1. Introduction
Airborne Laser Scanning (ALS) can capture large-scale point clouds of urban scenes. The point cloud classification of outdoor scenes can provide high-precision semantic maps for autonomous driving, improve the accuracy of vehicle positioning, and reconstruct a three-dimensional model of the city, which plays an important role in urban planning and dynamic management. In addition, it can improve the efficiency of resource utilization. Effectively labeling the correct class for all points in the scene is an important basis for the widespread adoption of point clouds [
1,
2,
3,
4]. However, a laser point cloud has a huge data number, high redundancy, and uneven scene distribution, which may lead to huge challenges in the point cloud classification. Therefore, it is of great significance to classify the three-dimensional point cloud in large outdoor scenes.
Currently, the number of point clouds with manual labeling in outdoor large scenes is not enough. However, machine learning can learn and classify point clouds in the case of less sample training data, and the speed is faster. At present, the point cloud classification methods can be mainly divided into two strategies: the single point-based classification and object-based classification methods.
The point-based point cloud classification is the classification of each individual point in a point cloud; this strategy uses points as the basic unit to extract features, train models, and predict class labels. There are three main steps: the neighborhood selection, feature extraction, and single point classification based on the features and classifiers.
(1) Neighborhood selection. In the neighborhood selection process, the commonly used point cloud neighborhood forms are: K nearest neighbors [
5], radius neighborhoods [
6], and column neighborhoods [
7]. The parameter of neighborhood estimation is highly dependent on prior knowledge, and it is greatly affected by the change of the point cloud density [
8,
9]. For example, Hackel et al. constructed a multi-level scale pyramid, and a total of 144-dimensional features such as eigenvalues of the covariance matrix were extracted for each point in each pyramid. Subsequently, Random Forest was used for training and finally classified outdoor road scenes [
10], and a better classification effect was obtained. Therefore, the selection based on multi-scale neighborhood is an important method for extracting single point effective features.
(2) Features extraction. The local feature of a point cloud is an abstract depiction of the environment around a given point. It is difficult to classify a point cloud by a single local feature. The common practice is to fuse multiple point cloud local features for classification. Normal and curvature are simple local features that clearly show some local information about the point cloud, such as the fact that the normal direction can represent the partial tangent plane of the point cloud, and the curvature can represent the smoothness of the point. For example, Fanxuan et al. [
11] optimized the matching accuracy of point pairs in point clouds based on the curvature information, and the registration accuracy of point clouds was further improved. Geometric features are also common local features, also known as shape descriptors. For example, in the spin image [
12], the main idea is to set up an image with the normal vector as the center; the image rotates around the axis. The number of 3D points encountered by each pixel in the point cloud is taken as its gray value. Finally, a two-dimensional array representing the local information of the three-dimensional space, that is, the rotated image feature, is obtained. The 3D Shape Context (3DSC) feature [
13] is based on the specified point to construct a spherical region. In the support region, the grid is divided into three coordinate directions: the radial direction, direction angle and elevation angle. Following this, a feature histogram is constructed by entering the number of points in the grid. The 3DSC is simple in construction, strong in discrimination and insensitive to noise, but it is time-consuming. The Unique Shape Context (USC) descriptor [
14] improves the 3DSC to avoid ambiguities in the classification. Point Feature Histograms (PFH) [
15] are local features, which construct a feature histogram with the angles and distances of the normal vectors of any two points in the specified point neighborhood. The descriptor can accurately describe the local features of the points, but the computation is large and the real-time performance is poor. Fast Point Feature Histograms (FPFH) [
16] are a simplification of PFH, which greatly reduce the time consumption while retaining most of the description performance of PFH. FPFH have an excellent performance, and are widely used in the field of point cloud classification, segmentation and registration [
17]. Although these features can express the local features of the point cloud, they do not take into account the characteristics of the ALS point cloud, which has the characteristics of relative sparse, rich elevation information, as well as a horizontal and vertical distribution.
