
Derivative-Free Iterative One-Step Reconstruction for Multispectral CT

1
Institute of Basic Sciences in Engineering Science, University of Innsbruck, Technikerstrasse 13, 6020 Innsbruck, Austria
2
Department of Mathematics, University of Innsbruck Technikerstrasse 13, 6020 Innsbruck, Austria
*
Authors to whom correspondence should be addressed.
J. Imaging 2024, 10(5), 98; https://doi.org/10.3390/jimaging10050098
Submission received: 16 February 2024
/
Revised: 19 April 2024
/
Accepted: 19 April 2024
/
Published: 24 April 2024
(This article belongs to the Special Issue Image Processing and Computer Vision: Algorithms and Applications)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Image reconstruction in multispectral computed tomography (MSCT) requires solving a challenging nonlinear inverse problem, commonly tackled via iterative optimization algorithms. Existing methods necessitate computing the derivative of the forward map and potentially its regularized inverse. In this work, we present a simple yet highly effective algorithm for MSCT image reconstruction, utilizing iterative update mechanisms that leverage the full forward model in the forward step and a derivative-free adjoint problem. Our approach demonstrates both fast convergence and superior performance compared to existing algorithms, making it an interesting candidate for future work. We also discuss further generalizations of our method and its combination with additional regularization and other data discrepancy terms.
1. Introduction
Classical computed tomography (CT) is based on the inversion of the linear Radon transform, where a scalar-valued attenuation map of the patient is recovered from observation of its Radon transform derived from projection data. Here and below is the image domain in dimensions, and is the set of integration lines. While sufficient in many applications, the linear problem ignores the polychromatic nature of the X-rays and the energy-dependent absorption characteristics of real-world objects. The sample is more accurately represented by a family of attenuation maps dependent on the photon energy . Recovering a single from projection data using a single energy bin results in a mixture of density maps from different energies resulting in severe nonuniqueness. Additionally, the nonlinearity results in beam hardening artifacts that may be partially accounted for by iterative algorithms or analytic modeling [1,2,3,4,5,6]. In order to overcome such weaknesses, the idea of multispectral CT (MSCT) is to measure projection data for different energy bands, which are then used to reconstruct multiple attenuation maps. The reconstruction problem, however, becomes nonlinear and much more challenging than pure Radon inversion [7,8,9,10,11,12,13]. In this work, we develop a simple and efficient strategy for tackling the nonlinearity.
1.1. Multispectral CT
Specifically, in this work, we use the material decomposition paradigm in MSCT. In the material decomposition approach, it is assumed that the energy-dependent attenuation maps can be written as , where are the densities of M separate materials (with ) to be recovered and are known and tabled absorption characteristic of the m-th material. The aim is to recover the material densities from data collected for several energy bands. This does not only allow to improve image quality, but also offers a broad range of applications, as it reconstructs multiple images encoding different characteristics of specific regions, which enables a deeper understanding of the object under examination. Recent significant advancements in the manufacturing of energy-sensitive sensors [14,15] has considerably increased the interest in and applicability of MSCT.
Assuming B spectral measurements , the material decomposition problem in MSCT can be written as the problem of recovering based on the modeling equation . Here, is the Radon transform applied to the m-th material density map , and is a nonlinear map. Classical CT would correspond to the unrealistic case where the application of the pointwise logarithm in the modeling equation results in a linear inverse problem. In MSCT, one accounts for the full nonlinear problem for the unknown density maps .
1.2. Two-Step and One-Step Algorithms
Various algorithms have been developed for solving the reconstruction problem in MSCT. They can be broadly classified into two categories: two-step methods and one-step algorithms. The idea of earlier two-step methods is to perform Radon inversion and material decomposition in two separate steps. Material decomposition can be performed either in the projection domain (before Radon inversion) or in the image domain (after Radon inversion). Both methods have their specific advantages and disadvantages. The image-domain decomposition approach allows incorporating prior information about the objects that is naturally contained in the image domain . However, the nonlinear nature of the problem leads to approximate linear models that introduce severe reconstruction artifacts. The projection-domain decomposition approach, on the other hand, allows working with the correct nonlinear model. However, the prior structure in the Radon domain is not directly available. See the works [12,13,16,17,18] and references therein for proposed two-step approaches.
One-step methods reconstruct the material densities through iterative minimization techniques and thus overcome the drawbacks of both two-step methods. For some one-step algorithms, we refer to [7,8,11,19,20,21,22,23,24]. Despite their superior performance, such one-step iterative algorithms are computationally expensive. Existing methods require many iterative steps due to poor conditioning of the problem with computationally expensive iterative steps. The algorithms proposed in this paper are specific one-step algorithms that address these two drawbacks of existing one-step methods. The structure of our proposed algorithm is shown in Figure 1.
1.3. Our Contributions
The following list summarizes the main contributions of this paper:
- We present a novel derivative-free algorithm designed to combine the advantages of one-step and two-step approaches. To achieve this, we introduce a simple and computationally efficient iterative update that incorporates appropriate preconditioning.
- Image reconstruction is performed in the image domain, which naturally allows for the inclusion of an image smoothness prior. Our method can be combined with additional regularization. However, in order to show the method in its pure form, we will not include such a modification.
- Our methods integrate benefits of two-step approaches by separating iterative updates into two parts. Moreover, the main ingredient that makes the algorithm efficient is the use of the full nonlinear forward model but linearization around zero for the adjoint problem. In addition to avoiding computation and evaluation of the derivative of the forward map, this also allows for including simple but efficient channel preconditioning.
