
PERSEUS-HUB: Interactive and Collective Exploration of Large-Scale Graphs


Abstract
:1. Introduction
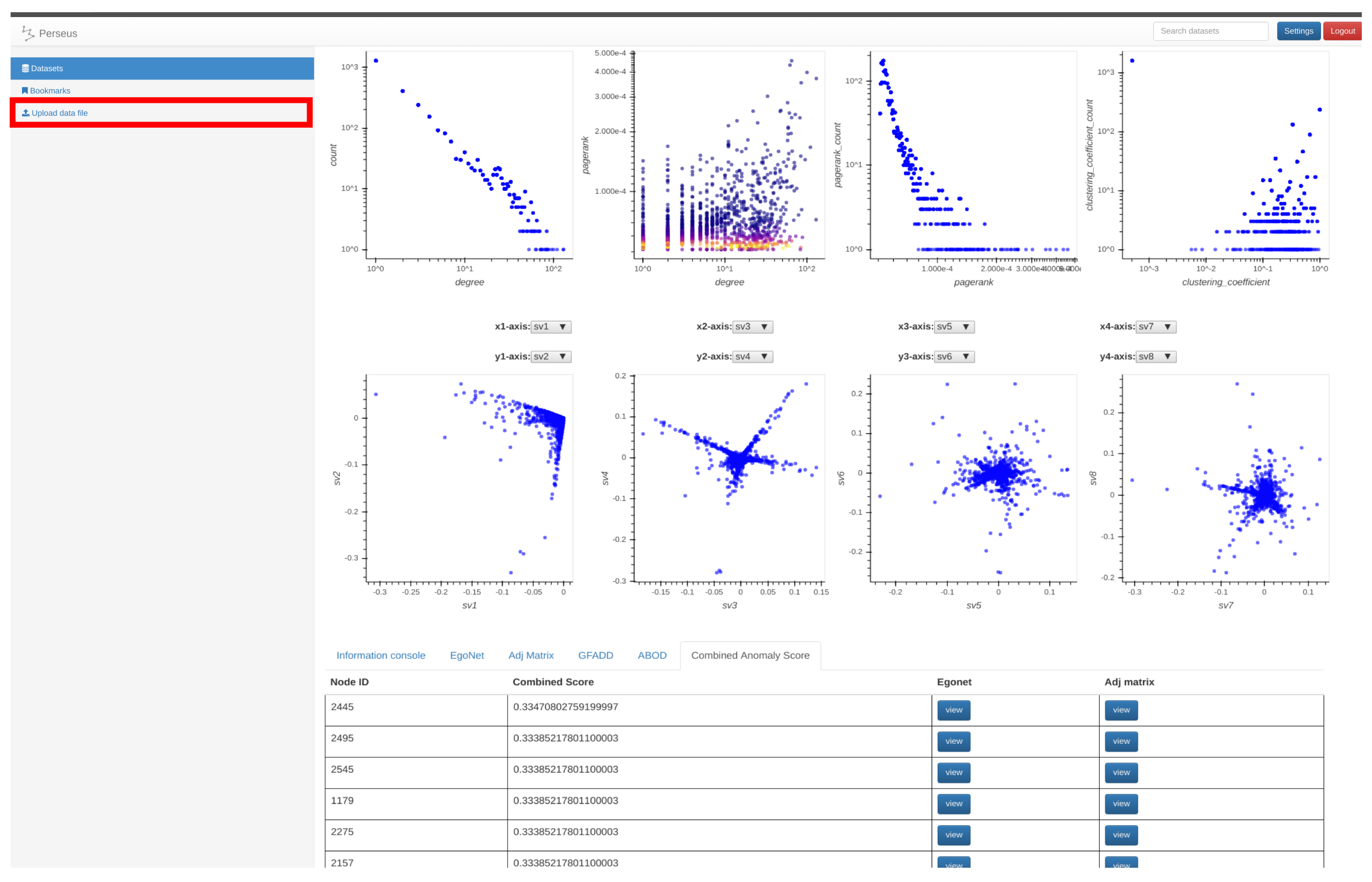
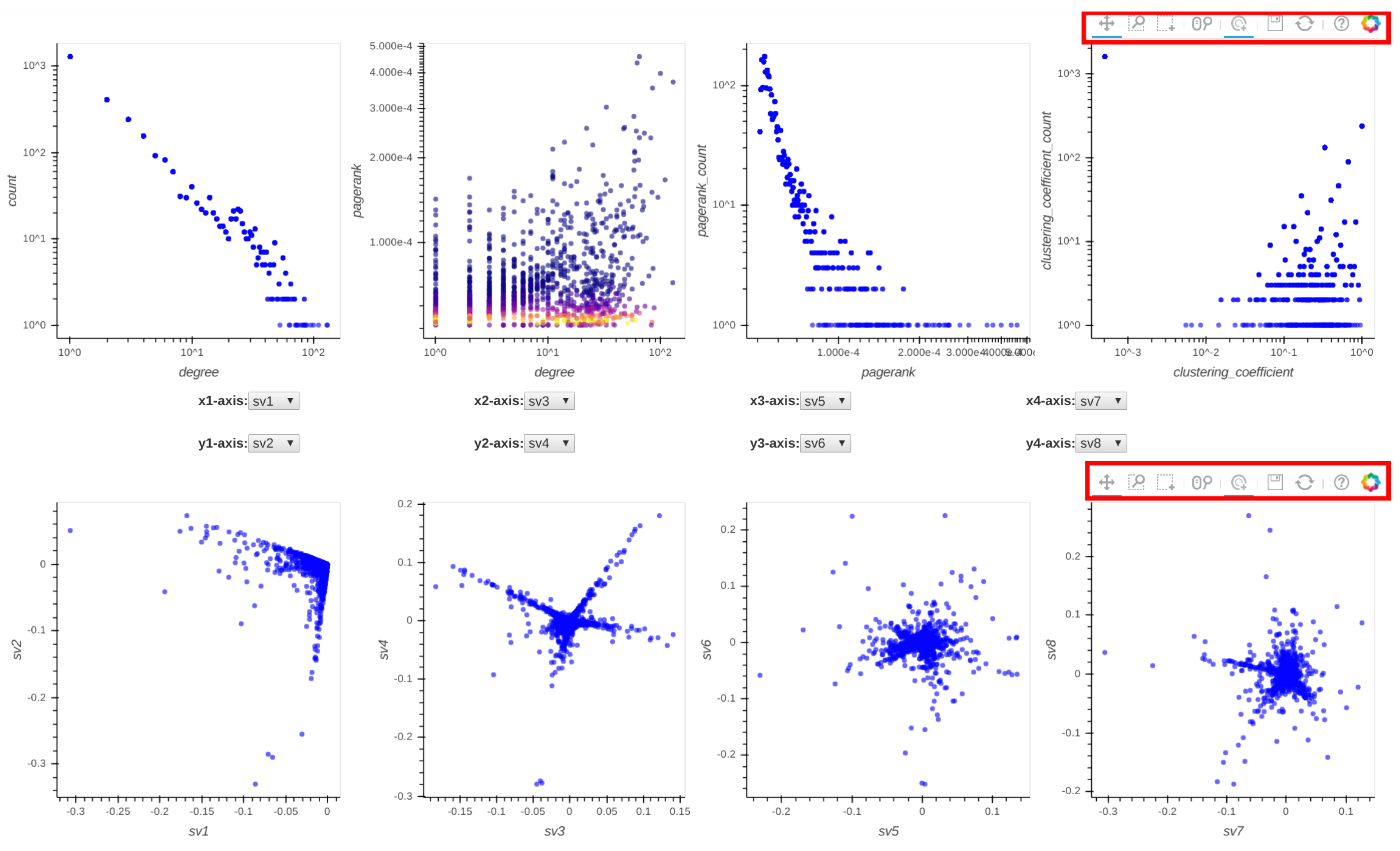
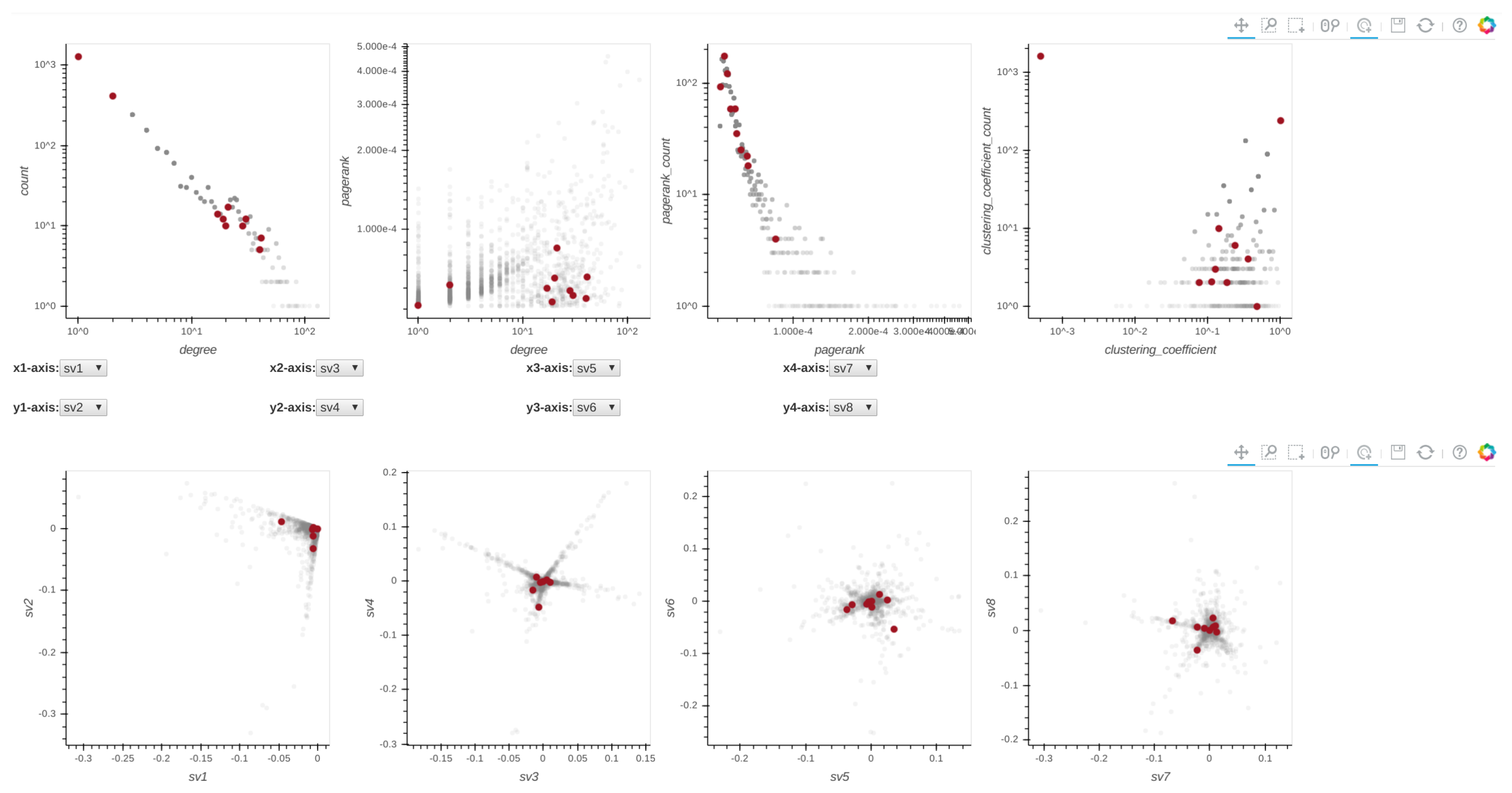
- Two-Level Summarization Scheme: To summarize the input graph efficiently, Perseus-Hub interactively visualizes both aggregate and node-specific patterns. It summarizes the graph data in terms of univariate and bivariate distributions—such as the clustering coefficient distribution and the degree vs. PageRank distribution—to reveal different aspects of the input graph. The compliance to or deviation from common laws in the distributions (e.g., power-law pattern in social networks) can guide attention to specific nodes or graph regions. At the aggregate level, points that are close to each other in the plots are aggregated into ‘super-points’ to efficiently render, visualize, and support interaction with the distribution plots for graphs with even millions of nodes. At the node-specific level, detailed information can be obtained for fine-granularity analysis such as queries for per node statistics.
