
Identifying High Quality Document–Summary Pairs through Text Matching


Abstract
:1. Introduction
2. Related Works
2.1. Automatic Text Summarization
2.2. Text Matching
3. Corpus Construction and Analysis
4. Approach
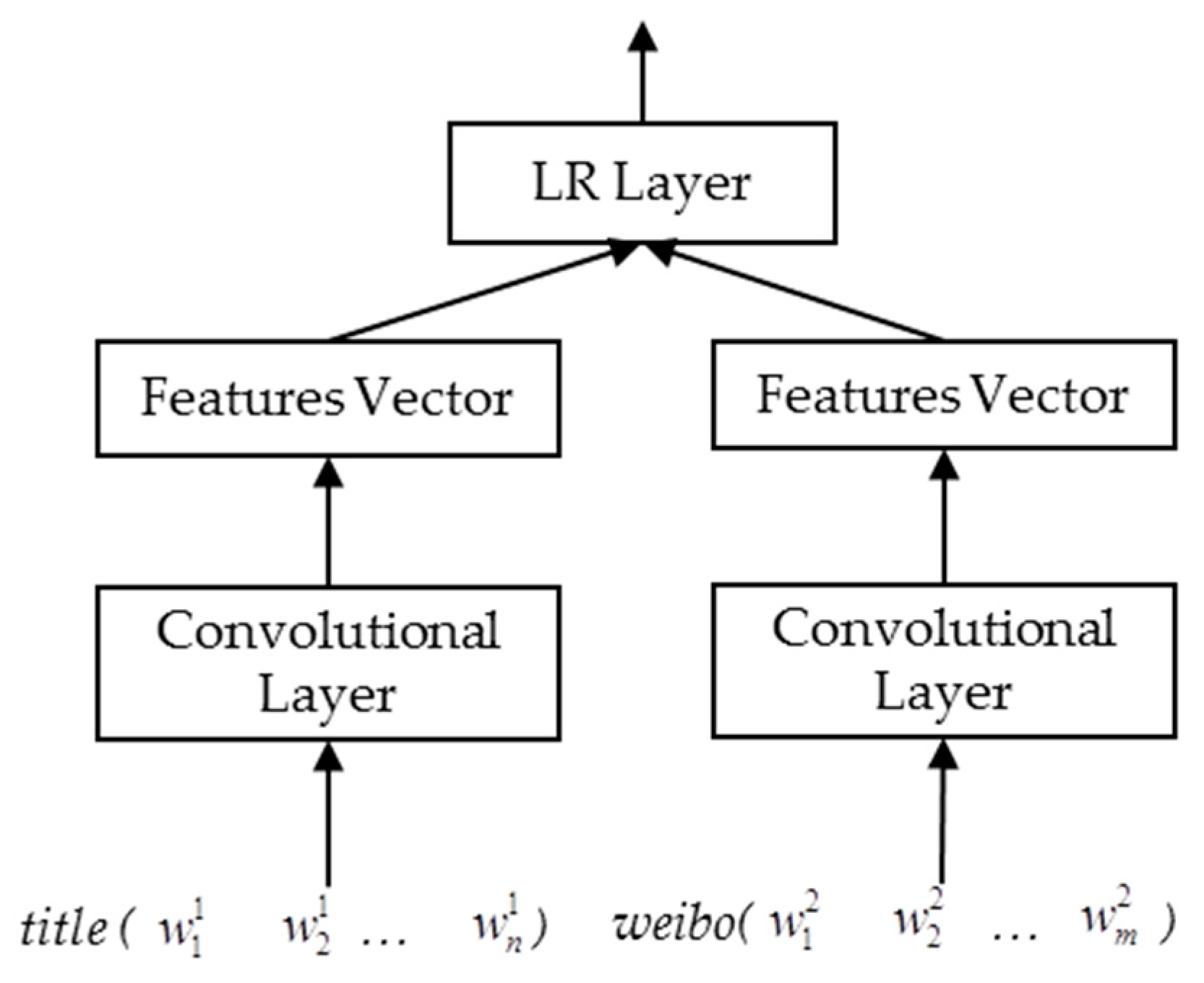
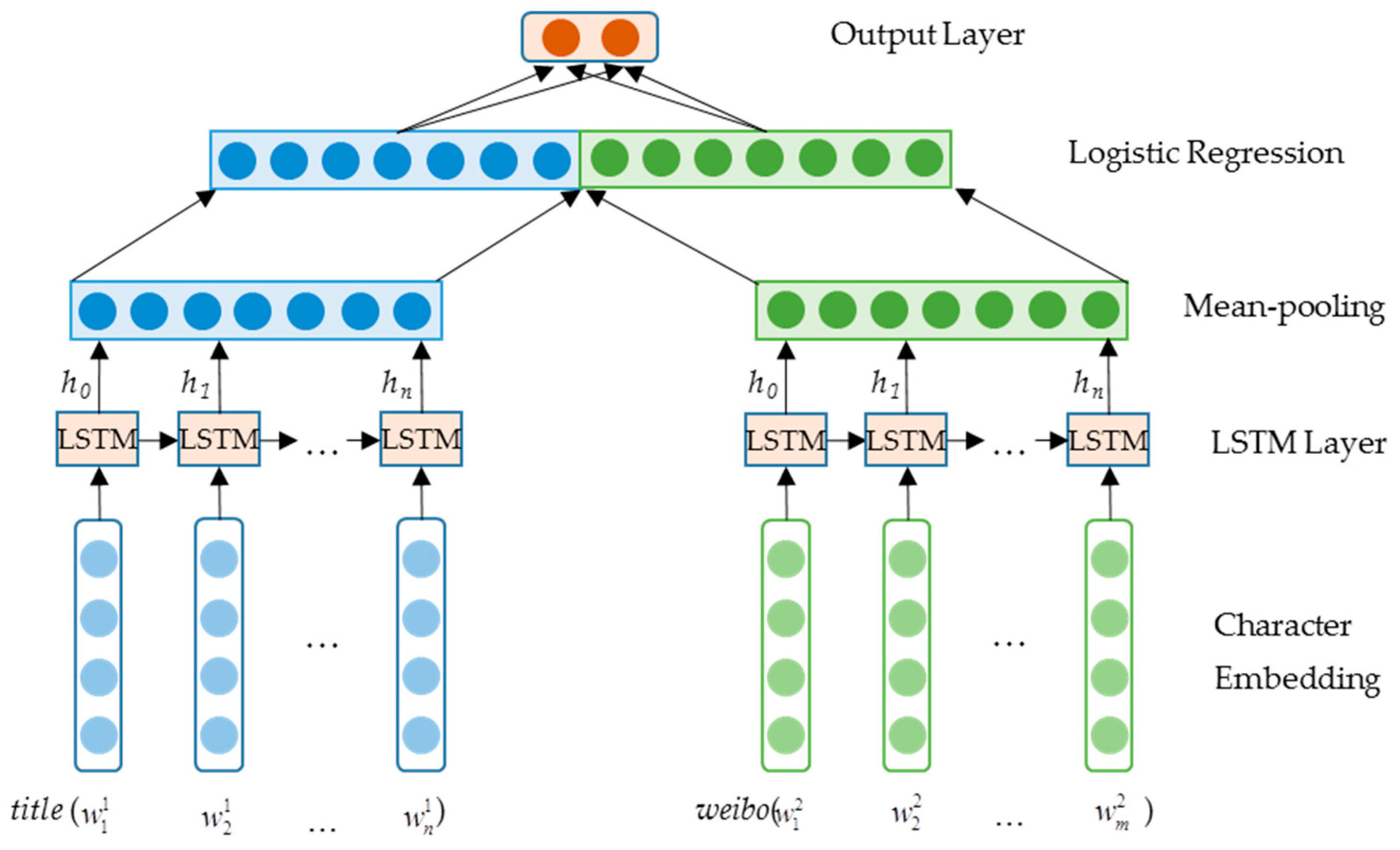
4.1. Overview
4.2. Baselines
4.2.1. Supporting Vector Machines (SVM)
4.2.2. Latent Semantic Indexing (LSI)
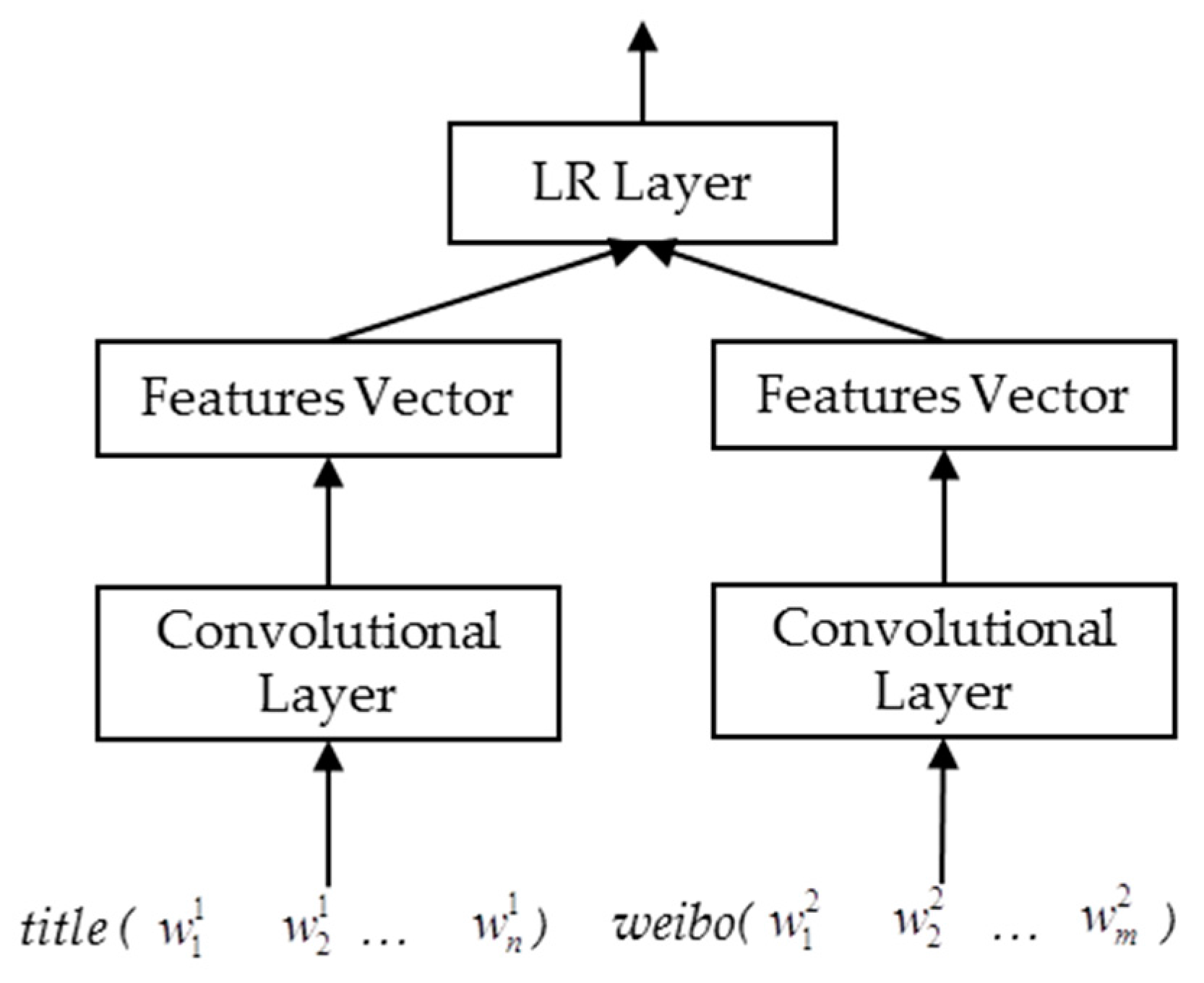
4.2.3. Convolutional Neural Networks (CNN)
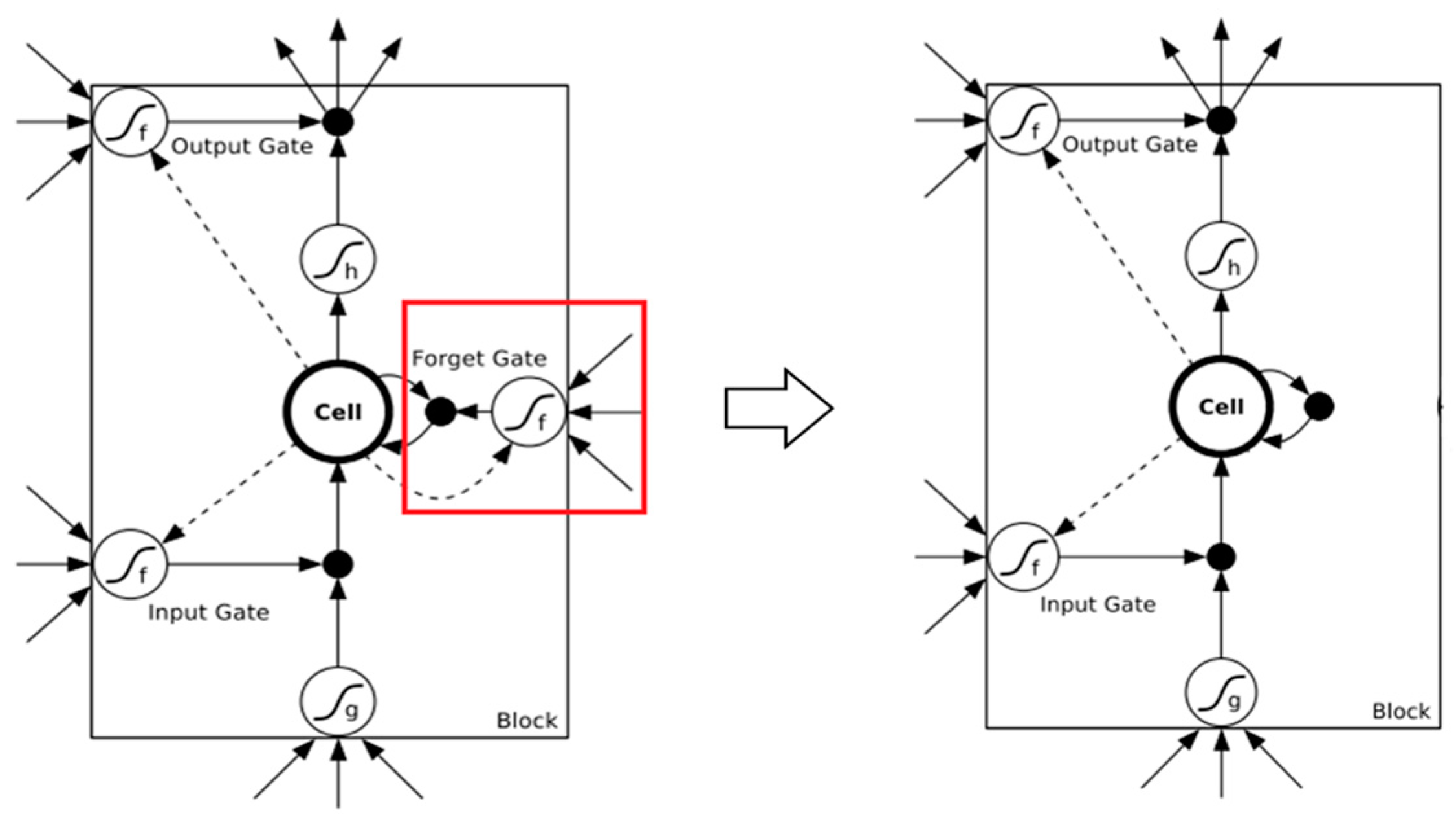
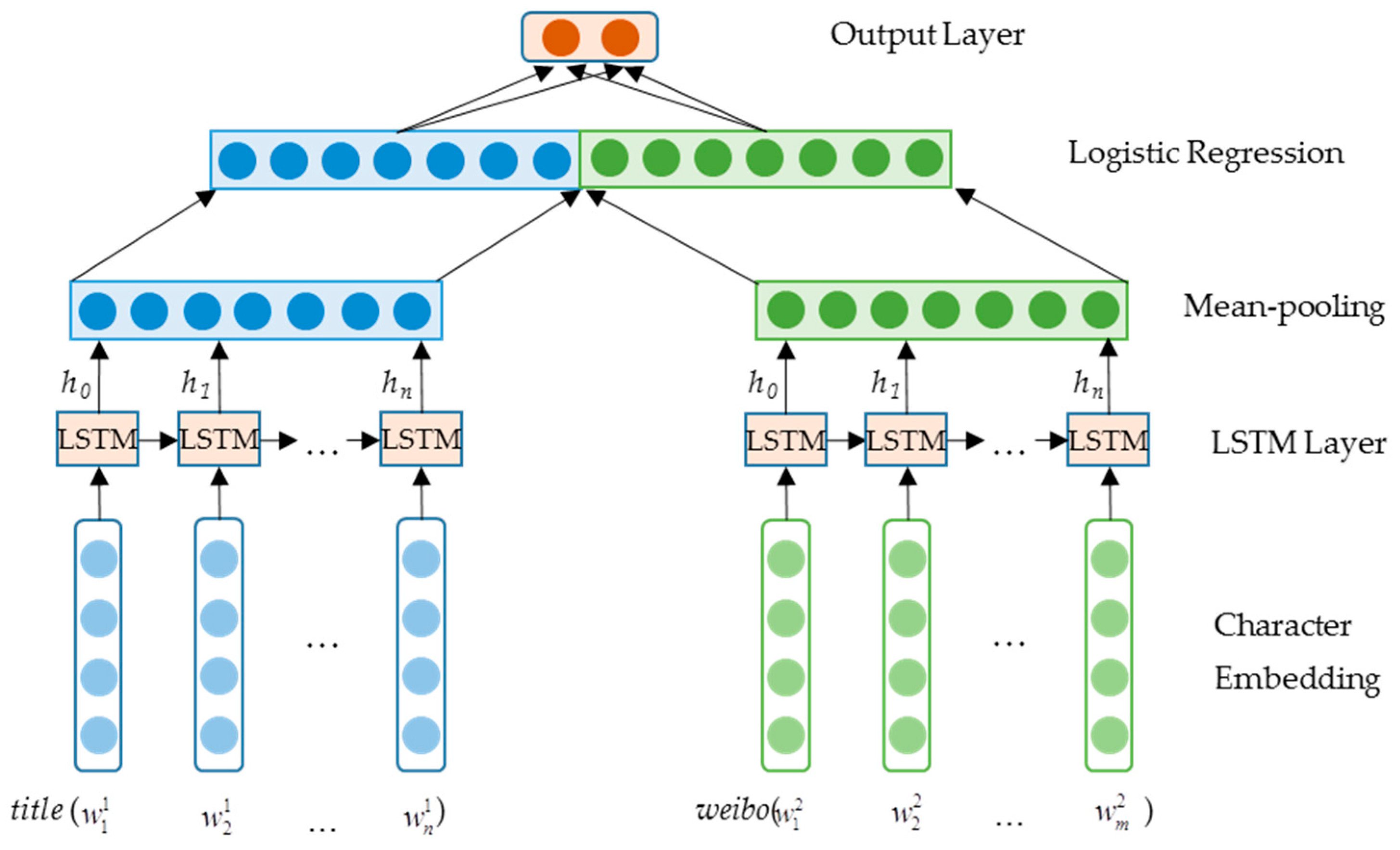
4.3. Long Short-Term Memory (LSTM)
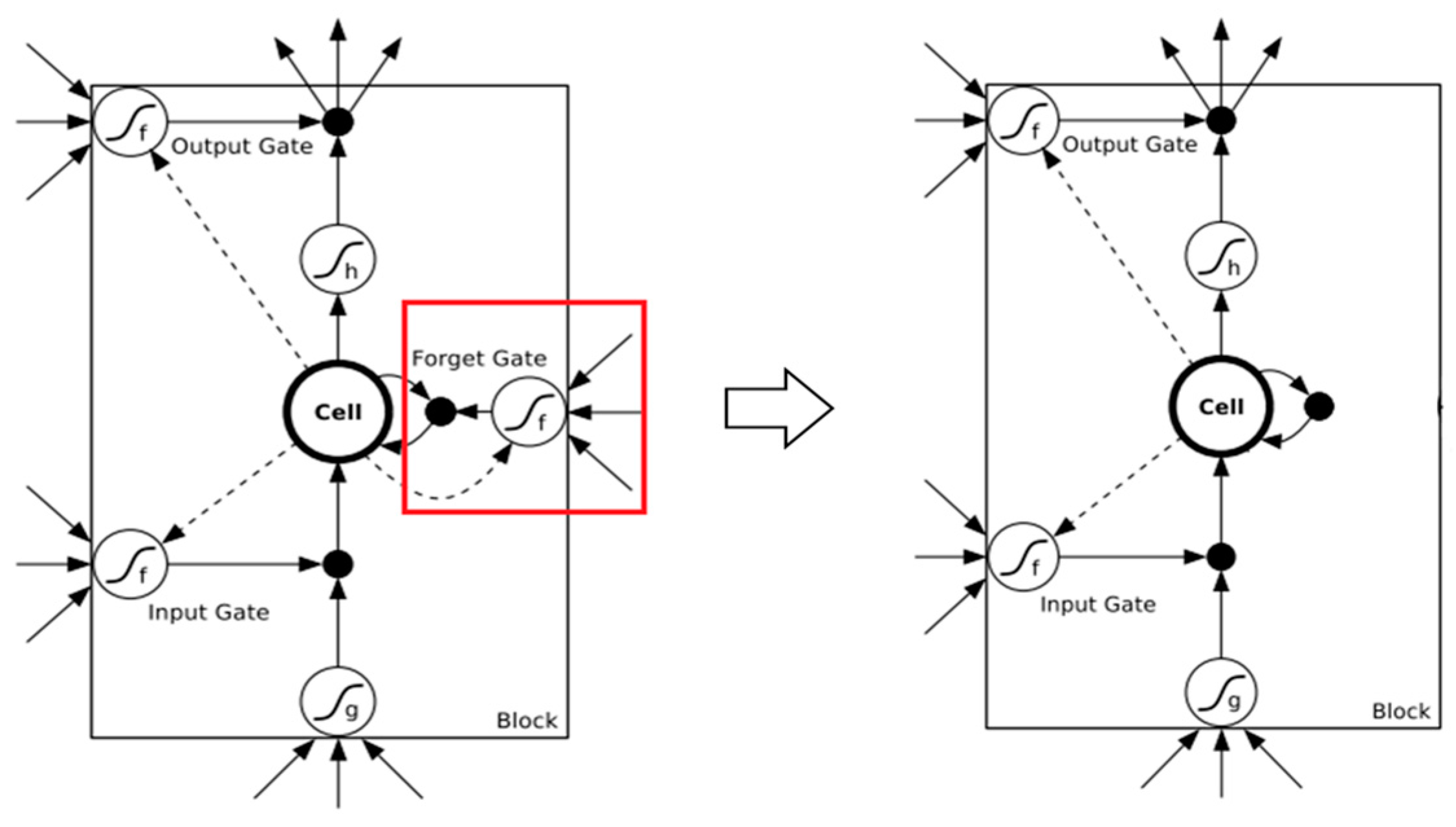
4.4. Improved LSTM
5. Experiments
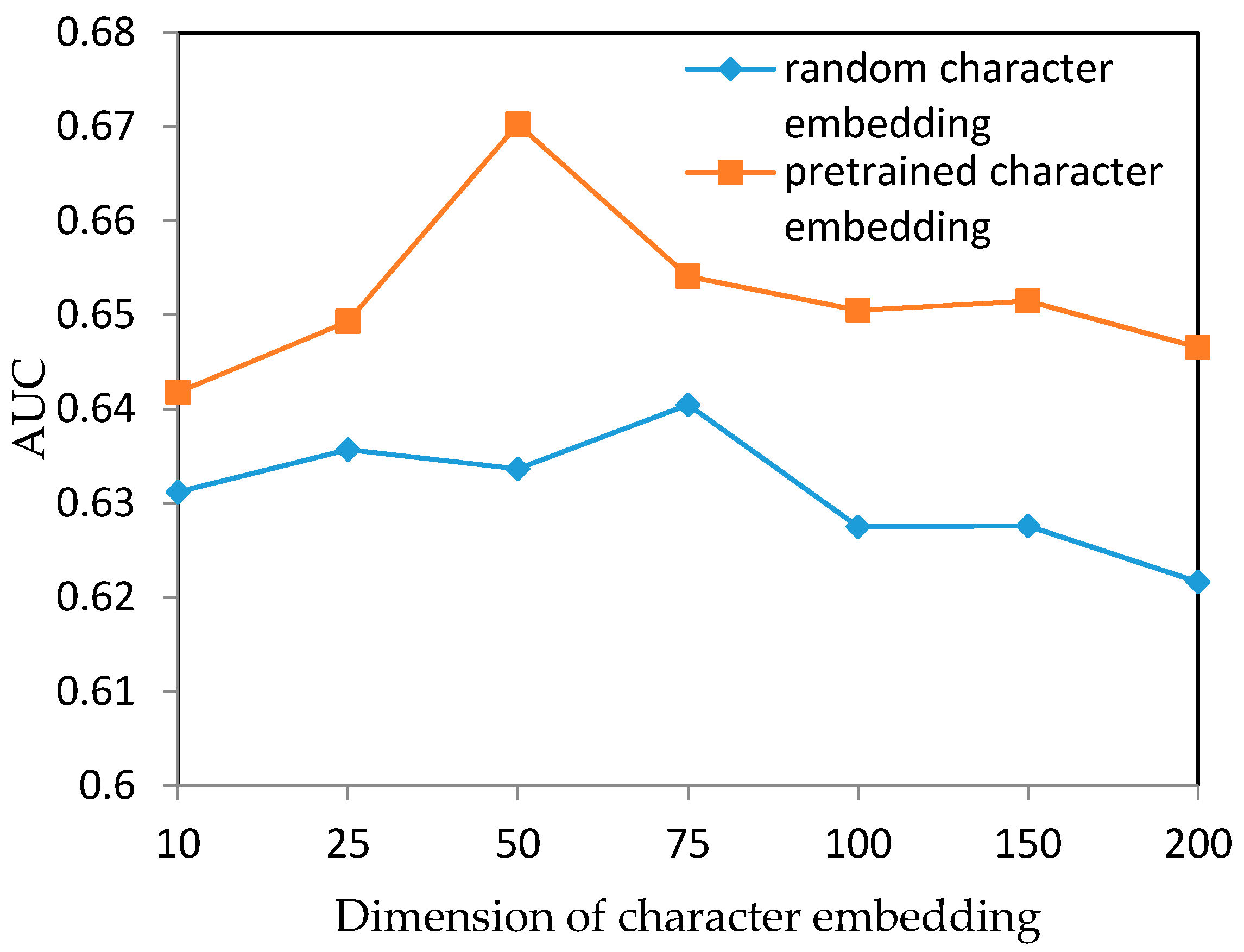
5.1. Experimental Settings
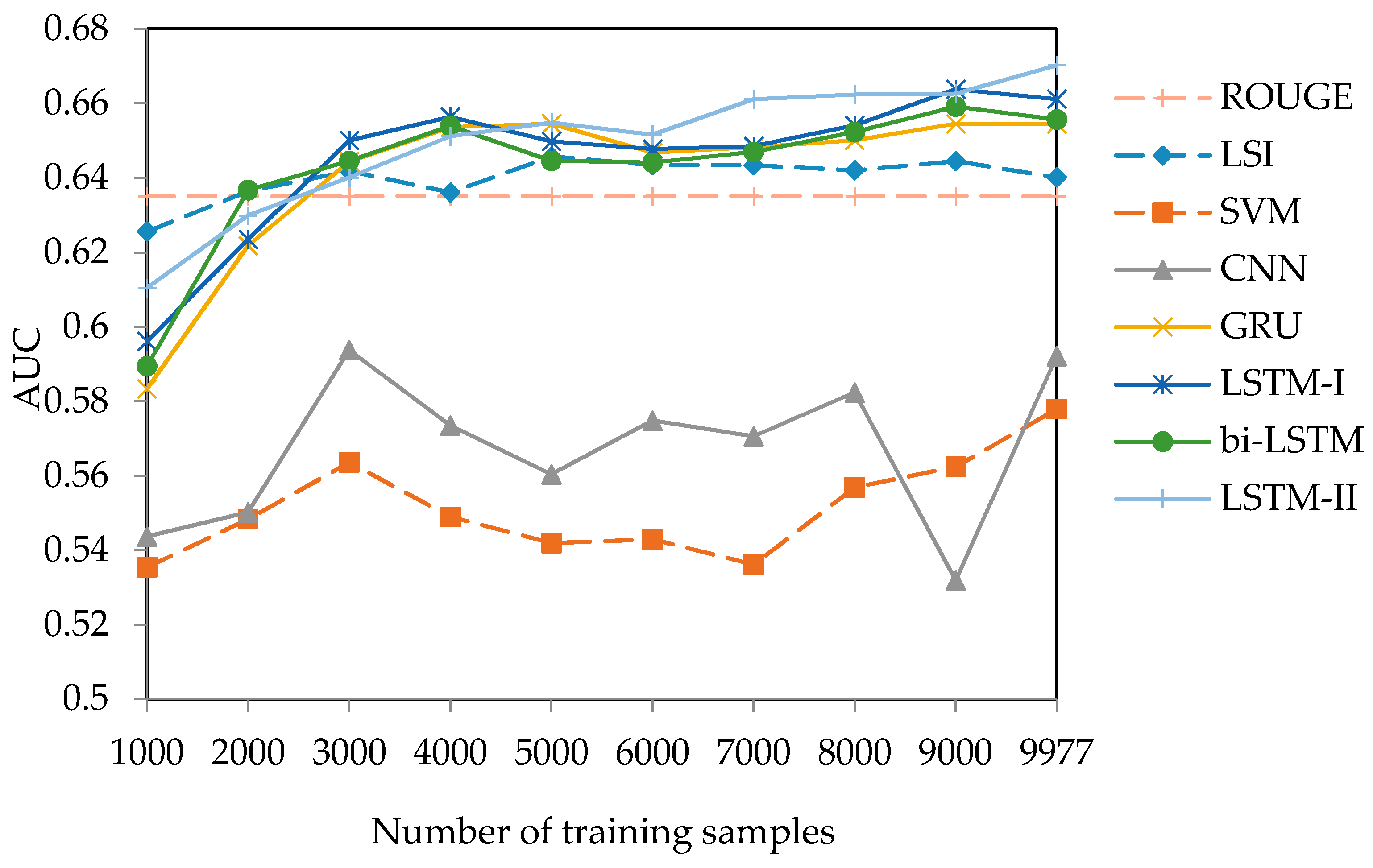
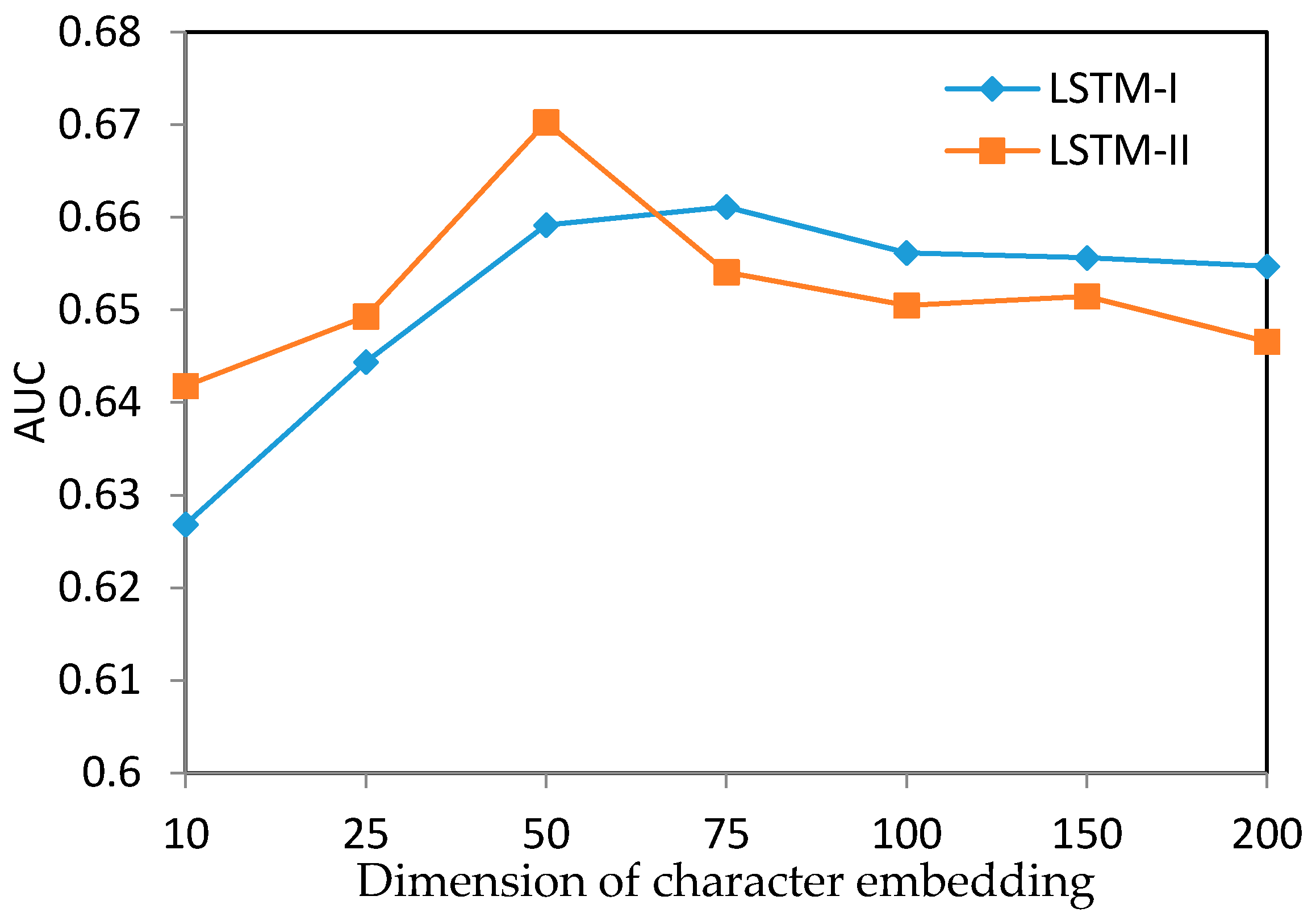
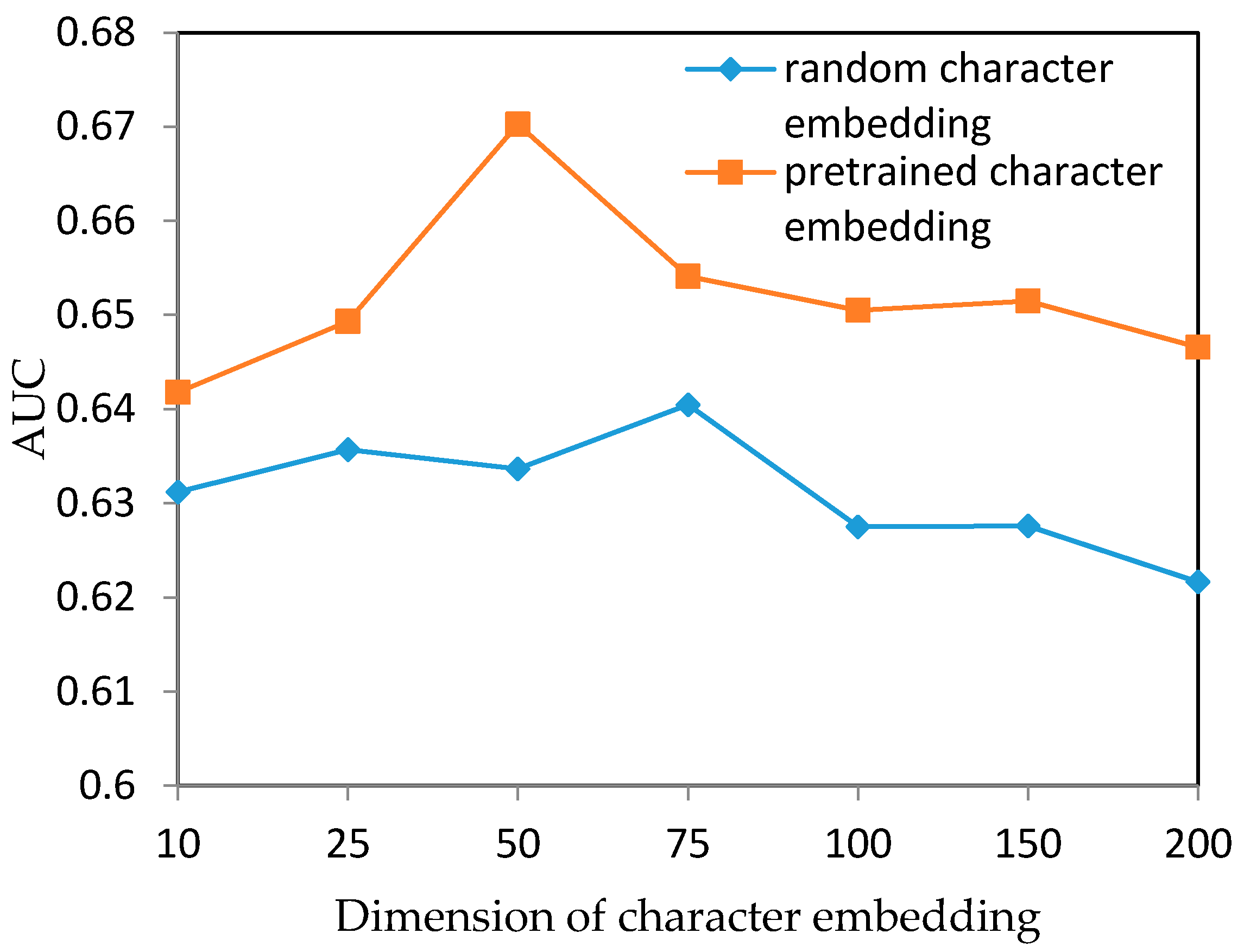
5.2. Experiment Results
5.3. Discussion
5.4. Case Study
5.5. Text Summarization
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Hovy, E.; Lin, C.Y. Automated Text Summarization and the SUMMARIST System. In Proceedings of the Workshop on TIPSTER’98, Baltimore, MD, USA, 13–15 October 1998; pp. 197–214. [Google Scholar]
- Gambhir, M.; Gupta, V. Recent automatic text summarization techniques: A survey. Artif. Intell. Rev. 2017, 47, 1–66. [Google Scholar] [CrossRef]
- Bhatia, N.; Jaiswal, A. Trends in extractive and abstractive techniques in text summarization. Int. J. Comput. Appl. 2015, 117, 21–24. [Google Scholar] [CrossRef]