2. Mathematical Modelling of MSCT
We assume that the object to be imaged lies in some domain and consists of a combination of M different materials with densities with . Each material has a separate mass attenuation coefficient , which is a known function of the X-ray energy e. The total energy dependent (linear) X-ray attenuation coefficient is then given by:
Assuming that the material specific attenuation functions are known, the goal is to recover densities from indirect x-ray measurements using different energy bins.
2.1. Continuous Model
We start with continuous modeling, where the quantities involved are functions on continuous domains that will be discretized later. Suppose that X-ray energy with a known incident spectral density is sent along a line from the source position to the detector position. While propagating along ℓ, the X-rays are attenuated according to defined in (1). This results in an outgoing spectral density at the detector. The energy-sensitive detector with the spectral profile records the integral . Denoting the product of the incident spectral density of the source and the spectral sensitivity of the detector by , referred to as the effective spectrum, the recorded data are given by:
The data in Equation (2) represent a single measurement in MSCT. The goal of material decomposition in MSCT is to determine the density distributions from multispectral X-ray measurements obtained by varying the line ℓ and the effective spectra s.
For simplicity of presentation, we consider parallel beam mode, where any line is parametrized by its normal vector and its distance r from the origin. In this case, is given by the classical Radon transform of . Assuming further a total number of B different effective spectra and writing , we obtain the continuous MSCT forward model:
Equation (3) gives the complete continuous forward model in material decomposition in multispectral CT. The unknown f consists of M functions defined on the image domain and the data of B functions defined on the projection domain . The methods that we describe, however, would also work with a three-dimensional image domain and a general projection domain of lines in .
2.2. Discretization
In order to avoid technical details and to concentrate on the main ideas, we derive the algorithm for the discrete forward model throughout this paper. For that purpose, we represent the material densities via a discrete column vector and the Radon transform via a matrix , where is the number of discretization points in the image domain and is the number of lines used in the projection domain. Furthermore, we discretize the effective energy spectra by vectors and the known material attenuations by vectors , where E is number of discretization points of the energy variable. The discretization of (3) yields the following discrete image reconstruction problem.
Problem 1 (Discrete MSCT image reconstruction problem).
Recover the unknown from data where:
Here and below, we use the convention that the boldface notation indicates that the scalar function exp is applied pointwise to a vector in . Furthermore, in (4):
- The columns of are the discrete material images;
- is the discretized Radon transform;
- The columns of are the discretized material attenuations;
- The columns of the discretized effective spectra;
- The columns of are the observed spectral data.
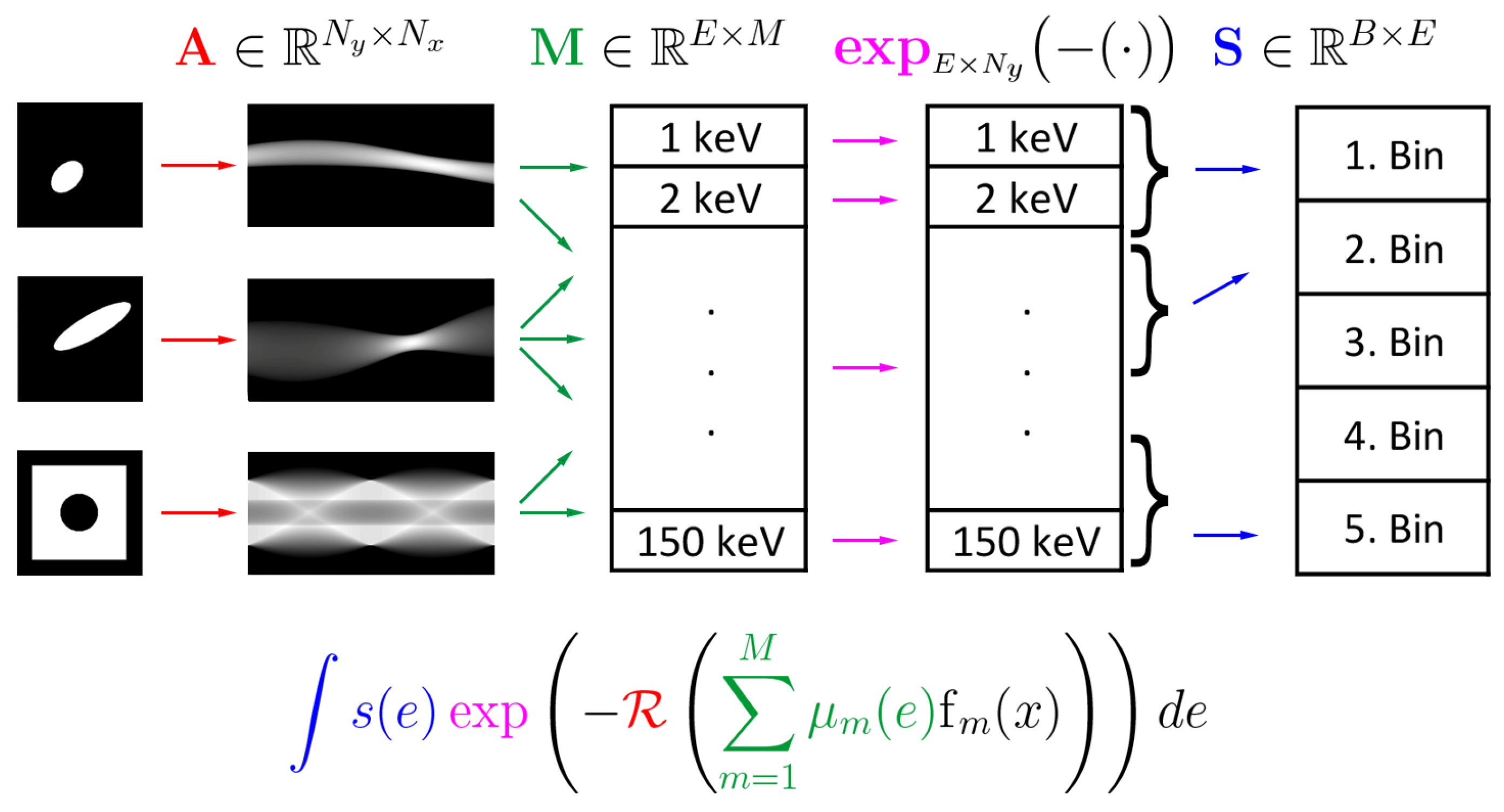
Note that we included the transpose operations in (4) such that all involved linear operations can be written as matrix multiplications from left. Alternatively, we can also write , reflecting the fact that the discrete Radon transform operates on the columns and the matrices and on the rows of . At some places, we will denote operation of on X from the right by such that we have . The structure of the discrete forward model is illustrated in Figure 2.
