Optimal Dynamic Portfolio with Mean-CVaR Criterion

1
Federal Reserve Bank of New York, New York, NY 10045, USA
2
University of North Carolina at Charlotte, Department of Mathematics and Statistics, Charlotte, NC 28223, USA
*
Author to whom correspondence should be addressed.
Risks 2013, 1(3), 119-147; https://doi.org/10.3390/risks1030119
Submission received: 6 August 2013
/
Revised: 19 October 2013
/
Accepted: 4 November 2013
/
Published: 11 November 2013
(This article belongs to the Special Issue Systemic Risk and Reinsurance)
Abstract
:Value-at-risk (VaR) and conditional value-at-risk (CVaR) are popular risk measures from academic, industrial and regulatory perspectives. The problem of minimizing CVaR is theoretically known to be of a Neyman–Pearson type binary solution. We add a constraint on expected return to investigate the mean-CVaR portfolio selection problem in a dynamic setting: the investor is faced with a Markowitz type of risk reward problem at the final horizon, where variance as a measure of risk is replaced by CVaR. Based on the complete market assumption, we give an analytical solution in general. The novelty of our solution is that it is no longer the Neyman–Pearson type, in which the final optimal portfolio takes only two values. Instead, in the case in which the portfolio value is required to be bounded from above, the optimal solution takes three values; while in the case in which there is no upper bound, the optimal investment portfolio does not exist, though a three-level portfolio still provides a sub-optimal solution.
Keywords:
conditional value-at-risk; mean-CVaR portfolio optimization; risk minimization; Neyman–Pearson problemMSC Classification:
91G10; 91B30; 90C46JEL Classification:
G11; G32; C611. Introduction
The portfolio selection problem published by Markowitz [1] in 1952 is formulated as an optimization problem in a one-period static setting with the objective of maximizing expected return, subject to the constraint of variance being bounded from above. In 2005, Bielecki et al. [2] published the solution to this problem in a dynamic complete market setting. In both cases, the measure of risk of the portfolio is chosen as variance and the risk-reward problem is understood as the “mean-variance” problem.
Much research has been done in developing risk measures that focus on extreme events in the tail distribution where the portfolio loss occurs (variance does not differentiate loss or gain), and quantile-based models have thus far become the most popular choice. Among those, conditional value-at-risk (CVaR), developed by Rockafellar and Uryasev [3,4], also known as expected shortfall by Acerbi and Tasche [5], has become a prominent candidate to replace variance in the portfolio selection problem. On the theoretical side, CVaR is a “coherent risk measure”, a term coined by Artzner et al. [6,7] in pursuit of an axiomatic approach for defining properties that a ‘good’ risk measure should possess. On the practical side, the convex representation of CVaR from Rockafellar and Uryasev [3] opened the door for convex optimization for the mean-CVaR problem and gave it vast advantage in implementation. In a one-period static setting, Rockafellar and Uryasev [3] demonstrated how linear programming can be used to solve the mean-CVaR problem, making it a convincing alternative to the Markowitz [1] mean-variance concept.
The work of Rockafellar and Uryasev [3] has raised huge interest for extending this approach. Acerbi and Simonetti [8] and Adam et al. [9] generalized CVaR to a spectral risk measure in a static setting. A spectral risk measure is also known as weighted value-at-risk (WVaR) by Cherny [10], who, in turn, studied its optimization problem. Ruszczynski and Shapiro [11] revised CVaR into a multi-step dynamic risk measure, namely the “conditional risk mapping for CVaR”, and solved the corresponding mean-CVaR problem using Rockafellar and Uryasev’s [3] technique for each time step. When expected return is replaced by expected utility, the utility-CVaR portfolio optimization problem is often studied in a continuous-time dynamic setting; see Gandy [12] and Zheng [13]. More recently, the issue of robust implementation is dealt with in Quaranta and Zaffaroni [14], Gotoh et al. [15], Huang et al. [16] and El Karoui et al. [17]. Research on systemic risk that involves CVaR can be found in Acharya et al. [18], Chen et al. [19] and Adrian and Brunnermeier [20].
To the best of our knowledge, no complete characterization of a solution has been done for the mean-CVaR problem in a continuous-time dynamic setting. Similar to Bielecki et al. [2], we reduce the problem to a combination of a static optimization problem and a hedging problem with the complete market assumption. Our main contribution is that in solving the static optimization problem, we find a complete characterization, whose nature is different than what is known in the literature. As a pure CVaR minimization problem without the expected return constraint, Sekine [21], Li and Xu [22] and Melnikov and Smirnov [23] found the optimal solution to be binary. This is confirmed to be true for more general law-invariant risk (preference) measure minimization by Schied [24] and He and Zhou [25]. The key to finding the solution that is binary is the association of the mean-CVaR problem with the Neyman–Pearson problem. We observe in Section 2.1 that the stochastic part of CVaR minimization can be transformed into shortfall risk minimization using the representation (CVaR is the Fenchel–Legendre dual of the expected shortfall) given by Rockafellar and Uryasev [3]. Föllmer and Leukert [26] characterized the solution to the latter problem in a general semimartingale complete market model to be binary, where they have demonstrated its close relationship to the Neyman–Pearson problem of hypothesis testing between the risk neutral probability measure, , and the physical probability measure, P.
