
Forecasting Stock Market Prices Using Machine Learning and Deep Learning Models: A Systematic Review, Performance Analysis and Discussion of Implications

 , , , and
, , , and
Abstract
:1. Introduction
- One of the unique contributions of this review article is that it is not just limited to summarizing the research articles. Extra effort is put into implementing the well-known machine learning and deep learning models to understand their nature and performance. Along with our review, a comparative analysis of various algorithms is presented in this article. The machine learning and deep learning ensemble algorithms are tested on TAINIWALCHM and AGROPHOS stock data, which fall under the umbrella of the chemical industry market sector.
- In this review article, detailed future research directions are included. Future research avenues for researchers are identified based on the conducted study stock trend analysis and classification, pattern identification, and candlestick chart pattern analysis using computer vision.
2. Comprehensive Summary of Theoretical Basis
2.1. Basic Machine Learning Algorithm
2.1.1. Linear Regression
2.1.2. K-Nearest Neighbor (KNN)
2.1.3. Support Vector Machine (SVM)
2.1.4. Naïve Bayes Algorithm
2.1.5. Logistic Regression
2.2. Forecasting of Stock Market Using Time Series Forecasting
2.2.1. ARIMA
2.2.2. FB Prophet Model
2.3. Deep Learning Methods
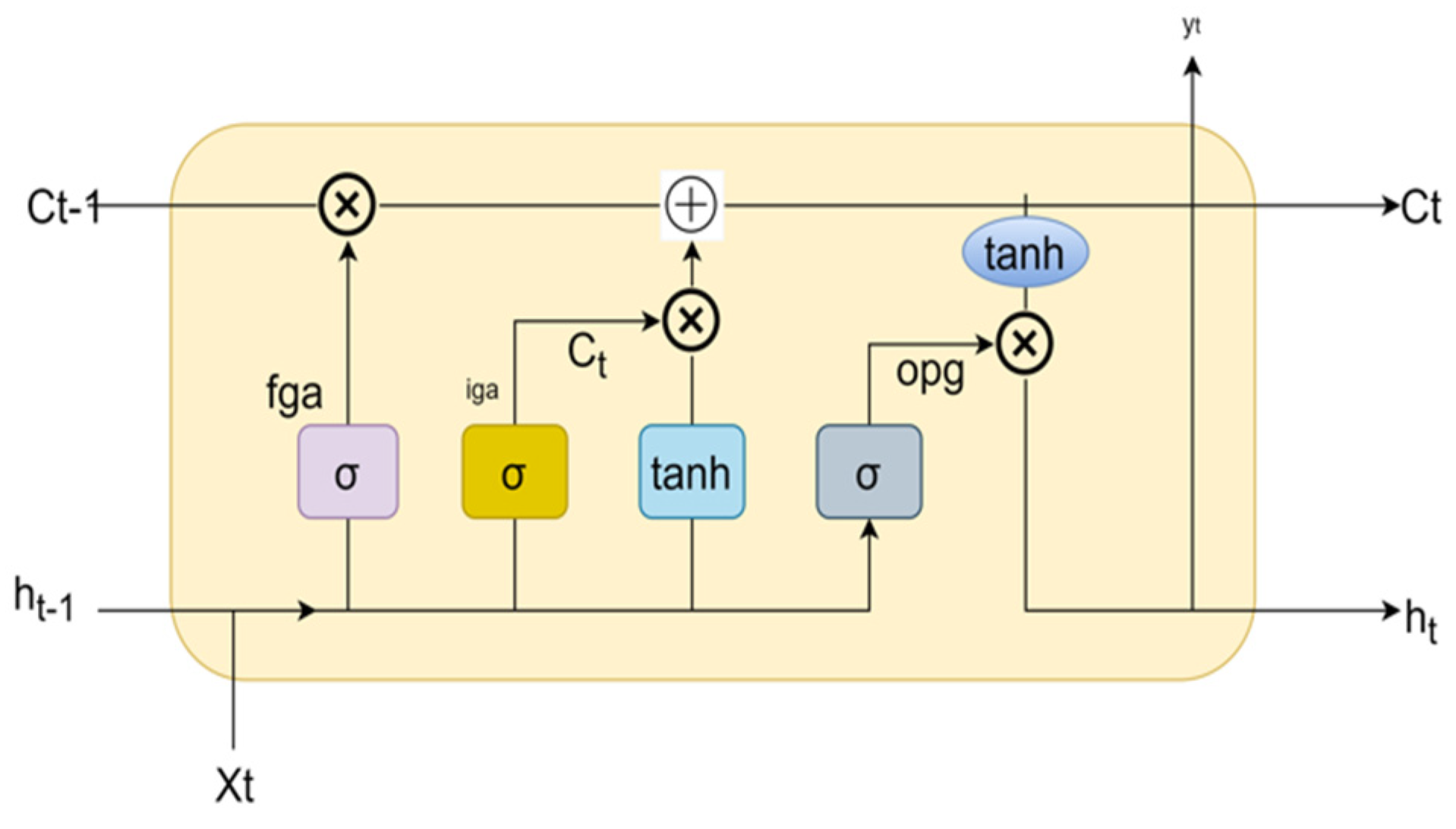
2.3.1. Long Short-Term Memory (LSTM)
2.3.2. Gated Recurrent Neural Network (GRU)
- (1)
- Update gate
- (2)
- Reset gatewhere is update gate, is reset gate, σ represents sigmoid function, is neuron gate, is previous weight, ht−1 is the result of the preceding GRU block, and is the current input.
