
Automated Detection of Persuasive Content in Electronic News

Informatics Department, Institut Teknologi Sepuluh Nopember, Surabaya 60111, Indonesia
*
Author to whom correspondence should be addressed.
Informatics 2023, 10(4), 86; https://doi.org/10.3390/informatics10040086
Submission received: 31 July 2023
/
Revised: 29 September 2023
/
Accepted: 21 October 2023
/
Published: 21 November 2023
(This article belongs to the Section Machine Learning)
Abstract
:Persuasive content in online news contains elements that aim to persuade its readers and may not necessarily include factual information. Since a news article only has some sentences that indicate persuasiveness, it would be quite challenging to differentiate news with or without the persuasive content. Recognizing persuasive sentences with a text summarization and classification approach is important to understand persuasive messages effectively. Text summarization identifies arguments and key points, while classification separates persuasive sentences based on the linguistic and semantic features used. Our proposed architecture includes text summarization approaches to shorten sentences without persuasive content and then using classifiers model to detect those with persuasive indication. In this paper, we compare the performance of latent semantic analysis (LSA) and TextRank in text summarization methods, the latter of which has outperformed in all trials, and also two classifiers of convolutional neural network (CNN) and bidirectional long short-term memory (BiLSTM). We have prepared a dataset (±1700 data and manually persuasiveness-labeled) consisting of news articles written in the Indonesian language collected from a nationwide electronic news portal. Comparative studies in our experimental results show that the TextRank–BERT–BiLSTM model achieved the highest accuracy of 95% in detecting persuasive news. The text summarization methods were able to generate detailed and precise summaries of the news articles and the deep learning models were able to effectively differentiate between persuasive news and real news.
1. Introduction
Native ads can be categorized as a type of persuasive information and defined as promotional material concealed as a news article to persuade its readers [1]. Consequently, it is understandable if the readers assume the information conveyed by native ads to be true, despite being clearly labeled as promotional. A news article that contains an advertisement of a product or company may include misleading information because the author of the article tends to use persuasive sentences to increase the interest towards the news article. The larger the interest of readers towards the news article, the more persuasive the message becomes [2].
Reading persuasive news has several effects on the reader. The most prominent effect arises when readers are presented with persuasive news that is delivered in a positive frame. When readers perceive a news story that is presented in a positive frame as a form of persuasion or advertising, then the readers are likely to not believe and dismiss the conveyed message [3]. Readers must have an understanding of persuasive techniques that are used in persuasive content. One persuasive technique is portraying a company positively (ethos) [4]. Ethos seeks to portray a company as a group of people or a team with a positive attitude toward a product or service. These opinions usually appear to be credible, especially when a group of people are in conformity with these opinions. An example of a persuasive sentence is as follows: “Looking for a budget computer but with high specifications? Check out www.xyz.com (accessed on 29 May 2023), the number one computer e-commerce site in Indonesia. We have a wide range of computers that are suitable for students and office workers!”. Therefore, there is a need for a new computational approach that is able to recognize persuasive sentences so that readers are not easily deceived when reading persuasive content.
Natural language processing (NLP) uses various techniques to understand, analyze, and manipulate text. NLP encompasses tasks such as text classification, which allows for the classification of text or documents into appropriate categories or labels based on their characteristics or content, as well as text summarization, which aids in creating a concise summary of long texts. NLP research closely related to persuasive news recognition belongs to fake news research. Although efforts have been made to develop fake news detection techniques, significant challenges still exist in recognizing persuasive news that often has striking similarities to fake news. Such difficulties can be attributed to both texts’ complex linguistic, semantic, and structural aspects, which complicate their clear separation. As a result, further research is needed to develop more sophisticated and effective methods that can accurately distinguish persuasive news from fake news and make a valuable contribution to improving the understanding and evaluation of information in the digital era. According to Molina [1], persuasive content is a category of online content that can be grouped under the label of fake news. They define persuasive content as content that contains persuasive elements that may not include factual information. The majority of researchers recommend deep learning approaches for detecting fake news. For example, BERT–BiLSTM can detect fake news [5], BERT can detect Indonesian fake news [6], and fake news can be detected by a hybrid deep learning model that uses a CNN and RNN [7].
Only a few studies have attempted to detect fake news written in languages other than English. This research focuses on detecting persuasive news written in Indonesian. The Indonesian language is ranked 11th out of the top 200 most spoken languages [8]. This indicates the importance of the Indonesian language. Furthermore, we created a dataset that was obtained through scraping of news articles from several news portals. This dataset consists of news articles covering several topics in a given period. Data collection was carried out carefully and attention paid to the reliability and accuracy of the news sources used. In addition, this dataset has gone through processing and filtering stages to ensure only important information is retained. The annotator gives the label for the dataset. However, according to the annotator in the case of news containing persuasive elements, only a few sentences in news articles appear.
Due to the size of a news corpus that is generally very large, there exists an NLP technique, namely text summarization, that can be used to create a summary of a large corpus of news articles for an efficient understanding of the large corpus. The TextRank model is one of the most widely used text summarization methods, which is based on the PageRank model proposed by Google cofounders. The summary generated by TextRank has been proven to be of high quality and has been found to be very similar to summaries created by humans [9]. We used the TextRank model in our proposed persuasive news detection system.
Recognizing persuasive sentences with a text summarization and classification approach is very important because it makes it possible to understand and analyze persuasive messages effectively. The text summarization approach helps identify arguments and key points in a persuasive text, giving a clearer picture of the author’s message. Meanwhile, the classification approach helps separate persuasive sentences from those that are not persuasive, paying attention to the linguistic and semantic features used in those sentences. By combining these two approaches, we can effectively recognize sentences with a convincing purpose, increasing our understanding of persuasive texts and helping us evaluate arguments more critically.
This work has an objective to propose an architecture for the detection of persuasive news using text summarization methods and pre-trained deep learning models to make readers aware whether or not a news article contains persuasive elements. Our comparison studies in these experiments have addressed how well different combinations of text-summarizing techniques and deep learning models perform. In this study, we compare two text summarization methods, namely, TextRank and LSA. TextRank has the ability to extract relevant phrases or keywords from text documents, while LSA can semantically recognize important sentences and the relationship between them. Furthermore, we explore the use of text summarization models, TextRank and LSA, as well as compare the performance of two classifiers, BiLSTM and CNN, using word-embedding BERT and roBERTa. BiLSTM and CNN are models that were used in our previous research, and both models outperformed the LSTM model [10]. The results obtained in the research “Vietnamese Hate and Offensive Detection using PhoBERT-CNN and Social Media Streaming Data” conducted by Tran were optimistic and reliable enough to complete the task, helped reduce the occurrence of hate or offensive comments, and established a healthy and safe environment [11]. We discuss the advantages and disadvantages of each model and evaluate how well it performs. Finally, we compare the model with the highest performance to state-of-the-art models to show that our method works. The addition of text summarization is motivated by the desire to obtain a high-quality summary of the news articles and, as a result, improve the learning process of the models on the proposed dataset.
This research is part of a larger study that focuses on the detection of native ads using several implicit characteristics of native ads, one of them being persuasive content. The following is the structure of the remainder of this study. Section 2 presents a review of studies that are related to the detection of persuasive news. Section 3 presents the proposed approach and its main components. Section 4 details the implementation and setup of the experiment. Section 5 presents the findings and evaluation of the experiment. Section 6 concludes the paper and states future works.
2. Related Work
Due to the lack of a computational method for detecting persuasive news, we conducted a review of the literature on studies that compare deep learning models, compare studies that combine text summarization methods with deep learning models, and studies that are closely related to the detection of fake news.
Other studies compared several deep learning methods for text classification to determine the model with the best performance. Fouad [12] investigated and assessed the performance of various deep learning models for detecting Arabic fake news. They evaluated five different deep learning models, namely, CNN, LSTM, BiLSTM, CNN + LSTM, and CNN + BiLSTM. Ramya [13] proposed a deep-learning-based fake news detection system using CNN, LSTM, and BiLSTM. They evaluated the models’ performance based on accuracy, precision, recall, and F1 score using a complex problem dataset called LIAR, and performance analysis was performed on each of the LIAR dataset’s training, validation, and testing sets. Asghar [14] explored the use of various deep learning models for the detection of rumors on Twitter. The proposed system was shown to effectively classify tweets into rumors and non-rumors using BiLSTM and CNN. Bidirectional long short-term memory (BiLSTM) is a type of recurrent neural network (RNN) that is well-suited for sequential data processing such as NLP tasks. Long short-term memory (LSTM) is a specific type of RNN designed to address the vanishing gradient problem and capture long-term dependencies in sequential data, while a convolutional neural network (CNN) is a type of neural network originally developed for image processing tasks that has also been successfully applied to text and sequential data.
