Development of Machine Learning Model to Predict the 5-Year Risk of Starting Biologic Agents in Patients with Inflammatory Bowel Disease (IBD): K-CDM Network Study

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
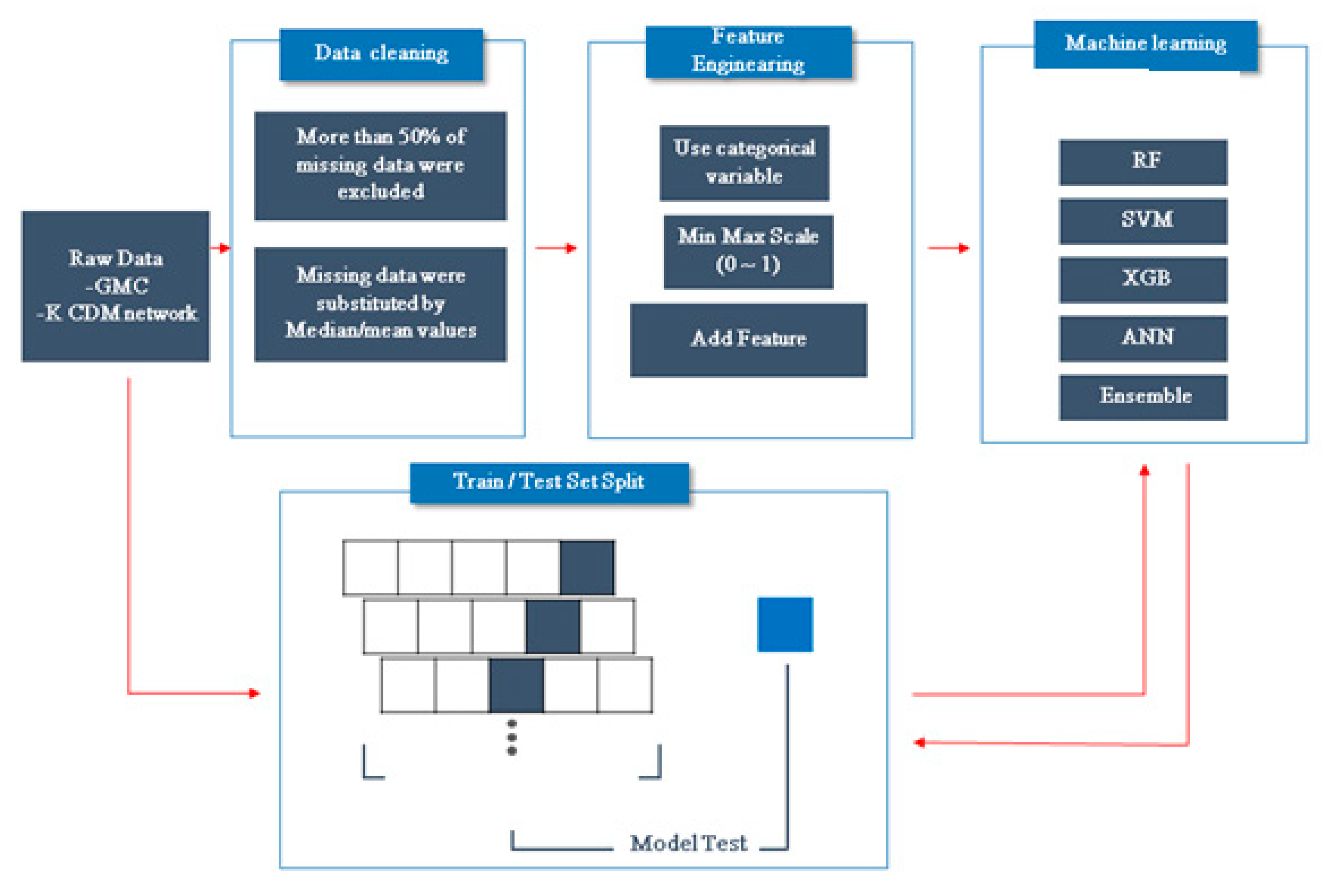
2. Methods
2.1. Institutional Ethic Review Board Approval of the Study Design
2.2. GMC and Korean Common Data Model (K-CDM) Network Database
2.3. Definition of IBD
2.4. Definition of Disease Related Outcomes (Starting Biologic Agents in 5 Year after Diagnosis of IBD)
2.5. Predictor Variables
2.6. Missing Covariates
2.7. Development of a ML Model
2.8. Model Performance
3. Results
3.1. GMC and K-CDM Cohorts
3.2. Internal Validation of an ML-Based Algorithm for Predicting Starting Biologic Agents within 5 Years of IBD Diagnosis
3.3. External Validation of the ML-Based Algorithm for Predicting Starting Biologic Agents within 5 Years of IBD Diagnosis
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- de Groof, E.J.; Rossen, N.G.; van Rhijn, B.D.; Karregat, E.P.; Boonstra, K.; Hageman, I.; Bennebroek Evertsz, F.; Kingma, P.J.; Naber, A.H.; van den Brande, J.H.; et al. Burden of disease and increasing prevalence of inflammatory bowel disease in a population-based cohort in the Netherlands. Eur. J. Gastroenterol. Hepatol. 2016, 28, 1065–1072. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, Y.; Qian, J.M. The Challenge of Inflammatory Bowel Disease Diagnosis in Asia. Inflamm. Intest. Dis. 2017, 1, 159–164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bassi, A.; Dodd, S.; Williamson, P.; Bodger, K. Cost of illness of inflammatory bowel disease in the UK: A single centre retrospective study. Gut 2004, 53, 1471–1478. [Google Scholar] [CrossRef] [PubMed]
- Bahler, C.; Vavricka, S.R.; Schoepfer, A.M.; Brungger, B.; Reich, O. Trends in prevalence, mortality, health care utilization and health care costs of Swiss IBD patients: A claims data based study of the years 2010, 2012 and 2014. BMC Gastroenterol. 2017, 17, 138. [Google Scholar] [CrossRef]
- Ng, S.C.; Shi, H.Y.; Hamidi, N.; Underwood, F.E.; Tang, W.; Benchimol, E.I.; Panaccione, R.; Ghosh, S.; Wu, J.C.Y.; Chan, F.K.L.; et al. Worldwide incidence and prevalence of inflammatory bowel disease in the 21st century: A systematic review of population-based studies. Lancet 2018, 390, 2769–2778. [Google Scholar] [CrossRef]
- The global, regional, and national burden of inflammatory bowel disease in 195 countries and territories, 1990–2017: A systematic analysis for the Global Burden of Disease Study 2017. Lancet Gastroenterol. Hepatol. 2020, 5, 17–30. [CrossRef] [Green Version]
