
Design of a Quaternary Query Tree ALOHA Protocol Based on Optimal Tag Estimation Method

Abstract
:1. Introduction
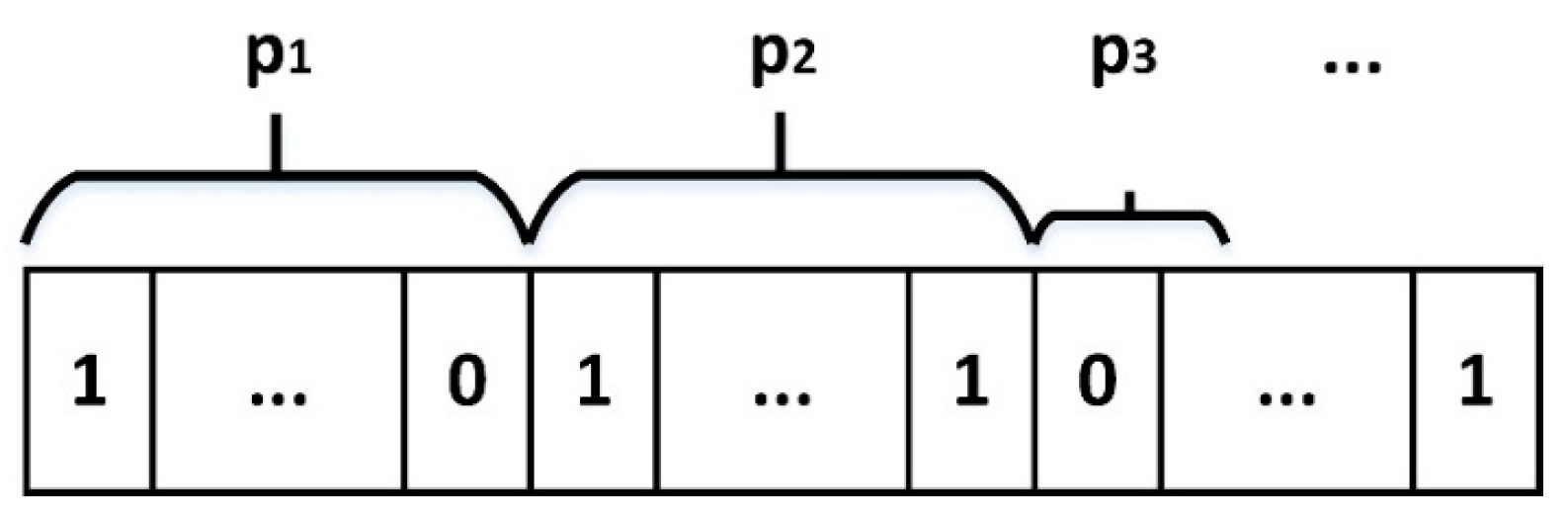
2. An Optimal Tag Estimation Method
2.1. Description of Tag Estimation Method
