5.5.1. Dataset
The two high-resolution remote sensing datasets used for object detection are described in
Section 4.3.1. This section introduces the remote sensing scene classification datasets used in the training of sceNet networks and the two regular image datasets used for transfer learning. For remote sensing scene classification, there are two public datasets: UCMerced-LandUse [
33] and Dataset-WHU-RS [
33]. UCMerced-LandUse contains 21 different scene categories, each category containing 100 high-resolution remote sensing images of 256 × 256 pixels. The Dataset-WHU-RS dataset contains 19 scene categories, a total of 950 images of 600 × 600 pixels. In order to expand the training samples, this paper will simply divide one remote sensing image with 600 × 600 pixels into nine 256 × 256 pixel sub-images. In the end, the two remote sensing datasets are merged together, and the data of the same category are merged. In addition, fine-grained similar scenes such as sparse density residential, medium density residential area, and intensive residential area are merged. After merging, there were 26 scene classes, averaging about 320 images per class. In addition, in order to further increase the training data, simple horizontal, vertical flip operations were used.
Next, the regular image scene classification dataset Places used in the transfer learning of sceNet network is introduced briefly. This dataset Places is a large-scale natural scene dataset, containing 205 categories and a total of 2.5 million images.
The data used in the transfer learning of objNet network were mainly extracted from the ImageNet 2012 dataset, in which positive samples were all images in two categories of airplane and military airplane and some airplane images crawled from the Internet, a total of 12,300 images; for negative samples, we picked a category that may appear in the remote sensing images, such as ships, harbors, mountains, etc., and removed the other 980 categories, such as sharks, hens, caps, etc., which might be useless for object identification in remote sensing images.
Figure 17 shows examples of the positive and negative samples of the dataset. For the convenience of the following description, this dataset is called NATURE-PLANE.
5.5.2. Environment and Evaluation
The experiment in this section was performed on Caffe. Caffe is widely used in the deep learning domain because of its advantages of being clear, simple, fast, and fully open source. The platform had two NVIDIA GeForce GTX 980 video cards, 16 GB memory, CPU i5-4460. For a detection result with IoU overlap with a real object coincidence degree no less than a threshold (usually set to 0.5), the detection result is considered correct; besides, if there are multiple detections, then only one is considered right, while the rest are false detections. In this paper, we used the precision and recall curve (PR curve) and the average precision (AP) to evaluate the detection performance synthetically. The evaluation method and code used the PASCAL VOC2007 standard. Accuracy and recall are defined as Formulas (17) and (18), respectively:
where
is true positive, the number of true boxes, that is the number of objects correctly detected;
is false positive, the number of false positives, that is the number of false detection results;
is false negative, the number of false negative cases, that is the true number of objects that were missed.