- Hu, B.; Chen, Q.; Zhu, F. LCSTS: A Large Scale Chinese Short Text Summarization Dataset. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1967–1972. [Google Scholar]
- Hu, B.; Lu, Z.; Li, H.; Chen, Q. Convolutional Neural Network Architectures for Matching Natural Language Sentences. arXiv, 2015; arXiv:1503.03244. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv, 2014; arXiv:1409.0473. [Google Scholar]
- Yu, L.; Hermann, K.M.; Blunsom, P.; Pulman, S. Deep Learning for Answer Sentence Selection. arXiv, 2014; arXiv:1412.1632. [Google Scholar]
- Zhou, X.; Hu, B.; Chen, Q.; Tang, B.; Wang, X. Answer Sequence Learning with Neural Networks for Answer Selection in Community Question Answering. arXiv, 2015; arXiv:1506.06490. [Google Scholar]
- Zhou, X.; Hu, B.; Chen, Q.; Wang, X. An Auto-Encoder for Learning Conversation Representation Using LSTM. In Proceedings of the International Conference on Neural Information Processing, Istanbul, Turkey, 9–12 November 2015; pp. 310–317. [Google Scholar]
- Liu, P.; Qiu, X.; Chen, J.; Huang, X. Deep Fusion LSTMs for Text Semantic Matching. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1034–1043. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv, 2014; arXiv:1412.3555. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1422–1432. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Das, D.; Martins, A.F. A survey on automatic text summarization. Lit. Surv. Lang. Stat. II Course CMU 2007, 4, 192–195. [Google Scholar]
