Current 3D ear recognition approaches exploit 3D ear data or both 3D and co-register 2D ear data. This section discusses some well-known and recent 3D ear recognition methods and highlights the contributions of this paper.
2.1. Ear Detection and Segmentation
Detection and recognition are the two major components of a complete biometrics system. In this section, a summary of ear detection and segmentation approaches are provided. The existing ear detecting and ear region extracting approaches have been based on 2D or 3D profile images.
One of the 3D ear detection approaches was proposed by Chen and Bhanu, who combined 2D side face images and 3D profile range images to detect and extract human ears [
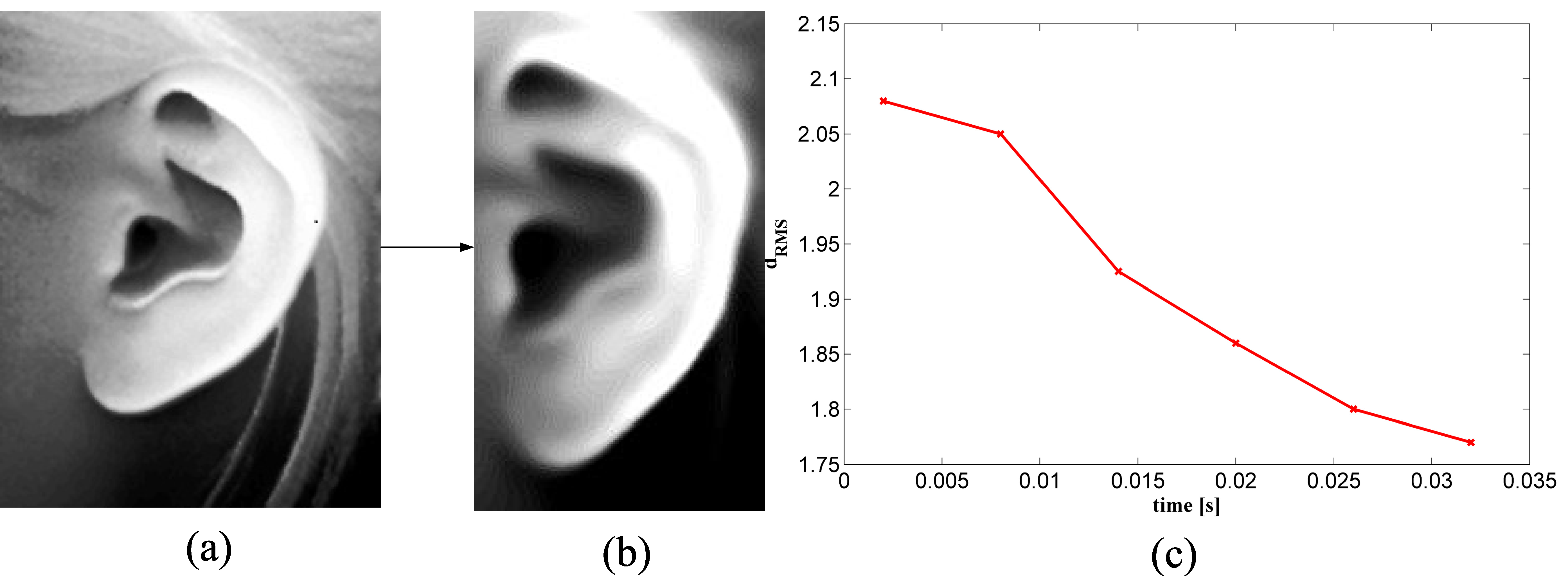
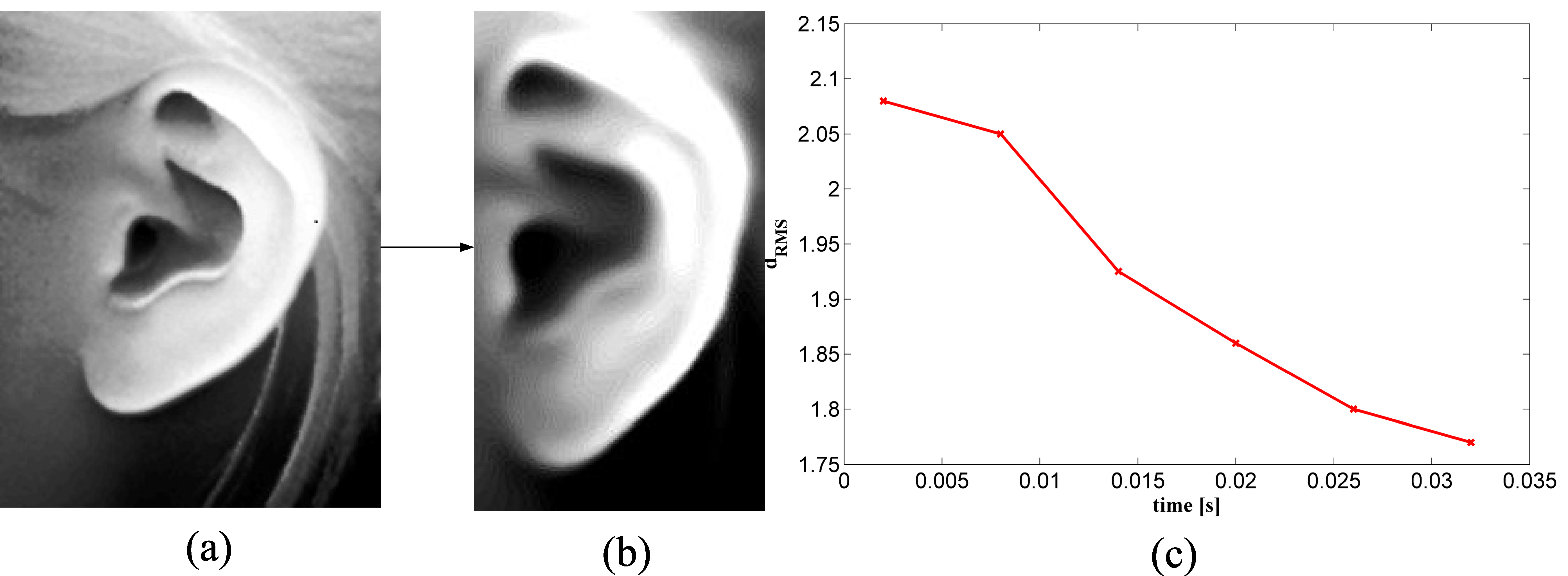
11]. The edges were extracted to locate potential ear regions called regions-of-interest (ROIs). Then the reference 3D ear shape model, which was a set of discrete 3D vertices on the ear helix and the antihelix parts, was matched with individual ear images by following a modified ICP procedure. The ROI with the minimum Root Mean Square (RMS) error was considered to be the ear region. In a previous [
14], Abdel-Mottaleb and Zhou put forward a 3D ear recognition approach in which the ear regions were segmented by locating the ridges and ravines on the profile images. However, it may be difficult to detect the ridges and ravines when the ear is partly occluded. In another study [
15], Prakash and Gupta proposed a rotation and scale invariant ear detection technique from 3D profile images using graph inherent structural details of the ear in 3D range data. Maity et al. used an active contour algorithm and a tree structured graph to segment the ear region in [
16]. Yan and Bowyer exploited an ear extracting approach based on ear pit detection and Active Contour Algorithm [
17]. They found the ear pit using skin detection, curvature estimation, and surface segmentation and classification. Then an active contour algorithm was implemented to outline the ear region. All of the ear images on the University of Notre Dame (UND) database were correctly segmented using the combination of color and depth images in the active contour algorithm. However, since this method has to locate the nose tip and ear pit on the profile image, this algorithm may not be robust enough to pose variations or hair covering.
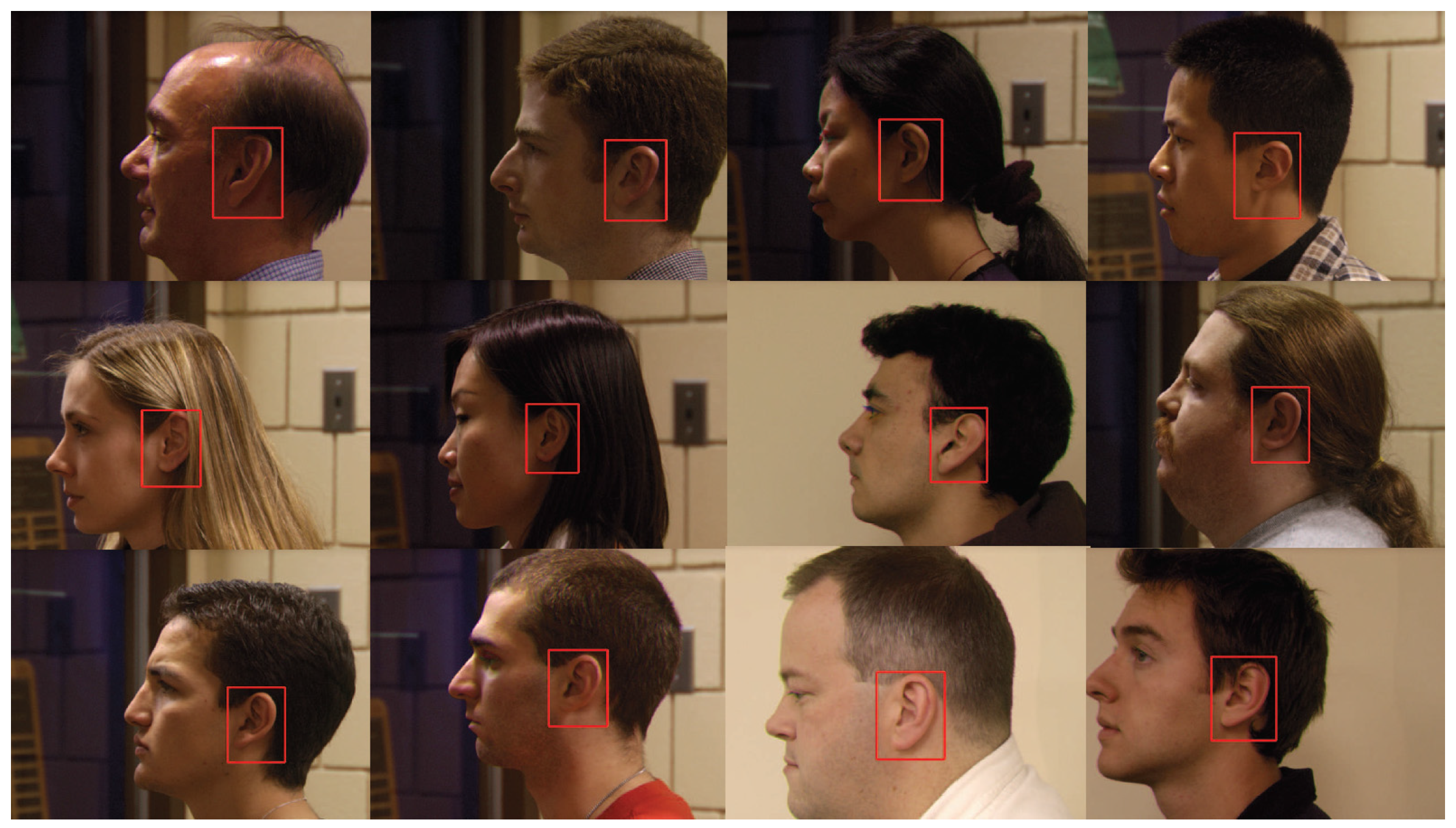
Researchers proposed some learning algorithms to detect ears under complex background from 2D images, where corresponding 3D ear data could thenbe extracted from the co-registered 3D images if necessary. Islam [
12] detected ear regions on 2D profile images using a detector based on the AdaBoost algorithm. They argued that it was efficient and robust to noisy background and pose variation. Abaza et al. [
18] modified the Adaboost algorithm and, in doing so, reduced the training time significantly. Shih et al. [
19] presented a two-step ear detection system utilized arc-masking candidate extraction and AdaBoost polling verification. Firstly, the ear candidates were extracted by the arc-masking edge search algorithm; then the ear was located by rough AdaBoost polling verification. Yuan and Zhang [
20] used the improved AdaBoost algorithm to detect ears under complex backgrounds. They sped up the detection procedure and reported a good detection rate on three test data sets.
