
Harnessing the Power of ChatGPT for Automating Systematic Review Process: Methodology, Case Study, Limitations, and Future Directions
 ,
,  , , and
, , and 
Abstract
:1. Introduction
- ✓
- To investigate the potential of ChatGPT in generating relevant keywords and phrases for literature search in water and wastewater management applications and water quality monitoring.
- ✓
- To compare the accuracy and efficiency of utilizing ChatGPT for screening and filtering studies to be included in an SR, in contrast to conventional methods.
- ✓
- To assess the completeness and accuracy of employing ChatGPT in extracting and synthesizing information from abstracts and full-text articles of the selected studies.
- ✓
- To compare the quality and rigor of the SR process when utilizing ChatGPT against traditional SR methods. This comparison will consider various metrics, including reproducibility, bias, and transparency.
- ✓
- To provide comprehensive guidance on the best practices for integrating ChatGPT into the methodology of SRs specifically focused on water and wastewater management.
2. Research Methodology
2.1. Exploring ChatGPT: Characteristics and Interactions
2.2. Automation of SR Process Using ChatGPT
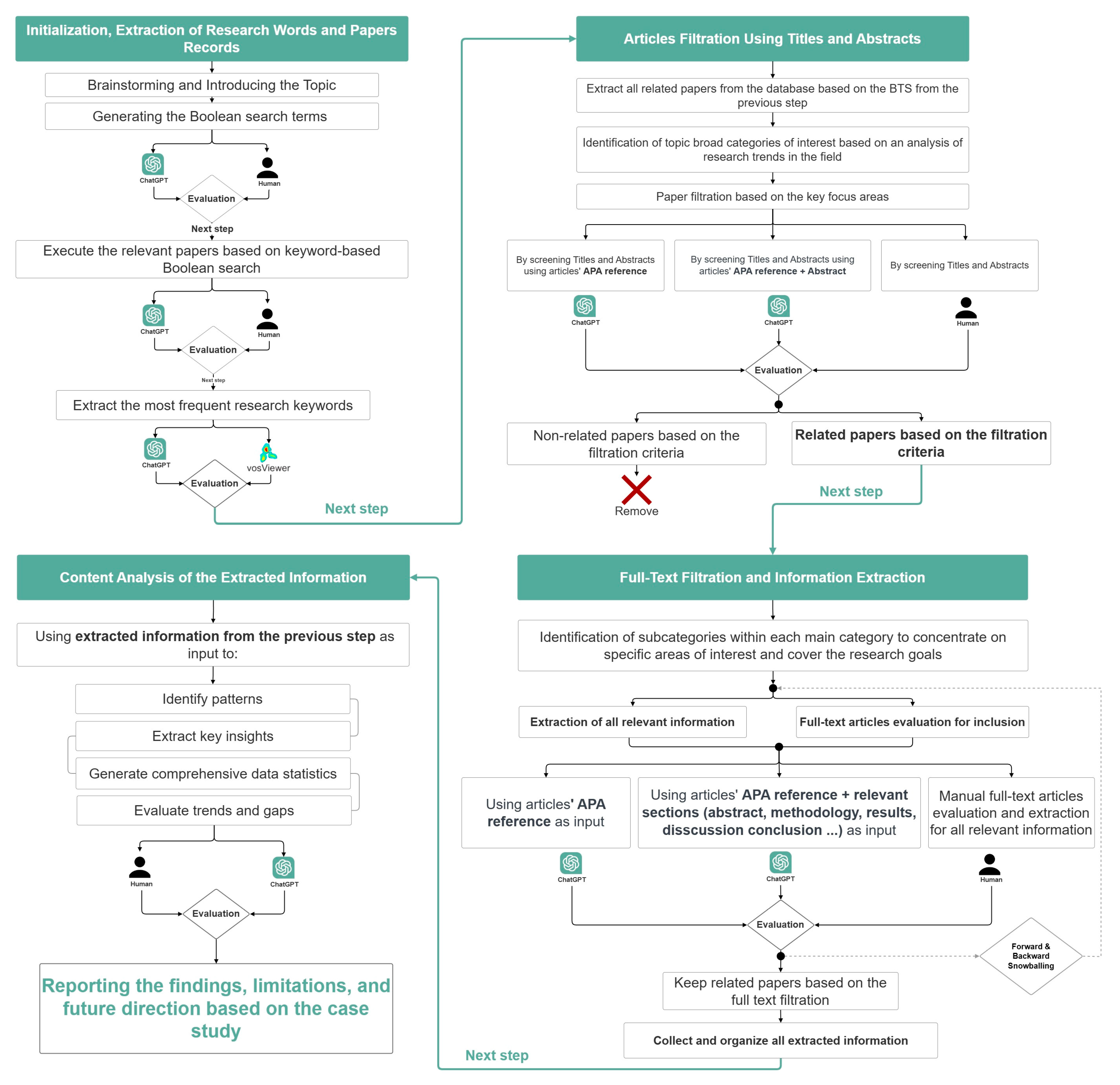
2.2.1. Initialization, Extraction of Research Words and Articles Records
2.2.2. Articles Filtration Using Titles and Abstracts
2.2.3. Full-Text Filtration and Information Extraction
2.2.4. Content Analysis of the Extracted Information
2.3. Case Study Selection
3. Results and Discussion
3.1. Research Words Generation, Article Exrcation, and Keywords Retiveal
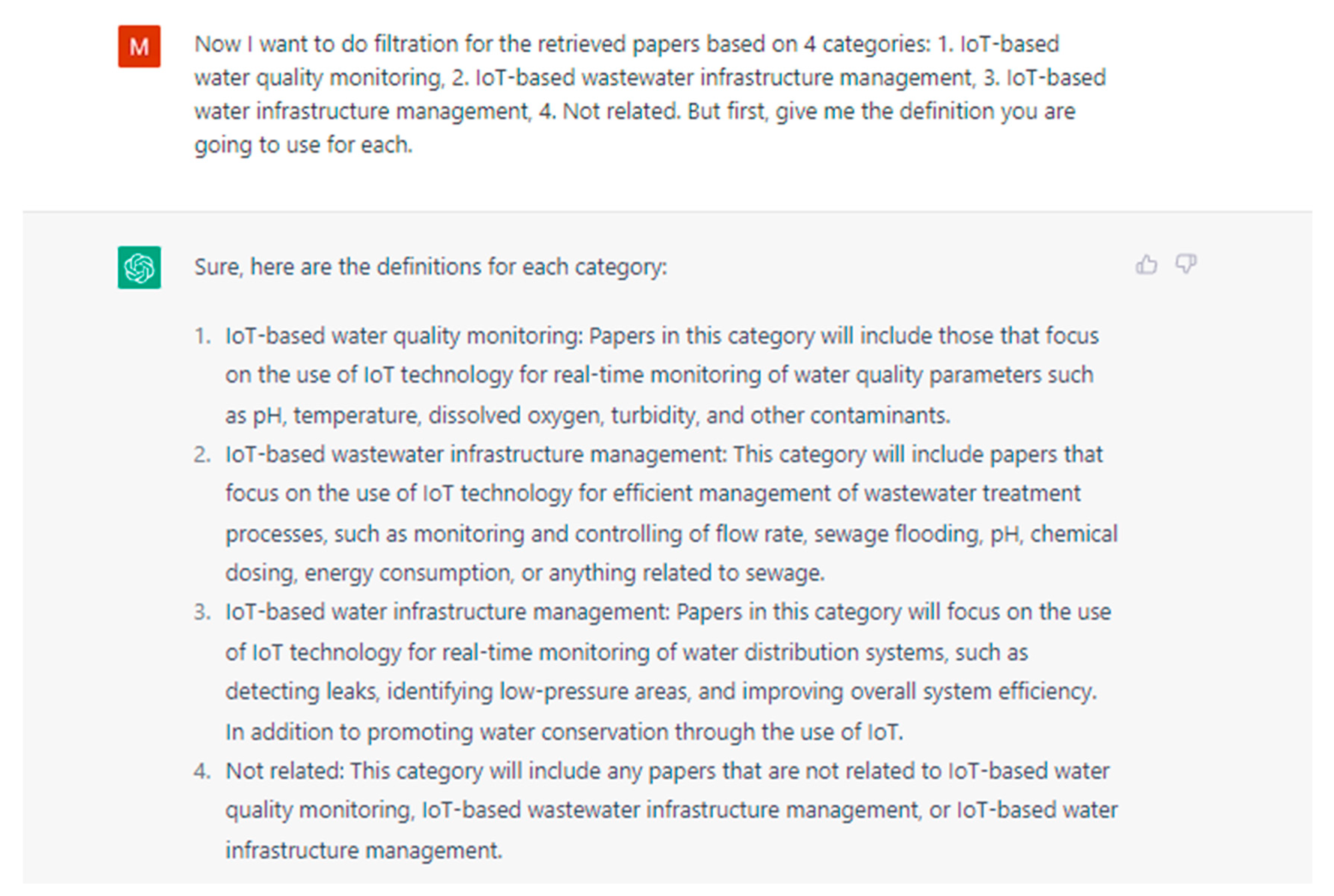
3.2. First-Round Article Classification and Filtration (Title and Abstract)
3.3. Second-Round Article Filtration (Full-Text) and Information Extraction