(3) Single point classification based on features and classifiers. Currently, machine learning is an important method for classification problems. The single-point classification based on machine learning takes the feature vector of the point as the input and the class label of the single point as the output. Common machine learning algorithms can accomplish this classification task, such as AdaBoost [
18], Random Forest [
19] and Support Vector Machine (SVM) [
20]. This kind of method uses a classifier to learn the local features of each point, after which the parameters in the classifier are determined based on the training dataset. Finally, the test set is classified by the classifier. This classification strategy can more accurately segment the boundary regions between different adjacent objects, and this method has a better performance in detail. However, due to the extremely large number of points, the calculation amount is large. Thus, the model training is slow, and there are also some misclassifications of local regions. However, there are always some errors in the final classification results. Therefore, the initial classification results are required to further optimize according to the characteristics of the point cloud.
In order to solve the above-mentioned problems, an ALS point cloud classification algorithm based on a single point multi-feature fusion is proposed. This kind of algorithm is based on the point as the basic processing unit, and the classification process assigns labels to each point in the point cloud to realize a point cloud classification. The proposed method extracts the local features of each point by constructing a multi-scale neighborhood space, along with two new features: a normal angle distribution histogram (NAD) and latitude sampling histogram (LSH) are proposed. Following this, SVM is used for training and classification. However, since each point is classified, there is a problem regarding some edge points being misclassified. In this regard, the initial classification results are further optimized according to the neighborhood classification optimization of multi-scale pyramids. Experiments prove that the classification algorithm has a higher accuracy.
The main contributions of this paper are as follows:
(1) Two local features are proposed, that is, the NAD histogram and the LSH histogram. The differences of different objects in the normal distribution, and the difference of the neighborhood points around different objects in the horizontal and vertical directions of the three-dimensional space, can be fully utilized to more effectively represent the characteristics of different objects.
