
Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation

College of Information Engineering, Henan University of Science and Technology, Luoyang 471000, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2024, 14(8), 3441; https://doi.org/10.3390/app14083441
Submission received: 15 March 2024
/
Revised: 9 April 2024
/
Accepted: 13 April 2024
/
Published: 18 April 2024
(This article belongs to the Section Computing and Artificial Intelligence)
Abstract
:The multi-armed bandit (MAB) problem is a typical problem of exploration and exploitation. As a classical MAB problem, the stochastic multi-armed bandit (SMAB) is the basis of reinforcement learning recommendation. However, most existing SMAB and MAB algorithms have two limitations: (1) they do not make full use of feedback from the environment or agent, such as the number of arms and rewards contained in user feedback; (2) they overlook the utilization of different action selections, which can affect the exploration and exploitation of the algorithm. These limitations motivate us to propose a novel dynamic grouping within the minimax optimal strategy in the stochastic case (DG-MOSS) algorithm for reinforcement learning recommendation for small and medium-sized data scenarios. DG-MOSS does not require additional contextual data and can be used for recommendation of various types of data. Specifically, we designed a new exploration calculation method based on dynamic grouping which uses the feedback information automatically in the selection process and adopts different action selections. During the thorough training of the algorithm, we designed an adaptive episode length to effectively improve the training efficiency. We also analyzed and proved the upper bound of DG-MOSS’s regret. Our experimental results for different scales, densities, and field datasets show that DG-MOSS can yield greater rewards than nine baselines with sufficiently trained recommendation and demonstrate that it has better robustness.
1. Introduction
Reinforcement learning is a canonical formalism for studying how an agent learns to take optimal actions by repeated interactions with a stochastic environment [1]. Meanwhile, reinforcement learning is a branch of artificial intelligence based on reward maximization [2]. The goal of an agent is to take actions in an uncertain environment to maximize the cumulative reward. Therefore, reinforcement learning faces the dilemma of exploration and exploitation (EE). The multi-armed bandit (MAB) problem is a classical problem of EE balance in reinforcement learning [3]. As a serialized decision problem, the MAB problem is applied in many practical scenarios, such as the recommendation algorithm [4,5], keyword selection in search engines [6], and network channel selection [7]. In recent years, recommendation algorithms have been applied to various cutting-edge fields, such as integrating cognitive models with recommender systems [8], using binary codes in recommendation systems [9], and developing personality-aware recommendation systems [10]. Due to the significant developments of deep learning, many recommender systems equipped with natural language processing techniques have been emerging in recent years [11,12]. However, deep learning methods have weak interpretability and require large-scale data training and do not match the recommendation needs of small and medium-sized e-commerce platforms, emerging fields, niche communities, or professional fields. Traditional reinforcement learning recommendation methods are aimed at small and medium-sized scenarios to meet the needs of strong stability, interpretability, and fast learning. The stochastic multi-armed bandit (SMAB) problem is a classical MAB problem in which an agent at each stage chooses one arm (or action) and receives a reward from it. The SMAB problem is an invaluable sequential decision-making framework, and it serves as an essential tool in recommendation applications, Internet advertising, information searching, etc. For example, in recommendation applications, it has been applied to optimize sequential (or interactive) recommendations of products and news articles [13]. The reward of each arm is independent and follows an unknown distribution. Since the agent does not know the process generating the reward, the agents need to explore different arms and exploit the seemingly most rewarding arms. When we do not choose the best arm, we obtain a difference between the current reward and the best reward. This difference is the regret. The goal of reinforcement learning is to not only optimize costs and expenditures but also to maximize rewards. In the SMAB problem, the agent must balance between exploiting known policies and exploring randomized ones to achieve good performance.
With the penetration of stochastic problems in the MAB problem, the application of the SMAB problem in various fields has been extensively studied in different variants [14]. Many problems in recommendation [15,16] are related to the SMAB problem. As a result, the SMAB problem is widely used to optimize shopping, media streaming, and advertisement [17]. Each round of bandit learning corresponds to an interaction with a user, where the algorithm selects an arm (e.g., product, movie, or advertisement), observes the user’s response (e.g., purchase, stream, or read), and determines which arm to recommend to each user to generate the maximum click revenue. If we choose the best arm every time, how can new arms be recommended? This is the classic problem with EE. However, existing algorithms have an insufficiency problem related to the full use of feedback information [18,19,20] from the environment or agents, and this along with the problem of selecting different actions [21] represent two significant issues that need to be considered in EE recommendation.
To address the above issues, we propose a novel reinforcement learning algorithm called DG-MOSS, which stands for dynamic grouping within the minimax optimal strategy in the stochastic case. Our algorithm introduces a dynamic grouping mechanism with a threshold that is associated with feedback information from agents. At the same time, we add the exploration probability c that is set to ensure the adaptability to different environmental datasets. DG-MOSS makes full use of the number of arms, rewards are contained in user feedback, and the data with different densities are in different value ranges. It adaptively and dynamically adjusts the balance of exploration and exploitation through the change of full utilization of feedback from agents. Only arms whose error falls within an allowable range are added to the dynamic grouping and simultaneously provided as multiple actions for selection. Moreover, our algorithm does not require additional context information, ensuring the generalization of various data. However, making full use of feedback during training requires sufficient training episodes, which poses a challenge for reducing the training time. Therefore, this paper mainly focuses on the SMAB problem with EE in recommendation, and our main contributions are summarized as follows.
- We propose a new dynamic grouping within the minimax optimal strategy in the stochastic case (DG-MOSS) algorithm for reinforcement learning and providing multiple action selections. The algorithm uses dynamic grouping to ensure the balance of exploration and exploitation, and fully considers the feedback information in the selection process in a sufficient training recommendation.
- This paper presents the design of an adaptive episode length to effectively improve the training efficiency so that the parameters of the episode in the training are automatically rather than manually adjusted.
- We analyze and prove DG-MOSS’s upper bound of the regret value, which provides strong theoretical support for the feasibility of the algorithm.
