A Survey of Attacks Against Twitter Spam Detectors in an Adversarial Environment



Abstract
1. Introduction
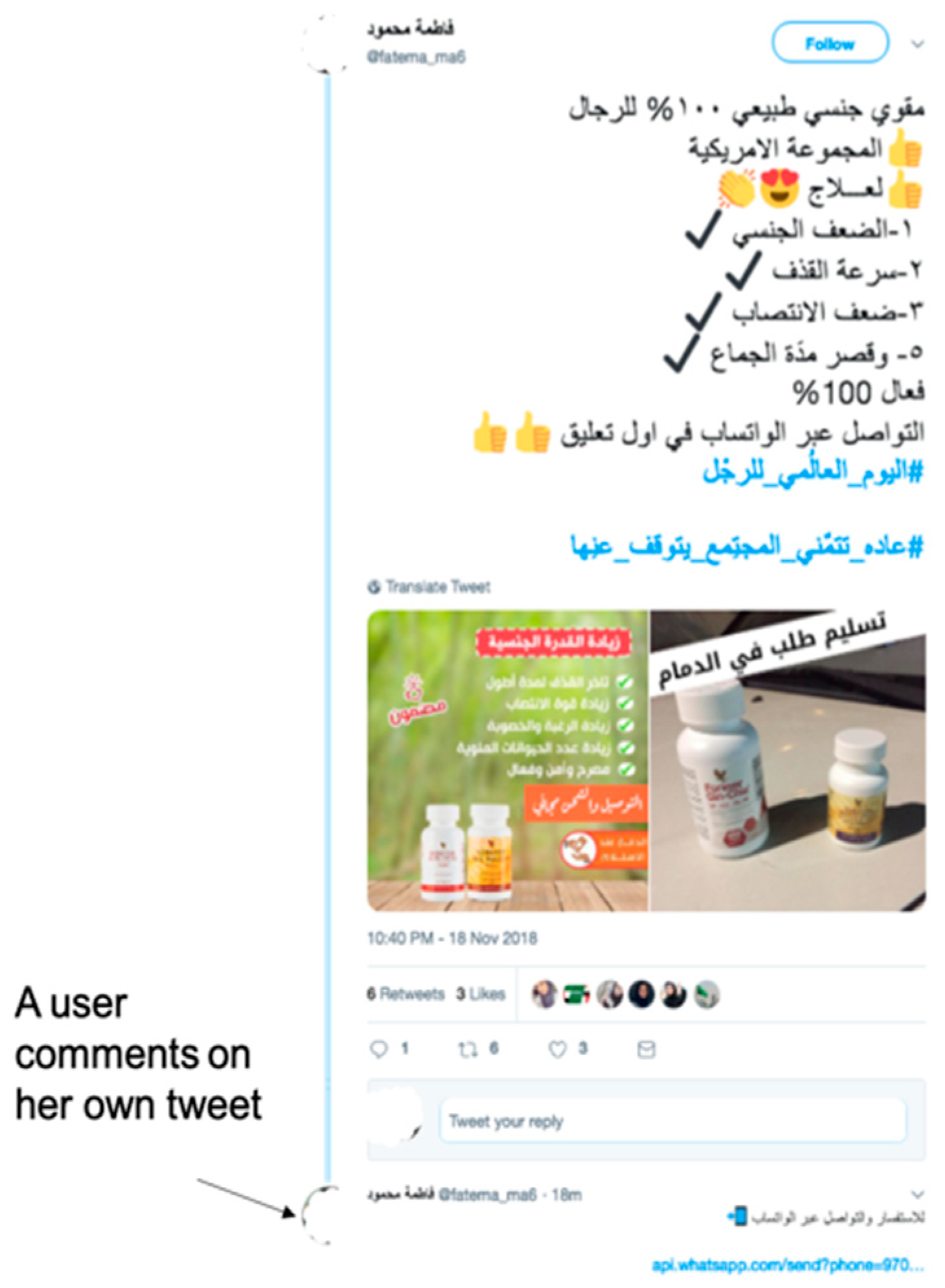
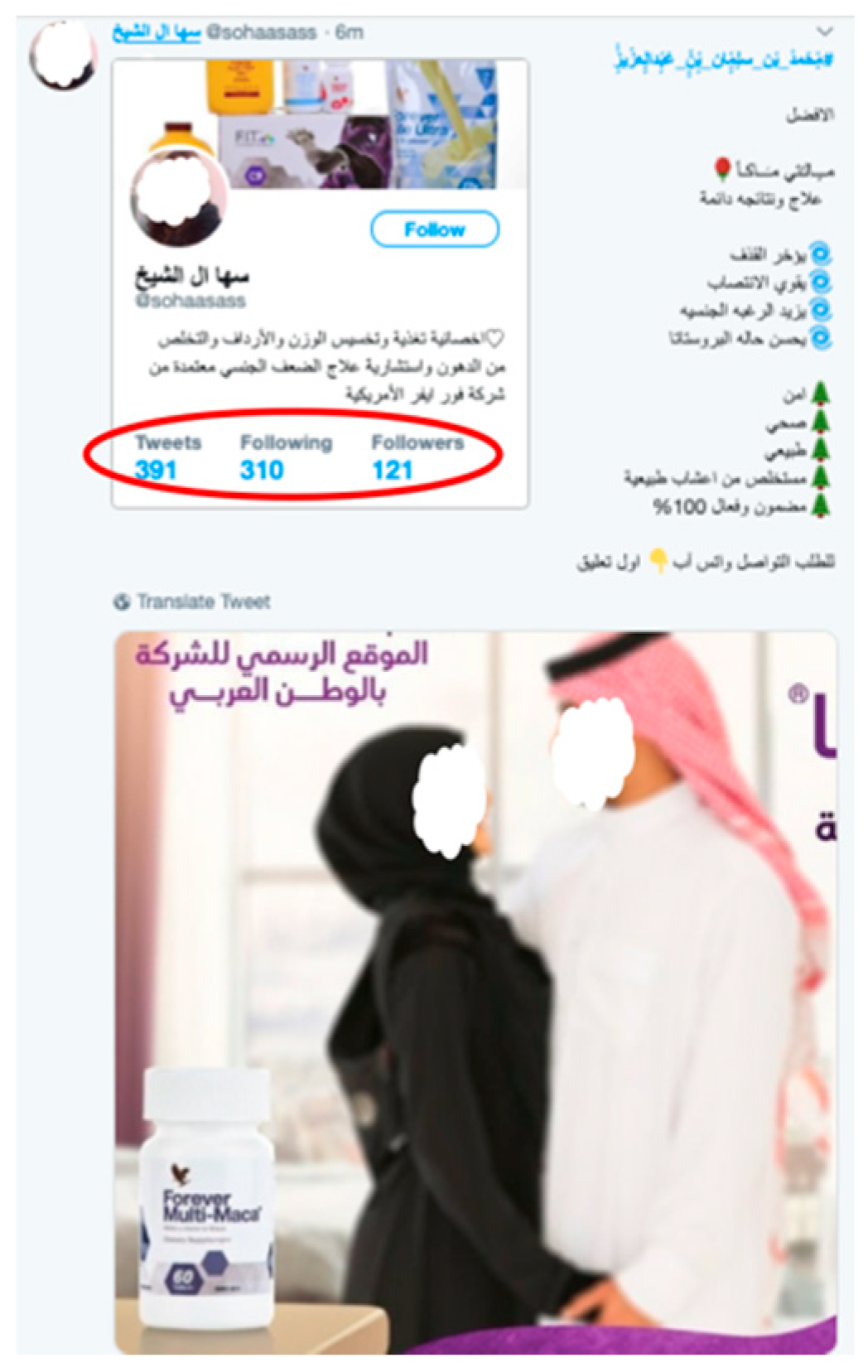
- After observing Arabic trending hashtags, it was found that there were very active spam campaigns spreading advertisements for untrustworthy drugs targeting Arabic-speaking users. These campaigns were studied and examples of a new type of spam tweet, which we called the adversarial spam tweet that can be used by an adversary to attack Twitter spam detectors, are presented.
- A general survey of the possible adversarial attacks against OSNs’ spam detectors is provided. The paper proposed different hypothetical attack scenarios against Twitter spam detectors using common frameworks for formulizing attacks against ML systems.
- In addition, potential defense mechanisms that could reduce the effect of such attacks are investigated. Ideas proposed in the literature are generalized to identify potential adversarial attacks and countermeasures. Twitter, which is one of the most popular OSN platforms, is used as a case study, and it is the source of all examples of attacks reported herein.
