Transfer Learning for Improved Audio-Based Human Activity Recognition



Abstract
:1. Introduction
- the combinatorial usage of temporal, frequency, and wavelet acoustic features;
- the extensive exploration of the temporal evolution of these features by means of hidden Markov Models (HMMs) including both class-specific and universal ones; and
- a statistical transfer learning module specifically designed to address potential data imbalances.
2. Problem Formulation
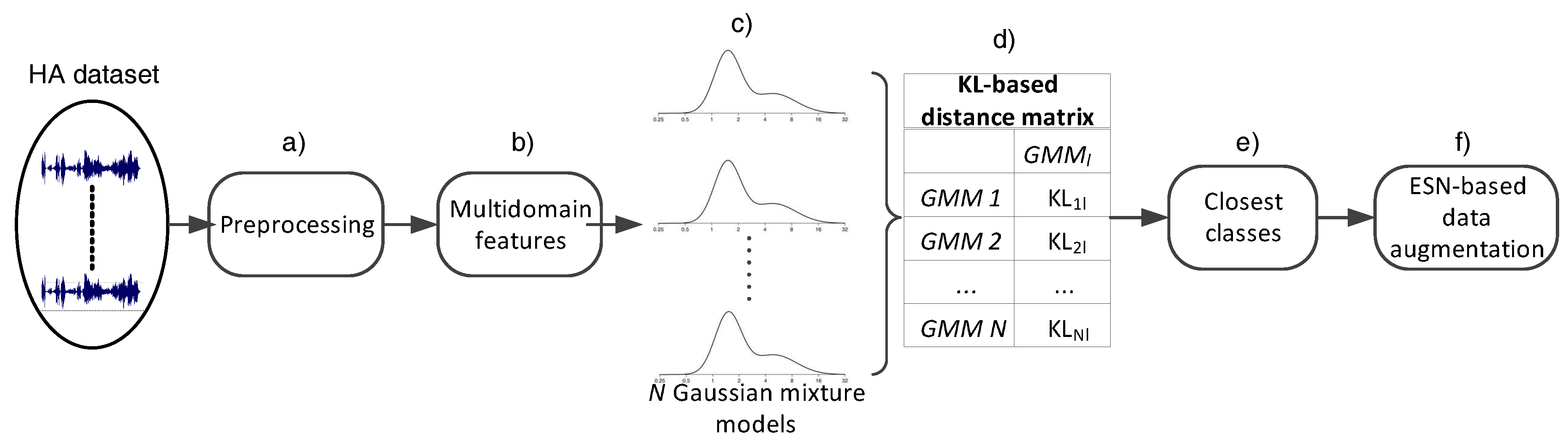
3. Transfer Learning-Based AHAR
3.1. Acoustic Signal Parameterization
3.1.1. Mel Frequency Cepstral Coefficients (MFCC)
3.1.2. MPEG-7 Audio Standard Low Level Descriptors (LLDs)
- Audio Spectrum Centroid: The center of the log-frequency spectrum’s gravity is given by this descriptor. Omitting power coefficients bellow 62.5 Hz (which are represented by a single coefficient) makes able the avoidance of the effect of a non-zero DC component.
- Audio Spectrum Spread: The specific LLD is a measure of signal’s spectral shape and corresponds to the second central moment of the log-frequency spectrum. It is computed by taking the root mean square deviation of the spectrum from its centroid.
- Audio Spectrum Flatness: This descriptor is a measure of how flat a particular portion of the spectrum of the signal is and represents the deviation of the signal’s power spectrum from a flat shape. The power coefficients are taken from non-overlapping frames while the spectrum is typically divided into -octave resolution logarithmically spaced overlapping frequency bands. The ASF is derived as the ratio of the geometric mean and the arithmetic mean of the spectral power coefficients within a band.
