Investigating the Statistical Distribution of Learning Coverage in MOOCs



Abstract
:1. Introduction
2. Related Work
2.1. MOOC Learning Behavior
2.2. Zipf’s Law
3. Dataset and Methods
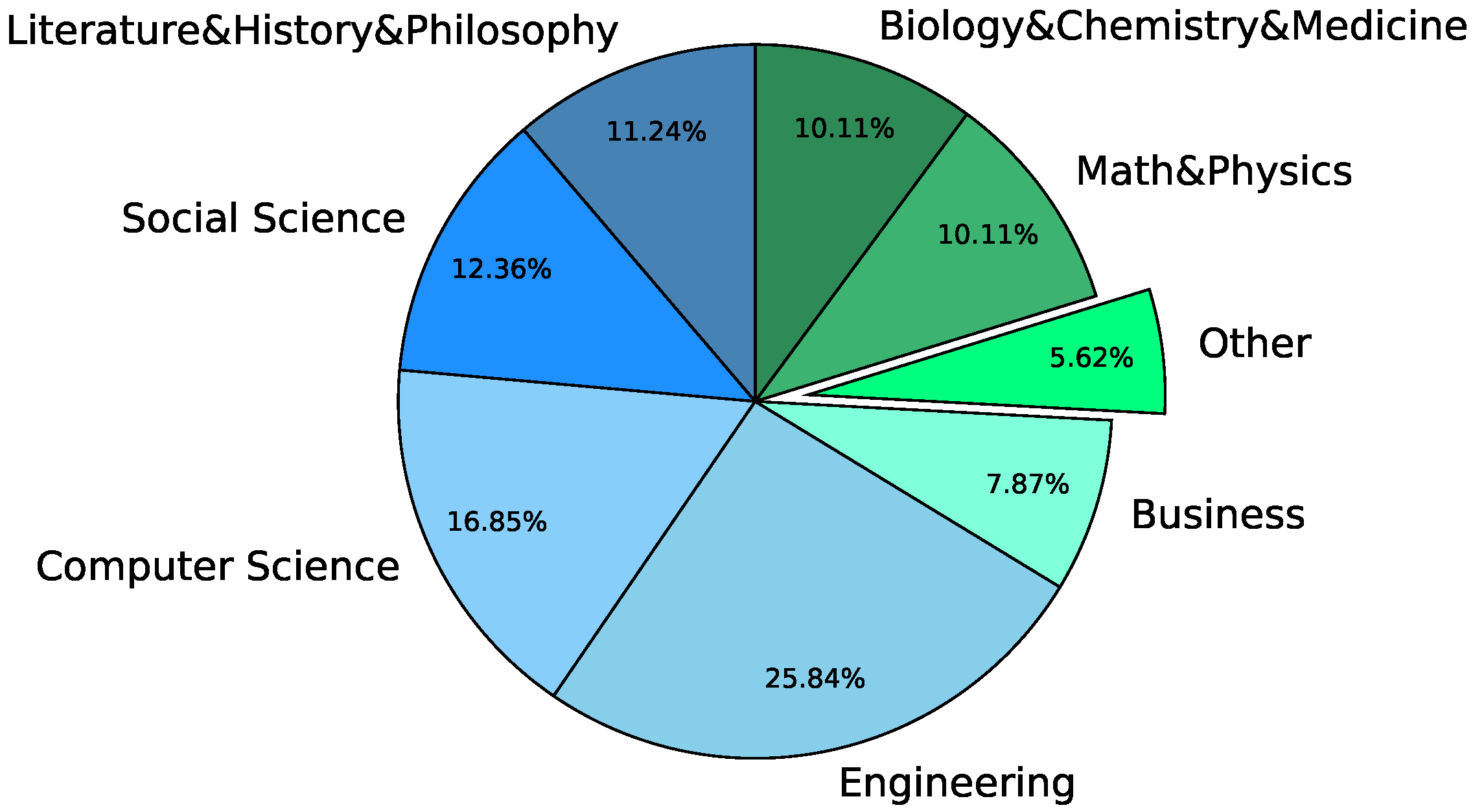
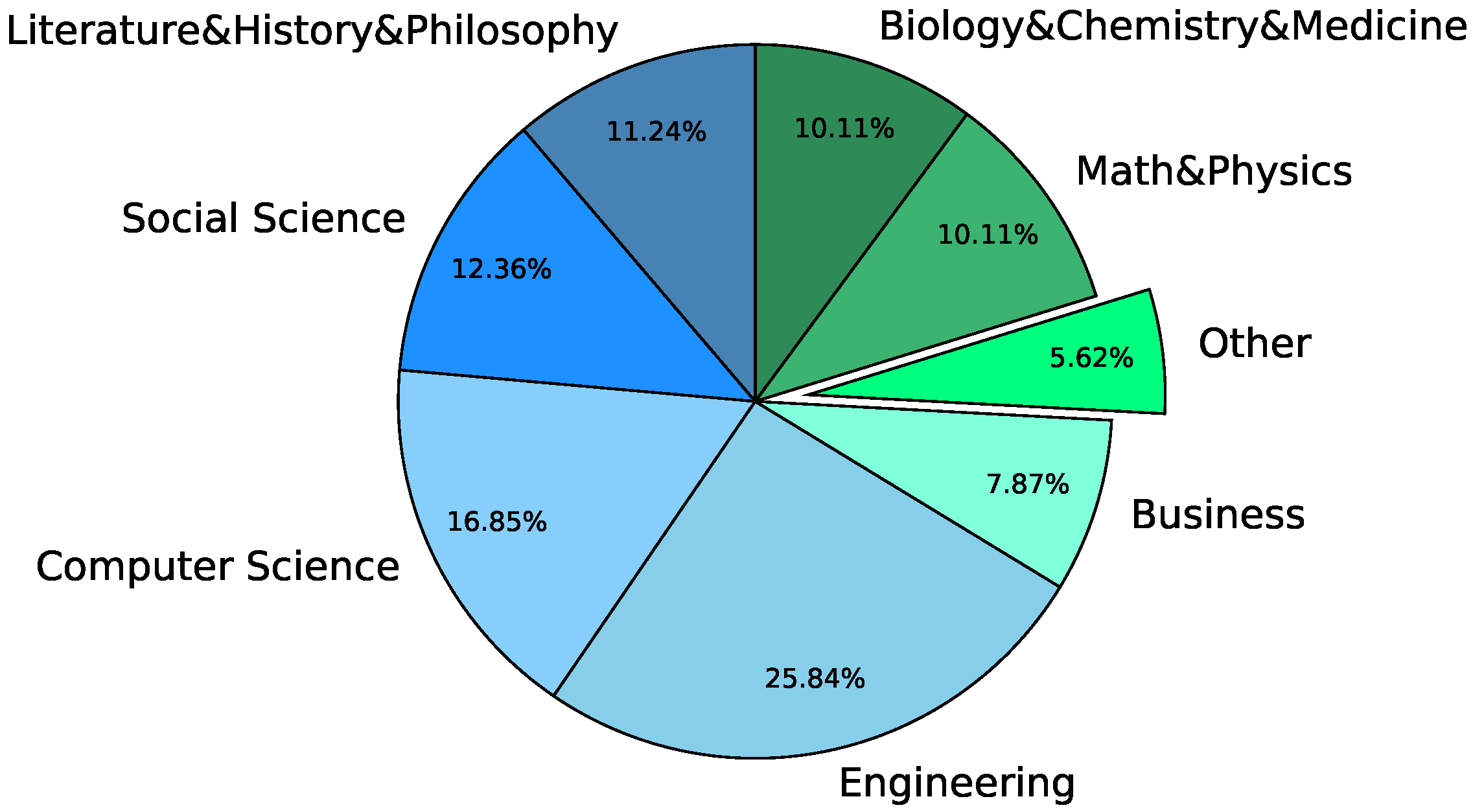
3.1. Dataset
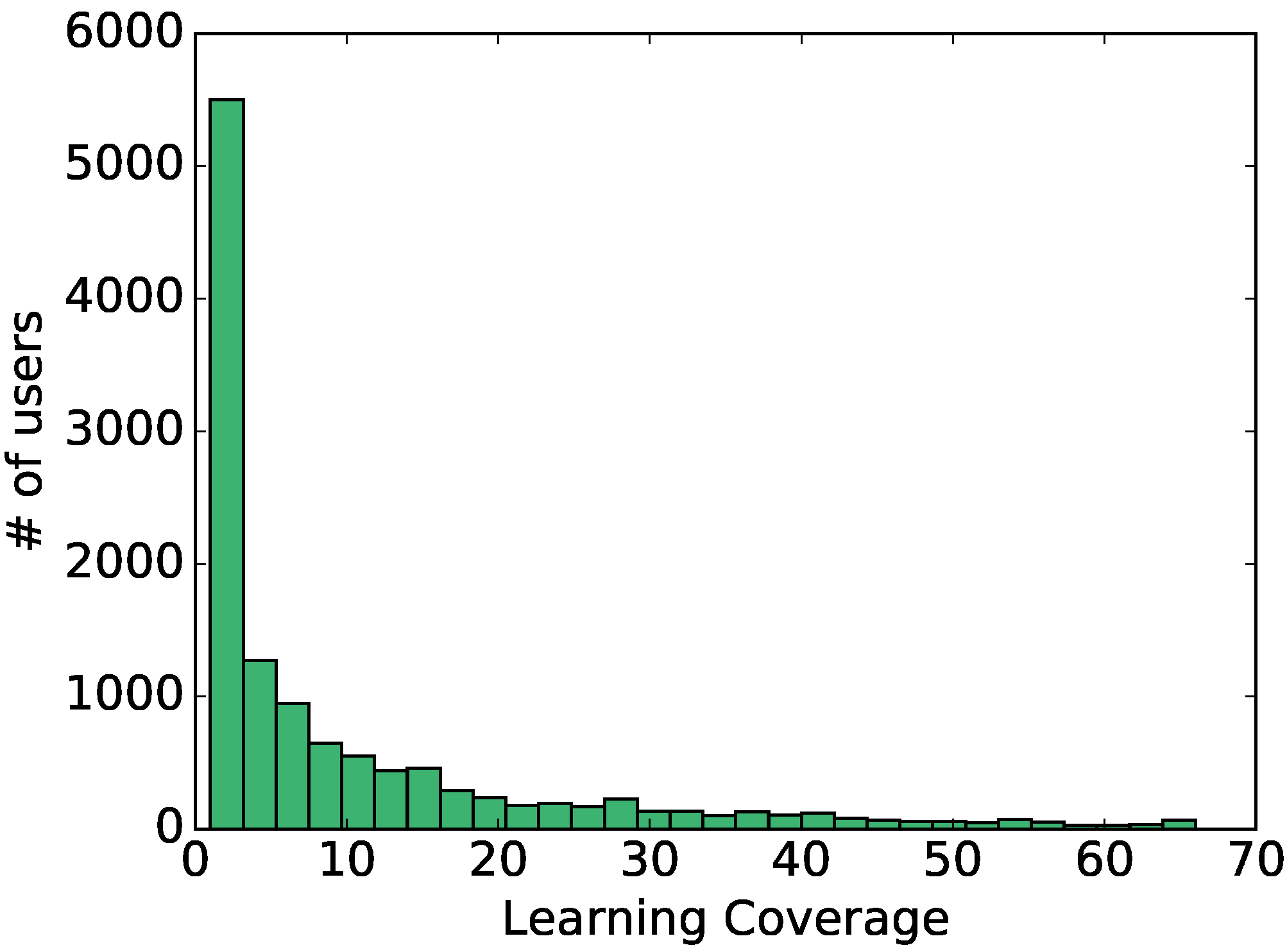
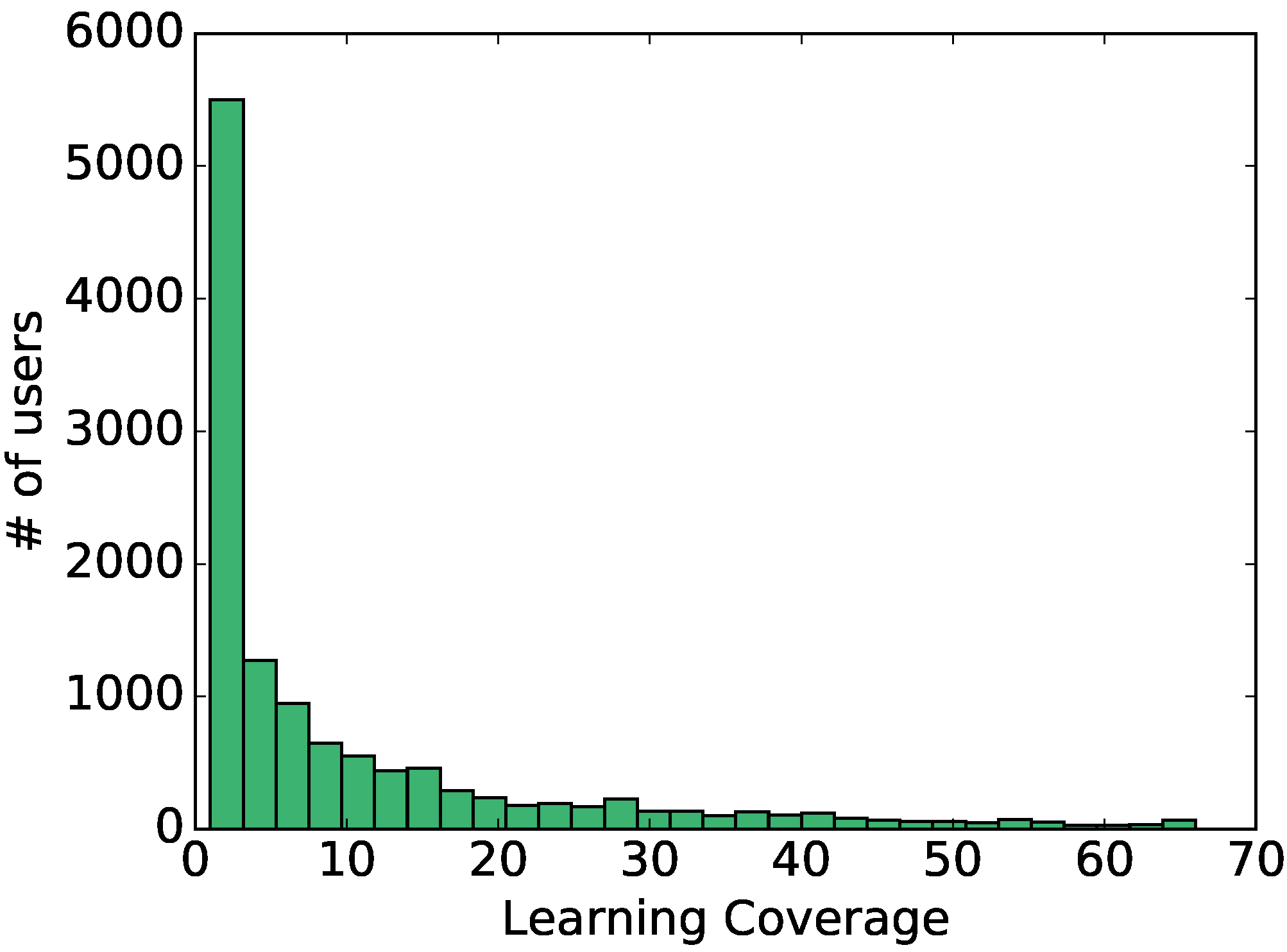
3.2. Learning Coverage
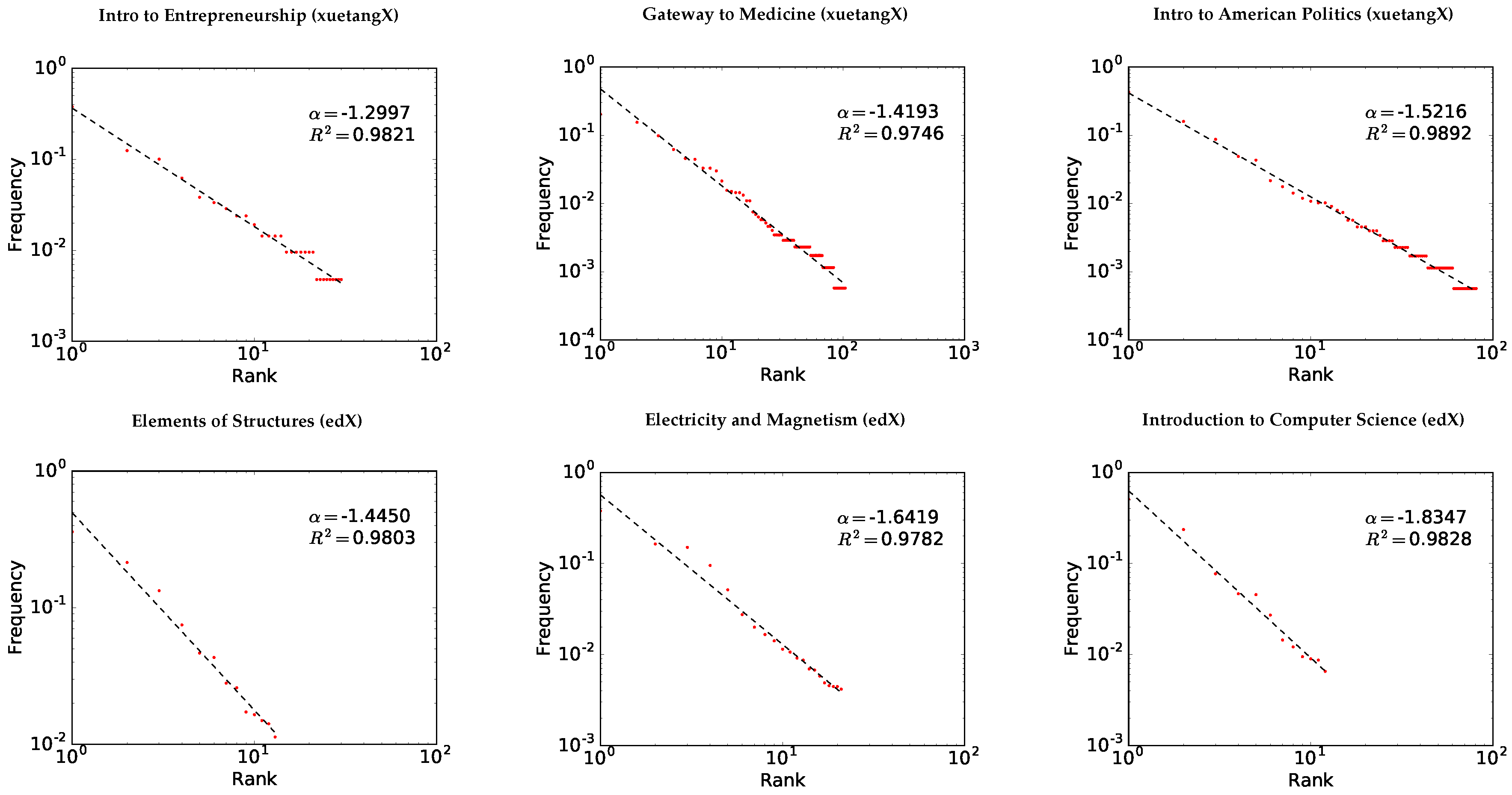
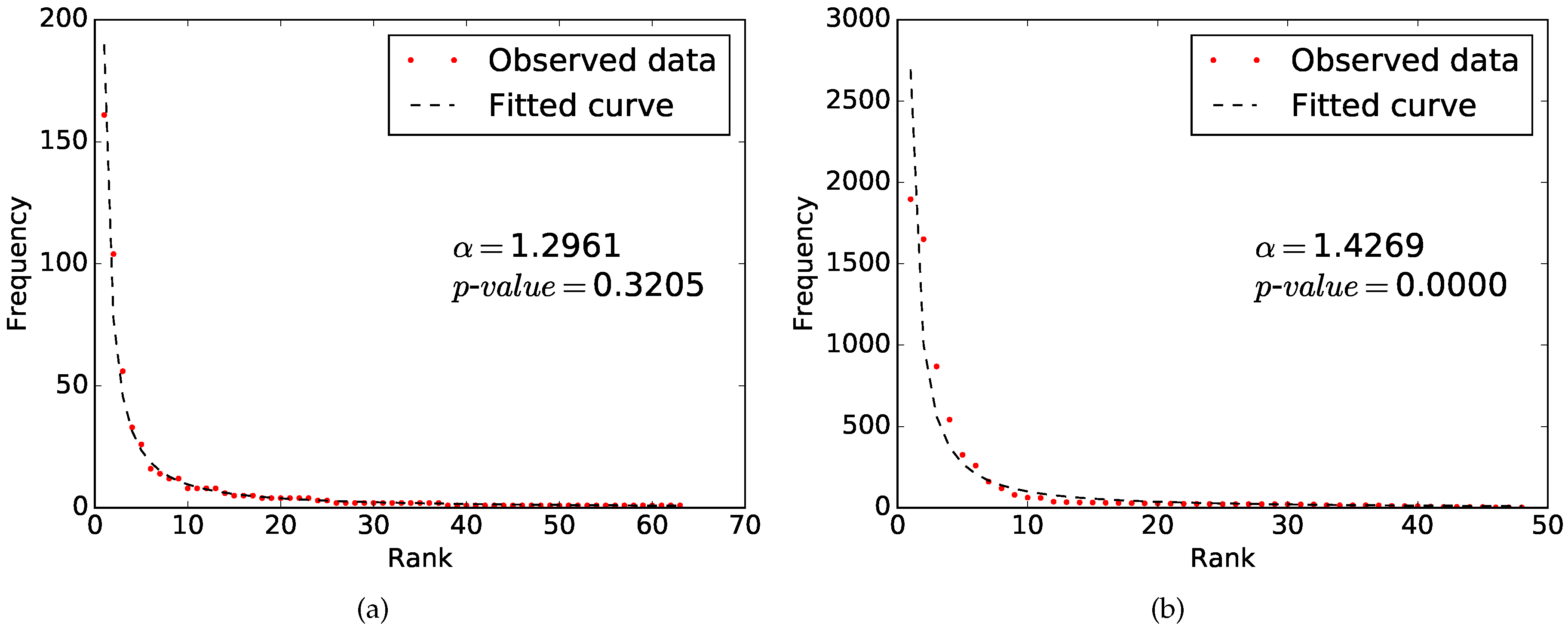
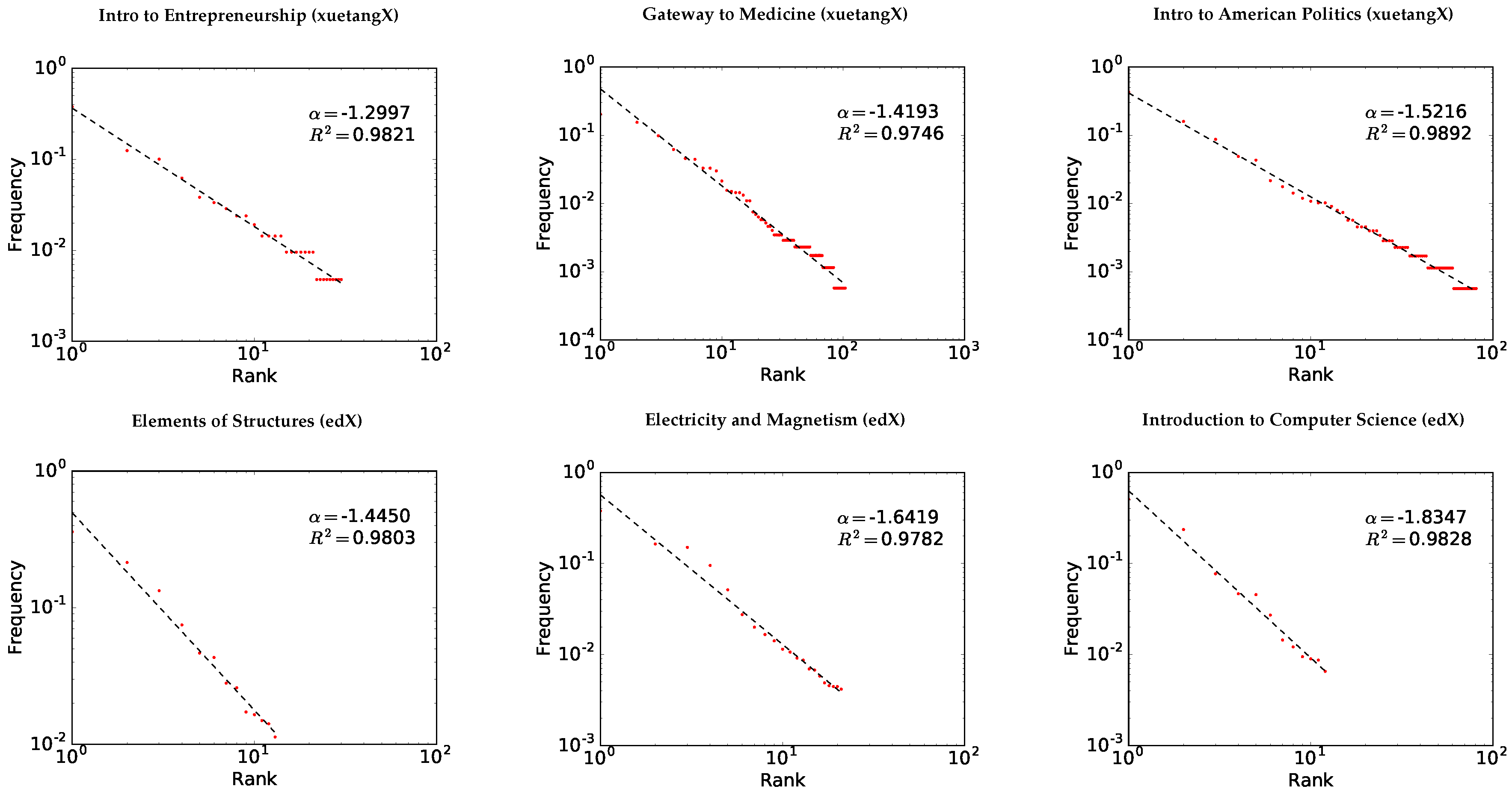
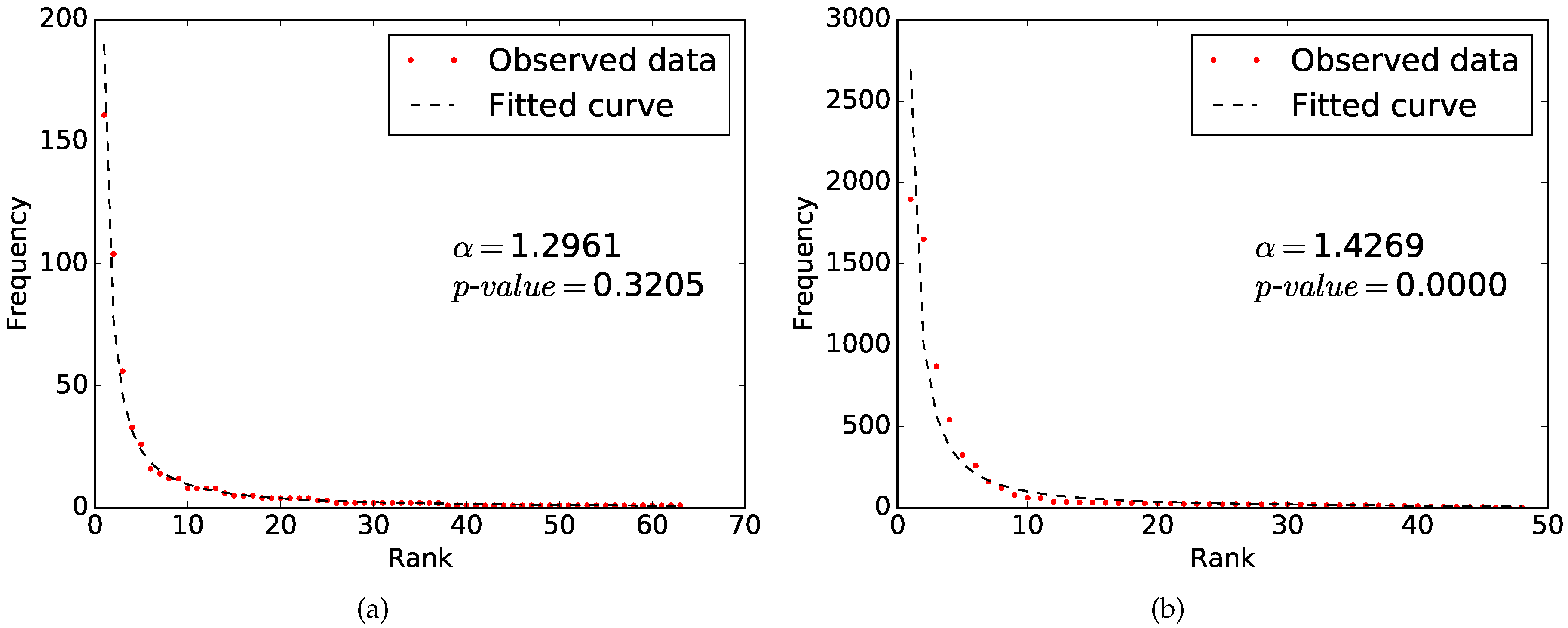
3.3. Fitting Zipf’s Law
3.4. Goodness-of-fit Test
| : The data of learning coverage is consistent |
| with a Zipf distribution with parameter . |
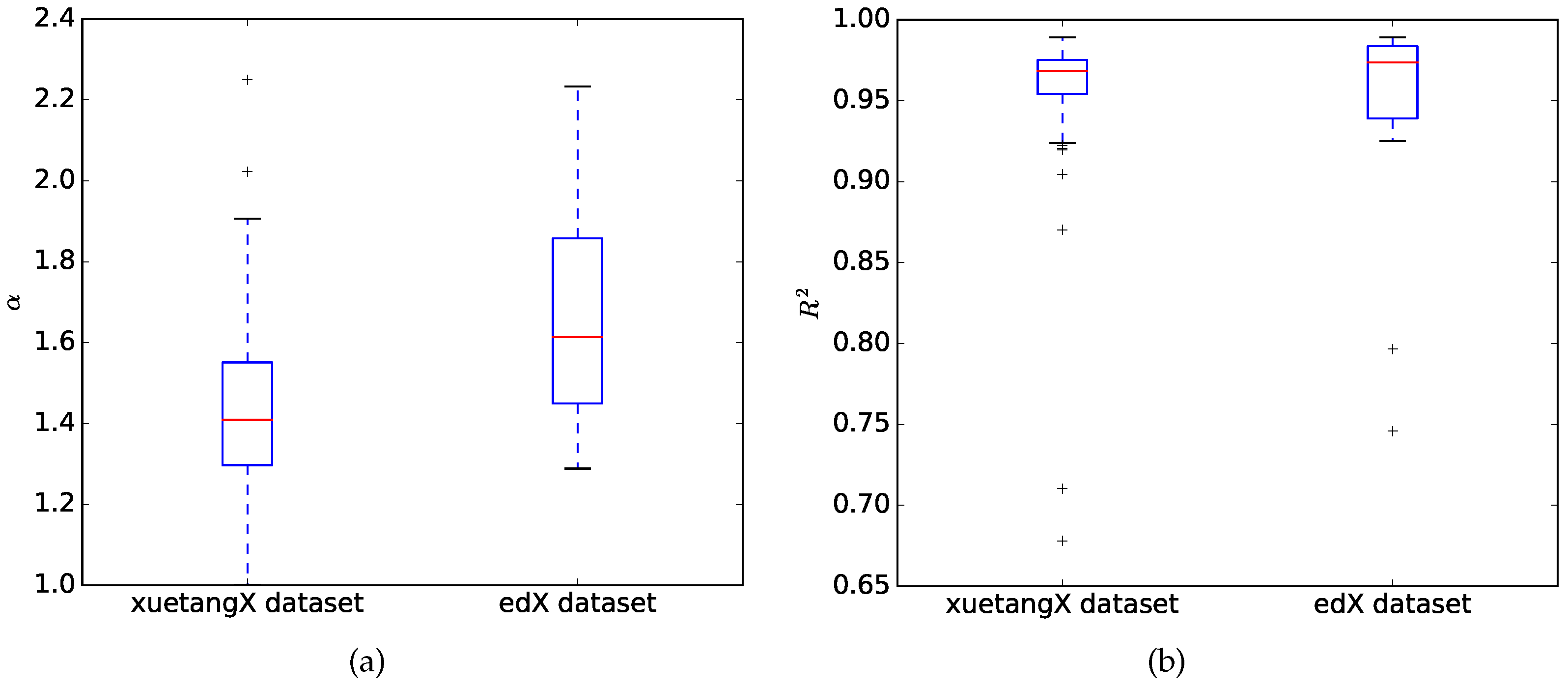
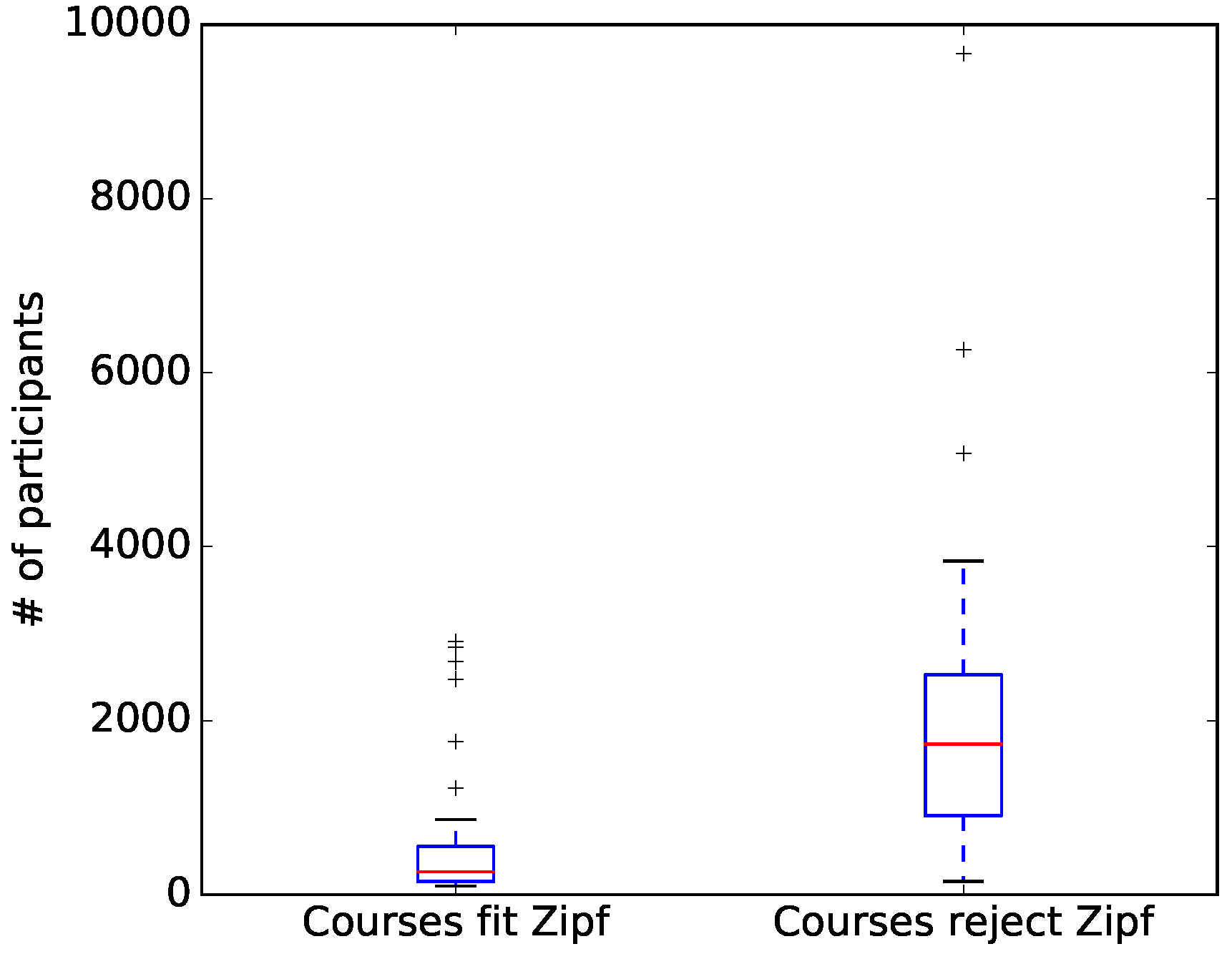
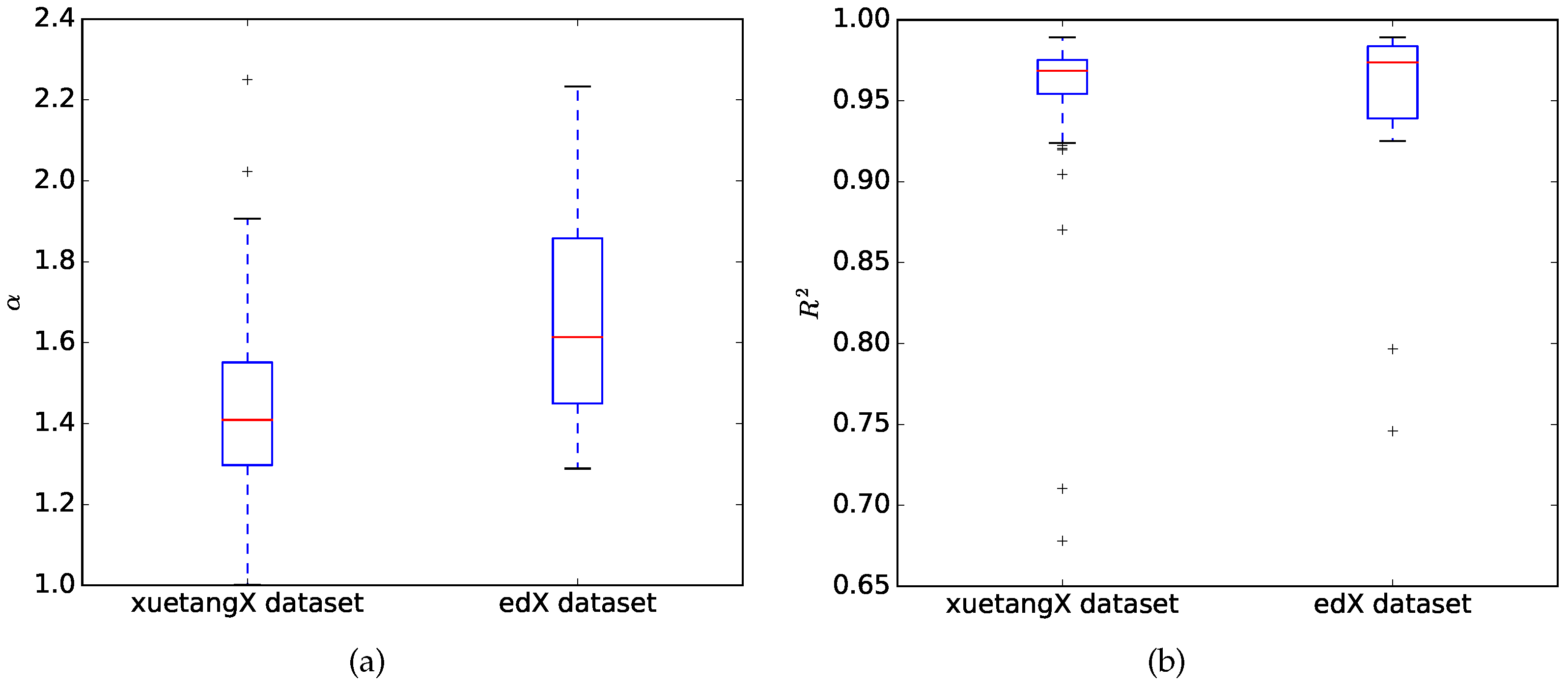
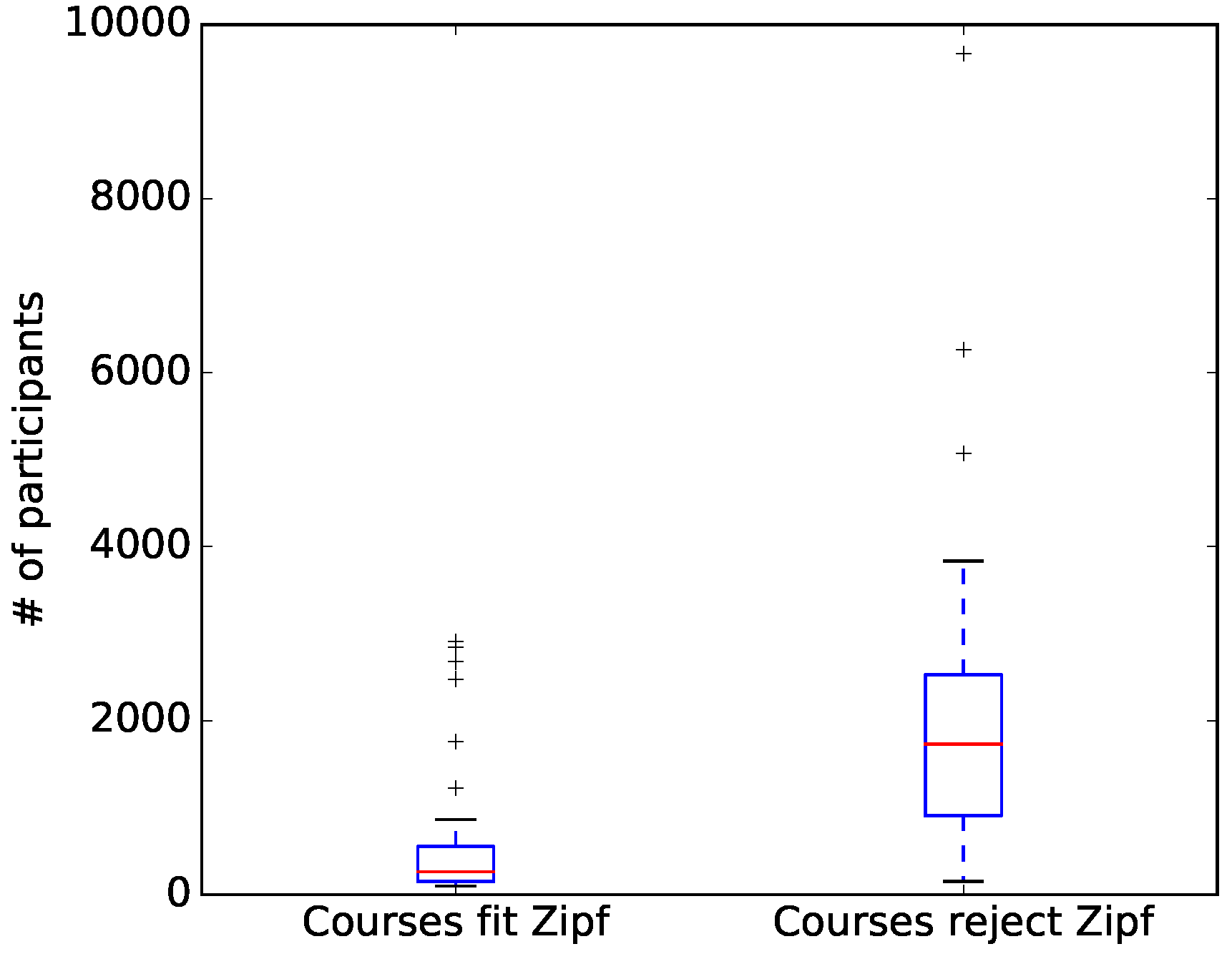
4. Results