2. Literature Review
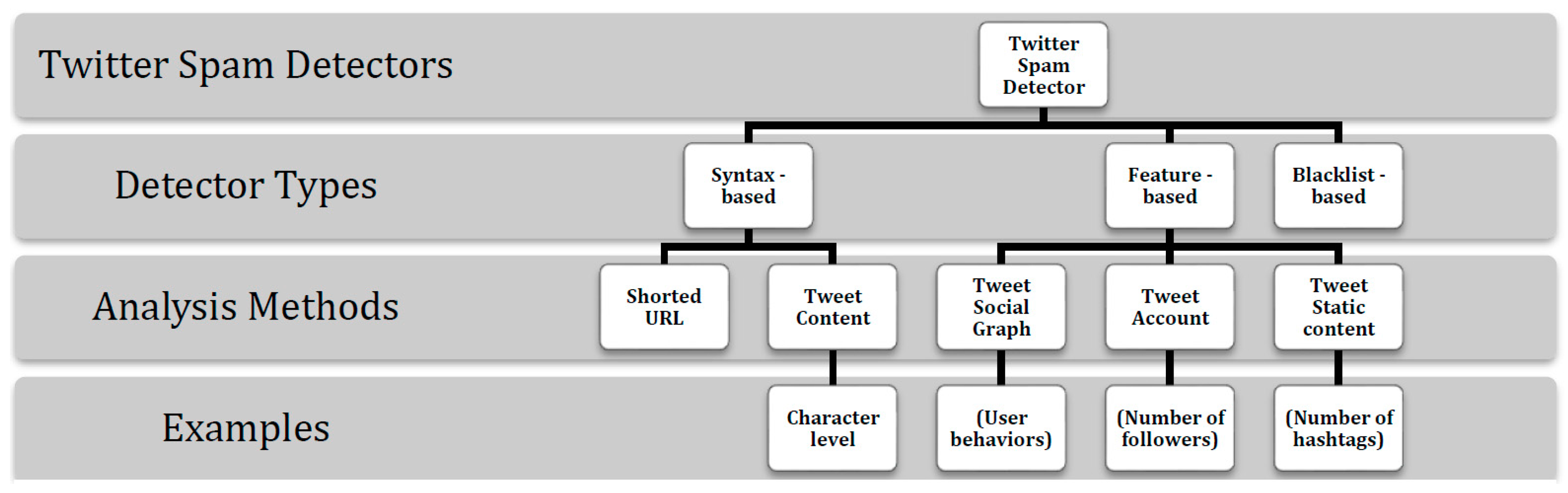
2.1. Techniques for Twitter Spam Detection
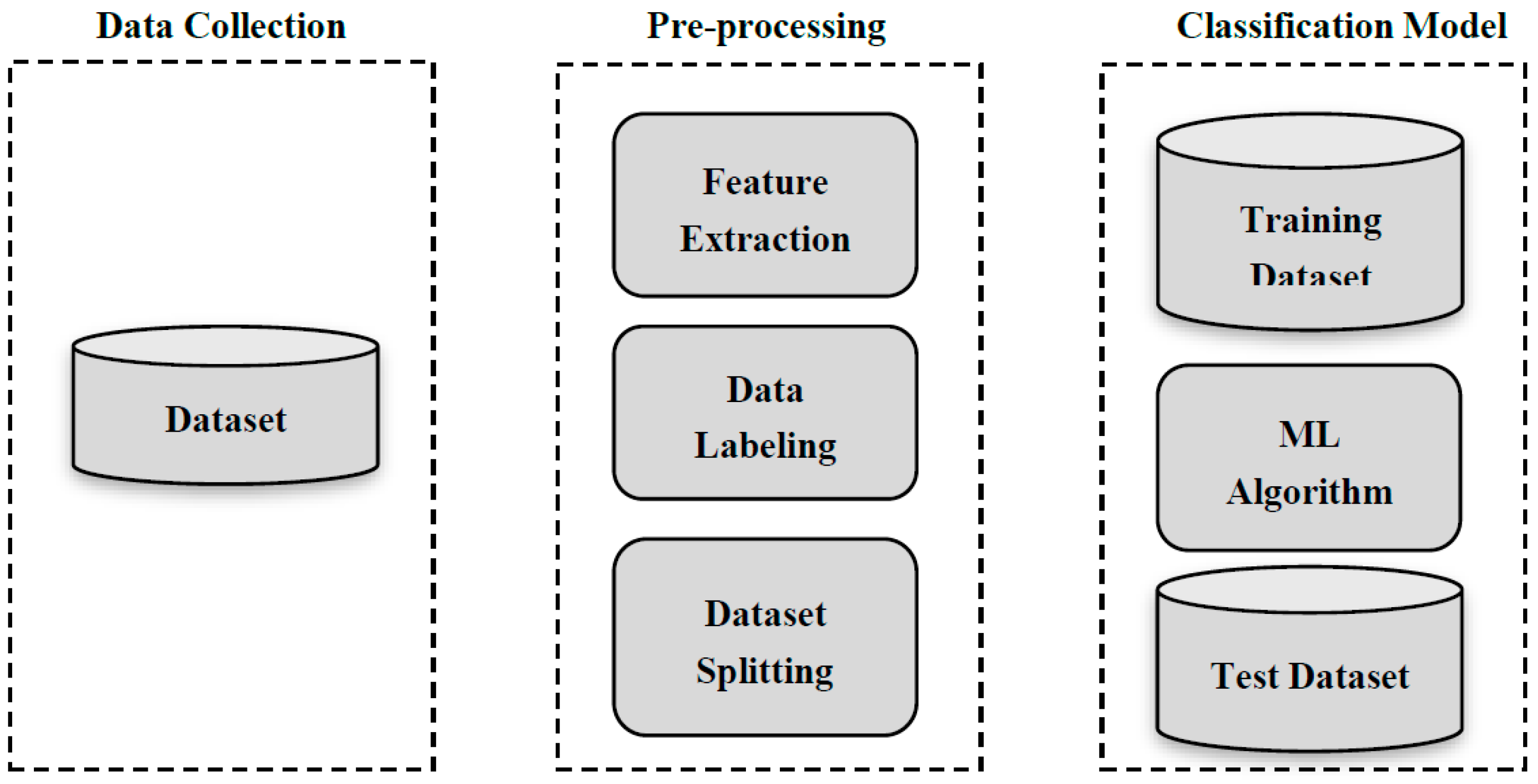
2.2. Process of Detecting Spam through ML
2.3. Detecting Spam Tweets using ML Techniques
2.4. Detecting Spam Campaigns on Twitter
2.5. Security of Twitter Spam Detectors
2.6. Adversarial Attacks against Twitter Spam Detectors
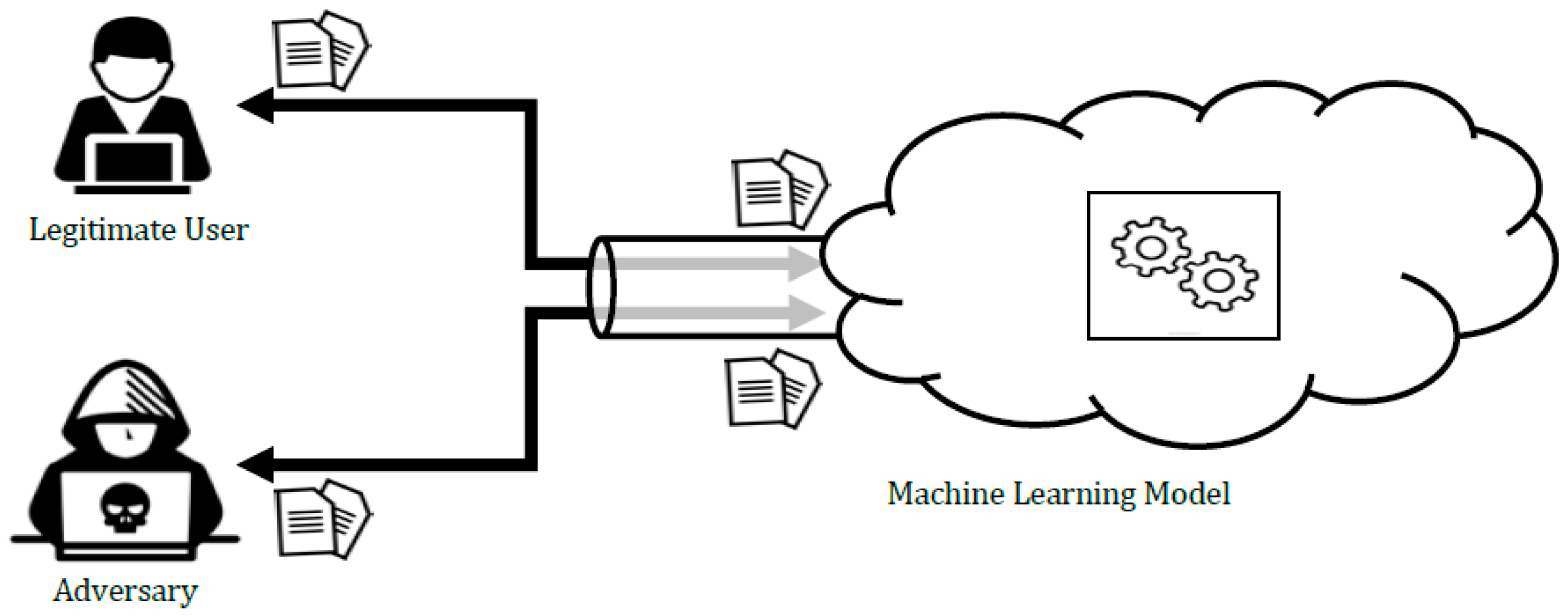
3. Adversarial Machine Learning
3.1. Taxonomy of Attacks Against ML
- Causative: The attack influences the training data to cause misclassification.