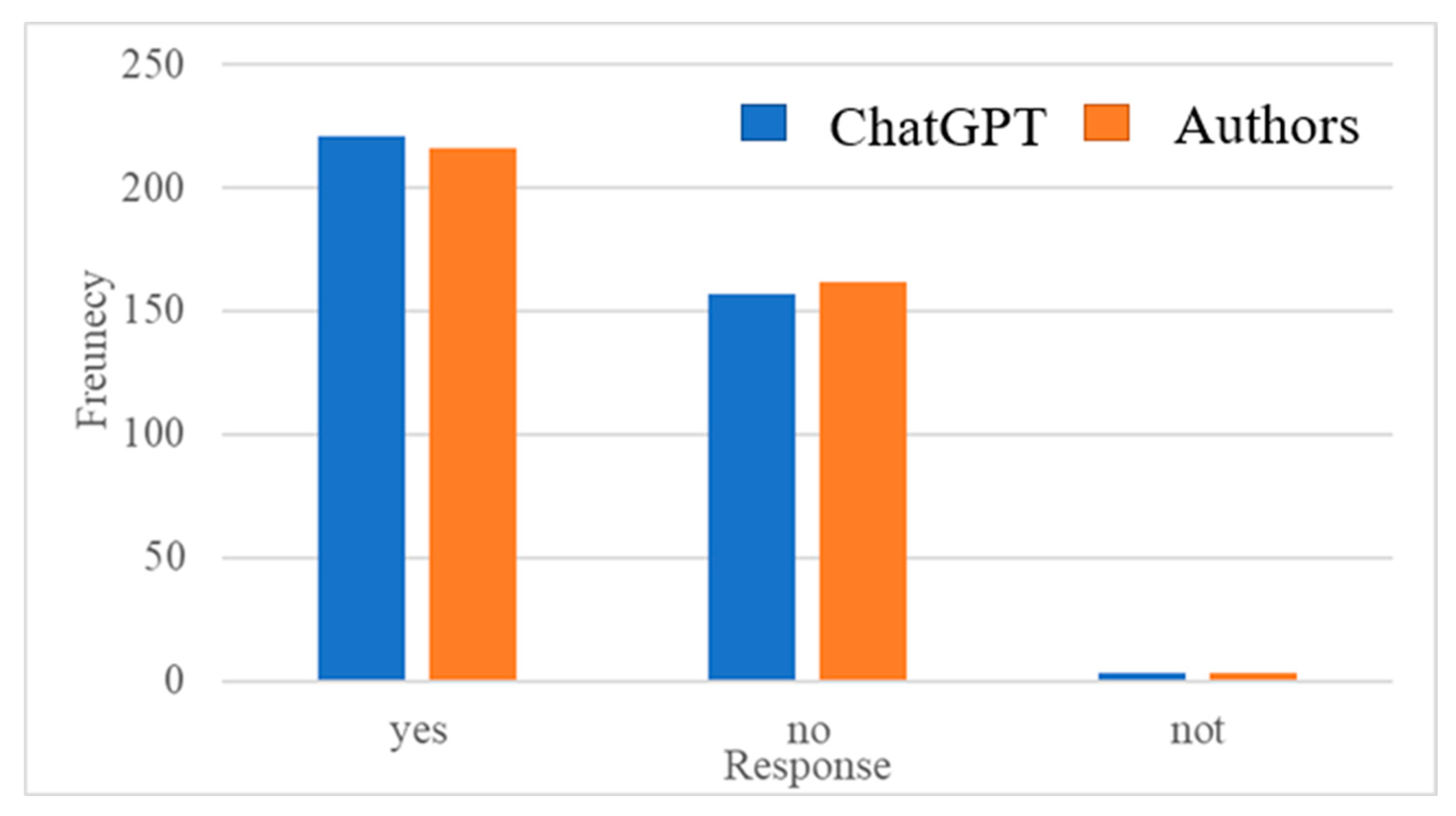
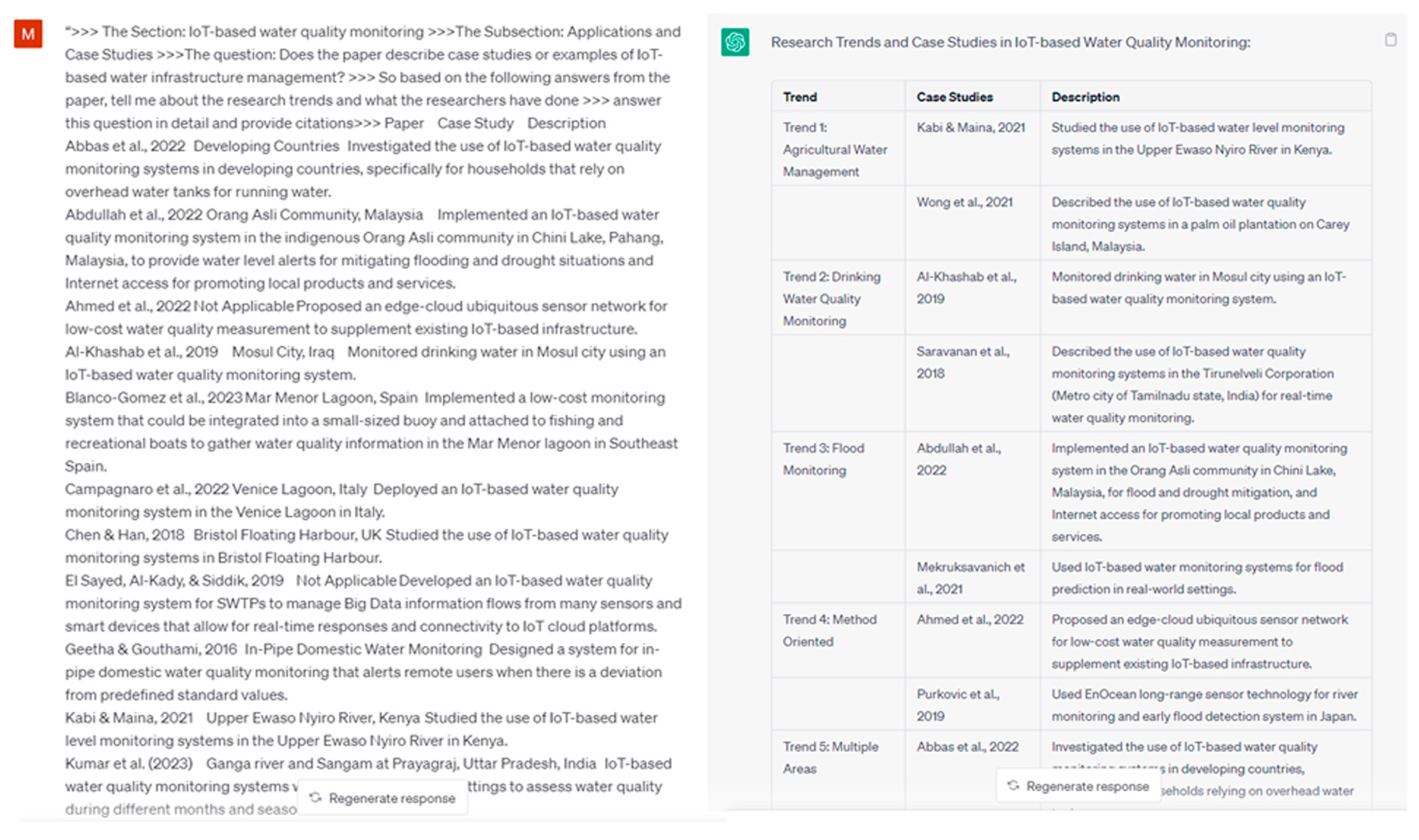
3.4. Analysis and Interpretation of Extracted Information
4. ChatGPT Strengths, Limitations, and Future Directions in Automating SR Process
4.1. Strengths of ChatGPT in SR Process
- Full Automation: ChatGPT contributes to automating several tasks in the SR process, such as generating research questions, suggesting BRTs, categorizing the relevant articles, discarding unrelated ones, proposing sub-categories to be covered for each main category, generating research questions to aid in information extraction from the articles, and extracting all relevant information. This level of automation facilitated by ChatGPT helps streamline the SR process and decrease the time and errors.
- Enhanced accuracy and efficiency: ChatGPT offers a valuable advantage by improving the accuracy and efficiency of filtering and classifying articles. Researchers can benefit from its ability to swiftly identify relevant studies, reducing uncertainty, and saving significant time and effort. Moreover, ChatGPT’s proficiency in natural language processing aids in precise content analysis, minimizing the risk of errors, and omissions in research interpretation.
- Time-saving: ChatGPT demonstrates significant potential in saving time during SRs, which are known to be time-consuming and resource-intensive processes that require high levels of expertise and attention to detail. ChatGPT assists in this process by swiftly analyzing and summarizing large volumes of the literature, aiding researchers in identifying relevant studies and extracting key information more efficiently. In our study, ChatGPT played a significant role in tasks such as filtering, categorizing, and content analysis, which resulted in decreased time and effort as well as reduced sources of uncertainty. However, it is important to note that human experts should carefully review ChatGPT-generated summaries.