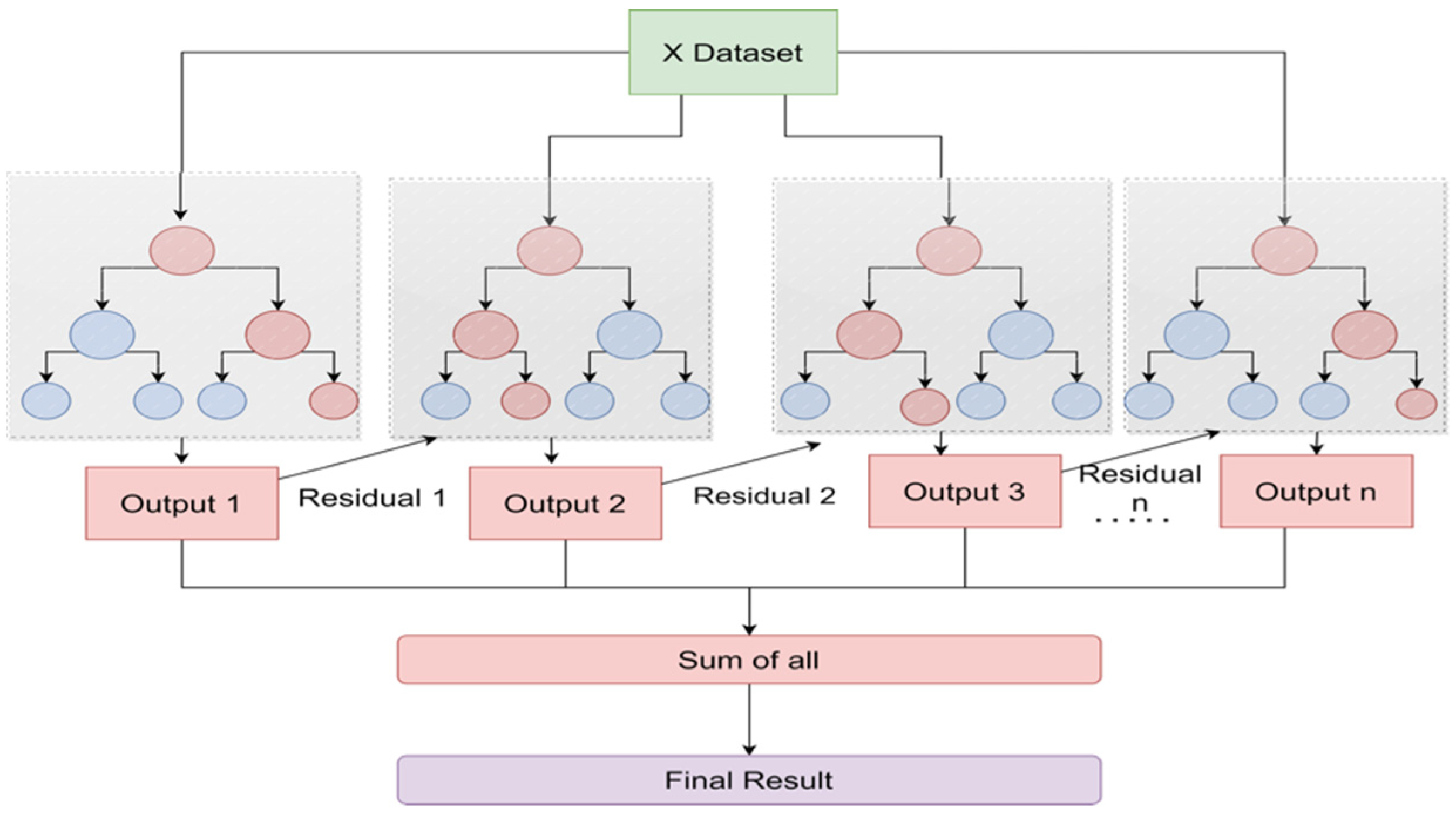
2.4. Ensemble Learning Methods
2.4.1. Random Forest Algorithm
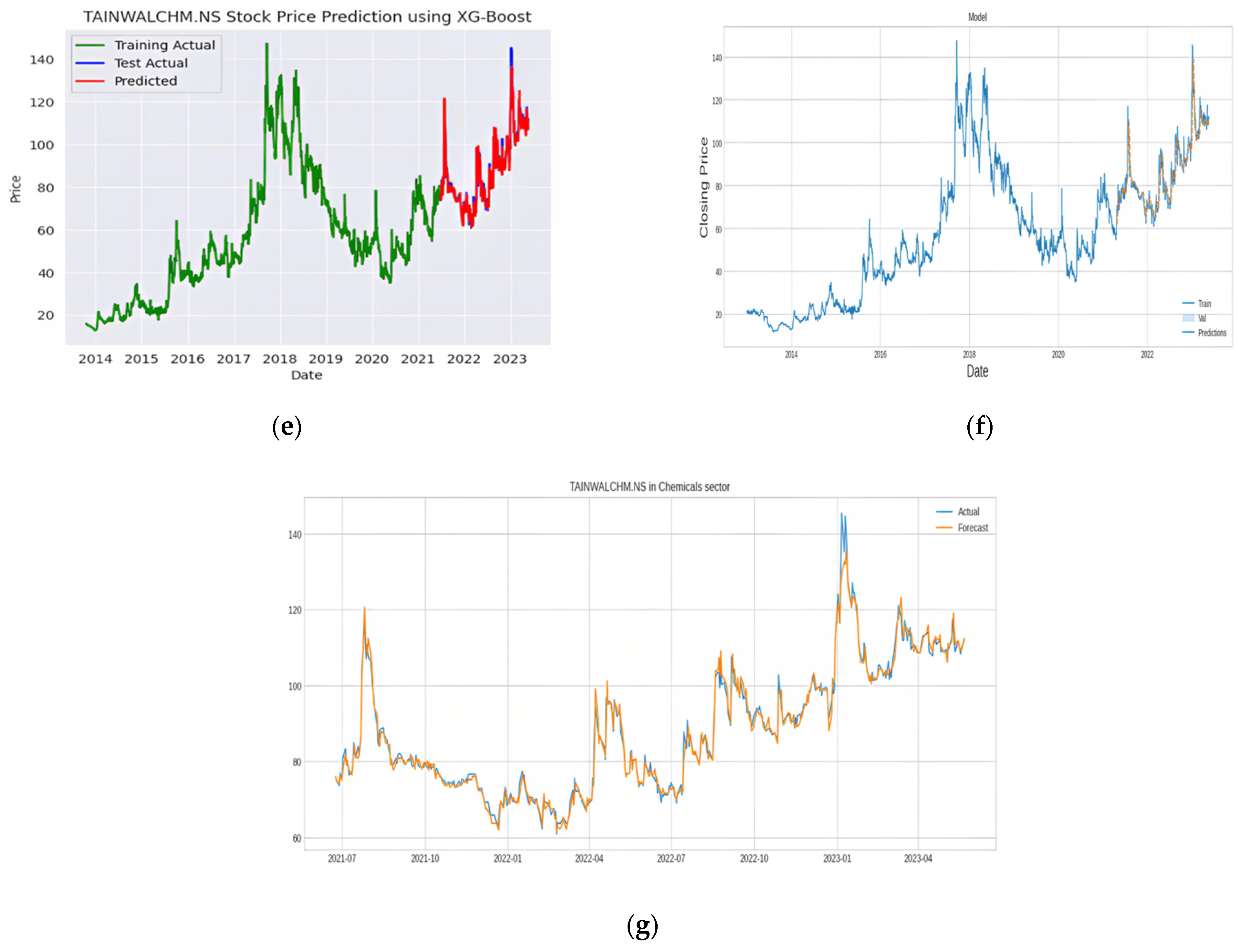
2.4.2. XG-Boost Regression Algorithm
2.4.3. E-SVR-RF (Ensemble Support Vector Machine–Random Forest)
3. General Machine Learning Pipeline
4. Significance of Ensemble Modeling
5. Implications and Limitations of the Study
6. Future Research Directions
6.1. Trend Analysis and Classification
6.2. Pattern Identification Using Computer Vision
6.3. Chart Pattern Analysis Using Computer Vision
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Agrawal, Manish, Piyush Kumar Shukla, Rajit Nair, Anand Nayyar, and Mehedi Masud. 2022. Stock Prediction Based on Technical Indicators Using Deep Learning Model. Computers, Materials & Continua 70: 287–304. [Google Scholar]
- Ali, Syed Shahan, Muhammad Mubeen, and Adnan Hussain. 2018. Prediction of stock performance by using logistic regression model: Evidence from Pakistan Stock Exchange (PSX). Asian Journal of Empirical Research 15: 212. [Google Scholar]
- Ampomah, Ernest Kwame, Gabriel Nyame, Zhiguang Qin, Prince Clement Addo, Enoch Opanin Gyamfi, and Micheal Gyan. 2021. Stock Market Prediction with Gaussian Naïve Bayes Machine Learning Algorithm. Informatica 45: 2. [Google Scholar] [CrossRef]
- Baheti, Radhika, Gauri Shirkande, Sneha Bodake, Janhavi Deokar, and Archana K. 2021. Stock Market Analysis from Social Media and News using Machine Learning Techniques. International Journal on Data Science and Machine Learning with Applications 1: 59–67. [Google Scholar]
- Ballings, Michel, Dirk Van den Poel, Nathalie Hespeels, and Ruben Gryp. 2015. Evaluating multiple classifiers for stock price direction prediction. Expert Systems with Applications 42: 7046–56. [Google Scholar] [CrossRef]
- Banik, Shouvik, Nonita Sharma, Monika Mangla, Sachi Nandan Mohanty, and Selvarajan Shitharth. 2022. LSTM based decision support system for swing trading in stock market. Knowledge-Based Systems 239: 107994. [Google Scholar] [CrossRef]
- Bansal, Malti, Apoorva Goyal, and Apoorva Choudhary. 2022. Stock Market Prediction with High Accuracy using Machine Learning Techniques. Procedia Computer Science 215: 247–65. [Google Scholar] [CrossRef]
- Barra, Silvio, Salvatore Mario Carta, Andrea Corriga, Alessandro Sebastian Podda, and Diego Reforgiato Recupero. 2020. Deep learning and time series-to-image encoding for financial forecasting. IEEE/CAA Journal of Automatica Sinica 7: 683–92. [Google Scholar] [CrossRef]
- Bustos, Oscar, Alexandra Pomares, and Enrique Gonzalez. 2017. A comparison between SVM and multilayer perceptron in predicting an emerging financial market: Colombian stock market. Paper presented at 2017 Congreso Internacional de Innovacion y Tendencias en Ingenieria (CONIITI), Bogotá, Colombia, October 4–6; pp. 1–6. [Google Scholar]
- Cagliero, Luca, Jacopo Fior, and Paolo Garza. 2023. Shortlisting machine learning-based stock trading recommendations using candlestick pattern recognition. Expert Systems with Applications 216: 119493. [Google Scholar] [CrossRef]
- Di Persio, Luca, and Oleksandr Honchar. 2017. Recurrent neural networks approach to the financial forecast of Google assets. International Journal of Mathematics and Computers in Simulation 11: 7–13. [Google Scholar]
- Dospinescu, Nicoleta, and Octavian Dospinescu. 2019. A Profitability Regression Model In Financial Communication Of Romanian Stock Exchange’s Companies. Ecoforum Journal 8: 4. [Google Scholar]
- Gite, Shilpa, Shruti Patil, Deepak Dharrao, Madhuri Yadav, Sneha Basak, Arundarasi Rajendran, and Ketan Kotecha. 2023. Textual Feature Extraction Using Ant Colony Optimization for Hate Speech Classification. Big Data and Cognitive Computing 7: 45. [Google Scholar] [CrossRef]
- Grigoryan, Hakob. 2017. Stock Market Trend Prediction Using Support Vector Machines and Variable Selection Methods. Advances in Intelligent Systems Research (AISR) 2017: 210–13. [Google Scholar] [CrossRef] [Green Version]
