1. Introduction
Rising sea levels increase the risk of coastal flooding depending on the relative rate of mean sea/land level changes [
1,
2,
3]. The impacts are linked to concurrent near-term trends as well as gradual escalation of long-term coastal inundation risk over time [
4]. Estuaries and coastal areas should adapt to changing climate and implement the necessary mitigation measures. A complex process such as a storm surge is sensitive to abrupt changes in several storm parameters, such as intensity, surface atmospheric pressure at the center of the storm, maximum sustained wind speed, size, and forward speed, in addition to the effects driven by the characteristics of dynamic coastal settings, such as shoreline geography, estuaries, and bay barriers [
5]. The interdependency of these different factors make it notoriously hard to predict the timing and intensity of the hydrodynamic response (e.g., water levels and currents) [
6,
7,
8,
9]. Parametric models conventionally incorporate historical or synthetic hurricanes using storm size, intensity, and track, allowing for the prediction of storm surge heights and overland flooding [
10,
11].
During a storm surge event (caused by tropical or extratropical cyclones), the potential impacts extend beyond the surge itself and could exacerbate flooding and structural damage. This can be further intensified by the surface gravity waves due to the superimposed storm tide [
12]. Wave driven set-ups can contribute up to
of the total increase in water level (including both typical fluctuations and any additional rise) along the coast [
13]. The combination of elevated water levels along with the destructive power of waves poses a tremendous danger to densely populated areas adjacent to coastal waters. The U.S. Atlantic and Gulf Coasts, for example, are expected to experience a sea level rise of, on average, 0.25–0.30 m in 30 years (2020–2050) [
14]. This further increases the vulnerability of coastal regions to compound flooding (CF), where the interaction of rainfall, rivers, and ocean storm surges combine and create a cataclysmic force [
15]. To overcome these challenges, physics-based approaches, such as hydrodynamic models, have been used to estimate hydrological processes and flood hazards/the probability of particular events that require land–atmosphere–ocean coupling [
16]. Although these models explain the nature of flooding phenomena and show great skill for a wide variety of flood prediction scenarios, they usually deal with the physical dynamics and require various types of datasets, as the occurrence of floods varies with time and space [
17,
18]. This requires a large amount of computation, which makes short-term predictions very challenging. The reader is kindly referred to [
17,
19,
20] for the comprehensive studies related to the development of physics-based models, their challenges, and capabilities.
Hydrodynamic modeling has also been extensively used to investigate the spatial and temporal variability of storm surges. Hydrodynamic models are widely utilized to describe coastal ocean processes and near-shore circulation and to simulate future scenarios of possible storm surge flooding [
21]. These models are well-developed to account for the inherent uncertainties associated with sea level rise and storm surges. They also consider the relative impacts of different meteorological forces in total water levels [
22,
23]. However, these models are computationally demanding and time consuming. This limits their ability to simulate large complex domains or ensembles of events.
Some parametric models, such as the Bayesian model averaging, autoregressive integrated moving average, and peak over threshold methods, are among the most preferred methods to predict the statistical behavior of storm surge flooding [
24,
25]. However, these models are, at times, computationally demanding and typically sophisticated. Furthermore, generalizing the potential impacts of a storm surge for a particular geographical area to other areas with different parameters and settings is not a reliable approach [
23]. Flood prediction requires constructing a minimum of a decade of non-tidal residual data from measurement by sea-level gauges [
26]. In small datasets, i.e., those with a lack of large-sample observational data, even a few outliers will significantly alter the model or affect the correlation among the predicting variables [
27].
Low-fidelity numerical storm surge models such as SLOSH (Sea, Lake, and Overland Surges from Hurricane) [
28] are used by emergency managers and researchers to assist in forecasting the hydrodynamic response to a predicted hurricane track, size, and intensity. These models have significant uncertainty when used for forecasting [
29,
30]. Coupling ADCIRC (ADvanced CIRCulation model) [
31] with WAM (WAve prediction Model) [
32], STWAVE (Steady-State Spectral Wave Model) [
33], or SWAN (Simulating WAves Nearshore) [
34] is a widely used method for generating high-resolution storm surge models of specific regions [
35,
36]. Considering their additional wave forcing processes, finer mesh sizes, and smaller time steps, high-fidelity models are computationally more expensive [
37]; thus, the accurate and quick assessment of hurricane-induced flooding has always been a challenging task.