- Saranyamol, C.; Sindhu, L. A survey on automatic text summarization. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 7889–7893. [Google Scholar]
- Schluter, N.; Søgaard, A. Unsupervised extractive summarization via coverage maximization with syntactic and semantic concepts. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 840–844. [Google Scholar]
- Cao, Z.; Wei, F.; Li, S.; Li, W.; Zhou, M.; Wang, H. Learning Summary Prior Representation for Extractive Summarization. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language, Beijing, China, 26–31 July 2015; pp. 829–833. [Google Scholar]
- Yogatama, D.; Liu, F.; Smith, N.A. Extractive Summarization by Maximizing Semantic Volume. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1961–1966. [Google Scholar]
- Ganesan, K.; Zhai, C.; Han, J. Opinosis: A Graph-based Approach to Abstractive Summarization of Highly Redundant Opinions. In Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, China, 23–27 August 2010; pp. 340–348. [Google Scholar]
- Li, W. Abstractive Multi-document Summarization with Semantic Information Extraction. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1908–1913. [Google Scholar]
- Nallapati, R.; Zhou, B.; Gulcehre, C.; Xiang, B. Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond. arXiv, 2016; arXiv:1602.06023. [Google Scholar]
- Fuentes, M.; Alfonseca, E.; Rodríguez, H. Support vector machines for query-focused summarization trained and evaluated on pyramid data. In Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions; Association for Computational Linguistics, Prague, Czech Republic, 25–27 June 2007; pp. 57–60. [Google Scholar]
- Wong, K.F.; Wu, M.; Li, W. Extractive summarization using supervised and semi-supervised learning. In Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1; Association for Computational Linguistics, Manchester, UK, 18–22 August 2008; pp. 985–992. [Google Scholar]
- Erkan, G.; Radev, D.R. Lexrank: Graph-based lexical centrality as salience in text summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar]
- Mihalcea, R. Graph-based Ranking Algorithms for Sentence Extraction, Applied to Text Summarization. In Proceedings of the ACL 2004 on Interactive Poster and Demonstration Sessions, ACLdemo’04, Barcelona, Spain, 21–26 July 2004. [Google Scholar]
- Hatzivassiloglou, V.; Klavans, J.L.; Holcombe, M.L.; Barzilay, R.; Kan, M.Y.; McKeown, K.R. Simfinder: A flexible clustering tool for summarization. In Proceedings of the NAACL Workshop on Automatic Summarization, Pittsburgh, PA, USA, 2–7 June 2001. [Google Scholar]
