
Are ChatGPT’s Free-Text Responses on Periprosthetic Joint Infections of the Hip and Knee Reliable and Useful?
 , , , and
, , , and
Abstract
:1. Introduction
2. Materials and Methods
3. Results
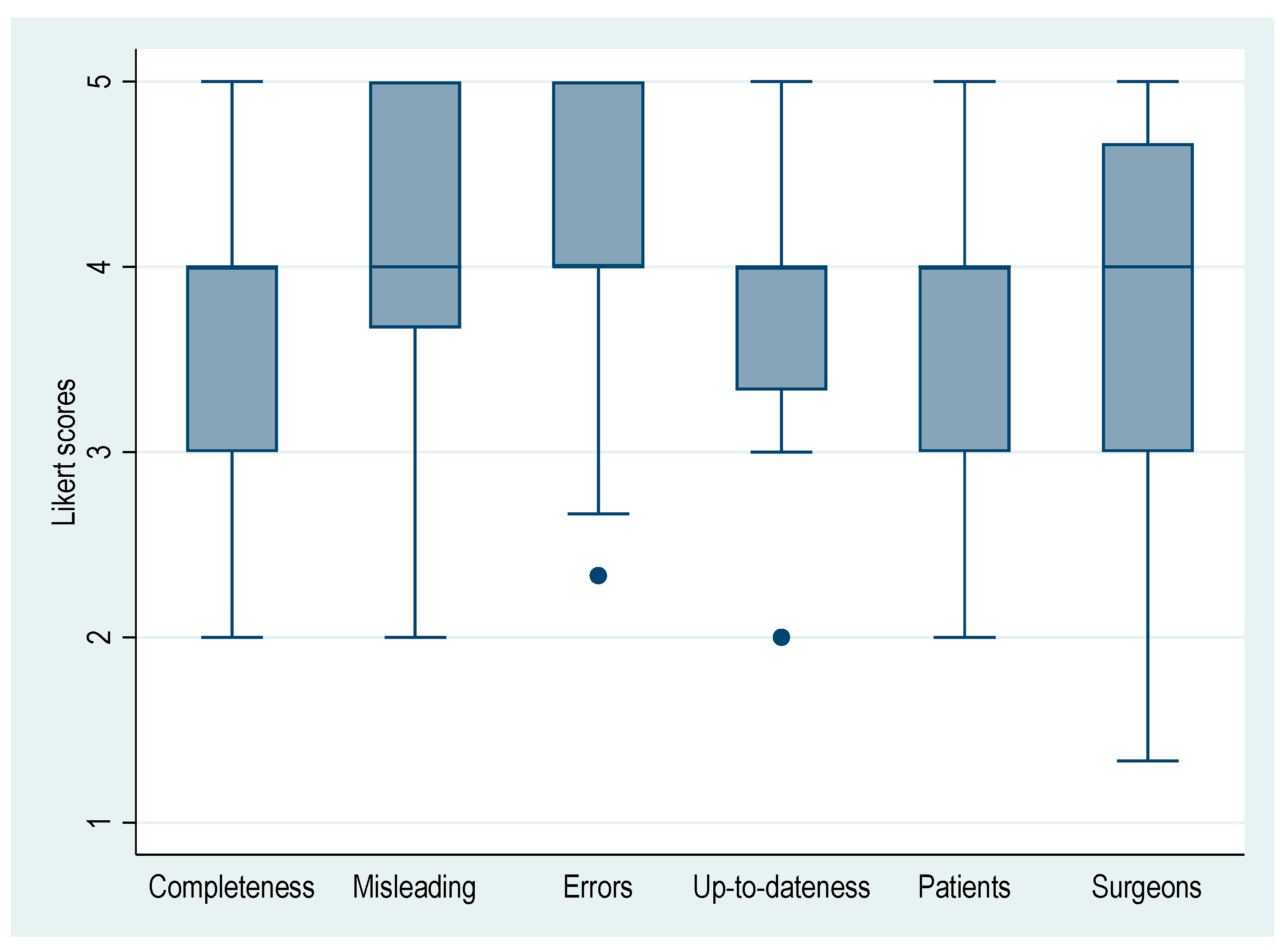
3.1. Overall Total Agreement
3.2. Agreement on Evaluated Aspects
3.3. Agreement Based on Individual Questions (Q1–27)
3.4. Inter-Rater Reliability (IRR) Based on Subtopics
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A Guide to Deep Learning in Healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef] [PubMed]
- Schwendicke, F.; Singh, T.; Lee, J.-H.; Gaudin, R.; Chaurasia, A.; Wiegand, T.; Uribe, S.; Krois, J.; IADR e-Oral Health Network and the ITU WHO Focus Group AI for Health. Artificial Intelligence in Dental Research: Checklist for Authors, Reviewers, Readers. J. Dent. 2021, 107, 103610. [Google Scholar] [CrossRef] [PubMed]
- Uz, C.; Umay, E. “Dr ChatGPT”: Is It a Reliable and Useful Source for Common Rheumatic Diseases? Int. J. Rheum. Dis. 2023, 26, 1343–1349. [Google Scholar] [CrossRef] [PubMed]
- Lo, C.K. What Is the Impact of ChatGPT on Education? A Rapid Review of the Literature. Educ. Sci. 2023, 13, 410. [Google Scholar] [CrossRef]
- Kumah-Crystal, Y.; Mankowitz, S.; Embi, P.; Lehmann, C.U. ChatGPT and the Clinical Informatics Board Examination: The End of Unproctored Maintenance of Certification? J. Am. Med. Inform. Assoc. 2023, 30, 1558–1560. [Google Scholar] [CrossRef]
- Liu, S.; Wright, A.P.; Patterson, B.L.; Wanderer, J.P.; Turer, R.W.; Nelson, S.D.; McCoy, A.B.; Sittig, D.F.; Wright, A. Using AI-Generated Suggestions from ChatGPT to Optimize Clinical Decision Support. J. Am. Med. Inform. Assoc. 2023, 30, 1237–1245. [Google Scholar] [CrossRef]
- Kunze, K.N.; Jang, S.J.; Fullerton, M.A.; Vigdorchik, J.M.; Haddad, F.S. What’s All the Chatter about?: Current Applications and Ethical Considerations of Artificial Intelligence Language Models. Bone Jt. J. 2023, 105, 587–589. [Google Scholar] [CrossRef]
- Hoch, C.C.; Wollenberg, B.; Lüers, J.-C.; Knoedler, S.; Knoedler, L.; Frank, K.; Cotofana, S.; Alfertshofer, M. ChatGPT’s Quiz Skills in Different Otolaryngology Subspecialties: An Analysis of 2576 Single-Choice and Multiple-Choice Board Certification Preparation Questions. Eur. Arch. Otorhinolaryngol. 2023, 280, 4271–4278. [Google Scholar] [CrossRef]
- Humar, P.; Asaad, M.; Bengur, F.B.; Nguyen, V. ChatGPT Is Equivalent to First-Year Plastic Surgery Residents: Evaluation of ChatGPT on the Plastic Surgery In-Service Examination. Aesthetic Surg. J. 2023, sjad130. [Google Scholar] [CrossRef]
- Jung, L.B.; Gudera, J.A.; Wiegand, T.L.T.; Allmendinger, S.; Dimitriadis, K.; Koerte, I.K. ChatGPT Passes German State Examination in Medicine with Picture Questions Omitted. Dtsch. Ärzteblatt Int. 2023, 120, 373–374. [Google Scholar] [CrossRef]