(2) A multilevel single-point features fusion method based on a multi-neighborhood space and multi-resolution is proposed. The multi-scale space is constructed by changing the resolution of the point cloud and the number of the neighborhood. The features of the multi-scale are extracted from each single point, and the features are fused. Following this, the SVM classifier is used to classify the features and the better classification results have also been achieved.
(3) A fast optimization method for classification results based on a multi-scale pyramid is proposed. By changing the resolution of the point cloud, a multi-scale pyramid is constructed, and the neighbor points are further re-selected. After this, the misclassifications are eliminated according to the initial classification results of the neighbors for a post-processing optimization.
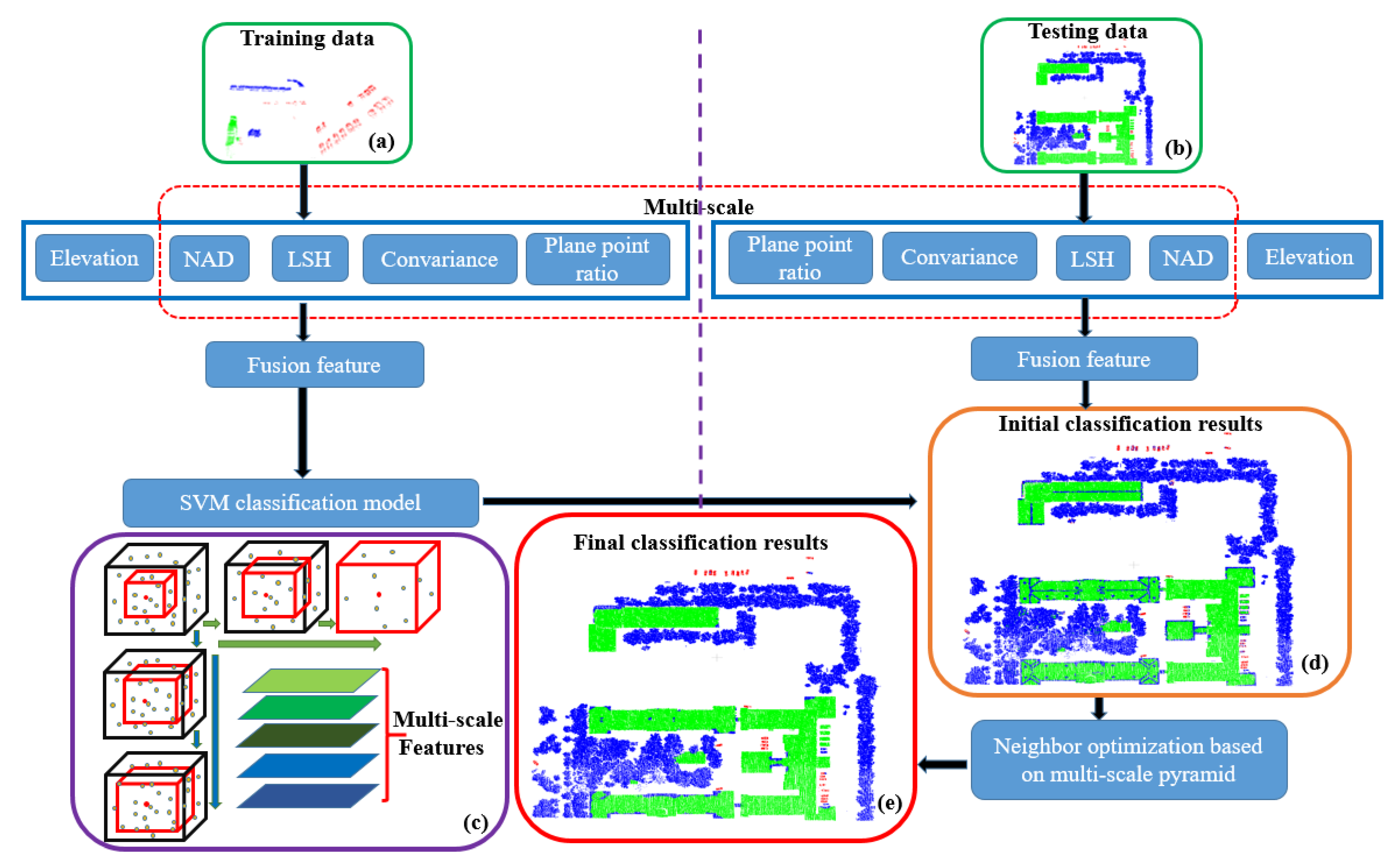
2. Method
As shown in
Figure 1, the algorithm flow is given as follows. In the training part, for the point cloud scene shown in
Figure 1a, multiple features of each point are first extracted. Multi-scale and multiple features are fused to a fusion feature. The SVM classifier model is then trained using the fusion features of the training set. In the test part, for the point cloud scene shown in
Figure 1b, the fusion feature is first obtained. As shown in
Figure 1c, the test points are initially classified using the trained SVM classification model. Following this, the point clouds of different resolutions are obtained by down-sampling the point cloud, in order to construct a multi-scale point cloud pyramid. The corresponding classification labels of the different neighboring points in the different scales are searched. Finally, the label which has the most number in the neighbors is taken as the class label of the current point. The final point cloud classification result is obtained, as shown in
Figure 1d.
2.1. Point Feature Extraction
In the classification task of the 3D point cloud data, the feature extraction of the point cloud plays a crucial role. It can seriously affect the final classification result. A well-behaved feature descriptor should reflect obvious differences between different types of points in the point cloud. At the same time, the descriptor should be robust and have a strong anti-interference ability. It is difficult for a single feature descriptor to have the above characteristics, so that a plurality of feature descriptor fusion methods are at present widely used. In the single point-based classification algorithm, this paper uses a variety of feature fusion methods to improve the accuracy of the classification algorithm. The specific features are as follows:
2.1.1. Feature Description
The height is a very intuitive feature in a 3D point cloud. Generally speaking, points with large height are buildings, trees or objects with larger elevation values in the real world. When the elevation value is small, the probability is greater if the point is a vehicle point. Thus, the elevation feature is set to:
where
is the distance of the
i-th point from the estimated ground to the elevation value.
