
Endoscopic Laser-Based 3D Imaging for Functional Voice Diagnostics

 ,
, 
Abstract
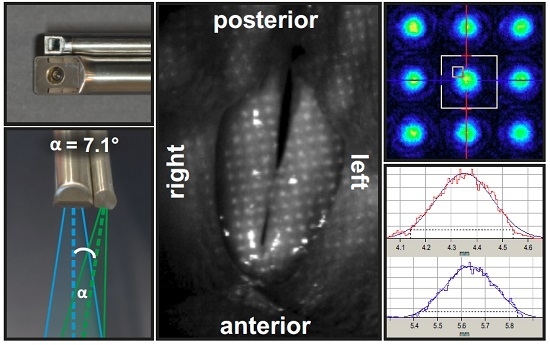
:
1. Introduction
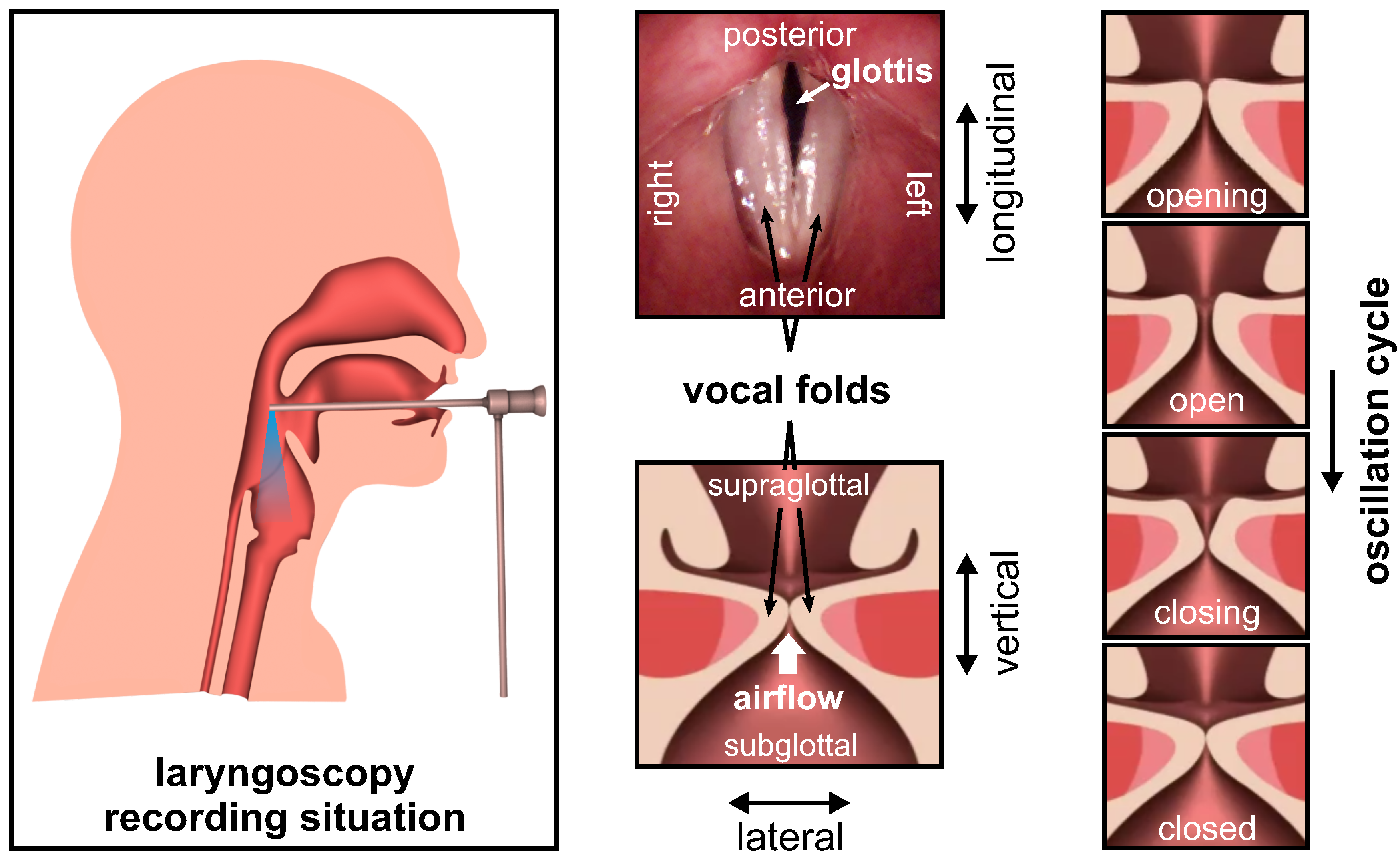
2. Materials and Methods
2.1. Experimental Set-Up
2.1.1. Overview
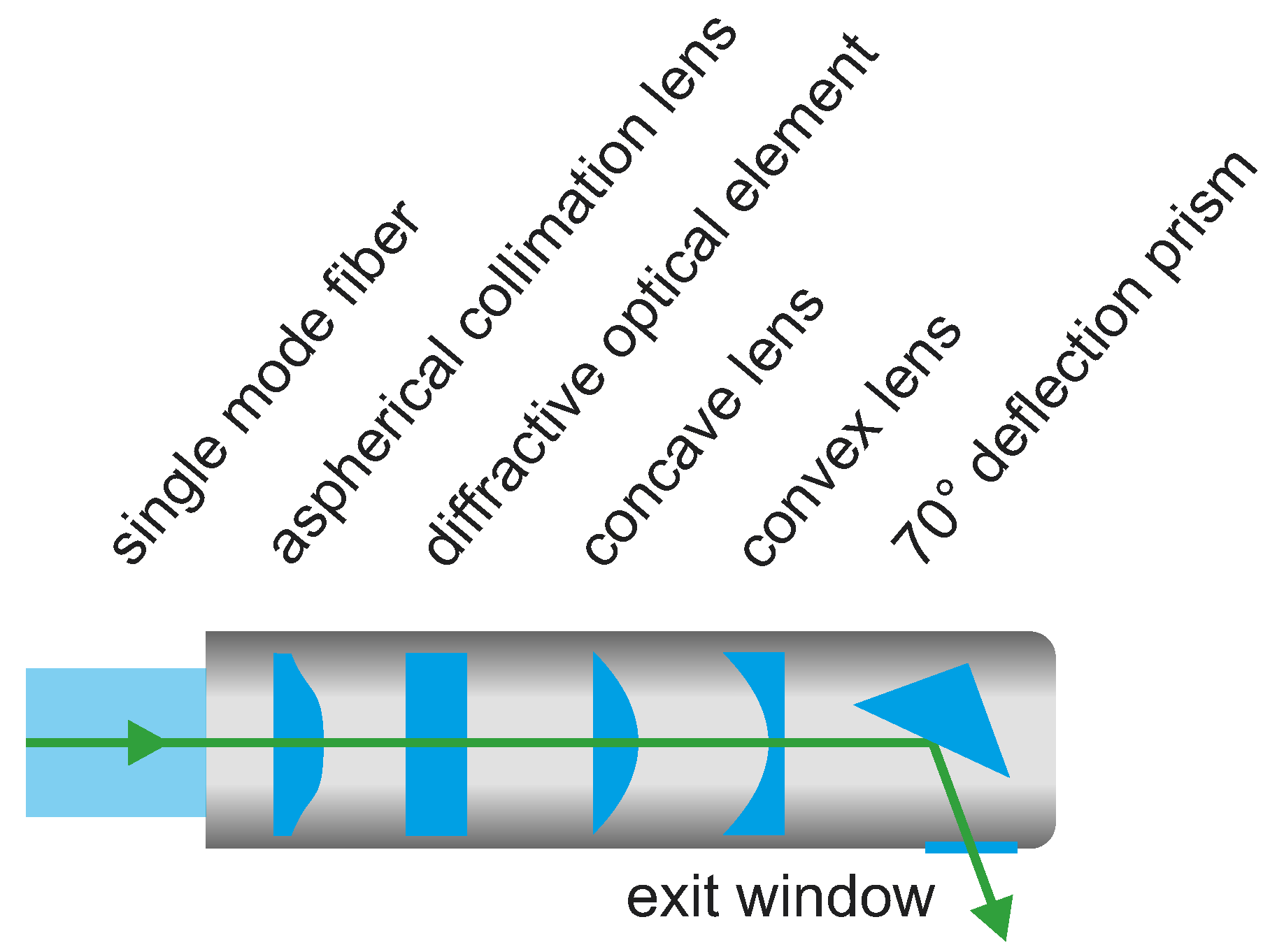
2.1.2. Technical Realization of Laser Projection Unit
2.2. Reconstruction Procedure
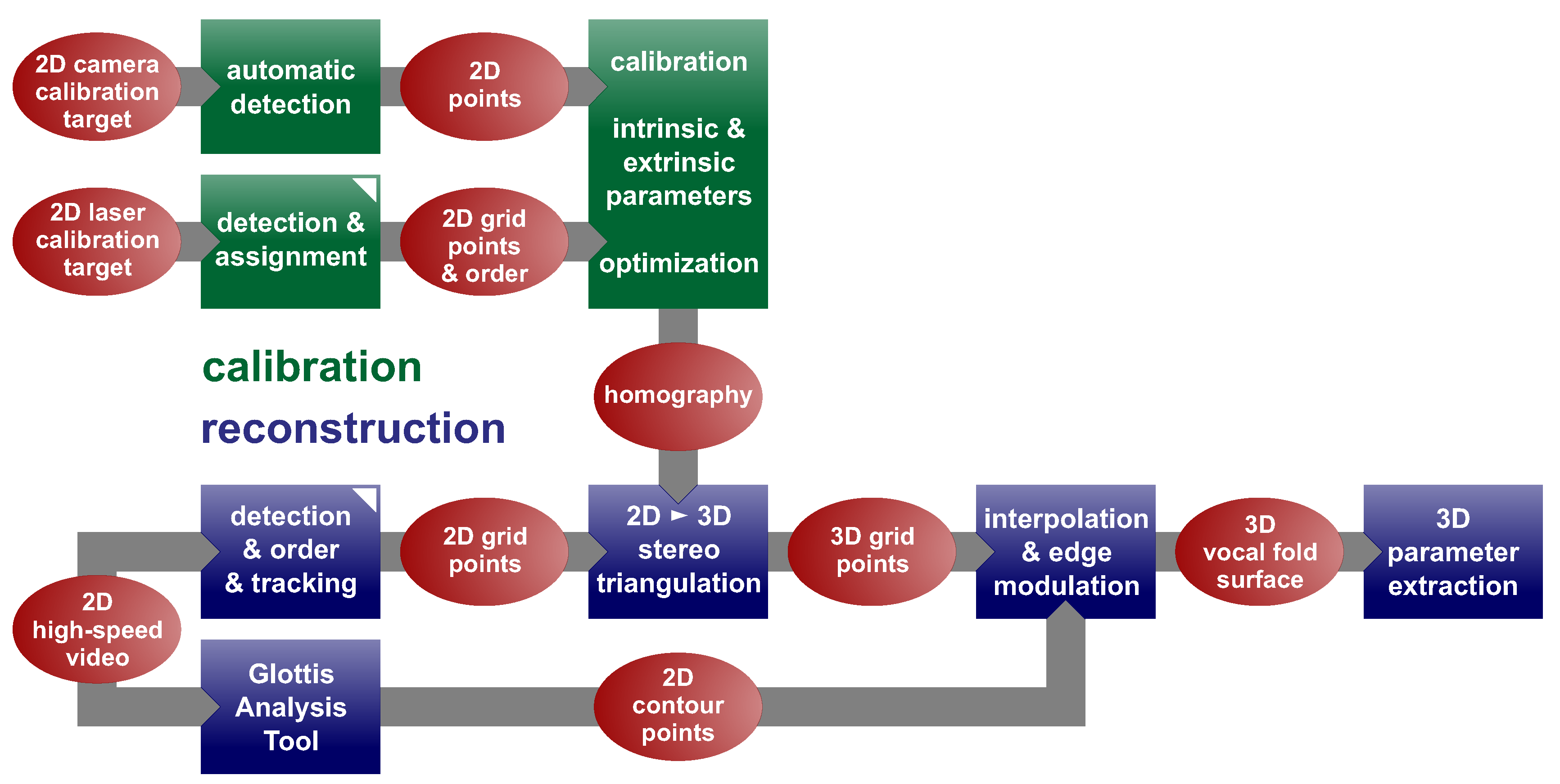
2.2.1. Overview
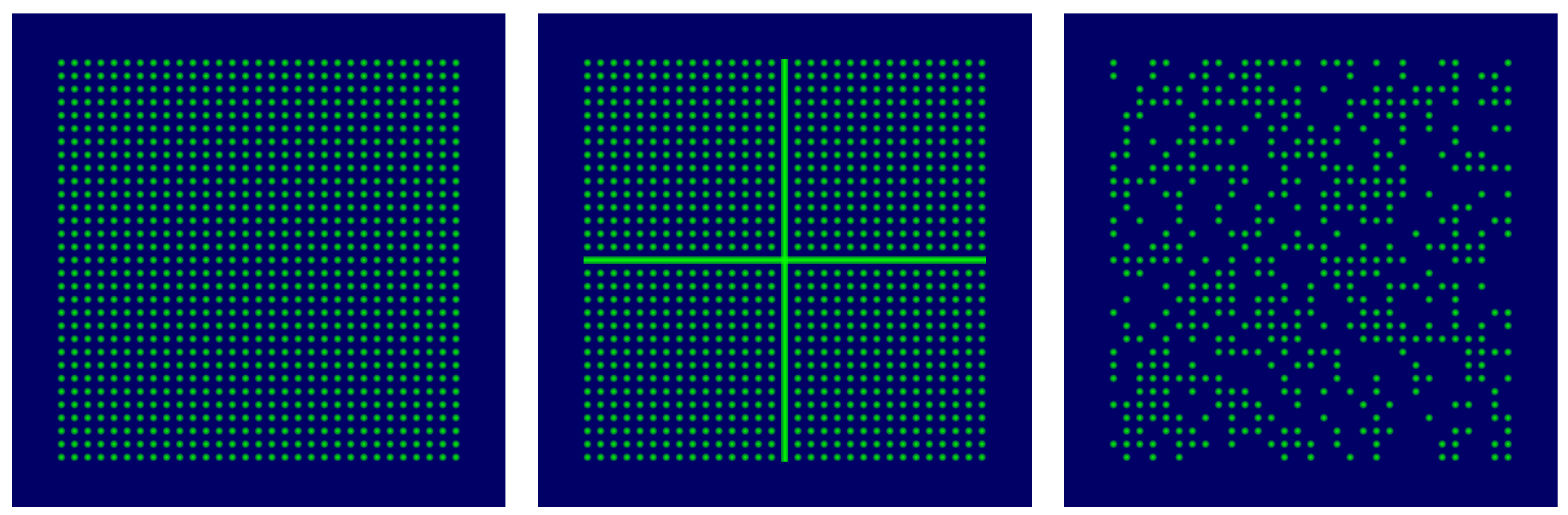
2.2.2. Challenges and Automation of Calibration Process
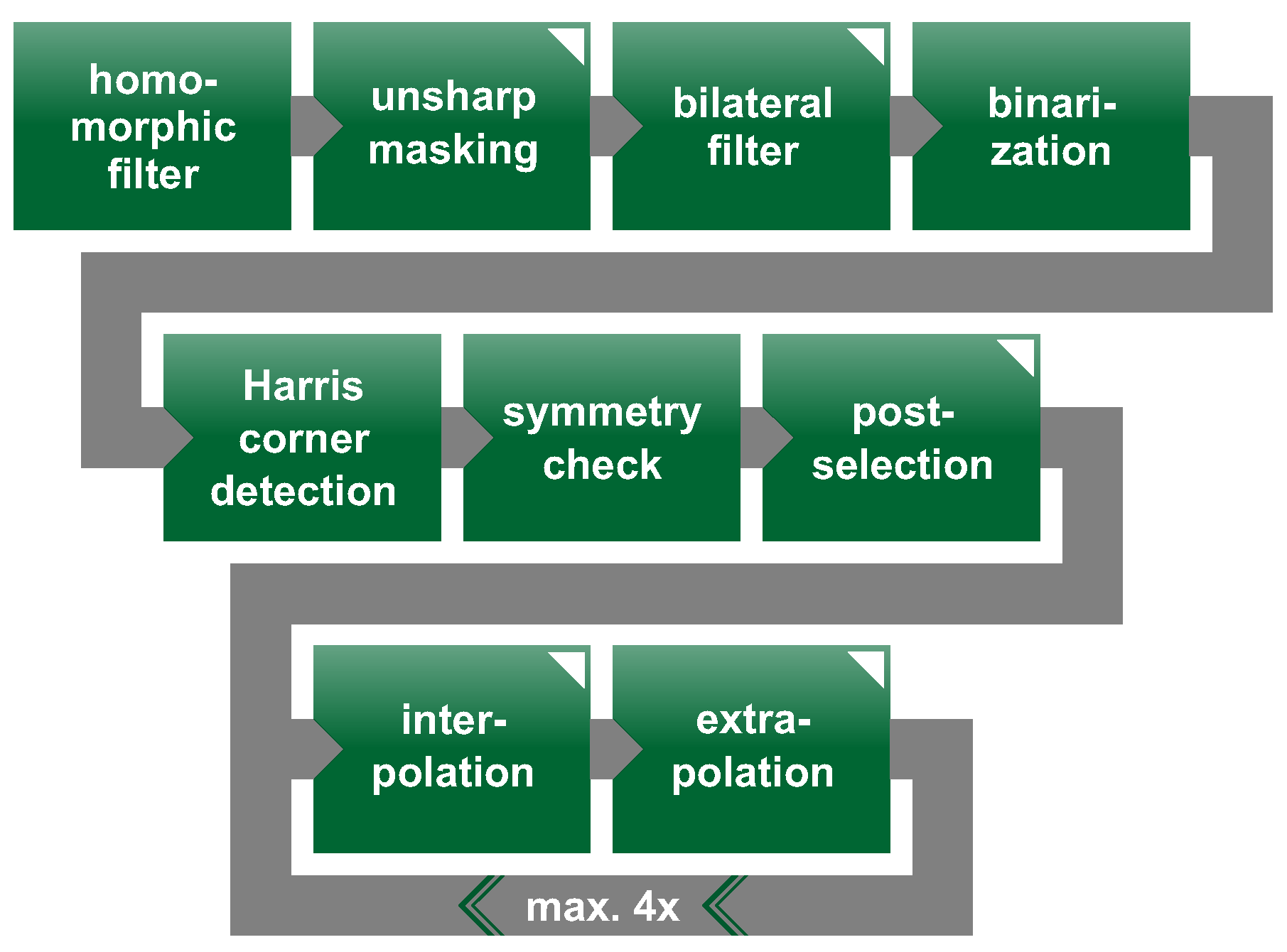
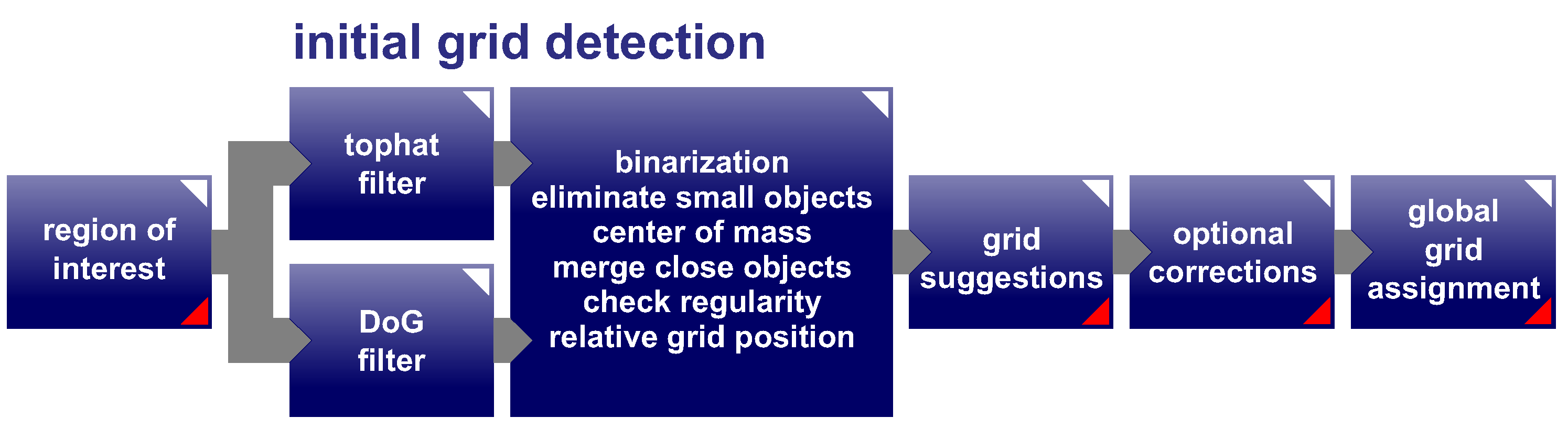
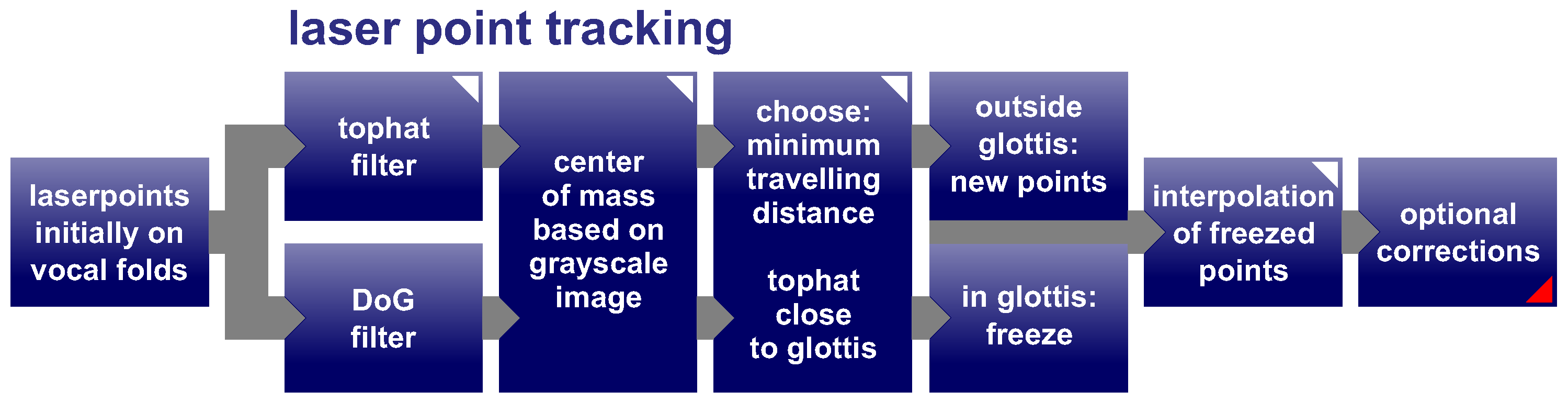
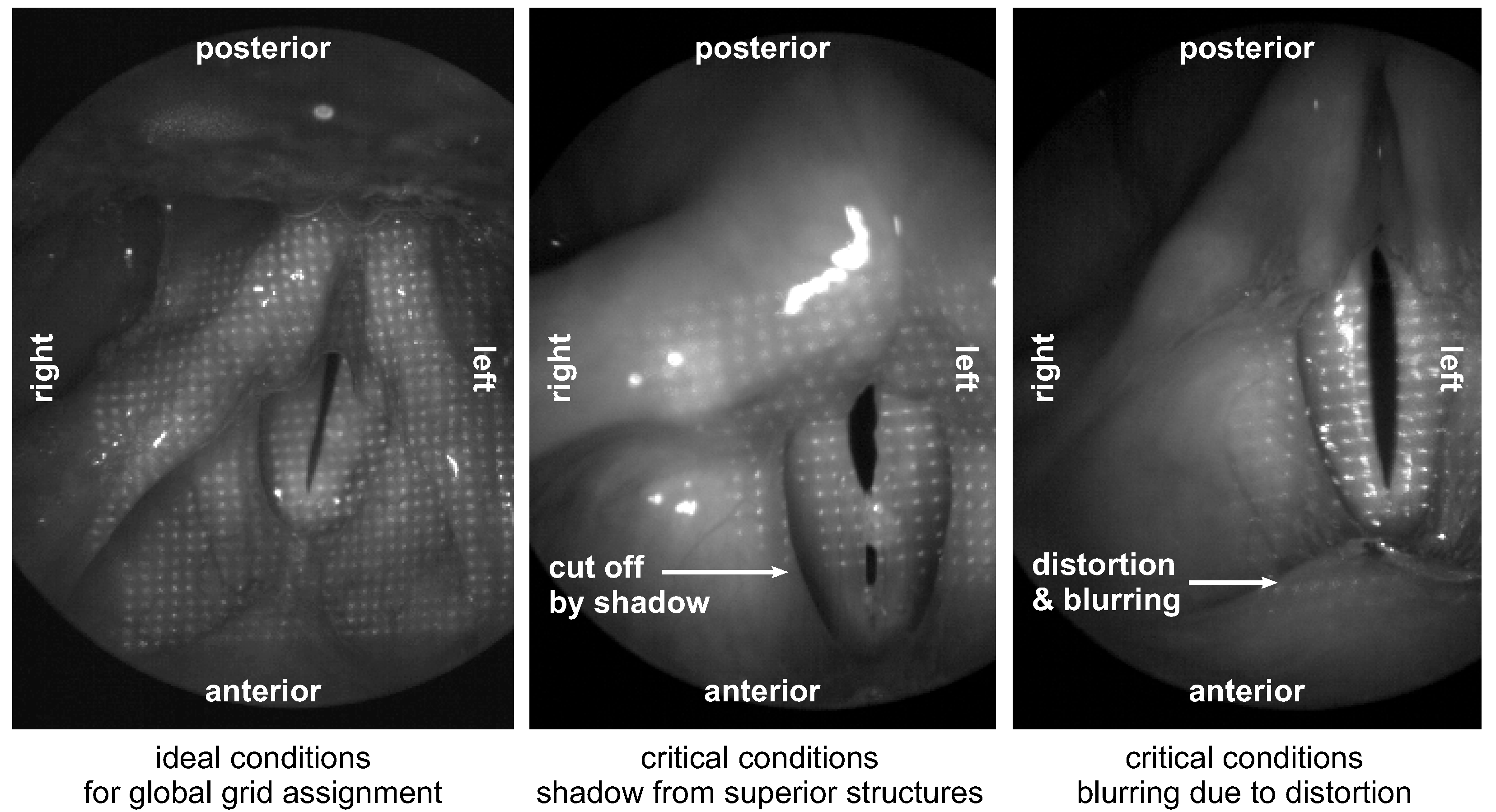
2.2.3. Challenges and Automation of Laser Point Detection
3. Results and Discussion
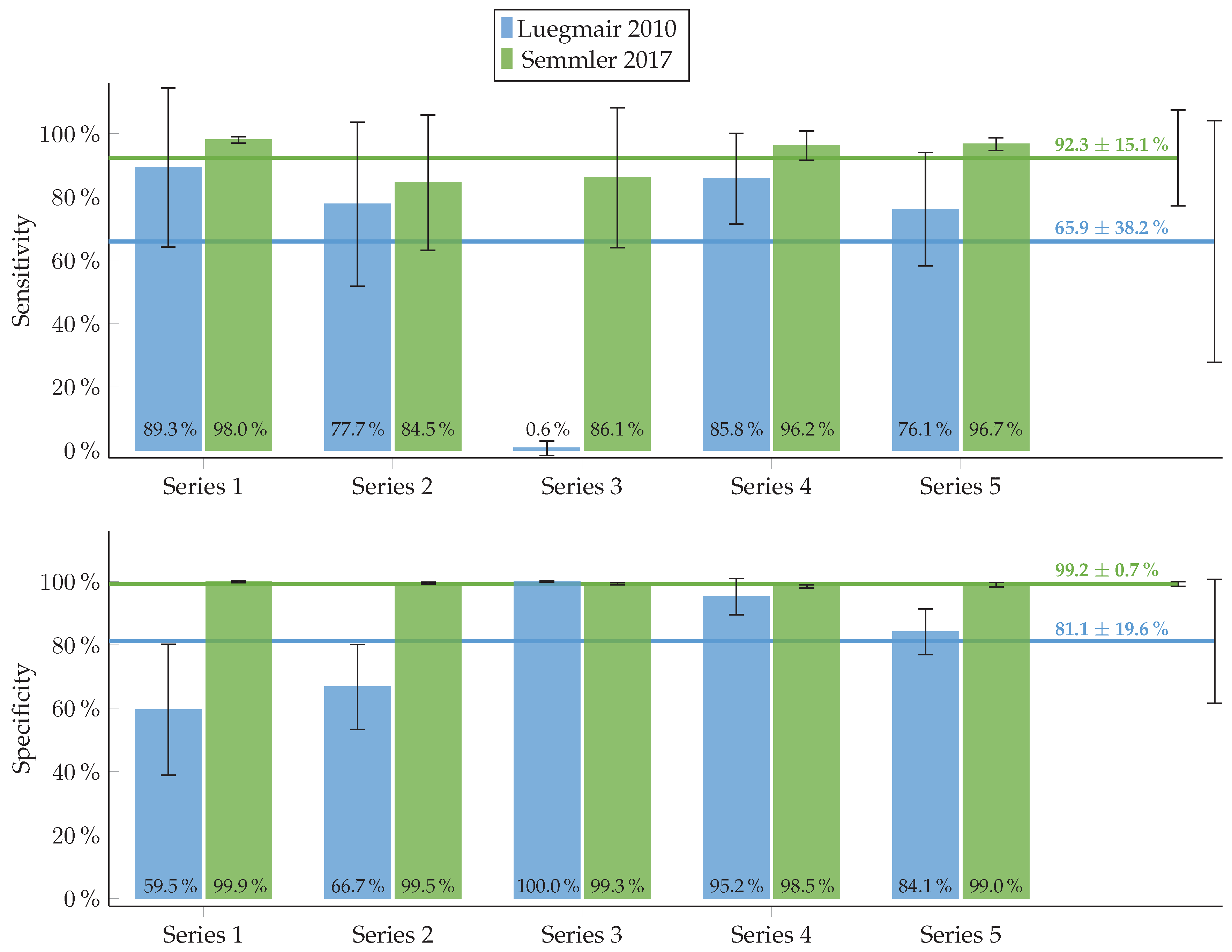
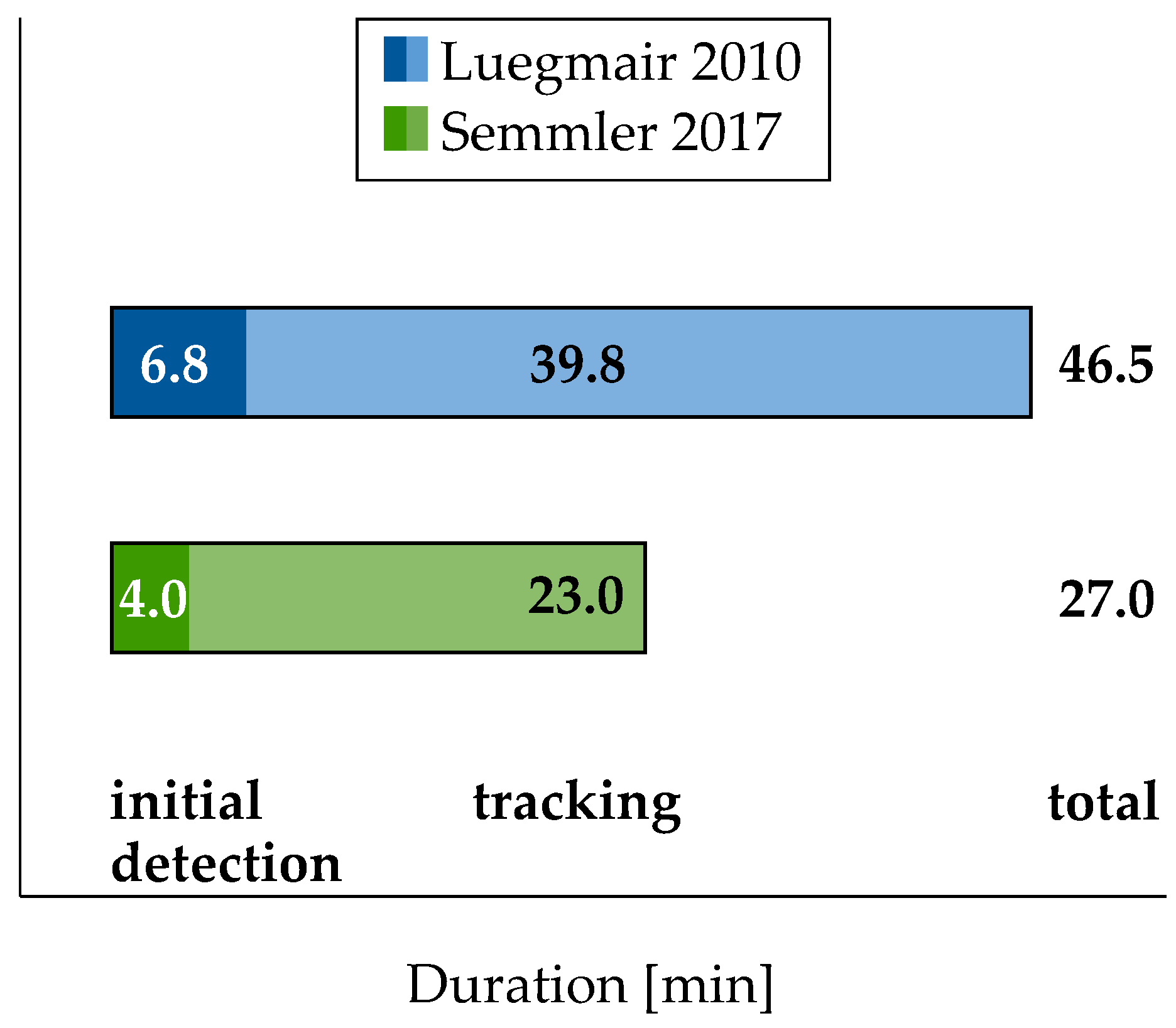
3.1. Evaluation of Automated Calibration Algorithm
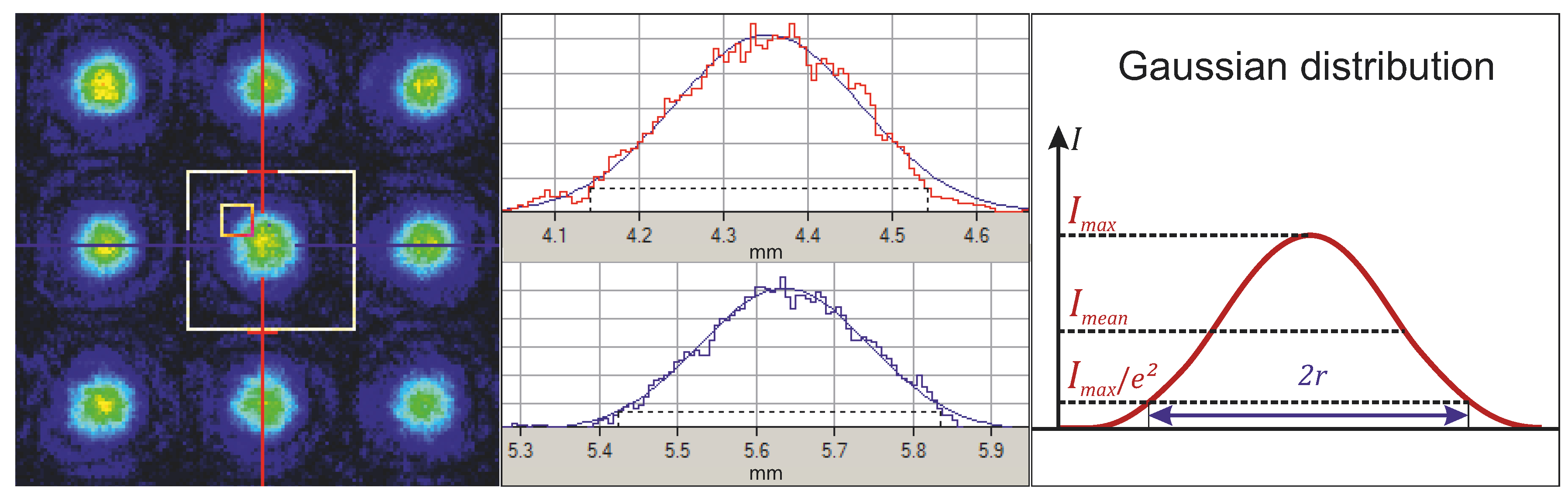
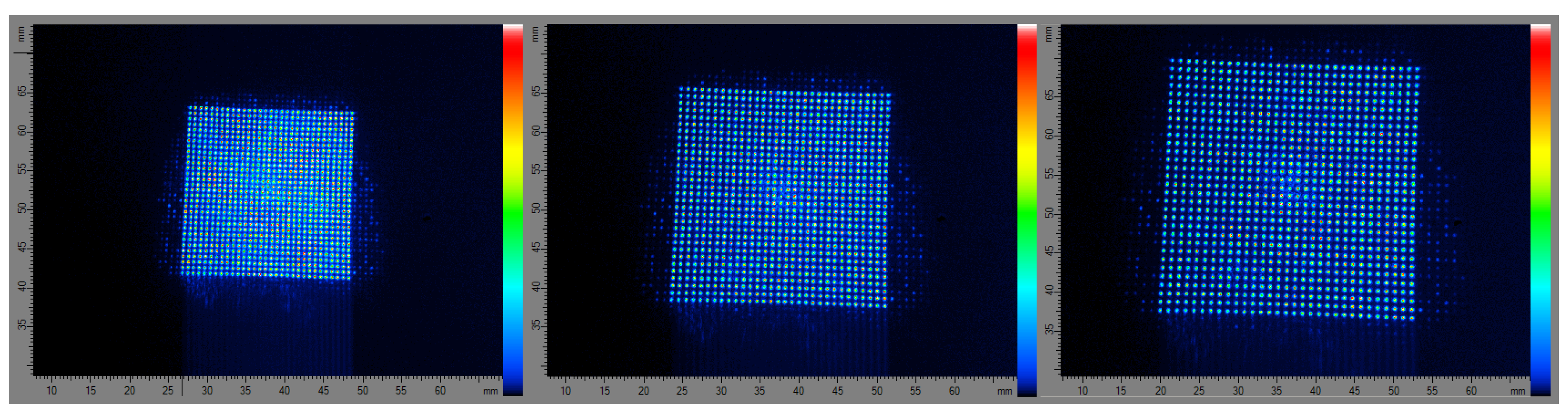
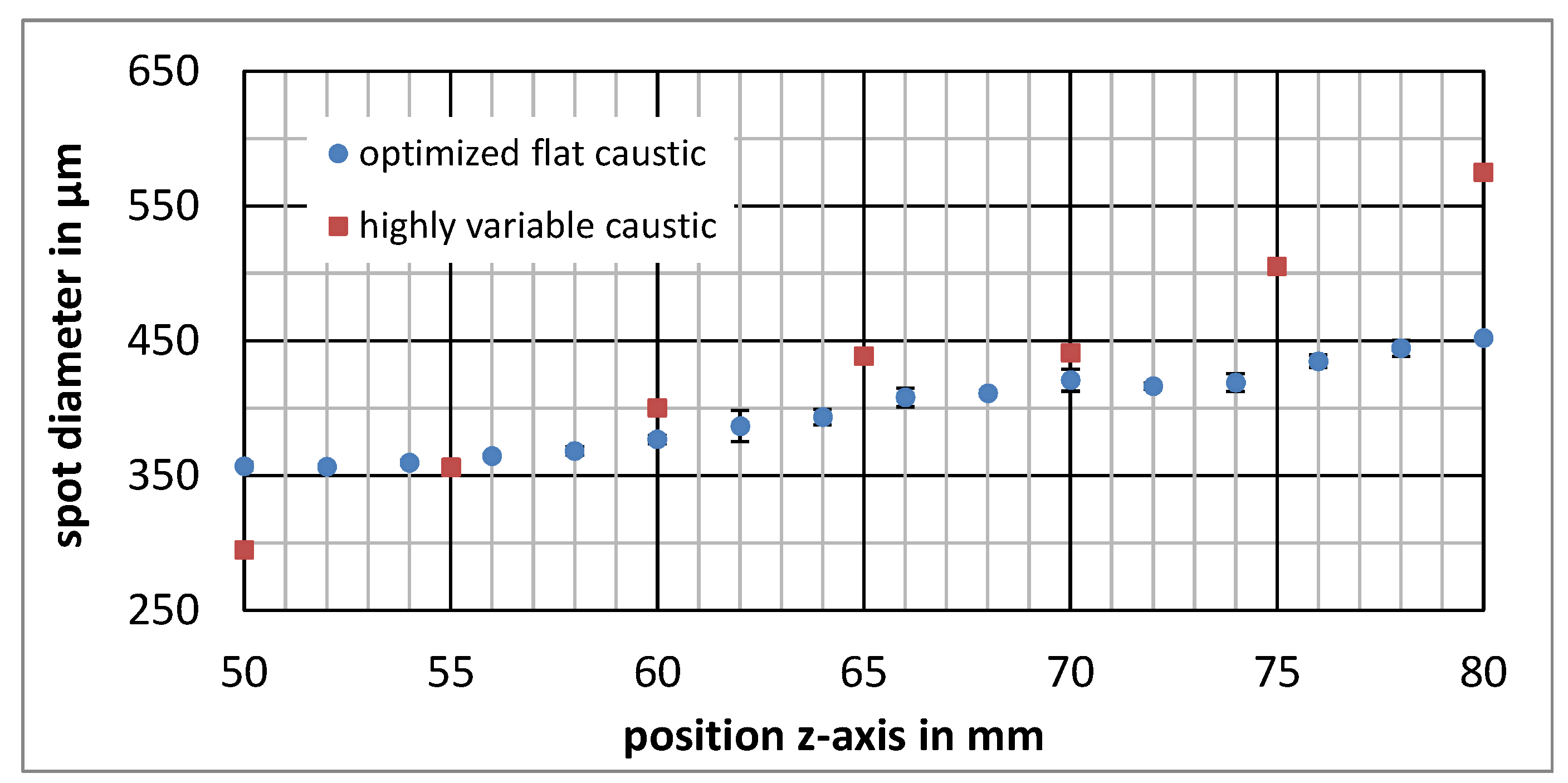
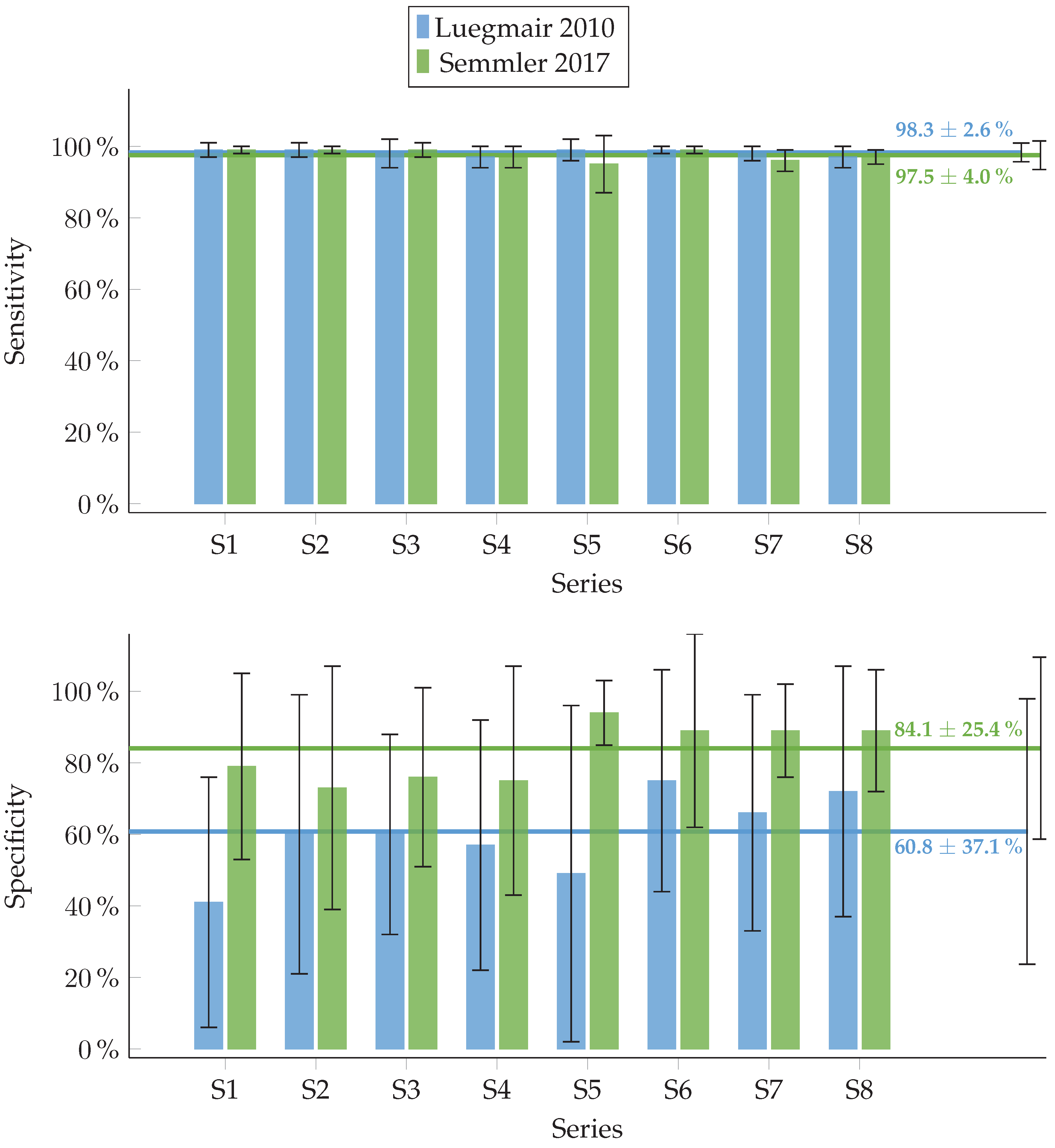
3.2. Evaluation of Automated Laser Point Detection Algorithm