- Llewellyn, C.; Grover, C.; Oberlander, J. Improving Topic Model Clustering of Newspaper Comments for Summarisation. In Proceedings of the ACL 2016 Student Research Workshop, Berlin, Germany, 7–12 August 2016; pp. 43–50. [Google Scholar]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies; IEEE Press: Hoboken, NJ, USA, 2001. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. arXiv, 2014; arXiv:1408.5882. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A Neural Attention Model for Abstractive Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Cheng, J.; Lapata, M. Neural Summarization by Extracting Sentences and Words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 484–494. [Google Scholar]
- Over, P.; Dang, H.; Harman, D. DUC in context. Inf. Process. Manag. 2007, 43, 1506–1520. [Google Scholar] [CrossRef]
- Owczarzak, K.; Dang, H.T. Overview of the TAC 2011 summarization track: Guided task and AESOP task. In Proceedings of the Text Analysis Conference (TAC 2011), Gaithersburg, MD, USA, 14–15 November 2011. [Google Scholar]
- Napoles, C.; Gormley, M.; Van Durme, B. Annotated Gigaword. In Proceedings of the Joint Workshop on Automatic Knowledge Base Construction and Web-Scale Knowledge Extraction, Montreal, Canada, 7–8 June 2012; pp. 95–100. [Google Scholar]
- Nakov, P.; Màrquez, L.; Moschitti, A.; Magdy, W.; Mubarak, H.; Freihat, A.A.; Glass, J.; Randeree, B. SemEval-2016 Task 3: Community Question Answering. In Proceedings of the 10th International Workshop on Semantic Evaluation, San Diego, CA, USA, 16–17 June 2016. [Google Scholar]