Surrogate models are another approach to overcome this huge obstacle by simplifying approximations of more complex, higher-order models [
10]. The Surge and Wave Island Modeling Study (SWIMS) [
38] in the USACE, for example, developed a fast surrogate model by simulating hundreds of hurricanes to predict peak storm surges and hurricane responses in only a couple of seconds, which is an advantage over high-fidelity coupled simulations. Considering this issue, in a national-scale effort, the U.S. Army Engineer Research and Development Center developed a statistical analysis and probabilistic modeling tool named the StormSim Coastal Hazards Rapid Prediction System (StormSim-CHRPS) [
39]. The tool preserves the accuracy of the high-fidelity hydrodynamic numerical simulation methods, such as ADCIRC, while significantly reducing computational demands, making it more convenient for real-time emergency management applications. The intricate input/output relationships inherent in high-fidelity numerical models are approximated using a machine learning method called Gaussian process metamodeling (GPM), enabling the rapid prediction of the peak storm surge and hurricane responses within seconds and for different hurricane scenarios.
Lee et al. [
37] sought to enhance coastal resilience by providing a rapid storm surge prediction surrogate model called C1PKNet, a combination of a convolutional neural network model (CNN), principal component analysis, and a k-means clustering method, which was trained efficiently on a dataset of 1031 high-fidelity storm surge simulations. The resulting model is capable of predicting peak storm surges from realistic tropical cyclone track time series. A few studies, such as [
40,
41], even consider global warming, earth–moon–sun gravitational attractions, and storm surges to estimate the coastal sea level at an hourly temporal scale. The model in [
40] was developed using an artificial neural network (ANN) approach called long short-term memory (LSTM) and trained on the ECMWF (European Center for Medium-Range Weather Forecasts) reanalysis dataset, ERA5 (more information on raw input data generation using ERA5 is available in
Section 5.1).
To the best of our knowledge, only a limited number of researchers, such as [
37,
42,
43,
44] aimed to assess the concept of ANN ensemble learning for storm surge prediction. Braakmann-Folgmann et al. [
43], for example, developed a combined convolutional and recurrent neural network to analyze both the spatial and the temporal evolution of sea level anomalies in the northern and central Pacific Ocean. They show how neural network architectures outperform simple regression to improve predictions for the future sea level. A novel deep learning architecture was implemented by [
44] in contrast to a primitive model called the general ocean circulation model ensemble or NEMO (Nucleus for European Modelling of the Ocean). Their aim was to reduce the uncertainty associated with accurate sea level predictions and also to show the importance of sea level and atmospheric inputs for shorter forecast times. In the latter study, the ensemble ANN method for sea level forecasting known as HIDRA (HIgh-performance Deep tidal Residual estimation method using Atmospheric data) implements variants of temporal convolutional networks (TCN) and LSTM to encode temporal features of atmospheric and sea-level data. The dataset was trained on a 10-year (2006–2016) time series of atmospheric surface fields using a single member of the ECMWF atmospheric ensemble.
More recent papers such as [
42,
43] investigated the capability of different combinations of neural network (NN) models to predict surge levels. The fundamental core of this research revolves around selecting the best NN architecture for an ensemble approach to outperform a simple probabilistic model. Tiggeloven et al. [
43], for example, combined a CNN-LSTM (ConvLSTM) model to capture the spatio-temporal dependencies for peak water level observations. This research has important implications for the sensitivity analysis of predictor variables and investigates how uncertainty in the predictions changes with input or architecture complexity. Tropical cyclones can also be parametrically represented via the joint probabilities method (JPM) [
45]. However, the parametric description of complex systems, such as large-scale, non-frontal, low-pressure tropical cyclones, is intrinsically difficult to determine. As an alternative approach to these models, data-driven methods such as multiple linear regression [
26,
46], decision tree, ANN [
40,
42,
43,
47,
48,
49,
50], and support vector machine [
51,
52] have been widely used for the prediction of storm surge heights. In most of studies where data-driven surrogate models are trained with physics-based simulations, such as ADCIRC [
37,
42,
52], a major hurdle is the lack of sufficiently long datasets for training, validating and testing the surrogate models. As [
53] explains, a long record in a storm surge reconstruction dataset is critical to capture as many storm events as possible; thus low-probability, high-impact, extreme events could be accounted for.
This review paper is structured as follows.
Section 2 highlights the general concept of neural network ensembles and introduces several challenges and limitations. A theoretical framework for the geometry of neural networks, transfer learning, and their application to storm surge prediction models and different ensemble generation methods (i.e., how to combine the predictions from multiple models) are presented in
Section 3.
Section 4 discusses the less-debated topic of ensemble pruning and fine-tuning, the next stage after ensemble generation.
Section 5 introduces data preparation considerations on developing an ensemble of neural networks, and different sources of datasets commonly used to predict storm surge levels are presented as well.