It has been experimentally shown that the learning algorithms perform better than the algorithms based on ear edge detection or ear template matching on 2D images. However, shallow learning models such as Adaboost algorithm also lack robustness in realistic scenarios, which may contain occlusion, illumination variation, scaling, and rotation.
Recently, convolution neural network (CNN) has significantly pushed forward the development of image classification and object detection [
21]. Girshick et al. [
22] proposed a new framework of object detection called Regions with CNN features (R-CNN). The R-CNN approach achieved the best result on the Pattern Analysis, Statistical modelling and Computational Learning Visual Object Classes (PASCAL VOC 2010) Challenge. Then a modified network called Faster R-CNN was proposed by Ren et al. [
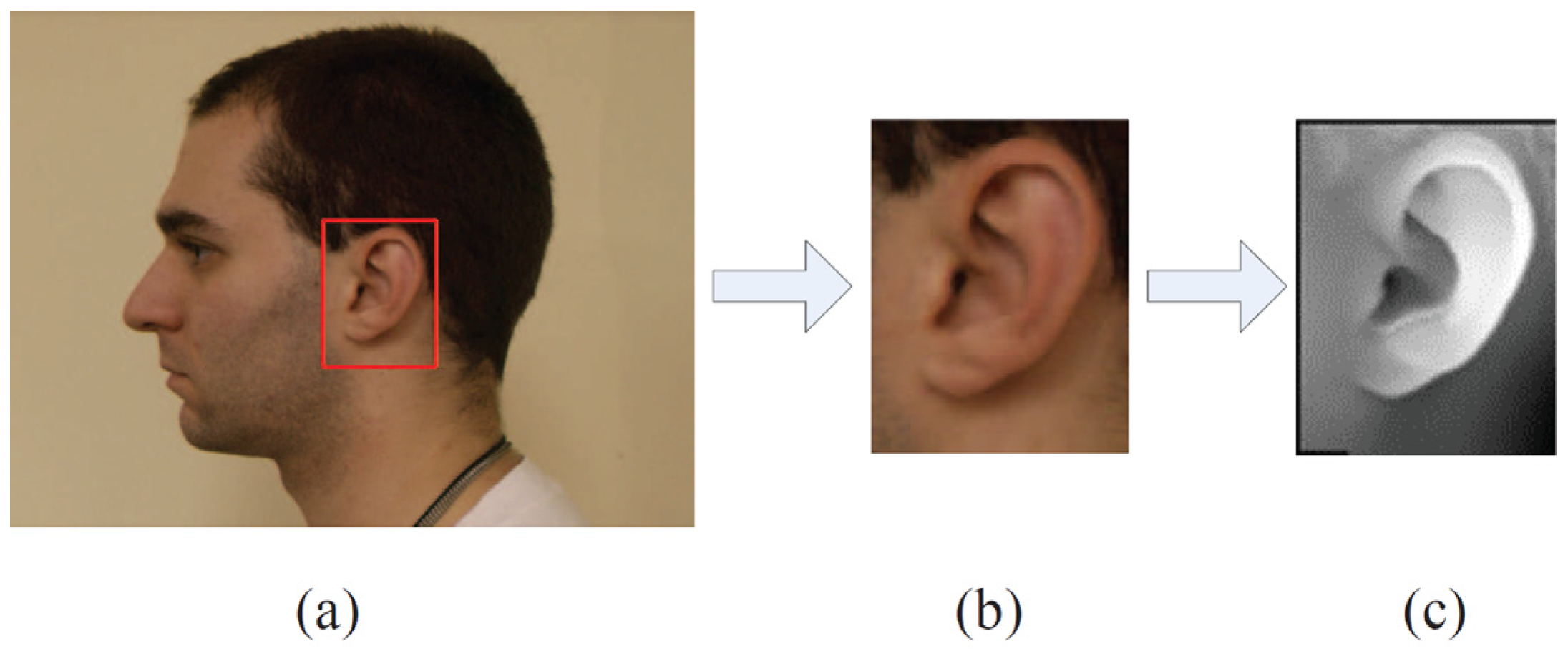
23]. In this work, they introduced a Region Proposal Network (RPN) which shared the full-image convolutional features with the detection network. The detection system has a frame rate of 5 fps on Graphics Processing Unit (GPU), while achieving 70.4% mAP on PASCAL VOC 2012. Schemes based on Faster R-CNN have obtained impressive performance on object detection in images captured from real world situations. However, the application of ear detection using the Faster R-CNN algorithm has not been reported so far. In this work, ear images were coarsely extracted from 2D profile images utilizing an ear detection algorithm based on Faster R-CNN frameworks.
