Towards Clustering of Mobile and Smartwatch Accelerometer Data for Physical Activity Recognition


Abstract
:1. Introduction
2. Related Work
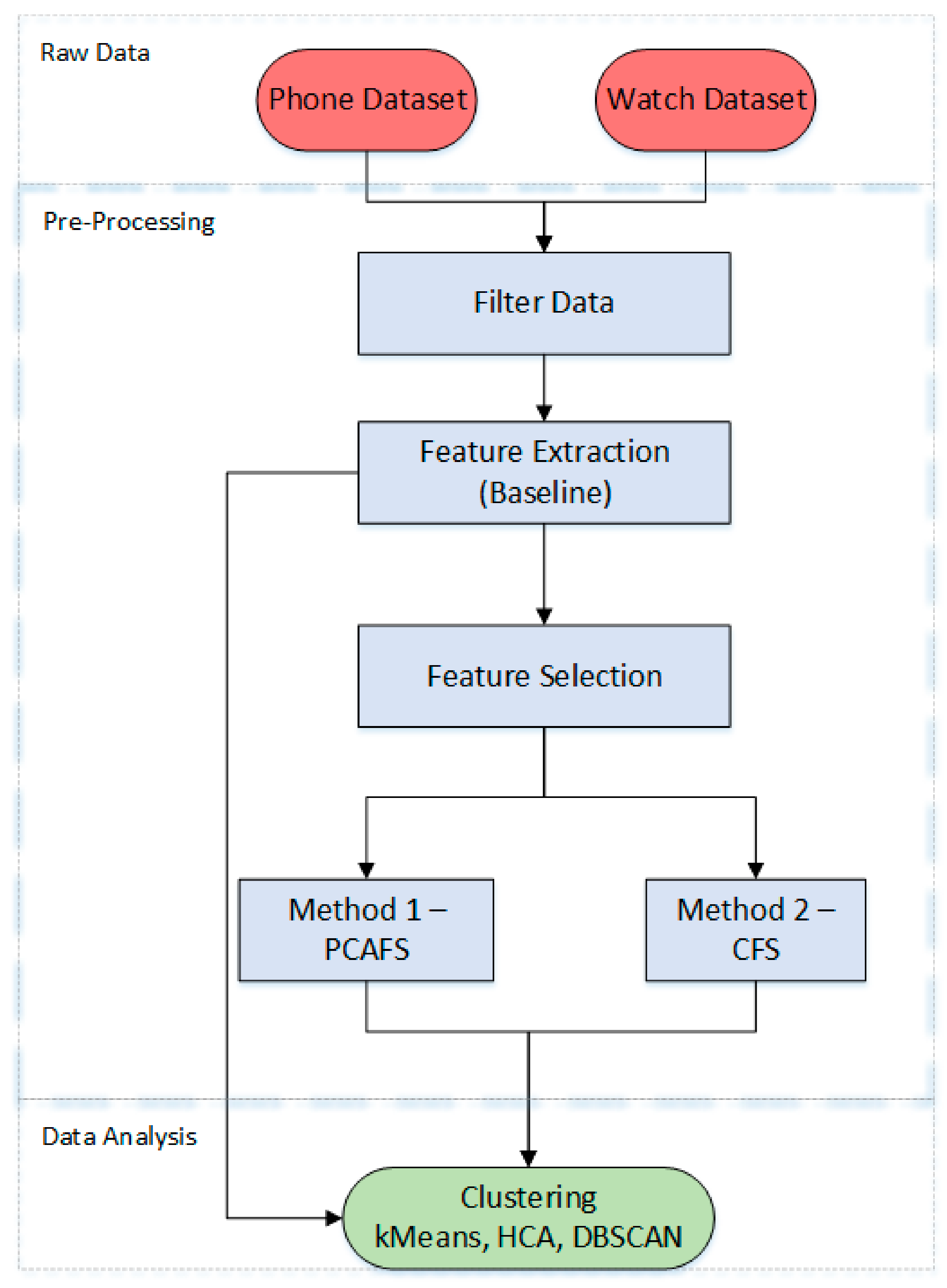
3. Materials and Methods
3.1. Raw Data
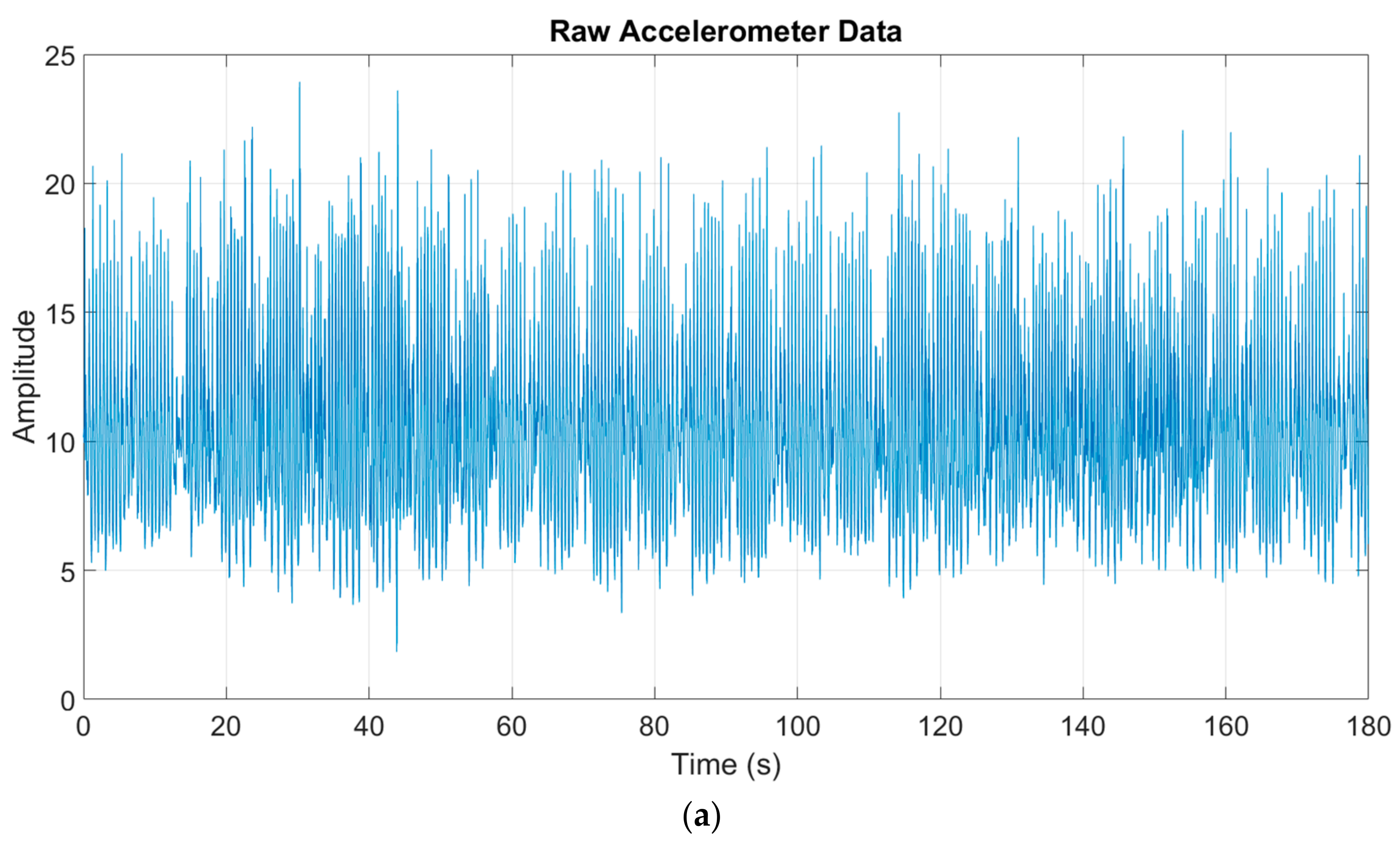
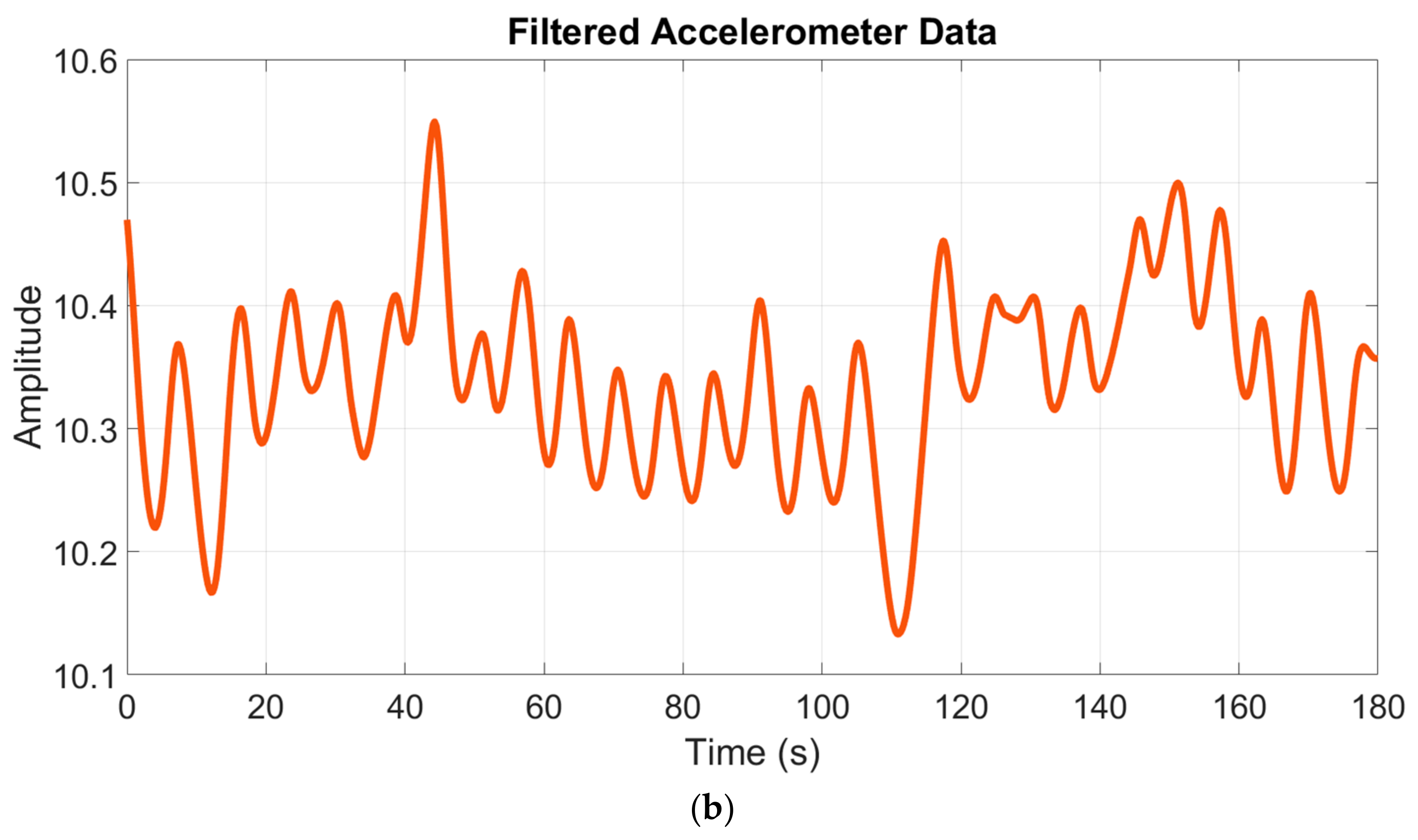
3.2. Preprocessing and Feature Extraction
3.3. Feature Selection
