
Distinguishing Log-Concavity from Heavy Tails

Department of Mathematics, Aarhus University, Ny Munkegade 118, DK-8000 Aarhus C, Denmark
*
Author to whom correspondence should be addressed.
Risks 2017, 5(1), 10; https://doi.org/10.3390/risks5010010
Submission received: 14 November 2016
/
Revised: 10 January 2017
/
Accepted: 17 January 2017
/
Published: 7 February 2017
(This article belongs to the Special Issue Selected Papers from the 6th Gerber-Shiu Workshop and the 3rd Modeling of Heavy-Tail Phenomena Workshop)
{kind=link}
{kind=link}
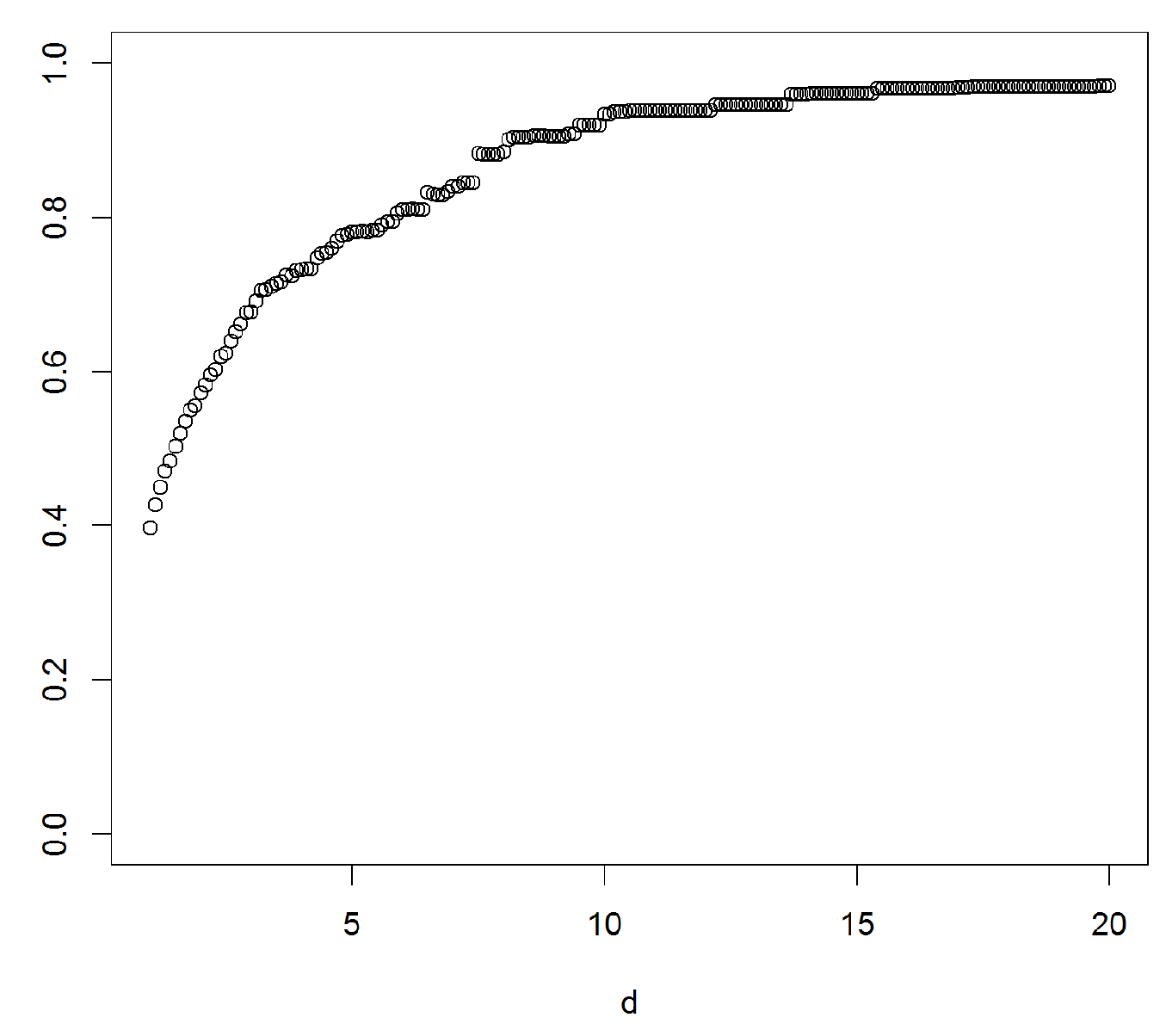{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Well-behaved densities are typically log-convex with heavy tails and log-concave with light ones. We discuss a benchmark for distinguishing between the two cases, based on the observation that large values of a sum occur as result of a single big jump with heavy tails whereas are of equal order of magnitude in the light-tailed case. The method is based on the ratio , for which sharp asymptotic results are presented as well as a visual tool for distinguishing between the two cases. The study supplements modern non-parametric density estimation methods where log-concavity plays a main role, as well as heavy-tailed diagnostics such as the mean excess plot.
MSC:
60E05; 60G50; 62G201. Introduction
General interest towards non-parametric thinking has increased over the last few years. One example is density estimation under shape constraints instead of requiring the membership of a parametric family. Here, a particularly robust alternative to parametric tests is provided by searching for the best fitting log-concave density. Another example is the mean excess plot that aims at distinguishing light and heavy tails.
Throughout the paper, we consider i.i.d. random variables with common distribution F having density f and tail . Then, X is (right) heavy-tailed if for all and light-tailed otherwise. The density f is log-concave, if , where is a concave function. If is convex, then f is log-convex. This paper aims to illustrate that light-tailed asymptotic behaviour is associated with log-concave densities. Likewise, log-convexity seems to be connected to heavy-tailed behaviour. One can use the connection to assess potential heavy-tailedness by searching for patterns that are typically present among distributions with log-concave or log-convex densities.
Log-concavity is a widely studied topic in its own right [1,2]. There also exists substantial literature regarding its connections to probability theory and statistics [3,4]. Several papers concentrate on the statistical estimation of density functions assuming log-concavity [5,6]. This is due to the fact that log-concavity provides desirable statistical properties for estimators. For instance, maximum likelihood estimation becomes applicable and the estimate is unique. The topic is discussed in detail in the beginning of [7]. Unfortunately, much less emphasis seems to be put on verification of the log-concavity property itself. Specifically, it seems to be relatively little studied if it is feasible that the sample be generated by a log-concave distribution. See, for example [8,9].
A distribution with a log-concave density f is necessarily light-tailed. In contrast, f is log-convex in the tail in the standard examples of heavy tails such as regular variation, the lognormal distribution and Weibull case with . An important class of heavy-tailed distributions are the subexponential ones defined by . The intuition underlying this definition is the principle of a single big jump: is large if one of is large, whereas the other remains typical. This then motivates
being close to 1. In contrast, the folklore is that contribute equally to with light tails. We are not aware of general rigorous formulations of this principle, but it is easily verified in explicit examples like a gamma or normal F (see further below) and, for a large number of summands rather than just 2, it is supported by conditioned limit theorems (see e.g., ([10] (VI.5))). However, it was recently shown in [4] that these properties of R hold in greater generality and that asymptotic properties of the corresponding conditioned random variable
provide a sharp borderline between log-convexity and log-concavity.