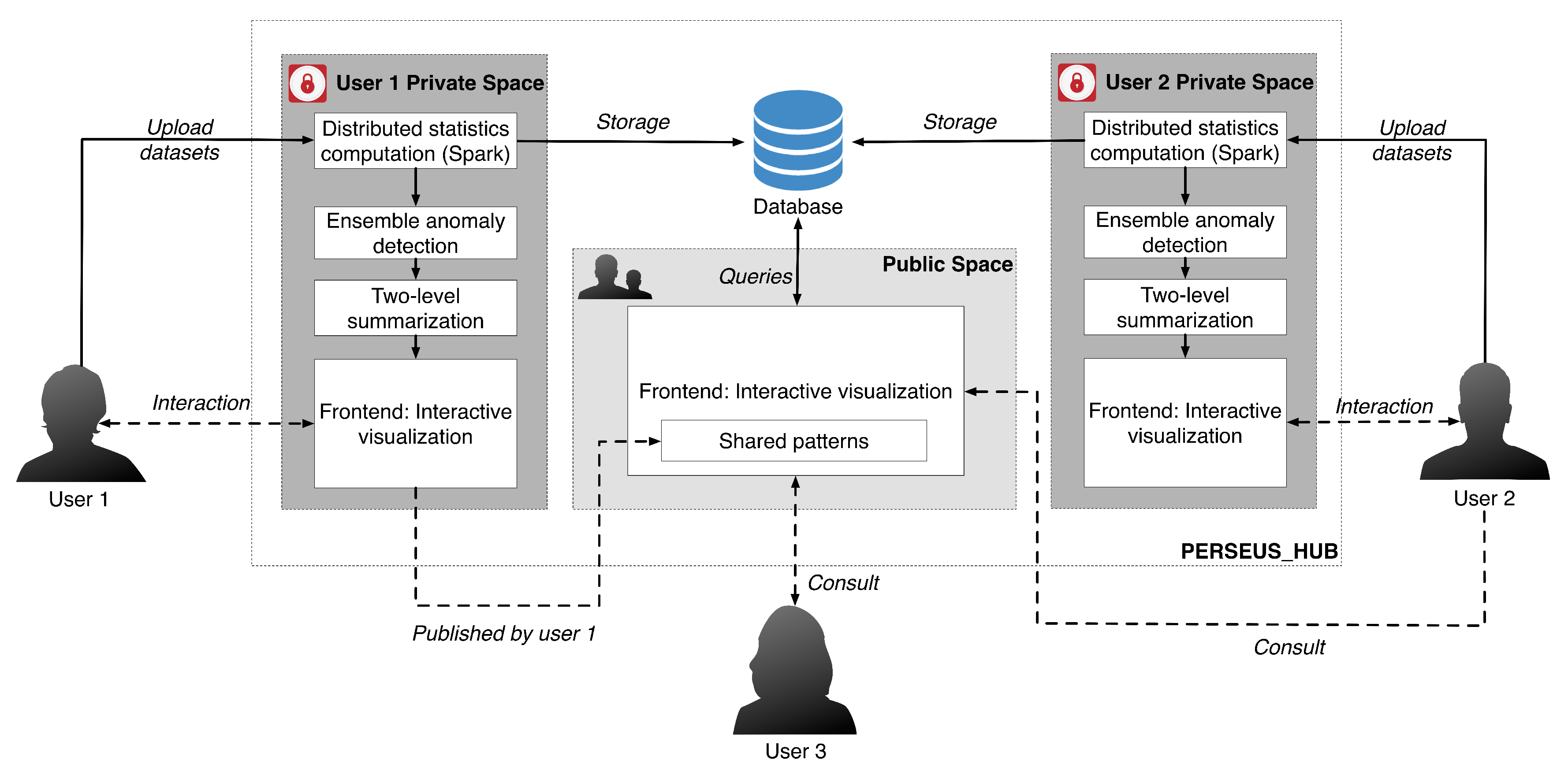
- Collective Data Analysis: To make graph analysis effective and comprehensive for non-experts, Perseus-Hub supports publicly sharing processed data and discovered patterns to help other analysts with their exploration. The Perseus-Hub service runs on a public AWS (Amazon Web Service) EMR (Elastic MapReduce) Spark cluster and displays datasets and discovered patterns, enabling collective analysis and ‘shared’ knowledge. Especially non-experts can benefit from interacting with the discoveries of expert users, and this has potential to advance the knowledge in interdisciplinary domains.
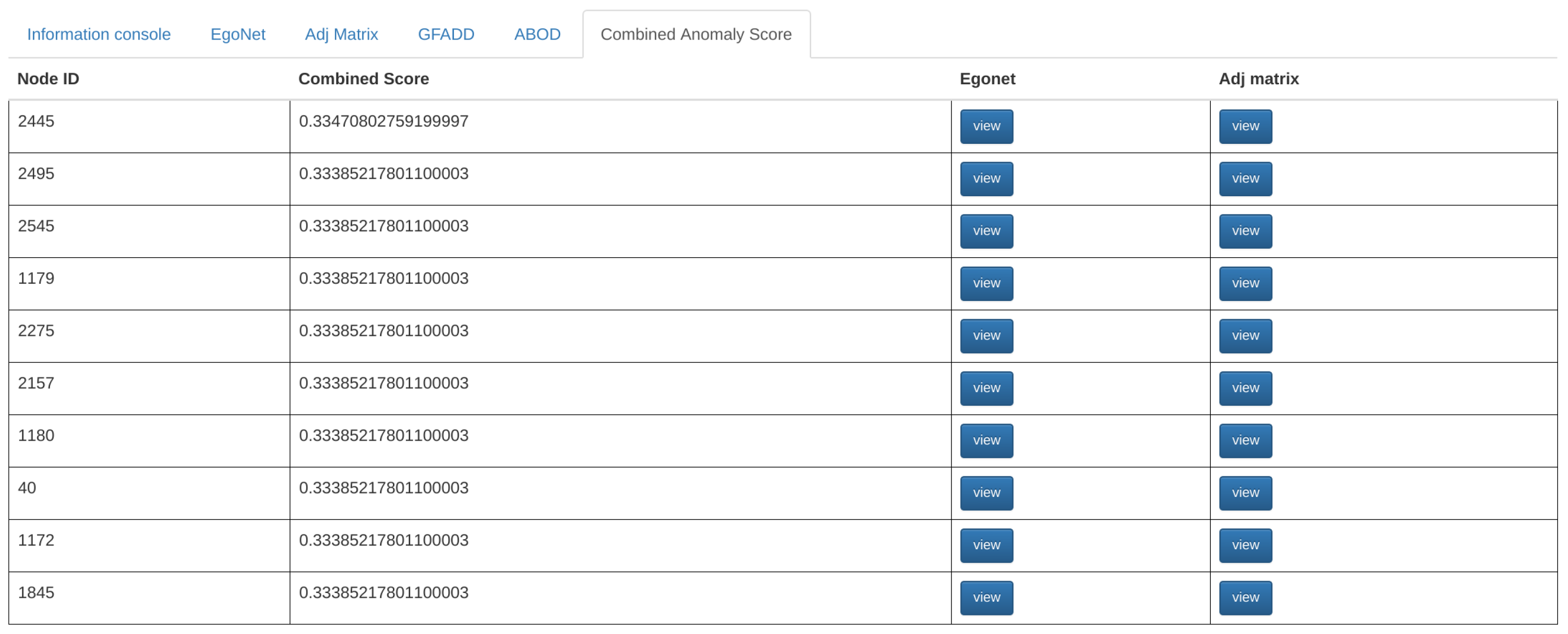
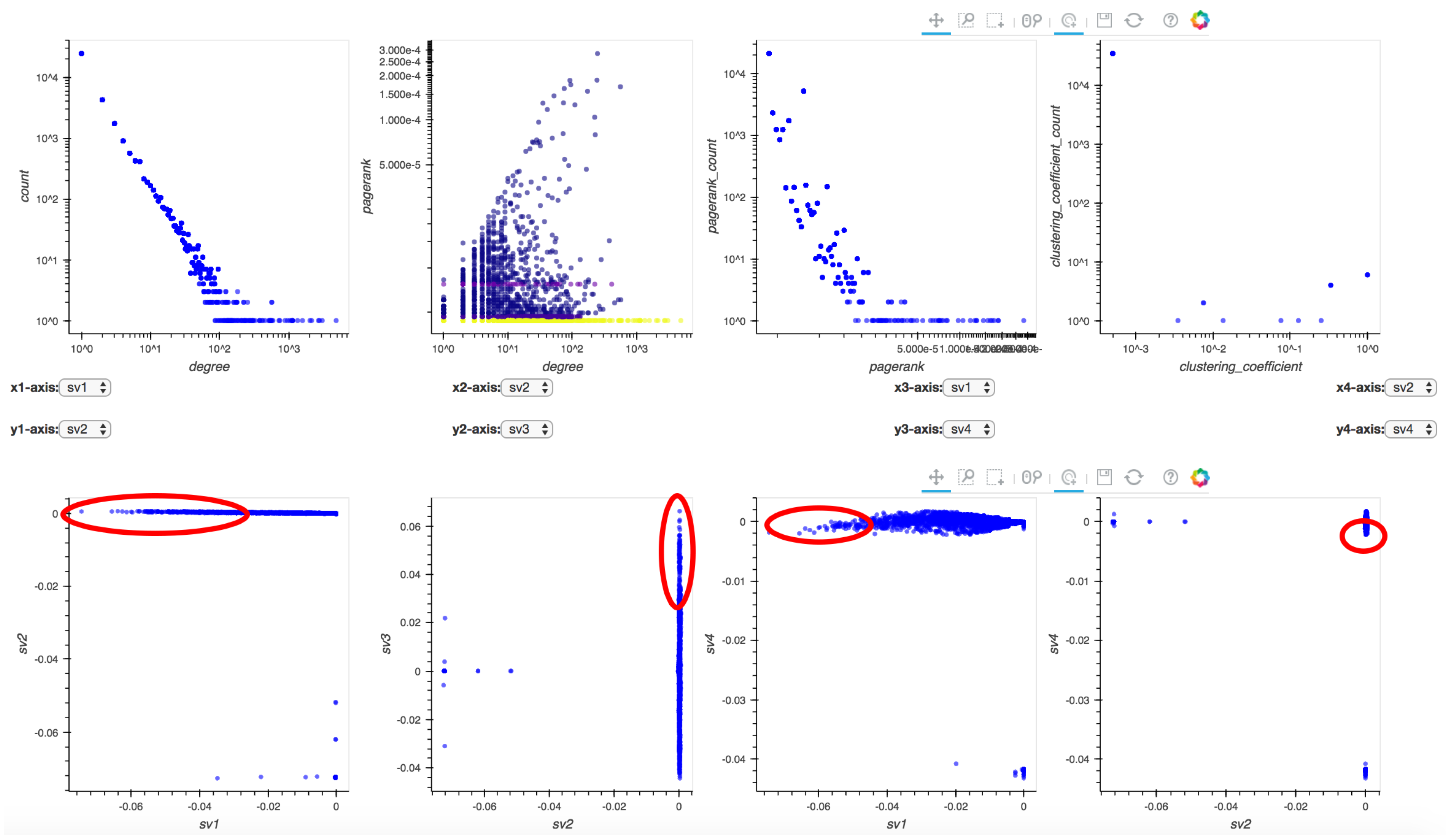
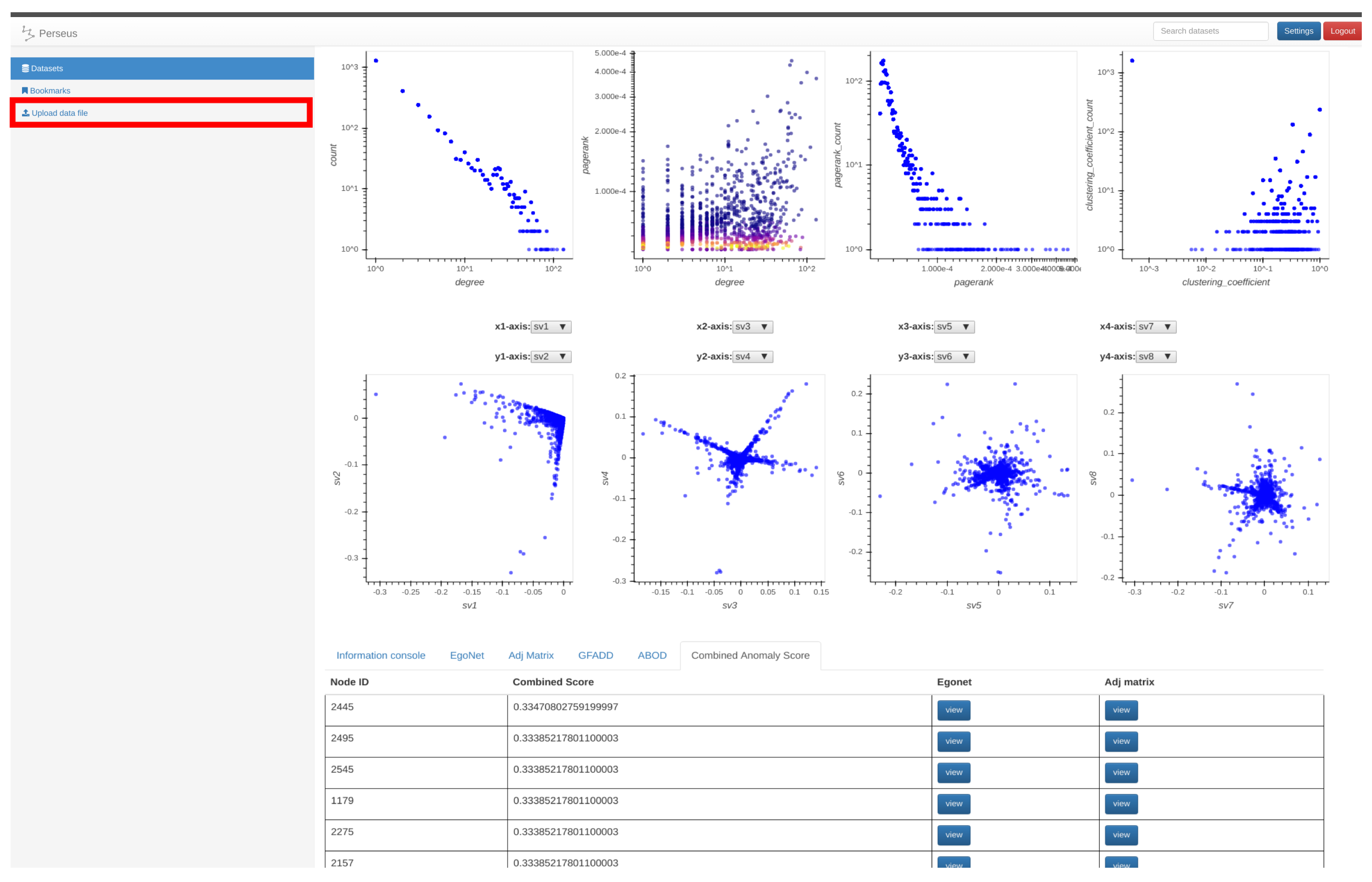
- Ensemble Anomaly Detection: In addition to collective data analysis that can guide user attention to regions that are identified as interesting by other analysts or experts, Perseus-Hub runs multiple scalable anomaly detection algorithms on the summarized statistics distributions to identify outliers of various types in an ensemble manner. For this purpose, the system leverages algorithms such as G-FADD (Grid Fast Anomaly Detection algorithm given Duplicates [11]), a fast, density- based anomaly detection method to find local and global outliers in the distribution plots, as well as ABOD (Angle Based Outlier Detection [12]), an angle-based outlier detection method that is particularly suitable for analyzing highly dimensional data.
2. Related Work
2.1. Graph Visualization and Interactive Analytics
2.2. Anomaly Detection
3. Perseus-Hub: System Description
3.1. Module 1: Efficient Computation of Graph Statistics
3.1.1. Degree Centralities and Degree Distribution
3.1.2. PageRank Centralities and PageRank Distribution
| Algorithm 1 Weighted PageRank (wpr). | |
| Input: weighted edges RDD : <srcID, (dstID, w)>, total number of iteration: iter_max, dampling factor: d | |
| Output: Weighted PageRank RDD, : <nodeID, > | |
| nodeID | // Set of all node IDs |
| // Getting total number of nodes in the graph | |
| < | // Initializing for each node as |
| while iter ≤ iter_max do | |
| temp = group by srcID (key), | // Joining edges with of srcID |
| join with by srcID (key) | // temp: <<><>> |
| contribs = map temp to in Equation (1) | // calculating contribution term for each node |
| reduce contribs by key, | // adding up all contribution term, |
| multiply the sum by d and add (1-d)/N | // update weighted PageRank for each node |
| iter | |
| end while | |
| return | |
3.1.3. Clustering Coefficient
| Algorithm 2 CCFinder [45]. | |