Adding the expected return constraint to WVaR minimization (CVaR is a particular case of WVaR), Cherny [10] found conditions under which the solution to the mean-WVaR problem was still binary and conditions under which the solution does not exist. In this paper, we discuss all cases for solving the mean-CVaR problem depending on a combination of two criteria: the level of the Radon–Nikodým derivative, , relative to the confidence level of the risk measure; and the level of the return requirement. More specifically, when the portfolio is uniformly bounded from above and below, we find the optimal solution to be nonexistent or binary in some cases and, more interestingly, take three values in the most important case (see Case 4 of Theorem 3.15). When the portfolio is unbounded from above, in most cases (see Case 2 and 4 in Theorem 3.17), the solution is nonexistent, while portfolios of three levels still give sub-optimal solutions. Since the new solution we find can take not only the upper or the lower bound, but also a level in between, it can be viewed in part as a generalization of the binary solution for the Neyman–Pearson problem with an additional constraint on expectation.
This paper is organized as follows. Section 2 formulates the dynamic portfolio selection problem and compares the structure of the binary solution and the three-level solution, with an application of exact calculation in the Black–Scholes model. Section 3 details the analytic solution in general, where the proofs are delayed to the Appendix. Section 4 lists possible future work.
2. The Structure of the Optimal Portfolio
2.1. Main Problem
Let be a filtered probability space that satisfies the usual conditions, where is trivial and . The market model consists of tradable assets: one riskless asset (money market account) and d risky assets (stock). Suppose the risk-free interest rate, r, is a constant and the stock, , is a d-dimensional real-valued locally-bounded semimartingale process. Let the number of shares invested in the risky asset, , be a d-dimensional predictable process, such that the stochastic integral with respect to is well-defined. Then, the value of a self-financing portfolio, , evolves according to the dynamics:
Here, and are interpreted as inner products if the risky asset is multidimensional . The portfolio selection problem is to find the best strategy, , to minimize the conditional value-at-risk (CVaR) of the final portfolio value, , at confidence level , while requiring the expected value to remain above a constant z.1 In addition, we require uniform lower bound and upper bound on the value of the portfolio over time, such that . Therefore, our main dynamic problem is:
Note that the no-bankruptcy condition can be imposed by setting the lower bound to be , and the portfolio value can be unbounded from above by taking the upper bound as . Our solution will be based on the following complete market assumption.
Assumption 2.1 There is no free lunch with vanishing risk (as defined in Delbaen and Schachermayer [27]), and the market model is complete with a unique equivalent local martingale measure, , such that the Radon–Nikodým derivative, , has a continuous distribution.
Under the above assumption, any -measurable random variable can be replicated by a dynamic portfolio. Thus, the dynamic optimization problem Equation (1) can be reduced to: first, find the optimal solution, , to the main static problem:
if it exists, and then, find the dynamic strategy that replicates the -measurable random variable, . Here, the expectations, E and , are taken under the physical probability measure, P, and the risk neutral probability measure, , respectively. Constant is assumed to satisfy , and the additional capital constraint is the key to making sure that the optimal solution can be replicated by a dynamic self-financing strategy with initial capital .
Using the equivalence between the conditional value-at-risk and the Fenchel–Legendre dual of the expected shortfall derived in Rockafellar and Uryasev [3]:
the CVaR optimization problem Equation (2) can be reduced to an expected shortfall optimization problem, which we name the two-constraint problem:
- Step 1: minimization of expected shortfall
- Step 2: minimization of conditional value-at-risk
To compare our solution to existing ones in the literature, we also name an auxiliary problem, which simply minimizes the conditional value-at-risk without the return constraint, the one-constraint problem: Step 1 in Equation (4) is replaced by:
- Step 1: minimization of expected shortfall
Step 2 in Equation (5) remains the same.
2.2. Main Result
This subsection is devoted to a conceptual comparison between the solutions to the one-constraint problem and the two-constraint problem. The solution to the expected shortfall minimization problem in Step 1 of the one-constraint problem is found by Föllmer and Leukert [26] under Assumption 2.1 to be binary in nature:
where is the indicator function and set A is defined as the collection of states where the Radon–Nikodým derivative is above a threshold, . This particular structure, in which the optimal solution, , takes only two values, namely, the lower bound, , and x, is intuitively clear once the problems of minimizing expected shortfall and hypothesis testing between P and are connected in Föllmer and Leukert [26], the later being well-known to possess a binary solution by the Neyman–Pearson Lemma. There are various ways to prove the optimality. Other than the Neyman–Pearson approach, it can be viewed as the solution from a convex duality perspective; see Theorem 1.19 in Xu [29]. In addition, a simplified version to the proof of Proposition 3.14 gives a direct method using the Lagrange multiplier for convex optimization.
The solution to Step 2 of one-constraint problem and, thus, to the main problems in Equations (1) and (2), as a pure risk minimization problem without the return constraint is given in Schied [24], Sekine [21] and Li and Xu [22]. Since Step 2 only involves minimization over a real-valued number, x, the binary structure is preserved through this step. Under some technical conditions, the solution to Step 2 of the one-constraint problem is shown by Li and Xu [22] (Theorem 2.10 and Remark 2.11) to be:
where is the solution to the capital constraint () in Step 1 and the first order Euler condition () in Step 2:
A static portfolio holding only the riskless asset will yield a constant portfolio value, , with . The diversification by dynamically managing the exposure to risky assets decreases the risk of the overall portfolio by an amount shown in Equation (9). One interesting observation is that the optimal portfolio exists regardless of whether the upper bound on the portfolio is finite or not . This conclusion will change drastically as we add the return constraint to the optimization problem.
The main result of this paper is to show that the optimal solution to the two-constraint problem and, thus, main problem Equation (1) and Equation (2), does not have a Neyman–Pearson type of binary solution, which we call two-line configuration in Equation (8); instead, it has a three-line configuration. Proposition 3.14 and Theorem 3.15 prove that, when the upper bound is finite , and under some technical conditions, the solution to Step 2 of the two-constraint problem turns out to be:
where is the solution to the capital constraint and the first order Euler condition, plus the additional return constraint ():
The sets in Equations (14)–(16) are defined by different levels of the Radon–Nikodým derivative:
When the upper bound is infinite , Theorem 3.17 shows that the solution for the optimal portfolio is no longer a three-line configuration. It can be pure money market account investment (one-line), binary (two-line) or very likely nonexistent. In the last case, the infimum of the CVaR can still be computed, and a sequence of three-line configuration portfolios can be found with their CVaR converging to the infimum.