- Extensive experiments were conducted on four different scales, densities, and field datasets with total rewards and average rewards evaluation metric settings. The experimental results demonstrate that the proposed approach outperforms nine baseline competitors. Furthermore, random attacks and average attacks prove that DG-MOSS has better robustness with sufficiently trained recommendation.
2. Related Works
The problem in recommendation is to determine which arm or action should be selected each time to maximize the reward [22]. The best way to solve this problem, rather than attempting every possible solution blindly, which is a lengthy process, is by utilizing policies. These policies are called bandit algorithms. Over time, a bandit algorithm learns to maximize the user response and then to update its policy [17]. To date, a number of bandit algorithms have balanced the problems of EE in the MAB and SMAB problems.
The -greedy algorithm [20] is the first introduced by Watkins to explore with a small probability and to exploit with the probability of 1-. However, it does not take into account the feedback information after arm selection, such as average rewards and selection times. The Boltzmann algorithm [18] controls the exploration probability according to the temperature parameter t, which also has the above problem.
The CNAME algorithm [19] computes exploration probabilities and selects the number of actions with the smallest reward. However, it only considers one kind of feedback information for the number of arms. The Upper Confidence Bound (UCB) algorithm [3] focuses on the classic SMAB setting where each arm has a fixed but unknown reward distribution. It directly calculates the arm to be selected based on the known average rewards and selection times of each arm rather than selecting randomly. When using the UCB algorithm, all arms must be selected once in the initial stage, so the generalization ability is weak. Therefore, many improved algorithms are proposed based on the UCB algorithm. The FP-UCB algorithm [23] uses the underlying parameter set for faster learning based on the UCB algorithm. Considering the stochastic case, the minimax optimal strategy in the stochastic case (MOSS) algorithm [24] is worthy of further study. It is based on the UCB algorithm, and each arm has an index to measure its performance so that it selects the arm with the maximum index. The R-MOSS algorithm [25] extends MOSS with time slots for SMAB problems. The BBANK algorithm [26] and the BSMAB algorithm [27] are batched, stochastic, multi-armed bandit algorithms. BBANK gives specific conditions for dynamic time steps. The BSMAB expects regrets that improve over the best known regret bounds for any number of batches, but the paper only provides theoretical proof.
3. Problem Formulation
First, we formulate the problem. At each time step , the agent selects each arm (or action) k once in the set A of K possible arms. When the action is at time t, . We assume that a random true reward from arm k is selected in its th selection. We denote the average experience reward at the current round as and return 0 at the beginning of each round. is the historical value of the average experience reward, which changes once during every round and does not include the reward at the current round. Meanwhile is pulled according to a probability distribution with a mean as . We set an array in order to put the arm whose absolute value of the difference between and is less than the expected error of the current arm and obtain average expected error in this process. The from the current round denotes that is the threshold between the total number of arm pulls S and the number of the current arm pulled s. Then, by using this probability of the number in , we choose the process of exploring or exploiting. Let be the empirical mean of arm k after s pulls of this arm. When the explore process begins, we control index value through , and the problem is parameterized by on . The goal of the agent is to select a sequence of actions that maximizes the expected cumulative reward , where the reward vectors are identically distributed and independent at different times. When the agent does not know the true parameter , the optimal arm from parameter is denoted as . Clearly, the optimal choice is to select the best decision or the best arm that with the maximum mean value (), at this time . We assume that the agent knows the set of possible parameters and is a finite set. We denote the set , which is the collection of optimal arms corresponding to all parameters . The expected cumulative regret of a stochastic bandit algorithm with respect to the best constant decision is defined as
The minimax rate of the expected cumulative regret is to minimize , where the minimal is taken over all cases and the supremum over for the stochastic case with rewards in .
4. DG-MOSS
Firstly, the classical stochastic multi-armed bandit algorithms of UCB and UCB1 [3] are introduced. The MOSS [24] based on UCB1 is used to solve the stochastic case. These two kinds of classical algorithms are not explored and exploited in the whole range as they do not deal with the differences of data in different ranges in recommendation. To solve those shortcomings, we propose DG-MOSS and prove the upper bound of the regret.
4.1. Action Selection
In the SMAB problem, the value of each action can be estimated by the reward obtained, and then the action with the largest value can be selected. Due to the uncertainty of action estimates, the UCB algorithm and its variants have been developed.
4.1.1. UCB
The UCB [3] in Algorithm 1 introduces exploration in the process of action selection and considers the estimated value of the non-greedy action to ensure the effect of exploration. When , this algorithm is the UCB1 algorithm.
| Algorithm 1 UCB |
Input: all arms
|
Where is the average reward obtained from arm k, S is the number of times arm k has been played so far, arm k is one of arm from all arms, and s is the overall number of times that all arms have been played so far.
4.1.2. MOSS
MOSS [24] in Algorithm 2 is inspired by UCB1 for the stochastic case, where each arm selects the maximum index at each round. The symbols appearing in MOSS are defined in Section 3.
| Algorithm 2 MOSS (minimax optimal strategy in the stochastic case) |
Input: all arms
|
4.2. DG-MOSS Algorithm Description
DG-MOSS in Algorithm 3 uses dynamic grouping to ensure the balance between exploration and exploitation. In any particular environment, DG-MOSS needs to ensure a balance between exploration and exploitation. Whether the effect of exploration is better or worse than that of exploitation depends on the accurate value of the estimation, the uncertainty of the environment, and the number of remaining operations. Therefore, we use multiple feedback information to reduce the dependence of the algorithm on the data context. Aiming at balancing between exploration and exploitation, we propose a new exploration calculation method based on dynamic grouping in Algorithm 3 with some details explained below.
| Algorithm 3 DG-MOSS |
| Input: Select each arm k in the set A once of K possible arms.