- Gururaj, Vaishnavi, V. R. Shriya, and K. Ashwini. 2019. Stock Market Prediction using Linear Regression and Support Vector Machines. International Journal of Applied Engineering Research 14: 1931–34. [Google Scholar]
- Hu, Weilong, Yain-Whar Si, Simon Fong, and Raymond Yiu Keung Lau. 2019. A formal approach to candlestick pattern classification in financial time series. Applied Soft Computing 84: 105700. [Google Scholar] [CrossRef]
- Hu, Zexin, Yiqi Zhao, and Matloob Khushi. 2021. A survey of forex and stock price prediction using deep learning. Applied System Innovation 4: 9. [Google Scholar] [CrossRef]
- Jiang, Weiwei. 2021. Applications of deep learning in stock market prediction: Recent progress. Expert Systems with Applications 184: 115537. [Google Scholar] [CrossRef]
- Jose, Jithina, Suja Cherukullapurath Mana, and B. Keerthi Samhitha. 2019. An Efficient System to Predict and Analyze Stock Data using Hadoop Techniques. International Journal of Recent Technology and Engineering (IJRTE) 8: 1039–43. [Google Scholar] [CrossRef]
- Kaczmarek, Tomasz, and Katarzyna Perez. 2021. Building portfolios based on machine learning predictions. Economic Research-Ekonomska Istraživanja 35: 19–37. [Google Scholar] [CrossRef]
- Kaninde, Sumedh, Manish Mahajan, Aditya Janghale, and Bharti Joshi. 2022. Stock Price Prediction Using Facebook Prophet. International Journal of Research in Engineering and Science 44: 03060. [Google Scholar] [CrossRef]
- Kardani, Navid, Annan Zhou, Majidreza Nazem, and Shui-Long Shen. 2020. Improved prediction of slope stability using a hybrid stacking ensemble method based on finite element analysis and field data. Journal of Rock Mechanics and Geotechnical Engineering 13: 188–201. [Google Scholar] [CrossRef]
- Kedar, S. V. 2021. Stock Market Increase and Decrease using Twitter Sentiment Analysis and ARIMA Model. Turkish Journal of Computer and Mathematics Education (TURCOMAT) 12: 146–61. [Google Scholar] [CrossRef]
- Khairi, Teaba W. A., Rana M. Zaki, and Wisam A. Mahmood. 2019. Stock Price Prediction using Technical, Fundamental and News based Approach. Paper presented at 2019 2nd Scientific Conference of Computer Sciences (SCCS), Baghdad, Iraq, March 27–28. [Google Scholar]
- Khan, Wasiat, Mustansar Ali Ghazanfar, Muhammad Awais Azam, Amin Karami, Khaled H. Alyoubi, and Ahmed S. Alfakeeh. 2020. Stock market prediction using machine learning classifiers and social media, news. Journal of Ambient Intelligence and Humanized Computing 13: 3433–56. [Google Scholar] [CrossRef]
- Kumar, Deepak, Pradeepta Kumar Sarangi, and Rajit Verma. 2021. A systematic review of stock market prediction using machine learning and statistical techniques. Materials Today: Proceedings 49: 3187–91. [Google Scholar] [CrossRef]
- Kumar, Saurav, and Dhruba Ningombam. 2018. Short-Term Forecasting of Stock Prices Using Long Short Term Memory. Paper presented at 2018 International Conference on Information Technology (ICIT), Hong Kong, China, December 29–31. [Google Scholar]
- Lambert, Clive. 2009. Candlestick Charts: An Introduction to Using Candlestick Charts. Petersfield: Harriman House Limited. [Google Scholar]
- Li, Audeliano Wolian, and Guilherme Sousa Bastos. 2020. Stock Market Forecasting Using Deep Learning and Technical Analysis: A Systematic Review. IEEE Access 8: 185232–242. [Google Scholar] [CrossRef]
- Li, Yang, and Yi Pan. 2021. A novel ensemble deep learning model for stock prediction based on stock prices and news. International Journal of Data Science and Analytics 13: 139–49. [Google Scholar] [CrossRef] [PubMed]
- Lim, Kian-Ping, and Robert Brooks. 2011. The evolution of stock market efficiency over time: A survey of the empirical literature. Journal of Economic Surveys 25: 69–108. [Google Scholar] [CrossRef]
- Lim, Yi Xuan, and Consilz Tan. 2021. Do negative events really have deteriorating effects on stock performance? A comparative study on Tesla (US) and Nio (China). Journal of Asian Business and Economic Studies 29: 105–19. [Google Scholar] [CrossRef]