2.3. Example: Exact Calculation in the Black–Scholes Model
We show the closed-form calculation of the three-line configuration presented in Equations (12)–(16), as well as the corresponding optimal dynamic strategy in the benchmark Black–Scholes Model. Suppose an agent is trading between a money market account with interest rate r and one stock2 that follows geometric Brownian motion with instantaneous rate of return μ, volatility σ and initial stock price . The endowment starts at , and bankruptcy is prohibited at any time, , before the final horizon, T. The optimal portfolio, , in Equation (8) for the one constraint problem is a binary option with expected return . The expected terminal value, , is required to be above a fixed level z to satisfy the return constraint. When z is low, namely, , the return constraint is non-binding, and obviously the two-line configuration, , is optimal. Let be the highest expected value achievable by any self-financing portfolio starting with initial capital (see Definition 3.2 and Lemma 3.3). When the return requirement becomes meaningful, i.e., , the three-line configuration, , provided by Equation (12), becomes optimal.
Since the Radon–Nikodým derivative, , is a scaled power function of the final stock price, which has a log-normal distribution, the probabilities in Equations (14)–(16) can be computed in closed-form:
where and is the cumulative distribution function of a standard normal random variable. From these, the solution, , to Equations (15) and (16) can be found numerically and, thus, the from Equation (12). The formulae3 for the dynamic value of the optimal portfolio, , the corresponding dynamic hedging strategy, 4, and the associated final minimal risk, , are:
where we define: and
Numerical results comparing the minimal risk for various levels of upper-bound and return constraint z are summarized in Table 1. As expected, the upper bound on the portfolio value, , has no impact on the one-constraint problem, as and are optimal whenever . On the contrary, in the two-constraint problem, the stricter the return requirement, z, the more the three-line configuration, , deviates from the two-line configuration, . Stricter return requirement (higher z) implies higher minimal risk ; while a less strict upper bound (higher ) decreases minimal risk . Notably, under certain conditions in Theorem 3.17, for all levels of return , when , approaches , as the optimal solution ceases to exist in the limiting case.

{kind=link}
Table 1.
Black–Scholes example for one-constraint (pure CVaR minimization) and two-constraint (mean-CVaR optimization) problems with parameters: , , , , , , , . Consequently, and .
| One-Constraint Problem | Two-Constraint Problem | ||||||
|---|---|---|---|---|---|---|---|
| 30 | 50 | 30 | 30 | 50 | |||
| z | 20 | 25 | 25 | ||||
| 19.0670 | 19.0670 | 19.1258 | 19.5734 | 19.1434 | |||
| 14.5304 | 14.5304 | 14.3765 | 12.5785 | 14.1677 | |||
| 0.0068 | 0.1326 | 0.0172 | |||||
| −15.2118 | −15.2118 | −15.2067 | −14.8405 | −15.1483 | |||
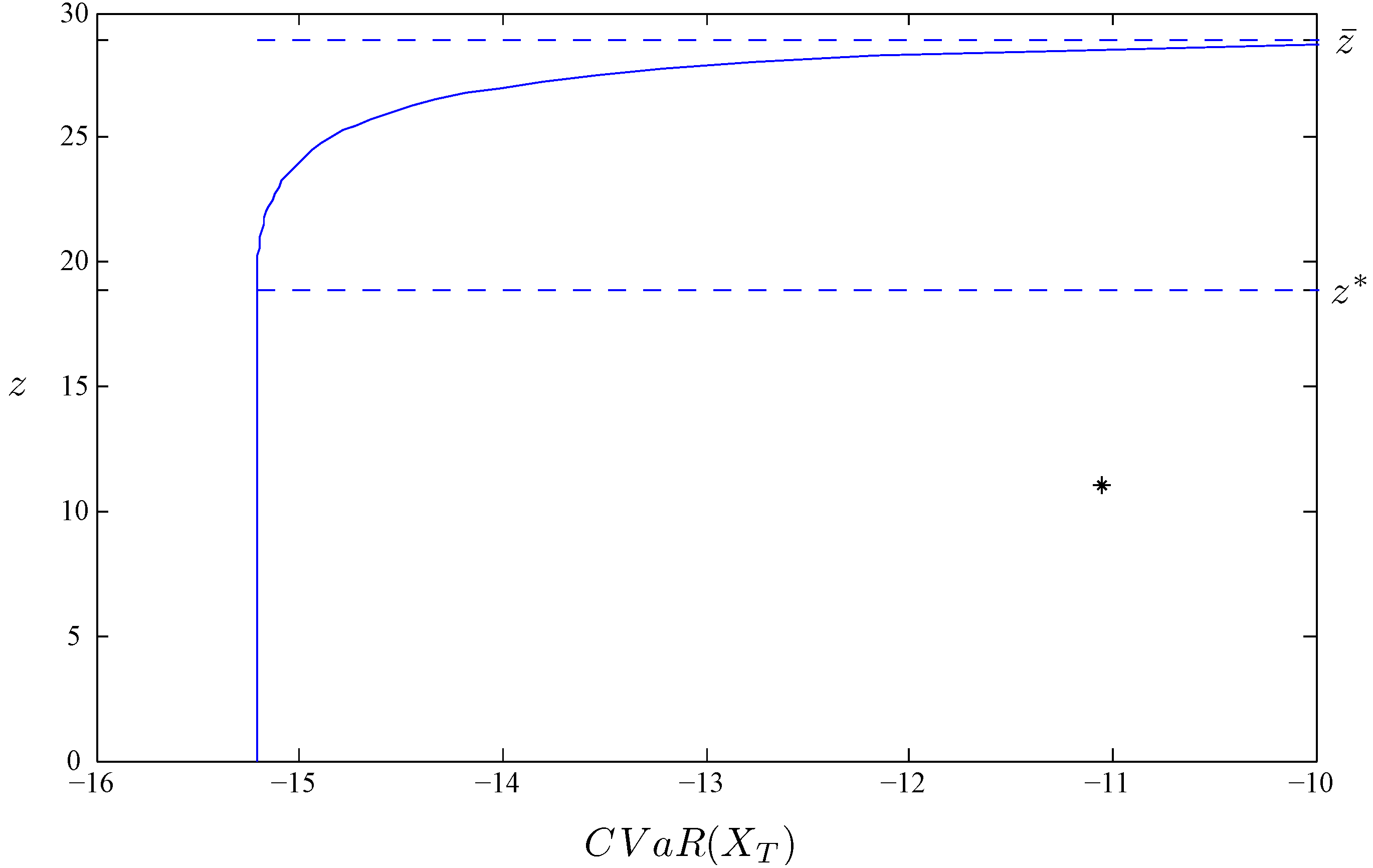
Figure 1.
