1. Introduction
Software has become an essential and fundamental part of modern society. Every software system is built to meet a set of needs and conditions. This set is known as Software Requirements (SRs) [
1]. Generally, there are two types of SRs [
2,
3]. The first one concerns with the functional behavior of the software (software services) and it is called functional requirements (FRs). An example of FR from MHC-PMS (Mental Health Care-Patient Management System) is [
1]: “The MHC-PMS shall generate monthly management reports showing the cost of drugs prescribed by each clinic during that month”. Non-functional requirements (NFRs), the second type, focus on system restrictions and everything that is not related to software functionality (quality attributes) such as reliability, performance, portability, etc.
The very first step in developing a software system is SR elicitation [
4]. In this step, developers work with the customer to find out what services the software should provide [
5]. It is very important to implement the requirements elicitation step carefully because the overall development process can be seen as a derivation of the collected SRs [
6]. Therefore, SRs should be solid and valid such that further modifications are limited in the future to save time and cost in the development process. Any change in the SRs after starting of source code implementation is considered to be a very timely and costly operation [
7,
8].
SR elicitation is a challenging task for developers and engineers [
9,
10,
11,
12]. SRs are written in natural languages and describe different aspects of the target software [
1,
13,
14]. Mainly, software developers need to understand, analyze, and validate SRs manually. For example, the collected SRs need to be categorized and grouped in different clusters in order to break down the target project into a set of sub-projects [
9]. Eventually, each sub-project covers a set of related SRs and developed by a separate and specialized developer team. Moreover, these groups of SRs need to be analyzed to generate Software Requirement Specifications (SRSs), which can be used for validating and verifying the final software product. A software developer needs to extract all related SRs before