- Peery, A.F.; Crockett, S.D.; Barritt, A.S.; Dellon, E.S.; Eluri, S.; Gangarosa, L.M.; Jensen, E.T.; Lund, J.L.; Pasricha, S.; Runge, T.; et al. Burden of Gastrointestinal, Liver, and Pancreatic Diseases in the United States. Gastroenterology 2015, 149, 1731–1741.e3. [Google Scholar] [CrossRef] [Green Version]
- Jairath, V.; Feagan, B.G. Global burden of inflammatory bowel disease. Lancet Gastroenterol. Hepatol. 2020, 5, 2–3. [Google Scholar] [CrossRef] [Green Version]
- Ng, S.C.; Tang, W.; Ching, J.Y.; Wong, M.; Chow, C.M.; Hui, A.J.; Wong, T.C.; Leung, V.K.; Tsang, S.W.; Yu, H.H.; et al. Incidence and phenotype of inflammatory bowel disease based on results from the Asia-pacific Crohn’s and colitis epidemiology study. Gastroenterology 2013, 145, 158–165.e2. [Google Scholar] [CrossRef]
- Limsrivilai, J.; Stidham, R.W.; Govani, S.M.; Waljee, A.K.; Huang, W.; Higgins, P.D. Factors That Predict High Health Care Utilization and Costs for Patients with Inflammatory Bowel Diseases. Clin. Gastroenterol. Hepatol. Off. Clin. Pract. J. Am. Gastroenterol. Assoc. 2017, 15, 385–392.e2. [Google Scholar] [CrossRef] [Green Version]
- Khan, N.H.; Almukhtar, R.M.; Cole, E.B.; Abbas, A.M. Early corticosteroids requirement after the diagnosis of ulcerative colitis diagnosis can predict a more severe long-term course of the disease—A nationwide study of 1035 patients. Aliment. Pharmacol. Ther. 2014, 40, 374–381. [Google Scholar] [CrossRef]
- Song, L.; Li, D.; Zeng, X.; Wu, Y.; Guo, L.; Zou, Q. nDNA-Prot: Identification of DNA-binding proteins based on unbalanced classification. BMC Bioinform. 2014, 15, 298. [Google Scholar] [CrossRef] [Green Version]
- Gupta, S.; Tran, T.; Luo, W.; Phung, D.; Kennedy, R.L.; Broad, A.; Campbell, D.; Kipp, D.; Singh, M.; Khasraw, M.; et al. Machine-learning prediction of cancer survival: A retrospective study using electronic administrative records and a cancer registry. BMJ Open 2014, 4, e004007. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Vinuesa, R.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Felländer, A.; Langhans, S.D.; Tegmark, M.; Fuso Nerini, F. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 2020, 11, 233. [Google Scholar] [CrossRef] [Green Version]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [Green Version]
- Waljee, A.K.; Sauder, K.; Patel, A.; Segar, S.; Liu, B.; Zhang, Y.; Zhu, J.; Stidham, R.W.; Balis, U.; Higgins, P.D.R. Machine Learning Algorithms for Objective Remission and Clinical Outcomes with Thiopurines. J. Crohn’s Colitis 2017, 11, 801–810. [Google Scholar] [CrossRef] [Green Version]