4. Outlook
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ruben, R.J. Redefining the survival of the fittest: Communication disorders in the 21st century. Laryngoscope 2000, 110, 241–245. [Google Scholar] [CrossRef] [PubMed]
- Stevens, K.N. Acoustic Phonetics; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Patel, R.R.; Dubrovskiy, D.; Döllinger, M. Measurement of Glottal Cycle Characteristics Between Children and Adults: Physiological Variations. J. Voice 2014, 28, 476–486. [Google Scholar] [CrossRef] [PubMed]
- Bohr, C.; Kräck, A.; Dubrovskiy, D.; Eysholdt, U.; Svec, J.; Psychogios, G.; Ziethe, A.; Döllinger, M. Spatiotemporal Analysis of High-Speed Videolaryngoscopic Imaging of Organic Pathologies in Males. J. Speech Lang. Hear. Res. 2014, 57, 1148–1161. [Google Scholar] [CrossRef] [PubMed]
- Echternach, M.; Döllinger, M.; Sundberg, J.; Traser, L.; Richter, B. Vocal fold vibrations at high soprano fundamental frequencies. J. Acoust. Soc. Am. 2013, 133, EL82–EL87. [Google Scholar] [CrossRef] [PubMed]
- Petermann, S.; Kiesburges, S.; Ziethe, A.; Schützenberger, A.; Döllinger, M. Evaluation of Analytical Modeling Functions for the Phonation Onset Process. Comput. Math. Methods Med. 2016, 2016, 8469139. [Google Scholar] [CrossRef] [PubMed]
- Schützenberger, A.; Kunduk, M.; Döllinger, M.; Alexiou, C.; Dubrovskiy, D.; Semmler, M.; Seger, A.; Bohr, C. Laryngeal High-Speed Videoendoscopy: Sensitivity of Objective Parameters towards Recording Frame Rate. BioMed Res. Int. 2016, 2016, 4575437. [Google Scholar] [CrossRef] [PubMed]
- Svec, J.G.; Schutte, H.K. Videokymography: High-speed line scanning of vocal fold vibration. J. Voice 1996, 10, 201–205. [Google Scholar] [CrossRef]
- Lohscheller, J.; Eysholdt, U. Phonovibrogram Visualization of Entire Vocal Fold Dynamics. Laryngoscope 2008, 118, 753–758. [Google Scholar] [CrossRef] [PubMed]
- Döllinger, M.; Berry, D.A. Computation of the three-dimensional medial surface dynamics of the vocal folds. J. Biomech. 2006, 39, 369–374. [Google Scholar] [CrossRef] [PubMed]
- Döllinger, M.; Berry, D.A.; Kniesburges, S. Dynamic vocal fold parameters with changing adduction in ex-vivo hemilarynx experiments. J. Acoust. Soc. Am. 2016, 139, 2372. [Google Scholar] [CrossRef] [PubMed]