Efficient frontier for mean-CVaR portfolio selection.

Figure 1 plots the efficient frontier of the above mean-CVaR portfolio selection problem with fixed upper bound . The curve between return level and are the mean-CVaR efficient portfolio from various three-line configurations, while the straight line is the same mean-CVaR efficient two-line configuration when the return constraint is non-binding. The star positioned at , where , corresponds to the portfolio that invests purely in the money market account. In contrast to its position on the traditional capital market Line (the efficient frontier for a mean-variance portfolio selection problem), the pure money market account portfolio is no longer efficient in the mean-CVaR portfolio selection problem.
3. Analytical Solution to the Portfolio Selection Problem
Under Assumption 2.1, the solution to the main mean-CVaR optimization problem Equation (2), i.e., the two-constraint problem Equations (4) and (5), will be discussed in two separate cases where the upper bound for the portfolio value is finite or infinite. The main results are stated in Theorem 3.15 and Theorem 3.17, respectively. To create a flow showing clearly how the optimal solutions are related to the two-line and three-line configurations, all proofs will be delayed to the Appendix.
3.1. Case : Finite Upper Bound
We first define the general three-line configuration and its degenerate two-line configurations. Recall from Section 2.2 the definitions of the sets, , are:
Definition 3.1 Suppose .
- 1.
- Any three-line configuration has the structure .
- 2.
- The two-line configuration is associated with the above definition in the case , and .The two-line configuration s associated with the above definition in the case , , and .The two-line configuration is associated with the above definition in the case , , and .
Moreover:
- 1.
- General constraints are the capital constraint and the equality part of the expected return constraint for a three-line configuration :
- 2.
- Degenerated Constraints 1 are the capital constraint and the equality part of the expected return constraint for a two-line configuration :Degenerated Constraints 2 are the capital constraint and the equality part of the expected return constraint for a two-line configuration :Degenerated Constraints 3 are the capital constraint and the equality part of the expected return constraint for a two-line configuration :
Note that Degenerated Constraints 1 correspond to the general constraints when ; Degenerated Constraints 2 correspond to the general constraints when ; and Degenerated Constraints 3 correspond to the general constraints when .
We use the two-line configuration , where the value of the random variable, X, takes either the upper or the lower bound, as well as its capital constraint to define the ‘bar-system’ from which we calculate the highest achievable return.
Definition 3.2 (The bar-system) For fixed , let be a solution to the capital constraint in Degenerated Constraints 3 for the two-line configuration . In the bar-system, , and are associated with the constant, , in the sense , where and . Define the expected return of the bar-system as .
Lemma 3.3 is the highest expected return that can be obtained by a self-financing portfolio with initial capital , whose value is bounded between and :
In the following lemma, we vary the x value in the two-line configurations and , while maintaining the capital constraints, respectively. We observe their expected returns to vary between values and in a monotone and continuous fashion.
Lemma 3.4 For fixed .
- 1.
- Given any , let b be a solution to the capital constraint in Degenerated Constraints 1 for the two-line configuration . Define the expected return of the resulting two-line configuration as .5 Then is a continuous function of x and decreases from to as x increases from to .
- 2.
- Given any , let a be a solution to the capital constraint in Degenerated Constraints 2 for the two-line configuration . Define the expected return of the resulting two-line configuration as . Then, is a continuous function of x and increases from to as x increases from to .
From now on, we will concern ourselves with requirements on the expected return in the interval, , because, on one side, Lemma 3.3 ensures that there are no feasible solutions to main problem Equation (2) if we require an expected return higher than . On the other side, Lemma 3.3, Lemma 3.4 and Theorem 3.11 lead to the conclusion that a return constraint where is too weak to differentiate the two-constraint problem from the one-constraint problem, as their optimal solutions concur.
Definition 3.5 For fixed and a fixed level , define and to be the corresponding x value for two-line configurations and that satisfy Degenerated Constraints 1 and Degenerated Constraints 2 , respectively.
Definition 3.5 implies when we fix the level of expected return, z, we can find two particular feasible solutions: , satisfying and ; and , satisfying and . The values, and , are well defined, because Lemma 3.4 guarantees to be an invertible function in both cases. We summarize in the following lemma whether the two-line configurations satisfying the capital constraints meet or fail the return constraint as x ranges over its domain, , for the two-line and three-line configurations in Definition 3.1.
Lemma 3.6 For fixed and a fixed level .
