3.1. Parametric Estimators
Let
be a sample of independent random vectors, where
and
. Assume that the star body
K is given and Assumption 1 is satisfied. From now on, we suppose that
K is symmetric w.r.t. the origin. We consider a model family
of continuously differentiable densities for the star-generalized radius
R on
, see (
4).
is the parameter space which is assumed to be compact. Suppose that
is a continuous function.
Next we give two reasonable model classes for
:
- (1)
Modified exponential model.
,
with the expectation
- (2)
Weibull model.
,
with the expectation
Let
. In this section the aim is to fit the specific parametric model for the density
to the data by estimating the parameters
θ and
μ where
is given according to (
5) and (
4) with
. Therefore, the two models [1] and [2] fulfill the condition
which ensures the differentiability of the density
at zero.
For the statistical analysis we suppose that the data
are given and these data comprise independent random vectors having density
. Suppose that
θ and
μ are interior points of
and
, respectively. The concentrated log likelihood function (constant addends can be omitted) reads as follows
We introduce the maximum likelihood estimators
of
θ and
μ as joint maximizers of the likelihood function:
Under appropriate assumptions, the maximum-likelihood-estimator are asymptotically normally distributed (cf. Theorem 5.1 in [
18], p. 463)
where
is the symbol for convergence in distribution and the information matrix is given by
with
and
3.2. Nonparametric Estimators without Scale Fit
In the present section we deal with nonparametric estimators in the context of star-shaped distributions. This type of estimators is of special interest if no suitable parametric model can be found. The cdf of R will be denoted by .
3.2.1. Estimating μ and
Let
be the sample as in
Section 3.1. In the following the focus is on the estimation of the parameter
μ and the distribution function of the generalized radius
R.
First we choose an estimator for
μ. For this purpose we assume that
. In view of Lemma 1,
is an unbiased estimator for the unknown parameter
μ. Define
and
for
. Using this definition, an estimator for the cdf of
(cf. (
3)) is given by the formula
for
. At a first glance,
just approximates the empirical distribution function
which is not available from the data because of the unknown
μ. We can prove that
converges to
, in fact at the same rate as every common empirical distribution function converges to the cdf. This is the assertion of the following theorem.
Theorem 1. Suppose that Assumption 1 is satisfied, is Lipschitz-continuous on , and If further f is bounded on , then, for , Here the condition (
9) ensures that
which in turn is an assumption for the law of iterated logarithm of
.
3.2.2. Density Estimation
In the remainder of
Section 3.2, we establish an estimator for the density
in the case of a bounded generator function
g, and provide statements on convergence properties of the estimator. An estimator for
μ is available by Formula (
7), the estimation of
g is still an open problem. If we want to estimate
g, then it is necessary that this function is identifiable. In (
2), however, function
g is determined up to a constant factor. Therefore, we require
to obtain the uniqueness and identifiability. As a consequence, we get, according to [
12]
In the following we adopt the approach introduced in Section 2 of [
7] to the present much more general situation. This approach combines the advantages of two estimators and avoids their disadvantages. Let
be a function having a derivative
with
for
and the property
. We introduce the random variable
and denote the inverse function of
ψ by Ψ. The transformation using
ψ is applied to adjust the volcano effect described above. In view of (
4), the density
χ of
is given by
for
. This equation implies the following formula for
g:
The next step is to establish the estimator for
χ. Nonparametric estimators have the advantage that they are flexible and there is no need to assume a specific model. Let us consider the transformed sample
with
. Further we apply the following kernel density estimator for
χ:
where
is the bandwidth and
k the kernel function. Note that
represents the usual kernel density estimator for
χ based upon the
’s and including a boundary correction at zero (the second addend in the outer parentheses of (
10)). The mirror rule is used as a simple boundary correction. Other more elegant corrections can be applied at the price of a higher technical effort. The properties of
are essentially influenced by the bandwidth
b. Since the kernel estimator shows reasonable properties only in the case of bounded
χ, we have to guarantee by suitable assumptions that
in order to get the boundedness of
χ (see below). On the basis of
, we can establish the following estimator for
:
where
This approach has the property that the theory of kernel density estimators applies here (cf. [
19]). The kernel estimators are a very popular type of nonparametric density estimators because of their comparatively simple structure. In the literature the reader can find a lot of hints concerning the choice of the bandwidth.
Let us add here some words to the comparison between this paper and [
7]. Although the main idea for the construction of estimators is the same, there is a difference in the definition of the generator functions (say
g and
). Considering the special case
, identity
can be established for
. This causes some changes in the formulas. For more details in a particular case, see Section 3 in [
20].
3.2.3. Assumptions Ensuring Convergence Properties of Estimators
Next we provide the assumptions for the theorems below. Assumption 2 concerns the parameter and the function k of the kernel estimator whereas Assumption 3 is posed on function ψ.
Assumption 2. (a) We assume thatwith constants . (b) Suppose that the kernel function is continuous and vanishes outside the interval , and has a Lipschitz continuous derivative on . Moreover, assume that holds for ,for even , where is an integer. Note that continuity of the derivative at an enclosed boundary point means that the one-sided derivative exists and is the limit of the derivatives in a neighbourhood of this point. Symmetric kernel functions
k satisfying (
12) are called kernels of order
p. Assumption 2 ensures that the bias of the density estimator
converges to zero at a certain rate. Under Assumption 2 with
and
, the estimator
is indeed a density. The case
is added to complete the presentation and is of minor practical importance unless we have a very large sample size (cf. the discussion in [
21]). From the asymptotic theory for density estimators, it is known that the Epanechnikov kernel
is an optimal kernel of order 2 (i.e., in the case
in Assumption 2) with respect to the asymptotic mean square error (cf. [
19]). This kernel function is simple in structure and leads to fast computations. The consideration of optimal kernels can be extended to higher-order kernels. It turned out that their use is advantageous only in the case of sufficiently large sample sizes (for instance, for a size greater than 1000).
Assumption 3. The -th order derivative of exists and is continuous on , is positive and bounded on for some integer , and is bounded on . The functions and have bounded derivatives on with some . Moreover, Notice that in Assumption 3 we require that the right-sided limit of the
-th order derivative of
is finite at zero. Hence Assumption 3 implies that
and
with a finite constant
. On the other hand, it follows from (
13) that
with a finite constant
. Therefore,
χ is bounded under Assumption 3.
Example 10. Letwith a constant . Then , , Hence, Assumption 3 is satisfied for every .
Another condition is required now for .
Assumption 4. For any bounded subset Q of , the partial derivatives of exist and are bounded on Q, and is Hölder continuous of order on Q for each .
Assumption 5. For any bounded subset Q of , is Hölder continuous of order .
If Assumption 3 is fulfilled, the function has second order derivatives , and these are bounded on bounded subsets of , then the Assumption 4 is satisfied.
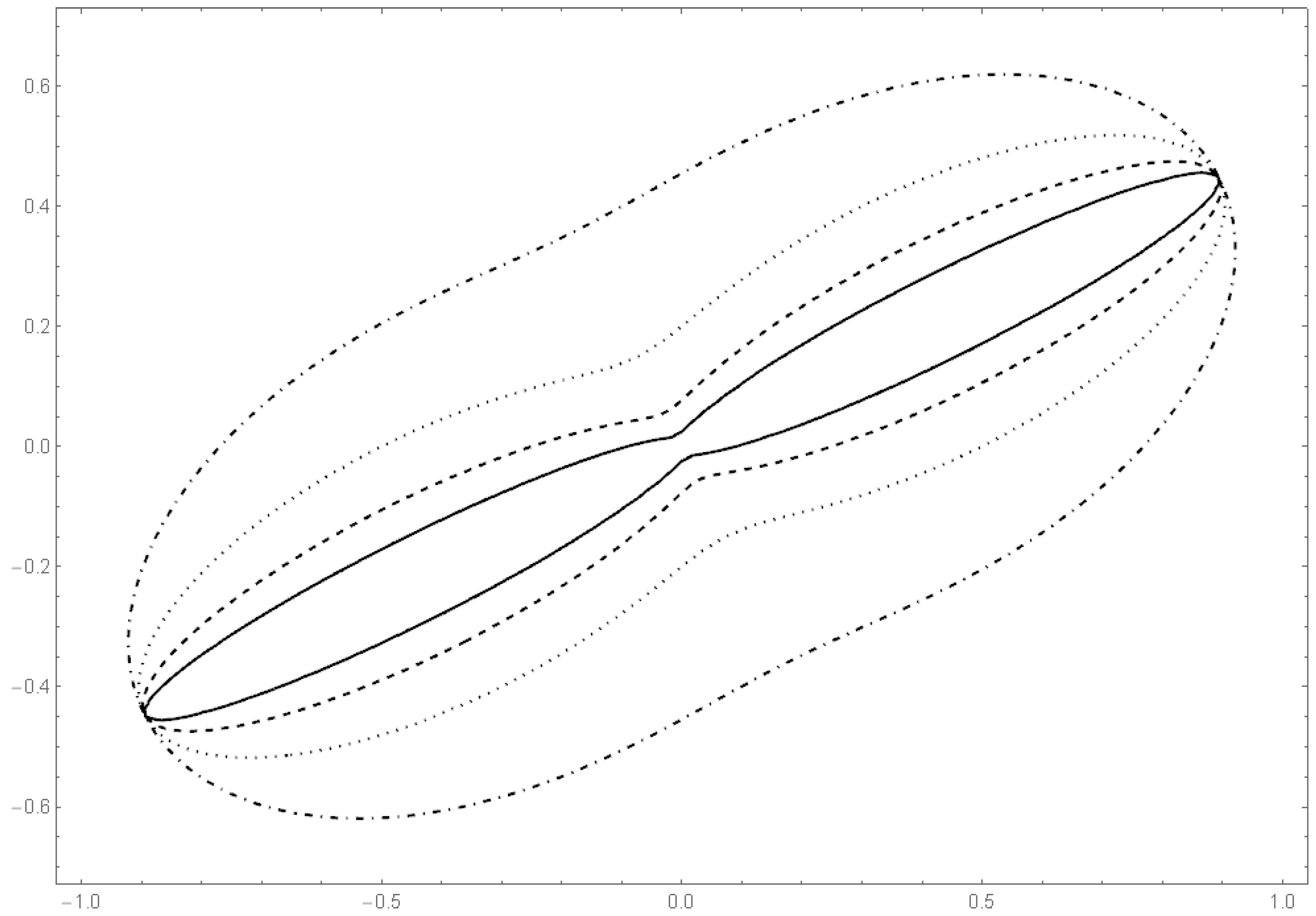
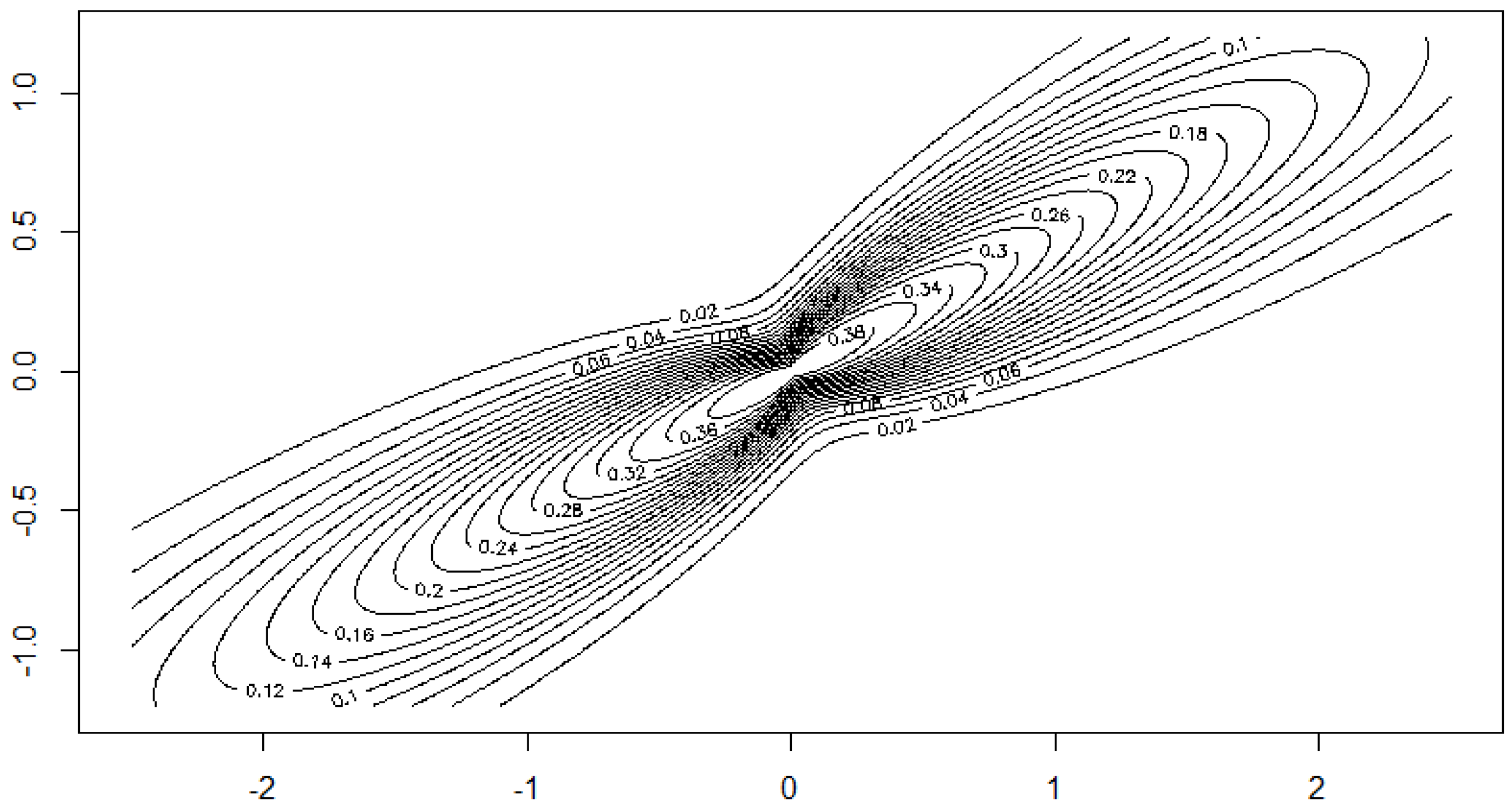
Example 11. We consider the q-norm/antinorm: ,Therefore, Assumption 4 is fulfilled in the case , and Assumption 5 is fulfilled in the case . Examples 1 and 2: (Continued) One can show that exists for , and is bounded. Moreover, is Lipschitz continuous on . Hence, Assumption 4 is satisfied.
