Assisting Forensic Identification through Unsupervised Information Extraction of Free Text Autopsy Reports: The Disappearances Cases during the Brazilian Military Dictatorship



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Historical Context and Motivation
1.2. Automatic Information Extraction of Medical, Anthropological, and Forensic Information
2. Materials and Methods
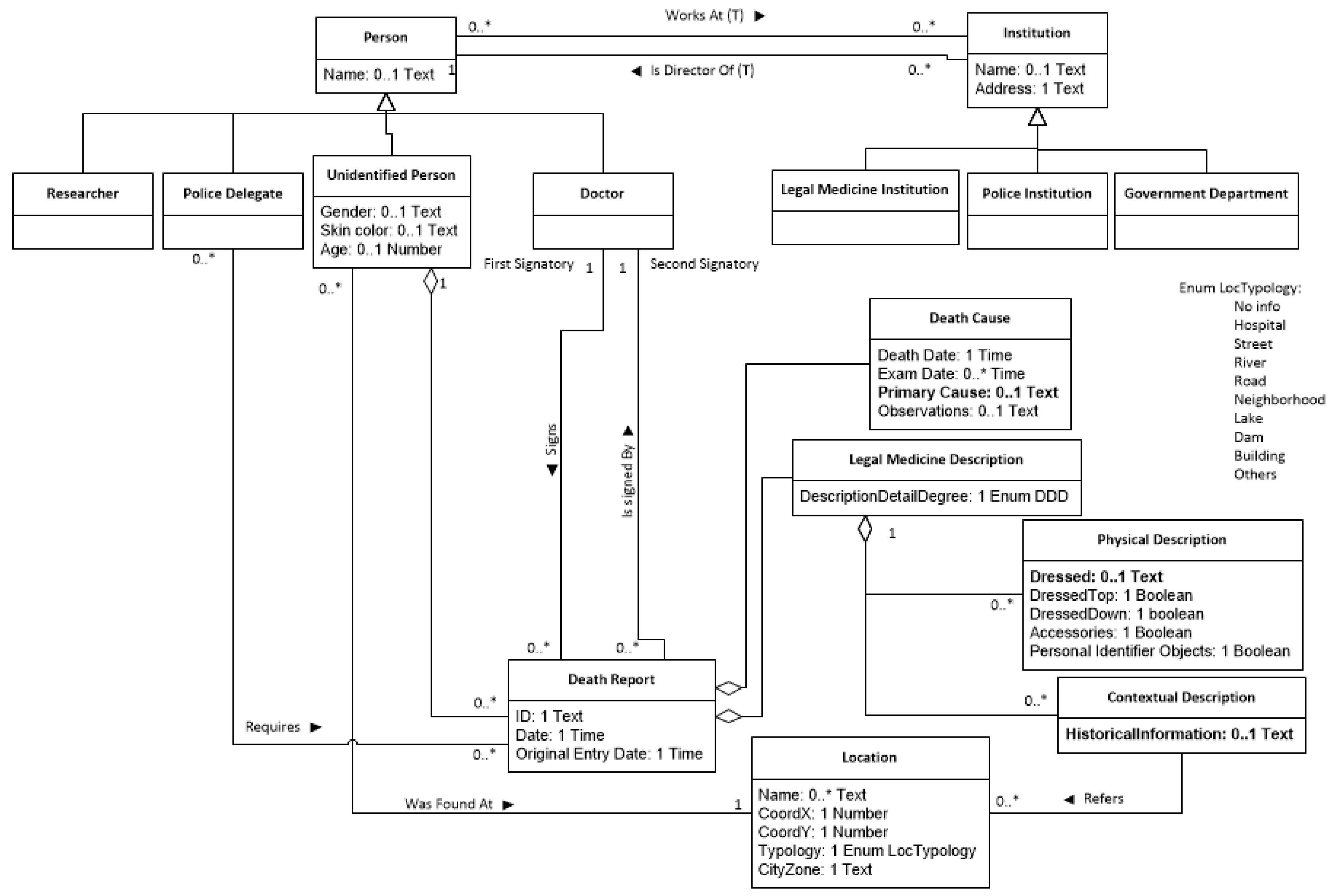