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Liyanagunawardena, T.R.; Adams, A.A.; Williams, S.A. MOOCs: A systematic study of the published literature 2008-2012. Int. Rev. Res. Open Distrib. Learning 2013, 14, 202–227. [Google Scholar] [CrossRef]
- Seaton, D.T.; Bergner, Y.; Chuang, I.; Mitros, P.; Pritchard, D.E. Who does what in a massive open online course? Commun. ACM 2014, 57, 58–65. [Google Scholar] [CrossRef]
- Qiu, J.; Tang, J.; Liu, T.X.; Gong, J.; Zhang, C.; Zhang, Q.; Xue, Y. Modeling and predicting learning behavior in MOOCs. In Proceedings of the 9th ACM International Conference on Web Search and Data Mining, San Francisco, CA, USA, 22–25 February 2016; pp. 93–102. [Google Scholar]
- Men, C.; Li, X.; Du, Z.; Liu, J.; Li, M.; Zhang, X. Zipf’s Law in MOOC Learning Behavior. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017. [Google Scholar]
- Saadatdoost, R.; Sim, A.T.H.; Jafarkarimi, H.; Mei Hee, J. Exploring MOOC from education and Information Systems perspectives: A short literature review. Educ. Rev. 2015, 67, 505–518. [Google Scholar] [CrossRef]
