Single-Class Data Descriptors for Mapping Panax notoginseng through P-Learning



Abstract
:1. Introduction
2. Materials and Methods
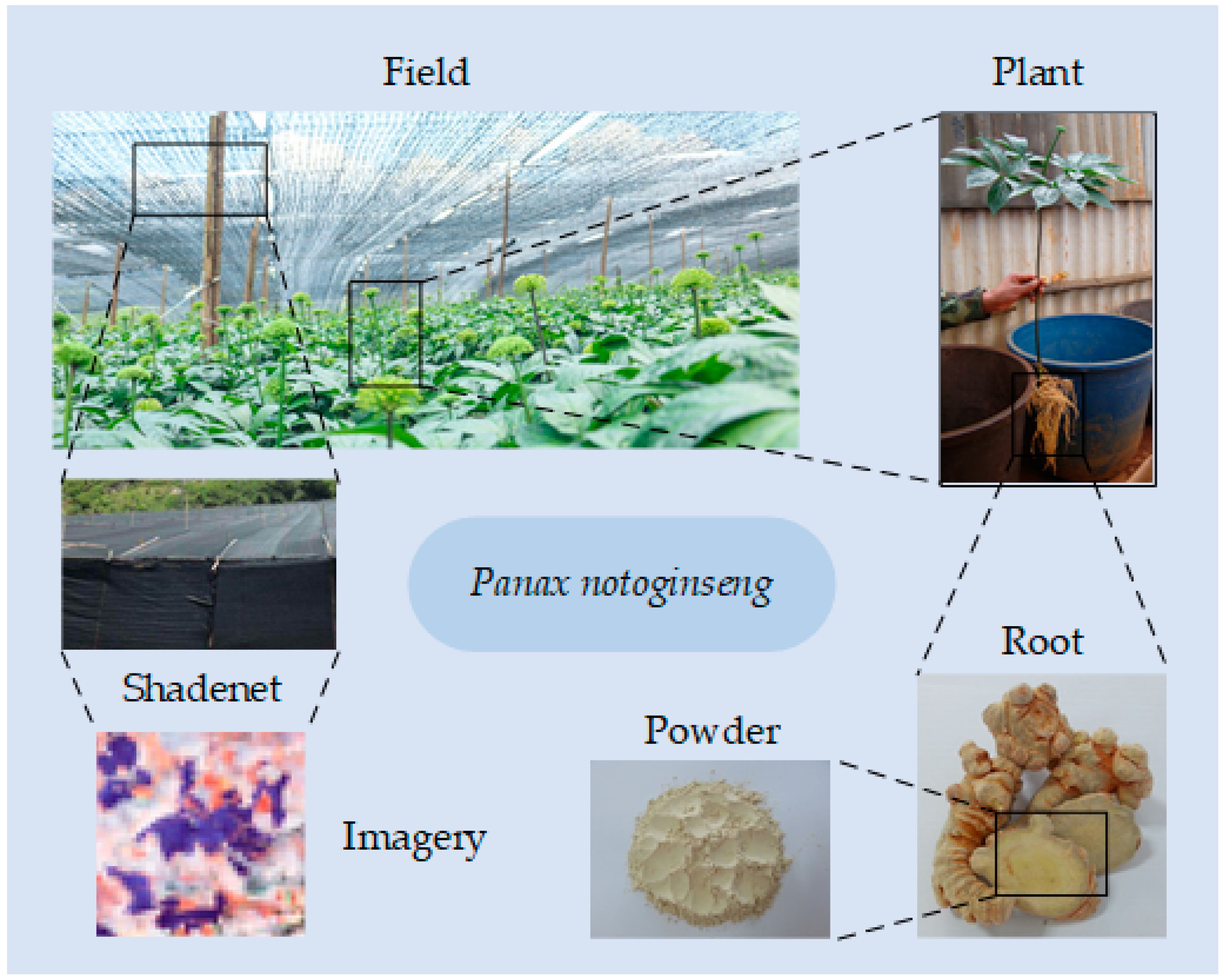
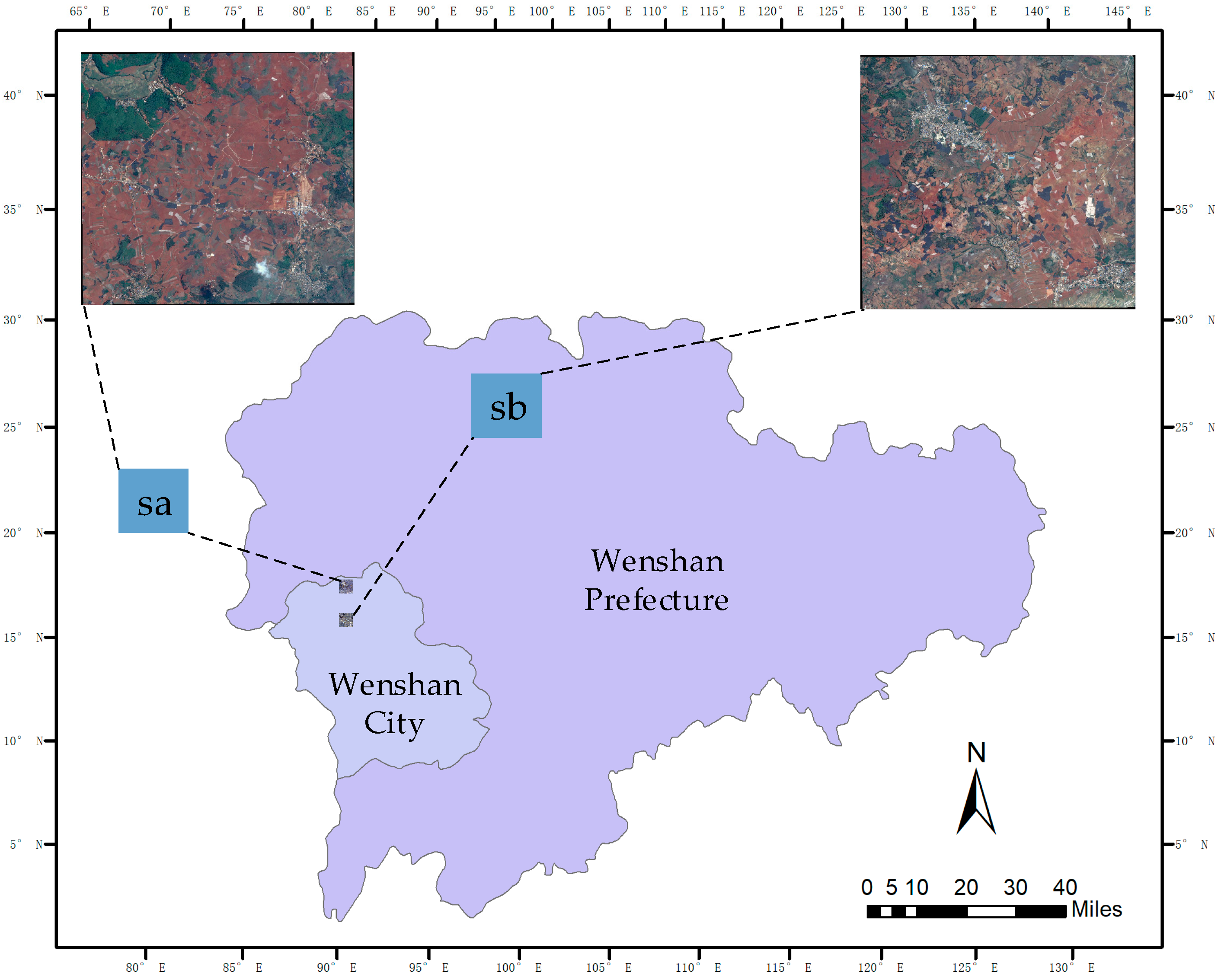
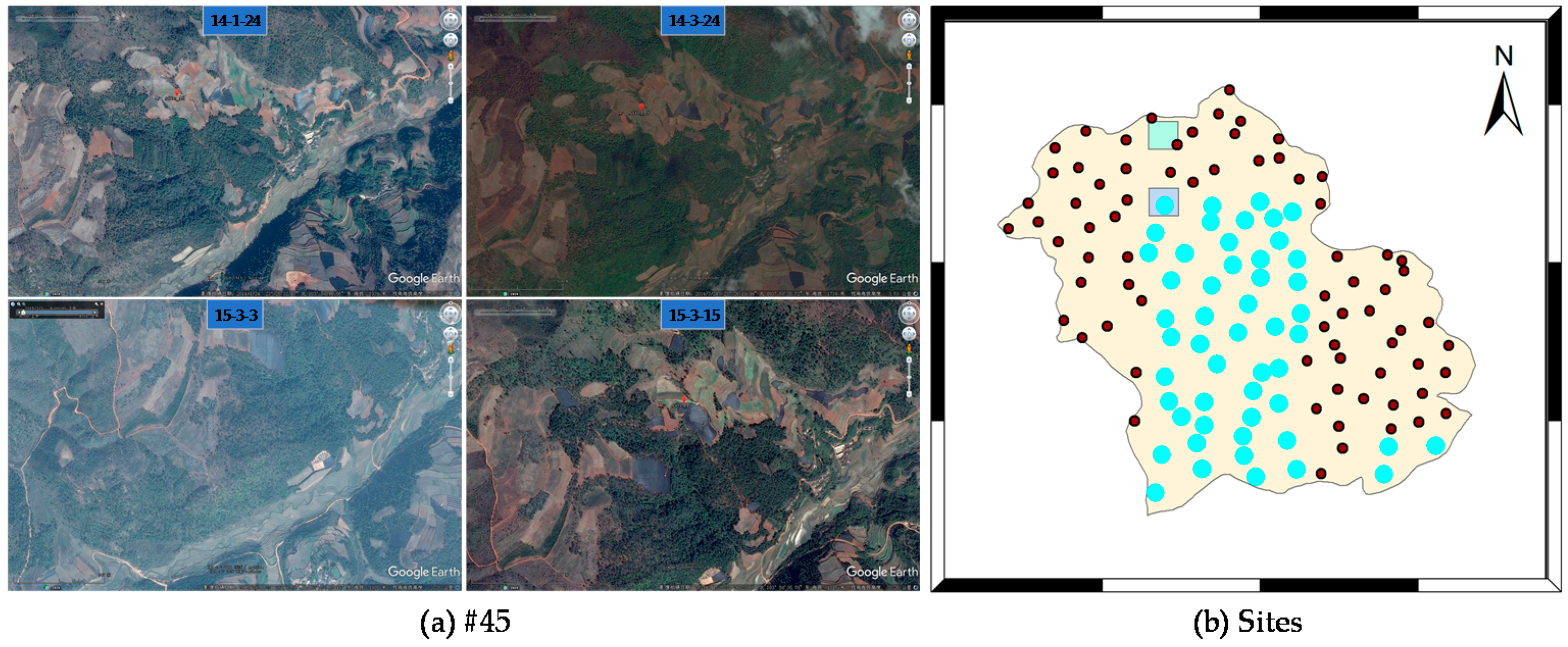
2.1. Study Area and Data
2.2. Shadenet Structures
2.3. Design Sets
2.4. Single-Class Data Descriptors (SCDDs)
2.5. Performance Evaluation
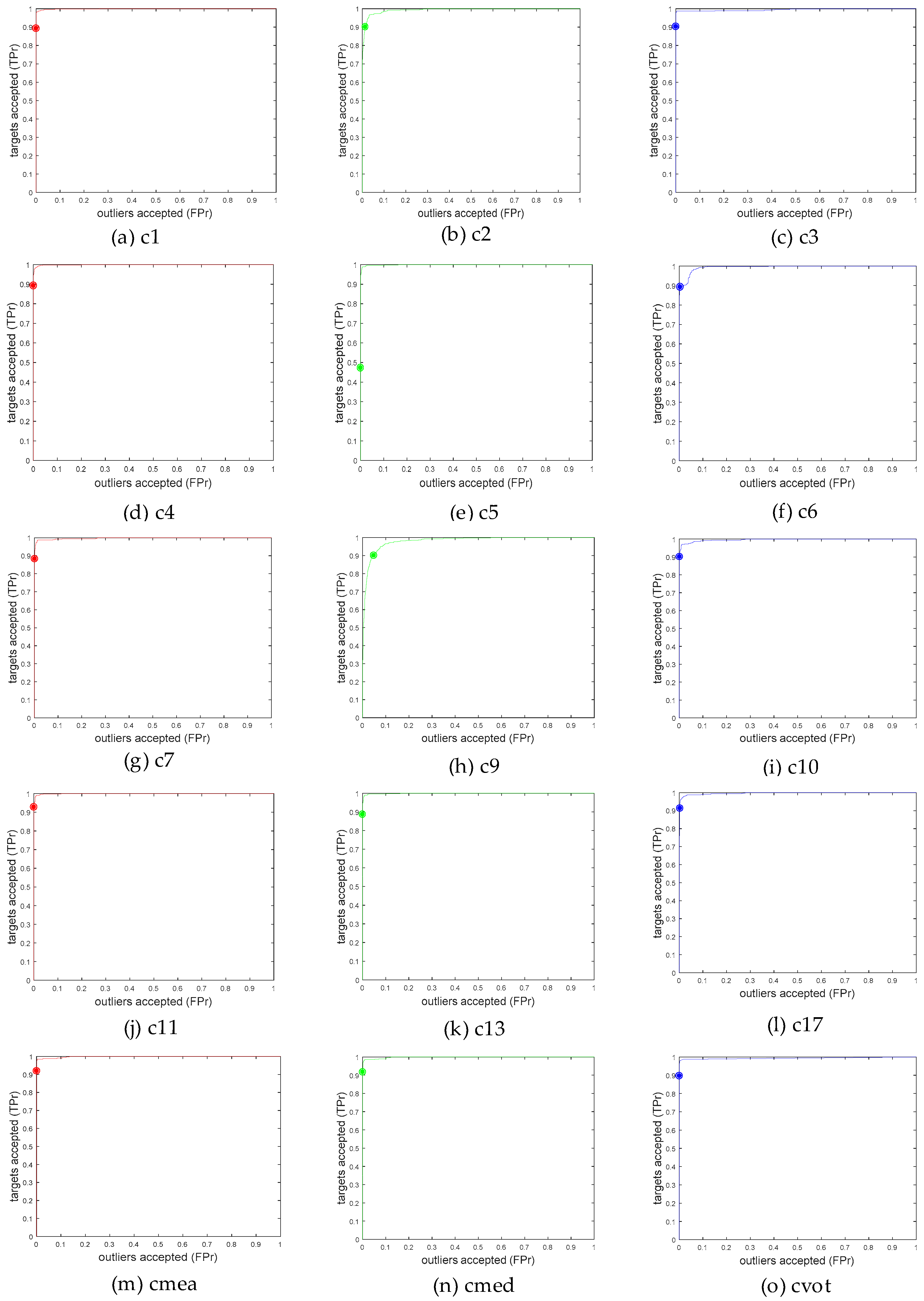
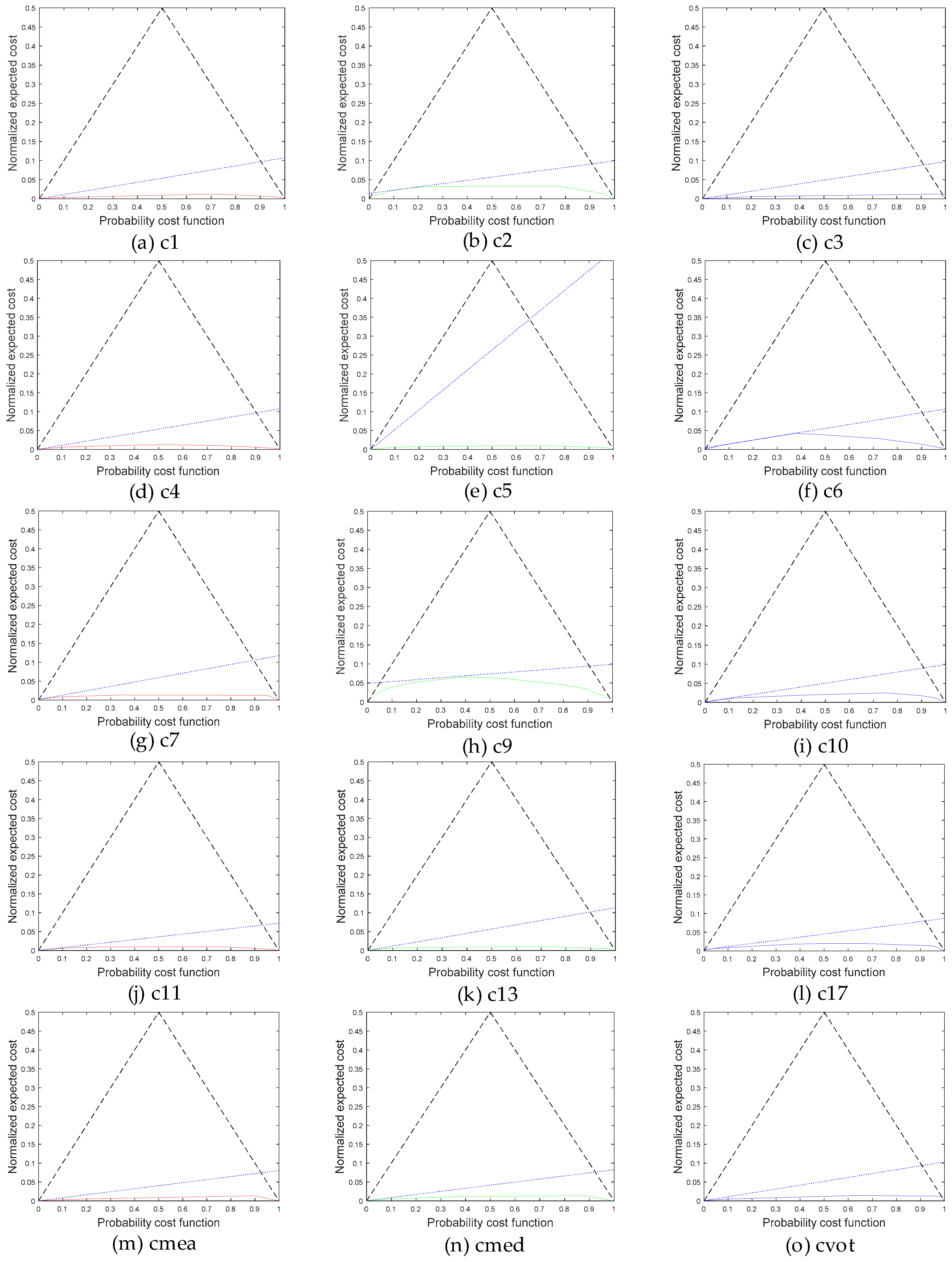
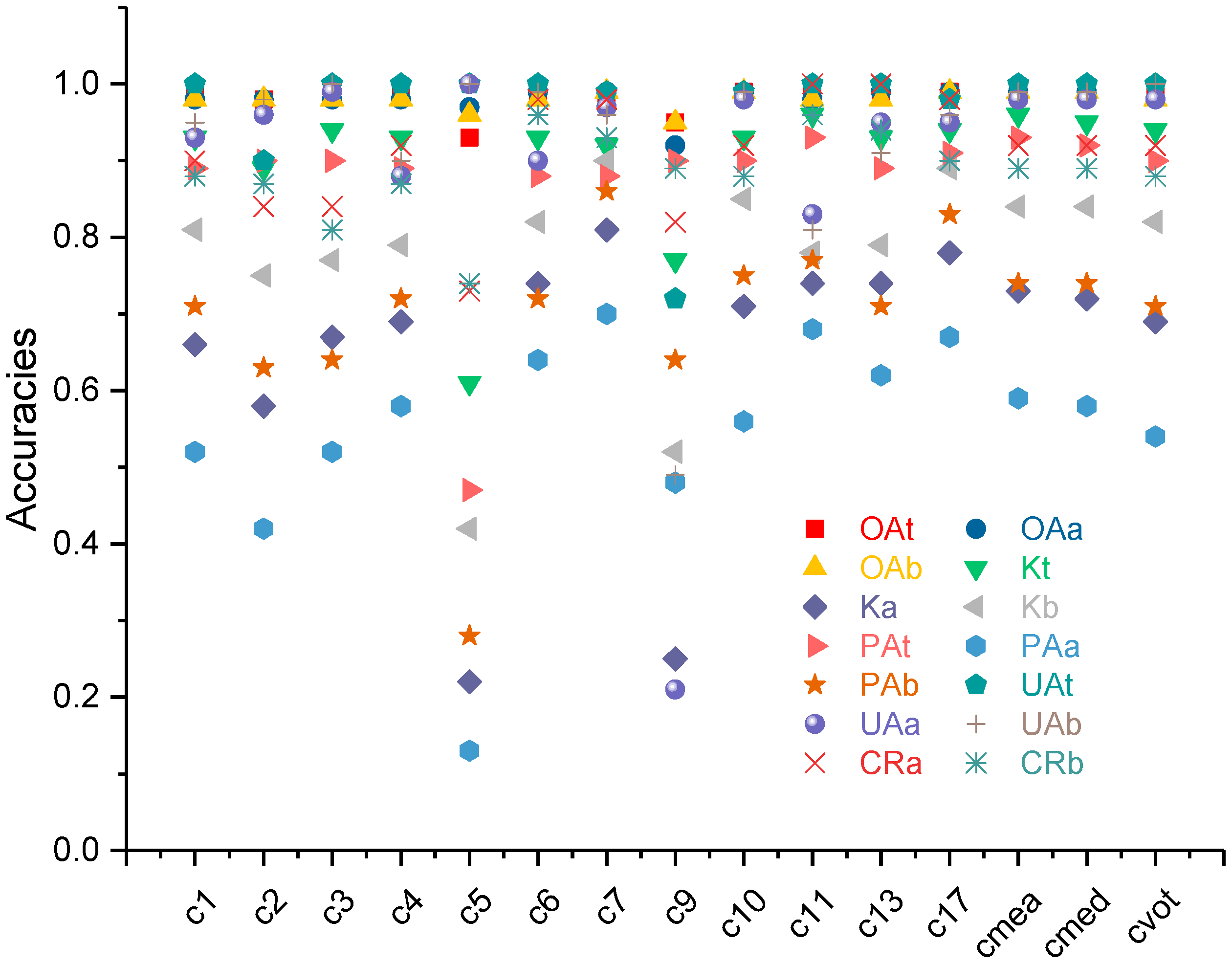
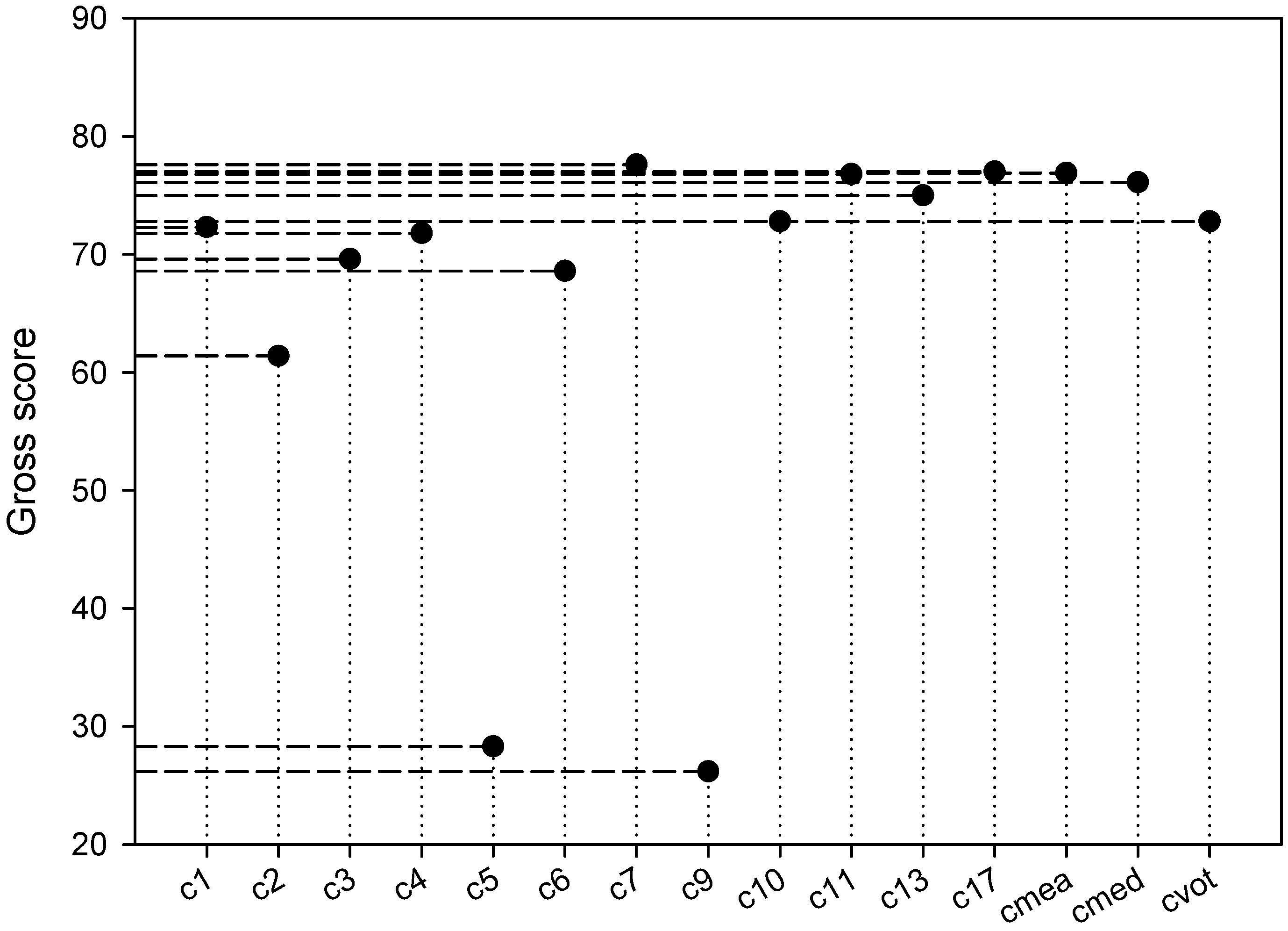