2.1. The “Disappearances in São Paulo” Corpus
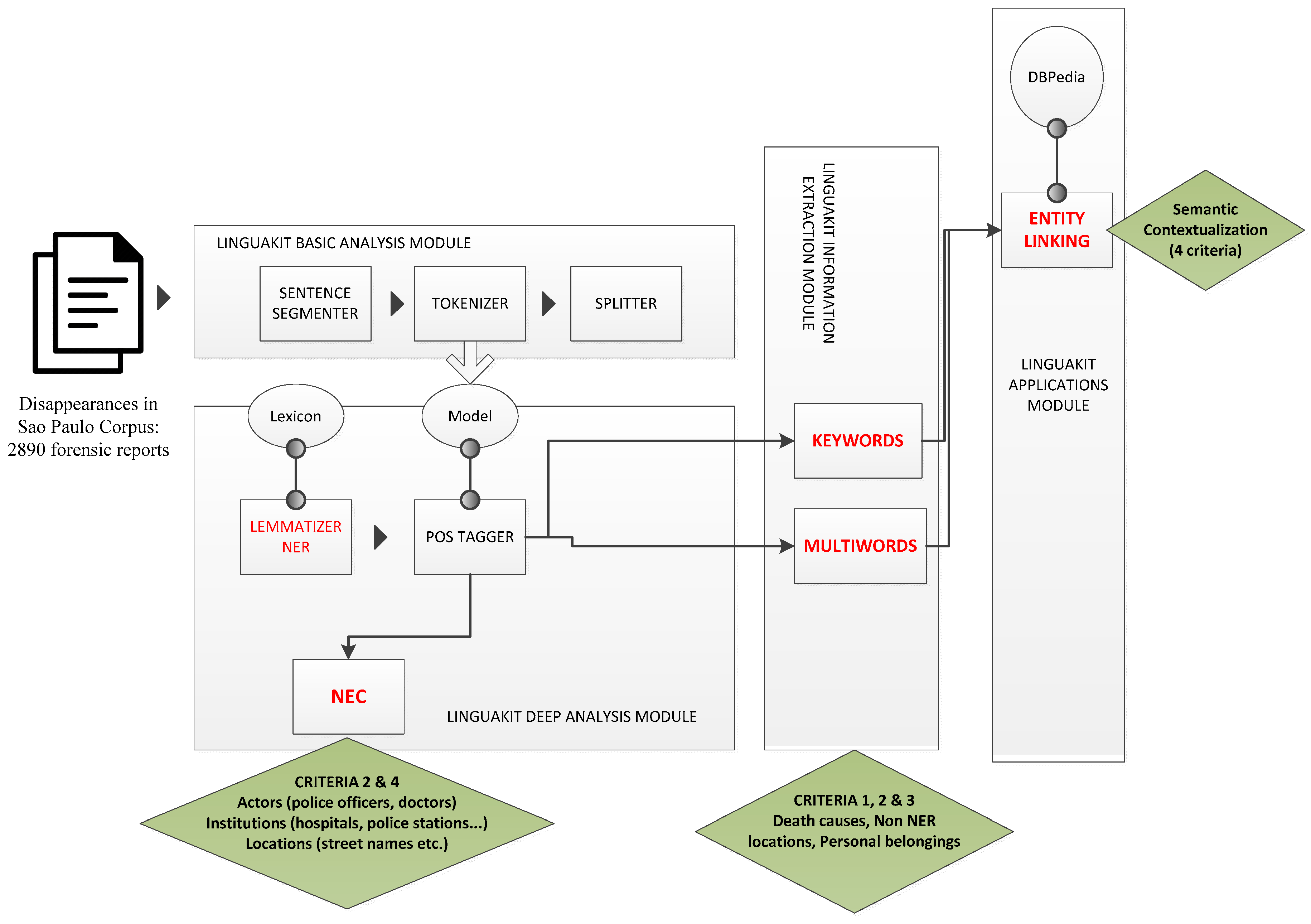
2.2. Unsupervised Information Extraction in Portuguese: Linguakit Suite
3. Results
3.1. Results Analysis
3.2. Visualizing Results in an Interactive Dashboard
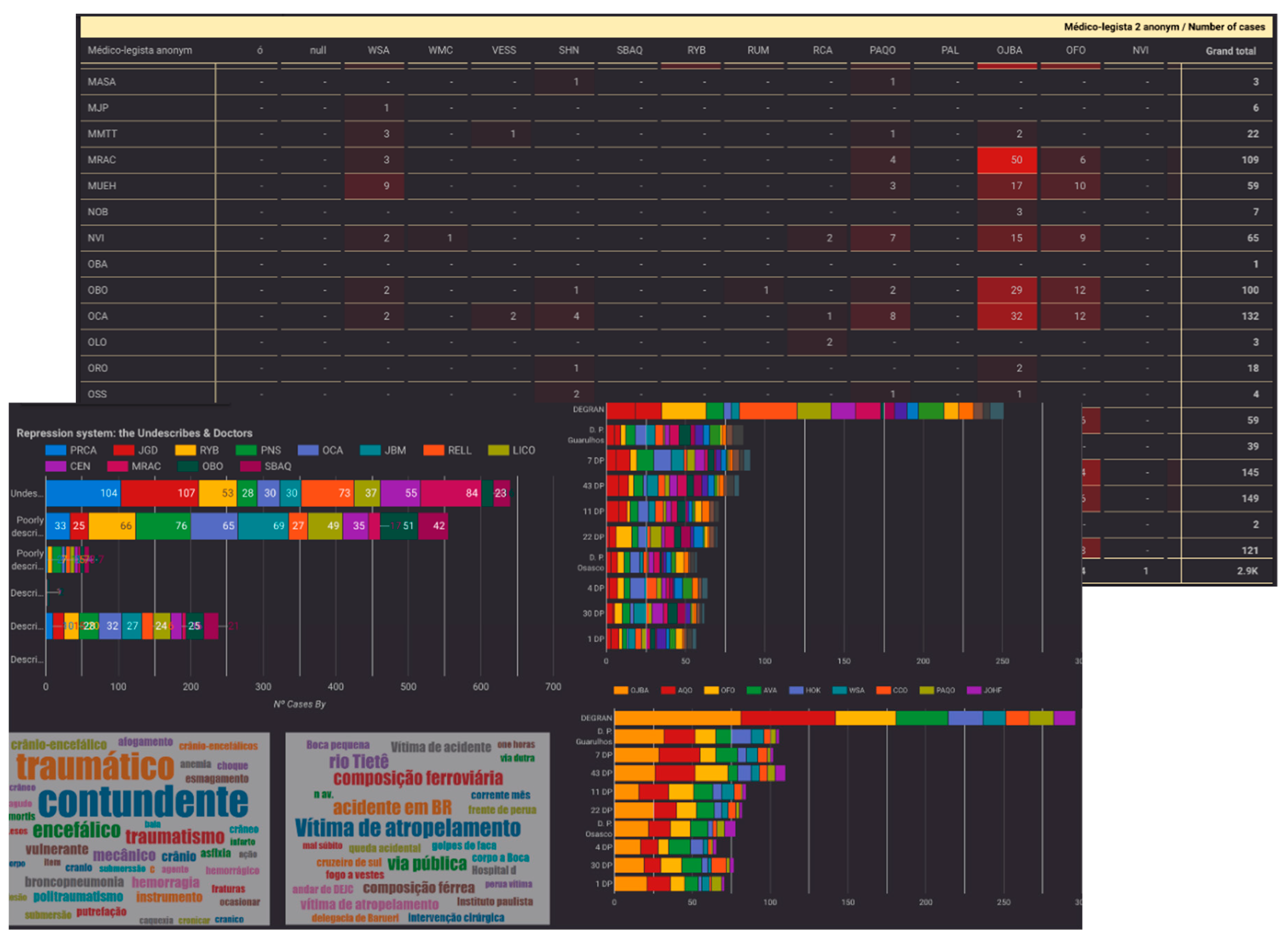
- The information extracted by NEC and categorized as PERSON and their correlation matrix (see Figure 7, top). Here, each