In this paper, we provide a wider perspective in terms of both sharper and more general limit results and of the usefulness for visual statistical data exploration. To this end, we propose a feature based nonparametric test. It can be used as a visual aid in identification of log-concavity or heavy-tailed behaviour. It complements earlier ways to detect signs of heavy-tailedness such as the mean excess plot [11]. Further tests based on probabilistic features have been previously utilised in e.g., [12,13,14].
2. Background
A property holds eventually, if there exists a number so that the property holds in the set . Standard asymptotic notation is used for limiting statements. These and basic properties of regularly varying functions with parameter α, denoted RV(α), can be recalled from e.g., [15].
We note that the principle of a single big jump relates to the fact that joint distributions of independent random variables concentrate probability mass to different regions. For example, a distribution with tail function satisfies
for and
for , as . We refer to [16,17,18,19] for related work in this direction. It is shown in Lemma 1.2 of [4] that log-concavity or log-concavity of the density is closely related to the occurrence of the principle of a single big jump. A further observation in this direction is the following lemma. It states that contour lines of joint densities of independent variables behave differently for log-concave and log-convex densities, and thereby leads naturally to different concentrations of probability mass of joint densities (recall that a contour line corresponding to a value of joint density is the set of points in the plane defined as ).
Lemma 1.
Suppose and are i.i.d. unbounded non-negative random variables. Assume further that they have a common twice differentiable density function f of the form
where h is a strictly increasing function.
If f is log-concave (log-convex), then, for any fixed , there exists a convex (concave) function defining a contour line of corresponding to p such that for all .
Lemma 1 implies that log-convex and log-concave densities cause maximal points of joint densities to accumulate into different regions in the plane. Log-convex densities tend to put probability mass near the axis, while log-concave densities have a tendency to concentrate mass near the graph of the identity function. The exponential density is the limiting case where all contour lines are straight lines. More generally, for , where is an integration constant, the contour lines are circles for , straight lines for , and parabolas for .
3. Theoretical Results
The emphasis of the paper is on the mathematical formulation of the connection between log-convexity and the principle of a single big jump. However, some additional theoretical results are provided concerning convergence rates of the conditional ratio defined in Equation (3). These rates, or estimates for the rates, are obtained in some standard distribution classes. Their proofs are mainly based on sharp asymptotics of subexponential distributions obtained in [20,21,22]. Recall that some main classes of such distributions are RV, meaning regularly varying ones, where with and are slowly varying, Weibull tails with for some , and lognormal tails which are close to the case of for and some ; we refer in the following to this class as lognormal type tails.
3.1. Convergence Properties
Define the function by
It can be viewed as a generalisation of the function considered in [4] and has the same interpretation as in the case with densities: if both and contribute equally to the sum , then g should eventually obtain values close to 0; similarly, if only one of the variables tends to be the same magnitude as the whole sum, then g is close to 1 for large d. Note also that g is scale independent in the sense that for all . Due to this property, two or more samples can be standardised to have, say, equal means in order to obtain graphs on the same scale.
In Proposition 1, sharp asymptotic forms of g are exhibited in some classes of distributions.
Proposition 1.
The following convergence rates hold for g defined in Equation (3).
- Let X be RV with , eventually decreasing density f. Then,
- Let X be Weibull distributed with . Then,
- Let X be of lognormal type. Then,
Remark 1.
In the case of Weibull and lognormal distributions, the implication is that converges to 1 at a larger rate than their associated hazard rates tend to zero. In addition, inspection of the proof shows
This implies that the actual convergence rate can not be substantially larger than in the regularly varying case, where the leading term is explicitly identified.
The light-tailed case appears to be more difficult to study than the heavy-tailed case. Difficulty arises mainly from the lack of good asymptotical approximations for probabilities of the form when decays much faster than . Interestingly, the full asymptotic form of g can be recovered in the special case of the normal distribution if we allow X to obtain negative values.
Proposition 2.
Suppose that X is normally distributed with and . Then,
The following theorem can be used to assess if a sample is coming from a source with log-concave density. It can be seen as a natural continuation as well as a generalisation to [4].
Theorem 1.
Assume the density f is twice differentiable and eventually log-concave. Then,
Similarly, if f is eventually log-convex, then
4. Statistical Application: Visual Test
Suppose is a sequence of i.i.d. vectors whose components are also i.i.d. One can formulate the empirical counterpart of Quantity (3) by setting
where
and is the indicator function of the event A.
Remark 2.
Equation (9) requires as input a two-dimensional sequence of random variables. One can form such a sequence from a real valued i.i.d. source using any pairing of the . Obvious examples are to take to take the set as all pairings of the or as a randomly sampled subset of these pairings. If the data is truly i.i.d, this should not have any effect on the outcome.
4.1. Examples and Applications
A graph of as function of d can be used to determine if the data support the density being log-concave or light-tailed behaviour. According to Theorem 1, the graph should then stay below . Figure 1, Figure 2, Figure 3 and Figure 4 illustrate such graphs using experimental data.
The test method is visual. A similar idea has been used at least in the classical mean excess plot, where one visually assesses if the tail excess in the sample points is increasing at the level, as is the case for heavy tails.
4.2. Finer Diagnostics
The idea of plotting as a function of d was introduced as a graphical test for distinguishing between heavy-tailed and log-concave light tailed distributions. It seems reasonable to ask if the plot can be used for finer diagnostics, in particular to further specify the tail behaviour of F when F was found to be heavy-tailed. Such an idea would be based on the rate of convergence of to 1.
