
A Discriminative Framework for Action Recognition Using f-HOL Features


Abstract
:1. Introduction
2. Related Literature
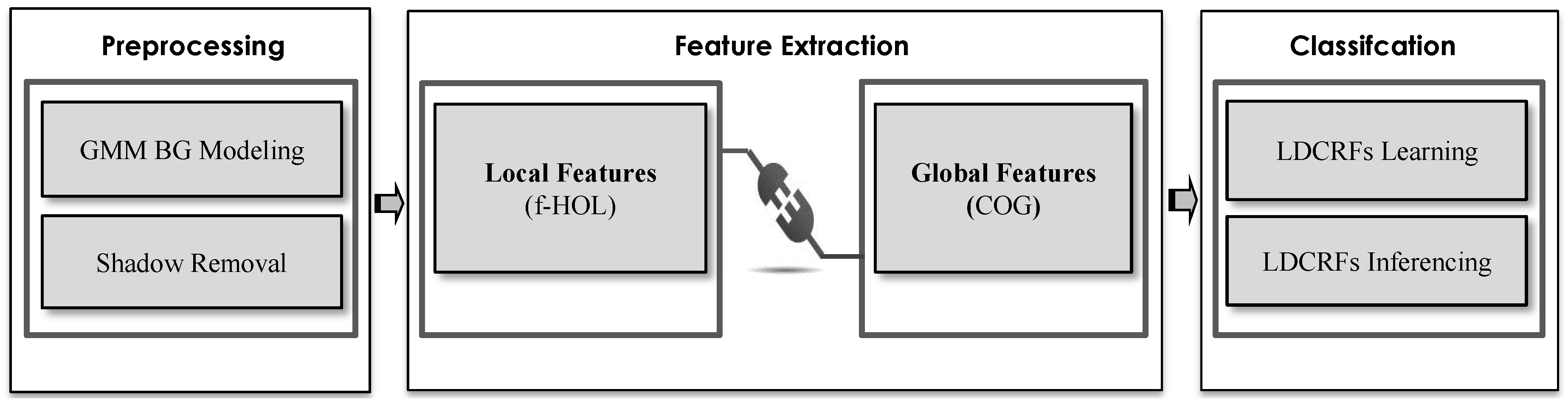
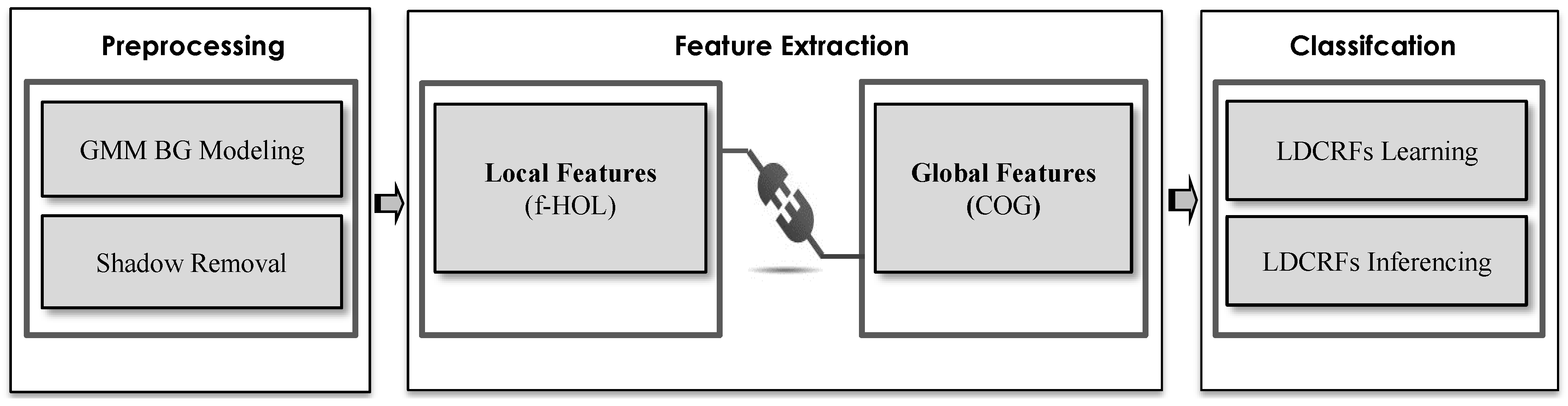
3. Proposed Methodology