- Passby, L.; Jenko, N.; Wernham, A. Performance of ChatGPT on Dermatology Specialty Certificate Examination Multiple Choice Questions. Clin. Exp. Dermatol. 2023, llad197. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Bernstein, J. Not the Last Word: ChatGPT Can’t Perform Orthopaedic Surgery. Clin. Orthop. Relat. Res. 2023, 481, 651–655. [Google Scholar] [CrossRef] [PubMed]
- O’Connor, S. Open Artificial Intelligence Platforms in Nursing Education: Tools for Academic Progress or Abuse? Nurse Educ. Pract. 2023, 66, 103537. [Google Scholar] [CrossRef] [PubMed]
- Lum, Z.C. Can Artificial Intelligence Pass the American Board of Orthopaedic Surgery Examination? Orthopaedic Residents Versus ChatGPT. Clin. Orthop. Relat. Res. 2023; ahead of print. [Google Scholar] [CrossRef]
- Strony, J.; Brown, S.; Choong, P.; Ghert, M.; Jeys, L.; O’Donnell, R.J. Musculoskeletal Infection in Orthopaedic Oncology: Assessment of the 2018 International Consensus Meeting on Musculoskeletal Infection. J. Bone Jt. Surg. 2019, 101, e107. [Google Scholar] [CrossRef]
- Valentini, M.; Skzandera, J.; Smolle, M.A.; Scheipl, S.; Leithner, A.; Andreou, D. Artificial Intelligence Bot ChatGPT: Is It a Trustworthy and Reliable Source of Information for Patients? [Abstract]. In Proceedings of the 35th Annual Meeting of the European Musculo-Skeletal Oncology Society, Brussels, Belgium, 11 May 2023. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Elmahdy, M.; Sebro, R. A Snapshot of Artificial Intelligence Research 2019-2021: Is It Replacing or Assisting Physicians? J. Am. Med. Inform. Assoc. 2023, 30, 1552–1557. [Google Scholar] [CrossRef] [PubMed]
- King, H.; Williams, B.; Treanor, D.; Randell, R. How, for Whom, and in What Contexts Will Artificial Intelligence Be Adopted in Pathology? A Realist Interview Study. J. Am. Med. Inform. Assoc. 2023, 30, 529–538. [Google Scholar] [CrossRef]
- Leithner, A.; Maurer-Ertl, W.; Glehr, M.; Friesenbichler, J.; Leithner, K.; Windhager, R. Wikipedia and Osteosarcoma: A Trustworthy Patients’ Information? J. Am. Med. Inform. Assoc. 2010, 17, 373–374. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Q | Full-Text Question (Hip & Knee 2018 ICM) |
|---|---|
| Q1 | What nutritional markers are the most sensitive and specific for surgical site infections and periprosthetic infections (SSIs/PJIs)? Does improvement in nutritional status reduce the risk of SSI/PJI? |
| Q2 | What preoperative screening for infections should be performed in patients undergoing revision hip or knee arthroplasty because of presumed aseptic failure? |
| Q3 | Should patients undergoing outpatient total joint arthroplasty (TJA) receive additional postoperative prophylactic antibiotics? |
| Q4 | Is there a role for the use of antibiotic-impregnated cement in primary total joint arthroplasty (TJA)? |