- Salton, G.; Wong, A.; Yang, C.-S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Tamaki, H.; Raghavan, P.; Vempala, S. Latent Semantic Indexing: A Probabilistic Analysis. In Proceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, New York, NY, USA, 1–4 June 1998; pp. 159–168. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Golub, G.H.; Reinsch, C. Singular value decomposition and least squares solutions. Numer. Math. 1970, 14, 403–420. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A. Deep Convolutional Neural Network Textual Features and Multiple Kernel Learning for Utterance-level Multimodal Sentiment Analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2539–2544. [Google Scholar]
- Poria, S.; Cambria, E.; Gelbukh, A. Aspect extraction for opinion mining with a deep convolutional neural network. Knowl. Based Syst. 2016, 108, 42–49. [Google Scholar] [CrossRef]
- Wang, B.; Liu, K.; Zhao, J. Inner Attention based Recurrent Neural Networks for Answer Selection. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1288–1297. [Google Scholar]
- Tan, M.; dos Santos, C.; Xiang, B.; Zhou, B. Improved Representation Learning for Question Answer Matching. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 464–473. [Google Scholar]
- Nie, Y.; An, C.; Huang, J.; Yan, Z.; Han, Y. A Bidirectional LSTM Model for Question Title and Body Analysis in Question Answering. In Proceedings of the 2016 IEEE First International Conference on Data Science in Cyberspace, Changsha, China, 13–16 June 2016; pp. 307–311. [Google Scholar]
