Data Provenance for Agent-Based Models in a Distributed Memory

Abstract
:1. Introduction
2. Background
2.1. Spatial Simulation
2.2. Agent-Based Models
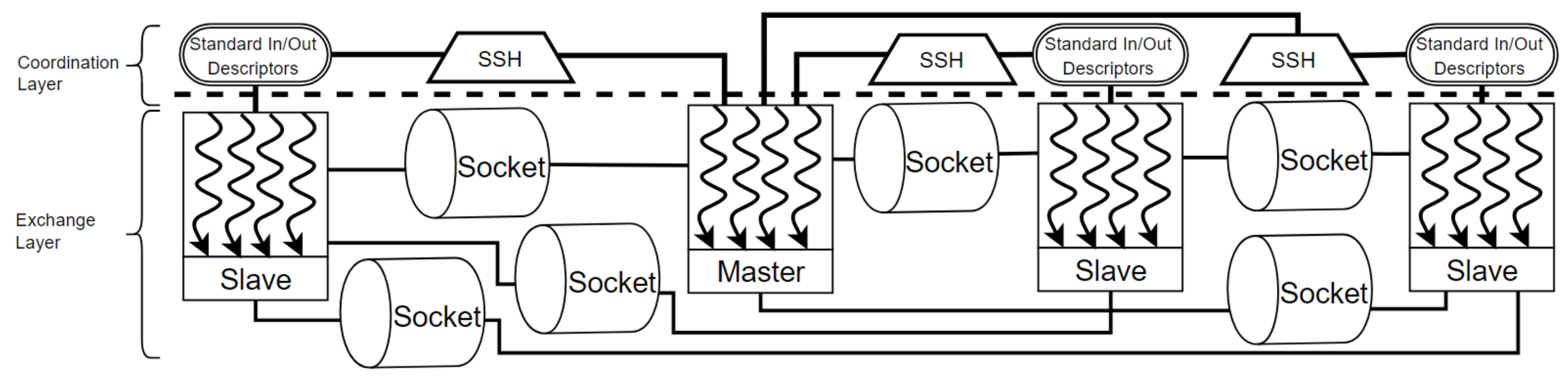
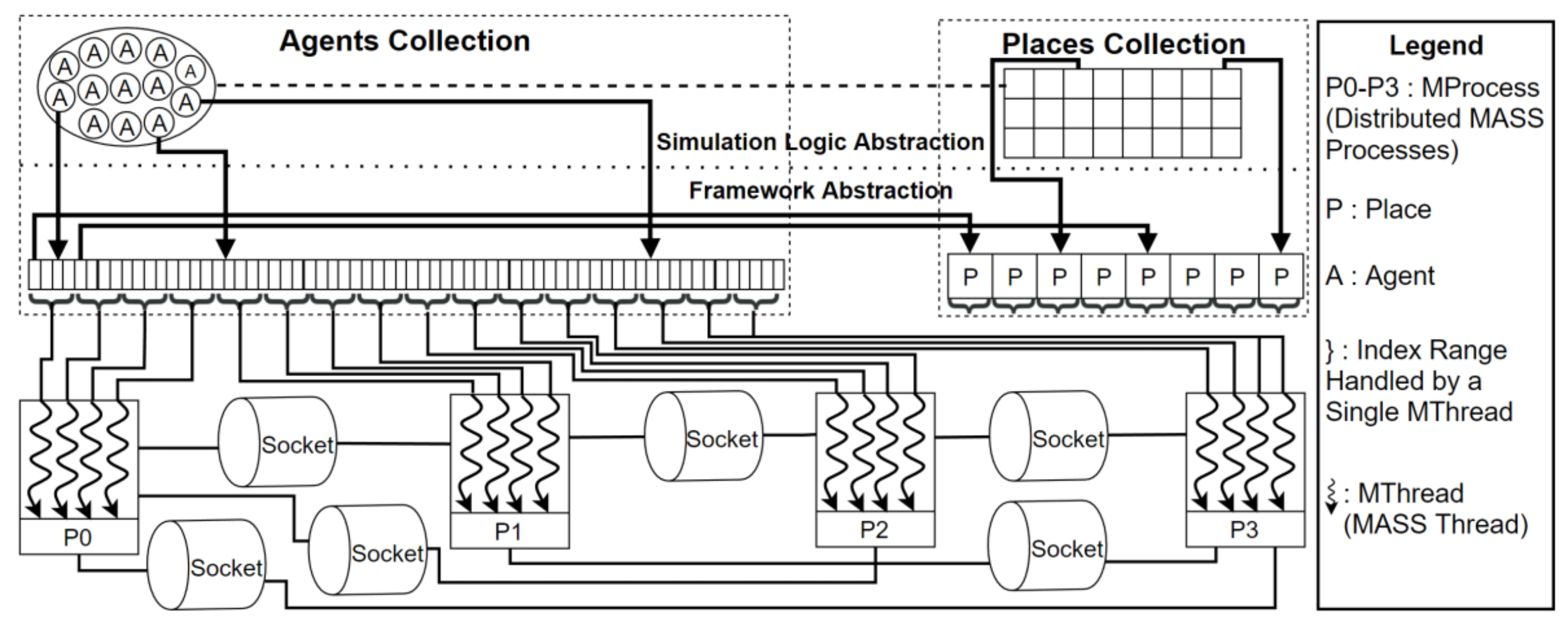
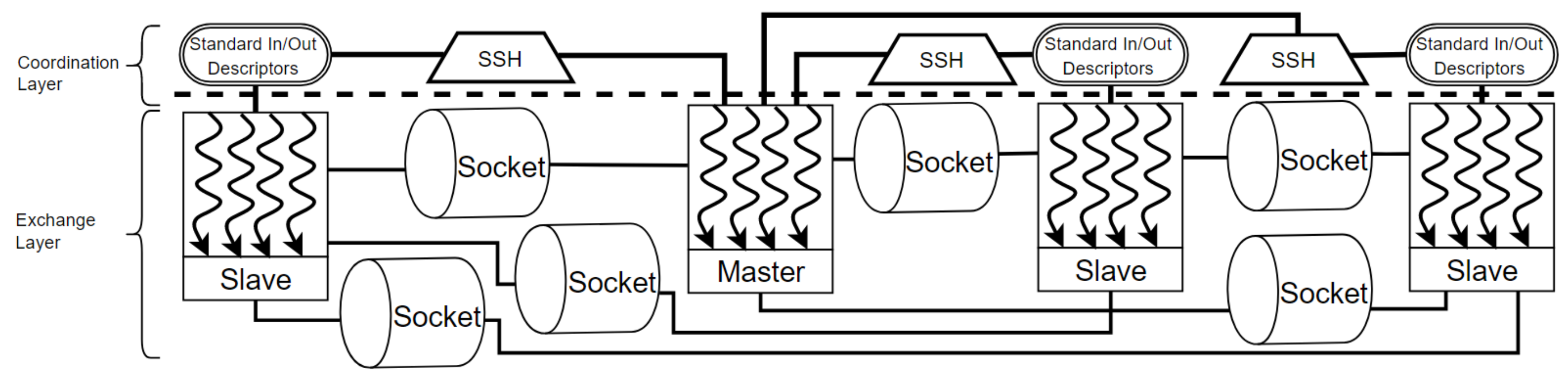
2.3. Multi-Agent Spatial Simulation (MASS)
3. Motivation
3.1. Research Questions
- ⚬
- RQ1 Can provenance be captured to support ABM in a distributed setting?
- ⚬
- RQ2 Can provenance capture overhead be limited as the number of agents, space and simulation iterations scale?
- PT1
- Can provenance of shared resources be captured in a distributed memory?
- PT2
- Can the full context of individual agent behaviors (e.g., coordination and state of agents and spatial data) be traced to simulation logic?
- PT3
- Can agent spatial relationships be obtained directly from framework provenance?
- PT1
- focuses on relating data of various execution contexts with provenance that expresses how the data were used. PT1 also aims to resolve data identity in distributed message passing and disambiguate concurrent intra-process procedure invocation contexts.
3.2. Use Cases
- A researcher analyzes agent decisions to understand individual agent behavior.