- Manish, Kumar, and M. Thenmozhi. 2014. Forecasting stock index returns using ARIMA-SVM, ARIMA-ANN, and ARIMA-random forest hybrid models. International Journal of Banking Accounting and Finance 5: 284–308. [Google Scholar]
- Mann, Jordan, and J. Nathan Kutz. 2016. Dynamic mode decomposition for financial trading strategies. Quantitative Finance 16: 1643–55. [Google Scholar] [CrossRef] [Green Version]
- Manojlović, Teo, and Ivan Štajduhar. 2015. Predicting stock market trends using random forests: A sample of the Zagreb stock exchange. Paper presented at International Convention on Information and Communication Technology Electronics and Microelectronics, Opatija, Croatia, May 25–29. [Google Scholar]
- Mashadihasanli, Tamerlan. 2022. Stock Market Price Forecasting Using the Arima Model: An Application to Istanbul, Turkiye. Journal of Economic Policy Researches 9: 439–54. [Google Scholar] [CrossRef]
- Mohapatra, Sabyasachi, Rohan Mukherjee, Arindam Roy, Anirban Sengupta, and Amit Puniyani. 2022. Can Ensemble Machine Learning Methods Predict Stock Returns for Indian Banks Using Technical Indicators? Journal of Risk and Financial Management 8: 350. [Google Scholar] [CrossRef]
- Mukherjee, Somenath, Bikash Sadhukhan, Nairita Sarkar, Debajyoti Roy, and Soumil De. 2021. Stock market prediction using deep learning algorithms. CAAI Transactions on Intelligence Technology 8: 82–94. [Google Scholar] [CrossRef]
- Nabipour, Mojtaba, Pooyan Nayyeri, Hamed Jabani, S. Shahab, and Amir Mosavi. 2020. Predicting Stock Market Trends Using Machine Learning and Deep Learning Algorithms Via Continuous and Binary Data; a Comparative Analysis. IEEE Access 8: 150199–212. [Google Scholar] [CrossRef]
- Nikou, Mahla, Gholamreza Mansourfar, and Jamshid Bagherzadeh. 2019. Stock price prediction using DEEP learning algorithm and its comparison with machine learning algorithms. Intelligent Systems in Accounting, Finance and Management 26: 164–74. [Google Scholar] [CrossRef]
- Nti, Isaac Kofi, Adebayo Felix Adekoya, and Benjamin Asubam Weyori. 2020. A comprehensive evaluation of ensemble learning for stock-market prediction. Journal of Big Data 7: 1–40. [Google Scholar] [CrossRef] [Green Version]
- Obthong, Mehtabhorn, Nongnuch Tantisantiwong, Watthanasak Jeamwatthanachai, and Gary Wills. 2020. A Survey on Machine Learning for Stock Price Prediction: Algorithms and Techniques. Paper presented at 2nd International Conference on Finance, Economics, Management and IT Business, Prague, Czech Republic, May 5–6. [Google Scholar]
- Parray, Irfan Ramzan, Surinder Singh Khurana, Munish Kumar, and Ali A. Altalbe. 2020. Time series data analysis of stock price movement using machine learning techniques. Soft Computing 24: 16509–17. [Google Scholar] [CrossRef]
- Patel, Jigar, Sahil Shah, Priyank Thakkar, and Ketan Kotecha. 2015. Predicting stock and stock price index movement using Trend Deterministic Data Preparation and machine learning techniques. Expert Systems with Applications 42: 259–68. [Google Scholar] [CrossRef]
- Pathak, Ashwini, and Sakshi Pathak. 2020. Study of Machine learning Algorithms for Stock Market Prediction. International Journal of Engineering Research & Technology (IJERT) 9: 6. [Google Scholar]
- Polamuri, Subba Rao, Kudipudi Srinivas, and A. Krishna Mohan. 2019. Stock Market Prices Prediction using Random Forest and Extra Tree Regression. International Journal of Recent Technology and Engineering 8: 1224–28. [Google Scholar] [CrossRef]
- Pramod, B. S., and Mallikarjuna Shastry Pm. 2021. Stock Price Prediction Using LSTM. Test Engineering and Management 83: 5246–51. [Google Scholar]
- Qiu, Jiayu, Bin Wang, and Changjun Zhou. 2020. Forecasting stock prices with long-short term memory neural network based on attention mechanism. PLoS ONE 15: e0227222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raghavendra, Kumar, Pardeep Kumar, and Yugal Kumar. 2021. Analysis of financial time series forecasting using deep learning model. Paper presented at 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Uttar Pradesh, India, January 28–29; pp. 877–81. [Google Scholar]