Initialize: episode number , episode length , number of iterations .
|
Steps 2∼8 are dynamic grouping processes. Steps 9∼18 are the action selection processes, which keep the balance between exploration and exploitation. Steps 10, 14, and 16 represent three different action sections. Step 1 utilizes T to control the training process. In step 2, we use an array to measure the current value of each arm. In step 4, is the threshold between the total number of arm pulls S and the number of the current arm pulled s. In step 5, the absolute value is used to save the allowable error between the true reward and the expected value of each round in selecting an arm, and it is lower than the corresponding value in the . During each round, records the error between the true reward and expected value of this round in arm pulling. In step 6, only arms within the allowable error are added to achieve grouping. The allowable error is defined as the error between the true reward and the expected value of the current round in arm pulling. Each arm is calculated separately at the end of the arm selection process. Steps 9∼10 are to select the arm with the maximum reward value from A using the dynamic array . Steps 12∼14 are to select the arm with the maximum reward value from . If steps 9∼14 are not executed, then step 16 selects the arm with s = 0. Then, we choose exploration or exploitation based on whether the number of values in the array is greater than a certain threshold at this time. The threshold is related to the number of arms and can be regarded as a fixed parameter. The probability parameter is a selectable probability related to K. In the experiment of DG-MOSS, .
Sufficient training is required for the full utilization of feedback information; hence, the reasonable reduction in training episodes should be taken into consideration. In Section 4.3, we designed the idea of derived from the inference of the upper bound of the DG-MOSS regret, including and Equations (13) and (20). Based on the function , we introduce the total time step T, grouping parameter , and feedback information to jointly affect the episodes in the calculation of the confidence interval width. Considering the differences of learning process, the episode length related to the return value of the agent is proposed. The implementation of dynamic grouping uses to calculate the number of control episodes each time when the array is updated.
4.3. The Upper Bound of the DM-MOSS Regret
In this section, we provide the upper bound of the regret of DG-MOSS.
Lemma 1.
Chernoff–Hoeffding inequality
Let be independent and identically distributed random variables with values on the interval , and let . For all , , , we have
and
Theorem 1.
DG-MOSS satisfies supremun , where is a probability, and . The supremum is selected from all sets of K probability distributions on the interval .
Proof.
Without loss of generality, we assume that the true optimal arm is , , and are probability parameters, and we rewrite the expected regret in Equation (1) as follows:
Let be the number of actions (or arms) and be the time horizon. The algorithm follows at each time step .
Let .
We assume , and .
By Wald’s identity [28], we have for an arm k. Then, we define its index value as
where is the empirical mean of arm k after s pulled of this arm.
Tightly upper bounding is difficult because of the heavy dependence on the random variables .
For an arm , to decouple the arms, we introduce the key thresholds for and . By defining
we obtain
The Abel transformation was proposed by Norwegian mathematician Abel in the 19th century. Given a function and a real number y, the Abel transformation can be defined as . is the Abel transformation of function . By using an Abel transformation in Equation (6), we have
To bound the second sum of Equation (7), we adopt the stopping times and remark that, in the process, by the definition of DG-MOSS, we have . Because once we choose the -th arm k, its index is always lower than that of , and we can safely come to the following conclusion:
Let and set to meet the condition .
Bounding meets .
Let . When , we obtain
Now, let us assign a value to , where is the smallest integer larger than x. For , because , we have , and 8 . Therefore:
where and c is the parameter from Equation (3). By using Chernoff–Hoeffding’s inequality [29] in Lemma 1 and Equation (10), we obtain:
By substituting with in Equation (12), we obtain:
Because for any , we have , we obtain
This is a convention to check whether is the maximum of when using , and we finally have
Thus, is bounded.
Let denote the reward obtained by , when it is pulled for the t-th time. The random variables are independent and identically distributed. Using Chernoff–Hoeffding’s inequality in Lemma 1 for any and , we have
With and satisfying a non-increasing function, we get
Since and are fixed, we obtain
We use a stripping parameter s with the form
Next, let us integrate :
We use a stripping parameter again with the form , and set .
From the choice of , we finally use the upper bounded by . When we integrate this quantity again, we can obtain
Eventually, we have a conclusion
From Algorithm 3, , and , we obtain the upper bound of the regret value from Equation (2)
The probability , is bounded regardless of the value of . Therefore, we conclude that the DG-MOSS algorithm has an upper bound of the regret value, so this algorithm is stable. □
The proof of the upper bound of DG-MOSS confirms that the actions selected based on DG-MOSS satisfy this theorem, providing a solid theoretical basis for recommendation for small and medium-sized datasets.
5. Experiments
The goal of the agent is to take actions against the environment to maximize the reward. So, this section illustrates the progress of DG-MOSS in recommendation and compares the total rewards and average rewards of this algorithm with the other nine algorithms on four datasets of different sizes and sparsity. The analysis of parameters and adaptive are presented in this section too.
5.1. Experiment Platform and Data Preprocessing
We implemented our experiments in PowerLeader PR4865P server with an Intel XEON Gold 6132 CPU and 1T memory. The experiments were developed on Reinforcement Learning architecture in the CentOS 7 system. Importing numpy, matplotlib, math, pandas and time modules helps Python programmers to efficiently perform numerical computations, data analysis, visualization, and handle tasks related to time. Different low coupling modules were implemented in the code to ensure the scalability of the experiments.
We used four datasets: a random dataset with a normal distribution of reward (Random data-ND), the Alibaba Tianchi dataset (Alibaba) (Available online: https://tianchi.aliyun.com/dataset/dataDetail (accessed on 15 March 2024)), MovieLens (Available online: https://grouplens.org/datasets/movielens (accessed on 15 March 2024)), and the advertising dataset (Ads-CTR-Optimisation) (Available online: https://segmentfault.com/a/1190000018871668 (accessed on 15 March 2024)). The datasets were preprocessed for recommendation as follows before the experiments.
Random data-ND simulates normal distribution data by using the normal function in numpy and then obtains a value randomly. The input parameters are the mean and variance of the normal distribution. In these experiments, we established nine normal distributions with different means and variances to represent the nine arms and performed the functions with different parameters according to the selected arms.