Section 6 discusses some important factors and parameters regarding the best model selection and how the performance of the selected ensemble is evaluated. Finally, in
Section 7, a summary is presented.
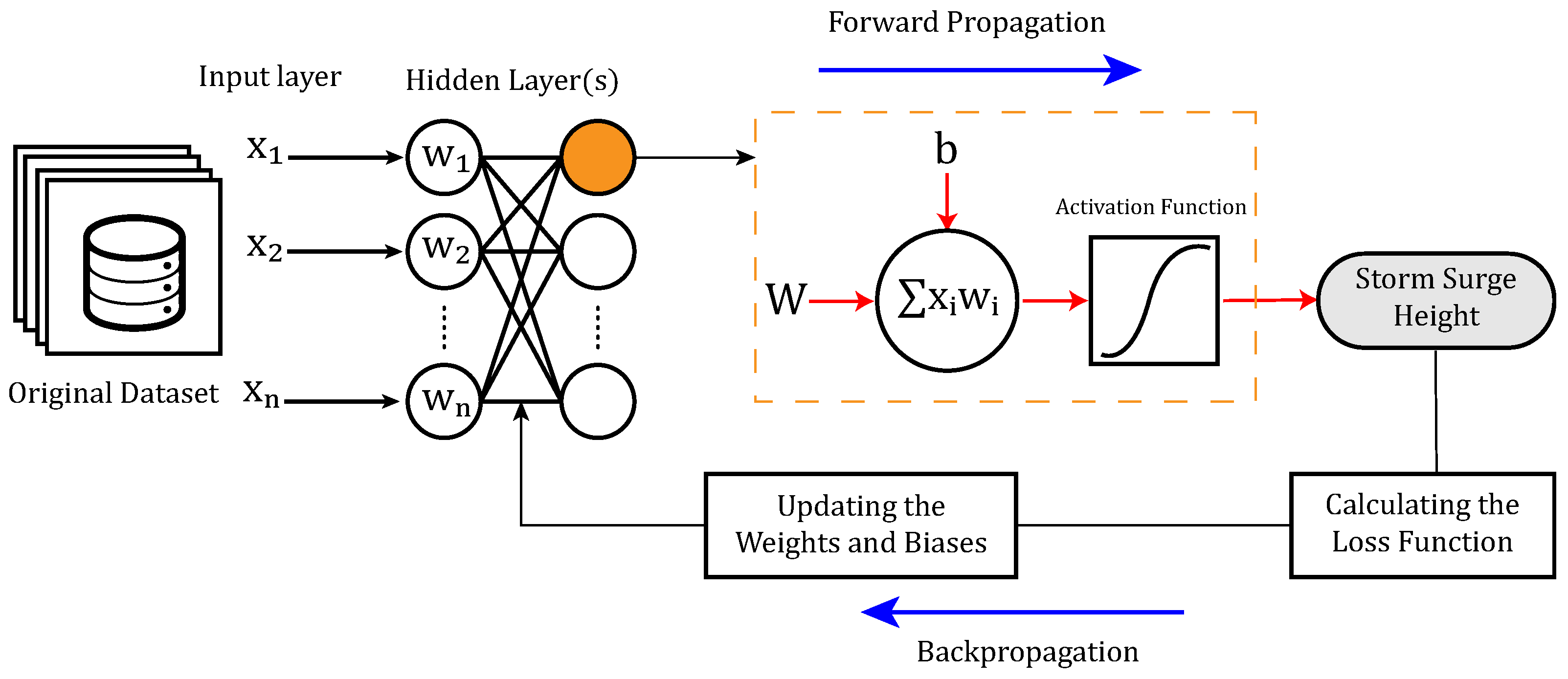
2. Neural Network Ensemble
Ensemble learning refers to techniques that involve combining the predictions of several base estimators based on classification or regression problems, aiming at improving predictability. This approach has gained a lot of attention in recent years, and the reported results regarding sea level rise projections have been satisfactory, such as in [
7,
44,
54]. Ensembles have been reported to achieve higher certified robustness than single machine learning algorithms, as discussed in
Section 2. Therefore, coastal hydrodynamic modeling techniques have been applied in ensemble with data-driven models such as deep learning techniques, especially neural networks, to develop ocean circulation and flood simulation models. This is due to the popularity and application of the finite element methods in numerical hydrodynamic models and their adequate modeling resolution [
55,
56,
57]. These numerical models are conventionally applied to probabilistic coastal ocean forecast systems such as Surge Guidance System Forecasts (ASGS) or NOAA P-Surge to accommodate thousands of simulations [
58].