3.2.4. Properties of the Density Estimator
First we provide the result on strong convergence of the density estimator.
Theorem 2. Suppose that the p-th order derivative of g exists and is bounded on for some even integer . Moreover, assume that condition (9) as well as Assumptions 1 to 3 are satisfied for the given p. Let Assumption 4 or Assumption 5 be satisfied. In the first case define , in the latter case . Then, for any compact set D with and , For any compact set D with and , Theorem 2 applies in particular to the Euclidean case
. Since Assumption 2 is weaker than the corresponding assumption on the kernel in [
7], Theorem 2 extends Theorem 3.1 in [
7] even in the case of
. The convergence rate in (
15) is the same as that known for one-dimensional kernel density estimators and cannot be improved under the assumptions posed here (cf. [
22]).
The next theorem represents the result about the asymptotic normality of the estimator .
Theorem 3. Suppose that the assumptions of Theorem 2 and Assumption 4 are satisfied. Let such that is continuous at .- (i)
DefineThenwhere - (ii)
If additionally holds true with a constant , then, for ,
The assertion of Theorem 3 can be used to construct an asymptotic confidence region for
. Term
describes the asymptotic behaviour of the the bias of the estimator
whereas the fluctuations of the estimator are represented by
. In view of Theorem 3,
converges in distribution to
. The mean squared deviation of the leading terms in the asymptotic expansion of
is thus given by
The minimization of this function w.r.t.
b leads to the asymptotically optimal bandwidth
The bandwidth
converges at rate
to zero. Under the conditions of Theorem 3(ii),
has the convergence rate
. This convergence rate of
is better than that of a nonparametric density estimator but slower than the usual rate
for parametric estimators. In principle, Formula (
16) could be used for the optimal choice of the bandwidth. However, one would need then an estimator for
and typically, estimators of derivatives of densities do not exhibit a good performance unless
n is very large. As a resort, one can consider a bandwidth which makes reference to a specific radius distribution.
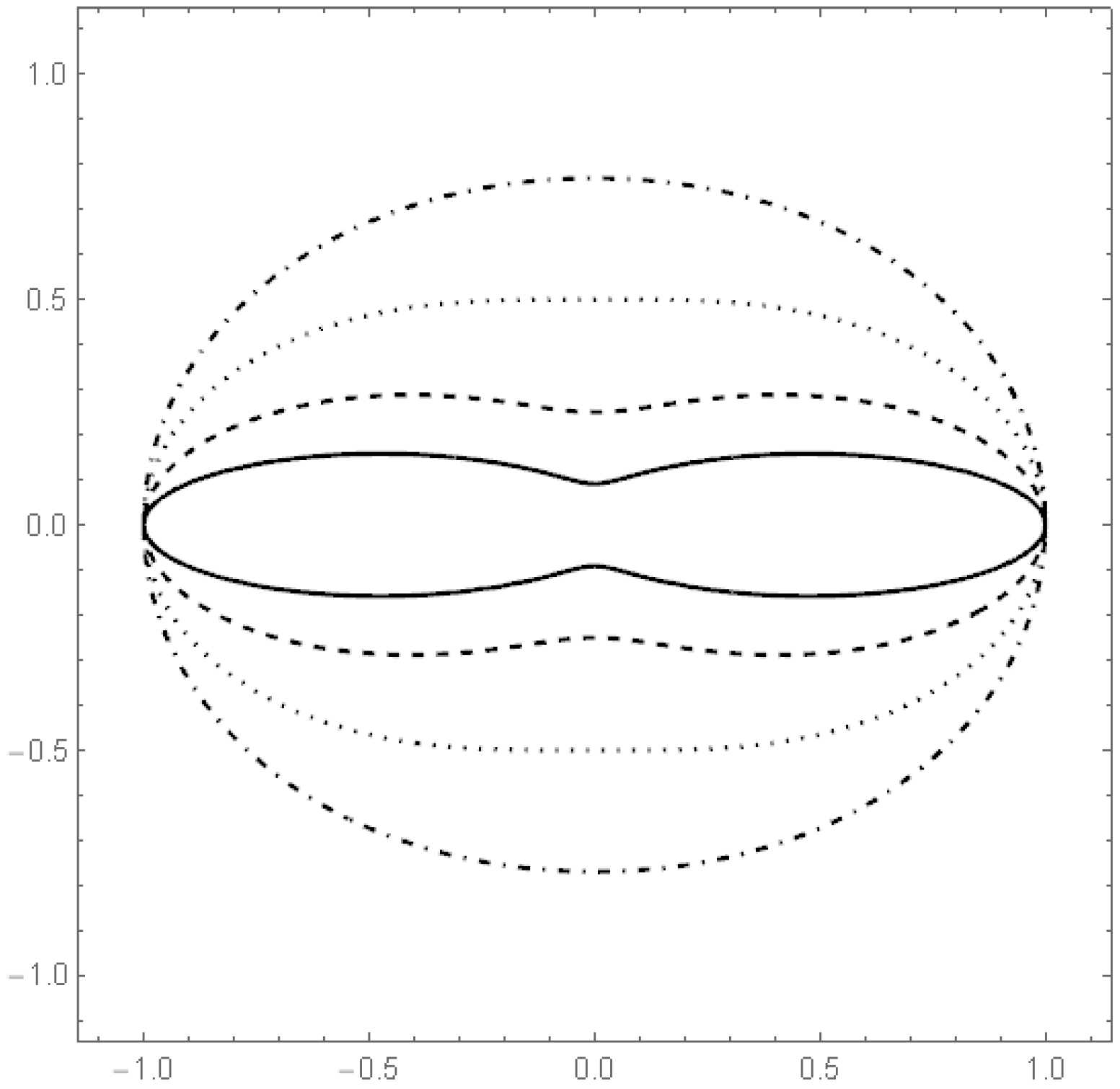
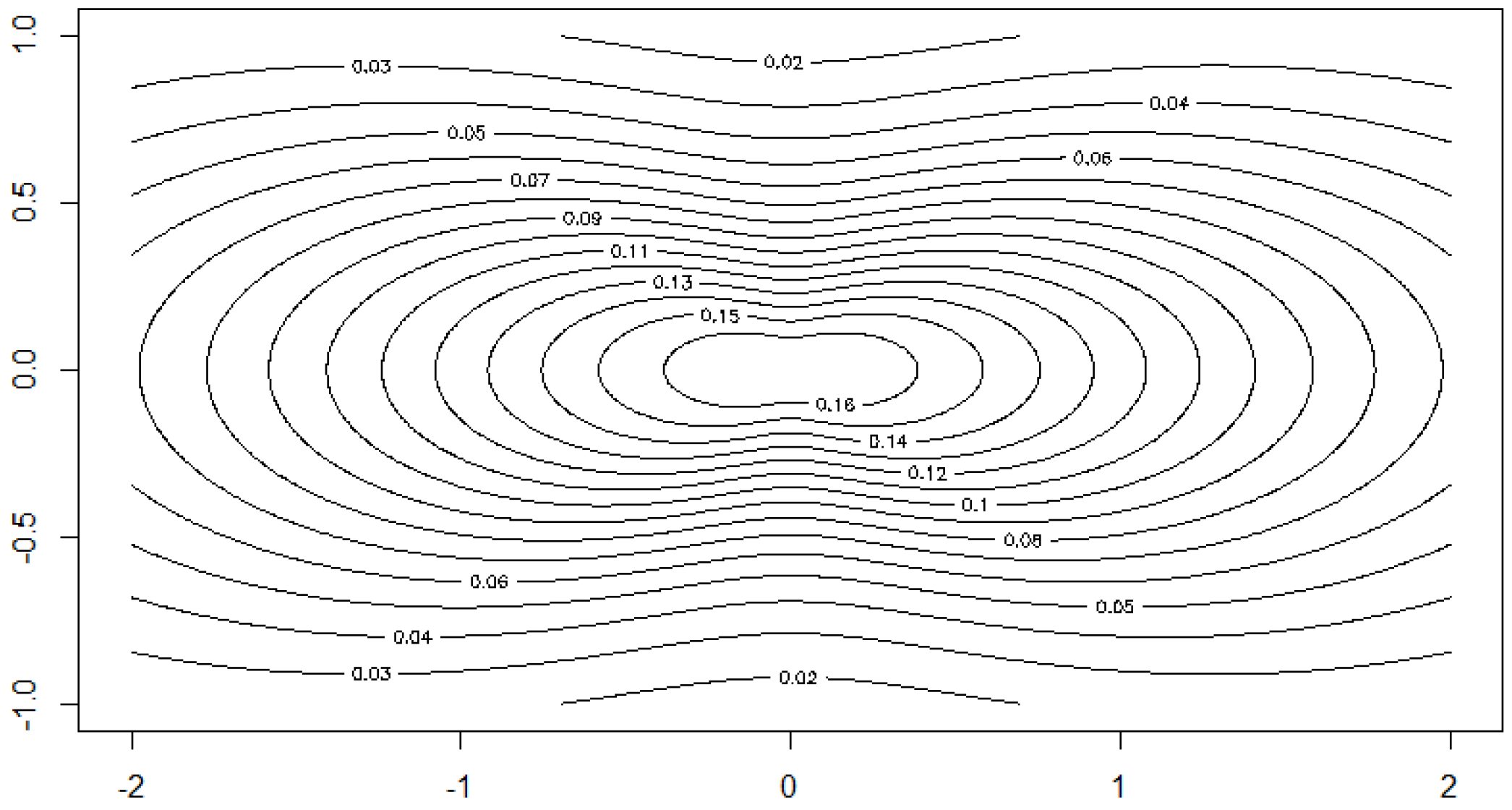
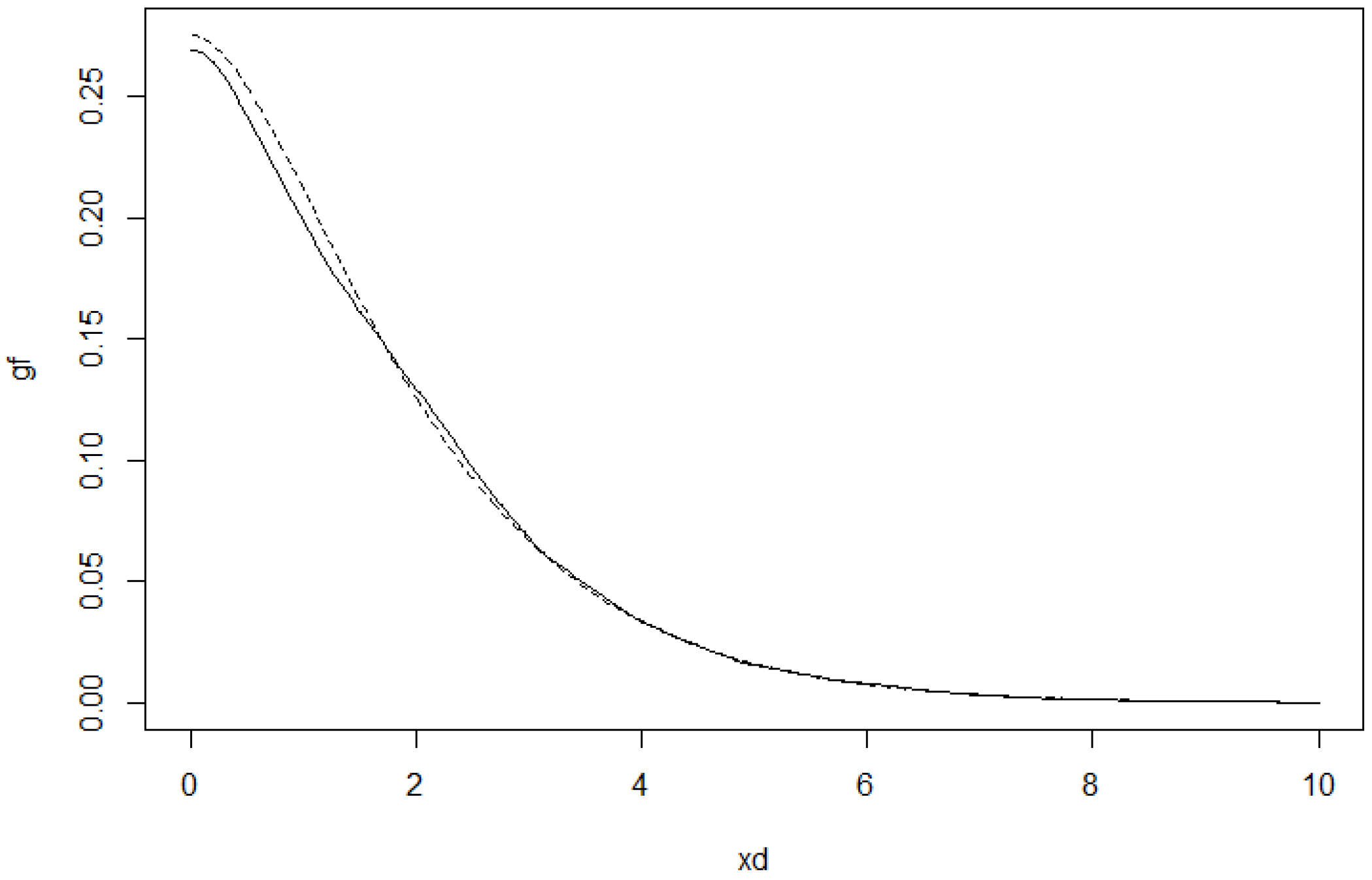
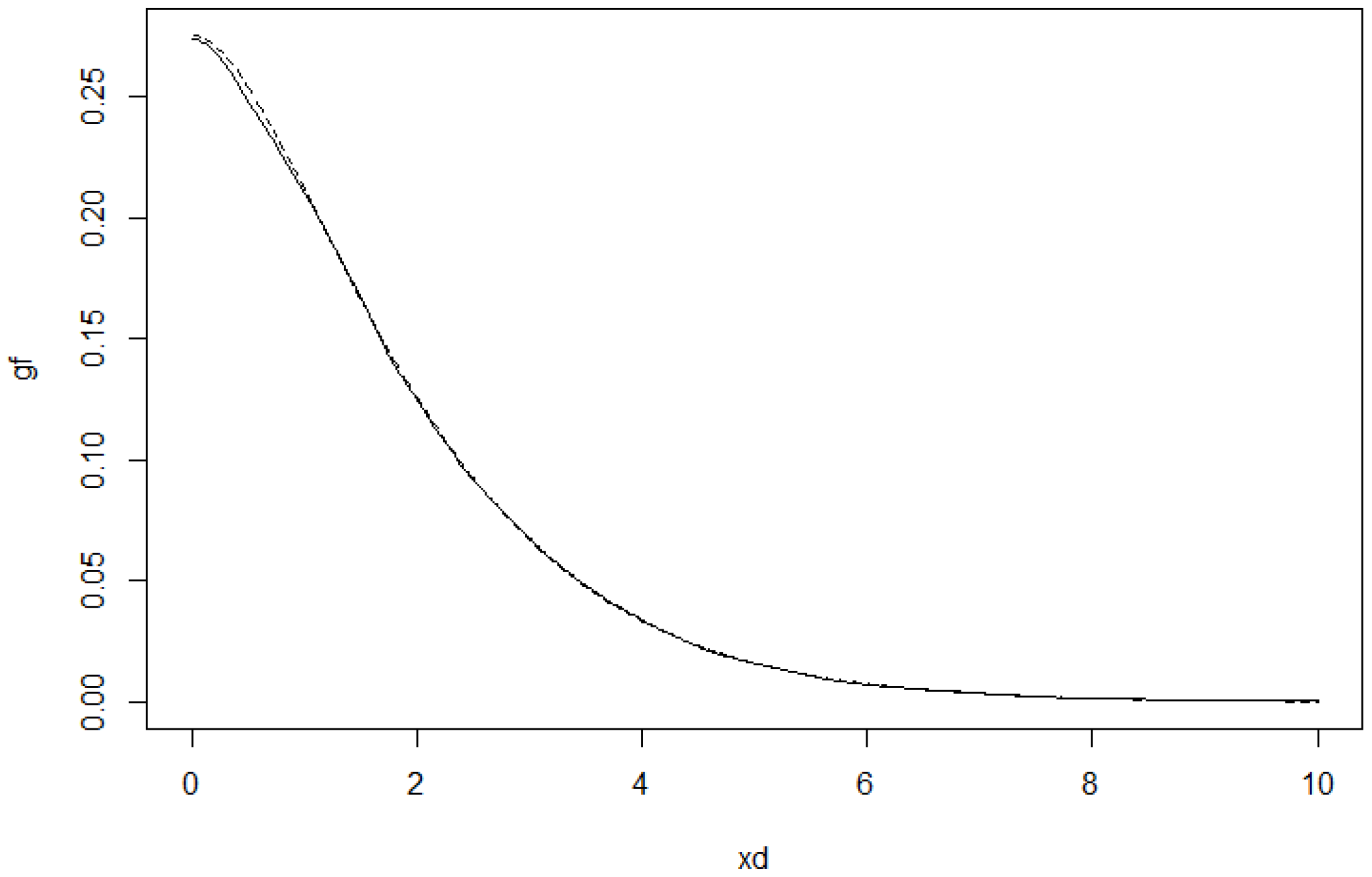
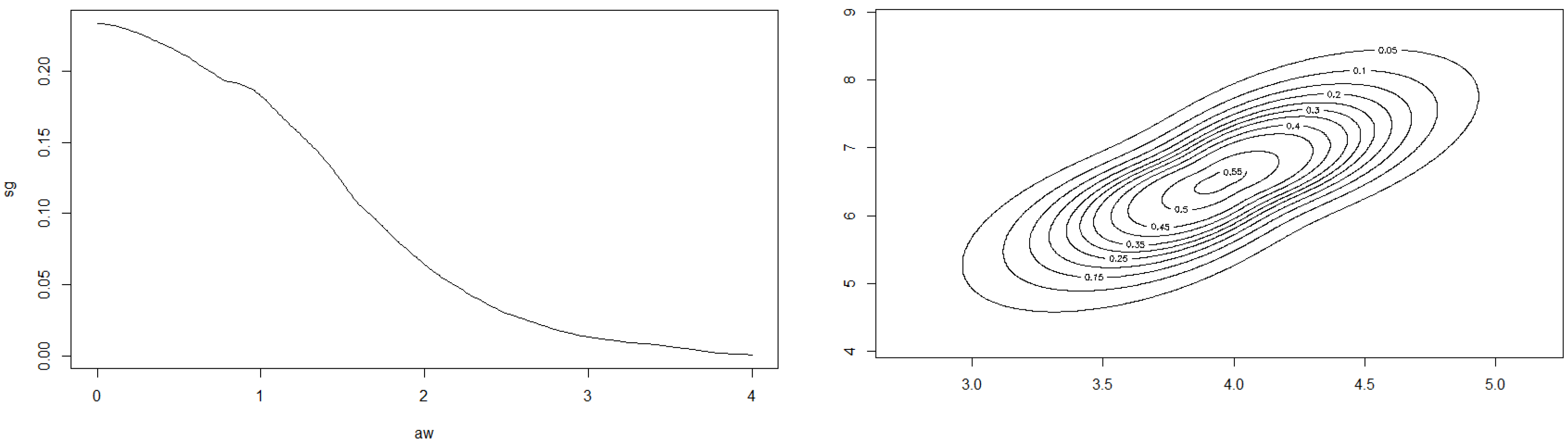
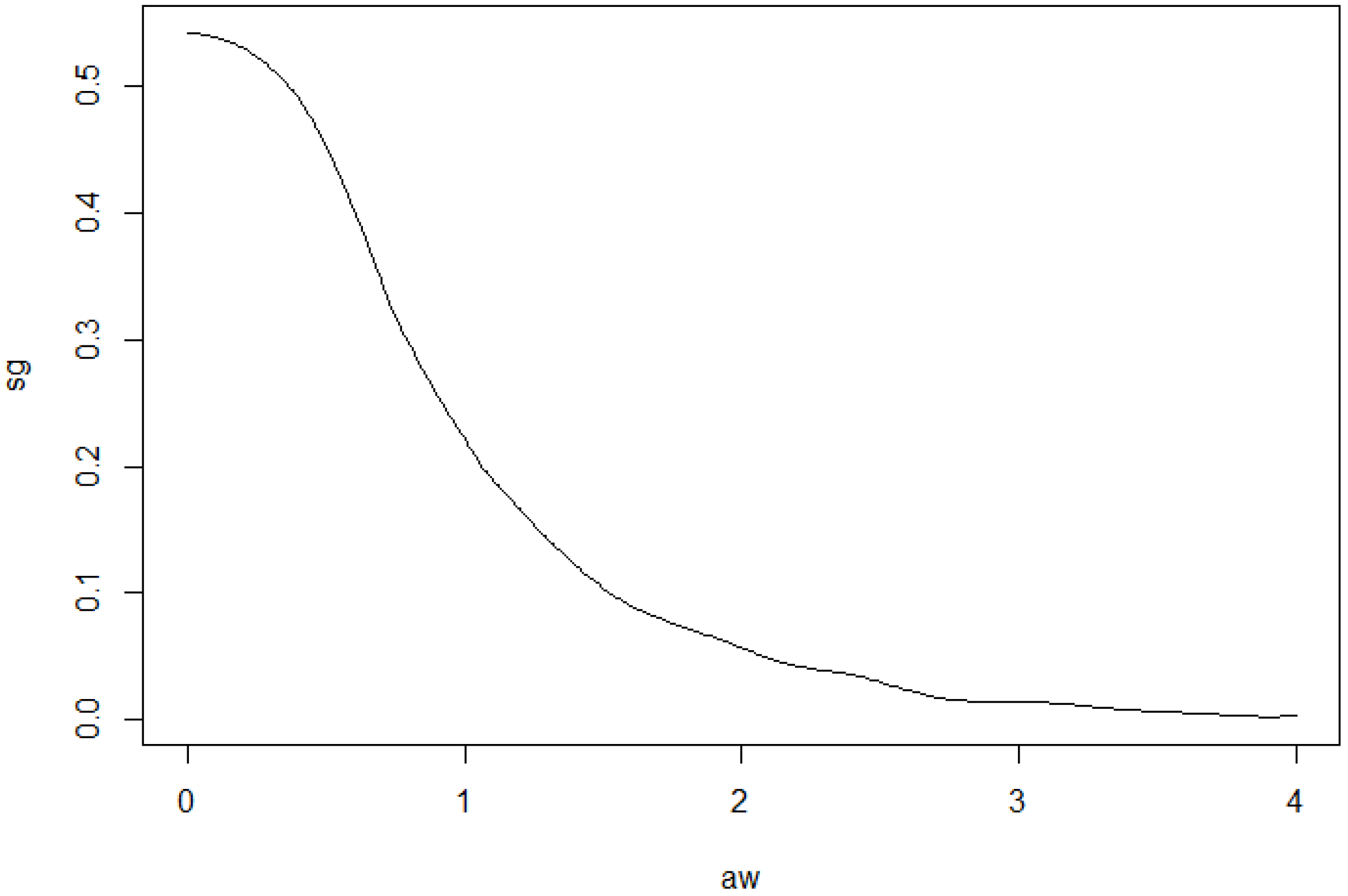
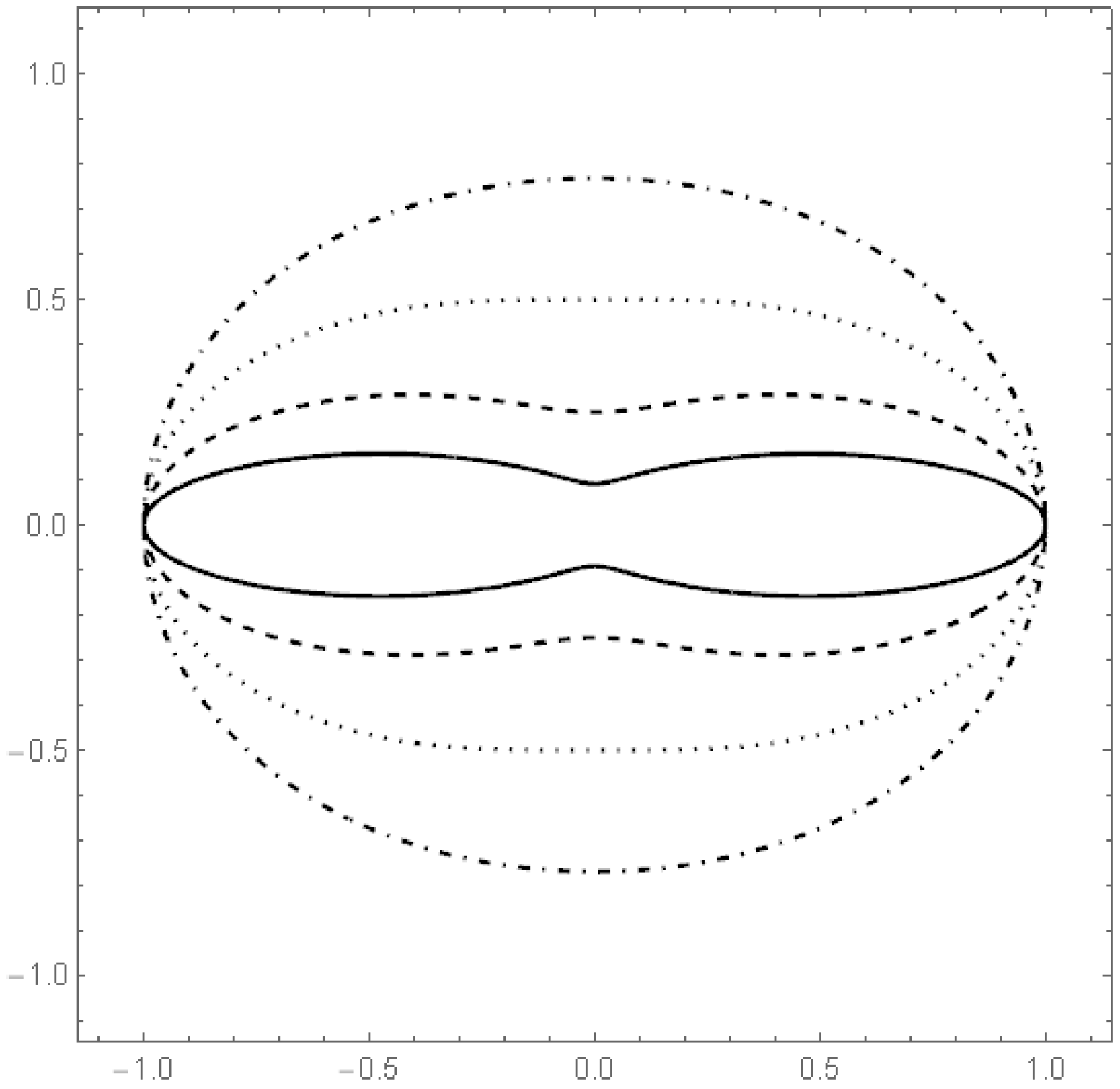
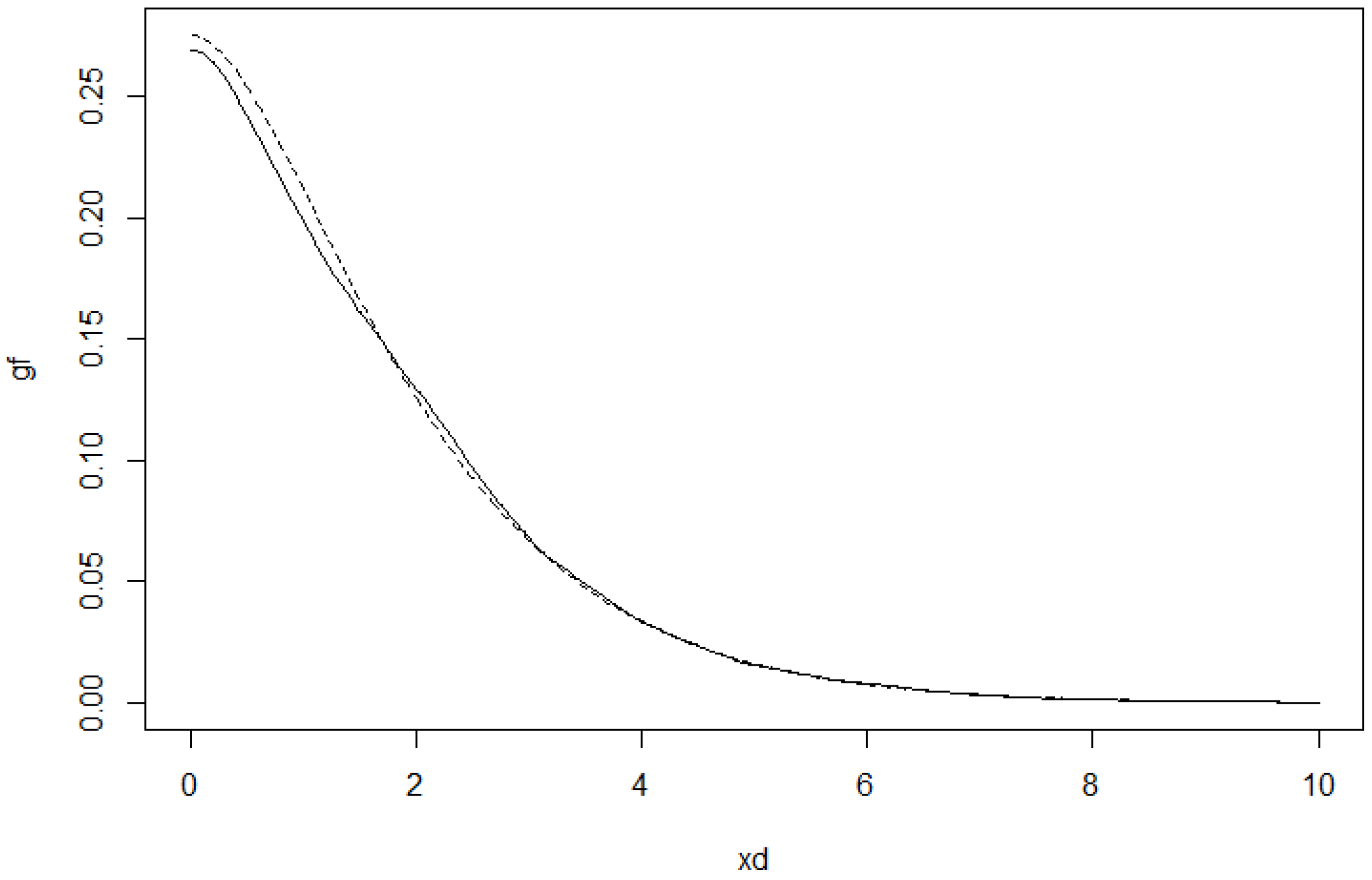
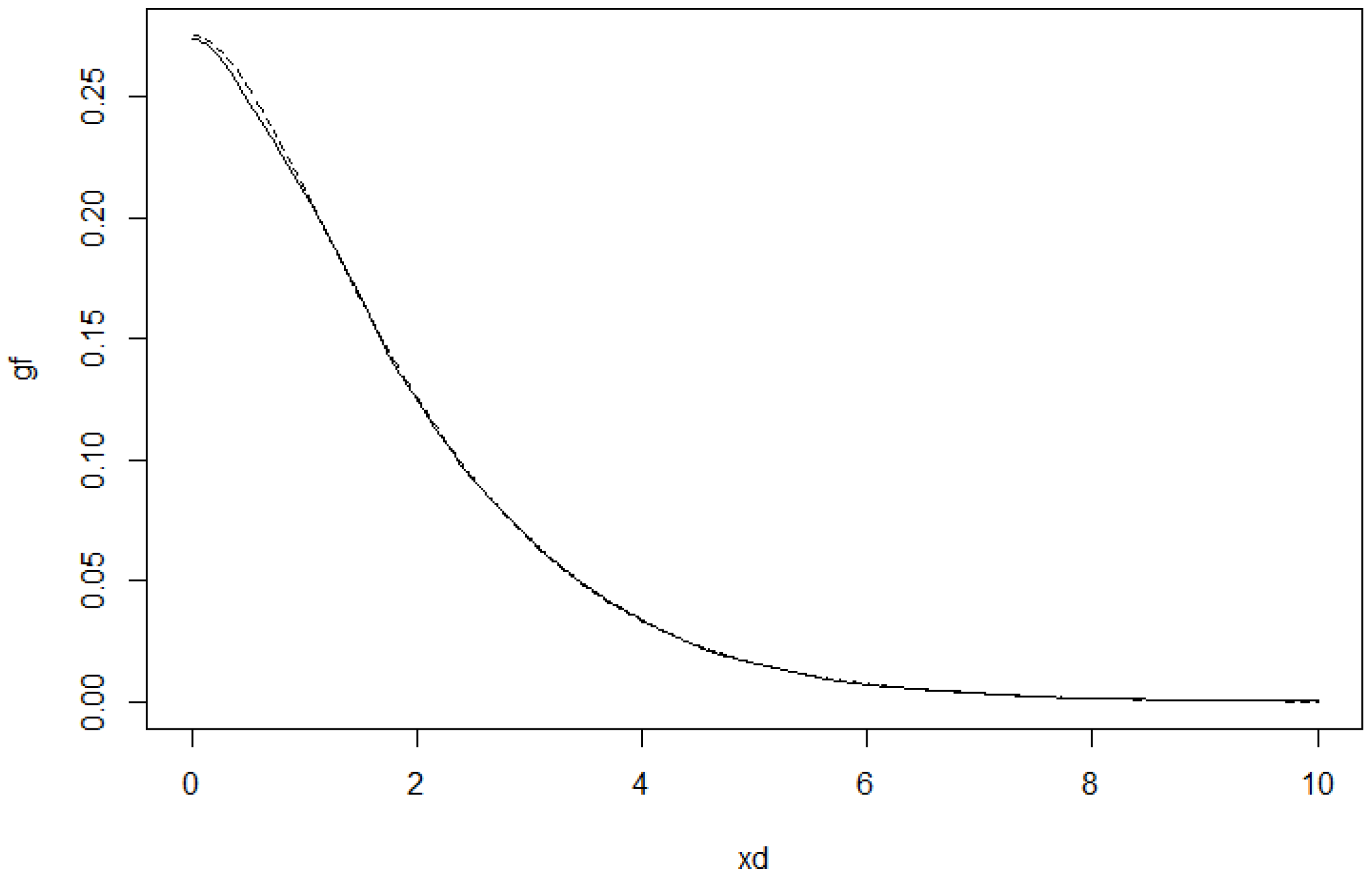
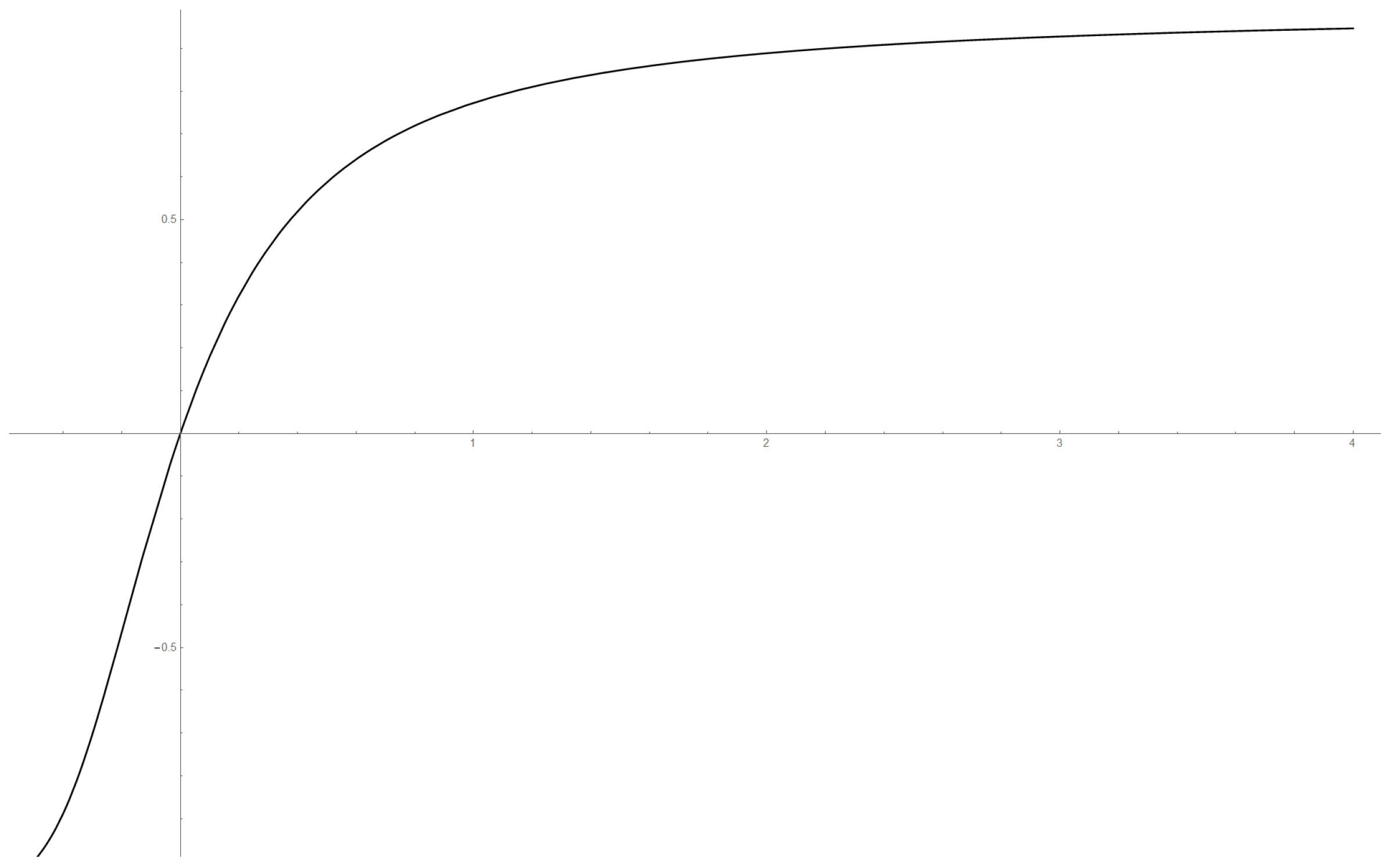
To illustrate how the estimators work in practice, we simulated data from a
q-norm distribution with
and the radius distribution to be the modified exponential distribution with
