
Regional Flood Frequency Analysis in the Volta River Basin, West Africa


Abstract
:1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RFFA Methods | Advantages | Disadvantages |
|---|---|---|
| Index flood method | The multiplication of regional estimate with at-site statistic reduces the uncertainties associated with regionalization. | This method is sensitive to the homogeneity assumption and the formation of regions. |
| Regional shape estimation method | This method is more effective when higher-order L-moment ratios are equal at each site. | The conditions for good performance of this method are not physically plausible. |
| Region of influence method | The explicit construction of a region is not necessary. | It is difficult to define the appropriate weights. |
| Hierarchical approach | This method uses more information to estimate the distribution parameters. | This method may produce abrupt changes in the parameters from one site to another. |
| Fractional membership approach | The explicit construction of a region is not necessary. | It is difficult to define the appropriate weights. |
| Bayesian method | This model accounts for sources of uncertainty, and the homogeneity of the sites is not required. | The prior distributions of parameters are not precise and do not add more precision to the estimates [3]. |
| Probability regional envelope curves | This method is more effective to estimate very high flood quantiles. | The logarithmic transformations may introduce biases in the estimates. |
| Canonical correlation analysis method | Possibility to predict multiple dependent variables from multiple independent variables. | One is constrained to identify linear relationship, which may not be reasonable. |
2. Methodology
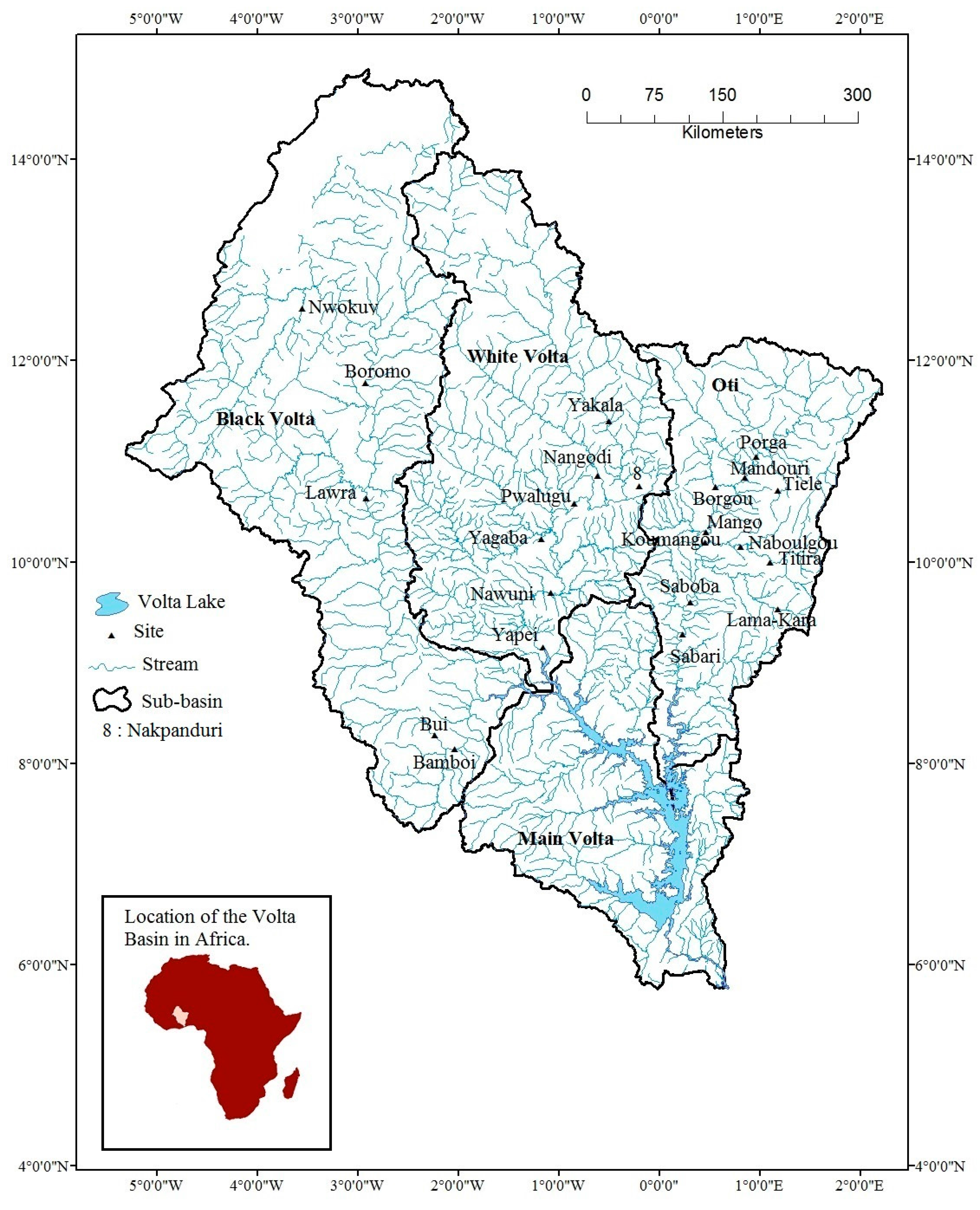
2.1. Study Area and Data
2.2. L-Moment

| Stations | Periods | Inter-Site Correlation Squared (R2 ) |
|---|---|---|
| Nwokuy, Boromo | 1955–1973 | 0.19 |
| Boromo, Lawra | 1955–1973 | 0.06 |
| Lawra, Bui | 1954–1973 | 0.01 |
| Bui, Bamboi | 1954–1973 | 0.01 |
| Yakala, Nangodi | 1958–1973 | 0.10 |
| Nangodi, Nakpanduri | 1958–1972 | 0.37 |
| Nakpanduri, Pwalugu | 1958–1972 | 0.21 |
| Pwalugu, Yagaba | 1958–1973 | 0.00 |
| Yagaba, Nawuni | 1958–1973 | 0.00 |
| Nawuni, Yapei | 1953–1967 | 0.00 |
| Tiele, Porga | 1963–1973 | 0.21 |