- Improved reproducibility: While ChatGPT’s responses were found to be influenced by the user prompts, the same procedure can be replicated multiple times by following the same guidelines and adhering to the recommended approach. This enhances the reproducibility of the results, allowing for consistent outcomes to be obtained through repeated application of the methodology. ChatGPT’s responses are markedly affected by the user prompts, and the same procedure can be reproduced several times by conducting the same procedures and following the recommendations.
- Flexibility: The method introduced utilizing ChatGPT for automating the SR process can be applied for conducting SRs across various fields. This flexibility allows for the potential utilization of ChatGPT in various research domains, providing opportunities for its application beyond the specific context of the current study.
4.2. Limitations of ChatGPT in SR Process
- Limited ability to extract full-text articles: Despite ChatGPT’s capability to suggest and adjust BSTs based on user requests, it is not optimized for article extraction, which may impact the comprehensiveness of the SR. As a result, ChatGPT’s limitations in extracting articles may constrain the SR process’s completeness.
- Limited ability to extract all information from articles: Despite ChatGPT’s capability to filter, categorize articles, and extract text information, it may encounter limitations in extracting all relevant information, especially if the information is presented in non-standard formats such as figures or other non-textual forms. This may result in incomplete extraction of relevant data, particularly from articles that utilize non-traditional data presentation methods, potentially impacting the comprehensiveness and accuracy of the extracted information during the SR process.
- Dependence on input data: ChatGPT’s performance highly depends on the input data quality. If the data is biased or incomplete, GPT’s output may be similarly flawed.
- Limited Access to Real-Time Data: One notable drawback of ChatGPT in its application to automating the SR process pertains to its dependence on a pre-existing database. ChatGPT relies solely on the information it was trained on, lacking access to real-time data from the internet. Consequently, the model’s knowledge and comprehension are confined to the training data, limiting its ability to incorporate the latest research studies, publications, and emerging evidence. This limitation poses challenges in providing comprehensive and up-to-date information throughout the systematic review process.
- Length of prompts: While ChatGPT has the ability to generate high-quality responses, the length and complexity of the prompts used can impact the accuracy and coherence of the generated text. Our study revealed that longer prompts tended to result in more accurate and relevant responses, but also required more time and effort to prepare. Conversely, shorter prompts were easier and quicker to generate, but may have led to less accurate or incomplete responses. Hence, balancing the prompt’s length and complexity with the generated text’s accuracy and relevance is important. Additionally, careful consideration should be given to the prompt formulation process to ensure that the generated responses meet the desired quality standards in the context of the SR process.