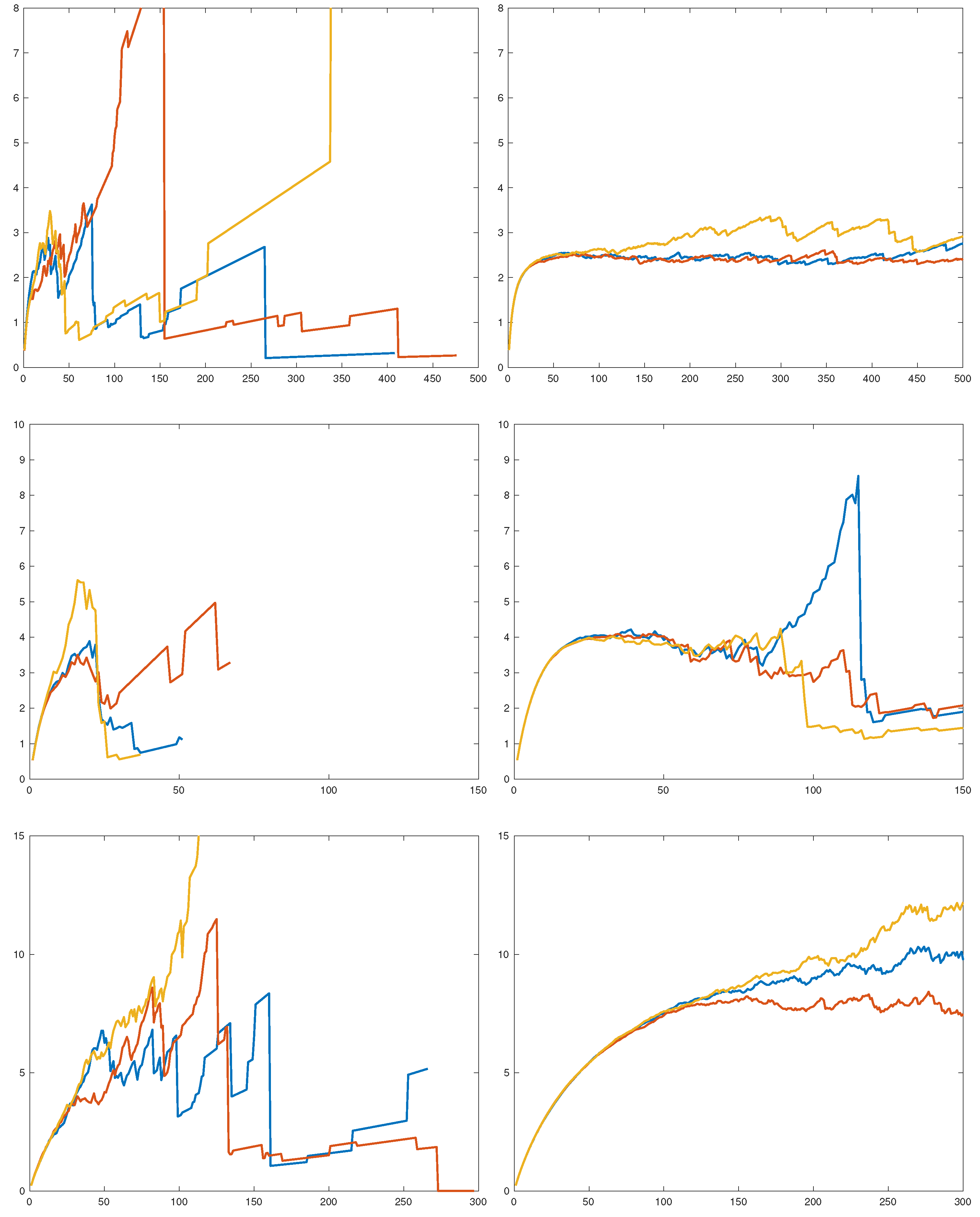
To gain some preliminary insight, we simulated and i.i.d pairs of r.v.’s from an F which was either RV(1.5), lognormal(0,1) or Weibull(0.4). The results are in Figure 5 as plots of , with three runs in each subfigure.
A first conclusion is that a sample size of is grossly insufficient for drawing conclusions about the way in which approaches 1—random fluctuations take over long before a systematic trend is apparent. The sample size is presumably unrealistic in most cases, but even for this, the picture is only clear in the RV case. Here, seems to have a limit c, as it should be, and the plot is in good agreement with the value 2.4 = of c predicted by Proposition 1.
Whether a limit exists in the lognormal or Weibull case is less clear. The results of Proposition 1 are less definite here, but, actually, a heuristic argument suggests that the limit c should exist and be . To this end, let be the order statistics. According to subexponential theory (see, in particular, [25]), are asymptotically independent given , with having asymptotic distribution F and being of the form with , and E as in the proof of Proposition 1. For large d, this gives
In the lognormal or Weibull case, one has and so . Taking expectations gives the conjecture.
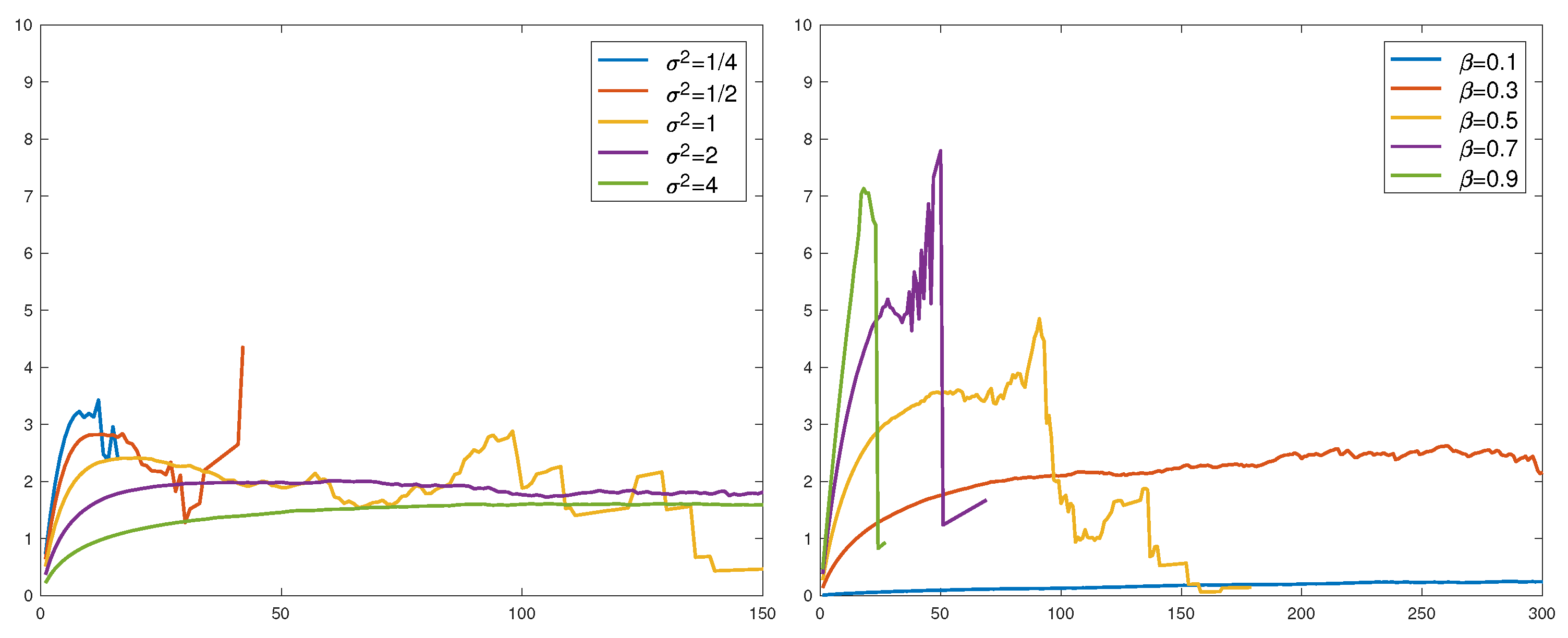
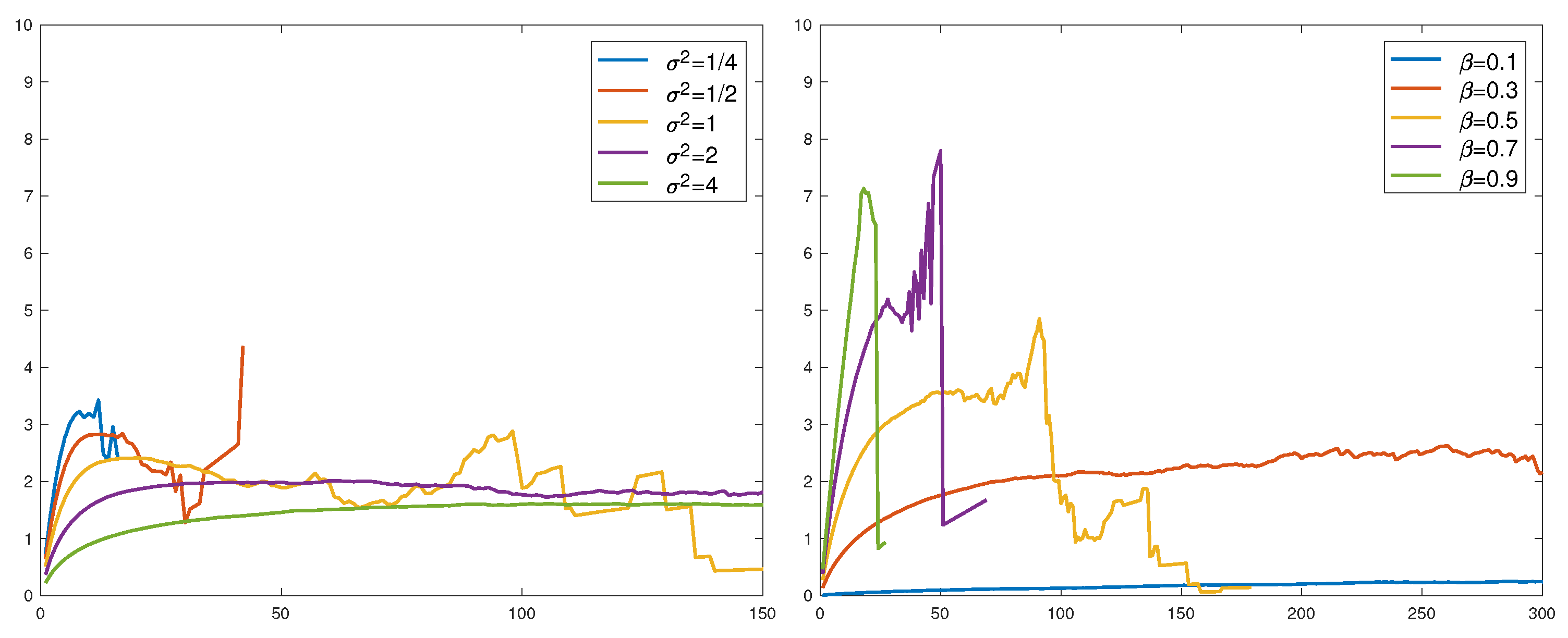
For the Weibull, , and the part of Figure 5 is rather inconclusive concerning the conjecture. We did one more run with over a range of parameters (the variance of for the lognormal and β for the Weibull). All were normalized to have mean 1 so that the conjecture would assert convergence to . This is not seen in the results in Figure 6. Large values of and small values of β could appear to give convergence, but not to 2.
It should be noted that the heuristics give the correct result in the RV case. Namely, here we can take and . This easily gives so that Quantity (10) is approximately , as rigorously verified in Proposition 1.
The overall conclusion is that the finer diagnostic value of the method is quite limited, and restricted to RV and sample sizes which may be unrealistically large in many contexts.
5. Proofs
Proof of Lemma 1.
Suppose h is concave and . The contour line corresponding to value p is formed as the set of points that satisfy , or equivalently
Firstly, is convex as the inverse of an increasing concave function. Secondly, the composition of an increasing convex function and a convex function remains convex. Thus, as a function of x, Expression (12) defines a convex function when . Thus, one can define .
If h is convex, the proof is analogous. ☐
The following technical lemma is needed in the proof of Proposition 1. It applies to Pareto, Weibull and lognormal type distributions. Indeed, condition (13) follows from Proposition 1.2; (ii) of [21] and further needed assumptions are easily verified apart from strong subexponentiality, which is known to hold in the mentioned examples.
Lemma 2.
