Finding Group-Based Skyline over a Data Stream in the Sensor Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We present the problem of finding the G-Skyline with k points over a data stream in the sensor network. This query will provide much more useful information.
- We present a sharing strategy to make us compute the new G-Skyline based on the existing result. According to the pruning theorems, lots of groups will be pruned without computation.
- We propose two algorithms to compute the new G-Skyline over a data stream.
- The experiments are performed based on three kinds of synthetic datasets.
2. Related Work
3. Preparations
3.1. Definitions and Theorems
3.2. Algorithm in Static Data
- (1)
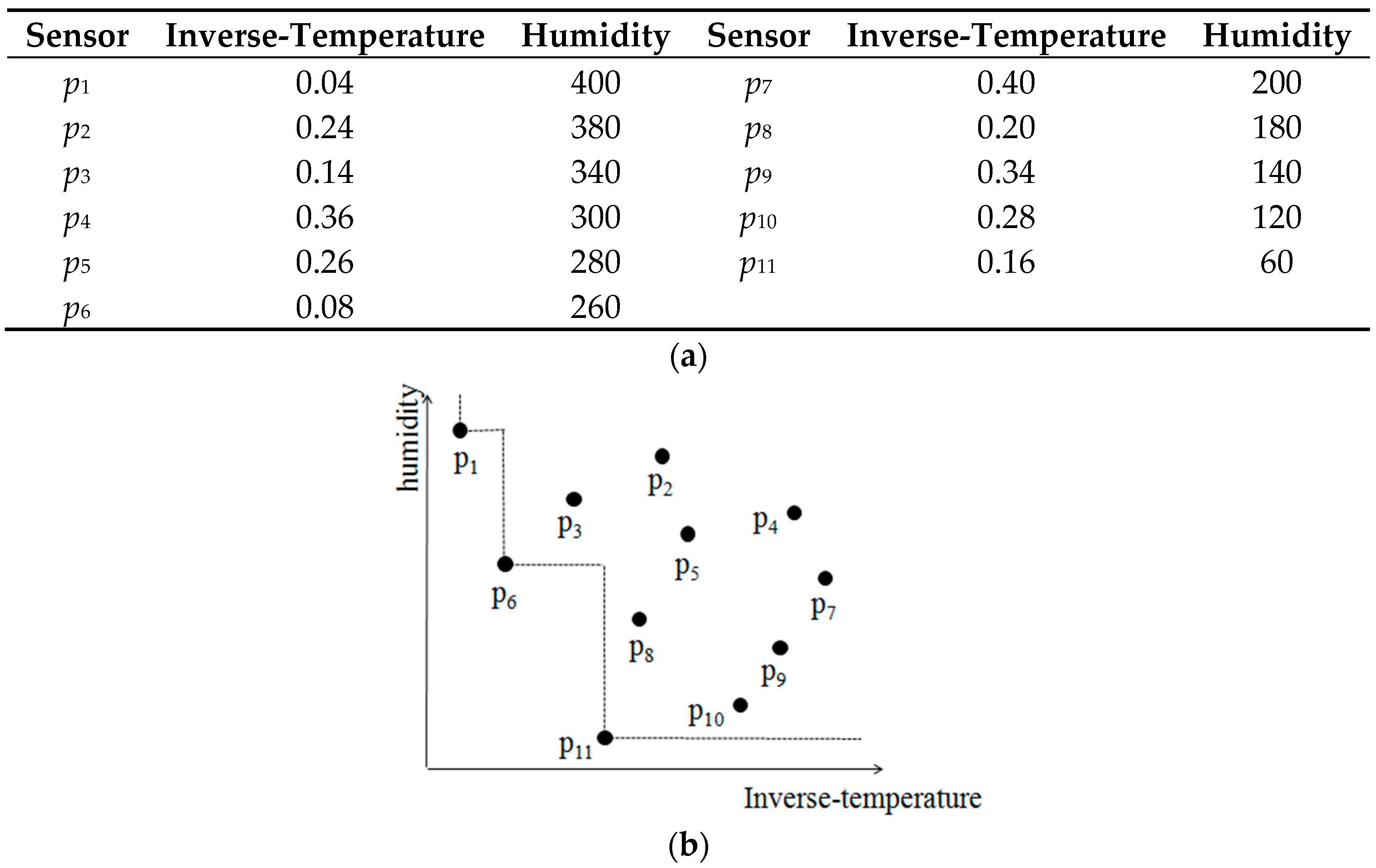
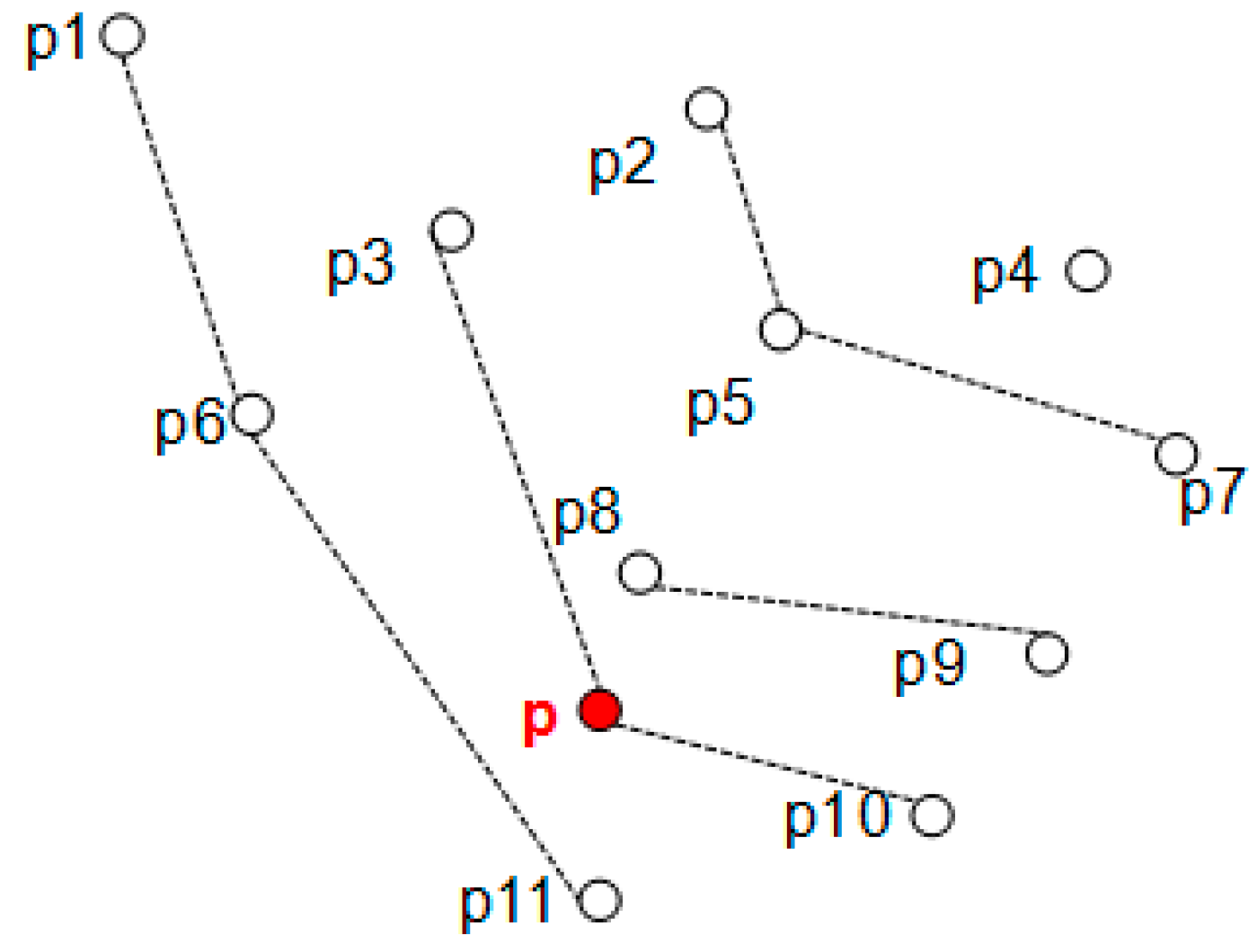
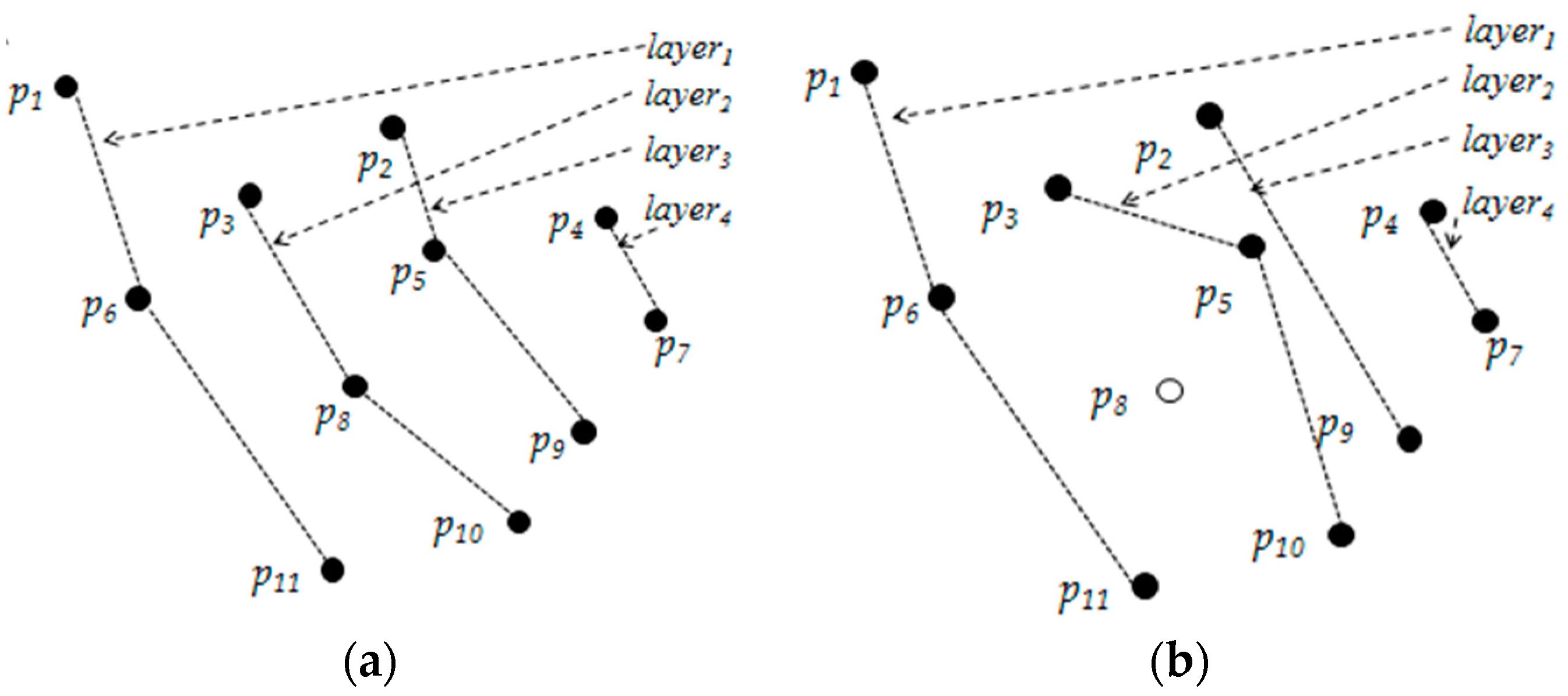