- Döllinger, M.; Berry, D.A. Visualization and Quantification of the Medial Surface Dynamics of an Excised Human Vocal Fold During Phonation. J. Voice 2006, 20, 401–413. [Google Scholar] [CrossRef] [PubMed]
- Sommer, D.E.; Tokuda, I.T.; Peterson, S.D.; Sakakibara, K.I.; Imagawa, H.; Yamauchi, A.; Nito, T.; Yamasoba, T.; Tayama, N. Estimation of inferior-superior vocal fold kinematics from high-speed stereo endoscopic data in vivo. J. Acoust. Soc. Am. 2014, 136, 3290–3300. [Google Scholar] [CrossRef] [PubMed]
- Hoppe, U.; Rosanowski, F.; Döllinger, M.; Lohscheller, J.; Schuster, M.; Eysholdt, U. Glissando: Laryngeal motorics and acoustics. J. Voice 2003, 17, 370–376. [Google Scholar] [CrossRef]
- Larsson, H.; Hertegard, S. Calibration of high-speed imaging by laser triangulation. Logop. Phoniatr. Vocol. 2004, 29, 154–161. [Google Scholar] [CrossRef] [PubMed]
- Patel, R.R.; Donohue, K.D.; Johnson, W.C.; Archer, S.M. Laser projection imaging for measurement of pediatric voice. Laryngoscope 2011, 121, 2411–2417. [Google Scholar] [CrossRef] [PubMed]
