FAST-FUSION: An Improved Accuracy Omnidirectional Visual Odometry System with Sensor Fusion and GPU Optimization for Embedded Low Cost Hardware †





Abstract
:1. Introduction
2. Related Works
2.1. Omnidirectional Visual Odometry
2.2. Visual Odometry Challenges
- Scale ambiguity due to the incapacity to perceive the scene depth without any prior information about the environment or an additional source of information.
- Estimation degeneration on pure rotations due to the low overlap between consecutive images.
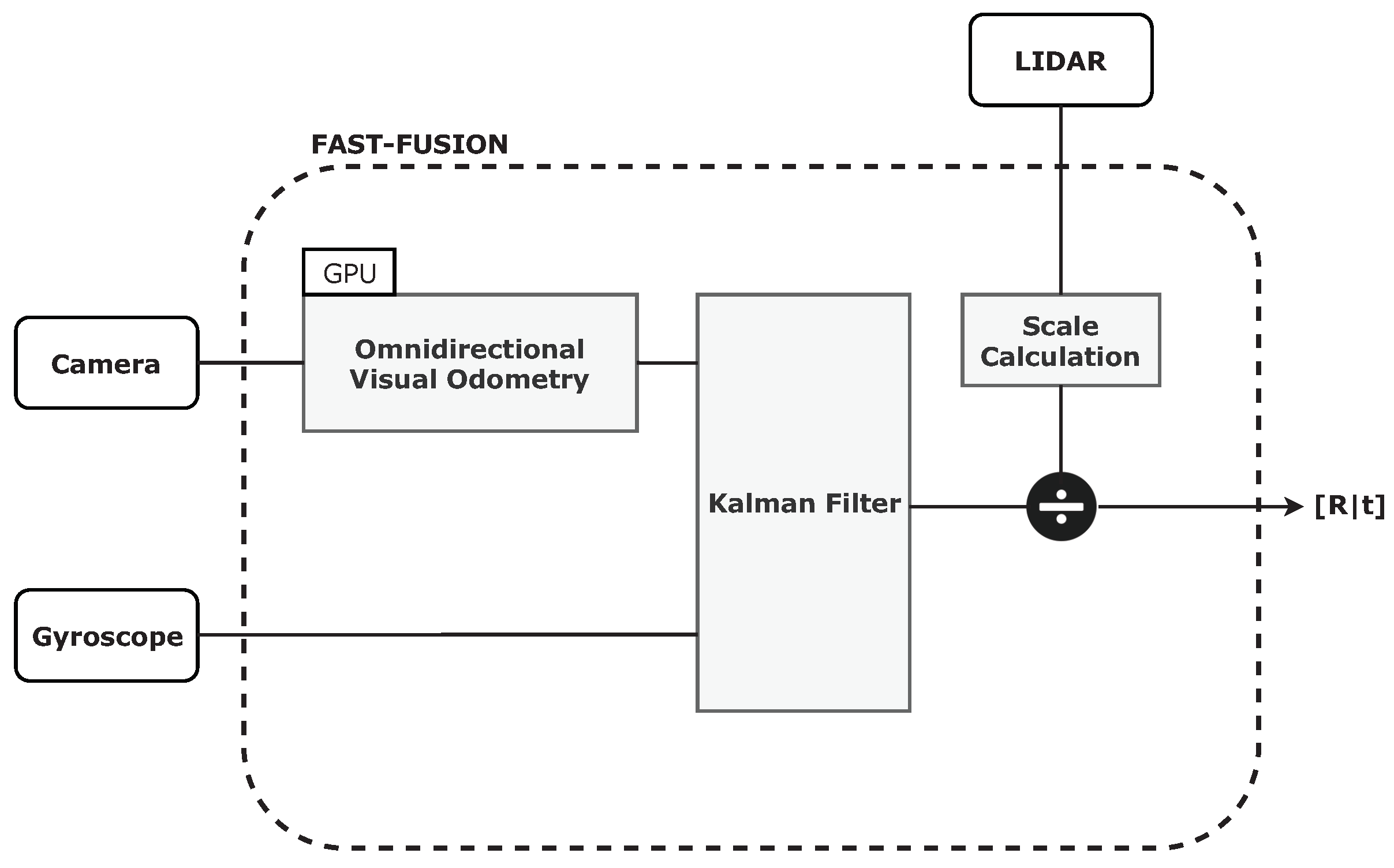
3. FAST-FUSION System Architecture
4. FAST-FUSION Approach
4.1. Omnidirectional Visual Odometry
- Application of a camera model that converts 2-D feature pixels in the omnidirectional image in 3-D unit vectors.
