1. Introduction and Background
Water accumulated and stored in the winter snowpack of mountainous regions constitutes a critical source of annual streamflow for much of the Western United States, providing approximately 75% of annual discharge [
1]. Improved understanding of how snow water equivalent (SWE) is spatially distributed in mountainous terrain can assist hydrologic models to provide better estimates of total basin SWE and forecasts of the timing, magnitude and seasonal volume of snowmelt runoff. Such information is valuable for a number of applications, such as agricultural planning, reservoir management and flood forecasting, among others.
The spatial distribution of SWE can be highly variable in mountainous terrain [
2], where its understanding is most critical for quantifying snow as a water resource. Associations between physiographic characteristics of a basin (e.g., elevation, radiation, vegetation, aspect, slope angle) and SWE at a given point have been used to estimate the spatial distribution of SWE in mountainous terrain using various field sampling and statistical methods, e.g., [
2,
3,
4,
5,
6,
7,
8,
9]. However, there are many substantial challenges to such studies in both field data collection and modeling methods to provide the most accurate representations of the spatial distribution and total volume of SWE in a basin. In particular, when SWE is not directly measured, but rather estimated using snow depth and either a fixed density value or one that is varied based on a single parameter (e.g., elevation). Therefore, when using this approach, one of the major challenges is the characterization of the spatial distribution of snow density, which is a critical component to calculating SWE. This is important because while proportionally, the differences in snow density may be conservative when compared to depth due to its limited range of potential values, when used to calculate SWE, a relatively small change in density can have a substantial impact on an estimate of total basin SWE [
10].
Due to the highly dynamic nature of snow characteristics, particularly near the time of peak accumulation, it is optimal for the field data collection to occur as quickly as possible to minimize the bias from temporal changes in the snow. Because of the time-consuming nature of obtaining density samples, previous field-based studies have sampled more intensively for depth than for density (or SWE directly), e.g., [
2,
4,
5,
6,
8]. This approach must be carefully balanced with an assurance that the density data collected are representative of the time and place of interest. Previous research has stated that snow depth varies more than snow density in alpine areas, so the major source of variation in SWE is variation in snow depth, especially during the melt season [
3,
11]. However, few studies have quantified these effects and how they vary near the time of peak accumulation. This challenge has also been noted by Adams [
12], who suggests that while variability in density lessens throughout the melt season, before, the primary onset of melt density exhibits considerable variability. This can be further exacerbated in high relief mountain areas where the timing of melt and, therefore, inhomogeneity in density at a fixed point in time can be considerable.
The spatial arrangement of samples, both with respect to the greater basin and to each other, in a given study can also have a substantial influence on the resulting analysis and modeling [
13]. It is possible that variability in snow density that exists in the field may not be captured statistically if sampling is not specifically designed to do so. Studies have attempted to capture the effects of physiography on the spatial distribution of density [