- Reddy, Niveditha N., E. Naresh, and Vijaya Kumar B. P. 2020. Predicting Stock Price Using Sentimental Analysis Through Twitter Data. Paper presented at 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, July 2–4. [Google Scholar]
- Ren, Rui, Desheng Dash Wu, and Tianxiang Liu. 2019. Forecasting Stock Market Movement Direction Using Sentiment Analysis and Support Vector Machine. IEEE Systems Journal 13: 760–70. [Google Scholar] [CrossRef]
- Sadorsky, Perry. 2021. A Random Forests Approach to Predicting Clean Energy Stock Prices. Journal of Risk and Financial Management 14: 48. [Google Scholar] [CrossRef]
- Salles, Thiago, Marcos Gonçalves, Victor Rodrigues, and Leonardo Rocha. 2018. Improving random forests by neighborhood projection for effective text classification. Information Systems 77: 1–21. [Google Scholar] [CrossRef]
- Sathish Kumar, R., R. Girivarman, S. Parameshwaran, and V. Sriram. 2020. Stock Price Prediction Using Deep Learning and Sentimental Analysis. JETIR 7: 346–54. [Google Scholar]
- Seethalakshmi, Ramaswamy. 2018. Analayis of stock market predictor variables using linear regression. International Journal of Pure and Applied Mathematics 119: 369–78. [Google Scholar]
- Setiani, Ida, Meilany Nonsi Tentua, and Sunggito Oyama. 2020. Prediction of Banking Stock Prices Using Naïve Bayes Method. Journal of Physics Conference Series 1823: 012059. [Google Scholar] [CrossRef]
- Shah, Dev, Haruna Isah, and Farhana Zulkernine. 2019. Stock Market Analysis: A Review and Taxonomy of Prediction Techniques. International Journal of Financial Studies 7: 26. [Google Scholar] [CrossRef] [Green Version]
- Shahi, Tej Bahadur, Ashish Shrestha, Arjun Neupane, and William Guo. 2020. Stock Price Forecasting with Deep Learning: A Comparative Study. Mathematics and Computer Science 8: 1441. [Google Scholar] [CrossRef]
- Sharaf, Marwa, Ezz El-Din Hemdan, Ayman El-Sayed, and Nirmeen A. El-Bahnasawy. 2022. An efficient hybrid stock trend prediction system during COVID-19 pandemic based on stacked-LSTM and news sentiment analysis. Multimedia Tools and Applications 28: 1–33. [Google Scholar] [CrossRef]
- Shen, Jingyi, and M. Omair Shafiq. 2020. Short-term stock market price trend prediction using a comprehensive deep learning system. Journal of Big Data 7: 1–33. [Google Scholar] [CrossRef]
- Sidra, Mehtab, and Jaydip Sen. 2020. A time series analysis-based stock price prediction using machine learning and deep learning models. arXiv arXiv:2004.11697. [Google Scholar]
- Smita, Mrinalini. 2021. Logistic Regression Model For Predicting Performance of S&P BSE30 Company Using IBM SPSS. International Journal of Mathematics Trends and Technology 67: 118–34. [Google Scholar] [CrossRef]
- Soni, Payal, Yogya Tewari, and Deepa Krishnan. 2022. Machine Learning approaches in stock price prediction: A systematic review. Journal of Physics Conference Series 2161: 012065. [Google Scholar] [CrossRef]
- Sprenger, Timm O., and Isabell M. Welpe. 2011. News or noise? The stock market reaction to different types of company-specific news events. SSRN Electronic Journal. [Google Scholar] [CrossRef]
- Suresh, N., B. Priya, and G. Lakshmi. 2022. Historical Analysis and Forecasting of Stock Market Using Fbprophet. South Asian Journal of Engineering and Technology 12: 152–57. [Google Scholar] [CrossRef]
- Tanuwijaya, Julius, and Seng Hansun. 2019. LQ45 Stock Index Prediction using k-Nearest Neighbors Regression. International Journal of Recent Technology and Engineering 8: 2388–91. [Google Scholar] [CrossRef]
- Umer, Muhammad, Muhammad Awais, and Muhammad Muzammul. 2019. Stock Market Prediction Using Machine Learning (ML) Algorithms. ADCAIJ Advances in Distributed Computing and Artificial Intelligence Journal 8: 97–116. [Google Scholar] [CrossRef]
- Venkat, Projects. 2022. Stock Market Trend Prediction Using K-Nearest Neighbor (KNN) Algorithm. Journal of Engineering Sciences 3: 32–44. [Google Scholar]