| Input: edge_list: <srdID, dstID> | |
| Output: Local Clustering Coefficient for every node, lccRdd: <nodeID, lcc> | |
| nodeID | |
| // Getting the total number of nodes in the graph | |
| edge_list = <srdID, dstID> ∪ <dstID, srdID> | // Getting reversed edges |
| edge_list = group edge_list by nodeID (key), | // Appending nbrDeg to <nodeID, [(nbrIDs)]> |
| append neighbor degree after nbrID | // <nodeID, [(nbrID, nbrDeg)]> |
| fonlRdd = createFONL(edge_list) | // Creating FONL Structure |
| save fonlRdd both in memory and on disk | |
| candRdd = map fonlRdd to <nbrID, (nodeID, [(nbrIDs)])> | // Creating Candidate List |
| ∀ nbrIDi∈ [(nbrIDs)], nbrDegi≥ nbrDeg | |
| triRdd = join candRdd with fonlRdd by nodeID, | // Counting the number of triangles |
| compute triCounts = | fonlRdd.[(nbrIDs)] ∩ candRdd.[(nbrIDs)] | | |
| map to the form <nodeID, triCounts> and reduce by nodeID | |
| lccRdd = map triRdd to get local clustering coefficient using Equation (3) | // Computing lccRdd |
| return lccRdd | |
| function createFONL(edge_list) | |
| compute nodeDeg, ∀ nodeID ∈ edge_list | |
| [(nbrIDs)] = sort or | |
| // Filtering and sorting edge_list | |
| by (nbrDeg and nbrID) in ascending order | |
| return <nodeID, nodeDeg, [(nbrIDs)]> | |
| end function | |
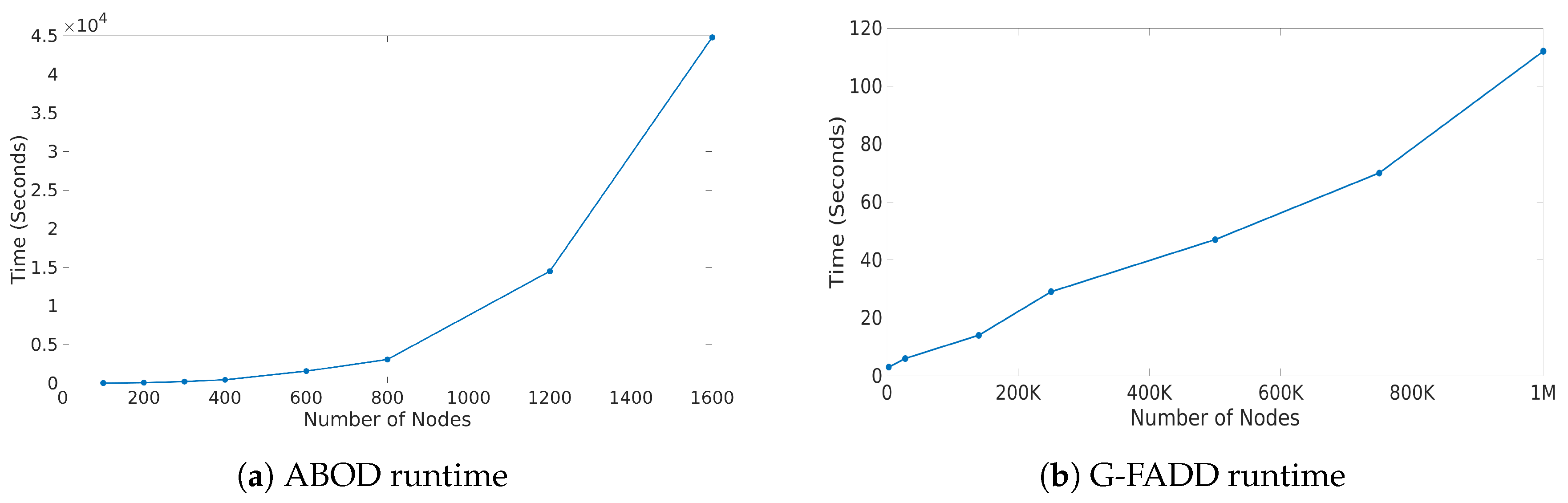
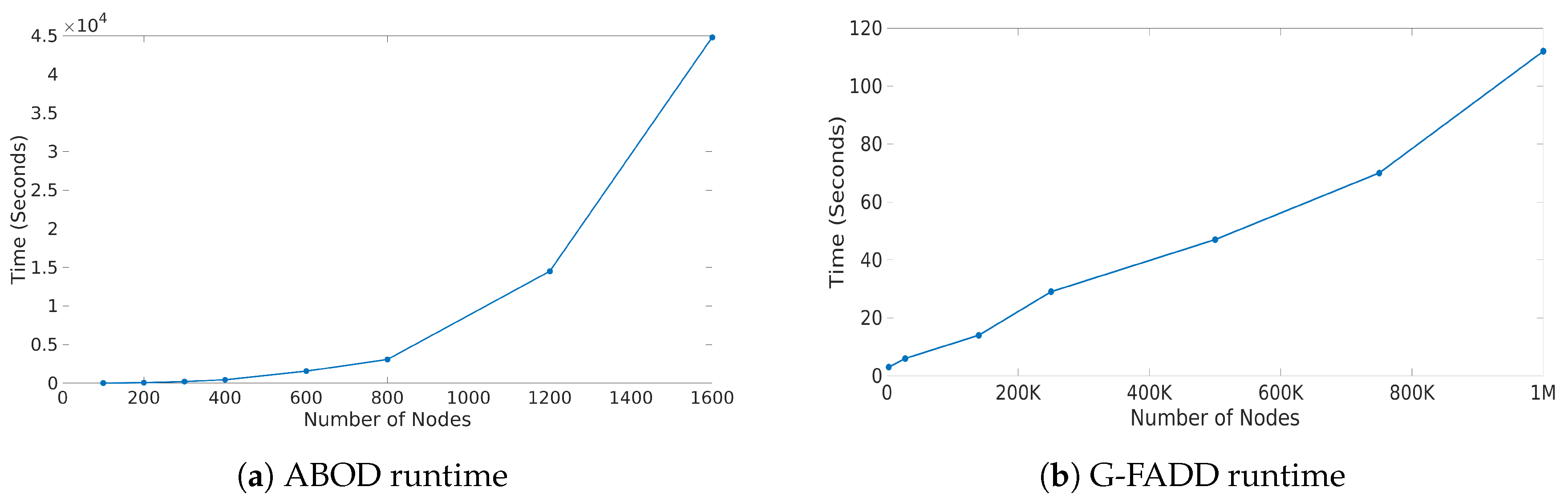
3.1.4. Execution Time Analysis
3.2. Module 2: Multi-View, Ensemble Anomaly Detection
3.2.1. Multi-View, Ensemble Anomaly Detection: Approach
- ABOD (Angle Based Outlier Detection [12]), an anomaly detection method that assesses the variance in the angles between the different vectors of a point to other points. ABOD is particularly effective for high-dimensional data since effects from the “curse of dimensionality” are alleviated compared to purely distance-based approaches.
- G-FADD (Grid-Based Fast Outlier Detection algorithm given Duplicates [38]), a density-based anomaly detection method that is remarkably fast in determining outliers from multi-dimensional points with a large number of (near-) duplicates (i.e., points that have almost the same coordinates). Specifically, by considering identical coordinates in an n-dimensional space as a super node with their duplicate count information, G-FADD can compute anomalousness scores much faster than other density-based approaches such as LOF [37] (Local Outlier Factor), which do not treat duplicate nodes specially, and are inefficient at handling real datasets with many near-duplicate points. The time complexity of LOF is near-quadratic with respect to the number of duplicates, whereas for G-FADD it is near-linear.