- A colleague interprets the corresponding simulation logic and configuration to understand simulation execution.
- An analyst debugs execution of distributed operations to verify the agent behavior exhibited in the first case.
- A model designer would like to perform some detailed spatial analysis of a model in development.
3.2.1. Use Case 1: Understand Agent Behavior
3.2.2. Use Case 2: Understand Simulation Execution
3.2.3. Use Case 3: Debug Distributed Execution
3.2.4. Use Case 4: Analyze Agent-Spatial Relationships
4. Method
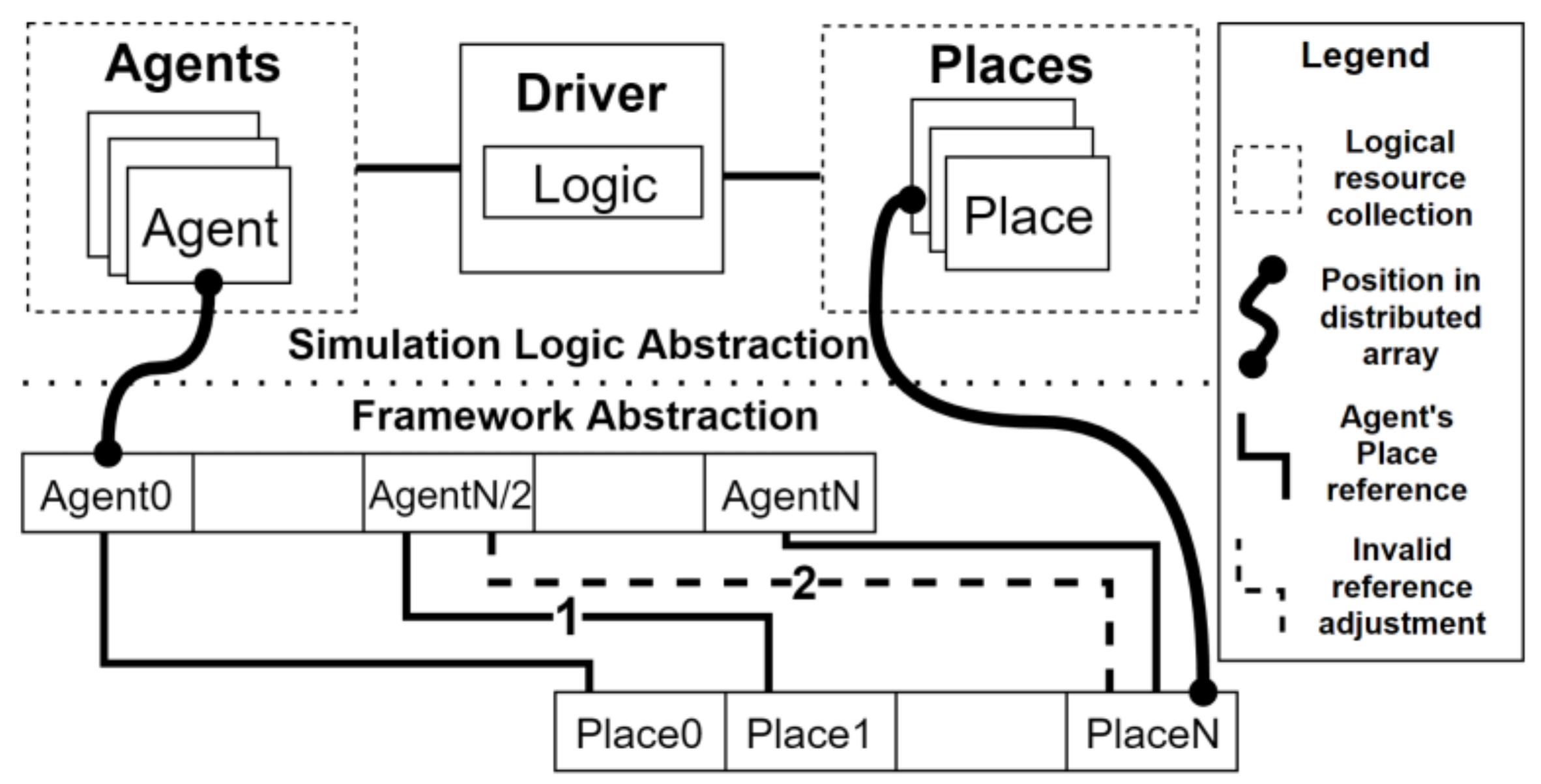
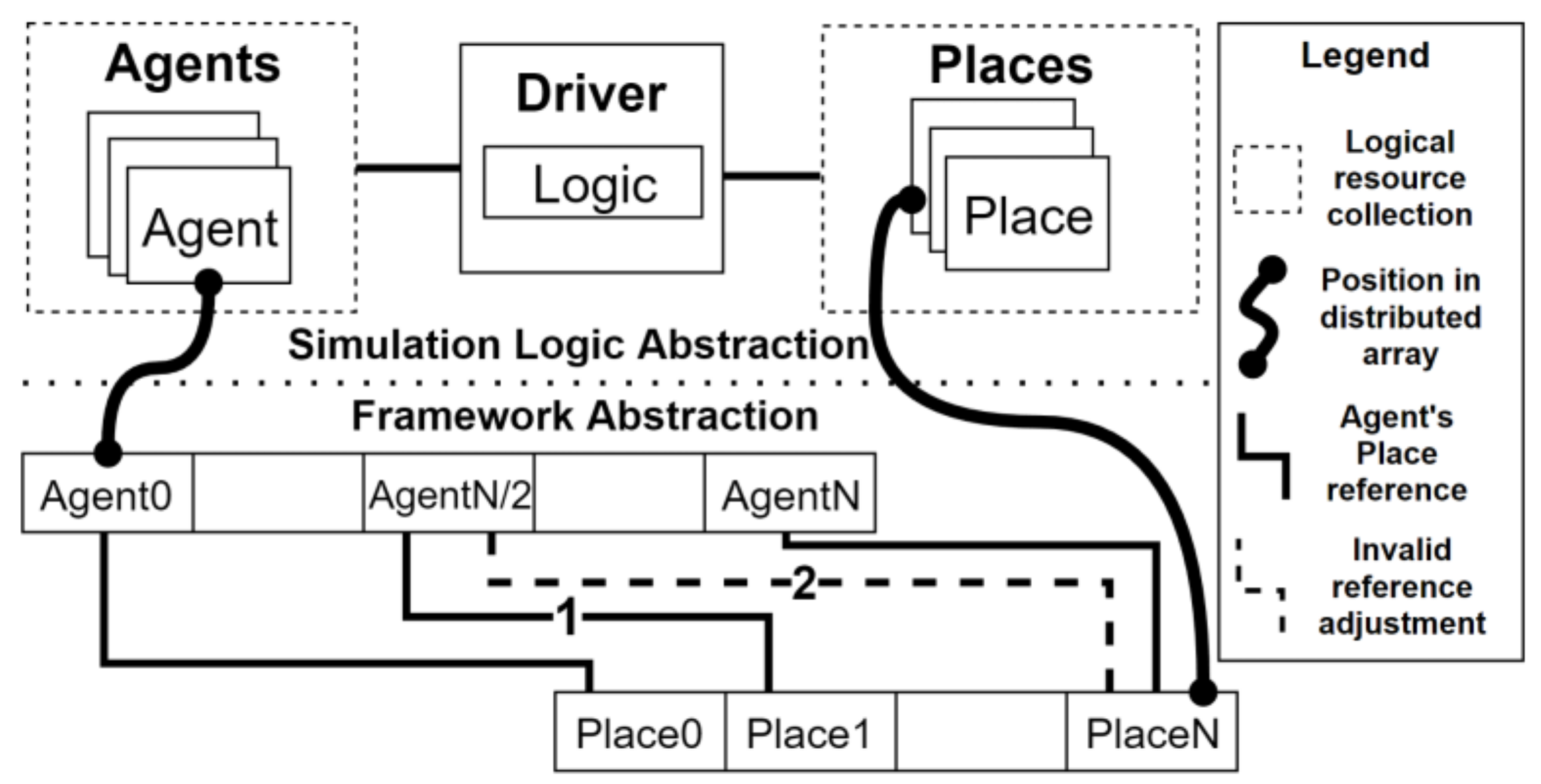
4.1. Challenge: Consistently Identifying Distributed Resources
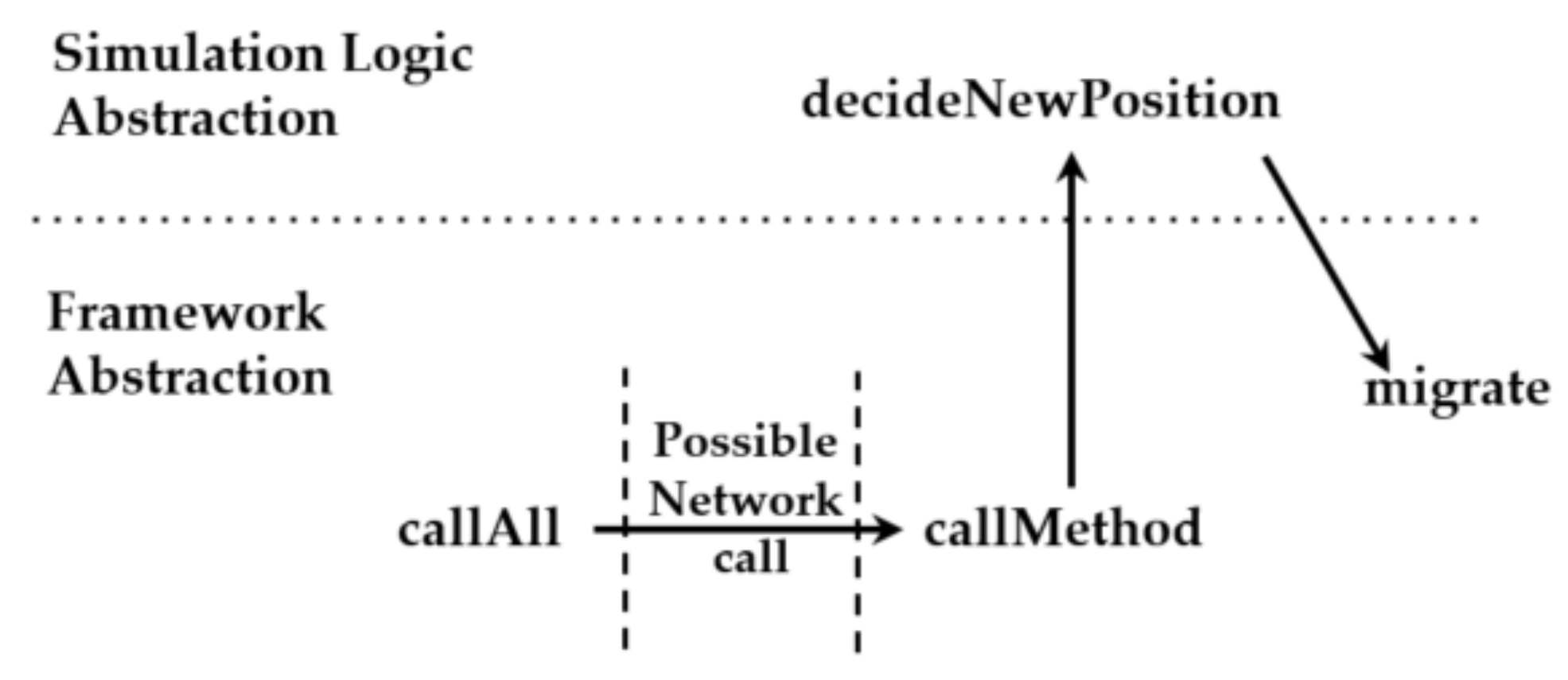
4.2. Challenge: Ordering Operations in Shared Memory Programming
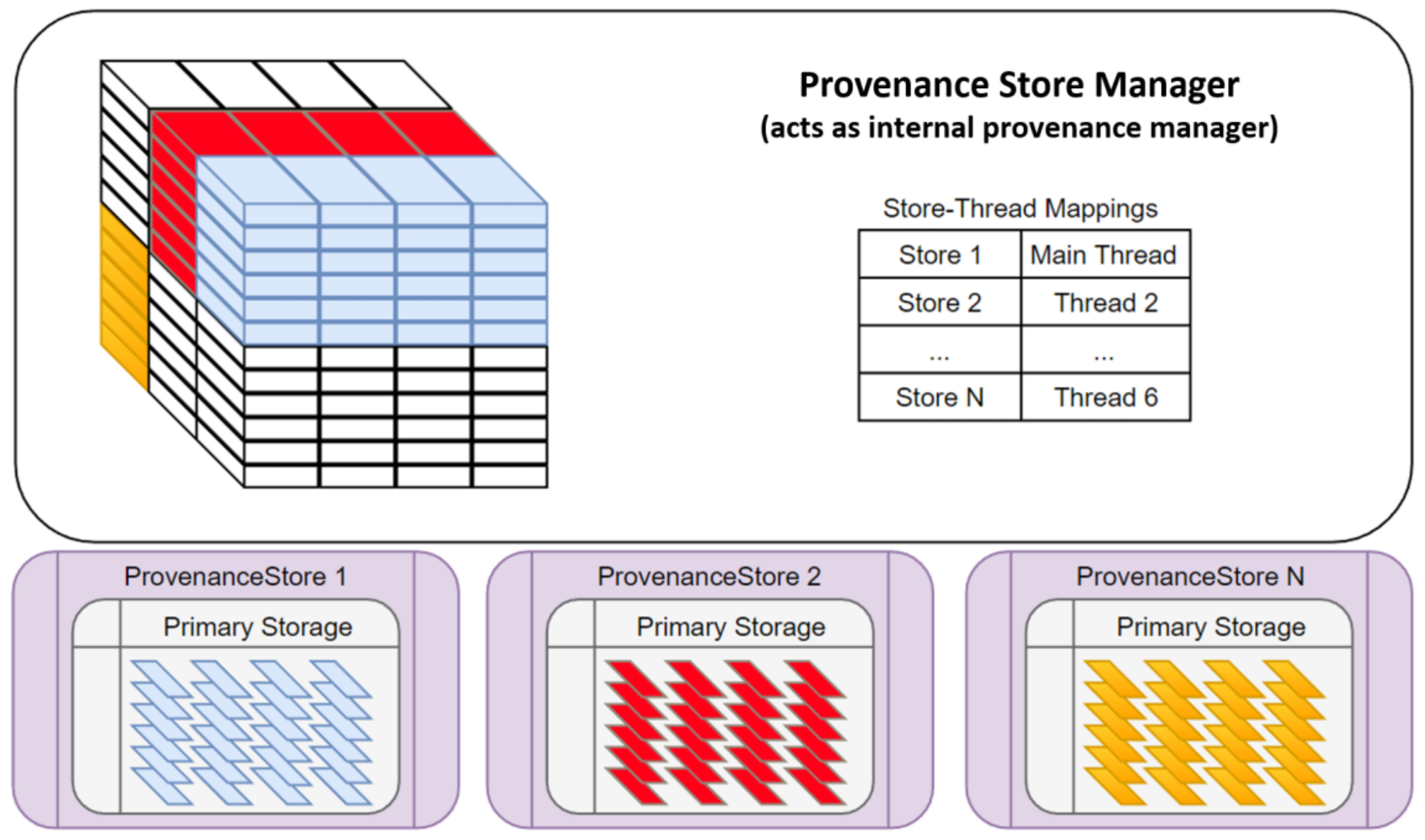
4.3. Challenge: Persisting Provenance in a Highly Resource Constrained Environment
4.4. Challenge: Achieving Acceptable Performance Overhead
4.5. Challenge: Supporting Machine Unawareness
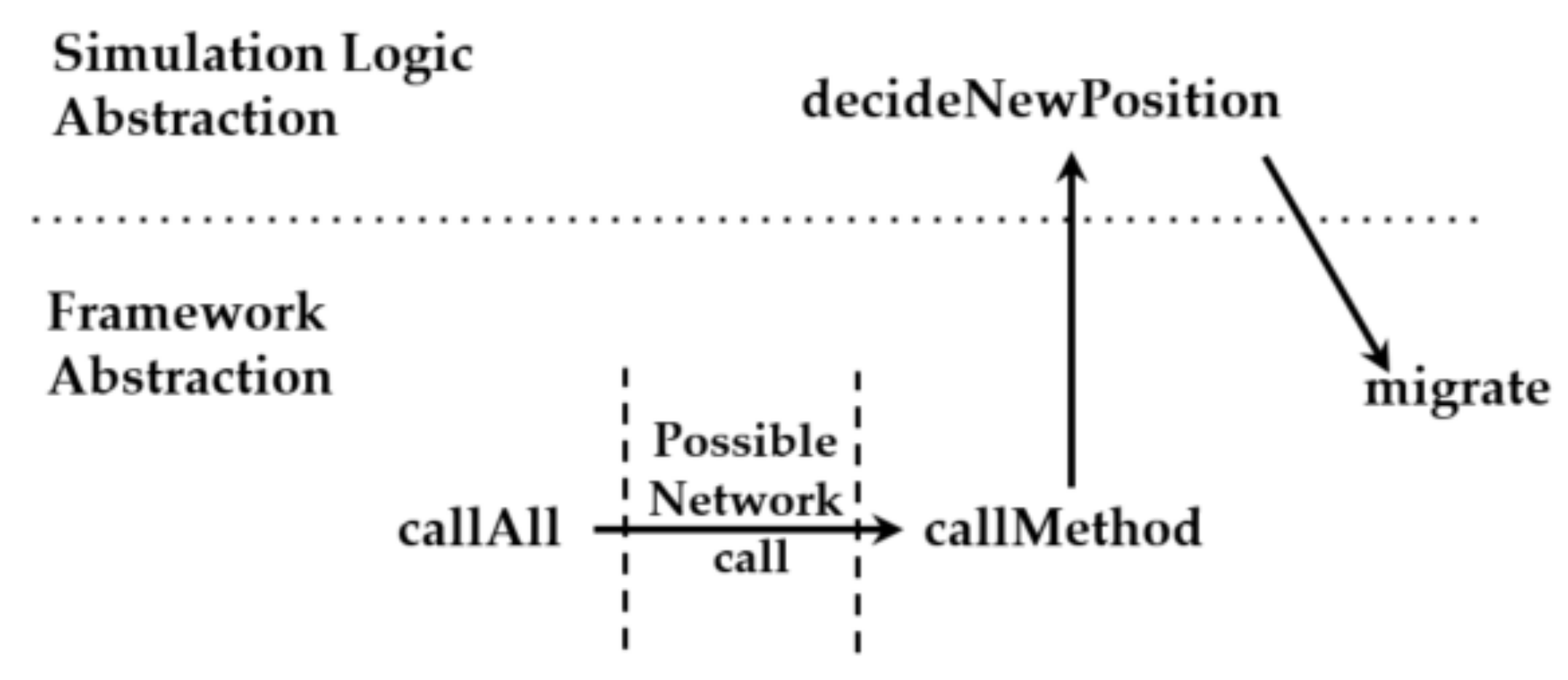
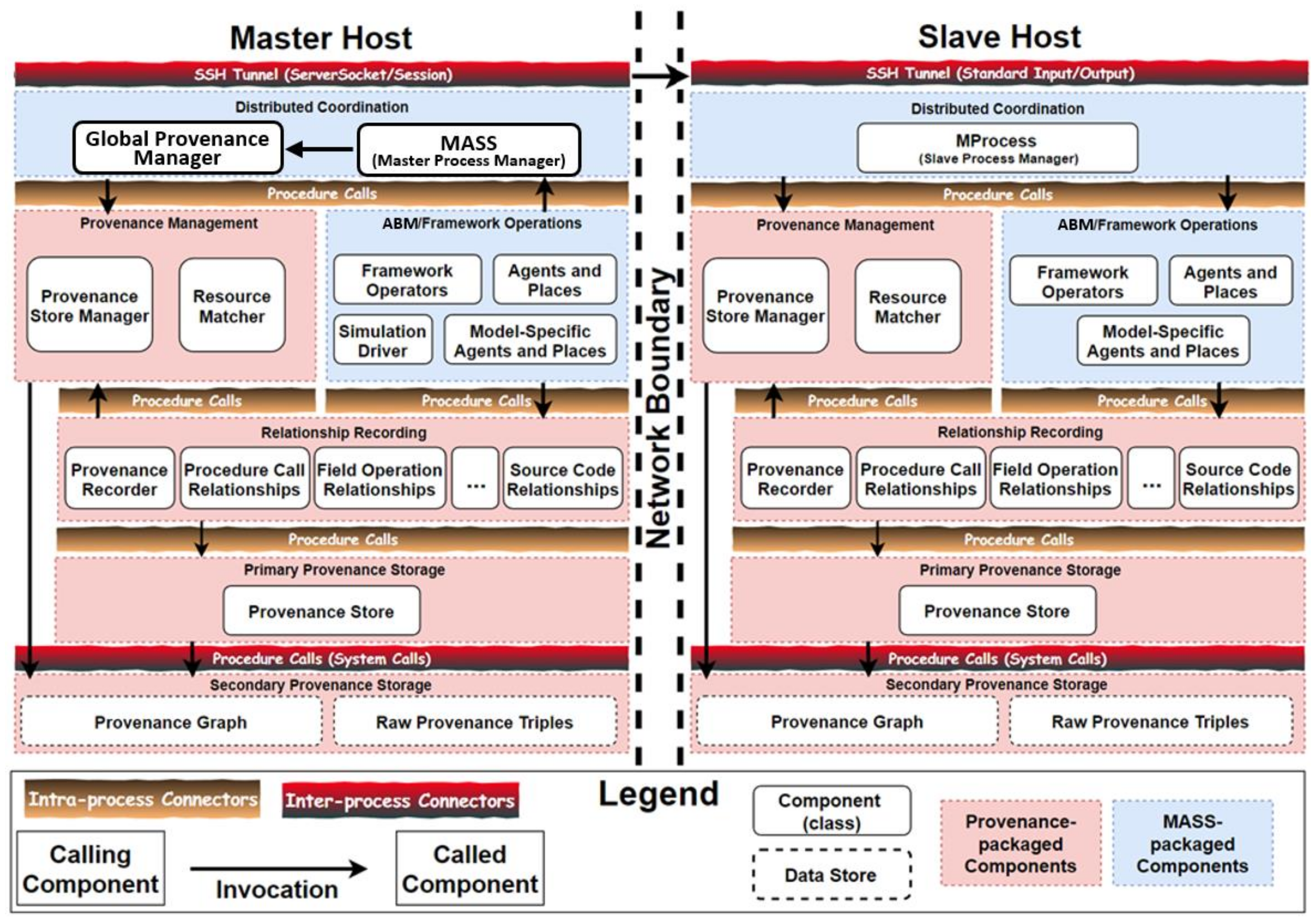
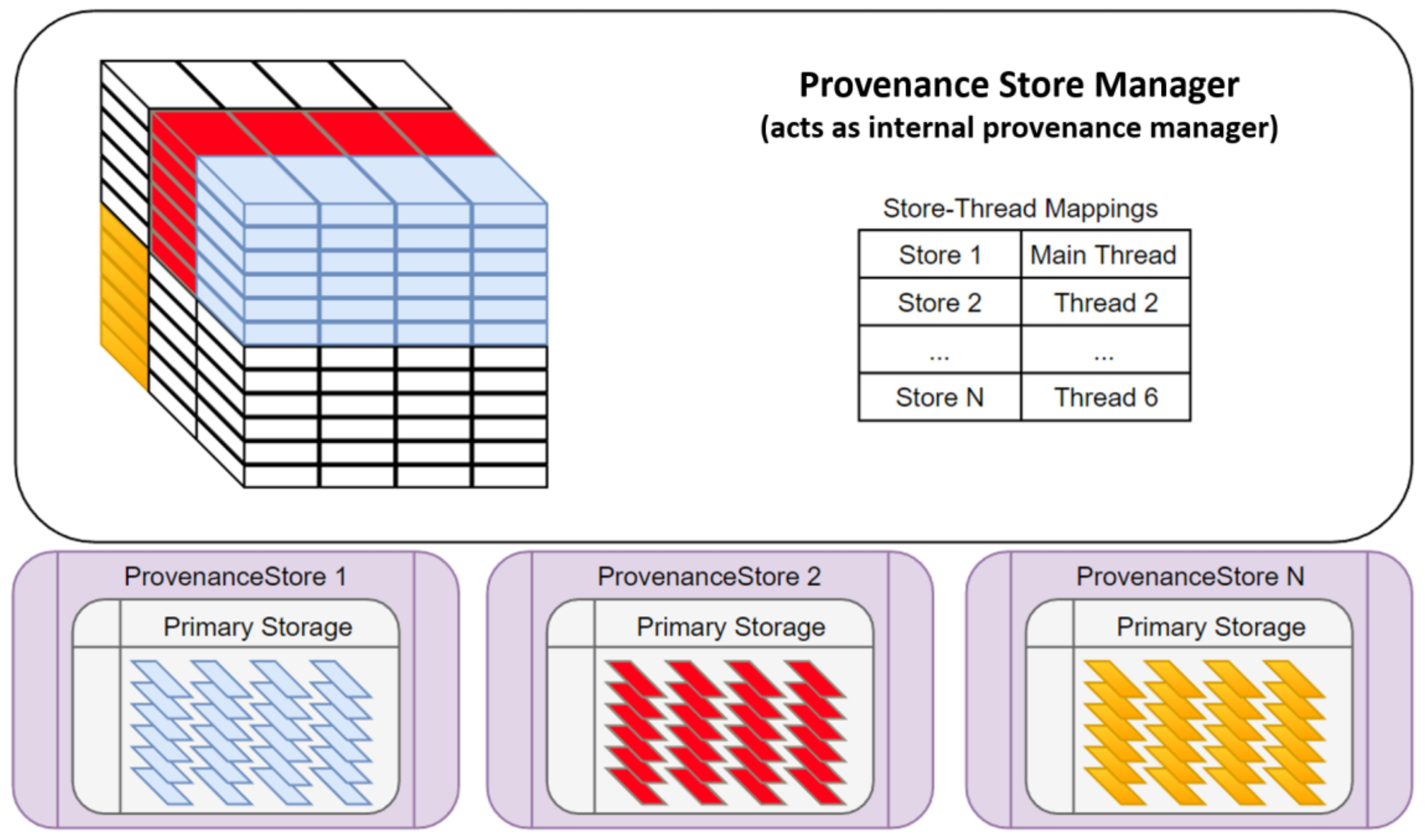