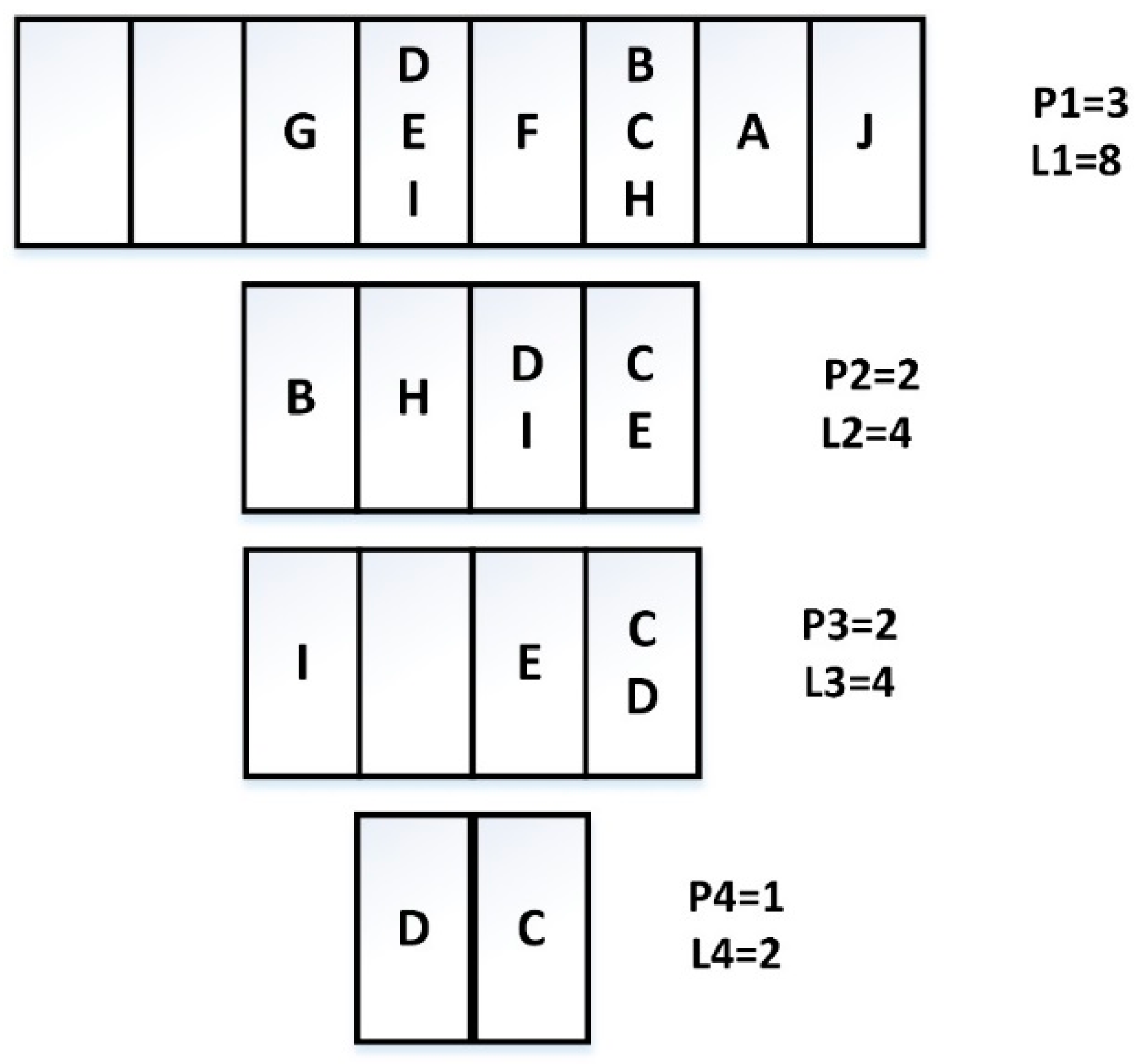
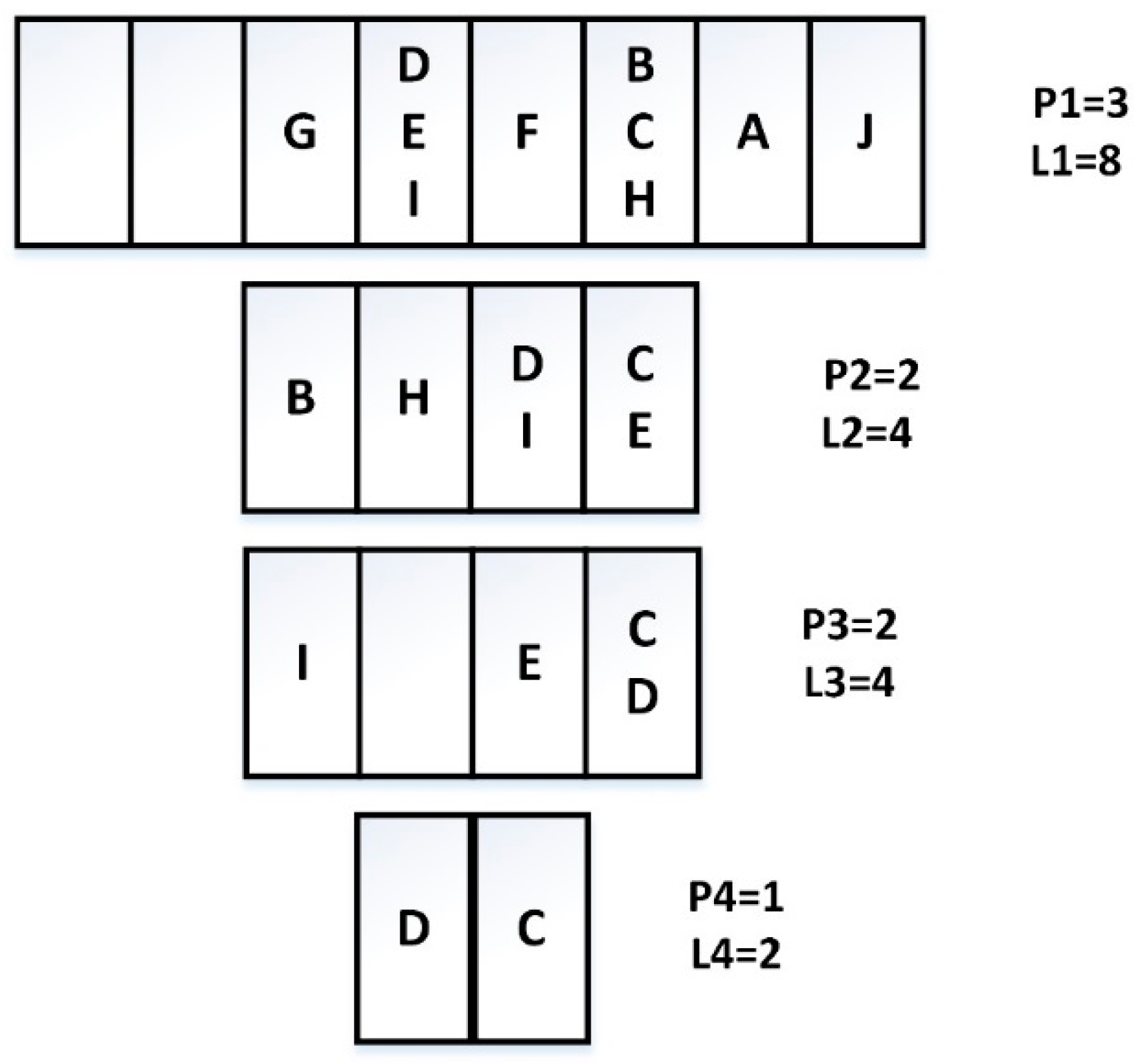
2.2. Example Analysis
3. A 4-Ary Query Tree ALOHA Protocol Based on Optimal Tag Estimation
3.1. QTA and 4-Ary QTA
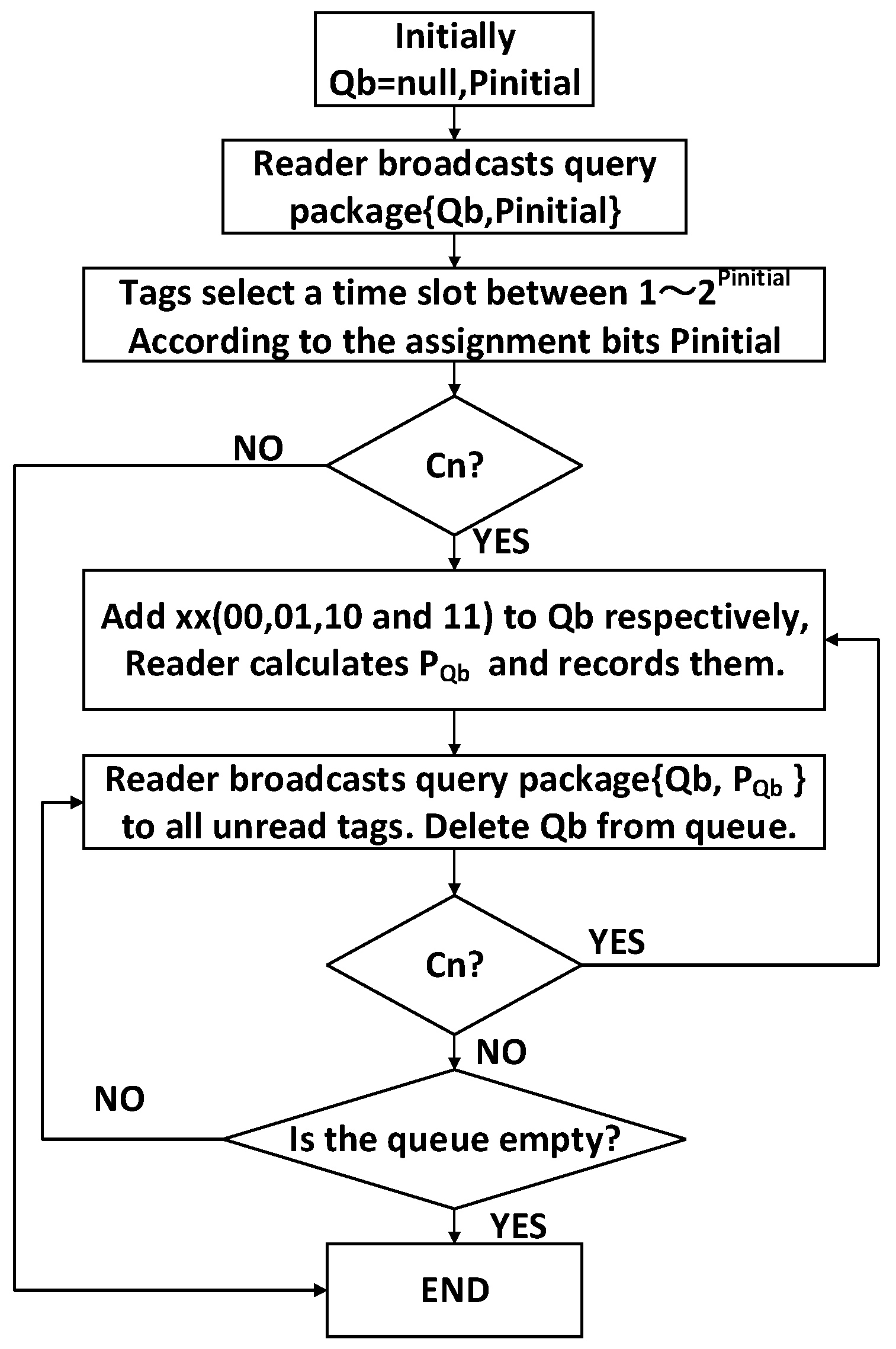