| Q5 | Is there a concern for contamination of the surgical field by particles, such as cement, that may escape the wound intraoperatively by coming into contact with the ceiling light or facial masks and fall back into the wound? |
| Q6 | Does the surgical approach (parapatellar vs. subvastus) during primary total knee arthroplasty (TKA) affect the incidence of subsequent surgical site infections/periprosthetic joint infections (SSIs/PJIs)? |
| Q7 | Can implant factors (i.e., type of bearing) influence the thresholds for serum and synovial markers in acute and chronic periprosthetic joint infections (PJIs)? |
| Q8 | Should patients with cellulitis following total joint arthroplasty be treated with antibiotic therapy? |
| Q9 | What clinical findings (e.g., fever, erythema, reduced range of motion) are most sensitive and specific for the diagnosis of periprosthetic joint infections (PJIs)? |
| Q10 | Do patients with adverse local tissue reactions (ALTRs) have a higher incidence of periprosthetic joint infections (PJIs)? |
| Q11 | Does the presence of both an erythrocyte sedimentation rate (ESR) and C-reactive protein (CRP) below the periprosthetic joint infection (PJI) thresholds rule out the diagnosis of a PJI? |
| Q12 | Are there significant differences in the yield of culture between preoperative aspiration and intraoperative culture samples? If so, which result should be utilized? |
| Q13 | What metrics should be considered to determine the timing of reimplantation after two-stage exchange arthroplasty of the infected hip or knee? |
| Q14 | Is there a difference in the treatment outcome for periprosthetic joint infections (PJIs) caused by a single organism and a polymicrobial PJI? |
| Q15 | Should patients with periprosthetic joint infections (PJIs) caused by a fungus undergo the typical two week antimicrobial holiday prior to reimplantation? |
| Q16 | Should early postoperative infection and acute hematogenous infection be treated and managed differently? |
| Q17 | Is debridement, antibiotics and implant retention (DAIR) an emergency procedure for patients with acute periprosthetic joint infection (PJI) or should patient optimization be implemented prior to surgery to enhance the success of this procedure? |
| Q18 | What are the indications and contraindications for a one-stage exchange arthroplasty for the treatment of chronic periprosthetic joint infections (PJIs)? |
| Q19 | Which antibiotic(s) should be added to a cement spacer in patients with periprosthetic joint infections (PJIs) caused by multiresistant organisms? |
| Q20 | What is the optimal timing for reimplantation of a two-stage exchange arthroplasty of the hip and knee? |
| Q21 | Do all metallic implants need to be removed to eradicate periprosthetic joint infections (PJIs)? Does this apply to other metal hardware present (e.g., hook plates, cables) as well? |