- Wei, Z.; Wang, W.; Bradfield, J.; Li, J.; Cardinale, C.; Frackelton, E.; Kim, C.; Mentch, F.; Van Steen, K.; Visscher, P.M.; et al. Large sample size, wide variant spectrum, and advanced machine-learning technique boost risk prediction for inflammatory bowel disease. Am. J. Hum. Genet. 2013, 92, 1008–1012. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, A.; Bergquist, S.; Montz, E.; Rose, S. Mental Health Risk Adjustment with Clinical Categories and Machine Learning. Health Serv. Res 2018, 53 (Suppl. 1), 3189–3206. [Google Scholar] [CrossRef]
- Papini, S.; Pisner, D.; Shumake, J.; Powers, M.B.; Beevers, C.G.; Rainey, E.E.; Smits, J.A.J.; Warren, A.M. Ensemble machine learning prediction of posttraumatic stress disorder screening status after emergency room hospitalization. J. Anxiety Disord. 2018, 60, 35–42. [Google Scholar] [CrossRef]
- Tandon, N.; Tandon, R. Using machine learning to explain the heterogeneity of schizophrenia. Realizing the promise and avoiding the hype. Schizophr. Res. 2019, 214, 70–75. [Google Scholar] [CrossRef] [PubMed]
- Mocanu, D.C.; Mocanu, E.; Stone, P.; Nguyen, P.H.; Gibescu, M.; Liotta, A. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science. Nat. Commun. 2018, 9, 2383. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Galatzer-Levy, I.R.; Ma, S.; Statnikov, A.; Yehuda, R.; Shalev, A.Y. Utilization of machine learning for prediction of post-traumatic stress: A re-examination of cortisol in the prediction and pathways to non-remitting PTSD. Transl. Psychiatry 2017, 7, e1070. [Google Scholar] [CrossRef]
- Breen, M.S.; Thomas, K.G.F.; Baldwin, D.S.; Lipinska, G. Modelling PTSD diagnosis using sleep, memory, and adrenergic metabolites: An exploratory machine-learning study. Hum. Psychopharmacol. 2019, 34, e2691. [Google Scholar] [CrossRef] [Green Version]
- Dwyer, D.B.; Falkai, P.; Koutsouleris, N. Machine Learning Approaches for Clinical Psychology and Psychiatry. Annu. Rev. Clin. Psychol. 2018, 14, 91–118. [Google Scholar] [CrossRef]
- Sinkala, M.; Mulder, N.; Martin, D. Machine Learning and Network Analyses Reveal Disease Subtypes of Pancreatic Cancer and their Molecular Characteristics. Sci. Rep. 2020, 10, 1212. [Google Scholar] [CrossRef] [Green Version]
- Tang, F.; Xiao, C.; Wang, F.; Zhou, J. Predictive modeling in urgent care: A comparative study of machine learning approaches. Jamia Open 2018, 1, 87–98. [Google Scholar] [CrossRef] [Green Version]
- Park, R.W. Sharing clinical big data while protecting confidentiality and security: Observational health data sciences and informatics. Healthc. Inform. Res. 2017, 23, 1–3. [Google Scholar] [CrossRef] [Green Version]