preparing the final specifications (SRS) that describe them. As a result, grouping SRs into a set of clusters helps developers to better understand and realize the target software project. In addition, it helps to design initial architecture of the software product as these clusters represent components or sub-systems that should be implemented and reused [
1,
15].
There is a lack of tools or methodologies to automatically classify and cluster the collected SRs. On the one hand, some works are found in the literature with the goal of non-functional SR classification [
16,
17,
18]. On the other hand, functional SR clustering has never been considered in the literature. In this paper, a generic framework to automatically cluster functional SRs based on their semantics is proposed. The proposed framework can be used with any clustering algorithms and distance measures.
This paper presents a hierarchical clustering approach to semantically cluster functional SRs. The proposed approach takes as an input, FR statements of a software product in a flat list, which is documented in an SRS document. This document is an official statement about what developers should implement [
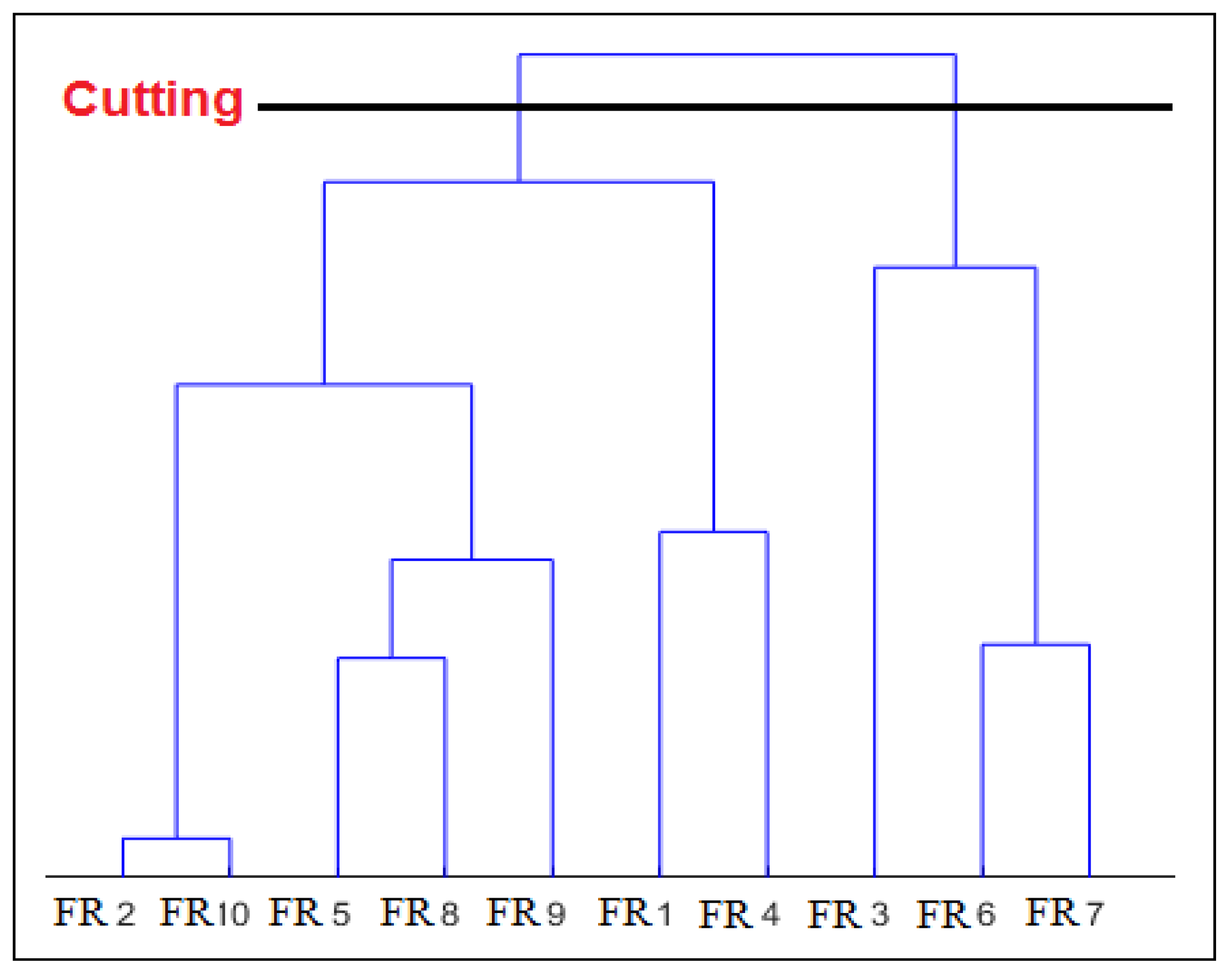
19]. The approach returns as output of a set of semantic clusters based on a semantic similarity measure. First, the input is preprocessed with a proposed preprocessing step to increase the accuracy of the clustering algorithm. Then, the Agglomerative Hierarchical Clustering (AHC) algorithm is applied to cluster the target functional SRs into a set of clusters. During the clustering process, a dendrogram report is generated to visualize the progressive clustering of the functional SRs. This can be useful for software engineers to have an idea of a suitable number of clusters into which the functional SRs categorized. In other words, it can be helpful for software engineers in deciding how to break down the target project into different sub-projects.
Our proposal makes the following contributions:
- -
A hierarchical clustering approach to clustering software FRs based on their semantics.
- -
A dynamic clustering framework, which can be extended to include different clustering algorithms and distance measures.