There have been several studies that combine deep learning models with several NLP techniques in an attempt to achieve higher accuracy of text classification. Samadi [15] compared the effectiveness of various combinations of pre-trained models and neural classifiers for detecting fake news. They combined three different neural classifiers, namely, single-layer perceptron (SLP), multi-layer perceptron (MLP), and CNN, with different pre-trained contextual text representation models, namely, BERT, RoBERTa, GPT2, and funnel transformer.
Ding [16] compared machine learning and BERT-based models for automated key phrase extraction for word-level and character-level sequence labeling. As a baseline, they used unsupervised key extraction methods such as term frequency (TF), term frequency–inverse document frequency (TF–IDF), and TextRank, as well as supervised machine learning methods such as conditional random field (CRF), BiLSTM, and BiLSTM–CRF. TextRank is an algorithm used in NLP and text summarization that was proposed by Mihalcea [17]. The method extracts and summarizes relevant information from text based on the relationships between words in the text. To [18] introduced a novel comparison between different multilingual and monolingual BERT models. The experimental results indicated that monolingual models were able to produce promising results compared to other multilingual models and previous text summarizing models for Vietnamese.
Memes may activate biases that are associated with culture or society and sometimes have persuasive intent. Beskow [19] proposed Meme-Hunter, a multi-modal deep learning model for classifying images on the internet as memes or non-memes and evaluated and compared its performance with uni-modal models. In another recent study, Gupta [20] proposed a transfer learning approach to enhance BERT-based models in various modalities for the detection of persuasive techniques in memes. Studies on the detection of fake news are closely related to studies on the detection of persuasive news. Persuasive news is a type of content that is classified as fake news. The persuasive element is an integral part of the complex phenomenon of fake news, requiring careful investigation and analysis within the academic realm to uncover the dynamics and associated implications. Understanding the complex relationship between persuasive techniques and the creation of false information plays an important role because it can provide an in-depth understanding of the mechanisms underlying the spread and acceptance of fake news. This will facilitate the development of robust preventive measures and effective detection strategies. Deep learning has been used in the majority of studies on fake news detection. A strategy to identify fake news was put forth by Sadeghi [5] and relied on natural language inference (NFI) methodology. They enhanced several machine learning and deep learning models with the use of different word-embedding methods. The results showed that the BERT–BiLSTM model achieved the highest accuracy. Fawaid [6] used the BERT model as the basis of their research and compared its performance with CNN and BiLSTM for the detection of fake news written in the Indonesian language.
The majority of recent studies on the detection of fake news, the topic most closely related to the detection of fake news, have used a deep learning approach. It is difficult for researchers to respond to the question: “How effective can the combination of text summarization and deep learning be in accurately detecting persuasive news?” The next chapter describes a proposed computational architecture for detecting persuasive news by combining text summarization and deep learning approaches. It is hoped that this research can provide new insights and a deeper understanding of the effectiveness of this combination in accurately detecting persuasive news.
3. Models
In this section, we detail the methods and proposed models that are used in this study to detect persuasive content in electronic news. The proposed models are comprised of a combination of text summarization methods and deep learning models. A flexible model provides the possibility to use different text summarization methods in order to create a quality summary of the news articles and different deep learning models as the classifier. Firstly, we review the text summarization methods and then detail the deep learning models that we use in this study.
3.1. Text Summarization
In NLP, creating a short summary that delivers the most important and relevant information within the original content and adequately representing the meaning of the entirety of the content is a difficult task for researchers. There exist several techniques to summarize long texts such as Luhn [21], Edmundson [22], and LexRank [23]. However, in an attempt to create a higher quality summary, researchers have employed text summarization techniques based on accessing information from the entirety of the text and semantically recognizing important sentences. The important aspects of TextRank are that it does not require a deep linguistic knowledge of a language and it does not require a specifically annotated language corpora for training, which makes it very portable for various domains, genres, or languages.
Gong and Liu [24] proposed using latent semantic analysis techniques to semantically identify key sentences in order to construct a summary using latent semantic analysis (LSA). LSA uses singular value decomposition (SVD) for general text summarization because it was inspired by latent semantic indexing (LSI), which uses LSI as its foundation. The ability of SVD to represent and record the link between terms, allowing for the semantic grouping of terms and sentences, is one of its distinctive features.
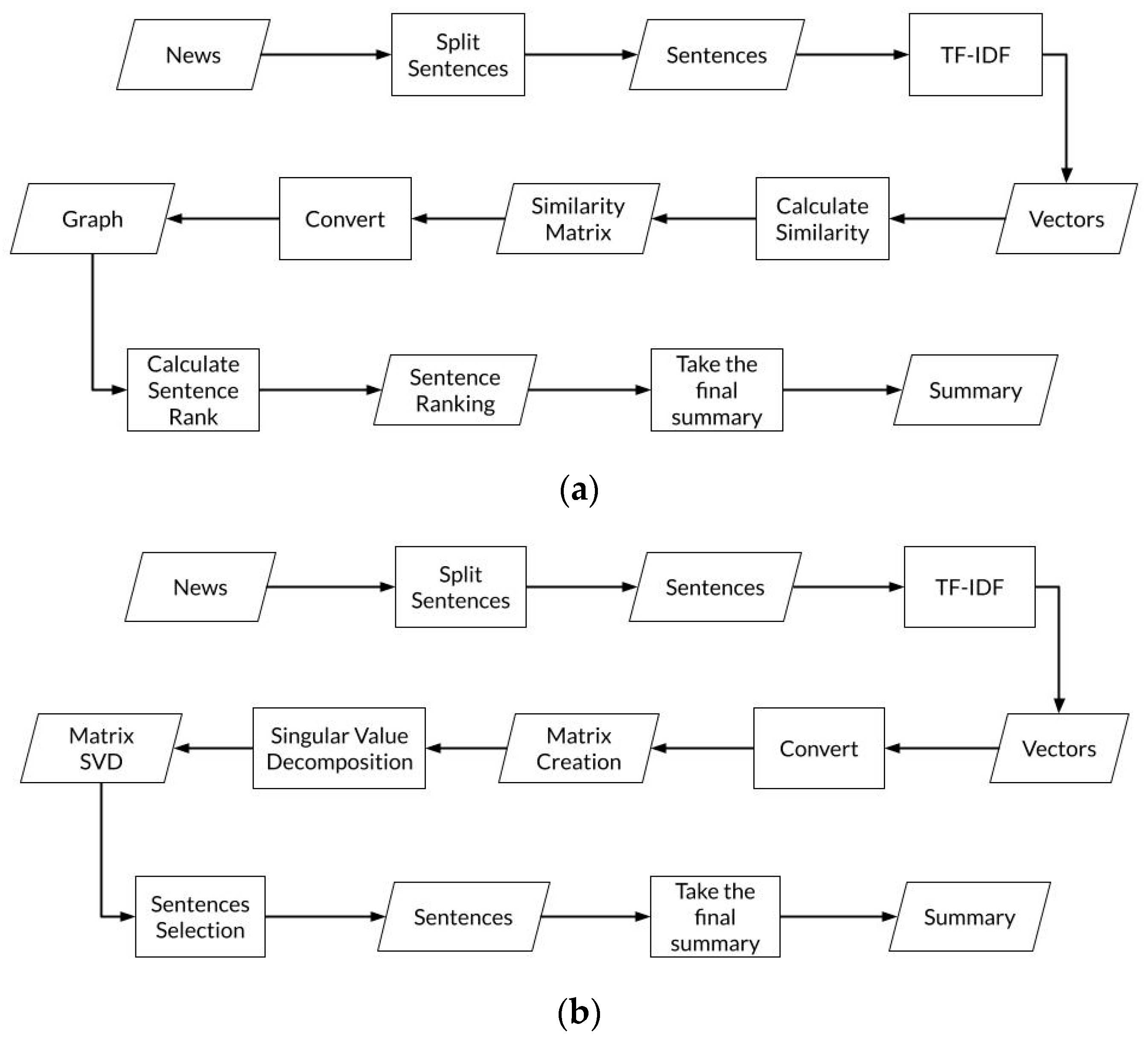
The TextRank and LSA model create a summary as the output. Figure 1 shows an example of the output generated by TextRank and LSA. The matrix used by TextRank and LSA are different. TextRank uses a similarity matrix that calculates the similarity value between vectors. LSA uses a term by sentences matrix that represents the occurrence of a term within a sentence. The result of both methods is a summary of a news article. The following section explains how the output of both methods is connected to the classifiers.
