Automatically Specifying a Parallel Composition of Matchers in Ontology Matching Process by Using Genetic Algorithm



Abstract
:1. Introduction
2. Ontology Matching
2.1. OWL
2.2. Terminology
2.3. Ontology Matching System
3. Related Work
4. Genetic Algorithm
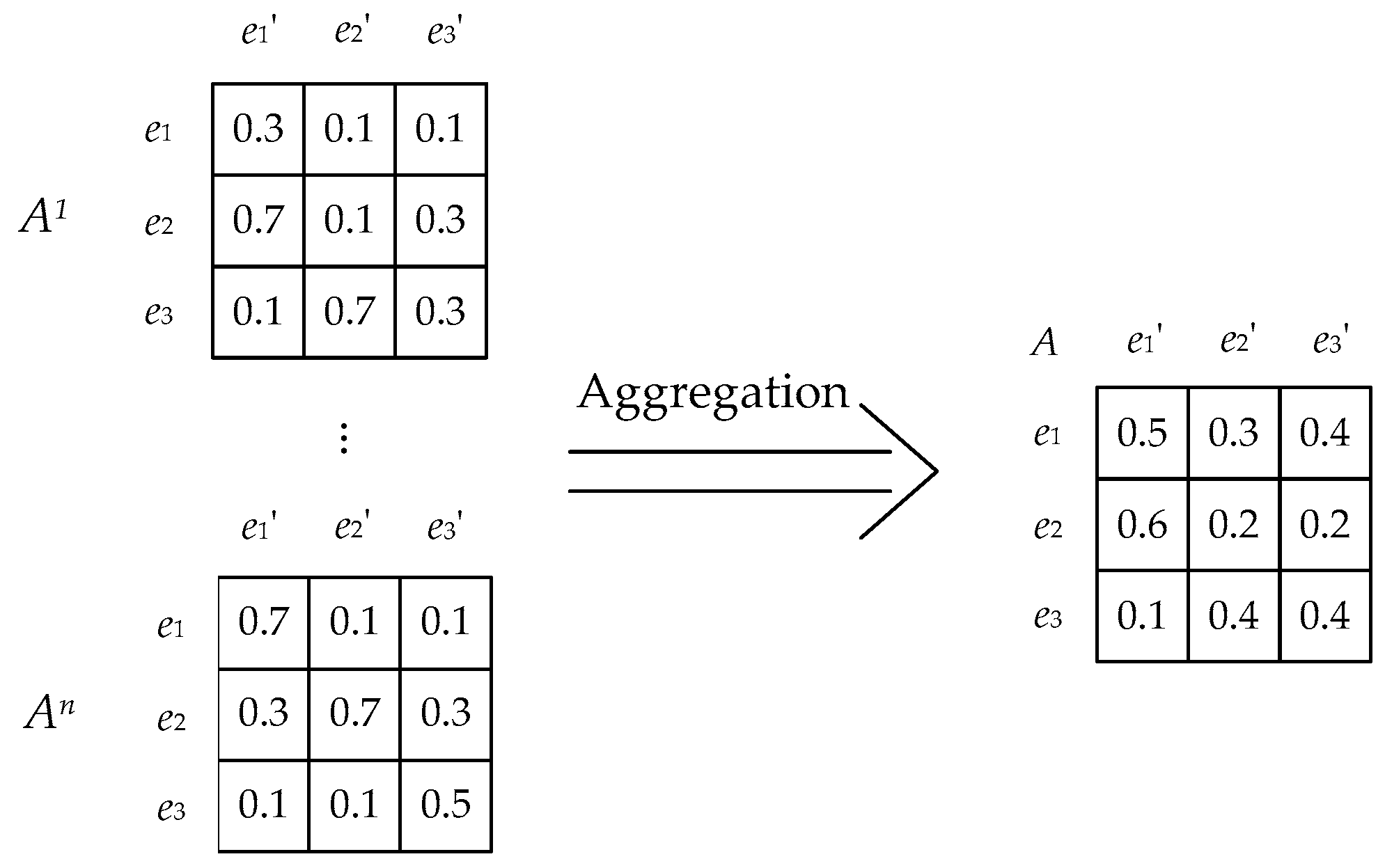
4.1. Implementation of the Weighted Aggregation by Using Genetic Algorithm
4.1.1. The Chromosome
4.1.2. The Fitness Function
4.1.3. Selection
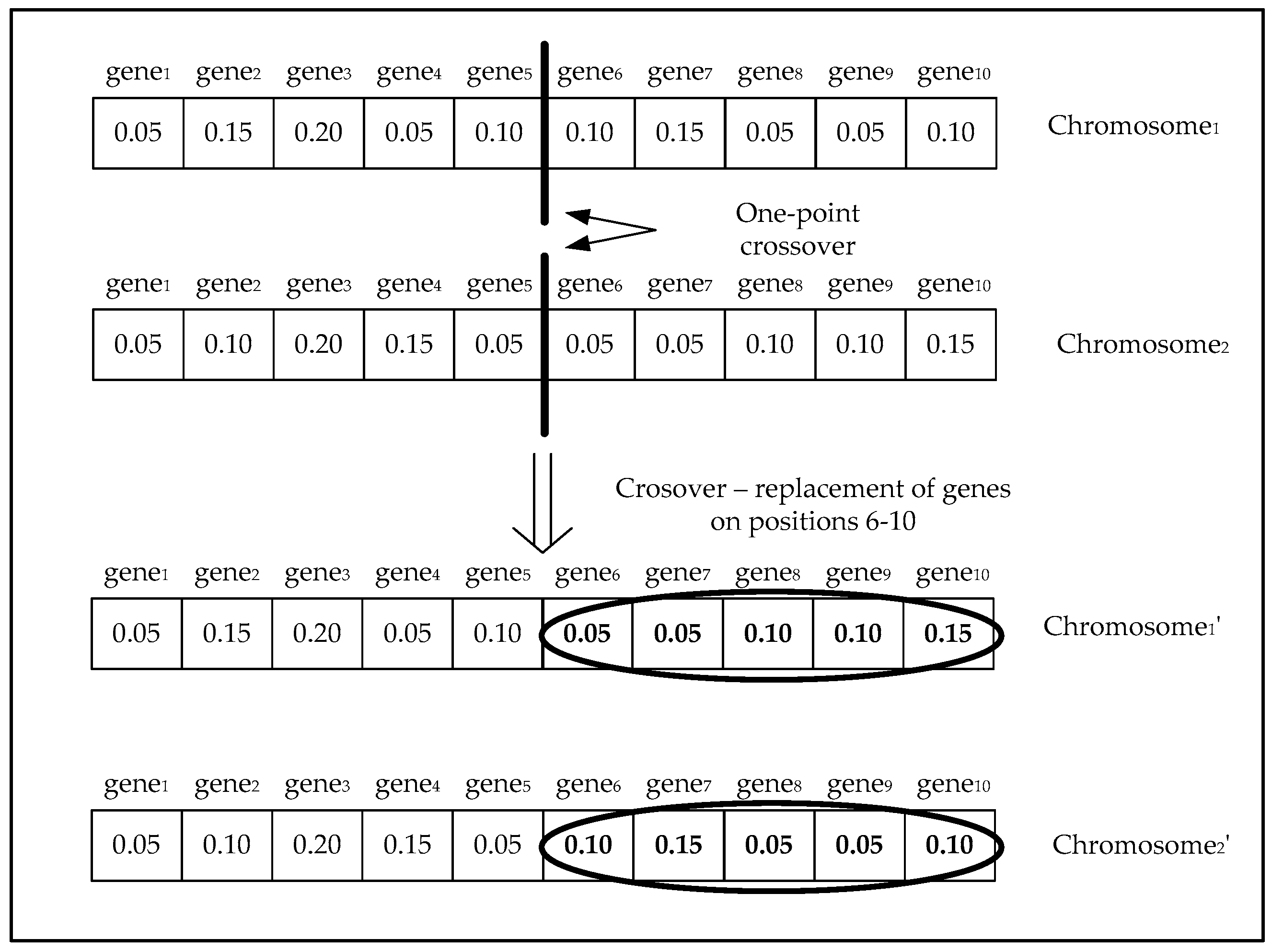
4.1.4. Genetic Operators
- Randomly generate the crossover point.