- Exploratory: The attack exploits knowledge about the deployed classifier to cause misclassifications without influencing training data.
- Integrity violation: An adversary evades detection without compromising normal system operations.
- Availability violation: An adversary compromises the normal system functionalities available to legitimate users.
- Privacy violation: An adversary obtains private information about the system (such as its users, data, or characteristics) by reverse-engineering the learning algorithm.
- Targeted attacks focus on a particular instance.
- Indiscriminate attacks encompass a wide range of instances.
3.2. Common Types of Threat Models
3.3. Adversarial Attacks and Defense Strategies
3.3.1. Causative Attacks
3.3.2. Causative Defense Methods
3.3.3. Exploratory Attacks
3.3.4. Exploratory Defense Methods
4. Taxonomy of Attacks Against Twitter Spam Detectors
4.1. Methodology
- Categorizing attacks by their influence and type of violation (such as causative integrity attacks).
- Identifying the attack’s settings, which include an adversary’s goal, knowledge, and capability.
- Defining the attack strategy, which includes potential attack steps.
4.2. Potential Attack Scenarios
4.2.1. Causative Integrity Attacks
- As the adversary’s knowledge of the system is considered to be perfect, it is not necessary to send probing tweets to gain knowledge.
- The adversary would carefully craft a large number of malicious tweets.
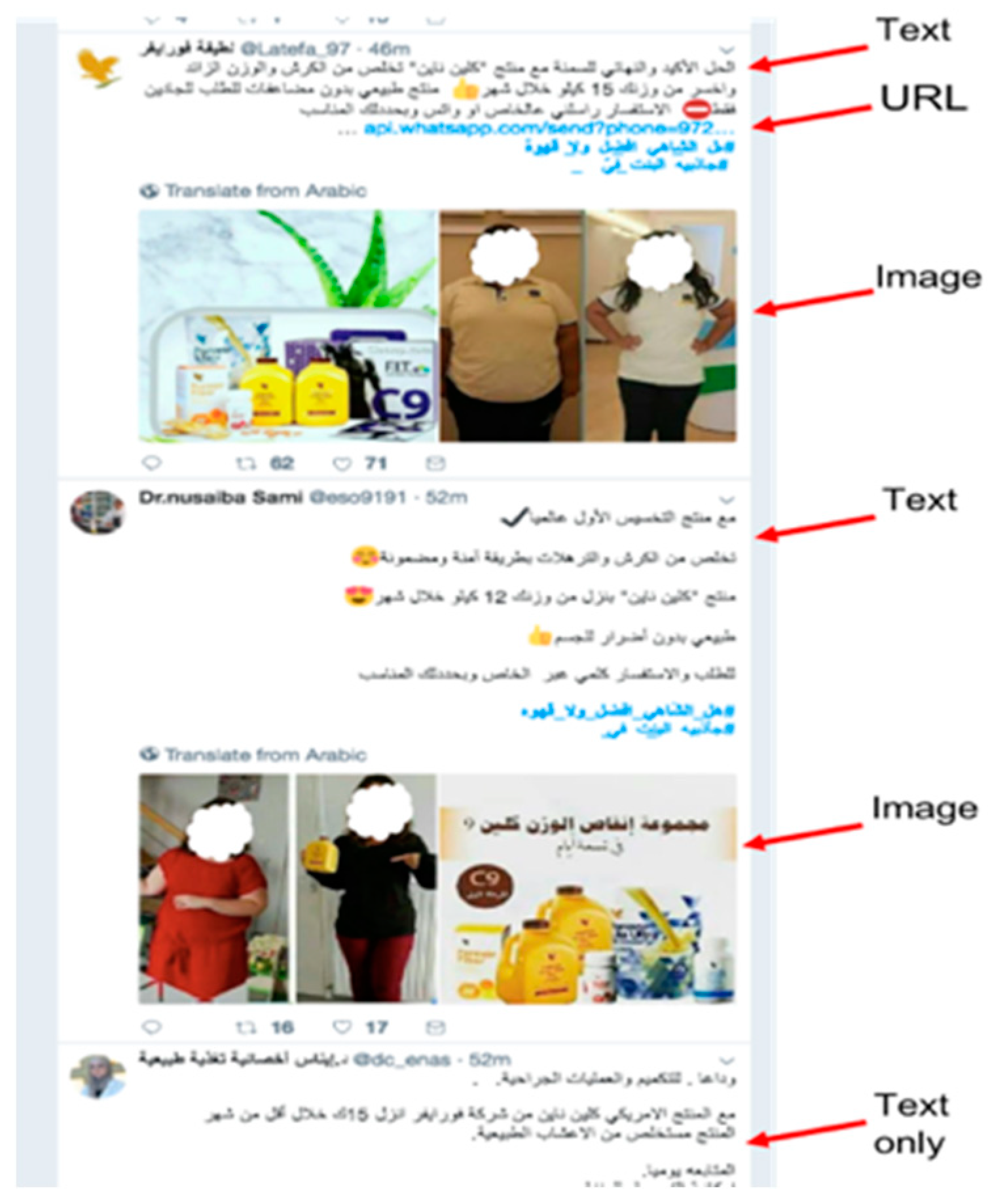
- The crafted tweets must resemble non-spam tweets and include both spam components, such as malicious URLs, and non-spam components or words (see Figure 6).
- The adversary would then post these tweets randomly using different trending hashtags and hope that these malicious tweets are used by Twitter when retraining their system.
- As the adversary has zero knowledge about the system, sending probing tweets to gain knowledge is required (privacy violation).
- A probing attack is an exploratory type of attack and is discussed in the next section.
- The adversary crafts samples with spurious or fake features and posts these samples with trending hashtags to trick Twitter’s spam detectors into using these samples for retraining.
- If Twitter spam detectors are trained on these samples, the adversary will discard these spurious features in future tweets to bypass the classifier.
- As the adversary has zero knowledge about the system, sending probing tweets to gain knowledge is required (privacy violation).
- A probing tweet (see Section 4.2.4 Figure 9) helps the adversary to learn how the classifier works; on this basis, the adversary can craft malicious tweets.
- Depending on the knowledge that the adversary gains, he or she can either flip the nearest or farthest samples from the deployed classifier’s decision boundary.
- If the adversary did not learn more about the classifier, he or she can randomly flip the label of some tweets.
- He or she then randomly posts these tweets using different trending hashtags and hopes that these malicious tweets are used by Twitter when retraining their system.
4.2.2. Causative Availability Attack
- As the adversary’s knowledge about the system is considered to be perfect, sending probing tweets to gain knowledge is not required.
- The adversary carefully crafts a large number of misleading tweets that consist of a combination of spam and non-spam components.
- The adversary needs to contaminate a very large proportion of training data for this attack to be successful. Using crowdsourcing sites or spambots to generate contaminated tweets helps the adversary to launch such an attack.
- The last step is to post these tweets randomly using different trending hashtags so that they quickly spread in the hope that Twitter will use them when retraining their system.
- As the adversary’s knowledge about the system is considered to be perfect, sending probing tweets to gain knowledge is not required.
- On the basis of the adversary’s knowledge, he or she builds a dictionary of words or phrases that are frequently used by legitimate users and uses this to craft malicious tweets.
- The adversary posts tweets that contain a large set of tokens (non-spam words, phrases, or tweet structure) from the dictionary in trending hashtags.
- If these tweets are used to train the system, non-spam tweets are more likely to be classified as spam because the system gives a higher spam score to tokens used in the attack.