Various types of neural networks are helpful to solve regression prediction problems where the aim is to predict the output of a continuous value such as water levels. Multilayer perceptrons (MLPs), a classical type of neural network, can reconstruct and validate atmospheric forcing, such as maximum sustained wind speed [
59,
60,
61]. Convolutional neural networks (CNNs) have been developed to capture spatial and temporal dependencies for surge-level observations on a grid-based dataset and could potentially identify and predict regional and global patterns in storm and climate datasets [
62]. They can also extract water bodies from remote sensing images [
63]. Recurrent neural networks (RNNs) could be helpful in modeling storm behavior and time series of water levels in a sequence prediction framework [
43], which requires a longer training time (not dependent on a fixed input size) compared to CNNs. Long short-term memory (LSTM), a subtype of RNN, is a successful model and has been used to capture long-term temporal dependencies of meteorological forcing [
64,
65] and to analyze the rapid intensification and occurrences of cyclones [
66]. A diverse set of base learners (individual learners of the ensemble), such as MLPs, CNNs, and RNNs with appropriate training and tuning, is one empirical way to improve model performance by generating more complex models [
67].
The focus of this paper is to introduce ensemble methods that can predict storm surge levels using a supervised ANN. Some challenges associated with using ANNs are the inability to capture peak water levels (due to the complex and nonlinear nature of the physical processes) [
65,
68], long-term processes (which are unavailable due to instrument failures, insufficient data, or sparse observational records), and predictions of storm surges at ungauged sites [
43,
69]. However, when utilized appropriately, ANN ensemble models have the potential to provide better and faster results than finite element hydrodynamic models.
Figure 1 emphasizes the essential need for rapid prediction models, e.g., ENNs, by presenting a benchmark for the Aransas Wildlife Refuge station in Texas during and following Hurricane Harvey in 2017 [
39]. This descriptive example compares storm surge predictions from a rapid empirical prediction model against water level observations from NOAA tide gauges and predictions from operational ADCIRC runs performed at the U.S. Army Engineer Research and Development Center’s Coastal and Hydraulics Laboratory (ERDC-CHL). Hurricane Harvey started as a modest tropical storm in August. However, after re-forming over the Bay of Campeche, it intensified rapidly into a category 4 hurricane. Harvey made its landfall along the central Texas coast and then stalled for four days, resulting in unprecedented rainfall, exceeding 1520 mm and resulting in a surge reaching 1.4 m across southeastern Texas [
70].
Figure 1 also highlights the rate of change and meteorological and oceanographic observations during the hurricane. Forecasts are typically updated at 6 hour intervals. However, for unusual storm scenarios comparable to Hurricane Harvey with rapid approach trajectories or extended durations within flood plains, the expected update intervals can be reduced to 3 h or even shorter.
A thorough and extensive literature review can be found in [
1,
71], where machine learning models are compared to traditional physically based models.
4. Ensemble Pruning and Fine-Tuning
An ensemble model is a systematic process of combining individual diverse base predictive learners to produce robust and accurate predictions. The concept of an ensemble model might be potent enough for the default parameters to shine; however, many studies, such as [
117,
118,
119,
120,
121,
122], acknowledge that the accuracy could be improved further through tuning. An intuitive approach is to alter the network’s setup in a process known as pruning. This is followed by fine-tuning the hyperparameters of the diverse base learners through the regular process of developing the networks. Pruning entails reducing trivial (or redundant) parameters from an existing network systematically [
123]. In the case that the model has poor performance after pruning, the hyperparameters are fine-tuned, i.e., the parameters of each individual model are adjusted, and then the models are retrained to restore the best possible accuracy [
121]. The result is an ensemble of relatively accurate and robust fine-tuned models with a lower correlation between the independent predictions and residuals [
119]. A general scheme on pruning and fine-tuning steps in a neural network ensemble is shown in
Figure 11.
Pruning: The main idea of pruning networks is to reduce the complexity and energy required to implement large trained networks and make predictions on new input data in real time [
124]. This could be a crucial stage in predicting storm surge time series [
54,
55], such that accurate real-time predictions of storm surge can help emergency management officials issue evacuation orders, take preemptive measures to protect infrastructures, and minimize the economic impact of the storm. Typically, the initial network is large and tends to achieve higher accuracy; generating a smaller network with comparable precision is preferable. This approach has seen a significant amount of growth over the past decade [
123]. However, a handful of studies, such as [
125,
126,
127], addressed the process of ensemble pruning, especially in predicting time series of water surface elevations during or after storms. One major reason is that some ensemble techniques, such as the Adaboost algorithm, inherently mitigate overfitting by independently optimizing input parameters to reach an optimal value. Once the accuracy of individual base learners slightly surpasses random guessing, the final model is proven to reduce generalization error, yielding enhanced performance as a strong learner [
123]. Furthermore, NN ensemble pruning can also be interpreted as a special type of stacking technique (as introduced in
Section 3) in which a meta-learner is applied to improve the predictive performance of the models [
128].