- Banda, J.M.; Halpern, Y.; Sontag, D.; Shah, N.H. Electronic phenotyping with APHRODITE and the Observational Health Sciences and Informatics (OHDSI) data network. AMIA Summits Transl. Sci. Proc. 2017, 2017, 48. [Google Scholar]
- You, S.C.; Lee, S.; Cho, S.Y.; Park, H.; Jung, S.; Cho, J.; Yoon, D.; Park, R.W. Conversion of National Health Insurance Service-National Sample Cohort (NHIS-NSC) Database into Observational Medical Outcomes Partnership-Common Data Model (OMOP-CDM). Stud. Health Technol. Inform. 2017, 245, 467. [Google Scholar]
- Choi, Y.I.; Kim, Y.J.; Chung, J.W.; Kim, K.O.; Kim, H.; Park, R.W.; Park, D.K. Effect of Age on the Initiation of Biologic Agent Therapy in Patients with Inflammatory Bowel Disease: Korean Common Data Model Cohort Study. JMIR Med. Inform. 2020, 8, e15124. [Google Scholar] [CrossRef]
- Lee, J.; Lee, J.S.; Park, S.H.; Shin, S.A.; Kim, K. Cohort Profile: The National Health Insurance Service-National Sample Cohort (NHIS-NSC), South Korea. Int. J. Epidemiol. 2017, 46, e15. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef]
- Bengio, Y.; Lee, H. Editorial introduction to the Neural Networks special issue on Deep Learning of Representations. Neural Netw. Off. J. Int. Neural Netw. Soc. 2015, 64, 1–3. [Google Scholar] [CrossRef]
- Siegel, C.A. Refocusing IBD patient management: Personalized, proactive, and patient-centered care. Am. J. Gastroenterol. 2018, 113, 1440–1443. [Google Scholar] [CrossRef]
- Piotrowska, M.; Krajewska, J.; Fichna, J.; Majchrzak, K. Strategies in Crohn’s disease treatment—“step-up” vs.“top-down”. Postepy Biochem. 2020, 65, 313–317. [Google Scholar]
- Lee, W.-J.; Briars, L.; Lee, T.A.; Calip, G.S.; Suda, K.J.; Schumock, G.T. Top-down versus step-up prescribing strategies for tumor necrosis factor alpha inhibitors in children and young adults with inflammatory bowel disease. Inflamm. Bowel Dis. 2016, 22, 2410–2417. [Google Scholar] [CrossRef]
- Shen, B. Step-up vs. top-down therapy for Crohn’s disease: Medicine vs. surgery. Nat. Rev. Gastroenterol. Hepatol. 2017, 14, 693–695. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Derivation and Internal Validation Set from GMC Database (n = 1299) | External Validation Set from K-CDM Database (n = 1987) | |
|---|---|---|
| Demographic features and follow-up | ||
| Duration of follow-up, weeks | 152.0 ± 157.6 | 183.0 ± 198.6 |
| Males, n (%) | 782 (60.2%) | 1310 (65.9%) |
| Age, years | 44.3 ± 19.3 | 45.8 ± 17.7 |
| IBD subtype | ||
| Ulcerative colitis | 763 (58.7%) | 1060 (53.3%) |
| Crohn’s disease | 536 (41.3%) | 927 (46.7%) |
| Disease behavior at diagnosis | ||
| Age at diagnosis | 36.5 ± 18.3 | 36.7 ± 16.7 |
| Phenotype of IBD | ||