- 2.
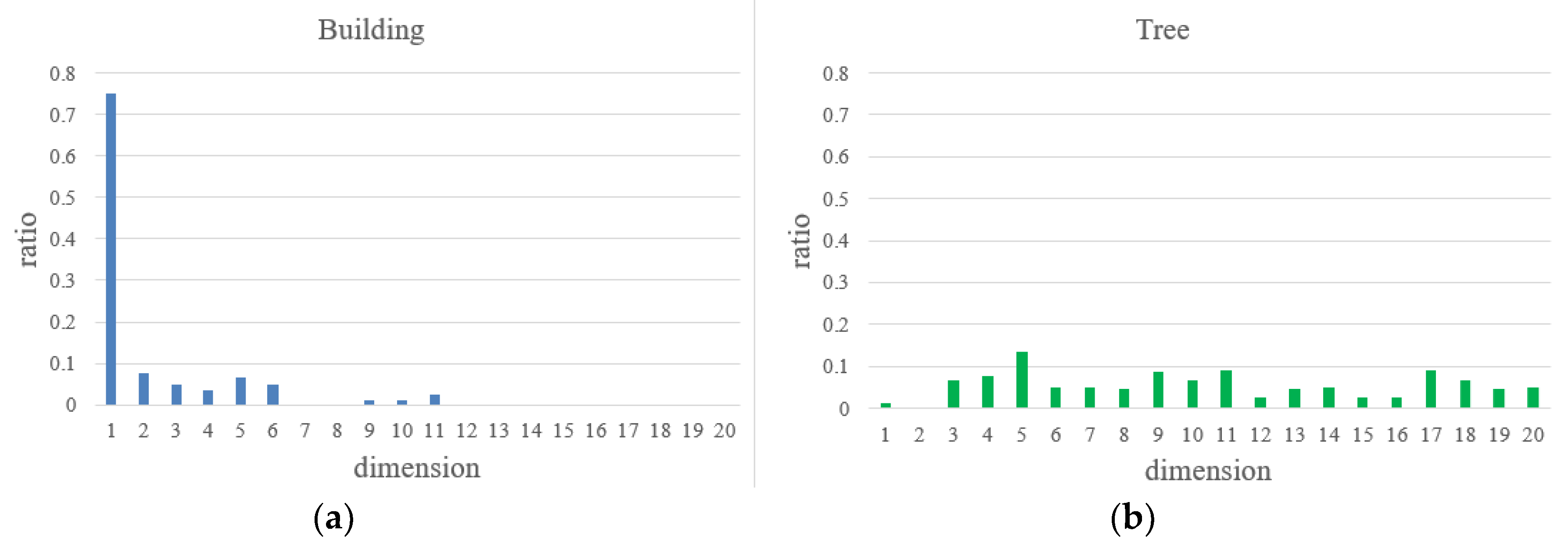
Normal angle distribution histogram
In the large scale scene, the normal direction of different objects has obvious differences. For artificial objects, such as buildings and vehicles, since the surface is relatively regular, almost all points are in the same direction, pointing in the direction of the vertical plane. However, due to the scattered distribution of the whole point cloud, the normal direction of the point cloud has a large scattered nature, and the direction does not point to a fixed direction in a uniform way. Therefore, we calculate the histogram of each point and its own normal angle distribution value in the local neighborhood point set to express the relationship between the normal of the point and the normal of the points in the neighboring region. The angle between the two normal vectors in three-dimensional space should be between
. But considering that the normal of the point on the plane can have opposite directions when the angle is larger than
, the corresponding angle is set to
. Following this, the angle of the normal vectors is defined as
. Considering efficiency and resolving power, we divide this interval into equal
parts, that is, construct a
dimensional histogram. After this, the number of points falling within each cell is taken as the value of the interval in the histogram. Finally, the normalization process is performed to form a histogram of the normal angle distribution, called NAD. This feature can distinguish different classes of points based on the normal angular distributions. The specific calculation formulas are as follows:
where
and
represent the normal vectors of the current point and the
j-th neighbor point, respectively.
represents the inverse cosine function.