3. Results and Analysis
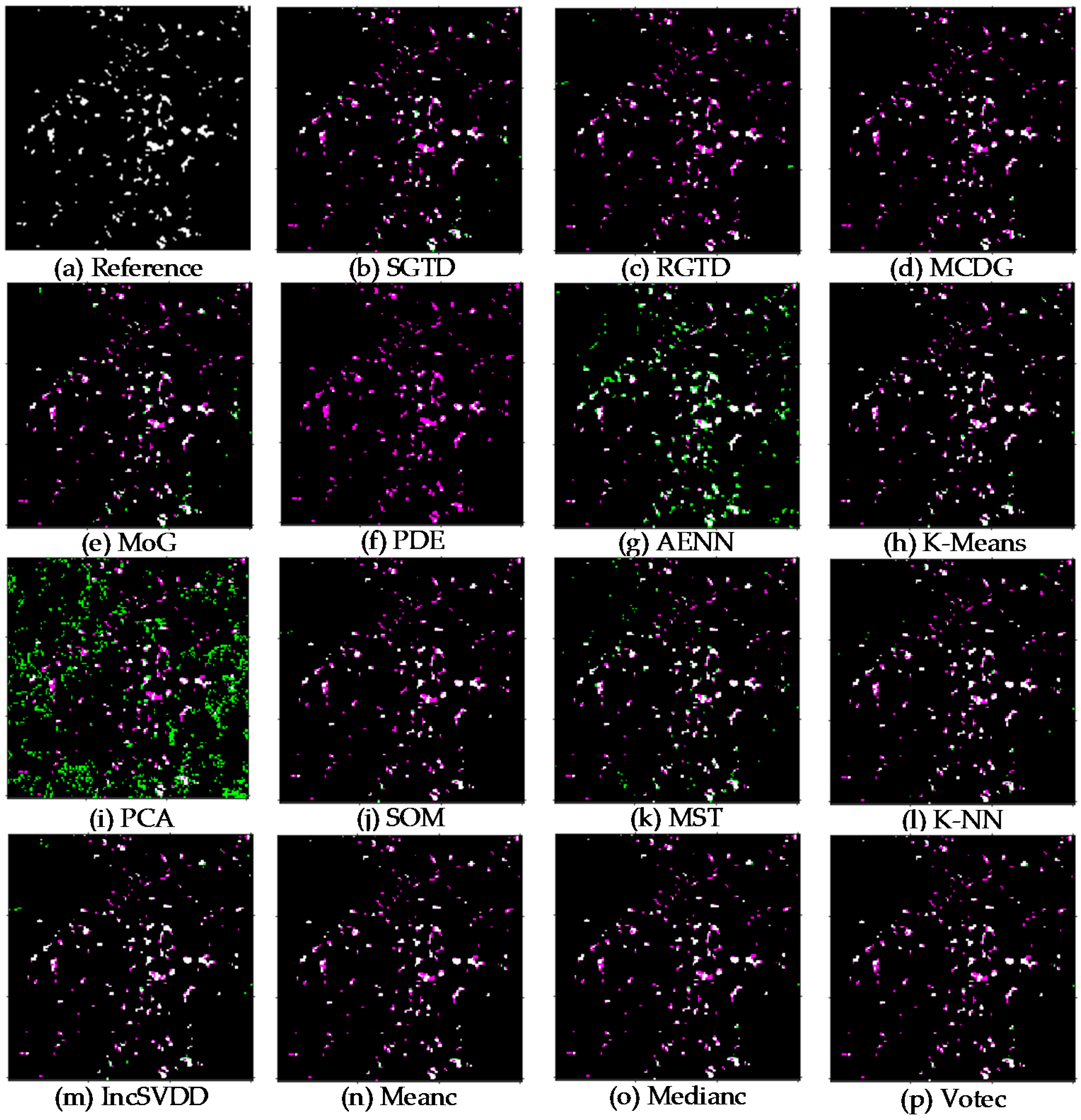
3.1. Resultant Maps
3.2. Measuring Performance
4. Discussion
4.1. Selection Criteria
4.2. Scoring Model
4.3. McNemar’s Test
4.4. Special Concerns and Limitations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tsai, C. A brief introduction to traditional Chinese medicine. In 30 Years’ Review of China’s Science and Technology; World Scientific: Singapore, 1981; pp. 125–138. [Google Scholar]
- Li, X.; Yang, G.; Li, X.; Zhang, Y.; Yang, J.; Chang, J.; Sun, X.; Zhou, X.; Guo, Y.; Xu, Y.; et