The average detection accuracy of
can be measured by a single value, which is a representative comprehensive evaluation of the index, called the area under the
curve, as shown in Formula (19).
5.5.3. Result Analysis
In order to prove the validity of the transfer learning, this section firstly gives the classification accuracy of the object and scene feature extraction network in the training process and then gives the influence of the feature extraction on the detection effect before and after the transfer learning. Furthermore, the effectiveness of scene feature fusion is illustrated by contrasting the detection performance before and after the context scene feature fusion. Finally, we compare the other algorithms to prove the validity of the proposed remote sensing object detection algorithm based on deep learning with scene feature fusion.
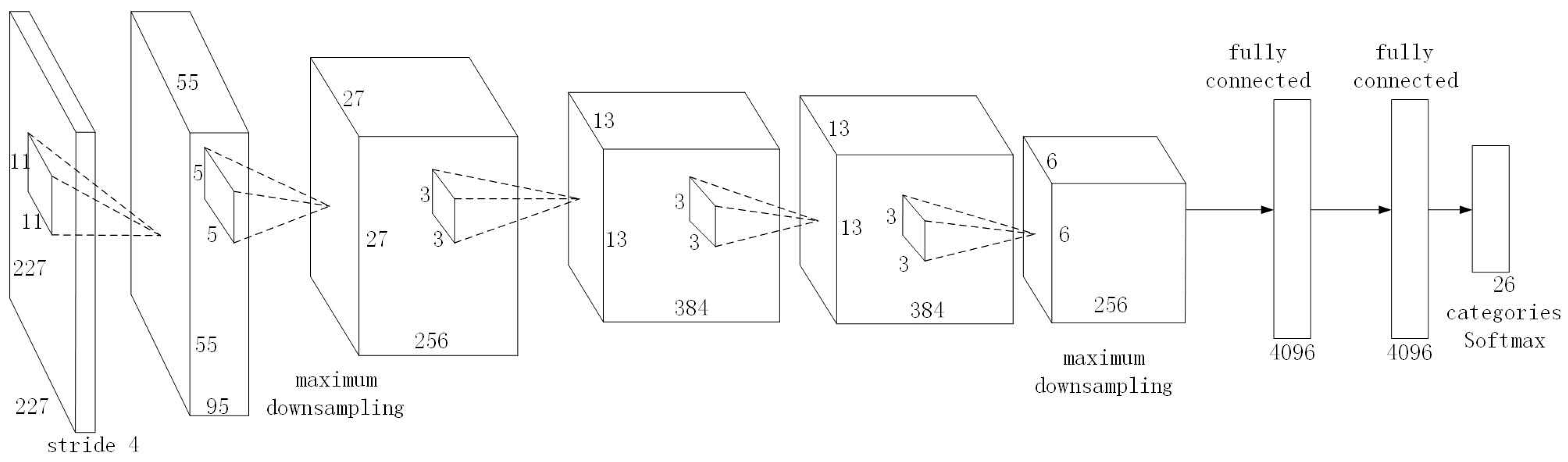
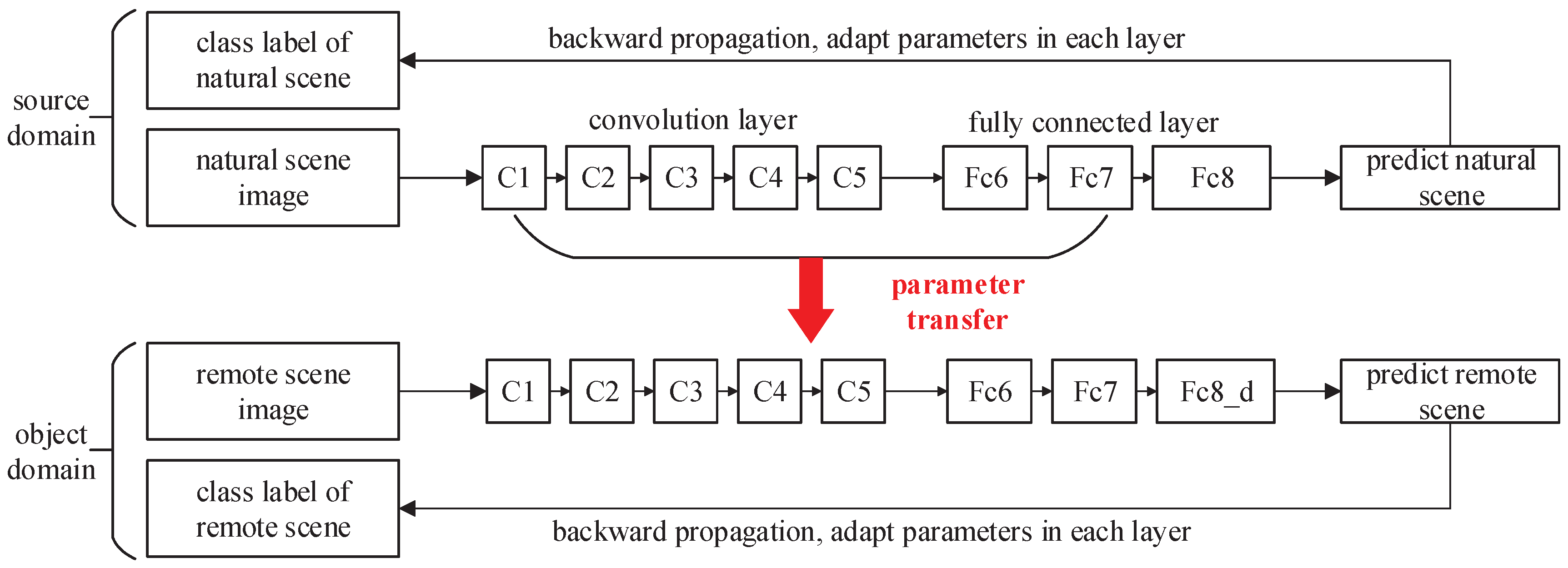
Because the sceNet network uses the classic AlexNet network structure, there are many trained parameter models based on the network, which can be used for transfer learning. During the training process, the parameter models of AlexNet, CaffeNet, Places205-AlexNet, and Hybrid-AlexNet were used for transfer learning in this paper. AlexNet and CaffeNet were trained on the ImageNet2012 dataset, and CaffeNet has a very similar architecture to AlexNet, except for two small modifications: training without data augmentation and exchanging the order of pooling and normalization layers. Places205-AlexNet is a parameter model trained on the Places dataset. Hybrid-AlexNet was trained on the dataset combining the Place dataset with the ImageNet2012 dataset for a total of 3.6 million images in 1183 categories.
Table 5 shows the classification accuracy of the remote sensing scene using different transfer learning models, where “AlexNet-RSI” indicates the learned network model without transfer learning and “xx-TL” denotes the network transferred from different models.
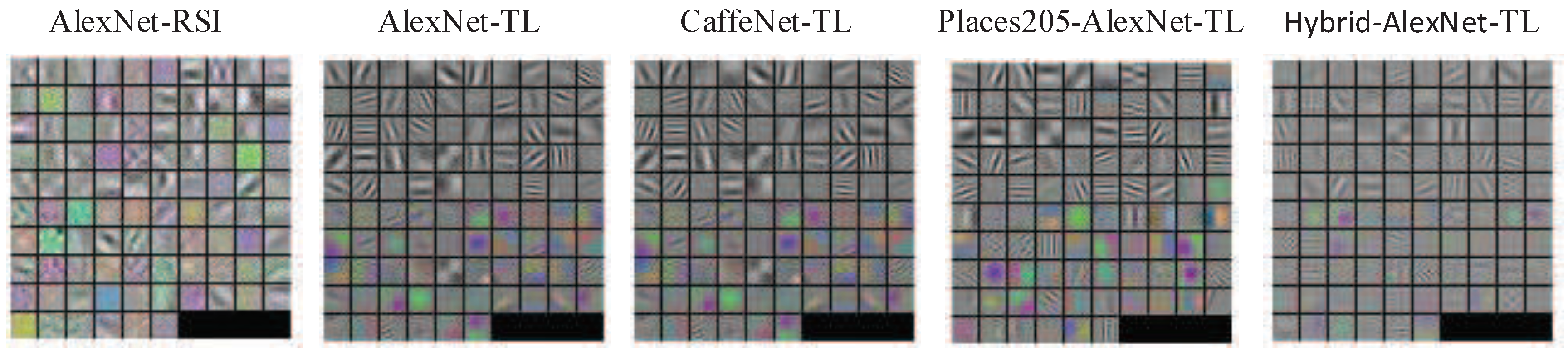
Table 5 reveals that the accuracy of the network trained with transfer learning was much higher than that of a network trained directly using remote sensing scene data. After transfer learning, the accuracy of the Hybrid-AlexNet network trained on the Place and ImageNet 2012 datasets was the highest, so we used the Hybrid-AlexNet-TL model to extract the feature of the object context scene. In addition, by visualizing the convolution kernel parameters of the first convolution layer, as shown in
Figure 18, this shows that the convolution kernel of the network with transfer learning learned more edge features, and without transfer learning, the first layer of the network simply learned some simple fuzzy color information.
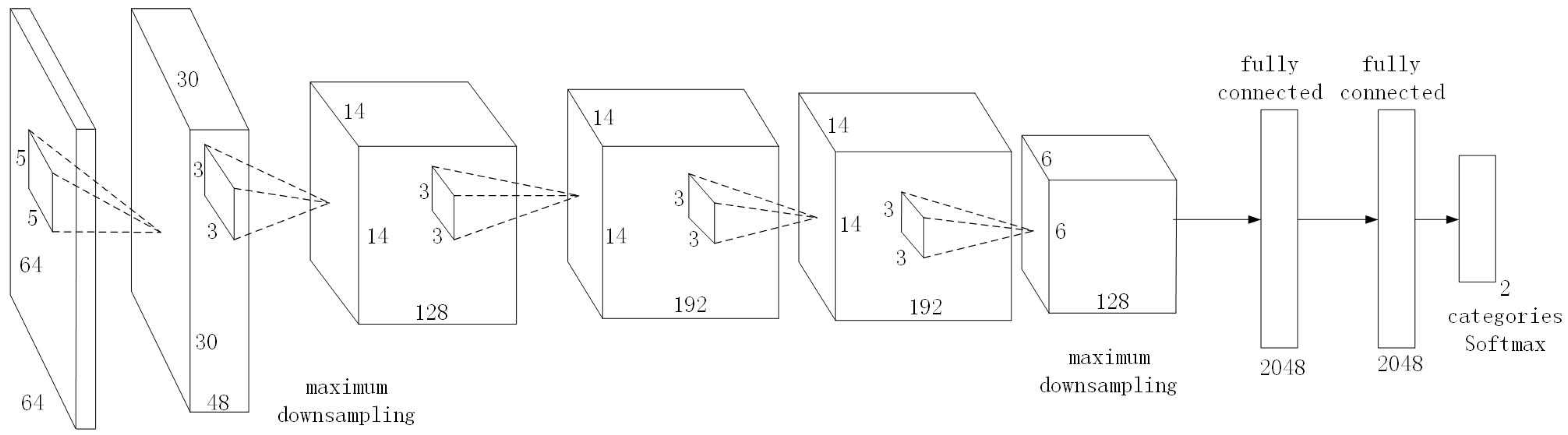
For the training of object classification network objNet, because the network structure was designed in this paper, there was no trained model for transfer learning, so it was necessary to pre-train the transferable model parameters. Therefore, we used the NATURE-PLANE dataset introduced in
Section 5.4.1 to pre-train objNet. However, in practice, it appears that if we pre-train the objNet directly using ImageNet2012’s complete data and resume training using the NATURE-PLANE dataset, a better classification result could be obtained.