- Khalil, H.; Ebner, M. MOOCs completion rates and possible methods to improve retention—A literature review. In Proceedings of the World Conference on Educational Multimedia, Hypermedia and Telecommunications, Tampere, Finland, 23–27 June 2014; Number 1. pp. 1305–1313. [Google Scholar]
- Gaebel, M. MOOCs: Massive Open Online Courses; EUA: Brussels, Belgium, 2014. [Google Scholar]
- Breslow, L.; Pritchard, D.E.; DeBoer, J.; Stump, G.S.; Ho, A.D.; Seaton, D.T. Studying learning in the worldwide classroom: Research into edX’s first MOOC. Res. Pract. Assess. 2013, 8, 13–25. [Google Scholar]
- Ho, A.D.; Reich, J.; Nesterko, S.O.; Seaton, D.T.; Mullaney, T.; Waldo, J.; Chuang, I. HarvardX and MITx: The first year of open online courses, fall 2012-summer 2013. In Ho, AD, Reich, J., Nesterko, S., Seaton, DT, Mullaney, T., Waldo, J., & Chuang, I. (2014). HarvardX and MITx: The first year of open online courses (HarvardX and MITx Working Paper No. 1); MIT Office of Digital Learning; HarvardX Research Committee: Cambridge, MA, USA, 2014. [Google Scholar]
- Kizilcec, R.F.; Piech, C.; Schneider, E. Deconstructing disengagement: analyzing learner subpopulations in massive open online courses. In Proceedings of the 3rd International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–12 April 2013; pp. 170–179. [Google Scholar]
- Phan, T.; McNeil, S.G.; Robin, B.R. Students’ patterns of engagement and course performance in a Massive Open Online Course. Comput. Educ. 2016, 95, 36–44. [Google Scholar] [CrossRef]
- Anderson, A.; Huttenlocher, D.; Kleinberg, J.; Leskovec, J. Engaging with Massive Online Courses. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 687–698. [Google Scholar]
- Evans, B.J.; Baker, R.B.; Dee, T.S. Persistence patterns in Massive Open Online Courses (MOOCs). J. Higher Educ. 2016, 87, 206–242. [Google Scholar] [CrossRef]