al. Traditional Chinese medicine in cancer care: A review of controlled clinical studies published in Chinese. PLoS ONE 2013, 8, e60338. [Google Scholar]
- Stone, R. Lifting the veil on traditional Chinese medicine. Science 2008, 319, 709–710. [Google Scholar] [CrossRef] [PubMed]
- Xiong, X. Integrating traditional Chinese medicine into Western cardiovascular medicine: An evidence-based approach. Nat. Rev. Cardiol. 2015, 12, 374. [Google Scholar] [CrossRef] [PubMed]
- Harvey, A.L.; Edrada-Ebel, R.; Quinn, R.J. The re-emergence of natural products for drug discovery in the genomics era. Nat. Rev. Drug Discov. 2015, 14, 111–129. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dong, J. The relationship between traditional Chinese medicine and modern medicine. Evid.-Based Complement. Altern. 2013, 2013, 153148. [Google Scholar] [CrossRef] [PubMed]
- Xue, T.; Roy, R. Studying traditional Chinese medicine. Science 2003, 300, 740–741. [Google Scholar] [CrossRef] [PubMed]
- General Administration of Quality Supervision, Inspection and Quarantine of the People’s Republic of China. Provisions for the Protection of Products of Geographical Indication. Available online: http://www.wipo.int/edocs/lexdocs/laws/en/cn/cn041en.pdf (accessed on 10 August 2018).
- Addor, F.; Grazioli, A. Geographical indications beyond wines and spirits. J. World Intellect. Prop. 2002, 5, 865–897. [Google Scholar] [CrossRef]
- Standing Committee of the National People’s Congress. Law of the People’s Republic of China on Traditional Chinese Medicine. Available online: http://www.gov.cn/xinwen/2016-12/26/content_5152773.htm (accessed on 10 August 2018).