4,
8] by choosing sample locations that qualitatively represent the different elevations and aspects of the given watershed. This methodology may not account for unique combinations (and interactions) of multiple physiographic parameters that may be associated with density. Research has noted scale breaks in snow depth within which sampling should take place [
14], but no similar research has specifically been applied to density.
The spatial distribution of the snow density component of SWE models has been parameterized in several ways in previous research. In some cases, a uniform spatial distribution of the average of measured densities [
6,
8] is used due to the poor results of models correlating density to independent variables. Other research has found significant correlations between density and basin physiography [
4,
5], but with only a small number of density samples (
n = 10 or less). Snow depth has also been assumed to provide a direct corollary to SWE, making the assumption of uniform (although not specified) density throughout a basin [
7]. Many of these findings, often using small sample sizes, have not quantified the effect varying parameterizations of depth and density may have on estimates of SWE. Lopez-Moreno
et al. [
9] used three different model types to predict the spatial distribution of snow density in three small (1–2 km
2) plots in the Spanish Pyrenees, but these models were deemed largely inadequate due to the marked variability in correlations between density and depth, as well as other terrain characteristics examined.
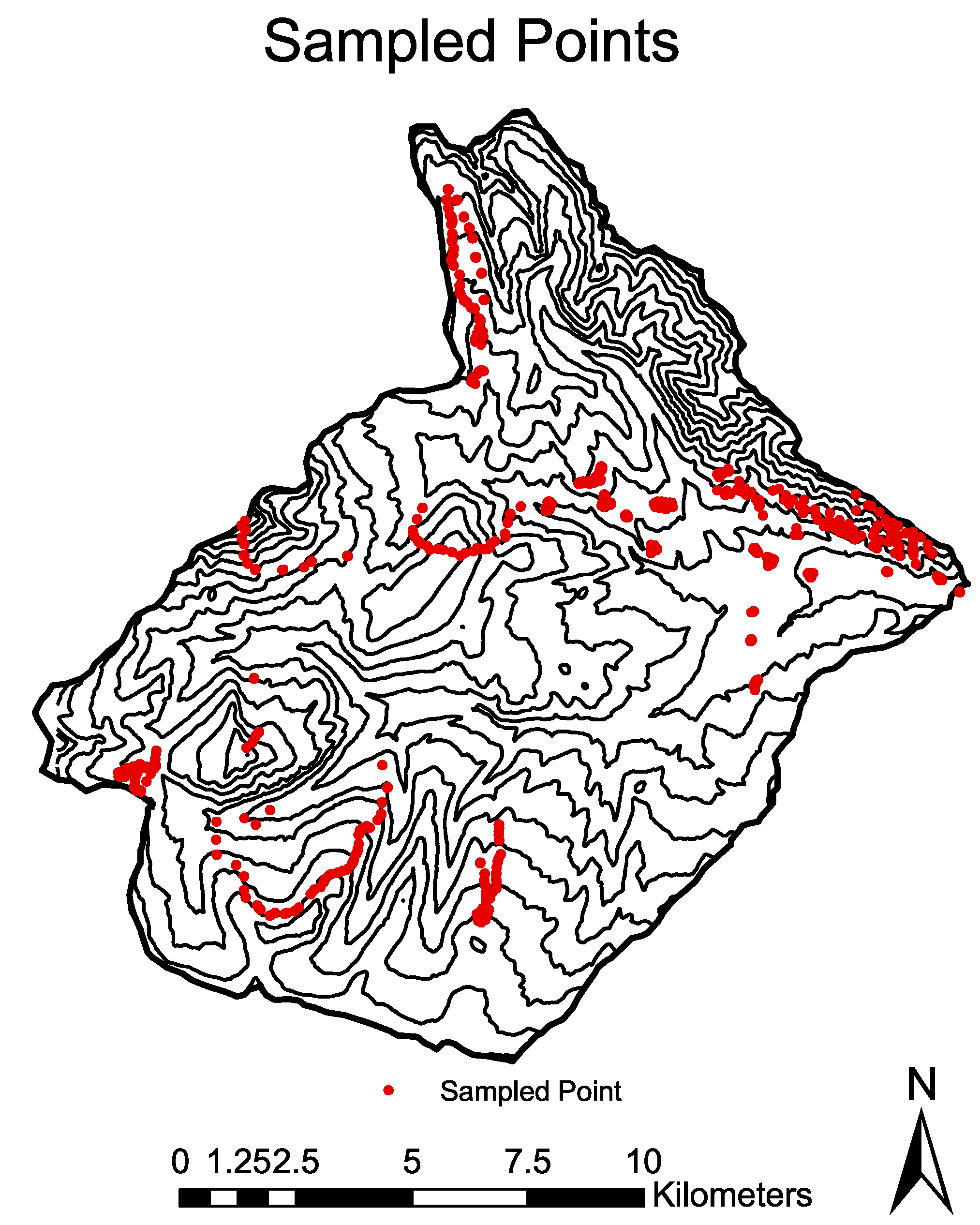
This paper presents a comprehensive field study aimed at modeling the effect of the spatial variability of snow density in estimating total basin SWE for a complex mountainous watershed. A novel sampling strategy was used to collect a very large number of samples (>1000) of SWE and snow depth (allowing for calculation of density) throughout a 207-km2 mountainous basin. Three models of the spatial distribution of snow density were developed and combined with two models of the spatial distribution on snow depth to obtain estimates of total basin SWE. An analysis of the effect of varying parameterizations of snow depth and density on estimates of the total volume of SWE stored in a basin is provided. This study highlights that snow density can be highly variable near the time of peak accumulation, especially in a high relief basin. This indicates the importance of adequate sampling and modeling of snow density if separate depth and density models are to be used for SWE estimations, as estimates of total basin SWE can vary widely depending on the models used.
2. Study Area
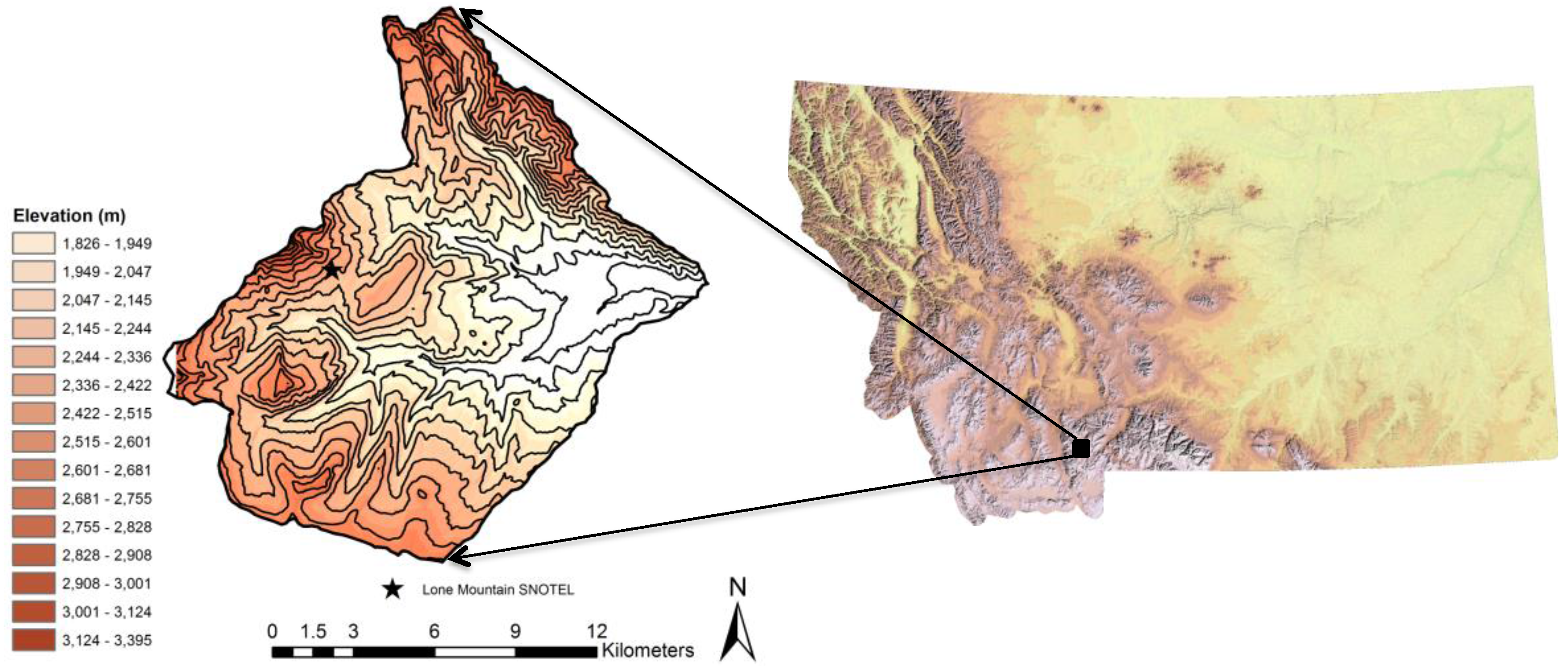
This study was conducted in the West Fork of the Gallatin River Basin (West Fork Basin) in southwest Montana, approximately 45°16′N, 111°26′W (
Figure 1). Elevations in the basin range from 1825 m at the confluence of the West Fork of the Gallatin with the Gallatin River to 3405 m at the top of Lone Peak (1580 m of total vertical relief), covering an area of 207 km
2. The West Fork Basin is physiographically diverse, ranging from low elevation grass and sagebrush cover, to mid-elevation conifer forests, to high elevation steep rocky alpine terrain. Approximately 52% of the basin contains conifer forests, with the land cover in the remaining areas consisting primarily of grass and sagebrush in the lower elevations and rocky alpine terrain at the higher elevations. The basin is partially developed, containing a small community (Big Sky, MT, USA) and ski resorts on Lone Peak and Pioneer mountains in the western portion of the basin.