- Zhang, Z.; Yao, D.; Pang, Y.; Lu, X. Chinese Textual Entailment Recognition Enhanced with Word Embedding; Springer International Publishing: Cham, Switzerland, 2015; pp. 89–100. [Google Scholar]
- Lyu, C.; Lu, Y.; Ji, D.; Chen, B. Deep Learning for Textual Entailment Recognition. In Proceedings of the 2015 IEEE 27th International Conference on Tools with Artificial Intelligence, Salerno, Italia, 9–11 November 2015; pp. 154–161. [Google Scholar]
- Rocktäschel, T.; Grefenstette, E.; Hermann, K.M.; Kočiský, T.; Blunsom, P. Reasoning about Entailment with Neural Attention. arXiv, 2015; arXiv:1509.06664. [Google Scholar]
- Vapnik, V.; Guyon, I.; Hastie, T. Support vector machines. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Landauer, T.K.; Foltz, P.W.; Laham, D. An introduction to latent semantic analysis. Discourse Process. 1998, 25, 259–284. [Google Scholar] [CrossRef]
- Dahl, G.E.; Sainath, T.N.; Hinton, G.E. Improving deep neural networks for LVCSR using rectified linear units and dropout. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, Canada, 26–31 May 2013; pp. 8609–8613. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, ELRA, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Theano Development Team. Theano: A Python framework for fast computation of mathematical expressions. arXiv, 2016; arXiv:160502688T.