Alibaba randomly samples the advertising display click logs (26 million records) of 1.14 million users within 8 days from the Taobao website to form the original backbone of the sample. This dataset was preprocessed before use. First, we removed unnecessary columns, such as (desensitized by user ID), and (resource bit), and (1 means no click and 0 means click). Then, we processed the remaining data in rows, removed the advertisements that had not been clicked, that is, the rows where (0 means no click and 1 means click) is 0, and then removed the column. After processing, was classified. Every 10,000 IDs were grouped into one group and integrated into one arm. The number of advertising data in this group is the reward number of this arm. We expanded the current column; one column represents one arm. Meanwhile, we filled the excess blanks with 0 and set the ID to 1. Finally, we used the sample function in pandas to deal with confusion. This completes the dataset with only 0, 1, and 85 arms. The dataset includes 430,000 rows and 85 columns, but each row has only one arm with a reward value, so the data of this dataset are relatively sparse.
Movielens is actually a recommendation system and virtual community website. It was founded by the GroupLens project team at the School of Computer Science and Engineering at Minnesota University. It is a non-commercial experimental site for research purposes. The GroupLens research group has produced a MovieLens dataset based on the data provided by the MovieLens website, which contains multiple movie scoring datasets. After decompressing the file, we obtained three files: movies.dat, ratings.dat, and user.dat. We integrated the data into a table with user ID, movie ID, and score. We specified that when the score is greater than 3, the value of the arm is 1; otherwise, it is 0.
Ads-CTR-Optimisation collects the click data of 10 advertising spaces within a certain period of time, with a total number of 10,000. There are multiple advertising spaces for clicking at the same time. The format of this dataset is complete, but the problem is that the number of arms and the amount of data need to be expanded into rows and columns. First, we expanded the rows. We copied an existing piece of data and added it to the end until the number of rows reached 100,000 and then expanded the columns in the same way. We also added some empty columns to prevent the data from being too dense. After this processing, we obtained an advertising dataset of 80 columns and 100,000 rows.
5.2. Experimental Results and Analysis
In this section, the experiments show two advantages of DG-MOSS over other common models and the performance of DG-MOSS with the same parameters. We compare it with the standard state-of-the-art models that have been explained and introduced in the related work as baselines: -greedy [20] and Boltzmann [18], CNAME [19], UCB [3], UCB1 [3], FP-UCB [23], BBANK [26], MOSS [24], and R-MOSS [25].
5.2.1. Total Rewards
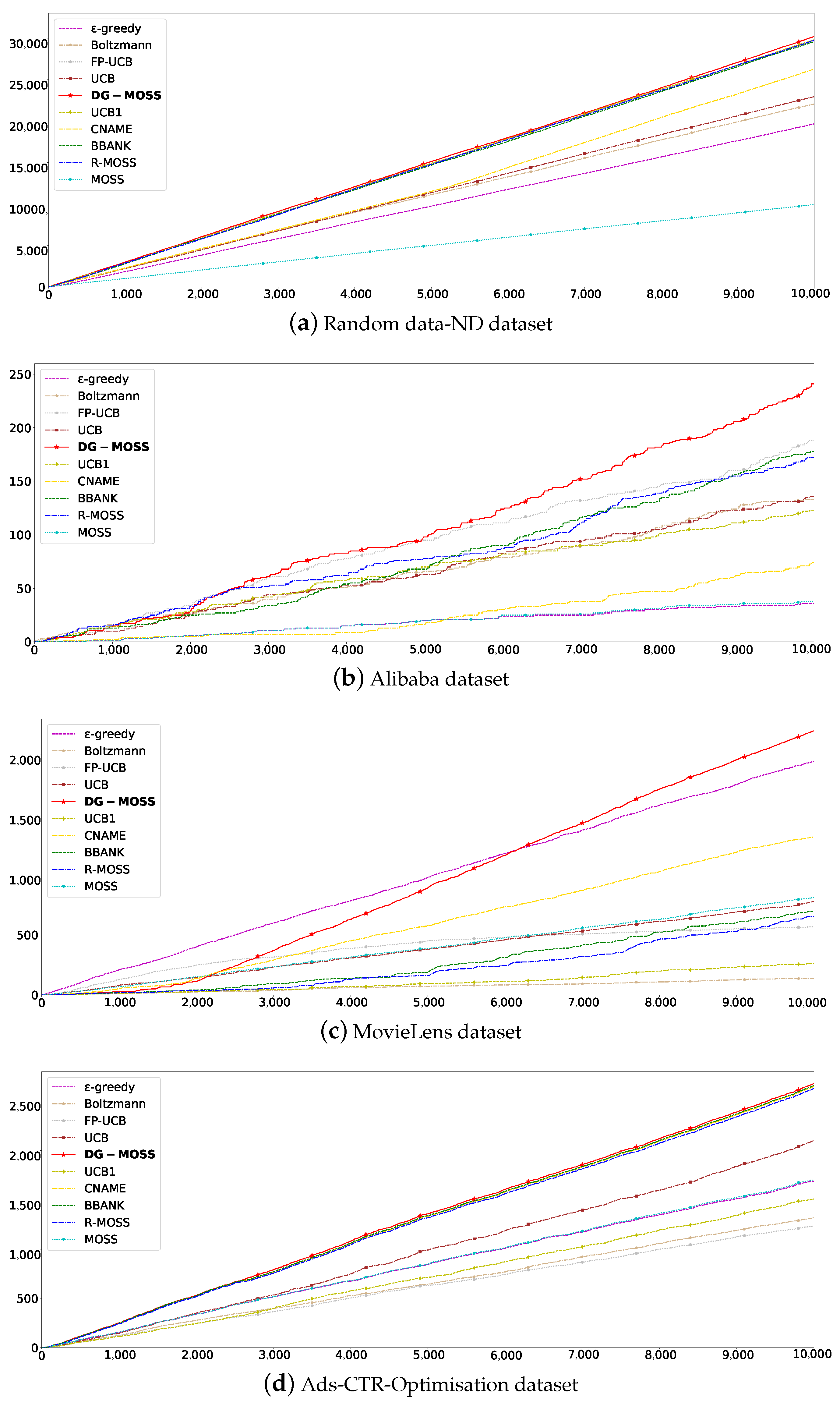
Reinforcement learning is based on the reward hypothesis. All goals can be described by maximizing the expected cumulative rewards. In order to obtain the best behavior in reinforcement learning, we need to maximize the expected cumulative reward. Therefore, the algorithm with a large total reward value can perform the best. Figure 1a–d correspond to Random data-ND, Alibaba, MovieLens, and Ads-CTR-Optimisation datasets, respectively. Figure 1a is a data-dense dataset in which the total reward value of DG-MOSS is slightly higher than that of Boltzmann controlled by random parameters and extended time slots approaching R-MOSS. Figure 1b,c represent sparse datasets with a medium data scale. With the increase in the number of iterations, the total reward value increases steadily and is finally better than all compared algorithms. Figure 1d is a small-sized sparse dataset. In Figure 1a–d,we can observe significant variations in the total rewards among the nine contrasting methods across four distinct datasets. This disparity arises from the distinct scenarios considered by each strategy and the disparate methodologies employed in computing rewards. Particularly in Figure 1b, which entails more intricate shopping data, fluctuations during training may occur due to the complexity of information involved. Regarding Figure 1c, given the heightened subjective nature of music data, DG-MOSS can leverage post-interaction feedback more effectively as training progresses. In the iteration, the total reward value not only maintains linear growth but is also better than other algorithms. Due to the different densities of datasets in different parts, DG-MOSS can adapt to different datasets with sufficiently trained recommendation, particularly when dealing with sparse datasets.