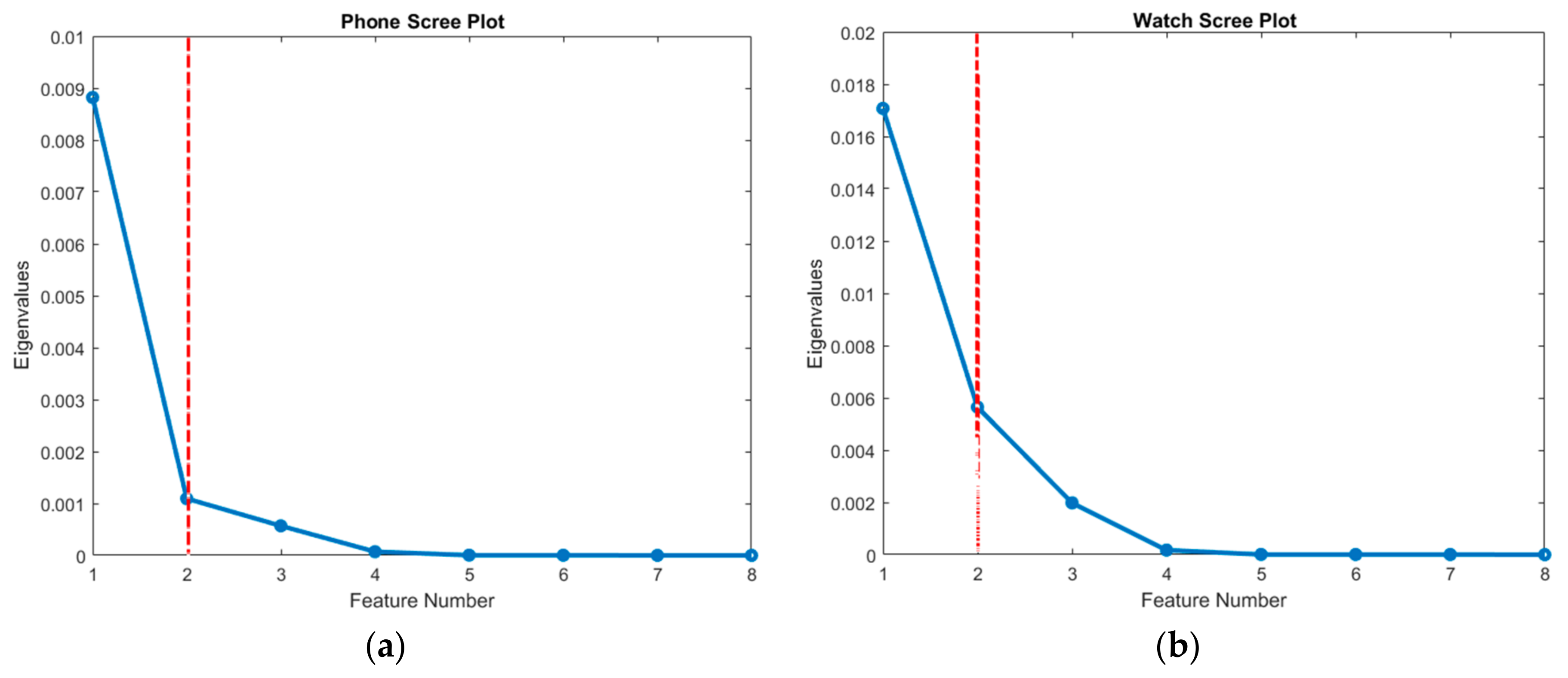
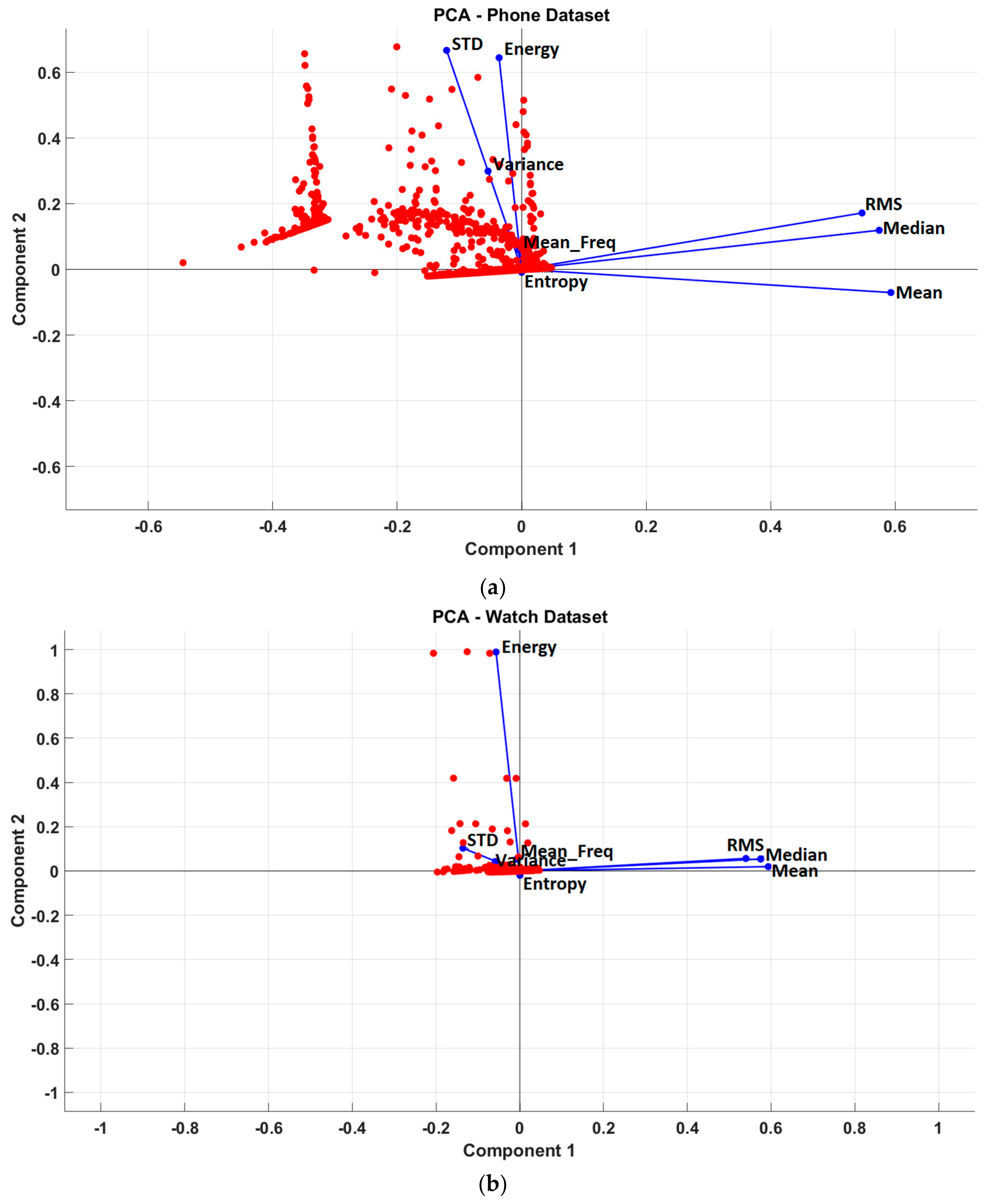
3.3.1. Method 1—Principle Component Analysis Feature Selection (PCAFS)
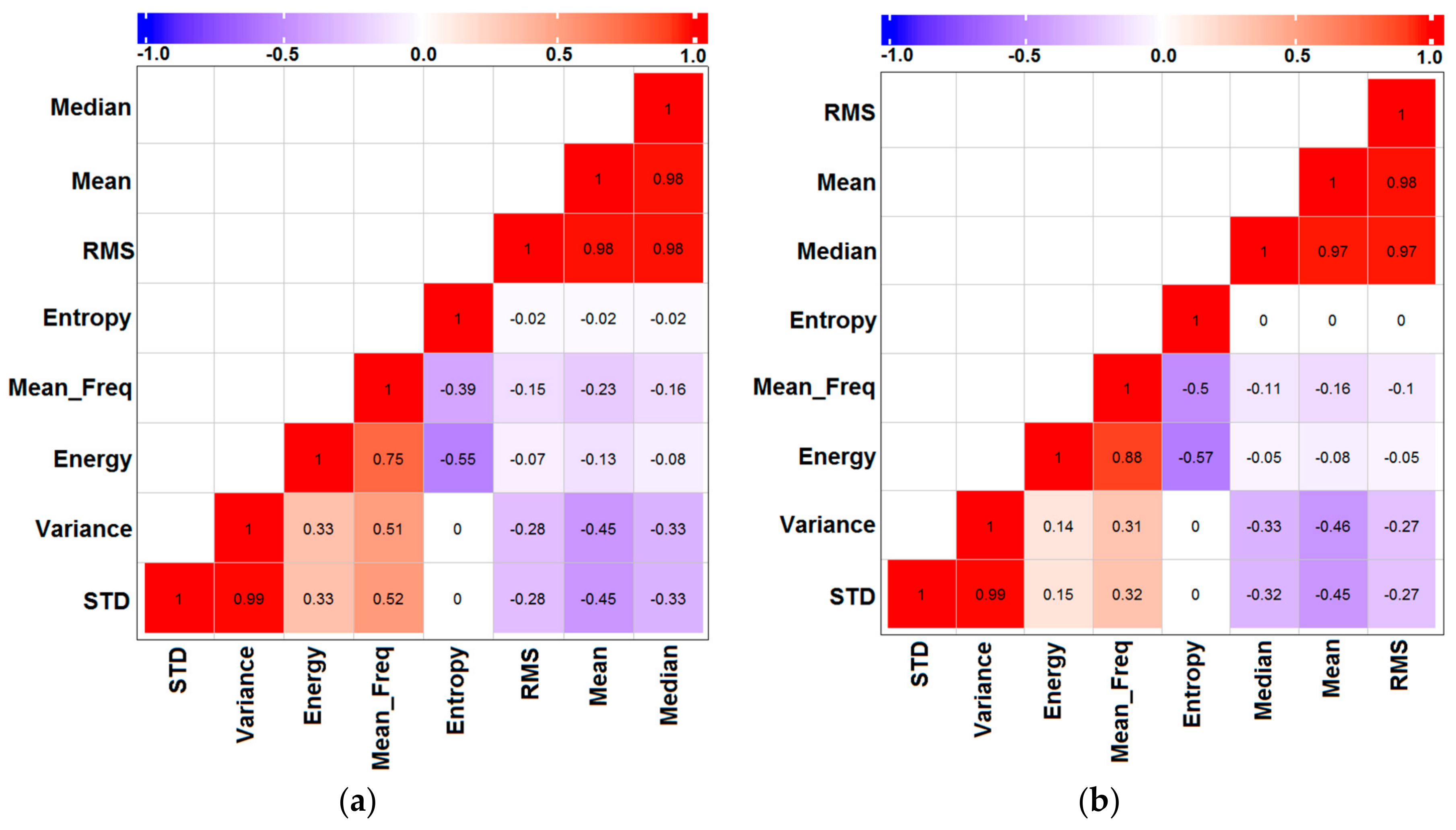
3.3.2. Method 2—Correlation Feature Selection (CFS)
3.4. Clustering Algorithms
4. Results
4.1. Determining k for k-Means Clustering
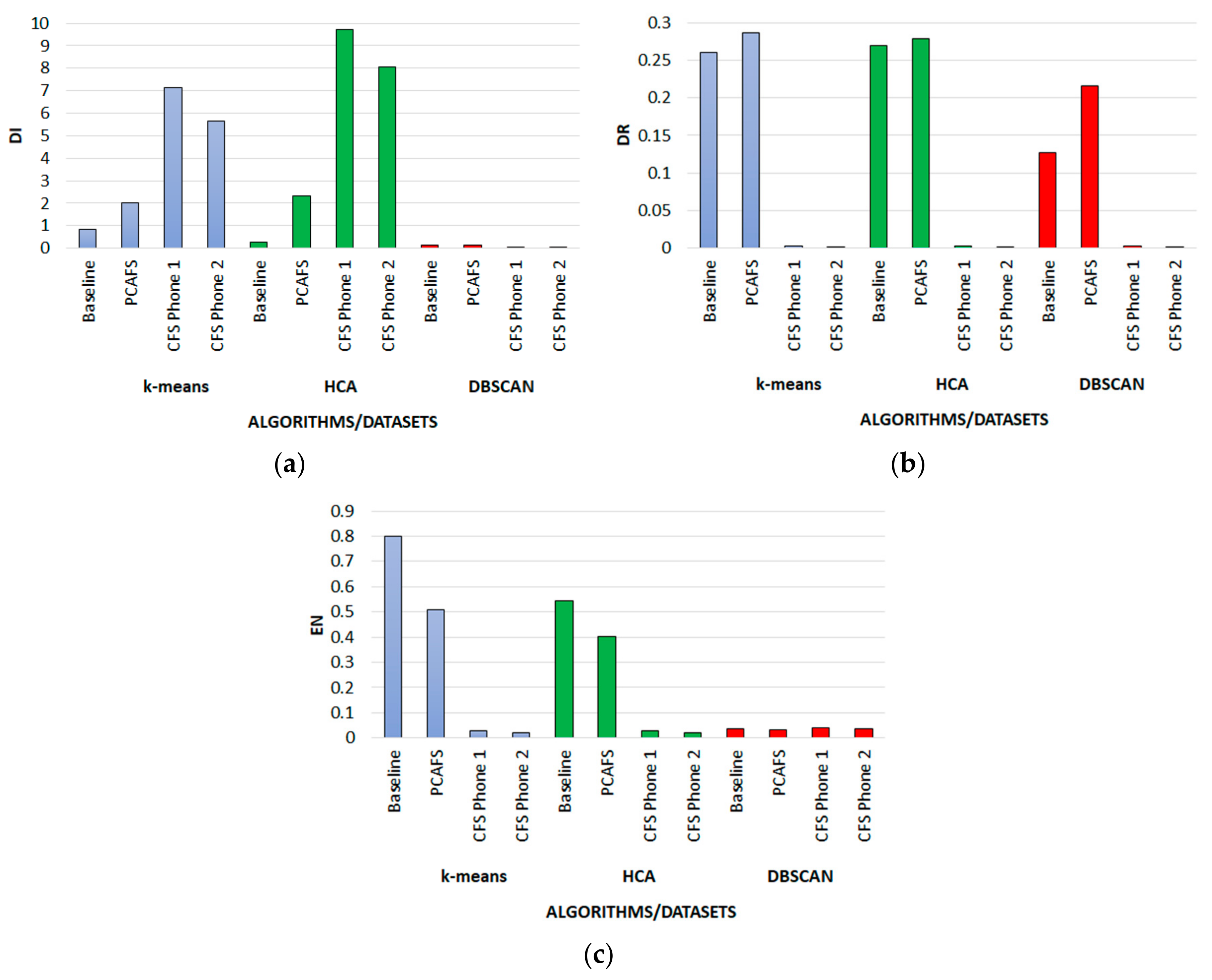
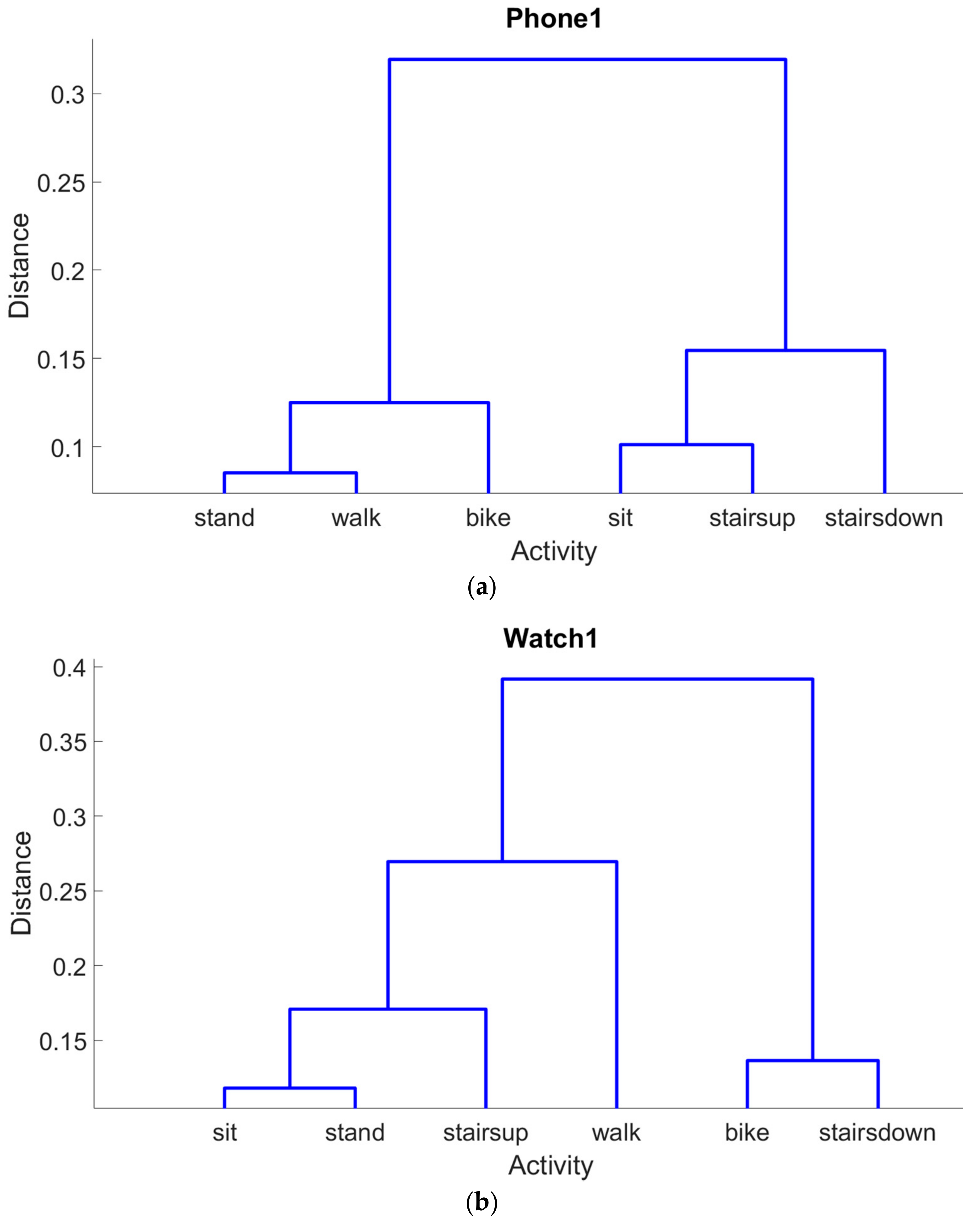