row and/or column represents a doctor that signed forensic reports. Each cell specifies the number of reports signed together. Colored cells in reddish tones show emergent islands of intensive cooperation between the same couple of doctors in negligently described reports. This has allowed the experts to focus their study on certain doctors and their cases as possible collaborators of the regime's practices.
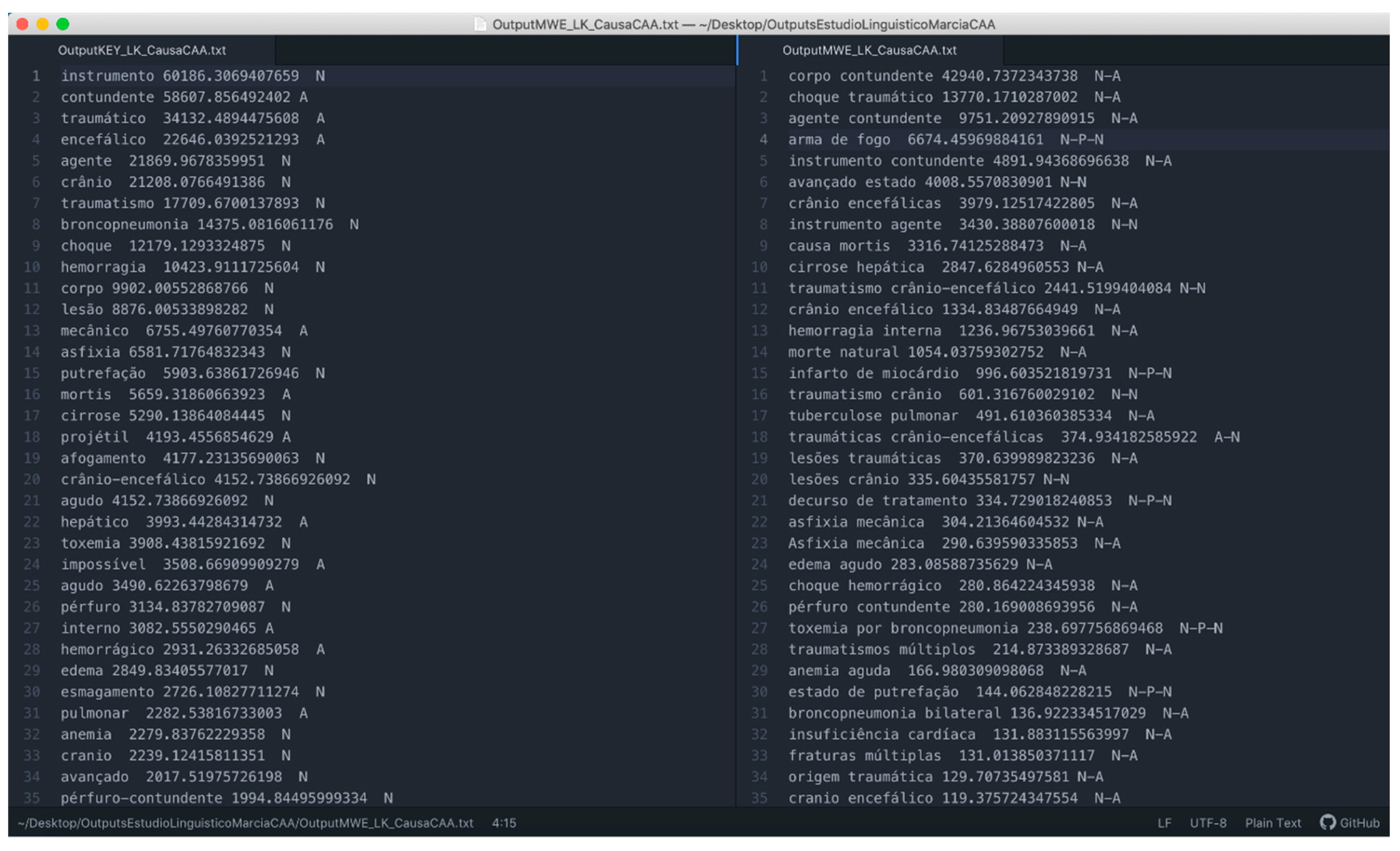
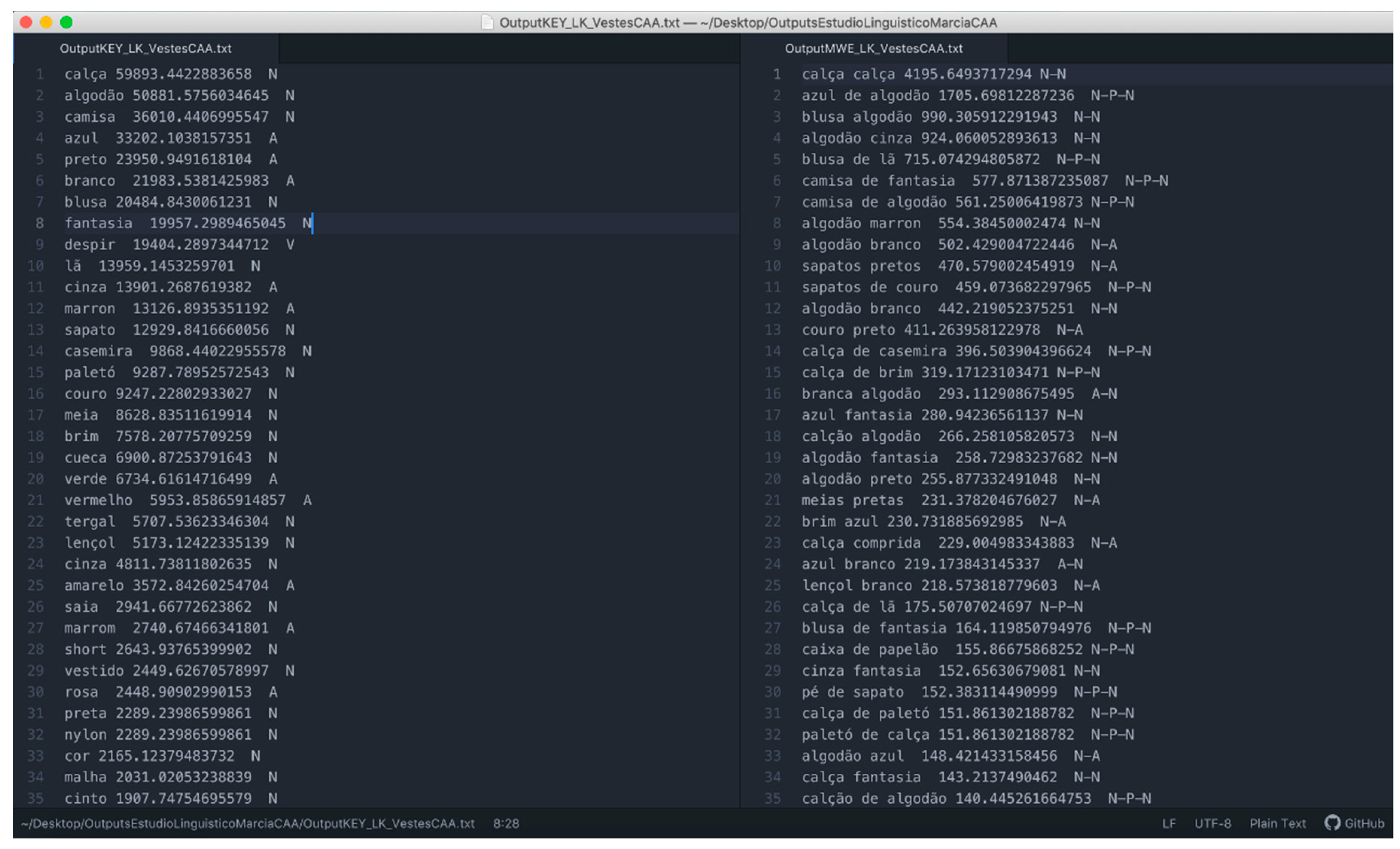
- The information extracted in the studies of keywords and multiword combinations has been visualized as word clouds of separate terms for each of the criteria: Common causes of death, terminology related to clothing, and terminology related to locations that do not respond to proper names (see Figure 7, bottom left).