- Token limitations: ChatGPT limits the number of tokens that can be processed simultaneously. This means that the length of the input sequence (i.e., prompt plus generated text) is limited and may require multiple iterations or segmentation to generate longer responses. Our study encountered this limitation when attempting to generate longer responses. This limitation can affect the efficiency and effectiveness of the ChatGPT’s model for certain tasks, especially in Phase 2, where the filtration occurred by feeding the ChatGPT with some parts from the article.
- Memory limitations: The ChatGPT ‘s ability to recall previous prompts and maintain a coherent and accurate discourse on a specific topic is a crucial consideration, as it can impose constraints that impact its scalability and applicability to certain tasks. Within our study, we encountered restrictions related to memory capacity, wherein ChatGPT occasionally struggled to provide responses that remained focused on the precise topic, leading to deviations or inaccuracies in its understanding of our prompts. This was particularly noticeable when working with large datasets or engaging in multiple iterations, highlighting the potential impact of memory limitations on the model’s performance.
4.3. Future Perspectives: Expanding the Potential of ChatGPT in SR
- Conducting the snowballing procedure using ChatGPT: This approach involves utilizing ChatGPT to search the database using BSTs, applying the first round of filtering based on abstracts, and then collecting remaining articles along with their references (backward) and cited publications (forward). These collected articles would undergo another round of abstract screening before proceeding to the second level of filtering. Automating the snowballing procedure with ChatGPT could streamline the filtration process, making it more efficient and time-saving for researchers.
- Developing more sophisticated algorithms to extract information from articles: Advanced techniques such as entity recognition and topic modeling could be employed to enhance the accuracy and precision of information extraction from articles. These techniques can enable ChatGPT to identify and extract relevant information more effectively, particularly from non-standard formats such as tables, figures, and other complex structures commonly found in scholarly literature.
- Improving the interpretability of ChatGPT’s output: Efforts could be made to develop tools or techniques to visualize and comprehend ChatGPT’s output. This may involve creating visual representations or graphical displays that aid in understanding the generated summaries or recommendations. Additionally, developing more transparent algorithms, which are easier for researchers to comprehend, can improve the interpretability of ChatGPT’s output.
- Expanding the scope of input data for ChatGPT: One potential avenue for enhancing the performance of ChatGPT in conducting SRs could be to explore the model’s applicability on data from fields with more relevant articles. This could involve testing the content analysis capabilities of ChatGPT by inputting a large amount of data and examining the conclusions drawn by the model. Additionally, employing ChatGPT on data from new fields can serve as a valuable means to test the robustness and integrity of the developed methodology in response to different aspects.
- Access to Real-Time Data: The SR process using ChatGPT can benefit from several avenues for improvement. Firstly, ChatGPT can provide accurate, current information regarding articles based on real-time access to databases, such as Scopus and Web of Science. In addition, internet connectivity enhances data retrieval and screening capabilities by allowing users to access a broader range of sources. Secondly, dynamic search strategies enable real-time feedback to be integrated into iterative enhancements. Thirdly, automated citation management and reference management, integration of collaborative platforms, and access to diverse perspectives and global research materials enhance the SR process. However, the success of these enhancements critically hinges on the particular implementation, ethical considerations, and rigorous validation of retrieved information.
5. Ethical Considerations in Utilizing AI-Language Models
6. Concluded Remarks and Recommendations
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Paré, G.; Trudel, M.-C.; Jaana, M.; Kitsiou, S. Synthesizing Information Systems Knowledge: A Typology of Literature Reviews. Inf. Manag. 2015, 52, 183–199. [Google Scholar] [CrossRef]
- Yuan, Y.; Hunt, R.H. Systematic Reviews: The Good, the Bad and the Ugly. Am. J. Gastroenterol. 2009, 104, 1086–1092. [Google Scholar] [CrossRef] [PubMed]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Keele University: Keele, UK, 2004. [Google Scholar]
- Mulrow, C.D. Systematic Reviews: Rationale for Systematic Reviews. BMJ 1994, 309, 597–599. [Google Scholar] [CrossRef] [PubMed]