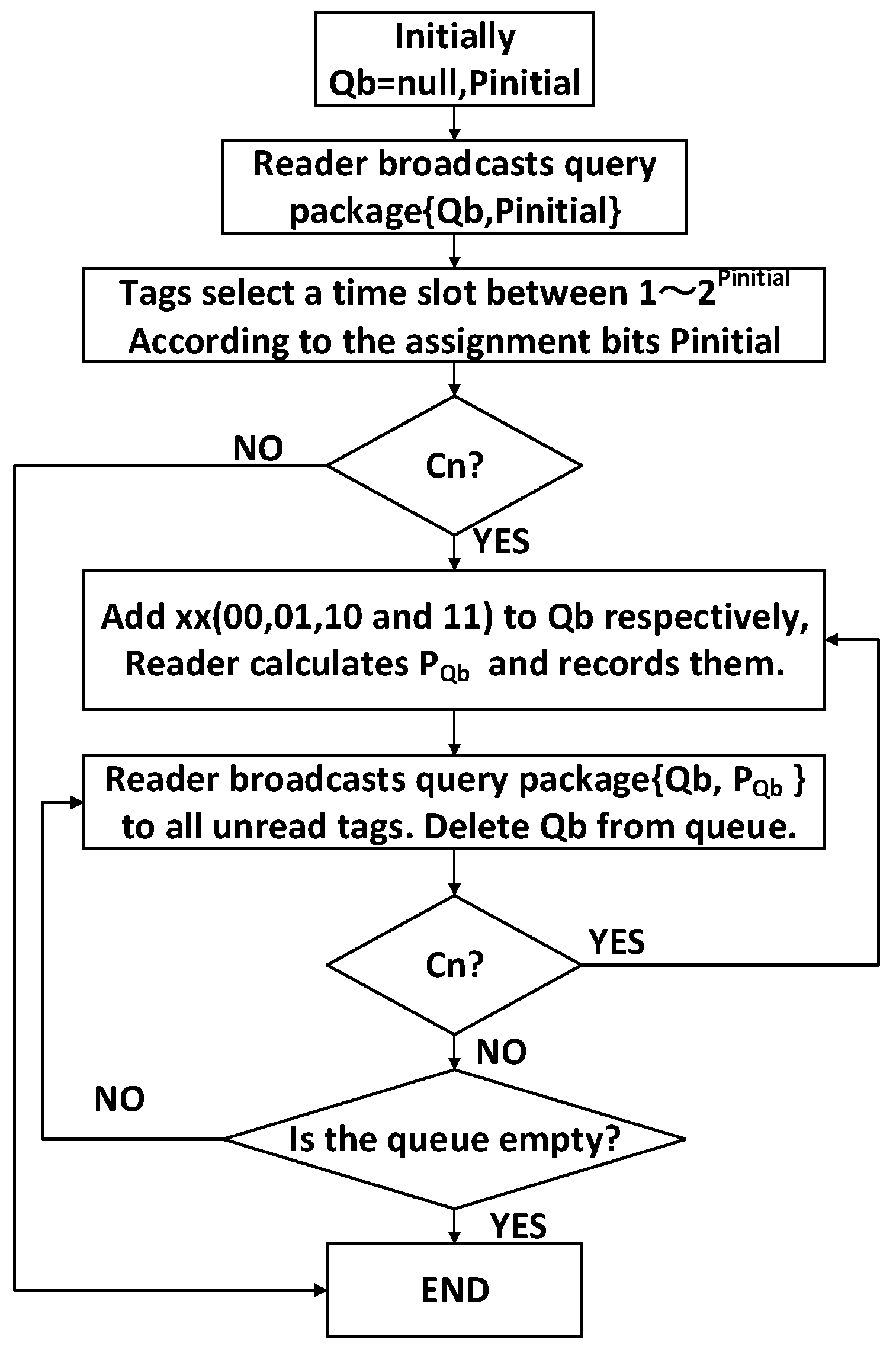
3.2. Description of the Proposed Algorithm
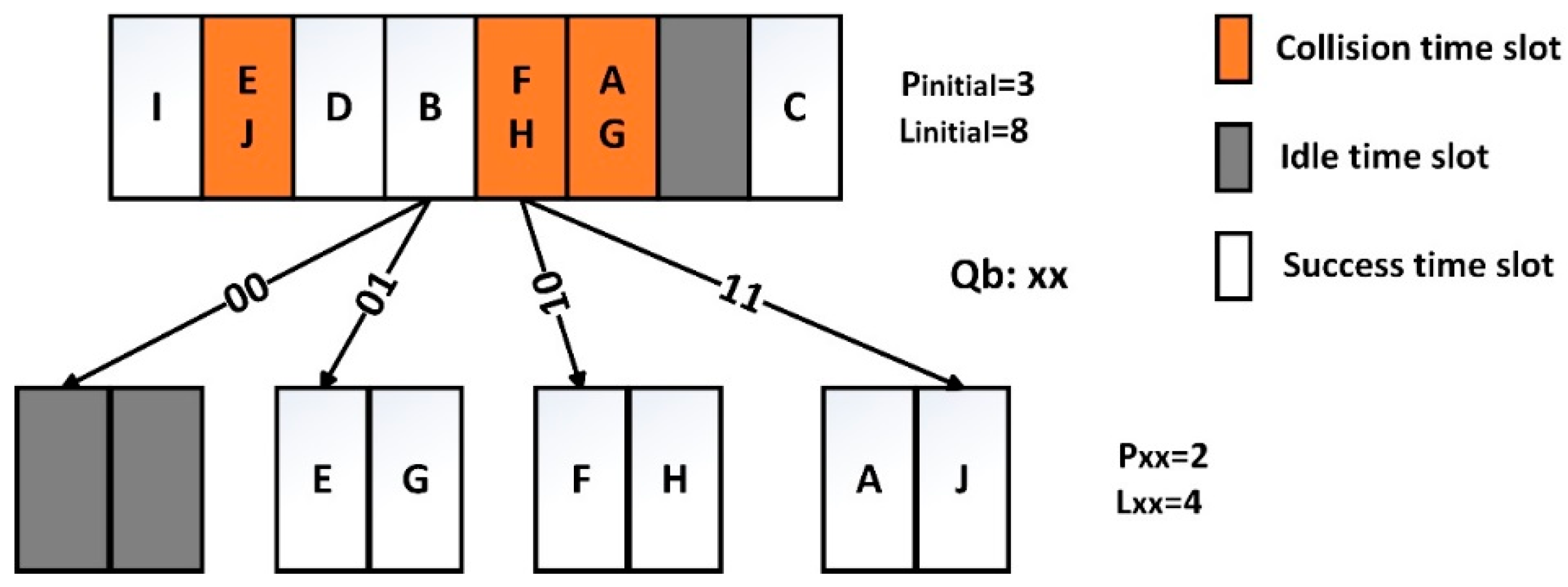
- Empty node (En): There is no tag responding to the reader’s query, resulting in a waste of the time slot.