5.2.2. Average Rewards
The average reward is the average of reward values of all rounds, which can better reflect the convergence and stability of the algorithm. Figure 2a–d correspond to Random data-ND, Alibaba, MovieLens, and Ads-CTR-Optimisation datasets, respectively. In Figure 2a, DG-MOSS is better than Boltzmann [18], CNAME [19], UCB1 [3], FP-UCB [23], BBANK [26], and R-MOSS [25], which all perform stably on this dataset, and the average reward is higher than MOSS [24] up to 2. In Figure 2b, the average reward of DG-MOSS is better than CNAME [19], which also has gradually stable performance. In Figure 2c, the average reward of DG-MOSS gradually exceeds -greedy [20], which performs stably in this dataset. All algorithms are stable, as shown in Figure 2d. For the datasets Figure 2a,b,d, the average reward remains stable, and the value obtained is the maximum. For the dataset Figure 2c, the average reward increases in learning and reaches a stable peak in all algorithms. It is worth noting that, in the initial period, the average reward value of DG-MOSS fluctuates drastically rather than evolving steadily. This may be because initially, a large number of arms does not interact with the reinforcement learning agent, resulting in less stable feedback. In Figure 2, the red line represents DG-MOSS, which performs well on all four datasets after sufficient training due to its ability to not only fully utilize feedback information but also to employ multiple action selection.
5.2.3. Parameter Analysis
There are some algorithms whose parameter sizes and ranges are specified, such as -greedy [20], Boltzmann [18], and UCB1 [3]. We kept the basic parameters () and exploration coefficient parameters () of each algorithm consistent to ensure the fairness of the experiment. The basic parameters () exist in the original algorithm; some exist and some do not. In DG-MOSS, are fixed in , and are the exploration probability c. The term in the current round signifies the threshold demarcating the total number of arm pulls, denoted as S, and the number of pulls from the current arm, denoted as s. As the exploration probability c undergoes alterations, there are corresponding shifts in both the average reward and average regret. Consequently, for fairness in comparison, the selection of identical parameter values was made. This approach ensures consistency across different exploration probabilities, facilitating a more precise evaluation of outcomes under varied conditions. Here, the exploration probability was used. Although random algorithms -greedy [20], Boltzmann [18] and CNAME [19]; upper bound of confidence algorithms UCB [3] and UCB1 [3]; grouping algorithms FP-UCB [23] and BBANK [26]; and optimal strategy algorithms MOSS [24] and R-MOSS [25] have better performance, DG-MOSS has the maximum average reward and the lowest average regret. This shows the stability of the algorithm.
In the analysis of these parameters, the average rewards and average regrets of DG-MOSS are shown in Table 1. We used the dynamic grouping to improve reinforcement learning algorithm of MOSS by increasing the exploration coefficient.
According to step 9 of Algorithm 3, it can be inferred that the value of probability parameter is related to the control of action selection. The quantity of dynamically grouped data also plays a significant role, and the varying impacts of different parameters on the final results further indicate the intentional design of probability parameters in DG-MOSS. Here, the selection of exploration parameters is related to K. The K used in this Ads-CTR-Optimisation datasets experiment is 85. We can choose according to the actual situation. Through experimental comparison, we use as the probability parameter . The average rewards of different probability parameters are shown in Table 2.
5.2.4. Adaptive
In Algorithm 3, we set episode length related to the return value of the agent, which is adaptively proposed. Compared with the initial 1000 in different scenarios, Random data-ND is a dense dataset, Alibaba and Movie are sparse datasets with large scale, and Ads-CTR-Optimisation is a medium-sized sparse dataset. The number of episodes is reduced, as shown in Table 3.
The experimental results show that the episode difference with large-scale and dense datasets can reach more than 956 (1000-44), and the episode difference between medium-scale datasets can also reach more than 362 (1000-638). So, the optimization effect is obvious. Thus, significant improvements are attributed to the combined influence of the total time step T, grouping parameter , and feedback information to jointly affect the episodes, which synergistically complement each other when integrated with the dynamic grouping process in recommendation interactions. There is no need to adjust the parameters manually and adjust the episode in the training automatically.