4.2. Results of the Phone Datasets
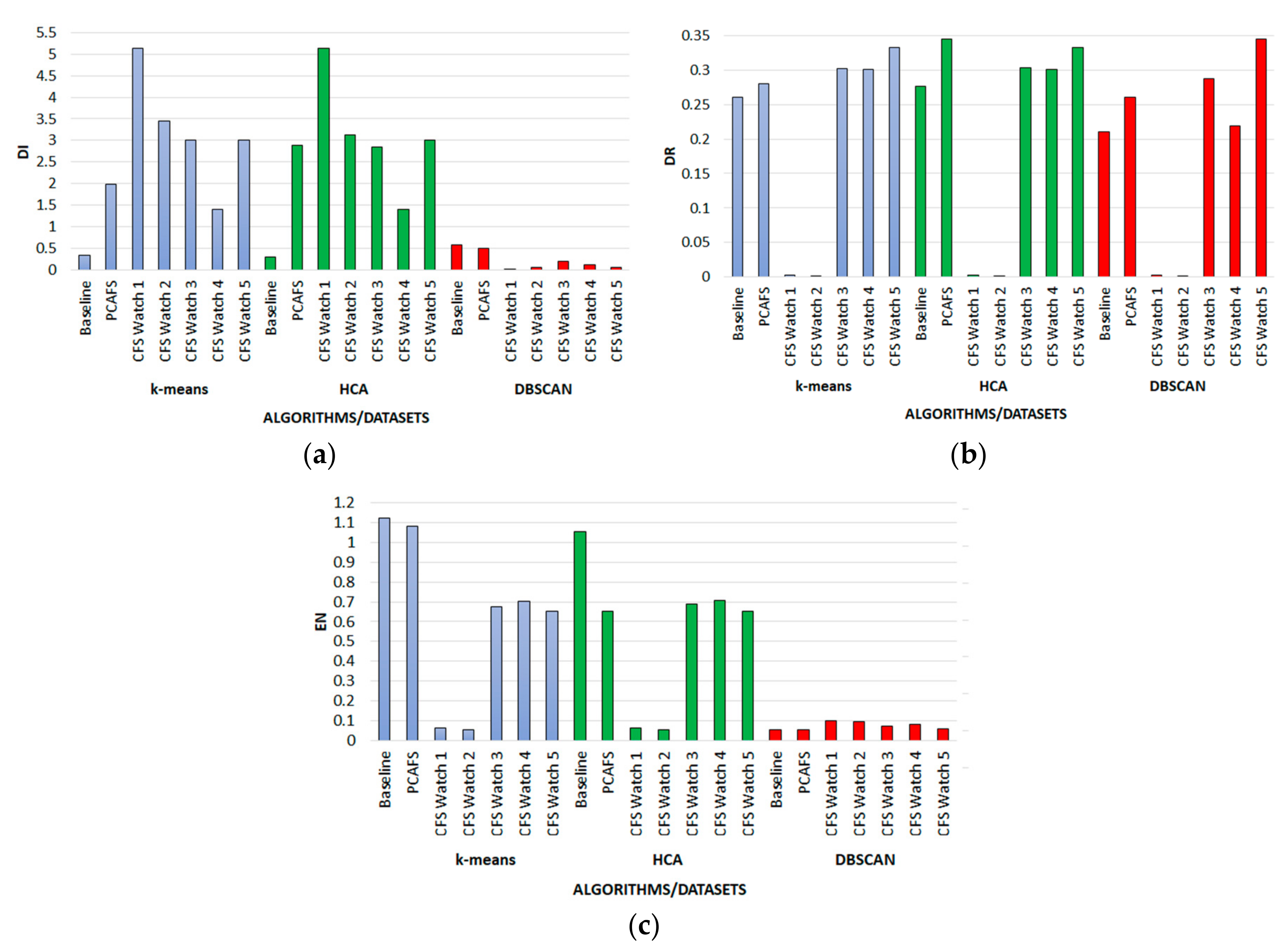
4.3. Results of the Watch Datasets
4.4. Efficiency Analysis
5. Discussion
6. Conclusions
Author Contributions
Conflicts of Interest
References
- Williamson, J.; Liu, Q.; Lu, F.; Mohrman, W.; Li, K.; Dick, R.; Shang, L. Data Sensing and Analysis: Challenges for Wearables. In Proceedings of the The 20th Asia and South Pacific Design Automation Conference (ASP-DAC), Chiba, Japan, 19–22 January 2015; pp. 136–141. [Google Scholar]
- Mukhopadhyay, S.C. Wearable Sensors for Human Activity Monitoring: A Review. IEEE Sens. J. 2015, 15, 1321–1330. [Google Scholar] [CrossRef]
- Sheth, A. Computing for human experience: Semantics-empowered sensors, services, and social computing on the ubiquitous Web. IEEE Internet Comput. 2010, 14, 88–91. [Google Scholar] [CrossRef] [Green Version]
- Cisco. Cisco Visual Networking Index: Global Mobile Data Traffic Forecast Update, 2014–2019; Cisco: San Jose, CA, USA, 2015. [Google Scholar]
- Quantified Self Labs. Quantified Self. Available online: http://quantifiedself.com (accessed on 31 January 2018).