Figure 1a describes the TextRank method that was used in this research. The document is divided into several sentences. After the document is divided into sentences, the similarity between sentences is calculated. This similarity can be calculated using various methods, such as TF–IDF. The similarity matrix generated in the previous step is then used to create a graph. In this graph, each sentence becomes a node, and each pair of sentences with high similarity is connected by an edge. In this step, sentence ranking is calculated. Ranking is carried out by spreading the rank value from each node to its neighboring nodes. The rank value is higher if the node is connected to many other nodes with a high rank. Sentences with high ranking are chosen to be the summary. The number of sentences chosen can be determined manually or automatically. Overall, TextRank is a simple and easy-to-implement algorithm. This algorithm can generate accurate and relevant text summaries of the original document.
Figure 1b describes the LSA method that was used in this research. The document is divided into several sentences. After the document is divided into sentences, word weighting is performed. Word weighting aims to give different weights to each word in the document. These weights are then used to measure the importance of the word in the document. Furthermore, the frequency of word occurrence in each sentence is calculated. This frequency is then stored in the term–document matrix. This matrix has the same dimensions as the number of words in the document multiplied by the number of sentences in the document. The term–document matrix is reduced in dimensionality using the singular value decomposition (SVD) technique. SVD is used to choose the most important dimensions in the term–document matrix. These dimensions are then used to represent the document in semantic space. Sentences are selected based on the values in matrix V. Sentences with high values in the first dimension are selected as summaries. The first dimension of matrix V represents the relationship between the document and the main theme of the document. Therefore, sentences with high values in the first dimension represent the main theme of the document.
3.2. Classifier
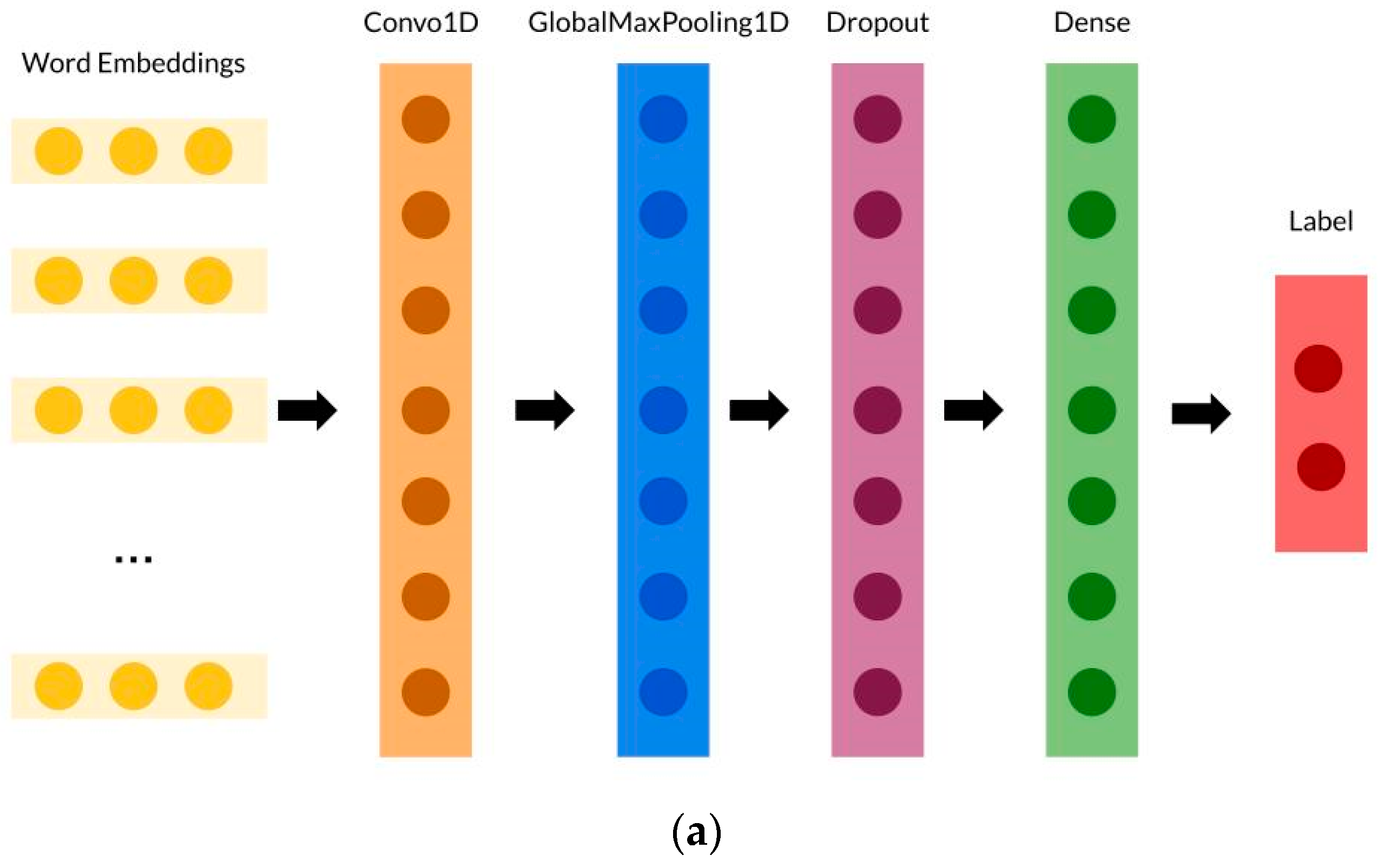
Figure 2 shows the architecture of the two deep learning models used in this study. The layers of both models are similar to one another, in which the only difference is the layer after the word embedding and before the globalmaxpooling1d layer. Word embedding is utilized to assist in the classification process. The word-embedding models used in this study are BERT and roBERTa. The input to the word-embedding models is the news articles that have been summarized using the text summarization methods explained in Section 3.1. The classification process is the last process after word embedding. The purpose of this study is to evaluate and compare the performance of several text summarization methods, word embeddings, and deep learning models for the detection of persuasive news written in the Indonesian language. Therefore, we propose the use of two deep learning models that have been widely used in NLP applications.
3.2.1. Bidirectional Long Short-Term Memory (BiLSTM)
Long short-term memory (LSTM) solves Vanilla RNN’s vanishing and exploding gradient problems by introducing a memory cell to store and access information over long periods of time, as well as three gates (input gate, output gate, and forget gate) to control the flow of information that comes in and out of the cell [25]. However, there is a limitation in using LSTM to model sentences because the sequence information stored is only in the forward direction. An additional LSTM layer that reverses the direction of information flow was proposed to access sequence information in both the forward and backward directions [26]. BiLSTM combines the forward and backward LSTM layers, has better learning capabilities, and the capacity to provide additional contextual information.
Figure 2b describes the BiLSTM method that was used in this research. The output of the word embedding from BERT is processed by the BiLSTM. The output of the word embedding contains a CLS token that will be input to BiLSTM. The CLS token combines the strengths of BiLSTM to understand the relationships between words. The CLS token represents the overall meaning of the sentence. BiLSTM learns important features from the word embedding, such as word patterns, sentence patterns, and para-graph patterns. The output of BiLSTM is then processed using globalmaxpooling1d. Maxpooling summarizes information in the sentence. Globalmaxpooling1d takes the maximum value in each dimension of the BiLSTM output. This is performed to summarize the information that was learned by BiLSTM. The output of globalmaxpooling1d is then processed using a dropout and dense layer. The dropout layer helps to prevent overfitting, while the dense layer combines all the features learned by BiLSTM in order to make predictions.
3.2.2. Convolutional Neural Network (CNN)
CNN is a multilayer network, and, therefore, the output of a layer becomes the input to the next layer. It is usually comprised of an input layer, one to several hidden layers, and an output layer. There are several types of layers that are present within a CNN [27]. The raw input to the network is contained in the input layer, while the convolution layer is in charge of calculating the output volume by performing dot product operations between all of the filters and image patches. This model has been used to solve a variety of image processing and automated NLP problems, including opinion analysis, question answers, and text analysis [28].
Figure 2a describes the CNN method that was used in this research. The output of the word embedding from BERT is processed by a convolutional layer. This convolutional layer learns important features from the word embedding, such as word patterns, sentence patterns, and paragraph patterns. The output of the convolutional layer is then processed using globalmaxpooling1d. Globalmaxpooling1d takes the maximum value in each dimension of the convolutional layer output. This is performed to summarize the information that was learned by CNN. The output of globalmaxpooling1d is then processed using a dropout and dense layer. The dropout layer helps to prevent overfitting, while the dense layer combines all the features that was learned by CNN in order to make predictions.