. The
Figure 7 and
Figure 8 include graphs of the underlying function
g and its estimator in two cases.
3.2.5. Reference Bandwidth
Let us consider an estimator
with Epanechnikov kernel, function
ψ as in Example 10, and modified exponential radius density in the case
. According to (
16), the reference bandwidth is then
where
This formula was generated using the computer algebra system Mathematica. The parameter
τ can be estimated by utilizing the above Formula (
6) for the expectation of the radius.
3.3. Semiparametric Estimators Involving a Scale and a Parameter Fit
In this section we consider the situation where the contour of the body
K depends on scale parameters
. Suppose that
. We introduce the diagonal matrix
and a master body
, which is symmetric w.r.t. the origin. Define
and
. The distribution of
is concentrated on the boundary
of
. We assume that
is given such that
Otherwise,
is rescaled. Suppose that
depends on a further parameter vector
where the parameter space
is a compact set. Then
The parameter vector
θ is able to describe the shape of the boundary of body
K, see Examples 1 and 2 (parameters
and
). From Lemma 1, we obtain
and
Here we see that (
17) results in
. The density is given by
In this context, a scaling problem occurs concerning
g. Assume that
g is a suitably given generator function satisfying
. Then
is a modified generator for every
with
. For any
, we obtain the same model when
g is replaced by
and
is replaced by
for
. To get uniqueness, we choose
t such that
Let
as above. Then
represents the variance of the
j-th component of
X. Based on this property, the sample variances of the components of
X can be used as estimators for
:
Moreover, we have the sample correlations
In the following we use the notation diag. If θ is unknown, we consider moment estimators based on the correlations. For this we need the following assumptions.
Assumption 6. Let I be a subset of with cardinality q. There is a vector such that for , Assume that has bounded partial derivatives, and θ is an interior point of Θ.
Assumption 7. For any bounded subset Q of , the partial derivatives , of exist, are bounded for , and , is Hölder continuous of order on for each .
Assumption 8. For any bounded subset Q of , is Hölder continuous of order .
Examples 1 and 2: (Continued) Similarly as above, it can be proven that Assumption 7 is fulfilled.
Let
be the sample version of
ρ. Then
is the estimator for
θ,
. Define
. With this definition,
is determined according to Formula (
8). The following result on the convergence rate of
can be proven:
Theorem 4. Suppose that Assumptions 1 and 6 are satisfied, andLet be bounded on . Then, for , In this section the transformed sample
is given by
with
ψ as in
Section 3.2. The estimator
for the generator