- Make a crossover of two chromosomes interchanging the values of genes after the crossover point.
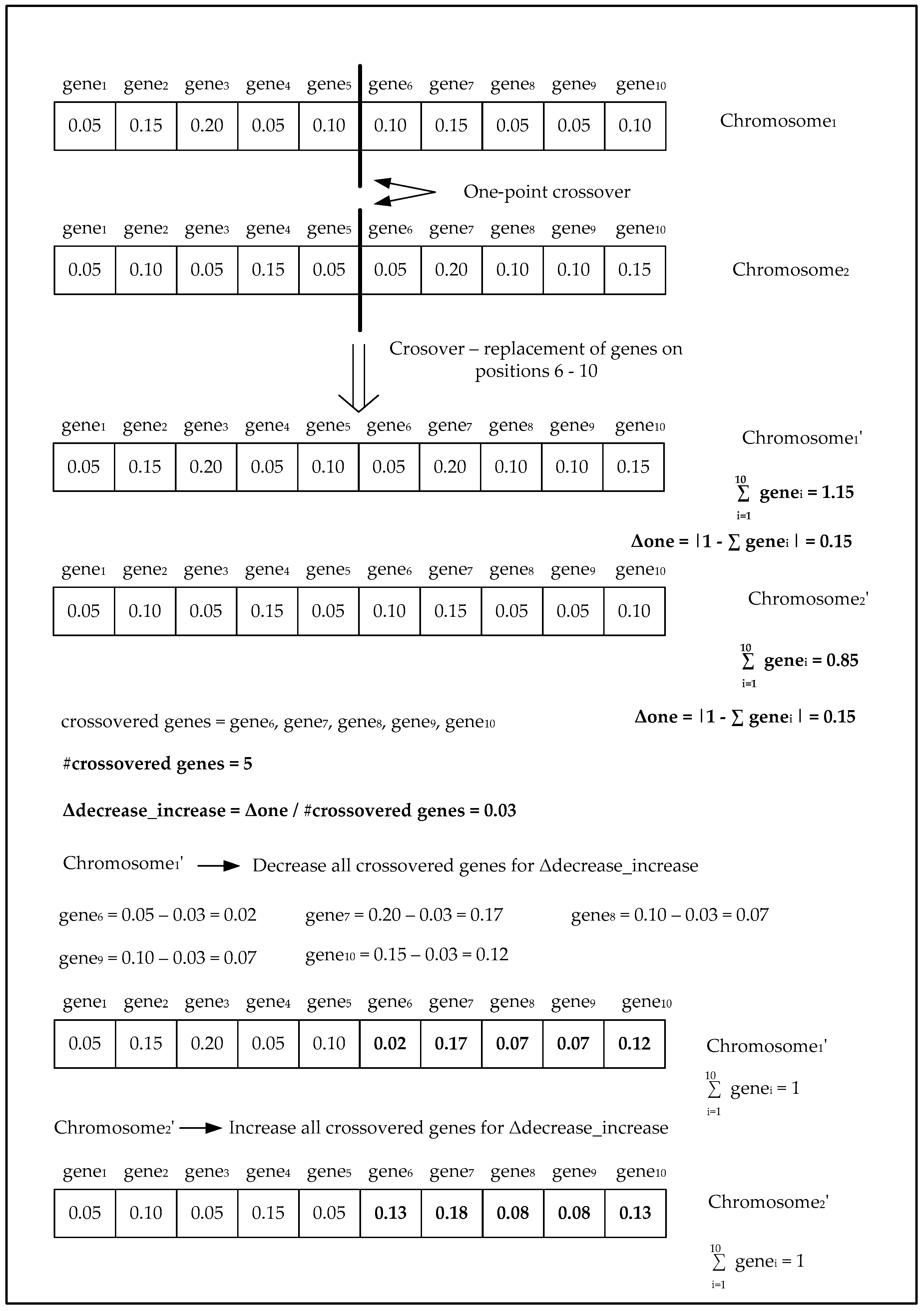
- Check the sum of genes’ values ∑genei within the newly created chromosomes. If the sum of genes’ values is not equal to 1 then:
- ○
- Calculate the absolute difference Δone between 1 and the sum of genes’ values ∑genei
- ○
- Calculate the value Δdecrease_increase, which is equal to quotient of the absolute difference Δone and number of genes after the crossover point
- ○
- Decrease (or increase) all genes’ values that are found after the defined crossover point for Δdecrease_increase value to adjust the sum of genes’ values ∑genei to be equal to 1.