Remark 1 (Recalibration).
With we obtain:
Thus, with ⊙ denoting pointwise multiplication (also known as Hadamard product) and ⊘ the pointwise division, we get:
This means that the recalibrated forward model is the same as the original forward model with normalized effective spectra . The matrix with normalized spectra can be written as .
In this work we, use rescaled data, to which we apply the pointwise logarithm and the corresponding least squares (LSQ) functional.
Definition 1 (Forward model and LSQ functional).
We define the logarithmic forward model and the LSQ functional by:
where is defined in (4), are the given data, the modified data, and the pointwise logarithm.
Using the notations of Definition 1, material decomposition in MSCT amounts to the near solution of or the near minimization of .
Remark 2 (Noise modelling).
In the statistical context, LSQ minimization derives from maximum likelihood estimation using a Gaussian noise model on . From a statistical perspective, maximum likelihood estimation for Poisson noise on Y might be more reasonable, resulting in . As the focus in this paper is the derivation of an efficient reconstruction algorithm rather than statistical optimality, we work with . However, we expect that our strategy can also be applied to instead of .
Remark 3 (Regularization).
Due to the ill-conditioning of , the reconstruction problem has to be regularized [25,26]. In the context of LSQ minimization, a natural approach is variational regularization, where one considers instead of with a regularization functional . Recently, in [27], the plug-and-play method has been identified as a regularization technique where the regularization is incorporated by a denoiser. Another class is given by iterative regularization [28], where regularization comes from early stopping. All these regularization methods require the gradient of , which we compute below.
3. Algorithm Development
In this section, we derive the proposed algorithms for MSCT based on channel preconditioning (CP). The first one (CP-full) integrates channel preconditioning into a gradient scheme. In the second algorithm (CP-fast), the derivative of the forward map is replaced by the derivative at zero. Both methods greatly reduce the number of iterations compared to standard gradient methods and the numerical cost per iteration compared to Newton type methods. Before presenting our algorithms, we start by computing derivatives and gradients and recall existing gradient and Newton type methods.
3.1. Derivatives Computation
Standard algorithms for minimizing (8) require the derivative of the forward map and the gradient of the LSQ functional that we compute next. Recall the original and logarithmic MSCT forward operator and the LSQ functional defined by (4), (7), and (8). We equip and with the Hilbert space structure induced by the standard inner product . Furthermore, we use to denote the derivative of at location and and to denote the derivative and the gradient of at X, respectively.
Remark 4 (Gradients, inner products, and preconditioning).
By the definition of gradients, we have , where denotes the adjoint of a linear operator. Furthermore, by the chain rule, . Gradients and adjoints depend on the chosen inner product. For example, the inner product on the image space with a positive-definite matrix yields the modified gradient . Choosing such that has improved condition significantly improves gradient based methods for minimizing .
Remark 5 (Some calculus rules).
For the following computation we use some elementary calculus rules listed next. Let be vector valued functions and a scalar function with derivative . Then, for , we have:
As usual, we define the vector value functions by pointwise application and .
We have the following explicit expressions for derivatives, adjoints, and gradients.
Theorem 1 (Derivatives computation).
Proof.
The proof is given in the Appendix A. □
For CP-fast, the derivative of at zero plays a central role.
Remark 6 (Derivative at zero).
Let us consider the derivative at the zero image . In this case, we have , and therefore, and . Using that , we get:
The derivative may also be seen as the linearization of around zero. It has been used previously in MSCT and can be simply derived by first order Taylor series approximation [12]. In fact, with , we find:
The final expression in (19) in matrix notation is (16) and (18). For dual energy CT (the case where ), the use of the inverse of has been proposed in [29]. We emphasize that while we utilize the linearization as an auxiliary tool, we actually solve the full nonlinear problem. However, the linearized LSQ problem is also of interest in its own. Theoretically proven convergent algorithms for such problems can be found in [30,31].
The derivatives in Theorem 1 have a clear composite structure that we exploit in our algorithms. This is discussed next.
Remark 7 (Composite structure of derivatives).
Consider as a signal of size with M channels (each channel is a material) and data of size with B channels (each channel represents an energy bin). Then, we can write , where the following nonlinear function:
operates on the multichannel sinogram along the (horizontal) channel dimension and are the normalized effective spectra. Application of the chain rule and some computations results in:
from which we recover (12) and (14). Furthermore, for the zero material sinogram , we get and with as in Remark 6. Equations (21)–(23) factorize the derivative and its adjoint into two separate parts: a high-dimensional ill-posed but linear part operating in the pixel dimension and small size well-posed but nonlinear part operating in the channel dimension. Our algorithms will target this structure for fast and effective iterative updates.