Suppose and are non-negative i.i.d. variables with a common density f, where the hazard rate is eventually decreasing with . Assume further that
Then,
If in addition , then
Proof.
Equality (13) implies subexponentiality of . Writing
and observing that the nominator on the right-hand side is of order proves Equation (14) since by subexponentiality.
Equality (13) implies
On the other hand, writing
gives
Proof of Proposition 1.
Suppose X is regularly varying with index α. In light of Lemma 2, we only need to establish
The contribution to the l.h.s of Equation (17) from
is of order for any and . Thus, it can be neglected. We are left with estimating
We will bound this quantity from above and below, assuming .
Firstly,
Now, given , is approximately distributed as for large x where . Hence, dominated convergence gives
We get
Here, the error terms and are of order . The latter error comes from Taylor expansion of function around point . The fact that f is assumed eventually decreasing guarantees that , when .
Secondly, for the lower bound, we have that
As before, we get
for error terms and of order .
Repeating the argument with arbitrarily small and combining the upper and lower estimates allows one to deduce
as , which proves the claim.
Suppose then that X is Weibull distributed. Now assumptions of Lemma 2 are satisfied with . Since for some depending on α, we only need to find the order of
In fact, proceeding similarly as in the regularly varying case, it can be seen that Quantity (18) equals
It is known that , where , converges in distribution to a standard exponential variable, as . Because , it holds for that
(the interchange of expectation and convergence is justified by dominated convergence). In addition, the same error term can be used for any y.
Thus, Quantity (19) can be written as
Equation (20) follows from the fact that conditionally to , all probability mass concentrates near small values of .
Gathering estimates and using Equation (14) of Lemma 2 yields
Proof of Proposition 2.
Note first that and are independent in the normal case. Denote so that . Let be the mean excess function of Z (inverse hazard rate). It is then standard that is of order and that converges in distribution to a standard exponential. Writing
it follows in the same way as in the proof or Proposition 1 that the r.h.s. of Equation (21) is . This proves the claim. ☐
Proof of Theorem 1.
Suppose f is log-concave and twice differentiable. Since
it suffices to show that, for a fixed z, it holds that
where
In fact, by symmetry, one only needs to show
It is known from the proof of Proposition 2.1 of [4] that is increasing in . Since is non-negative and integrates to one over interval , there exists a number such that when and when . Therefore,
which proves Inequality (23). Generally, if f is log-concave and twice differentiable in the set , then is increasing in the set . The difference from the presented calculation vanishes in the limit , and thus Inequality (7) holds.