- Needleman, I.G. A Guide to Systematic Reviews. J. Clin. Periodontol. 2002, 29, 6–9. [Google Scholar] [CrossRef]
- Agbo, C.; Mahmoud, Q.; Eklund, J. Blockchain Technology in Healthcare: A Systematic Review. Healthcare 2019, 7, 56. [Google Scholar] [CrossRef] [Green Version]
- FitzGerald, C.; Hurst, S. Implicit Bias in Healthcare Professionals: A Systematic Review. BMC Med. Ethics 2017, 18, 19. [Google Scholar] [CrossRef] [Green Version]
- Milne-Ives, M.; de Cock, C.; Lim, E.; Shehadeh, M.H.; de Pennington, N.; Mole, G.; Normando, E.; Meinert, E. The Effectiveness of Artificial Intelligence Conversational Agents in Health Care: Systematic Review. J. Med. Internet Res. 2020, 22, e20346. [Google Scholar] [CrossRef]
- Abu-Odah, H.; Su, J.; Wang, M.; Lin, S.-Y.; Bayuo, J.; Musa, S.S.; Molassiotis, A. Palliative Care Landscape in the COVID-19 Era: Bibliometric Analysis of Global Research. Healthcare 2022, 10, 1344. [Google Scholar] [CrossRef]
- Aarseth, W.; Ahola, T.; Aaltonen, K.; Økland, A.; Andersen, B. Project Sustainability Strategies: A Systematic Literature Review. Int. J. Proj. Manag. 2017, 35, 1071–1083. [Google Scholar] [CrossRef]
- Shaban, I.A.; Eltoukhy, A.E.E.; Zayed, T. Systematic and Scientometric Analyses of Predictors for Modelling Water Pipes Deterioration. Autom. Constr. 2023, 149, 104710. [Google Scholar] [CrossRef]
- Silva, M. A Systematic Review of Foresight in Project Management Literature. Procedia Comput. Sci. 2015, 64, 792–799. [Google Scholar] [CrossRef]
- Karam, A.; Eltoukhy, A.E.E.; Shaban, I.A.; Attia, E.-A. A Review of COVID-19-Related Literature on Freight Transport: Impacts, Mitigation Strategies, Recovery Measures, and Future Research Directions. Int. J. Environ. Res. Public Health 2022, 19, 12287. [Google Scholar] [CrossRef] [PubMed]
- Araújo, A.G.; Pereira Carneiro, A.M.; Palha, R.P. Sustainable Construction Management: A Systematic Review of the Literature with Meta-Analysis. J. Clean. Prod. 2020, 256, 120350. [Google Scholar] [CrossRef]
- Hussein, M.; Eltoukhy, A.E.E.; Karam, A.; Shaban, I.A.; Zayed, T. Modelling in Off-Site Construction Supply Chain Management: A Review and Future Directions for Sustainable Modular Integrated Construction. J. Clean. Prod. 2021, 310, 127503. [Google Scholar] [CrossRef]
- Taiwo, R.; Shaban, I.A.; Zayed, T. Development of Sustainable Water Infrastructure: A Proper Understanding of Water Pipe Failure. J. Clean. Prod. 2023, 398, 136653. [Google Scholar] [CrossRef]
- Michalski, A.; Głodziński, E.; Böde, K. Lean Construction Management Techniques and BIM Technology—Systematic Literature Review. Procedia Comput. Sci. 2022, 196, 1036–1043. [Google Scholar] [CrossRef]
- Abdelkader, E.M.; Zayed, T.; Faris, N. Synthesized Evaluation of Reinforced Concrete Bridge Defects, Their Non-Destructive Inspection and Analysis Methods: A Systematic Review and Bibliometric Analysis of the Past Three Decades. Buildings 2023, 13, 800. [Google Scholar] [CrossRef]
- Elshaboury, N.; Al-Sakkaf, A.; Mohammed Abdelkader, E.; Alfalah, G. Construction and Demolition Waste Management Research: A Science Mapping Analysis. Int. J. Environ. Res. Public Health 2022, 19, 4496. [Google Scholar] [CrossRef]
- Eltoukhy, A.E.E.; Chan, F.T.S.; Chung, S.H. Airline Schedule Planning: A Review and Future Directions. Ind. Manag. Data Syst. 2017, 117, 1201–1243. [Google Scholar] [CrossRef]
- Hassan, L.K.; Santos, B.F.; Vink, J. Airline Disruption Management: A Literature Review and Practical Challenges. Comput. Oper. Res. 2021, 127, 105137. [Google Scholar] [CrossRef]
- Aromataris, E.; Riitano, D. Systematic Reviews. AJN Am. J. Nurs. 2014, 114, 49–56. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meline, T. Selecting Studies for Systemic Review: Inclusion and Exclusion Criteria. Contemp. Issues Commun. Sci. Disord. 2006, 33, 21–27. [Google Scholar] [CrossRef]
- Wohlin, C. Guidelines for Snowballing in Systematic Literature Studies and a Replication in Software Engineering. In Proceedings of the 18th International Conference on Evaluation and Assessment in Software Engineering, London, UK, 13–14 May 2014; ACM: New York, NY, USA, 2014; pp. 1–10. [Google Scholar]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G. Preferred Reporting Items for Systematic Reviews and Meta-Analyses: The PRISMA Statement. Int. J. Surg. 2010, 8, 336–341. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sarkis-Onofre, R.; Catalá-López, F.; Aromataris, E.; Lockwood, C. How to Properly Use the PRISMA Statement. Syst. Rev. 2021, 10, 117. [Google Scholar] [CrossRef]
- Aydın, Ö.; Karaarslan, E. OpenAI ChatGPT Generated Literature Review: Digital Twin in Healthcare. SSRN Electron. J. 2022. [Google Scholar] [CrossRef]
- Cascella, M.; Montomoli, J.; Bellini, V.; Bignami, E. Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios. J. Med. Syst. 2023, 47, 33. [Google Scholar] [CrossRef]