- Khan, S.; Marzec, E. Wearables: On-body computing devices are ready for business. In Tech Trends 2014: Inspiring Disruption, deloitte, ed.; Deloitte University Press: London, UK, 2014; pp. 54–64. [Google Scholar]
- Machado, I.P.; Luísa Gomes, A.; Gamboa, H.; Paixão, V.; Costa, R.M. Human activity data discovery from triaxial accelerometer sensor: Non-supervised learning sensitivity to feature extraction parametrization. Inf. Process. Manag. 2015, 51, 204–214. [Google Scholar] [CrossRef]
- Bonato, P. Wearable Sensors and Systems. From Enabling Technology to Clinical Applications. IEEE Eng. Med. Biol. Soc. Mag. 2010, 29, 25–36. [Google Scholar] [CrossRef] [PubMed]
- Sung, M.; Marci, C.; Pentland, A. Wearable Feedback Systems For Rehabilitation. J. Neuroeng. Rehabil. 2005, 2, 17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopresti, A.L.; Hood, S.D.; Drummond, P.D. A review of lifestyle factors that contribute to important pathways associated with major depression: Diet, sleep and exercise. J. Affect. Disord. 2013, 148, 12–27. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rawassizadeh, R.; Momeni, E.; Dobbins, C.; Gharibshah, J.; Pazzani, M. Scalable Daily Human Behavioral Pattern Mining from Multivariate Temporal Data. IEEE Trans. Knowl. Data Eng. 2016, 28, 3098–3112. [Google Scholar] [CrossRef]
- Lee, M.W.; Khan, A.M.; Kim, T.-S. A single tri-axial accelerometer-based real-time personal life log system capable of human activity recognition and exercise information generation. Pers. Ubiquitous Comput. 2011, 15, 887–898. [Google Scholar] [CrossRef]
- Kurzweil, R. The Singularity Is Near: When Humans Transcend Biology; Viking Penguin: New York, NY, USA, 2005. [Google Scholar]
- Walter, C. Kryder’s Law. Sci. Am. 2005, 293, 32–33. [Google Scholar] [CrossRef] [PubMed]
- Rawassizadeh, R.; Pierson, T.J.; Peterson, R.; Kotz, D. NoCloud: Exploring Network Disconnection through On-Device Data Analysis. IEEE Pervasive Comput. 2018, 17, 64–74. [Google Scholar] [CrossRef]
- Lee, I.-M.; Shiroma, E.J. Using Accelerometers to Measure Physical Activity in Large-Scale Epidemiological Studies: Issues and Challenges. Br. J. Sports Med. 2014, 48, 197–201. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.-S.; Cho, S.-B. Recognizing multi-modal sensor signals using evolutionary learning of dynamic Bayesian networks. Pattern Anal. Appl. 2012. [Google Scholar] [CrossRef]
- Qiu, Z.; Doherty, A.R.; Gurrin, C.; Smeaton, A.F. Mining User Activity as a Context Source for Search and Retrieval. In Proceedings of the 2011 International Conference on Semantic Technology and Information Retrieval (STAIR), Tempe, AZ, USA, 13–15 June 2011; pp. 162–166. [Google Scholar]
- Phan, T. Generating Natural-Language Narratives from Activity Recognition with Spurious Classification Pruning. In Proceedings of the Third International Workshop on Sensing Applications on Mobile Phones—PhoneSense’12, Toronto, ON, Canada, 6 November 2012; ACM Press: New York, NY, USA, 2012; pp. 1–5. [Google Scholar]
- Lu, Y.; Wei, Y.; Liu, L.; Zhong, J.; Sun, L.; Liu, Y. Towards unsupervised physical activity recognition using smartphone accelerometers. Multimed. Tools Appl. 2017, 76, 10701–10719. [Google Scholar] [CrossRef]
- Stisen, A.; Blunck, H.; Bhattacharya, S.; Prentow, T.S.; Kjærgaard, M.B.; Dey, A.; Sonne, T.; Jensen, M.M. Smart Devices are Different: Assessing and Mitigating Mobile Sensing Heterogeneities for Activity Recognition. In Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems (SenSys’15), Seoul, Korea, 1–4 November 2015; ACM Press: New York, NY, USA, 2015; pp. 127–140. [Google Scholar]
- Villar, J.R.; Menéndez, M.; Sedano, J.; de la Cal, E.; González, V.M. Advances in Intelligent Systems and Computing. In 10th International Conference on Soft Computing Models in Industrial and Environmental Applications; Herrero, Á., Sedano, J., Baruque, B., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2015; Volume 368, pp. 39–48. [Google Scholar]
- Rawassizadeh, R.; Price, B.A.; Petre, M. Wearables: Has the Age of Smartwatches Finally Arrived? Commun. ACM 2014, 58, 45–47. [Google Scholar] [CrossRef]
- Uddin, M.; Salem, A.; Nam, I.; Nadeem, T. Wearable Sensing Framework for Human Activity Monitoring. In Proceedings of the 2015 Workshop on Wearable Systems and Applications, Florence, Italy, 15 May 2015; pp. 21–26. [Google Scholar]
- Saeedi, R.; Purath, J.; Venkatasubramanian, K.; Ghasemzadeh, H. Toward Seamless Wearable Sensing: Automatic On-Body Sensor Localization for Physical Activity Monitoring. In Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Chicago, IL, USA, 26–30 August 2014; IEEE: Chicago, IL, USA, 2014; pp. 5385–5388. [Google Scholar]
- Morales, J.; Akopian, D. Physical activity recognition by smartphones, a survey. Biocybern. Biomed. Eng. 2017, 37, 388–400. [Google Scholar] [CrossRef]
- Fortino, G.; Gravina, R.; Guerrieri, A.; Di Fatta, G. Engineering Large-Scale Body Area Networks Applications. In Proceedings of the 8th International Conference on Body Area Networks, Boston, MA, USA, 30 September–2 October 2013; pp. 363–369. [Google Scholar]
- Lara, O.D.; Labrador, M.A. A Survey on Human Activity Recognition using Wearable Sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef] [Green Version]
- Dias, R.; Machado da Silva, J. A Flexible Wearable Sensor Network for Bio-Signals and Human Activity Monitoring. In Proceedings of the 2014 11th International Conference on Wearable and Implantable Body Sensor Networks Workshops, Zurich, Switzerland, 16–19 June 2014; IEEE: Zurich, Switzerland, 2014; pp. 17–22. [Google Scholar]
- Dias, A.; Fisterer, B.; Lamla, G.; Kuhn, K.; Hartvigsen, G.; Horsch, A. Measuring Physical Activity with Sensors: A Qualitative Study. Med. Inform. 2009, 150, 475–479. [Google Scholar] [CrossRef]
- Mamizuka, N.; Sakane, M.; Kaneoka, K.; Hori, N.; Ochiai, N. Kinematic quantitation of the patellar tendon reflex using a tri-axial accelerometer. J. Biomech. 2007, 40, 2107–2111. [Google Scholar] [CrossRef] [PubMed]
- Mayagoitia, R.E.; Nene, A.V.; Veltink, P.H. Accelerometer and rate gyroscope measurement of kinematics: An inexpensive alternative to optical motion analysis systems. J. Biomech. 2002, 35, 537–542. [Google Scholar] [CrossRef]
- Lyons, G.M.; Culhane, K.M.; Hilton, D.; Grace, P.A.; Lyons, D. A description of an accelerometer-based mobility monitoring technique. Med. Eng. Phys. 2005, 27, 497–504. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Sapir, I.; Markovic, S.; Wagenaar, R.; Little, T. Continuous Functional Activity Monitoring Based on Wearable Tri-axial Accelerometer and Gyroscope. In Proceedings of the 2011 5th International Conference on Pervasive Computing Technologies for Healthcare (PervasiveHealth), Dublin, Ireland, 23–26 May 2011; pp. 370–373. [Google Scholar]