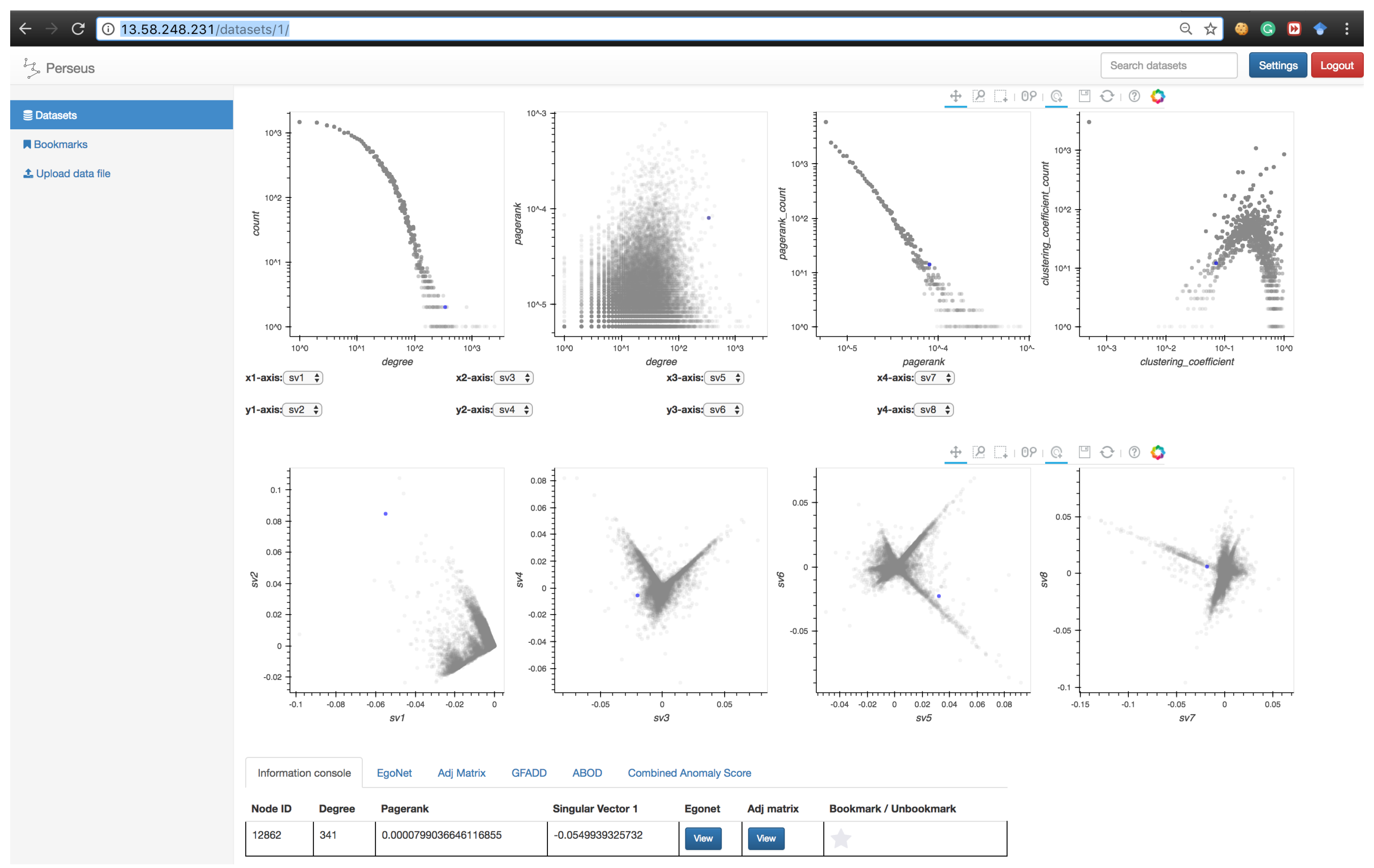
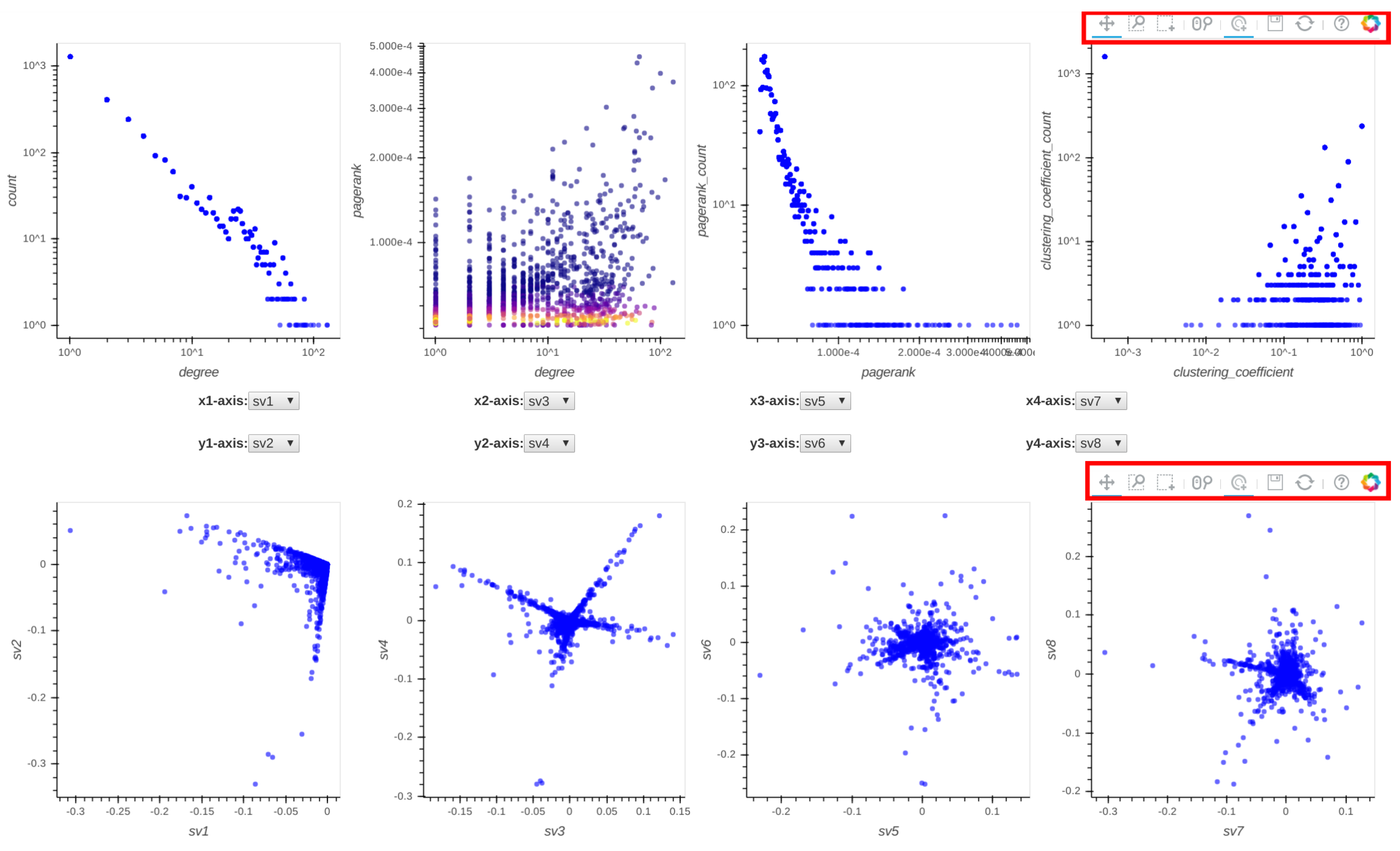
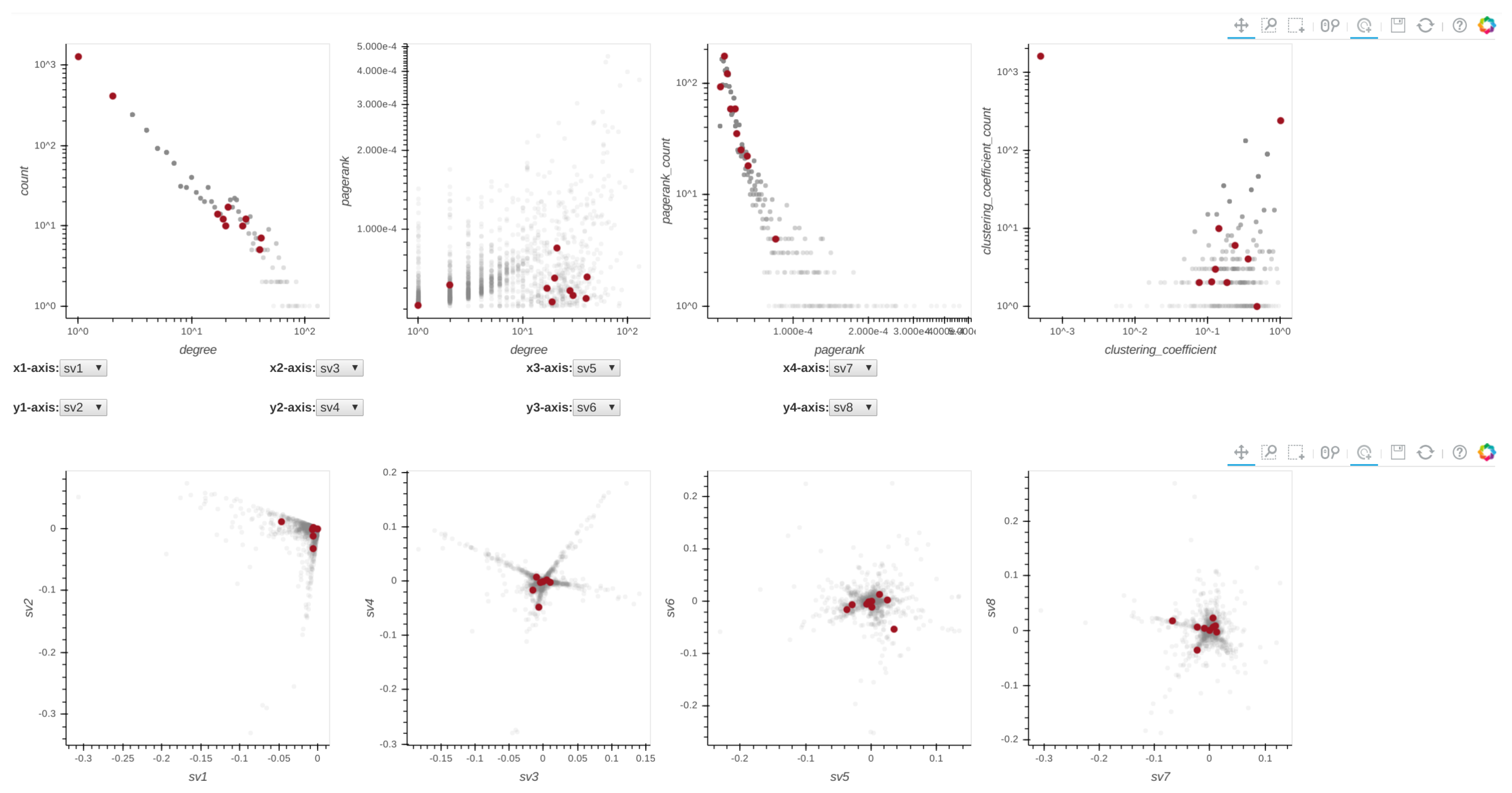
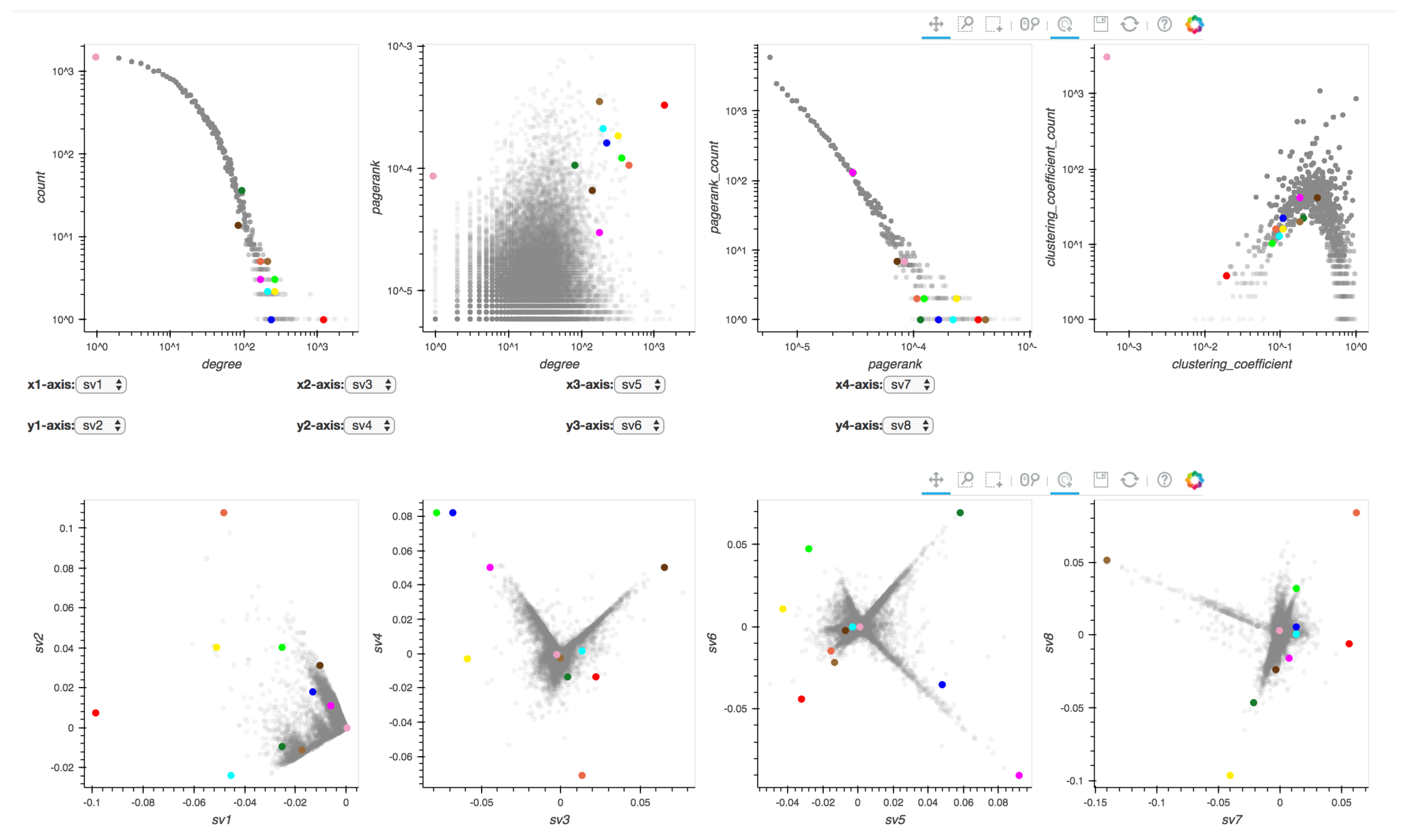
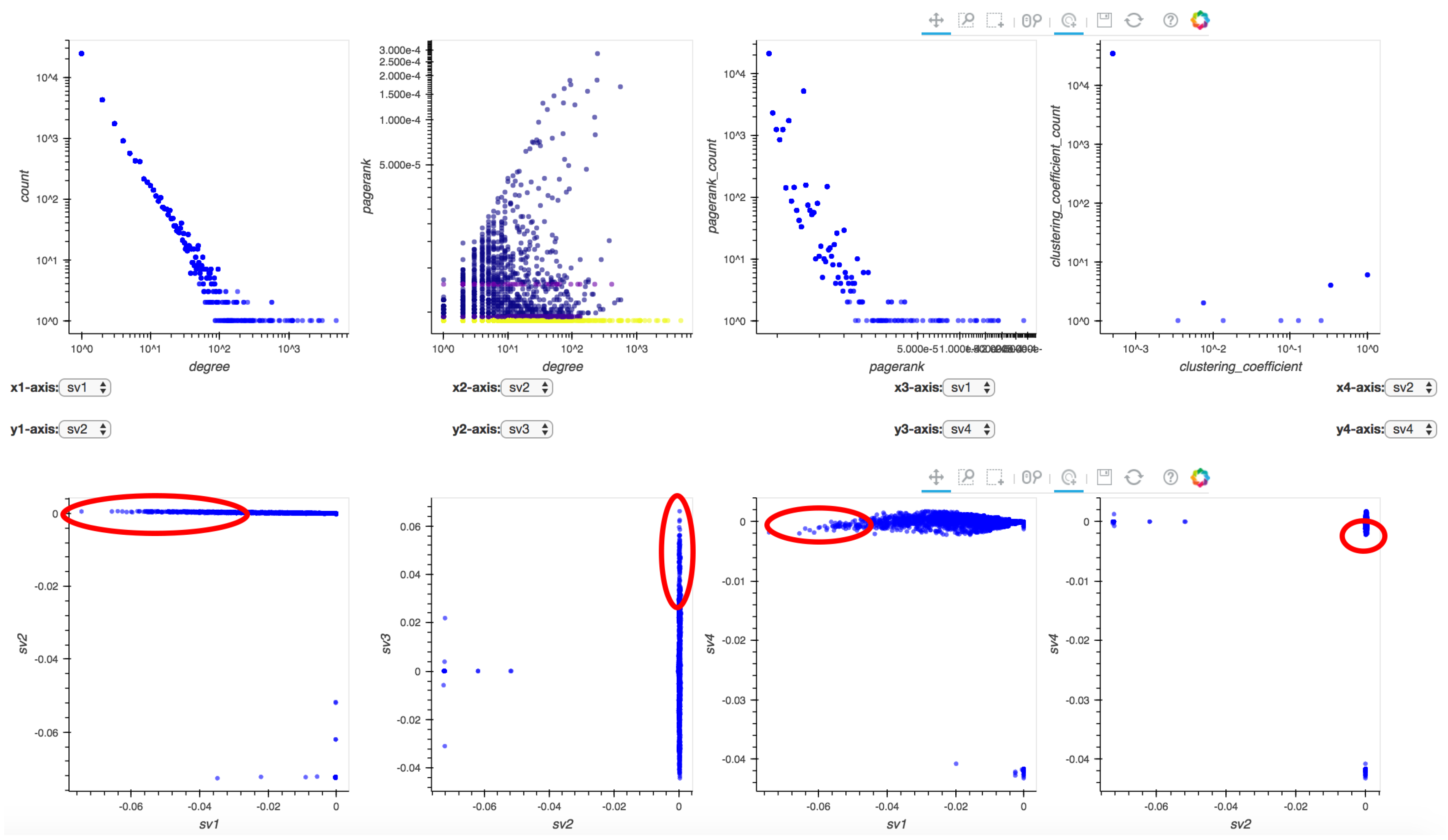
- : Degree distribution plot,
- : Two-dimensional distribution (or correlation plot) of degree vs. PageRank,
- : PageRank distribution plot,
- : Clustering coefficient distribution plot,
- to : Five pairwise singular vector () plots— vs. , vs. , vs. , vs. and vs. , respectively (where is the singular vector of a graph’s adjacency matrix). By default, the frontend shows the first four pairs of singular vectors. However, when Perseus-Hub computes the combined anomalousness scores, all plots are considered.
3.2.2. Scalability
3.3. Module 3: Frontend Visualization
3.3.1. Aggregated Summarization