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv, 2012; arXiv:1212.5701. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Summary | Document |
|---|---|
| The CVs from postgraduate students were rejected. The company said: undergraduate students were enough. | On the 6th, the job fair for graduate students majoring in science and technology was held in Jiangsu Province. During the fair, the CV from a postgraduate student named Xie was refused because the employer said an undergraduate student was enough. Many companies also declared that they would only need undergraduates. Some postgraduates exclaimed that they found that it was more difficult to be employed, despite having learned three years more. Do you agree? |
| Summary | Document |
|---|---|
| The accumulated number of organ donation in our country reached 5384 | Until 9th November, the accumulated number of organ donation in our country reached 5384 and the total number of donated organs reached 14,721. However, currently there are only 169 hospitals around China that has at least one qualifications for organ transplantation, with only over 20 surgeons having the ability to do heart and lung transplantations. As China has stepped into the international organ transplant family, our top priority is to cultivate transplant medicine talents. |
| Summary | Document |
|---|---|
| Are you a middle-class person? | The family finance investigation by Southwestern University of Finance and Economics in 2015 showed: In 2015, the average property for a Chinese family was 919 thousand RMB (China yuan), 69.2% of which were house properties. An adult person from a Chinese middle-class family has an average of 127 thousand dollars (about 810 thousand RMB), which accounts for 21.4% in the adult population. |
| Summary | Document |
|---|---|
| The schedule of “Die Hard 5” was determined, being premiered on March 14 nationwide | “Die Hard 5” officially announced as screening in the mainland cinema on March 14. This series have gone through 25 glorious years, and won the love of the world fans. The film has taken more than $200 million in overseas box offices in just two weeks. Bruce Willis, aged 58 years old, will powerfully return, will fight terrorists once again and help his son this time. |
| Title | Document |
|---|---|
| Those superior “foreign hospitals” have difficulty in landing. | The policy for hospitals of foreign and individual properties has been attempted for over a year, but there is only one newly established hospital. Constrained by the medical system and market concept, most of them are acclimatized currently. The primary affairs of these hospitals are still international-transfer treatments and medical training cooperation for senior markets, with the landing in most areas still needing time. |
| Dataset | 1′ | 2′ | 3′ | 1′ + 2′ + 3′ | 4′ | 5′ | 4′ + 5′ |
|---|---|---|---|---|---|---|---|
| Train | 877 | 976 | 1875 | 3728 | 2932 | 3317 | 6249 |
| Develop | 64 | 63 | 144 | 271 | 197 | 211 | 408 |
| Test | 178 | 216 | 227 | 521 | 301 | 197 | 498 |
| Document Length | Document Count | Proportion (%) |
|---|---|---|
| 0~19 | 4 | 0.04 |
| 20~29 | 384 | 3.85 |
| 30~39 | 3718 | 32.27 |
| 40~49 | 5192 | 52.04 |
| 50~80 | 679 | 6.81 |
| total | 9977 | 100 |
| Method | Training Set (AUC) | Test Set (AUC) |
|---|---|---|
| ROUGE-based | 0.6221 | 0.6351 |
| LSI | 0.6160 | 0.6413 |
| SVM | 0.5304 | 0.5777 |
| CNN | 0.5217 | 0.6054 |
| GRU | 0.6186 | 0.6545 |
| LSTM-I | 0.6202 | 0.6611 |
| bi-LSTM | 0.6223 | 0.6557 |
| LSTM-II | 0.6318 | 0.6703 |
| Data Set | LSTM-I (AUC) | LSTM-II (AUC) |
|---|---|---|
| Five-Class | 0.6587 | 0.6640 |
| Two-Class | 0.6611 | 0.6702 |
| Summary | Document |
|---|---|
| Hundreds of primary school students participated in the “little TOEFL” examination, even top students in English claimed that the problems were hard. | At 9 a.m. on the 23th, the ETSTOEFL Junior examination, which is also known as the “little TOEFL” began in Jiangcheng City and it was the first examination. It attracted participants from hundreds of students from primary schools. The “little TOEFL” needs comprehensive abilities of listening, speaking, reading and writing as well as focusing more on practice. Many top students in English claimed that the examination was hard. |
| Model | Training Pairs Number | R-1 | R-2 | R-L |
|---|---|---|---|---|
| RNN-context-A [4] | 2,400,591 | 0.299 | 0.174 | 0.272 |
| RNN-context-B | 1,920,472 | 0.312 | 0.195 | 0.294 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, Y.; Xiang, Y.; Tang, B.; Chen, Q.; Wang, X.; Zhu, F. Identifying High Quality Document–Summary Pairs through Text Matching. Information 2017, 8, 64. https://doi.org/10.3390/info8020064
Hou Y, Xiang Y, Tang B, Chen Q, Wang X, Zhu F. Identifying High Quality Document–Summary Pairs through Text Matching. Information. 2017; 8(2):64. https://doi.org/10.3390/info8020064
Chicago/Turabian StyleHou, Yongshuai, Yang Xiang, Buzhou Tang, Qingcai Chen, Xiaolong Wang, and Fangze Zhu. 2017. "Identifying High Quality Document–Summary Pairs through Text Matching" Information 8, no. 2: 64. https://doi.org/10.3390/info8020064