- Vaishya, R.; Misra, A.; Vaish, A. ChatGPT: Is This Version Good for Healthcare and Research? Diabetes Metab. Syndr. Clin. Res. Rev. 2023, 17, 102744. [Google Scholar] [CrossRef]
- Halaweh, M. ChatGPT in Education: Strategies for Responsible Implementation. Contemp. Educ. Technol. 2023, 15, ep421. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models. PLOS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Zhai, X. ChatGPT for Next Generation Science Learning. XRDS Crossroads ACM Mag. Stud. 2023, 29, 42–46. [Google Scholar] [CrossRef]
- Rudolph, J.; Tan, S.; Tan, S. ChatGPT: Bullshit Spewer or the End of Traditional Assessments in Higher Education? J. Appl. Learn. Teach. 2023, 6, 342–362. [Google Scholar] [CrossRef]
- Prieto, S.A.; Mengiste, E.T.; García de Soto, B. Investigating the Use of ChatGPT for the Scheduling of Construction Projects. Buildings 2023, 13, 857. [Google Scholar] [CrossRef]
- You, H.; Ye, Y.; Zhou, T.; Zhu, Q.; Du, J. Robot-Enabled Construction Assembly with Automated Sequence Planning Based on ChatGPT: RoboGPT. arXiv 2023, arXiv:2304.11018. [Google Scholar]
- Alkaissi, H.; McFarlane, S.I. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 2023, 15, e35179. [Google Scholar] [CrossRef] [PubMed]
- Salvagno, M.; Taccone, F.S.; Gerli, A.G. Can Artificial Intelligence Help for Scientific Writing? Crit. Care 2023, 27, 75. [Google Scholar] [CrossRef] [PubMed]
- Zheng, H.; Zhan, H. ChatGPT in Scientific Writing: A Cautionary Tale. Am. J. Med. 2023. [Google Scholar] [CrossRef]
- Dergaa, I.; Chamari, K.; Zmijewski, P.; Ben Saad, H. From Human Writing to Artificial Intelligence Generated Text: Examining the Prospects and Potential Threats of ChatGPT in Academic Writing. Biol. Sport 2023, 40, 615–622. [Google Scholar] [CrossRef]
- Khosravi, H.; Shafie, M.R.; Hajiabadi, M.; Raihan, A.S.; Ahmed, I. Chatbots and ChatGPT: A Bibliometric Analysis and Systematic Review of Publications in Web of Science and Scopus Databases. arXiv 2023, arXiv:2304.05436. [Google Scholar]
- Lecler, A.; Duron, L.; Soyer, P. Revolutionizing Radiology with GPT-Based Models: Current Applications, Future Possibilities and Limitations of ChatGPT. Diagn. Interv. Imaging 2023, 104, 269–274. [Google Scholar] [CrossRef]
- Hosseini, M.; Horbach, S.P.J.M. Fighting Reviewer Fatigue or Amplifying Bias? Considerations and Recommendations for Use of ChatGPT and Other Large Language Models in Scholarly Peer Review. Res. Integr. Peer. Rev. 2023, 8, 4. [Google Scholar] [CrossRef]
- Fang, T.; Yang, S.; Lan, K.; Wong, D.F.; Hu, J.; Chao, L.S.; Zhang, Y. Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation. arXiv 2023, arXiv:2304.01746. [Google Scholar]
- Sallam, M. ChatGPT Utility in Healthcare Education, Research, and Practice: Systematic Review on the Promising Perspectives and Valid Concerns. Healthcare 2023, 11, 887. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, R.; Shaughnessy, D.; Gill, K.A.R.; Robinson, K.A.; Li, T.; Agai, E. Are ChatGPT and Large Language Models “the Answer” to Bringing Us Closer to Systematic Review Automation? Syst. Rev. 2023, 12, 72. [Google Scholar] [CrossRef] [PubMed]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Zeng, G. On the Confusion Matrix in Credit Scoring and Its Analytical Properties. Commun. Stat. Theory Methods 2020, 49, 2080–2093. [Google Scholar] [CrossRef]
- Jan, F.; Min-Allah, N.; Saeed, S.; Iqbal, S.Z.; Ahmed, R. IoT-Based Solutions to Monitor Water Level, Leakage, and Motor Control for Smart Water Tanks. Water 2022, 14, 309. [Google Scholar] [CrossRef]
- Singh, M.; Ahmed, S. IoT Based Smart Water Management Systems: A Systematic Review. Mater. Today Proc. 2021, 46, 5211–5218. [Google Scholar] [CrossRef]
- Zulkifli, C.Z.; Garfan, S.; Talal, M.; Alamoodi, A.H.; Alamleh, A.; Ahmaro, I.Y.Y.; Sulaiman, S.; Ibrahim, A.B.; Zaidan, B.B.; Ismail, A.R.; et al. IoT-Based Water Monitoring Systems: A Systematic Review. Water 2022, 14, 3621. [Google Scholar] [CrossRef]
- Alshami, A.; Elsayed, M.; Mohandes, S.R.; Kineber, A.F.; Zayed, T.; Alyanbaawi, A.; Hamed, M.M. Performance Assessment of Sewer Networks under Different Blockage Situations Using Internet-of-Things-Based Technologies. Sustainability 2022, 14, 14036. [Google Scholar] [CrossRef]
- Haluza, D.; Jungwirth, D. Artificial Intelligence and Ten Societal Megatrends: An Exploratory Study Using GPT-3. Systems 2023, 11, 120. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Zhang, X.; Chen, H.; Cheng, W. Exploring the Limits of ChatGPT for Query or Aspect-Based Text Summarization. arXiv 2023, arXiv:2302.08081. [Google Scholar]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Question |
|---|---|
| 1 | What is the Internet of Things? |
| 2 | What are the applications of the IoT so far? |
| 3 | What are the requirements to build the IoT system? |
| 4 | What are the infrastructures from the Civil engineering perspective? |
| 5 | How can the concept of the IoT be implemented in the domain of water and wastewater management? |