- A Random sample consensus (RANSAC) approach to select the inliers from the entire set of 3-D unit vectors.
- Motion estimation using the epipolar constraint and linear triangulation.
4.2. Motion Scale Calculation
- Transformation of the range measurement of the LIDAR into the camera referential frame;
- projection of the LIDAR measures in the camera referential frame into the omnidirectional image;
- search for associations between image features and LIDAR measures in the omnidirectional image; and
- scale calculation using the associations found.
4.3. Orientation Correction
4.4. Heterogeneous Computing Optimizations
- randomSample()—calculation of a random set of matches of size 8;
- essentialMatrix()—calculation of the essential matrix E using the given set; and,
- getInliers()—calculation of the set of inliers for the given essential matrix E.
- Load the routine input data correspondent to all the RANSAC iterations.
- Write all the data to the correspondent kernel at once using 16-way vector types.
- Execute the kernel to all the data in a 16-way vectorized way and load it to a single output array.
- Read all the output data at once and label the corresponding RANSAC iteration to it.
5. Results
5.1. Processing Time
5.2. Motion Estimation
6. Discussion
6.1. Processing Time
6.2. Motion Estimation
- Perform a reasonable estimation of the motion scale;
- have the ability to deal with pure rotations; and,
- present real-time performance.
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| VO | Visual odometry |
| SLAM | Simultaneous localization and mapping |
| API | Application programming interface |
| KF | Kalman filter |
| SVD | Single value decomposition |
| CPU | Central processing unit |
| GPU | Graphical processing unit |
| QPU | Quad processing unit |
| ROS | Robot operating system |
| OpenCL | Open computing language |
| GNSS | Global navigation satellite systems |
| LIDAR | Light detection and ranging |
| DSO | Direct sparse odometry |
| SVO | Semi-direct visual odometry |
| SIFT | Scale-invariant feature transform |
| UML | Unified modeling language |
References
- Bonin-Font, F.; Ortiz, A.; Oliver, G. Visual Navigation for Mobile Robots: A Survey. J. Intell. Robot. Syst. 2008, 53, 263. [Google Scholar] [CrossRef]
- Kelly, A.; Stentz, A.; Amidi, O.; Bode, M.; Bradley, D.; Diaz-Calderon, A.; Happold, M.; Herman, H.; Mandelbaum, R.; Pilarski, T.; et al. Toward Reliable Off Road Autonomous Vehicles Operating in Challenging Environments. Int. J. Robot. Res. 2006, 25, 449–483. [Google Scholar] [CrossRef]
- Aqel, M.O.A.; Marhaban, M.H.; Saripan, M.I.; Ismail, N.B. Review of visual odometry: Types, approaches, challenges, and applications. SpringerPlus 2016, 5, 1897. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nister, D.; Naroditsky, O.; Bergen, J. Visual odometry. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2004, Washington, DC, USA, 27 June–2 July 2004. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Fraundorfer, F. Visual Odometry [Tutorial]. IEEE Robot. Autom. Mag. 2011, 18, 80–92. [Google Scholar] [CrossRef]
- Gräter, J.; Schwarze, T.; Lauer, M. Robust scale estimation for monocular visual odometry using structure from motion and vanishing points. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 475–480. [Google Scholar] [CrossRef]
- Zhang, Z.; Rebecq, H.; Forster, C.; Scaramuzza, D. Benefit of large field-of-view cameras for visual odometry. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar] [CrossRef] [Green Version]