- Vo, Nguyen, and Robert Ślepaczuk. 2022. Applying Hybrid ARIMA-SGARCH in Algorithmic Investment Strategies on S&P500 Index. Entropy 24: 158. [Google Scholar] [CrossRef] [PubMed]
- Vuong, Pham Hoang, Trinh Tan Dat, Tieu Khoi Mai, and Pham Hoang Uyen. 2022. Stock-Price Forecasting Based on XGBoost and LSTM. Computer Systems Science & Engineering 40: 237–46. [Google Scholar]
- Xu, Ying, Cuijuan Yang, Shaoliang Peng, and Yusuke Nojima. 2020. A hybrid two-stage financial stock forecasting algorithm based on clustering and ensemble learning. Applied Intelligence 50: 3852–67. [Google Scholar] [CrossRef]
- Yadav, Ashima, and Dinesh Kumar Vishwakarma. 2019. Sentiment analysis using deep learning architectures: A review. Artificial Intelligence Review 53: 4335–85. [Google Scholar] [CrossRef]
- Yang, Liu. 2019. Novel volatility forecasting using deep learning-long short term memory recurrent neural networks. Expert Systems with Applications 132: 99–109. [Google Scholar]
- Zhong, Xiao, and David Enke. 2019. Predicting the daily return direction of the stock market using hybrid machine learning algorithms. Financial Innovation 5: 1–20. [Google Scholar] [CrossRef]
- Zhou, Xingyu, Zhisong Pan, Guyu Hu, Siqi Tang, and Cheng Zhao. 2018. Stock Market Prediction on High-Frequency Data Using Generative Adversarial Nets. Mathematical Problems in Engineering 2018: 4907423. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Yongqiong. 2020. Stock price prediction using the RNN model. Journal of Physics Conference Series 1650: 032103. [Google Scholar] [CrossRef]
- Zhu, Zhe, and Kexin He. 2022. Prediction of Amazon’s Stock Price Based on ARIMA, XGBoost, and LSTM Models. Proceedings of Business and Economic Studies 5: 127–36. [Google Scholar] [CrossRef]
- Zizi, Youssef, Amine Jamali-Alaoui, Badreddine El Goumi, Mohamed Oudgou, and Abdeslam El Moudden. 2021. An Optimal Model of Financial Distress Prediction: A Comparative Study between Neural Networks and Logistic Regression. Risks 9: 200. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| Model type | Stacked ensemble model |
| Libraries | Keras, TensorFlow, sklearn |
| Algorithms | Random Forest + XG-Boost + LSTM |
| Training/testing size | 80% for training and 20% for testing |
| Loss function | MSE |
| Optimizer | Adam |
| Maximum epochs | 50 |
| Random Forest Configuration | |
| Number of estimators | [50, 100, 200] |
| Maximum depth | [3, 5, 7] |
| Maximum features | [‘sqrt’, ‘log2’] |
| Hyperparameter tuning method | Grid search |
| XG-Boost Configuration | |
| Maximum depth | [3, 4, 5] |
| Learning rate | [0.1, 0.01, 0.001] |
| Number of estimators | [50, 100, 150, 500, 1000] |
| Hyperparameter tuning method | Grid search |
| LSTM Configuration | |
| LSTM Layers | 2 |
| Dropout rate | 0.2 |
| Dense layer | 25 units |
| Batch size | 32 |
| Hyperparameter tuning method | Grid search |
| TANIWALCHM | AGROPHOS | |||
|---|---|---|---|---|
| Algorithm | RMSE | R2 | RMSE | R2 |
| SVR | 4.525 | 0.9279 | 1.5074 | 0.9432 |
| MLPR | 2.5893 | 0.9611 | 2.4764 | 0.9472 |
| KNN | 4.4249 | 0.9311 | 4.7877 | 0.7262 |
| LSTM | 5.6241 | 0.8867 | 5.2494 | 0.8809 |
| Random forest | 87.8839 | 0.9818 | 98.5633 | 0.9428 |
| XG-Boost | 2.0686 | 0.9842 | 1.7618 | 0.9379 |
| Random Forest + XG-Boost + LSTM | 2.0247 | 0.9921 | 1.2658 | 0.9897 |
| Sr No | Algorithm Name | Gap Analysis | Performance Evaluation |
|---|---|---|---|
| 1 | Linear regression | Linear regression assumes a linear relationship between dependent and independent variables and is not suitable for most real-time applications, and is used to perform observations on readily accessible sample data (Gururaj et al. 2019). | This is a regression type of algorithm that shows graphs in a linear way, where in RMSE is 3.22, MAE is 2.53, MSE is 10.37, and R-squared is 0.73 (Gururaj et al. 2019). |