g is calculated using Formulas (
10) and (
11) from the previous section. The following estimator for the density has thus been established:
The next two theorems show the results concerning strong convergence and asymptotic normality of the density estimator:
Theorem 5. Suppose that the p-th order derivative of g exists and is bounded on for some even integer . Where needed, with this p, assume further that Assumptions 1, 2, 3, 6, (1) and (18) are satisfied. Let Assumption 7 or Assumption 8 be satisfied, and define in the first case and in the latter case .Then the claim of Theorem 2 holds true for estimator defined in (19). Theorem 6. Suppose that the assumptions of Theorem 5 are satisfied. Let such that is continuous at . Assume that holds true with a constant . Then for ,where is defined in (19), The remarks following Theorems 2 and 3 are valid similarly.
3.4. Applications
For many decades, statistical applications of multivariate distribution theory were manly based upon Gaussian and elliptically contoured distributions. Studies using non-elliptically contoured star-shaped distributions were basically made during the last two decades and are dealing in most cases with p-generalized normal distributions. Such distributions are convex or radially concave contoured if or respectively, and are also called power exponential distributions. Moreover, common elliptically contoured power exponential (ecpe) distributions build a particular class of the wide class of star-shaped distributions that allows modeling much more flexible contours than elliptically ones.
The class of ecpe distributions is used in a crossover trial on insulin applied to rabbits in [
23], in image denoising in [
24] and in colour texture retrieval in [
25]. Applications of multivariate
g-and-
h distributions to jointly modeling body mass index and lean body mass are demonstrated in [
26] and accompanied by star-shaped contoured density illustrations. The
-elliptically contoured distributions build another big class of star-shaped distributions and are used in [
27] to explore to which extent orientation selectivity and contrast gain control can be used to model the statistics of natural images. Mixtures of ecpe distributions are considered for bioinformation data sets in [
28]. Texture retrieval using the
p-generalized Gaussian densities is studied in [
29]. A random vector modeling data from quantitative genetics presented in [
30] are shown in [
31] to be more likely to have a power exponential distribution different from a normal one. The reconstruction of the signal induced by cosmic strings in the cosmic microwave background, from radio-interferometric data, is made in [
32] based upon generalized Gaussian distributions. These distributions are also used in [
33] for voice detection.