- Khokhar, A.A.; Prasanna, V.K.; Shaaban, M.E.; Wang, C. Heterogeneous computing: Challenges and opportunities. Computer 1993, 26, 18–27. [Google Scholar] [CrossRef] [Green Version]
- Mittal, S.; Vetter, J.S. A Survey of CPU-GPU Heterogeneous Computing Techniques. ACM Comput. Surv. 2015, 47, 69:1–69:35. [Google Scholar] [CrossRef]
- Stone, J.E.; Gohara, D.; Shi, G. OpenCL: A Parallel Programming Standard for Heterogeneous Computing Systems. Comput. Sci. Eng. 2010, 12, 66–73. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geiger, A.; Ziegler, J.; Stiller, C. StereoScan: Dense 3d reconstruction in real-time. In Proceedings of the 2011 IEEE Intelligent Vehicles Symposium (IV), Baden-Baden, Germany, 5–9 June 2011. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct Sparse Odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Matsuki, H.; von Stumberg, L.; Usenko, V.; Stueckler, J.; Cremers, D. Omnidirectional DSO: Direct Sparse Odometry with Fisheye Cameras. IEEE Robot. Autom. Lett. 2018, 3, 3693–3700. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Caruso, D.; Engel, J.; Cremers, D. Large-scale direct SLAM for omnidirectional cameras. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014. [Google Scholar] [CrossRef] [Green Version]
- Corke, P.; Strelow, D.; Singh, S. Omnidirectional visual odometry for a planetary rover. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 4, pp. 4007–4012. [Google Scholar] [CrossRef] [Green Version]
- Scaramuzza, D.; Siegwart, R. Appearance-Guided Monocular Omnidirectional Visual Odometry for Outdoor Ground Vehicles. IEEE Trans. Robot. 2008, 24, 1015–1026. [Google Scholar] [CrossRef] [Green Version]
- Tardif, J.P.; Pavlidis, Y.; Daniilidis, K. Monocular visual odometry in urban environments using an omnidirectional camera. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008. [Google Scholar] [CrossRef]
- Valiente, D.; Gil, A.; Reinoso, Ó.; Juliá, M.; Holloway, M. Improved Omnidirectional Odometry for a View-Based Mapping Approach. Sensors 2017, 17, 325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valiente, D.; Gil, A.; Payá, L.; Sebastián, J.; Reinoso, Ó. Robust Visual Localization with Dynamic Uncertainty Management in Omnidirectional SLAM. Appl. Sci. 2017, 7, 1294. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Wang, X.; Li, S. Spherical-Model-Based SLAM on Full-View Images for Indoor Environments. Appl. Sci. 2018, 8, 2268. [Google Scholar] [CrossRef] [Green Version]
- Strelow, D.; Singh, S. Motion Estimation from Image and Inertial Measurements. Int. J. Robot. Res. 2004, 23, 1157–1195. [Google Scholar] [CrossRef]
- Konolige, K.; Agrawal, M.; Solà, J. Large-Scale Visual Odometry for Rough Terrain. In Robotics Research; Kaneko, M., Nakamura, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 201–212. [Google Scholar]
- Usenko, V.C.; Engel, J.; Stückler, J.; Cremers, D. Direct visual-inertial odometry with stereo cameras. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1885–1892. [Google Scholar]
- Kneip, L.; Chli, M.; Siegwart, R. Robust Real-Time Visual Odometry with a Single Camera and an IMU. In Proceedings of the British Machine Vision Conference 2011, Dundee, UK, 29 August–2 September 2011. [Google Scholar] [CrossRef] [Green Version]
- Nützi, G.; Weiss, S.; Scaramuzza, D.; Siegwart, R. Fusion of IMU and Vision for Absolute Scale Estimation in Monocular SLAM. J. Intell. Robot. Syst. 2011, 61, 287–299. [Google Scholar] [CrossRef] [Green Version]
- Frost, D.P.; Kahler, O.; Murray, D.W. Object-aware bundle adjustment for correcting monocular scale drift. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar] [CrossRef]