- Skyline Layers. Firstly, all the points in D with 2-dimension are sorted with increasing x-coordinate value, then all the points in this order are processed by binary search to find which layer each point belongs to. Because the Pwise algorithm only compute the G-Skyline for the given group size k, so just the first k skyline layers need to be constructed. The point with minimum y-coordinate in layeri is referred as the tail point of layeri. An example of skyline layers is shown in Figure 3, and p11 is the tail point of layer1.When the dimension space is higher, each point is processed in order and is inserted to a layer or a new layer is started. The data are sorted in one dimension firstly, then in order to find an existing layer the point belongs to, this point should be compared with all points in existing layers.
- (2)
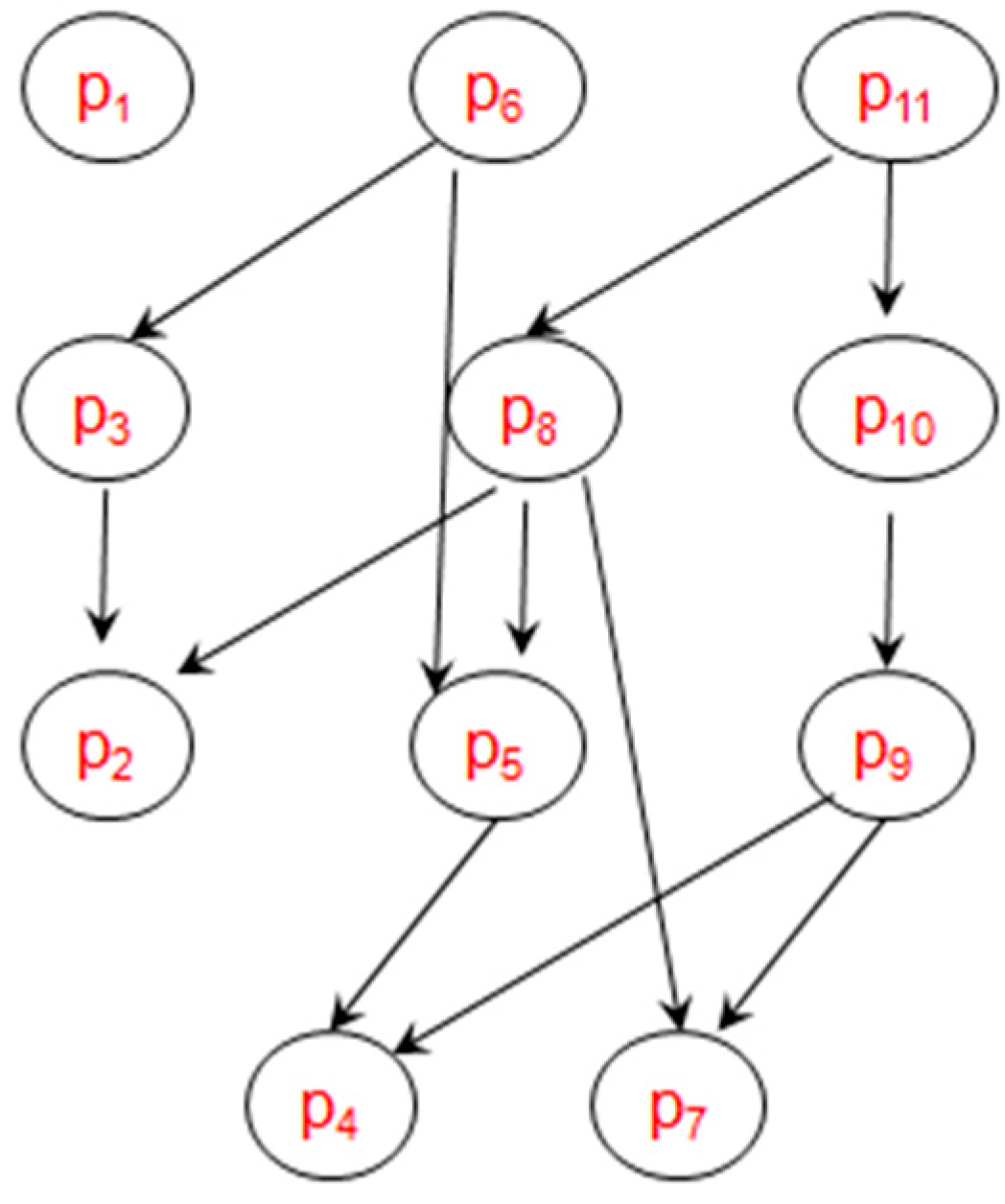
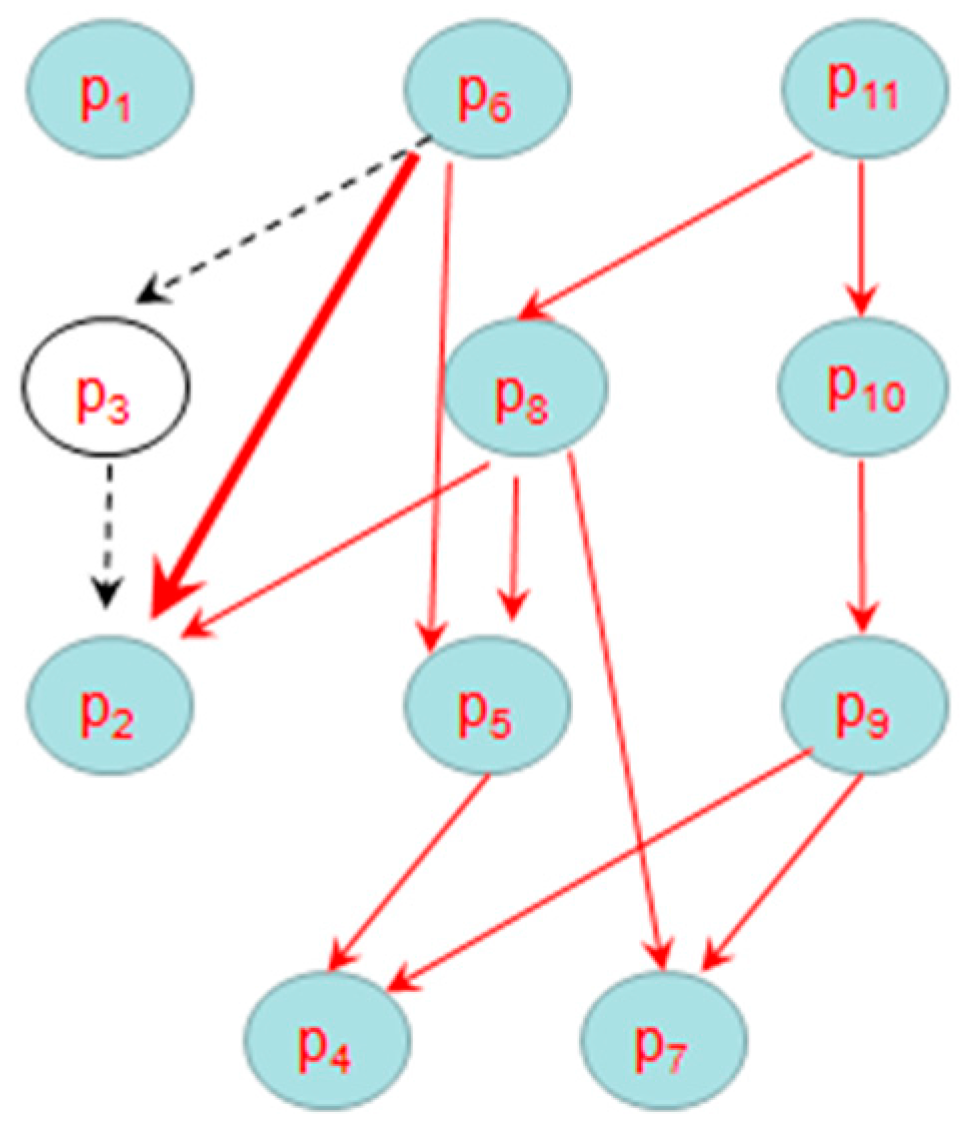
- Construct Directed Skyline Graph (DSG). The DSG is a data structure which reflects the dominance relations between the first k layers. It is constructed based on skyline