N represents the number of neighbors for the current point.
denotes the number of points for the normal angle at the range
.
denotes the final normal angle eigenvalue vector of the normal angle distribution. The histogram of the normal angle distributions for the randomly selected building points and tree points are shown in
Figure 2.
- 3.
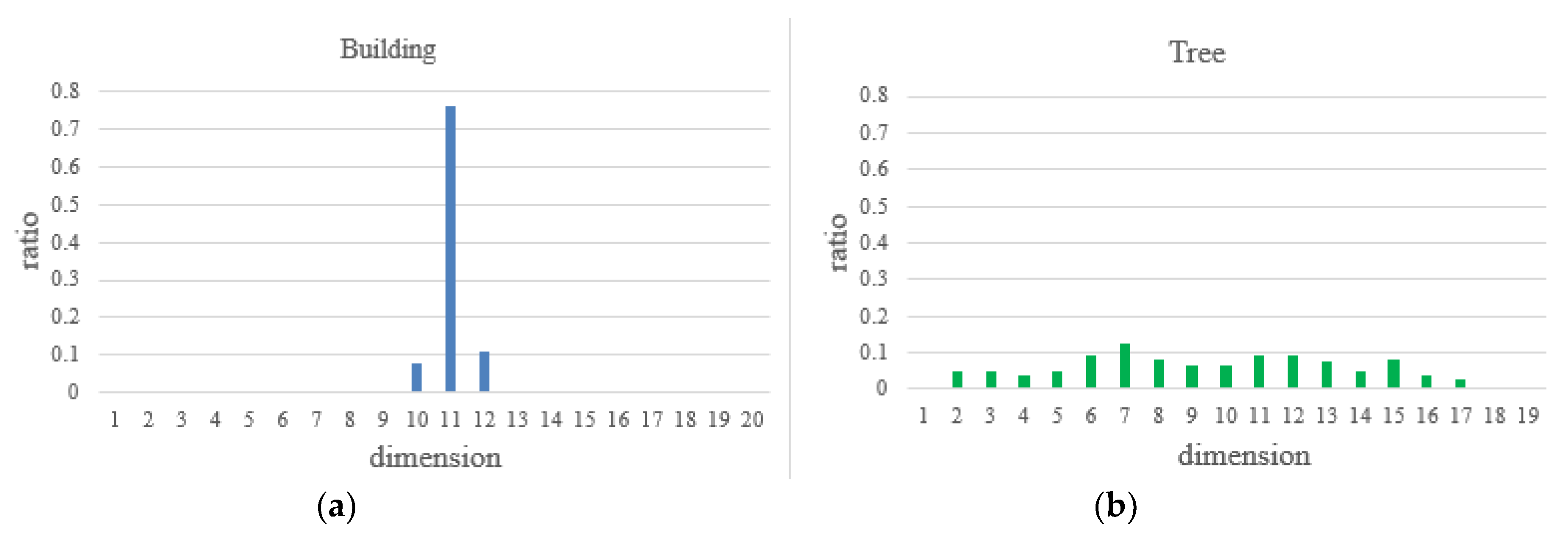
Latitudinal sampling histogram
In the outdoor large scene environment, as for almost all points belonging to different objects, the surrounding neighborhood points have great differences in the latitudinal distribution in the three-dimensional space. For example, a building surface, which is parallel to the ground, has its neighborhood points mainly distributed near the “equator”. For the points belonging to the trees, the distribution of the neighborhood points is more random and extensive, hardly concentrated in a certain latitude interval. Therefore, the selected point is regarded as the center of the sphere, and the distribution histogram of the neighborhood points in the latitudinal direction is counted. Following this, the feature of the point can be expressed. The feature is called LSH. The LSH feature can be used to distinguish different classes of points according to the distribution of neighborhood points in the latitude direction. The LSH has the advantages of anti-occlusion, without interference from the local coordinate system, as well as high efficiency. In this paper,
Dl spaces are equally divided along the latitude direction. Following this, the number of points falling into each cell is counted to form a feature vector of the
Dl dimension. The specific calculation formulas are:
where
and
represent the three-dimensional coordinates of the current point and its
j-th neighbor point, respectively.
represents the unit vector of the positive direction of the
axis.
represents the number of points in
of the neighborhood points along the latitudinal direction.
represents the final feature vector of LSH. The LSHs of the randomly selected building points and tree points are compared, as shown in
Figure 3.