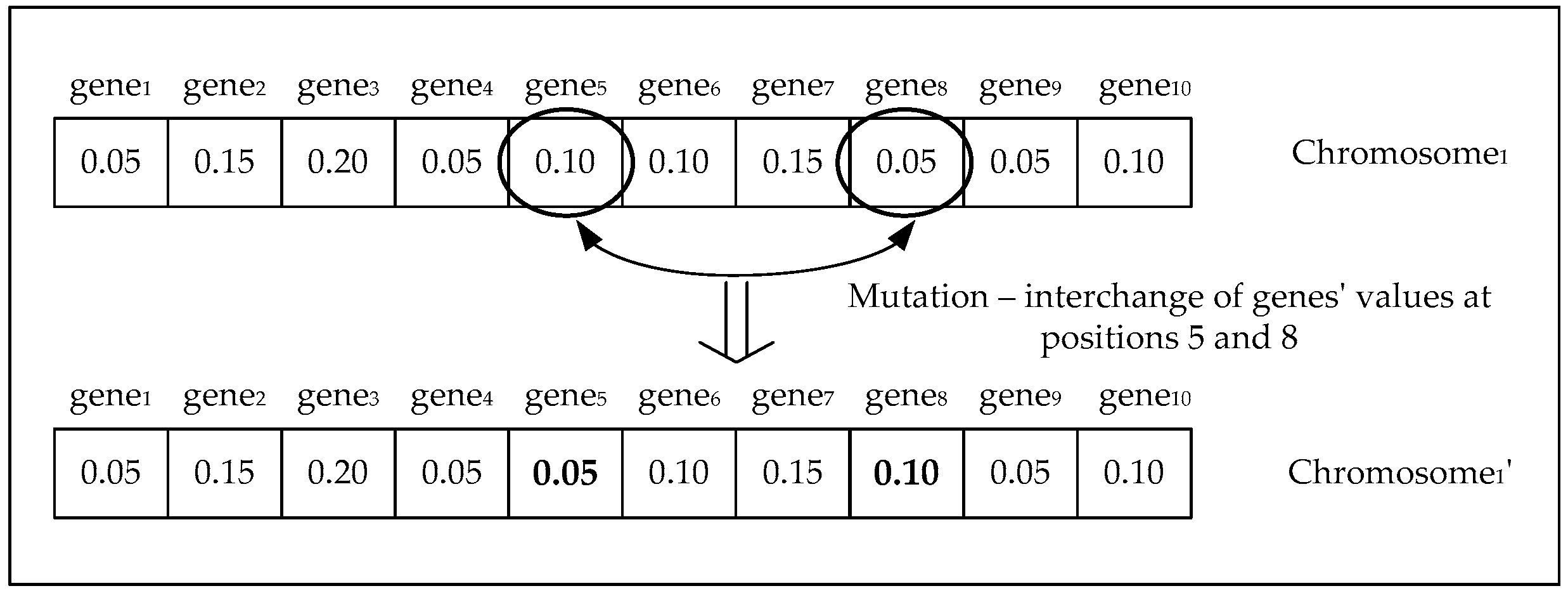
- Randomly select two genes within the chromosome on which the mutation will be performed.
- Interchange the values of the selected genes within the chromosome.
4.2. Evolution Process in the Genetic Algorithm
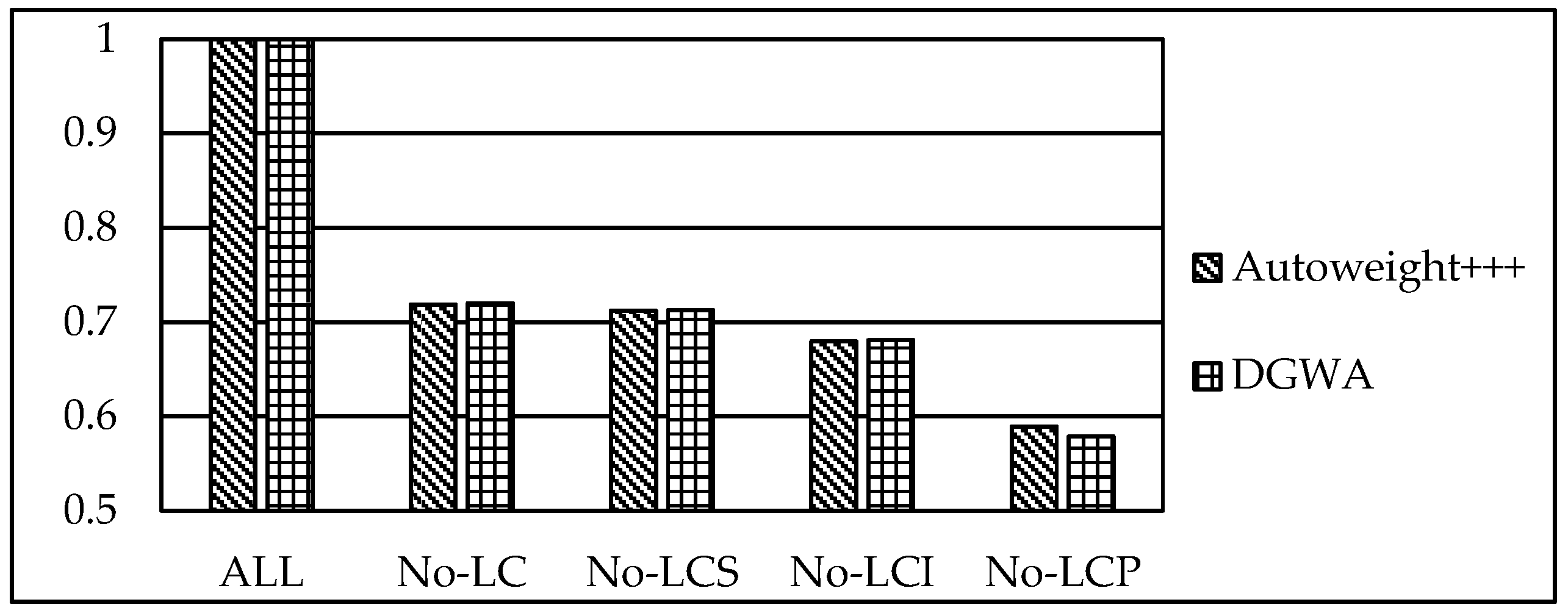
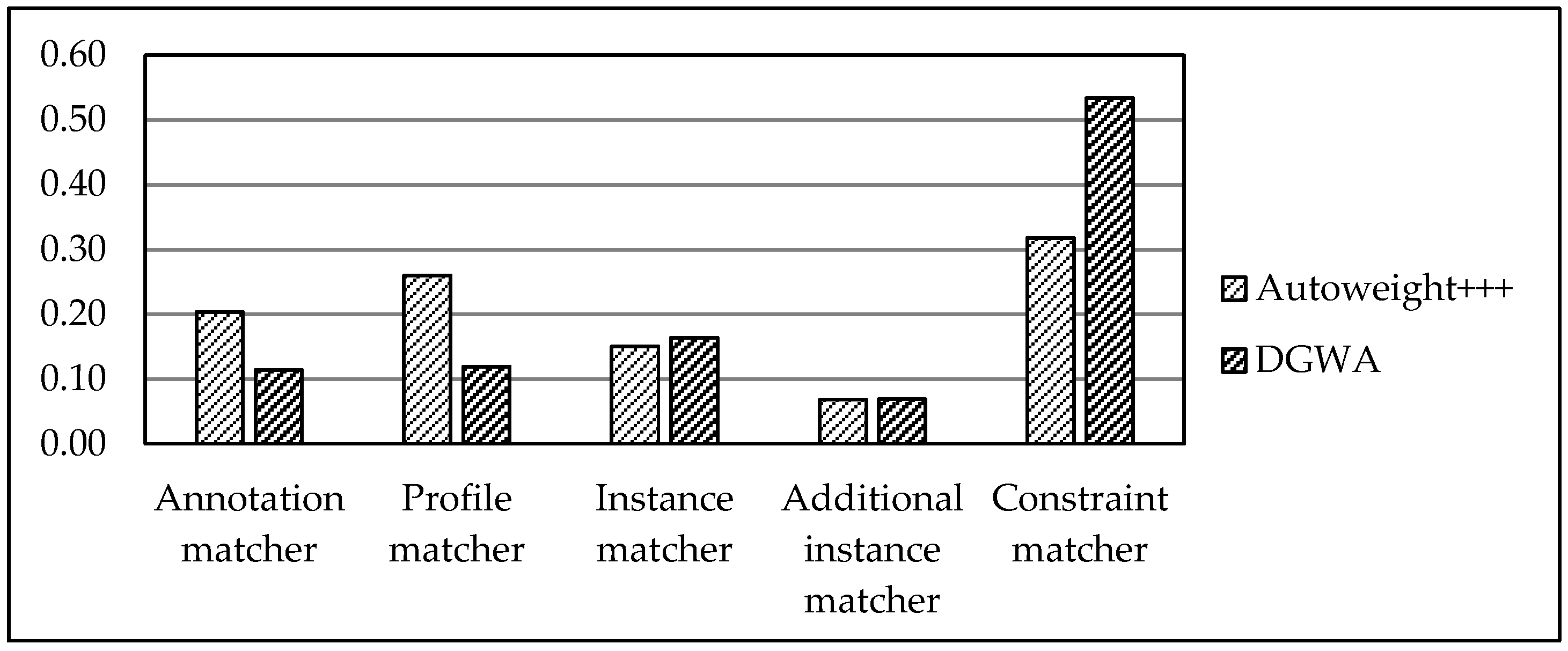
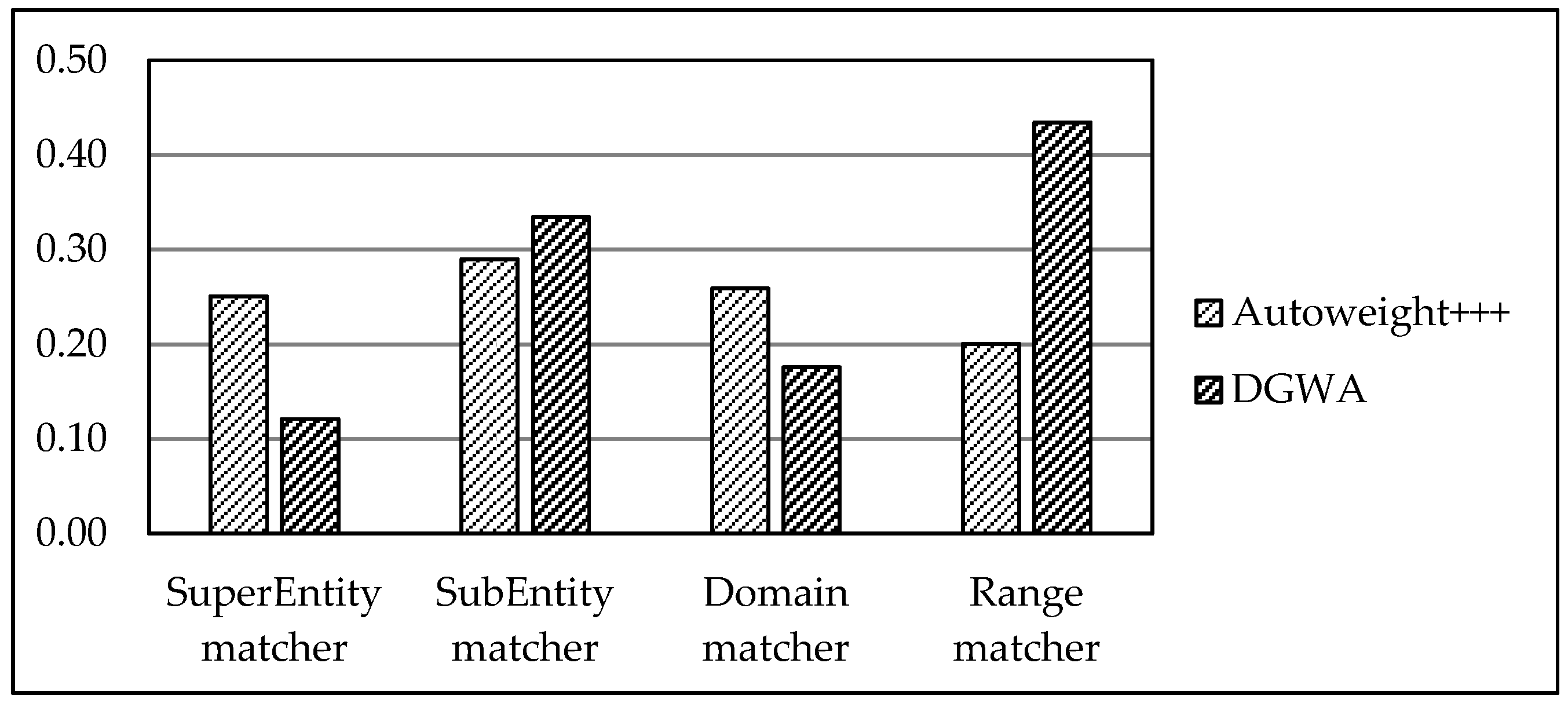
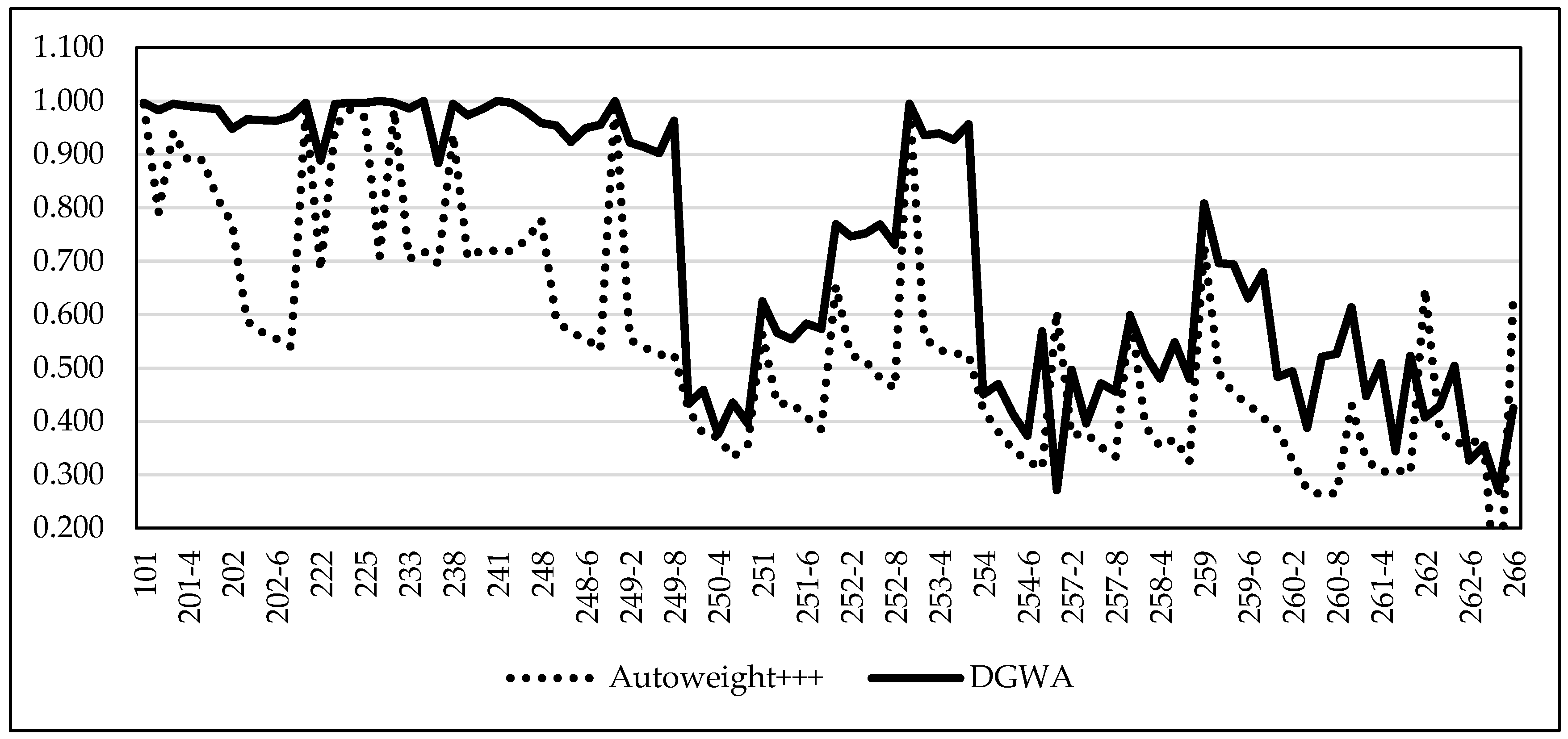
5. Evaluation
- Precision, which is the ratio of correctly found correspondences over the total number of correspondences returned by the matching system,
- Recall, which is the ratio of correctly found correspondences over the total number of all correct correspondences between two ontologies,
- F-Measure, which is the harmonic mean of precision and recall.
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Gulić, M.; Vrdoljak, B.; Banek, M. CroMatcher: An ontology matching system based on automated weighted aggregation and iterative final alignment. J. Web Semant. 2016, 41, 50–71. [Google Scholar] [CrossRef]
- Borst, P.; Akkermans, H.; Top, J. Engineering ontologies. Int. J. Hum.-Comput. Stud. 1997, 46, 365–406. [Google Scholar] [CrossRef]
- Antoniou, G.; Harmelen, F.V. Web Ontology Language: OWL. In Handbook on Ontologies; Staab, S., Studer, R., Eds.; International Handbooks on Information Systems; Springer: Berlin/Heidelberg, Germany, 2009; pp. 91–111. ISBN 978-3-540-92673-3. [Google Scholar]
- Euzenat, J.; Shvaiko, P. Ontology Matching, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2013; ISBN 3-540-49611-4. [Google Scholar]