- 1.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 1, satisfies the expected return constraint: ;
- 2.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 1, fails the expected return constraint: ;
- 3.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 2, fails the expected return constraint: ;
- 4.
- If we fix , the two-line configuration , which satisfies the capital constraint in Degenerated Constraints 2, satisfies the expected return constraint: .
We turn our attention to solving Step 1 of the two-constraint problem (4):
Step 1: minimization of expected shortfall:
Notice that a solution is called for any given real number, x, independent of the return level, z, or capital level . From Lemma 3.6 and the fact that the two-line configurations are optimal solutions to Step 1 of the one-constraint problem (see Theorem 3.11), we can immediately draw the following conclusion.
Proposition 3.7 For fixed and a fixed level .
- 1.
- If we fix , then there exists a two-line configuration which is the optimal solution to Step 1 of the two-constraint problem;
- 2.
- If we fix , then there exists a two-line configuration , which is the optimal solution to Step 1 of the two-constraint problem.
When , Lemma 3.6 shows that the two-line configurations, which satisfy the capital constraints () do not generate high enough expected return () to be feasible anymore. It turns out that a novel solution of the three-line configuration is the answer: it can be shown to be both feasible and optimal.
Lemma 3.8 For fixed and a fixed level . Given any , let the pair of numbers, (), be a solution to the capital constraint in the general constraints for the three-line configuration . Define the expected return of the resulting three-line configuration as . Then, is a continuous function, which decreases from to a number below z:
- 1.
- When from Definition 3.2 of a bar-system, the three-line configuration degenerates to and .
- 2.
- When and , decreases continuously as b decreases and a increases.
- 3.
- In the extreme case when , the three-line configuration becomes the two-line configuration ; in the extreme case when , the three-line configuration becomes the two-line configuration . In either case, the expected value is below z by Lemma 3.6.
Proposition 3.9 For fixed and a fixed level . If we fix , then there exists a three-line configuration that satisfies the general constraints, which is the optimal solution to Step 1 of the two-constraint problem.
Combining Proposition 3.7 and Proposition 3.9, we arrive at the following result on the optimality of the three-line configuration.
Theorem 3.10 (Solution to Step 1: Minimization of Expected Shortfall)
For fixed and a fixed level . and the corresponding value function, , described below, are optimal solutions to Step 1: minimization of expected shortfall of the two-constraint problem:
- : any random variable with values in satisfying both the capital constraint and the return constraint .
- : any random variable with values in satisfying both the capital constraint and the return constraint .
- : , where are determined by and as in (17) satisfying the general constraints: and .
- : , where are determined by as in Definition 3.1 satisfying both the capital constraint and the return constraint .
- : , where are associated to as in Definition 3.2 satisfying both the capital constraint and the return constraint .
To solve Step 2 of the two-constraint problem Equation (5) and, thus, the main problem Equation (2), we need to minimize
where has been computed in Theorem 3.10. Depending on the z level in the return constraint being lenient or strict, the solution is sometimes obtained by the two-line configuration, which is optimal to the one-constraint problem and other times obtained by a true three-line configuration. To proceed in this direction, we recall the solution to the one-constraint problem from Li and Xu [22].
Theorem 3.11 (Theorem 2.10 and Remark 2.11 in Li and Xu [22] when )
- 1.
- Suppose . is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- 2
- Suppose .
- If (see Definition 3.2 for the bar-system), then is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- Otherwise, let be the solution to the equation . Associate sets and to level . Define , so that configurationsatisfies the capital constraint .6, and the associated minimal risk is:
Definition 3.12 In part 2 of Theorem 3.11, define in the first case when ; define in the second case when .
We see that when z is smaller than , the binary solutions, and , provided in Theorem 3.11 are indeed the optimal solutions to Step 2 of the two-constraint problem. However, when z is greater than , these two-line configurations are no longer feasible in the two-constraint problem. We now show that the three-line configuration is not only feasible, but also optimal. First, we establish the convexity of the objective function and its continuity in a Lemma.
Lemma 3.13 is a convex function for and, thus, continuous.
Proposition 3.14 For fixed and a fixed level .
Suppose . The solution, (and, consequently, and ), to the equations:
exists. (what we call the ‘double-star system’) is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
Putting together Proposition 3.14 with Theorem 3.11, we arrive at the main theorem of this paper.
Theorem 3.15 (Minimization of conditional value-at-risk when )
For fixed .
- 1.
- Suppose and . The pure money market account investment is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- 2.
- Suppose and . The optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem does not exist, and the minimal risk is:
- 3.
- Suppose and (see Definition 3.12 for ).
- If (see Definition 3.2), then the bar-system is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- Otherwise, the star-system defined in Theorem 3.11 is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- (4)
- Suppose and . The double-star-system defined in Proposition 3.14 is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
We observe that the pure money market account investment is rarely optimal. When the Radon–Nikodým derivative is bounded above by the reciprocal of the confidence level of the risk measure (), a condition not satisfied in the Black–Scholes Model, the solution does not exist unless the return requirement coincides with the risk-free rate. When the Radon–Nikodým derivative exceeds with positive probability and the return constraint is low, , the two-line configuration, which is optimal to the minimization problem without the return constraint, is also the optimal to the mean-CVaR problem. However, in the more interesting case in which the return constraint is materially high, , the optimal three-line-configuration sometimes takes the value of the upper bound, , to raise the expected return at the cost of the minimal risk, which will be at a higher level. This analysis complies with the numerical example shown in Section 2.3.
3.2. Case : No Upper Bound
We first restate the solution to the one-constraint problem from Li and Xu [22] in the current context: when , where we interpret and .
Theorem 3.16 (Theorem 2.10 and Remark 2.11 in Li and Xu [22] when )
- 1.