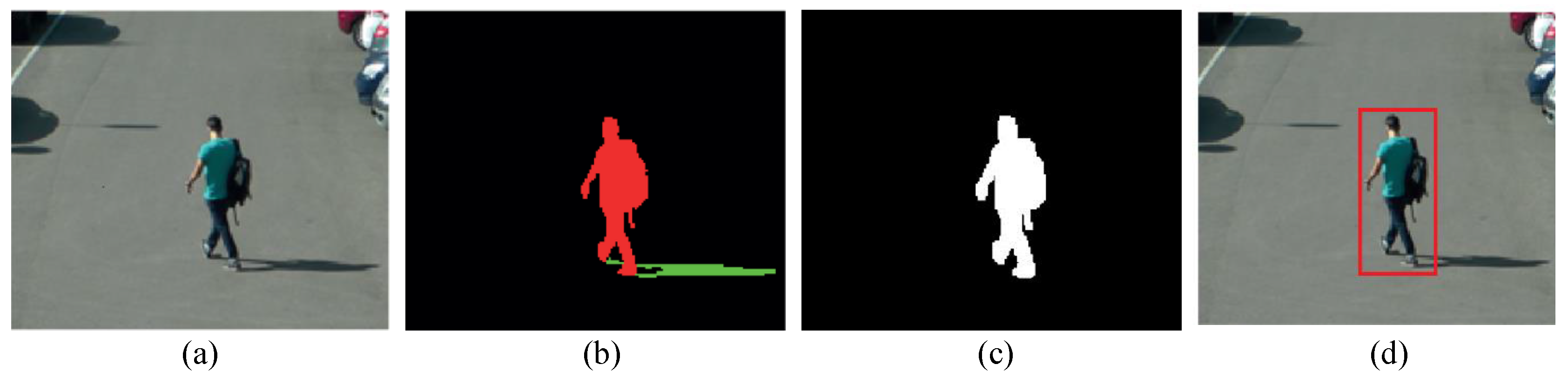
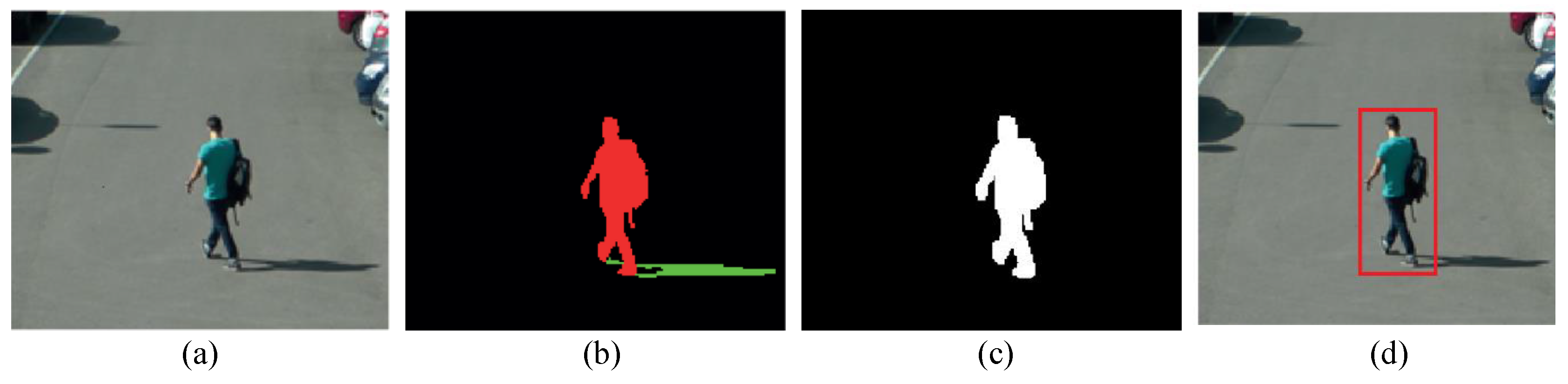
3.1. Background Subtraction and Shadow Removal
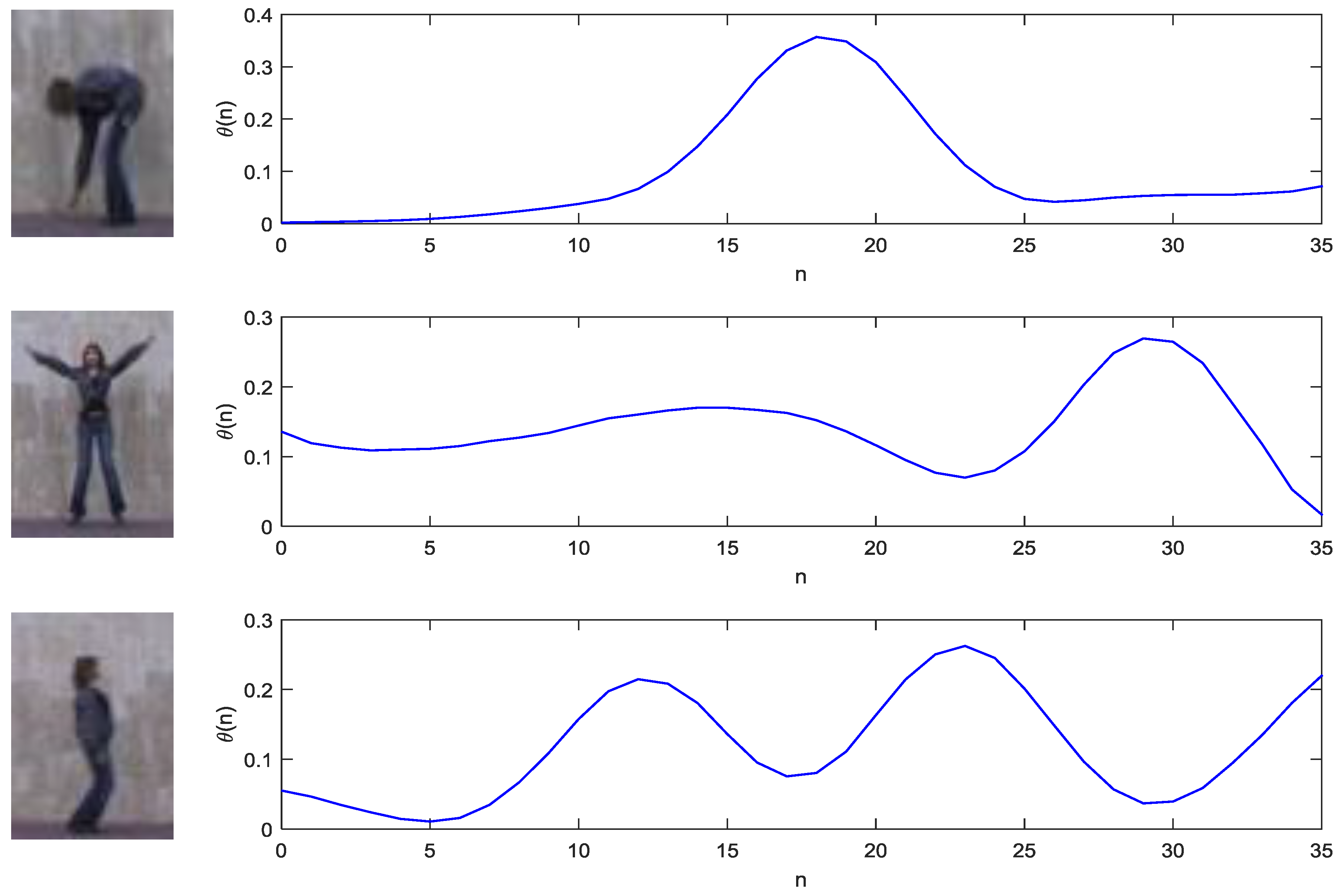
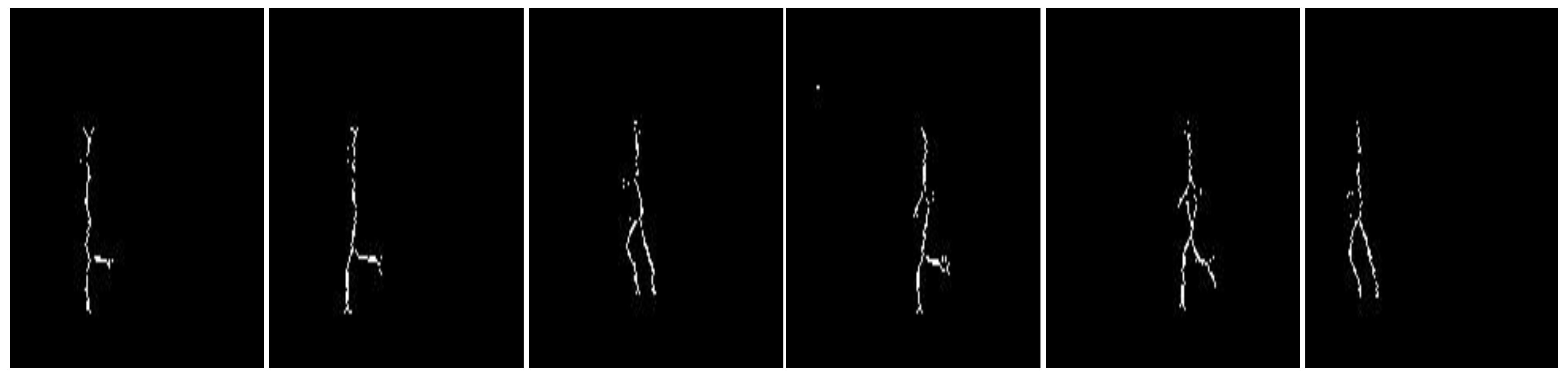