5.2.5. Robustness
Regardless of the type of user data, such as movies, shopping, or advertising, which has an open nature, some businesses or individuals inject fake data into the recommendation system from the perspective of their own interests, attempting to alter the recommendation results. This is known as a recommendation attack. Common recommendation attacks include random attacks and average attacks. Random attacks involve adding 1%, 3%, 5%, and 10% of random entries to attack. Average attacks involve adding 1%, 3%, 5%, and 10% of entries to attack, with the mean of the dataset being added as one of the entries. Under attack conditions with 1%, 3%, and 5% data, the fluctuations of DG-MOSS remain within a small range. The attack with 10% data is relatively strong and has some impact on all models. Since this study focuses on maximizing rewards for recommendations, the robustness is demonstrated by achieving the maximum reward value even under different attack conditions, which helps in selecting the arms. As shown in Table 4, Table 5 and Table 6. DG-MOSS performs the best under all attack conditions, which indicates that this algorithm has good robustness.
6. Conclusions
For reinforcement learning recommendation for small and medium-sized data scenarios, considering dynamic interactive feedback, this paper presents a novel SMAB algorithm called DG-MOSS that utilizes adaptive episode in training, which is based on improved MOSS by incorporating dynamic grouping from environment feedback information to ensure the balance of exploration and exploitation and maximizing rewards for recommendations. This algorithm can increase the degree of exploration and exploitation according to the dynamic grouping, solving the insufficiency problem and making full use of feedback information. On the one hand, through analysis and proof, this paper gives the upper bound of the regret value of DG-MOSS, which provides strong theoretical support. On the other hand, extensive experiments were undertaken on four datasets (Random data-ND, Alibaba, MovieLens, and Ads-CTR-Optimisation) with total rewards and average rewards. The maximum reward improvement compared to the second-best model reaches 1.02%, while the improvement compared to the worst baseline model can reach up to 36.32%. In summary, DG-MOSS is a stable and robust SMAB algorithm in recommendation. Extensive studies focus on combining deep learning and reinforcement learning to address problems. In the future, we will continue to investigate adaptive approaches based on big data by adding deep learning.
Author Contributions
Methodology, J.F.; supervision, J.Z.; software, J.F.; writing—original draft, J.F.; formal analysis, J.Z.; writing—review and editing, J.Z. and X.Z.; resources, Z.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported in part by the Program for Science and Technology Innovation Talents in the University of Henan Province under Grant No. 22HASTIT014, the Science and Technology Research and Development Plan Joint Fund Project in Henan Province under Grant No. 222103810031, the International Science and Technology Cooperation Project in Henan Province under Grant No. 232102521005, and the Key Technologies Research and Development Program of Henan Province under Grant No. 222102210080.
Data Availability Statement
Data of this paper are available and can be accessed via https://tianchi.aliyun.com/dataset/dataDetail (accessed on 15 March 2024), https://grouplens.org/datasets/movielens (accessed on 15 March 2024), and https://segmentfault.com/a/1190000018871668 (accessed on 15 March 2024).
Acknowledgments
Thanks to Tingkun Nie from Guangxi Youjiang Water Resources Development Co., Ltd., for assistance with the software used in this work.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
References
- Sutton, R.; Barto, A. Reinforcement learning: An Introduction. Robotica 1999, 17, 229–235. [Google Scholar] [CrossRef]
- Silver, D.; Singh, S.; Precup, D. Reward is enough. Artif. Intell. 2021, 299, 103535. [Google Scholar] [CrossRef]
- Auer, P. Finite-time analysis of the multiarmed bandit problem. Robotica 2002, 47, 235–256. [Google Scholar]
- Gutowski, N.; Amghar, T.; Camp, O. Gorthaur: A portfolio approach for dynamic selection of multi-armed bandit algorithms for recommendation. In Proceedings of the 31th International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; pp. 1164–1171. [Google Scholar]
- Tong, X.; Wang, P.; Niu, S. Reinforcement learning-based denoising network for sequential recommendation. Appl. Intell. 2023, 53, 1324–1335. [Google Scholar] [CrossRef]
- Qin, J.; Wei, Q.; Zhou, B. Research on optimal selection strategy of search engine keywords based on multi-armed bandit. In Proceedings of the 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 726–734. [Google Scholar]
- Takeuchi, S.; Hasegawa, M.; Kanno, K. Dynamic channel selection in wireless communications via a multi-armed bandit algorithm using laser chaos time series. Sci. Rep. 2020, 10, 1574. [Google Scholar] [CrossRef]
- Angulo, C.; Falomir, Z.; Anguita, D. Bridging cognitive models and recommender systems. Cogn. Comput. 2020, 12, 426–427. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Pan, Q. Learning binary codes with neural collaborative filtering for efficient recommendation systems. Knowl. Based Syst. 2019, 172, 64–75. [Google Scholar] [CrossRef]