The only automated SWE data for the basin is provided by the Lone Mountain SNOwpack TELemetry (SNOTEL) site, located in a small meadow in the west-central portion of the basin at an elevation of 2706 m. As of 1 April 2012 (the time of field sampling), the Lone Mountain SNOTEL site was reporting 104% of median SWE based on a 21-year record (1991–2012), at 434 mm.
Figure 1.
Location map showing the state of Montana, USA, with an inset of the West Fork of the Gallatin River Basin in southwest Montana; 100-m contour interval. The star shows the location of the Lone Mountain SNOTEL site.
Figure 1.
Location map showing the state of Montana, USA, with an inset of the West Fork of the Gallatin River Basin in southwest Montana; 100-m contour interval. The star shows the location of the Lone Mountain SNOTEL site.
5. Discussion
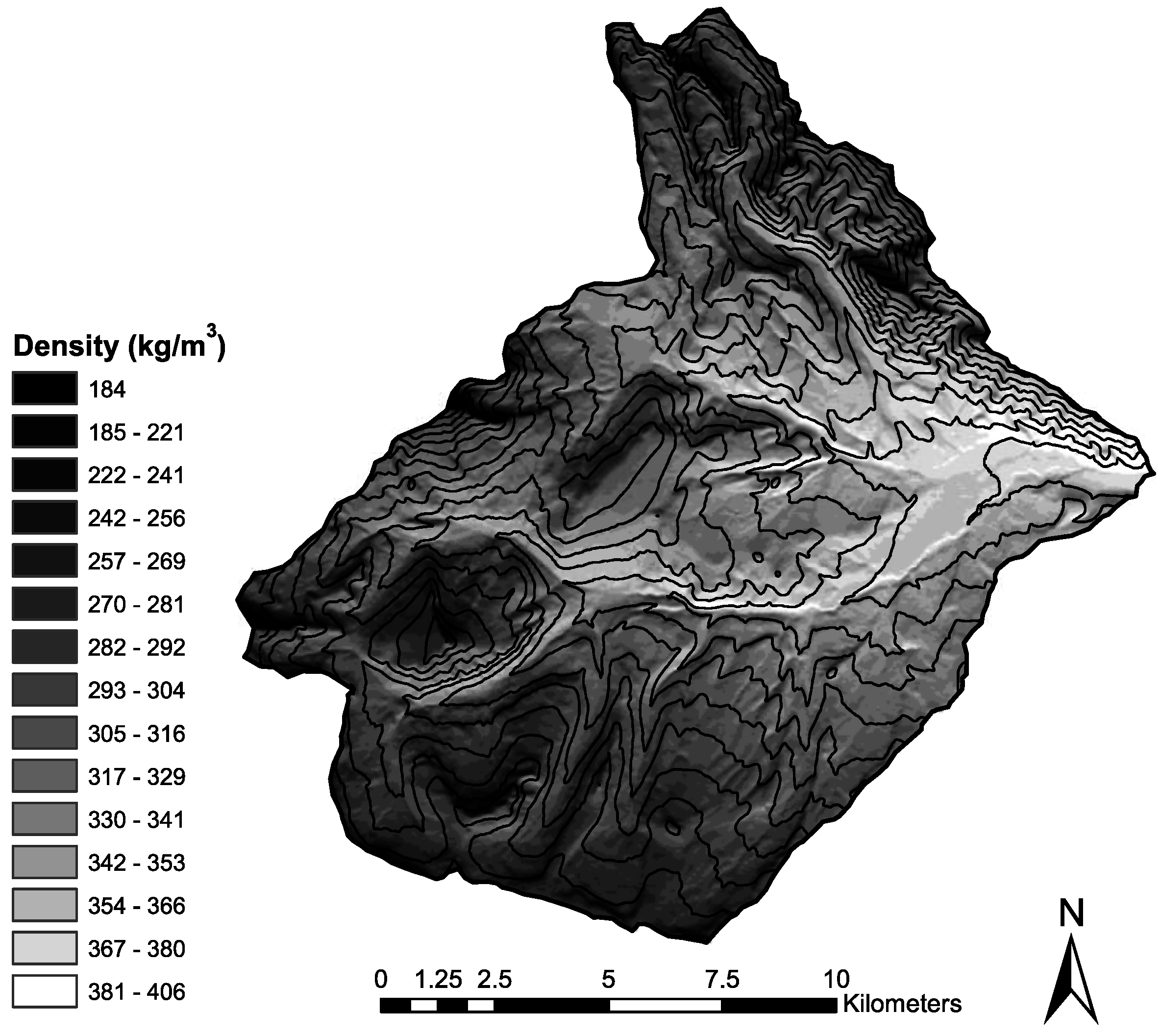
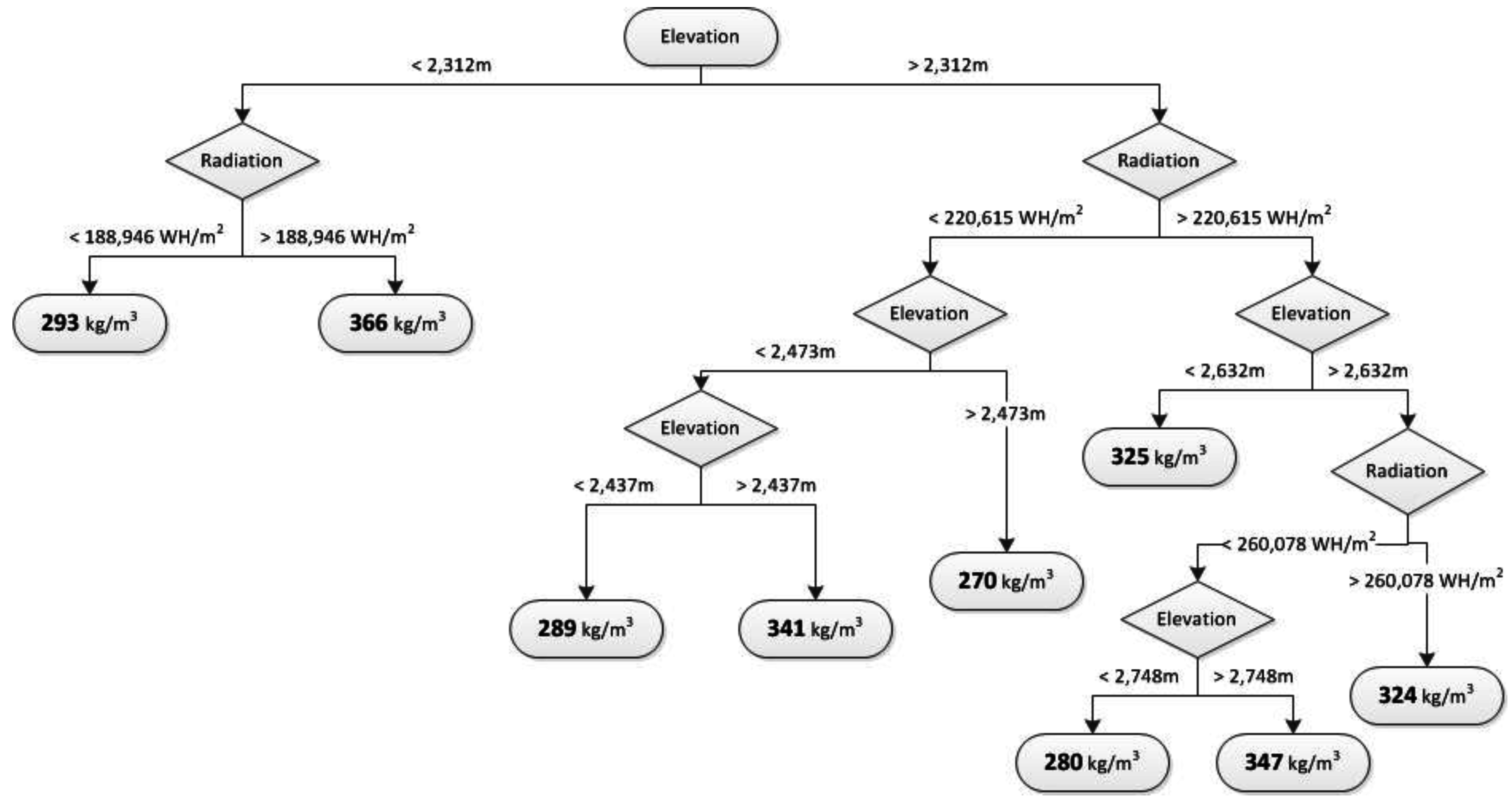
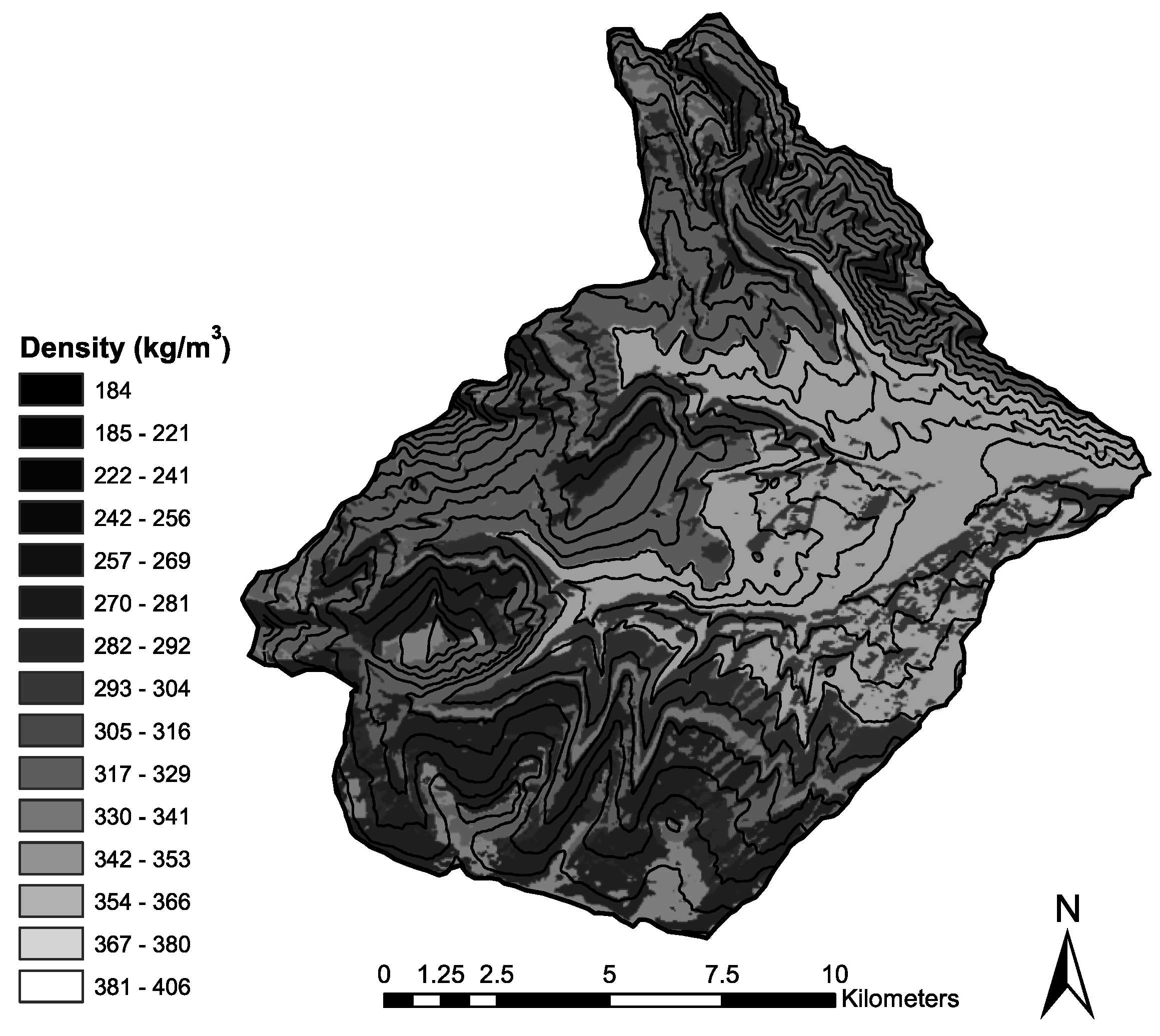
Snow density displayed considerable spatial variability throughout the West Fork Basin at the time of sampling, near peak accumulation. Significant correlations between the spatial distribution of density and the independent variables of elevation and incoming solar radiation were found using both regression tree and multiple linear regression modeling. Both methods showed density to decrease with increasing elevation, increase with increasing radiation, and vice versa. One split of the regression tree modeled a higher snow density with increasing elevation in the highest elevation areas, possibly due to increased wind compaction of snow in the exposed alpine portions of the basin.