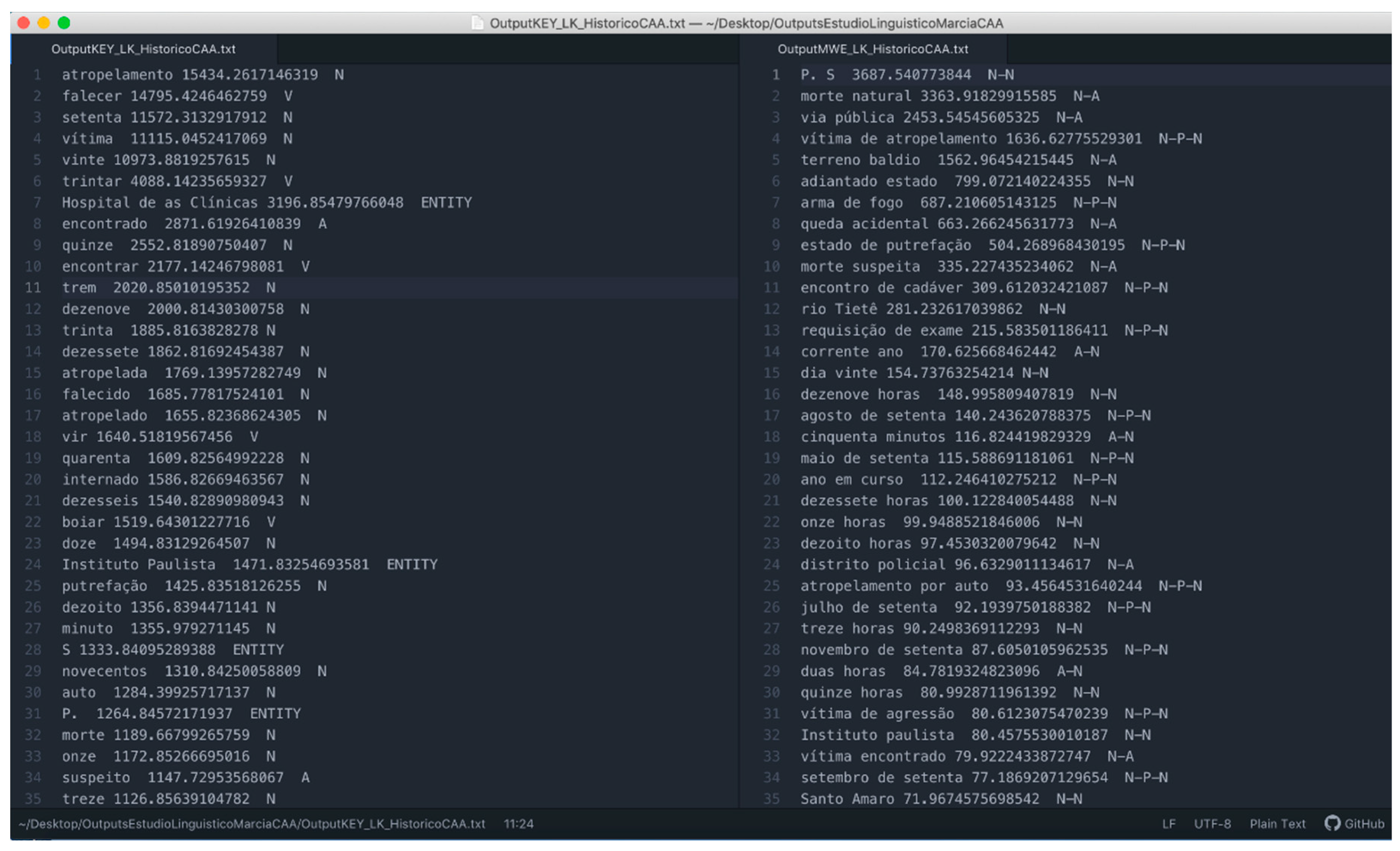
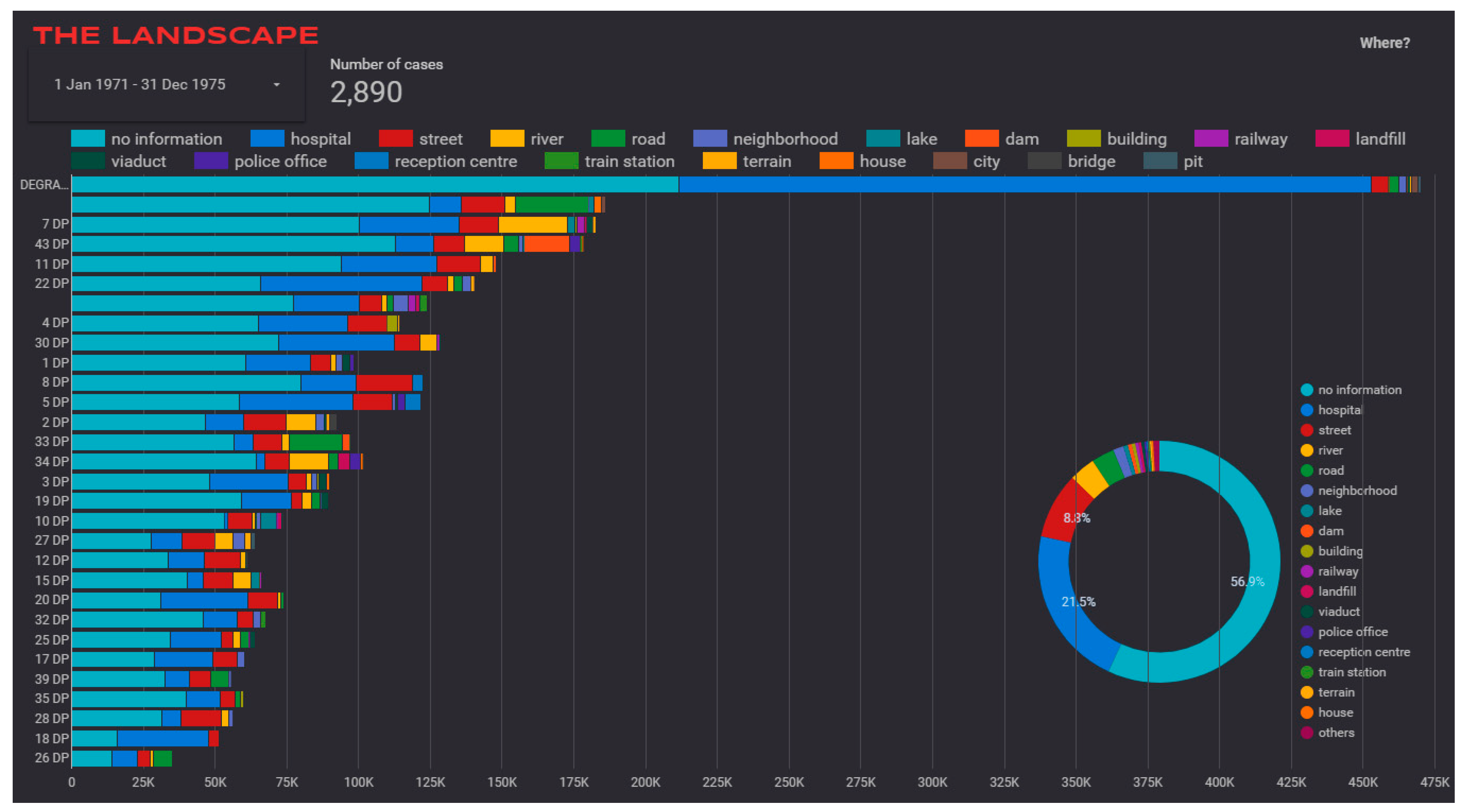
- Finally, the NEC information about proper names of locations has been displayed by the number of related reports (such as police stations responsible for requesting each report) (see Figure 7, bottom right) and the terms extracted from the reports. The information extracted about locations that do not correspond to proper names have also been visualized in a similar way (see Figure 8).
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ogren, P.V.; Savova, G.K.; Chute, C.G. Constructing evaluation corpora for automated clinical named entity recognition. In Building Sustainable Health Systems, Proceedings of the Medinfo 2007: 12th World Congress on Health (Medical) Informatics, Brisbane, Australia, 20–24 August 2007; IOS Press: Amsterdam, The Netherlands, 2007. [Google Scholar]
- Neamatullah, I.; Douglass, M.M.; Lehman, L.H.; Reisner, A.; Villarroel, M.; Long, W.J.; Szolovits, P.; Moody, G.B.; Mark, R.G.; Clifford, G.D. Automated de-identification of free-text medical records. BMC Med. Inform. Decis. Mak. 2008, 8, 32. [Google Scholar] [CrossRef] [PubMed]
- Uzuner, O.; Solti, I.; Xia, F.; Cadag, E. Community annotation experiment for ground truth generation for the i2b2 medication challenge. J. Am. Med. Inform. Assoc. 2010, 17, 519–523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deleger, L.; Li, Q.; Lingren, T.; Kaiser, M.; Molnar, K.; Stoutenborough, L. Building gold standard corpora for medical natural language processing tasks. In Proceedings of the AMIA Annual Symposium Proceedings, Chicago, IL, USA, 3–7 November 2012. [Google Scholar]
- Torii, M.; Wagholikar, K.; Liu, H. Using machine learning for concept extraction on clinical documents from multiple data sources. J. Am. Med. Inform. Assoc. 2011, 18, 580–587. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bodnari, A.; Deléger, L.; Lavergne, T.; Névéol, A.; Zweigenbaum, P. A Supervised Named-Entity Extraction System for Medical Text. In Proceedings of the CLEF, Valencia, Spain, 23–26 September 2013. [Google Scholar]