layers: all the points in D are calculated according to the increasing layers. For every point p, it should be compared with all the points in the previous layers and get their dominance relations, for the points which dominate p, they will be added to p’s parents list, and p will be added to their children list. An example of DSG is shown in Figure 4 based on the data in Figure 1. In order to look clarity, all the indirect dominant relations are omitted, such as p11 p2.
- (3)
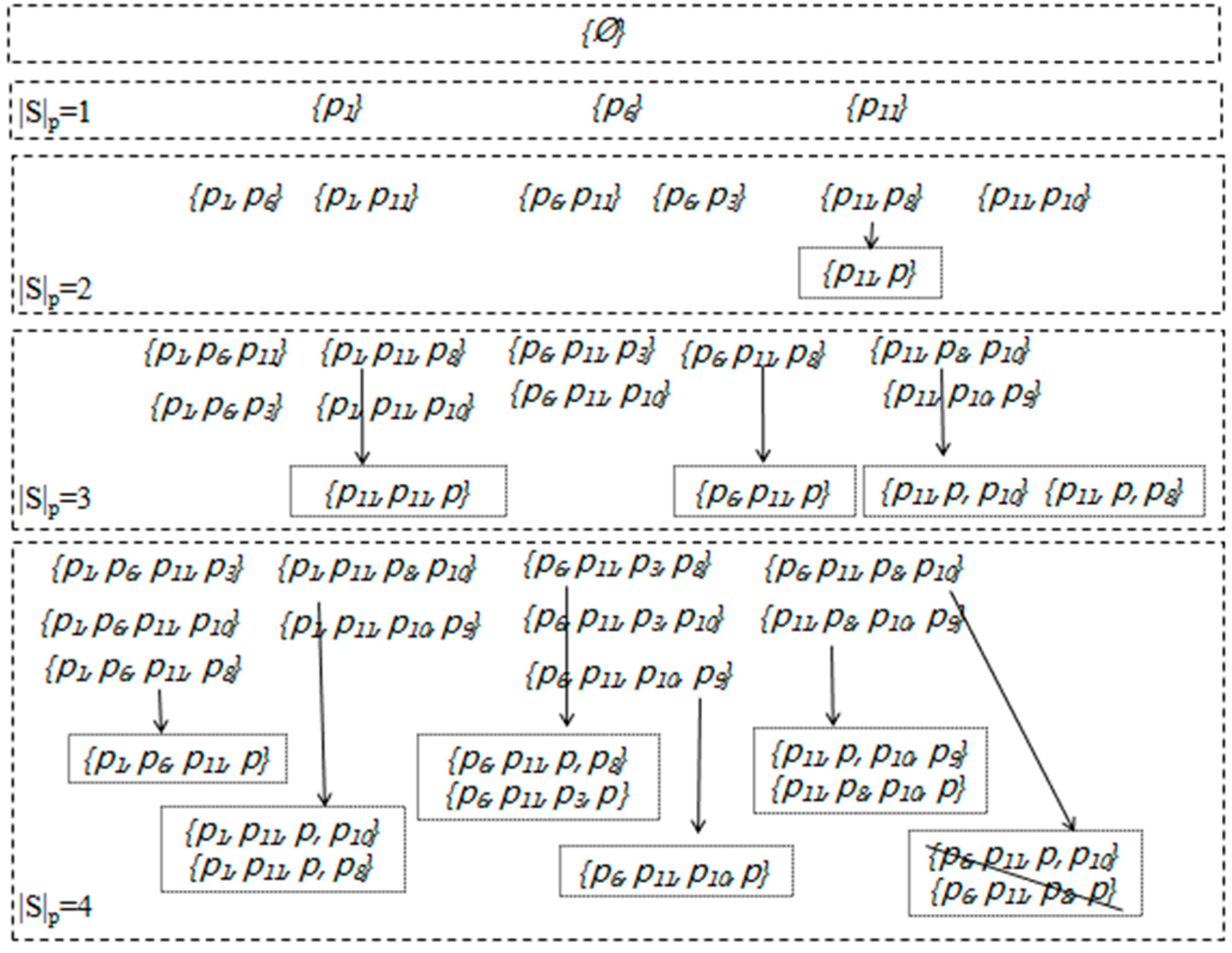
- Compute G-Skyline. Based on the skyline layers and DSG, the algorithm performs by the classic set enumeration tree search framework. According to Theorem 2, the algorithm firstly prunes the non-G-Skyline groups as soon as possible, because if a group is not the G-Skyline group, it should not be expanded further, then according to Theorem 3, the algorithm prunes the point from the tail set of each node. Finally, the G-Skyline is returned.