| 2 | Support vector machine | SVM’s excellent memory efficiency and effectiveness make it an ideal estimating technique in high-dimensional space. The shortcoming of SVM is that it might experience overfitting, but it performs exceptionally well on tiny datasets (Pathak and Pathak 2020; Grigoryan 2017). | This is a classification type of algorithm, and when used for stock prediction, the results are as follows: accuracy is 68.2, recall is 65.2, precision is 64.2, and F1-Score is 64.9% (0.65). When used as a support vector regression (SVR) algorithm, the evaluation parameters are as follows: SMAPE = 5.59, R-squared = 1.69, and RMSE = 43.36. |
| 3 | K-nearest neighbor | KNN is an algorithm that skips the learning step, so it may not generalize effectively. With a huge dataset, it takes longer since it must sort all the distances from the unknown item (Tanuwijaya and Hansun 2019; Pathak and Pathak 2020). | This is a classification type of ML algorithm in which the results of stock prediction are as follows: accuracy is 65.2, recall is 63.6, precision is 64.8, and F1 Score is 64.1% (0.64). For KNN regressor, the evaluation parameters are as follows: SMAPE = 14.32, R-squared = −2.42, and RMSE = 56.44 (Venkat 2022). |
| 4 | Gaussian naïve Bayes | Models with an integrated GNB algorithm will yield feature extraction and feature scaling outcomes that are superior to those already achieved using models that incorporate either the GNB algorithm or feature scaling (Setiani et al. 2020; Ampomah et al. 2021). | Gaussian naïve Bayes used by authors in their research. Kendall’s Test of Concordance is used in this feature, which is scaled and extracted. The results are as follows: accuracy is 84, F1 Score is 62.44% (0.62), specificity is 0.70, and AUC values is 0.90 (Bansal et al. 2022). |
| 5 | Logistic regression | Both binary and multiclass classification use this algorithm. The findings obtained via logistic regression are the most accurate; however, identifying the best-fitting feature is necessary (Pathak and Pathak 2020; Ali et al. 2018). | In this algorithm, with the help of research papers, various financial factors are considered through which factors are grouped for prediction. The results of this algorithm are as follows: accuracy is 78.6, recall is 76.6, precision is 77.8, and F1 Score is 77.1% (0.77) (Pathak and Pathak 2020; Ali et al. 2018). |
| 6 | ARIMA | ARIMA can be considered because it is a unique model with significant coefficients and passes all the diagnostic tests (Mashadihasanli 2022). | ARIMA is a time series forecasting technique for predicting market or stock prices. It is a combination or integration of autoregressive moving averages; the results are as follows: RMSE, 88.05; MAE, 65.88; and MAPE, 5.73, and if performed with sentiment analysis, the RMSE score is 6.41 (Kedar 2021). |
| 7 | FB Prophet | Prophet can use regression models to determine seasonality on a daily, monthly, and annual basis, as well as effects related to holidays (Suresh et al. 2022; Kaninde et al. 2022). | This algorithm was created by Facebook for time series forecasting. One of its advantages is that it does not consider holidays or null values. The result of its RMSE is achieved 93 (Suresh et al. 2022; Kaninde et al. 2022). |
| 8 | GRU | GRU is a neural network approach that is an improvement upon RNN but has fewer parameters than LSTM, so it trains faster. Also, the chances of overfitting are lower compared to RNN, and it can handle long-term dependency (Shahi et al. 2020). | GRU is a deep learning algorithm that has fewer parameters and handles short-term data properly. The evaluation parameters of GRU are, without sentiment analysis, MAE = 42.8, RMSE = 47.31, and R-squared = 0.879, and with sentiment analysis based on news evaluation parameters, MAE = 24.472, RMSE = 29.153, and R-squared = 0.967 (Shahi et al. 2020). |