- Liu, M.; Kang, J.; Mckelroy, E. Examining learners’ perspective of taking a MOOC: reasons, excitement, and perception of usefulness. Educ. Media Int. 2015, 52, 129–146. [Google Scholar] [CrossRef]
- Hood, N.; Littlejohn, A.; Milligan, C. Context counts: How learners’ contexts influence learning in a MOOC. Comput. Educ. 2015, 91, 83–91. [Google Scholar] [CrossRef]
- Perna, L.W.; Ruby, A.; Boruch, R.F.; Wang, N.; Scull, J.; Ahmad, S.; Evans, C. Moving through MOOCs: understanding the progression of users in Massive Open Online Courses. Educ. Res. 2014, 43, 421–423. [Google Scholar] [CrossRef]
- Ho, A.D.; Chuang, I.; Reich, J.; Coleman, C.A.; Whitehill, J.; Northcutt, C.G.; Williams, J.J.; Hansen, J.D.; Lopez, G.; Petersen, R. Harvardx and MITx: Two years of open online courses fall 2012-summer 2014. In Ho, AD, Reich, J., Nesterko, S., Seaton, DT, Mullaney, T., Waldo, J., & Chuang, I. (2014). HarvardX and MITx: The first year of open online courses (HarvardX and MITx Working Paper No. 1); MIT Office of Digital Learning; HarvardX Research Committee: Cambridge, MA, USA, 2015. [Google Scholar]
- Li, W. Zipf’s law everywhere. Glottometrics 2002, 5, 14–21. [Google Scholar]
- Adamic, L.A.; Huberman, B.A. Zipf’s law and the Internet. Glottometrics 2002, 3, 143–150. [Google Scholar]
- Gabaix, X. Zipf’s law for cities: An explanation. Q. J. Econ. 1999, 114, 739–767. [Google Scholar] [CrossRef]
- Fujiwara, Y. Zipf law in firms bankruptcy. Phys. A Stat. Mech. Its Appl. 2004, 337, 219–230. [Google Scholar] [CrossRef]
- Okuyama, K.; Takayasu, M.; Takayasu, H. Zipf’s law in income distribution of companies. Phys. A Stat. Mech. Its Appl. 1999, 269, 125–131. [Google Scholar] [CrossRef]
- Yamakami, T. A Zipf-like distribution of popularity and hits in the mobile web pages with short life time. In Proceedings of the 2006 Seventh International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT’06), Taipei, Taiwan, 4–7 December 2006; pp. 240–243. [Google Scholar]