- Broder, A. A Taxonomy of Web Search. SIGIR Forum 2002, 36, 3–10. [Google Scholar] [CrossRef]
- Gulić, M.; Magdalenić, I.; Vrdoljak, B. Automatically Specifying Parallel Composition of Matchers in Ontology Matching Process. In Proceedings of the Research Conference on Metadata and Semantic Research (MTSR 2011), Izmir, Turkey, 12–14 October 2011; García-Barriocanal, E., Cebeci, Z., Okur, M.C., Öztürk, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 22–33. [Google Scholar]
- Mao, M.; Peng, Y.; Spring, M. A Harmony based adaptive ontology mapping approach. In Proceedings of the International Conference on Semantic Web and Web Services (SWWS 2008), Las Vegas, NV, USA, 14–17 July 2008; Arabnia, H.R., Marsh, A., Eds.; CSREA Press: Athens, GA, USA, 2008; pp. 336–342. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms (Complex Adaptive Systems), 1st ed.; MIT Press: Cambridge, MA, USA, 1998; ISBN 0-262-63185-7. [Google Scholar]
- Feng, X.; Lau, F.C.M.; Gao, D. A New Bio-inspired Approach to the Traveling Salesman Problem. In Proceedings of the International Conference on Complex Sciences, Shanghai, China, 23–25 February 2009; Zhou, J., Ed.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1310–1321. [Google Scholar]
- Euzenat, J.; Roşoiu, M.E.; Trojahn, C. Ontology matching benchmarks: Generation, stability, and discriminability. J. Web Semant. 2013, 21, 30–48. [Google Scholar] [CrossRef] [Green Version]