Table 6 lists the classification accuracy of different pre-trained objNet networks, where objNet-RSI denotes the network model obtained without using transfer learning.
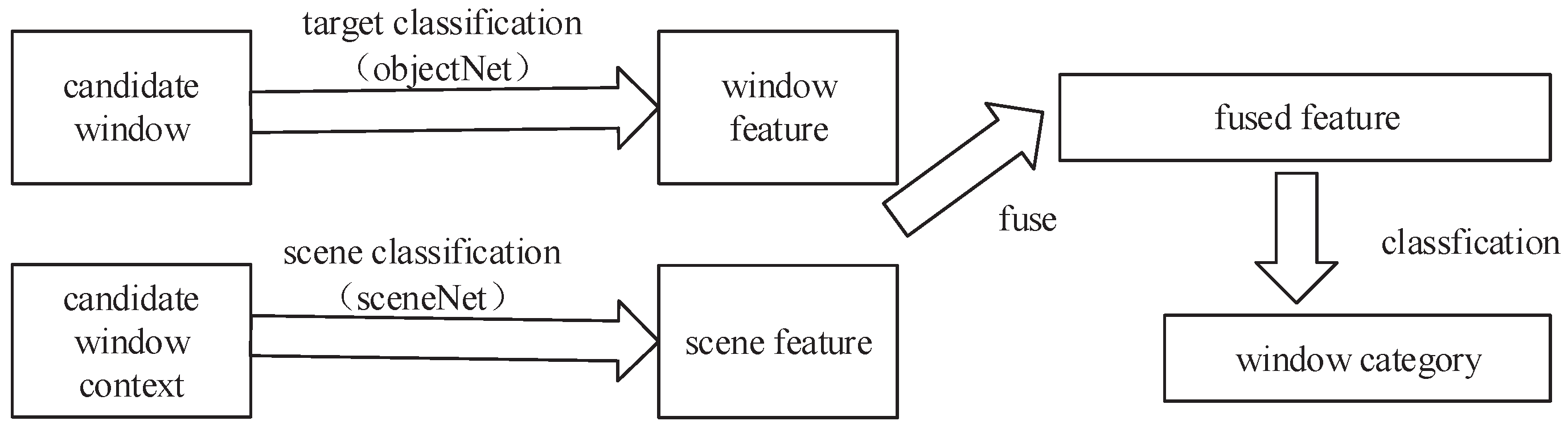
After the training of the objNet network and sceNet network was complete, we used the two networks for feature extraction and classification detection. We first compared the detection performance before and after using transfer learning in objNet when there was no scene feature fusion. Then, to fuse the scene features, in the fusion, we also compared the effect of sceNet before and after transfer. That is, there was in total four groups of experiments, and the four groups of experiments had a progressive relationship, in which the fourth set of experiments was our proposed algorithm. In order to simplify the following description, we named each experiment and the configuration of each set of experiments as listed in