3.1.3. Perceptual Wavelet Packets (PWP)
3.2. Identifying Statistically-Closely Located Classes
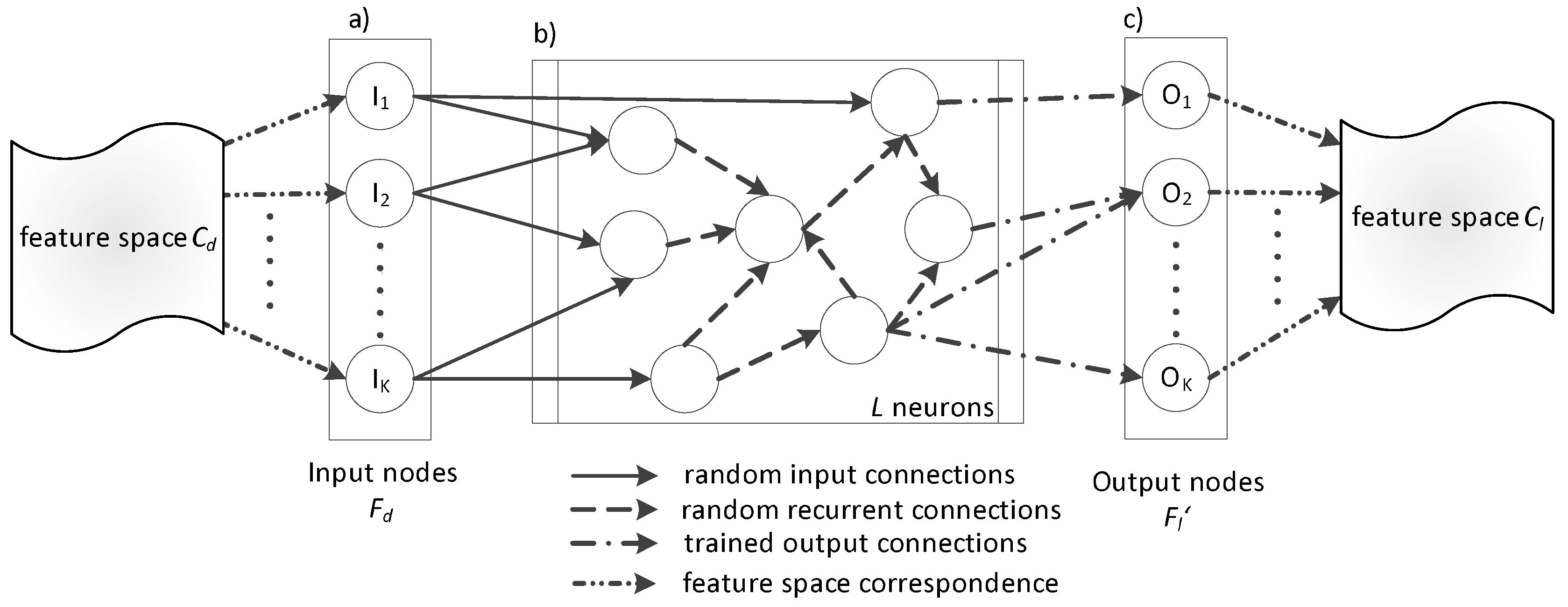
3.3. ESN-Based Transfer Learning
3.3.1. RN Learning
3.3.2. Application of
3.4. Pattern Recognition of Human Activities
- Class specific HMMs: During this phase, we create one HMM to represent each sound class (using data associated with the specific class alone) and we follow the left–right topology, which is typically used by the community due to the nature of most sounds.
- Universal HMM [34,35]: During this phase, one HMM is created based on the entire training dataset while adapted versions of it are used to represent each sound class. In this case we use fully-connected (or ergodic) HMMs where every possible transition is permitted by the model which comprises a more appropriate choice given the variability of the entire dataset.
4. Experimental Set-Up and Analysis of the Results
4.1. The Dataset
4.2. System Parameterization
4.2.1. Feature Extraction
4.2.2. ESN
4.2.3. HMM
- number of states: and , while
- number of Gaussian components: and
4.3. Experimental Results
- brew coffee–dish washing,
- cooking–use microwave oven,
- take a shower–teeth brushing, and
- no activity–hand washing.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef] [Green Version]
- Xu, Y.; Helal, A. Scalable Cloud Sensor Architecture for the Internet of Things. IEEE Internet Things J. 2016, 3, 285–298. [Google Scholar] [CrossRef]
- Chen, L.; Hoey, J.; Nugent, C.D.; Cook, D.J.; Yu, Z. Sensor-Based Activity Recognition. IEEE Trans. Syst. Man Cybern. C 2012, 42, 790–808. [Google Scholar] [CrossRef]
- Ntalampiras, S.; Roveri, M. An incremental learning mechanism for human activity recognition. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–6. [Google Scholar] [CrossRef]
- DCASE 2017 Workshop. Available online: http://www.cs.tut.fi/sgn/arg/dcase2017/ (accessed on 25 June 2018).