- Urzúa, C.M. Testing for Zipf’s law: A common pitfall. Econ. Lett. 2011, 112, 254–255. [Google Scholar] [CrossRef]
- Izsák, F. Maximum likelihood estimation for constrained parameters of multinomial distributions—Application to Zipf–Mandelbrot models. Comput. Stat. Data Anal. 2006, 51, 1575–1583. [Google Scholar] [CrossRef]
- Clauset, A.; Shalizi, C.R.; Newman, M.E. Power-law distributions in empirical data. SIAM Rev. 2009, 51, 661–703. [Google Scholar] [CrossRef]
- Chernoff, H.; Lehmann, E.L. The use of maximum likelihood estimates in χ2 tests for goodness of fit. Ann. Math. Stat. 1954, 25, 579–586. [Google Scholar] [CrossRef]
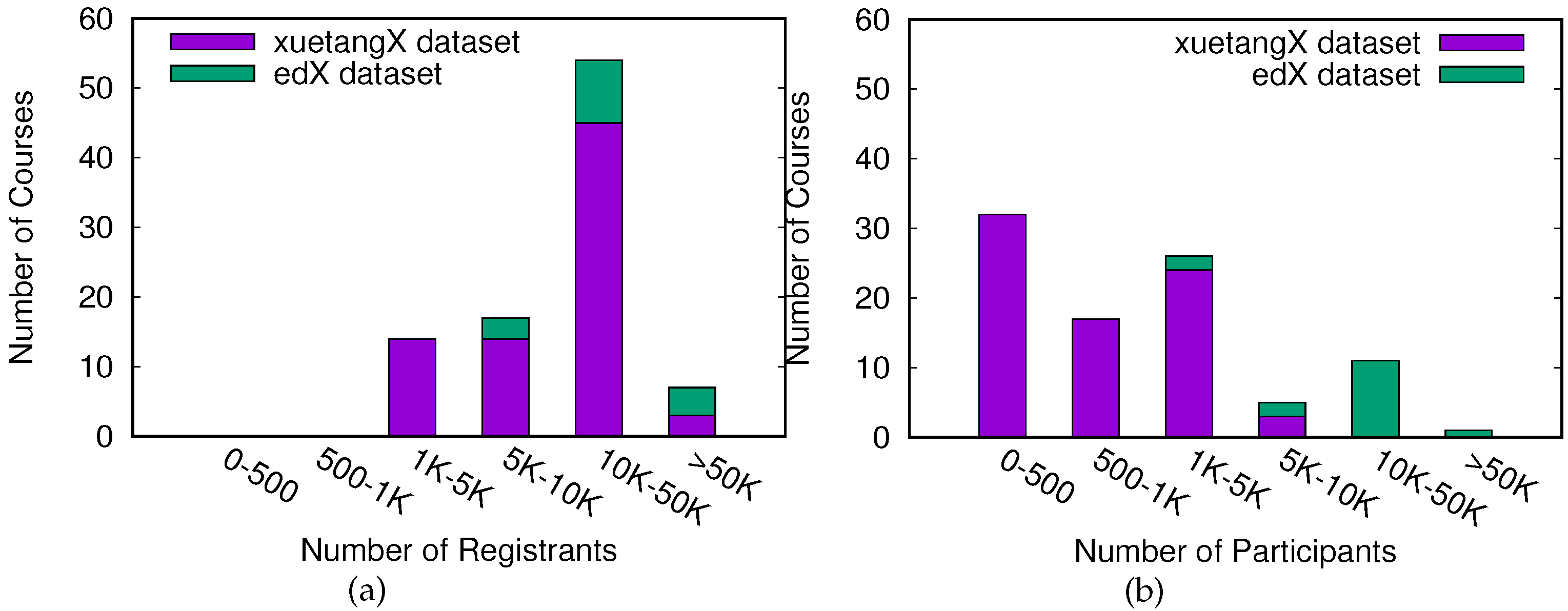

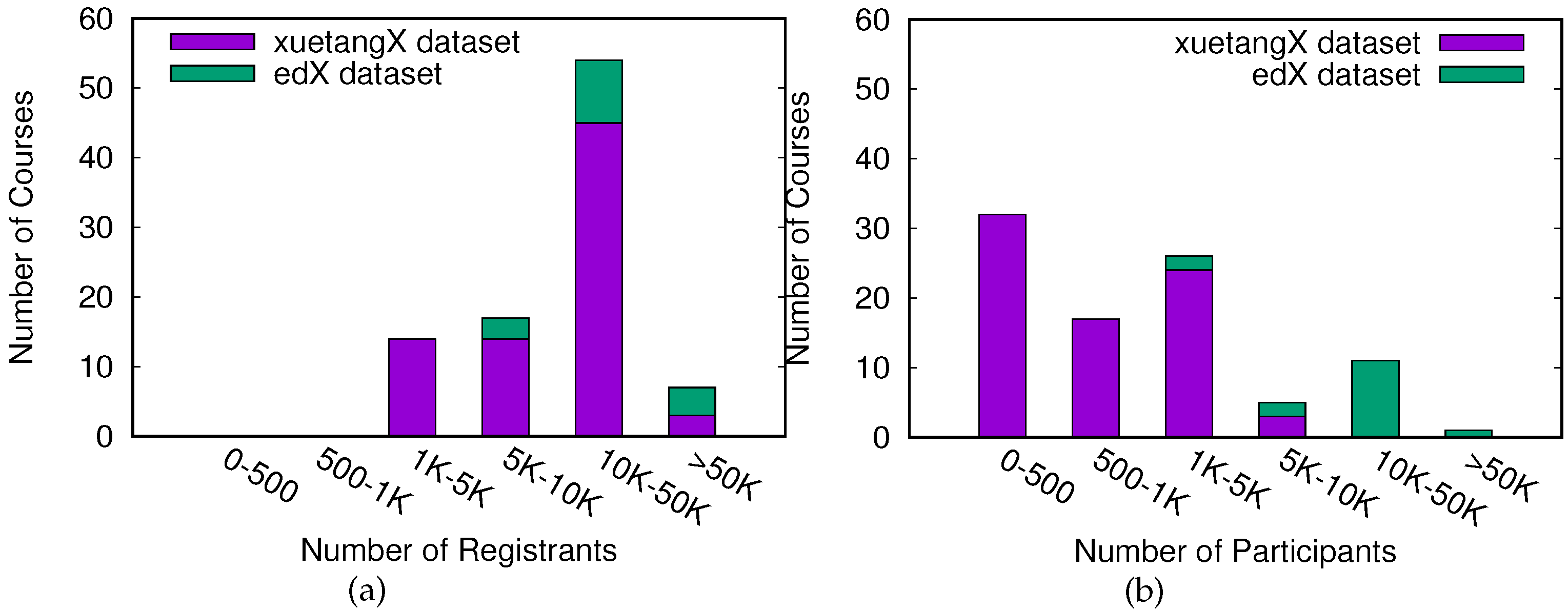{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | xuetangX Dataset | edX Dataset | ||
|---|---|---|---|---|