3.2. Feature Extraction
Mat element = getStructuringElement(MORPH_CROSS, Size(3, 3));
do
{
erode(img, eroded, element);
dilate(eroded, temp, element);
subtract(img, temp, temp);
bitwise_or(skel, temp, skel);
eroded.copyTo(img);
done = (norm(img) == 0);
} while (!done).
Fusion of Local and Global Action Features
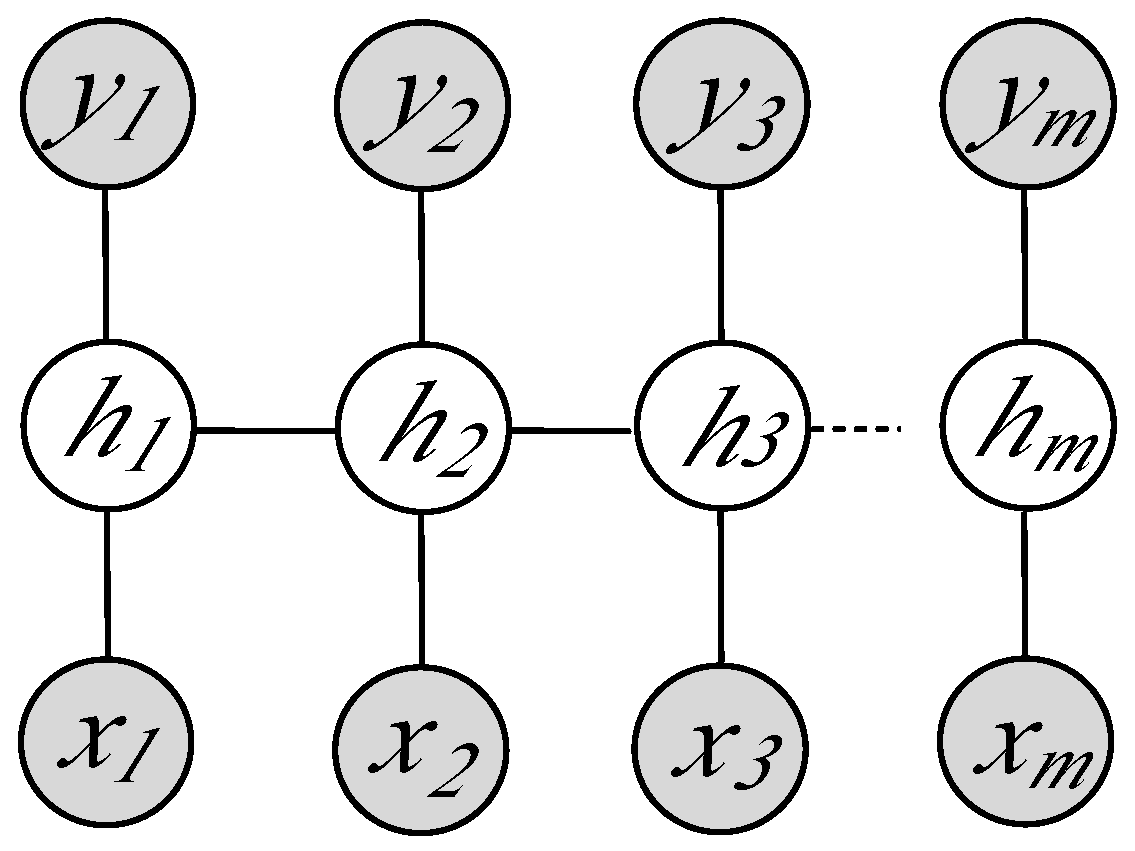
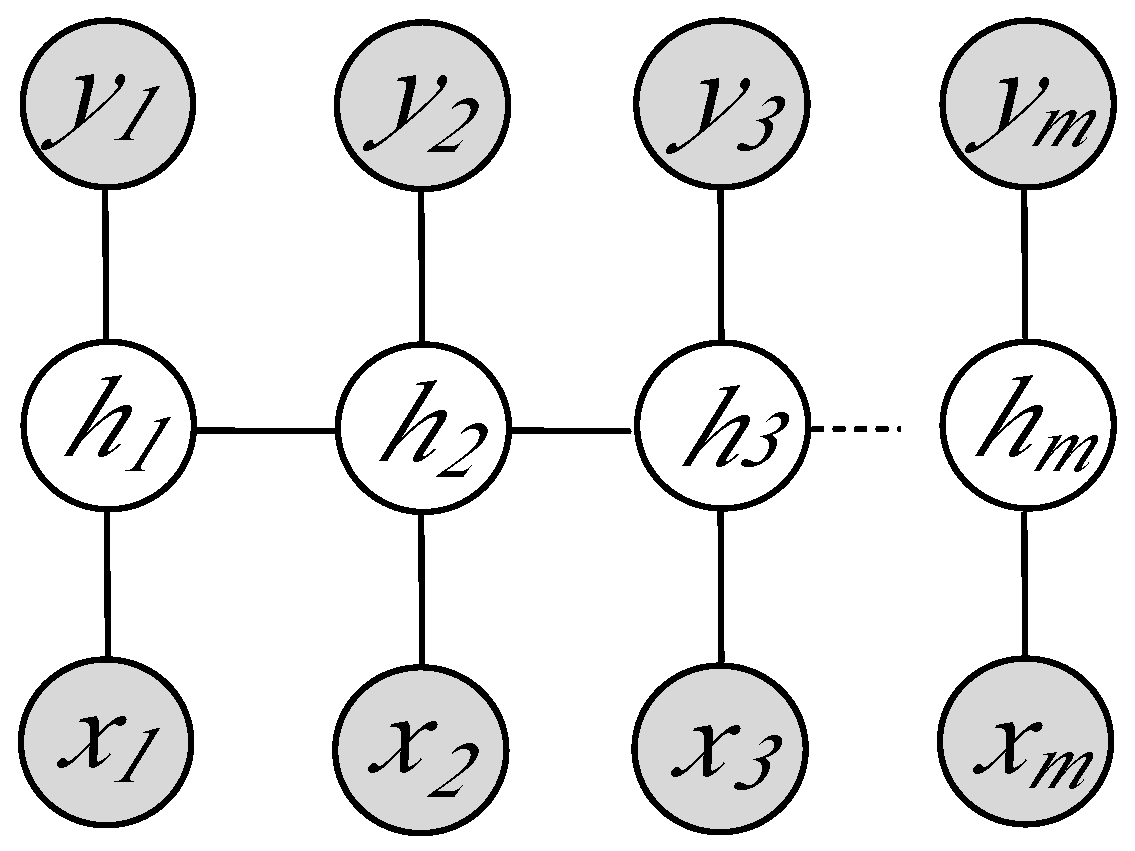
3.3. Action Classification
4. Experiments and Results
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Laptev, I.; Pérez, P. Retrieving actions in movies. In Proceedings of the IEEE 11th International Conference on Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–21 October 2007.