| Q22 | Does the use of cemented or cementless components at the time of reimplantation affect the success of treating chronic periprosthetic joint infections (PJIs)? If yes, what is the optimal antibiotic(s), dosage and cement to maximize antibiotic delivery and mechanical properties of the cement? |
| Q23 | What are surgical alternatives to hip disarticulation in patients with persistent joint infections? |
| Q24 | When should rifampin be added to the regimen of antibiotics for management of patients with periprosthetic joint infections (PJIs) undergoing surgical treatment? |
| Q25 | (A) What is the optimal length of administration for antibiotic treatment following resection arthroplasty? (B) What is the optimal mode of administration for antibiotic treatment following resection arthroplasty? |
| Q26 | Which patients should be considered for administration of long-term suppressive oral antibiotic instead of surgical treatment in patients with chronic periprosthetic joint infections (PJIs)? |
| Q27 | Is there a benefit for the engagement of a multidisciplinary team for the management of patients with periprosthetic joint infections (PJIs)? |
| Aspects (Abbreviation) | Likert Scale | |
|---|---|---|
| Is the provided information complete? (Completeness) | 5 | Strongly agree |
| 4 | Agree | |
| 3 | Neutral | |
| 2 | Disagree | |
| 1 | Strongly disagree | |
| Is the provided answer misleading? (Misleading) * | 1 | Strongly agree |
| 2 | Agree | |
| 3 | Neutral | |
| 4 | Disagree | |
| 5 | Strongly disagree | |
| Are there relevant factual errors in the provided information? (Errors) * | 1 | Strongly agree |
| 2 | Agree | |
| 3 | Neutral | |
| 4 | Disagree | |
| 5 | Strongly disagree | |
| Is the provided information up to date? (Up-to-dateness) | 5 | Strongly agree |
| 4 | Agree | |
| 3 | Neutral | |
| 2 | Disagree | |
| 1 | Strongly disagree | |
| Is the provided answer a good source of information for patients? (Patients) | 5 | Strongly agree |
| 4 | Agree | |
| 3 | Neutral | |
| 2 | Disagree | |
| 1 | Strongly disagree | |
| Is the provided answer a good source of information for orthopedic surgeons? (Surgeons) | 5 | Strongly agree |
| 4 | Agree | |
| 3 | Neutral | |
| 2 | Disagree | |
| 1 | Strongly disagree | |
| Aspects | Mean ± SD | Fleiss’ Kappa * | 95% CI (Lower, Upper) | p |
|---|---|---|---|---|
| Completeness | 3.80 ± 0.63 | 0.848 | 0.699, 0.996 | <0.001 |
| Misleading | 4.04 ± 0.67 | 0.743 | 0.601, 0.886 | <0.001 |
| Errors | 4.14 ± 0.58 | 0.880 | 0.724, 1.035 | <0.001 |
| Up-to-dateness | 3.90 ± 0.45 | 0.584 | 0.434, 0.734 | <0.001 |
| Patients | 3.69 ± 0.64 | 0.627 | 0.478, 0.776 | <0.001 |
| Surgeons | 3.63 ± 0.95 | 0.505 | 0.383, 0.628 | <0.001 |
| Question (Q) | Mean ± SD | Fleiss’ Kappa * | 95% CI (Lower, Upper) | p |
|---|---|---|---|---|
| Q1 | 4.44 ± 0.51 | 0.775 | 0.313, 1.273 | 0.001 |