- Fan, Z.; Miao, C.; Qiao, X.; Zheng, Y.; Chen, H.; Chen, Y.; Xu, L.; Zhao, L.; Guan, H. Diversity, distribution, and antagonistic activities of rhizobacteria of Panax notoginseng. J. Ginseng Res. 2016, 40, 97–104. [Google Scholar] [CrossRef] [PubMed]
- Park, H.J.; Kim, D.H.; Park, S.J.; Kim, J.M.; Ryu, J.H. Ginseng in traditional herbal prescriptions. J. Ginseng Res. 2012, 36, 225–241. [Google Scholar] [CrossRef] [PubMed]
- Wei, J.X.; Du, Y.C. Modern Science Research and Application of Panax Notoginseng; Yunnan Science and Technology Press: Kunming, China, 1996. [Google Scholar]
- Zhou, Y.Q.; Chen, S.L.; Zhang, B.G.; Zhang, J.S.; Zhang, J.; Chen, Z.J.; Cun, X.M. Studies on the resources survey methods of Panax notogingseng based on remote sensing. China J. Chin. Mater. Med. 2005, 30, 1902–1905. [Google Scholar]
- The State Council of the People’s Republic of China. Several Opinions of the State Council on Supporting and Promoting the Development of Traditional Chinese Medicine. Available online: http://www.gov.cn/zwgk/2009-05/07/content_1307145.htm (accessed on 10 August 2018).
- The State Council Information Office of the Peoples Republic of China. Health Service Development Plan of Traditional Chinese Medicine (2015–2020). Available online: http://www.gov.cn/zhengce/ content/2015-05/07/content_9704.htm (accessed on 10 August 2018).
- The Ministry of Science and Technology of the People’s Republic of China. Outline of Traditional Chinese Medicine Innovation and Development Plan (2006–2020). Available online: http://www.most.gov.cn/tztg/200703/t20070320_42240.htm (accessed on 10 August 2018).
- Sun, X.; Lin, D.; Wu, W.; Lv, Z. Translational Chinese medicine: A way for development of traditional Chinese medicine. Chin. Med. 2011, 2, 186–190. [Google Scholar] [CrossRef]
- Sanchez-Hernandez, C.; Boyd, D.S.; Foody, G.M. One-class classification for mapping a specific land-cover class: SVDD classification of fenland. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1061–1073. [Google Scholar] [CrossRef]
- Boyd, D.S.; Foody, G.M. Changing Land Cover; Global Environmental Issues; John Wiley & Sons: Hoboken, NJ, USA, 2004; pp. 65–94. [Google Scholar]
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Xiao, X.; Qin, Y.; Dong, J.; Zhang, G.; Kou, W.; Jin, C.; Zhou, Y.; Zhang, Y. Mapping paddy rice planting area in wheat-rice double-cropped areas through integration of Landsat-8 OLI, MODIS, and PALSAR images. Sci. Rep. 2015, 5, 10088. [Google Scholar] [CrossRef] [PubMed]
- Thenkabail, P.S.; Knox, J.W.; Ozdogan, M.; Gumma, M.K.; Congalton, R.G.; Wu, Z.; Milesi, C.; Finkral, A.; Marshall, M.; Mariotto, I.; et al. Assessing future risks to agricultural productivity, water resources and food security: How can remote sensing help? Photogramm. Eng. Rem. Sens. 2012, 78, 773–782. [Google Scholar]
- Foody, G.M.; Mathur, A.; Sanchez-Hernandez, C.; Boyd, D.S. Training set size requirements for the classification of a specific class. Remote Sens. Environ. 2006, 104, 1–14. [Google Scholar] [CrossRef]
- Song, B.; Li, P.; Li, J.; Plaza, A. One-class classification of remote sensing images using kernel sparse representation. IEEE J-STARS 2016, 9, 1613–1623. [Google Scholar] [CrossRef]
- Chen, C.H. An overview of recent progress on information processing for remote sensing. In Information Processing for Remote Sensing; World Scientific: Singapore, 1999; pp. 39–49. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Wilkinson, G.G. Results and implications of a study of fifteen years of satellite image classification experiments. IEEE Trans. Geosci. Remote Sens. 2005, 43, 433–440. [Google Scholar] [CrossRef]
- Chen, C.H. Frontiers of Remote Sensing Information Processing; World Scientific: Singapore, 2003. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Wan, B.; Guo, Q.; Fang, F.; Su, Y.; Wang, R. Mapping US urban extents from MODIS data using one-class classification method. Remote Sens. 2015, 7, 10143–10163. [Google Scholar] [CrossRef]
- Mathieu, P.P.; Aubrecht, C. Earth Observation Open Science and Innovation; Springer Open: Cham, Switzerland, 2018; pp. 165–218. [Google Scholar]
- Tse, C.H.; Lam, E.Y. Geological applications of machine learning on hyperspectral remote sensing data. Proc. SPIE Int. Soc. Opt. Eng. 2015, 9405, 940512. [Google Scholar]
- Brown, M.E.; Lary, D.J.; Vrieling, A.; Stathakis, D.; Mussa, H. Neural networks as a tool for constructing continuous NDVI time series from AVHRR and MODIS. Int. J. Remote Sens. 2008, 29, 7141–7158. [Google Scholar] [CrossRef] [Green Version]
- Lary, D.J.; Remer, L.A.; MacNeill, D.; Roscoe, B.; Paradise, S. Machine Learning and Bias Correction of MODIS Aerosol Optical Depth. IEEE Geosci. Remote Sens. Lett. 2009, 6, 694–698. [Google Scholar] [CrossRef]
- Aurin, D.A.; Mannino, A. A Database for Developing Global Ocean Color Algorithms for Colored Dissolved Organic Material, CDOM Spectral Slope, and Dissolved Organic Carbon. In Proceedings of the Ocean Optics XXI, Glasgow, Scotland, UK, 8–12 October 2012. [Google Scholar]
- Lary, D.J.; Alavi, A.H.; Gandomi, A.H.; Walker, A.L. Machine learning in geosciences and remote sensing. Geosci. Front. 2016, 7, 3–10. [Google Scholar] [CrossRef]
- Khobragade, A.N.; Raghuwanshi, M.M. Contextual Soft Classification Approaches for Crops Identification Using Multi-sensory Remote Sensing Data: Machine Learning Perspective for Satellite Images; Springer International Publishing: Cham, Switzerland, 2015; pp. 333–346. [Google Scholar]
- FAO. Development of a Framework for Good Agricultural Practices. Available online: http://www.fao.org/docrep/meeting/006/y8704e.htm (accessed on 10 August 2018).