More recently, the considerations in [
11] opened a new field of financial applications of more general star-shaped asymptotic distributions, where suitably scaled sample clouds converge onto a deterministic set.
Figure 3 in [
34] represents a sample cloud which might be modeled with a density being star-shaped w.r.t. a fan having six cones that include sample points and other cones that do not. Note, however, that Figure 1 d-f in the same paper do not reflect a homogeneous density but might be compared in some sense to the level sets of the characteristic functions of certain polyhedral star-shaped distributions in [
16], Figure 5.2.
When modeling Lymphoma data, [
35] analyze sample clouds of points, see Figures 2 and 3, which might be interpreted as mixtures of densities having contours in part looking similar like that in [
36] where flow cytometric data, Australian Institute of Sport data and Iris data are analyzed, or like that of certain skewed densities as they were (analytically derived and) drawn in [
37]. In a similar manner, Figures 2 and 5 in [
20] indicate that mixtures of different types of star-shaped distributions might be suitable for modeling residuals of certain stock exchange indices. It could be of interest to closer study in future work more possible connections of all the models behind.
The following numerical examples of the present section are aimed to illustrate the agricultural and financial application of the estimators described in this paper. To this end, we make use of the new particular non-elliptically contoured but star-shaped distribution class introduced in
Section 2.2 of the present paper.
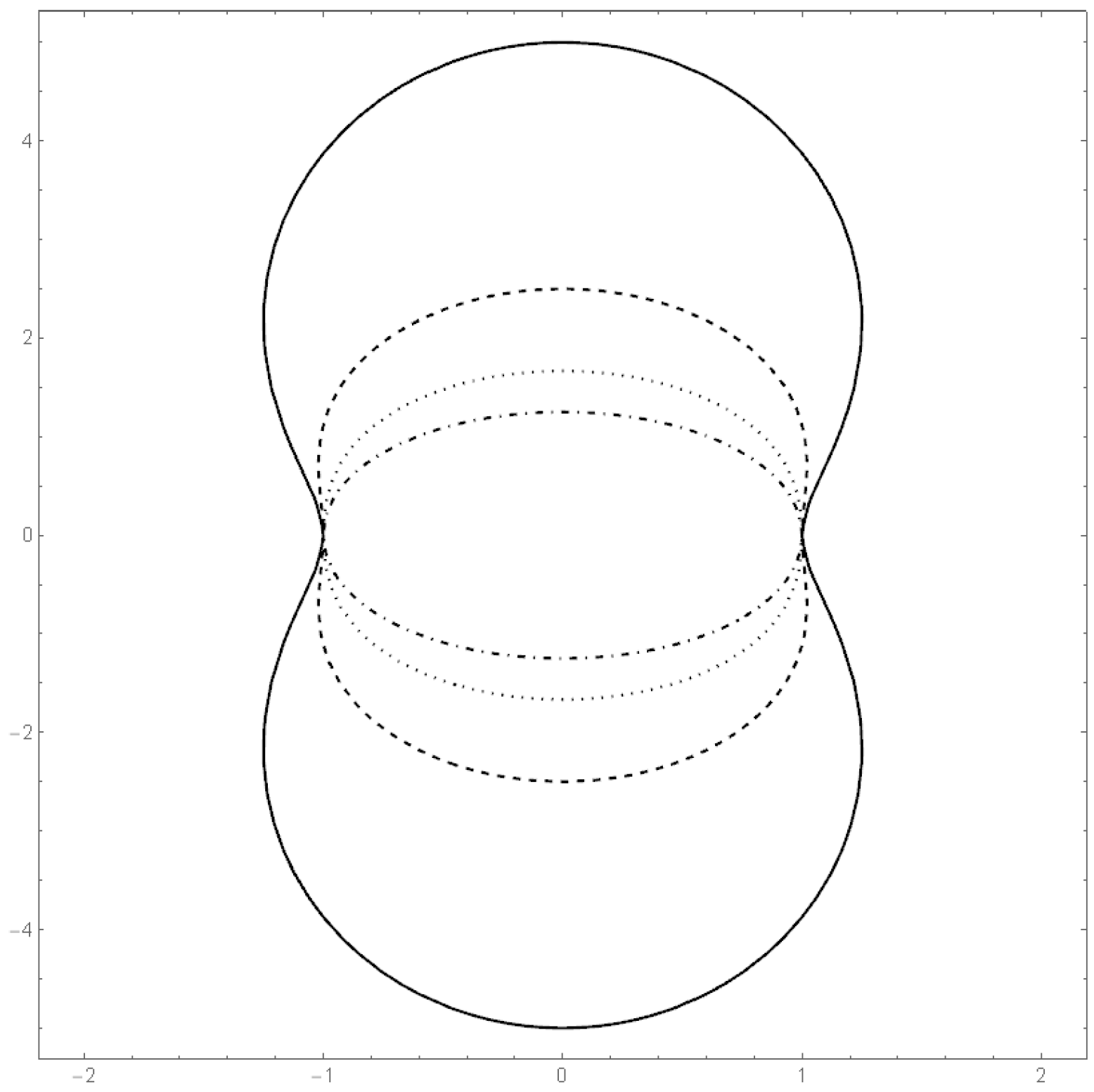
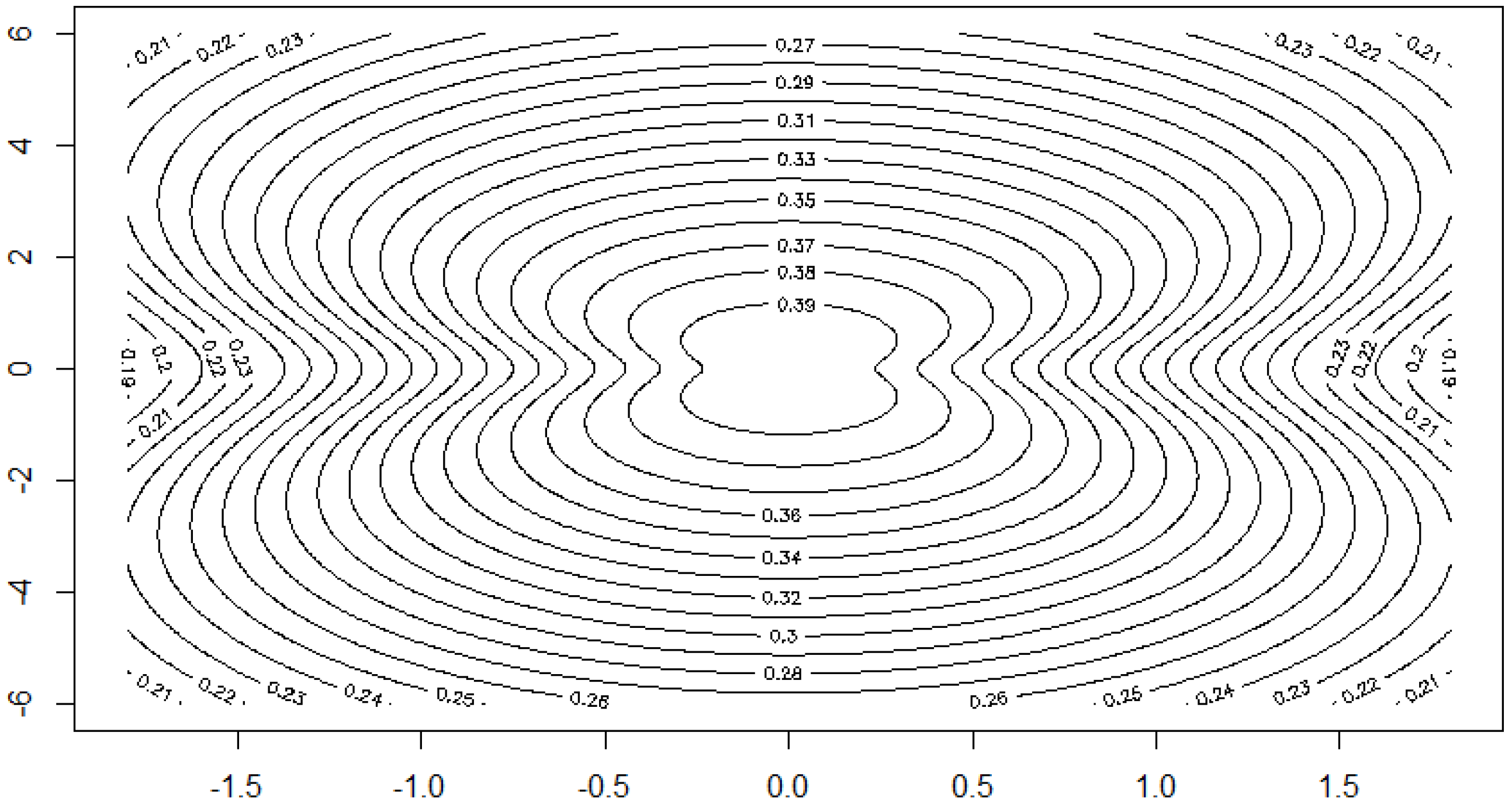