- Jiang, M.; Chen, Y.; Liu, M.; Rosenbloom, S.T.; Mani, S.; Denny, J.C.; Xu, H. A study of machine-learning-based approaches to extract clinical entities and their assertions from discharge summaries. J. Am. Med. Inform. Assoc. 2011, 18, 601–606. [Google Scholar] [CrossRef] [PubMed]
- Teles, M.A.D.A.; Lisboa, S.K. A Vala de Perus: Um Marco Histórico na Busca da Verdade e da Justiça. In Vala Clandestina de Perus: Desaparecidos políticos, um Capítulo Não Encerrado da História Brasileira; Instituto Macuco: São Paulo, Brazil, 2012; pp. 51–102. (In Portuguese) [Google Scholar]
- Teles, J. Mortos e desaparecidos políticos: Reparação ou impunidade; Humanitas FFLCH/USP: São Paulo, Brazil, 2001. (In Portuguese) [Google Scholar]
- Somigliana, C. Apuntes sobre la importancia de la actuación del Estado burocrático durante el período de la desaparición forzada de personas en la Argentina. Taller Rev. Soc. C. Y Política 2000, 5, 9–19. (In Spanish) [Google Scholar]
- Crenzel, E.A. Otra literatura: Los registros burocráticos y las huellas de las desapariciones en la Argentina. Estudios Teor. Lit. 2014, 3, 29–42. (In Spanish) [Google Scholar]
- Hattori, M.L.; de Abreu, R.; Tauhyl, S.A.P.M.; Alberto, L.A. O caminho burocrático da morte e a máquina de fazer desaparecer: Propostas de análise da documentação do Instituto Médico Legal-SP para antropologia forense1 2. Rev. Do Arq. 2014, 6, 1–21. (In Portuguese) [Google Scholar]
- Gamallo, P.; Garcia, M.; Pineiro, C.; Martinez-Castaño, R.; Pichel, J.C. LinguaKit: A Big Data-based multilingual tool for linguistic analysis and information extraction. In Proceedings of the 2018 Fifth International Conference on Social Networks Analysis, Management and Security (SNAMS), Valencia, Spain, 15–18 October 2018. [Google Scholar]
- Google Data Studio 2019. Available online: https://datastudio.google.com/ (accessed on 5 July 2019).