- Dargie, W. Adaptive Audio-Based Context Recognition. IEEE Trans. Syst. Man Cybern. A 2009, 39, 715–725. [Google Scholar] [CrossRef] [Green Version]
- Galván-Tejada, C.E.; Galván-Tejada, J.I.; Celaya-Padilla, J.M.; Delgado-Contreras, J.R.; Magallanes-Quintanar, R.; Martinez-Fierro, M.L.; Garza-Veloz, I.; López-Hernández, Y.; Gamboa-Rosales, H. An Analysis of Audio Features to Develop a Human Activity Recognition Model Using Genetic Algorithms, Random Forests, and Neural Networks. Mob. Inf. Syst. 2016, 2016. [Google Scholar] [CrossRef]
- Stork, J.A.; Spinello, L.; Silva, J.; Arras, K.O. Audio-based human activity recognition using Non-Markovian Ensemble Voting. In Proceedings of the 2012 IEEE RO-MAN: The 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 Septrmber 2012; pp. 509–514. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef] [Green Version]
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Acoustic Detection of Human Activities in Natural Environments. J. Audio Eng. Soc. 2012, 60, 686–695. [Google Scholar]
- Hasan, T.; Hansen, J.H.L. A Study on Universal Background Model Training in Speaker Verification. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1890–1899. [Google Scholar] [CrossRef]
- Ntalampiras, S. A transfer learning framework for predicting the emotional content of generalized sound events. J. Acoust. Soc. Am. 2017, 141, 1694–1701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mun, S.; Shon, S.; Kim, W.; Han, D.K.; Ko, H. Deep Neural Network based learning and transferring mid-level audio features for acoustic scene classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 796–800. [Google Scholar] [CrossRef]
- Van den Oord, A.; Dieleman, S.; Schrauwen, B. Transfer learning by supervised pre-training for audio-based music classification. In Proceedings of the ISMIR 2014: 15th International Society for Music Information Retrieval, Taipei, Taiwan, 27–31 October 2014; p. 6. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Int. Res. 2002, 16, 321–357. [Google Scholar]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Xia, S.; Shao, M.; Fu, Y. Kinship Verification Through Transfer Learning. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence (IJCAI’11), Barcelona, Spain, 16–22 July 2011; AAAI Press: Palo Alto, CA, USA, 2011; Volume 3, pp. 2539–2544. [Google Scholar]
- Si, S.; Tao, D.; Geng, B. Bregman Divergence-Based Regularization for Transfer Subspace Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 929–942. [Google Scholar] [CrossRef]
- Gao, B.; Woo, W.L.; Dlay, S.S. Adaptive Sparsity Non-Negative Matrix Factorization for Single-Channel Source Separation. IEEE J. Sel. Top. Signal Process. 2011, 5, 989–1001. [Google Scholar] [CrossRef]
- Potamitis, I.; Ganchev, T. Generalized Recognition of Sound Events: Approaches and Applications. In Studies in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2008; pp. 41–79. [Google Scholar] [CrossRef]
- Mallat, S. A Wavelet Tour of Signal Processing, Third Edition: The Sparse Way, 3rd ed.; Academic Press: Orlando, FL, USA, 2008. [Google Scholar]
- Yost, W.A.; Shofner, W.P. Critical bands and critical ratios in animal psychoacoustics: An example using chinchilla data. J. Acoust. Soc. Am. 2009, 125, 315–323. [Google Scholar] [CrossRef] [PubMed]
- Nienhuys, T.G.W.; Clark, G.M. Critical Bands Following the Selective Destruction of Cochlear Inner and Outer Hair Cells. Acta Oto-Laryngol. 1979, 88, 350–358. [Google Scholar] [CrossRef]
- Ntalampiras, S. Implementation. Available online: https://sites.google.com/site/stavrosntalampiras/home (accessed on 23 June 2018).
- Ntalampiras, S.; Potamitis, I.; Fakotakis, N. Exploiting Temporal Feature Integration for Generalized Sound Recognition. EURASIP J. Adv. Signal Process. 2009, 2009, 807162. [Google Scholar] [CrossRef]
- Aucouturier, J.J.; Defreville, B.; Pachet, F. The bag-of-frame approach to audio pattern recognition: A sufficient model for urban soundscapes but not for polyphonic music. J. Acoust. Soc. Am. 2007, 122, 881–891. [Google Scholar] [CrossRef] [PubMed]
- Lukoševičius, M.; Jaeger, H. Survey: Reservoir Computing Approaches to Recurrent Neural Network Training. Comput. Sci. Rev. 2009, 3, 127–149. [Google Scholar] [CrossRef]
- Jaeger, H.; Haas, H. Harnessing Nonlinearity: Predicting Chaotic Systems and Saving Energy in Wireless Communication. Science 2004, 304, 78–80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Verstraeten, D.; Schrauwen, B.; Stroobandt, D. Reservoir-based techniques for speech recognition. In Proceedings of the 2006 IEEE International Joint Conference onNeural Networks (IJCNN ’06), Vancouver, BC, Canada, 16–21 July 2006; pp. 1050–1053. [Google Scholar] [CrossRef]
- Kim, H.G.; Haller, M.; Sikora, T. Comparison of MPEG-7 Basis Projection Features and MFCC applied to Robust Speaker Recognition. In Proceedings of the ODYSSEY 2004—The Speaker and Language Recognition Workshop, Toledo, Spain, 1 May–3 June 2004. [Google Scholar]
- Casey, M. MPEG-7 sound-recognition tools. IEEE Trans. Circuits Syst. Video Technol. 2001, 11, 737–747. [Google Scholar] [CrossRef] [Green Version]
- De Leon, P.J.P.; Inesta, J.M. Pattern Recognition Approach for Music Style Identification Using Shallow Statistical Descriptors. IEEE Trans. Syst. Man Cybern. C 2007, 37, 248–257. [Google Scholar] [CrossRef]
- Povey, D.; Chu, S.M.; Varadarajan, B. Universal background model based speech recognition. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 4561–4564. [Google Scholar] [CrossRef]
- Ntalampiras, S. A Novel Holistic Modeling Approach for Generalized Sound Recognition. IEEE Signal Process. Lett. 2013, 20, 185–188. [Google Scholar] [CrossRef]
- Ntalampiras, S. Universal background modeling for acoustic surveillance of urban traffic. Digit. Signal Process. 2014, 31, 69–78. [Google Scholar] [CrossRef]
- AmiDaMi Research Group. Available online: http://ingsoftware.reduaz.mx/amidami/ (accessed on 23 June 2018).