3.3. Our Problem
4. G-Skyline Query over Data Stream
4.1. Sharing Strategy
4.2. Computing G-Skyline for Point Arriving
| Algorithm 1. Update Skyline Layers When New Point Arrives |
| Input: the skyline layers of n active points, a new arriving point p |
| Output: the new skyline layers of active points |
| 1 for I = 1 to maxlayer do |
| 2 if the layer1’s tail point does not dominate p then |
| 3 p.layer = 1; |
| 4 else if layermax’s tail point dominates p then |
| 5 p.layer = maxlayer + 1; |
| 6 else |
| 7 calculate bin-search to find which layer p belongs to |
| 8 compare p with the points in p.layer to determine p’s position in the layer |
| 9 if there is a point in p.layer is dominated by p |
| 10 Denote all the points in p.layer dominated by p as D1 |
| 11 While (D1! = null) |
| 12 {For each point q in D1 |
| 13 Copy all the points in layer(q.layer+1) dominated by q to D2 |
| 14 q.layer = q.layer + 1; |
| 15 delete q from D1; |
| 16 D1 = D2; |
| } |
| 17 return the new skyline layers |
- (1)
- If p.layer > k. According to Theorem 1, the point of G-Skyline groups must in the first k layers, so if p.layer > k, pwill not affect the G-Skyline result.
- (2)
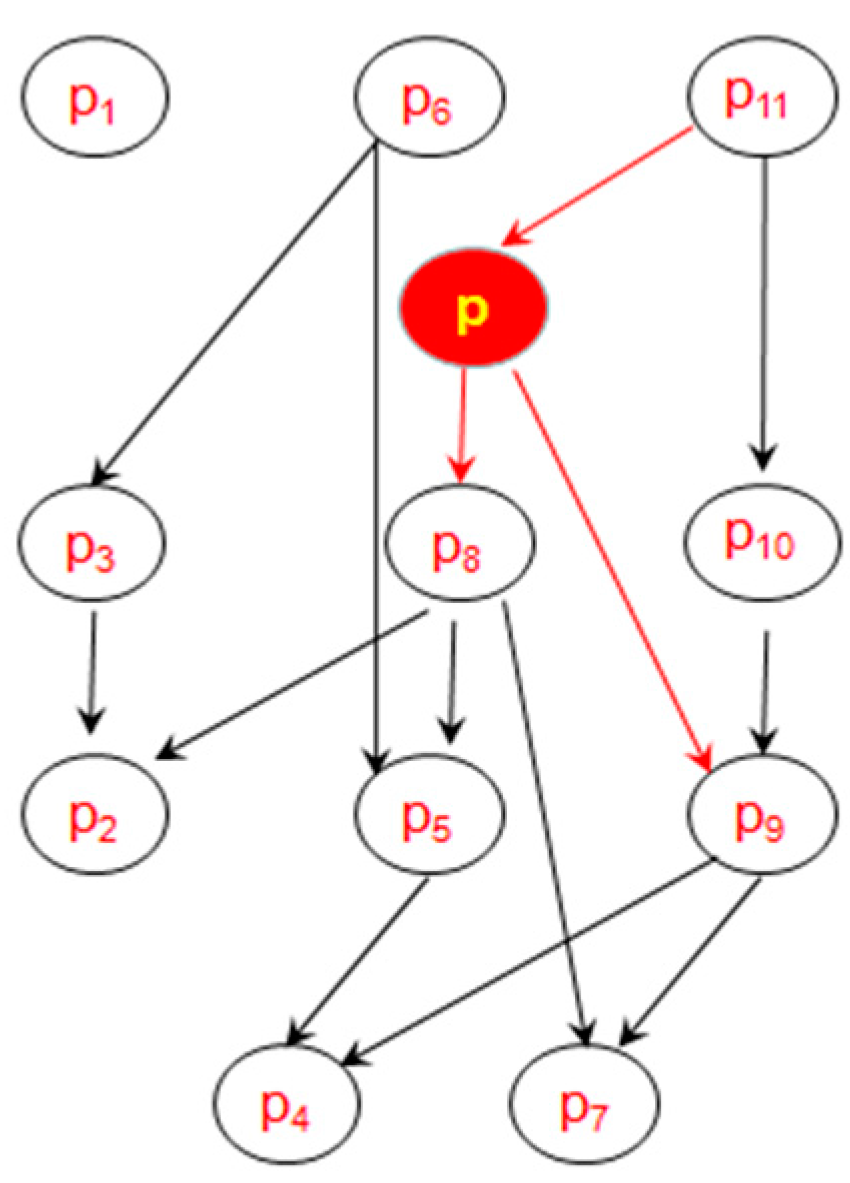
- If p.layer < k. In this case, p has no effect on the non-G-Skyline groups and the G-Skyline groups which do not contain all of p’s parents. However, the point p may only affect the G-Skyline groups which containing all of p’s parents, here we denote these groups as candidate groups.
| Algorithm 2. Point-Arriving-Algorithm |
| Input: a data set D with n active points, the corresponding skyline layers and DSG, group size k, a new arriving point p |
| Output: New G-Skyline groups |
| 1 update the skyline layers |
| 2 update the DSG |
| 3 for each group G in G-Skyline |
| 4 if G contains all of p’s parents |
| 5 if G does not contain p’s child |
| 6 G’ ← replace the leaf point of G by p |
| 7 insert G’ to G-Skyline |
| 8 if G contain p’s child |
| 9 G’← replace the leaf point of G by p |
| 10 insert G’to G-Skyline |
| 11 remove G from G-Skyline |
| 12 return New G-Skyline |
4.3. Updating G-Skyline for Point Expiring
| Algorithm 3. Update Skyline Layers for Point Expiring |
| Input: the skyline layers of n active points, a point p to expire |
| Output: the skyline layers of active points |
| 1 if p is the tail point of layerL |
| 2 for I = L to maxlayer-1 do |
| 3 (layeri).tail = (layeri+1).tail; |
| 4 else |
| 5 Initialize a set S = null; |
| 6 L’ = L; |
| 7 copy p to S; |
| 8 while(S! = null) |
| 9 {for each point p’ in S |
| 10 {for each child q in layerL’+1 of p’ |
| 11 {if S contains all parents of q in layerL’ |
| 12 q.layer = q.layer− 1; |
| 13 copy q to S; |
| } |
| 14 L’++; |
| 15 delete p’from S; |
| } |
| } |
| 16delete p |
| 17return the new skyline layers |
| Algorithm 4. Point-Expiring-Algorithm |
| Input: a data set D with n active points, the corresponding skyline layers and DSG, group size k, a point p to expire. |
| Output: New G-Skyline groups NGS |
| 1 update the skyline layers |
| 2 update the DSG |
| 3 for each group Gk in G-Skyline |
| 4 if G does not contain p |
| 5 Copy Gk to NGS |
| 6 for each group Gk+1 containing p in G-Skyline |
| 7 G’ ← remove p from Gk+1 |
| 8 insert G’ to NGS |
| 9 return NGS |
5. Experiments
5.1. Experiment Preparation
- PAA: Computing G-Skyline groups for a new point arriving.
- PEA: Computing G-Skyline groups for an old point expiring.
- PWise: Point-Wise algorithm of G-Skyline for static dataset in paper [1].