- Suppose . The pure money market account investment is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
- 2.
- Suppose . The star-system defined in Theorem 3.11 is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem, and the associated minimal risk is:
We observe that although there is no upper bound for the portfolio value, the optimal solution remains bounded from above, and the minimal is bounded from below. The problem of purely minimizing risk of a self-financing portfolio (bounded below by to exclude arbitrage) from initial capital, , is feasible in the sense that the risk will not approach , and the minimal risk is achieved by an optimal portfolio. When we add substantial return constraint to the minimization problem, although the minimal risk can still be calculated in the most important case (Case 4 in Theorem 3.17), it is truly an infimum and not a minimum, thus it can be approximated closely by a sub-optimal portfolio, but not achieved by an optimal portfolio.
Theorem 3.17 (Minimization of Conditional Value-At-Risk When )
For fixed .
- 1.
- Suppose and . The pure money market account investment is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- 2.
- Suppose and . The optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem does not exist, and the minimal risk is:
- 3.
- Suppose and . The star-system defined in Theorem 3.11 is the optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem, and the associated minimal risk is:
- 4.
- Suppose and . The optimal solution to Step 2: minimization of conditional value-at-risk of the two-constraint problem does not exist, and the minimal risk is:
Remark 3.18 From the proof of the above theorem in the Appendix, we note that in Case 4, we can always find a three-line configuration as a sub-optimal solution, i.e., there exists for every a corresponding portfolio , which satisfies the general constraints and produces a level close to the lower bound:
4. Future Work
The second part of Assumption 2.1, namely the Radon–Nikodým derivative, , having a continuous distribution, is imposed for the simplification it brings to the presentation in the main theorems. Further work can be done when this assumption is weakened. We expect that the main results should still hold, albeit in a more complicated form.7 It will also be interesting to extend the closed-form solution for mean-CVaR minimization by replacing CVaR with law-invariant convex risk measures in general. Another direction will be to employ dynamic risk measures into the current setting.
Although in this paper we focus on the complete market solution, to solve the problem in an incomplete market setting, which includes stochastic volatility or jump models, the exact hedging argument via the martingale representation theorem that translates the dynamic problem Equation (1) into the static problem Equation (2) has to be replaced by a super-hedging argument via the optional decomposition developed by Kramkov [30] and Föllmer and Kabanov [31]. The detail is similar to the process carried out for shortfall risk minimization in Föllmer and Leukert [26], convex risk minimization in Rudloff [32] and law-invariant risk preference in He and Zhou [25]. The curious question is: Will the three-line configuration remain optimal?
Acknowledgments
The findings and conclusions expressed are solely those of the author and do not represent views of the Federal Reserve Bank of New York or the staff of the Federal Reserve System.
Conflicts of Interest
The authors declare no conflict of interest.
A. Appendix
A.1. Proof of Lemma 3.3
The problem of
is equivalent to the expected shortfall problem:
Therefore, the answer is immediate. ⋄
A.2. Proof of Lemma 3.4
Choose . Let , where and . Choose such that . This capital constraint means . Since , and . Define . Similarly, corresponds to , where and and . Note that , and . We have:
For any given , choose ; then:
Therefore, z decreases continuously as x increases when . When , from Definition 3.2. When , and . Similarly, we can show that z increases continuously from to as x increases from to . ⋄
Lemma 3.6 is a logical consequence of Lemma 3.4 and Definition 3.5; Proposition 3.7 follows from Lemma 3.6; so their proofs will be skipped.
A.3. Proof of Lemma 3.8
Choose . Let configuration correspond to the pair, , where ,
,
. Similarly, let configuration correspond to the pair, . Define and . Since both and satisfy the capital constraint, we have:
This simplifies to the equation:
Then:
Suppose the pair, , is chosen, so that satisfies the budget constraint . For any given , choose small enough such that . Now choose , such that , and Equation (18) is satisfied. Then, also satisfies the budget constraint , and:
We conclude that the expected value of the three-line configuration decreases continuously as b decreases and a increases. ⋄
In the following, we provide the main proof of the paper: the optimality of the three-line configuration.
A.4. Proof of Proposition 3.9
Denote . According to Lemma 3.8, there exists a three-line configuration that satisfies the general constraints:
where:
As standard for convex optimization problems, if we can find a pair of Lagrange multipliers, and , such that is the solution to the minimization problem:
then is the solution to the constrained problem:
Define
Then, Equation (19) becomes:
Choose any , where , and denote and . Note that on set A, on set B and on set D. Then, the difference:
The last inequality holds because each term inside the expectation is greater than or equal to zero. ⋄
Theorem 3.10 is a direct consequence of Lemma 3.6, Proposition 3.7 and Proposition 3.9.
A.5. Proof of Lemma 3.13
The convexity of is a simple consequence of its definition (4). Real-valued convex functions on are continuous on its interior of the domain, so is continuous on . ⋄
A.6. Proof of Proposition 3.14
For , Step 2 of the two-constraint problem
is the minimum of the following five sub-problems after applying Theorem 3.10:
The last equality comes from the fact : As in Lemma 3.8, we know that when , the three-line configuration degenerates to the two-line configuration , where . Therefore, Case 3 dominates Case 2. In Case 5:
- Case 1
- Case 2
- Case 3
- Case 4
- Case 5
Therefore, Case 4 dominates Case 5. When and , Theorem 3.10 and Theorem 3.11 imply that the infimum in Case 4 is achieved either by or . Since we restrict where by Definition 3.12 in the first case, we need not consider this case in the current proposition. In the second case, Lemma 3.4 implies that (because ). By the convexity of , and then the continuity of :
Therefore, Case 3 dominates Case 4. We have shown that Case 3 actually provides the global infimum:
Now, we focus on , where satisfies the general constraints:
and the definition for sets , and are:
Note that (see Theorem 3.10). Since and , we rewrite the capital and return constraints as:
Differentiating both sides with respect to x, we get:
Since:
we get:
Therefore:
When the above derivative is zero, we arrive at the first order Euler condition:
To be precise, the above differentiation should be replaced by left-hand and right-hand derivatives, as detailed in the Proof for Corollary 2.8 in Li and Xu [22]. However, the first order Euler condition will turn out to be the same, because we have assumed that the Radon–Nikodým derivative, , has continuous distribution.