Correlations with elevation and radiation are related to snow density, because they are both physically-based parameters that heavily influence the snowpack energy balance at any given point in a basin [
4]. Snow density will increase with increased radiation, because the additional energy input can speed near-surface metamorphism, leading to larger grains, decreased pore space, and therefore, increased density. Additionally, areas that experience high radiation inputs will also be more likely to have snow surface melt introducing liquid water to the snowpack. This also increases density by filling pore space with liquid, as well as increasing grain sizes through liquid-ice interactions and enhanced metamorphism from the introduction of latent heat deeper in the pack as this water re-freezes [
10]. Increasing elevation is related to decreased densities because of colder air temperatures due to adiabatic cooling and deeper snow depths requiring more energy input to substantially lower the average density through the entire snowpack profile. While Elder
et al. [
4] note slope angle to be a significant predictor of density because of its relation to wind transport and avalanching, direct statistical correlations between slope angle and density were not identified in this study.
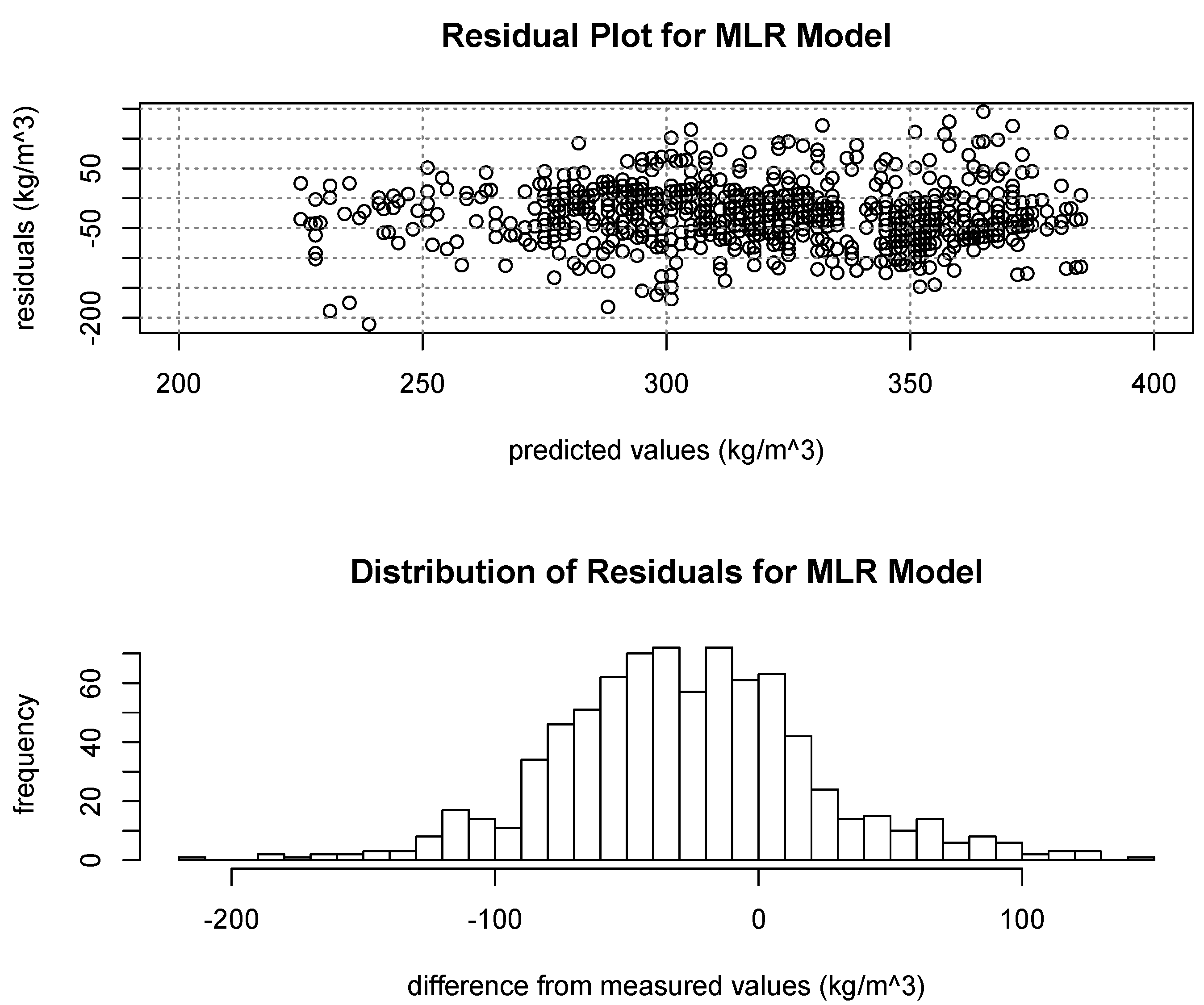
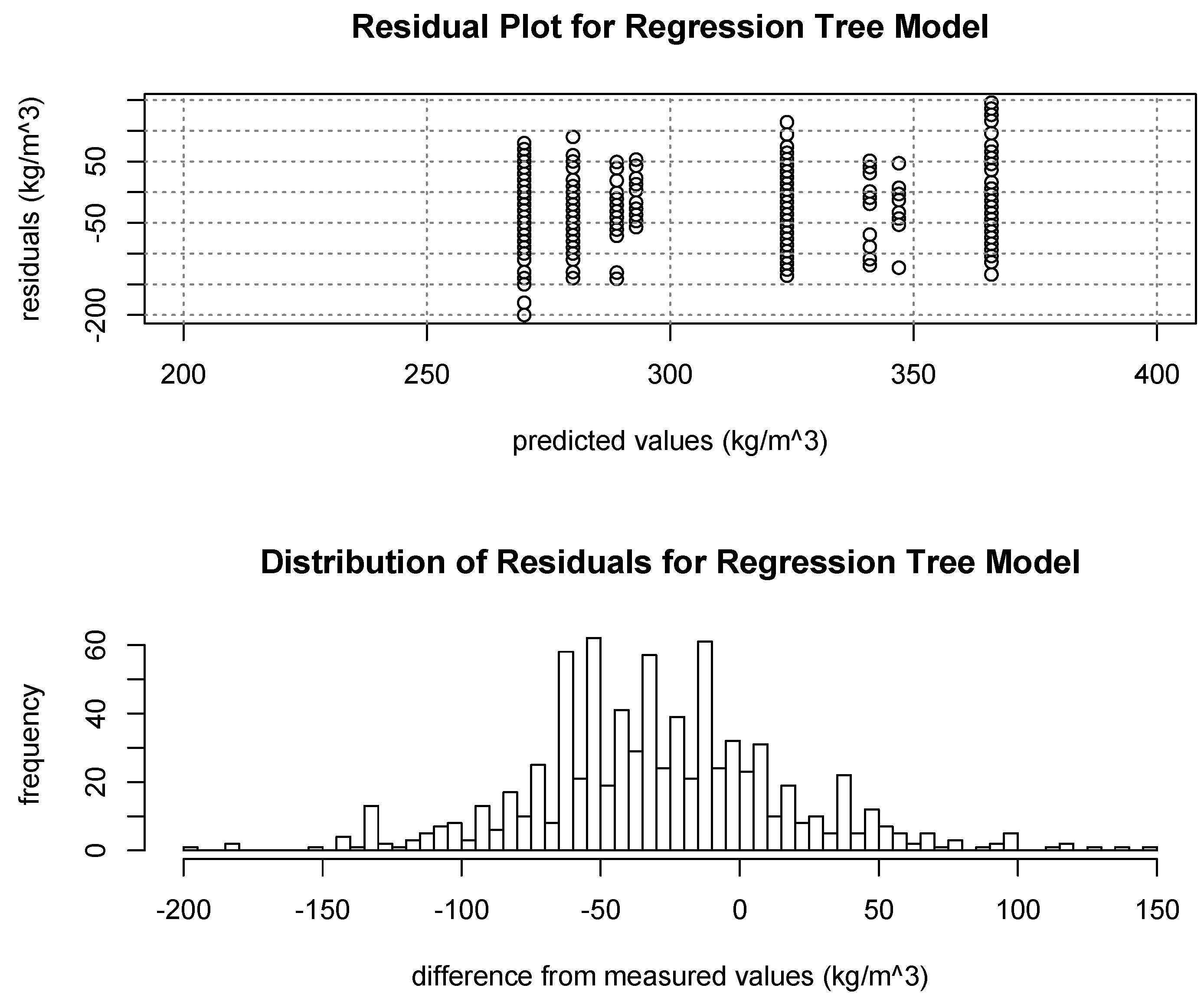
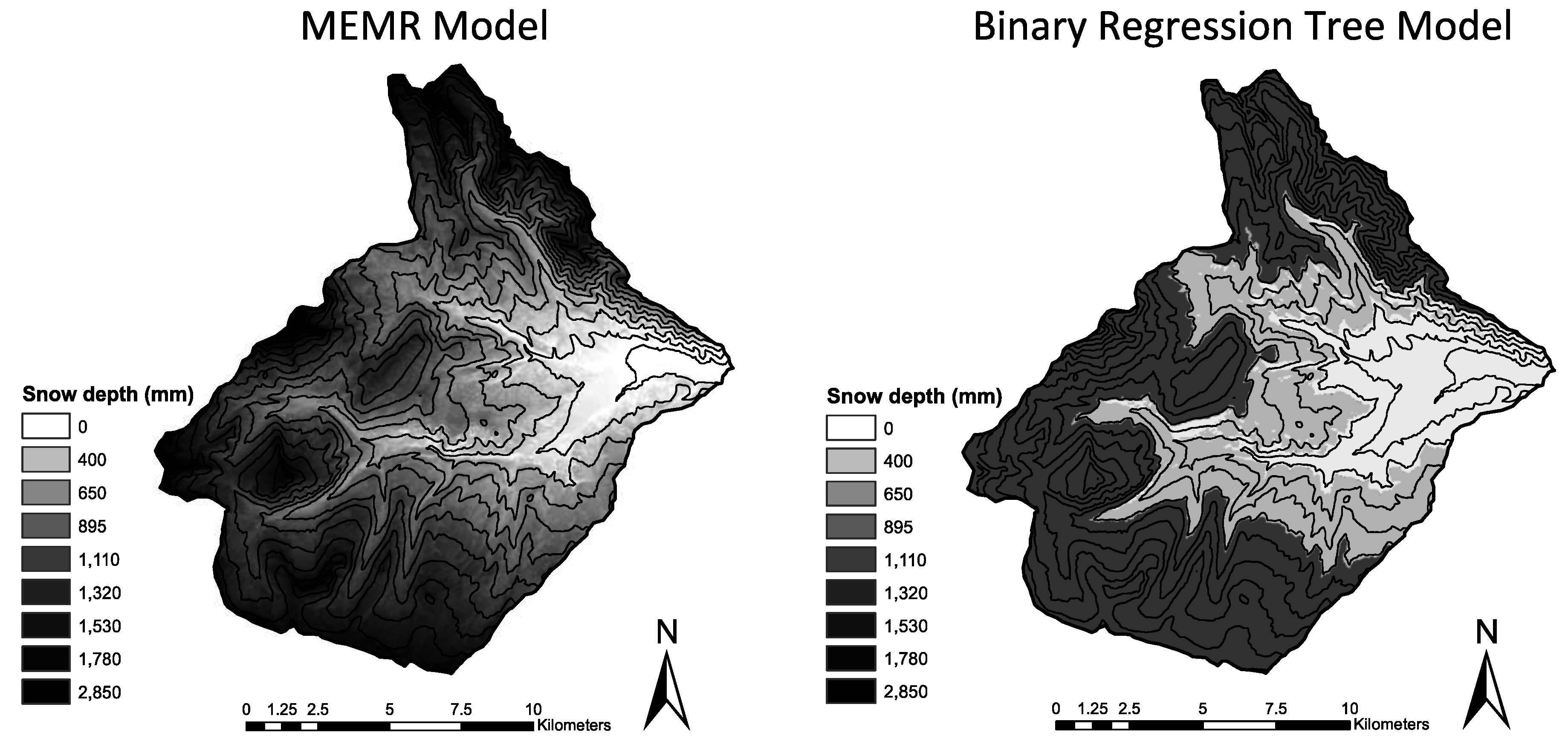
Both MLR and regression tree models were able to account for similar quantities of observed variation in snow density (39% and 41%, respectively), but provided notably different ranges of modeled values and spatial distributions. The MLR model provided a wider range of modeled densities and a continuous distribution of values, where the binary regression tree provided a narrower range and modeled nine discrete densities in its terminal nodes. The narrow range resulting from the