Table 7.
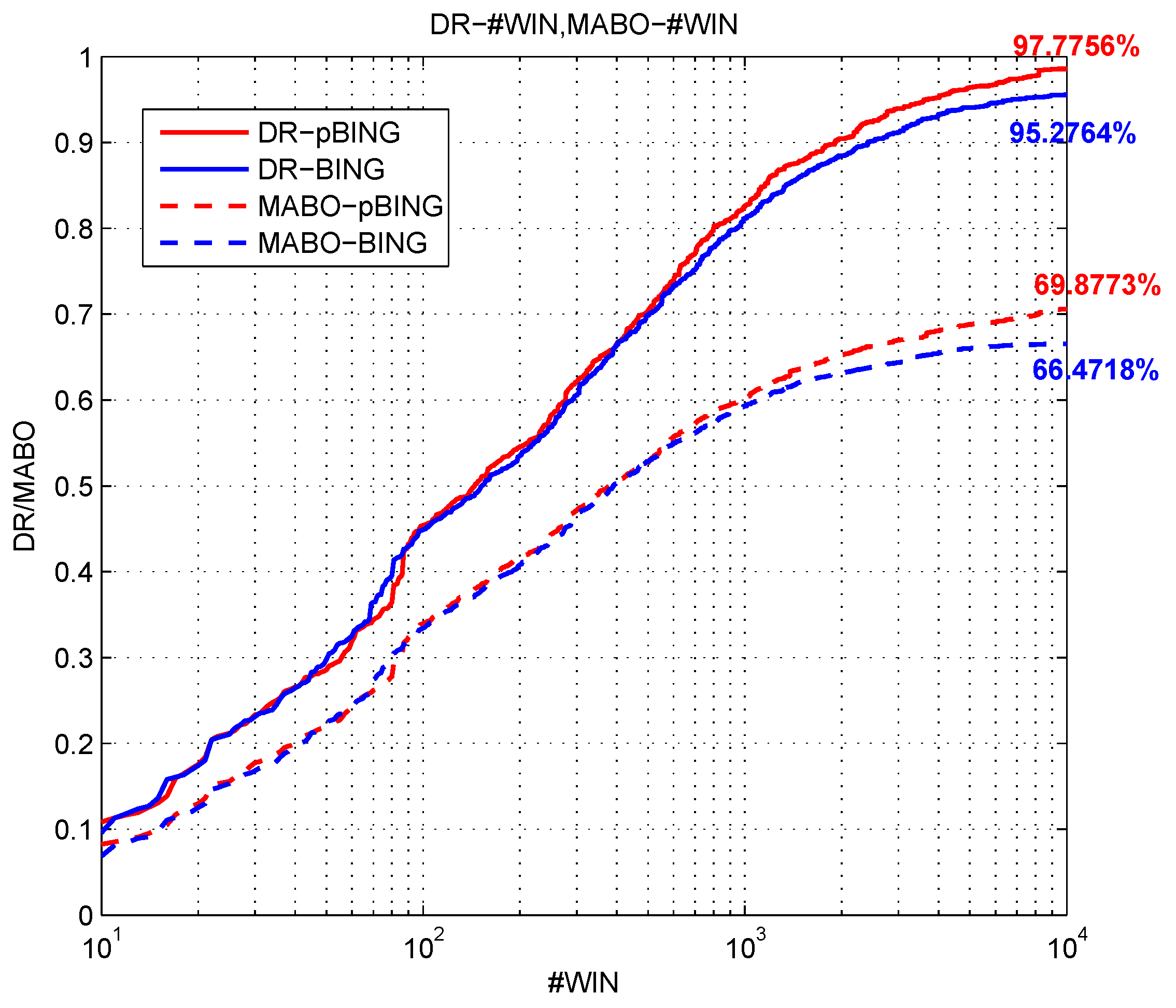
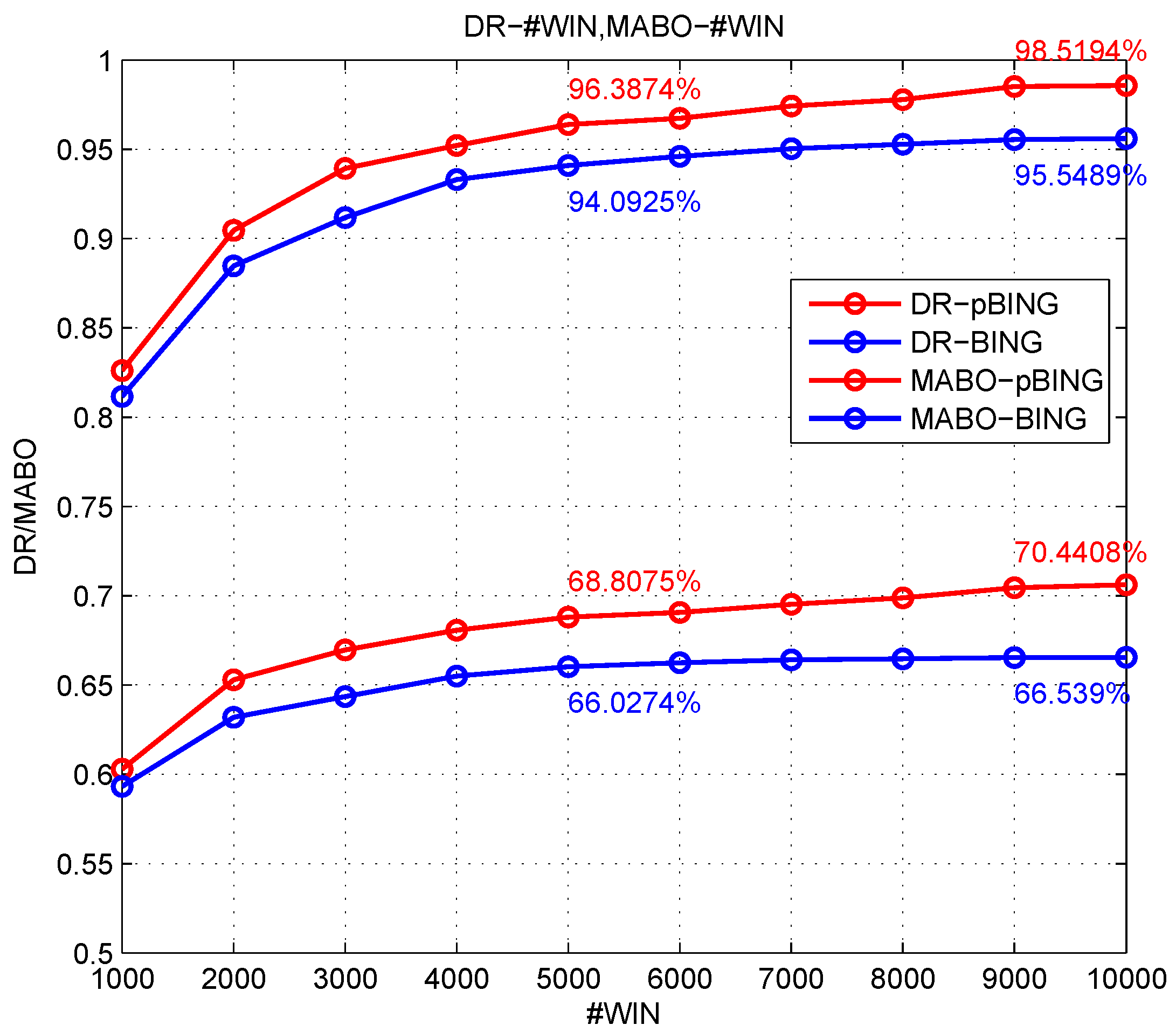
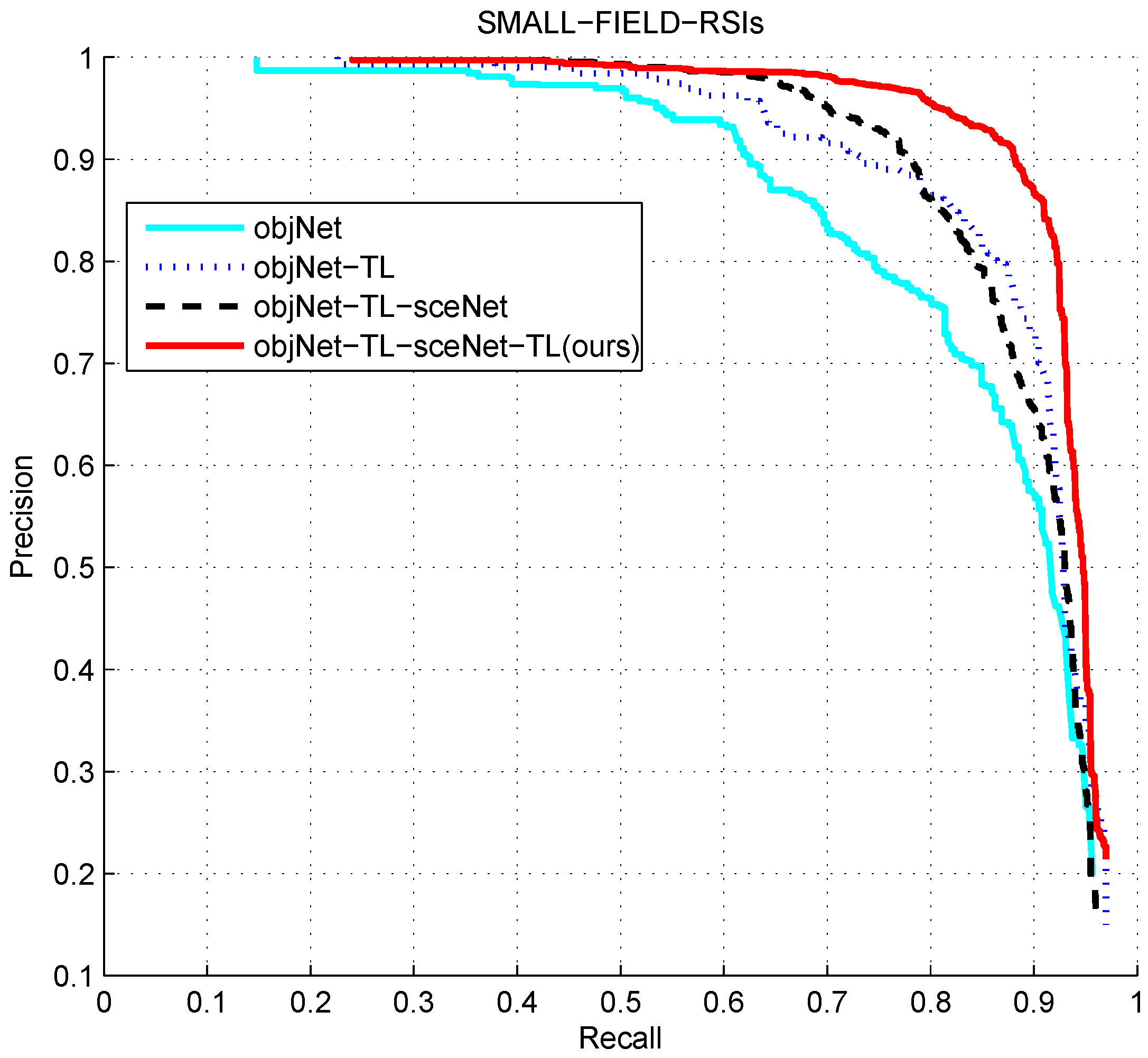
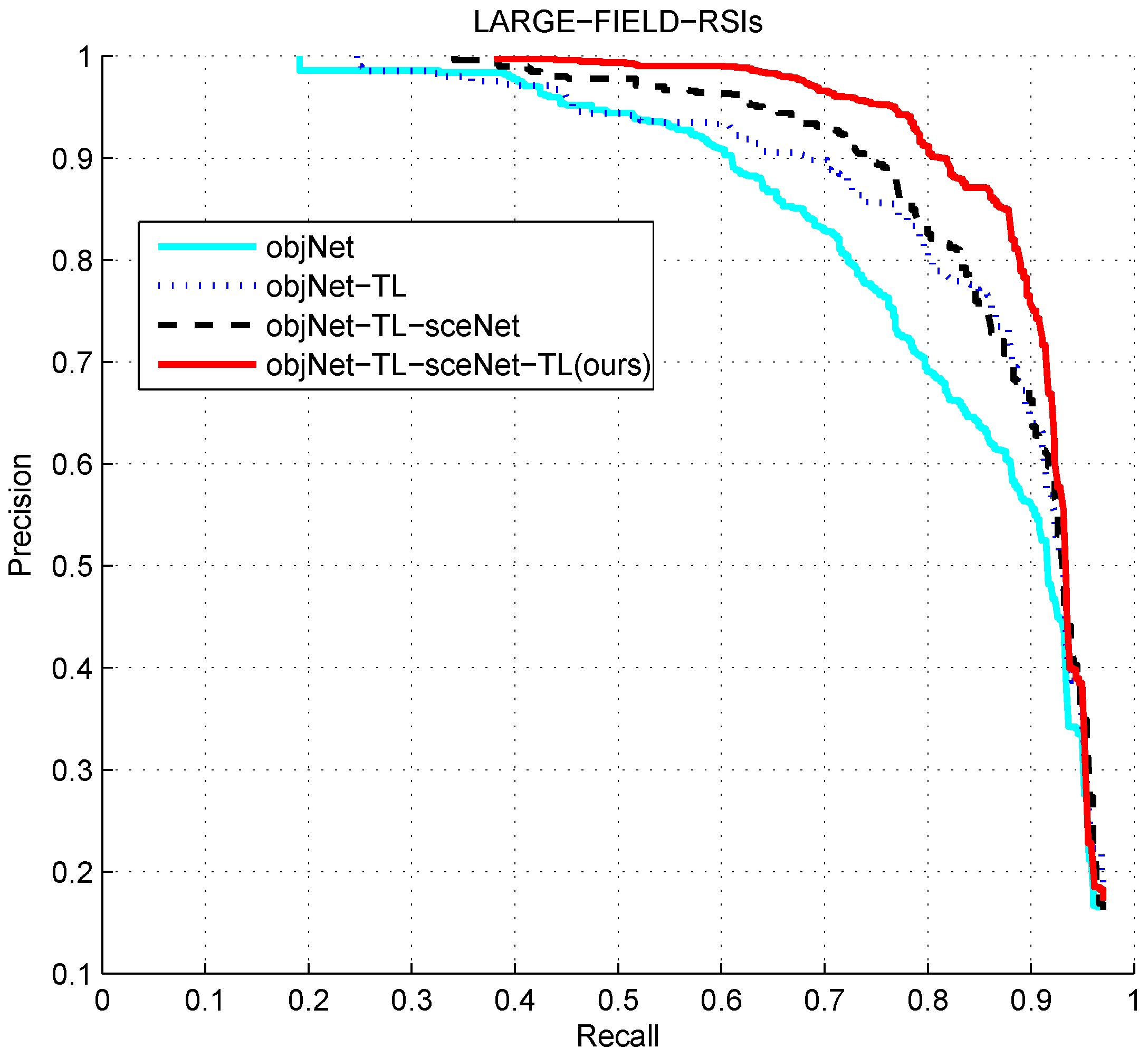
Figure 19 and
Figure 20 show the comparison of the results of the four experiments on two different dataset sizes. From the results of the experiments objNet and objNet-TL, it was revealed that the transfer learning of object the feature extraction network could improve the whole detection performance significantly. Before transfer learning, the accuracy of the curve decreased rapidly with the recall increasing, and the curve decreased slowly after transfer learning, which shows that the extracted feature of network after transfer learning made the classifier discriminate better, which means the transfer learning was effective. It can be concluded from the experiment objNet-TL-sceNet-TL that the detection efficiency on the two remote sensing datasets was better than that for the experiment without context scene feature fusion, indicating the effectiveness of the scene feature fusion. However, compared with objNet-TL-sceNet and objNet-TL, it is shown that when transfer learning was not employed, the improvement was not obvious, the possible reason for which being that the sceNet network has too many parameters for the limited remote sensing scene data, and if we directly trained the network using limited data without transfer learning, it would easily to over-fit, so that the extracted features would not be representative.