| Porga, Mandouri | 1963–1979 | 0.00 |
| Mandouri, Borgou | 1960–1979 | 0.00 |
| Borgou, Mango | 1960–1987 | 0.00 |
| Mandouri, Mango | 1959–1979 | 0.01 |
| Mango, Titira | 1962–1987 | 0.11 |
| Titira, Naboulgou | 1962–1987 | 0.62 |
| Naboulgou, Koumangou | 1962–1987 | 0.00 |
| Koumangou, Lama-Kara | 1959–1987 | 0.03 |
| Lama-Kara, Saboba | 1959–1987 | 0.00 |
| Mango, Saboba | 1959–1989 | 0.00 |
| Saboba, Sabari | 1959–1990 | 0.71 |
| Number | Site Name | River | Area (km2) | Main Slope (%) | Sample Length (Year) | L-cv | L-skew | L-kur |
|---|---|---|---|---|---|---|---|---|
| 1 | Nwokuy | Black Volta | 14,800 | 0.70 | 20 | 0.20 | 0.06 | 0.24 |
| 2 | Boromo | Black Volta | 35,000 | 0.40 | 19 | 0.15 | 0.01 | 0.06 |
| 3 | Lawra | Black Volta | 66,820 | 1.10 | 23 | 0.23 | 0.15 | 0.10 |
| 4 | Bui | Black Volta | 96,000 | 1.47 | 20 | 0.26 | 0.25 | 0.30 |
| 5 | Bamboi | Black Volta | 134,200 | 0.11 | 24 | 0.25 | 0.20 | 0.19 |
| 6 | Yakala | White Volta | 31,680 | 1.19 | 18 | 0.22 | −0.03 | −0.04 |
| 7 | Nangodi | Red Volta | 11,570 | 1.41 | 16 | 0.25 | 0.03 | 0.10 |
| 8 | Nakpanduri | White Volta | 1530 | 1.47 | 15 | 0.23 | −0.05 | 0.04 |