4.2.3. Exploratory Integrity Attack
- As the adversary does not have sufficient knowledge of how the Twitter spam detector works, sending probing tweets to gain knowledge is required.
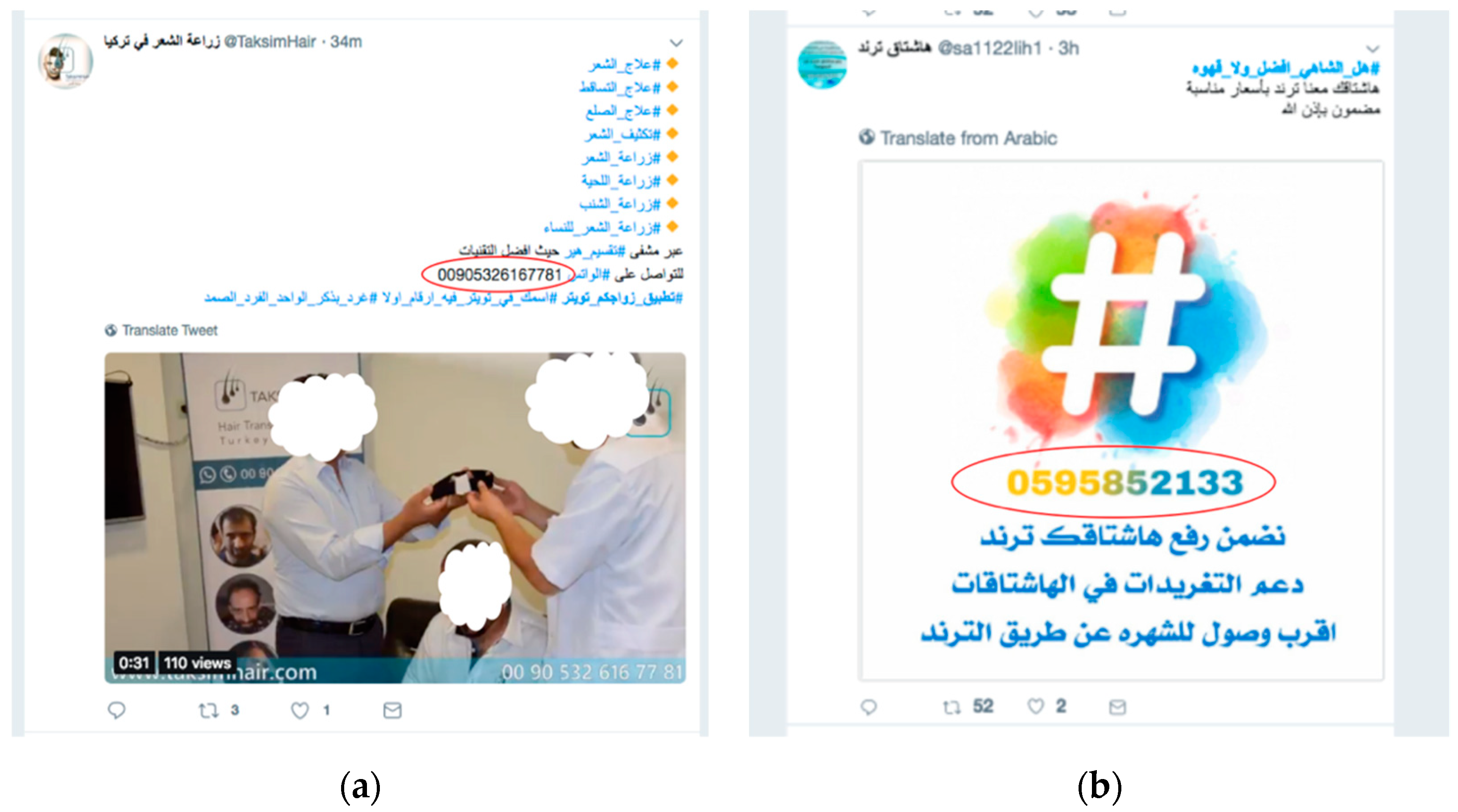
- The adversary sends a large number of tweets, each with different features, to learn about the system (see Figure 9).
- Using the information that is learned, the adversary carefully crafts tweets to evade detection.
- As the adversary’s knowledge of the system is considered to be perfect, sending probing tweets to gain knowledge is not required.
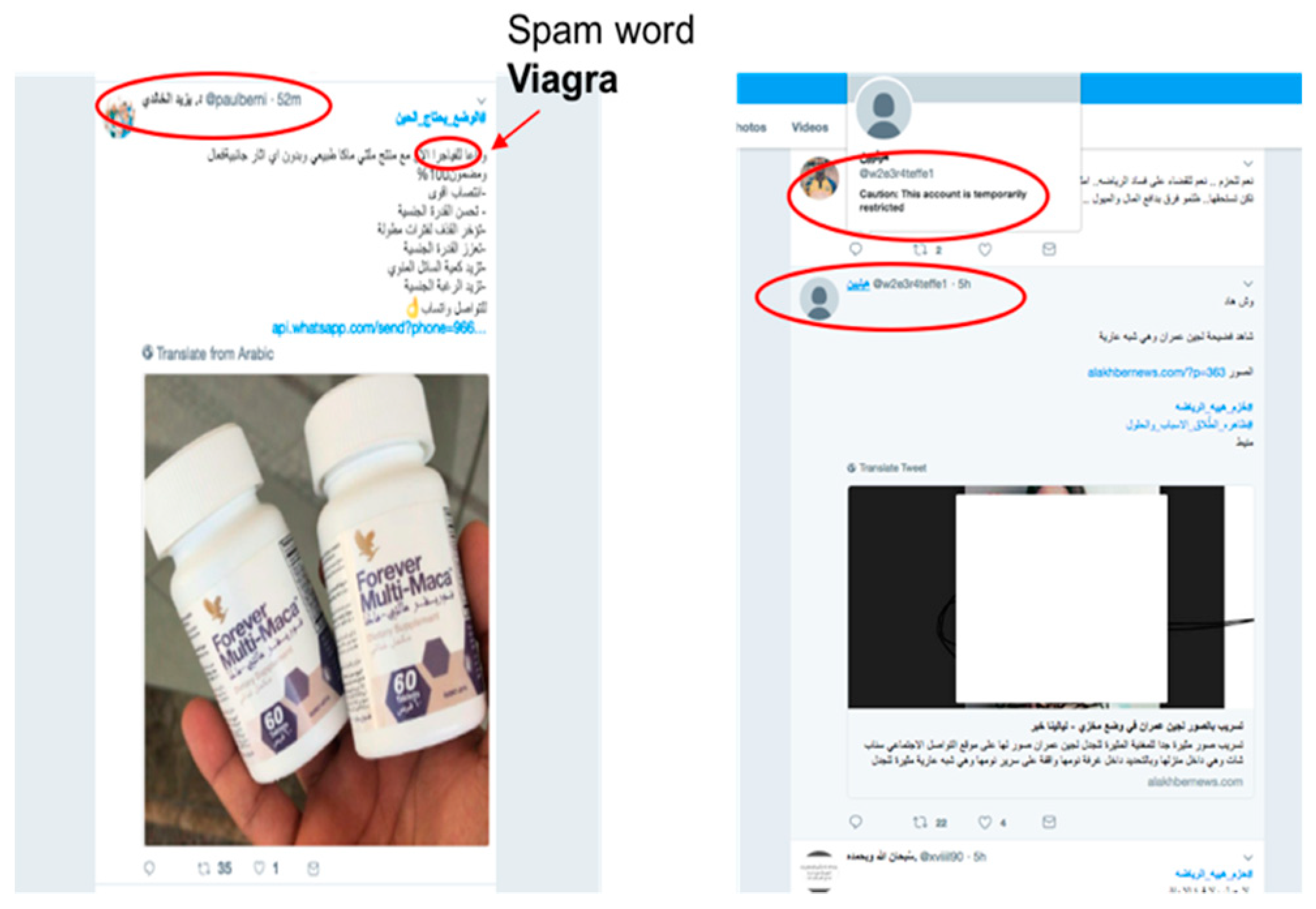
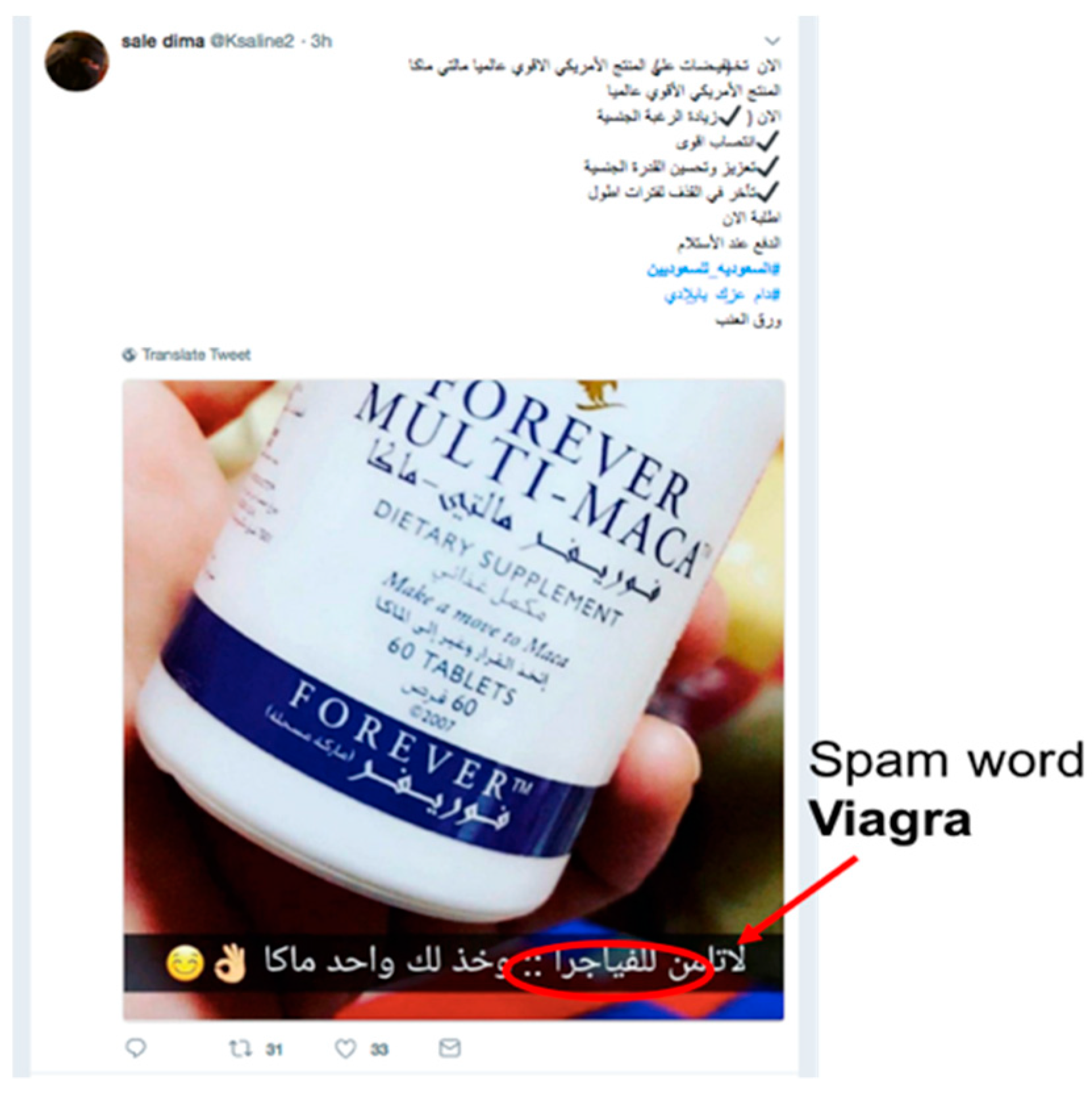
- Using his or her knowledge, the adversary carefully crafts tweets by modifying and obfuscating spam words (such as “Viagra”) or the tweet’s features to evade detection (such as the number of followers) (see Figure 10).
- As the adversary has zero knowledge about the system, the first step is to send probing tweets to learn how the system works (privacy violation).
- Using the exploited knowledge, the adversary builds a substitute model that can be used for launching different exploratory attacks [20].
- Once the substitute model is built, the adversary crafts different spam tweets to evade detection, and spam tweets that successfully evade the model are used against the Twitter spam detector.
4.2.4. Exploratory Availability Attack
- As the adversary has perfect knowledge about the system, sending probing tweets to gain knowledge is not required.
- Using the gained knowledge, the adversary carefully crafts spam tweets. As the adversary cannot influence training data, the adversary crafts tweets that require more time for the classifier to process, such as image-based tweets [33].
- The adversary then floods the system (for example, by using a particular trending hashtag) with spam tweets to prevent users from reading non-spam tweets and this causes difficulty in detecting spam tweets.
- As the adversary has zero knowledge about the system, the first step is to probe the classifier with some tweets to learn how it works.
- Using the exploited knowledge, the adversary crafts a large number of spam tweets and posts them with a specific hashtag to cause denial of service and make future attacks easier [20].
5. Potential Defense Strategies
5.1. Defenses Against Causative Attacks
5.2. Defenses Against Exploratory Attacks
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Al-Zoubi, A.; Alqatawna, J.; Faris, H. Spam profile detection in social networks based on public features. In Proceedings of the 2017 8th International Conference on Information and Communication Systems (ICICS), BIrbid, Jordan, 4–6 April 2017; p. 130. [Google Scholar]
- Gupta, A.; Kaushal, R. Improving spam detection in Online Social Networks. In Proceedings of the 2015 International Conference on Cognitive Computing and Information Processing (CCIP), Noida, India, 3–4 March 2015; p. 1. [Google Scholar]
- Barushka, A.; Hajek, P. Spam filtering using integrated distribution-based balancing approach and regularized deep neural networks. Appl. Intell. 2018, 48, 3538–3556. [Google Scholar] [CrossRef]
- Sedhai, S.; Sun, A. HSpam14: A Collection of 14 Million Tweets for Hashtag-Oriented Spam Research. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 223–232. [Google Scholar]
- Stringhini, G.; Kruegel, C.; Vigna, G. Detecting Spammers on Social Networks. In Proceedings of the 26th Annual Computer Security Applications Conference, ACSAC ’10, Austin, TX, USA, 6–10 December 2010. [Google Scholar]
- Yang, C.; Harkreader, R.; Gu, G. Empirical Evaluation and New Design for Fighting Evolving Twitter Spammers. IEEE Trans. Inf. Forensics Secur. 2013, 8, 1280–1293. [Google Scholar] [CrossRef]
- Benevenuto, F.; Magno, G.; Rodrigues, T.; Almeida, V. Detecting spammers on twitter. In Proceedings of the 2010 Collaboration, Electronic Messaging, Anti-Abuse and Spam Conference (CEAS), Redmond, DC, USA, 13–14 July 2010; Volume 6, p. 12. [Google Scholar]
- El-Mawass, N.; Alaboodi, S. Detecting Arabic spammers and content polluters on Twitter. In Proceedings of the 2016 Sixth International Conference on Digital Information Processing and Communications (ICDIPC), Beirut, Lebanon, 21–23 April 2016. [Google Scholar]
- Zhu, T.; Gao, H.; Yang, Y.; Bu, K.; Chen, Y.; Downey, D.; Lee, K.; Choudhary, A.N. Beating the Artificial Chaos: Fighting OSN Spam Using Its Own Templates. IEEE/ACM Trans. Netw. 2016, 24, 3856–3869. [Google Scholar] [CrossRef]
- Biggio, B.; Fumera, G.; Pillai, I.; Roli, F. A survey and experimental evaluation of image spam filtering techniques. Pattern Recognit. Lett. 2011, 32, 1436–1446. [Google Scholar] [CrossRef]
- Biggio, A.; Corona, I.; Maiorca, D.; Nelson, B.; Šrndić, N.; Laskov, P.; Giacinto, G.; Roli, F. Evasion Attacks against Machine Learning at Test Time. In Proceedings of the 2013 European Conference on Machine Learning and Knowledge Discovery in Databases - Volume Part III (ECMLPKDD’13), Prague, Czech Republic, 23–27 September 2013; pp. 387–402. [Google Scholar]
- Wang, D.; Navathe, S.B.; Liu, L.; Irani, D.; Tamersoy, A.; Pu, C. Click Traffic Analysis of Short URL Spam on Twitter. In Proceedings of the 9th IEEE International Conference on Collaborative Computing: Networking, Applications and Worksharing, Austin, TX, USA, 20–23 October 2013. [Google Scholar]
- Gupta, P.; Perdisci, R.; Ahamad, M. Towards Measuring the Role of Phone Numbers in Twitter-Advertised Spam. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security (ACM 2018), Incheon, Korea, 4 June 2018; pp. 285–296. [Google Scholar]