First, a covariance matrix for the selected point neighborhood is constructed. After this, eigenvalues of the covariance matrix are calculated as: , and the corresponding eigenvectors are calculated as: . Here, the covariance feature (CF) is obtained according to the relationship among the eigenvalues, as follows:
Following this, the final total covariance feature is: .
In outdoor large scale scenes, the classes of objects are complex and the surface shapes are also different. However, a considerable part of the surface of artificial objects exhibits planar characteristics, such as buildings, vehicles, etc. Meanwhile vegetation does not have planar characteristics, so the plane point ratio of the local point cloud can be used as a local feature to classify point clouds. The covariance feature can also reflect the planar characteristics to a certain extent, but it is greatly interfered by noise. For this reason, the Random Sample Consensus (RANSAC) [
21] is employed to fit the local neighborhood of the selected point. After this, the ratio of the plane points, called PPR (Plane Point Ratio), is calculated.
RANSAC is a method used to find the subset of data that is the best match for the model from the data set with random samples that are noisy but sufficient. The points matched with the model are called the inner points, and the points unmatched with the model are called the outer points. The plane is fitted using RANSAC as follows.
(1) Select three points randomly from all the neighborhood points and calculate the current model parameters. The model is as follows:
(2) Determine whether each point is an inlier, and then determine the inlier rate
of the current model:
where
di is the distance from the
i-th point to the plane.
Td is a fixed threshold.
Ji indicates whether it is an inlier or not.
is the number of neighborhood points.
(3) If the current inlier rate is larger than the previous optimal inlier rate, the optimal inlier rate is updated.
(4) To find the optimal model, repeat steps (1) to (3)
k times until the probability reaches
P:
The termination condition is:
When the RANSAC iteration is completed, the optimal inlier rate is the ratio of the plane points: .
2.1.2. Single Point Multi-Scale Multi-Feature Fusion
Since the features of the single point are dependent on the selected neighborhood space, different neighborhood spaces have different expression capabilities for different classes of point clouds. Additionally, the structure descriptions of point clouds with different resolutions also have certain differences. The local feature description of the single scale for a point is relatively single, and there are some noise points in the point cloud, which can make the simple feature of the single scale unable to accurately describe the feature of the single point. Therefore, a multilevel features fusion method based on the multi-neighborhood space and multi-resolution is proposed. As shown in
Figure 1c, the proposed method constructs the multi-scale space by changing the resolution and the number of neighborhoods of the point cloud. Following this, multi-scale features for each single point in the point cloud are extracted. Because the elevation feature is not affected by the scale changing, we select NAD, LSH, CF and PPR features to construct the multi-scale features. We extract the features of a single point in each scale by choosing µ neighborhoods with different resolutions and
different neighborhood sizes under the original resolution. The multi-scale features of each point are expressed respectively as
. Considering the validity of the features and the efficiency of the calculation, this generally results in
µ
5. In addition, the description of the single point feature only represents one characteristic of the point cloud. Therefore, it is necessary to fuse multiple features. After fusing the features, the multilevel features are expressed as follows:
Because we aim at an ALS point cloud, the extracted elevation features are only two-dimensional and play an important role in the point cloud classification. In addition, when the point cloud features are extracted, the values of each feature have been normalized to [0, 1]. In order to reflect the role of the non-zero feature value, the feature should be normalized again according to Formula (22) when the extracted feature
F is sparse. While the extracted feature
F is not sparse, there is no need to normalize the feature. Therefore, the constructed feature is
where
is the value of the
i-th row and the
j-th column in the normalized feature matrix
F*.
is the value of the
i-th row and the
j-th column in the feature matrix
F. is the vector of the
j-th column (for all the points) in the feature matrix
F.