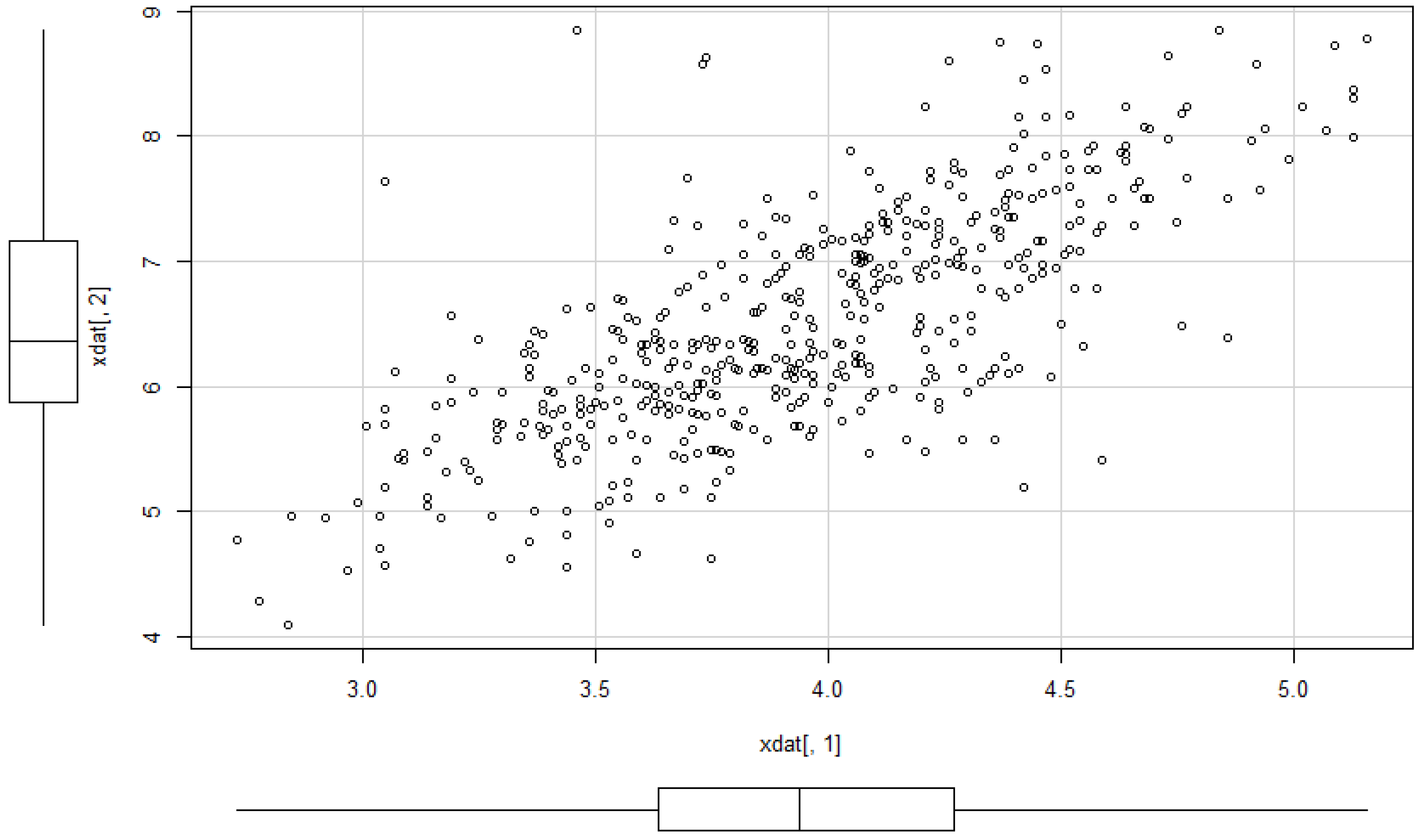
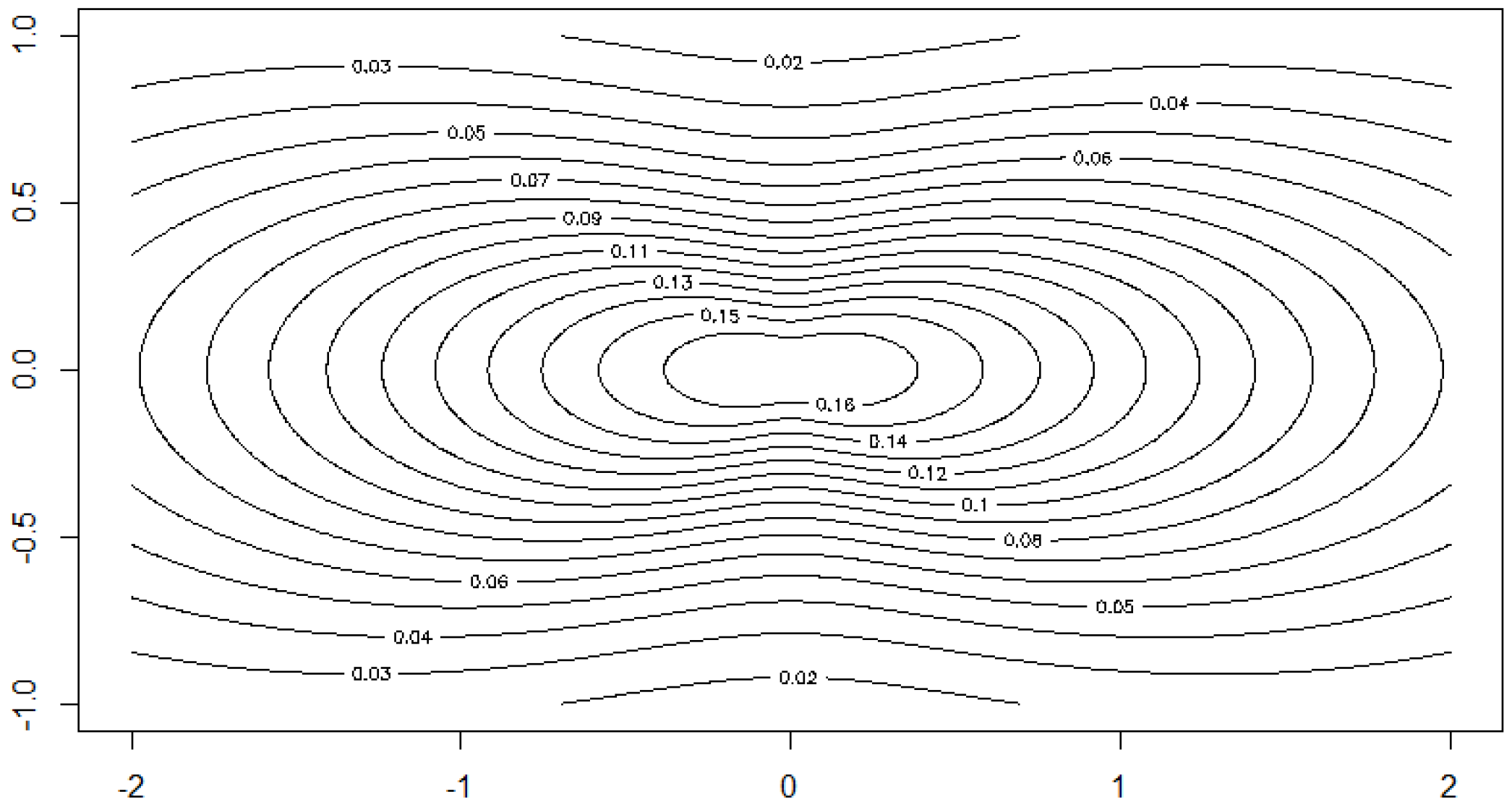
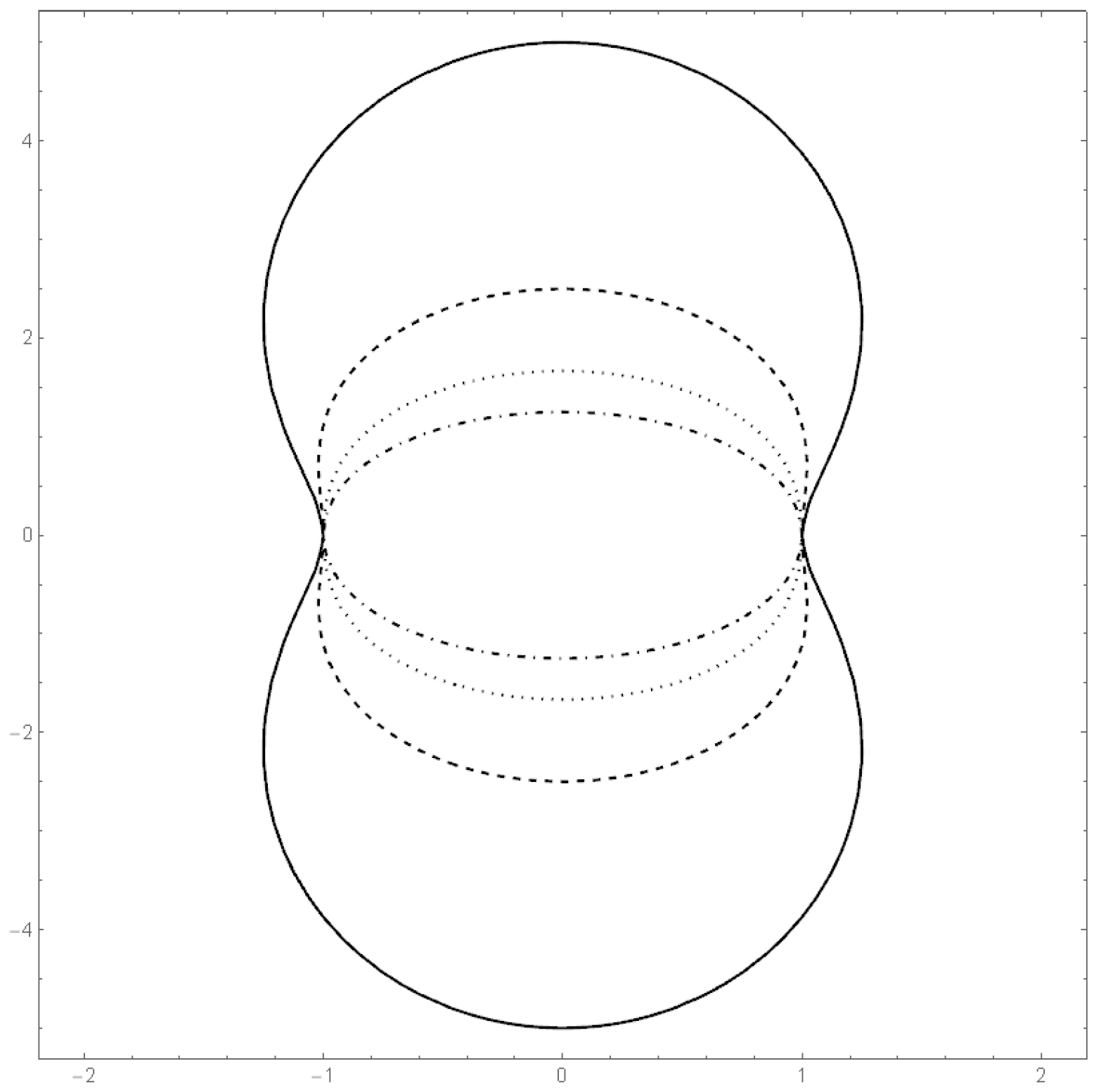
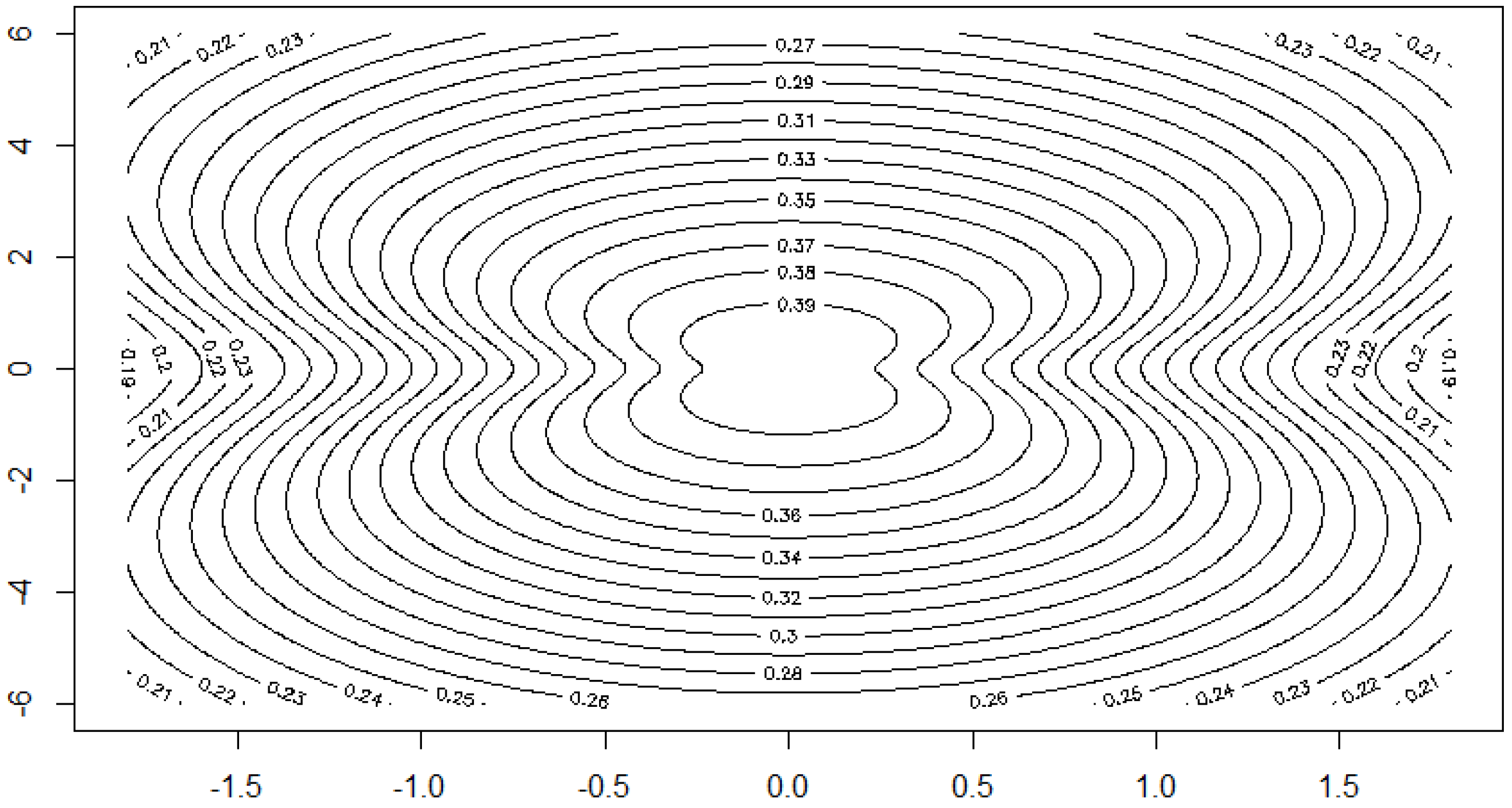
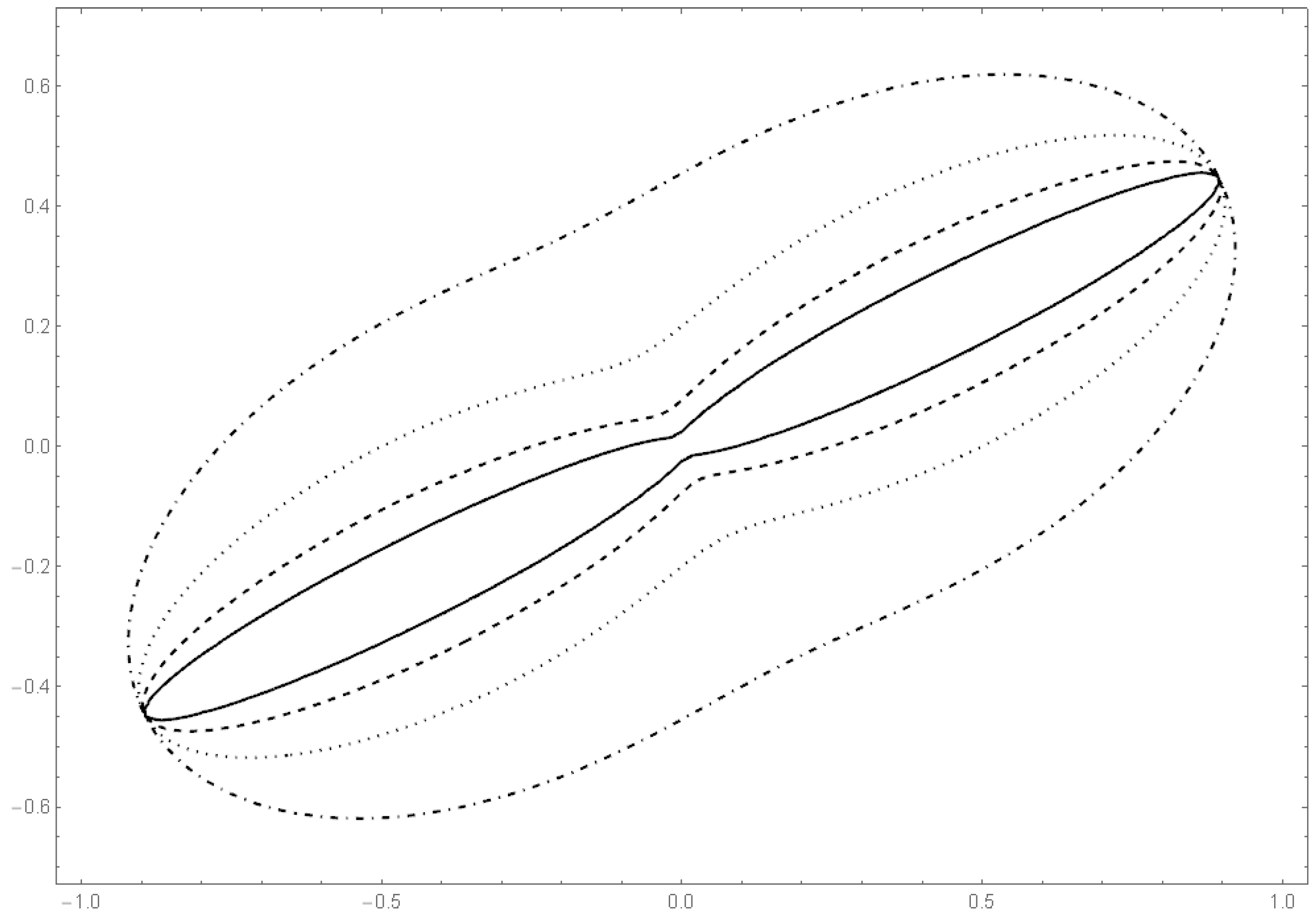
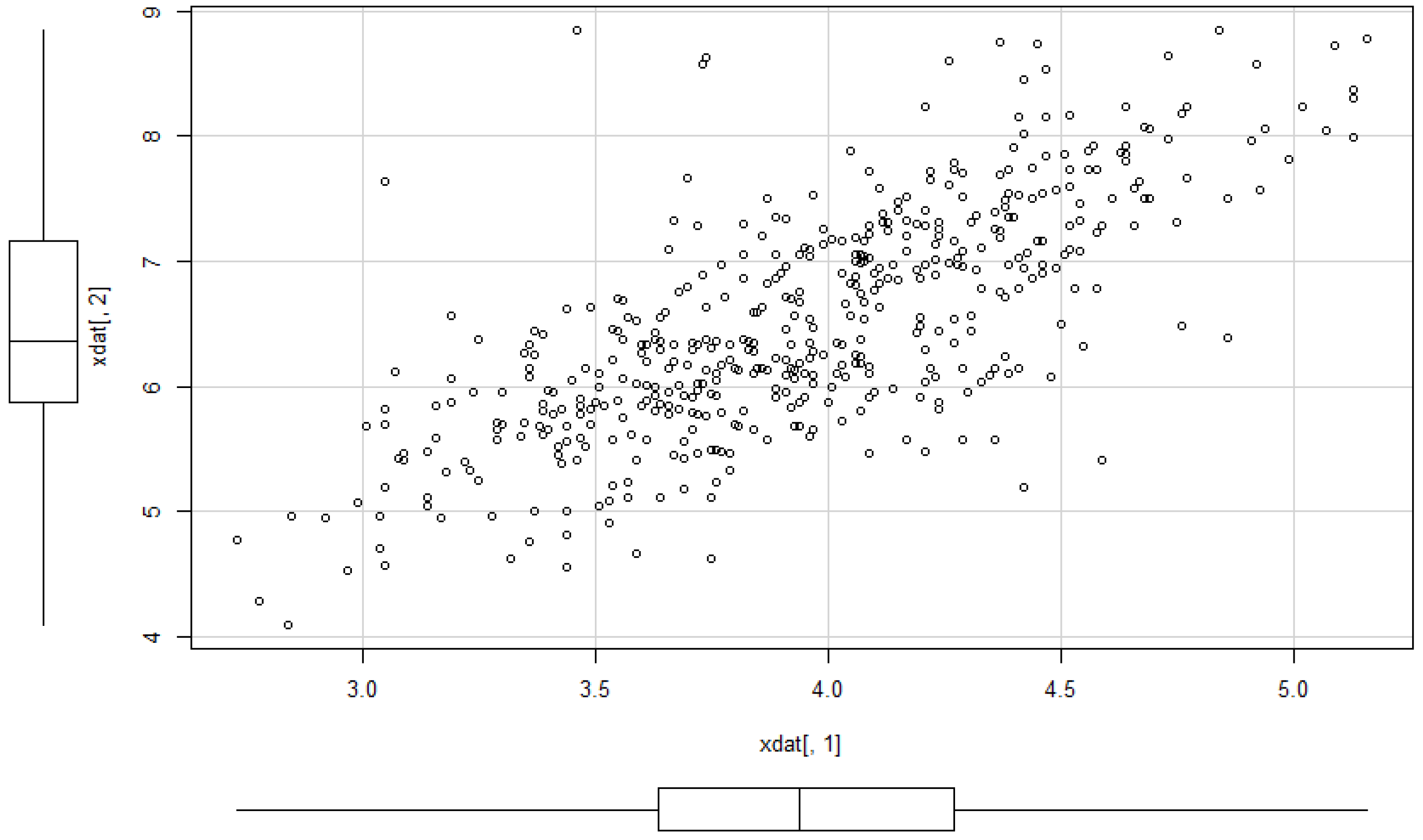
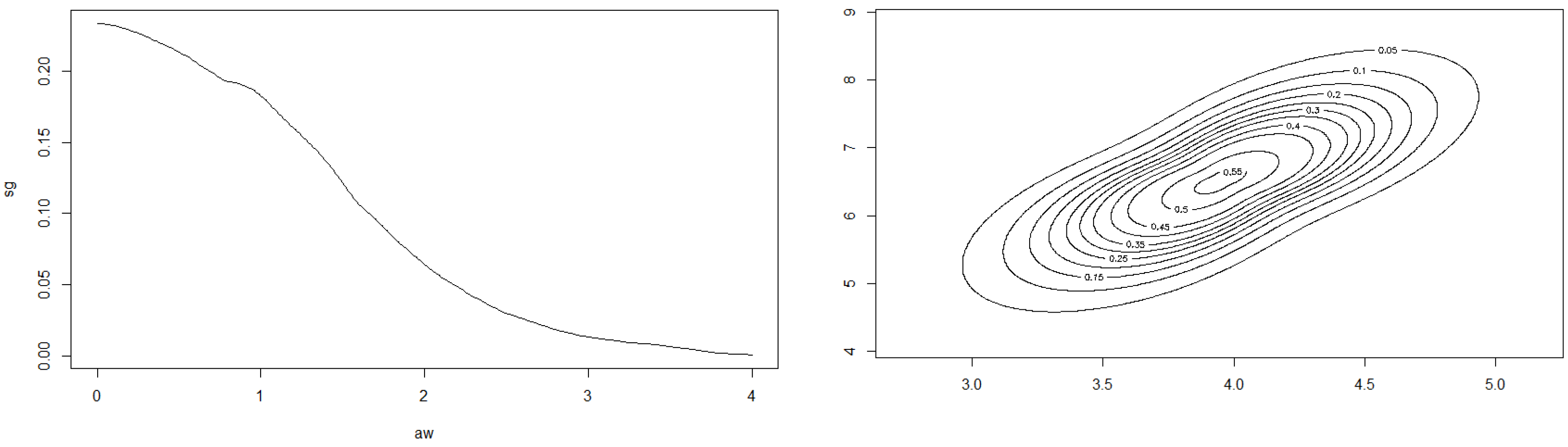
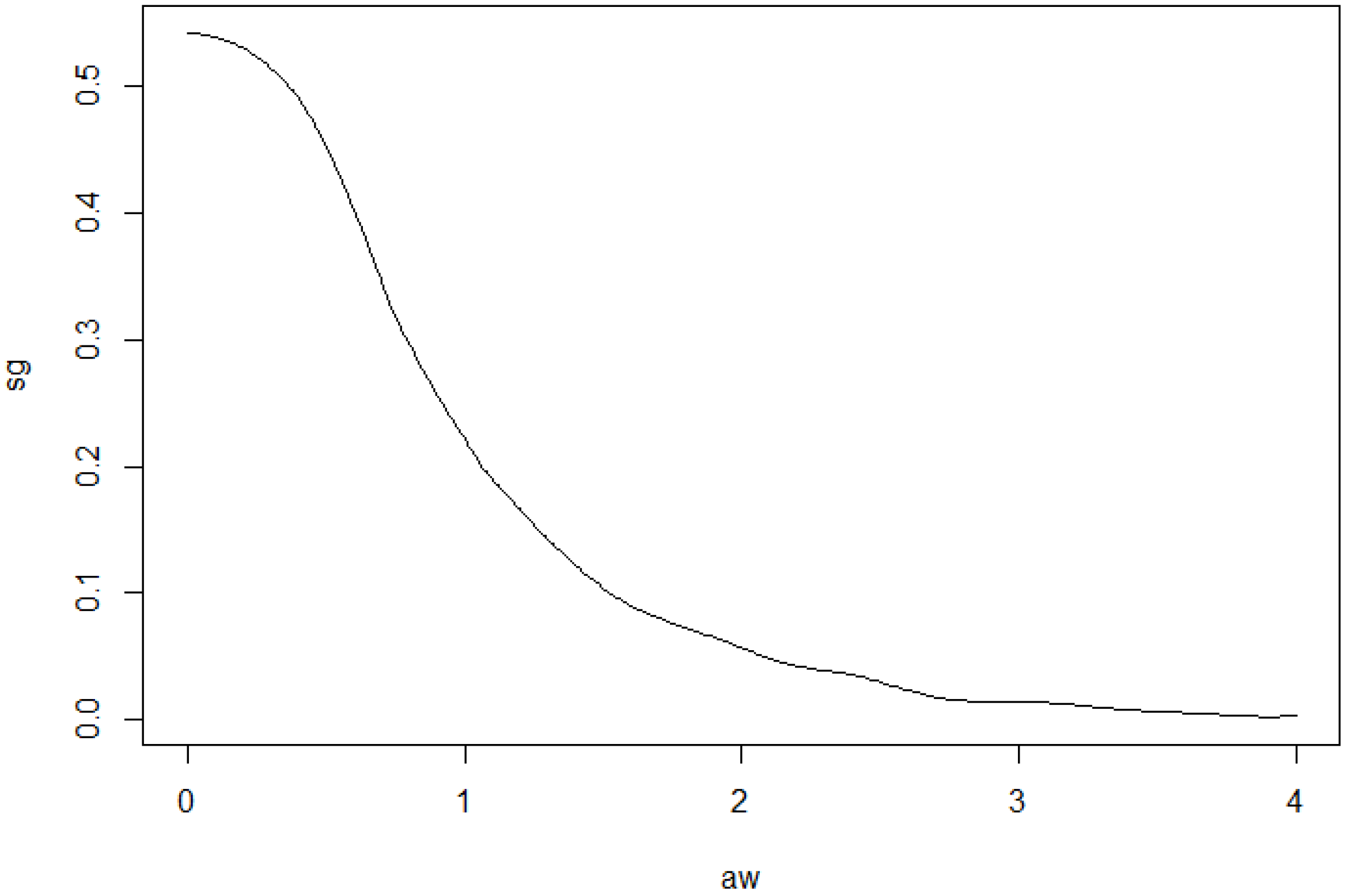
Example 12. Example 2 of Section 2.2 continued. We consider the class of bodies K of Example 2. Let . Figure 9 shows the dependence of the correlation on the parameter . Here we apply the above described methods to the dataset 5 of [
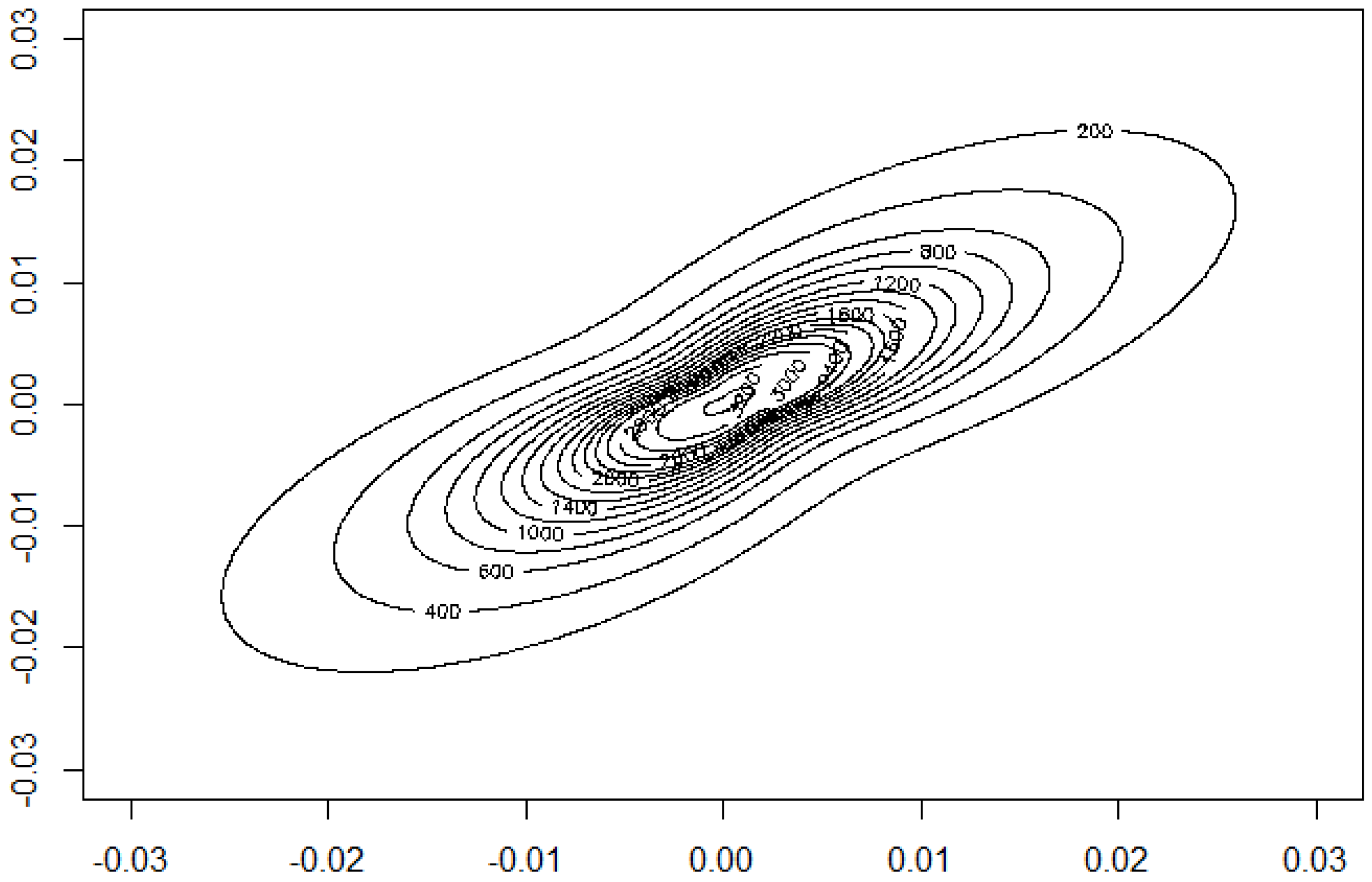
38]. The yield of grain and straw are the two variables. The sample correlation is 0.73077. Starting from that value, we can calculate the moment estimator for
:
. Moreover, we obtain
The data and the shape of the estimated multivariate density are depicted in
Figure 10 and
Figure 11.