- -
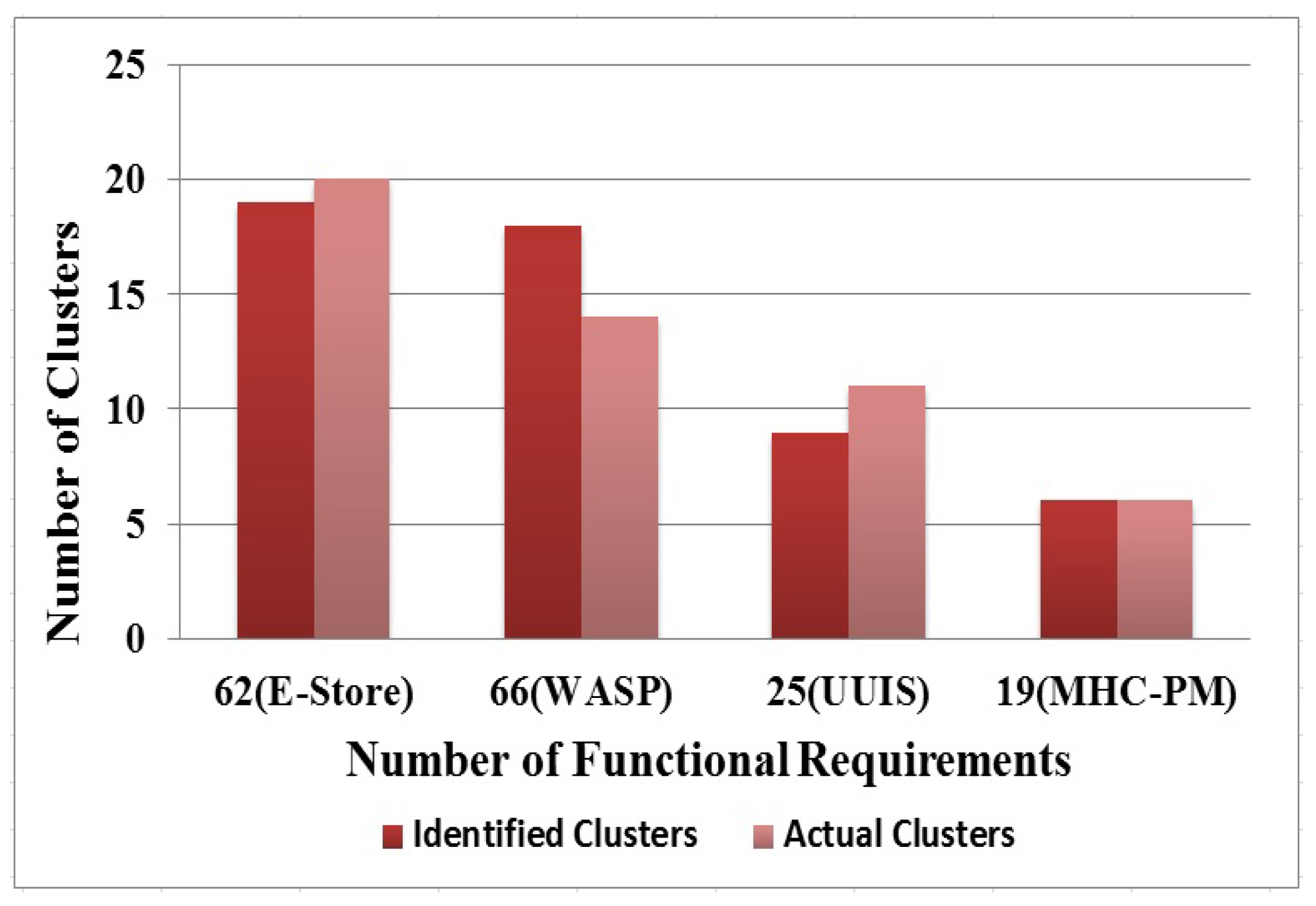
An empirical study to evaluate the proposed automatic clustering using four open-access software projects.
The remainder of this paper is organized into main six sections.
Section 2 introduces a motivational example of our proposal.
Section 3 presents the most recent work on the subject. The proposed approach is detailed in
Section 4. In
Section 5, we describe case studies and our research questions. In
Section 6, we analyze and discuss the experimental results. Finally, conclusions and future work are stated in
Section 7.
Author Contributions
Conceptualization and Research Idea by H.E.-S. and M.H.; Methodology, Software, Result Analysis and Validation by H.E.-S.; Writing—Original Draft Preparation by H.E.-S. and M.H.; Reviewing and Editing by A.-D.S and A.A.-S.
Funding
This research received no external funding.