- Dhelim, S.; Aung, N.; Bouras, M.A. A survey on personality-aware recommendation systems. Artif. Intell. Rev. 2022, 55, 2409–2454. [Google Scholar] [CrossRef]
- Yang, Y.; Chen, C.; Lu, T. Hierarchical reinforcement learning for conversational recommendation with knowledge graph reasoning and heterogeneous questions. IEEE Trans. Serv. Comput. 2023, 16, 3439–3452. [Google Scholar] [CrossRef]
- Pang, G.; Wang, X.; Wang, L.; Hao, F.; Lin, Y.; Wan, P.; Min, G. Efficient Deep Reinforcement Learning-Enabled Recommendation. IEEE Trans. Sci. Eng. 2023, 10, 871–886. [Google Scholar] [CrossRef]
- Gu, H.; Xia, Y.; Xie, H.; Shi, X.; Shang, M. Robust and efficient algorithms for conversational contextual bandit. Inf. Sci. 2024, 657, 119993. [Google Scholar] [CrossRef]
- Kanade, V.; Liu, Z.; Kanade, V. Distributed non-stochastic experts. Adv. Neural Inf. Process. Syst. 2012, 25, 260–268. [Google Scholar]
- Agrawal, P.; Tulabandula, T. Learning by repetition: Stochastic multi-armed bandits under priming effect. In Proceedings of the 36th International Conference on Uncertainty in Artificial Intelligence (UAI), Online, 3–6 August 2020; pp. 470–479. [Google Scholar]
- Gopalan, P.; Hofman, J.M.; Blei, D.M. Scalable recommendation with hierarchical poisson factorization. In Proceedings of the 31th International Conference on Uncertainty in Artificial Intelligence (UAI), Amsterdam, The Netherlands, 12–16 July 2015; pp. 326–335. [Google Scholar]
- Wang, L.; Bai, Y.; Sun, W. Fairness of exposure in stochastic bandits. In Proceedings of the 38th International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 7700–7709. [Google Scholar]
- Guo, X.; Song, J.; Fang, Y. Explain in Simple Terms Reinforcement Learning; Publishing House of Electronics Industry: Beijing, China, 2020. [Google Scholar]
- Zhang, X.; Zou, Q.; Liang, B. An adaptive algorithm in multi-armed bandit problem. Comput. Res. Dev. 2019, 56, 643–654. [Google Scholar]
- Green, L.; Fry, A.; Myerson, J. Discounting of delayed rewards: A life-span comparison. Psychol. Sci. 1994, 5, 33–36. [Google Scholar] [CrossRef]
- Hong, X.; Qiao, T.; Qingsheng, Z. A multiplier bootstrap approach to designing robust algorithms for contextual bandits. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9887–9899. [Google Scholar]
- Wang, T.; Shi, X.; Shang, M. Diversity-Aware Top-N Recommendation: A Deep Reinforcement Learning Way. In Proceedings of the 8th CCF International Conference on Big Data (CCF BigData), Chongqing, China, 22–24 October 2020; pp. 1324–1335. [Google Scholar]
- Panaganti, K.; Kalathil, D.M. Bounded regret for finitely parameterized multi-armed bandits. IEEE Control Syst. Lett. 2021, 5, 1073–1078. [Google Scholar] [CrossRef]
- Audibert, J.; Bubeck, S. Minimax policies for adversarial and stochastic bandits. In Proceedings of the 22nd International Conference on Learning Theory (COLT), Montreal, QC, Canada, 18–21 June 2009; pp. 217–226. [Google Scholar]
- Wei, L.; Srivastava, V. Nonstationary stochastic multiarmed bandits: Ucb policies and minimax regret. arXiv 2021, arXiv:2101.08980. [Google Scholar]
- Karpov, N.; Zhang, Q. Batched coarse ranking in multi-armed bandits. In Proceedings of the 34th International Conference on Neural Information Processing Systems (HeurIPS), Online, 6–12 December 2020; pp. 16037–16047. [Google Scholar]
- Esfandiari, H.; Karbasi, A.; Mehrabian, A.; Mirrokni, V. Regret bounds for batched bandits. In Proceedings of the 35th International AAAI Conference on Artifical Intelligence (AAAI), Online, 2–9 February 2021; pp. 7340–7348. [Google Scholar]
- Sun, D. Wald’s identity and geometric expectation. Am. Math. Mon. 2020, 127, 716. [Google Scholar] [CrossRef]
- Hoeffding, W. Probability inequalities for sums of bounded random variables. Am. Stat. Assoc. 1963, 58, 13–30. [Google Scholar] [CrossRef]
Figure 1.
Total rewards. (a–d) The X axis represents the value of total rewards, and the Y axis represents the training epochs.
Figure 1.
Total rewards. (a–d) The X axis represents the value of total rewards, and the Y axis represents the training epochs.

Figure 2.
Average rewards. (a–d) The X axis represents the value of total rewards, and the Y axis represents the training epochs.
Figure 2.
Average rewards. (a–d) The X axis represents the value of total rewards, and the Y axis represents the training epochs.


{kind=link}
{kind=link}
Table 1.
Description of parameters.
| Algorithms | Parameters 1 | Parameters 2 | Average Rewards | Average Regrets |
|---|---|---|---|---|
| -greedy | 0.05 | NULL | 0.1690 | 0.8310 |
| Boltzmann | 1 | NULL | 0.1318 | 0.8669 |
| CNAME | 0.1 | 0.2648 | 0.7342 | |
| UCB | NULL | 0.2103 | 0.7897 | |
| UCB1 | NULL | 0.1510 | 0.8490 | |
| FP-UCB | 0.1 | 0.1237 | 0.7562 | |
| BBANK | 0.1 | 0.2654 | 0.7346 | |
| MOSS | NULL | 0.1703 | 0.8297 | |
| R-MOSS | 0.1 | 0.2631 | 0.7369 | |
| DG-MOSS | 0.1 | 0.2681 | 0.7319 |
Table 2.
Probability parameters.
| Parameters | Average Rewards |
|---|---|
| 0.2076 | |
| 0.2673 | |
| 0.2681 | |
| 0.2656 | |
| 0.2659 |
Table 3.
Number of training episodes.
| Datasets | Episode |
|---|---|
| Initial | 1000 |
| Random data-ND | 24 |
| Alibaba | 44 |
| Movie | 34 |
| Ads-CTR-Optimisation | 638 |
Table 4.