2.2. Point Cloud Classification Based on SVM
SVM [
22] is achieved by maximizing the classification interval in the feature space. For non-linear data, SVM maps them into a high-dimensional feature space by a kernel function, which make the data into linear separable data in a high-dimensional feature space. Following this, it realizes a classification by maximizing the interval. In view of the excellent generalization ability of SVM, we use SVM as a classifier for the single point classification in point cloud data. As we know, the correlation between the point cloud single point feature and neighbor points features, and the Gauss kernel function only has one parameter
and a low model complexity. Thus, in the absence of prior knowledge, the Gauss kernel function is often better than other kernels. Therefore, we choose the Gauss kernel function as the kernel function. Here, the Gauss kernel function of the SVM classifier is defined as follows:
The fused feature space is
. The selected
n d-dimensional feature samples
:
After the feature transformation, the feature space is Z. We map data in the
X space to the
Z space
via the mapping function
. The function
satisfies the condition
, and the function
is a kernel function, while
is a mapping function. The Gauss kernel function is as follows:
The corresponding decision function is:
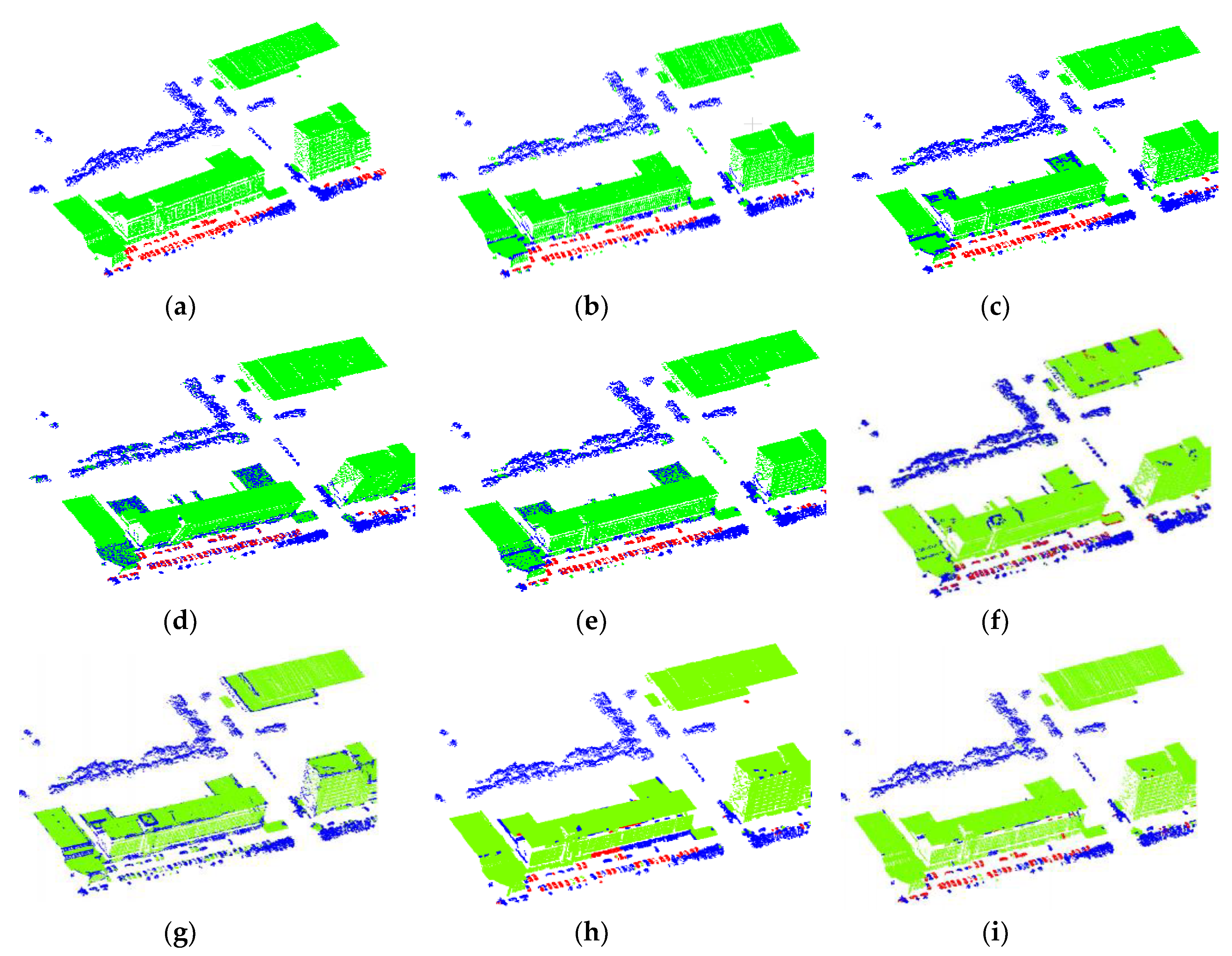
The SVM classifier is trained by the features of the training set, and the test set is classified by the trained classifier. The initial classification results for the point cloud in
Figure 1b are shown in
Figure 1d.
2.3. Neighborhood Optimization Based on Multi-Scale Pyramid
After the initial classification, the point clouds are basically classified correctly. Due to noise and other reasons, there are still some misclassifications in some details (such as edges). As shown in
Figure 1d, most of the points in the scene have been correctly classified, and only a small part of them are misclassified. They mainly concentrate on edges and other places, and most of the points around the misclassified points are correctly classified. Therefore, it is necessary to further optimize the initial classification results to achieve a more accurate classification of the point clouds. Because local information is used as a feature to classify point clouds, the feature extraction relies heavily on a local region selection. In addition, the single point is taken as the basic unit of classification. Each point has its own characteristics, but because the two