- George, N.A.; de Mul, F.F.M.; Qiu, Q.; Rakhorst, G.; Schutte, H.K. Depth-kymography: High-speed calibrated 3D imaging of human vocal fold vibration dynamics. Phys. Med. Biol. 2008, 53, 2667–2675. [Google Scholar] [CrossRef] [PubMed]
- Wurzbacher, T.; Voigt, I.; Schwarz, R.; Döllinger, M.; Hoppe, U.; Penne, J.; Eysholdt, U.; Lohscheller, J. Calibration of laryngeal endoscopic high-speed image sequences by an automated detection of parallel laser line projections. Med. Image Anal. 2008, 12, 300–317. [Google Scholar] [CrossRef] [PubMed]
- Patel, R.; Donohue, K.; Lau, D.; Unnikrishnan, H. In vivo measurement of pediatric vocal fold motion using structured light laser projection. J. Voice 2013, 27, 463–472. [Google Scholar] [CrossRef] [PubMed]
- Luegmair, G.; Kniesburges, S.; Zimmermann, M.; Sutor, A.; Eysholdt, U.; Döllinger, M. Optical reconstruction of high-speed surface dynamics in an uncontrollable environment. IEEE Trans. Med. Imaging 2010, 29, 1979–1991. [Google Scholar] [CrossRef] [PubMed]