Acknowledgments
We thank the anonymous reviewers for their comments. In addition, We thank LIRMM laboratory (
https://www.lirmm.fr/), which will pay the publication fee.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SRs | Software Requirements |
| FRs | Functional Requirements |
| NFRs | Non-Functional Requirements |
| SRSs | Software Requirement Specifications |
| AHC | Agglomerative Hierarchal Clustering |
| SVM | Support Vector Machine |
| StdDev | Standard Deviation |
| MHC-PMS | Mental Health Care-Patient Management System |
References
- Sommerville, I. Software Engineering, 9th ed.; Addison-Wesley Publishing Company: Boston, MA, USA, 2010. [Google Scholar]
- Davis, A.M. Software Requirements: Objects, Functions, and States; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Pressman, R. Software Engineering: A Practitioner’s Approach, 7th ed.; McGraw-Hill, Inc.: New York, NY, USA, 2010. [Google Scholar]
- Kotonya, G.; Sommerville, I. Requirements Engineering: Processes and Techniques, 1st ed.; Wiley: Hoboken, NJ, USA, 1998. [Google Scholar]
- Pitangueira, A.; Tonella, P.; Susi, A.; Maciel, R.; Barros, M. Minimizing the stakeholder dissatisfaction risk in requirement selection for next release planning. Inf. Softw. Technol. 2017, 87, 104–118. [Google Scholar] [CrossRef]
- Pitangueira, A.M.; Maciel, R.S.P.; Barros, M. Software requirements selection and prioritization using SBSE approaches: A systematic review and mapping of the literature. J. Syst. Softw. 2015, 103, 267–280. [Google Scholar] [CrossRef]
- McGee, S.; Greer, D. Towards an understanding of the causes and effects of software requirements change: Two case studies. Requir. Eng. 2012, 17, 133–155. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, A.; Ducasse, S.; Gírba, T. Semantic Clustering: Identifying Topics in Source Code. Inf. Softw. Technol. 2007, 49, 230–243. [Google Scholar] [CrossRef]
- Zowghi, D.; Coulin, C. Requirements elicitation: A survey of techniques, approaches, and tools. In Engineering and Managing Software Requirements; Aurum, A., Wohlin, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 19–46. [Google Scholar]
- Sommerville, I.; Sawyer, P.; Viller, S. Viewpoints for requirements elicitation: A practical approach. In Proceedings of the 1998 Third International Conference on Requirements Engineering, Colorado Springs, CO, USA, 10 April 1998; pp. 74–81. [Google Scholar]
- Bitencourt, A.S.; Paiva, D.M.; Cagnin, M.I. Requirements elicitation from business process model in bpmn: A systematic review. In Proceedings of the XII Brazilian Symposium on Information Systems on Brazilian Symposium on Information Systems: Information Systems in the Cloud Computing Era, Florianopolis, Brazil, 17–20 May 2016; pp. 200–207. [Google Scholar]
- Azmeh, Z.; Mirbel, I.; Crescenzo, P. Highlighting stakeholder communities to support requirements decision-making. In Requirements Engineering: Foundation for Software Quality; Doerr, J., Opdahl, A.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 190–205. [Google Scholar]
- Kamalrudin, M.; Grundy, J.; Hosking, J. Tool support for essential use cases to better capture software requirements. In Proceedings of the IEEE/ACM International Conference on Automated Software Engineering (ASE’10), Antwerp, Belgium, 20–24 September 2010; pp. 255–264. [Google Scholar]
- Sagar, V.B.R.V.; Abirami, S. Conceptual modeling of natural language functional requirements. J. Syst. Softw. 2014, 88, 25–41. [Google Scholar] [CrossRef]
- Alebrahim, A. Framework for identifying meta-requirements. In Bridging the Gap between Requirements Engineering and Software Architecture: A Problem-Oriented and Quality-Driven Method; Springer: Wiesbaden, Germany, 2017; pp. 51–109. [Google Scholar]
- Harsimran, K.; Ashish, S. Non-functional requirements research: Survey. Int. J. Sci. Eng. Appl. 2015, 3, 172–182. [Google Scholar] [CrossRef]
- Deocadez, R.; Harrison, R.; Rodriguez, D. Automatically classifying requirements from app stores: A preliminary study. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference Workshops (REW), Lisbon, Portugal, 4–8 September 2017; pp. 367–371. [Google Scholar]
- Ishrar, H.; Leila, K.; Olga, O. Using linguistic knowledge to classify non-functional requirements in srs documents. In Natural Language and Information Systems; Kapetanios, E., Sugumaran, V., Spiliopoulou, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 287–298. [Google Scholar]
- IEEE-SA Standards Board. IEEE Recommended Practice for Software Requirements Specifications; IEEE Std 830-1998; IEEE: Piscataway, NJ, USA, 1998; pp. 1–40. [Google Scholar]
- National Research Council of Italy. Natural Language Requirements Dataset. Available online: http://fmt.isti.cnr.it/nlreqdataset/ (accessed on 3 June 2018).