To finish this proof, we need to show that there exists an where the first order Euler condition is satisfied. From Lemma 3.8, we know that as , and . Therefore:
As , and . Therefore:
This derivative coincides with the derivative of the value function of the two-line configuration that is optimal on the interval, , provided in Theorem 3.10 (see Proof for Corollary 2.8 in Li and Xu [22]). Again, when and , Theorem 3.10 and Theorem 3.11 imply that the infimum of is achieved either by or . Since we restrict where by Definition 3.12 in the first case, we need not consider this case in the current proposition. In the second case, Lemma 3.4 implies that (because ). This, in turn, implies:
We have just shown that there exist some , such that . By the convexity of , this is the point where it obtains the minimum value. Now:
⋄
A.7. Proof of Theorem 3.15
Case 3 and 4 are already proven in Theorem 3.11 and Proposition 3.14. In Case 1, where and , is both feasible and optimal by Theorem 3.11. In Case 2, fix arbitrary . We will look for a two-line solution with the right parameters, , which satisfies both the capital constraint and return constraint:
where:
and produces a CVaR level close to the lower bound:
First, we choose . To find the remaining two parameters, and , so that Equations (20) and (21) are satisfied, we note:
and conclude that it is equivalent to finding a pair of and , such that the following two equalities are satisfied:
where we denote . If we can find a solution, , to the equation:
then:
and we have the solutions for Equations (20) and (21). It is not difficult to prove that the fraction, , increases continuously from zero to one as a increases from zero to . Therefore, we can find a solution, , where Equation (22) is satisfied. By definition Equation (3):
The difference:
Under Assumption 2.1, the solution in Case 2 is almost surely unique; the result is proven. ⋄
Proof of Theorem 3.17. Case 1 and 3 are obviously true in light of Theorem 3.16. The proof for Case 2 is similar to that in the Proof of Theorem 3.15, so we will not repeat it here. Since in Case 4, is only a lower bound in this case. We first show that it is the true infimum obtained in Case 4. Fix arbitrary . We will look for a three-line solution with the right parameters , which satisfies the general constraints:
where:
and produces a CVaR level close to the lower bound:
First, we choose , , , where we define . To find the remaining two parameters, and , so that Equation (23) and (24) are satisfied, we note:
and conclude that it is equivalent to finding a pair of and , such that the following two equalities are satisfied:
where we denote . If we can find a solution, , to the equation:
then:
and we have the solutions for Equations (23) and (24). It is not difficult to prove that the fraction, , increases continuously from zero to as b increases from zero to . Therefore, we can find a solution, , where Equation (25) is satisfied. By definition Equation (3):
The difference:
Under Assumption 2.1, the solution in Case 4 is almost surely unique; the result is proven. ⋄
References
- H. Markowitz. “Portfolio selection.” J. Financ. 7 (1952): 77–91. [Google Scholar]
- T. Bielecki, H. Jin, S.R. Pliska, and X.Y. Zhou. “Continuous-time mean-variance portfolio selection with bankruptcy prohibition.” Math. Financ. 15 (2005): 213–244. [Google Scholar] [CrossRef]
- R.T. Rockafellar, and S. Uryasev. “Optimization of conditional value-at-risk.” J. Risk 2 (2000): 21–51. [Google Scholar]
- R.T. Rockafellar, and S. Uryasev. “Conditional value-at-risk for general loss distributions.” J. Bank. Financ. 26 (2002): 1443–1471. [Google Scholar] [CrossRef]
- C. Acerbi, and D. Tasche. “On the coherence of expected shortfall.” J. Bank. Financ. 26 (2002): 1487–1503. [Google Scholar] [CrossRef]
- P. Artzner, F. Delbaen, J.-M. Eber, and D. Heath. “Thinking coherently.” Risk 10 (1997): 68–71. [Google Scholar]
- P. Artzner, F. Delbaen, J.-M. Eber, and D. Heath. “Coherent measures of risk.” Math. Financ. 9 (1999): 203–228. [Google Scholar] [CrossRef]
- C. Acerbi, and P. Simonetti. Portfolio Optimization with Spectral Measures of Risk. Working Paper; Milan, Italy: Abaxbank, 2002. [Google Scholar]
- A. Adam, M. Houkari, and J.P. Laurent. “Spectral risk measures and portfolio selection.” J. Bank. Financ. 32 (2008): 1870–1882. [Google Scholar] [CrossRef]
- A.S. Cherny. “Weighted V@R and its properties.” Financ. Stoch. 10 (2006): 367–393. [Google Scholar] [CrossRef]
- A. Ruszczyński, and A. Shapiro. “Conditional risk mapping.” Math. Oper. Res. 31 (2006): 544–561. [Google Scholar] [CrossRef]
- R. Gandy. “Portfolio Optimization With Risk Constraints.” Ph.D. Thesis, University of Ulm, Ulm, Germany, July 2005. [Google Scholar]
- H. Zheng. “Efficient frontier of utility and CVaR.” Math. Methods Oper. Res. 70 (2009): 129–148. [Google Scholar] [CrossRef]
- A.G. Quaranta, and A. Zaffaroni. “Robust optimization of conditional value at risk and portfolio selection.” J. Bank. Financ. 32 (2008): 2046–2056. [Google Scholar] [CrossRef]
- J.Y. Gotoh, K. Shinozaki, and A. Takeda. “Robust portfolio techniques for mitigating the fragility of CVaR minimization and generalization to coherent risk measures.” Quant. Financ. 13 (2013): 1621–1635. [Google Scholar] [CrossRef]
- D. Huang, S. Zhu, F.J. Fabozzi, and M. Fukushima. “Portfolio selection under distributional uncertainty: A relative robust CVaR approach.” Eur. J. Oper. Res. 203 (2010): 185–194. [Google Scholar] [CrossRef] [Green Version]
- N. El Karoui, A.E.B. Lim, and G.Y. Vahn. “Performance-Based Regularization in Mean-CVaR Portfolio Optimization.” Working Paper. 2012. Available online: http://arxiv.org/abs/1111.2091 (accessed on 6 August 2013).