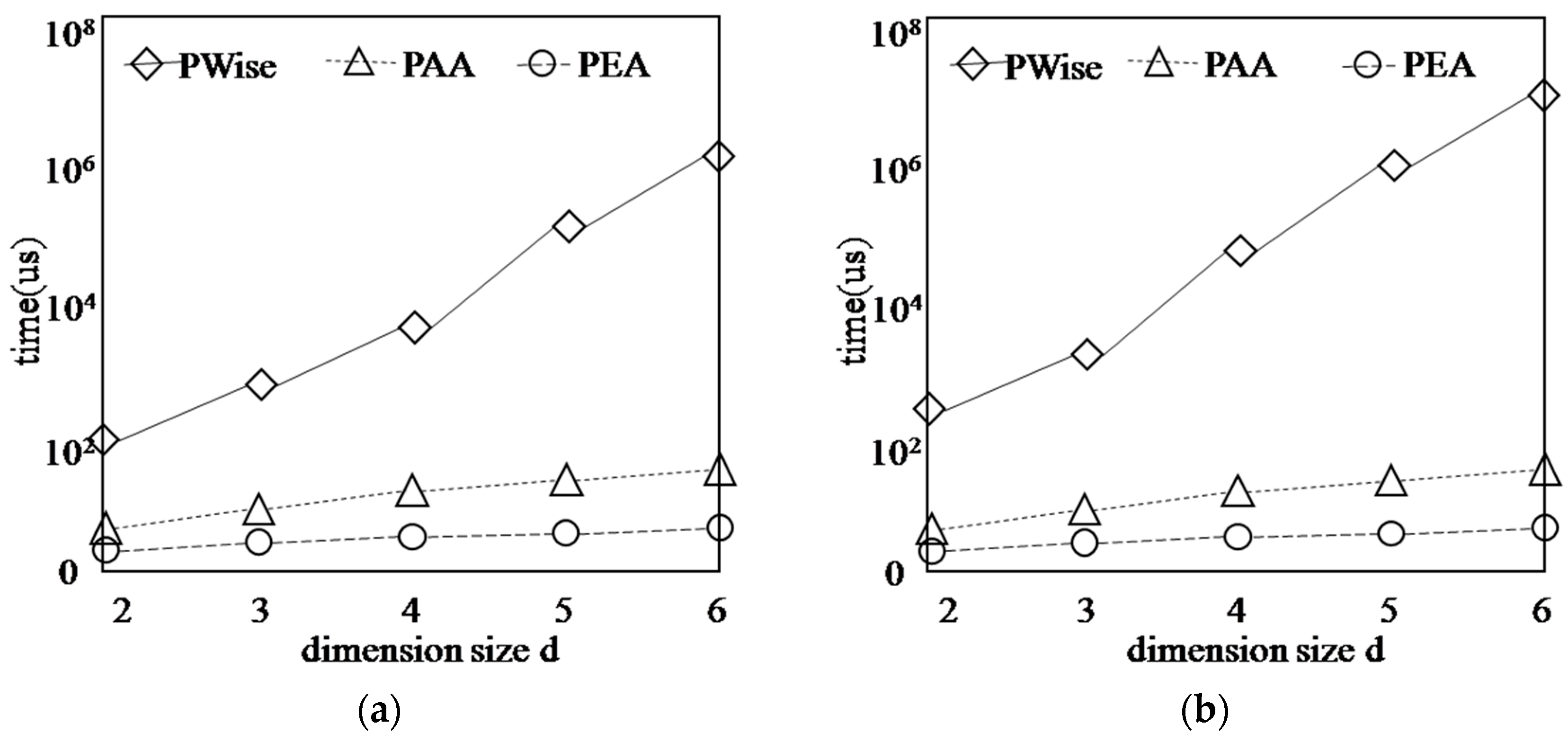
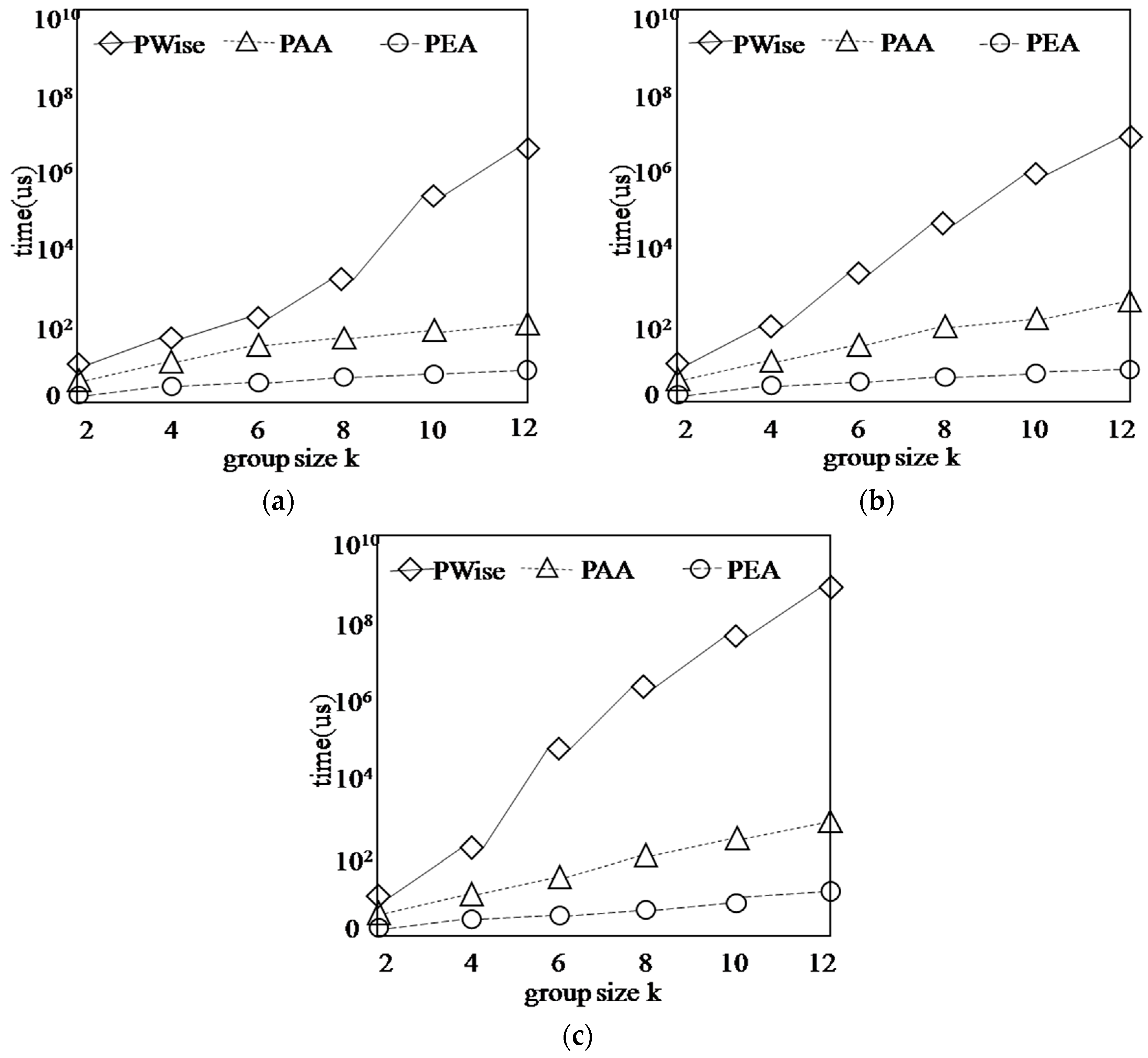
5.2. Updating Skyline Layers
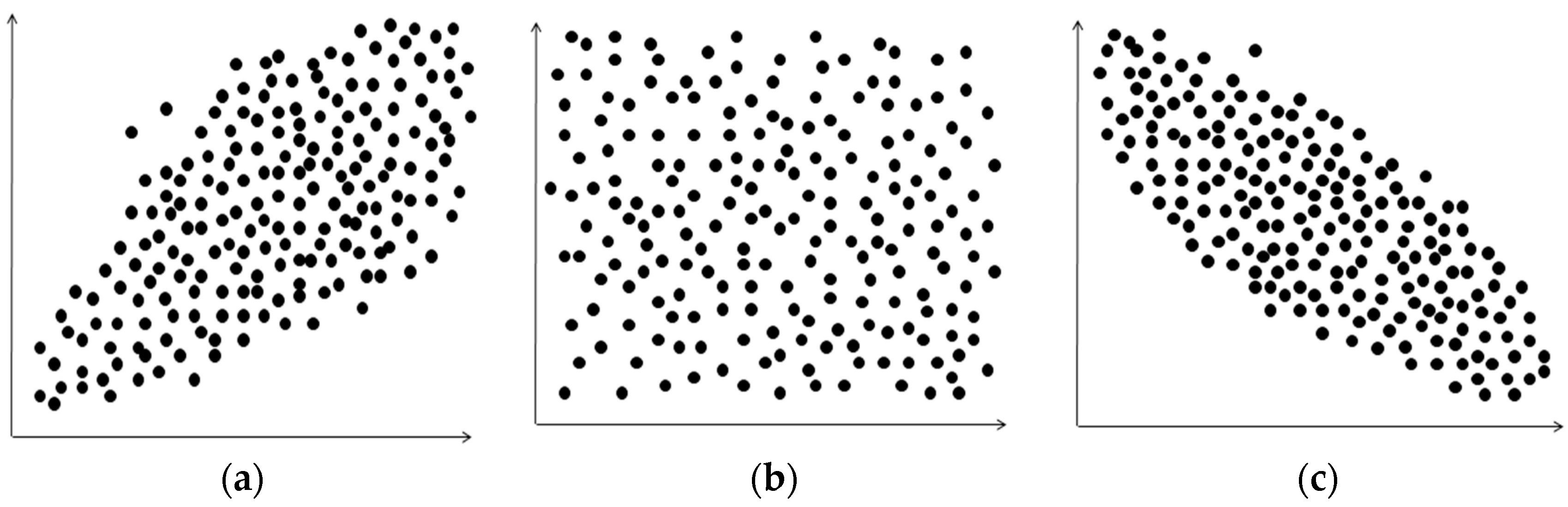
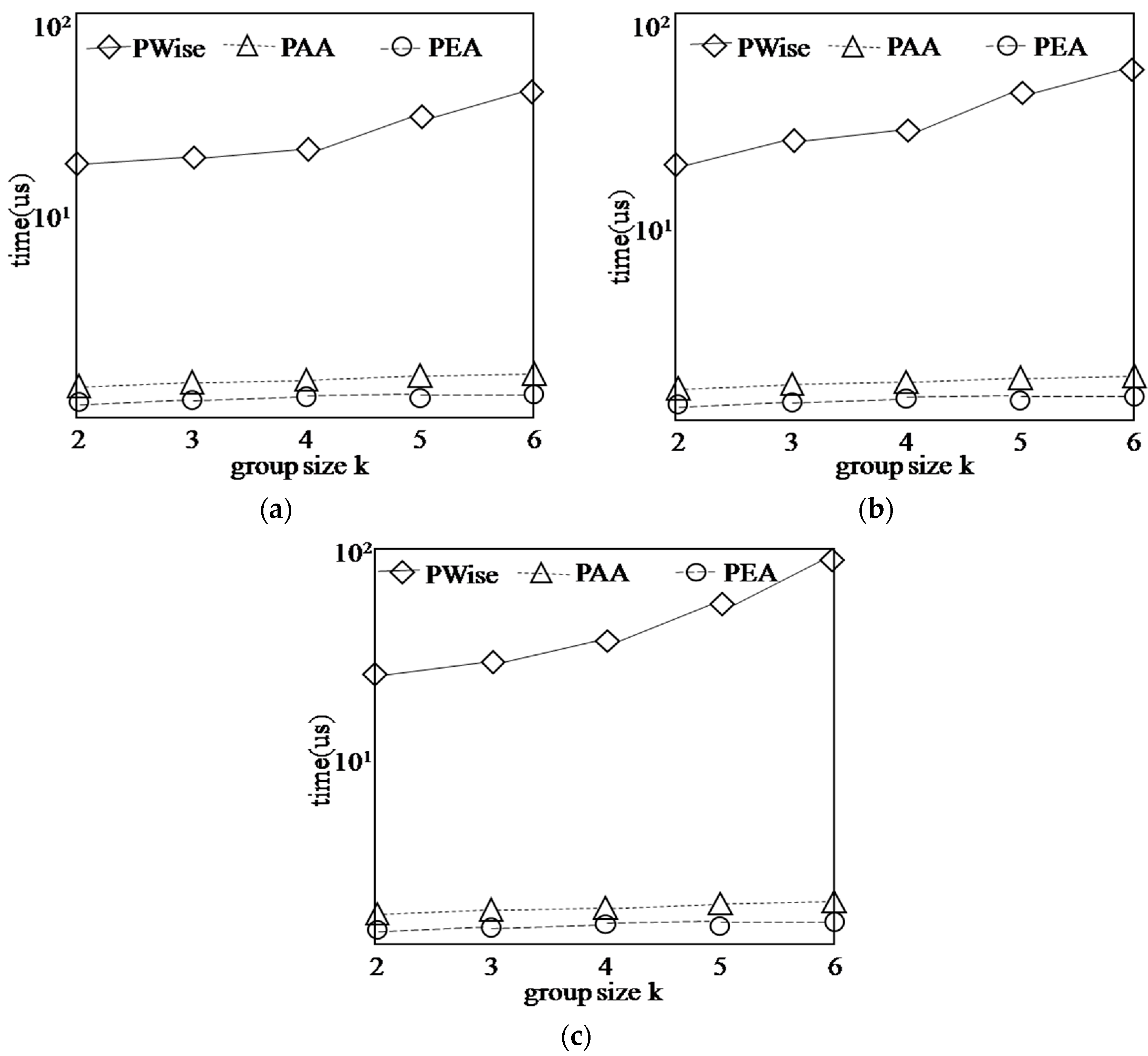
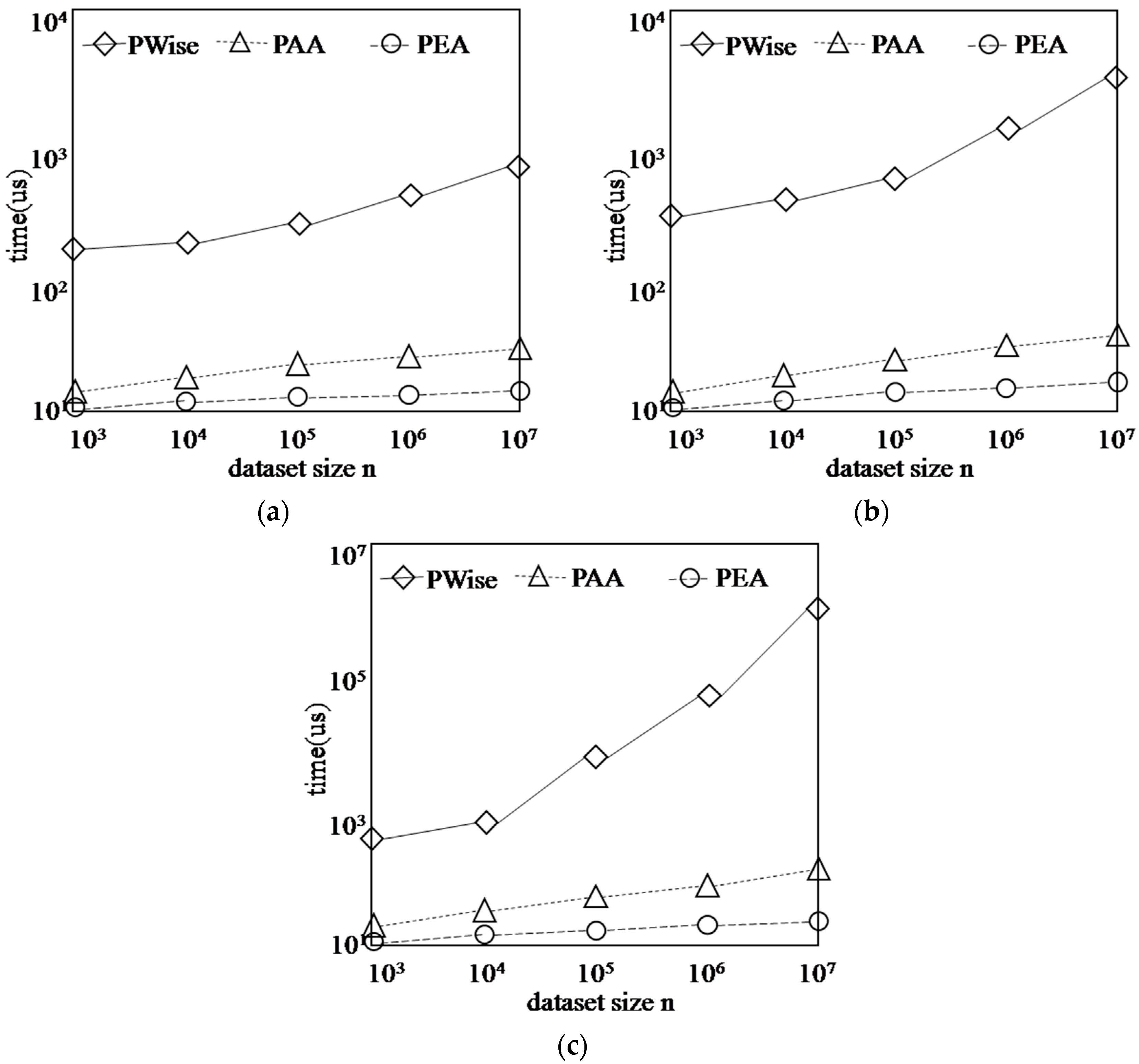
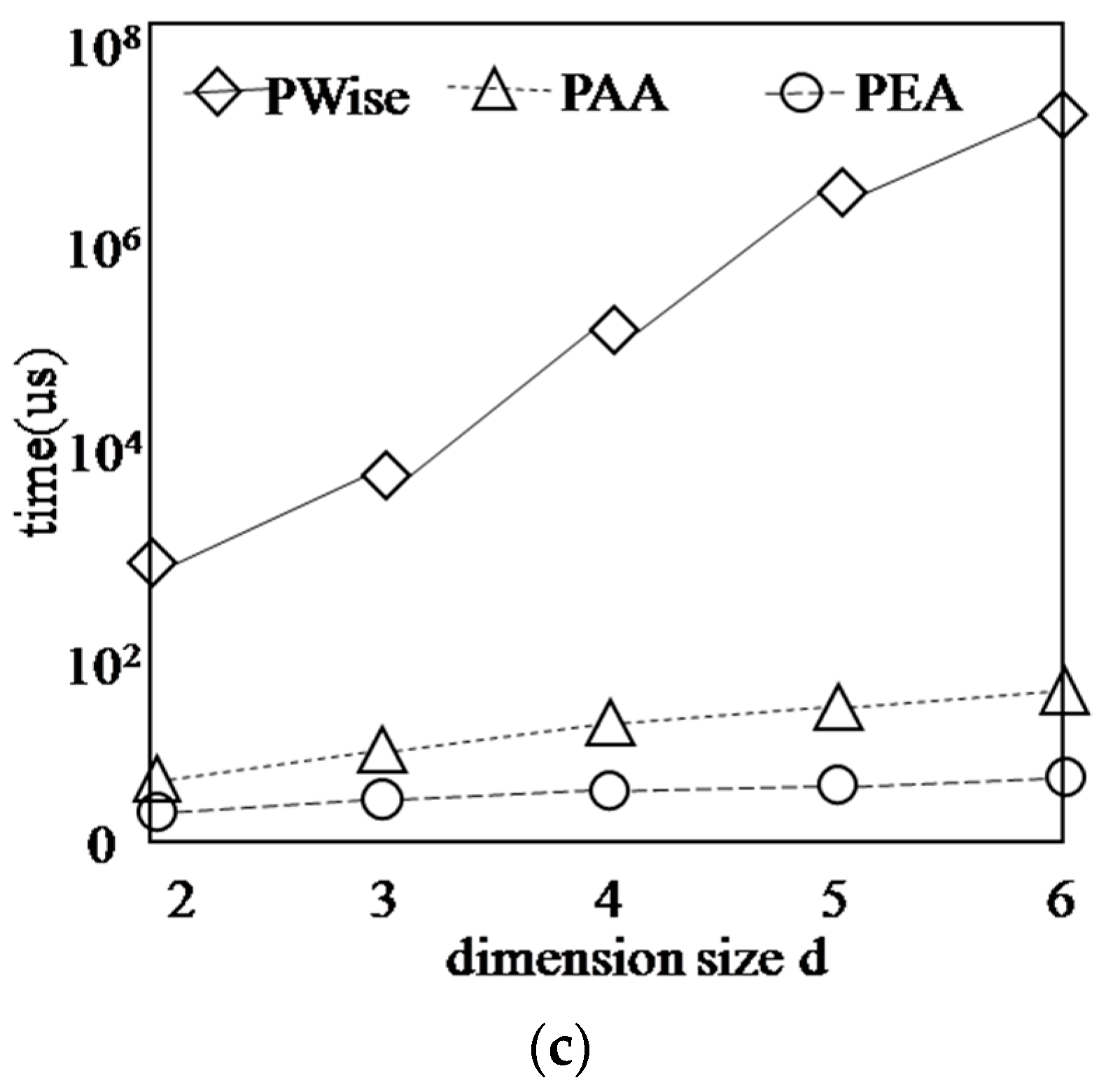
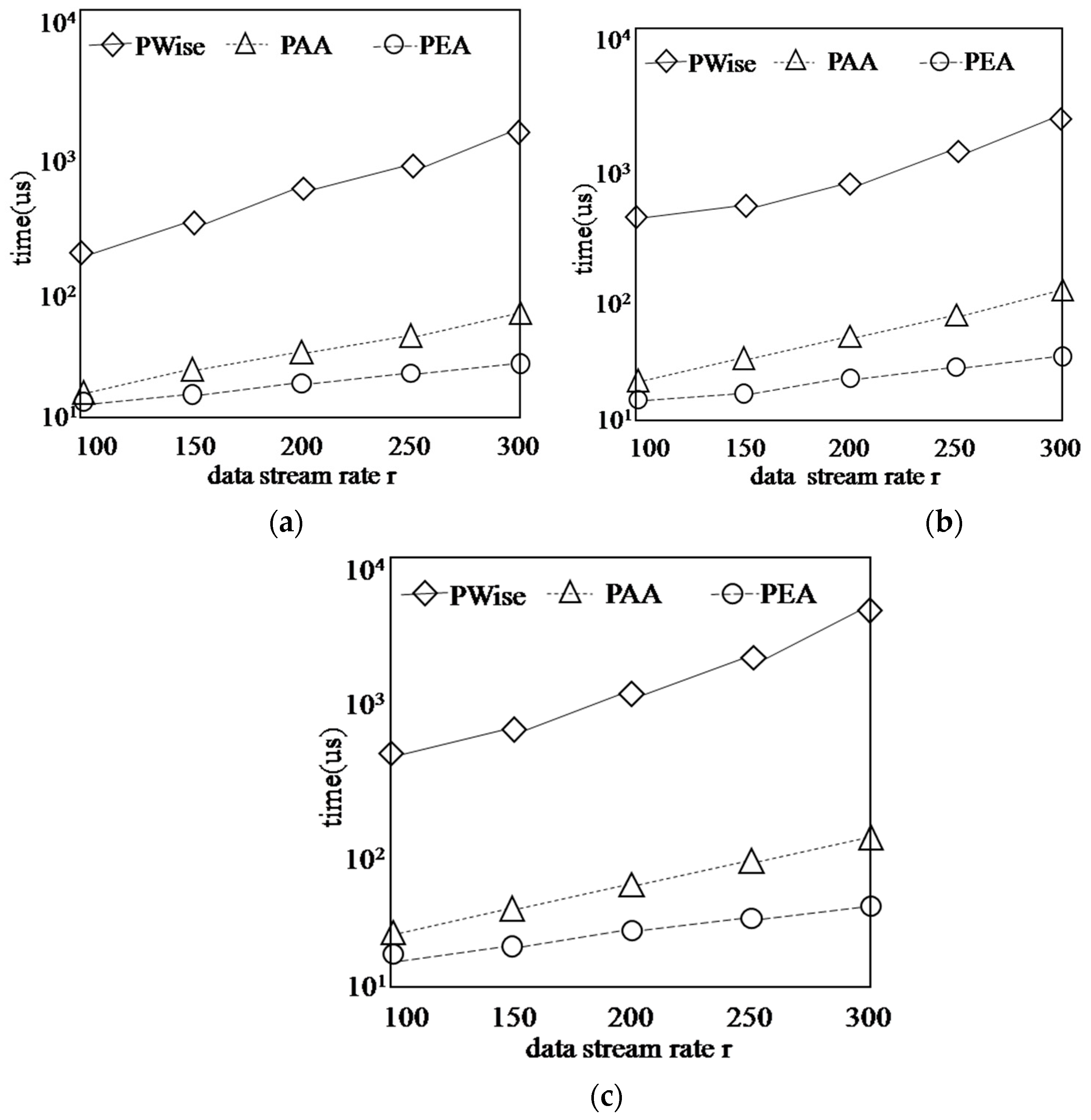
5.3. Performance with Respect to the Synthetic Data
6. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Liu, J.; Xiong, L.; Pei, J. Finding Pareto Optimal Groups: Group-based Skyline. In Proceedings of the International Conference on Very Large Databases (VLDB), Hilton Waikoloa, HI, USA, 31 August–4 September 2015; pp. 2086–2097. [Google Scholar]
- Borzsonyi, S.; Kossmann, D.; Stocker, K. The skyline operator. In Proceedings of the 17th International Conference on Data Engineering, Heidelberg, Germany, 2–6 April 2001; pp. 421–430. [Google Scholar]
- Chomicki, J.; Godfrey, P.; Gryz, J. Skyline with presorting. In Proceedings of the 19th International Conference on Data Engineering, Bangalore, India, 5–8 March 2003; pp. 717–719. [Google Scholar]
- Tan, K.; Eng, P.; Ooi, B. Efficient progressive skyline computation. In Proceedings of the 27th International Conference on Very Large Data Bases (VLDB), Roma, Italy, 14–15 September 2001; pp. 301–310. [Google Scholar]
- Kossmann, D.; Ramsak, F.; Rost, S. Shooting stars in the sky an online algorithm for skyline queries. In Proceedings of the 28th International Conference on Very Large Data Bases (VLDB), Hong Kong, China, 20–23 August 2002; pp. 275–286. [Google Scholar]
- Pei, J.; Jin, W.; Ester, M.; Tao, Y. Catching the best views of skyline: Asemantic approach based on decisive subspaces. In Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 253–264. [Google Scholar]
- Lee, J.; Hwang, S.W. Toward efficient multidimensional subspace skyline computation. VLDB J. 2014, 23, 129–145. [Google Scholar] [CrossRef]