- Mezarobba, G. Entre reparações, meias verdades e impunidade: O difícil rompimento com o legado da ditadura no Brasil. Rev. Int. Direitos Hum. 2010, 7, 7–26. (In Portuguese) [Google Scholar]
- Ministério da Justiça e Segurança Pública—Sobre a comissão. 2019. Available online: https://www.justica.gov.br/seus-direitos/anistia/sobre-a-comissao/sobre-a-comissao (accessed on 25 May 2019). (In Portuguese)
- Comissão Nacional da Verdade (CNV). Relatório Final da Comissão Nacional da Verdade; DF. 3350 ISBN; Comissão Nacional da Verdade: Brasília, Brazil, 2014. (In Portuguese) [Google Scholar]
- Barcellos, C. O Globo Repórter sobre a vala de Perus. In Mortos e desaparecidos políticos: Reparação ou impunidade; Humanitas FFLCH/USP: São Paulo, Brazil, 2001; pp. 213–226. (In Portuguese) [Google Scholar]
- Godoy, M. A Casa da Vovó: Uma Biografia do DOI-Codi (1969–1991), O Centro de Sequestro, Tortura E Morte da Ditadura Militar; Alameda Casa Editorial: São Paulo, Brazil, 2015. (In Portuguese) [Google Scholar]
- Asociación Latinoamericana de Antropología Forense. Guía latinoamericana de buenas prácticas para la aplicación en antropología forense; ALAF: Antigua, Guatemala, 2016. (In Spanish) [Google Scholar]
- Carnaz, G.; Quaresma, P.; Nogueira, V.B.; Antunes, M.; Ferreira, N.N.M.F. A Review on Relations Extraction in Police Reports. In Proceedings of the New Knowledge in Information Systems and Technologies, La Toja, Spain, 6–19 April 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Mujtaba, G.; Shuib, L.; Raj, R.G.; Rajandram, R.; Shaikh, K. Automatic Text Classification of ICD-10 Related CoD from Complex and Free Text Forensic Autopsy Reports. In Proceedings of the 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016. [Google Scholar]
- Partridge, C. Business Objects: Re-Engineering for Re-Use; Butterworth-Heinemann: Oxford, UK, 1996. [Google Scholar]
- Armstrong, D.J. The quarks of object-oriented development. Commun. ACM 2006, 49, 123–128. [Google Scholar] [CrossRef]
- Surya, M.; Padmavathi, S. A Survey of Object-Oriented Programming Languages. Available online: http://users.soe.ucsc.edu/~vrk/Reports/oopssurvey.pdf (accessed on 16 December 2014).
- Gonzalez-Perez, C. A conceptual modelling language for the humanities and social sciences RCIS'12. In Proceedings of the Sixth International Conference on Research Challenges in Information Science, Valencia, Spain, 16–18 May 2012. [Google Scholar]
- Gonzalez-Perez, C. Information Modelling for Archaeology and Anthropology: Software Engineering Principles for Cultural Heritage; Springer: Berlin, Germany, 2018. [Google Scholar]
- Martin-Rodilla, P.; Gonzalez-Perez, C. Assessing the learning curve in archaeological information modelling: Educational experiences with the Mind Maps and Object-Oriented paradigms. In Proceedings of the 45th Computer Applications and Quantitative Methods in Archaeology (CAA 2017), Atlanta, GA, USA, 13–16 March 2017. [Google Scholar]
- Gonzalez-Perez, C.; Martin-Rodilla, P. Teaching Conceptual Modelling in Humanities and Social Sciences. Rev. Humanidades Dig. 2017, 1, 408–416. [Google Scholar] [CrossRef]
- Gonzalez-Perez, C.; Martin-Rodilla, P. Using model views to assist with model conformance and extension. In Proceedings of the 2016 IEEE Tenth International Conference on Research Challenges in Information Science (RCIS), Grenoble, France, 1–3 June 2016. [Google Scholar]
- OMG. UML 2.4.1 Superstructure Specification. August 2012. Available online: http://www.omg.org/ (accessed on 5 June 2019).