- V. Acharya, L. Pedersen, T. Philippon, and M. Richardson. Measuring Systemic Risk. Working Paper; Cleveland, OH, U.S.A.: Federal Reserve Bank of Cleveland, 2010. [Google Scholar]
- C. Chen, G. Iyengar, and C.C. Moallemi. “An axiomatic approach to systemic risk.” Manag. Sci. 59 (2013): 1373–1388. [Google Scholar] [CrossRef]
- T. Adrian, and M.K. Brunnermeier. CoVaR. Working Paper No. w17454; Princeton, NJ, USA: National Bureau of Economic Research, 2011. [Google Scholar]
- J. Sekine. “Dynamic minimization of worst conditional expectation of shortfall.” Math. Financ. 14 (2004): 605–618. [Google Scholar] [CrossRef]
- J. Li, and M. Xu. “Risk minimizing portfolio optimization and hedging with conditional value-at-risk.” Rev. Futures Mark. 16 (2008): 471–506. [Google Scholar]
- A. Melnikov, and I. Smirnov. “Dynamic hedging of conditional value-at-risk.” Insur.: Math. Econ. 51 (2012): 182–190. [Google Scholar] [CrossRef]
- A. Schied. “On the Neyman–Pearson problem for law-invariant risk measures and robust utility functionals.” Ann. Appl. Probab. 14 (2004): 1398–1423. [Google Scholar] [CrossRef]
- X.D. He, and X.Y. Zhou. “Portfolio choice via quantiles.” Eur. J. Oper. Res. 203 (2011): 185–194. [Google Scholar] [CrossRef]
- H. Föllmer, and P. Leukert. “Efficient hedging: Cost versus shortfall risk.” Financ. Stoch. 4 (2000): 117–146. [Google Scholar]
- F. Delbaen, and W. Schachermayer. “A general version of the fundamental theorem of asset pricing.” Math. Ann. 300 (1994): 463–520. [Google Scholar] [CrossRef]
- P. Krokhmal, J. Palmquist, and S. Uryasev. “Portfolio optimization with CVaR objective and constraints.” J. Risk 4 (2001): 43–68. [Google Scholar]
- M. Xu. “Minimizing shortfall risk using duality approach—An application to partial hedging in incomplete markets.” Ph.D. Thesis, Carnegie Mellon University, Pittsburgh, PA, USA, April 2004. [Google Scholar]
- D. Kramkov. “Optional decomposition of supermartingales and hedging contingent claims in incomplete security markets.” Probab. Theory Relat. Fields 105 (1996): 459–479. [Google Scholar] [CrossRef]
- H. Föllmer, and Y.M. Kabanov. “Optional decomposition and Lagrange multipliers.” Financ. Stoch. 2 (1998): 69–81. [Google Scholar]
- B. Rudloff. “Convex hedging in incomplete markets.” Appl. Math. Financ. 14 (2007): 437–452. [Google Scholar] [CrossRef]
- 1.Krokhmal et al. [28] showed conditions under which the problem of maximizing expected return with the CVaR constraint is equivalent to the problem of minimizing CVaR with the expected return constraint. In this paper, we use the term mean-CVaR problem for both cases.
- 2.It is straight-forward to generalize the calculation to the multi-dimensional Black–Scholes Model. Since we provide in this paper an analytical solution to the static CVaR minimization problem, calculation in other complete market models can be carried out as long as the dynamic hedge can be expressed in a simple manner.
- 3. coincides with the dynamic value of a European option with payoff , and coincides with its delta-hedge.
- 4.Note that since the solution, , is binary and the solution, , takes three values, they share the practical difficulty as all digital options do near expiration, namely, the hedge ratio can be very big in magnitude at the boundary near expiration, which makes it impractical to do the hedging properly. We point out that this property is not shared by the optimal solution to the mean-variance type of problems.
- 5.Threshold b and, consequently, sets B and D are all dependent on x through the capital constraint; therefore, is not a linear function of x.
- 6.Equivalently, can be viewed as the solution to the capital constraint and the first order Euler condition in Equation (10) and (11). Then, (what we call the ‘star-system’) is the optimal solution to Step 2: minimization of conditional value-at-risk of the one-constraint problem
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Li, J.; Xu, M. Optimal Dynamic Portfolio with Mean-CVaR Criterion. Risks 2013, 1, 119-147. https://doi.org/10.3390/risks1030119
AMA Style
Li J, Xu M. Optimal Dynamic Portfolio with Mean-CVaR Criterion. Risks. 2013; 1(3):119-147. https://doi.org/10.3390/risks1030119
Chicago/Turabian StyleLi, Jing, and Mingxin Xu. 2013. "Optimal Dynamic Portfolio with Mean-CVaR Criterion" Risks 1, no. 3: 119-147. https://doi.org/10.3390/risks1030119