| 6 | What are the academic insights about implementing the IoT in water and wastewater management? |
| No. | ChatGPT Reference | Doi Check | Title Check |
|---|---|---|---|
| 1 | AlFuqaha, A., Guizani, M., Mohammadi, M., Aledhari, M., & Ayyash, M. (2015). Internet of things: A survey on enabling technologies, protocols, and applications. IEEE Communications Surveys & Tutorials, 17(4), 2347-2376. https://doi.org/10.1109/COMST.2015.2444095 | Correct | Correct |
| 2 | Akbar, M., & Khan, M. S. (2018). IoT-based smart wastewater management system. International Journal of Distributed Sensor Networks, 14(6), 1550147718781026. https://doi.org/10.1177/1550147718781026 | DOI not found | Correct |
| 3 | Arumugam, S., & Selvamani, S. (2020). Internet of things (IoT) based smart water management system: A review. Journal of Ambient Intelligence and Humanized Computing, 11(10), 4369-4390. https://doi.org/10.1007/s12652-020-02770-w | Incorrect | Correct |
| 4 | Dong, J., Li, Y., & Li, X. (2019). A review of internet of things-based smart water management systems. Journal of Sensors, 2019, 1-11. https://doi.org/10.1155/2019/2567391 | DOI not found | Incorrect |
| 5 | Kaur, P., Kumar, M., & Singh, P. (2021). IoT-enabled water management: A review. In I. Ahmad, S. Shafi, S. S. Gill, & V. Chang (Eds.), Internet of things and big data analytics towards next-generation intelligence (pp. 381-398). Springer. https://doi.org/10.1007/978-981-33-6965-5_17 | DOI not found | Incorrect |
| 6 | Kumar, M., Kumar, V., & Al-Fuqaha, A. (2021). An overview of cyber-physical system-based water management in smart cities. Journal of Sensor and Actuator Networks, 10(2), 19. https://doi.org/10.3390/jsan10020019 | DOI not found | Incorrect |
| ChatGPT | VOS Viewer | Similarity (%) | Number of Unique Keywords from ChatGPT |
|---|---|---|---|
| 50 | 50 | 20 | 40 |
| 100 | 100 | 28 | 72 |
| 180 | 180 | 23 | 138 |
| 200 | 200 | 21 | 158 |
| 50 | 263 | 68 | 16 |
| Sub-Category | Question | Water Quality Monitoring | Water Infrastructure Management | Wastewater Infrastructure Management. | Objectives |
|---|---|---|---|---|---|
| Answers (YES) | |||||
| Sensors’ development | 1-1: Sensor development. | 26 | 28 | 36 | Identify trends in sensor development and manufacturing, study the advantages of employing several sensors, investigate the frequency of sensor use, categorize sensors according to their functionality, and investigate the methods used to evaluate sensor performance. |
| 1-2: Use of different types of sensors. | 18 | 37 | 19 | ||
| 1-3: sensors performance evaluation. | 21 | 15 | 15 | ||
| Data transmission | 2-1: Data collection and transmission method. | 33 | 45 | 38 | Identify trends and anomalies in transmission methods, including the utilization of wireless communications, the types of wireless technologies employed, and the frequency of their occurrence in the examined papers. Analyze, also, the effectiveness of utilizing various communication technologies. |
| 2-2: Use of wireless communication. | 31 | 38 | 31 | ||
| 2-3: Connectivity performance evaluation. | 7 | 5 | 5 | ||
| Data analysis | 3-1: Data analysis methods. | 20 | 33 | 14 | Define frequently applied data analysis techniques, including AI and ML techniques, and study the trends in visualization approaches. |
| 3-2: Use of ML algorithms. | 6 | 11 | 0 | ||
| 3-3: Data visualization to facilitate decision-making. | 12 | 19 | 17 | ||
| Case studies | 4-1: The use in real-world settings. | 28 | 39 | 28 | Identify trends in the implementation of IoT-based systems in various real-world contexts and the outcomes and advantages of these implementations. |
| 4-2: Benefits and outcomes. | 17 | 37 | 27 | ||
| limitations and gaps | 5-1: limitations and gaps in current research. | 14 | 24 | 15 | Define the limitations and gaps identified by the authors, the obstacles encountered in implementing their systems, the offered solutions, and the recommendations for overcoming them. |
| 5-2: Implementation challenges. | 25 | 42 | 23 | ||
| 5-3: Recommendations or solutions. | 20 | 37 | 16 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alshami, A.; Elsayed, M.; Ali, E.; Eltoukhy, A.E.E.; Zayed, T. Harnessing the Power of ChatGPT for Automating Systematic Review Process: Methodology, Case Study, Limitations, and Future Directions. Systems 2023, 11, 351. https://doi.org/10.3390/systems11070351
Alshami A, Elsayed M, Ali E, Eltoukhy AEE, Zayed T. Harnessing the Power of ChatGPT for Automating Systematic Review Process: Methodology, Case Study, Limitations, and Future Directions. Systems. 2023; 11(7):351. https://doi.org/10.3390/systems11070351
Chicago/Turabian StyleAlshami, Ahmad, Moustafa Elsayed, Eslam Ali, Abdelrahman E. E. Eltoukhy, and Tarek Zayed. 2023. "Harnessing the Power of ChatGPT for Automating Systematic Review Process: Methodology, Case Study, Limitations, and Future Directions" Systems 11, no. 7: 351. https://doi.org/10.3390/systems11070351