- Success node (Sn): All response tags are successfully identified by the reader, and there are no collided tags in Sn. The success node does not have branch nodes in the query tree, and the corresponding prefix will not generate new prefixes in the queue.
- Collision node (Cn): The collision occurs as multiple tags respond to the reader’s query simultaneously. The collided tags in Cn will be recognized in its branch nodes, and the reader will attach two binary bits 00, 01, 10, 11 to the corresponding prefix to generate the longer prefixes in queue.
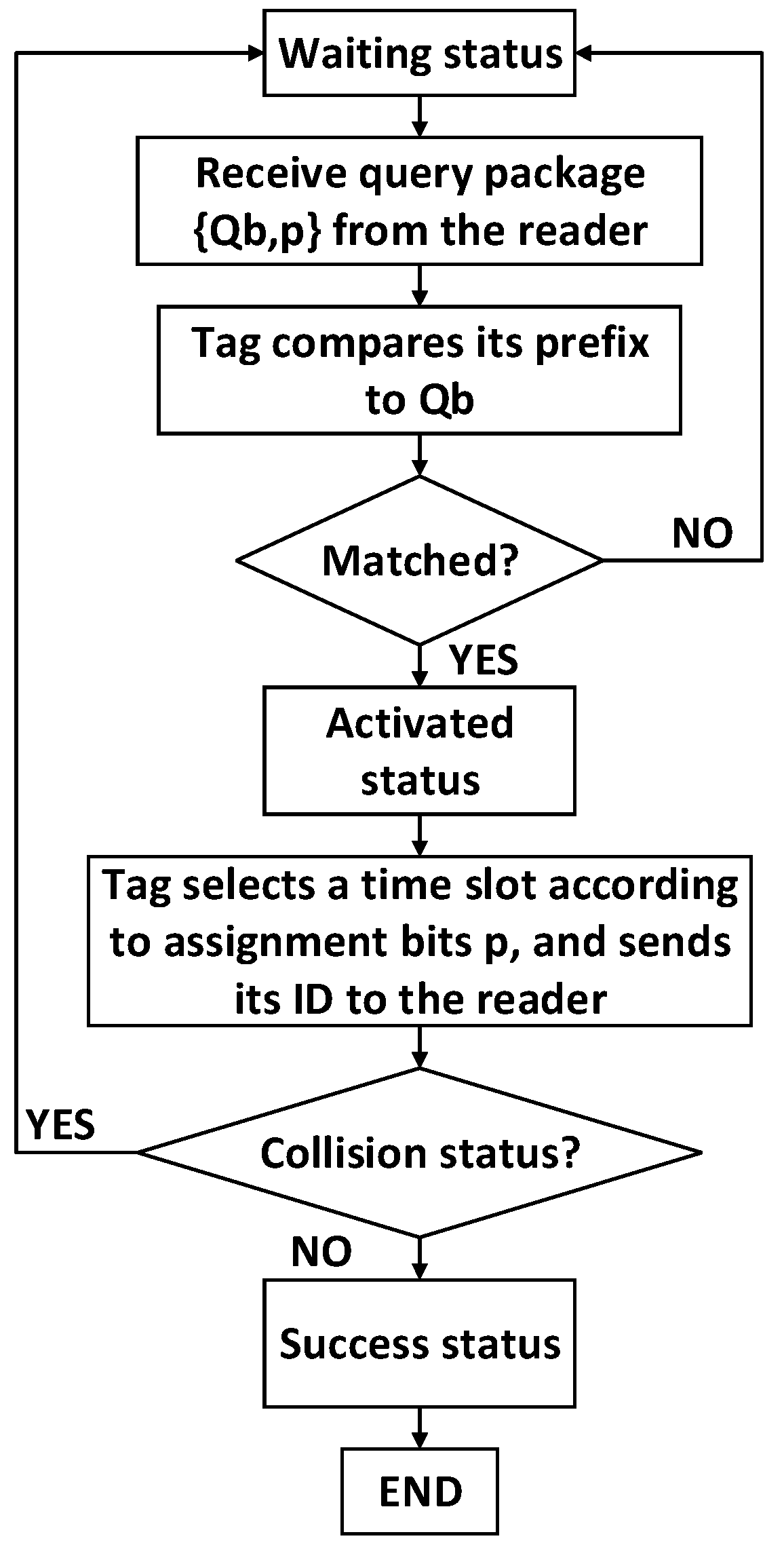
3.3. Flowchart of 4QTAP
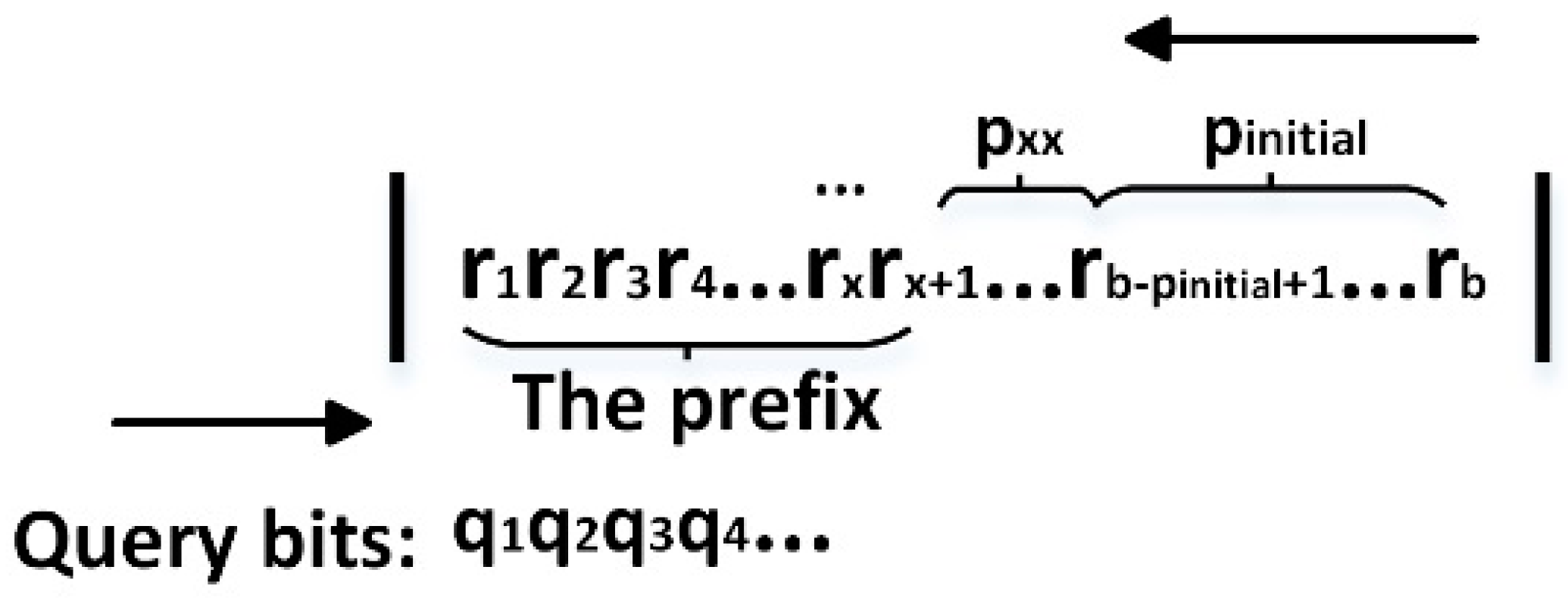
- Qb: The shorthand notation of query bits. It is a serial binary bits , where qx is 0 or 1, and 1 ≤ x ≤ b, b is the number of bits in the tag ID. Every Qb determines a leaf node in the 4-ary tree, and Qb has two statuses—in initial node of 4-ary tree, Qb is null; in leaf nodes of 4-ary tree, Qb is valid.