- Luegmair, G.; Mehta, D.D.; Kobler, J.B.; Döllinger, M. Three-Dimensional Optical Reconstruction of Vocal Fold Kinematics Using High-Speed Video With a Laser Projection System. IEEE Trans. Med. Imaging 2015, 34, 2572–2582. [Google Scholar] [CrossRef] [PubMed]
- Semmler, M.; Kniesburges, S.; Birk, V.; Ziethe, A.; Patel, R.; Döllinger, M. 3D Reconstruction of Human Laryngeal Dynamics Based on Endoscopic High-Speed Recordings. IEEE Trans. Med. Imaging 2016, 35, 1615–1624. [Google Scholar] [CrossRef] [PubMed]
- International Commission on Non-Ionizing Radiation Protection. Guidelines on Limits of Exposure to Laser Radiation of Wavelengths between 180 nm and 1000 μm. Health Phys. 2013, 105, 271–295. [Google Scholar]
- World Medical Association. WMA Declaration of Helsinki: Ethical principles for medical research involving human subjects. JAMA 2013, 310, 2191–2194. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Döllinger, M.; Dubrovskiy, D.; Patel, R. Spatiotemporal analysis of vocal fold vibrations between children and adults. Laryngoscope 2012, 122, 2511–2518. [Google Scholar] [CrossRef] [PubMed]
- Polesel, A.; Ramponi, G.; Mathews, V.J. Image enhancement via adaptive unsharp masking. IEEE Trans. Image Process. 2000, 9, 505–510. [Google Scholar] [CrossRef] [PubMed]