- Casey, M. General sound classification and similarity in MPEG-7. Organ. Sound 2001, 6, 153–164. [Google Scholar] [CrossRef] [Green Version]
- The Reservoir Computing Toolbox. Available online: https://github.com/alirezag/matlab-esn (accessed on 23 June 2018).
- A Scientific Computing Framework for LUAJIT. Available online: http://www.torch.ch (accessed on 25 June 2018).
- GoogleHome. Available online: https://store.google.com/product/google_home (accessed on 23 June 2018).



{kind=link}
{kind=link}
| Human Activity | 10-Second Audio Clips |
|---|---|
| Brew coffee | 245 |
| Cooking | 132 |
| Use microwave oven | 42 |
| No activity | 16 |
| Taking a shower | 428 |
| Washing dishes | 134 |
| Washing hands | 70 |
| Brushing teeth | 92 |
| Responded | Brew Coffee | Cooking | Use Oven | Taking a Shower | Dish Washing | Hand Washing | Teeth Brushing | No Activity | |
|---|---|---|---|---|---|---|---|---|---|
| Presented | |||||||||
| Brew coffee | 90.3/92/90.1/95.7 | -/-/-/- | -/-/-/- | 3.3/2.4/3/- | 6.4/5.6/6.9/4.3 | -/-/-/- | -/-/-/- | -/-/-/- | |
| Cooking | -/-/-/- | 88.5/93.3/91/94.3 | 11/6.7/8.1/5.7 | -/-/-/- | -/-/-/- | -/-/-/- | -/-/-/- | 0.5/0/0.9/- | |
| Use oven | 1.9/-/-/- | 14.4/12.3/12.7/7.1 | 76.9/85.2/84.8/92.9 | -/-/-/- | -/-/-/- | -/-/-/- | -/-/-/- | 6.8/2.5/2.5/- | |
| Taking a shower | -/-/-/- | -/-/-/- | -/-/-/- | 91.7/93/92.2/97.8 | -/-/-/- | -/-/-/- | 5.9/4.9/5.7/2.2 | 2.4/2.1/2.1/- | |
| Dish washing | 12.4/12.1/12.1/9.6 | -/-/-/- | -/-/-/- | 3.7/3.6/3.6/- | 83.9/84.3/84.3/90.4 | -/-/-/- | -/-/-/- | -/-/-/- | |
| Hand washing | -/-/-/- | -/-/-/- | -/-/-/- | 3.6/-/-/- | -/-/-/- | 78.9/92.5/92.5/95.6 | -/-/-/- | 17.5/7.5/7.5/4.4 | |
| Teeth brushing | -/-/-/- | -/-/-/- | -/-/-/- | 14.9/10.8/11.4/4.8 | -/-/-/- | -/-/-/- | 80.6/87.9/87/95.2 | 4.5/1.3/1.6/- | |
| No activity | 6.7/-/-/- | -/-/-/- | -/-/-/- | -/-/-/- | -/-/-/- | 19.3/12.6/13.7/4.9 | -/-/-/- | 74/87.4/86.3/95.1 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ntalampiras, S.; Potamitis, I. Transfer Learning for Improved Audio-Based Human Activity Recognition. Biosensors 2018, 8, 60. https://doi.org/10.3390/bios8030060
Ntalampiras S, Potamitis I. Transfer Learning for Improved Audio-Based Human Activity Recognition. Biosensors. 2018; 8(3):60. https://doi.org/10.3390/bios8030060
Chicago/Turabian StyleNtalampiras, Stavros, and Ilyas Potamitis. 2018. "Transfer Learning for Improved Audio-Based Human Activity Recognition" Biosensors 8, no. 3: 60. https://doi.org/10.3390/bios8030060
APA StyleNtalampiras, S., & Potamitis, I. (2018). Transfer Learning for Improved Audio-Based Human Activity Recognition. Biosensors, 8(3), 60. https://doi.org/10.3390/bios8030060