- Davis, N. Controlled-environment agriculture-past, present and future. Food Technol. 1985, 39, 124–126. [Google Scholar]
- Silva, J.; Bacao, F.; Caetano, M. Specific Land Cover Class Mapping by Semi-Supervised Weighted Support Vector Machines. Remote Sens. 2017, 9, 181. [Google Scholar] [CrossRef]
- Mack, B.; Roscher, R.; Stenzel, S.; Feilhauer, H.; Schmidtlein, S.; Waske, B. Mapping raised bogs with an iterative one-class classification approach. ISPRS J. Photogramm. 2016, 120, 53–64. [Google Scholar] [CrossRef]
- Liu, X.; Liu, H.; Gong, H.; Lin, Z.; Lv, S. Appling the one-class classification method of maxent to detect an invasive plant Spartina alterniflora with time-series analysis. Remote Sens. 2017, 9, 1120. [Google Scholar] [CrossRef]
- Marconcini, M.; Fernández-Prieto, D.; Buchholz, T. Targeted land-cover classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4173–4193. [Google Scholar] [CrossRef]
- Sahare, M.; Gupta, H. A review of multi-class classification for imbalanced data. Int. J. Adv. Comput. Res. 2012, 2, 160–164. [Google Scholar]
- Sun, Y.; Wong, A.K.C.; Kamel, M.S. Classification of imbalanced data: A review. Int. J. Pattern Recogn. Artif. Intell. 2009, 23, 687–719. [Google Scholar] [CrossRef]
- Tax, D.M.J. One-Class Classification: Concept-Learning in the Absence of Counter-Examples. Ph.D. Thesis, Delft University of Technology, Delft, The Netherlands, 2001; p. 65. [Google Scholar]
- Khan, S.S.; Madden, M.G. One-class classification: Taxonomy of study and review of techniques. Knowl. Eng. Rev. 2014, 29, 345–374. [Google Scholar] [CrossRef]
- Normile, D. The new face of traditional Chinese medicine. Science 2003, 299, 188–190. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Dong, K.; Yang, Z.; Dong, Y.; Tang, L.; Zheng, Y. Allelopathy autotoxcity effect of successive cropping obstacle and its alleviate mechanism by intercropping. Chin. Agric. Sci. Bull. 2017, 33, 91–98. [Google Scholar]
- Fu, G.; Zhang, Q.; Liang, C.; Cheng, Z. Stereoscopic planting pattern of kernel-used apricot and medicinal plants in the loess drought hilly region in West Henan Province. Med. Plant 2011, 2, 5–11. [Google Scholar]
- Panigrahy, S.; Sharma, S.A. Mapping of crop rotation using multidate Indian remote rensing satellite digital data. ISPRS J. Photogramm. 1997, 52, 85–91. [Google Scholar] [CrossRef]
- Pirkouhi, M.G.; Nobahar, A.; Dadashi, M.A. Effects of variety, planting pattern and density of plant phenology traits basil plants (Ocimum basilicum L.). Int. J. Agric. Crop Sci. 2012, 4, 1221–1227. [Google Scholar]
- Yunusa, I.A.M. Effects of planting density and plant arrangement pattern on growth and yields of maize (Zea mays L.) and soya bean (Glycine max (L.) Merr.) grown in mixtures. J. Agric. Sci. 1989, 112, 1–8. [Google Scholar] [CrossRef]
- Song, C.; Woodcock, C.E.; Seto, K.C.; Lenney, M.P.; Macomber, S.A. Classification and change detection using Landsat TM data: When and how to correct atmospheric effects? Remote Sens. Environ. 2001, 75, 230–244. [Google Scholar] [CrossRef]
- Yang, D.; Chen, J.; Zhou, Y.; Chen, X.; Chen, X.; Cao, X. Mapping plastic greenhouse with medium spatial resolution satellite data: Development of a new spectral index. ISPRS J. Photogramm. 2017, 128, 47–60. [Google Scholar] [CrossRef]
- Von Elsner, B.; Briassoulis, D.; Waaijenberg, D.; Mistriotis, A.; Von Zabeltitz, C.; Gratraud, J.; Russo, G.; Suay-Cortes, R. Review of structural and functional characteristics of greenhouses in European Union countries: Part I, design requirements. J. Agric. Eng. Res. 2000, 75, 1–16. [Google Scholar] [CrossRef]
- Foody, G.M.; Boyd, D.S.; Sanchez-Hernandez, C. Mapping a specific class with an ensemble of classifiers. Int. J. Remote Sens. 2007, 28, 1733–1746. [Google Scholar] [CrossRef]
- Mack, B.; Roscher, R.; Waske, B. Can I trust my one-class classification? Remote Sens. 2014, 6, 8779–8802. [Google Scholar] [CrossRef]
- McLachlan, G.; Peel, D. Finite Mixture Models; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Møller, M.F. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. In k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 1027–1035. [Google Scholar]
- Kohonen, T. The self-organizing map. Neurocomputing 1998, 21, 1–6. [Google Scholar] [CrossRef]
- Gallager, R.G.; Humblet, P.A.; Spira, P.M. A distributed algorithm for minimum-weight spanning trees. ACM Trans. Program. Lang. Syst. (TOPLAS) 1983, 5, 66–77. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Tax, D.; Ypma, A.; Duin, R. Support vector data description applied to machine vibration analysis. In Proceedings of the 5th Annual Conference of the Advanced School for Computing and Imaging, Heijen, The Netherlands, 15–17 June 1999; pp. 15–23. [Google Scholar]
- Parzen, E. On estimation of a probability density function and mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Jolliffe, I.T. Principal component analysis and factor analysis. In Principal Component Analysis; Springer: New York, NY, USA, 2002; pp. 150–166. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recogn. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recogn. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Drummond, C.; Holte, R.C. Explicitly representing expected cost: An alternative to ROC representation. In Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 198–207. [Google Scholar]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Ting, K.M. Matching model versus single model: A study of the requirement to match class distribution using decision trees. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2004; pp. 429–440. [Google Scholar]