- Sculley, D.; Otey, M.E.; Pohl, M.; Spitznagel, B.; Hainsworth, J.; Zhou, Y. Detecting adversarial advertisements in the wild. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’11, San Diego, CA, USA, 21–24 August 2011; pp. 274–282. [Google Scholar]
- Gao, H.; Yang, Y.; Bu, K.; Chen, Y.; Downey, D.; Lee, K.; Choudhary, A. Spam ain’t as diverse as it seems: Throttling OSN spam with templates underneath. In Proceedings of the 30th Annual Computer Security Applications Conference, ACM 2014, New Orleans, LA, USA, 8–12 December 2014; pp. 76–85. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. The Paradigm-Shift of Social Spambots: Evidence, Theories, and Tools for the Arms Race. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; pp. 963–972. [Google Scholar]
- Chen, L.; Ye, Y.; Bourlai, T. Adversarial Machine Learning in Malware Detection: Arms Race between Evasion Attack and Defense. In Proceedings of the 2017 European Intelligence and Security Informatics Conference (EISIC), Athens, Greece, 11–13 September 2017; pp. 99–106. [Google Scholar]
- Meda, C.; Ragusa, E.; Gianoglio, C.; Zunino, R.; Ottaviano, A.; Scillia, E.; Surlinelli, R. Spam detection of Twitter traffic: A framework based on random forests and non-uniform feature sampling. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 811–817. [Google Scholar]
- Washha, M.; Qaroush, A.; Sedes, F. Leveraging time for spammers detection on Twitter. In Proceedings of the 8th International Conference on Management of Digital EcoSystems, ACM 2016, Biarritz, France, 1–4 November 2016; pp. 109–116. [Google Scholar]
- Alabdulmohsin, I.M.; Gao, X.; Zhang, X. Adding Robustness to Support Vector Machines Against Adversarial Reverse Engineering. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 231–240. [Google Scholar]
- Biggio, B.; Fumera, G.; Roli, F. Security Evaluation of Pattern Classifiers under Attack. IEEE Trans. Knowl. Data Eng. 2014, 26, 984–996. [Google Scholar] [CrossRef]
- Sethi, T.S.; Kantardzic, M. Handling adversarial concept drift in streaming data. Expert Syst. Appl. 2018, 97, 18–40. [Google Scholar] [CrossRef]
- Sethi, T.S.; Kantardzic, M.; Lyu, L.; Chen, J. A Dynamic-Adversarial Mining Approach to the Security of Machine Learning. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1245. [Google Scholar] [CrossRef]
- Kaur, P.; Singhal, A.; Kaur, J. Spam detection on Twitter: A survey. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 2570–2573. [Google Scholar]
- Lalitha, L.A.; Hulipalled, V.R.; Venugopal, K.R. Spamming the mainstream: A survey on trending Twitter spam detection techniques. In Proceedings of the 2017 International Conference on Smart Technologies for Smart Nation (SmartTechCon), Bangalore, India, 17–19 August 2017; pp. 444–448. [Google Scholar]
- Lin, G.; Sun, N.; Nepal, S.; Zhang, J.; Xiang, Y.; Hassan, H. Statistical Twitter Spam Detection Demystified: Performance, Stability and Scalability. IEEE Access 2017, 5, 11142–11154. [Google Scholar] [CrossRef]
- Wu, T.; Liu, S.; Zhang, J.; Xiang, Y. Twitter Spam Detection Based on Deep Learning. In Proceedings of the 2017 Australasian Computer Science Week Multiconference, ACSW ’17, Geelong, Australia, 30 January–3 February 2017. [Google Scholar]
- Grier, C.; Thomas, K.; Paxson, V.; Zhang, M. @ spam: The underground on 140 characters or less. In Proceedings of the 2010 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 27–37. [Google Scholar]
- Chen, C.; Zhang, J.; Xiang, Y.; Zhou, W. Asymmetric self-learning for tackling Twitter Spam Drift. In Proceedings of the 2015 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Hong Kong, China, 26 April–1 May 2015; pp. 208–213. [Google Scholar]
- Al Twairesh, N.; Al Tuwaijri, M.; Al Moammar, A.; Al Humoud, S. Arabic Spam Detection in Twitter. In Proceedings of the 2016 2nd Workshop on Arabic Corpora and Processing Tools on Social Media, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Song, J.; Lee, S.; Kim, J. CrowdTarget: Target-based Detection of Crowdturfing in Online Social Networks. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security—CCS ’15, Denver, CO, USA, 12–16 October 2015; pp. 793–804. [Google Scholar]
- Barreno, M.; Nelson, B.; Sears, R.; Joseph, A.D.; Tygar, J.D. Can Machine Learning Be Secure? In Proceedings of the 2006 ACM Symposium on Information, Computer and Communications Security, ASIACCS ’06, Taipei, Taiwan, 21–24 March 2006; pp. 16–25. [Google Scholar]
- Barreno, M.; Nelson, B.; Joseph, A.D.; Tygar, J.D. The security of machine learning. Mach. Learn. 2010, 81, 121–148. [Google Scholar] [CrossRef]
- Huang, L.; Joseph, A.D.; Nelson, B.; Rubinstein, B.I.; Tygar, J.D. Adversarial Machine Learning. In Proceedings of the 2011 4th ACM Workshop on Security and Artificial Intelligence, AISec ’11, Chicago, IL, USA, 21 October 2011; pp. 43–58. [Google Scholar]
- Sethi, T.S.; Kantardzic, M. Data driven exploratory attacks on black box classifiers in adversarial domains. Neurocomputing 2018, 289, 129–143. [Google Scholar] [CrossRef]
- Wang, G.; Wang, T.; Zheng, H.; Zhao, B.Y. Man vs. Machine: Practical Adversarial Detection of Malicious Crowdsourcing Workers. In Proceedings of the 2014 23rd USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 239–254. [Google Scholar]
- Nilizadeh, S.; Labrèche, F.; Sedighian, A.; Zand, A.; Fernandez, J.; Kruegel, C.; Stringhini, G.; Vigna, G. POISED: Spotting Twitter Spam Off the Beaten Paths. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ACM 2017, Dallas, TX, USA, 30 October–3 November 2017; pp. 1159–1174. [Google Scholar]