- pan: When the pan tool is selected, the user can move the cloud of points in each distribution plot by holding the left mouse button and moving the cursor in the direction they want to move the graph.
- box-zoom: When the box-zoom tool is selected, the user can box-select a region in the distribution plot they would like to zoom in.
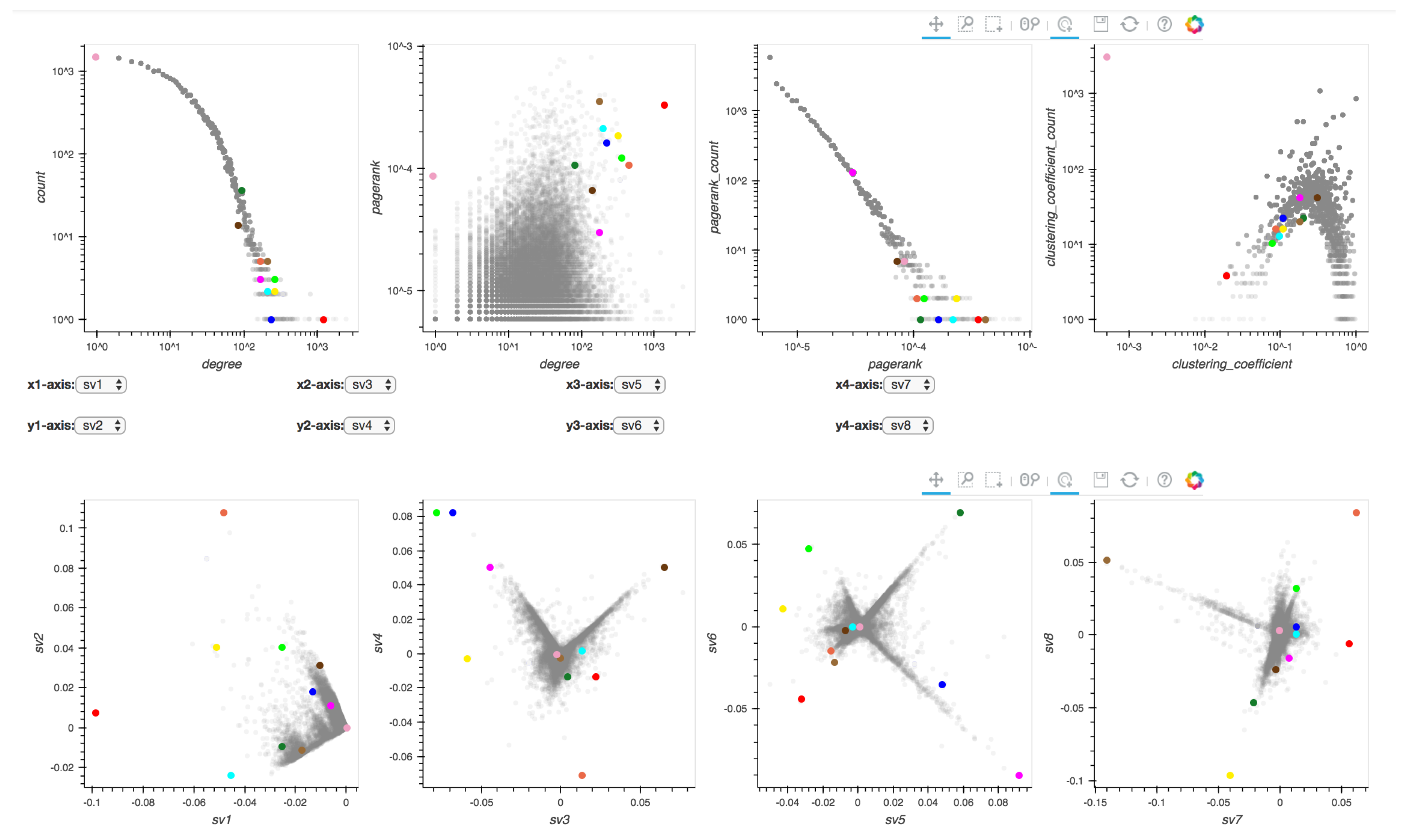
- box-select: When the box-select tool is selected, the user can box-select and highlight a region of points in the selected distribution plot. Since all plots are linked, the corresponding points in the other plots are highlighted at the same time. This can be useful when a user wants to track micro-clusters of points across different ‘views’ (or graph properties).
- wheel-zoom: When the wheel-zoom tool is selected, the user can scroll over a given distribution plot to zoom in or out.