- Reiss, A.; Stricker, D. Creating and Benchmarking a New Dataset for Physical Activity Monitoring. In Proceedings of the 5th Workshop on Affect and Behaviour Related Assistance (ABRA), Crete, Greece, 6–8 June 2012; ACM Press: New York, NY, USA, 2012. [Google Scholar]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data. Pervasive Comput. 2004, 3001, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Song, W.; Ade, C.; Broxterman, R.; Barstow, T.; Nelson, T.; Warren, S. Activity Recognition in Planetary Navigation Field Tests Using Classification Algorithms Applied to Accelerometer Data. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), San Diego, CA, USA, 28 August–1 September 2012; Volume 2012, pp. 1586–1589. [Google Scholar]
- Ravi, N.; Dandekar, N.; Mysore, P.; Littman, M.L. Activity Recognition from Accelerometer Data. In Proceedings of the 17th Conference on Innovative Applications of Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; Volume 20, pp. 1541–1546. [Google Scholar]
- Mannini, A.; Sabatini, A.M. Machine learning methods for classifying human physical activity from on-body accelerometers. Sensors 2010, 10, 1154–1175. [Google Scholar] [CrossRef] [PubMed]
- Krishnan, N.C.; Panchanathan, S. Analysis of low resolution accelerometer data for continuous human activity recognition. In Proceedings of the 2008 IEEE International Conference on Acoustics, Speech and Signal Processing, Las Vegas, NV, USA, 31 March–4 April 2008; pp. 3337–3340. [Google Scholar]
- Bonomi, A.G.; Goris, A.H.C.; Yin, B.; Westerterp, K.R. Detection of Type, Duration, and Intensity of Physical Activity Using an Accelerometer. Med. Sci. Sports Exerc. 2009, 41, 1770–1777. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Srivastava, P.; Wong, W.-C. Hierarchical Human Activity Recognition Using GMM. In Proceedings of the AMBIENT 2012: The Second International Conference on Ambient Computing, Applications, Services and Technologies, Barcelona, Spain, 23–28 September 2012; pp. 32–37. [Google Scholar]
- Mokaya, F.; Nguyen, B.; Kuo, C.; Jacobson, Q.; Rowe, A.; Zhang, P. MARS: A Muscle Activity Recognition System Enabling Self-configuring Musculoskeletal Sensor Networks. In Proceedings of the 12th ACM/IEEE Conference on Information Processing in Sensor Networks (IPSN), Philadelphia, PA, USA, 8–11 April 2013; pp. 191–202. [Google Scholar]
- Long, X.; Yin, B.; Aarts, R.M. Single-Accelerometer-Based Daily Physical Activity Classification. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009; Volume 2009, pp. 6107–6110. [Google Scholar]
- Abdullah, S.; Lane, N.D.; Choudhury, T. Towards Population Scale Activity Recognition: A Framework for Handling Data Diversity. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; pp. 851–857. [Google Scholar]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M.P. Preprocessing Techniques for Context Recognition from Accelerometer Data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- MathWorks. Practical Introduction to Frequency-Domain Analysis. Available online: http://www.mathworks.co.uk/help/signal/examples/practical-introduction-to-frequency-domain-analysis.html (accessed on 3 September 2014).
- Maner, W.L.; Garfield, R.E.; Maul, H.; Olson, G.; Saade, G. Predicting term and preterm delivery with transabdominal uterine electromyography. Obstet. Gynecol. 2003, 101, 1254–1260. [Google Scholar] [PubMed]
- Guyon, I.; Elisseeff, A. An Introduction to Variable and Feature Selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Bins, J.; Draper, B.A.B. Feature selection from huge feature sets. In Proceedings of the Eighth IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001; Volume 2, pp. 159–165. [Google Scholar] [CrossRef]
- Jeng, Y.-L.; Wu, T.-T.; Huang, Y.-M.; Tan, Q.; Yang, S.J.H. The Add-on Impact of Mobile Applications in Learning Strategies: A Review Study. J. Educ. Technol. Soc. 2010, 13, 3–11. [Google Scholar]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Liu, H. Feature Selection for High-Dimensional Data: A Fast Correlation-Based Filter Solution. Int. Conf. Mach. Learn. 2003, 3, 856–863. [Google Scholar]
- Haindl, M.; Somol, P.; Ververidis, D.; Kotropoulos, C. Feature Selection Based on Mutual Correlation. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2006; pp. 569–577. [Google Scholar]
- Jain, A.K. Data Clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Wagstaff, K.; Cardie, C.; Rogers, S.; Schroedl, S. Constrained K-means Clustering with Background Knowledge. In Proceedings of the Eighteenth International Conference on Machine Learning (ICML), Williamstown, MA, USA, 28 June–1 July 2001; pp. 577–584. [Google Scholar]
- Wu, X.; Kumar, V.; Ross Quinlan, J.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Yu, P.S.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2007, 14, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Forero, M.G.; Sroubek, F.; Cristóbal, G. Identification of tuberculosis bacteria based on shape and color. Real-Time Imaging 2004, 10, 251–262. [Google Scholar] [CrossRef] [Green Version]
- Kikhia, B.; Boytsov, A.; Hallberg, J.; Sani, Z.H.; Jonsson, H.; Synnes, K. Structuring and Presenting Lifelogs based on Location Data. Image (IN) 2011, 4, 5–24. [Google Scholar]
- Fischer, B.; Buhmann, J.M. Bagging for path-based clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1411–1415. [Google Scholar] [CrossRef]
- Rokach, L.; Maimon, O. Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: New York, NY, USA, 2005; ISBN 0-387-24435-2. [Google Scholar]
- Maimon, O.; Rokach, L. Data Mining and Knowledge Discovery Handbook, 2nd ed.; Maimon, O., Rokach, L., Eds.; Springer: New York, NY, USA, 2010; Volume 40, ISBN 9780387098227. [Google Scholar]
- Xu, R.; Wunsch, D. Survey of Clustering Algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Birant, D.; Kut, A. ST-DBSCAN: An algorithm for clustering spatial–temporal data. Data Knowl. Eng. 2007, 60, 208–221. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of Internal Clustering Validation Measures. In Proceedings of the IEEE Internatinal Conference on Data Mining, Sydney, NSW, Australia, 13–17 December 2010; pp. 911–916. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning with Applications in R; Springer: Berlin/Heidelberg, Germany, 2015; ISBN 9780387781884. [Google Scholar]
- Senliol, B.; Gulgezen, G.; Yu, L.; Cataltepe, Z. Fast Correlation Based Filter (FCBF) with a different search strategy. In Proceedings of the 23rd International Symposium on Computer and Information Sciences (ISCIS’08), Istanbul, Turkey, 27–29 October 2008; pp. 27–29. [Google Scholar]
- WikiChip. A11 Bionic—Apple. Available online: https://en.wikichip.org/wiki/apple/ax/a11 (accessed on 13 April 2018).