- Chen, C.; Zhang, J.; Chen, X.; Xiang, Y.; Zhou, W. 6 million spam tweets: A large ground truth for timely Twitter spam detection. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 7065–7070. [Google Scholar]
- Mateen, M.; Iqbal, M.A.; Aleem, M.; Islam, M.A. A hybrid approach for spam detection for Twitter. In Proceedings of the 2017 14th International Bhurban Conference on Applied Sciences and Technology (IBCAST), Islamabad, Pakistan, 10–14 January 2017; pp. 466–471. [Google Scholar]
- Sedhai, S.; Sun, A. Semi-Supervised Spam Detection in Twitter Stream. IEEE Trans. Comput. Soc. Syst. 2018, 5, 169–175. [Google Scholar] [CrossRef]
- Gupta, S.; Khattar, A.; Gogia, A.; Kumaraguru, P.; Chakraborty, T. Collective Classification of Spam Campaigners on Twitter: A Hierarchical Meta-Path Based Approach. In Proceedings of the 2018 World Wide Web Conference, International World Wide Web Conferences Steering Committee, Lyon, France, 23–27 April 2018; pp. 529–538. [Google Scholar]
- Cresci, S.; Di Pietro, R.; Petrocchi, M.; Spognardi, A.; Tesconi, M. Social Fingerprinting: Detection of Spambot Groups Through DNA-Inspired Behavioral Modeling. IEEE Trans. Dependable Secur. Comput. 2018, 15, 561–576. [Google Scholar] [CrossRef]
- Biggio, B.; Roli, F. Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning. arXiv 2017, arXiv:1712.03141. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer Encoding: One Hot Way to Resist Adversarial Examples. In Proceedings of the 2018 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. In Proceedings of the 2018 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–24 May 2018. [Google Scholar]
- Biggio, B. Support Vector Machines Under Adversarial Label Noise. JMLR Workshop Conf. Proc. 2011, 20, 97–112. [Google Scholar]
- Laishram, R.; Phoha, V.V. Curie: A method for protecting SVM Classifier from Poisoning Attack. arXiv 2016, arXiv:1606.01584. [Google Scholar]
- Newsome, J.; Karp, B.; Song, D. Paragraph: Thwarting Signature Learning by Training Maliciously. In Recent Advances in Intrusion Detection; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; pp. 81–105. [Google Scholar]
- Lowd, D.; Meek, C. Good Word Attacks on Statistical Spam Filters. In Proceedings of the CEAS 2005, Conference on Email and Anti-Spam, Stanford, CA, USA, 21–22 July 2005. [Google Scholar]
- Baracaldo, N.; Chen, B. Mitigating Poisoning Attacks on Machine Learning Models: A Data Provenance Based Approach. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security (AISec ‘17), Dallas, TX, USA, 3 November 2017. [Google Scholar]
- Biggio, B.; Corona, I.; Fumera, G.; Giacinto, G.; Roli, F. Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks. In International Workshop on Multiple Classifier Systems; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 350–359. [Google Scholar]
- Chan, P.P.; He, Z.M.; Li, H.; Hsu, C.C. Data sanitization against adversarial label contamination based on data complexity. Int. J. Mach. Learn. Cybern. 2018, 9, 1039–1052. [Google Scholar] [CrossRef]
- He, Z.; Su, J.; Hu, M.; Wen, G.; Xu, S.; Zhang, F. Robust support vector machines against evasion attacks by random generated malicious samples. In Proceedings of the 2017 International Conference on Wavelet Analysis and Pattern Recognition (ICWAPR), Ningbo, China, 9–12 July 2017; pp. 243–247. [Google Scholar]
- Biggio, B.; Fumera, G.; Roli, F. Adversarial Pattern Classification using Multiple Classifiers and Randomisation. In Proceedings of the 12th Joint IAPR International Workshop on Structural and Syntactic Pattern Recognition (SSPR 2008), Orlando, FL, USA, 4–6 December 2008; Volume 5342, pp. 500–509. [Google Scholar]
- Bruckner, M. Static Prediction Games for Adversarial Learning Problems. J. Mach. Learn. Res. JMLR 2012, 13, 2617–2654. [Google Scholar]
- Corona, I.; Giacinto, G.; Roli, F. Adversarial attacks against intrusion detection systems: Taxonomy, solutions and open issues. Inf. Sci. 2013, 239, 201–225. [Google Scholar] [CrossRef]
- Dalvi, N.; Domingos, P.; Sanghai, S.; Verma, D. Adversarial Classification. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’04, Seattle, WA, USA, 22–25 August 2004; pp. 99–108. [Google Scholar]
- Kantchelian, A.; Afroz, S.; Huang, L.; Islam, A.C.; Miller, B.; Tschantz, M.C.; Greenstadt, R.; Joseph, A.D.; Tygar, J.D. Approaches to adversarial drift. In Proceedings of the 2013 ACM Workshop on Artificial Intelligence and Security—AISec ’13, Berlin, Germany, 4 November 2013; pp. 99–110. [Google Scholar]
- Miller, B.; Kantchelian, A.; Afroz, S.; Bachwani, R.; Dauber, E.; Huang, L.; Tschantz, M.C.; Joseph, A.D.; Tygar, J.D. Adversarial Active Learning. In Proceedings of the 2014 Workshop on Artificial Intelligent and Security Workshop—AISec ’14, Scottsdale, AZ, USA, 7 November 2014; pp. 3–14. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Category | Feature Name | Description |
|---|---|---|
| Account-based features | account_age | The number of days since the creation of an account. |
| no_followers | The number of followers of an account. | |
| no_friends | The number of friends an account has. | |
| no_favorites | The number of favorites an account received. | |
| no_lists | The number of lists an account is a member of. | |
| no_reputation | The ratio of the number of followers and the total followers and friends of an account. | |
| no_statuses | The number of tweets an account has. | |