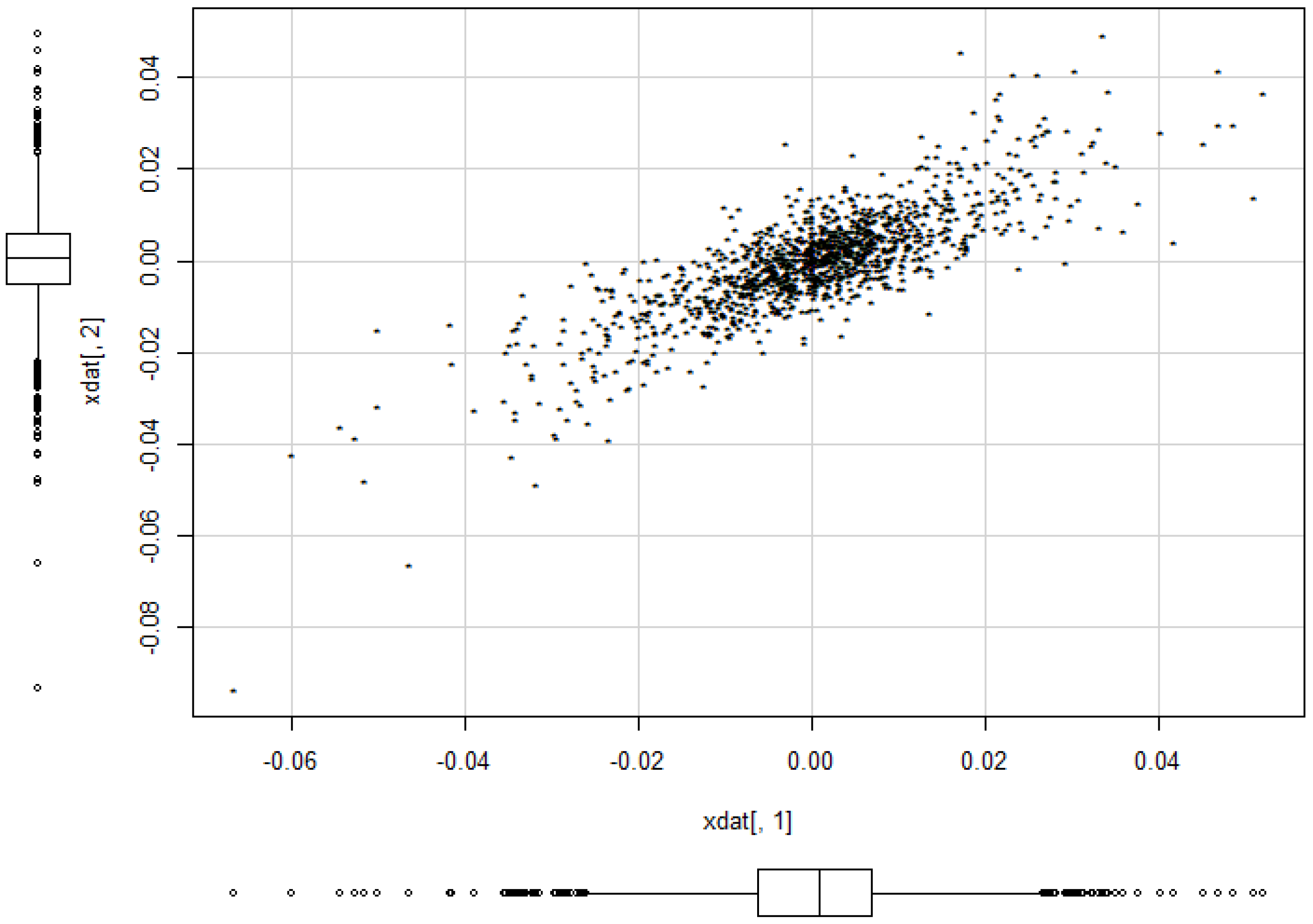
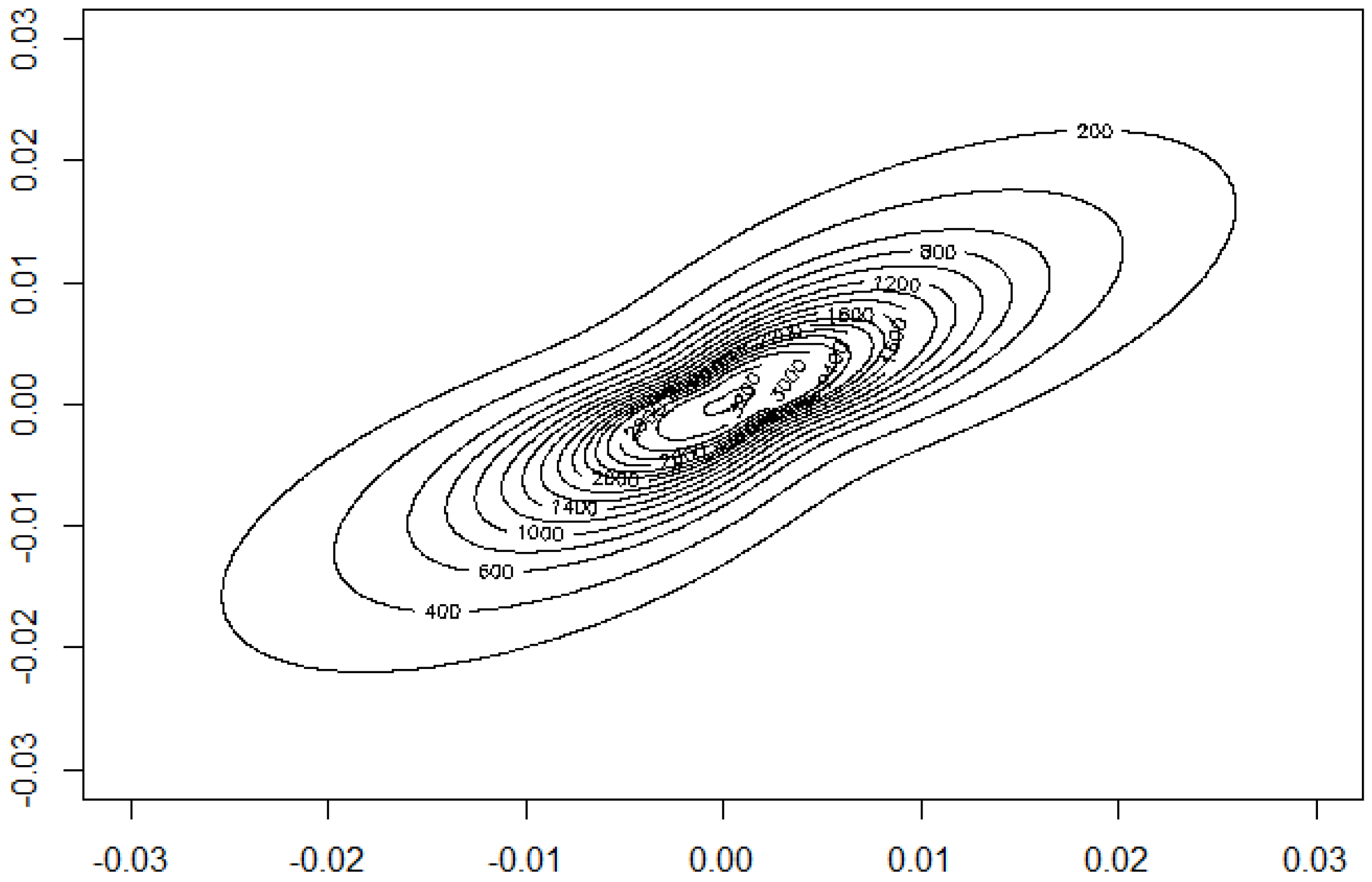
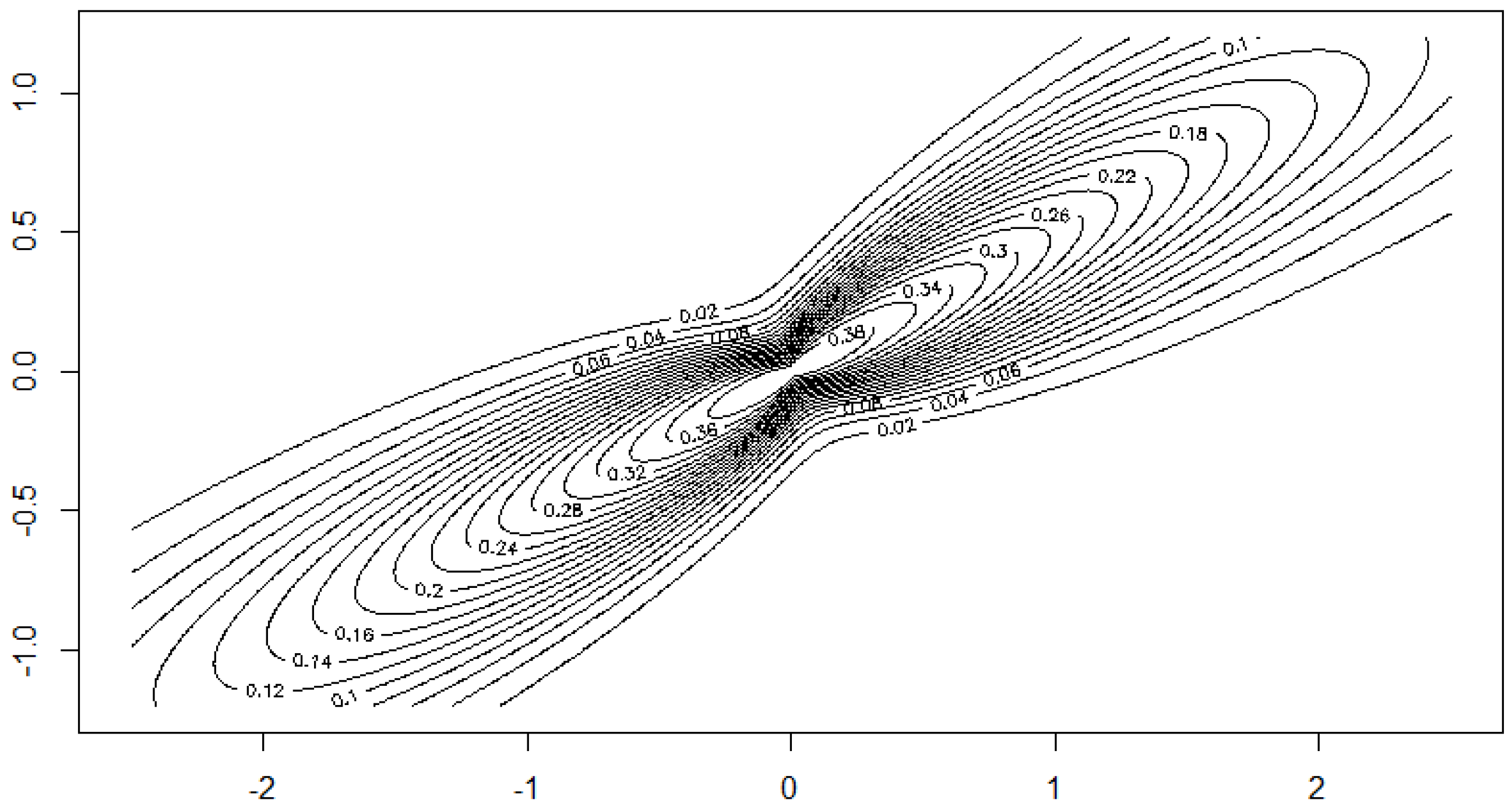
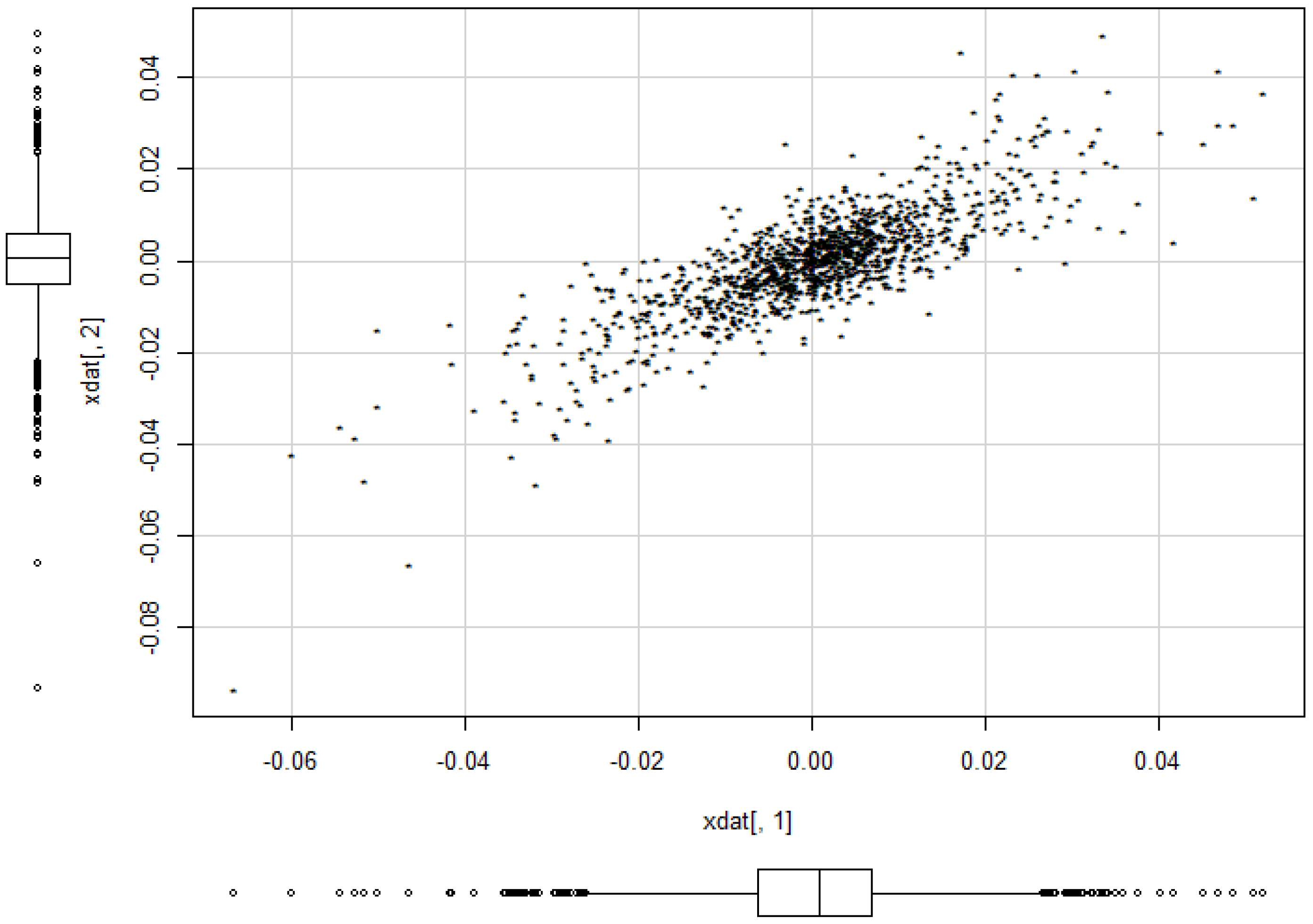
Example 13. We want to illustrate the potential of our approach for applications to financial data and consider daily index data from Morgan Stanley Capital International of the countries Germany and UK for the period August 2011 to June 2016. The data indicate the continuous daily return values computed as logarithm of the ratio of two subsequent index values. The modelling of MSCI data using elliptical models is considered in [5]. The data are depicted in Figure 12. A visual inspection seems to give some preference for our model from Section 2.2 compared to the elliptically contoured model. Figure 13 and Figure 14 show the estimated model for the data. The basic numerical results are: Further we proceed with proving the results.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}