If f is eventually log-convex, the proof is analogous and Inequality (8) holds. ☐
Author Contributions
The authors contributed equally to this work.
Conflicts of Interest
The authors declare no conflict of interest.
References
- M.Y. An. “Logconcavity versus logconvexity: A complete characterization.” J. Econom. Theory 80 (1998): 350–369. [Google Scholar] [CrossRef]
- A. Saumard, and J.A. Wellner. “Log-concavity and strong log-concavity: A review.” Stat. Surv. 8 (2014): 45–114. [Google Scholar] [CrossRef] [PubMed]
- R.C. Gupta, and N. Balakrishnan. “Log-concavity and monotonicity of hazard and reversed hazard functions of univariate and multivariate skew-normal distributions.” Metrika 75 (2012): 181–191. [Google Scholar] [CrossRef]
- J. Lehtomaa. “Limiting behaviour of constrained sums of two variables and the principle of a single big jump.” Stat. Probab. Lett. 107 (2015): 157–163. [Google Scholar] [CrossRef]
- M. Cule, R. Samworth, and M. Stewart. “Maximum likelihood estimation of a multi-dimensional log-concave density.” J. R. Stat. Soc. Ser. B Stat. Methodol. 72 (2010): 545–607. [Google Scholar] [CrossRef]
- G. Walther. “Inference and modeling with log-concave distributions.” Stat. Sci. 24 (2009): 319–327. [Google Scholar] [CrossRef]
- F. Balabdaoui, K. Rufibach, and J.A. Wellner. “Limit distribution theory for maximum likelihood estimation of a log-concave density.” Ann. Stat. 37 (2009): 1299–1331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- M.L. Hazelton. “Assessing log-concavity of multivariate densities.” Stat. Probab. Lett. 81 (2011): 121–125. [Google Scholar] [CrossRef]
- L. Dümbgen, and K. Rufibach. “Maximum likelihood estimation of a log-concave density and its distribution function: Basic properties and uniform consistency.” Bernoulli 15 (2009): 40–68. [Google Scholar] [CrossRef] [Green Version]
- S. Asmussen, and P.W. Glynn. “Stochastic simulation: Algorithms and analysis.” In Stochastic Modelling and Applied Probability. New York, NY, USA: Springer, 2007, Volume 57. [Google Scholar]
- S. Ghosh, and S. Resnick. “A discussion on mean excess plots.” Stoch. Process. Appl. 120 (2010): 1492–1517. [Google Scholar] [CrossRef]
- M.E. Crovella, and M.S. Taqqu. “Estimating the heavy tail index from scaling properties.” Methodol. Comput. Appl. Probab. 1 (1999): 55–79. [Google Scholar] [CrossRef]
- J. Del Castillo, J. Daoudi, and R. Lockhart. “Methods to distinguish between polynomial and exponential tails.” Scand. J. Stat. 41 (2014): 382–393. [Google Scholar] [CrossRef]
- Y.R. Gel, W. Miao, and J.L. Gastwirth. “Robust directed tests of normality against heavy-tailed alternatives.” Comput. Stat. Data Anal. 51 (2007): 2734–2746. [Google Scholar] [CrossRef]
- N.H. Bingham, C.M. Goldie, and J.L. Teugels. “Regular variation.” In Encyclopedia of Mathematics and Its Applications. Cambridge, UK: Cambridge University Press, 1989, Volume 27. [Google Scholar]
- H. Albrecher, C.Y. Robert, and J.L. Teugels. “Joint asymptotic distributions of smallest and largest insurance claims.” Risks 2 (2014): 289–314. [Google Scholar] [CrossRef] [Green Version]
- I. Armendáriz, and M. Loulakis. “Conditional distribution of heavy tailed random variables on large deviations of their sum.” Stoch. Process. Appl. 121 (2011): 1138–1147. [Google Scholar] [CrossRef] [Green Version]
- S.G. Bobkov, and G.P. Chistyakov. “On concentration functions of random variables.” J. Theor. Probab. 28 (2015): 976–988. [Google Scholar] [CrossRef]
- A.R. Pruss. “Comparisons between tail probabilities of sums of independent symmetric random variables.” Ann. Inst. Henri Poincaré Probab. Stat. 33 (1997): 651–671. [Google Scholar] [CrossRef]
- S. Asmussen, and D. Kortschak. “Error rates and improved algorithms for rare event simulation with heavy Weibull tails.” Methodol. Comput. Appl. Probab. 17 (2015): 441–461. [Google Scholar] [CrossRef]
- A. Baltrūnas, and E. Omey. “The rate of convergence for subexponential distributions and densities.” Liet. Math. J. 42 (2002): 1–14. [Google Scholar] [CrossRef]
- E. Omey, and E. Willekens. “Second order behaviour of the tail of a subordinated probability distribution.” Stoch. Process. Appl. 21 (1986): 339–353. [Google Scholar] [CrossRef]
- B. Pfaff, and A. McNeil. “evir: Extreme Values in R. 2012. R Package Version 1.7-3.” Available online: https://CRAN.R-project.org/package=evir (accessed on 14 November 2016).