- Sadek, S.; Al-Hamadi, A.; Michaelis, B.; Sayed, U. Human Action Recognition via Affine Moment Invariants. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR’12), Tsukuba, Japan, 11–15 November 2012; pp. 218–221.
- Sadek, S.; Al-Hamadi, A.; Michaelis, B.; Sayed, U. Human Action Recognition: A Novel Scheme Using Fuzzy Log-Polar Histogram and Temporal Self-Similarity. EURASIP J. Adv. Signal Process. 2011, 2011, 1–9. [Google Scholar] [CrossRef]
- Johansson, G. Visual motion perception. Sci. Am. 1975, 232, 76–88. [Google Scholar] [CrossRef] [PubMed]
- Sadek, S.; Al-Hamadi, A. Vision-Based Representation and Recognition of Human Activities in Image Sequences. Ph.D. Thesis, Otto-von-Guericke-Universität Magdeburg (IIKT), Magdeburg, Germany, 2013. [Google Scholar]
- Aggarwal, J.K.; Cai, Q. Human motion analysis: A review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Fathi, A.; Mori, G. Action recognition by learning mid-level motion features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar]
- Sadek, S.; Al-Hamadi, A.; Michaelis, B.; Sayed, U. An SVM approach for activity recognition based on chord-length-function shape features. In Proceedings of the IEEE International Conference on Image Processing (ICIP’12), Orlando, FL, USA, 30 September–3 October 2012; pp. 767–770.
- Blank, M.; Gorelick, L.; Shechtman, E.; Irani, M.; Basri, R. Actions as space-time shapes. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Washington, DC, USA, 17–21 October 2005; Volume 2, pp. 1395–1402.
- Chakraborty, B.; Bagdanov, A.D.; Gonzàlez, J. Towards Real-Time Human Action Recognition. Pattern Recognit. Image Anal. 2009, 5524, 425–432. [Google Scholar]
- Sadek, S.; Al-Hamadi, A.; Michaelis, B.; Sayed, U. Towards Robust Human Action Retrieval in Video. In Proceedings of the British Machine Vision Conference (BMVC’10), Aberystwyth, UK, 31 August–3 September 2010; pp. 1–11.
- Sadek, S.; Al-Hamadi, A.; Michaelis, B.; Sayed, U. A Statistical Framework for Real-Time Traffic Accident Recognition. J. Signal Inf. Process. (JSIP) 2010, 1, 77–81. [Google Scholar] [CrossRef]
- Efros, A.A.; Berg, A.C.; Mori, G.; Malik, J. Recognizing action at a distance. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, pp. 726–733.
- Sullivan, J.; Carlsson, S. Recognizing and tracking human action. In Proceedings of the 7th European Conference on Computer Vision, Copenhagen, Denmark, 28–31 May 2002; Volume 1, pp. 629–644.
- Nowozin, S.; Bakir, G.; Tsuda, K. Discriminative subsequence mining for action classification. In Proceedings of the Eleventh IEEE International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1919–1923.
- Liu, J.; Shah, M. Learning human actions via information maximization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008.
- Little, L.; Boyd, J.E. Recognizing people by their gait: The shape of motion. Int. J. Comput. Vis. 1998, 1, 1–32. [Google Scholar]
- Cutler, R.; Davis, L.S. Robust real-time periodic motion detection, analysis, and applications. IEEE Trans. PAMI 2000, 22, 781–796. [Google Scholar] [CrossRef]
- Shechtman, E.; Irani, M. Space-time behavior based correlation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 405–412.
- Bobick, A.; Davis, J. The Recognition of Human Movement Using Temporal Templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Rodriguez, M.D.; Ahmed, J.; Shah, M. Action MACH: A spatio-temporal maximum average correlation height filter for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Anchorage, AK, USA, 23–28 June 2008.
- Fernando, B.; Gavves, E.; Oramas, M.J.; Ghodrati, A.; Tuytelaars, T. Modeling video evolution for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5378–5387.
- Kantorov, V.; Laptev, I. Efficient feature extraction, encoding, and classification for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 2593–2600.
- Ikizler, N.; Forsyth, D. Searching video for complex activities with finite state models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007.