3.2. Gradient and Newton—One-Step Algorithms
It is helpful to start with gradient based method for minimizing the LSQ functional (8). Our first method, CP-full, can be seen as a modified version of a hybrid between the standard gradient iteration (or Landweber’s method) and the Gauss–Newton method. Our second method, CP-fast, involves a simplification based on linearization around zero.
Gradient-based one-step algorithms for solving the MSCT problem using the LSQ functional start with the optimality condition and fixed point equations derived from it. Applying a nonstationary positive-definite preconditioner and a step size results in:
Explicit expressions for and are given by (7) and (14). Particular choices for the preconditioner and the step size yield various iterative solution methods. including Landweber’s iteration, the steepest descent method, Gauss–Newton iteration, Newton-CG iterations, or Quasi-Newton methods. To motivate our algorithm, it is most educational to discuss the Landweber and the Gauss–Newton iteration.
- Landweber method:
- In the context of inverse problems, the standard gradient method with a constant step size is known as the (nonlinear) Landweber iteration , which is (24) for the case where is the identity and . Landweber’s iteration is stable, robust, and easy to implement. It is even applicable in ill-posed cases, where, with an appropriate stopping criterion, it serves as a regularization method [32]. On the other hand, it is also known to be slow in the sense that many iterative steps are required. In our case, this is due to the ill-conditioning of the forward operator.
- Gauss–Newton method:
- Several potential accelerations of Landweber’s method exist, and preconditioning seems one of the most natural ones. In the context of nonlinear least squares, the Gauss–Newton method and its variants are well-established and effective. In this case, one chooses the preconditioner in (24), which results in:The Gauss–Newton method (25) has the potential to significantly reduce the required number of iterations. On the other hand, each one of these iterations is numerically costly, as it requires inversion of the nonstationary normal operator . Moreover, due to ill conditioning, the inversion needs to be regularized [28,33,34]. The algorithms proposed in this paper use simplifications that do not need to be regularized and avoid the costly inversion of the normal operator.
3.3. Proposed Algorithms
Now we move on to the proposed iterative algorithms for MSCT. We start with CP-full, which is a gradient-based algorithm with channel preconditioning. We then derive CP-fast, which is a derivative-free iterative algorithm using a stationary adjoint problem.
- CP-full:
- The first proposed algorithm is an instance of (24). Instead of no preconditioning, as in Landweber’s method, or the costly preconditioning , as in the Gauss–Newton method, we propose preconditioning with the channel mixing term only. That is, we exploit the factorization and propose the choice for the preconditioner. This results in the following CP-full iteration:While efficiently addressing the nonlinearity via a Gauss–Newton-type preconditioner in the channel dimension, it is computationally much less costly than the full Gauss–Newton update. Instead of inverting , which in matrix form has size in the Gauss–Newton method, it requires inversion of the smaller matrices only, which can be done separately for each pixel in the projection domain. Assuming and , this dramatically reduces the cost of preconditioning from to per iterative update.
- CP-fast:
- In the derivative-free version, we go one step further and completely avoid the derivative . For that purpose, we replace the derivative in (26) by the derivative at zero. According to Remark 6, we have with . Now, with denoting the pseudoinverse of , we arrive at the iterative update:We refer to (27) as the derivative-free fast channel-preconditioned (cp-fast) iteration. It only involves the derivative at zero, which can be computed once before the actual iteration. In this sense, it is actually derivative-free and fast. It can be interpreted as using the full nonlinear model for the forward problem, the linearization at zero for the adjoint problem, and including channel preconditioning.
Both iterations (26) and (27) are of fixed-point type and we, therefore, expect convergence for sufficiently small step sizes. Theoretically, proving convergence seems possible, but this is beyond the scope of this paper. As (26) is of gradient type, it seems easier to derive convergence for CP-full, while for the derivative free version CP-fast, such a proof seems challenging. Note further that for the results presented below, we integrated a positivity constraint by alternating iterative updates with the orthogonal projection onto the cone of nonnegative images.
4. Numerical Simulations
We compared our algorithms CP-full and CP-fast to existing iterative one-step algorithms in MSCT. Our evaluation builds on [11], which compares five such algorithms and provides open source code (https://github.com/SimonRit/OneStepSpectralCT, accessed on 13 July 2022.) that is used for our results. We compare CP-full and CP-fast with the best performing one of [11], and further with a two-step method.
4.1. Comparison Methods
The work [11] compares the following iterative one-step algorithms for MSCT in terms of memory usage and convergence speed to reach a fixed image quality threshold:
- Ref. [19] derives a nonlinear CG method for a weighted LSQ term;
Specifically, ref. [11] found the algorithm of [21] (referred to as Mechlem2018) to be significantly faster than the other four methods, and thus, we use it for comparison.
In addition, we compare with the algorithm [17] (referred to as Niu2014) as a prime example of an image domain two-step method. They use a penalized weighted least squares estimation technique applied to an empirical linear model. Note that more recently, data-driven methods based on neural networks and deep learning have also been proposed. Such methods are beyond the scope of this manuscript and we refer the interested reader to the review articles [10,36].
4.2. Numerical Implementation
For the presented results, we build on the Matlab code of [11], which we extend with our algorithms. In particular, we work with base materials (water, iodine, and gadolinium) and energy bins. The energy variable is discretized using uniform nodes between 0 and 150 keV. The attenuation functions and energy spectra used are shown in Figure 3. We use image pixels and line integrals for the Radon transform. In particular the code https://github.com/SimonRit/OneStepSpectralCT (accessed on 13 July 2022) creates matrices:
- for the base materials;
- for the effective energy spectra;
- for the Radon transform.