| p-Value | p-Value | |||
| Mean | 1.3068 | 0.3707 | 1.4268 | 0.0000 |
| Min. | 0.8915 | 0.0000 | 1.2352 | 0.0000 |
| 1Q | 1.2107 | 0.0000 | 1.2898 | 0.0000 |
| Median | 1.2998 | 0.1863 | 1.4222 | 0.0000 |
| 3Q | 1.3709 | 0.8420 | 1.5296 | 0.0000 |
| Max. | 1.9751 | 1.0000 | 1.6860 | 0.0000 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Men, C.; Du, Z.; Liu, J.; Li, M.; Zhang, X. Investigating the Statistical Distribution of Learning Coverage in MOOCs. Information 2017, 8, 150. https://doi.org/10.3390/info8040150
Li X, Men C, Du Z, Liu J, Li M, Zhang X. Investigating the Statistical Distribution of Learning Coverage in MOOCs. Information. 2017; 8(4):150. https://doi.org/10.3390/info8040150
Chicago/Turabian StyleLi, Xiu, Chang Men, Zhihui Du, Jason Liu, Manli Li, and Xiaolei Zhang. 2017. "Investigating the Statistical Distribution of Learning Coverage in MOOCs" Information 8, no. 4: 150. https://doi.org/10.3390/info8040150