neighboring points are very close to each other and their neighborhoods are also very close, the extracted features will be very similar, which leads them to be more likely to be classified into the same class. Therefore, the neighbors of the misclassified points are also often misclassified. It is difficult to correct the misclassified points if only the points in the smaller local regions are used for the optimization. Therefore, we propose a classification results optimization method based on the multi-scale pyramid. The specific method is as follows:
First, voxel filters with different radius scales are used to down-sample the point cloud after an initial classification, as shown in Formula (24). Each minimum voxel scale is twice as large as the last down-sampling, and sparse point clouds are gradually obtained. Following this, the q-level pyramid is constructed, and the initial classes of all the points in each level are retained. According to the characteristics of the point cloud down-sampling reflecting the structure information of the shape, the scale pyramid is constructed on three scales of q = 3 in this paper.
Following this, the corresponding k-d tree is constructed from the point cloud in each layer of the pyramid. For each point in the original point cloud, a k-d tree is used to search for the radius of the nearest neighbors in the point cloud after the down-sampling. The class labels of the
m point clouds searched within the radius of the
l-th level are
,
i = 1,…, m,
l = 1,..,
q; the radius parameters are different when each layer of the point cloud chooses its nearest neighbor. The method of calculation is as follows:
In the formula, r represents the scale radius parameter. is the resolution used by the current down-sampling point cloud. k is a fixed ratio threshold.
Finally, the initial labels of all the nearest neighbors in the q levels are counted. The discriminant function represents the fact that when belongs to class C, its value is 1; otherwise, its value is 0. This is used to count the number of the initial labels belonging to each class. As shown in Formula (27), the mode label is selected as the new class label for the current point.
Not only do the optimized point cloud classification results avoid a situation where the nearest neighbor is also misclassified, but they also solve the problem of too many far points in a large scale, thus achieving better results. The optimized point cloud classification results are shown in
Figure 1e.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}