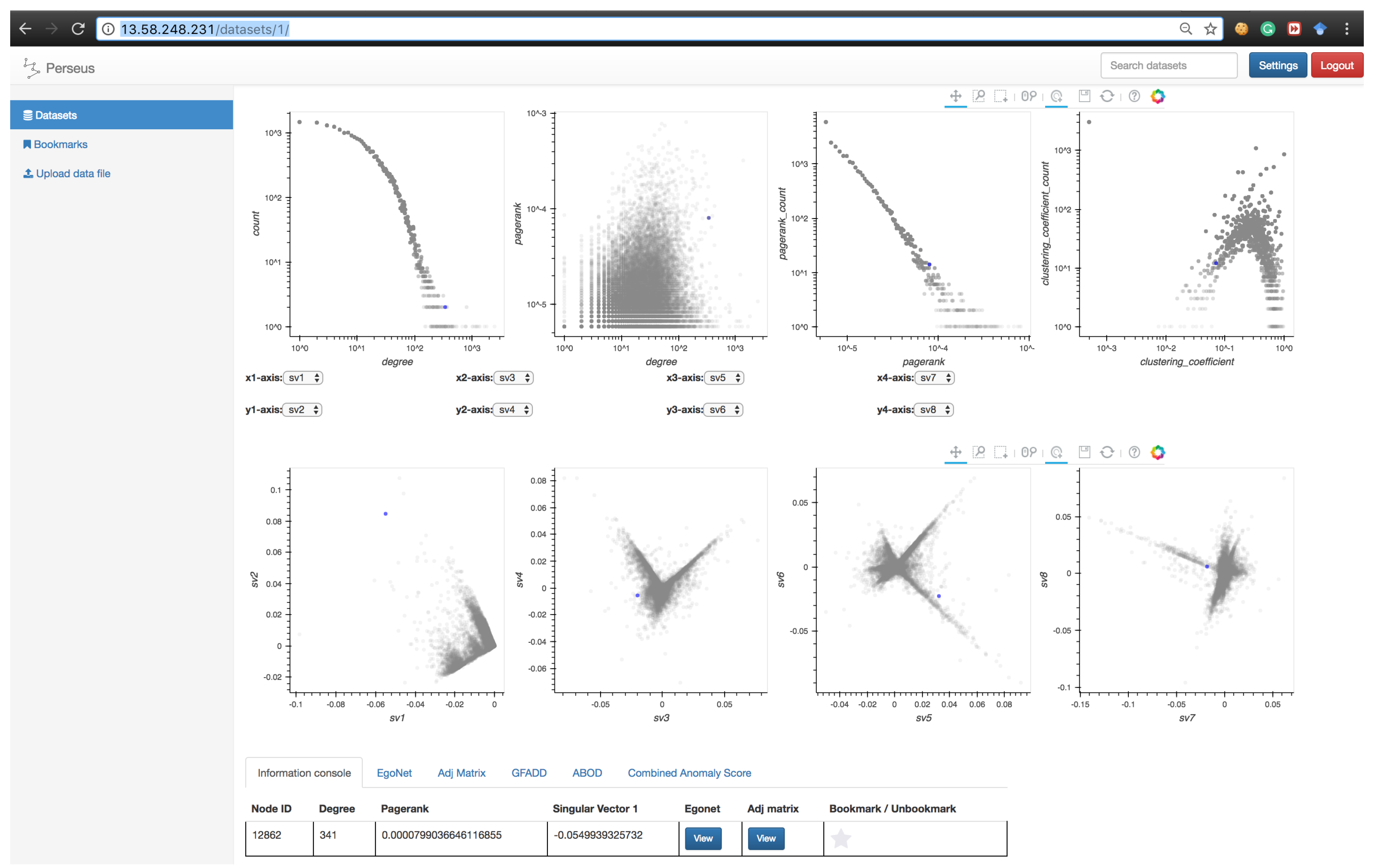
- tap: When the tap tool is selected, the user can left click on a specific single point. This is useful when the user wants to explore a single node (via the information console, egonet, or adjacency matrix) instead of using the box-select tool.
- save: When the user clicks on the save button, the corresponding distribution plots are saved in png format.
- reset: When the reset button is clicked, the distribution plots are re-positioned to their original setup and the previously selected points are unselected.
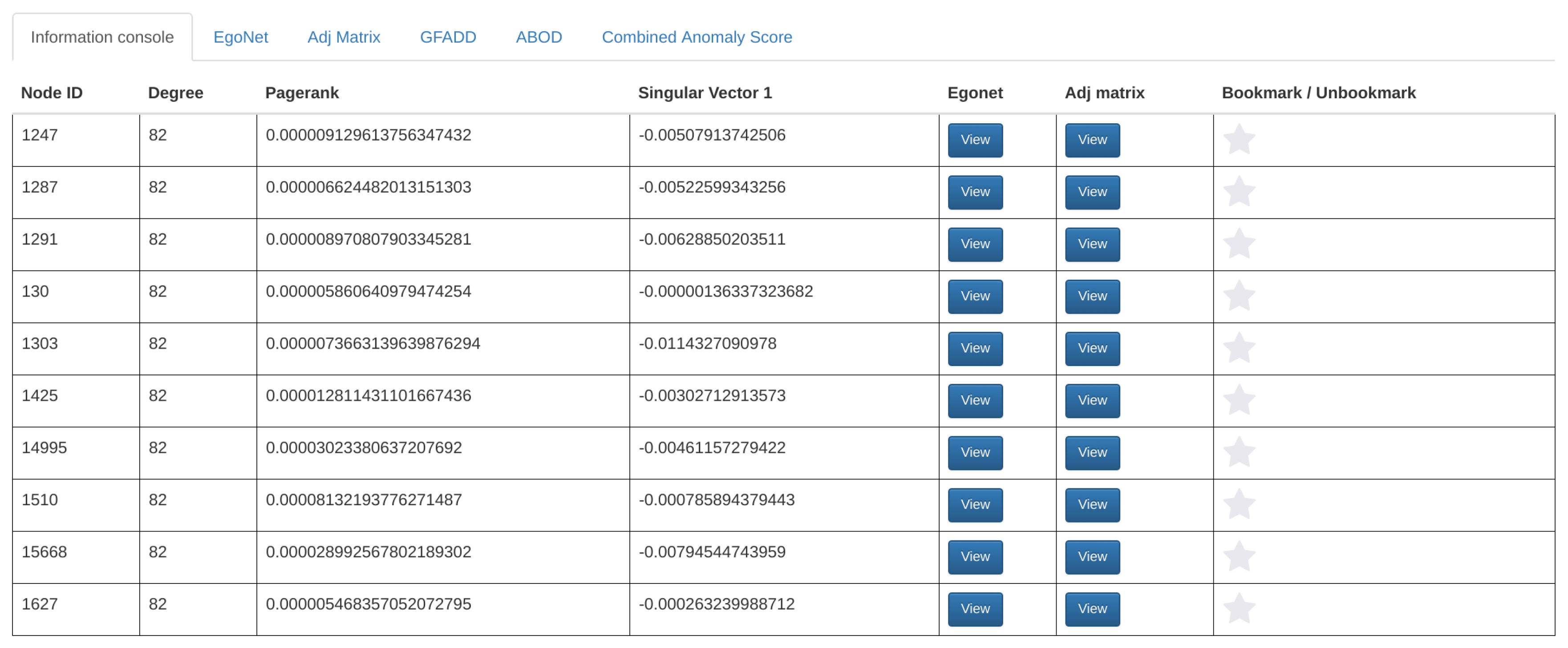
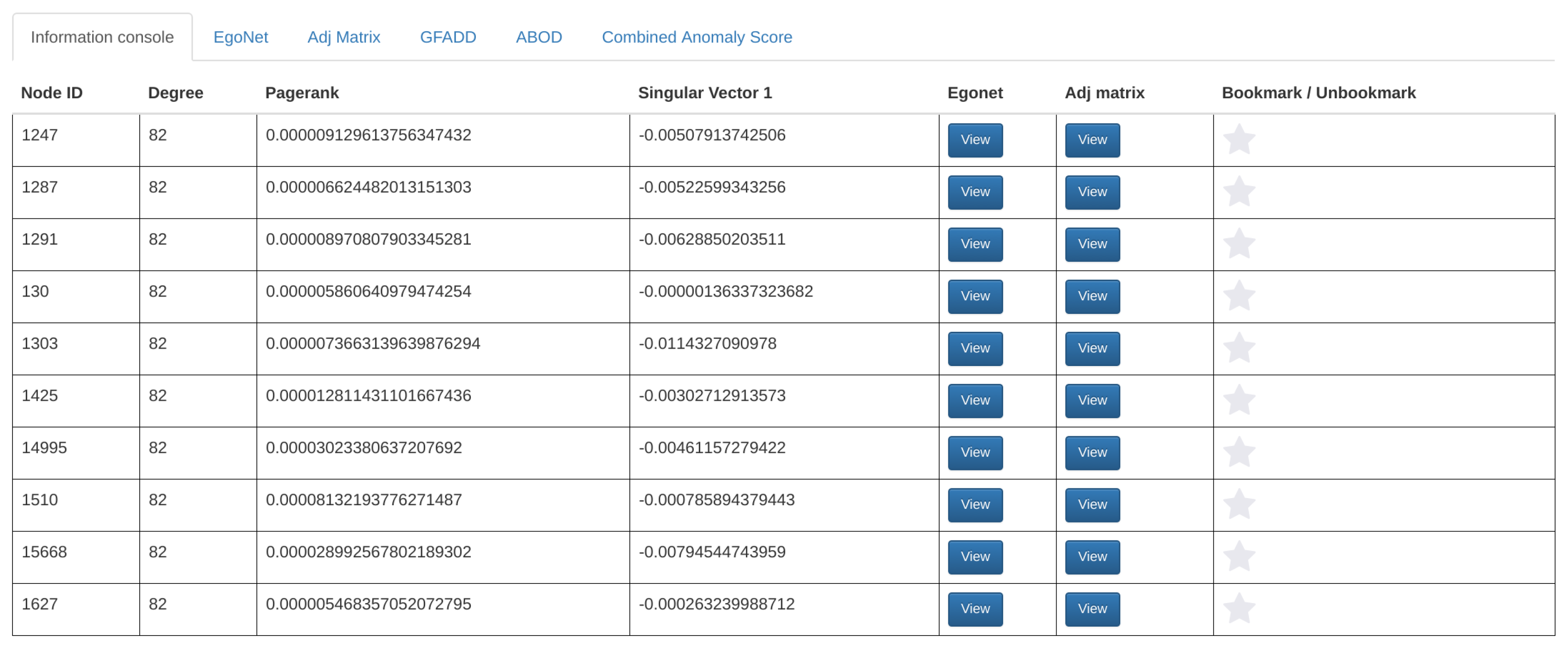
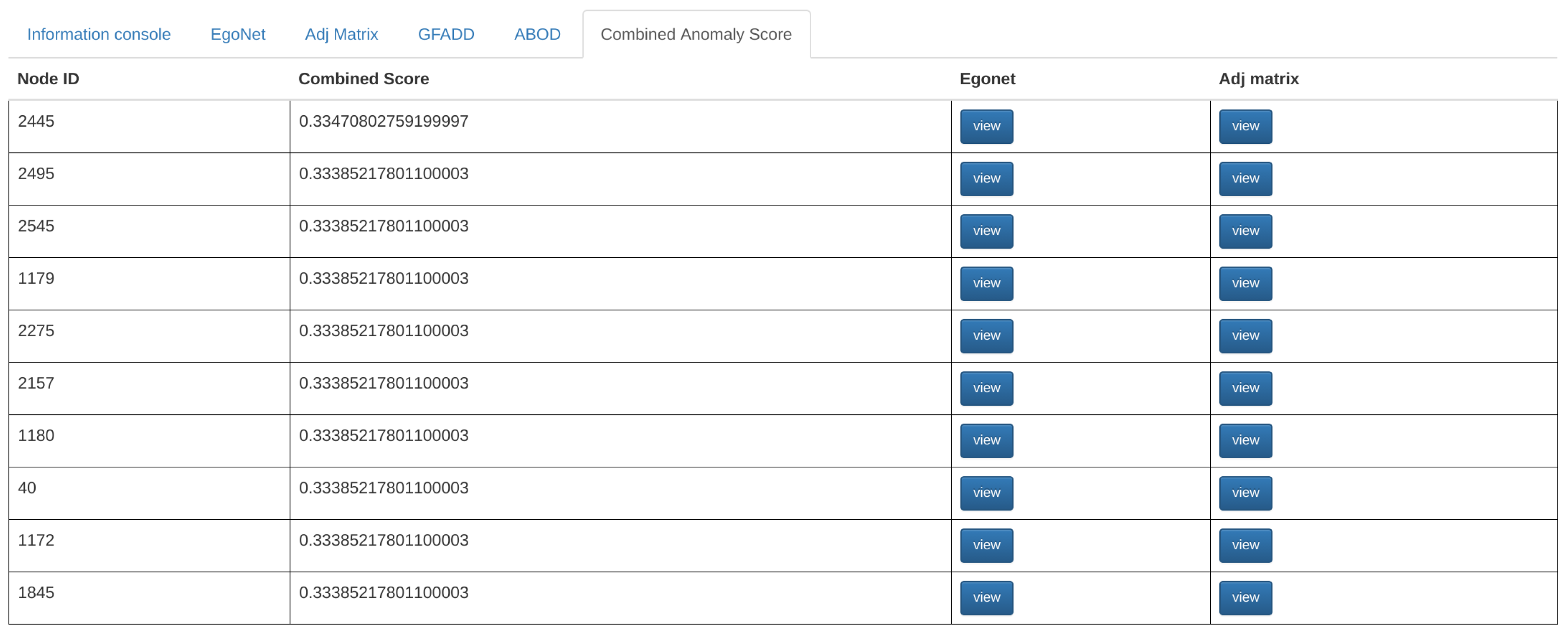
3.3.2. Node-Specific Summarization
4. Perseus-Hub: Web Application Integration
- Authentication module: The web application includes a user registration and authentication module where new users can register and start processing and sharing their data immediately. This module is also the foundation of some other user-controlled features, which are elaborated on below.