- Chaudhury, K.N.; Dabhade, S.D. Fast and Provably Accurate Bilateral Filtering. IEEE Trans. Image Process. 2016, 25, 2519–2528. [Google Scholar] [CrossRef] [PubMed]
- Otsu, N. A Threshold Selection Method from Gray-Level Histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, Z.; Wu, Y. Recognition of corners of planar pattern image. In Proceedings of the 8th World Congress on Intelligent Control and Automation, Jinan, China, 7–9 July 2010; pp. 6342–6346. [Google Scholar]
- Lindeberg, T. Image Matching Using Generalized Scale-Space Interest Points. J. Math. Imaging Vis. 2015, 52, 3–36. [Google Scholar] [CrossRef]
- Luegmair, G. 3D Reconstruction Of Vocal Fold Surface Dynamics in Functional Dysphonia. Ph.D. Thesis, Friedrich-Alexander-Universität Erlangen Nürnberg, Erlangen, Germany, 2014. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Inner Corners of Checkerboard | Outer Corners of Checkerboard | |
|---|---|---|
| Detected by algorithm | True positive (TP) | False positive (FP) |
| Not detected by algorithm | False negative (FN) | True negative (TN) |
| Discernible | Indiscernible | |
|---|---|---|
| Laser Points | Laser Points | |
| Detected by algorithm (not freezed) | True positive (TP) | False positive (FP) |
| Not detected by algorithm (freezed) | False negative (FN) | True negative (TN) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Semmler, M.; Kniesburges, S.; Parchent, J.; Jakubaß, B.; Zimmermann, M.; Bohr, C.; Schützenberger, A.; Döllinger, M. Endoscopic Laser-Based 3D Imaging for Functional Voice Diagnostics. Appl. Sci. 2017, 7, 600. https://doi.org/10.3390/app7060600
Semmler M, Kniesburges S, Parchent J, Jakubaß B, Zimmermann M, Bohr C, Schützenberger A, Döllinger M. Endoscopic Laser-Based 3D Imaging for Functional Voice Diagnostics. Applied Sciences. 2017; 7(6):600. https://doi.org/10.3390/app7060600
Chicago/Turabian StyleSemmler, Marion, Stefan Kniesburges, Jonas Parchent, Bernhard Jakubaß, Maik Zimmermann, Christopher Bohr, Anne Schützenberger, and Michael Döllinger. 2017. "Endoscopic Laser-Based 3D Imaging for Functional Voice Diagnostics" Applied Sciences 7, no. 6: 600. https://doi.org/10.3390/app7060600