- Xia, T.; Zhang, D. Refreshing the sky: The compressed skycube withefficient support for frequent updates. In Proceedings of the International Conference on Management of Data and Symposium on Principles Database and System, Chicago, IL, USA, 27–29 June 2006; pp. 491–502. [Google Scholar]
- Li, Y.Y.; Li, Z.Y.; Dong, M.X. Efficient subspace skyline query based on user preference using MapReduce. Ad. Hoc. Netw. 2015, 35, 105–115. [Google Scholar] [CrossRef]
- Chan, C.Y.; Jagadish, H.V.; Tan, K.L.; Tung, A.K.; Zhang, Z. Findingk-dominant skylines in high dimensional space. In Proceedings of the International Conference on Management of Data and Symposium on Principles Database and System, Chicago, IL, USA, 27–29 June 2006; pp. 503–514. [Google Scholar]
- Miao, X.Y.; Gao, Y.; Chen, G.; Zhang, T. k-Dominant skyline queries on incomplete data. Inf. Sci. 2016, 367, 990–1011. [Google Scholar] [CrossRef]
- Lee, J.; You, G.; Hwang, S. Personalized top-k skyline queries in high-dimensional space. Inf. Syst. 2009, 34, 45–61. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, B.; Lin, D. Incremental evaluation of top-k combinatorial metric skyline query. Knowl. Based Syst. 2015, 74, 89–105. [Google Scholar] [CrossRef]
- Zhang, W.; Lin, X.; Zhang, Y.; Pei, J.; Wang, W. Threshold-based probabilistic top k dominating query. VLDB J. 2010, 19, 283–305. [Google Scholar] [CrossRef]
- Jiang, T.; Zhang, B.; Gao, Y.; Le, G.X. Efficient top k query processing on mutual skyline. J. Comput. Res. Dev. 2013, 50, 986–997. [Google Scholar]
- Son, W.; Stehn, F.; Knauer, C. Top-k Manhattan Spatial Skyline Queries. Inf. Process. Lett. 2017, 123, 27–35. [Google Scholar] [CrossRef]
- Answering skyline queries on probabilistic data using the dominance of probabilistic tuples. Inf. Sci. 2016, 340, 58–85.
- Pei, J.; Jiang, B.; Lin, X.; Yuan, Y. Probabilistic skylines on uncertain data. In Proceedings of the 33rd International Conference on Very Large Data Bases, Vienna, Austria, 23–27 September 2007; pp. 15–26. [Google Scholar]