- Exploration module: The dashboard page of the web application is filled with a collection of recently added datasets. This data “feed” will be enhanced with suggestion algorithms in the future for better personalization.
- Search module: When a user uploads her raw data, she is asked to enter a descriptive title for them. This piece of metadata provides a simple indexing method for the users to either search for a specific dataset or browse for datasets with a similar title.
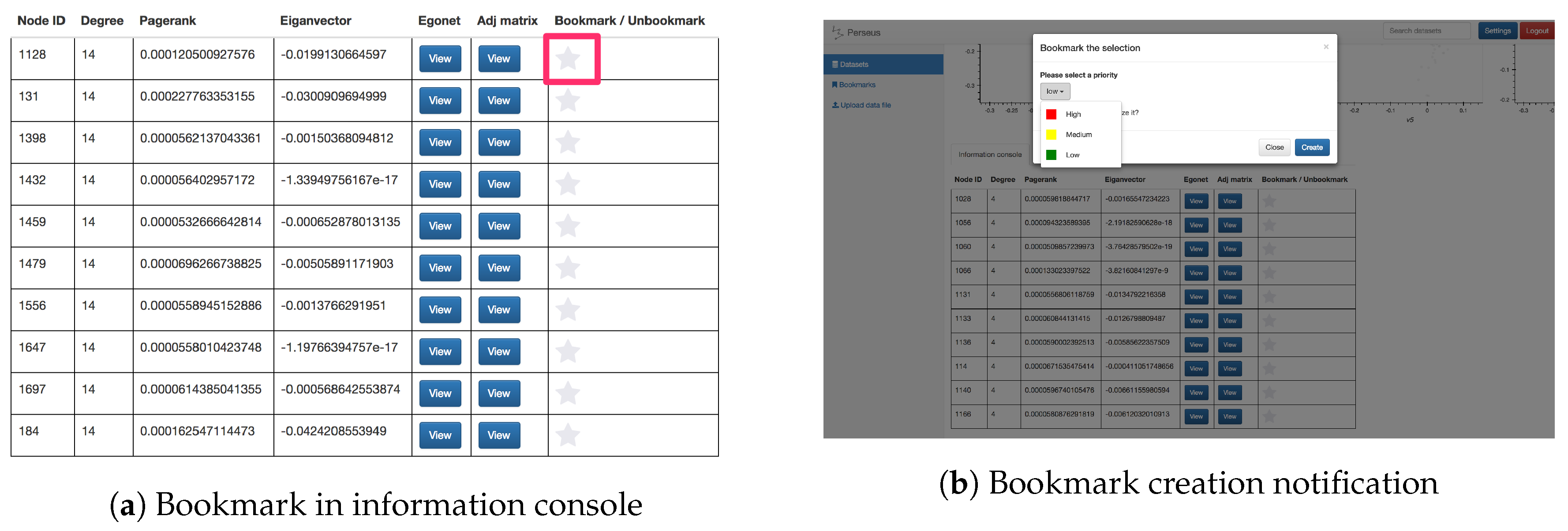
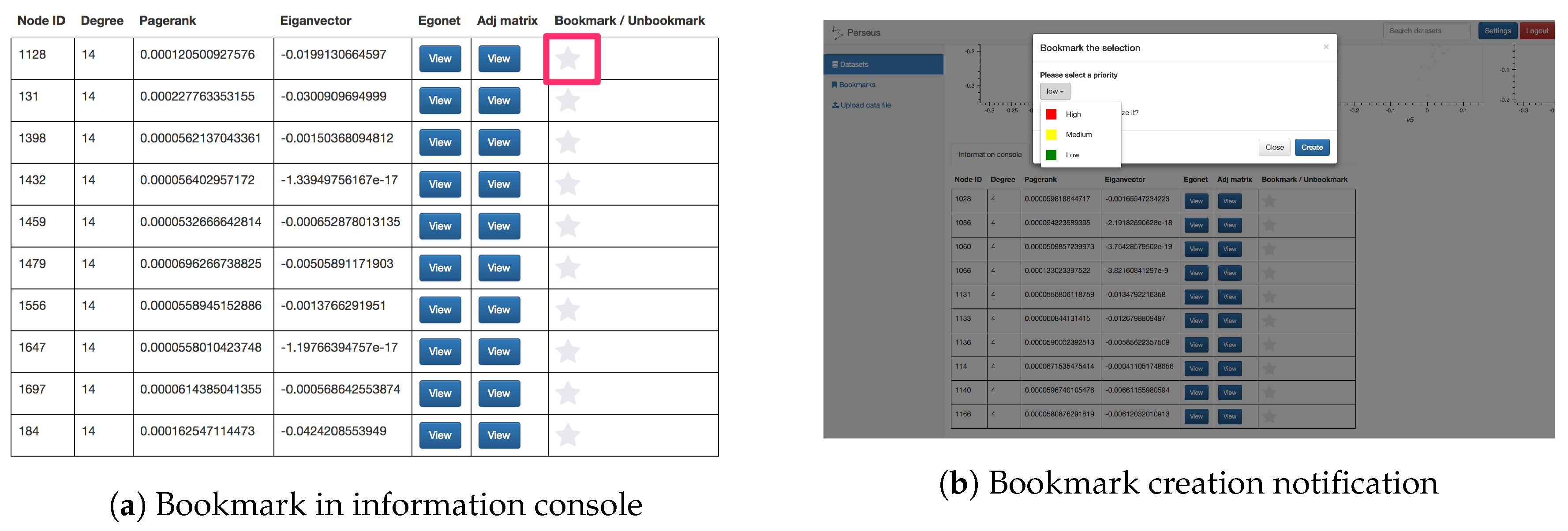
- Bookmark module: The bookmark feature allows users to mark a specific node within a dataset by clicking on the “star” button next to the statistics in the information console. This feature gives users a finer-grained choice to mark their interest, e.g., a specific point in social networking datasets. Moreover, users can set a priority flag for their bookmarks, enabling better categorization and recognition for the creator. For collective analysis, users can choose to share their bookmarks publicly so that other analysts can incorporate these findings in their exploration process. Screenshots of the bookmark button and bookmark creation are shown in Figure 10.
5. Case Study
5.1. The Citation Network
5.2. The Social Network
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kuramochi, M.; Karypis, G. Frequent Subgraph Discovery. In Proceedings of the 2001 1st IEEE International Conference on Data Mining (ICDM), San Jose, CA, USA, 29 November–2 December 2001; pp. 313–320. [Google Scholar]
- Leardi, R. Multi-way analysis with applications in the chemical sciences, age smilde, Rasmus Bro and Paul Geladi, Wiley, Chichester, 2004, ISBN 0-471-98691-7, 381 pp. J. Chemometr. 2005, 19, 119–120. [Google Scholar] [CrossRef]
- Tong, H.; Faloutsos, C. Center-piece subgraphs: Problem definition and fast solutions. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’06), New York, NY, USA, 20–23 August 2006; ACM: New York, NY, USA, 2006; pp. 404–413. [Google Scholar]
- Sondhi, P.; Sun, J.; Tong, H.; Zhai, C. SympGraph: A framework for mining clinical notes through symptom relation graphs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’12), Beijing, China, 12–16 August 2012; pp. 1167–1175. [Google Scholar]
- Backstrom, L.; Kumar, R.; Marlow, C.; Novak, J.; Tomkins, A. Preferential behavior in online groups. In Proceedings of the International Conference on Web Search and Web Data Mining (WSDM ’08), New York, NY, USA, 11–12 February 2008; ACM: New York, NY, USA, 2008; pp. 117–128. [Google Scholar]
- Barabási, A.L.; Jeong, H.; Néda, Z.; Ravasz, E.; Schubert, A.; Vicsek, T. Evolution of the social network of scientific collaborations. Physica A 2002, 311, 590–614. [Google Scholar] [CrossRef]
- Stolper, C.D.; Kahng, M.; Lin, Z.; Foerster, F.; Goel, A.; Stasko, J.; Chau, D.H. Glo-stix: Graph-level operations for specifying techniques and interactive exploration. IEEE Trans. Vis. Comput. Graph. 2014, 20, 2320–2328. [Google Scholar] [CrossRef] [PubMed]
- Chau, D.H.; Kittur, A.; Hong, J.I.; Faloutsos, C. Apolo: Making Sense of Large Network Data by Combining Rich User Interaction and Machine Learning. In Proceedings of the 17th ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), San Diego, CA, USA, 21–24 August 2011. [Google Scholar]
- Koutra, D.; Jin, D.; Ning, Y.; Faloutsos, C. Perseus: An Interactive Large-Scale Graph Mining and Visualization Tool. Proc. VLDB Endow. 2015, 8, 1924–1927. [Google Scholar] [CrossRef]
- Jin, D.; Sethapakdi, T.; Koutra, D.; Faloutsos, C. PERSEUS3: Visualizing and Interactively Mining Large-Scale Graphs. In Proceedings of the WOODSTOCK ’97, El Paso, TX, USA, July 1997. [Google Scholar]
- Lee, J.Y.; Kang, U.; Koutra, D.; Faloutsos, C. Fast Anomaly Detection Despite the Duplicates. In Proceedings of the 22nd International Conference on World Wide Web (WWW Companion Volume), Rio de Janeiro, Brazil, 13–17 May 2013; pp. 195–196. [Google Scholar]
- Kriegel, H.P.; Zimek, A.; Hubert, M.S. Angle-based outlier detection in high-dimensional data. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 444–452. [Google Scholar]
- Pienta, R.; Kahng, M.; Lin, Z.; Vreeken, J.; Talukdar, P.; Abello, J.; Parameswaran, G.; Chau, D.H. FACETS: Adaptive Local Exploration of Large Graphs. In Proceedings of the 2017 SIAM International Conference on Data Mining. Society for Industrial and Applied Mathematics, Houston, TX, USA, 27–29 April 2017. [Google Scholar]
- Wongsuphasawat, K.; Qu, Z.; Moritz, D.; Chang, R.; Ouk, F.; Anand, A.; Mackinlay, J.; Howe, B.; Heer, J. Voyager 2: Augmenting Visual Analysis with Partial View Specifications. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; ACM: New York, NY, USA, 2017; pp. 2648–2659. [Google Scholar]
- May, T.; Steiger, M.; Davey, J.; Kohlhammer, J. Using signposts for navigation in large graphs. Comput. Gr. Forum 2012, 31, 985–994. [Google Scholar] [CrossRef]
- Henry, N.; Fekete, J.D.; McGuffin, M.J. NodeTrix: A hybrid visualization of social networks. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1302–1309. [Google Scholar] [PubMed]
- Zhao, J.; Collins, C.; Chevalier, F.; Balakrishnan, R. Interactive exploration of implicit and explicit relations in faceted datasets. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2080–2089. [Google Scholar] [PubMed]
- Kairam, S.; Riche, N.H.; Drucker, S.; Fernandez, R.; Heer, J. Refinery: Visual exploration of large, heterogeneous networks through associative browsing. Comput. Gr. Forum 2015, 34, 301–310. [Google Scholar] [CrossRef]
- Akoglu, L.; Chau, D.H.; Kang, U.; Koutra, D.; Faloutsos, C. OPAvion: Mining and Visualization in Large Graphs. In Proceedings of the 2012 ACM International Conference on Management of Data (SIGMOD), Scottsdale, AZ, USA, 20–24 May 2012; ACM: New York, NY, USA, 2012; pp. 717–720. [Google Scholar]
- Kang, U.; Tsourakakis, C.E.; Faloutsos, C. PEGASUS: A Peta-Scale Graph Mining System—Implementation and Observations. In Proceedings of the 9th IEEE International Conference on Data Mining (ICDM), Miami, FL, USA, 6–9 December 2009. [Google Scholar]
- Akoglu, L.; McGlohon, M.; Faloutsos, C. OddBall: Spotting Anomalies in Weighted Graphs. In Proceedings of the 14th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Hyderabad, India, 21–24 June 2010. [Google Scholar]
- Kang, U.; Lee, J.Y.; Koutra, D.; Faloutsos, C. Net-Ray: Visualizing and Mining Web-Scale Graphs. In Proceedings of the 18th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Tainan, Taiwan, 13–16 May 2014. [Google Scholar]
- Dunne, C.; Shneiderman, B. Motif Simplification: Improving Network Visualization Readability with Fan, Connector, and Clique Glyphs. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), Paris, France, 27 April–2 May 2013; ACM: New York, NY, USA, 2013; pp. 3247–3256. [Google Scholar]
- Nielsen, J. Website Response Times. 21 June 2010. Available online: http://www.nngroup.com/articles/website-response-times/ (accessed on 17 November 2015).