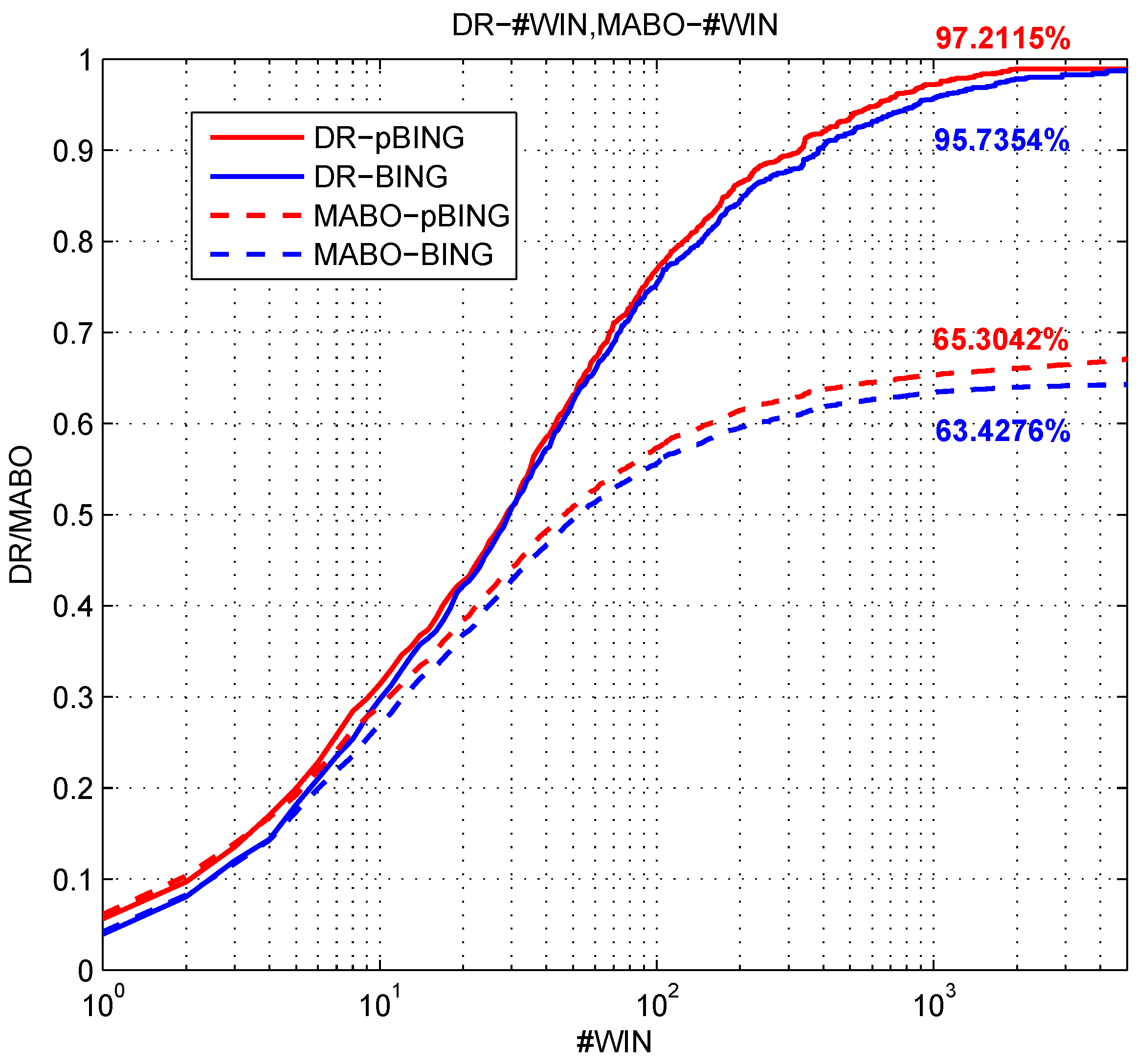
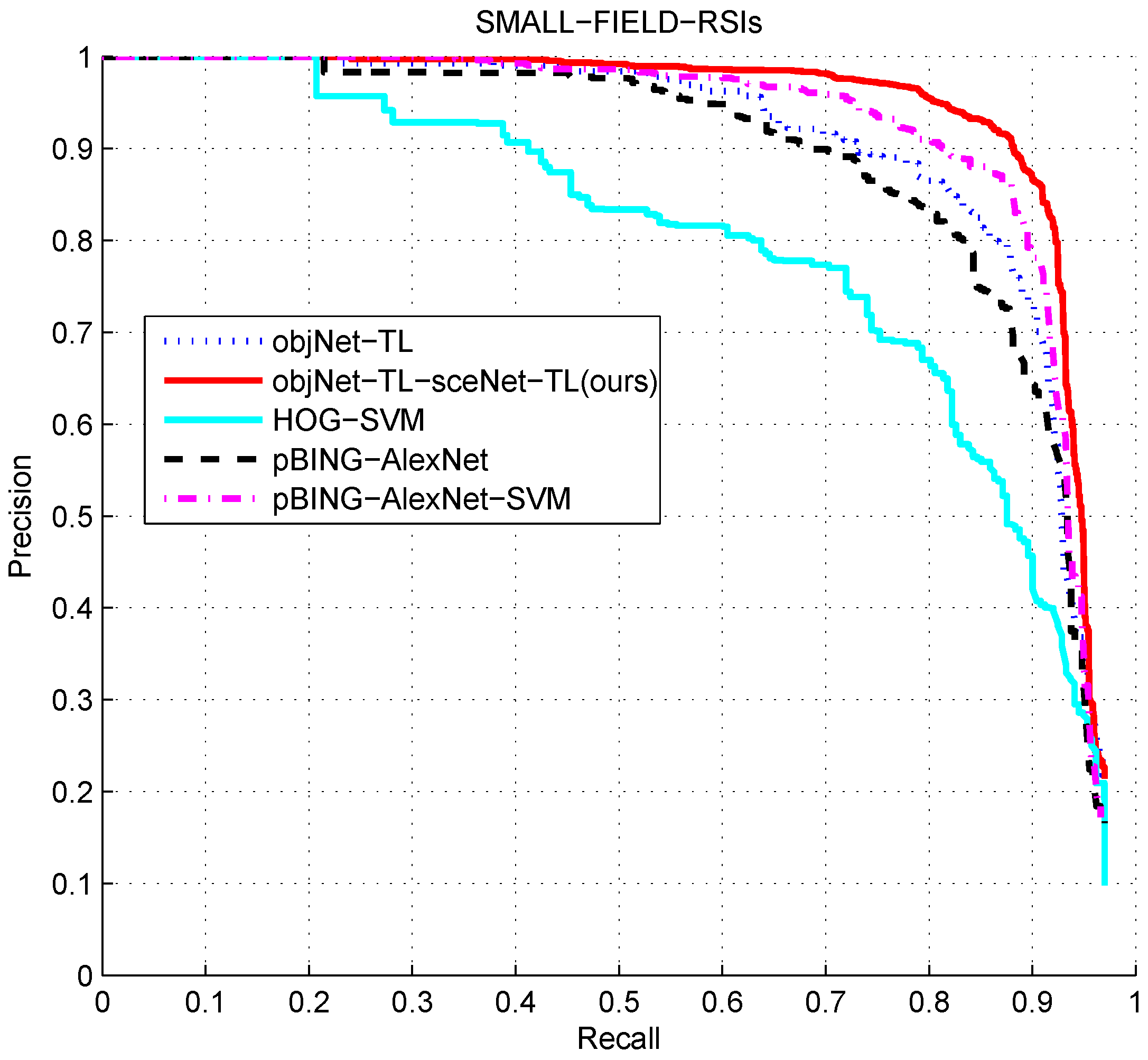
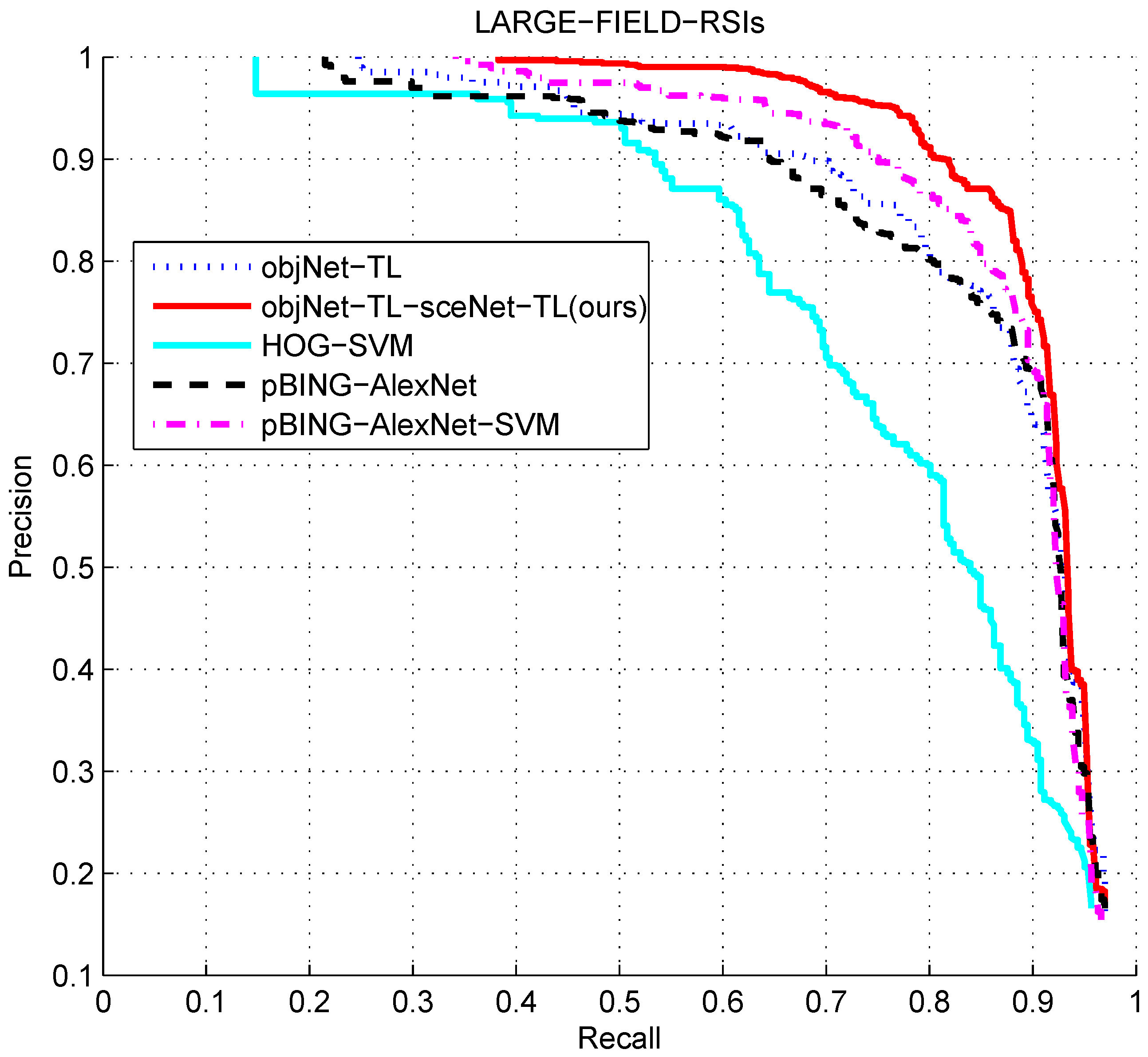
Finally, we compared the proposed algorithm objNet-TL-sceNet-TL with the other algorithms. Firstly, in order to prove the effectiveness of the deep features, we used the HOG algorithm [
34] to extract the feature of the candidate region and used the SVM algorithm and the hard negative mining method to train the detector; we called it HOG-SVM. In addition, this paper compared the R-CNN algorithm [
14]. This algorithm achieved a breakthrough in the PASCAL VOC2007 object detection task. It first uses the selective search algorithm to generate about 2000 candidate regions for each image and then uses the AlexNet network to extract features, and finally classifies each region using linear SVM classification. From the analysis of
Section 4.3.2, we can see that the selective search algorithm is not suitable for large-sized remote sensing images. Therefore, this paper replaced the candidate region proposal with the pBING algorithm proposed in this paper. Furthermore, we compared the detection performance of the two methods of R-CNN: directly obtaining classification results by the AlexNet network and extracting features by AlexNet, then classifying by SVM. For convenience, the two algorithms are called pBING-AlexNet and pBING-AlexNet-SVM, respectively.
Figure 21 and
Figure 22 show the comparison of the detection performance of each algorithm on two different sizes of remote sensing images.