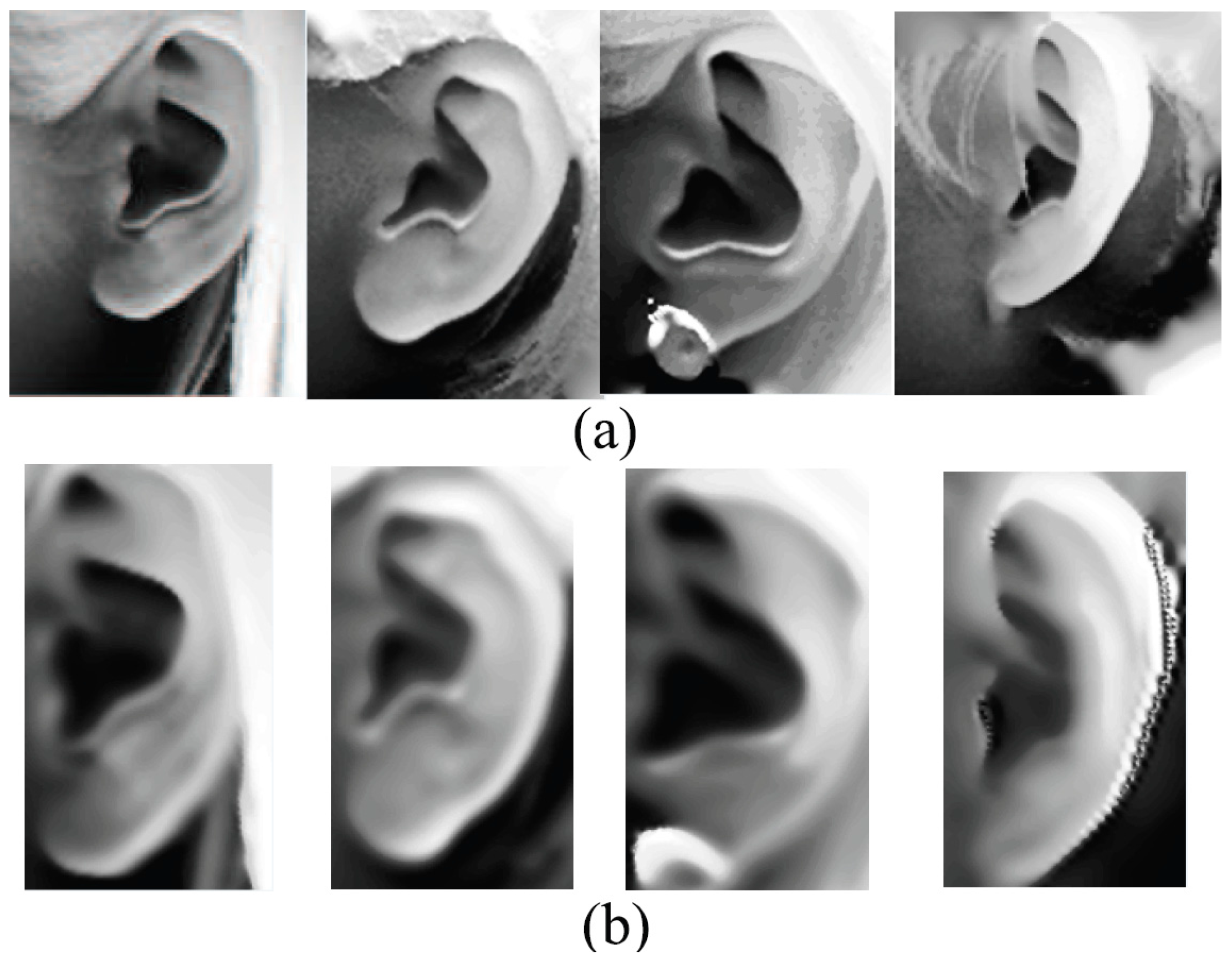
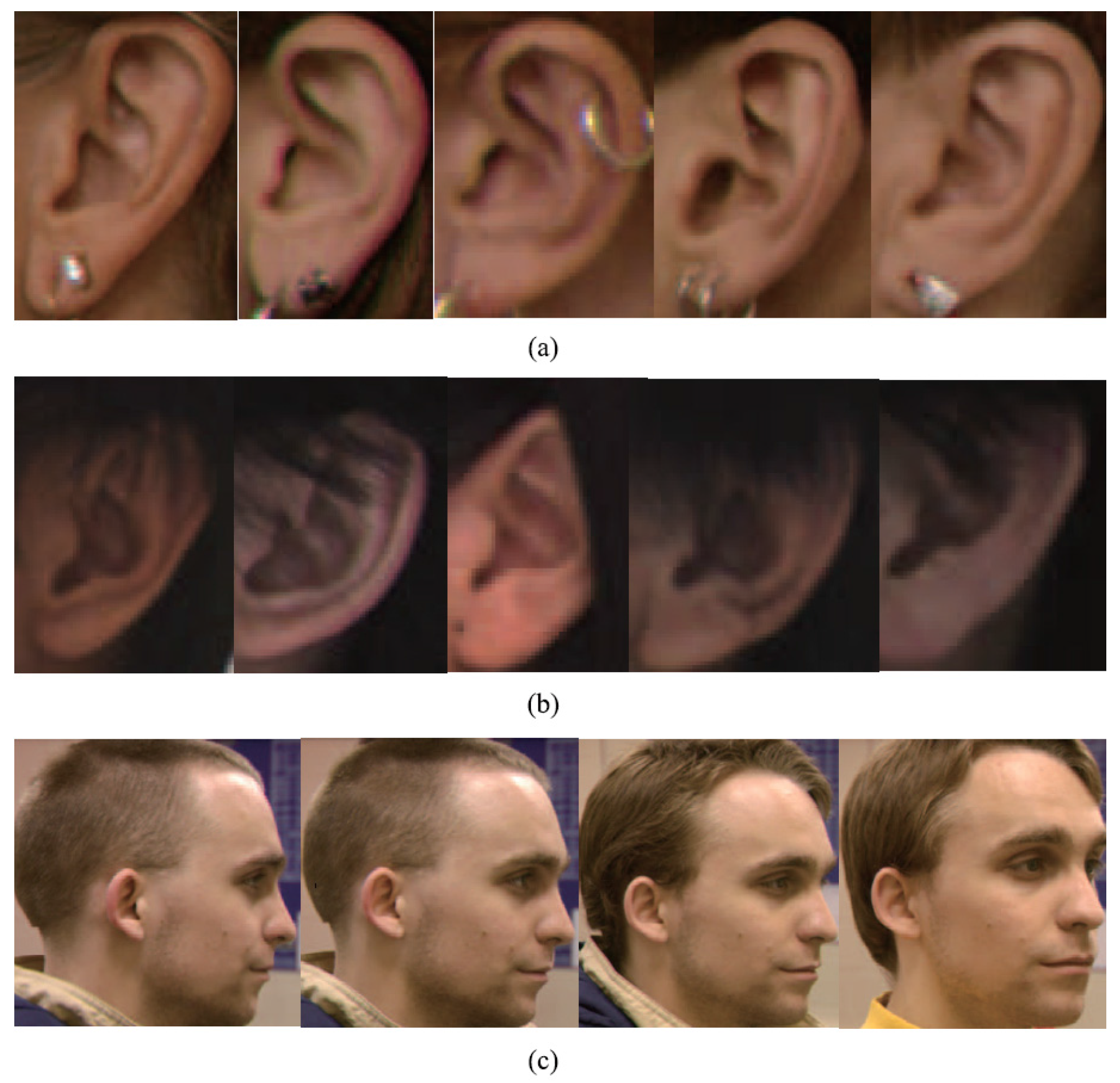
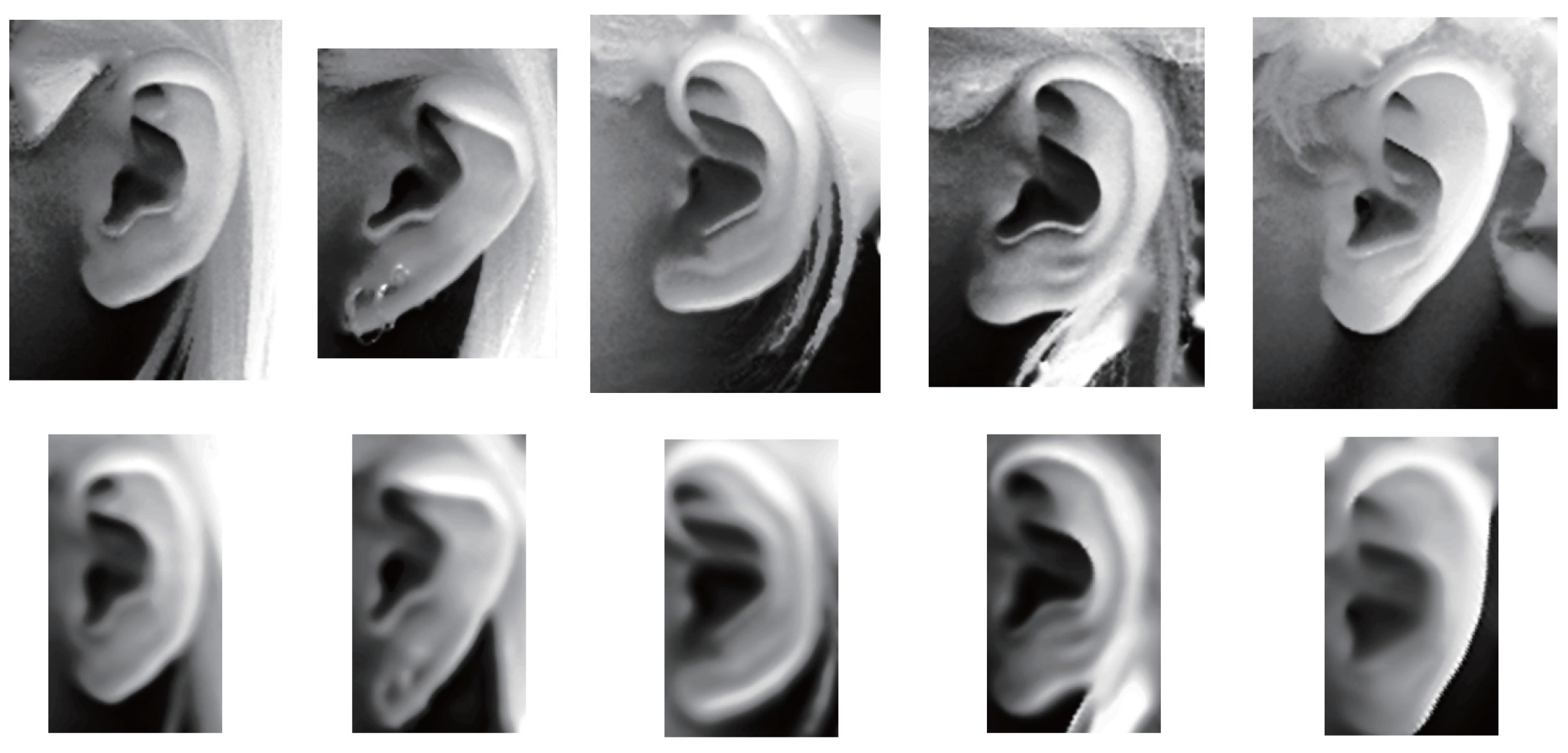
Ear data that has been extracted from profile views can be basically classified as pure data which are extracted along the ear edge and the rectangular ear region data. However, automatic extracting approaches of pure ear data based on 2D or 3D ear edge information are not robust to background noise or minor hair covering around the ear. As to ear region data, there is a lot of hair and face skin data in most cases. As we know, the hair data are considered to be a negative influence for an ear recognition system; in comparison with the ear, the flat face skin surface is not feature-rich. Researchers have experimentally demonstrated that the non-ear data barely have a positive contribution to recognition. After removing pure ear data manually from the ear region data, which are segmented by an AdaBoost detector, the rank-one recognition rate is only 27.2% [
24].
2.2. 3D Ear Recognition
Existing 3D ear recognition approaches utilizing 3D point cloud or range images can be basically classified as local feature matching, ICP global registration, or a combination of both.