| Systemic steroid use at diagnosis, n (%) | 712 (54.8%) | 733 (36.9%) |
| IBD related outcome (biologic agent) | ||
| Commencement of Biologic agents, n (%) | 135 (10.4%) | 146 (7.3%) |
| Ulcerative colitis, n | 65 | 70 |
| Crohn’s disease, n | 70 | 76 |
| Duration of disease before the first biologic agent use (mean ±SD)(week) | 117.3 ± 18.5 | 232.5 ± 22.2 |
| Laboratory data(at first visit to hospital with symptom) | ||
| Hemoglobin (g/dL) | 12.9 ± 2.2 | 13.1 ± 2.1 |
| Hematocrit (%) | 38.7 ± 5.6 | 38.9 ± 5.6 |
| White blood cell count (103/㎕) | 8.3 ± 3.6 | 8.1 ± 3.5 |
| Serum total bilirubin (mg/dL) | 0.7 ± 0.5 | 0.7 ± 0.5 |
| Serum protein (g/dL) | 7.8 ± 15.3 | 8.3 ± 19.9 |
| Serum albumin (g/dL) | 4.1 ± 0.6 | 5.1 ± 0.5 |
| Serum BUN (mg/dL) | 12.7 ± 5.9 | 12.9 ± 5.0 |
| Serum creatinine (mg/dL) | 1.0 ± 3.7 | 1.0 ± 4.8 |
| Serum hsCRP (mg/L) † | 2.1 ± 3.8 | 1.8 ± 3.6 |
| Serum uric acid (mg/dL) | 5.2 ± 1.6 | 4.9 ± 1.5 |
| Serum cholesterol (mg/dL) | 161.8 ± 41.0 | 170.3 ± 42.0 |
| Model | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|
| LR | 0.77 | 0.69 | 0.83 |
| SVM | 0.70 | 0.65 | 0.76 |
| RF | 0.62 | 0.58 | 0.69 |
| ANN | 0.77 | 0.73 | 0.82 |
| XGB | 0.82 | 0.77 | 0.83 |
| Ensemble | 0.75 | 0.73 | 0.85 |
| Model | Sensitivity (%) | Specificity (%) | AUROC (%) |
|---|---|---|---|
| LR | 0.74 | 0.69 | 0.76 |
| SVM | 0.68 | 0.68 | 0.72 |
| RF | 0.67 | 0.67 | 0.73 |
| ANN | 0.61 | 0.60 | 0.66 |
| XGB | 0.70 | 0.71 | 0.80 |
| Ensemble | 0.71 | 0.71 | 0.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, Y.I.; Park, S.J.; Chung, J.-W.; Kim, K.O.; Cho, J.H.; Kim, Y.J.; Lee, K.Y.; Kim, K.G.; Park, D.K.; Kim, Y.J. Development of Machine Learning Model to Predict the 5-Year Risk of Starting Biologic Agents in Patients with Inflammatory Bowel Disease (IBD): K-CDM Network Study. J. Clin. Med. 2020, 9, 3427. https://doi.org/10.3390/jcm9113427
Choi YI, Park SJ, Chung J-W, Kim KO, Cho JH, Kim YJ, Lee KY, Kim KG, Park DK, Kim YJ. Development of Machine Learning Model to Predict the 5-Year Risk of Starting Biologic Agents in Patients with Inflammatory Bowel Disease (IBD): K-CDM Network Study. Journal of Clinical Medicine. 2020; 9(11):3427. https://doi.org/10.3390/jcm9113427
Chicago/Turabian StyleChoi, Youn I, Sung Jin Park, Jun-Won Chung, Kyoung Oh Kim, Jae Hee Cho, Young Jae Kim, Kang Yoon Lee, Kwang Gi Kim, Dong Kyun Park, and Yoon Jae Kim. 2020. "Development of Machine Learning Model to Predict the 5-Year Risk of Starting Biologic Agents in Patients with Inflammatory Bowel Disease (IBD): K-CDM Network Study" Journal of Clinical Medicine 9, no. 11: 3427. https://doi.org/10.3390/jcm9113427