- Foody, G.M. Classification accuracy comparison: Hypothesis tests and the use of confidence intervals in evaluations of difference, equivalence and non-inferiority. Remote Sens. Environ. 2009, 113, 1658–1663. [Google Scholar] [CrossRef] [Green Version]
- Hwang, J.P. A new weighted approach to imbalanced data classification problem via support vector machine with quadratic cost function. Expert Syst. Appl. 2011, 38, 8580–8585. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cloud (%) | Number | Percentages |
|---|---|---|
| 0–10 | 3 | 3.41 |
| 10–20 | 7 | 7.95 |
| 20–40 | 13 | 14.77 |
| 40–60 | 17 | 19.32 |
| 60–80 | 23 | 26.14 |
| 80–100 | 25 | 28.41 |
| Types | Predicted Label | ||
|---|---|---|---|
| Target | Other | ||
| Actual Label | Target | true positive (TP) | false positive (FP) |
| Other | false negative (FN) | true negative (TN) | |
| c1 | c2 | c3 | c4 | c5 | c6 | c7 | c9 | c10 | c11 | c13 | c17 | Cmea | Cmed | Cvot | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FNR | 0.11 | 0.10 | 0.10 | 0.11 | 0.53 | 0.12 | 0.12 | 0.10 | 0.10 | 0.07 | 0.11 | 0.09 | 0.07 | 0.08 | 0.10 |
| FPR | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| P | 1.00 | 0.90 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.72 | 0.99 | 1.00 | 1.00 | 0.98 | 1.00 | 1.00 | 1.00 |
| R | 0.89 | 0.90 | 0.90 | 0.89 | 0.47 | 0.88 | 0.88 | 0.90 | 0.90 | 0.93 | 0.89 | 0.91 | 0.93 | 0.92 | 0.90 |
| F1 | 0.94 | 0.90 | 0.95 | 0.94 | 0.64 | 0.94 | 0.93 | 0.80 | 0.94 | 0.96 | 0.94 | 0.94 | 0.96 | 0.96 | 0.95 |
| AUC | 1.00 | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 |
| C. | FN+ | FP+ | P– | R– | F1– | AUC– | OAt– | Kt– | PAt– | UAt– | OAa– | Ka– | PAa– | UAa– | CRa– | Rank– |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| c1 | c5 | c9 | c9 | c5 | c5 | c9 | c5 | c5 | c5 | c9 | c9 | c5 | c5 | c9 | c5 | 15 |
| c2 | c6 | c2 | c2 | c6 | c9 | cvot | c9 | c9 | c6 | c2 | c5 | c9 | c2 | c11 | c9 | 14 |
| c3 | c7 | c17 | c17 | c7 | c2 | c2 | c2 | c2 | c7 | c17 | c2 | c2 | c9 | c4 | c2 | 13 |
| c4 | c13 | c10 | c10 | c13 | c7 | c3 | c7 | c7 | c13 | c10 | c1 | c1 | c3 | c6 | c3 | 12 |
| c5 | c4 | c7 | c7 | c4 | c6 | c17 | c6 | c6 | c4 | c7 | c4 | c3 | c1 | c1 | c1 | 11 |
| c6 | c1 | c1 | c6 | c1 | c13 | c10 | c13 | c13 | c1 | c6 | c3 | cvot | cvot | c13 | c4 | 10 |
| c7 | c10 | c3 | c13 | c10 | c10 | c7 | c10 | c10 | c10 | c13 | cvot | c4 | c10 | c17 | c10 | 9 |
| c9 | c2 | c4 | c1 | c2 | c4 | cmea | c4 | c4 | c2 | c1 | c11 | c10 | cmed | c2 | cmea | 8 |
| c10 | c9 | c6 | c4 | c9 | c1 | cmed | c1 | c1 | c9 | c4 | c10 | cmed | c4 | c7 | cmed | 7 |
| c11 | c3 | c11 | c3 | c3 | c17 | c6 | c17 | c17 | c3 | c3 | c6 | cmea | cmea | cmea | cvot | 6 |
| c13 | cvot | c13 | cvot | cvot | c3 | c1 | c3 | c3 | cvot | cvot | cmed | c6 | c13 | cmed | c6 | 5 |
| c17 | c17 | cmea | cmed | c17 | cvot | c13 | cvot | cvot | c17 | cmed | cmea | c13 | c6 | c10 | c7 | 4 |
| cmea | cmed | cmed | c11 | cmed | cmed | c5 | cmed | cmed | cmed | c11 | c13 | c11 | c17 | cvot | c17 | 3 |
| cmed | c11 | cvot | cmea | c11 | c11 | c11 | c11 | c11 | c11 | cmea | c17 | c17 | c11 | c3 | c11 | 2 |
| cvot | cmea | c5 | c5 | cmea | cmea | c4 | cmea | cmea | cmea | c5 | c7 | c7 | c7 | c5 | c13 | 1 |
| C. | FN– | FP– | P+ | R+ | F1+ | AUC+ | OAt+ | Kt+ | PAt+ | UAt+ | OAa+ | Ka+ | PAa+ | UAa+ | CRa+ | Rank+ |
| M./C. | j1 | j2 | j3 | j4 | j5 | Sign– |
|---|---|---|---|---|---|---|
| i1 | x11|s11 | x12|s12 | x13|s13 | x14|s14 | x15|s15 | – |
| i2 | x21|s21 | x22|s22 | x23|s23 | x24|s24 | x25|s25 | – |
| i3 | x31|s31 | x32|s32 | x33|s33 | x34|s34 | x35|s35 | + |
| i4 | x41|s41 | x42|s42 | x43|s43 | x44|s44 | x45|s45 | + |
| i5 | x51|s51 | x52|s52 | x53|s53 | x54|s54 | x55|s55 | + |
| Score | Sc1 | Sc2 | Sc3 | Sc4 | Sc5 | Sign+ |
| c1 | c2 | c3 | c4 | c5 | c6 | c7 | c9 | c10 | c11 | c13 | c17 | Cmea | Cmed | Cvot | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CDt | 3 | 4 | 3 | 3 | 7 | 3 | 3 | 6 | 3 | 3 | 3 | 3 | 2 | 3 | 3 |
| CIa | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| CIb | 1 | 2 | 1 | 1 | 2 | 1 | 1 | 3 | 1 | 2 | 1 | 1 | 1 | 1 | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, F.; Pu, S. Single-Class Data Descriptors for Mapping Panax notoginseng through P-Learning. Appl. Sci. 2018, 8, 1448. https://doi.org/10.3390/app8091448
Deng F, Pu S. Single-Class Data Descriptors for Mapping Panax notoginseng through P-Learning. Applied Sciences. 2018; 8(9):1448. https://doi.org/10.3390/app8091448
Chicago/Turabian StyleDeng, Fei, and Shengliang Pu. 2018. "Single-Class Data Descriptors for Mapping Panax notoginseng through P-Learning" Applied Sciences 8, no. 9: 1448. https://doi.org/10.3390/app8091448
APA StyleDeng, F., & Pu, S. (2018). Single-Class Data Descriptors for Mapping Panax notoginseng through P-Learning. Applied Sciences, 8(9), 1448. https://doi.org/10.3390/app8091448