handwriting recognition system using convolutional neural network. Neural Comput. Appl. 2021, 33, 2249–2261. [Google Scholar] [CrossRef]
- Alwagdani, M.S.; Jaha, E.S. Deep Learning-Based Child Handwritten Arabic Character Recognition and Handwriting Discrimination. Sensors 2023, 23, 6774. [Google Scholar] [CrossRef]
- Zakraoui, J.; Saleh, M.; Al-Maadeed, S.; AlJa’am, J.M. A study of children emotion and their performance while handwriting Arabic characters using a haptic device. Educ. Inf. Technol. 2023, 28, 1783–1808. [Google Scholar] [CrossRef]
- El-Sawy, A.; Loey, M.; El-Bakry, H. Arabic handwritten characters recognition using convolutional neural network. WSEAS Trans. Comput. Res. 2017, 5, 11–19. [Google Scholar]
- Lamghari, N.; Raghay, S. Recognition of Arabic Handwritten Diacritics using the new database DBAHD. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1743, p. 012023. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Fukushima, K.; Miyake, S. Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Visual Pattern Recognition. In Competition and Cooperation in Neural Nets; Amari, S.I., Arbib, M.A., Eds.; Springer: Berlin/Heidelberg, Germany, 1982; pp. 267–285. [Google Scholar]
- Al-Turaiki, I.; Altwaijry, N. Hijja Dataset. 2019. Available online: https://github.com/israksu/Hijja2 (accessed on 10 January 2024).
- Alkhateeb, J.H. An effective deep learning approach for improving off-line arabic handwritten character recognition. Int. J. Softw. Eng. Comput. Syst. 2020, 6, 53–61. [Google Scholar]
- Nayef, B.H.; Abdullah, S.N.H.S.; Sulaiman, R.; Alyasseri, Z.A.A. Optimized leaky ReLU for handwritten Arabic character recognition using convolution neural networks. Multimed. Tools Appl. 2022, 81, 2065–2094. [Google Scholar] [CrossRef]
- Alheraki, M.; Al-Matham, R.; Al-Khalifa, H. Handwritten Arabic Character Recognition for Children Writing Using Convolutional Neural Network and Stroke Identification. Hum.-Centric Intell. Syst. 2023, 3, 147–159. [Google Scholar] [CrossRef]
- Bin Durayhim, A.; Al-Ajlan, A.; Al-Turaiki, I.; Altwaijry, N. Towards Accurate Children’s Arabic Handwriting Recognition via Deep Learning. Appl. Sci. 2023, 13, 1692. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Santosh, K.; Nattee, C. Template-based Nepali natural handwritten alphanumeric character recognition. Sci. Technol. Asia 2007, 12, 20–30. [Google Scholar]
- Moetesum, M.; Diaz, M.; Masroor, U.; Siddiqi, I.; Vessio, G. A survey of visual and procedural handwriting analysis for neuropsychological assessment. Neural Comput. Appl. 2022, 34, 9561–9578. [Google Scholar] [CrossRef]
- Das, N.; Reddy, J.M.; Sarkar, R.; Basu, S.; Kundu, M.; Nasipuri, M.; Basu, D.K. A statistical–topological feature combination for recognition of handwritten numerals. Appl. Soft Comput. 2012, 12, 2486–2495. [Google Scholar] [CrossRef]
- Sharma, A.K.; Thakkar, P.; Adhyaru, D.M.; Zaveri, T.H. Handwritten Gujarati character recognition using structural decomposition technique. Pattern Recognit. Image Anal. 2019, 29, 325–338. [Google Scholar] [CrossRef]
- Mukherji, P.; Rege, P.P. Shape feature and fuzzy logic based offline devnagari handwritten optical character recognition. J. Pattern Recognit. Res. 2009, 4, 52–68. [Google Scholar] [CrossRef] [PubMed]
- Itseez. Open Source Computer Vision Library. 2015. Available online: https://github.com/itseez/opencv (accessed on 15 January 2024).
- Abadi, M.; Agarwal, A.; Barham, P. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: http://tensorflow.org/ (accessed on 7 March 2024).
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 15 February 2024).