- A. McNeil. “Estimating the tails of loss severity distributions using extreme value theory.” Astin Bull. 27 (1997): 117–137. [Google Scholar] [CrossRef]
- H. Albrecher, and S. Asmussen. “Ruin probabilities.” In Advanced Series on Statistical Science & Applied Probability. Hackensack, NJ, USA: World Scientific Publishing, 2010, Volume 14. [Google Scholar]
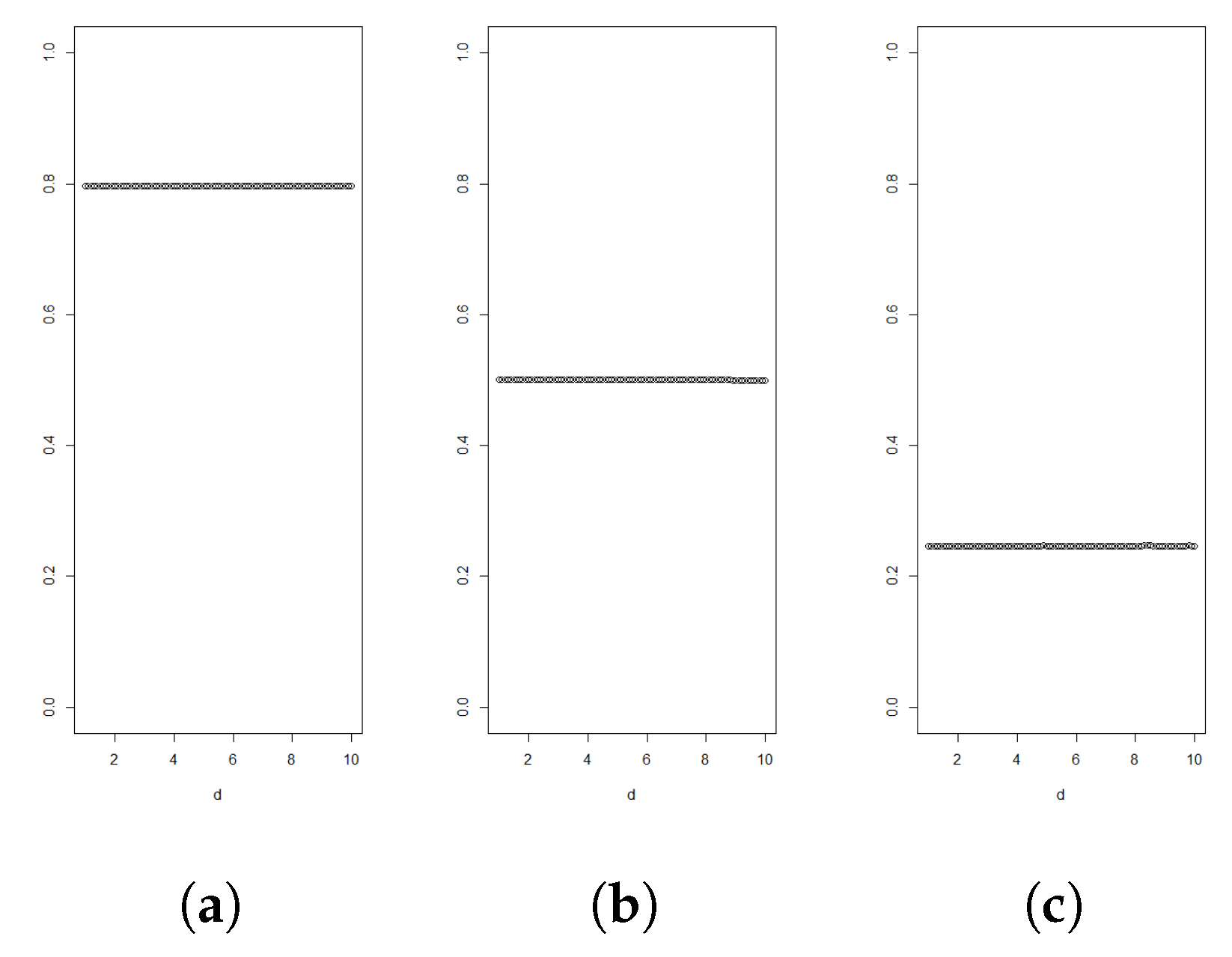
Figure 1.
Graphs of for for Gamma distributed random variables with shapes and 5 in figures (a), (b) and (c), respectively. All variables are standardised to have mean 3.
Figure 1.
Graphs of for for Gamma distributed random variables with shapes and 5 in figures (a), (b) and (c), respectively. All variables are standardised to have mean 3.

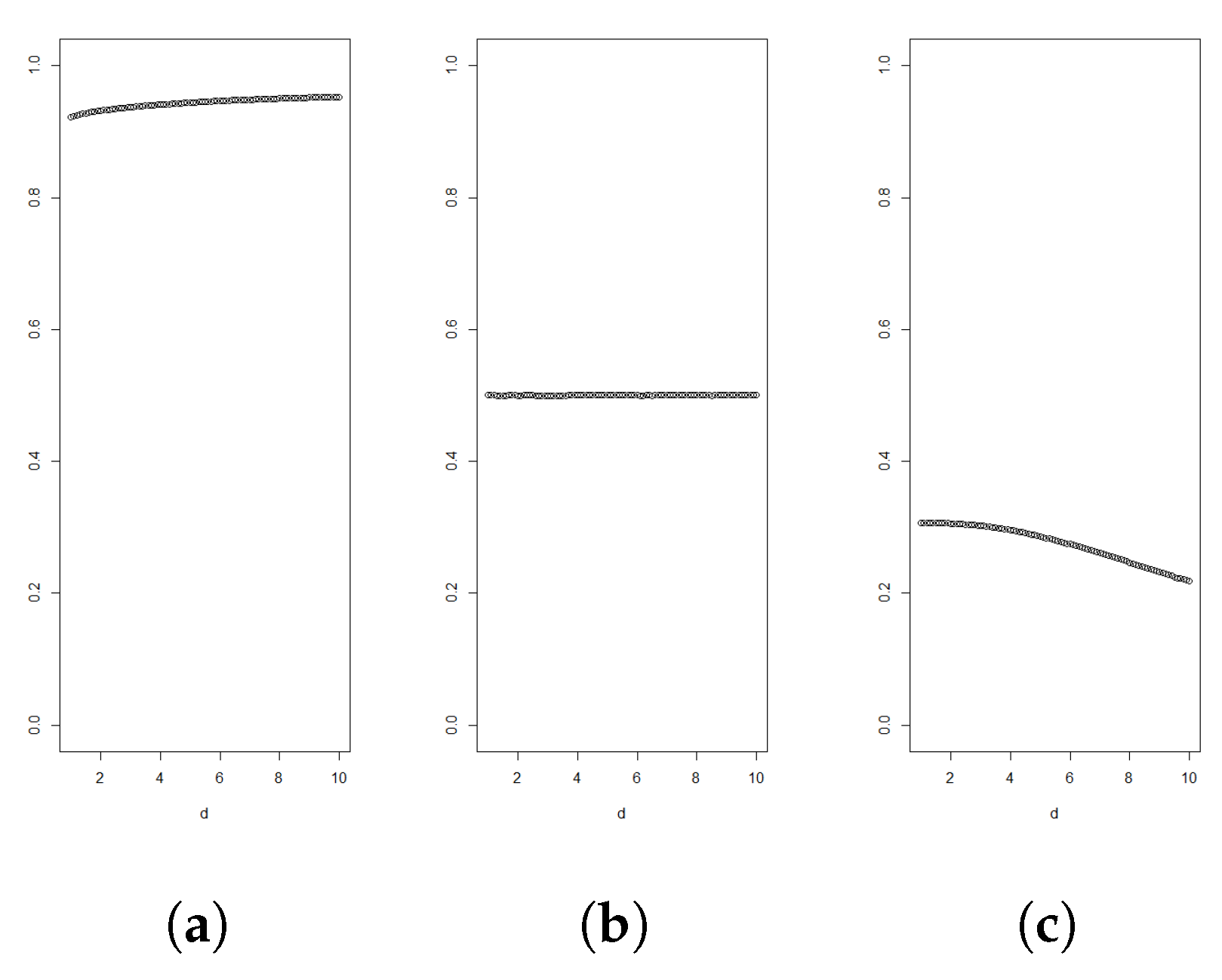
Figure 2.
Graphs of for for Weibull distributed random variables with shapes and 5 in figures (a), (b) and (c), respectively. All variables are standardised to have mean 3.
Figure 2.