3.3. Proposed Method
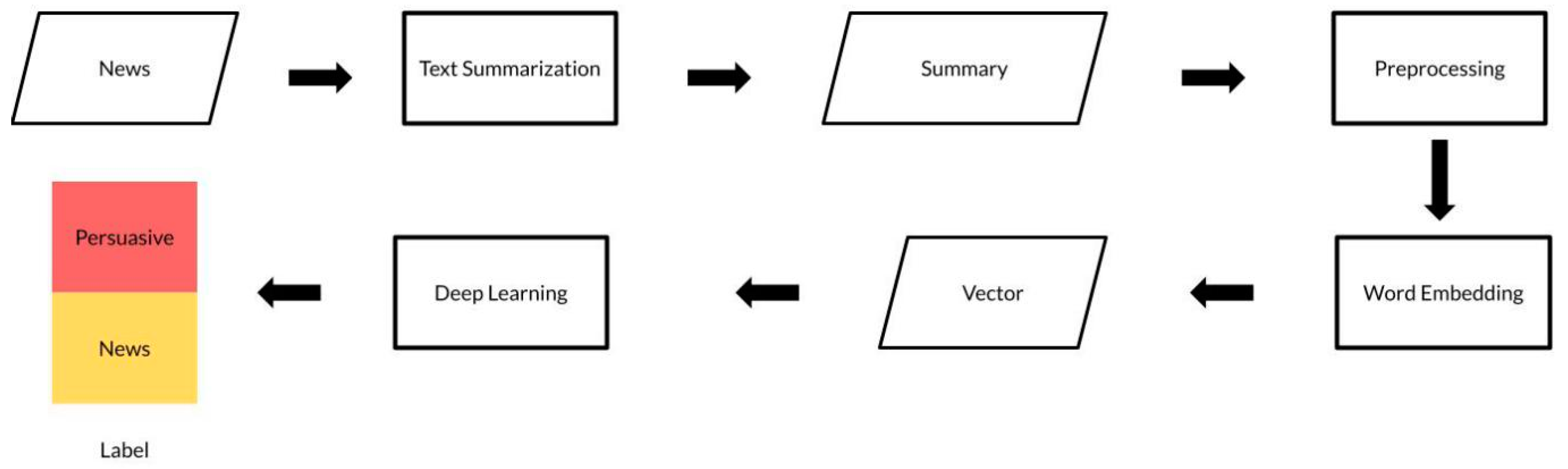
Figure 3 shows the proposed model used to detect persuasive news. The method we have developed represents a breakthrough in this domain. We combine text summarization, word embedding, and deep learning to create an algorithm capable of automatically identifying persuasive news with a high degree of accuracy. We utilize text summarization as an initial step to summarize and identify the core of the news, considering that persuasive elements can be embedded in just a few sentences. Subsequently, we apply deep learning for accurate classification, distinguishing whether the news contains persuasive elements or not.
The process is initiated by collecting news content from various sources, such as news websites, articles, or other sources. The original news content is used as input to the text summarization phase. The news content is processed using text summarization techniques. Text summarization is used to generate concise summaries or quotes that capture the main points of a longer text. It involves different methods, such as extractive approaches that select crucial sentences from the original text and abstractive approaches that create new sentences conveying the essence of the text. The output of this phase are summaries of the news articles.
After obtaining the text summaries, the next step is preprocessing. This involves a series of steps to clean and prepare the text to make it more machine-readable. Preprocessing includes carrying out case folding, punctuation removal, tokenization, lemmatization, and stop word removal. After preprocessing is completed, the preprocessed text is transformed into word vector representations (word embedding). Word embedding is used to convert words within the text into numerical vectors that represent the contextual meaning of the words. These models have been trained on extensive collections of text, enabling them to effectively grasp the associations between words. Through word embedding, words within the text can be represented as high-dimensional vectors. These vector representations encompass valuable semantic details including word context within sentences and the connections between words. The final step is to use a classification model. The classification model takes the word vectors as input and classifies them into the appropriate label, either persuasive news or real news.
4. Experiments
4.1. Dataset
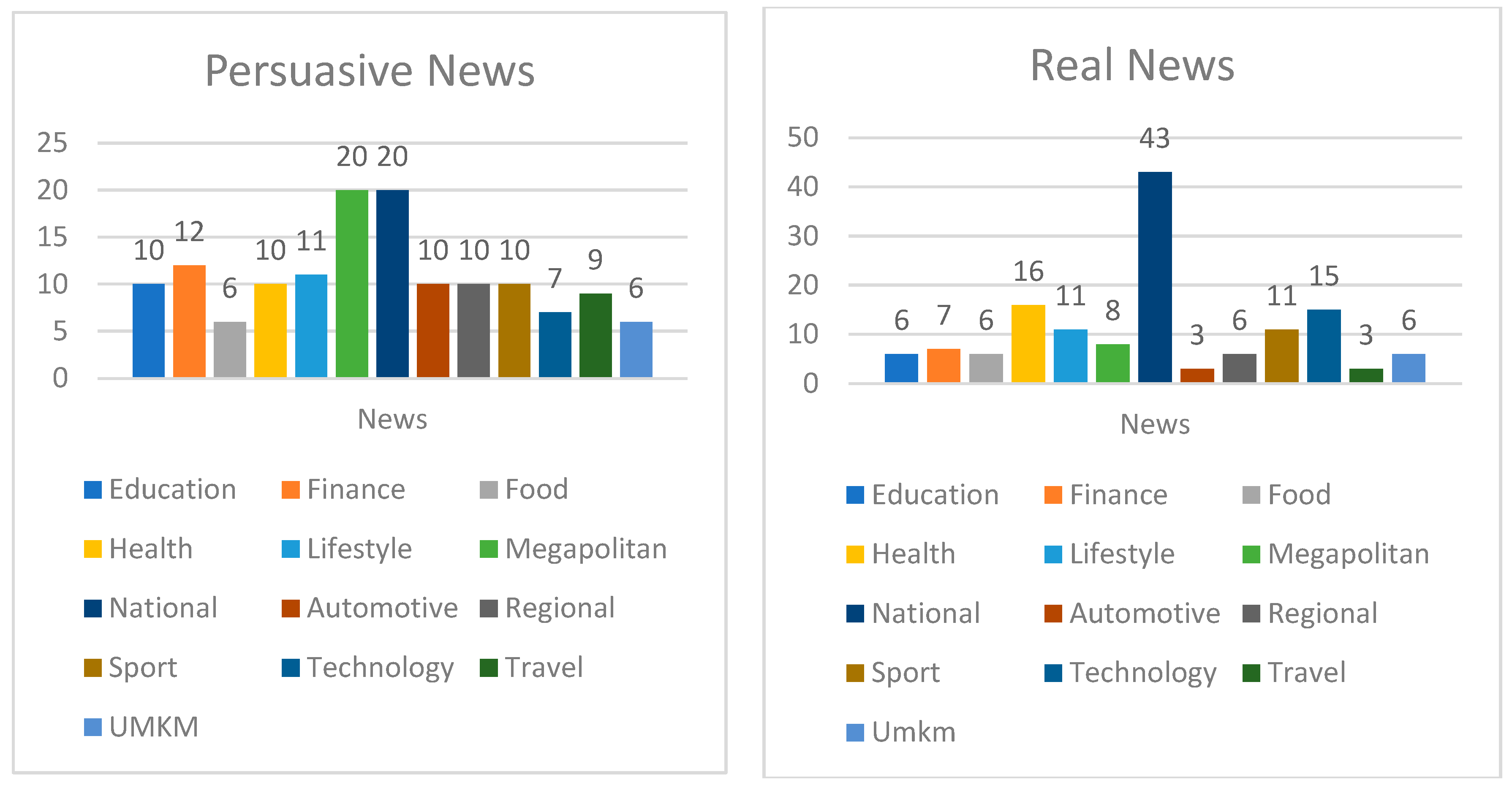
The experiment was conducted on Indonesian news articles collected from six online news portals in Indonesia. Table 1 describes the news portals used in this study. We collected approximately 12,000 news articles from these six news portals. We explore various news categories and choose the most up-to-date news that is applicable to the current situation. Furthermore, the news must contain a greater emphasis on text rather than images. If the images outweigh the text, the process of summarizing the text does not function as intended. We used scraping techniques to collect articles from six online news portals. We built the dataset for six months and were assisted by three annotators. The annotators were selected based on their previous experience working for news companies and their academic focus on news. We conducted detailed interviews and reviewed the work that the annotators had performed. The annotators were involved in labeling the collected articles. The label ‘0’ was given to articles considered persuasive news, and a label of ‘1’ was given to articles considered to be real news. There are several processes that we perform to select datasets. First, we check the number of paragraphs in the news details. Because we use text summarization, where the method summarizes the article, the number of paragraphs in the details has to be at least four. Secondly, we identify slang words in the article, because we only used formal news in this study. Finally, we discussed with the annotator to determine the dataset to be used by looking at the article’s credibility. The credibility of news can be judged based on several factors: clear news sources, news writers, news supported by facts and data, writing style, and additional sources of information. We used 1708 articles from various news categories. Only the body of an article can be used by a text classification algorithm [7]. Within the dataset, there are 854 persuasive news and 854 real news. The real news categories include education, finance, food, health, lifestyle, megapolitan, national, automotive, regional, sport, technology, travel, and small and medium enterprise (SME). Figure 4 shows the distribution of categories for the persuasive news and real news labels. Furthermore, Table 2 shows the overall statistics of the dataset that used in the text summarization process.