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar] [CrossRef]
- LaValle, S.M.; Branicky, M.S.; Lindemann, S.R. On the relationship between classical grid search and probabilistic roadmaps. Int. J. Robot. Res. 2004, 23, 673–692. [Google Scholar] [CrossRef]
- Iqbal, U.; Barthelemy, J.; Li, W.; Perez, P. Automating visual blockage classification of culverts with deep learning. Appl. Sci. 2021, 11, 7561. [Google Scholar] [CrossRef]
- Iqbal, U.; Barthelemy, J.; Perez, P.; Davies, T. Edge-computing video analytics solution for automated plastic-bag contamination detection: A case from remondis. Sensors 2022, 22, 7821. [Google Scholar] [CrossRef]
- Barthélemy, J.; Verstaevel, N.; Forehead, H.; Perez, P. Edge-computing video analytics for real-time traffic monitoring in a smart city. Sensors 2019, 19, 2048. [Google Scholar] [CrossRef] [PubMed]
- Riaz, M.Z.B.; Iqbal, U.; Yang, S.Q.; Sivakumar, M.; Enever, K.; Khalil, U.; Ji, R.; Miguntanna, N.S. SedimentNet—A 1D-CNN machine learning model for prediction of hydrodynamic forces in rapidly varied flows. Neural Comput. Appl. 2023, 35, 9145–9166. [Google Scholar] [CrossRef]
- Iqbal, U.; Barthelemy, J.; Perez, P. Prediction of hydraulic blockage at culverts from a single image using deep learning. Neural Comput. Appl. 2022, 34, 21101–21117. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Class | Form | Count | No. | Class | Form | Count |
|---|---|---|---|---|---|---|---|
| 1 | ¸alif | ا، أ، إ، ـأ، ـإ | 2869 | 16 | ṭā¸ | ط، طـ ، ـطـ ، ـط | 1925 |
| 2 | bā¸ | ب، بـ ، ـبـ ، ـب | 1899 | 17 | ẓā¸ | ظ، ظـ ، ـظـ ، ـظ | 1886 |
| 3 | tā¸ | ت، تـ ، ـتـ ، ـت | 1920 | 18 | ҅ayn | ع، عـ ، ـعـ ، ـع | 1906 |
| 4 | ṯā¸ | ث، ثـ ، ـثـ ، ـث | 1734 | 19 | ġayn | غ، غـ ، ـغـ ، ـغ | 2012 |
| 5 | ğīm | ج، جـ ، ـجـ ، ـج | 1891 | 20 | fā¸ | ف، فـ ، ـفـ ، ـف | 2024 |
| 6 | ḥā¸ | ح، حـ ، ـحـ ، ـح | 1921 | 21 | qāf | ق، قـ ، ـقـ ، ـق | 2030 |
| 7 | khā¸ | خ، خـ ، ـخـ ، ـخ | 1869 | 22 | kāf | ك، كـ ، ـكـ ، ـك | 2019 |
| 8 | dāl | د، ـد | 931 | 23 | lām | ل، لـ ، ـلـ ، ـل | 2011 |
| 9 | āl | ذ، ـذ | 915 | 24 | mīm | م، مـ ، ـمـ ، ـم | 1955 |
| 10 | rā¸ | ر، ـر | 898 | 25 | nūn | ن، نـ ، ـنـ ، ـن | 1913 |
| 11 | zāy | ز، ـز | 944 | 26 | hā¸ | ه، هـ ، ـهـ ، ـه | 2180 |
| 12 | sīn | س، سـ ، ـسـ ، ـس | 1845 | 27 | wāw | و، ـو | 872 |
| 13 | īn | ش، شـ ، ـشـ ، ـش | 1876 | 28 | yā¸ | ي، يـ ، ـيـ ، ي | 1903 |
| 14 | ṣād | ص، صـ ، ـصـ ، ـص | 1709 | 29 | hamzah | ء، ؤ، ئ، ـئ | 1846 |
| 15 | ḍād | ض، ضـ ، ـضـ ، ـض | 1852 | ||||
| Total | 51,555 | ||||||
| Training Loss | Training Accuracy | Validation Loss | Validation Accuracy | |
|---|---|---|---|---|
| Dhad Dataset | ||||
| MobileNet | 0.0691 | 0.9796 | 0.2278 | 0.9396 |
| DenseNet121 | 0.0941 | 0.9717 | 0.2357 | 0.9342 |
| ResNet50 | 0.0371 | 0.9908 | 0.2810 | 0.9289 |
| Hijja Dataset | ||||
| MobileNet | 0.1035 | 0.9722 | 0.4466 | 0.8774 |
| DenseNet121 | 0.1154 | 0.9680 | 0.4359 | 0.8920 |
| ResNet50 | 0.0674 | 0.9838 | 0.5419 | 0.8789 |
| Test Accuracy | Test Loss | Score | Precision | Recall | J-Index | |
|---|---|---|---|---|---|---|
| Dhad Dataset | ||||||