Graphs of for for Weibull distributed random variables with shapes and 5 in figures (a), (b) and (c), respectively. All variables are standardised to have mean 3.
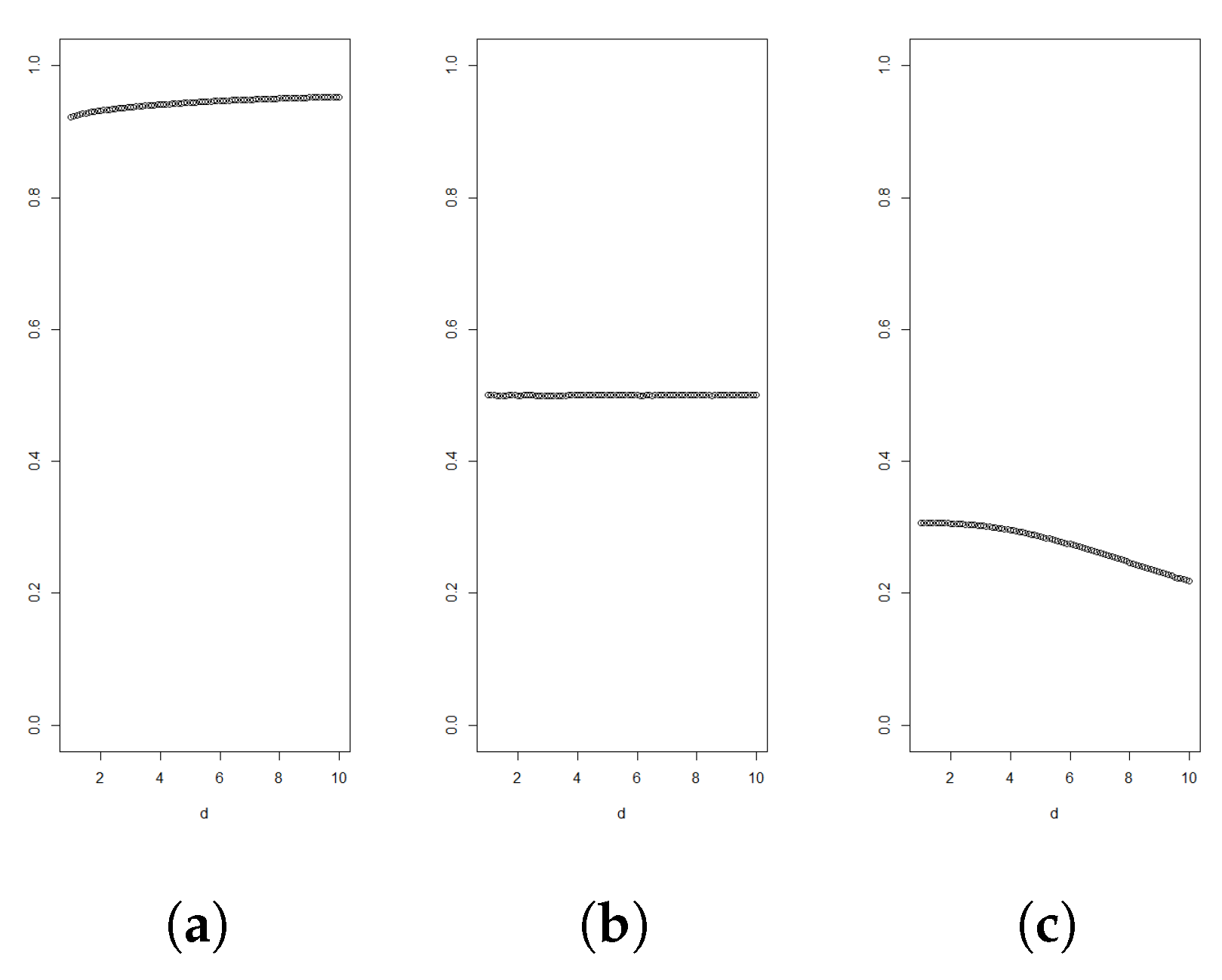
Figure 3.
Graph of from a classical set of Danish fire insurance data that can be obtained for instance from data set ‘danish’ in the R package [23]. The data is scaled to have mean 1. The sample is traditionally used to illustrate how heavy-tailed data behaves. A similar set of data was previously used in [24]. The graph supports the usual finding that the data set is heavy-tailed.
Figure 3.
Graph of from a classical set of Danish fire insurance data that can be obtained for instance from data set ‘danish’ in the R package [23]. The data is scaled to have mean 1. The sample is traditionally used to illustrate how heavy-tailed data behaves. A similar set of data was previously used in [24]. The graph supports the usual finding that the data set is heavy-tailed.
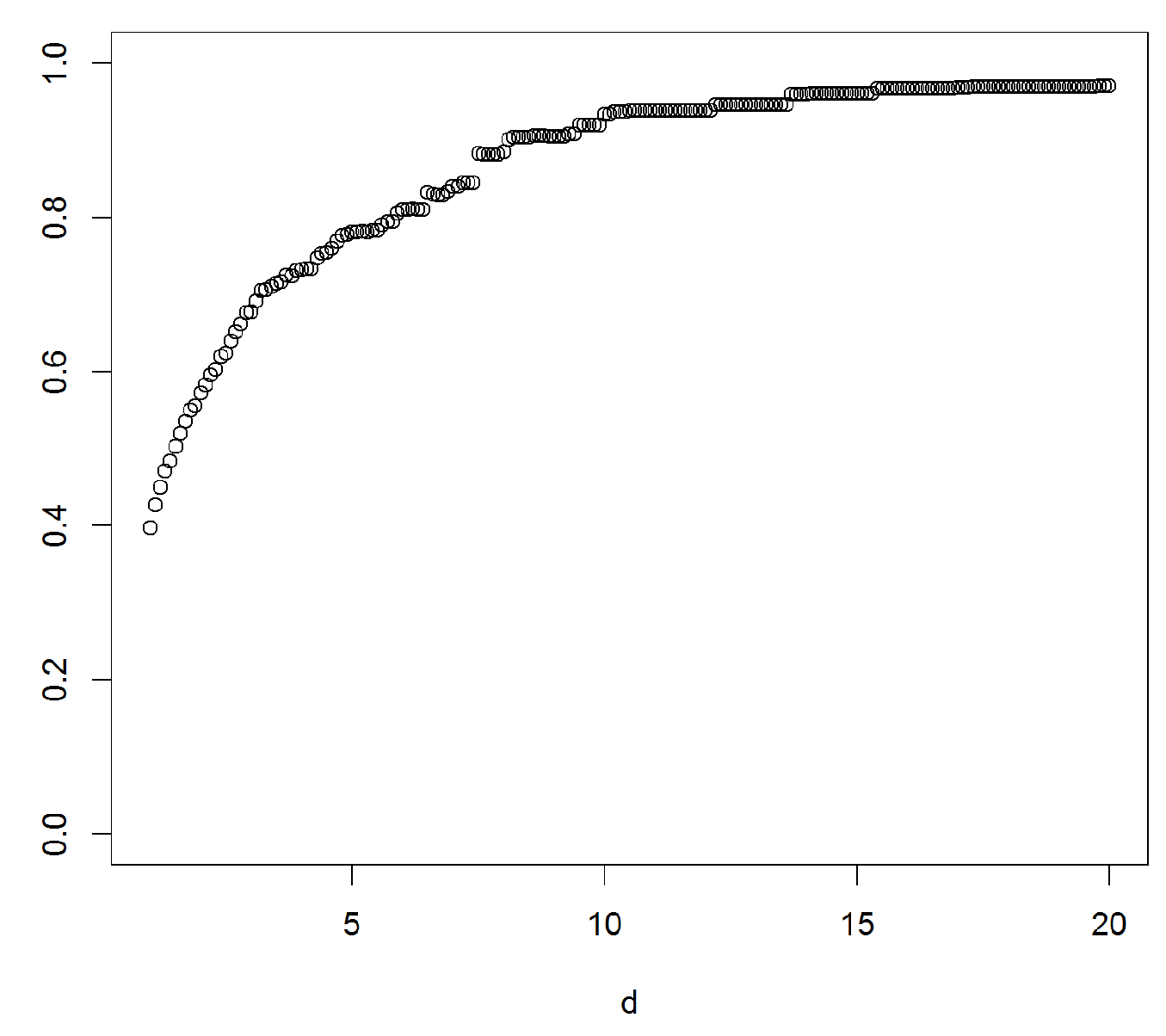
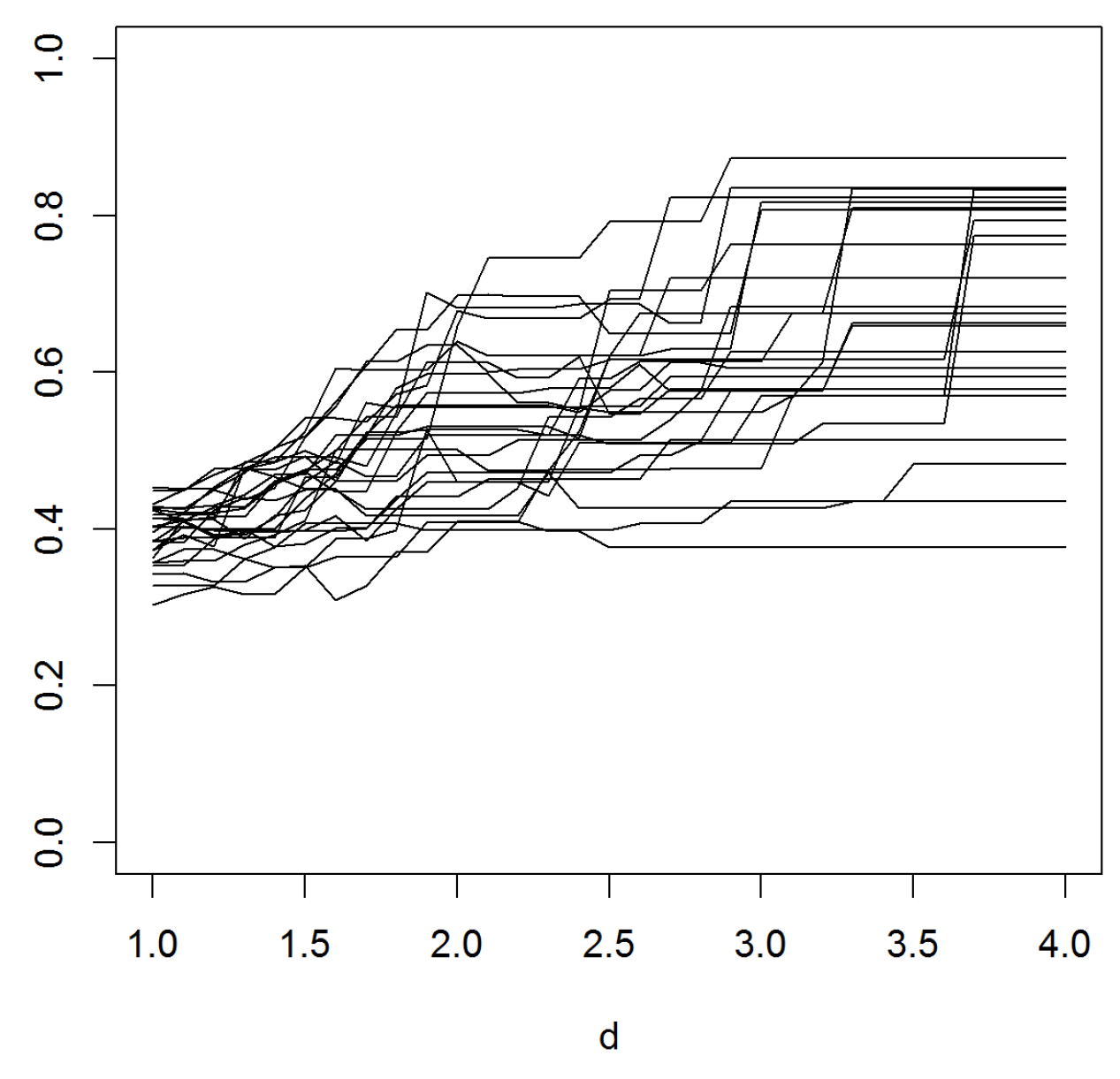
Figure 4.
The graphs of multiple versions of based on a dataset obtained from Hansjörg Albrecher (private communication) and related to occurrences of floods in a particular area. The data is scaled to have mean 1. The sample size is . Bivariate vectors were sampled several times randomly without replacement from the original data. The overall appearance of the paths points to the data being heavy- rather than light-tailed.
Figure 4.
The graphs of multiple versions of based on a dataset obtained from Hansjörg Albrecher (private communication) and related to occurrences of floods in a particular area. The data is scaled to have mean 1. The sample size is . Bivariate vectors were sampled several times randomly without replacement from the original data. The overall appearance of the paths points to the data being heavy- rather than light-tailed.
Figure 5.
. Pareto in the first row, lognormal in the second, and Weibull in the last. (left), (right).
Figure 5.
. Pareto in the first row, lognormal in the second, and Weibull in the last. (left), (right).

Figure 6.
. Lognormal (left), Weibull (right).
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Asmussen, S.; Lehtomaa, J. Distinguishing Log-Concavity from Heavy Tails. Risks 2017, 5, 10. https://doi.org/10.3390/risks5010010
AMA Style
Asmussen S, Lehtomaa J. Distinguishing Log-Concavity from Heavy Tails. Risks. 2017; 5(1):10. https://doi.org/10.3390/risks5010010
Chicago/Turabian StyleAsmussen, Søren, and Jaakko Lehtomaa. 2017. "Distinguishing Log-Concavity from Heavy Tails" Risks 5, no. 1: 10. https://doi.org/10.3390/risks5010010
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.