4.6. Distributed Provenance Capture Architecture
4.7. ProvMASS Requirements
4.7.1. MASS-Related Properties
4.7.2. Provenance-Related Properties
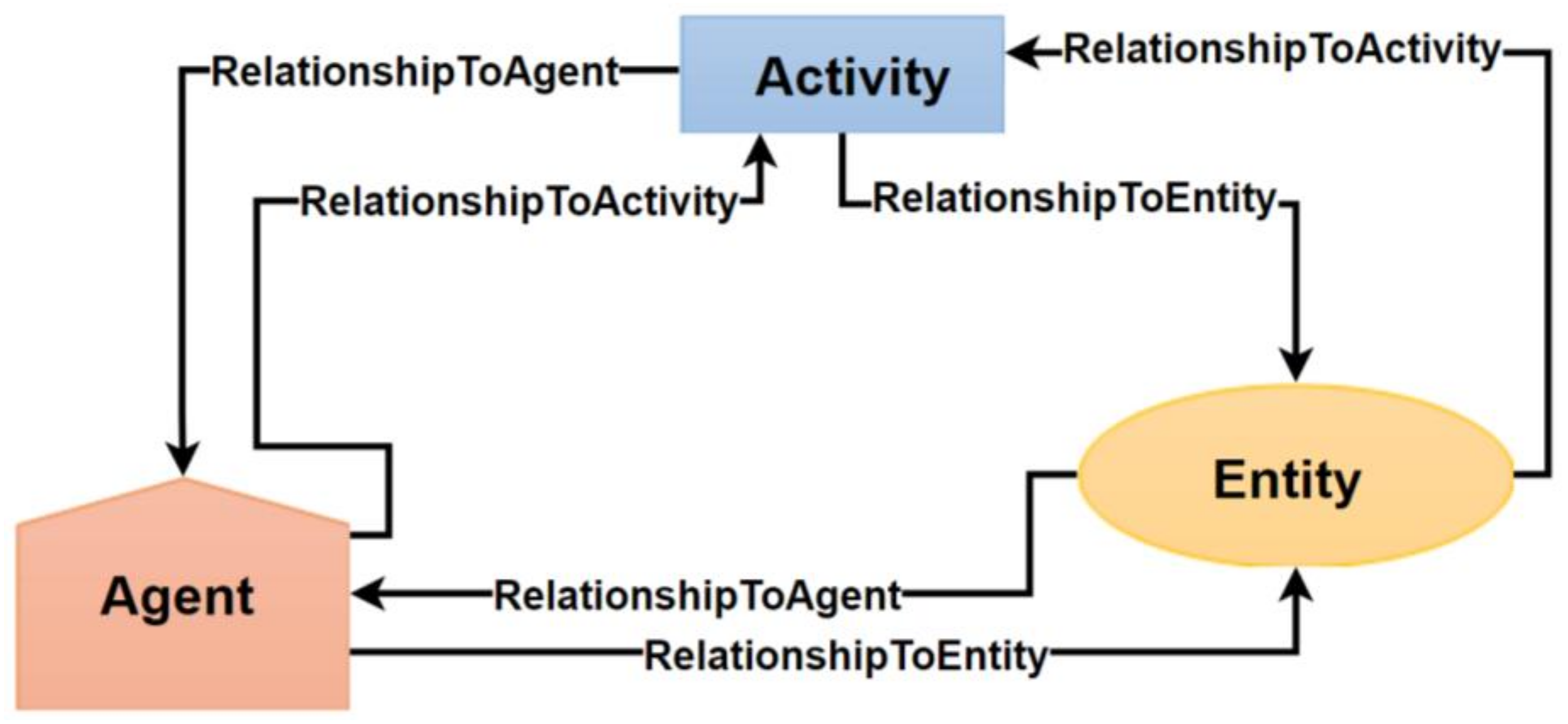
4.8. Provenance Model
4.8.1. Directed Graph
4.8.2. ABM Concept Mapping with the PROV Ontology
5. Results
5.1. Provenance Queries
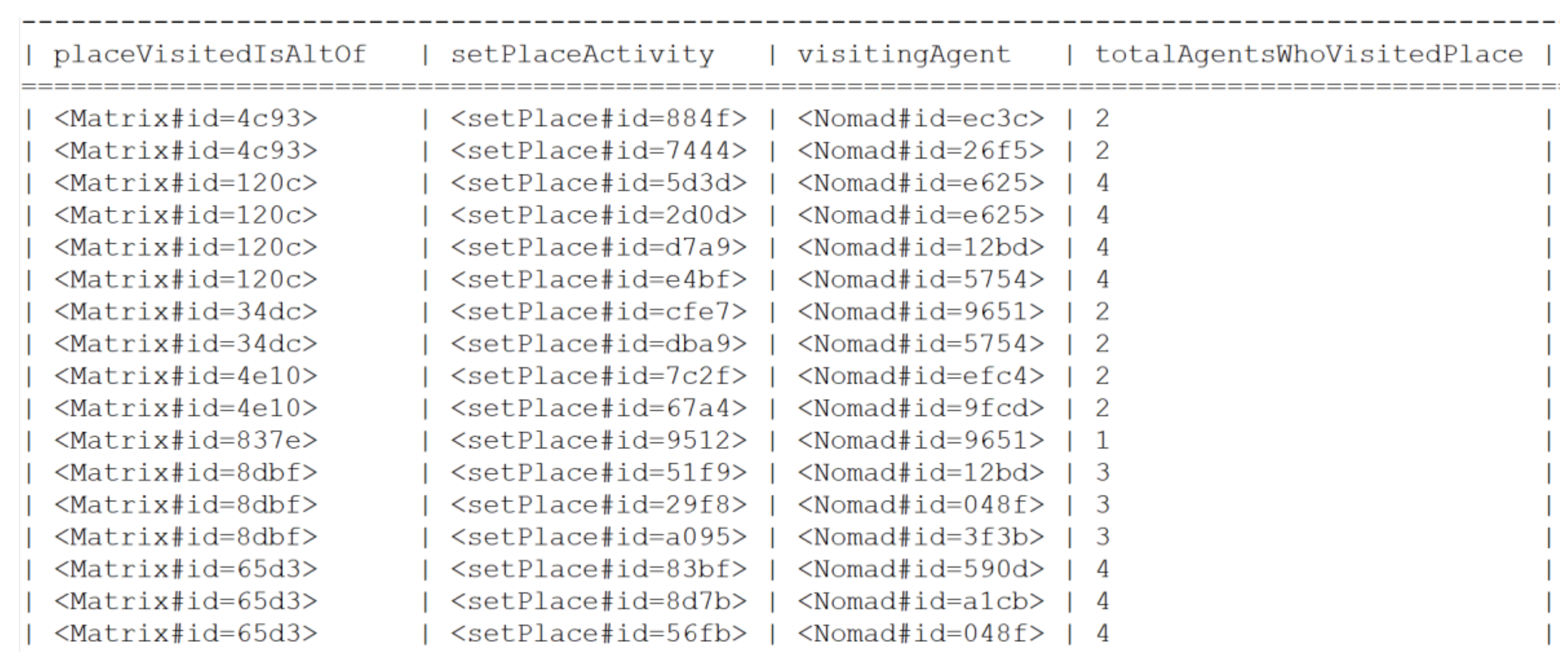
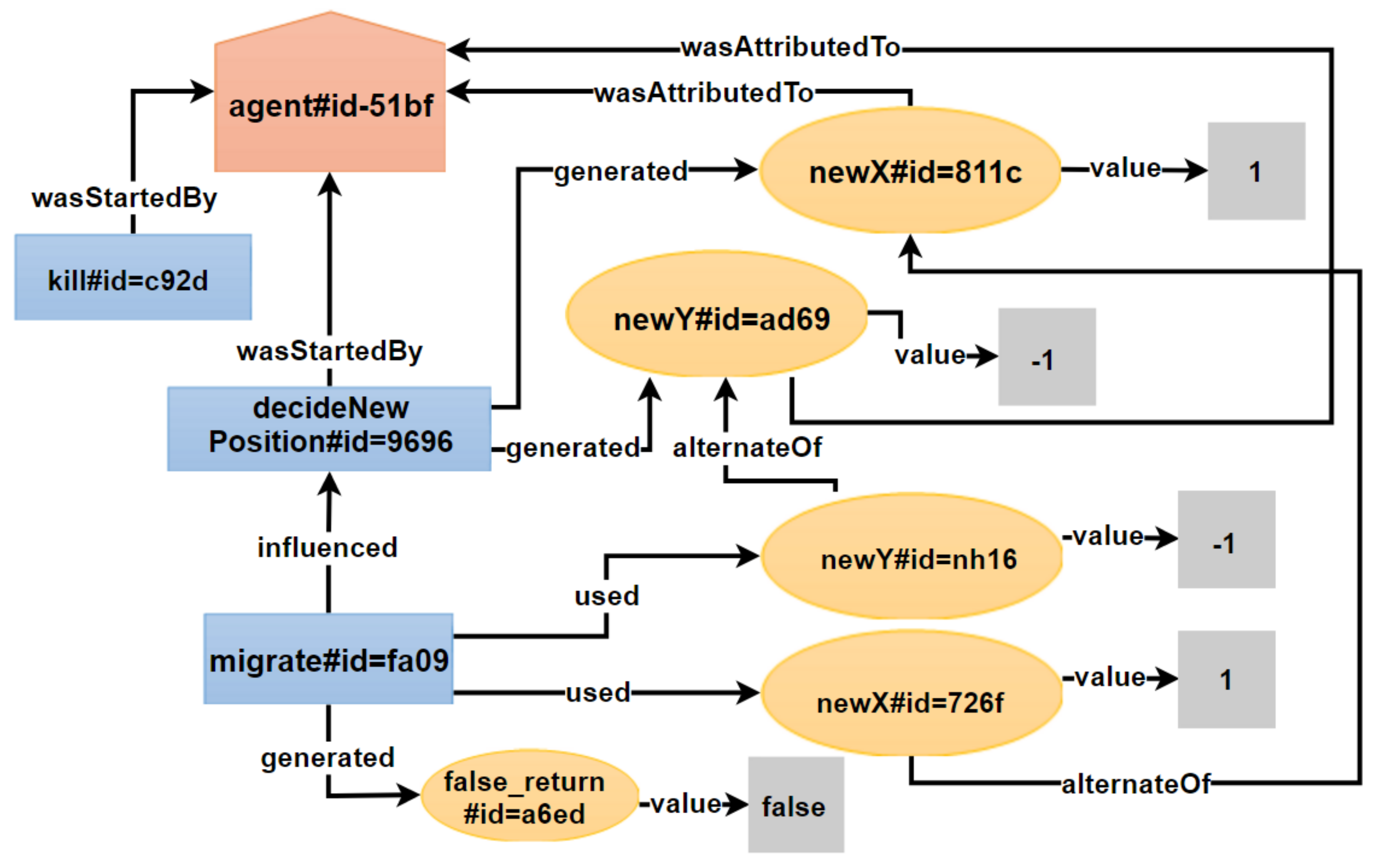
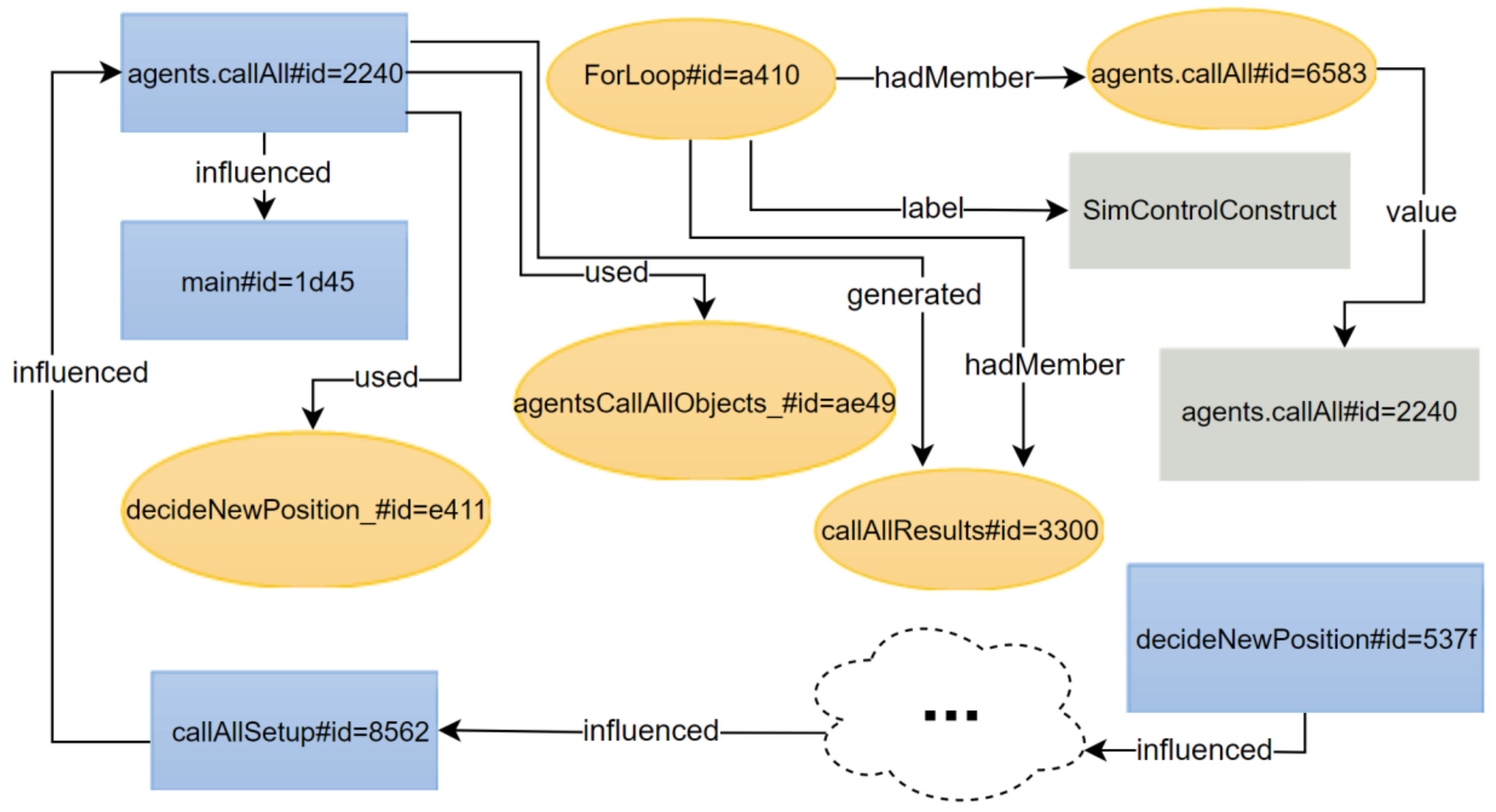
5.1.1. UC1: Individual Agent Behavior in SugarScape
5.1.2. UC2: Simulation Specification and Execution in SugarScape
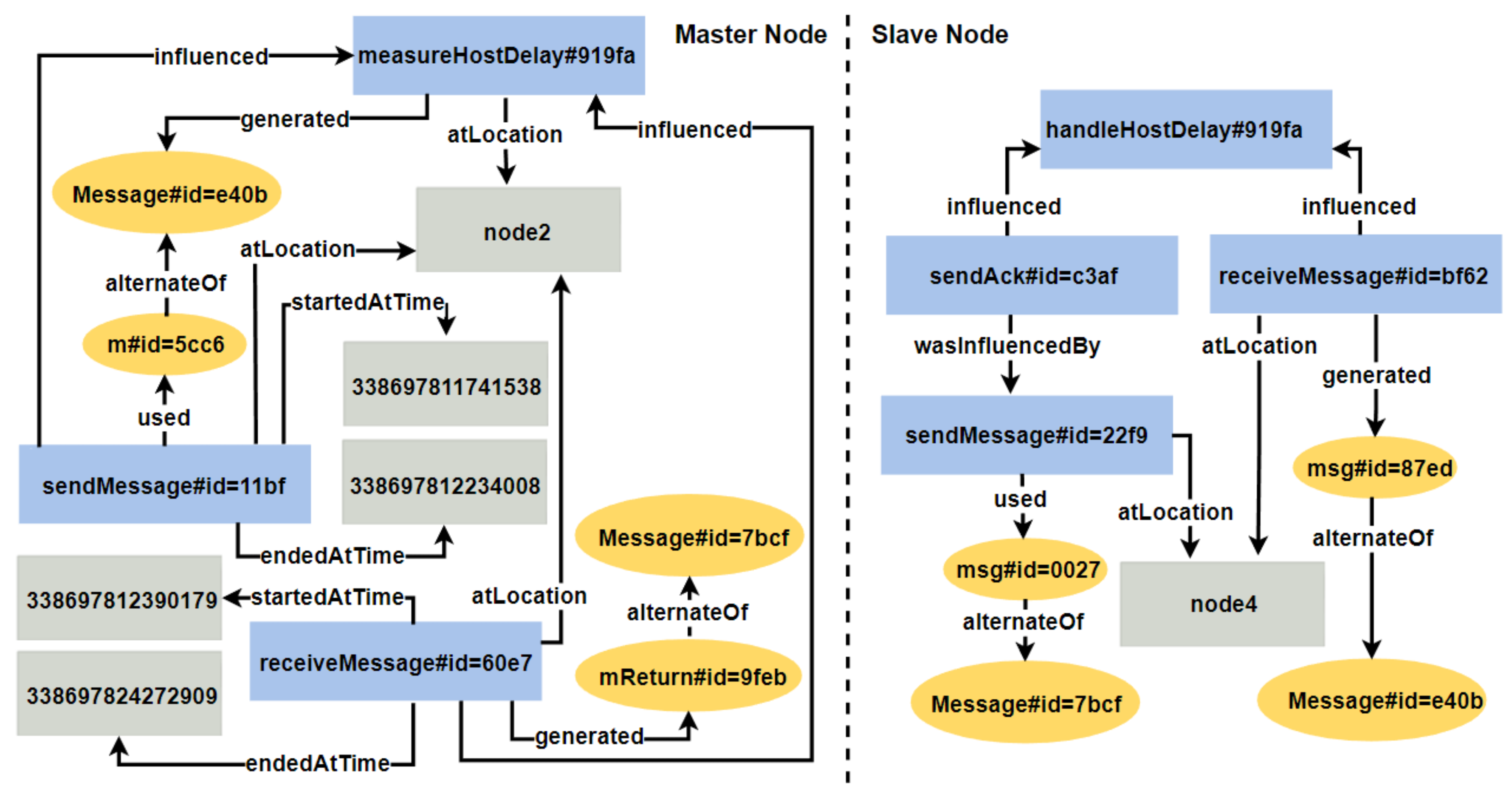
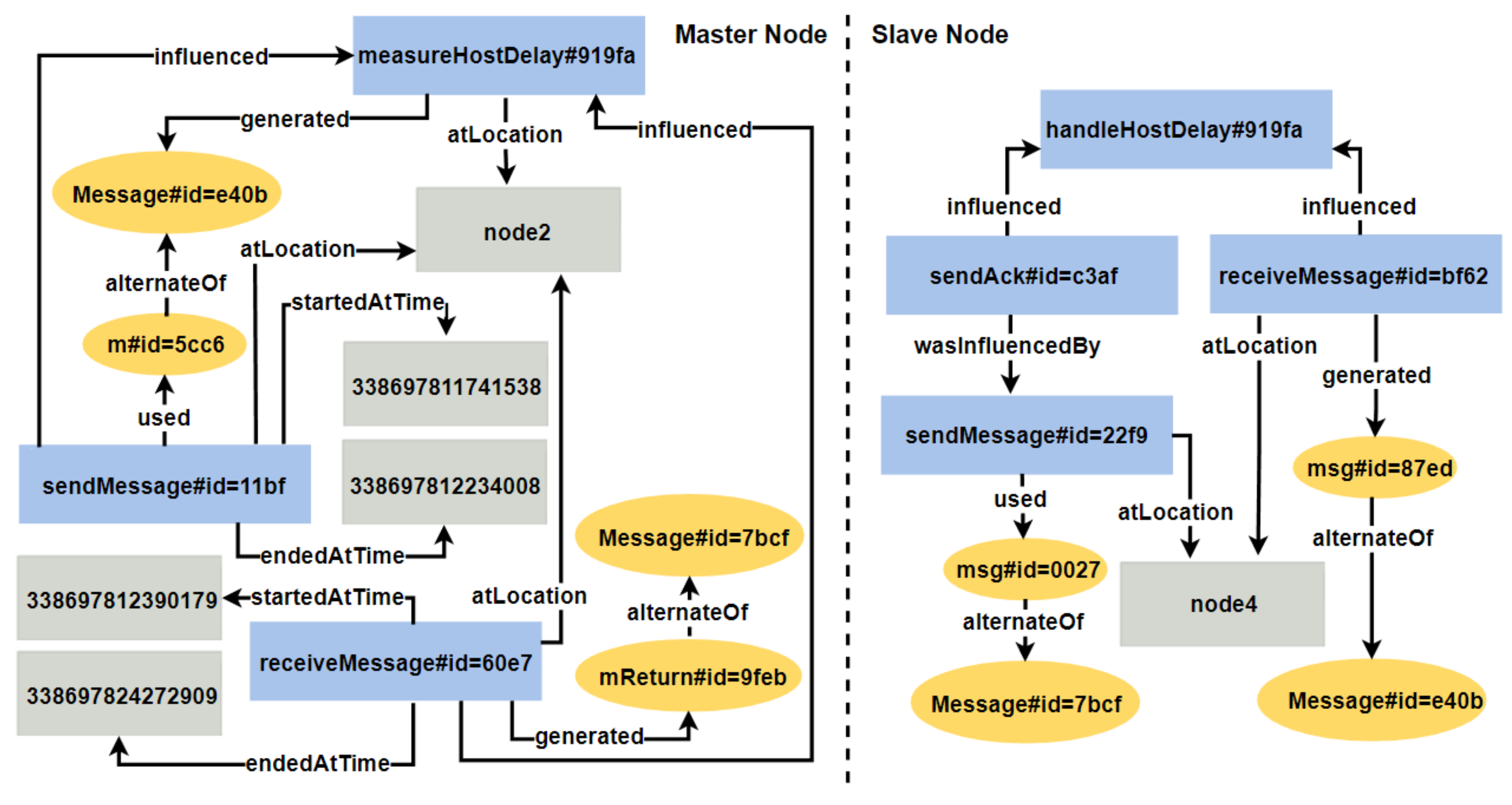
5.1.3. UC3: Distributed Execution in RandomWalk
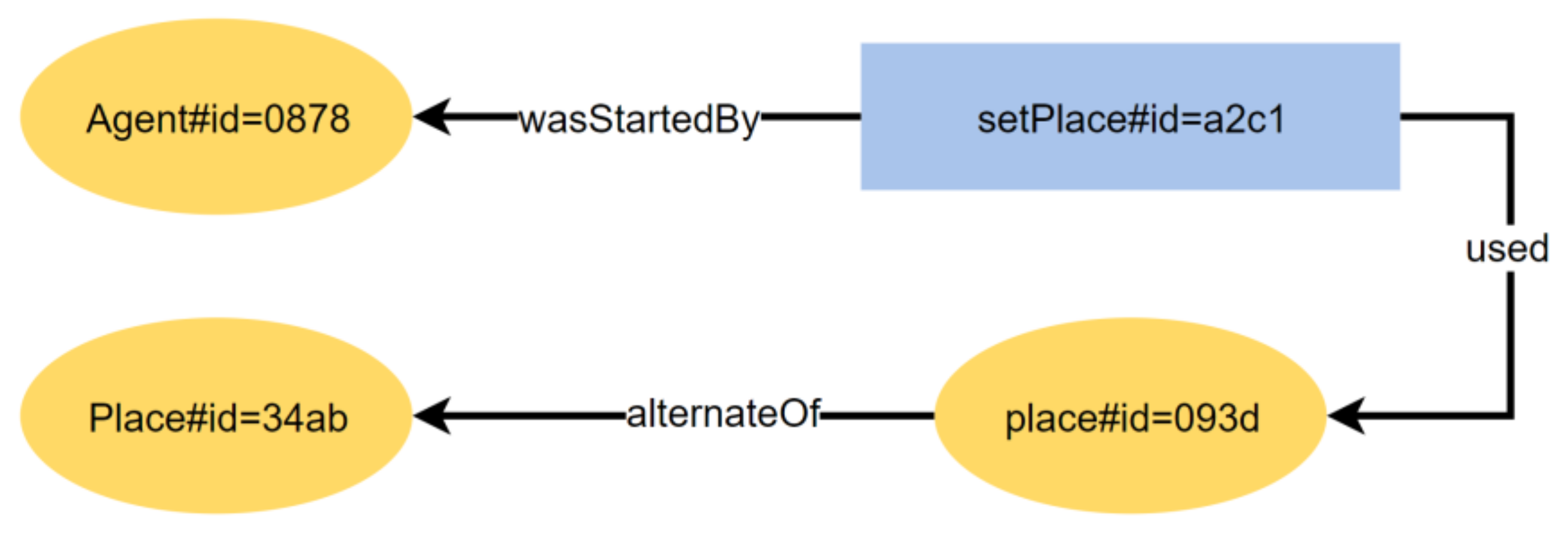
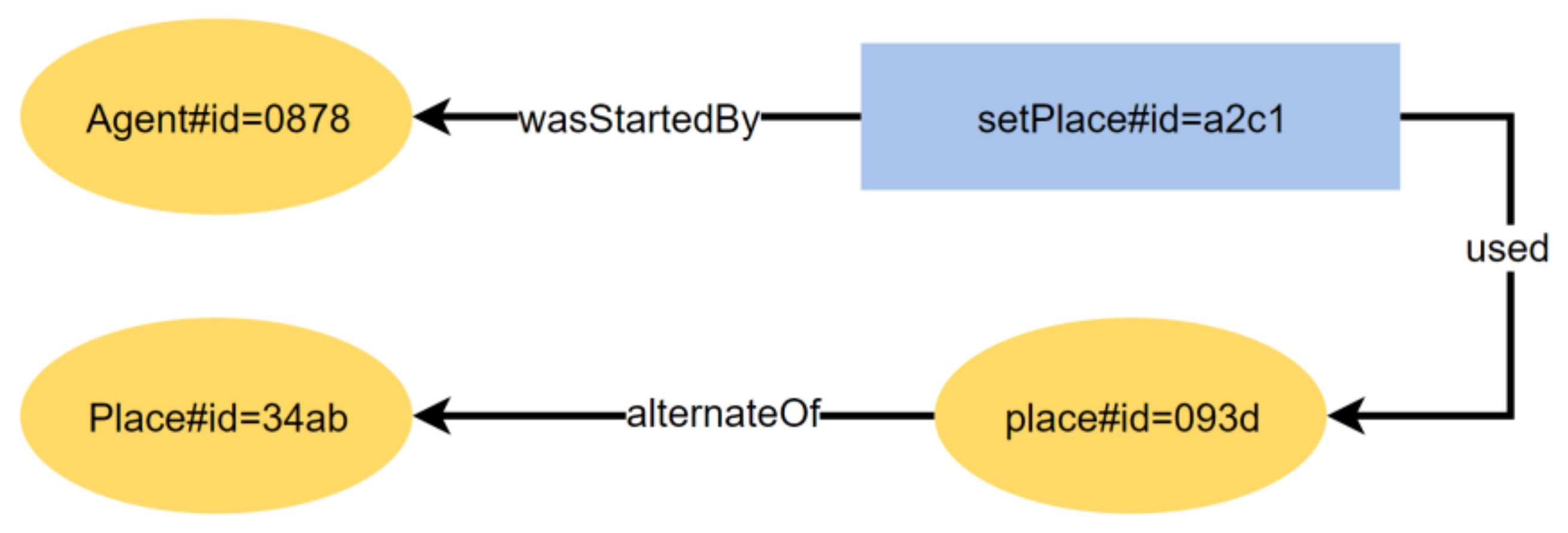
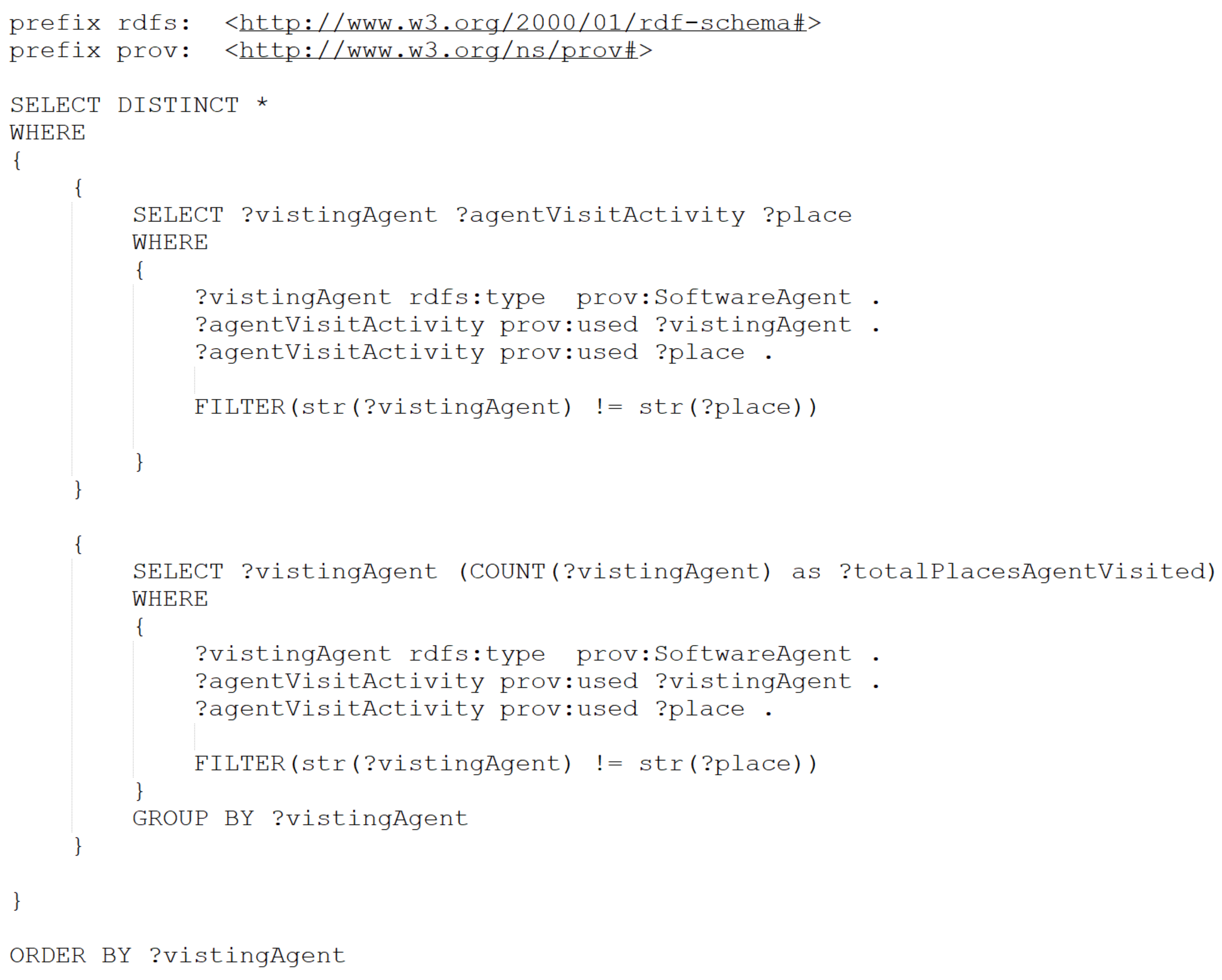
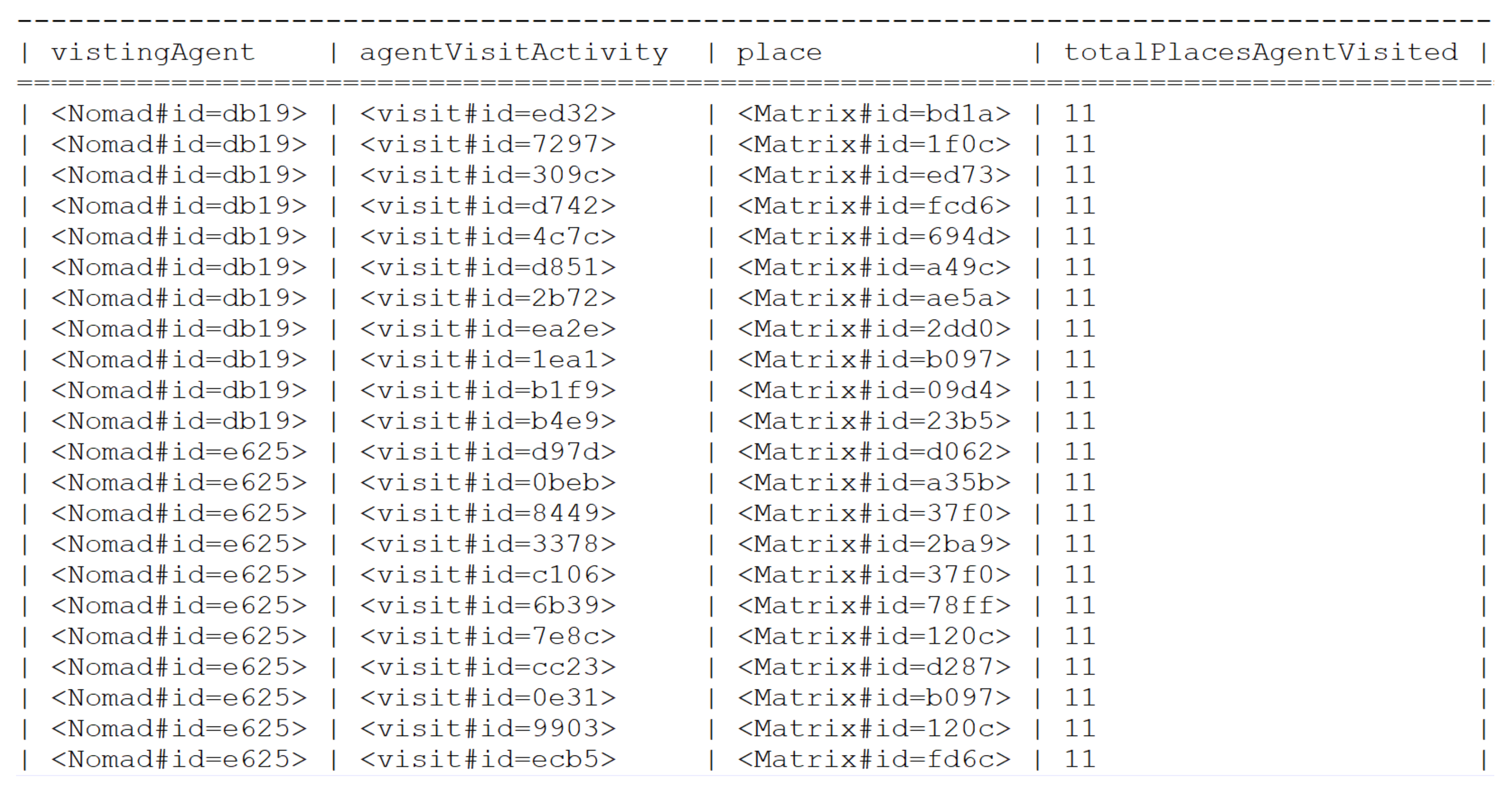
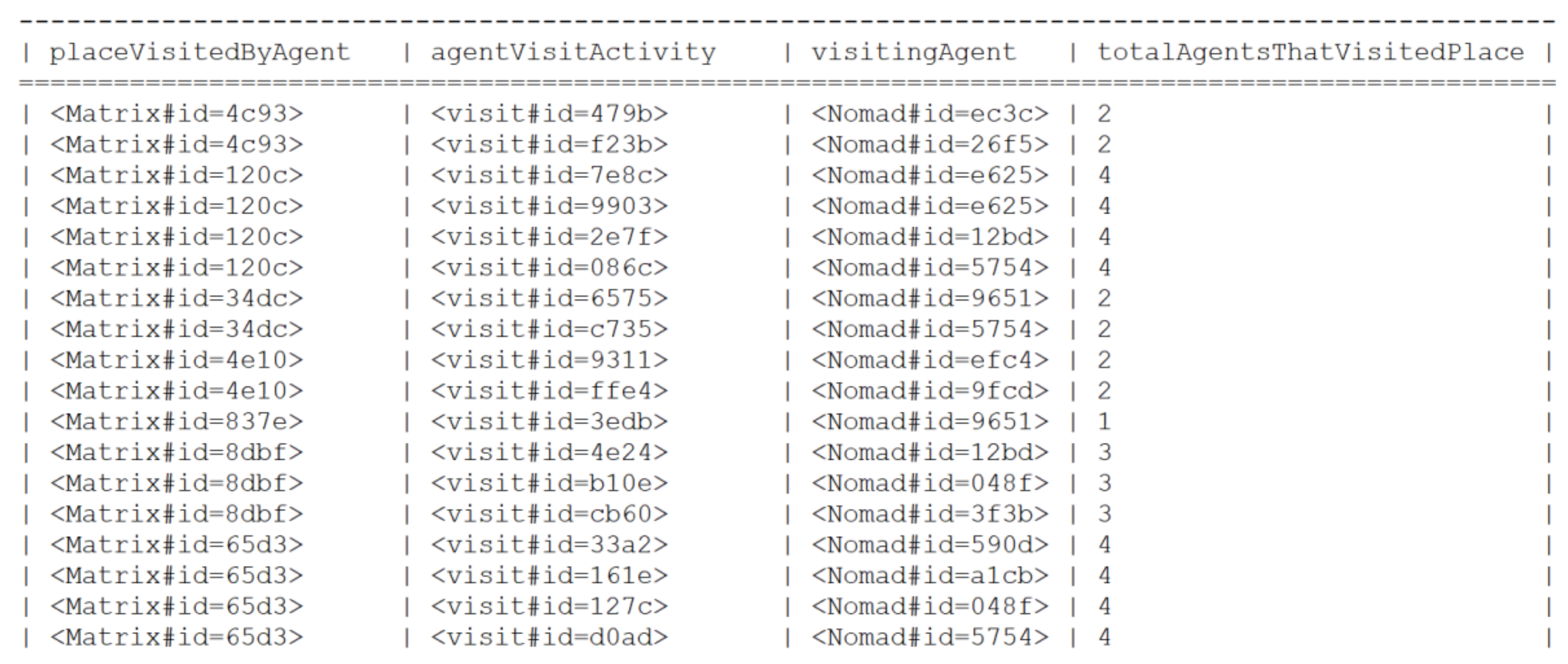
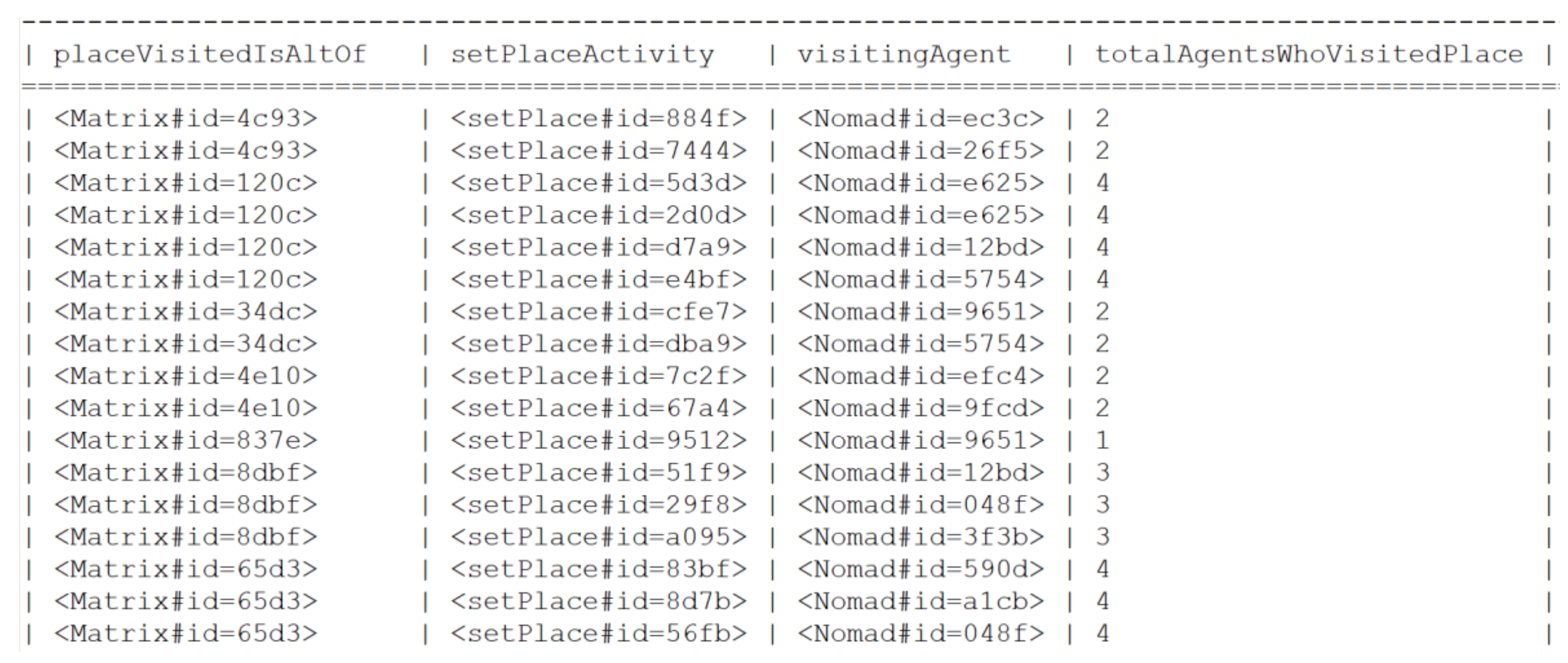
5.1.4. UC4: Agent Spatial Relationships in RandomWalk
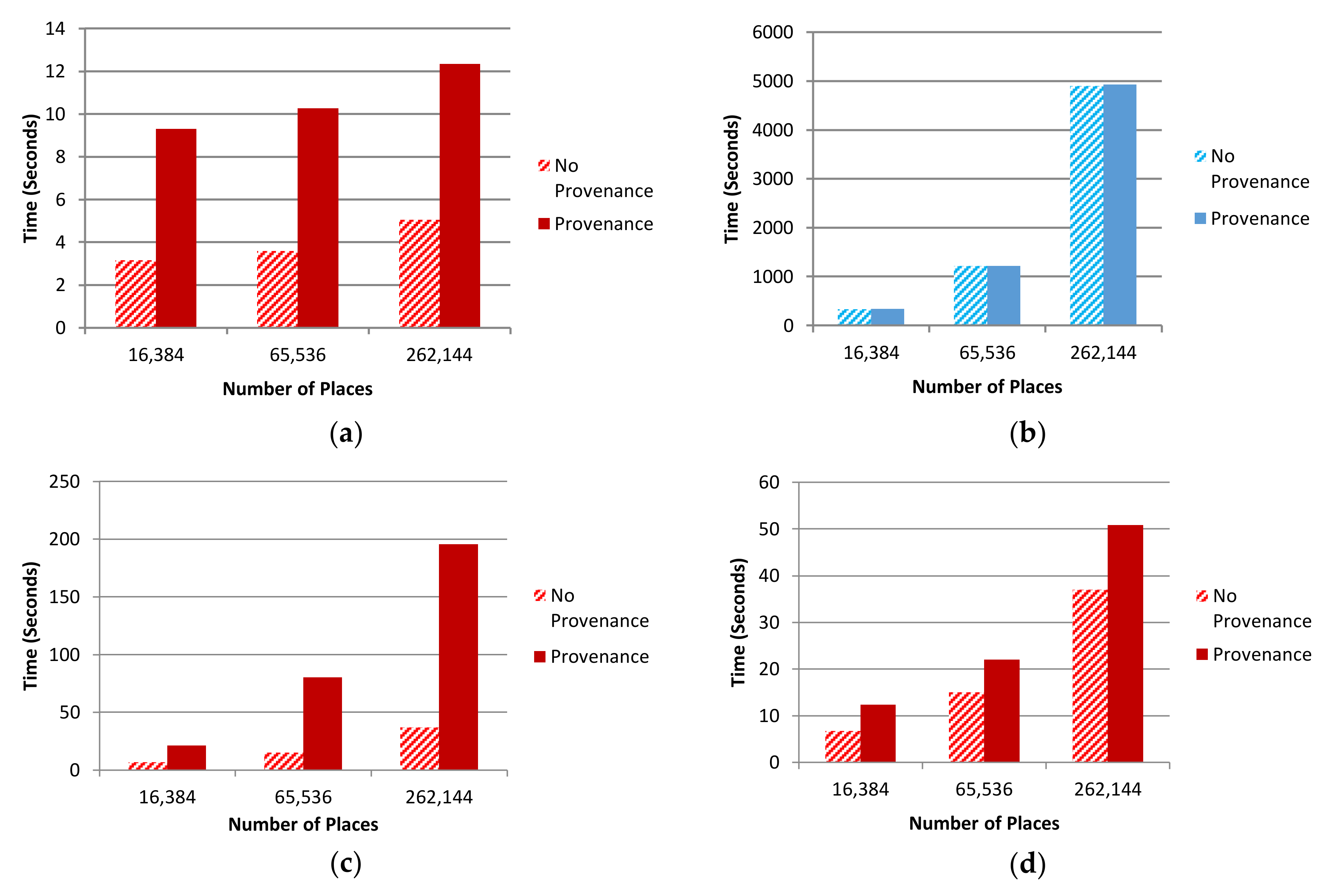
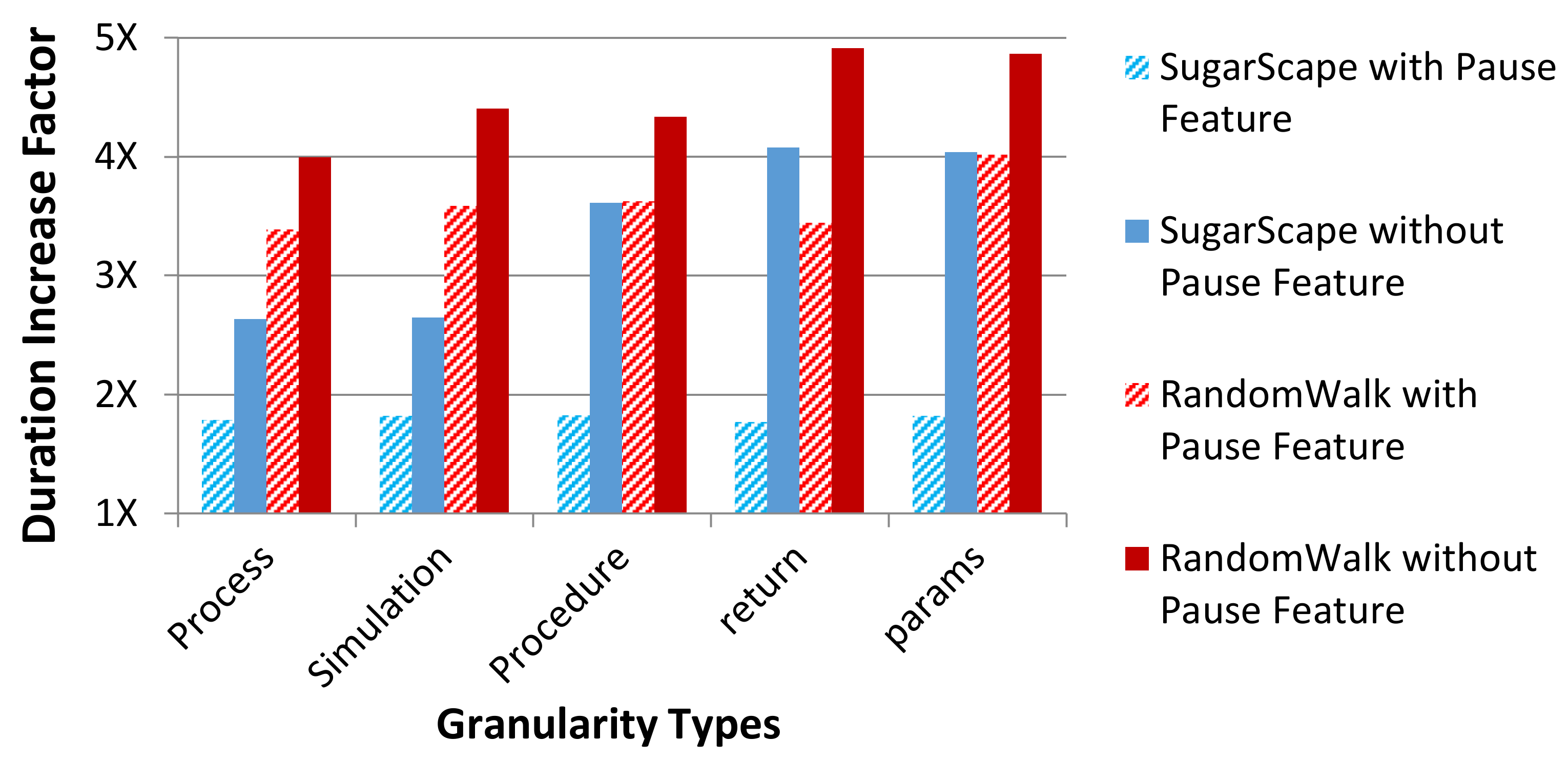
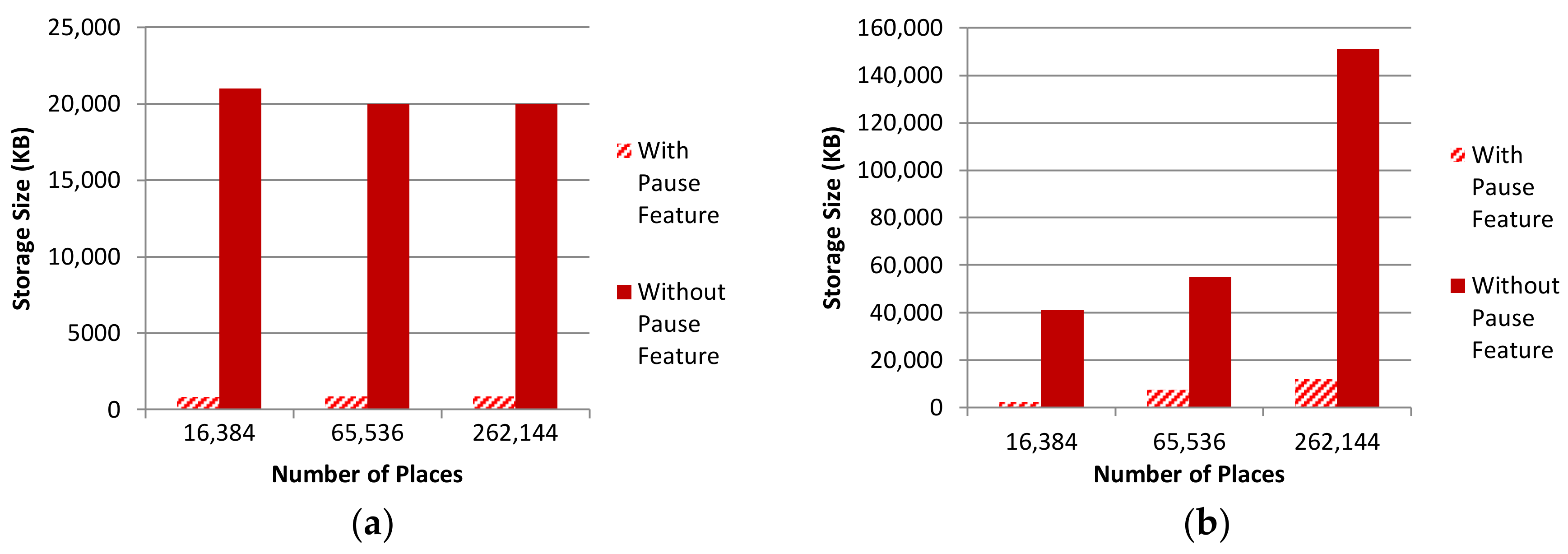
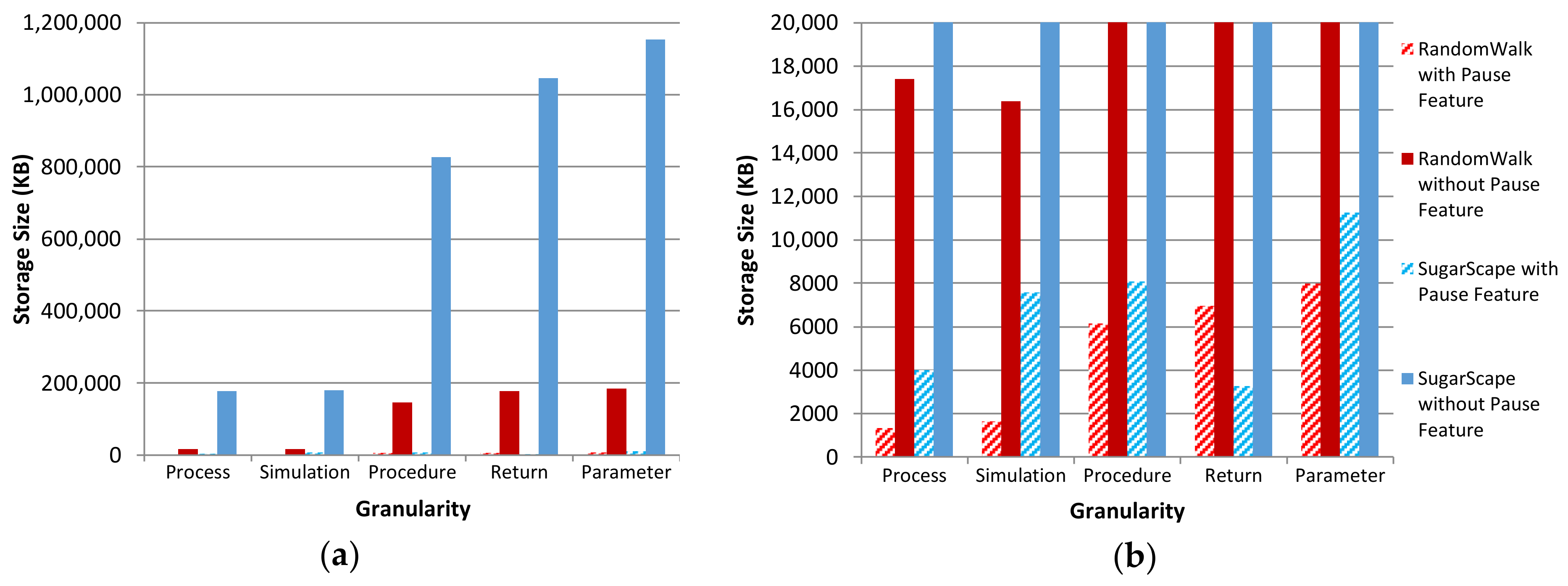
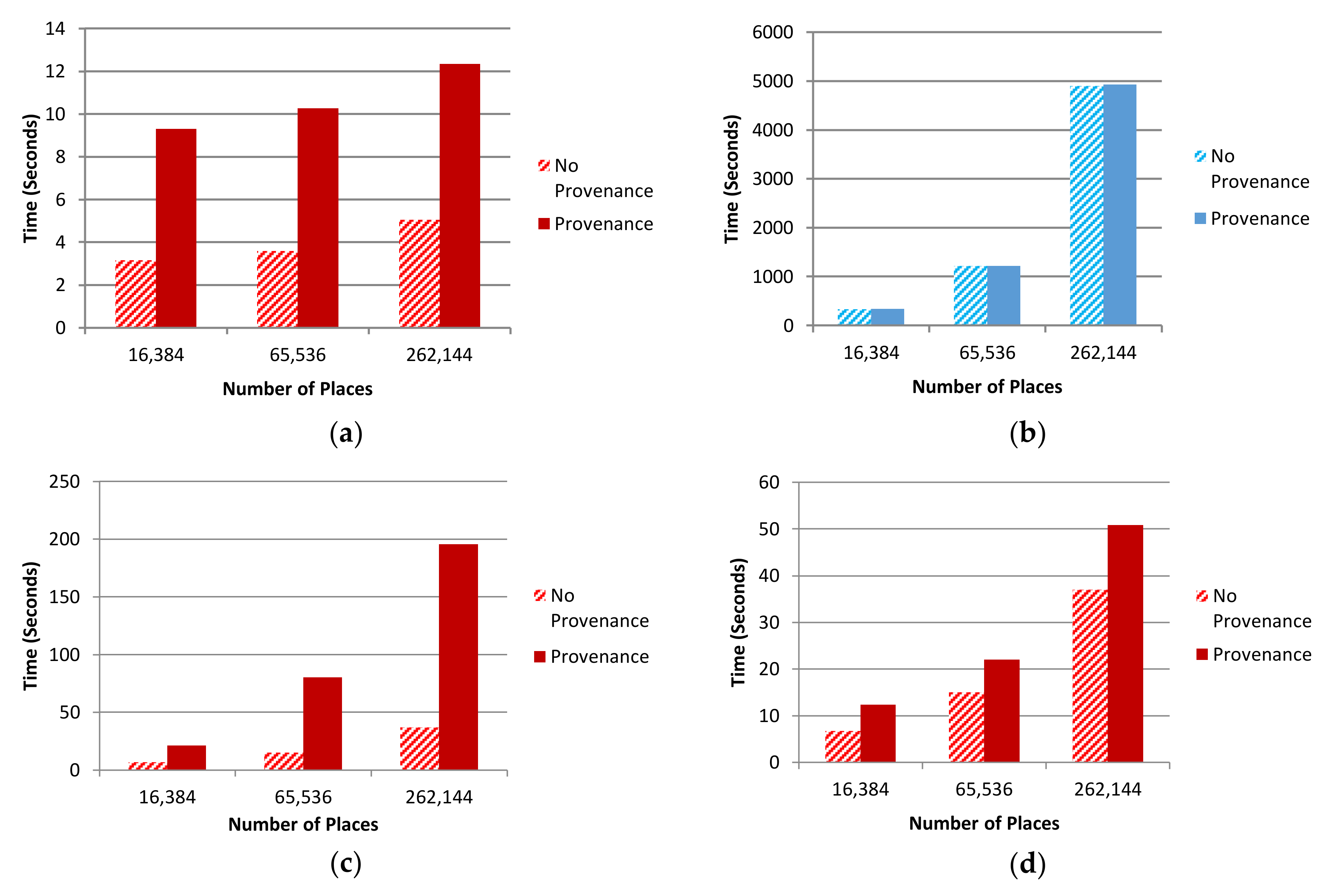