- Olivera, N.; Garg, A.; Horvitz, E. Layered representations for learning and inferring office activity from multiple sensory channels. Comput. Vis. Image Underst. 2004, 96, 163–180. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. Correlated topic models. Adv. Neural Inf. Process. Syst. 2006, 18, 147–154. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the SIGIR99 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Berkeley, CA, USA, 15–19 August 1999; pp. 50–57.
- Zivkovic, Z. Improved adaptive Gausian mixture model for background subtraction. In Proceedings of the 17th International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004.
- Bar-Shalom, Y.; Li, X.R. Estimation and Tracking: Principles, Techniques, and Software; Artech House: Boston, MA, USA, 1993. [Google Scholar]
- Ahmad, M.; Lee, S.W. Human Action Recognition Using Shape and CLG-motion Flow From Multi-view Image Sequences. J. Pattern Recognit. 2008, 7, 2237–2252. [Google Scholar] [CrossRef]
- Bakheet, S.; Al-Hamadi, A. A Hybrid Cascade Approach for Human Skin Segmentation. Br. J. Math. Comput. Sci. 2016, 17, 1–18. [Google Scholar] [CrossRef]
- Matas, J.; Galambos, C.; Kittler, J.V. Robust Detection of Lines Using the Progressive Probabilistic Hough Transform. Comput. Vis. Image Underst. 2000, 78, 119–137. [Google Scholar] [CrossRef]
- Deufemia, V.; Risi, M.; Tortora, G. Sketched symbol recognition using Latent-Dynamic Conditional Random Fields and distance-based clustering. Pattern Recognit. 2014, 47, 1159–1171. [Google Scholar] [CrossRef]
- Ramírez, G.A.; Fuentes, O.; Crites, S.L.; Jimenez, M.; Ordonez, J. Color Analysis of Facial Skin: Detection of Emotional State. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 474–479.
- Morency, L.P.; Quattoni, A.; Darrell, T. Latent-dynamic discriminative models for continuous gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 17–22 June 2007.
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the Eighteenth International Conference on Machine Learning, Williamstown, MA, USA, 28 June–1 July 2001; pp. 282–289.
- Sadek, S.; Al-Hamadi, A.; Michaelis, B.; Sayed, U. An Efficient Method for Real-Time Activity Recognition. In Proceedings of the International Conference on Soft Computing and Pattern Recognition (SoCPaR’10), Cergy Pontoise/Paris, France, 7–10 December 2010; pp. 7–10.
- Bregonzio, M.; Gong, S.; Xiang, T. Recognising action as clouds of space-time interest points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–26 June 2009.
- Zhang, Z.; Hu, Y.; Chan, S.; Chia, L.T. Motion context: A new representation for human action recognition. In Proceedings of the 10th European Conference on Computer Vision (ECCV), Marseille, France, 12–18 October 2008; Volume 4, pp. 817–829.
- Sadek, S.; Al-Hamadi, A.; Krell, G.; Michaelis, B. Affine-Invariant Feature Extraction for Activity Recognition. ISRN Mach. Vis. J. 2013, 1, 1–7. [Google Scholar] [CrossRef]
- Niebles, J.; Wang, H.; Fei-Fei, L. Unsupervised learning of human action categories using spatial-temporal words. Int. J. Comput. Vis. 2008, 79, 299–318. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action | Walk | Run | Jump | P-Jump | Jack | Side | Bend | Skip | Wave1 | Wave2 |
|---|---|---|---|---|---|---|---|---|---|---|
| Walk | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Run | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Jump | 0.00 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| P-jump | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Jack | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Side | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.06 | 0.00 | 0.00 | |
| Bend | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Skip | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Wave1 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Wave2 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bakheet, S.; Al-Hamadi, A. A Discriminative Framework for Action Recognition Using f-HOL Features. Information 2016, 7, 68. https://doi.org/10.3390/info7040068
Bakheet S, Al-Hamadi A. A Discriminative Framework for Action Recognition Using f-HOL Features. Information. 2016; 7(4):68. https://doi.org/10.3390/info7040068
Chicago/Turabian StyleBakheet, Samy, and Ayoub Al-Hamadi. 2016. "A Discriminative Framework for Action Recognition Using f-HOL Features" Information 7, no. 4: 68. https://doi.org/10.3390/info7040068