- Gulić, M.; Vrdoljak, B.; Banek, M. CroMatcher—Results for OAEI 2016. In Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, 17–21 October 2016; Shvaiko, P., Euzenat, J., Jiménez-Ruiz, E., Cheatham, M., Hassanzadeh, O., Ryutaro, I., Eds.; CEUR-WS.org: Aachen, Germany, 2016; Volume 1766, pp. 153–160. [Google Scholar]
- Gulić, M.; Vrdoljak, B.; Banek, M. CroMatcher—Results for OAEI 2015. In Proceedings of the 10th International Workshop on Ontology Matching Co-Located with the 14th International Semantic Web Conference (ISWC 2015), Bethlehem, PA, USA, 12 October 2015; Shvaiko, P., Euzenat, J., Jiménez-Ruiz, E., Cheatham, M., Hassanzadeh, O., Eds.; CEUR-WS.org: Aachen, Germany, 2015; Volume 1545, pp. 130–135. [Google Scholar]
- Gulić, M.; Vrdoljak, B. CroMatcher—Results for OAEI 2013. In Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, 21 October 2013; Shvaiko, P., Euzenat, J., Srinivas, K., Mao, M., Jiménez-Ruiz, E., Eds.; CEUR-WS.org: Aachen, Germany, 2013; Volume 1111, pp. 117–122. [Google Scholar]
- Euzenat, J.; Meilicke, C.; Stuckenschmidt, H.; Shvaiko, P.; Trojahn, C. Ontology Alignment Evaluation Initiative: Six Years of Experience. In Journal on Data Semantics XV; Spaccapietra, S., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6720, pp. 158–192. ISBN 978-3-642-22630-4. [Google Scholar]
- Ontology Alignment Evaluation Initiative. Available online: http://oaei.ontologymatching.org/ (accessed on 25 April 2018).
- Antoniou, G.; Harmelen, F.V. Semantic Web Primer, 1st ed.; The MIT Press: Cambridge, MA, USA, 2004; ISBN 0-262-01210-3. [Google Scholar]
- Berners-Lee, T.; Jaffe, C.J. World Wide Web Consortium (W3C). Available online: http://www.w3.org/ (accessed on 24 April 2018).