regression tree model also emphasizes its inability to model outside of its observed range, which is another potential weakness of that model type. Even with the MLR model providing a wider range of estimates, both models estimated a narrower range of values than were measured in the field, resulting in a very similar pattern in the distribution of their residuals from observed values. The negative trend in
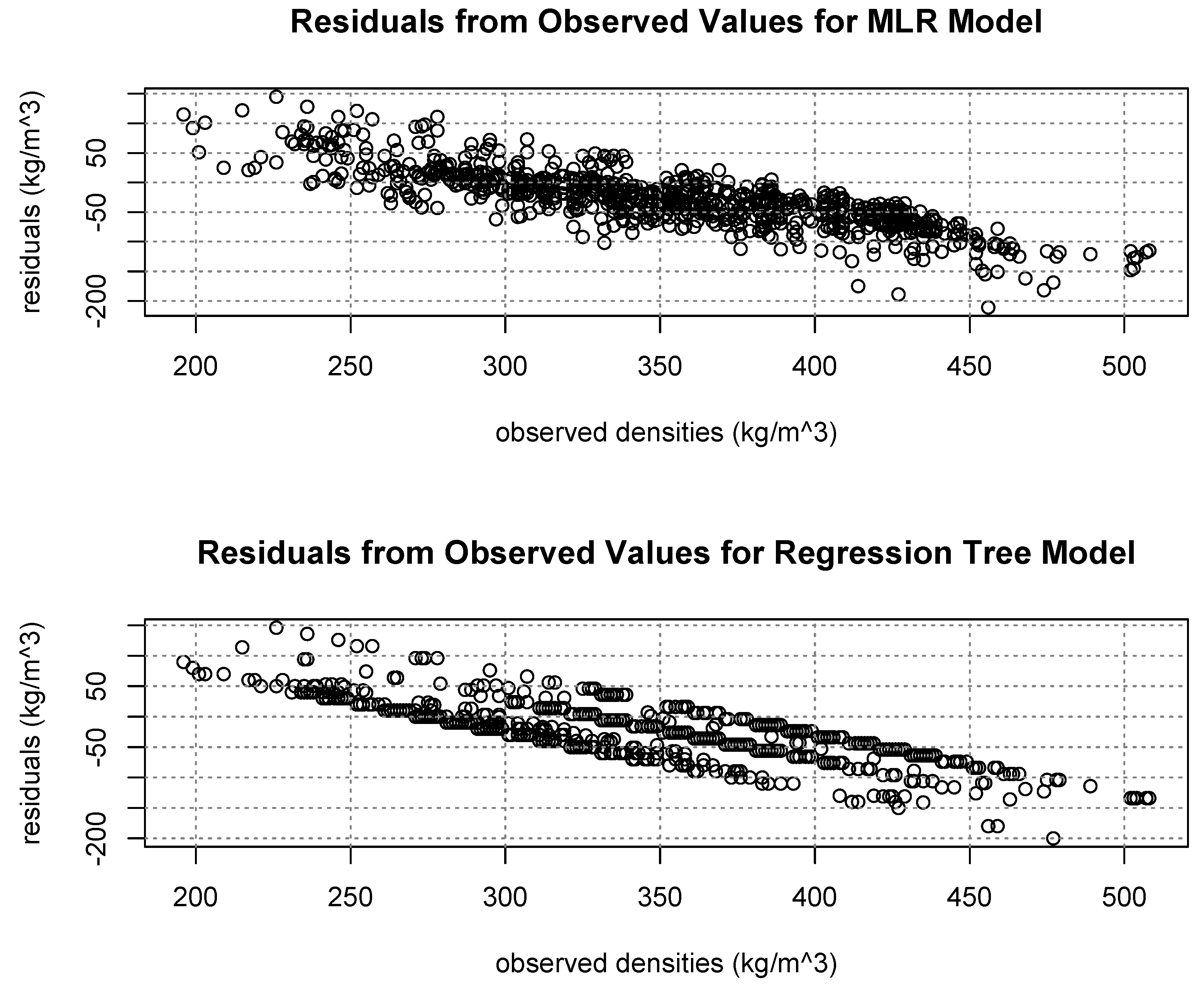
Figure 12 displays how these narrower ranges (compared to observed values) led to over-estimation of the lowest measured densities and under-estimation of the highest measured densities.
Figure 12.
Residuals from observed values showing general over-estimation for low densities and under-estimation for higher densities from both model types.
Figure 12.
Residuals from observed values showing general over-estimation for low densities and under-estimation for higher densities from both model types.