- Pujari, A.K.; Kagita, V.R.; Garg, A. Efficient computation for probabilistic skyline over uncertain preferences. Inf. Sci. 2015, 324, 146–162. [Google Scholar] [CrossRef]
- Lee, K.H.; Kim, J.; Kim, M.H. Simultaneous Processing of Multi-Skyline Queries with MapReduce. IEICE Trans. Inform. Syst. 2017, 100, 1516–1520. [Google Scholar]
- Zaman, A.; Siddique, M.A.; Morimoto, Y. Finding Key Persons on Social Media by Using MapReduce Skyline. Int. J. Netw. Comput. 2017, 7, 86–104. [Google Scholar] [CrossRef]
- Lin, X.; Yuan, Y.; Wang, W.; Lu, H. Stabbing the sky: Efficient skyline computation over sliding windows. In Proceedings of the IEEE 21st International Conference on Data Engineering, Tokyo, Japan, 5–8 April 2005; pp. 502–513. [Google Scholar]
- Morse, M.; Patel, J.-M.; Grosky, W.-I. Efficient continuous skyline computation. Inf. Sci. 2007, 177, 3411–3437. [Google Scholar] [CrossRef]
- Li, H.; Yoo, J. An efficient scheme for continuous skyline query processing over dynamic data set. In Proceedings of the International Conference on Big Data and Smart Computing, Bangkok, Thailand, 15–17 January 2014; pp. 54–59. [Google Scholar]
- Tiziano, D.M.; Salvatore, D.G.; Gabriele, M. A Multicore Parallelization of Continuous Skyline Queries on Data Streams. In Proceedings of the 21st International Conference on Parallel and Distributed Computing, Vienna, Austria, 24–28 August 2015; pp. 402–413. [Google Scholar]
- Su, I.-F.; Chung, Y.-C.; Lee, C. Top-k combinatorial skyline queries. In Proceedings of the 15th International Conference, DASFAA 2010, Tsukuba, Japan, 1–4 April 2010; pp. 79–93. [Google Scholar]
- Im, H.; Park, S. Group skyline computation. Inf. Sci. 2011, 188, 151–169. [Google Scholar] [CrossRef]
- Zhang, N.; Li, C.; Hassan, N.; Rajasekaran, S.; Das, G. On skyline groups. IEEE Trans. Knowl. Data Eng. 2014, 4, 942–956. [Google Scholar] [CrossRef]