- Shvaiko, P.; Euzenat, J. Ontology Matching: State of the Art and Future Challenges. IEEE Trans. Knowl. Data Eng. 2013, 25, 158–176. [Google Scholar] [CrossRef] [Green Version]
- Do, H.-H.; Rahm, E. COMA: A system for flexible combination of schema matching approaches. In Proceedings of the International Conference on Very Large Data Bases (VLDB 2002), Hong Kong, China, 20–23 August 2002; pp. 610–621. [Google Scholar]
- Aumueller, D.; Do, H.-H.; Massmann, S.; Rahm, E. COMA++—Schema and ontology matching with COMA. In Proceedings of the International Conference on Management of Data (SIGMOD 2005), Baltimore, MD, USA, 14–16 June 2005; ACM: New York, NY, USA, 2005; p. 906. [Google Scholar]
- Ngo, D.H.; Bellahsene, Z. Overview of YAM++—(Not) Yet Another Matcher for ontology alignment task. J. Web Semant. 2016, 41, 30–49. [Google Scholar] [CrossRef]
- Ehrig, M.; Sure, Y. Ontology mapping—An integrated approach. Semant. Web Res. Appl. 2004, 76–91. [Google Scholar] [CrossRef]
- Jian, N.; Hu, W.; Cheng, G.; Qu, Y. Falcon-AO: Aligning ontologies with falcon. In Proceedings of the K-CAP 2005 Workshop on Integrating Ontologies, Banff, AB, Canada, 2 October 2005; Ashpole, B., Ehrig, M., Euzenat, J., Stuckenschmidt, H., Eds.; CEUR-WS.org: Aachen, Germany, 2005; Volume 156, pp. 85–91. [Google Scholar]
- Castano, S.; Ferrara, A.; Montanelli, S. Matching ontologies in open networked systems: Techniques and applications. In Journal on Data Semantics V; Spaccapietra, S., Atzeni, P., Chu, W.W., Catarci, T., Sycara, K.P., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3870, pp. 25–63. ISBN 0302-9743. [Google Scholar]
- Bach, T.L.; Dieng-Kuntz, R.; Gandon, F. On ontology matching problems (for building a corporate semantic web in a multi-communities organization). In Proceedings of the 6th International Conference on Enterprise Information Systems (ICEIS 2004), Porto, Portugal, 14–17 April 2004; Seruca, I., Cordeiro, J., Hammoudi, S., Filipe, J., Eds.; Springer: Dodrecht, The Netherlands, 2004; pp. 236–243. [Google Scholar]
- Dang, T.T.; Gabriel, A.; Hertling, S.; Roskosch, P.; Wlotzka, M.; Zilke, J.R.; Janssen, F.; Paulheim, H. HotMatch results for OAEI 2012. In Proceedings of the 7th International Workshop on Ontology Matching (OM-2012) Collocated with the 11th International Semantic Web Conference (ISWC-2012), Boston, MA, USA, 11 November 2012; Shvaiko, P., Euzenat, J., Mao, M., Noy, N., Stuckenschmidt, H., Eds.; CEUR-WS.org: Aachen, Germany, 2012; Volume 946, pp. 145–151. [Google Scholar]
- Wang, P.; Wang, W. Lily results for OAEI 2016. In Proceedings of the 11th International Workshop on Ontology Matching Co-Located with the 15th International Semantic Web Conference (ISWC 2016), Kobe, Japan, 17–21 October 2016; Shvaiko, P., Euzenat, J., Jiménez-Ruiz, E., Cheatham, M., Hassanzadeh, O., Ryutaro, I., Eds.; CEUR-WS.org: Aachen, Germany, 2016; Volume 1766, pp. 178–184. [Google Scholar]
- Zhang, Y.; Wang, X.; He, S.; Liu, K.; Zhao, J.; Lv, X. IAMA results for OAEI 2013. In Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, 21 October 2013; Shvaiko, P., Euzenat, J., Srinivas, K., Mao, M., Jiménez-Ruiz, E., Eds.; CEUR-WS.org: Aachen, Germany, 2013; pp. 123–130. [Google Scholar]
- Gracia, J.; Asooja, K. Monolingual and cross-lingual ontology matching with CIDER-CL: Evaluation report for OAEI 2013. In Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, 21 October 2013; Shvaiko, P., Euzenat, J., Srinivas, K., Mao, M., Jiménez-Ruiz, E., Eds.; CEUR-WS.org: Aachen, Germany, 2013; Volume 1111, pp. 109–116. [Google Scholar]
- Smith, M. Neural Networks for Statistical Modeling, 1st ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1993; ISBN 0-442-01310-8. [Google Scholar]
- Kuo, I.-H.; Wu, T.-T. ODGOMS—Results for OAEI 2013. In Proceedings of the 8th International Workshop on Ontology Matching Co-Located with the 12th International Semantic Web Conference (ISWC 2013), Sydney, Australia, 21 October 2013; Shvaiko, P., Euzenat, J., Srinivas, K., Mao, M., Jiménez-Ruiz, E., Eds.; CEUR-WS.org: Aachen, Germany, 2013; pp. 153–160. [Google Scholar]
- Mao, M.; Peng, Y.; Spring, M. An adaptive ontology mapping approach with neural network based constraint satisfaction. J. Web Semant. 2010, 8, 14–25. [Google Scholar] [CrossRef]
- Xue, X.; Pan, J.-S. An overview on evolutionary algorithm based ontology matching. J. Inf. Hiding Multimed. Signal Process. 2018, 9, 75–88. [Google Scholar]
- Vázquez Naya, J.M.; Martínez Romero, M.; Loureiro, J.P.; Munteanu, C.R.; Pazos Sierra, A. Improving Ontology Alignment through Genetic Algorithms, 1st ed.; IGI Global: Hershey, PA, USA, 2010; ISBN 978-1-61520-893-7. [Google Scholar]
- Feng, Y.; Zhao, L.; Yang, J. GATuner: Tuning schema matching systems using genetic algorithms. In Proceedings of the 2nd International Workshop on Database Technology and Applications (DBTA2010), Wuhan, China, 27–28 November 2010; pp. 1–4. [Google Scholar]