In a previous study [
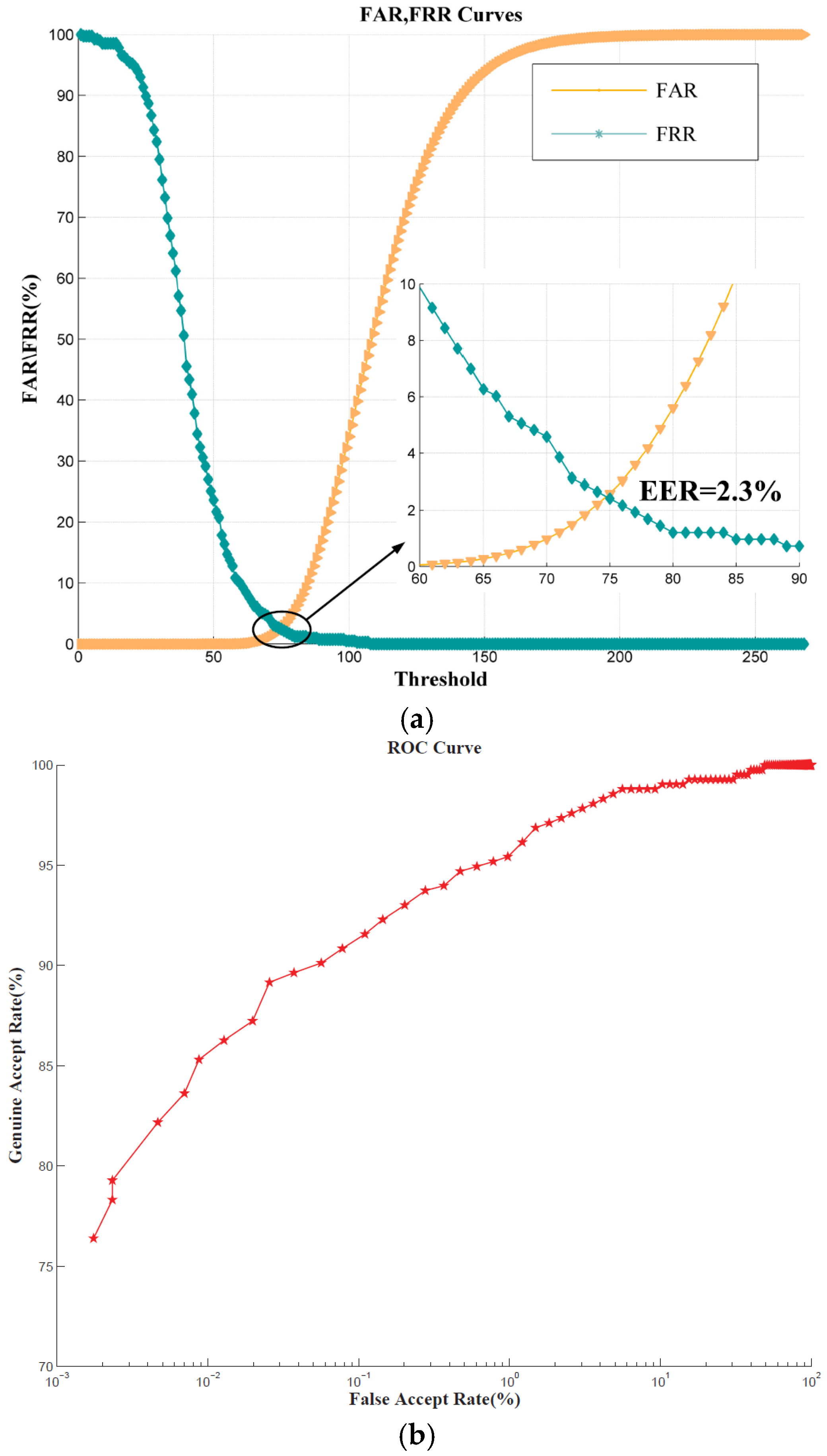
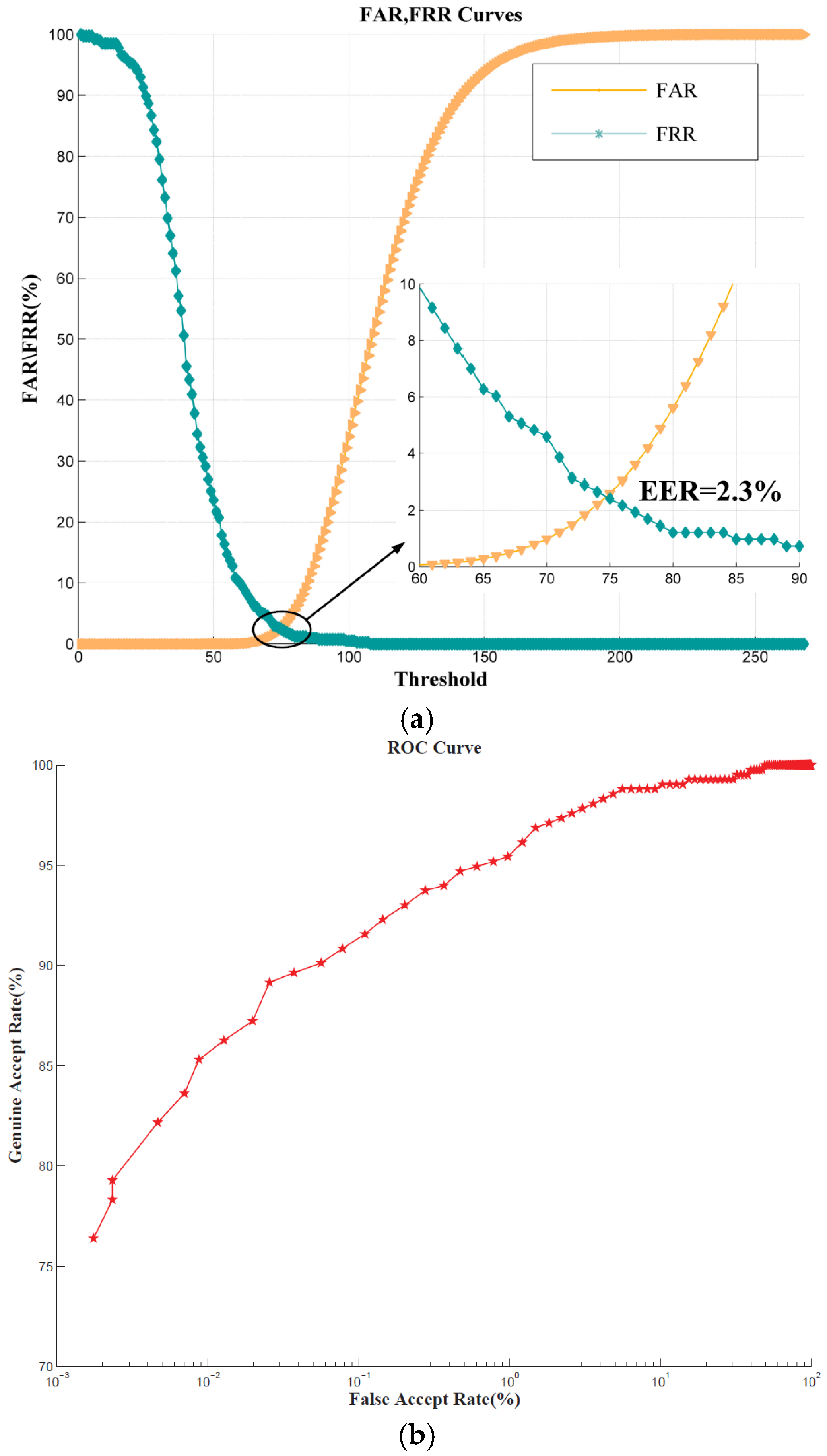
6], Sun et al. proposed a method to sort key points on point clouds for 3D ear shape matching and recognition. The Gaussian-weighted average of the mean curvature was utilized to select the salient key points. Then the angle between two feature vectors was used to calculate the similarity of two local features. Finally, the overall similarity of two ears was measured by the confidence weighted sum of all the measures. The approach achieved a rank-one recognition rate of 95.1% and an equal error rate (EER) of 4% on UND-J2 database. Zeng et al. proposed an ear recognition approach based on 3D key point matching in [
25]. The 3D key points were detected using the shape index image and the scale space theory. Then they constructed 3D Center-Symmetric Local Binary Pattern (CS-LBP) features and used a coarse to fine strategy for 3D key point matching. The rank-one recognition rate on UND-J2 database was 96.39%.
The ICP algorithm is widely used to align 3D rigid models [
26]. The algorithm obtains correspondences by looking for the closest points, and then minimizes the mean square distance between the pairs. Cadavid and Abdel-Mottaleb [
27] proposed an approach based on ICP for 3D ear recognition using video sequences. They obtained 84% rank-one recognition rate on a database of 61 gallery and 25 probe images. Yan and Bower compared three ear based human recognition techniques in [
28]. They explored the use of a Principal Component Analysis (PCA)-based approach on a range image representation of the 3D data, Hausdorff matching on edge images obtained from 3D ear images and an ICP approach on a point-cloud representation of the 3D data. They confirmed that ICP matching achieved the best performance. In their later work [
17], Yan and Bower put forward an approach of 3D ear recognition according to the RMS registration error of the ICP algorithm. They used a k-d tree data structure in the search for closest points and limited the maximum number of iterations to reduce the time consumption. The system achieved a rank-one recognition rate of 97.8% on the UND database in the identification stage and an EER of 1.2% in the verification stage. However, only beginning with a translation vector which was estimated from the ear pit location, it took 5–8 s to match a pair of ears on a dual processor 2.8 Gigahertz (GHz) Inter
® Pentium Xeon system. Therefore, this indicated that an initial guess of the full 3D (translation and rotation) transformation is significant for an ICP-based algorithm.
Recently, the coarse-to-fine ICP based 3D ear recognition algorithm which combines local feature extraction and ICP global registration has drawn extensive attention. The gallery-probe pairs are coarsely aligned based on the local information extracted from the feature correspondences in order to get a relatively accurate initial transformation, and then are finely matched via the ICP global registration.
Chen and Bhanu detected and aligned the helix of the gallery-probe pairs to get the initial rigid transformation in [
29]. Then the ICP algorithm iteratively refined the transformation to bring model ears and test ears into the best alignment. The recognition rate on a database of 30 subjects was 93.3%. In a previous study [
11], Chen and Bhanu created the ear helix/antihelix representation and the local surface patch (LSP) representation, which were employed to estimate the initial transformation for a modified ICP algorithm separately. They obtained 96.03% and 96.36% recognition rates, respectively, on the Collection F of the UND database. Due to the high dimensionality of LSP feature representation, in their later approach [
30], an embedding algorithm was employed to map the feature vectors to a low-dimensional space. The similarities for all model-test pairs were computed using the LSP features and ranked using SVM to generate a short list of candidate models for verification. The verification was performed by aligning a model with the test object via the ICP algorithm. On the UND Collection F, the rank-one recognition rate was 96.7%, and EER was 1.8%.
In a study by Islam et al. [
31], a coarse-to-fine hierarchical technique was used where the ICP algorithm was first applied on low and then on high resolution meshes of 3D ear data. The rank-one recognition rates of 93% and 93.98% were achieved respectively on UND Biometrics Database A and Database B. In a later approach [
12], Islam represented the 3D ear data with local 3D features (L3DF) to extract a set of key points for L3DF-based initial alignment, then the fine recognition result was obtained through the ICP algorithm. The system provided an identification rate of 93.5% on the UND-J database. Nevertheless, extraction of L3DF was relatively complex, so that the extraction time for a single ear was 22.2 s on an Inter
® Core
TM2 Quad 9550, 2.83 Gigahertz (GHz) machine.
Prakash and Gupta proposed a two-step matching technique which makes use of 3D and co-registered 2D ear images [
32]. They extracted a set of local 2D features points using the Speed Up Robust Feature (SURF) descriptor. Then the co-registered salient 3D data points were used to coarsely align 3D ear points. The final matching was performed by integration of Generalized Procrustes Analysis (GPA) with ICP (GPA-ICP). The technique achieved a verification accuracy of 98.30% with an EER of 1.8% on the UND-J2 database. The key points were extracted from the 2D ear images—compared with 3D local descriptors, the SURF descriptor may not be robust to pose and illumination variations.