- Chung, Y.; Su, I.; Lee, C. Efficient computation of combinatorial skyline queries. Inf. Syst. 2013, 38, 369–387. [Google Scholar] [CrossRef]
- Zhu, H.; Zhu, P.; Li, X. Computing skyline groups: An experimental evaluation. In Proceedings of the ACM Turing 50th Celebration Conference, Shanghai, China, 12–14 May 2017; pp. 48–65. [Google Scholar]
- Zhu, H.; Zhu, P.; Li, X. Parallelization of group-based skyline computation for multi-core processors. Concurr. Comput. Pract. Exp. 2017, 29, 124–141. [Google Scholar] [CrossRef]
- Magnani, M.; Assent, I. From stars to galaxies: Skyline queries on aggrgate data. In Proceedings of the 16th International Conference on Extending Database Technology, Genoa, Italy, 18–22 March 2013; pp. 477–488. [Google Scholar]
- Guo, X.; Li, H.; Wulamu, A.; Xie, Y.; Fu, Y. Efficient processing of skyline group queries over a data stream. Tsinghua Sci. Technol. 2016, 21, 29–39. [Google Scholar] [CrossRef]
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and Issues in Data Stream Systems. In Proceedings of the ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 1–16. [Google Scholar]


















© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, L.; Liu, G.; Cui, X.; Li, T. Finding Group-Based Skyline over a Data Stream in the Sensor Network. Information 2018, 9, 33. https://doi.org/10.3390/info9020033
Dong L, Liu G, Cui X, Li T. Finding Group-Based Skyline over a Data Stream in the Sensor Network. Information. 2018; 9(2):33. https://doi.org/10.3390/info9020033
Chicago/Turabian StyleDong, Leigang, Guohua Liu, Xiaowei Cui, and Tianyu Li. 2018. "Finding Group-Based Skyline over a Data Stream in the Sensor Network" Information 9, no. 2: 33. https://doi.org/10.3390/info9020033
APA StyleDong, L., Liu, G., Cui, X., & Li, T. (2018). Finding Group-Based Skyline over a Data Stream in the Sensor Network. Information, 9(2), 33. https://doi.org/10.3390/info9020033