- Martinez-Gil, J.; Alba, E.; Aldana-Montes, J.F. Optimizing ontology alignments by using genetic algorithms. In Proceedings of the First International Conference on Nature Inspired Reasoning for the Semantic Web, Karlsruhe, Germany, 27 October 2008; Guéret, C., Hitzler, P., Schlobach, S., Eds.; CEUR-WS.org: Aachen, Germany, 2008; Volume 419, pp. 1–15. [Google Scholar]
- Nikolov, A.; D’Aquin, M.; Motta, E. Unsupervised Data Linking Using a Genetic Algorithm; Knowledge Media Institute: Milton Keynes, UK, 2011; pp. 1–17. [Google Scholar]
- Jebari, K.; Madiafi, M. Selection Methods for Genetic Algorithms. Int. J. Emerg. Sci. 2013, 3, 333–344. [Google Scholar]
- OAEI 2016 Campaign—Benchmark Results. Available online: http://oaei.ontologymatching.org/2016/results/benchmarks/index.html (accessed on 25 April 2018).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Autoweight+++ | DWGA | Autoweight+++ | DWGA | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Test | R | P | F-M | R | P | F-M | Test | R | P | F-M | R | P | F-M |
| 101 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-4 | 0.792 | 0.963 | 0.869 | 0.792 | 0.950 | 0.864 |
| 201 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-6 | 0.719 | 0.959 | 0.822 | 0.730 | 0.946 | 0.824 |
| 201-2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-8 | 0.563 | 0.844 | 0.675 | 0.636 | 0.836 | 0.722 |
| 201-4 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259 | 0.568 | 0.798 | 0.664 | 0.660 | 0.753 | 0.703 |
| 201-6 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259-2 | 0.897 | 0.967 | 0.931 | 0.887 | 0.946 | 0.916 |
| 201-8 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259-4 | 0.846 | 0.954 | 0.897 | 0.887 | 0.967 | 0.925 |
| 202 | 0.866 | 0.944 | 0.903 | 0.856 | 0.944 | 0.898 | 259-6 | 0.825 | 0.920 | 0.870 | 0.712 | 0.832 | 0.767 |
| 202-2 | 0.980 | 1.000 | 0.990 | 0.980 | 1.000 | 0.990 | 254-6 | 0.728 | 1.000 | 0.843 | 0.728 | 1.000 | 0.843 |
| 202-4 | 0.918 | 0.989 | 0.952 | 0.928 | 0.990 | 0.958 | 254-8 | 0.637 | 1.000 | 0.778 | 0.485 | 0.942 | 0.640 |
| 202-6 | 0.887 | 0.978 | 0.930 | 0.866 | 0.955 | 0.908 | 257 | 0.334 | 0.847 | 0.479 | 0.334 | 0.459 | 0.387 |
| 202-8 | 0.877 | 0.989 | 0.930 | 0.877 | 0.989 | 0.930 | 257-2 | 0.819 | 1.000 | 0.900 | 0.788 | 1.000 | 0.881 |
| 221 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 257-4 | 0.758 | 1.000 | 0.862 | 0.728 | 1.000 | 0.843 |
| 222 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 257-6 | 0.516 | 0.945 | 0.668 | 0.425 | 0.934 | 0.584 |
| 223 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 257-8 | 0.455 | 0.883 | 0.601 | 0.273 | 0.819 | 0.410 |
| 224 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258 | 0.563 | 0.886 | 0.688 | 0.605 | 0.841 | 0.704 |
| 225 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-2 | 0.886 | 0.978 | 0.930 | 0.917 | 0.978 | 0.947 |
| 228 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-4 | 0.792 | 0.963 | 0.869 | 0.792 | 0.950 | 0.864 |
| 232 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-6 | 0.719 | 0.959 | 0.822 | 0.730 | 0.946 | 0.824 |
| 233 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 258-8 | 0.563 | 0.844 | 0.675 | 0.636 | 0.836 | 0.722 |
| 236 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259 | 0.568 | 0.798 | 0.664 | 0.660 | 0.753 | 0.703 |
| 237 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259-2 | 0.897 | 0.967 | 0.931 | 0.887 | 0.946 | 0.916 |
| 238 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259-4 | 0.846 | 0.954 | 0.897 | 0.887 | 0.967 | 0.925 |
| 239 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 259-6 | 0.825 | 0.920 | 0.870 | 0.712 | 0.832 | 0.767 |
| 240 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 254-6 | 0.728 | 1.000 | 0.843 | 0.728 | 1.000 | 0.843 |
| 241 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 254-8 | 0.637 | 1.000 | 0.778 | 0.485 | 0.942 | 0.640 |
| 246 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 257 | 0.334 | 0.847 | 0.479 | 0.334 | 0.459 | 0.387 |
| 247 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 257-2 | 0.819 | 1.000 | 0.900 | 0.788 | 1.000 | 0.881 |
| 248 | 0.846 | 0.932 | 0.887 | 0.846 | 0.932 | 0.887 | 257-4 | 0.758 | 1.000 | 0.862 | 0.728 | 1.000 | 0.843 |
| 248-2 | 0.980 | 1.000 | 0.990 | 0.990 | 1.000 | 0.995 | 257-6 | 0.516 | 0.945 | 0.668 | 0.425 | 0.934 | 0.584 |
| 248-4 | 0.928 | 1.000 | 0.963 | 0.928 | 1.000 | 0.963 | 257-8 | 0.455 | 0.883 | 0.601 | 0.273 | 0.819 | 0.410 |
| 248-6 | 0.897 | 1.000 | 0.946 | 0.897 | 1.000 | 0.946 | 258 | 0.563 | 0.886 | 0.688 | 0.605 | 0.841 | 0.704 |
| 248-8 | 0.877 | 0.989 | 0.930 | 0.877 | 0.989 | 0.930 | 258-2 | 0.886 | 0.978 | 0.930 | 0.917 | 0.978 | 0.947 |
| 249 | 0.743 | 0.889 | 0.809 | 0.763 | 0.914 | 0.832 | 258-4 | 0.792 | 0.963 | 0.869 | 0.792 | 0.950 | 0.864 |
| 249-2 | 0.990 | 1.000 | 0.995 | 0.990 | 1.000 | 0.995 | 258-6 | 0.719 | 0.959 | 0.822 | 0.730 | 0.946 | 0.824 |