| Q2 | 4.61 ± 0.61 | 0.182 | −0.212, 0.576 | 0.366 |
| Q3 | 4.22 ± 0.55 | 0.532 | 0.139, 0.926 | 0.008 |
| Q4 | 4.50 ± 0.51 | 0.556 | 0.094, 1.018 | 0.018 |
| Q5 | 5.00 ± 0.00 | 1.000 | - | - |
| Q6 | 4.22 ± 0.43 | 0.357 | −0.105, 0.819 | 0.130 |
| Q7 | 4.83 ± 0.38 | 1.000 | 0.583, 1.462 | <0.001 |
| Q8 | 4.44 ± 0.51 | 0.775 | 0.313, 1.237 | 0.001 |
| Q9 | 4.11 ± 0.76 | 0.654 | 0.320, 0.987 | <0.001 |
| Q10 | 2.94 ± 0.64 | 0.393 | 0.051, 0.736 | 0.024 |
| Q11 | 4.11 ± 0.32 | −0.125 | −0.587, 0.337 | 0.596 |
| Q12 | 4.11 ± 0.32 | 0.438 | −0.024, 0.899 | 0.063 |
| Q13 | 3.11 ± 0.32 | −0.125 | −0.587, 0.337 | 0.596 |
| Q14 | 3.89 ± 0.32 | 0.483 | −0.024, 0.899 | 0.063 |
| Q15 | 4.28 ± 0.46 | 0.446 | −0.016, 0.908 | 0.058 |
| Q16 | 1.94 ± 0.42 | 0.234 | −0.134, 0.602 | 0.212 |
| Q17 | 3.56 ± 0.51 | 0.550 | 0.088, 1.012 | 0.020 |
| Q18 | 4.06 ± 0.24 | −0.059 | −0.521, 0.403 | 0.803 |
| Q19 | 3.72 ± 0.58 | 0.349 | −0.048, 0.747 | 0.085 |
| Q20 | 3.56 ± 0.51 | 0.775 | 0.313, 1.237 | 0.001 |
| Q21 | 3.39 ± 0.70 | 0.811 | 0.446, 1.175 | <0.001 |
| Q22 | 3.17 ± 0.71 | 0.273 | −0.071, 0.616 | 0.120 |
| Q23 | 3.17 ± 0.71 | 1.000 | 0.656, 1.344 | <0.001 |
| Q24 | 4.94 ± 0.24 | −0.059 | −0.521, 0.403 | 0.803 |
| Q25 | 3.33 ± 0.49 | 0.500 | 0.038, 0.962 | 0.034 |
| Q26 | 3.11 ± 0.90 | 0.500 | 0.190, 0.810 | 0.002 |
| Q27 | 3.61 ± 0.61 | 0.299 | −0.095, 0.693 | 0.137 |
| Subtopic | Mean ± SD | Fleiss’ Kappa * | 95% CI (Lower, Upper) | p |
|---|---|---|---|---|
| Prevention (Q1–8) | 4.53 ± 0.53 | 0.685 | 0.528, 0.842 | <0.001 |
| Diagnosis (Q9–13) | 3.68 ± 0.73 | 0.640 | 0.492, 0.788 | <0.001 |
| Pathogen Factors (Q14) | 3.89 ± 0.32 | 0.438 | −0.024, 0.899 | 0.063 |
| Fungal (Q15) | 4.28 ± 0.46 | 0.446 | −0.016, 0.908 | 0.058 |
| Treatment (Q16–26) | 3.54 ± 0.95 | 0.704 | 0.616, 0.792 | <0.001 |
| Outcomes (Q27) | 3.61 ± 0.68 | 0.299 | −0.095, 0.693 | 0.137 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Draschl, A.; Hauer, G.; Fischerauer, S.F.; Kogler, A.; Leitner, L.; Andreou, D.; Leithner, A.; Sadoghi, P. Are ChatGPT’s Free-Text Responses on Periprosthetic Joint Infections of the Hip and Knee Reliable and Useful? J. Clin. Med. 2023, 12, 6655. https://doi.org/10.3390/jcm12206655
Draschl A, Hauer G, Fischerauer SF, Kogler A, Leitner L, Andreou D, Leithner A, Sadoghi P. Are ChatGPT’s Free-Text Responses on Periprosthetic Joint Infections of the Hip and Knee Reliable and Useful? Journal of Clinical Medicine. 2023; 12(20):6655. https://doi.org/10.3390/jcm12206655
Chicago/Turabian StyleDraschl, Alexander, Georg Hauer, Stefan Franz Fischerauer, Angelika Kogler, Lukas Leitner, Dimosthenis Andreou, Andreas Leithner, and Patrick Sadoghi. 2023. "Are ChatGPT’s Free-Text Responses on Periprosthetic Joint Infections of the Hip and Knee Reliable and Useful?" Journal of Clinical Medicine 12, no. 20: 6655. https://doi.org/10.3390/jcm12206655