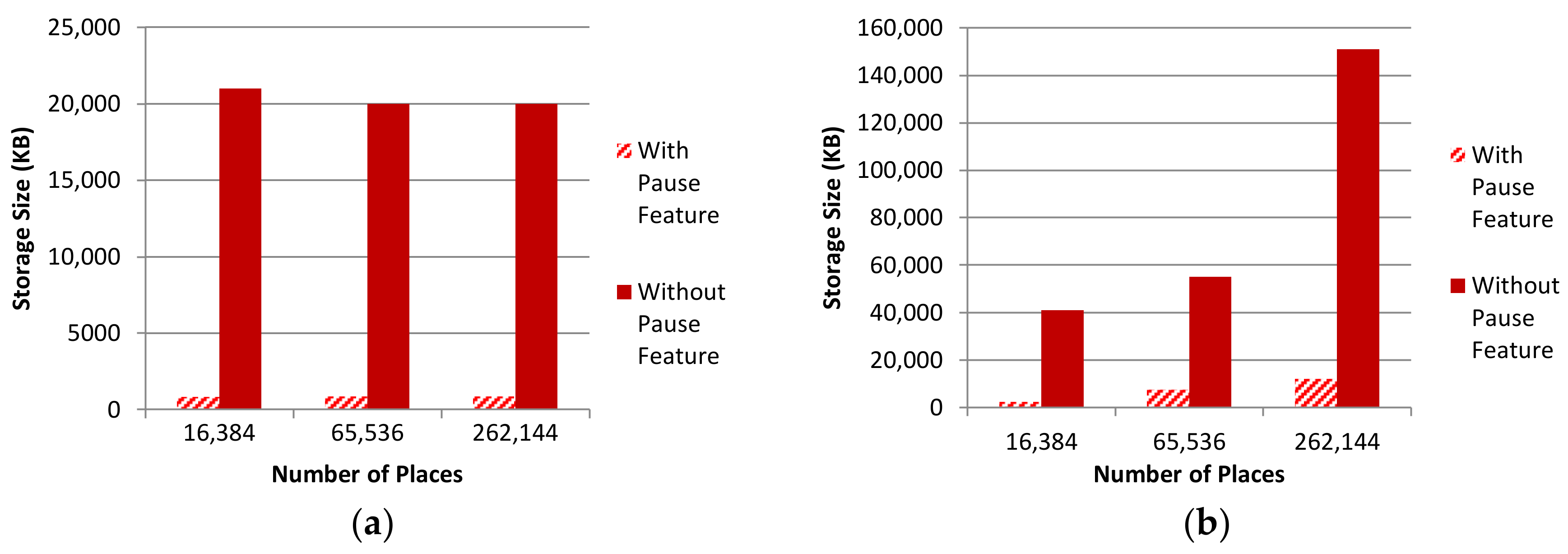
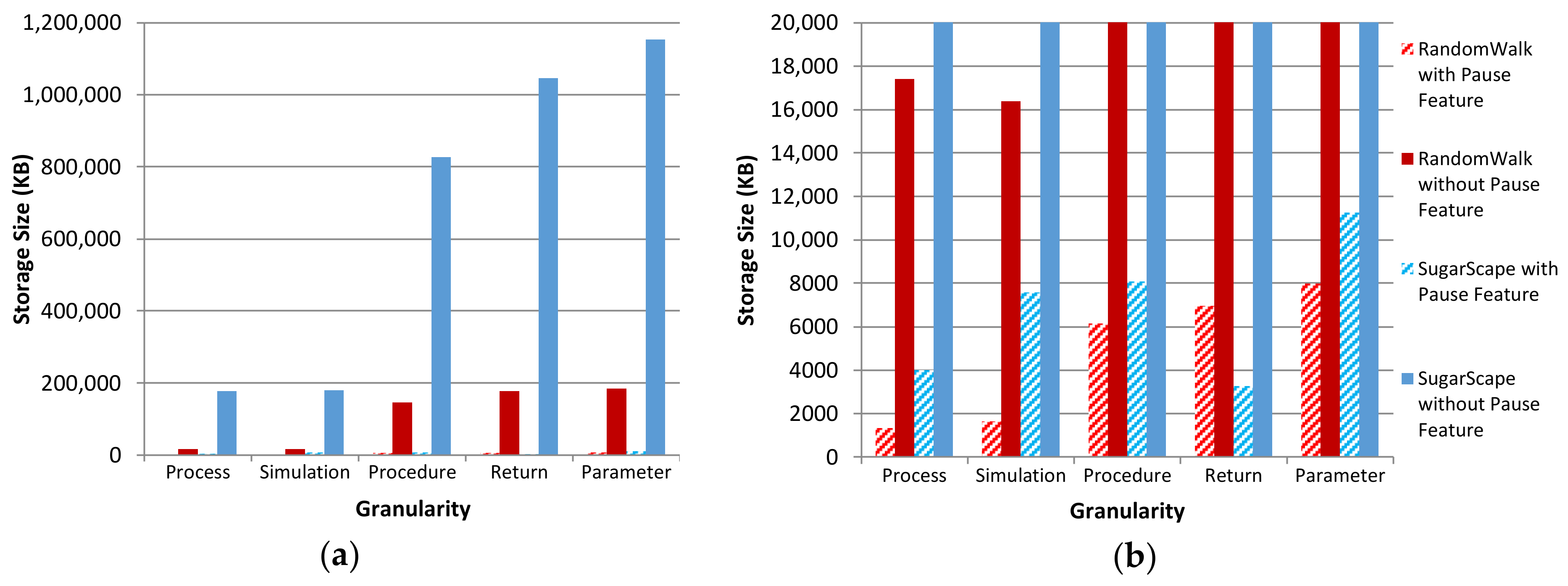
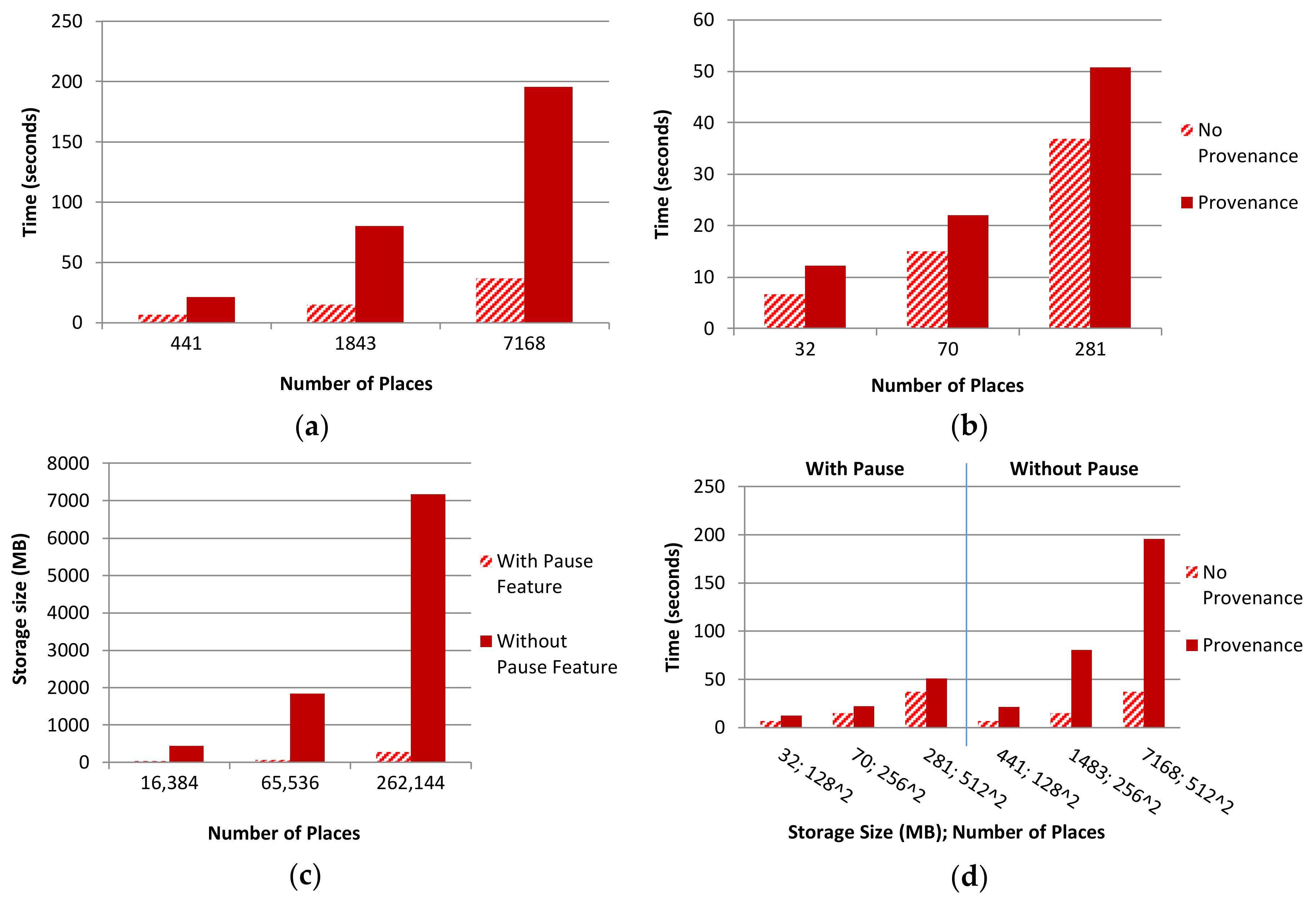
5.2. Performance Overhead Assessment
5.2.1. Agent-Scale Comparisons
5.2.2. Pause Provenance Comparisons
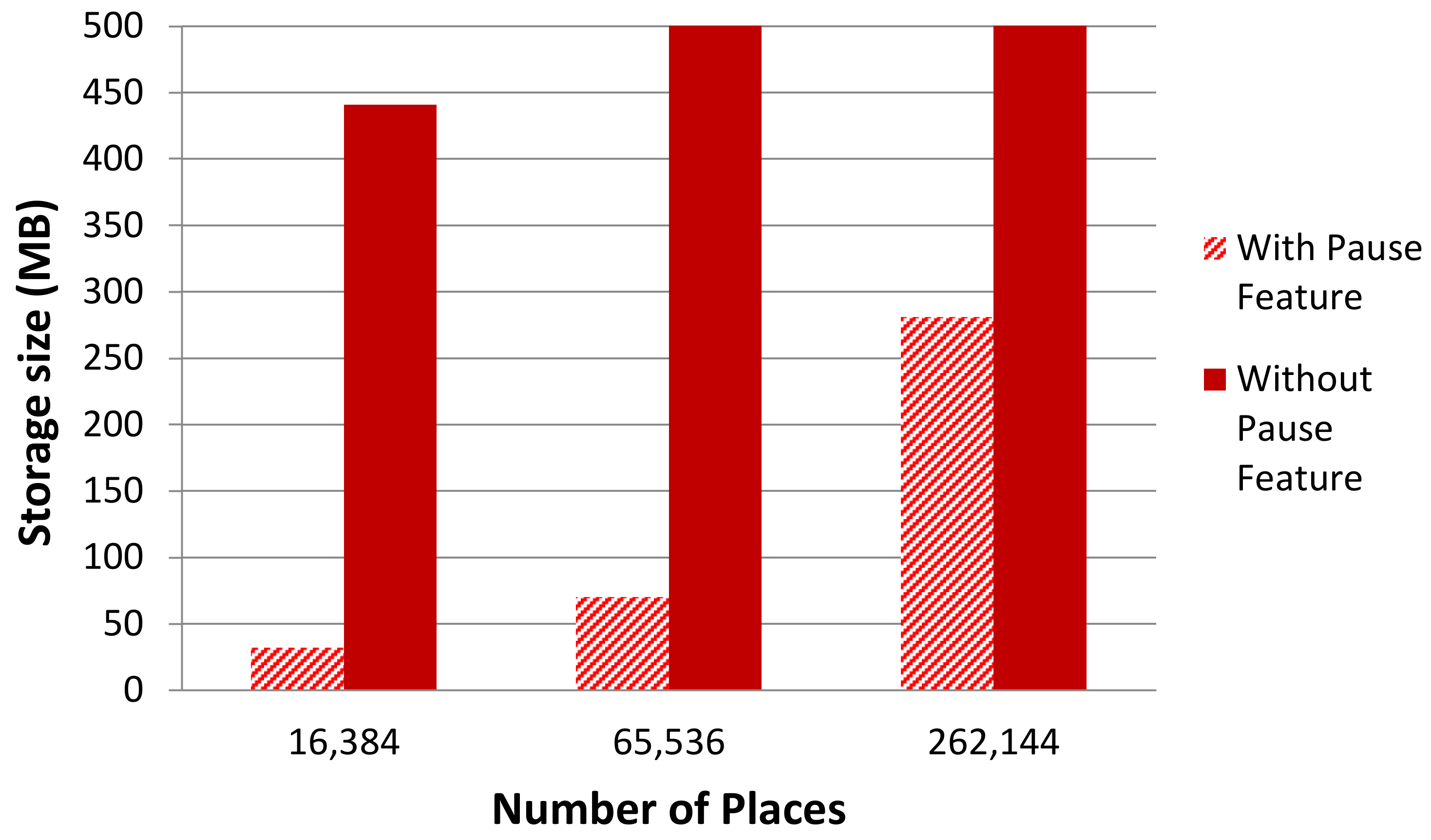
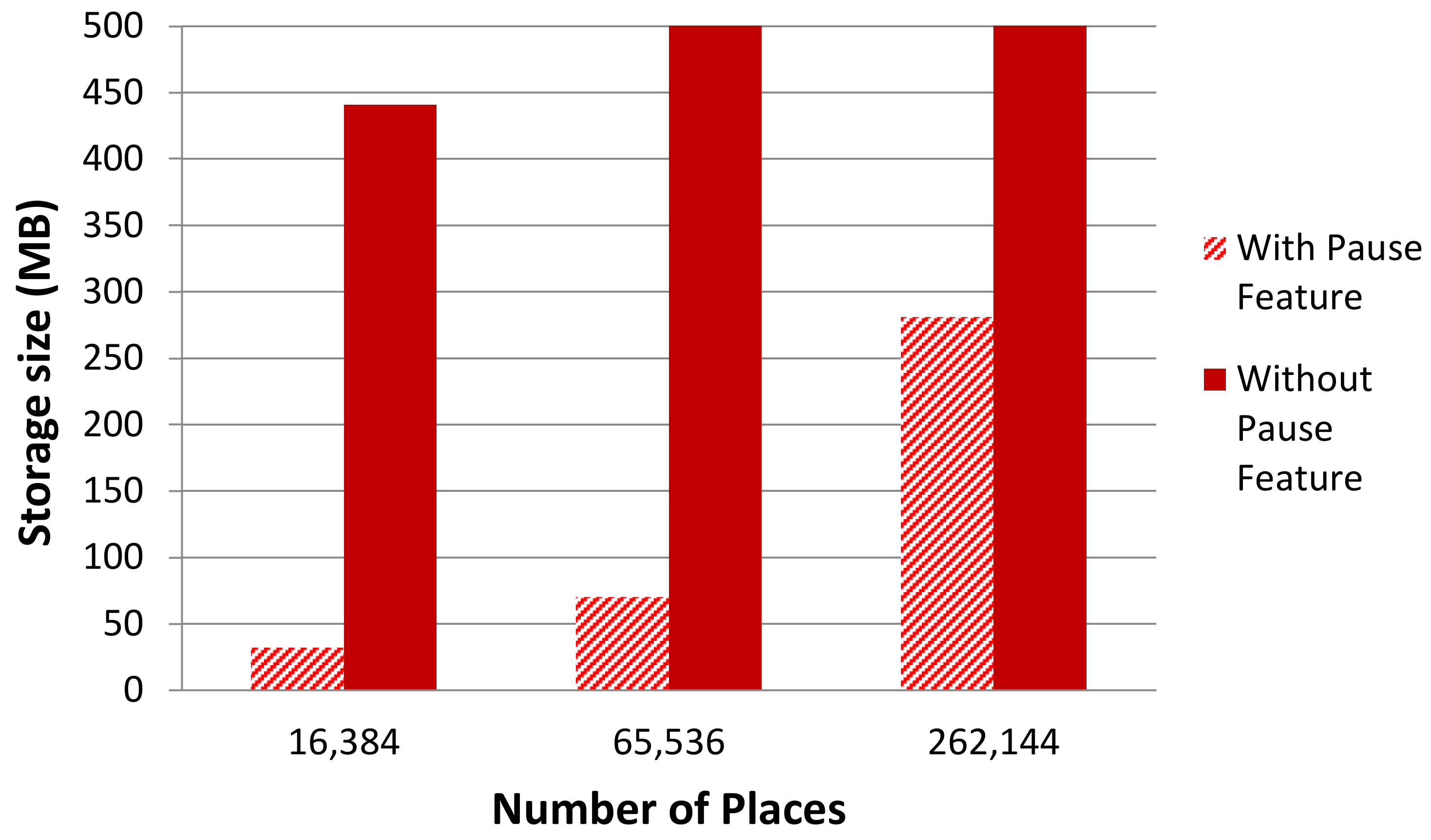
5.2.3. Storage Comparisons
5.2.4. Discussion
6. Limitations and Future Work
7. Related Work
7.1. Provenance Support for Multi-Agent Platforms
7.2. Provenance Support for Data Intensive Scalable Computing
7.3. Provenance for Shared Memory Programming
7.4. Distributed Application-Level Provenance
7.5. Connecting Layered Provenance
8. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
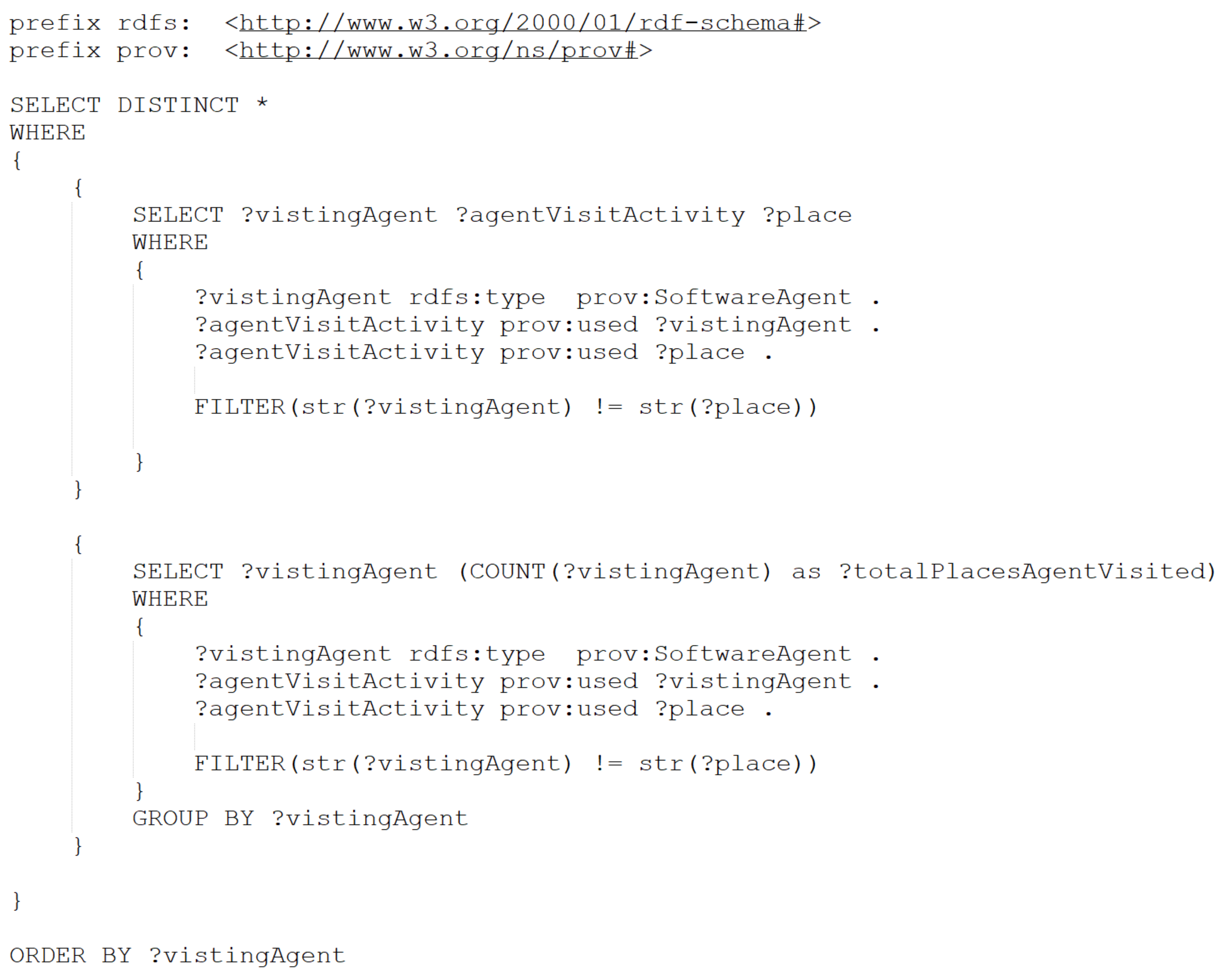



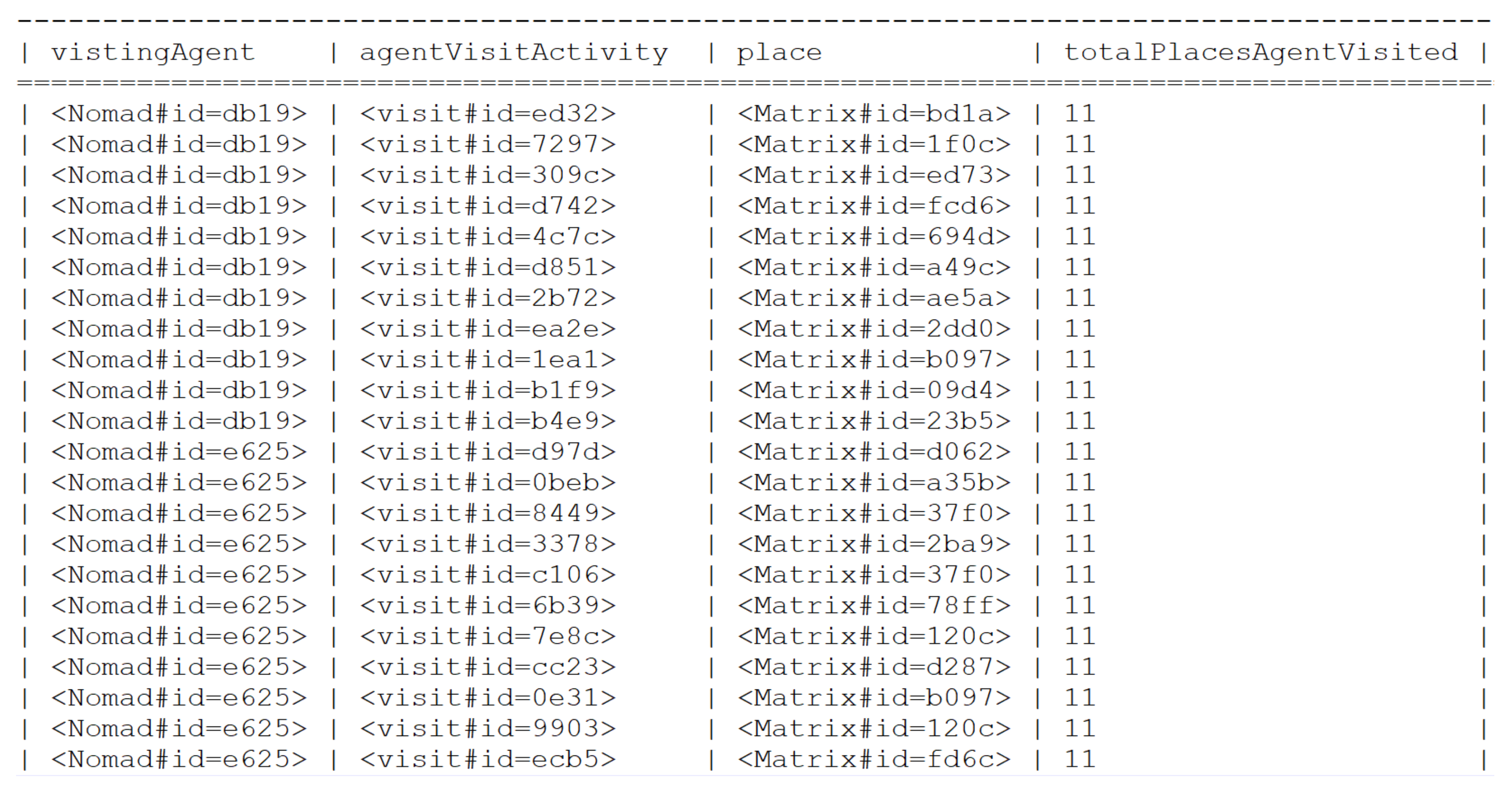
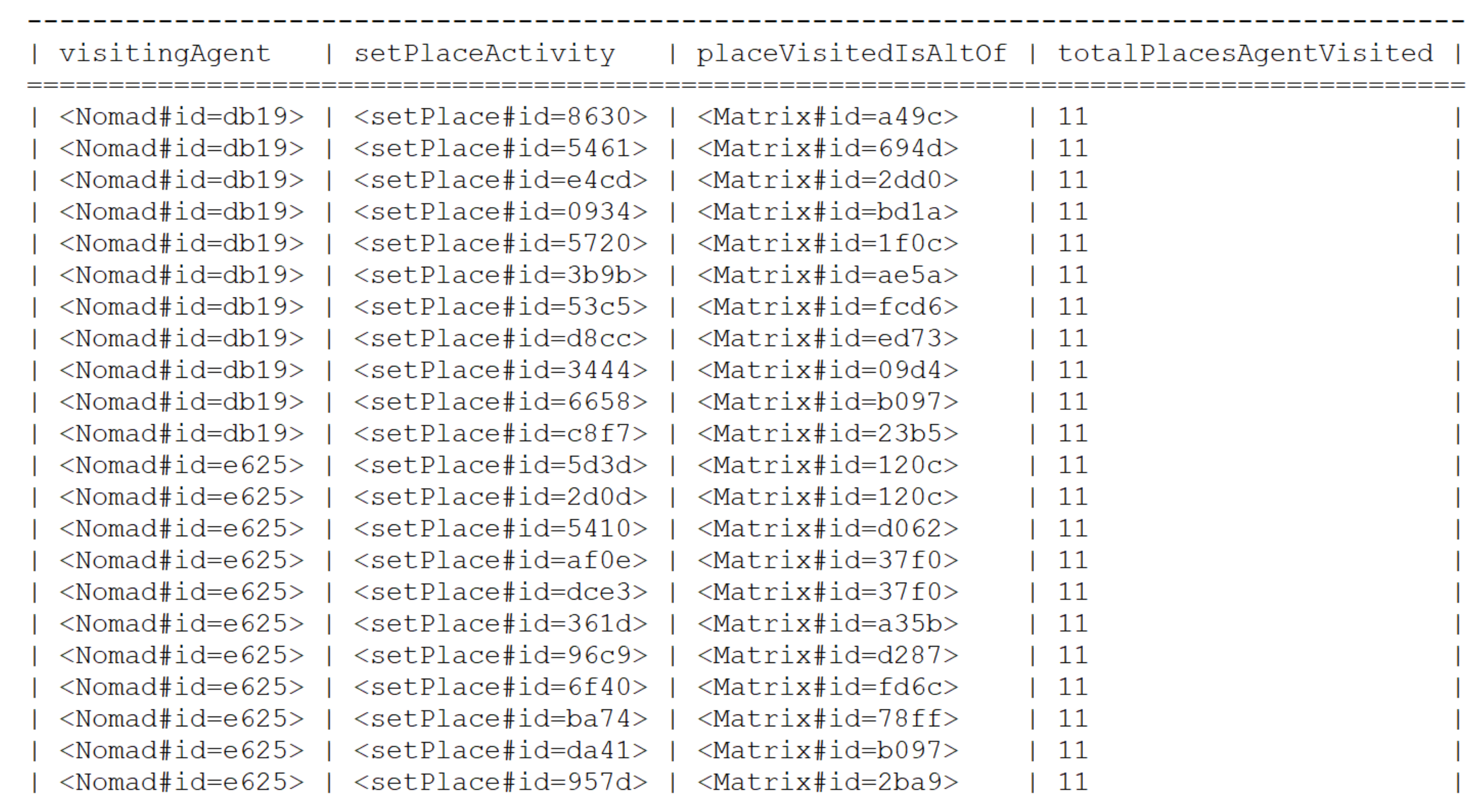
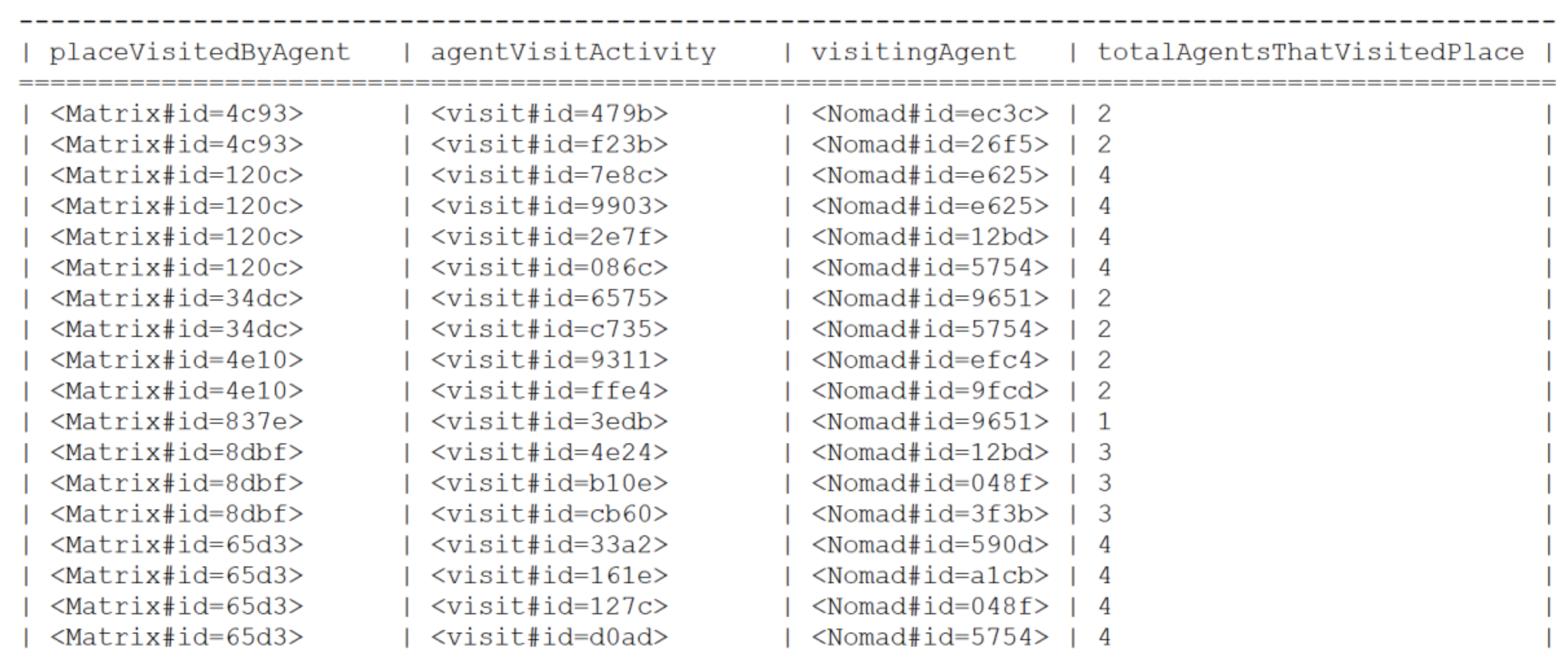
Appendix B
References
- Ferber, J. Multi-Agent Systems: An Introduction to Distributed Artificial Intelligence, 1st ed.; Addison-Wesley Reading: Boston, MA, USA, 1999; ISBN 978-0-201-36048-6. [Google Scholar]
- Ferber, J. Simulating with reactive agents. In Many-Agent Simulation and Artificial Life; Hillebrand, E., Stender, J., Eds.; IOS Press: Amsterdam, The Netherlands, 1994; pp. 8–30. [Google Scholar]