- Gräter, J.; Wilczynski, A.; Lauer, M. LIMO: Lidar-Monocular Visual Odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Wu, K.; Di, K.; Sun, X.; Wan, W.; Liu, Z. Enhanced Monocular Visual Odometry Integrated with Laser Distance Meter for Astronaut Navigation. Sensors 2014, 14, 4981–5003. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giubilato, R.; Chiodini, S.; Pertile, M.; Debei, S. Scale Correct Monocular Visual Odometry Using a LiDAR Altimeter. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3694–3700. [Google Scholar] [CrossRef]
- Zhang, H.; Martin, F. CUDA accelerated robot localization and mapping. In Proceedings of the 2013 IEEE Conference on Technologies for Practical Robot Applications (TePRA), Woburn, MA, USA, 22–23 April 2013; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Vargas, J.A.D.; Kurka, P.R.G. The Use of a Graphic Processing Unit (GPU) in a Real Time Visual Odometry Application. In Proceedings of the 2015 IEEE International Conference on Dependable Systems and Networks Workshops, Rio de Janeiro, Brazil, 22–25 June 2015; pp. 141–146. [Google Scholar] [CrossRef]
- Scaramuzza, D.; Martinelli, A.; Siegwart, R. A Flexible Technique for Accurate Omnidirectional Camera Calibration and Structure from Motion. In Proceedings of the Fourth IEEE International Conference on Computer Vision Systems (ICVS’06), New York, NY, USA, 4–7 January 2006. [Google Scholar] [CrossRef] [Green Version]
- Scaramuzza, D.; Martinelli, A.; Siegwart, R. A Toolbox for Easily Calibrating Omnidirectional Cameras. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006. [Google Scholar] [CrossRef] [Green Version]
- Harker, M.; O’Leary, P. First Order Geometric Distance (The Myth of Sampsonus). In Proceedings of the BMVC, Edinburgh, UK, 4–7 September 2006; pp. 87–96. [Google Scholar] [CrossRef] [Green Version]
- Kohlbrecher, S.; Meyer, J.; von Stryk, O.; Klingauf, U. A Flexible and Scalable SLAM System with Full 3D Motion Estimation. In Proceedings of the IEEE International Symposium on Safety, Security and Rescue Robotics (SSRR), Kyoto, Japan, 1–5 November 2011. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | B | C | ||||||
|---|---|---|---|---|---|---|---|---|
| Configuration | Serial | Parallel | Serial | Parallel | ||||
| Features per Bucket | 2 | 3 | 2 | 3 | 2 | 3 | 2 | 3 |
| Random Sample | 0.032 | 0.037 | 0.003 | 0.004 | 0.031 | 0.037 | 0.003 | 0.004 |
| Get Inliers | 0.054 | 0.072 | 0.036 | 0.042 | 0.055 | 0.075 | 0.035 | 0.041 |
| Essential Matrix | 0.255 | 0.251 | 0.095 | 0.096 | 0.247 | 0.249 | 0.094 | 0.094 |
| RANSAC | 0.336 | 0.361 | 0.140 | 0.150 | 0.337 | 0.360 | 0.139 | 0.146 |
| Process | 0.501 | 0.600 | 0.305 | 0.403 | 0.468 | 0.528 | 0.267 | 0.331 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguiar, A.; Santos, F.; Sousa, A.J.; Santos, L. FAST-FUSION: An Improved Accuracy Omnidirectional Visual Odometry System with Sensor Fusion and GPU Optimization for Embedded Low Cost Hardware. Appl. Sci. 2019, 9, 5516. https://doi.org/10.3390/app9245516
Aguiar A, Santos F, Sousa AJ, Santos L. FAST-FUSION: An Improved Accuracy Omnidirectional Visual Odometry System with Sensor Fusion and GPU Optimization for Embedded Low Cost Hardware. Applied Sciences. 2019; 9(24):5516. https://doi.org/10.3390/app9245516
Chicago/Turabian StyleAguiar, André, Filipe Santos, Armando Jorge Sousa, and Luís Santos. 2019. "FAST-FUSION: An Improved Accuracy Omnidirectional Visual Odometry System with Sensor Fusion and GPU Optimization for Embedded Low Cost Hardware" Applied Sciences 9, no. 24: 5516. https://doi.org/10.3390/app9245516