- p: The assignment bits of a tag; a tag can select a time slot according to p. In the initial node, it is expressed as pinitial; In leaf nodes of the 4-ary tree, it is expressed as pQb. The reader can calculate p based on Equation (11).
- Queue: The storage space in the reader, where all the Qbs are stored. If a Qb is used, it will be deleted from the Queue. If a node is Cn, four longer query bits Qb00, Qb01, Qb10, and Qb11 will be added to the Queue, and the reader will broadcast the longer Qbs to the unread tags in the subsequent process.
- Lookup table: In the process of identification, a lookup table is used to store all the assignment bits pQb.
- Waiting status: Tags wait to receive the reader’s query package {Qb, pQb}.
- Activated status: If the prefix of a tag matches the query bits (Qb), the tag is activated, and it select an assigned time slot to send its ID to the reader.
- Success status: There is only one tag responding in a time slot, the tag is identified successfully.
- Collision status: More than one tag responds in a time slot, a collision occurs, and all collided tags in this time slot are not identified by the reader.
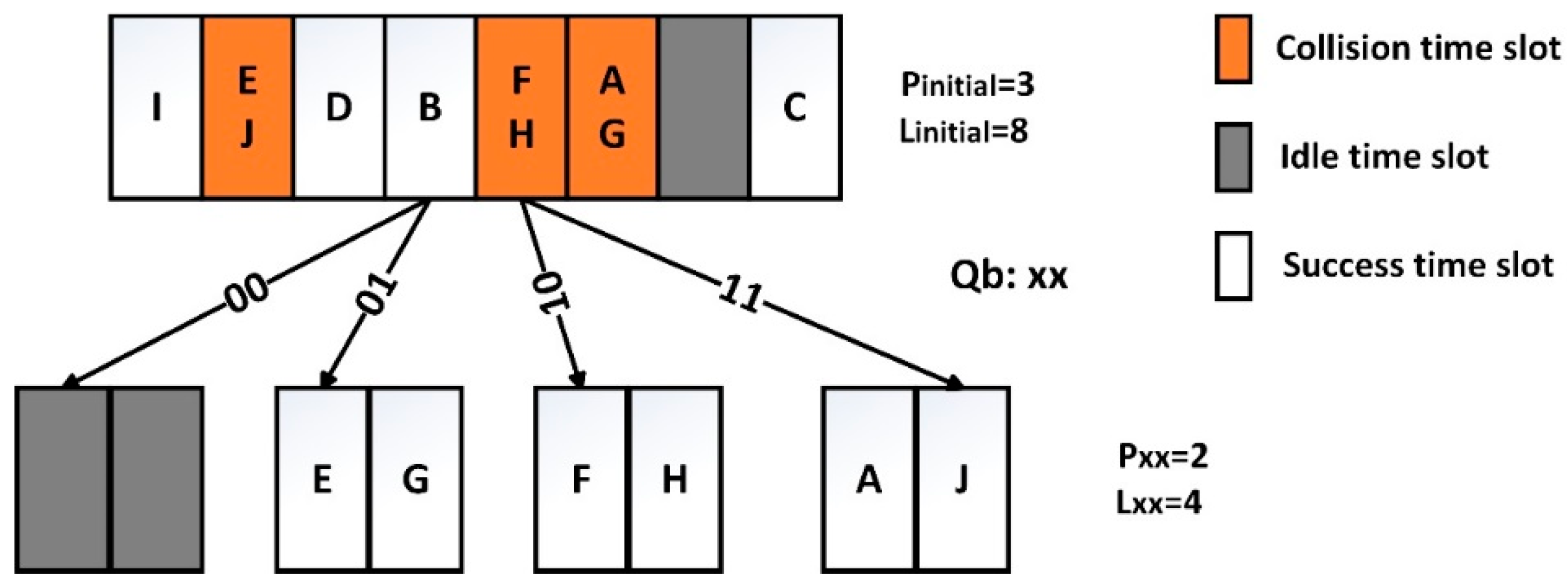
3.4. Example Analysis
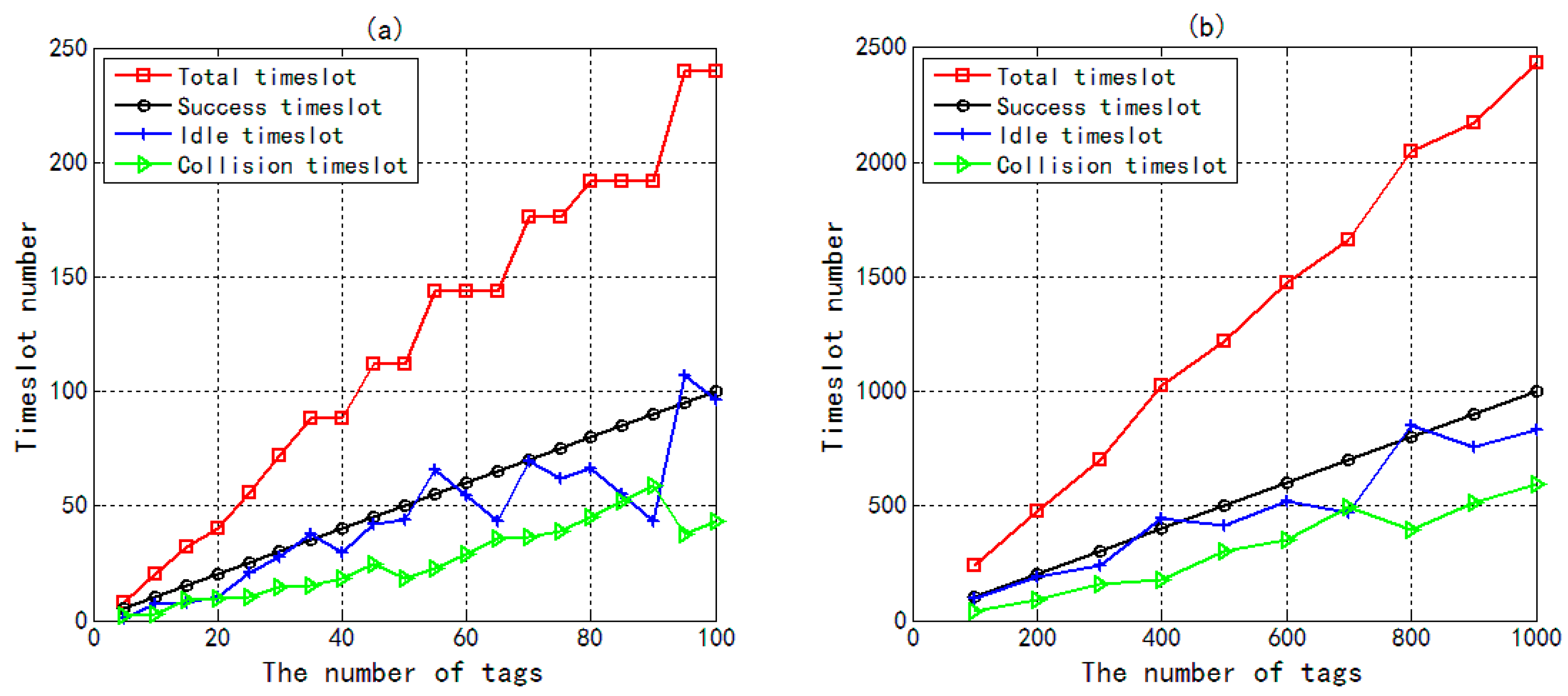
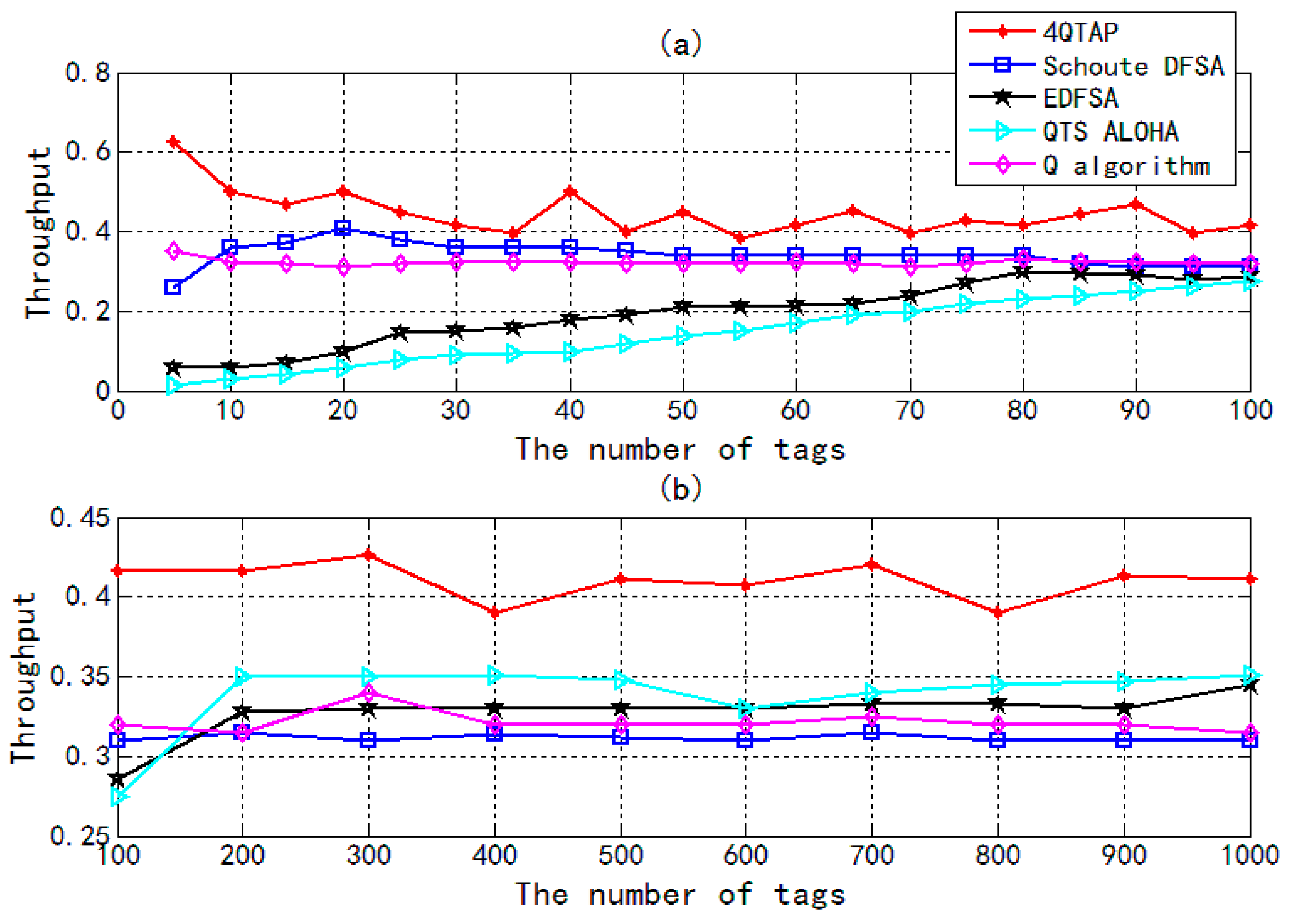
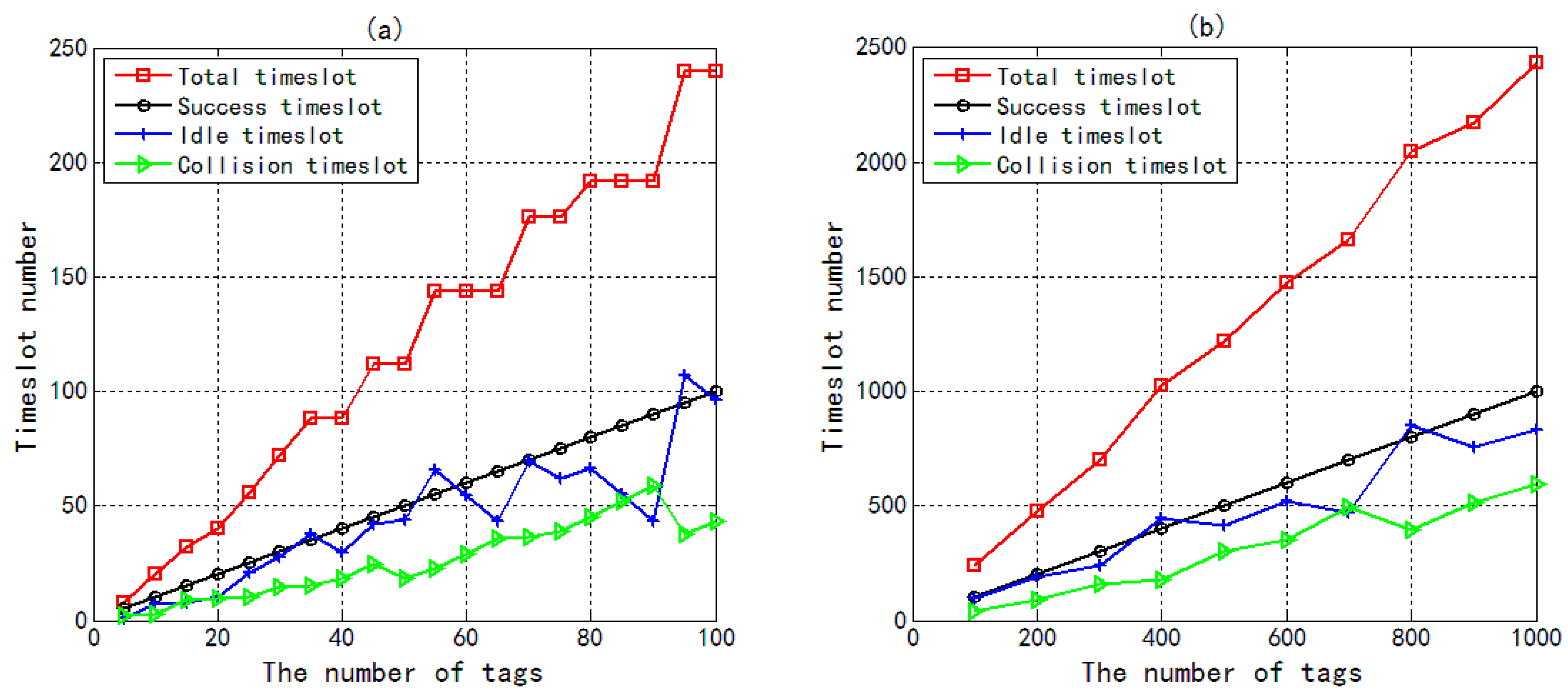
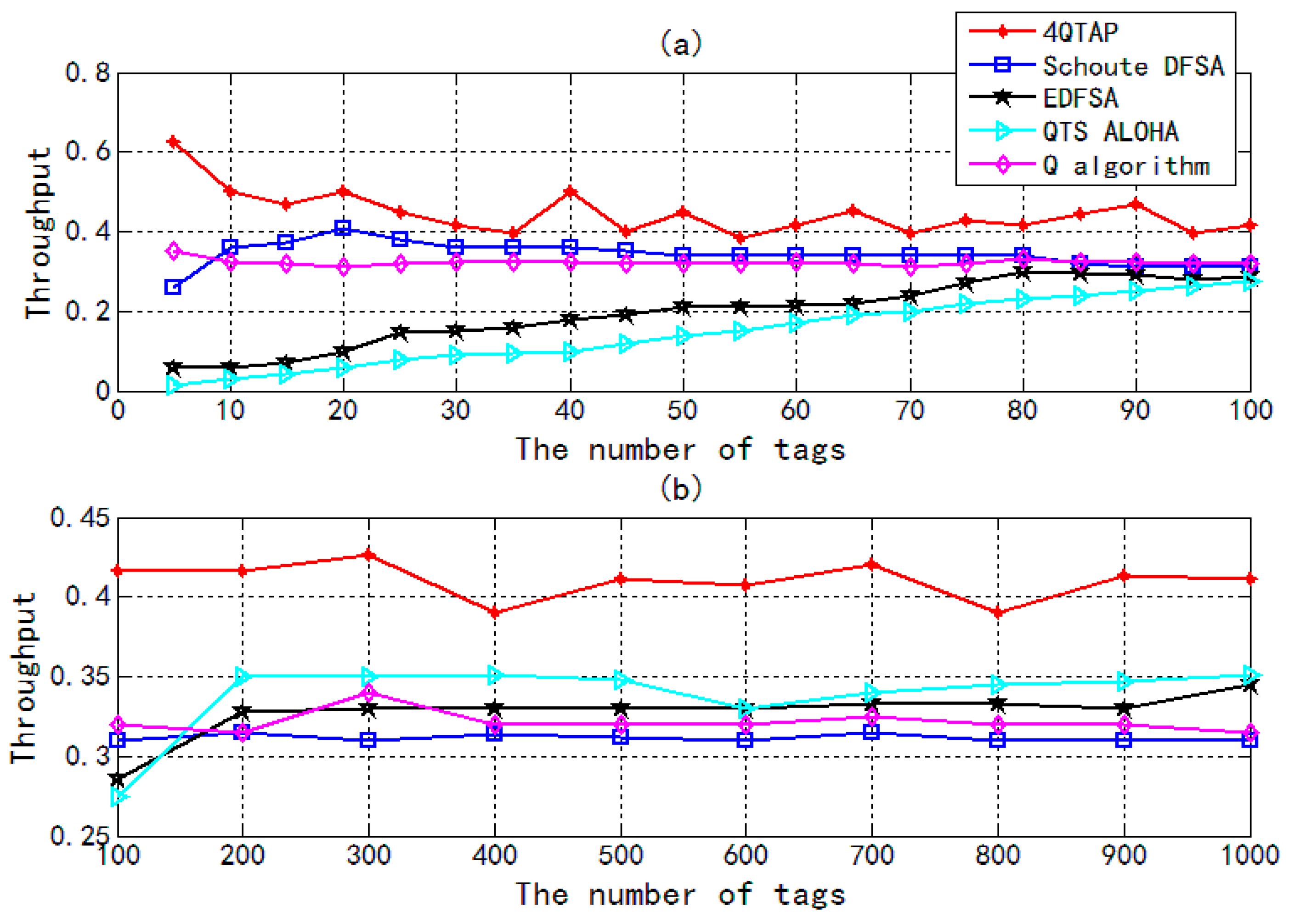
4. Simulation Results and Discussion
- (1)
- EDFSA: The algorithm estimates the number of unidentified tags first, then compares with the given maximum frame size. If the number of tags is much larger than the one that gives the optimal system efficiency, it divides the unread tags into some groups and allows only one group to respond.
- (2)
- QTS ALOHA: The length of a frame is chosen in the set (8, 16, 32, 64, 128, 256). If the size of the next identification frame is selected, the total number of time slots will equal to all frames multiplied by their size.
- (3)
- Schoute DFSA: The DFSA algorithm was presented by Schoute in 1983, and the number of collided tags is equal to 2.39 times the number of collided time slots.