- Stevens, R.; Zhao, J.; Goble, C. Using provenance to manage knowledge of in silico experiments. Brief. Bioinform. 2007, 8, 183–194. [Google Scholar] [CrossRef] [PubMed]
- Bose, R. A conceptual framework for composing and managing scientific data lineage. In Proceedings of the 4th International Conference on Scientific and Statistical Database Management, Melbourne, Australia, 21–24 January 2003; IEEE: Edinburgh, UK, 2002. [Google Scholar]
- Buneman, P.; Khanna, S.; Tan, W. Why and Where: A Characterization of Data Provenance. In Database Theory—ICDT 2001, Proceedings of the 8th International Conference on Database Theory; Springer: Berlin/Heidelberg, Germany; London, UK, 2001; pp. 316–330. [Google Scholar]
- Chen, P.; Plale, B.; Evans, T. Dependency Provenance in Agent Based Modeling. In Proceedings of the 9th International Conference on eScience, Beijing, China, 22–25 October 2013; pp. 180–187. [Google Scholar] [CrossRef]
- An, L. Modeling human decisions in coupled human and natural systems: Review of agent-based models. Ecol. Model. 2012, 229, 25–36. [Google Scholar] [CrossRef]
- Moreau, L.; Ludascher, B.; Bertram, A.; Ilkay, B.; Roger, S.; Bowers, S.; Callahan, S.; Chin, G.; Clifford, B.; Cohen, S.; et al. Special Issue: The First Provenance Challenge. Concurr. Comput. Pract. Exp. 2008, 20, 409–418. [Google Scholar] [CrossRef]
- Davis, B.D. Data Provenance for Multi-Agent Models in a Distributed Memory. Master’s Thesis, University of Washington, Bothell, WA, USA, 2017. [Google Scholar]
- Davis, B.D.; Featherston, J.; Fukada, M.; Asuncion, H.U. Data Provenance for Multi-Agent Models. In Proceedings of the 13th International Conference on eScience, Auckland, New Zealand, 24–27 October 2017; pp. 39–48. [Google Scholar] [CrossRef]
- O’Sullivan, D.; Perry, G.L. Spatial Simulation: Exploring Pattern and Process, 1st ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013; ISBN 978-1-119-97079-8. [Google Scholar]
- Dewdney, A.K. Sharks and fish wage an ecological war on the toroidal planet Wa-Tor. Sci. Am. 1984, 251, 14–22. [Google Scholar] [CrossRef]
- Epstein, J.M. Agent-based computational models and generative social science. Complexity 2011, 4, 41–60. [Google Scholar] [CrossRef]