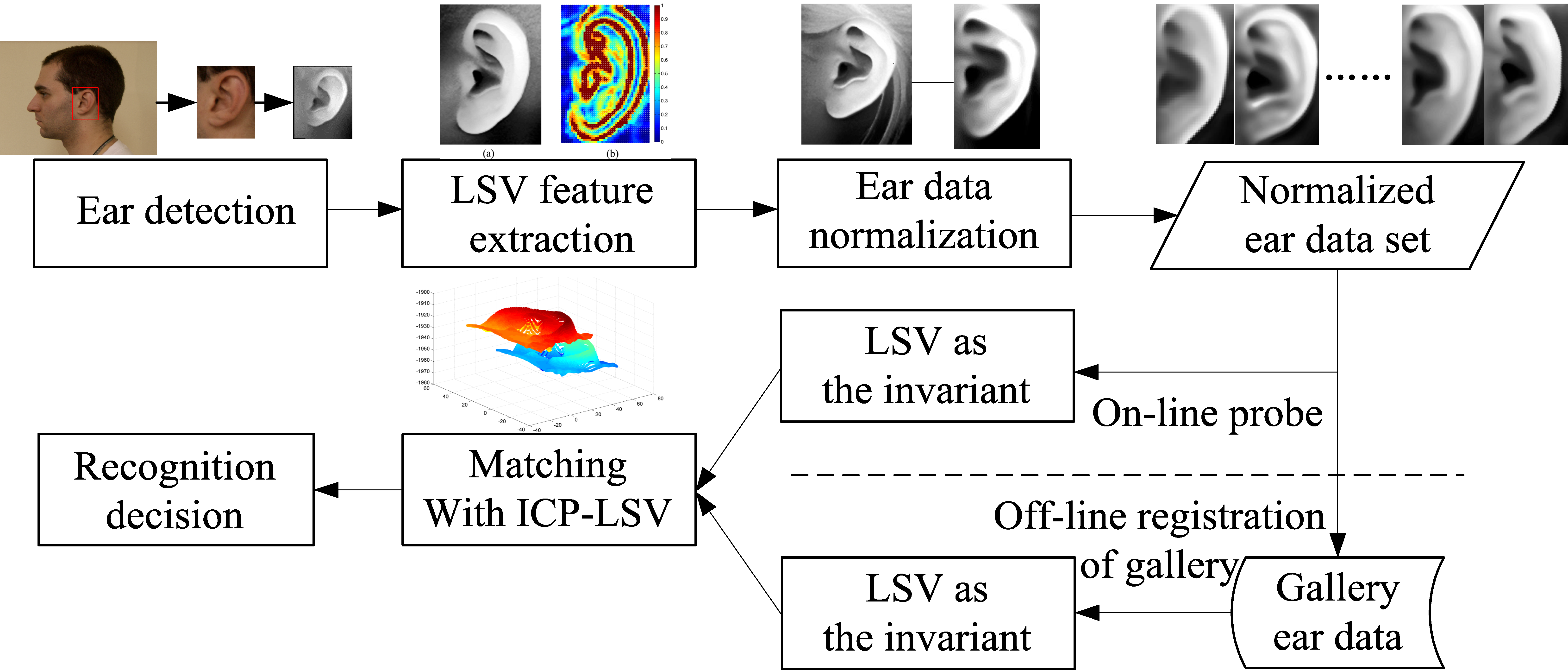
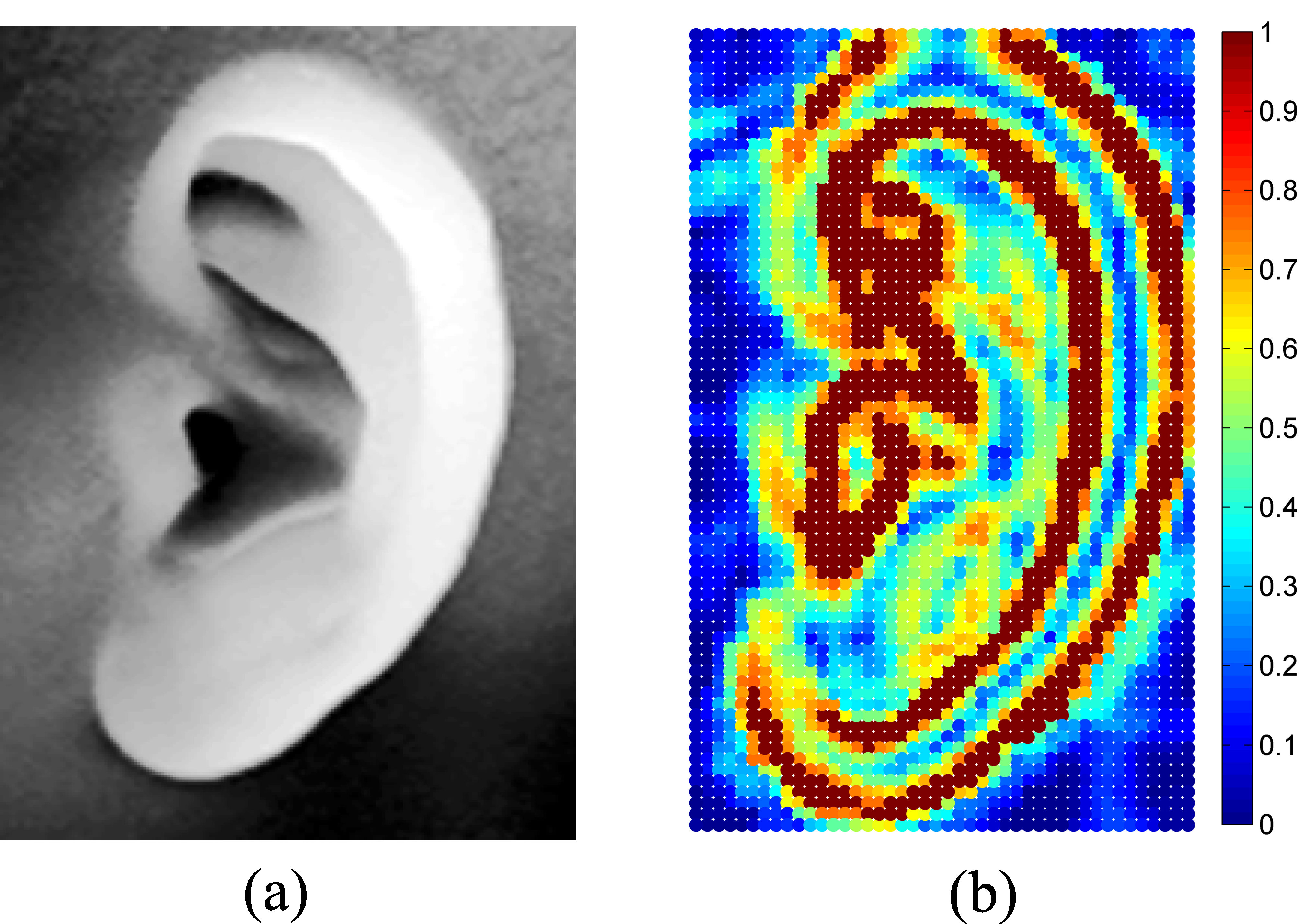
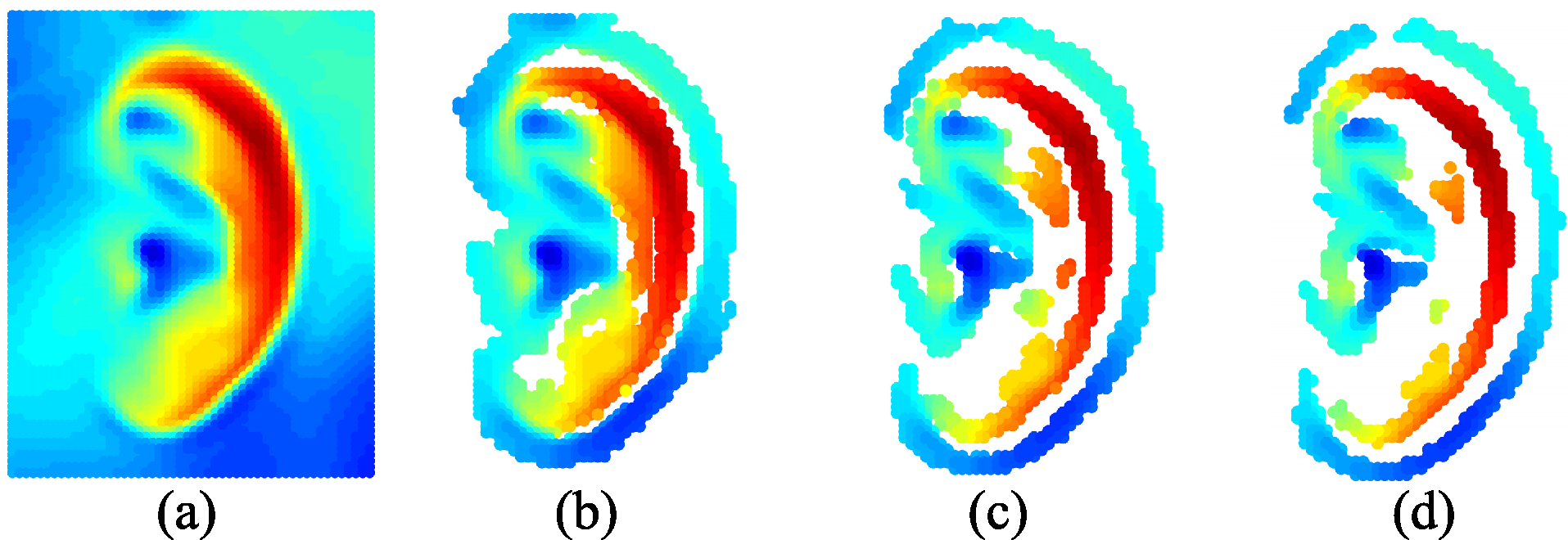
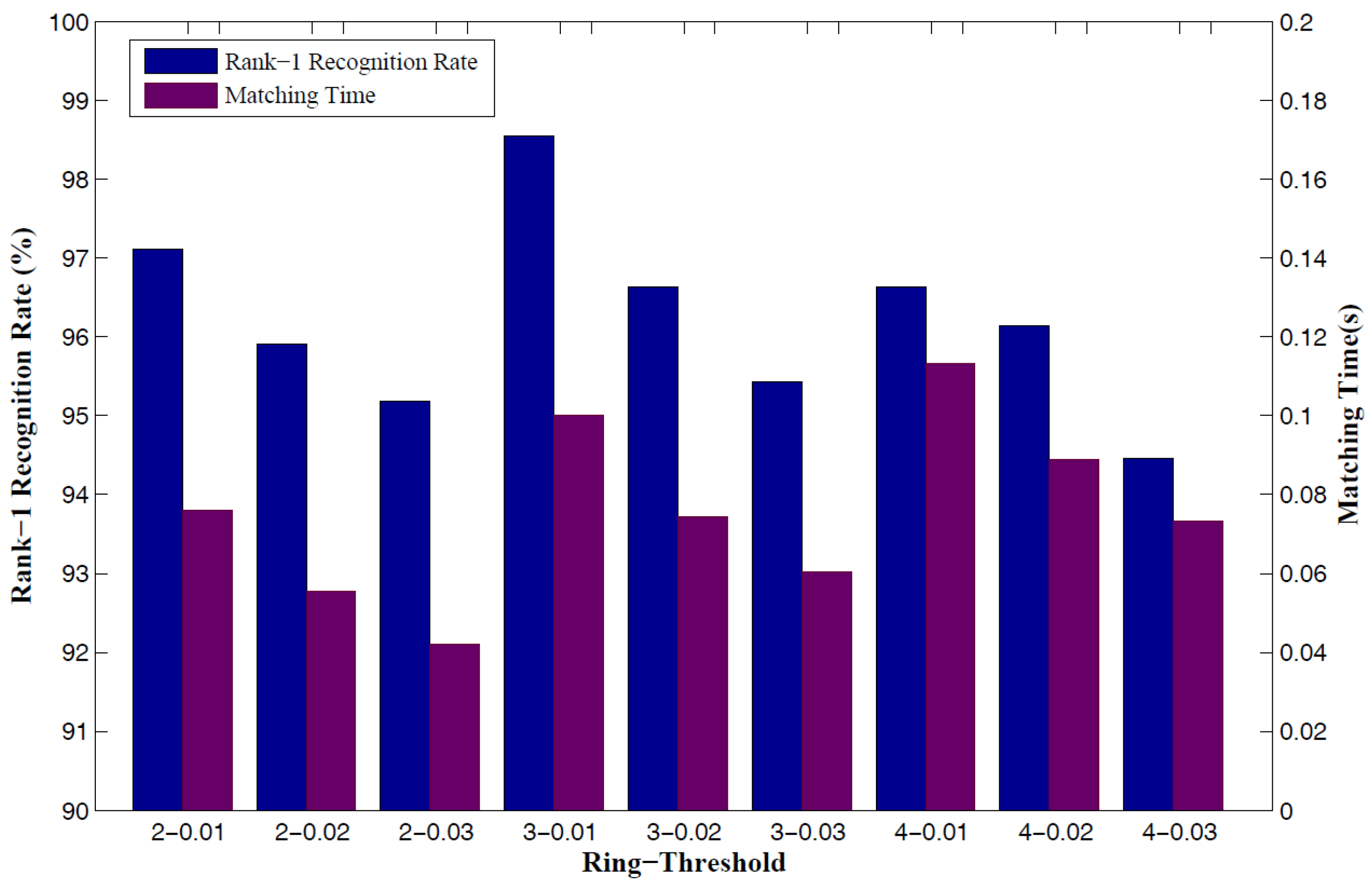
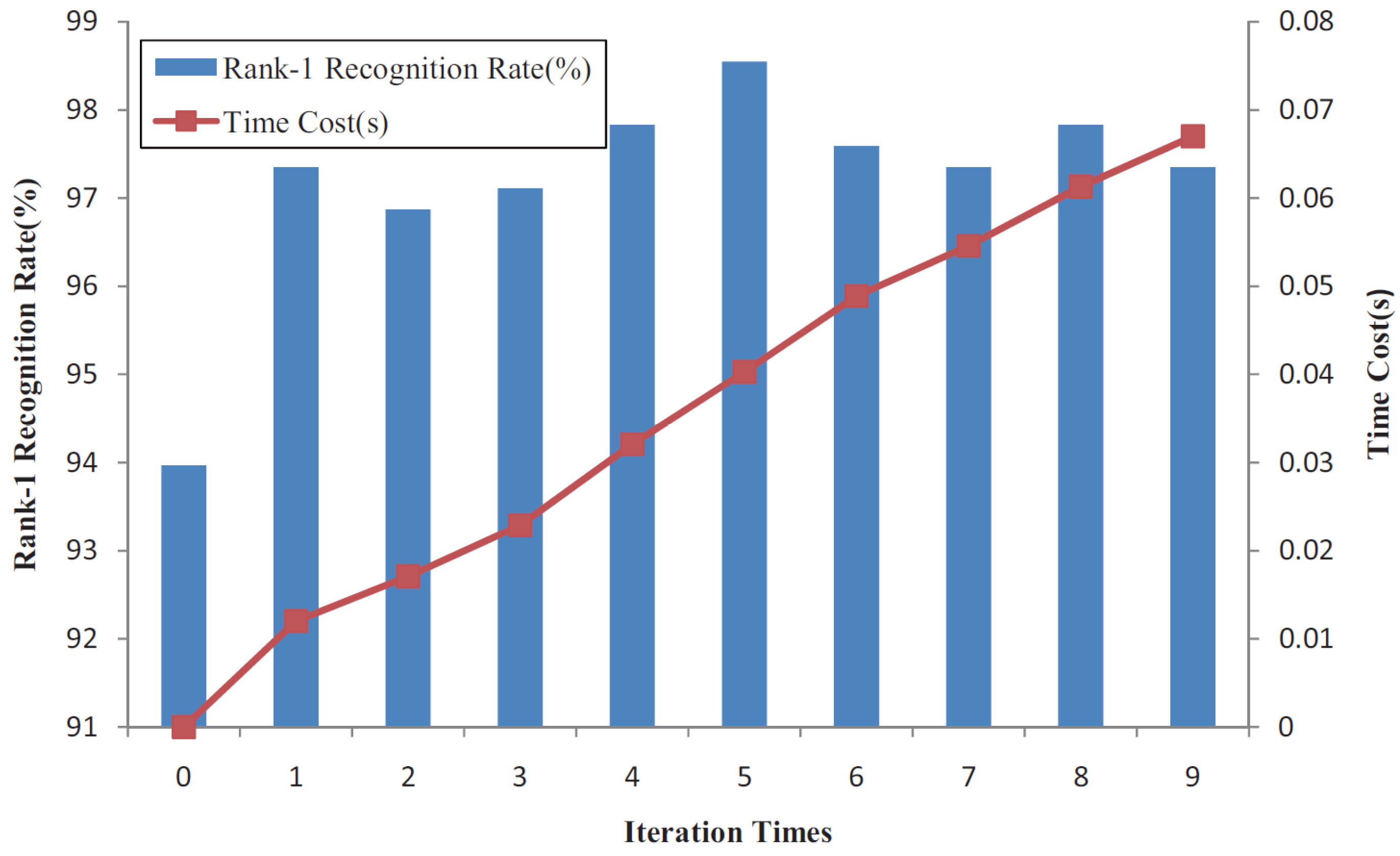
The schemes based on local feature matching and ICP global registration both have advantages and disadvantages for ear recognition. The matching method using local surface descriptors can represent free-form surfaces effectively, but it may cause