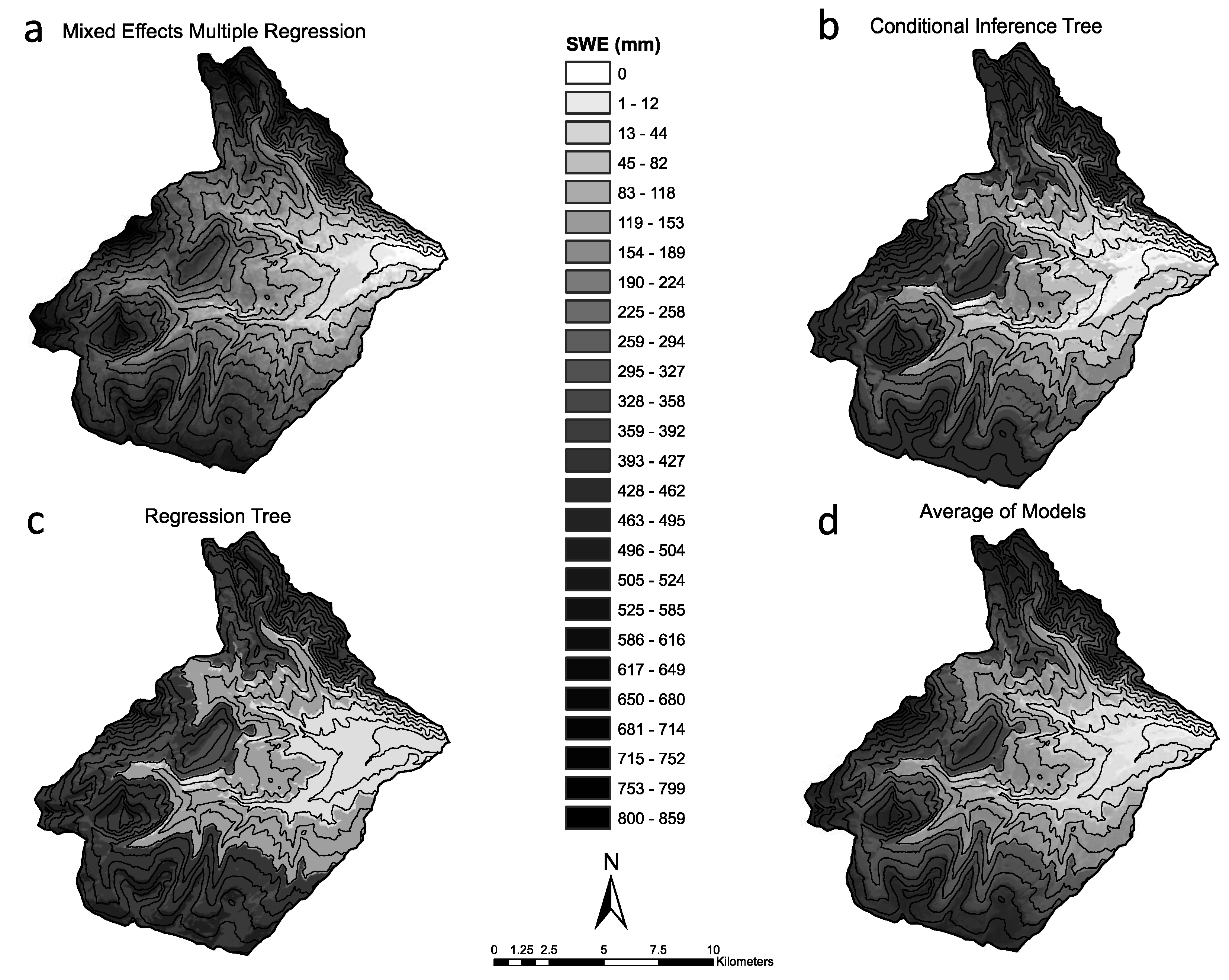
The continuous distribution of the modeled values resulting from MLR more accurately captures the continuous distribution of values found in the field. It was also able to more accurately model the tails of the distribution, which the regression tree model did not. Based on the similar measure of model fit, it could be argued that either could be an appropriate representation of the spatial distribution of snow density throughout the West Fork Basin for the purpose of estimating total basin SWE. However, each model has its own advantages. The continuous nature and modeled tails of the distribution resulting from the MLR model does provide a more realistic representation of how snow densities are distributed in nature. The regression tree model, however (while only predicting nine discrete density values to be modeled throughout the basin), did model large changes in density over short distances due to changes in received radiation in a more realistic manner. Conversely, the modeling of the 349-kg/m3 values in the highest elevations is anomalous compared to the general observations throughout the basin. Overall, considering the benefits and disadvantages of both model types, the MLR model is considered to provide a more realistic representation of the spatial distribution of snow density in the West Fork Basin. Despite this, it is recommended that both methods (and potentially additional) be developed and evaluated to determine which model, or a combination thereof, provides the best representation of the spatial distribution of density for a given purpose.
A substantial body of work has been devoted to quantifying the spatial distribution of SWE in mountainous terrain, generally utilizing separate characterizations of depth and density to obtain SWE estimates. Some of these have used spatially-distributed models of density [
4,
5]. Others used spatially-uniform models and after finding poor density model results [
8] or no significant correlations on which to model density [
6]. Alternatively, Clark
et al. [
2] found minimal spatial variation in their density measurements and decided to focus their analysis on snow depth instead of SWE. The lack of significant correlations in these studies could be related to two primary factors. First, significant differences in density simply may not have existed in the field when data were collected for previous studies. Second, the quantity and/or spatial arrangement of samples acquired did not provide the pertinent data to statistically correlate associations that may have existed in the field [
13,
20].
Two primary factors likely contributed to the strong correlations between density and physiography in this study. First, both the elevation range (1580 m) and spatial extent (207 km
2) of the West Fork Basin are notably larger than basins analyzed in previous field-based studies of SWE in mid-latitude mountainous regions (comparisons from Clark
et al. [
2]). This large extent and elevation range led to widely-varying characteristics of the snowpack near peak accumulation. Secondly, the acquisition of a large number of samples (
n = 1017) in areas of the basin quantified to be physiographically representative of the whole and over a range of spatial scales allowed for differences in density to be statistically correlated to elevation and radiation.
When using these spatially-distributed density models and a spatially-uniform parameterization of the average of measured densities to estimate total basin SWE, substantial differences in estimates were observed. When combined with the MEMR depth model, resulting SWE estimates had a range of 6.1% compared to the control models (in which estimates varied by ~1%), all estimating less SWE. Estimates of SWE utilizing the regression tree model for snow depth varied by 5.1%, with all estimates being higher than those derived from direct SWE measurements. The 14.1% total range of SWE estimates resulting from the six different combinations of depth and density parameterizations indicate that even with statistically-sound representations of the spatial distribution of density (and depth), model choice can still substantially influence SWE estimates. Because of these findings, it is recommended that if depth and density are to be combined to estimate SWE that a variety of spatial models (including spatially uniform, if desired) be analyzed to determine which are best for a given study. If multiple models are developed, estimates from the various models could also then be averaged or otherwise combined to obtain a final estimate of SWE, either as the total basin volume or a spatially-distributed representation.
Many important considerations exist when assessing the spatial distribution of snow density and comparing other studies that have done so. Snow density can be highly dynamic, spatially and temporally, especially through the transition from the accumulation to the ablation season. The annual timing, spatial patterns and rate of snowpack densification can vary substantially in different basins, mountain ranges and snow climates. In addition to differences that exist in the field, methods of sampling, data analysis and spatial modeling can also have an influence on the inferences obtained from any given body of work. This research emphasizes the importance of careful consideration of these factors, among others, when performing studies of the spatial distribution of snow density or SWE or analyzing the conclusions drawn by other research.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