| 9 | LSTM | In this algorithm, weights are adjusted for each long short-term memory data point via stochastic gradient descent. LSTM can handle more very long-term dependency compared to any other neural network algorithm (Shahi et al. 2020; Pramod and Pm 2021; Mukherjee et al. 2021). | LSTM is a more developed type of RNN and is a deep learning technique. This is one of the most used ML algorithms for stock forecasting, and when used along with sentiment analysis, it shows better results than without sentiment analysis. The result without sentiment analysis are MAE = 48.47, RMSE = 55.993, and R-squared = 0.867, and with sentiment analysis based on news evaluation parameters, are MAE = 17.689, RMSE = 23.070, and R-squared = 0.867 (Shahi et al. 2020). |
| 10 | Random forest | The effectiveness of random forest on large datasets is one of its advantages. It can be applied to classification and regression issues. The model becomes more random as a result, improving it. This model’s use of a huge number of trees slows it down, which is a drawback (Pathak and Pathak 2020; Polamuri et al. 2019). | This is an ensemble type of algorithm that is used for stock forecasting. The results for random forest are as follows: accuracy is 80.7, recall is 78.3, precision is 75.2, and F1 Score is 76.7% (0.77) (Pathak and Pathak 2020; Polamuri et al. 2019). |
| 11 | XG-Boost | XG-Boost is an ensembled learning technique that uses decision trees but in a sequential manner and uses gradient boosting in an iterative manner to obtain better results. XG-Boost is sensitive to hyperparameters and will not work as well on large datasets as random forest (Zhu and He 2022). | XG-Boost has the following evaluation parameter: MSE = 360.0 (Zhu and He 2022). |
| 12 | E-SVR-RF | Ensemble support vector regression and random forest shows improved accuracy as it leverages the advantages of both algorithms, and its robustness is increased, but due to the increased complexity of both algorithms, overfitting is an issue (Xu et al. 2020). | The E-SVR-RF ensembled algorithm shows the following evaluation parameters: MAPE = 1.335, MAE = 0.1537, RMSE = 0.0188, and MAE = 0.0485 (Xu et al. 2020). |
| 13 | XG-Boost + LSTM | Ensembling XG-Boost and LSTM can leverage the advantages of both algorithms. XG-Boost can handle linear and non-linear relationships and LSTM can handle long-term dependence. Due to this algorithm’s complexity, hyperparameter tuning can be an issue (Vuong et al. 2022). | The ensemble algorithm of XG-Boost + LSTM shows the following evaluation parameter: MSE = 3.465 (Vuong et al. 2022). |
| 14 | Blending ensemble (LSTM + GRU) | Blending ensemble (LSTM+GRU) is a combination of two to of the most-used improvements to RNN and solves the vanishing gradient problem. Both of them can handle long-term dependence well, and combining them would improve forecasting; also, overfitting can be reduced. It may require high computational power and time to train both LSTM and GRU (Li and Pan 2021). | The blending ensemble algorithm, which consists of a modified version of RNN, i.e., LSTM and GRU, has the following evaluation parameters: MSE = 186.32, MPA = 99.65, precision = 60%, Recall = 75%, F1-Score = 66.67% (Li and Pan 2021). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sonkavde, G.; Dharrao, D.S.; Bongale, A.M.; Deokate, S.T.; Doreswamy, D.; Bhat, S.K. Forecasting Stock Market Prices Using Machine Learning and Deep Learning Models: A Systematic Review, Performance Analysis and Discussion of Implications. Int. J. Financial Stud. 2023, 11, 94. https://doi.org/10.3390/ijfs11030094
Sonkavde G, Dharrao DS, Bongale AM, Deokate ST, Doreswamy D, Bhat SK. Forecasting Stock Market Prices Using Machine Learning and Deep Learning Models: A Systematic Review, Performance Analysis and Discussion of Implications. International Journal of Financial Studies. 2023; 11(3):94. https://doi.org/10.3390/ijfs11030094
Chicago/Turabian StyleSonkavde, Gaurang, Deepak Sudhakar Dharrao, Anupkumar M. Bongale, Sarika T. Deokate, Deepak Doreswamy, and Subraya Krishna Bhat. 2023. "Forecasting Stock Market Prices Using Machine Learning and Deep Learning Models: A Systematic Review, Performance Analysis and Discussion of Implications" International Journal of Financial Studies 11, no. 3: 94. https://doi.org/10.3390/ijfs11030094