mismatching within similar key points without global constraint. Although the ICP-based algorithm obtains high accuracy regarding the registering of 3D rigid models, it may be trapped in local minimum without an accurate initial rigid transformation. It is clear that the combination of local feature matching and ICP global registration in 3D ear recognition is effective. However, in the existing two-step alignment methods, the local feature points are extracted to refine the initial alignment, and then the results of matching are based on the ICP procedure using the original ear data. It treats all the points equally, regardless of how much useful information the point represents. However, it ignores the fact that not all the points in the coarsely segmented ear data make positive contributions to recognition. Since the local features can distinguish the useful data points from useless data, we do not have to utilize the original data to make the final decision according to the ICP-based matching.


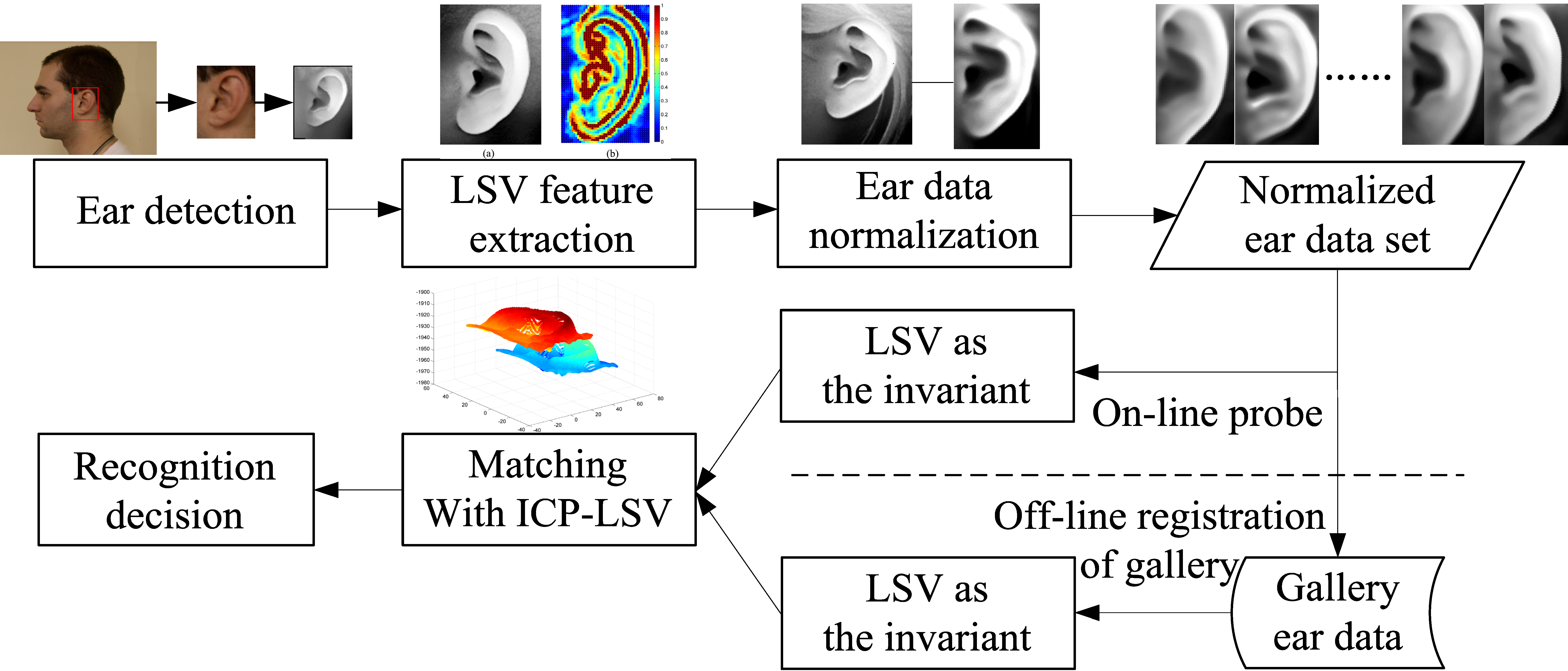
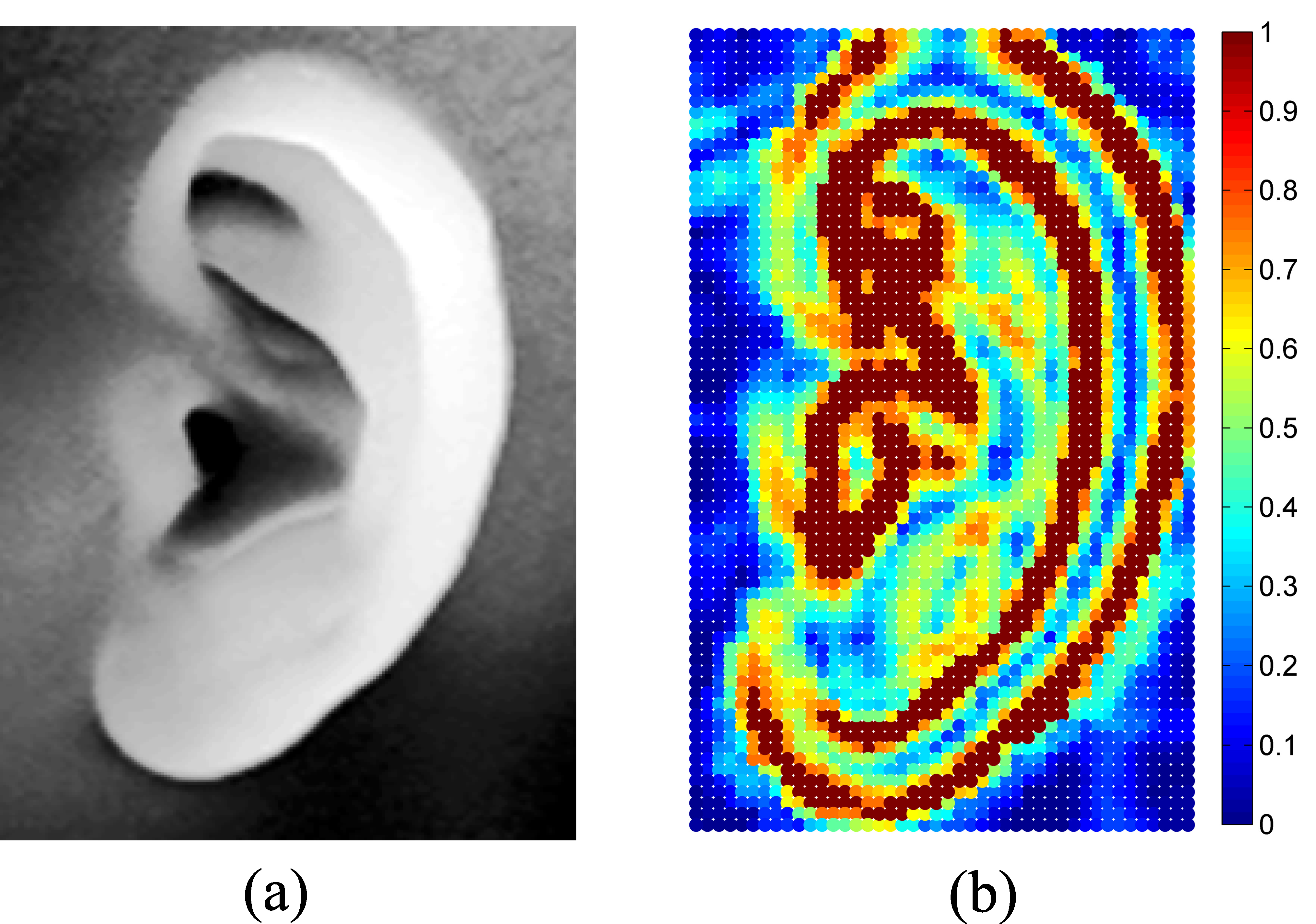
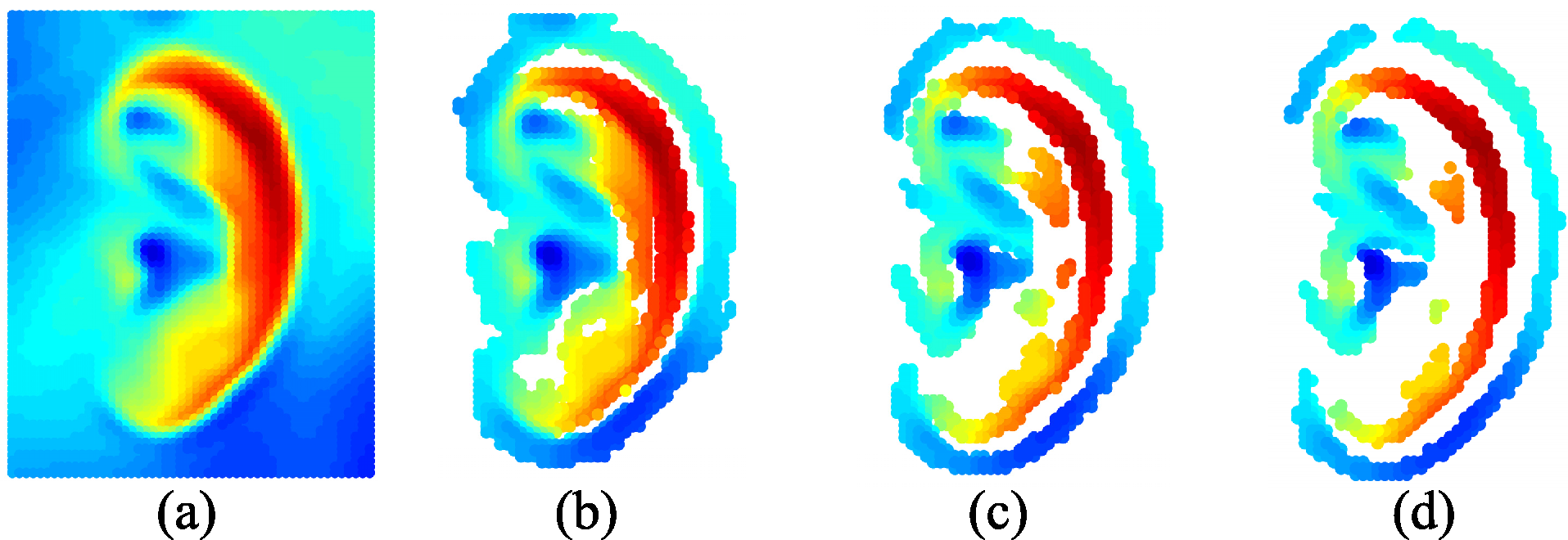

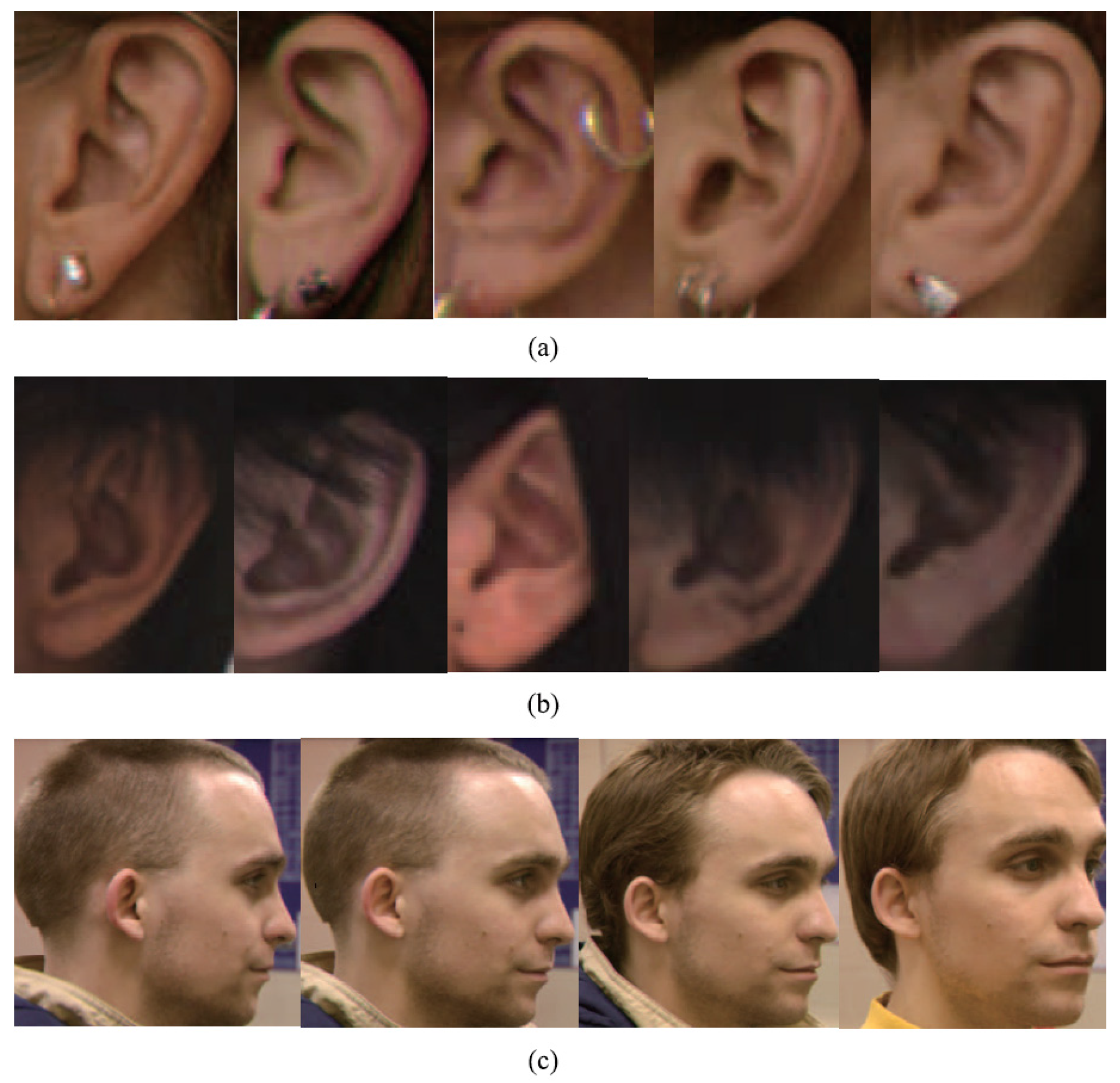
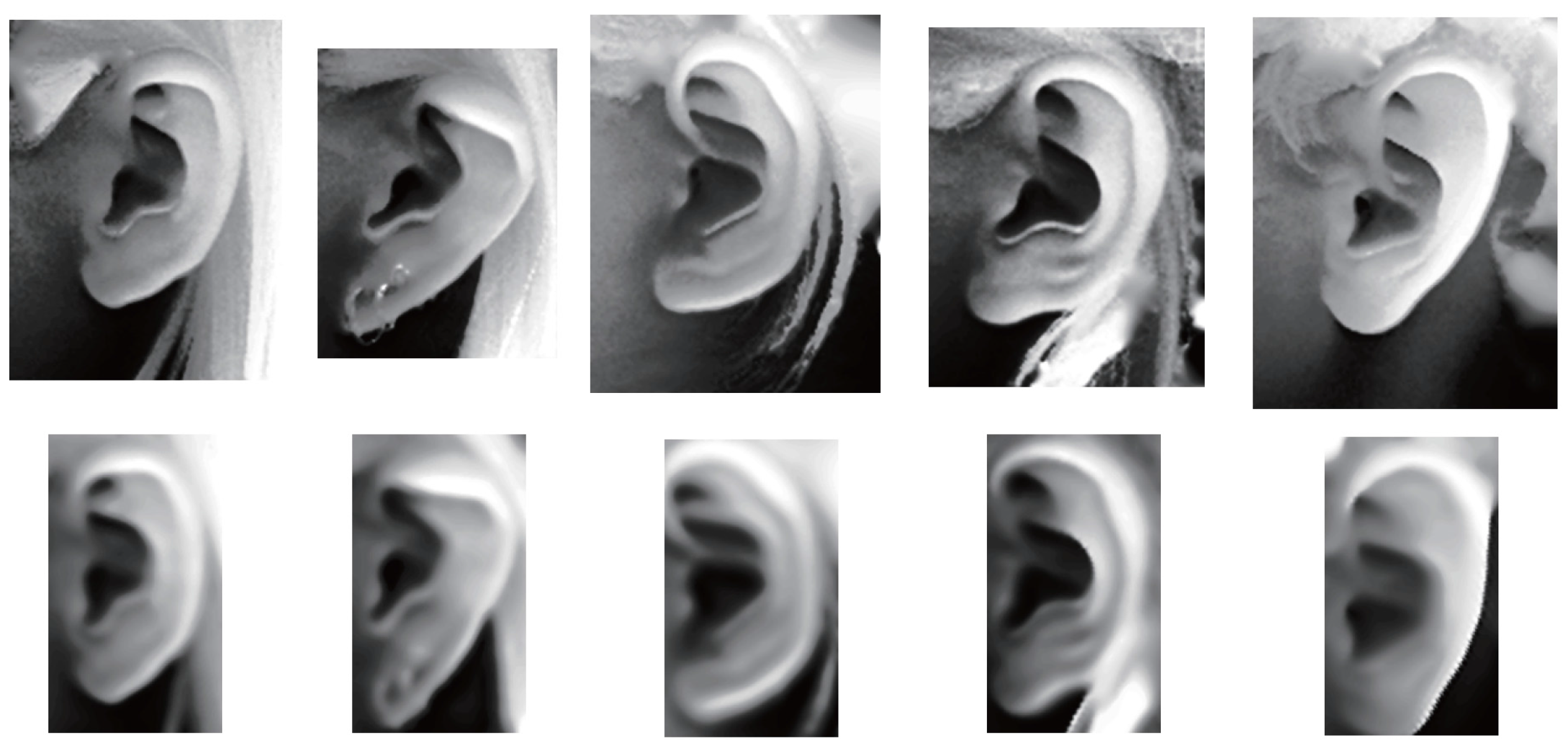

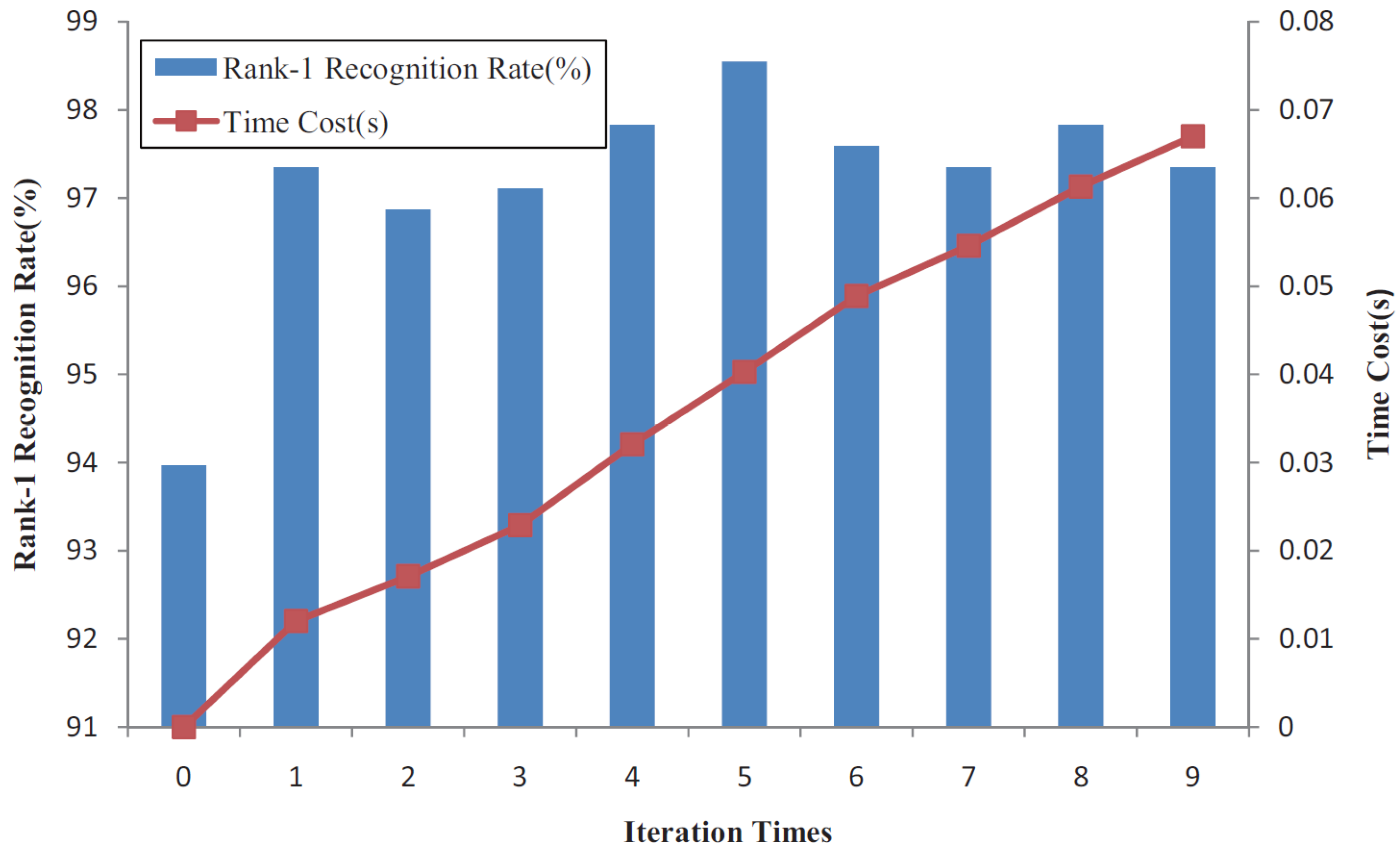
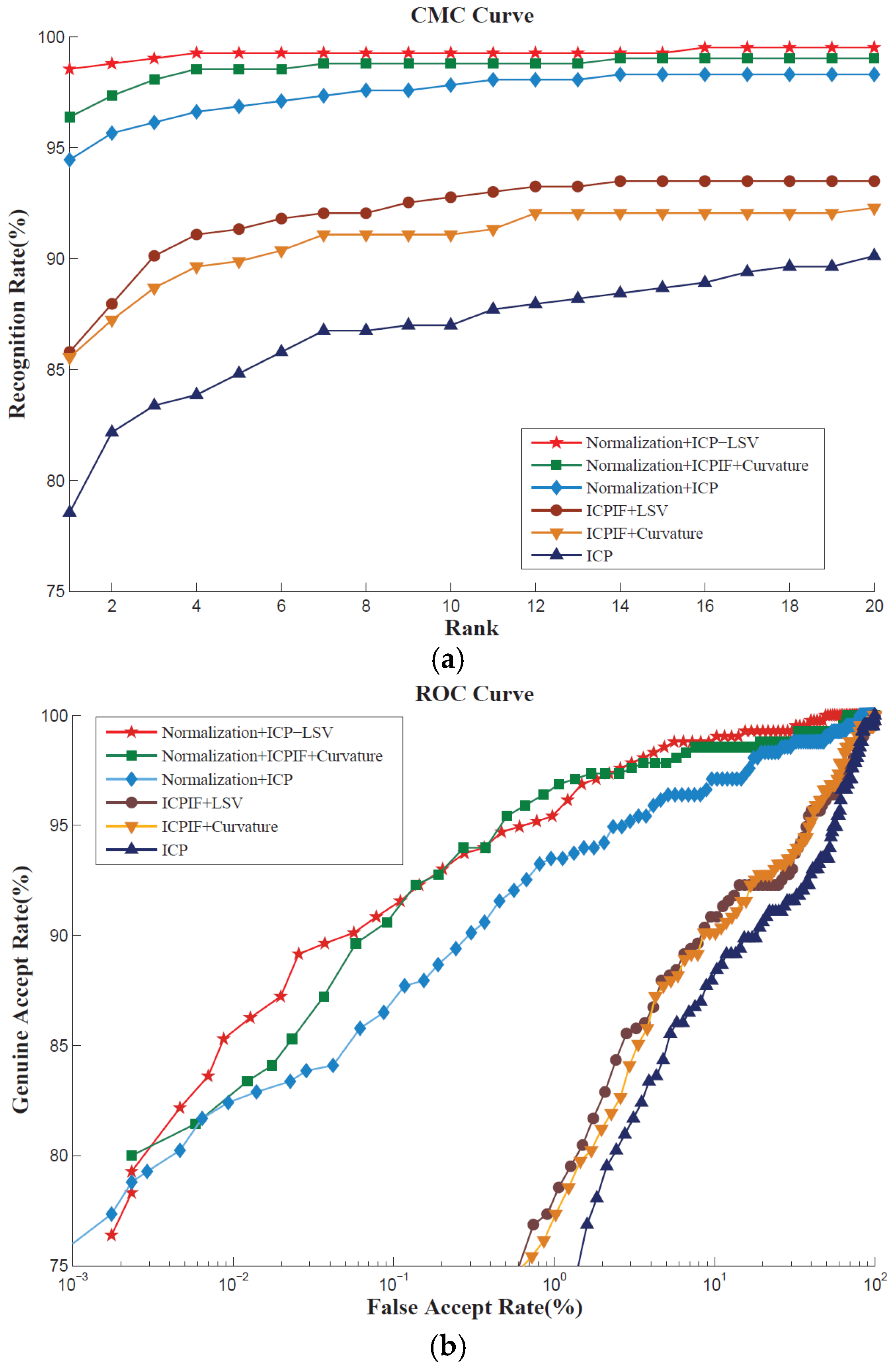

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}