The persuasive news dataset was not divided into training, validation, and training sets in advance. We used the five-fold cross-validation method, with each fold using 20% of the data as test data. A small dataset makes it possible to quickly evaluate various deep learning models to determine what performs best and what configuration is best.
4.2. Compared Method
We compared and evaluated the results of the experiment in this study to the results of previous studies that used the same approaches on similar case studies to that of our study because there is yet to be a computational method for the detection of persuasive news, so a comparison cannot be carried out directly on the same topic. The studies that are the most related to our study are those on the detection of fake news, in which the researchers conducted various experiments on fake news to evaluate their proposed methods. We also compared the results of this study to our previous research [10]. The following are the studies that we compared our results with:
4.3. Experimental Setup
We used the Python programming language for the experiment. Python is a popular programming language that provides programmers with a variety of libraries to make the programming process easier (Kartika et al., 2020). We used k-fold cross-validation to split the train data and test data. The Keras library was used to build deep learning models. The architecture of the CNN and BiLSTM referred to those used in the study by Fawaid et al. (2021). Table 3 shows the experimental setup. Furthermore, we developed the BiLSTM model using the dropout layer to avoid overfitting.
The word-embedding models used in this study were implemented using the Hugging Face transformers library. We used the BERT model that is comprised of 124 M parameters, 12 layers, and 768 hidden layer size. Furthermore, we used the roBERTa model that is comprised of 12 layers, 522 M parameters, 768 hidden layer size, and 12 attention heads.
For the performance comparison of the different approaches, we used accuracy, precision, recall, and F1 score as the evaluation metrics [30]. Accuracy refers to the degree of proximity of the predictions to the correct value, which is calculated by dividing the number of correct predictions by the total number of predictions. Precision measures the number of positive predictions that were actually positive, while recall (also known as sensitivity) measures the number of correctly identified actual positives. The definition of F1 score necessitates precision and recall when the cost of false positives and false negatives varies. These metrics are defined as follows:
Precision = TP/(TP + FP) Recall = TP/(TP + FN)
F1-Score = (2 (Recall × Precision))/(Recall + Precision) Accuracy = (TP + TN)/(TP + FP + FN + TN)
F1-Score = (2 (Recall × Precision))/(Recall + Precision) Accuracy = (TP + TN)/(TP + FP + FN + TN)
We also used the AUC score and the ROC curve to evaluate the performance of the classification models. The receiver operating characteristics (ROC) curve constitutes a crucial performance metric that reflects the ability of a model to differentiate between classes. The AUC score represents the area under the curve where a higher AUC score indicates that a model is better in differentiating between classes. The ROC curve is computed using the true positive rate (TPR) and false positive rate (FPR). TPR and FPR are calculated as follows:
False Positive Rate (FPR) = FP/(FP + TN)
True Positive Rate (TPR) = TP/(TP + FN)
True Positive Rate (TPR) = TP/(TP + FN)
If the obtained curve is close to the baseline or the 45-degree diagonal line of the ROC space, then the acquired results are unsatisfactory. On the other hand, if the curve is closer to the top left corner or the (0,1) coordinate of the ROC space, then the acquired results are satisfactory.
5. Results
5.1. Evaluation Metrics
The persuasive news dataset contains a collection of news article from six online news portals that has two labels, namely, persuasive news and real news. In this study, we used the proposed models to detect persuasive news using news article text.
To evaluate the performance of the models for the detection of persuasive news, we used an evaluation matrix. Table 4 shows the performance comparison of the proposed models. Bold numbers in Table 4 indicate models that have almost the same matrix confusion value, at least 90% of the 12 models we used. BERT obtains better results than roBERTa. TextRank also shows much better results than LSA. The BiLSTM model achieves a higher accuracy compared to the CNN model when used with different word embeddings. As for the word-embedding method, the BERT method exhibits a better performance than the roBERTa method. Furthermore, the TextRank method is able to outperform the LSA method.
5.2. Discussion
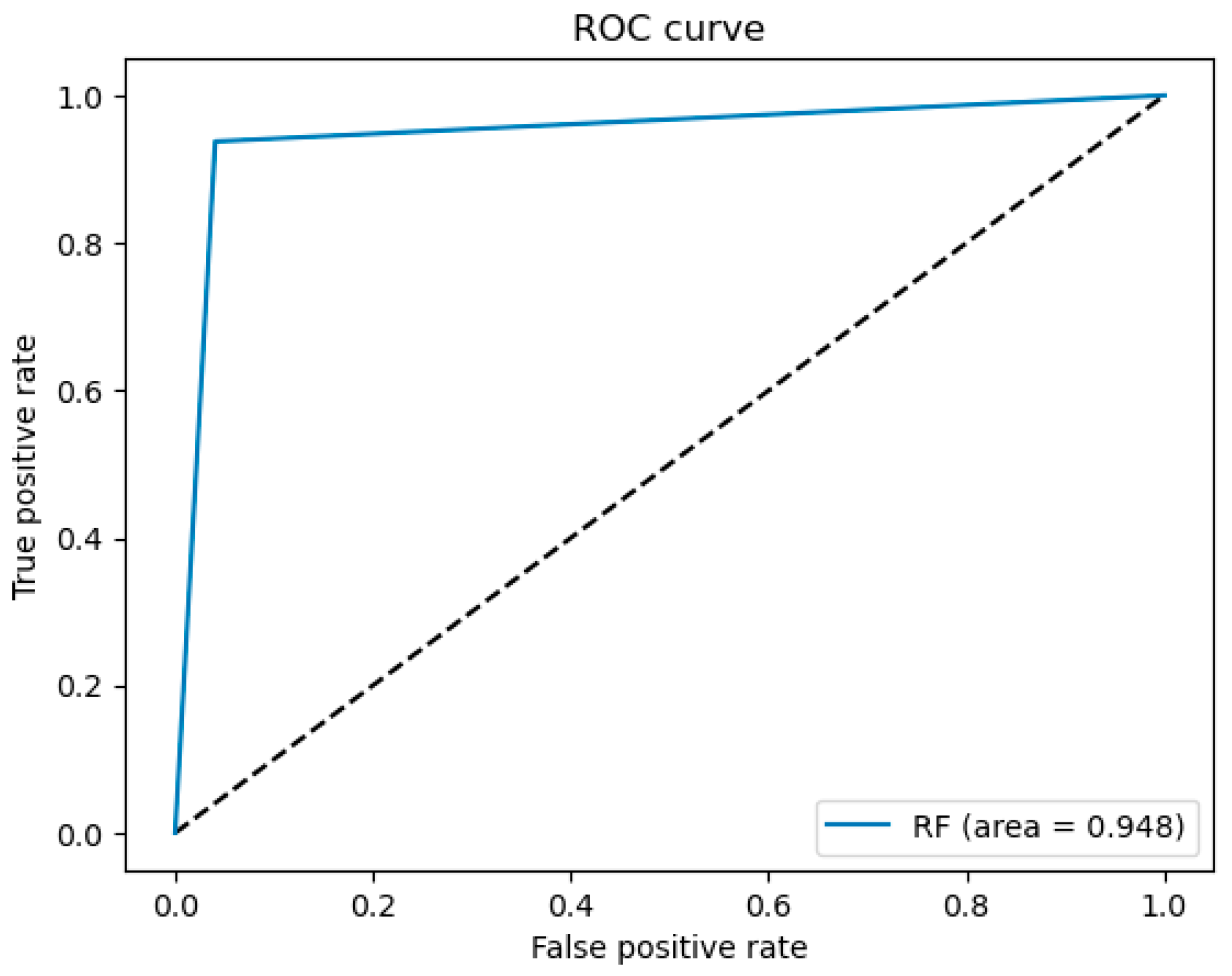
We conducted experiments with 12 experiments and produced four models with matrix confusion values of more than 90%. We tuned the parameters on the four models with matrix confusion values above 90% to find better results. The parameter tuning, we use changes the parameters of the layer or adds layers to the model. We also analyze whether tuning parameters will obtain values or vice versa. We add the k value to the k-fold. In Table 5 we use the value k = 5. We use k = 10 in four models, as can be seen in Table 5. Bold numbers in Table 5 show that TextRank–BERT–BiLSTM obtains the best value among other models with a confusion matrix value of 95%. The k-fold value affects the outcome on data sharing. We also perform ROC calculations. Figure 5 shows the ROC curve produced by the TextRank–BERT–BiLSTM model for the detection of persuasive news. The obtained curve is close to the (0,1) coordinate of the ROC space, indicating good performance.