- Balmer, M.; Rieser, M.; Meister, K.; Charypar, D.; Lefebvre, N.; Nagel, K. MATSim-T: Architecture and simulation times. In Multi-Agent Systems for Traffic and Transportation Engineering; IGI Global: Hershey, PA, USA, 2009; pp. 57–78. [Google Scholar]
- Okal, B.; Arras, K.O. Towards group-level social activity recognition for mobile robots. In IROS Assistance and Service Robotics in a Human Environments Workshop; International Society of Biomechanics: Chicago, IL, USA, 2014. [Google Scholar]
- Ferber, J.; Gutknecht, O.; Michel, F. From Agents to Organizations: An Organizational View of Multi-Agent Systems. In Proceedings of the International Workshop on Agent-Oriented Software Engineering, Melbourne, Australia, 15 July 2003; Lecture Notes in Computer Science; Giorgini, P., Miiler, J.P., Odell, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004. [Google Scholar]
- Morvan, G. Multi-level agent-based modeling-a literature survey. arXiv, 2012; arXiv:1205.0561. [Google Scholar]
- Gerber, C.; Siekmam, J.; Vierke, G. Holonic Multi-Agent Systems; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Mass_Java_Core—BitBucket. Available online: https://bitbucket.org/mass_library_developers/mass_java_core (accessed on 26 February 2018).