| 249-4 | 0.959 | 1.000 | 0.979 | 0.959 | 1.000 | 0.979 | 258-8 | 0.563 | 0.844 | 0.675 | 0.636 | 0.836 | 0.722 |
| 249-6 | 0.825 | 0.931 | 0.875 | 0.825 | 0.931 | 0.875 | 259 | 0.568 | 0.798 | 0.664 | 0.660 | 0.753 | 0.703 |
| 249-8 | 0.774 | 0.863 | 0.816 | 0.794 | 0.906 | 0.846 | 259-2 | 0.897 | 0.967 | 0.931 | 0.887 | 0.946 | 0.916 |
| 250 | 0.576 | 0.950 | 0.717 | 0.546 | 1.000 | 0.706 | 259-4 | 0.846 | 0.954 | 0.897 | 0.887 | 0.967 | 0.925 |
| 250-2 | 0.910 | 1.000 | 0.953 | 0.910 | 1.000 | 0.953 | 259-6 | 0.825 | 0.920 | 0.870 | 0.712 | 0.832 | 0.767 |
| 250-4 | 0.819 | 1.000 | 0.900 | 0.849 | 1.000 | 0.918 | 254-6 | 0.728 | 1.000 | 0.843 | 0.728 | 1.000 | 0.843 |
| 250-6 | 0.697 | 1.000 | 0.821 | 0.728 | 1.000 | 0.843 | 254-8 | 0.637 | 1.000 | 0.778 | 0.485 | 0.942 | 0.640 |
| 250-8 | 0.607 | 1.000 | 0.755 | 0.637 | 1.000 | 0.778 | 257 | 0.334 | 0.847 | 0.479 | 0.334 | 0.459 | 0.387 |
| 251 | 0.709 | 0.945 | 0.810 | 0.730 | 0.946 | 0.824 | 257-2 | 0.819 | 1.000 | 0.900 | 0.788 | 1.000 | 0.881 |
| 251-2 | 0.907 | 1.000 | 0.951 | 0.948 | 1.000 | 0.973 | 257-4 | 0.758 | 1.000 | 0.862 | 0.728 | 1.000 | 0.843 |
| 251-4 | 0.803 | 0.975 | 0.881 | 0.875 | 0.989 | 0.929 | 257-6 | 0.516 | 0.945 | 0.668 | 0.425 | 0.934 | 0.584 |
| 251-6 | 0.792 | 0.963 | 0.869 | 0.834 | 0.988 | 0.904 | 257-8 | 0.455 | 0.883 | 0.601 | 0.273 | 0.819 | 0.410 |
| 251-8 | 0.813 | 0.988 | 0.892 | 0.782 | 0.962 | 0.863 | 258 | 0.563 | 0.886 | 0.688 | 0.605 | 0.841 | 0.704 |
| 252 | 0.743 | 0.879 | 0.805 | 0.774 | 0.853 | 0.812 | 258-2 | 0.886 | 0.978 | 0.930 | 0.917 | 0.978 | 0.947 |
| 252-2 | 0.949 | 1.000 | 0.974 | 0.949 | 1.000 | 0.974 | 258-4 | 0.792 | 0.963 | 0.869 | 0.792 | 0.950 | 0.864 |
| 252-4 | 0.877 | 0.966 | 0.919 | 0.866 | 0.966 | 0.913 | 258-6 | 0.719 | 0.959 | 0.822 | 0.730 | 0.946 | 0.824 |
| 252-6 | 0.877 | 0.956 | 0.915 | 0.846 | 0.943 | 0.892 | 258-8 | 0.563 | 0.844 | 0.675 | 0.636 | 0.836 | 0.722 |
| 252-8 | 0.825 | 0.953 | 0.884 | 0.794 | 0.963 | 0.870 | 259-8 | 0.660 | 0.811 | 0.728 | 0.609 | 0.787 | 0.687 |
| 253 | 0.691 | 0.828 | 0.753 | 0.722 | 0.865 | 0.787 | 260 | 0.438 | 0.824 | 0.572 | 0.407 | 0.929 | 0.566 |
| 253-2 | 0.939 | 1.000 | 0.969 | 0.949 | 1.000 | 0.974 | 260-2 | 0.875 | 1.000 | 0.933 | 0.875 | 1.000 | 0.933 |
| 253-4 | 0.897 | 1.000 | 0.946 | 0.908 | 1.000 | 0.952 | 260-4 | 0.813 | 1.000 | 0.897 | 0.813 | 1.000 | 0.897 |
| 253-6 | 0.877 | 0.989 | 0.930 | 0.877 | 0.978 | 0.925 | 260-6 | 0.688 | 1.000 | 0.815 | 0.657 | 1.000 | 0.793 |
| 253-8 | 0.784 | 0.905 | 0.840 | 0.743 | 0.858 | 0.796 | 260-8 | 0.469 | 1.000 | 0.639 | 0.438 | 1.000 | 0.609 |
| 254 | 0.576 | 0.950 | 0.717 | 0.546 | 1.000 | 0.706 | 261 | 0.364 | 0.601 | 0.453 | 0.364 | 0.924 | 0.522 |
| 254-2 | 0.879 | 1.000 | 0.936 | 0.879 | 1.000 | 0.936 | 261-2 | 0.819 | 0.900 | 0.858 | 0.819 | 0.965 | 0.886 |
| 254-4 | 0.819 | 1.000 | 0.900 | 0.819 | 1.000 | 0.900 | 261-4 | 0.667 | 0.880 | 0.759 | 0.697 | 0.885 | 0.780 |
| 254-6 | 0.728 | 1.000 | 0.843 | 0.728 | 1.000 | 0.843 | 261-6 | 0.667 | 0.786 | 0.722 | 0.758 | 0.893 | 0.820 |
| 254-8 | 0.637 | 1.000 | 0.778 | 0.485 | 0.942 | 0.640 | 261-8 | 0.546 | 0.721 | 0.621 | 0.546 | 0.948 | 0.693 |
| 257 | 0.334 | 0.847 | 0.479 | 0.334 | 0.459 | 0.387 | 262 | 0.273 | 0.693 | 0.392 | 0.364 | 0.500 | 0.421 |
| 257-2 | 0.819 | 1.000 | 0.900 | 0.788 | 1.000 | 0.881 | 262-2 | 0.879 | 1.000 | 0.936 | 0.879 | 1.000 | 0.936 |
| 257-4 | 0.758 | 1.000 | 0.862 | 0.728 | 1.000 | 0.843 | 262-4 | 0.667 | 1.000 | 0.800 | 0.637 | 1.000 | 0.778 |
| 257-6 | 0.516 | 0.945 | 0.668 | 0.425 | 0.934 | 0.584 | 262-6 | 0.607 | 1.000 | 0.755 | 0.607 | 1.000 | 0.755 |
| 257-8 | 0.455 | 0.883 | 0.601 | 0.273 | 0.819 | 0.410 | 262-8 | 0.485 | 1.000 | 0.653 | 0.455 | 1.000 | 0.625 |
| 258 | 0.563 | 0.886 | 0.688 | 0.605 | 0.841 | 0.704 | 265 | 0.000 | 1.000 | 0.000 | 0.094 | 0.301 | 0.143 |
| 258-2 | 0.886 | 0.978 | 0.930 | 0.917 | 0.978 | 0.947 | 266 | 0.152 | 0.358 | 0.213 | 0.243 | 0.471 | 0.321 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gulić, M.; Vrdoljak, B.; Ptiček, M. Automatically Specifying a Parallel Composition of Matchers in Ontology Matching Process by Using Genetic Algorithm. Information 2018, 9, 138. https://doi.org/10.3390/info9060138
Gulić M, Vrdoljak B, Ptiček M. Automatically Specifying a Parallel Composition of Matchers in Ontology Matching Process by Using Genetic Algorithm. Information. 2018; 9(6):138. https://doi.org/10.3390/info9060138
Chicago/Turabian StyleGulić, Marko, Boris Vrdoljak, and Marina Ptiček. 2018. "Automatically Specifying a Parallel Composition of Matchers in Ontology Matching Process by Using Genetic Algorithm" Information 9, no. 6: 138. https://doi.org/10.3390/info9060138
APA StyleGulić, M., Vrdoljak, B., & Ptiček, M. (2018). Automatically Specifying a Parallel Composition of Matchers in Ontology Matching Process by Using Genetic Algorithm. Information, 9(6), 138. https://doi.org/10.3390/info9060138