- Eckhardt, J.; Vogelsang, A.; Fernández, D.M. Are “Non-functional” Requirements Really Non-functional? An Investigation of Non-functional Requirements in Practice. In Proceedings of the 38th International Conference on Software Engineering (ICSE’16), Austin, TX, USA, 14–22 May 2016; pp. 832–842. [Google Scholar]
- Sommerville, I.; Sawyer, P. Requirements Engineering: A Good Practice Guide, 1st ed.; Wiley: New York, NY, USA, 1997. [Google Scholar]
- Ghazarian, A.; Tehrani, M.S.; Ghazarian, A. A software requirements specification framework for objective pattern recognition: A set-theoretic classification approach. In Proceedings of the 2011 16th IEEE International Conference on Engineering of Complex Computer Systems, Las Vegas, NV, USA, 27–29 April 2011; pp. 211–220. [Google Scholar]
- Ghazarian, A. Characterization of functional software requirements space: The law of requirements taxonomic growth. In Proceedings of the 2012 20th IEEE International Requirements Engineering Conference (RE), Chicago, IL, USA, 24–28 September 2012; pp. 241–250. [Google Scholar]
- Rashwan, A.; Ormandjieva, O.; Witte, R. Ontology-based classification of non-functional requirements in software specifications: A new corpus and svm-based classifier. In Proceedings of the 2013 IEEE 37th Annual Computer Software and Applications Conference, Kyoto, Japan, 22–26 July 2013; pp. 381–386. [Google Scholar]
- Singh, P.; Singh, D.; Sharma, A. Classification of non-functional requirements from SRS documents using thematic roles. In Proceedings of the 2016 IEEE International Symposium on Nanoelectronic and Information Systems (iNIS), Gwalior, India, 19–21 December 2016; pp. 206–207. [Google Scholar]
- Kurtanović, Z.; Maalej, W. Automatically classifying functional and non-functional requirements using supervised machine learning. In Proceedings of the 2017 IEEE 25th International Requirements Engineering Conference (RE), Lisbon, Portugal, 4–8 September 2017; pp. 490–495. [Google Scholar]
- Rashwan, A. Semantic analysis of functional and non-functional requirements in software requirements specifications. In Proceedings of the 25th Canadian Conference on Advances in Artificial Intelligence (Canadian AI’12), Toronto, ON, Canada, 28–30 May 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 388–391. [Google Scholar]
- Shah, T.; Patel, S. A novel approach for specifying functional and non-functional requirements using rds (requirement description schema). Procedia Comput. Sci. 2016, 79, 852–860. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar]
- Term Freuency Weighting. Available online: http://opencourseonline.com/ (accessed on 3 November 2017).
- Porter, M.F. An algorithm for suffix stripping. Program 1980, 14, 130–137. [Google Scholar] [CrossRef]
- Salton, G.; Wong, A.; Yang, C.S. A vector space model for automatic indexing. Commun. ACM 1975, 18, 613–620. [Google Scholar] [CrossRef] [Green Version]
- Marcus, A.; Maletic, J.I. Recovering documentation-to-source-code traceability links using latent semantic indexing. In Proceedings of the 25th International Conference on Software Engineering (ICSE’03), Portland, OR, USA, 3–10 May 2003; pp. 125–135. [Google Scholar]
- Saied, M.A.; Abdeen, H.; Benomar, O.; Sahraoui, H. Could we infer unordered api usage patterns only using the library source code? In Proceedings of the 2015 IEEE 23rd International Conference on Program Comprehension (ICPC’15), Florence, Italy, 18–19 May 2015; pp. 71–81. [Google Scholar]
- Zhao, H.; Qi, Z. Hierarchical agglomerative clustering with ordering constraints. In Proceedings of the 2010 Third International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010; pp. 195–199. [Google Scholar]
- Menzies, T.; Krishna, R.; Pryor, D. The Promise Repository of Empirical Software Engineering Data. Available online: http://openscience.us/repo/requirements/requirements-other/wasp.html (accessed on 3 June 2018).
- Mental Health Care Patient Management System. Available online: https://bscs143.files.wordpress.com/2015/11/requirement-mhc-pms.docx (accessed on 3 June 2018).
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}