After row normalizing , we have for the MSCT forward model. Furthermore, noisy data Y are created with a different realistic forward model and Poisson noise added.
Besides , , , , and Y, we require implementations of for CP-fast and for CP-full. Computing is trivial and can be done in advance; are computed in each step of CP-fast using (22) and (23).
4.3. Results
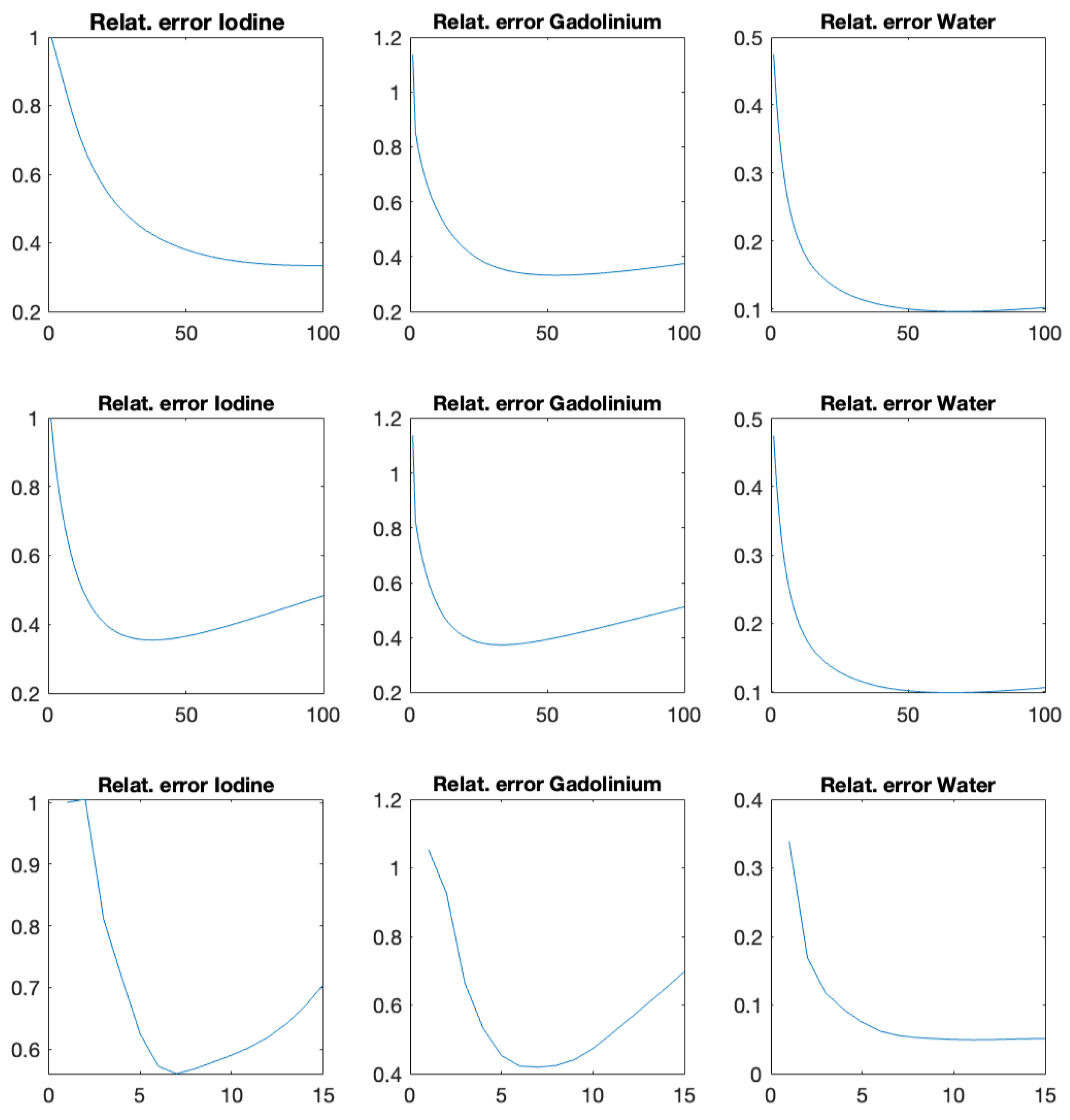
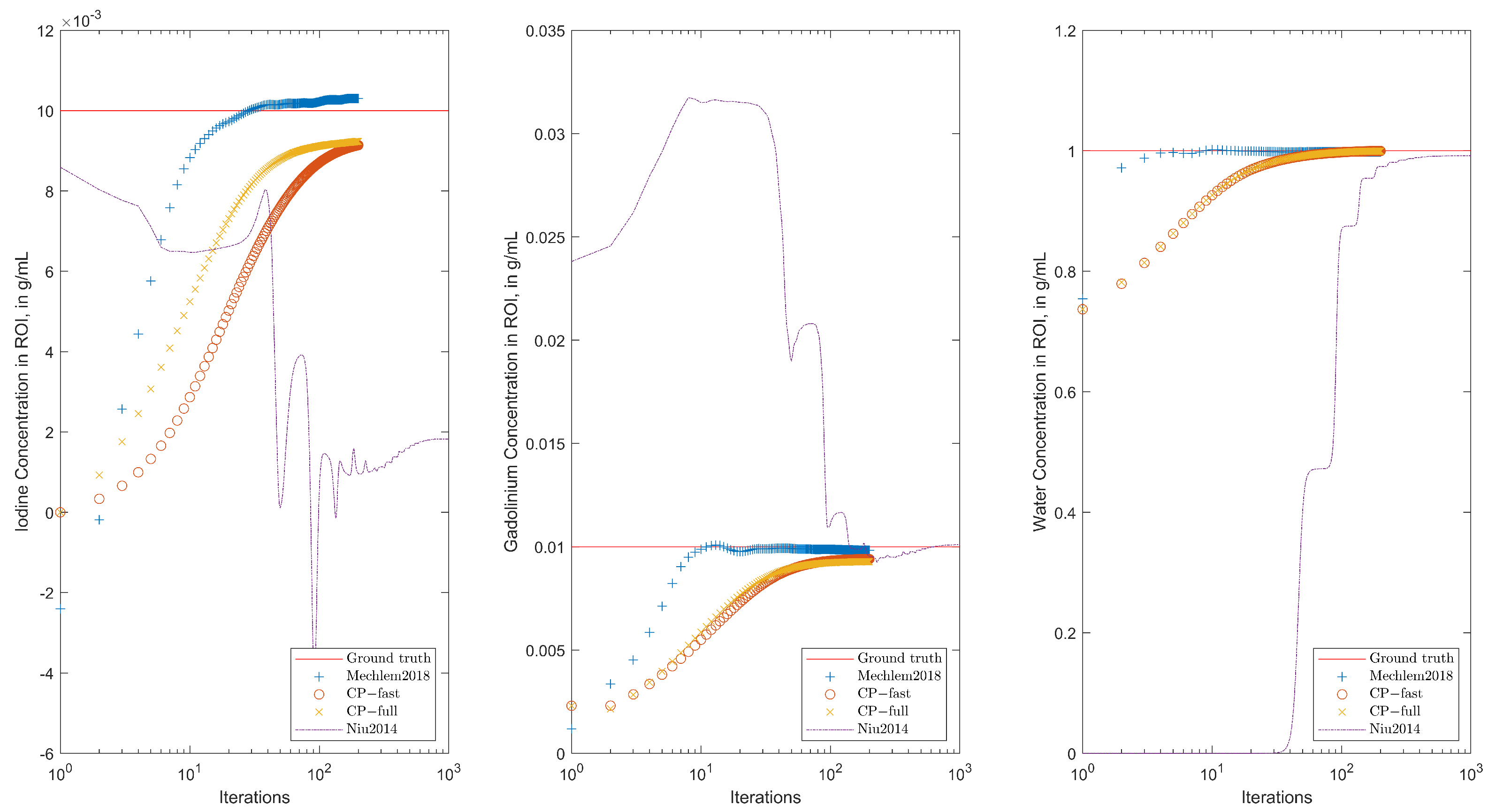
Reconstruction results using the proposed algorithms CP-fast (top row) and CP-full (second row) and the two comparison methods Mechlem2018 [21] (row three) and Niu2014 [17] (bottom row) can be seen in Figure 4. The phantom shown in the top row is made out of iodine (left), gadolinium (middle), and water (right). In all cases, we use noisy data and plot the iteration with minimal -reconstruction error , where is the ground truth. All calculations are performed on the same standard laptop, where one iteration of CP-full takes around six seconds, one iteration of CP-fast takes around one second, and one iteration of Mechlem2018 [21] about four seconds. These times are comparable to Niu2014 [17], which takes around 5 to 8 s when using 500 and 1000 CG iterations. Figure 5 shows the evolution of the relative -reconstruction error for various one-step methods. Note that for CP-fast, the minimum error in Iodine and Gadolinium is reached at approximately the same number of iterations, which shows efficient preconditioning and is important in application. Furthermore, we do not enforce that the sum over the three density images is one, and in the example, it indeed does not hold. The proposed algorithms turned out to be more stable than Mechlem2018 [21] and produce better results. In particular, CP-full gives the best results, while CP-fast is fastest.