- Emau, J.; Chuang, T.; Fukuda, M. A Multi-Process Library for Multi-Agent and Spatial Simulation. In Proceedings of the 2011 Pacific Rim Conference on Communications and Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 23–26 August 2011. [Google Scholar]
- Mistry, B.; Fukuda, M. Dynamic load balancing in multi-agent spatial simulation. In Proceedings of the 2015 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing (PACRIM), Victoria, BC, Canada, 24–26 August 2015. [Google Scholar]
- Ma, Z.; Fukuda, M. A multi-agent spatial simulation library for parallelizing transport simulations. In Proceedings of the 2015 IEEE Winter Simulation Conference (WSC), Huntington Beach, CA, USA, 6–9 December 2015. [Google Scholar]
- Bowzer, C.; Phan, B.; Cohen, K.; Fukuda, M. Collision-Free Agent Migration in Spatial Simulation. In Proceedings of the Communication Papers of the 2017 Federated Conference on Computer Science and Information Systems (FedCSIS 2017), Prague, Czech Republic, 3–6 September 2017. [Google Scholar]
- Chuang, T.; Fukuda, M. A Parallel Multi-Agent Spatial Simulation Environment for Cluster Systems. In Proceedings of the 16th International Conference on Computational Science and Engineering, Sydney, NSW, Australia, 3–5 December 2013. [Google Scholar]
- Pignotti, E.; Polhill, G.; Edwards, P. Using Provenance to Analyse Agent-based Simulations. In Proceedings of the EDBT/ICDT 2013 Joint Workshops, Genoa, Italy, 18–22 March 2013; ACM: New York, NY, USA, 2013; pp. 319–322. [Google Scholar] [CrossRef]
- Epstein, J.M.; Axtell, R. Growing Artificial Societies: Social Science from the Bottom Up, 1st ed.; Brookings Institution Press: Washington, DC, USA, 1996; ISBN 978-0-262-55025-3. [Google Scholar]
- Dunning, J.B.; Stewart, D.J.; Liu, J. Individual-Based Modeling. In Learning Landscape Ecology: A Practical Guide to Concepts and Techniques; Gergel, S.E., Turner, M.G., Eds.; Springer: New York, NY, USA, 2002; pp. 228–245. ISBN 978-0-387-21613-3. [Google Scholar]
- Railsback, S.F. Concepts from complex adaptive systems as a framework for individual-based modelling. Ecol. Model. 2011, 139, 47–62. [Google Scholar] [CrossRef]
- Batty, M. A Generic Framework for Computational Spatial Modeling. In Agent-Based Models of Geographical Systems; Springer, Dordrecht: Dordrecht, The Netherlands, 2012; pp. 19–50. ISBN 978-90-481-8927-4. [Google Scholar]
- Gurcan, O.; Dikenelli, O.; Bernon, C. A generic testing framework for agent-based simulation models. J. Simul. 2013, 7, 183–201. [Google Scholar] [CrossRef] [Green Version]
- Drummond, C. Replicability is not reproducibility: Nor is it good science. In Proceedings of the Evaluation Methods for Machine Learning Workshop, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Davison, A. Automated Capture of Experiment Context for Easier Reproducibility in Computational Research. Comput. Sci. Eng. 2012, 14, 48–56. [Google Scholar] [CrossRef]
- Simonson, N.; Wessels, S.; Fukada, M. Language and Debugging Support for Multi-Agent and Spatial Simulation. In Proceedings of the International Conference on Parallel and Distributed Processing Techniques and Applications (PDPTA), Las Vegas, NV, USA, 16–18 July 2012; pp. 373–379. [Google Scholar]
- Li, H.A. A Debugger of Parallel Multi-Agent Spatial Simulation. Available online: https://depts.washington.edu/dslab/MASS/reports/HongbinLi_final_au14.ppt (accessed on 26 February 2018).
- Interlandi, M.; Shah, K.; Tetali, S.D.; Gulzar, M.A.; Yoo, S.; Kim, M.; Millstein, T.; Condie, T. Titian: Data Provenance Support in Spark. Proc. VLDB Endow. 2015, 9, 216–227. [Google Scholar] [CrossRef]
- Malik, T.; Gehani, A.; Tariq, D.; Zaffar, F. Sketching Distributed Data Provenance. In Data Provenance and Data Management in eScience; Liu, Q., Bai, Q., Giugni, S., Williamson, D., Taylor, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 85–107. ISBN 978-3-642-29931-5. [Google Scholar]
- Tariq, D.; Ali, M.; Gehani, A. Towards Automated Collection of Application-Level Data Provenance. In Proceedings of the Theory and Practice of Provenance (TaPP), Boston, MA, USA, 14–15 June 2012; USENIX Association: Berkeley, CA, USA, 2012. [Google Scholar]
- Crawl, D.; Wang, J.; Altintas, I. Provenance for MapReduce-based Data-intensive Workflows. In Proceedings of the 6th Workshop on Workflows in Support of Large-Scale Science, Seattle, WA, USA, 12–18 November 2011; ACM: New York, NY, USA, 2011; pp. 21–30. [Google Scholar] [CrossRef]
- Park, H.; Ikeda, R.; Widom, J. RAMP: A System for Capturing and Tracing Provenance in MapReduce Workflows. In Proceedings of the International Conference on Very Large Data Bases (VLDB), Seattle, WA, USA, 29 August–3 September 2011; VLDB: Seattle, WA, USA, 2011; pp. 1351–1354. [Google Scholar]
- Wang, J.; Crawl, D.; Altintas, I. Kepler + Hadoop: A General Architecture Facilitating Data-intensive Applications in Scientific Workflow Systems. In Proceedings of the 9th Workshop on Workflows in Support of Large-Scale Science, Portland, LA, USA; ACM: New York, NY, USA, 2009; pp. 12:1–12:8. [Google Scholar] [CrossRef]
- Akoush, S.; Sohan, R.; Hopper, A. HadoopProv: Towards Provenance as a First Class Citizen in MapReduce. In Proceedings of the 5th International Workshop on the Theory and Practice of Provenance (TaPP), Edinburgh, Scotland, 8–9 July 2015; USENIX Association: Lombard, IL, USA, April 2013. [Google Scholar]
- Buyya, R. High Performance Cluster Computing: Architectures and Systems Vol. 1, 1st ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1999; ISBN 978-0-13-013785-2. [Google Scholar]
- Buyya, R. High Performance Cluster Computing: Architectures and Systems Vol. 2, 1st ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 1999; ISBN 978-0-13-013784-5. [Google Scholar]
- Terrizzano, T.; Schwarz, P.; Roth, M.; Colino, J.E. Data Wrangling: The Challenging Journey from the Wild to the Lake. In Proceedings of the Seventh Biennial Conference on Innovative Data Systems Research, Asilomar, CA, USA, 4–7 January 2015. [Google Scholar]
- Stein, B.; Morrison, A. The Enterprise Data Lake: Better Integration and Deeper Analytics. PwC Technol. Forecast Rethink. Integr. 2014, 1, 1–9. [Google Scholar]
- Suriarachchi, I.; Plale, B. Crossing analytic systems: A case for integrated provenance in data lakes. In Proceedings of the eScience, Baltimore, MD, USA, 23–27 October 2016; pp. 349–354. [Google Scholar] [CrossRef]
- PROV-Overview. Available online: https://www.w3.org/TR/2013/NOTE-prov-overview-20130430/ (accessed on 26 February 2018).
- PROV-O. Available online: https://www.w3.org/TR/prov-o/ (accessed on 26 February 2018).
- RDF—Semantic Web Standards. Available online: https://www.w3.org/RDF/ (accessed on 26 February 2018).
- Chen, P.; Evans, T.; Plale, B. Analysis of Memory Constrained Live Provenance. In Proceedings of the International Provenance and Annotation Workshop (IPAW), McLean, VA, USA, 7 June 2016; Springer: Cham, Switzerland, 2016; pp. 42–45. [Google Scholar] [CrossRef]
- Provenance in Netlogo. Available online: https://sourceforge.net/projects/pin/ (accessed on 26 February 2018).
- Gehani, A.; Tariq, D. SPADE: Support for Provenance Auditing in Distributed Environments. In Proceedings of the International Middleware Conference, Montreal, QC, Canada, 3–7 December 2012; Springer: New York, NY, USA, 2012. [Google Scholar]
- Muniswamy-Reddy, K.; Braun, U.; Holland, D.A.; Macko, P.; Maclean, D.; Margo, D.; Seltzer, M.; Smogor, R. Layering in Provenance Systems. In Proceedings of the USENIX Annual Technical Conference, San Diego, CA, USA, 14 June 2009. [Google Scholar]
- Lucia, B.; Ceze, L. Data provenance tracking for concurrent programs. In Proceedings of the International Symposium on Code Generation and Optimization (CGO), San Francisco, CA, USA, 7–11 February 2015; IEEE: Washington, DC, USA, 2015; pp. 146–156. [Google Scholar]
- Thalheim, J.; Bhatotia, P.; Fetzer, C. INSPECTOR: Data Provenance Using Intel Processor Trace. In Proceedings of the International Conference on Distributed Computing Systems, Nara, Japan, 27–30 June 2016; pp. 25–34. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Provenance Classes | ABM Concepts |
|---|---|
| Agent | User |
| Software Agent | Simulator, agents (i.e., ABM entities) |
| Entity | Fields, parameters, places, returns; source code instructions |
| Collection | Places, messages; arrays, conditionals and loops (in specification of simulation logic) |
| Activity | Procedure invocations, field operations (e.g., access and assignment) |
| Value | Descriptions of the content or state of any above classes; identifiers tying instructions to corresponding activities |
| Provenance Property | ABM Relationships |
|---|---|
| influenced | A called procedure was part of the calling procedure; A field access or assignment operation was part of a procedure |
| wasInfluencedBy | A portion of a calling procedure is represented by a called procedure; A procedure involved a field access or assignment operation |
| used | A procedure used a parameter; A field assignment used a field value |
| generated | A procedure provided a return; a field access provided a field value |
| wasStartedBy | A procedure or field operation was started by an agent |
| value | Any parameter, return, field accessed, or field assignment had a value (if immutable) or reference hashCode (if mutable); Identifiers tying instructions to corresponding activities |
| startedAtTime | A procedure was started at a system-time (in nanoseconds) |
| endedAtTime | A procedure ended (just before the return) at a system-time (in nanoseconds) |
| alternateOf | Procedure parameters and returns reference distributed application resources (e.g., agents, places, and messages); procedure parameters reference procedure call arguments; local variables reference returns |
| atLocation | A procedure was invoked at a host with the specified name (or internet protocol address) |
| wasAttributedTo | When a new datum is generated through local variable assignment or field assignment, it was attributed to the agent |
| Environment Property | Environment Configuration |
|---|---|
| Central processing unit | 1.6 GHz 4-core Intel i7 |
| Random access memory | 16 gigabytes |
| Network type and speed | 1 gigabit per second shared local area network |
| Operating system | Ubuntu version 16.04.1 |
| Java virtual machine configuration | Version 1.8.0, 64-bit data model, 9 gigabyte heap size |
| Configuration Property | Configuration Setting |
|---|---|
| Provenance granularity | Simulation-level (SP) |
| Agent filter | Range by ID filter 10 agents per host (reported results for execution on 12 and 14 hosts) |
| Pause feature | Capture is paused for all but 4 simulation operations (2 operations per iteration on all agents, for 2 iterations) |
| Provenance buffer | ~2 GB total reserved/~256 MB used; 2048 maximum stores per host (8 used), 219 characters per store (222 characters used out of 230 total buffered characters) |
| Number of places | Scale from 16,384 to 65,536 to 262,144 |
| Number of agents (RandomWalk at Small-Scale) | Scale from 640 to 1280 to 2560 |
| Number of agents (SugarScape) | Scale from 640 to 1280 to 2560 |
| Number of agents (RandomWalk at Full-Scale) | Scale from 16,384 to 65,536 to 262,144 |
| Simulation iterations | 25 |
| Total Simulation Operations | 77 in RandomWalk/103 in SugarScape |
| Runs averaged | 15 |
| Configuration Property * | Configuration Setting |
|---|---|
| Granularity | Range from process provenance or PP (coarse) to parameter provenance or PaP (fine) |
| Number of places | 1024 |
| Number of agents | 160 |
| Simulation iterations | 10 |
| Total Simulation Operations | 32 in RandomWalk/43 in SugarScape |
| Runs averaged | 20 |
| Configuration Property | Configuration Setting |
|---|---|
| Granularity | Simulation provenance (SP); Range from process provenance or PP (coarse) to parameter provenance or PaP (fine) |
| Agent filter | Range by ID filter 10 agents per host (reported results for execution on 12 and 14 hosts); None |
| Pause feature | On and off |
| Provenance buffer | ~2 GB total reserved/~256 MB used; 2048 maximum stores per host (8 used); |
| Number of places | Scale from 1024 and 16,384 to 65,536 to 262,144 |
| Number of agents (RandomWalk Small-Scale) | Scale from 640 to 1280 to 2560 |
| Number of agents (RandomWalk Full-Scale) | Scale from 16,384 to 65,536 to 262,144 |
| Number of agents (SugarScape) | Scale from 640 to 1280 to 2560 |
| Simulation iterations | 25 |
| Total Simulation Operations | 77 in RandomWalk/103 in SugarScape |
| Runs averaged | 15 |
| With pause | Without Pause | |||||
|---|---|---|---|---|---|---|
| Number of places | 16,385 | 65,636 | 262,144 | 16,385 | 65,636 | 262,144 |
| Number of Agents Vs. Storage Size (MB) | 640; 32 | 1240; 70 | 2560; 281 | 640; 441 | 1240; 1483 | 2560; 7168 |
| No Provenance (seconds) | 6.68 | 14.98 | 36.88 | 6.68 | 14.98 | 36.88 |
| Provenance (seconds) | 6.68 | 22.02 | 50.72 | 21.28 | 80.30 | 195.59 |
| Provenance Collected | Overhead Reported | Category |
|---|---|---|
| Data slice that includes procedure invocations; program slice consisting of conditional statements, read operations and write operations [6] | 250% (includes message passing and persistence in addition to collection) | Multi-Agent Modeling Platforms |
| Relationships between users and files, System calls (open, close, read, write, exec, fork, exit, clone truncate, and rename) [52] | 9–12% over normal execution of the BLAST genome sequencing tool | Distributed System Calls |
| System calls (from [52] aliased by procedure invocations, primitive parameters and return values [37]) | 5–13.8% additional execution time of four tinyhttpd procedures | Client–Server Applications |
| Relationships between provenance-aware applications with respect to file transactions (e.g., open, close, read, and write operations) [53] | Processing intensive: As low as 1.3% average overhead; system-call intensive: as high as 14% average overhead | Layered Systems |
| Read and write instructions with corresponding thread identifier as 64-bit word [54] | As high as 153% increase for Communication Traps (CTraps) and up to 50% increase for Last Writer Slices (LWS) | Symmetric Multiprocessing |
| Read and write memory operations by Pthreads [55] | 250–3500% execution time | Symmetric Multiprocessing |
| Output records (of a stage, shuffle step, etc.), input records, resilient distributed dataset (RDD) transformations that relate them [35] | 110–129% execution time | DISC Systems |
| Record-level derivations [41] | Under 10% on a typical MapReduce workload | DISC Systems |
| Input and output of MapReduce jobs [39] | 20–76% increase for Wordcount and Terasort jobs | DISC Systems |
| Dependencies between data and actor executions [38] | Under 100% increase in WordCount workflow execution | DISC Systems |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davis, D.B.; Featherston, J.; Vo, H.N.; Fukuda, M.; Asuncion, H.U. Data Provenance for Agent-Based Models in a Distributed Memory. Informatics 2018, 5, 18. https://doi.org/10.3390/informatics5020018
Davis DB, Featherston J, Vo HN, Fukuda M, Asuncion HU. Data Provenance for Agent-Based Models in a Distributed Memory. Informatics. 2018; 5(2):18. https://doi.org/10.3390/informatics5020018
Chicago/Turabian StyleDavis, Delmar B., Jonathan Featherston, Hoa N. Vo, Munehiro Fukuda, and Hazeline U. Asuncion. 2018. "Data Provenance for Agent-Based Models in a Distributed Memory" Informatics 5, no. 2: 18. https://doi.org/10.3390/informatics5020018
APA StyleDavis, D. B., Featherston, J., Vo, H. N., Fukuda, M., & Asuncion, H. U. (2018). Data Provenance for Agent-Based Models in a Distributed Memory. Informatics, 5(2), 18. https://doi.org/10.3390/informatics5020018