Moreover, the accuracy comparison between the TextRank–BERT–BiLSTM model and other approaches proposed in previous studies is shown in Table 6. Table 6 shows previous research that is most closely related to this study. We selected them based on the methods and objects used. Our research exclusively utilizes a dataset of persuasive news articles written in the Indonesian language. No similar studies have been conducted thus far. Additionally, we employ a combination of text summarization and deep learning for persuasive news article classification, a novel approach that has not been previously attempted. Nevertheless, we demonstrate the accuracy of our proposed method in Table 6, which is comparable to prior research on news article classification. On the persuasive dataset, bold numbers in Table 6 show that the TextRank–BERT–BiLSTM model achieved an accuracy of up to 95%. Our proposed TextRank–BERT–BiLSTM model obtained the same result as our previous research, in which BERT–BiLSTM was used to detect native ads [10]. Our proposed model obtained the same result using more than one dataset. Text summarization enhances the proposed model better with the use of larger data. Text summarization is advantageous in shortening the length of news articles and creating a quality summary of the articles, and, as a result, the detection of persuasive news becomes more accurate.
In the years following 2010, the development of deep learning methods has brought about significant advancements in the field of text classification [31]. Various model architectures have been proposed and applied to text classification tasks. In this context, methods such as machine learning perceptron (MLP), convolutional neural networks (CNN), attention, and transformers are among the commonly used models. One relevant study was conducted by Kumar [32], in which he detected fake news using various deep-learning-based approaches. This research also incorporated ensemble deep learning techniques and models with attention mechanisms. We attempted several text classification model architectures using a persuasive news dataset. Table 7 presents the evaluation matrix of various text classification model architectures. Bold numbers in Table 6 show that our proposed method yielded a significant performance that surpasses various other methods. These results indicate that our proposed approach has strong potential to outperform various methods in text classification tasks.
The detection of persuasive news is an ongoing real-world challenge, especially in political news and native ads. It is a difficult task for machines because they must understand the essence of real news and persuasive news. Focusing only on the important information in the news content can result in a more accurate detection of persuasive news. It was proven that generating a more accurate and high-quality summary lead to an increased accuracy of persuasive news detection. In this study, we proposed an approach that utilizes text summarization methods. Verma [33] conducted a comparative study on text summarization methods due to the fact that text summarization methods can change a large-sized document into a short and detailed summary. Therefore, text summarization methods play an important role in generating high quality summaries of a large-sized document, which was the motivation behind the use of these methods before further processing by the classifier in our proposed model.
In our experiment, the quality of the summaries created by two different text summarization methods were evaluated for the task of detecting persuasive news. Reimers [34] introduced the sentence-BERT (SBERT) model, a modification of the pretrained BERT network that uses Siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine similarity. This innovative approach aims to enhance the quality of text summarization by embedding sentences or text passages into semantically meaningful vector representations. In the evaluation of the word embedding models, the BERT model exhibited a higher efficiency than the roBERTa model. Based on the experimental results, the use of text summarization had a positive impact in enhancing the detection results. In the absence of a computational method to detect persuasive news, we believe that the obtained results are very satisfactory. Furthermore, the achieved results are promising due to the use of text summarization.
An important factor of text summarization that influences the performance of the proposed models is that text summarization methods are able to generate detailed and precise summaries of the news articles for an efficient and effective processing of these articles. Text summarization aids in reducing dimensionality by condensing the text, mitigating issues such as overfitting while also conserving computational resources. Text summarization enhances the ability of a classification model in making more accurate decisions by distilling essential information from news articles and enabling the model to focus on the core content. Even though the direct impact on accuracy might not be substantial, text summarization still provides a significant contribution in optimizing the news content analysis process.
TextRank has the ability to access information from the entirety of a text and explore the similarity between sentences in the text and calculate the importance of each sentence. TextRank was shown to be more efficient than LSA. We believe the reason for this is due to the number of sentences parameter in the LSA method. A tuning process or an optimization algorithm is needed to determine the optimal number of sentences used as the parameter due to the differing number of sentences in each news article.
5.3. Theoretical and Practical Implications
From a theoretical point of view, the proposed model contributes to text management in the news sector by combining text summarization and classifiers methods. First, a text summarization method summarizes the news to take the essence of the news. According to the annotator, persuasive content only has a few words in the news, so text summarization helps extract the essence of persuasive content. Second, the word-embedding method is carried out after obtaining the results of the text summarization to convert the news into a vector representation. Third, we use deep learning to classify the news as containing persuasive content. Our experiments show that TextRank–BERT–BiLSTM outperforms other methods.
From a practical point of view, with the rapid development of technology, the number of news readers on electronic news portals is becoming bigger, plus there is a lot of persuasive content in the news implicitly, which brings a significant challenge to distinguish news and persuasive content. In fact, readers who know the persuasive content in the news must be careful in reading. Persuasive content detection, as an easy and accurate detection method, is also a technology to support readers not being deceived by persuasive content. There is no persuasive content detection on the news yet. Therefore, this work can find out implicitly persuasive content in the news outside the advertising category with high accuracy.
6. Conclusions
In recent years, text summarization methods have been introduced and researchers have taken advantage of these methods to shorten large-sized documents and generate detailed and precise summaries of large-sized documents for an efficient processing of these documents. Currently, there is yet to be a computational method to handle the challenging and complex task of detecting persuasive news. Therefore, this study proposes a new architecture for detecting persuasive news. It compared the performance of different combinations of text summarization methods, word-embedding models, and deep learning models in detecting persuasive news. For this purpose, we proposed the use of two text summarization methods (TextRank and LSA), two word-embedding models (BERT and roBERTa), and two deep learning models (CNN and BiLSTM) and compared the results obtained by different combinations of the aforementioned methods for the detection of persuasive news.
From the experimental results, the models that used text summarization obtained better results than the models that did not use text summarization. An important factor of text summarization that influences the performance of the proposed models is that text summarization methods are able to generate detailed and precise summaries of the news articles for an efficient and effective processing of these articles. The TextRank method was able to outperform LSA when used in different combinations of methods, except when used in the roBERTa–CNN model, in which both methods achieved the same results. The BiLSTM model was able to consistently outperform the CNN model. The experimental results indicate that the use of BiLSTM in combination with TextRank and BERT is able to achieve a significantly high accuracy of 95% for the detection of persuasive news. The proposed TextRank–BERT–BiLSTM model was also shown to outperform state-of-the-art models in detecting persuasive news. Overall, the text summarization methods were able to generate detailed and precise summaries of the news articles and the deep learning models were able to effectively differentiate between persuasive news and real news.
7. Future Works
In future works, exploration of other text summarization methods can be carried out to determine whether they can improve the performance of detection models. Furthermore, the incorporation of other features such as the author of the article, the publication date, or the number of social media shares can be performed to enhance the performance of detection models. Moreover, evaluation of models on real-world datasets can be carried out to assess their performance in practice. We will also implement our proposed models in a bigger research project that will aim to detect native ads based on several implicit characteristics of native ads. The methods used in the proposed models and the performance of the proposed models in this study will be taken into consideration in generating a model for the detection of native ads.