| MobileNet | 0.9359 | 0.2468 | 0.94 | 0.94 | 0.94 | 0.88 |
| DenseNet121 | 0.9306 | 0.2510 | 0.93 | 0.93 | 0.93 | 0.87 |
| ResNet50 | 0.9228 | 0.3043 | 0.92 | 0.92 | 0.92 | 0.86 |
| Hijja Dataset | ||||||
| MobileNet | 0.8781 | 0.4677 | 0.88 | 0.88 | 0.88 | 0.78 |
| DenseNet121 | 0.8883 | 0.4619 | 0.89 | 0.89 | 0.89 | 0.80 |
| ResNet50 | 0.8705 | 0.6026 | 0.87 | 0.87 | 0.87 | 0.77 |
| Training Loss | Training Accuracy | Validation Loss | Validation Accuracy | |
|---|---|---|---|---|
| Dhad Dataset | 0.2554 | 0.9344 | 0.3862 | 0.8919 |
| Hijja Dataset | 0.5761 | 0.8354 | 0.8382 | 0.7515 |
| Test Accuracy | Test Loss | Score | Precision | Recall | J-Index | |
|---|---|---|---|---|---|---|
| Dhad Dataset | 0.8854 | 0.3988 | 0.89 | 0.89 | 0.89 | 0.79 |
| Hijja Dataset | 0.7484 | 0.8693 | 0.75 | 0.75 | 0.75 | 0.6 |
| Validation Accuracy | Test Accuracy | Score | Precision | Recall | J-Index | |
|---|---|---|---|---|---|---|
| Dhad Dataset | ||||||
| MobileNet (ImageNet Pre-Trained) + SVM | 0.8894 | 0.8848 | 0.88 | 0.88 | 0.88 | 0.79 |
| MobileNet (ImageNet Pre-Trained) + RF | 0.7775 | 0.7803 | 0.78 | 0.78 | 0.78 | 0.64 |
| MobileNet (ImageNet Pre-Trained) + MLP | 0.0801 | 0.0810 | 0.02 | 0.02 | 0.02 | 0.05 |
| MobileNet (Experiment One) + SVM | 0.7118 | 0.7100 | 0.71 | 0.71 | 0.71 | 0.71 |
| MobileNet (Experiment One) + RF | 0.6662 | 0.6656 | 0.66 | 0.65 | 0.66 | 0.50 |
| MobileNet (Experiment One) + MLP | 0.0556 | 0.0556 | 0.01 | 0.01 | 0.01 | 0.03 |
| Hijja Dataset | ||||||
| MobileNet (ImageNet Pre-Trained) + SVM | 0.7322 | 0.7256 | 0.73 | 0.73 | 0.73 | 0.57 |
| MobileNet (ImageNet Pre-Trained) + RF | 0.5346 | 0.5270 | 0.53 | 0.52 | 0.53 | 0.36 |
| MobileNet (ImageNet Pre-Trained) + MLP | 0.0770 | 0.0771 | 0.04 | 0.04 | 0.04 | 0.06 |
| MobileNet (Experiment One) + SVM | 0.3937 | 0.3839 | 0.37 | 0.38 | 0.37 | 0.24 |
| MobileNet (Experiment One) + RF | 0.3705 | 0.3591 | 0.34 | 0.35 | 0.34 | 0.22 |
| MobileNet (Experiment One) + MLP | 0.0578 | 0.0570 | 0.01 | 0.01 | 0.03 | 0.03 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AlMuhaideb, S.; Altwaijry, N.; AlGhamdy, A.D.; AlKhulaiwi, D.; AlHassan, R.; AlOmran, H.; AlSalem, A.M. Dhad—A Children’s Handwritten Arabic Characters Dataset for Automated Recognition. Appl. Sci. 2024, 14, 2332. https://doi.org/10.3390/app14062332
AlMuhaideb S, Altwaijry N, AlGhamdy AD, AlKhulaiwi D, AlHassan R, AlOmran H, AlSalem AM. Dhad—A Children’s Handwritten Arabic Characters Dataset for Automated Recognition. Applied Sciences. 2024; 14(6):2332. https://doi.org/10.3390/app14062332
Chicago/Turabian StyleAlMuhaideb, Sarab, Najwa Altwaijry, Ahad D. AlGhamdy, Daad AlKhulaiwi, Raghad AlHassan, Haya AlOmran, and Aliyah M. AlSalem. 2024. "Dhad—A Children’s Handwritten Arabic Characters Dataset for Automated Recognition" Applied Sciences 14, no. 6: 2332. https://doi.org/10.3390/app14062332
APA StyleAlMuhaideb, S., Altwaijry, N., AlGhamdy, A. D., AlKhulaiwi, D., AlHassan, R., AlOmran, H., & AlSalem, A. M. (2024). Dhad—A Children’s Handwritten Arabic Characters Dataset for Automated Recognition. Applied Sciences, 14(6), 2332. https://doi.org/10.3390/app14062332