5. Conclusions and Outlook
Image reconstruction in MSCT requires the solution of a nonlinear ill-posed problem. Iterative one-step methods are known to be accurate for this purpose. In this work, we propose two generic algorithms named CP-full (channel-preconditioned full gradient iteration) and CP-fast (channel-preconditioned fast iteration). Both algorithms use preconditioning in the channel dimen•sion only, which considerably accelerates the updates compared to Newton-type methods that require solving numerically costly linear inverse problems at each iteration. CP-fast replaces the derivative in the channel nonlinearity with linearization at zero, making it even more efficient. Both algorithms turn out to be fast and robust.
There are several future directions emerging from our work. First, proving the convergence of the two algorithms and demonstrating their regularization properties is important. Second, we will combine them with more realistic noise priors, such as Poisson noise, resulting in the maximum likelihood estimation (MLE) functional. Additionally, we will integrate explicit image priors, use plug-and-play strategies, and incorporate learned components.
Author Contributions
Conceptualization, M.H. and L.N.; methodology, M.H., L.N. and T.P.; software, T.P. and L.N; formal analysis, M.H. and L.N.; writing—original draft preparation, M.H., L.N. and T.P.; writing—review and editing, M.H., L.N. and T.P.; visualization, T.P.; supervision, M.H. and L.N. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Proof of Theorem 1
Proof.