Author Contributions
Conceptualization, B.R.P.D., D.S. and D.P.; methodology, B.R.P.D., D.S. and D.P.; software, B.R.P.D.; validation, B.R.P.D.; formal analysis, D.S. and D.P.; investigation, B.R.P.D. and D.S.; resources, B.R.P.D.; data curation, B.R.P.D. and D.S.; writing—original draft preparation, B.R.P.D.; writing—review and editing, D.S. and D.P.; visualization, B.R.P.D.; supervision, D.S. and D.P.; project administration, D.S.; funding acquisition, D.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ministry of Education, Culture, Research, and Technology of Indonesia under the 2023 PDUPT Research Grant, grant number 009/E5/PG.02.00.PL/2023, and funded by Institut Teknologi Sepuluh Nopember with a doctoral fellowship under the terms of contract 1333/IT2/T/HK.00.01/2022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are openly available in FigShare at doi: 10.6084/m9.figshare.8269931.v1, [35].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Molina, M.D.; Sundar, S.S.; Le, T.; Lee, D. “Fake News” Is Not Simply False Information: A Concept Explication and Taxonomy of Online Content. Am. Behav. Sci. 2019, 65, 180–212. [Google Scholar] [CrossRef]
- Vatandas, S. Gazete Haberlerinde Korku Sunumunun Göstergebilimsel Çözümlemesi (COVID-19 Örneğinde). Elektron. Sos. Bilim. Derg. 2021, 20, 1060–1079. [Google Scholar] [CrossRef]
- Ashwell, D.; Murray, N. When Being Positive Might Be Negative: An Analysis of Australian and New Zealand Newspaper Framing of Vaccination Post Australia’s No Jab No Pay Legislation. Vaccine 2020, 38, 5627–5633. [Google Scholar] [CrossRef] [PubMed]
- Romanova, I.D.; Smirnova, I.V. Persuasive Techniques in Advertising. Train. Lang. Cult. 2019, 3, 55–70. [Google Scholar] [CrossRef]
- Sadeghi, F.; Bidgoly, A.J.; Amirkhani, H. Fake News Detection on Social Media Using a Natural Language Inference Approach. Multimed. Tools Appl. 2022, 81, 33801–33821. [Google Scholar] [CrossRef]
- Fawaid, J.; Awalina, A.; Krisnabayu, R.Y.; Yudistira, N. Indonesia’s Fake News Detection Using Transformer Network. In ACM International Conference Proceeding Series; Association for Computing Machinery: New York, NY, USA, 2021; pp. 247–251. [Google Scholar]
- Nasir, J.A.; Khan, O.S.; Varlamis, I. Fake News Detection: A Hybrid CNN-RNN Based Deep Learning Approach. Int. J. Inf. Manag. Data Insights 2021, 1, 100007. [Google Scholar] [CrossRef]
- Eberhard, D.M.; Simons, G.F.; Fennig, C.D. What Are the Top 200 Most Spoken Languages? Ethnologue. 2020. Available online: https://www.ethnologue.com/guides/ethnologue200 (accessed on 15 May 2023).
- Suryavanshi, A.; Gujare, B.; Mascarenhas, A.; Tekwani, B. Hindi Multi-Document Text Summarization Using Text Rank Algorithm. Int. J. Comput. Appl. 2021, 174, 27–29. [Google Scholar] [CrossRef]
- Darnoto, B.R.P.; Siahaan, D.; Purwitasari, D. Deep Learning for Native Advertisement Detection in Electronic News: A Comparative Study. In Proceedings of the 2022 11th Electrical Power, Electronics, Communications, Controls and Informatics Seminar (EECCIS), Malang, Indonesia, 23–25 August 2022; pp. 304–309. [Google Scholar]
- Quoc Tran, K.; Trong Nguyen, A.; Hoang, P.G.; Luu, C.D.; Do, T.H.; Van Nguyen, K. Vietnamese Hate and Offensive Detection Using PhoBERT-CNN and Social Media Streaming Data. Neural Comput. Appl. 2023, 35, 573–594. [Google Scholar] [CrossRef]
- Fouad, K.M.; Sabbeh, S.F.; Medhat, W. Arabic Fake News Detection Using Deep Learning. Comput. Mater. Contin. 2022, 71, 3647–3665. [Google Scholar] [CrossRef]
- Ramya, S.P.; Eswari, R. Attention-Based Deep Learning Models for Detection of Fake News in Social Networks. Int. J. Cogn. Inform. Nat. Intell. 2021, 15, 1–25. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Habib, A.; Habib, A.; Khan, A.; Ali, R.; Khattak, A. Exploring Deep Neural Networks for Rumor Detection. J. Ambient. Intell Humaniz. Comput. 2021, 12, 4315–4333. [Google Scholar] [CrossRef]
- Samadi, M.; Mousavian, M.; Momtazi, S. Deep Contextualized Text Representation and Learning for Fake News Detection. Inf. Process Manag. 2021, 58, 102723. [Google Scholar] [CrossRef]
- Ding, L.; Zhang, Z.; Liu, H.; Li, J.; Yu, G. Automatic Keyphrase Extraction from Scientific Chinese Medical Abstracts Based on Character-Level Sequence Labeling. J. Data Inf. Sci. 2021, 6, 35–57. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, EMNLP 2004—A Meeting of SIGDAT, a Special Interest Group of the ACL Held in Conjunction with ACL 2004, Catalunya, Spain, 25–26 July 2004. [Google Scholar]
- To, H.Q.; Nguyen, K.V.; Nguyen, N.L.T.; Nguyen, A.G.T. Monolingual versus Multilingual BERTology for Vietnamese Extractive Multi-Document Summarization. In Proceedings of the 35th Pacific Asia Conference on Language, Information and Computation, PACLIC 2021, Shanghai, China, 7–12 November 2021. [Google Scholar]
- Beskow, D.M.; Kumar, S.; Carley, K.M. The Evolution of Political Memes: Detecting and Characterizing Internet Memes with Multi-Modal Deep Learning. Inf. Process Manag. 2020, 57, 102170. [Google Scholar] [CrossRef]
- Gupta, K.; Gautam, D.; Mamidi, R. Volta at SemEval-2021 Task 6: Towards Detecting Persuasive Texts and Images Using Textual and Multimodal Ensemble. Available online: https://aclanthology.org/2021.semeval-1.149/ (accessed on 15 May 2023).
- Luhn, H.P. The Automatic Creation of Literature Abstracts. IBM J. Res. Dev. 1958, 2, 159–165. [Google Scholar] [CrossRef]
- Edmundson, H.P. New Methods in Automatic Extracting. J. ACM 1969, 16, 264–285. [Google Scholar] [CrossRef]
- Erkan, G.; Radev, D.R. LexRank: Graph-Based Lexical Centrality as Salience in Text Summarization. J. Artif. Intell. Res. 2004, 22, 457–479. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, X. Generic Text Summarization Using Relevance Measure and Latent Semantic Analysis. In Proceedings of the SIGIR Forum (ACM Special Interest Group on Information Retrieval), Online, 11–15 July 2021; pp. 19–25. [Google Scholar]
- Hasanah, N.A.; Suciati, N.; Purwitasari, D. Identifying Degree-of-Concern on COVID-19 Topics with Text Classification of Twitters. Regist. J. Ilm. Teknol. Sist. Inf. 2021, 7, 50–62. [Google Scholar] [CrossRef]
- Dong, Y.; Fu, Y.; Wang, L.; Chen, Y.; Dong, Y.; Li, J. A Sentiment Analysis Method of Capsule Network Based on BiLSTM. IEEE Access 2020, 8, 37014–37020. [Google Scholar] [CrossRef]
- Priyadarshini, I.; Cotton, C. A Novel LSTM–CNN–Grid Search-Based Deep Neural Network for Sentiment Analysis. J. Supercomput. 2021, 77, 13911–13932. [Google Scholar] [CrossRef]
- Rhanoui, M.; Mikram, M.; Yousfi, S.; Barzali, S. A CNN-BiLSTM Model for Document-Level Sentiment Analysis. Mach Learn. Knowl Extr. 2019, 1, 832–847. [Google Scholar] [CrossRef]
- Aslam, N.; Ullah Khan, I.; Alotaibi, F.S.; Aldaej, L.A.; Aldubaikil, A.K. Fake Detect: A Deep Learning Ensemble Model for Fake News Detection. Complexity 2021, 2021, 5557784. [Google Scholar] [CrossRef]
- Elsaeed, E.; Ouda, O.; Elmogy, M.M.; Atwan, A.; El-Daydamony, E. Detecting Fake News in Social Media Using Voting Classifier. IEEE Access 2021, 9, 161909–161925. [Google Scholar] [CrossRef]
- Wang, Z. Deep Learning Based Text Classification Methods. Highlights Sci. Eng. Technol. 2023, 34, 238–243. [Google Scholar] [CrossRef]
- Kumar, S.; Asthana, R.; Upadhyay, S.; Upreti, N.; Akbar, M. Fake News Detection Using Deep Learning Models: A Novel Approach. Trans. Emerg. Telecommun. Technol. 2020, 31, 3767. [Google Scholar] [CrossRef]
- Verma, P.; Pal, S.; Om, H. A Comparative Analysis on Hindi and English Extractive Text Summarization. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2019, 18, 1–39. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 4 November 2019. [Google Scholar]
- Dataset Persuasive News. Available online: https://figshare.com/articles/dataset/Dataset_Persuasive_xlsx/23805354/1 (accessed on 30 July 2023).