- Freitas, C.; Mota, C.; Santos, D.; Oliveira, H.G.; Carvalho, P. Second HAREM: Advancing the State of the Art of Named Entity Recognition in Portuguese; European Languages Resources Association (ELRA): Valletta, Malta, 2010. [Google Scholar]
- Sarmento, L. SIEMÊS—A Named-Entity Recognizer for Portuguese Relying on Similarity Rules. In International Workshop on Computational, Processing of the Portuguese Language; Vieira, R., Quaresma, P., Nunes, M.D.G.V., Mamede, N.J., Oliveira, C., Dias, M.C., Eds.; Springer: Berlin, Germany, 2006; pp. 90–99. [Google Scholar]
- Padró, L.; Stanilovsky, E. Freeling 3.0: Towards wider multilinguality. In Proceedings of the LREC2012, Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Manning, C.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 22 June 2014. [Google Scholar]
- Pirovani, J.; de Oliveira, E. CRF+LG: A Hybrid Approach for the Portuguese Named Entity Recognition. In Intelligent Systems Design and Applications; Abraham, A., Muhuri, P.K., Muda, A.K., Gandhi, N., Eds.; Springer: Berlin, Germany, 2018; pp. 102–113. [Google Scholar]
- Collovini, S.; Machado, G.; Vieira, R. Extracting and Structuring Open Relations from Portuguese Text. In Computational Processing of the Portuguese Language; Silva, J., Ribeiro, R., Quaresma, P., Adami, A., Branco, A., Eds.; Springer: Cham, Switzerland, 2016; pp. 153–164. [Google Scholar]
- Gamallo, P.; Garcia, M. A resource-based method for named entity extraction and classification. In Proceedings of the Portuguese Conference on Artificial Intelligence, Lisbon, Portugal, 10–13 October 2011; Springer: Berlin, Germany, 2011. [Google Scholar]
- Garcia, M.; Gamallo, P. Yet Another Suite of Multilingual NLP Tools. In Languages, Applications and Technologies, Proceedings of the 4th International Symposium, SLATE 2015, Madrid, Spain, 18–19 June 2015; Springer: Cham, Switzerland, 2015; pp. 65–75. [Google Scholar]
- Gamallo, P.; Garcia, M. Entity Linking with Distributional Semantics. In Proceedings of the 12th International Conference, PROPOR, Tomar, Portugal, 13–15 July 2016; Springer: Berlin, Germany, 2016. [Google Scholar]
- Mendes, P.N.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight: Shedding light on the web of documents. In Proceedings of the 7th International Conference on Semantic Systems, Graz, Austria, 7–9 September 2011. [Google Scholar]
- Butler, J. Frames of War: When is life Grievable? Verso Books: Brooklyn, NY, USA, 2016. [Google Scholar]
- Martin-Rodilla, P. Digging into Software Knowledge Generation in Cultural Heritage; Springer: Basel, Switzerland, 2018. [Google Scholar]
- Odena, O. Using Specialist Software to Assist Knowledge Generation: An Example from a Study of Practitioners’ Perceptions of Music as a Tool for Ethnic Inclusion in Cross-Community Activities in Northern Ireland. In Advancing Race and Ethnicity in Education; Race, R., Lander, V., Eds.; Palgrave Macmillan: London, UK, 2014; pp. 178–192. [Google Scholar]
- Juristo, N.; Moreno, A.M. Basics of Software Engineering Experimentation; Springer: Berlin, Germany, 2013. [Google Scholar]
- Martin-Rodilla, P.; Panach, J.I.; Gonzalez-Perez, C.; Pastor, O. Assessing data analysis performance in research contexts: An experiment on accuracy, efficiency, productivity and researchers’ satisfaction. Data Knowl. Eng. 2018, 116, 177–204. [Google Scholar] [CrossRef]
- Wohlin, C.; Runeson, P.; Höst, M.; Ohlsson, M.C.; Regnell, B.; Wesslén, A. Experimentation in Software Engineering; Springer: Berlin, Germany, 2012. [Google Scholar]
- Panach, J.I.; España, S.; Dieste, O.; Pastor, O.; Juristo, N. In search of evidence for model-driven development claims: An experiment on quality, effort, productivity and satisfaction. Inf. Softw. Technol. 2015, 62, 164–186. [Google Scholar] [CrossRef] [Green Version]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin-Rodilla, P.; Hattori, M.L.; Gonzalez-Perez, C. Assisting Forensic Identification through Unsupervised Information Extraction of Free Text Autopsy Reports: The Disappearances Cases during the Brazilian Military Dictatorship. Information 2019, 10, 231. https://doi.org/10.3390/info10070231
Martin-Rodilla P, Hattori ML, Gonzalez-Perez C. Assisting Forensic Identification through Unsupervised Information Extraction of Free Text Autopsy Reports: The Disappearances Cases during the Brazilian Military Dictatorship. Information. 2019; 10(7):231. https://doi.org/10.3390/info10070231
Chicago/Turabian StyleMartin-Rodilla, Patricia, Marcia L. Hattori, and Cesar Gonzalez-Perez. 2019. "Assisting Forensic Identification through Unsupervised Information Extraction of Free Text Autopsy Reports: The Disappearances Cases during the Brazilian Military Dictatorship" Information 10, no. 7: 231. https://doi.org/10.3390/info10070231