By (4) and (10), we have:
This is (11). Now, using the (7), (9), (10) we have:
This is (12). Next, we turn over to the computation of the adjoints. We will only demonstrate this for (14), as (13) is verified in a similar manner. By elementary manipulations:
which is (14). Finally, with and (14), we obtain (15). □
References
- McDavid, W.D.; Waggener, R.G.; Payne, W.H.; Dennis, M.J. Spectral effects on three-dimensional reconstruction from X rays. Med. Phys. 1975, 2, 321–324. [Google Scholar] [CrossRef]
- Kiss, M.B.; Bossema, F.G.; van Laar, P.J.; Meijer, S.; Lucka, F.; van Leeuwen, T.; Batenburg, K.J. Beam filtration for object-tailored X-ray CT of multi-material cultural heritage objects. Herit. Sci. 2023, 11, 130. [Google Scholar] [CrossRef]
- Pan, X.; Siewerdsen, J.; La Riviere, P.J.; Kalender, W.A. Anniversary Paper: Development of X-ray computed tomography: The role of Medical Physics and AAPM from the 1970s to present. Med. Phys. 2008, 35, 3728–3739. [Google Scholar] [CrossRef] [PubMed]
- Herman, G.T. Correction for beam hardening in computed tomography. Phys. Med. Biol. 1979, 24, 81. [Google Scholar] [CrossRef]
- Van Gompel, G.; Van Slambrouck, K.; Defrise, M.; Batenburg, K.J.; De Mey, J.; Sijbers, J.; Nuyts, J. Iterative correction of beam hardening artifacts in CT. Med. Phys. 2011, 38, S36–S49. [Google Scholar] [CrossRef] [PubMed]
- Rigaud, G. On analytical solutions to beam-hardening. Sens. Imaging 2017, 18, 5. [Google Scholar] [CrossRef]
- Kazantsev, D.; Jørgensen, J.S.; Andersen, M.S.; Lionheart, W.R.; Lee, P.D.; Withers, P.J. Joint image reconstruction method with correlative multi-channel prior for X-ray spectral computed tomography. Inverse Probl. 2018, 34, 064001. [Google Scholar] [CrossRef]
- Rigie, D.S.; La Riviere, P.J. Joint reconstruction of multi-channel, spectral CT data via constrained total nuclear variation minimization. Phys. Med. Biol. 2015, 60, 1741. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Nagy, J.G.; Zhang, J.; Andersen, M.S. Nonlinear optimization for mixed attenuation polyenergetic image reconstruction. Inverse Probl. 2019, 35, 064004. [Google Scholar] [CrossRef]
- Arridge, S.R.; Ehrhardt, M.J.; Thielemans, K. (An overview of) Synergistic reconstruction for multimodality/multichannel imaging methods. Philos. Trans. R. Soc. A 2021, 379, 20200205. [Google Scholar] [CrossRef]
- Mory, C.; Sixou, B.; Si-Mohamed, S.; Boussel, L.; Rit, S. Comparison of five one-step reconstruction algorithms for spectral CT. Phys. Med. Biol. 2018, 63, 235001. [Google Scholar] [CrossRef] [PubMed]
- Heismann, B.; Balda, M. Quantitative image-based spectral reconstruction for computed tomography. Med. Phys. 2009, 36, 4471–4485. [Google Scholar] [CrossRef] [PubMed]
- Maaß, C.; Baer, M.; Kachelrieß, M. Image-based dual energy CT using optimized precorrection functions: A practical new approach of material decomposition in image domain. Med. Phys. 2009, 36, 3818–3829. [Google Scholar] [CrossRef]
- Willemink, M.J.; Persson, M.; Pourmorteza, A.; Pelc, N.J.; Fleischmann, D. Photon-counting CT: Technical principles and clinical prospects. Radiology 2018, 289, 293–312. [Google Scholar] [CrossRef] [PubMed]
- Kreisler, B. Photon counting Detectors: Concept, technical Challenges, and clinical outlook. Eur. J. Radiol. 2022, 149, 110229. [Google Scholar] [CrossRef] [PubMed]
- Schmidt, T.G. Optimal “image-based” weighting for energy-resolved CT. Med. Phys. 2009, 36, 3018–3027. [Google Scholar] [CrossRef]
- Niu, T.; Dong, X.; Petrongolo, M.; Zhu, L. Iterative image-domain decomposition for dual-energy CT. Med. Phys. 2014, 41, 041901. [Google Scholar] [CrossRef] [PubMed]
- Schirra, C.O.; Roessl, E.; Koehler, T.; Brendel, B.; Thran, A.; Pan, D.; Anastasio, M.A.; Proksa, R. Statistical reconstruction of material decomposed data in spectral CT. IEEE Trans. Med. Imaging 2013, 32, 1249–1257. [Google Scholar] [CrossRef]
- Cai, C.; Rodet, T.; Legoupil, S.; Mohammad-Djafari, A. A full-spectral Bayesian reconstruction approach based on the material decomposition model applied in dual-energy computed tomography. Med. Phys. 2013, 40, 111916. [Google Scholar] [CrossRef]
- Long, Y.; Fessler, J.A. Multi-material decomposition using statistical image reconstruction for spectral CT. IEEE Trans. Med. Imaging 2014, 33, 1614–1626. [Google Scholar] [CrossRef]
- Mechlem, K.; Ehn, S.; Sellerer, T.; Braig, E.; Münzel, D.; Pfeiffer, F.; Noël, P.B. Joint statistical iterative material image reconstruction for spectral computed tomography using a semi-empirical forward model. IEEE Trans. Med. Imaging 2017, 37, 68–80. [Google Scholar] [CrossRef]
- Weidinger, T.; Buzug, T.M.; Flohr, T.; Kappler, S.; Stierstorfer, K. Polychromatic iterative statistical material image reconstruction for photon-counting computed tomography. Int. J. Biomed. Imaging 2016, 2016, 5871604. [Google Scholar] [CrossRef]
- Barber, R.F.; Sidky, E.Y.; Schmidt, T.G.; Pan, X. An algorithm for constrained one-step inversion of spectral CT data. Phys. Med. Biol. 2016, 61, 3784. [Google Scholar]
- Chen, B.; Zhang, Z.; Xia, D.; Sidky, E.Y.; Pan, X. Non-convex primal-dual algorithm for image reconstruction in spectral CT. Comput. Med. Imaging Graph. 2021, 87, 101821. [Google Scholar] [CrossRef]