| 9 | Pwalugu | White Volta | 63,350 | 1.09 | 16 | 0.22 | 0.00 | 0.07 |
| 10 | Yagaba | White Volta | 10,600 | 0.45 | 16 | 0.26 | −0.23 | 0.11 |
| 11 | Nawuni | White Volta | 92,950 | 1.05 | 21 | 0.13 | −0.31 | 0.20 |
| 12 | Yapei | White Volta | 102,170 | 1.11 | 17 | 0.19 | 0.04 | 0.09 |
| 13 | Tiele | Magou | 836 | 1.56 | 13 | 0.17 | 0.21 | 0.16 |
| 14 | Porga | Pendjari | 22,280 | 0.33 | 27 | 0.28 | 0.13 | 0.13 |
| 15 | Mandouri | Oti | 29,100 | 0.80 | 21 | 0.21 | 0.01 | −0.03 |
| 16 | Borgou | Sansargou | 2280 | 0.99 | 28 | 0.31 | −0.03 | 0.06 |
| 17 | Mango | Oti | 35,650 | 0.33 | 37 | 0.32 | 0.23 | 0.07 |
| 18 | Titira | Keran | 3695 | 0.89 | 26 | 0.31 | 0.06 | −0.04 |
| 19 | Naboulgou | Keran | 5470 | 1.153 | 26 | 0.19 | 0.01 | 0.06 |
| 20 | Koumangou | Koumangou | 6730 | 0.70 | 29 | 0.14 | −0.03 | 0.19 |
| 21 | Lama-Kara | Kara | 1560 | 2.52 | 34 | 0.26 | 0.06 | 0.06 |
| 22 | Saboba | Oti | 53,090 | 1.44 | 32 | 0.24 | 0.11 | 0.01 |
| 23 | Sabari | Oti | 58,670 | 0.49 | 32 | 0.28 | 0.10 | 0.01 |
2.3. Data Screening
2.4. Identification of Homogeneous Groups
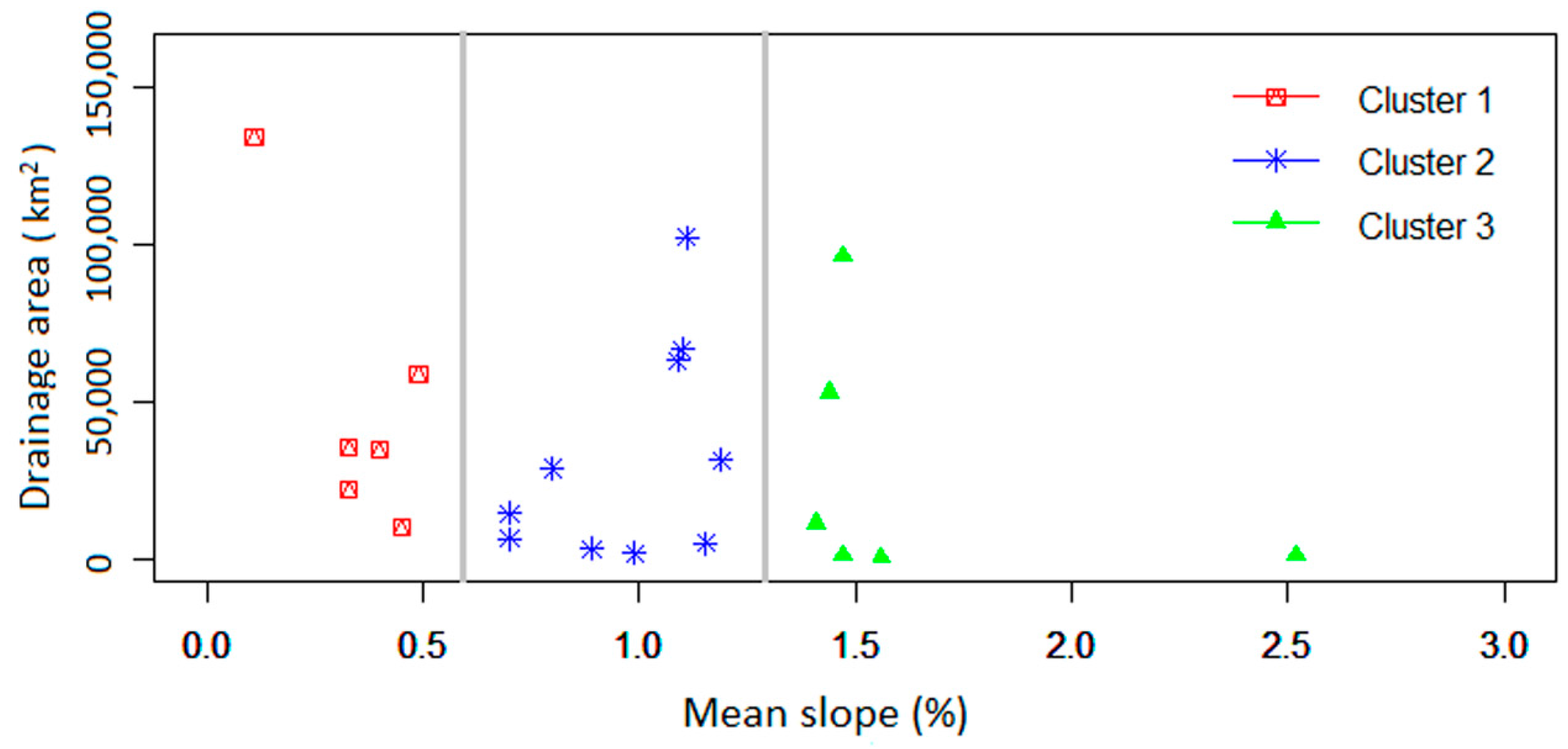
2.4.1. Cluster Analysis
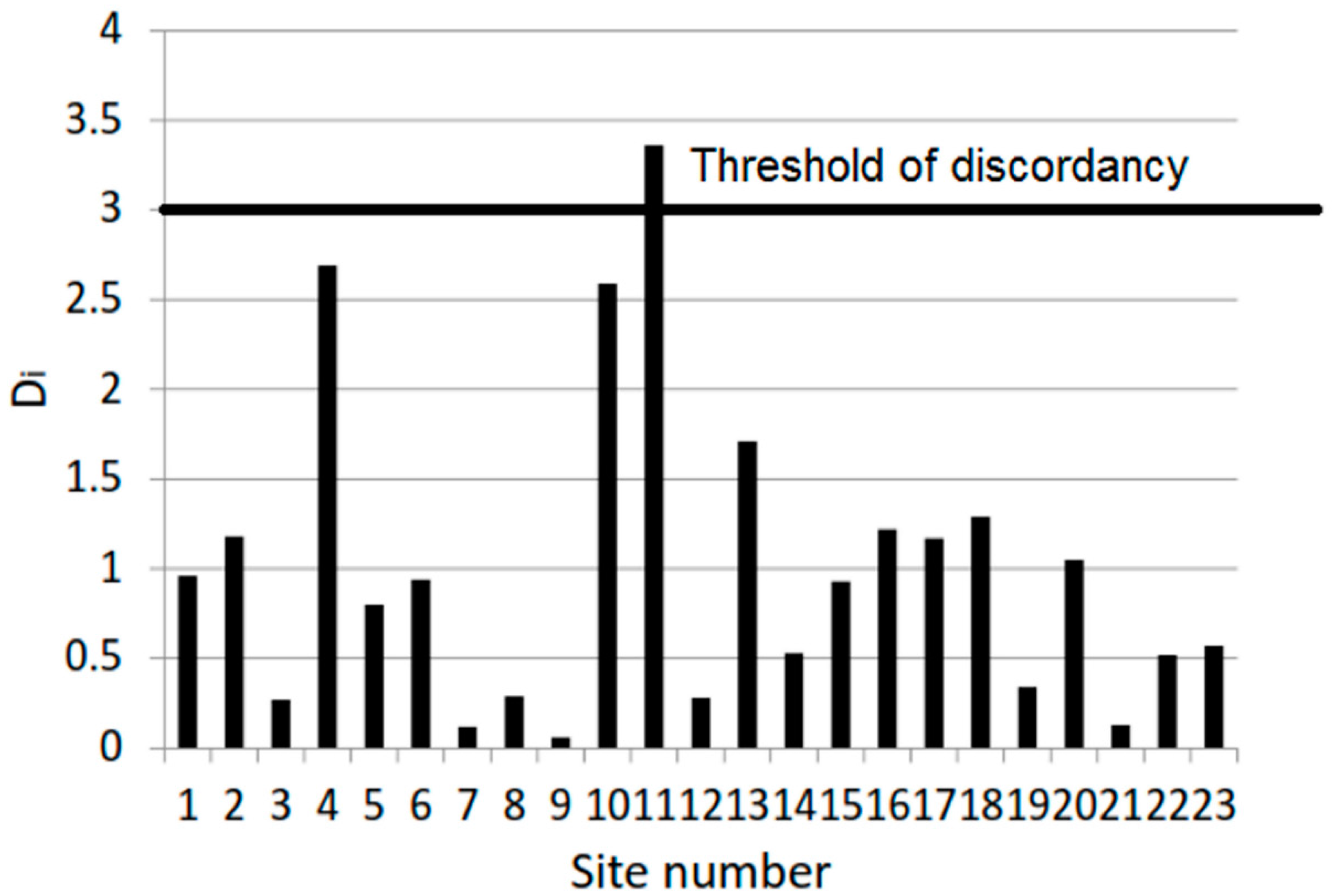