- (4)
- Q algorithm: In this algorithm, the value of Q is updated slot by slot according to the status of the preceding received slot, which can determine the frame size that can maximize the tag identification efficiency.
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dagan, H.; Shapira, A.; Teman, A.; Mordakhay, A.; Jameson, S.; Pikhay, E.; Dayan, V.; Roizin, Y.; Socher, E.; Fish, A. A Low-Power Low-Cost 24 GHz RFID Tag With a C-Flash Based Embedded Memory. IEEE J. Solid-State Circuits 2014, 49, 1942–1957. [Google Scholar] [CrossRef]
- Jang, S.; Kim, S.; Tentzeris, M.M. Low-cost flexible RFID tag for on-metal applications. In Proceedings of the IEEE International Symposium on Antennas and Propagation & USNC/URSI National Radio Science Meeting, Memphis, TN, USA, 6–11 July 2014; pp. 1298–1299.
- Wang, J.; Li, H.; Yu, F. Design of Secure and Low-cost RFID Tag Baseband. In Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing, Shanghai, China, 21–25 September 2007; pp. 2066–2069.
- Preradovic, S.; Karmakar, N.C. Chipless RFID: Bar code of the future. IEEE Microw. Mag. 2010, 11, 87–97. [Google Scholar] [CrossRef]
- Want, R. An Introduction to RFID Technology. IEEE Pervasive Comput. 2006, 5, 25–33. [Google Scholar] [CrossRef]
- Deng, F.; He, Y.; Li, B.; Zuo, L.; Wu, X.; Fu, Z. A CMOS pressure sensor tag chip for passive wireless applications. Sensors 2015, 15, 6872–6884. [Google Scholar] [CrossRef] [PubMed]
- Liu, L.; Lai, S. ALOHA-Based Anti-Collision Algorithms Used in RFID System. In Proceedings of the International Conference on Wireless Communications, Networking and Mobile Computing, WiCOM 2006, Wuhan, China, 22–24 September 2006; pp. 1–4.
- Cheng, T.; Jin, L. Analysis and Simulation of RFID Anti-collision Algorithms. In Proceedings of the 9th International Conference on Advanced Communication Technology, Gangwon-Do, Korea, 12–14 February 2007; pp. 697–701.
- Schoute, F.C. Dynamic frame length ALOHA. IEEE Trans. Commun. 1983, 31, 565–568. [Google Scholar] [CrossRef]
- Lee, S.R.; Joo, S.D.; Lee, C.W. An enhanced dynamic framed slotted ALOHA algorithm for RFID tag identification. In Proceedings of the International Conference on Mobile and Ubiquitous Systems: Networking and Services, MOBIQUITOUS 2005, San Diego, CA, USA, 17–21 July 2005; pp. 166–174.
- Chen, W.T. An Accurate Tag Estimate Method for Improving the Performance of an RFID Anticollision Algorithm Based on Dynamic Frame Length ALOHA. IEEE Trans. Autom. Sci. Eng. 2009, 6, 9–15. [Google Scholar] [CrossRef]
- He, Y.; Wang, X. An ALOHA-based improved anti-collision algorithm for RFID systems. IEEE Wirel. Commun. 2013, 20, 152–158. [Google Scholar]
- Lin, C.F.; Lin, Y.S. Efficient Estimation and Collision-Group-Based Anticollision Algorithms for Dynamic Frame-Slotted ALOHA in RFID Networks. IEEE Trans. Autom. Sci. Eng. 2010, 7, 840–848. [Google Scholar] [CrossRef]
- Wu, H.; Zeng, Y.; Feng, J.; Gu, Y. Binary Tree Slotted ALOHA for Passive RFID Tag Anticollision. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 19–31. [Google Scholar] [CrossRef]
- Myung, J.; Lee, W.; Srivastava, J. Adaptive Binary Splitting for Efficient RFID Tag Anti-Collision. IEEE Commun. Lett. 2006, 10, 144–146. [Google Scholar] [CrossRef]
- Yang, C.N.; Hu, L.J.; Lai, J.B. Query Tree Algorithm for RFID Tag with Binary-Coded Decimal EPC. IEEE Commun. Lett. 2012, 16, 1616–1619. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, S.; Lee, S.; Ahn, K. Improved 4-ary Query Tree Algorithm for Anti-Collision in RFID System. In Proceedings of the 2009 International Conference on Advanced Information Networking and Applications, Bradford, UK, 26–29 May 2009; pp. 699–704.
- Shakiba, M.; Singh, M.J.; Sundararajan, E.; Zavvari, A.; Islam, M.T. Extending birthday paradox theory to estimate the number of tags in RFID systems. PLoS ONE 2014, 9, e95425. [Google Scholar] [CrossRef] [PubMed]
- Yan, X.; Yin, Z.; Xiong, Y. QTS ALOHA: A Hybrid Collision Resolution Protocol for Dense RFID Networks. In Proceedings of the 2008 IEEE International Conference on E-Business Engineering, Xi’an, China, 22–24 October 2008; pp. 557–562.
- EPCglobal Standard Specification. EPC™ Radio-Frequency Identification Protocols Class-1 Generation-2 UHF RFID Protocol for Communications at 860 MHz–960 MHz Ver. 1.0.9; EPCglobal Inc.: Lawrenceville, NJ, USA, 2005; pp. 1–94. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Round | Query (R to T) | Response (T to R) | Tag1 (0001) | Tag2 (0011) | Tag3 (1000) | Tag4 (1101) | Queue |
|---|---|---|---|---|---|---|---|
| 1 | - | Collision | 0001 | 0011 | 1000 | 1101 | 00,01,10,11 |
| 2 | 00 | Collision | 0010 | 0011 | - | - | 01,10,11,0000,0001,0010,0011 |
| 3 | 01 | Empty | - | - | - | - | 10,11,0000,0001,0010,0011 |
| 4 | 10 | Success | - | - | 1000 | - | 11,0000,0001,0010,0011 |
| 5 | 11 | Success | - | - | - | 1101 | 0000,0001,0010,0011 |
| 6 | 0000 | Empty | - | - | - | - | 0001,0010,0011 |
| 7 | 0001 | Success | 0001 | - | - | - | 0010,0011 |
| 8 | 0010 | Empty | - | - | - | - | 0011 |
| 9 | 0011 | Success | - | 0011 | - | - | Empty |
© 2016 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, Z.; Deng, F.; Wu, X. Design of a Quaternary Query Tree ALOHA Protocol Based on Optimal Tag Estimation Method. Information 2017, 8, 5. https://doi.org/10.3390/info8010005
Fu Z, Deng F, Wu X. Design of a Quaternary Query Tree ALOHA Protocol Based on Optimal Tag Estimation Method. Information. 2017; 8(1):5. https://doi.org/10.3390/info8010005
Chicago/Turabian StyleFu, Zhihui, Fangming Deng, and Xiang Wu. 2017. "Design of a Quaternary Query Tree ALOHA Protocol Based on Optimal Tag Estimation Method" Information 8, no. 1: 5. https://doi.org/10.3390/info8010005