| Tweet content-based features | no_words | The number of words in a tweet. |
| no_chars | The number of characters in a tweet. | |
| no_hashs | The number of hashtags in a tweet. | |
| no_urls | The number of URLs in a tweet. | |
| no_phone | The number of phone numbers in a tweet. | |
| no_mentions | The number of mentions in a tweet. | |
| Relation-based features | Distance | The length of the distance between accounts. |
| Connectivity | The strength of the relationship between accounts. |
| Title | Methodology | Type of Spam | Type of Detector | Learning Approach | Results/Accuracy |
|---|---|---|---|---|---|
| 6 Million Spam Tweets—A Large Ground Truth for Timely Twitter Spam Detection [38] | Different ML algorithms were used; balanced and imbalanced datasets were tested. | Spam tweet | Feature-based | Supervised | RF outperformed other algorithms. |
| A Hybrid Approach for Spam Detection for Twitter [39] | J48, Decorate, and Naive-Bayes (NB). | Spam tweet | Feature-, user-, and graph-based | Supervised | J48 outperformed other algorithms. |
| Leveraging Time for Spammers Detection on Twitter [19] | Time-based features were used, and different ML algorithms were tested. | Spam tweet | Feature-based | Supervised | RF outperformed other algorithms. |
| Twitter spam detection based on Deep Learning [27] | Different ML algorithms with Word2Vector technique were used. | Spam tweet | Syntax-based | Supervised | RF with Worrd2Vec outperformed other algorithms. |
| Semi-supervised spam detection (S3D) [40] | Utilized four lightweight detectors (supervised and unsupervised) to detect spam tweets and updated the models periodically in batch mode. | Spam tweet | Feature-based and blacklist | Semi-supervised | The confidential labeling process, which uses blacklisted, near-duplicated, and reliable non-spam tweets, made the deployed classifier more efficient when detecting new spam tweets. |
| CrowdTarget: Target-based Detection of Crowdturfing in Online Social Networks [31] | Detected spam tweets that received retweets from malicious crowdsourcing users. It used four new retweet-based features and KNN as a classifier. | Spam tweet | Feature-based | Supervised | CrowdTarget detected malicious retweets created by crowdturfing users with a True Positive Rate of 0.98 and False Positive Rate of 0.01. |
| Beating the Artificial Chaos - Fighting OSN Spam using Its Own Templates [9] | Detected template-based spam, paraphrase spam, and URL-based spam. | Spam campaign | Syntax-based | Supervised | Template detection outperformed URL blacklist detection. |
| POISED—Spotting Twitter Spam Off the Beaten Paths [37] | Detected spam campaigns based on community and topic of interest. | Spam campaign | Syntax-based | Supervised and unsupervised | NB, SVM, and RF all achieved about 90% detection accuracy. |
| Collective Classification of Spam Campaigners on Twitter: A Hierarchical Meta-Path Based Approach (HMPS) [41] | Built heterogeneous networks and detected nodes connected by the same phone number or URL. | Spam campaign | Social graph-based | Supervised | HMPS outperformed feature- and content-based approaches. Prediction accuracy improved when using HMPS with feature- and user-based approaches. |
| Social Fingerprinting—Detection of Spambot Groups Through DNA-Inspired Behavioral Modeling [42] | Modeled users’ behavior using a DNA fingerprinting technique to detect spambots. | Spam campaign | Social graph-based | Supervised and unsupervised | The results showed that the proposed approach achieved better detection accuracy when using a supervised learning approach. |
| Type of Influence | Title | Name of Attack | Attack Target | Attack Method |
|---|---|---|---|---|
| Causative | Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning [46] | Poisoning | Regression Learning | Optimization-based poisoning attack, which uses different optimization approaches, and statistical-based poisoning attack (StatP), which queries a deployed model to find an estimate of the mean and covariance of training data. |
| Support vector machines under adversarial label noise [47] | Label Flipping | SVM | Two different label-flipping attacks were used: random and adversarial label flips. | |
| Curie—A method for protecting SVM Classifier from Poisoning Attack [48] | Label Flipping | SVM | Two label-flipping attacks were used. In the first, the loss maximization framework was used to select points that needed their label to be flipped. In the second attack, the selected data points were moved to other points in the feature space. | |
| Adversarial Machine Learning [34] | Dictionary | Spam filter | An adversary builds a dictionary of tokens learned from the targeted model and then sends attack messages to cause misclassification. | |
| Thwarting Signature Learning by Training Maliciously [49] | Red Herring | Polymorphic worm signature generation algorithms | An adversary sends messages with fake features to trick the deployed model. | |
| Man vs. Machine: Practical Adversarial Detection of Malicious Crowdsourcing Workers [36] | Poisoning | NB, BN, SVM, J48, RF | Two types of poisoning attacks were performed: Injecting misleading samples and altering training data. | |
| Exploratory | Data Driven Exploratory Attacks on Black Box Classifiers in Adversarial Domains [35] | Anchor Points (AP) and Reverse Engineering attacks (RE) | SVM, KNN, DT, RF | The AP attack is not affected by the chosen model (linear or non-linear), unlike RE, which is affected when a defender uses DT or RF. |