2.4.2. Homogeneity Test
2.5. Selection of the Regional Flood Frequency Distribution
2.6. Development of Regional Growth Curves
2.7. Development of Regression Models
3. Results and Discussion

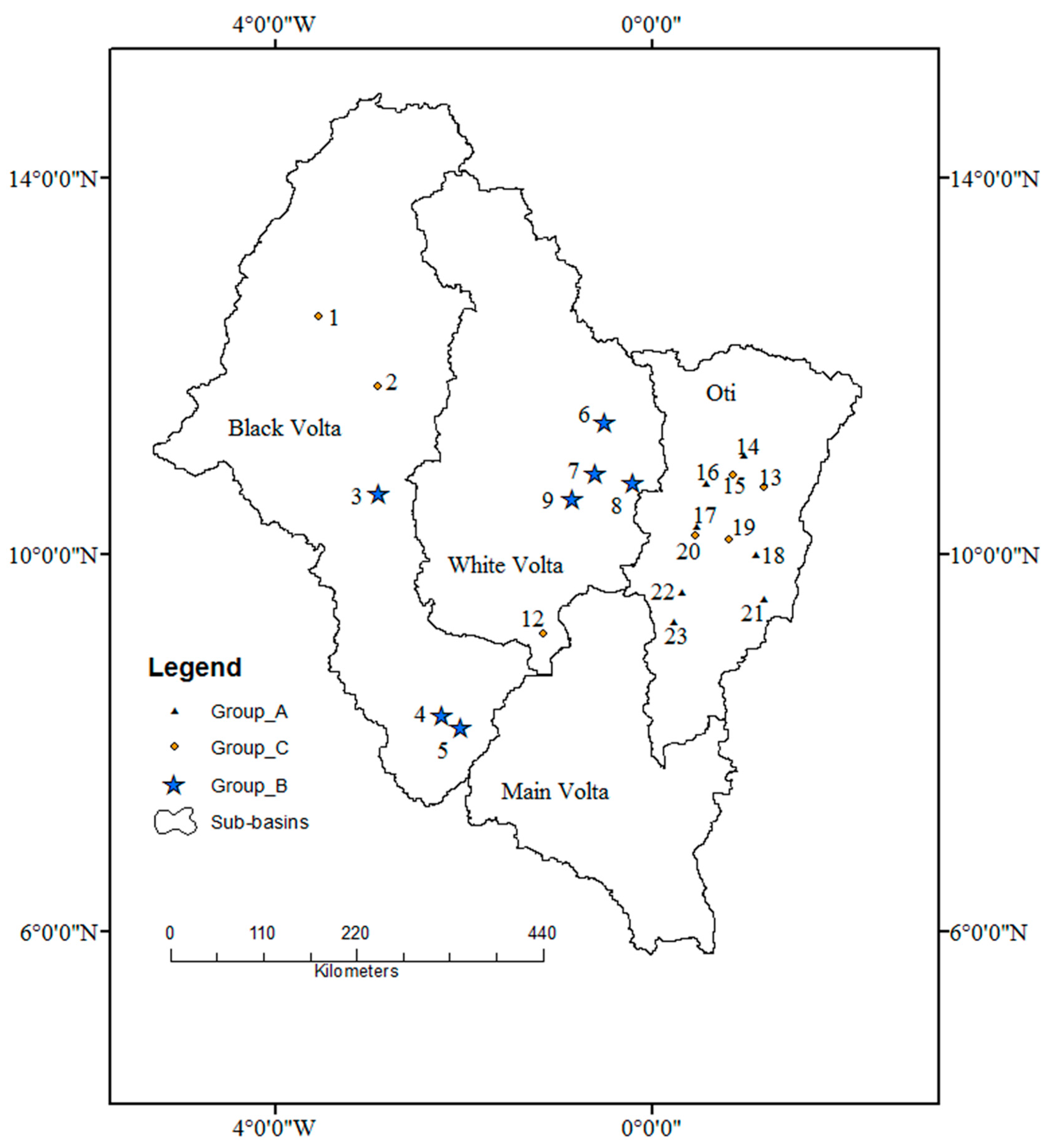
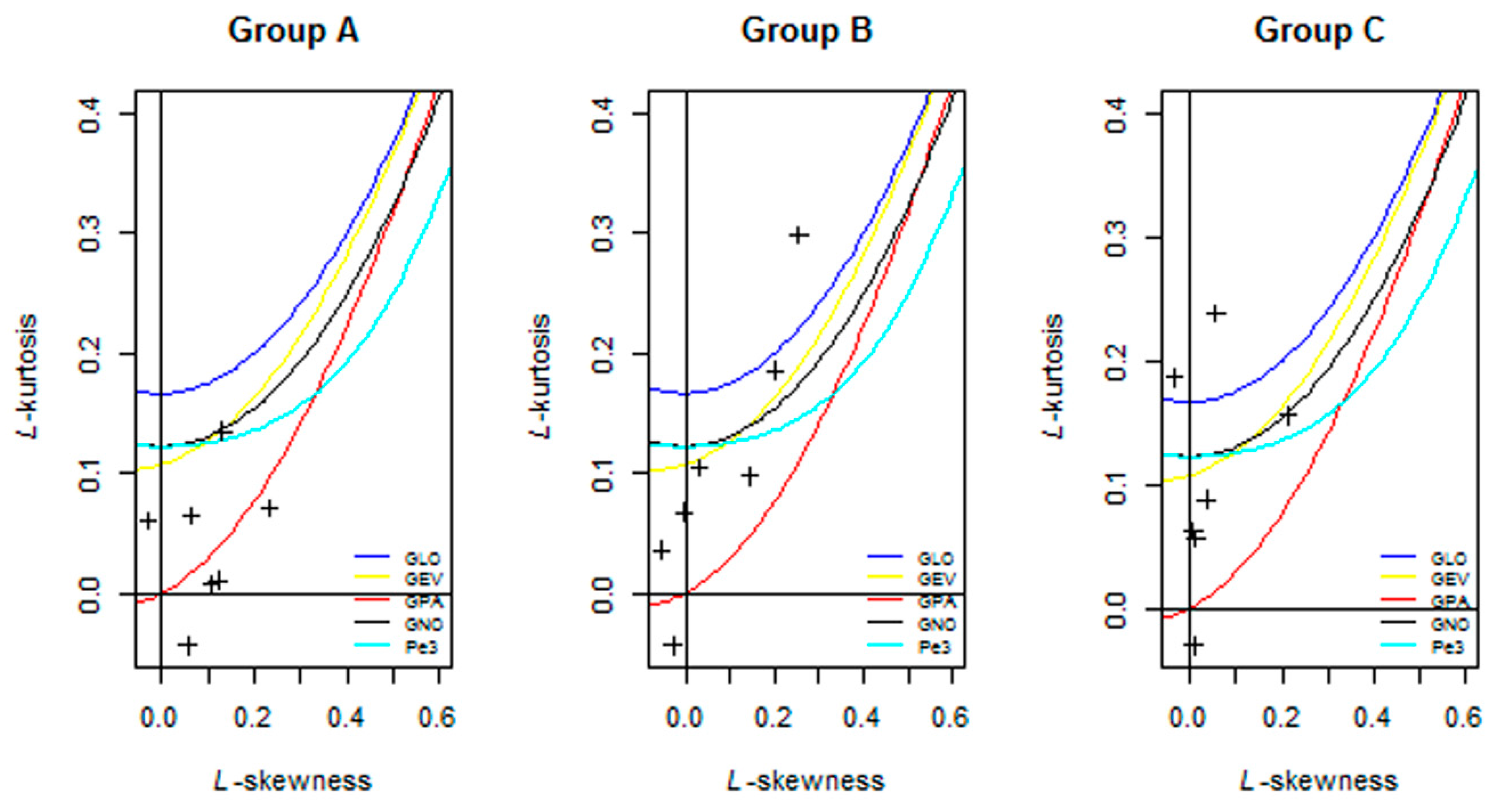
3.1. Formation of Homogeneous Groups

| Clusters | Number of Sites | H1 | H2 | H3 | Homogeneity |
|---|---|---|---|---|---|
| 1 | 6 | 0.44 | −0.32 | 0.39 | Homogeneous |
| 2 | 10 | 4.48 | 3.19 | 2.69 | Heterogeneous |
| 3 | 6 | 1.65 | 2.30 | 3.03 | Heterogeneous |
| Groups | Number of Sites | H1 | H2 | H3 | Homogeneity |
|---|---|---|---|---|---|
| A | 7 | 0.12 | 0.29 | 0.43 | Homogeneous |
| B | 7 | −2.02 | 0.70 | 0.98 | Homogeneous |
| C | 7 | −0.21 | −1.34 | −0.37 | Homogeneous |

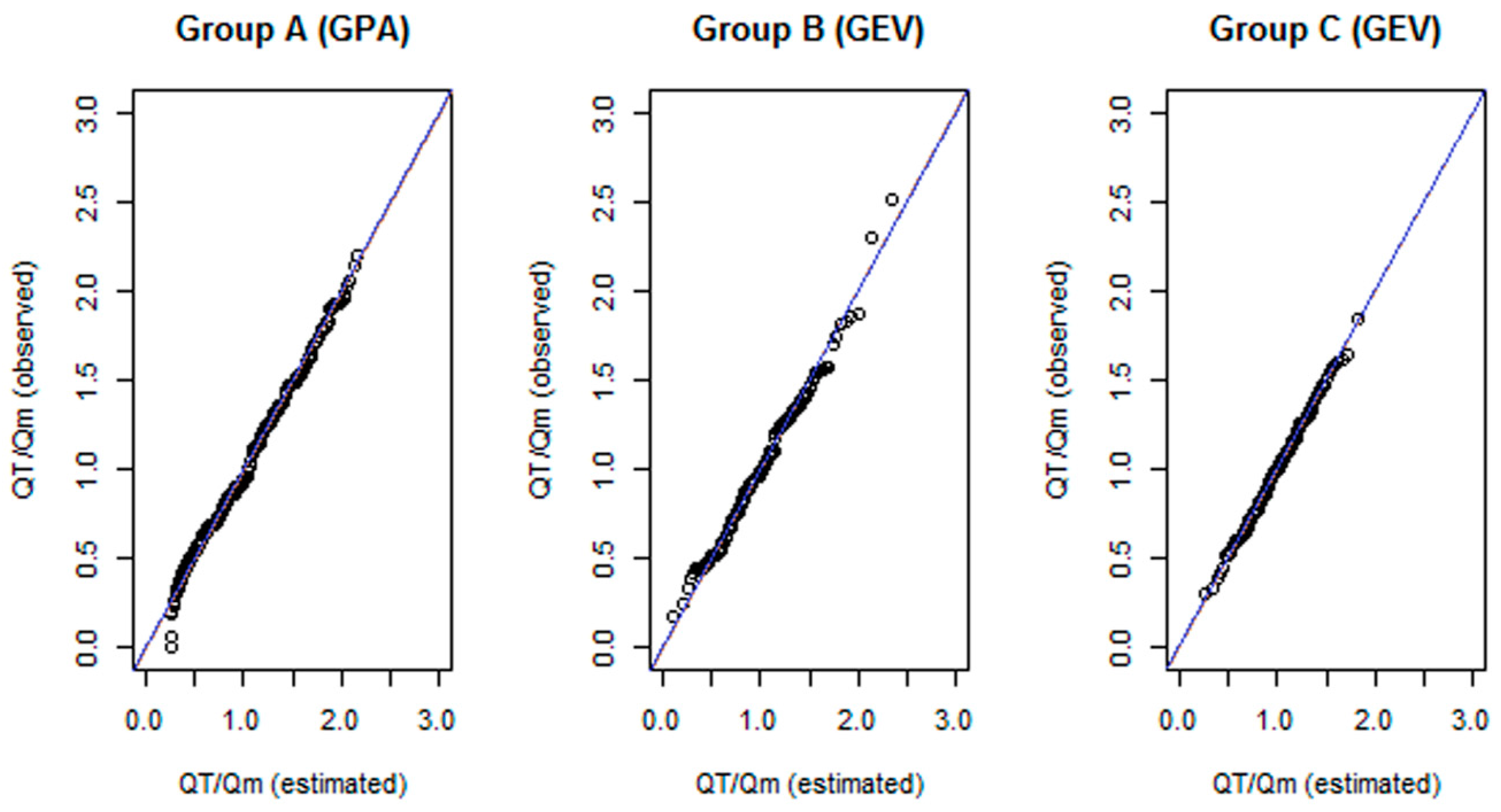
3.2. Selection of Appropriate Distributions
| Distribution | Group A | Group B | Group C |
|---|---|---|---|
| Generalized Pareto distribution | 0.55 | −2.57 | −3.57 |
| Generalized extreme value distribution | 4.29 | 0.39 | 0.15 |
| Pearson Type III distribution | 4.20 | 0.40 | 0.55 |
| Generalized normal distribution | 4.45 | 0.52 | 0.56 |