The major pruning techniques that are applicable to NN ensembles are as follows: (1) weight decay [
129], which involves adding a regularization term to the loss function that penalizes the complexity of the ensemble; (2) an error-based approach [
130], which involves calculating the prediction errors of each network in the ensemble and removing the networks with the highest error rates; and (3) neuron pruning [
131], which involves removing the neurons in each network of the ensemble that have the least impact on the network’s output.
Fine-tuning: Once a pruned ensemble is created, the next common stage is to perform fine-tuning, where the network is retrained using the pruned architecture, possibly with a smaller learning rate and fewer training epochs. Fine-tuning can help restore some of the accuracy lost during pruning and can lead to better generalization performance [
132].
Tuning methods cannot be overlooked since less complex but fine-tuned real-time predictive models could possibly result in accurate predictions of water level and flood extent [
118,
119]. which are essential for real-time monitoring and timely warnings of potential floods. When constructing predictive models, finding a set of optimal hyperparameters for each individual learner is a challenge. Tuning the base models (learners) individually and tuning all the models in an ensemble simultaneously are the two fundamental methods to determine the optimal parameters [
67]. In the former approach, the hyperparameter tuning process for each base model is often carried out as an independent procedure based on unique sets of hyperparameters. To illustrate, different base models in an ensemble may use different types of activation functions, optimization algorithms, regularization techniques, or learning rates. Tuning these hyperparameters separately can help ensure that each model is individually optimized and contributes to the overall performance of the ensemble. This conventional approach is described in [
133,
134]. It is important to note that the hyperparameter tuning process should also take into account the interactions between the base models in the ensemble [
128,
133] (the later approach). The weights assigned to each base model have a significant impact on the overall performance of the ensemble, so these weights may also need to be tuned in conjunction with the hyperparameters of each individual model. Such a kind of connection is usually more compatible with probabilistic approaches, such as Bayesian optimization [
135]. This method usually involves modeling the objective function (e.g., accuracy) as a Gaussian process [
136], which can be more efficient than other fine-tuning methods, such as grid search [
137] and random search [
138],in some cases, as it leverages previous evaluations of the objective function to better guide the search process [
139].
7. Summary
The present paper focuses on various approaches that can predict storm surge levels using ensemble neural networks. The challenges and limitations of accurately predicting peak water levels, which are often caused by complex interactions between ocean currents, winds, and atmospheric pressure systems, are also emphasized. Despite the limitations, supervised neural networks, specifically those utilizing the backpropagation technique, have proven to be a powerful tool for predicting storm surge levels, particularly for short-term forecasting. However, the accuracy of BPNN models can be limited by overfitting, which occurs when the model becomes too complex and fits the training data too closely. To address the limitations of single BPNN models, ensemble methods that combine multiple neural network models to improve accuracy and reduce overfitting are preferred. Ensemble methods involve generating multiple base learners (weak classifiers) and combining their predictions to create a strong learner. There are three leading meta-algorithms for combining weak learners: bootstrap aggregating (bagging), boosting, and sitting. Bagging involves generating multiple training datasets by randomly sampling from the original dataset with replacement, then training each base learner on a different dataset. Boosting involves iteratively training weak classifiers, with each subsequent model focusing on the samples that were misclassified by the previous model. Stacking involves training a meta-learner that combines the predictions of multiple base learners. As the networks grow larger, the importance of pruning and fine-tuning, as well as data preparation and wrangling, become unquestionable. Data preparation involves preprocessing and organizing raw data before training a group of neural networks together as an ensemble. The goal of this crucial step is to ensure that the input data are consistent, relevant, and suitable for use by the ensemble. The paper highlights different sources of input data type for storm surge prediction and the need for careful data preprocessing and wrangling to ensure accurate predictions. However, there is no one-size-fits-all approach for creating an ensemble of neural networks for predicting storm surge levels. Instead, it is essential to carefully evaluate the performance of different ensemble models and select the one that provides the best trade-off between bias and variance, accuracy, diversity, stability, generalization, and computational cost. Overall, the paper provides valuable insights into the use of ensemble methods for storm surge flood modeling, which can contribute to better predictions and preparedness for extreme weather events.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