| Evasion Attacks against Machine Learning at Test Time [11] | Evasion | SVM, Neural Network | A gradient-descent evasion attack was proposed. | |
| Good Word Attacks on Statistical Spam Filters [50] | Good Word | NB, Maximum entropy filter | Active and passive good word attacks against email spam filters were evaluated. | |
| Adding Robustness to Support Vector Machines Against Adversarial Reverse Engineering [20] | Reverse Engineering | SVM | Three different query selection methods, which help learn the decision boundary of deployed classifier, were used. Random, selective, and uncertainty sampling. | |
| Man vs. Machine: Practical Adversarial Detection of Malicious Crowdsourcing Workers [38] | Evasion | NB, BN, SVM, J48, RF | Two evasion attack were launched: Basic evasion attack and Optimal evasion attack, where an adversary knows features that need to be altered. |
| Type of Influence | Title | Name of Attack | Type of Classifier | Defense Category | Defense Method |
|---|---|---|---|---|---|
| Causative | Mitigating Poisoning Attacks on Machine Learning Models: A Data Provenance Based Approach [51] | Poisoning | SVM | Data Sanitization | Poisoned data are filtered out from the training dataset using a provenance framework that records the lineage of data points. |
| Curie- A method for protecting SVM Classifier from Poisoning Attack [48] | Poisoning | SVM | Data Sanitization | The data are clustered in the feature space, and the average distance of each point from the other points in the same cluster is calculated, with the class label considered a feature with proper weight. Data points with less than 95% confidence are removed from the training data. | |
| Bagging Classifiers for Fighting Poisoning Attacks in Adversarial Classification Tasks [52] | Poisoning | Bagging and weighted bagging ensembles | Data Sanitization | An ensemble construction method (bagging) is used to remove outliers (adversarial samples) from the training dataset. | |
| Data sanitization against adversarial label contamination based on data complexity [53] | Label Flipping | SVM | Data Sanitization | Data complexity, which measures the level of difficulty of classification problems, is used to distinguish adversarial samples in the training data. | |
| Support vector machines under adversarial label noise [47] | Label Flipping | SVM | Robust learning | Adjusting the kernel matrix of SVM depending on noisy (adversarial) samples’ parameters increases the robustness of the classifier. | |
| Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning [46] | Poisoning | Regression Learning | Robust learning | The TRIM algorithm, which regularizes linear regression by applying trimmed optimization techniques, was proposed. | |
| Exploratory | Robust support vector machines against evasion attacks by random generated malicious samples [54] | Evasion | SVM | Robust learning | The SVM classifier is trained with random malicious samples to enclose the decision function. |
| Adding Robustness to Support Vector Machines Against Adversarial Reverse Engineering [20] | Reverse Engineering | SVM | Randomization | A distribution of classifiers is learned and a decision boundary is picked randomly to make reverse engineering attacks harder to launch. | |
| Handling adversarial concept drift in streaming data [22] | Evasion | SVM | Disinformation | The importance of features is hidden and an ensemble of classifiers is used. | |
| Adversarial Pattern Classification using Multiple Classifiers and Randomization [55] | Evasion | Spam Filter, SVM, NB | Multiple Classifiers and Randomization | Multiple Classifiers Strategy (MCS), where different classifiers are trained by different features to randomize a model’s decision boundary. |
| Causative Attack | Exploratory Attack | |
|---|---|---|
| Attack | Poisoning | Probing |
| Red Herring | Evasion | |
| Label-Flipping | Reverse Engineering | |
| Good Word Attack | ||
| Defense | RONI | Randomization |
| Game Theory-based | Disinformation | |
| Multiple Learners |
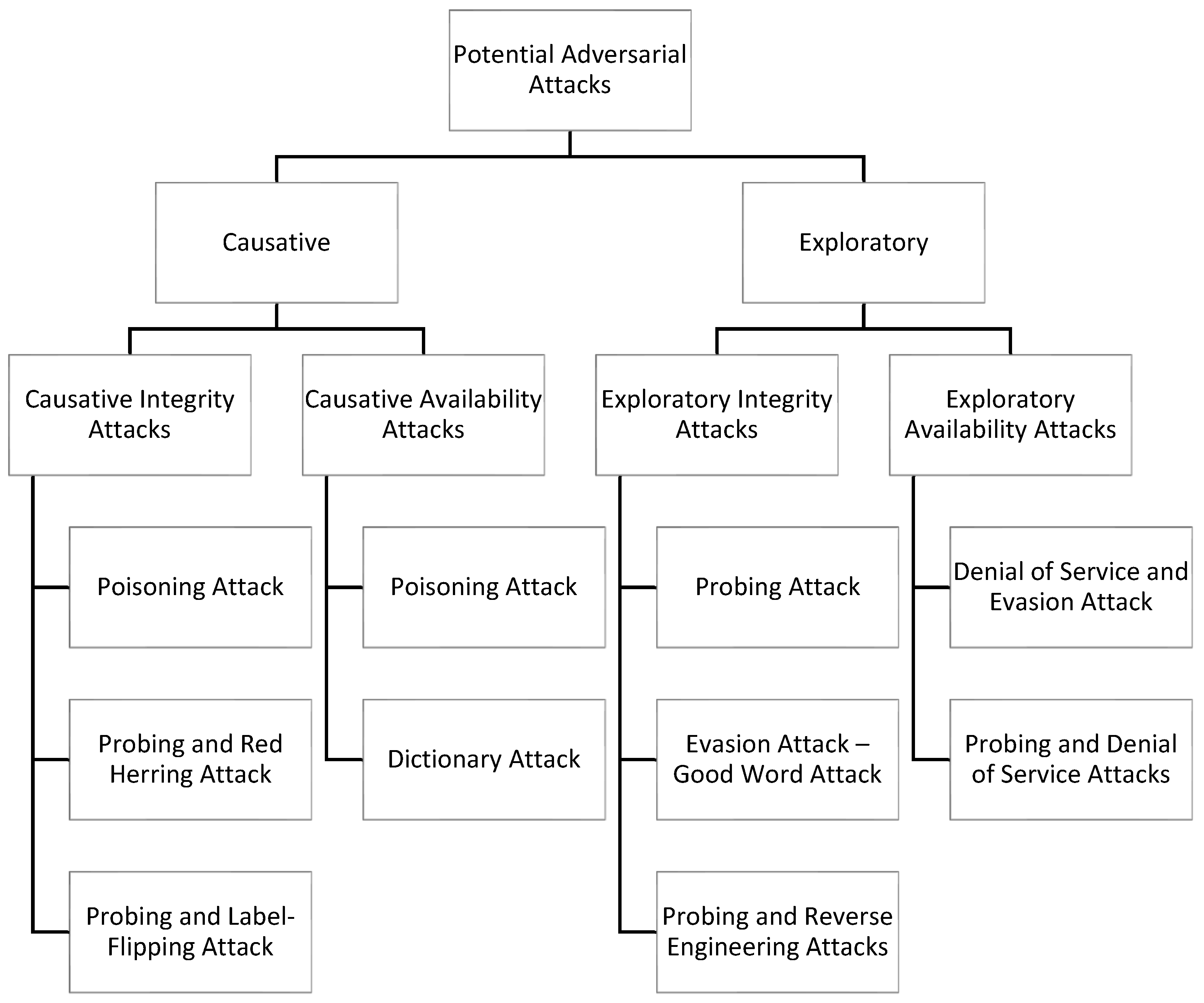
| Type of Influence | Potential Attack | Security Violation | Specificity |
|---|---|---|---|
| Causative | Poisoning Attack | Integrity | Targeted/Indiscriminate |
| Probing and Red Herring Attack | Integrity and Privacy | ||
| Probing and Label-Flipping Attack | Integrity and Privacy | ||
| Poisoning Attack | Availability | ||
| Dictionary Attack | Availability and Integrity | ||
| Exploratory | Probing Attack | Privacy | |
| Good Word Attack | Integrity | ||
| Probing and Reverse Engineering Attacks | Integrity and Privacy | ||
| Denial of Service and Evasion Attack | Availability and Integrity | ||
| Probing and Denial of Service Attacks | Availability, Integrity, and Privacy |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imam, N.H.; Vassilakis, V.G. A Survey of Attacks Against Twitter Spam Detectors in an Adversarial Environment. Robotics 2019, 8, 50. https://doi.org/10.3390/robotics8030050
Imam NH, Vassilakis VG. A Survey of Attacks Against Twitter Spam Detectors in an Adversarial Environment. Robotics. 2019; 8(3):50. https://doi.org/10.3390/robotics8030050
Chicago/Turabian StyleImam, Niddal H., and Vassilios G. Vassilakis. 2019. "A Survey of Attacks Against Twitter Spam Detectors in an Adversarial Environment" Robotics 8, no. 3: 50. https://doi.org/10.3390/robotics8030050
APA StyleImam, N. H., & Vassilakis, V. G. (2019). A Survey of Attacks Against Twitter Spam Detectors in an Adversarial Environment. Robotics, 8(3), 50. https://doi.org/10.3390/robotics8030050