| Generalized logistic distribution | 6.67 | 1.87 | 2.04 |


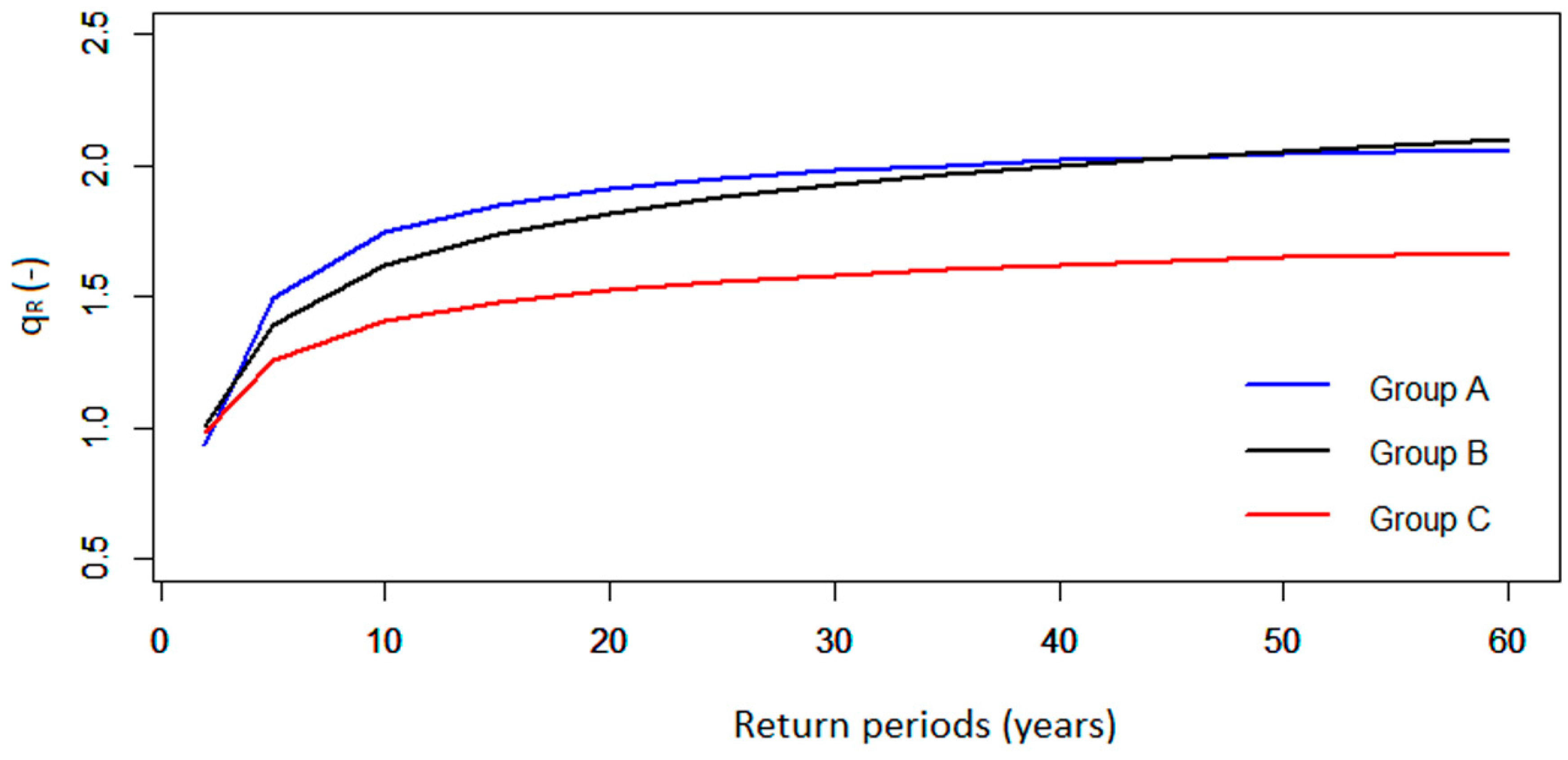
3.3. Flood Frequency Relationships
3.3.1. Regional Growth Curves
| Group | Distributions and Their Parameters | Quantile Functions |
|---|---|---|
| A | GPA : ε = 0.25; α = 1.22; k = 0.62 | = 0.25 + 1.97 |
| B style="border-bottom:solid thin" | GEV :ε = 0.82; α = 0.38; k = 0.12; | = 0.82 + 3.17 |
| C | GEV: ε = 0.88; α = 0.30; k = 0.23 | = 0.88 + 1.30 |

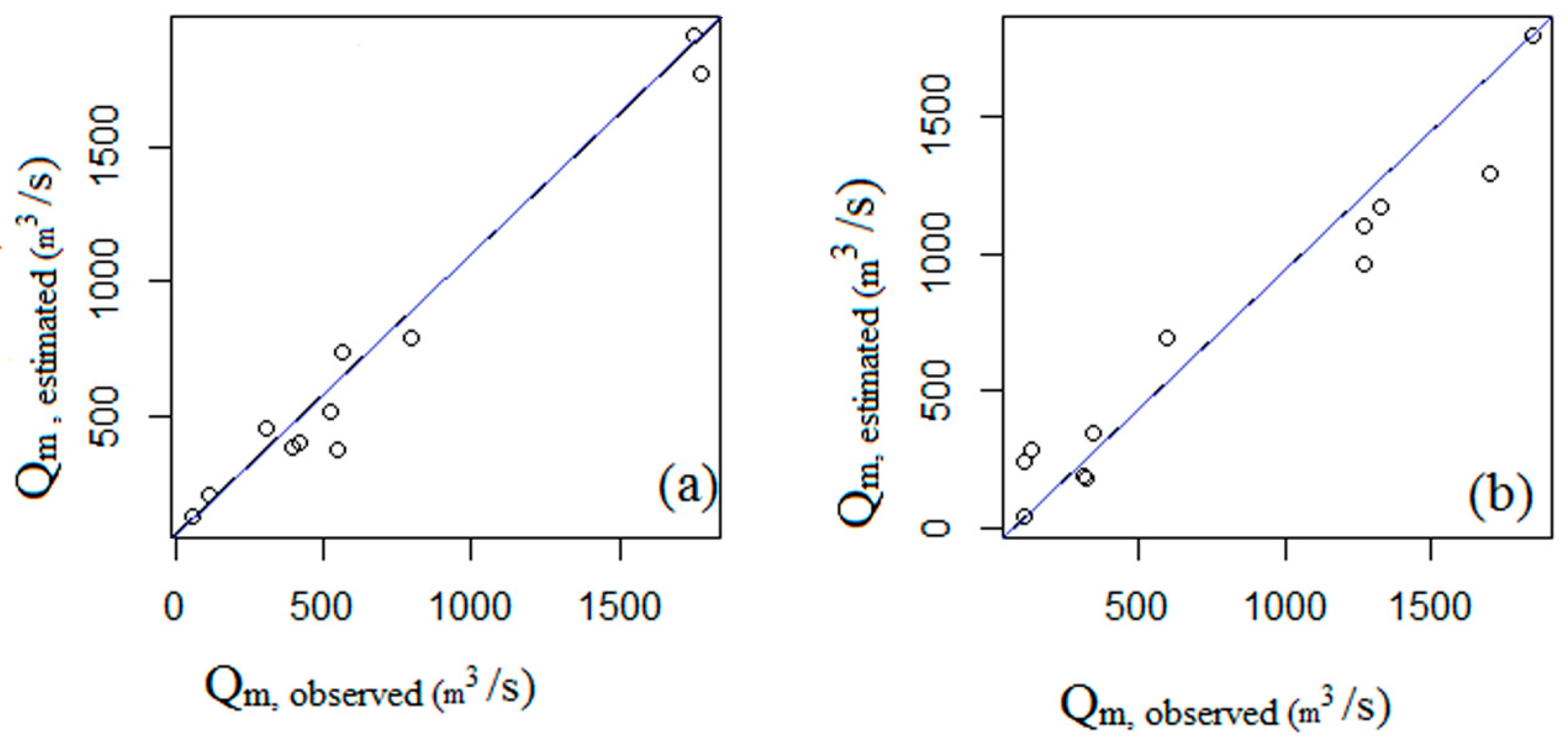
3.3.2. Regression Models
| Sub-Basins | Regression Models | |
|---|---|---|
| Oti River | 0.96 | |
| White Volta and Black Volta | 0.91 |
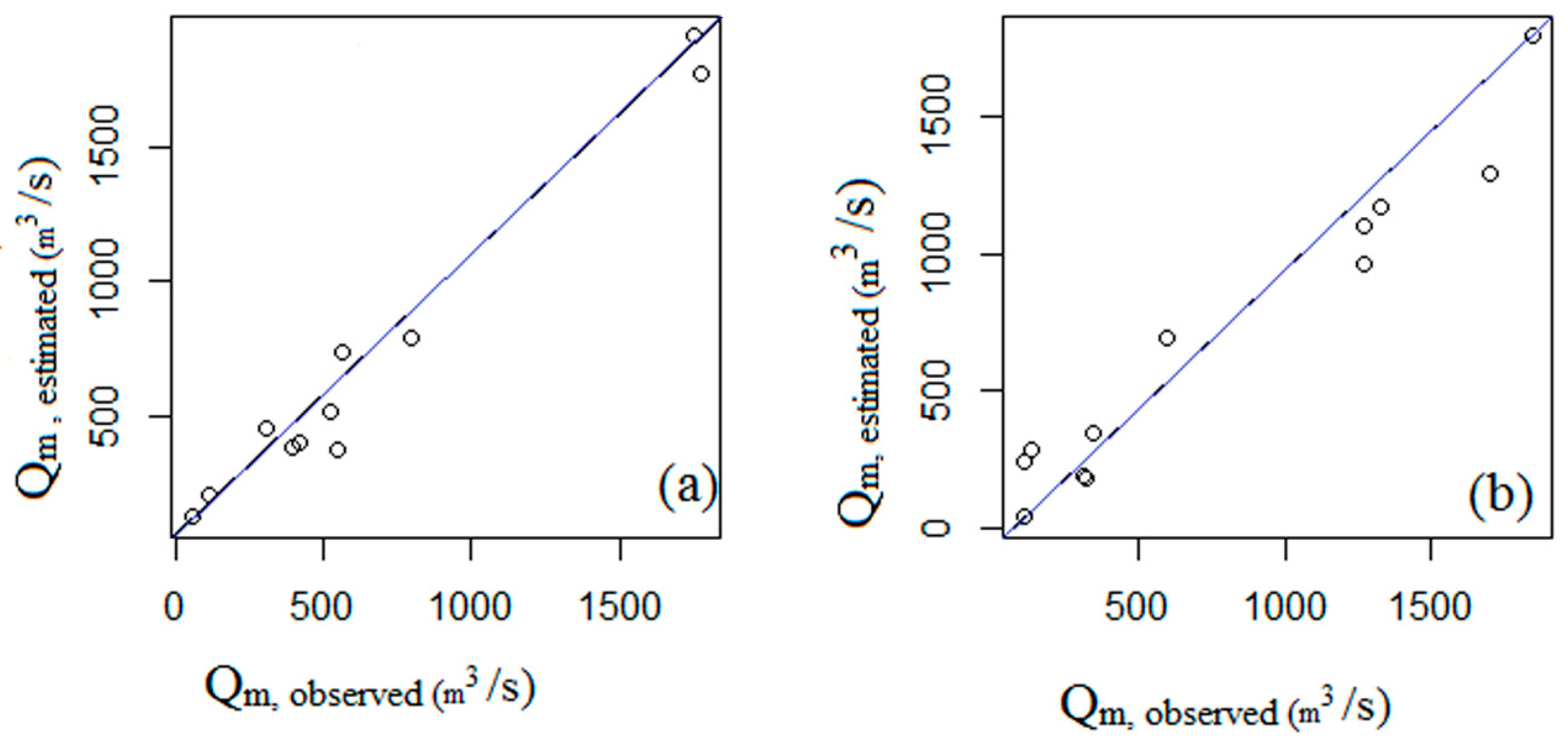
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Di Baldassarre, G.; Montanari, A.; Lins, H.; Koutsoyiannis, D.; Brandimarte, L.; Blöschl, G. Flood fatalities in Africa: From diagnosis to mitigation. Geophys. Res. Lett. 2010. [Google Scholar] [CrossRef]
- Sivapalan, M.; Takeuchi, K.; Franks, S.W.; Gupta, V.K.; Karambiri, H.; Lakshmi, V.; Liang, X.; McDonnell, J.J.; Mendiondo, E.M.; O’Connell, P.E.; et al. IAHS decade on Predictions in Ungauged Basins (PUB), 2003–2012: shaping an exciting future for the hydrological sciences. Hydrol. Sci. J. 2003, 48, 857–880. [Google Scholar] [CrossRef]