Random attacks (R) and average attacks (A) on the movie dataset.
| Algorithms | Original | 1% R | 3% R | 5% R | 10% R | 1% A | 3% A | 5% A | 10% A |
|---|---|---|---|---|---|---|---|---|---|
| -greedy | 0.1944 | 0.1932 | 0.2015 | 0.2070 | 0.2186 | 0.1969 | 0.2131 | 0.2291 | 0.2574 |
| Boltzmann | 0.0139 | 0.0192 | 0.0276 | 0.0368 | 0.0546 | 0.0143 | 0.0157 | 0.0181 | 0.0266 |
| CNAME | 0.2296 | 0.2266 | 0.1671 | 0.2496 | 0.2562 | 0.2420 | 0.2347 | 0.2696 | 0.2860 |
| UCB | 0.0778 | 0.0815 | 0.0870 | 0.0962 | 0.1092 | 0.0850 | 0.1022 | 0.1179 | 0.1504 |
| UCB1 | 0.0262 | 0.0357 | 0.0356 | 0.0415 | 0.0614 | 0.0310 | 0.0406 | 0.0411 | 0.0678 |
| FP-UCB | 0.0568 | 0.0421 | 0.0496 | 0.0546 | 0.0706 | 0.0636 | 0.0498 | 0.0547 | 0.0792 |
| BBANK | 0.1983 | 0.2379 | 0.2526 | 0.2562 | 0.2643 | 0.2421 | 0.2441 | 0.2494 | 0.2978 |
| MOSS | 0.0809 | 0.0847 | 0.0908 | 0.0983 | 0.1130 | 0.0887 | 0.1073 | 0.1220 | 0.1541 |
| R-MOSS | 0.0653 | 0.0621 | 0.0710 | 0.751 | 0.0908 | 0.0667 | 0.0752 | 0.0865 | 0.1430 |
| DG-MOSS | 0.2378 | 0.2396 | 0.2539 | 0.2585 | 0.2720 | 0.2422 | 0.2609 | 0.2729 | 0.2996 |
Table 5.
Random attacks (R) and average attacks (A) on the advertising dataset.
| Algorithms | Original | 1% R | 3% R | 5% R | 10% R | 1% A | 3% A | 5% A | 10% A |
|---|---|---|---|---|---|---|---|---|---|
| -greedy | 0.1690 | 0.1720 | 0.1756 | 0.1846 | 0.1935 | 0.1774 | 0.1896 | 0.2052 | 0.2405 |
| Boltzmann | 0.1318 | 0.1332 | 0.1460 | 0.1503 | 0.1568 | 0.1346 | 0.1469 | 0.1587 | 0.1805 |
| CNAME | 0.2648 | 0.2657 | 0.2712 | 0.2725 | 0.2829 | 0.2698 | 0.2841 | 0.3006 | 0.3315 |
| UCB | 0.2103 | 0.2088 | 0.2113 | 0.2289 | 0.2312 | 0.2091 | 0.2344 | 0.2409 | 0.2753 |
| UCB1 | 0.1510 | 0.1581 | 0.1584 | 0.1681 | 0.1780 | 0.1572 | 0.1695 | 0.1768 | 0.220 |
| FP-UCB | 0.1237 | 0.1180 | 0.1314 | 0.1400 | 0.1576 | 0.1190 | 0.1340 | 0.1392 | 0.1614 |
| BBANK | 0.2654 | 0.2684 | 0.2711 | 0.2755 | 0.2850 | 0.2745 | 0.2867 | 0.3011 | 0.3317 |
| MOSS | 0.1703 | 0.1736 | 0.1780 | 0.1855 | 0.1987 | 0.1786 | 0.1938 | 0.2082 | 0.2440 |
| R-MOSS | 0.2631 | 0.2640 | 0.2678 | 0.2719 | 0.2831 | 0.2704 | 0.2834 | 0.2983 | 0.2766 |
| DG-MOSS | 0.2681 | 0.2693 | 0.2723 | 0.2762 | 0.2853 | 0.2748 | 0.2868 | 0.3013 | 0.3322 |
Table 6.
Random attacks (R) and average attacks (A) on the shopping dataset.
| Algorithms | Original | 1% R | 3% R | 5% R | 10% R | 1% A | 3% A | 5% A | 10% A |
|---|---|---|---|---|---|---|---|---|---|
| -greedy | 0.0036 | 0.0075 | 0.0089 | 0.0076 | 0.0096 | 0.0041 | 0.0037 | 0.035 | 0.0040 |
| Boltzmann | 0.0133 | 0.0158 | 0.0153 | 0.0155 | 0.0199 | 0.0144 | 0.0151 | 0.0154 | 0.0155 |
| CNAME | 0.015 | 0.0156 | 0.0223 | 0.0178 | 0.0176 | 0.0284 | 0.0235 | 0.0252 | 0.0206 |
| UCB | 0.0136 | 0.0152 | 0.0195 | 0.0178 | 0.0182 | 0.0154 | 0.0189 | 0.0188 | 0.0196 |
| UCB1 | 0.0123 | 0.0148 | 0.0163 | 0.0157 | 0.0173 | 0.0155 | 0.0149 | 0.0158 | 0.0148 |
| FP-UCB | 0.0188 | 0.0202 | 0.0235 | 0.0233 | 0.0246 | 0.0214 | 0.0287 | 0.0265 | 0.0265 |
| BBANK | 0.0220 | 0.0241 | 0.0283 | 0.0266 | 0.0265 | 0.0291 | 0.0333 | 0.0343 | 0.0315 |
| MOSS | 0.0038 | 0.0071 | 0.0090 | 0.0078 | 0.0096 | 0.0038 | 0.0038 | 0.0038 | 0.0038 |
| R-MOSS | 0.0172 | 0.0145 | 0.0229 | 0.0220 | 0.0243 | 0.0228 | 0.0275 | 0.0239 | 0.0286 |
| DG-MOSS | 0.0223 | 0.0250 | 0.0283 | 0.0268 | 0.0280 | 0.0295 | 0.0339 | 0.0344 | 0.0316 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Feng, J.; Zhu, J.; Zhao, X.; Ji, Z. Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation. Appl. Sci. 2024, 14, 3441. https://doi.org/10.3390/app14083441
AMA Style
Feng J, Zhu J, Zhao X, Ji Z. Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation. Applied Sciences. 2024; 14(8):3441. https://doi.org/10.3390/app14083441
Chicago/Turabian StyleFeng, Jiamei, Junlong Zhu, Xuhui Zhao, and Zhihang Ji. 2024. "Dynamic Grouping within Minimax Optimal Strategy for Stochastic Multi-ArmedBandits in Reinforcement Learning Recommendation" Applied Sciences 14, no. 8: 3441. https://doi.org/10.3390/app14083441
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.