- Mishra, C.; Koudas, N. Interactive query refinement. In Proceedings of the 12th International Conference on Extending Database Technology (EDBT 2009), Saint Petersburg, Russia, 24–26 March 2009; pp. 862–873. [Google Scholar]
- Jiang, L.; Nandi, A. SnapToQuery: Providing Interactive Feedback during Exploratory Query Specification. PVLDB 2015, 8, 1250–1261. [Google Scholar] [CrossRef]
- Çetintemel, U.; Cherniack, M.; DeBrabant, J.; Diao, Y.; Dimitriadou, K.; Kalinin, A.; Papaemmanouil, O.; Zdonik, S.B. Query Steering for Interactive Data Exploration. In Proceedings of the Sixth Biennial Conference on Innovative Data Systems Research (CIDR 2013), Asilomar, CA, USA, 6–9 January 2013. [Google Scholar]
- Chatzopoulou, G.; Eirinaki, M.; Polyzotis, N. Query Recommendations for Interactive Database Exploration. In Proceedings of the 21st International Conference on Scientific and Statistical Database Management (SSDBM 2009), New Orleans, LA, USA, 2–4 June 2009; Winslett, M., Ed.; Springer: New Orleans, LA, USA, 2009; Volume 5566, pp. 3–18. [Google Scholar]
- Goethals, B.; Moens, S.; Vreeken, J. MIME: A Framework for Interactive Visual Pattern Mining. In Proceedings of the 17th ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), San Diego, CA, USA, 21–24 August 2011; ACM: New York, NY, USA, 2011; pp. 757–760. [Google Scholar]
- Vartak, M.; Rahman, S.; Madden, S.; Parameswaran, A.; Polyzotis, N. SeeDB: Efficient Data-driven Visualization Recommendations to Support Visual Analytics. Proc. VLDB Endow. 2015, 8, 2182–2193. [Google Scholar] [CrossRef]
- Shahaf, D.; Yang, J.; Suen, C.; Jacobs, J.; Wang, H.; Leskovec, J. Information cartography: Creating zoomable, large-scale maps of information. In Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2013), Chicago, IL, USA, 11–14 August 2013; pp. 1097–1105. [Google Scholar]
- Chau, D.H.; Akoglu, L.; Vreeken, J.; Tong, H.; Faloutsos, C. TOURVIZ: Interactive Visualization of Connection Pathways in Large Graphs. In Proceedings of the 18th ACM International Conference on Knowledge Discovery and Data Mining (SIGKDD), Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012. [Google Scholar]
- Rodrigues, J.F., Jr.; Tong, H.; Traina, A.J.M.; Faloutsos, C.; Leskovec, J. GMine: A System for Scalable, Interactive Graph Visualization and Mining. In Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Korea, 12–15 September 2006; pp. 1195–1198. [Google Scholar]
- Khoa, N.L.D.; Chawla, S. Robust Outlier Detection Using Commute Time and Eigenspace Embedding. In Proceedings of the 14th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Hyderabad, India, 21–24 June 2010; Springer: Berlin, Germany; Volume 6119, pp. 422–434. [Google Scholar]
- Akoglu, L.; Tong, H.; Koutra, D. Graph-based Anomaly Detection and Description: A Survey. Data Min. Knowl. Discov. (DAMI) 2014, 29, 626–688. [Google Scholar] [CrossRef]
- Ranshous, S.; Shen, S.; Koutra, D.; Harenberg, S.; Faloutsos, C.; Samatova, N.F. Anomaly detection in dynamic networks: A survey. WIREs Comput. Statist. 2015, 7, 223–247. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the ACM SIGMOD 2000 International Conference on Management of Data, Dalles, TX, USA, 15–18 May 2000; ACM: New York, NY, USA, 2000; Volume 29, pp. 93–104. [Google Scholar]
- Lee, J.Y.; Kang, U.; Koutra, D.; Faloutsos, C. Fast Outlier Detection Despite the Duplicates. In Proceedings of the WWW 2013 Companion, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Chakrabarti, D. Autopart: Parameter-free graph partitioning and outlier detection. In Proceedings of the 8th European Conference on Principles of Data Mining and Knowledge Discovery, Pisa, Italy, 20–24 September 2004; Springer: Berlin, Germany, 2004; pp. 112–124. [Google Scholar]
- Xu, X.; Yuruk, N.; Feng, Z.; Schweiger, T.A. Scan: A structural clustering algorithm for networks. In Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, CA, USA, 12–15 August 2007; ACM: New York, NY, USA, 2007; pp. 824–833. [Google Scholar]
- Jiang, M.; Cui, P.; Beutel, A.; Faloutsos, C.; Yang, S. Catchsync: catching synchronized behavior in large directed graphs. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 941–950. [Google Scholar]
- Faloutsos, M.; Faloutsos, P.; Faloutsos, C. On power-law relationships of the internet topology. In ACM SIGCOMM Computer Communication Review; ACM: New York, NY, USA, 1999; Volume 29, pp. 251–262. [Google Scholar]
- Prakash, B.A.; Sridharan, A.; Seshadri, M.; Machiraju, S.; Faloutsos, C. EigenSpokes: Surprising Patterns and Scalable Community Chipping in Large Graphs. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Hyderabad, India, 21–24 June 2010; pp. 435–448. [Google Scholar]
- Page, L.; Brin, S.; Motwani, R.; Winograd, T. The PageRank Citation Ranking: Bringing Order to the Web; Stanford Digital Library Technologies Project. In Proceedings of the 7th International World Wide Web Conference, Brisbane, Australia, 14–18 April 1998. [Google Scholar]
- Alemi, M.; Haghighi, H.; Shahrivari, S. CCFinder: Using Spark to find clustering coefficient in big graphs. J. Supercomput. 2017, 1–28. [Google Scholar] [CrossRef]
- Kriegel, H.P.; Kroger, P.; Schubert, E.; Zimek, A. Interpreting and unifying outlier scores. In Proceedings of the 2011 SIAM International Conference on Data Mining, Phoenix, AZ, USA, 28–30 April 2011. [Google Scholar]
- Wang, J.; Zuo, X.; Dai, Z.; Xia, M.; Zhao, Z.; Zhao, X.; Jia, J.; Han, Y.; He, Y. Disrupted functional brain connectome in individuals at risk for Alzheimer’s disease. Biol. Psychiatry 2013, 73, 472–481. [Google Scholar] [CrossRef] [PubMed]
- Leskovec, J. Stanford Large Network Dataset Collection. Available online: http://snap.stanford.edu/data/cit-HepTh.html (accessed on 17 November 2015).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node Analytics | Mixed Expertise | Auto Detection | Collective An. | Scalability | Domain-Ind. | |
|---|---|---|---|---|---|---|
| GLO-STIX [7] | ✗ | ✓ | ✓ | ✗ | ? | ✓ |
| FACETS [13] | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| Voyager 2 [14] | ✓ | ✓ | ✓ | ✗ | ✗ | ✓ |
| Signposts [15] | ✓ | ✗ | ✓ | ✗ | ✗ | ✗ |
| NodeTrix [16] | ✓ | ✗ | ✗ | ✗ | ✗ | ✗ |
| PivotSlice [17] | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
| Refinery [18] | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Apolo [8] | ✓ | ✓ | ✗ | ✗ | ✗ | ✓ |
| OPAvion [19] | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
| NetRay [22] | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Motif-Simp [23] | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ |
| PERSEUS [9,10] | ✓ | ✗ | ✓ | ✗ | ✓ | ✓ |
| Perseus-Hub | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ |
| Dataset | # Nodes | # Edges | Statistics Computation (s) | Average Response (ms) |
|---|---|---|---|---|
| cit-HepTh | 27,770 | 352,807 | 790.014 | 7.320 |
| Twitter_retweet | 35,366 | 78,058 | 711.592 | 8.311 |
| Color | Paper ID | Paper title |
|---|---|---|
| Red | 9905111 | “Large N Field Theories, String Theory and Gravity” |
| Cyan | 0201253 | “Supersymmetric Gauge Theories and the AdS/CFT Correspondence” |
| Orange | 9710046 | “Black Holes and Solitons in String Theory” |
| Green | 0109162 | “Quantum Field Theory on Noncommutative Spaces” |
| Purple | 0102085 | “A Review on Tachyon Condensation in Open String Field Theories” |
| Dark green | 0302030 | “Brane World Dynamics and Conformal Bulk Fields” |
| Yellow | 0101126 | ”M(atrix) Theory: Matrix Quantum Mechanics as a Fundamental Theory” |
| Blue | 0111208 | “Noncommutative Field Theories and (Super)String Field Theories” |
| Light brown | 211178 | “Supersymmetric D3 brane and N=4 SYM actions in plane wave backgrounds” |
| Brown | 9911022 | “Tests of M-Theory from N=2 Seiberg-Witten Theory” |
| Light pink | 0104127 | “Thermodynamic properties of the quantum vacuum” |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, D.; Leventidis, A.; Shen, H.; Zhang, R.; Wu, J.; Koutra, D. PERSEUS-HUB: Interactive and Collective Exploration of Large-Scale Graphs. Informatics 2017, 4, 22. https://doi.org/10.3390/informatics4030022
Jin D, Leventidis A, Shen H, Zhang R, Wu J, Koutra D. PERSEUS-HUB: Interactive and Collective Exploration of Large-Scale Graphs. Informatics. 2017; 4(3):22. https://doi.org/10.3390/informatics4030022
Chicago/Turabian StyleJin, Di, Aristotelis Leventidis, Haoming Shen, Ruowang Zhang, Junyue Wu, and Danai Koutra. 2017. "PERSEUS-HUB: Interactive and Collective Exploration of Large-Scale Graphs" Informatics 4, no. 3: 22. https://doi.org/10.3390/informatics4030022
APA StyleJin, D., Leventidis, A., Shen, H., Zhang, R., Wu, J., & Koutra, D. (2017). PERSEUS-HUB: Interactive and Collective Exploration of Large-Scale Graphs. Informatics, 4(3), 22. https://doi.org/10.3390/informatics4030022