- Cunnane, C. Methods and merits of regional flood frequency analysis. J. Hydrol. 1988, 100, 269–290. [Google Scholar] [CrossRef]
- Kjeldsen, T.R.; Smithers, J.C.; Schulze, R.E. Regional flood frequency analysis in the KwaZulu-Natal province, South Africa, using the index-flood method. J. Hydrol. 2002, 255, 194–211. [Google Scholar] [CrossRef]
- Kachroo, R.K.; Mkhandi, S.H.; Parida, B.P. Flood frequency analysis of southern Africa: I. Delineation of homogeneous regions. Hydrol. Sci. J. 2000, 45, 437–447. [Google Scholar] [CrossRef]
- Mkhandi, S.H.; Kachroo, R.K.; Gunasekara, T.A.G. Flood frequency analysis of southern Africa: II. Identification of regional distributions. Hydrol. Sci. J. 2000, 45, 449–464. [Google Scholar] [CrossRef]
- Padi, T.P.; Di Baldassarre, G.; Castellarin, A. Floodplain management in Africa: Large scale analysis of flood data. Phys. Chem. Earth 2011, 36, 292–298. [Google Scholar] [CrossRef]
- Dalrymple, T. Flood Frequency Analysis; Technical Report Water Supply Paper 1543-A; US Geological Survey: Washington, DC, USA, 1960.