Figure 1.
The flow of the two text summarizations methods: (a) TextRank, (b) LSA.

Figure 2.
The architecture of the two classifiers: (a) CNN, (b) BiLSTM.


Figure 3.
Proposed method (text summarization–deep learning).

Figure 4.
Distribution of categories for the persuasive news and real news labels.

Figure 5.
The ROC curve of the TextRank–BERT–BiLSTM model.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Description of six online news portals.
| URL | Description | Category | Scraping Period |
|---|---|---|---|
| Kompas.com (2000 Article) | Indonesia’s leading online news platform that provides up-to-date and reliable information on various aspects of life, from political news, economics, to sports and entertainment | Politics, economics, business, technology, sports, entertainment, and lifestyle | August–September 2022 |
| Detik.com (2000 Article) | A news portal that presents a variety of the latest information from within and outside the country including political, economic, and entertainment news with a simple appearance | National, regional, business, technology, entertainment, sports, science, automotive, property, and travel | September–October 2022 |
| Tempo.co (2000 Article) | A news portal that presents various investigative reports, political, economic news, and a variety of other interesting content with a critical and in-depth approach | Politics, economics, business, law, technology, sports, entertainment, lifestyle, and travel | October–November 2022 |
| Cnnindonesia.com (2000 Article) | A news site that presents national and international news in a style that combines multimedia journalism, covering political, economic, to technological and lifestyle news | National, international, political, economic, technological, sports, entertainment, lifestyle, health, and science | November–December 2022 |
| Viva.co.id (2000 Article) | A news and entertainment platform that provides the latest and interesting news about politics, economy, and lifestyle with a fresh look and varied content | Politics, economy, business, technology, entertainment, sports, lifestyle, property, travel, and automotive | December 2022–January 2023 |
| Sindonews.com (2000 Article) | A news portal that provides a variety of up-to-date information, especially in terms of politics, economics, sports, and law, with an in-depth and factual approach. | National, political, legal, economic, sports, technology, entertainment, and lifestyle. | January–February 2023 |
Table 2.
The statistics of the persuasive dataset.
| Category | Total Data | News Label | Persuasive Label | Average Sentences | Average Words |
|---|---|---|---|---|---|
| Education | 92 | 46 | 46 | 25 | 617 |
| Finance | 126 | 63 | 63 | 28 | 623 |
| Food | 145 | 72 | 73 | 24 | 683 |
| Health | 146 | 73 | 73 | 30 | 634 |
| Lifestyle | 150 | 75 | 75 | 25 | 617 |
| Megapolitan | 151 | 76 | 75 | 25 | 712 |
| National | 154 | 76 | 76 | 29 | 661 |
| Automotive | 161 | 80 | 81 | 24 | 701 |
| Regional | 164 | 82 | 82 | 25 | 636 |
| Sport | 165 | 83 | 82 | 20 | 607 |
| Technology | 166 | 83 | 83 | 24 | 617 |
| Travel | 72 | 36 | 36 | 27 | 684 |
| SME | 16 | 8 | 8 | 21 | 711 |
Table 3.
Experimental setup.
| Methods | Layers |
|---|---|
| BiLSTM | Bidirectional layer (units = 100), GlobalMaxPooling1D layer, dropout layer (rate = 0.2), dense layer (units = 2, activation = sigmoid) |
| CNN | Convo1D layer (filter = 32, kernel size = 3, activation = relu), GlobalMaxPooling1D, dropout layer (rate = 0.2), and dense layer (units = 2, activation = sigmoid) |
Table 4.
The performance comparison between the proposed models with the use of different combinations of text summarization methods, word-embedding models, and deep learning models.
Table 4.
The performance comparison between the proposed models with the use of different combinations of text summarization methods, word-embedding models, and deep learning models.
| Text Summarization | Word Embedding | Classifier | Accuracy | F1 Score | Precision | Recall | AUC |
|---|---|---|---|---|---|---|---|
| - | BERT | BiLSTM | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 |
| LSA | BERT | BiLSTM | 0.87 | 0.87 | 0.87 | 0.87 | 0.87 |
| TextRank | BERT | BiLSTM | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 |
| - | BERT | CNN | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 |
| LSA | BERT | CNN | 0.87 | 0.87 | 0.87 | 0.87 | 0.87 |
| TextRank | BERT | CNN | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 |
| - | roBERTa | BiLSTM | 0.85 | 0.846 | 0.856 | 0.84 | 0.84 |
| LSA | roBERTa | BiLSTM | 0.76 | 0.76 | 0.76 | 0.76 | 0.76 |
| TextRank | roBERTa | BiLSTM | 0.87 | 0.87 | 0.87 | 0.87 | 0.87 |
| - | roBERTa | CNN | 0.77 | 0.77 | 0.79 | 0.79 | 0.79 |
| LSA | roBERTa | CNN | 0.77 | 0.77 | 0.77 | 0.77 | 0.77 |
| TextRank | roBERTa | CNN | 0.84 | 0.84 | 0.84 | 0.84 | 0.84 |
Bold numbers indicate models that have almost the same matrix confusion value, at least 90% of the 12 models we used.
Table 5.
The performance comparison between the proposed models with parameter tuning.
| Method | Accuracy | Precision | Recall | F1 Score | AUC Score |
|---|---|---|---|---|---|
| BiLSTM–BERT–TextRank | 0.95 | 0.95 | 0.95 | 0.95 | 0.95 |
| BiLSTM–BERT | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 |
| CNN–BERT–TextRank | 0.94 | 0.94 | 0.94 | 0.94 | 0.94 |
| CNN–BERT | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 |
Bold numbers show that TextRank–BERT–BiLSTM obtains the best value among other models with a confusion matrix value of 95%.
Table 6.
The accuracy comparison between the proposed TextRank–BERT–BiLSTM model and other models.
| Method | Accuracy |
|---|---|
| BERT–BiLSTM FNID–FakeNewsNet dataset [5] | 0.90 |
| BERT–BiLSTM FNID-LIAR dataset [5] | 0.39 |
| BERT for Indonesia fake news [6] | 0.90 |
| Ensemble-based deep learning model [29] | 0.898 |
| BiLSTM for Arabic fake news [12] | 0.848 |
| BERT–BiLSTM for detection of native ads [10] | 0.95 |
| Ours (TextRank–BERT–BiLSTM) | 0.95 |
Bold numbers show that our proposed method yielded a significant performance that surpasses various other methods.
Table 7.
State-of-the-art comparison methods.
| Method | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| BERT (transformer) | 0.92 | 0.95 | 0.9 | 0.93 |
| BiLSTM–CNN–attention (attention) | 0.9 | 0.91 | 0.89 | 0.9 |
| BiLSTM–LSTM (ensemble model) | 0.57 | 0.61 | 0.53 | 0.45 |
| MLP (feed forward) | 0.88 | 0.88 | 0.88 | 0.88 |
| TextRank–BERT–BiLSTM (proposed method) | 0.95 | 0.95 | 0.95 | 0.95 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Darnoto, B.R.P.; Siahaan, D.; Purwitasari, D. Automated Detection of Persuasive Content in Electronic News. Informatics 2023, 10, 86. https://doi.org/10.3390/informatics10040086
AMA Style
Darnoto BRP, Siahaan D, Purwitasari D. Automated Detection of Persuasive Content in Electronic News. Informatics. 2023; 10(4):86. https://doi.org/10.3390/informatics10040086
Chicago/Turabian StyleDarnoto, Brian Rizqi Paradisiaca, Daniel Siahaan, and Diana Purwitasari. 2023. "Automated Detection of Persuasive Content in Electronic News" Informatics 10, no. 4: 86. https://doi.org/10.3390/informatics10040086
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.