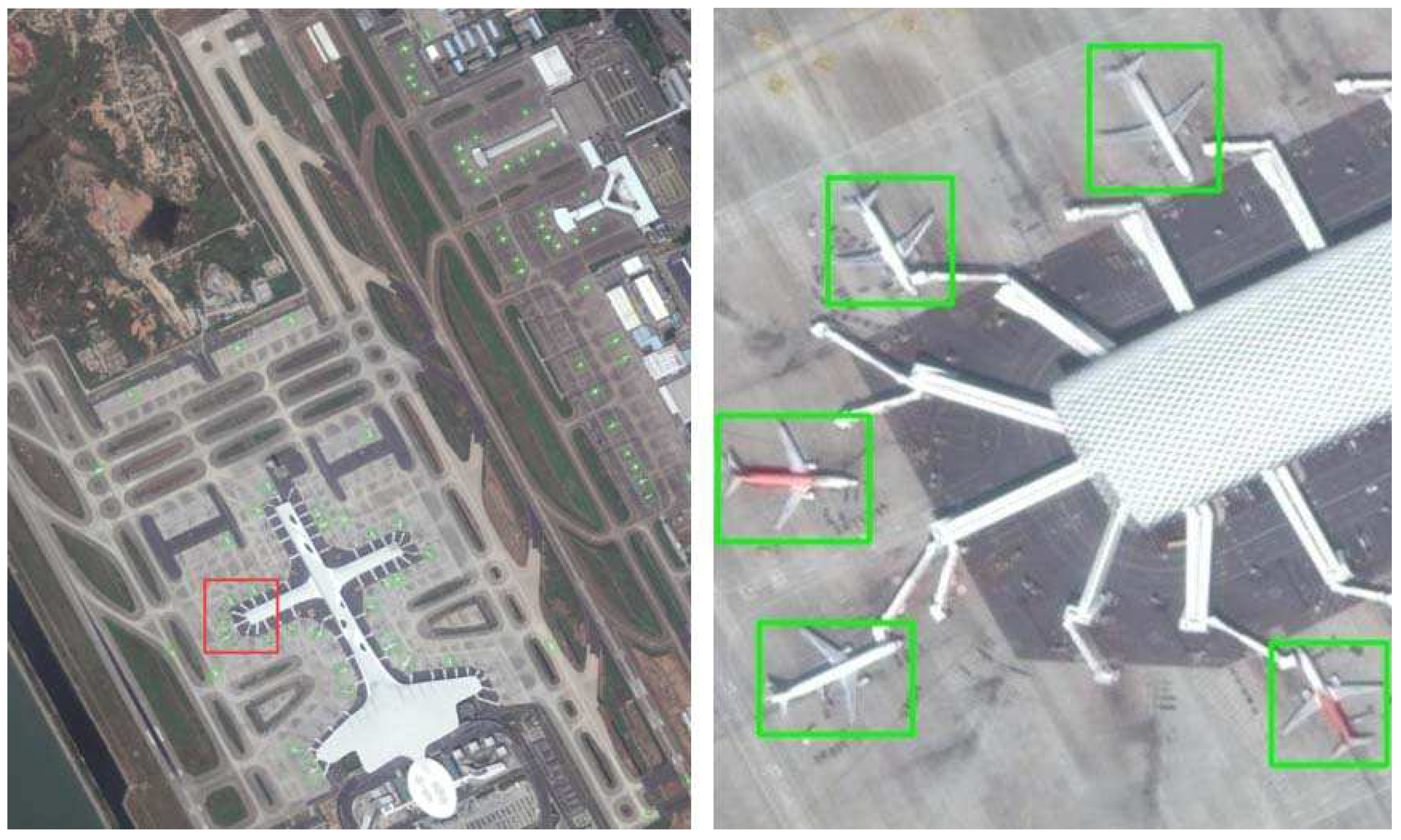
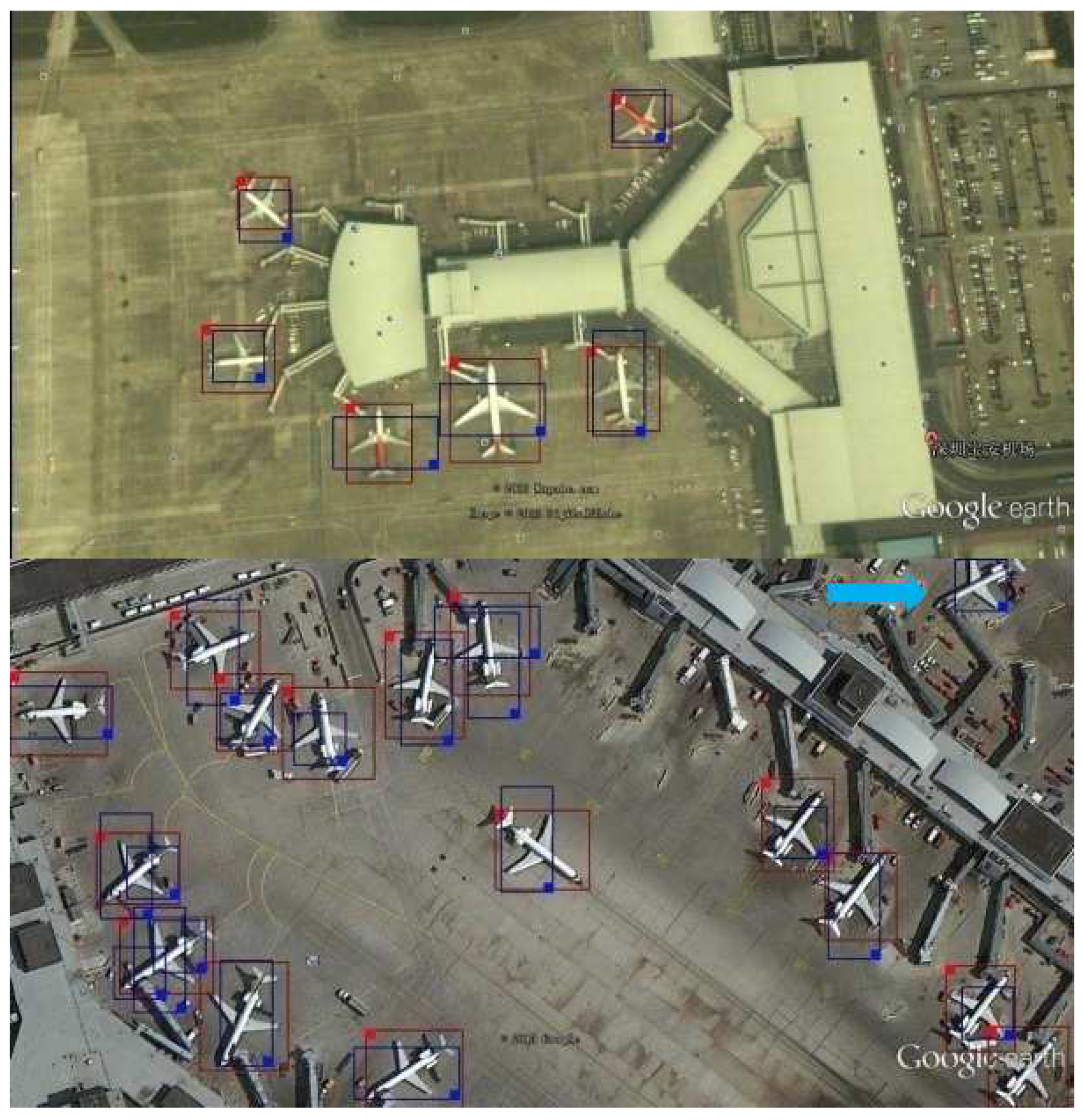
Figure 23 and
Figure 24 show the results of the objNet-TL-sceNet-TL algorithm on the SMALL-FIELD-RSIs and LARGE-FIELD-RSIs datasets, respectively. In each image, the red rectangles indicate the real objects marked by the dataset and the blue rectangles the final detection result of our algorithm. It appears that the vast majority of airplane objects can be correctly detected. It is noted that our algorithm can detect one airplane, which was not marked (missed by a human) on the dataset, and it is shown by the blue arrow in
Figure 23. The comparison details of average precision (AP) can be checked in
Table 8.
However, we found that if the airplane object was ambiguous and small, it may be missed. One missed airplane is pointed out by the red arrow in
Figure 24. The reason is that our candidate region proposal algorithm was not strong enough for objects that are too small and ambiguous, and it needs to be further improved in the future.

 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}