- Stedinger, J.R.; Lu, L.H. Appraisal of regional and index flood quantile estimators. Stoch. Hydrol. Hydraul. 1995, 9, 49–75. [Google Scholar] [CrossRef]
- Burn, D.H. An appraisal of the “region of influence” approach to flood frequency analysis. Hydrol. Sci. J. 1990, 35, 149–165. [Google Scholar] [CrossRef]
- Fiorentino, M.; Gabriele, S.; Rossi, F.; Versace, P. Hierarchical approach for regional flood frequency analysis. In Regional Flood Frequency Analysis; Singh, V.P., Ed.; D. Reidel Publishing Company: Norwell, MA, USA, 1987. [Google Scholar]
- Wiltshire, S.E. Regional flood frequency analysis II: Multivariate classification of drainage basins in Britain. Hydrol. Sci. J. 1986, 31, 335–346. [Google Scholar] [CrossRef]
- Gaume, E.; Gaál, L.; Viglione, A.; Szolgay, J.; Kohnová, S.; Blöschl, G. Bayesian MCMC approach to regional flood frequency analyses involving extraordinary flood events at ungauged sites. J. Hydrol. 2010, 394, 101–117. [Google Scholar] [CrossRef]
- Kuczera, G. A Bayesian Surrogate for Regional Skew in Flood Frequency Analysis. Water Resour. Res. 1983, 19, 821–832. [Google Scholar] [CrossRef]
- Ribatet, M.; Sauquet, E.; Grésillon, J.M.; Ouarda, T.B.M.J. Usefulness of the reversible jump Markov chain Monte Carlo model in regional flood frequency analysis. Water Resour. Res. 2007. [Google Scholar] [CrossRef]
- Castellarin, A. Probabilistic envelope curves for design-flood estimation at ungauged sites. Water Resour. Res. 2007. [Google Scholar] [CrossRef]
- Cavadias, G.S. Regional flood estimation by canonical correlation. Proc. Conf. Can. Soc. Civ. Eng. 1989, 11, 212–231. [Google Scholar]
- Ouarda, T.B.M.J.; Girard, C.; Cavadias, G.S.; Bobée, B. Regional flood frequency estimation with canonical correlation analysis. J. Hydrol. 2001, 254, 157–173. [Google Scholar] [CrossRef]
- Hosking, J.R.M.; Wallis, J.R. Regional Frequency Analysis: An Approach Based on L-Moments; Cambridge University Press: New York, NY, USA, 1997. [Google Scholar]
- Amisigo, B.A. Modelling River Flow in the Volta Basin of West Africa: A Data-Driven Framework. Ph.D. Thesis, University of Bonn, Bonn, Germany, 2005. [Google Scholar]
- Moniod, F.; Pouyaud, B.; Sechet, P. Monographies Hydrologiques ORSTOM N05:le Bassin du Fleuve Volta; Office de la Recherche Scientifique et Technique Outre-Mer: Paris, France, 1977. [Google Scholar]
- Hosking, J.R.M. L-moments: analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. B. 1990, 52, 105–124. [Google Scholar]
- Ward, J.H. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Ouarda, T.B.M.J.; Bâ, K.M.; Diaz-Delgado, C.; Cârsteanu, A.; Chokmani, K.; Gingras, H.; Quentin, E.; Trujillo, E.; Bobée, B. Intercomparison of regional flood frequency estimation methods at ungauged sites for a Mexican case study. J. Hydrol. 2007, 348, 40–58. [Google Scholar] [CrossRef]
- Vogel, R.M.; Fennessey, N.M. L-moment diagrams should replace product moment diagrams. Water Resour. Res. 1993, 29, 1745–1752. [Google Scholar] [CrossRef]
- Rosbjerg, D.; Blöschl, G.; Burn, H.D.; Castellarin, A.; Croke, B.; Di Baldassarre, G.; Iacobellis, V.; Kjeldsen, R.T.; Kuczera, G.; Merz, R.; et al. Prediction of floods in ungauged basins. In Runoff prediction in Ungauged Basins: Synthesis across Processes, Places and Scales; Blöschl, G., Sivapalan, M., Wagener, T., Viglione, A., Savenije, H., Eds.; Cambridge University Press: The Edinburgh Building, Cambridge, UK, 2013. [Google Scholar]
- Burn, D.H.; Goel, K.N. The formation of groups for regional flood frequency analysis. Hydrol. Sci. J. 2000, 45, 97–112. [Google Scholar] [CrossRef]
- Meigh, R.J.; Farquharson, K.A.; Sutcliffe, V.J. A worldwide comparison of regional flood estimation methods and climate. Hydrol. Sci. J. 1997, 42, 225–244. [Google Scholar] [CrossRef]
- Sutcliffe, J.V.; Farquharson, F.A.K. Flood frequency studies using regional methods. In Conference for Jacques Bernier; UNESCO Press: Paris, France, 1996. [Google Scholar]
- Lim, Y.H.; Lye, L.M. Regional flood estimation for ungauged basins in Sarawak, Malaysia. Hydrol. Sci. J. 2003, 48, 79–94. [Google Scholar] [CrossRef]
- Noto, L.V.; La Loggia, G. Use of L-moments approach for regional flood frequency analysis in Sicily, Italy. Water Resour. Manag. 2009, 23, 2207–2229. [Google Scholar] [CrossRef]
- Hingray, B.; Picouet, C.; Musy, A. Hydrologie 2: une science pour l’ingénieur; Presses polytechniques et universitaires romandes: Lausanne, Switzerland, 2009. (In French) [Google Scholar]
- Pandey, R.G.; Nguyen, V.T.V. A comparative study of regression based methods in regional flood frequency analysis. J. Hydrol. 1999, 225, 92–101. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komi, K.; Amisigo, B.A.; Diekkrüger, B.; Hountondji, F.C.C. Regional Flood Frequency Analysis in the Volta River Basin, West Africa. Hydrology 2016, 3, 5. https://doi.org/10.3390/hydrology3010005
Komi K, Amisigo BA, Diekkrüger B, Hountondji FCC. Regional Flood Frequency Analysis in the Volta River Basin, West Africa. Hydrology. 2016; 3(1):5. https://doi.org/10.3390/hydrology3010005
Chicago/Turabian StyleKomi, Kossi, Barnabas A. Amisigo, Bernd Diekkrüger, and Fabien C. C. Hountondji. 2016. "Regional Flood Frequency Analysis in the Volta River Basin, West Africa" Hydrology 3, no. 1: 5. https://doi.org/10.3390/hydrology3010005