- Nvidia Jetson. Available online: https://www.nvidia.com/en-us/autonomous-machines/embedded-systems-dev-kits-modules/ (accessed on 13 April 2018).
- Zhang, M.; Sawchuk, A.A. A Feature Selection-Based Framework for Human Activity Recognition Using Wearable Multimodal Sensors. In Proceedings of the 6th International Conference on Body Area Networks (BodyNets’11), Beijing, China, 7–8 November 2011; pp. 92–98. [Google Scholar]
- NHS Exercise. Available online: https://www.nhs.uk/live-well/exercise/ (accessed on 31 January 2018).
- Dobbins, C.; Rawassizadeh, R.; Momeni, E. Detecting Physical Activity within Lifelogs towards Preventing Obesity and Aiding Ambient Assisted Living. Neurocomputing 2017, 230, 110–132. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Sampling Frequency (Hz) |
|---|---|
| Smartphones | |
| 2 × LG Nexus 4 | 200 |
| 2 × Samsung Galaxy S3 | 150 |
| 2 × Samsung Galaxy S3 Mini | 100 |
| 2 × Samsung Galaxy S+ | 50 |
| Smartwatches | |
| 2 × LG Watch | 200 |
| 2 × Samsung Galaxy Gear | 100 |
| Domain | Feature | Definition |
|---|---|---|
| Time | Mean | Average acceleration |
| Median | Intermediate acceleration | |
| Standard Deviation | Measure of dispersion of acceleration from its mean | |
| Root Mean Square | Square root of the mean square of acceleration signal | |
| Variance | Measure of spread in the acceleration signal | |
| Frequency | Energy | Characterizes the frequency components of each activity |
| Entropy | Measure of consistency | |
| Mean Frequency | Average frequency |
| Phone Dataset | Watch Dataset | ||
|---|---|---|---|
| PCAFS | CFS | PCAFS | CFS |
| RMS, Median | [1] Entropy, STD | Mean, Median | [1] Entropy, STD |
| [2] Entropy, Variance | [2] Entropy, Variance | ||
| [3] Median, Entropy | |||
| [4] Mean, Entropy | |||
| [6] RMS, Entropy | |||
| Approach | Dataset | K | ||||
|---|---|---|---|---|---|---|
| 2 | 3 | 4 | 5 | 6 | ||
| Baseline | Phone | 0.761 | 0.7895 | 0.6657 | 0.6808 | 0.7223 |
| Watch | 0.6011 | 0.6887 | 0.7958 | 0.6946 | 0.6998 | |
| PCAFS | Phone | 0.7958 | 0.7573 | 0.7169 | 0.7354 | 0.7278 |
| Watch | 0.7396 | 0.7997 | 0.7001 | 0.719 | 0.7024 | |
| CFS | Phone (1) | 0.9994 | 0.9993 | 0.999 | 0.9988 | 0.8553 |
| Phone (2) | 0.9994 | 0.9989 | 0.9987 | 0.9987 | 0.9987 | |
| Watch (1) | 0.9987 | 0.9976 | 0.9962 | 0.9962 | 0.9965 | |
| Watch (2) | 0.9976 | 0.996 | 0.996 | 0.9966 | 0.9961 | |
| Watch (3) | 0.7462 | 0.8066 | 0.7155 | 0.7363 | 0.7401 | |
| Watch (4) | 0.7343 | 0.8045 | 0.7141 | 0.7338 | 0.7336 | |
| Watch (5) | 0.7861 | 0.6926 | 0.7058 | 0.735 | 0.7386 | |
| Dataset | Time (s) | |||
|---|---|---|---|---|
| k-Means | HCA | DBSCAN | ||
| Baseline | Phone | 1.23 | 42.25 | 150.48 |
| PCAFS | Phone | 0.39 | 30.56 | 177.86 |
| CFS | Phone (1) | 0.51 | 31.11 | 182.60 |
| Phone (2) | 0.36 | 32.51 | 181.60 | |
| Dataset | Time (s) | |||
|---|---|---|---|---|
| k-Means | HCA | DBSCAN | ||
| Baseline | Watch | 0.25 | 1.16 | 2.94 |
| PCAFS | Watch | 0.13 | 0.95 | 2.17 |
| CFS | Watch (1) | 0.11 | 0.90 | 3.04 |
| Watch (2) | 0.14 | 0.99 | 3.04 | |
| Watch (3) | 0.12 | 0.95 | 1.97 | |
| Watch (4) | 0.18 | 0.92 | 2.00 | |
| Watch (5) | 0.17 | 0.92 | 1.95 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dobbins, C.; Rawassizadeh, R. Towards Clustering of Mobile and Smartwatch Accelerometer Data for Physical Activity Recognition. Informatics 2018, 5, 29. https://doi.org/10.3390/informatics5020029
Dobbins C, Rawassizadeh R. Towards Clustering of Mobile and Smartwatch Accelerometer Data for Physical Activity Recognition. Informatics. 2018; 5(2):29. https://doi.org/10.3390/informatics5020029
Chicago/Turabian StyleDobbins, Chelsea, and Reza Rawassizadeh. 2018. "Towards Clustering of Mobile and Smartwatch Accelerometer Data for Physical Activity Recognition" Informatics 5, no. 2: 29. https://doi.org/10.3390/informatics5020029