- Scherzer, O.; Grasmair, M.; Grossauer, H.; Haltmeier, M.; Lenzen, F. Variational Methods in Imaging; Springer: New York, NY, USA, 2009; Volume 167. [Google Scholar]
- Benning, M.; Burger, M. Modern regularization methods for inverse problems. Acta Numer. 2018, 27, 1–111. [Google Scholar] [CrossRef]
- Ebner, A.; Haltmeier, M. Plug-and-Play image reconstruction is a convergent regularization method. arXiv 2022, arXiv:2212.06881. [Google Scholar] [CrossRef]
- Kaltenbacher, B.; Neubauer, A.; Scherzer, O. Iterative Regularization Methods for Nonlinear Ill-Posed Problems; Walter de Gruyter: Berlin, Germany, 2008. [Google Scholar]
- Fessler, J.A. Method for Statistically Reconstructing Images from a Plurality of Transmission Measurements Having Energy Diversity and Image Reconstructor Apparatus Utilizing the Method. U.S. Patent 6,754,298, 22 June 2004. [Google Scholar]
- Du, K.; Ruan, C.C.; Sun, X.H. On the convergence of a randomized block coordinate descent algorithm for a matrix least squares problem. Appl. Math. Lett. 2022, 124, 107689. [Google Scholar] [CrossRef]
- Rabanser, S.; Neumann, L.; Haltmeier, M. Analysis of the block coordinate descent method for linear ill-posed problems. SIAM J. Imaging Sci. 2019, 12, 1808–1832. [Google Scholar] [CrossRef]
- Hanke, M.; Neubauer, A.; Scherzer, O. A convergence analysis of the Landweber iteration for nonlinear ill-posed problems. Numer. Math. 1995, 72, 21–37. [Google Scholar] [CrossRef]
- Hanke, M. A regularizing Levenberg–Marquardt scheme, with applications to inverse groundwater filtration problems. Inverse Probl. 1997, 13, 79. [Google Scholar] [CrossRef]
- Rieder, A. On the regularization of nonlinear ill-posed problems via inexact Newton iterations. Inverse Probl. 1999, 15, 309. [Google Scholar] [CrossRef]
- Chambolle, A.; Pock, T. A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 2011, 40, 120–145. [Google Scholar] [CrossRef]
- Bousse, A.; Kandarpa, V.S.S.; Rit, S.; Perelli, A.; Li, M.; Wang, G.; Zhou, J.; Wang, G. Systematic Review on Learning-based Spectral CT. arXiv 2023, arXiv:2304.07588. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Flowchart of the structure of the algorithms proposed in this work. Specifically, we introduce CP-full and CP-fast, which differ in the specific form of the update (see Section 3.3). Details on the recalibration step are given in Remark 1.
Figure 1.
Flowchart of the structure of the algorithms proposed in this work. Specifically, we introduce CP-full and CP-fast, which differ in the specific form of the update (see Section 3.3). Details on the recalibration step are given in Remark 1.

Figure 2.
Illustration of the forward model in MSCT for materials, energy bins, and using values for energy discretization. First, the Radon transform is applied separately to each of the given material densities , , and , resulting in three material sinograms, which can be seen as a three-channel sinogram. Next, the matrix is applied to each pixel, resulting in 150 energy sinograms. To each of these sinograms, is applied pointwise, resulting in 150 virtual energy data maps. By applying the matrix pixel by pixel, one obtains the final data consisting of data maps. The continuous forward model can be visualized in a similar way by replacing the material images with continuous counterparts and the 150 energy channels with a function-valued channel.
Figure 2.
Illustration of the forward model in MSCT for materials, energy bins, and using values for energy discretization. First, the Radon transform is applied separately to each of the given material densities , , and , resulting in three material sinograms, which can be seen as a three-channel sinogram. Next, the matrix is applied to each pixel, resulting in 150 energy sinograms. To each of these sinograms, is applied pointwise, resulting in 150 virtual energy data maps. By applying the matrix pixel by pixel, one obtains the final data consisting of data maps. The continuous forward model can be visualized in a similar way by replacing the material images with continuous counterparts and the 150 energy channels with a function-valued channel.

Figure 3.
Physical parameters determining the forward model. (Top left): Attenuation functions. (Top right): Incident spectrum. (Bottom left): Spectral response of the detectors. (Bottom right): Effective spectra. The figures are based on code (modified) and data from [11].
Figure 3.
Physical parameters determining the forward model. (Top left): Attenuation functions. (Top right): Incident spectrum. (Bottom left): Spectral response of the detectors. (Bottom right): Effective spectra. The figures are based on code (modified) and data from [11].

Figure 4.
Ground truth phantom (top row) and reconstructions using CP-fast (second row), CP-full (third row), Mechlem2018 [21] (fourth row), and the two-step algorithm Niu2014 [17] (bottom).

Figure 5.
Relative reconstruction error using the proposed CP-fast (top), proposed CP-full (middle), and Mechlem2018 [21] (bottom) as a function of the iteration index.
Figure 5.
Relative reconstruction error using the proposed CP-fast (top), proposed CP-full (middle), and Mechlem2018 [21] (bottom) as a function of the iteration index.

Figure 6.
Reconstructed slices of the second phantom: Ground truth phantom (top row) and reconstructions using CP-fast (second row), CP-full (third row), Mechlem2018 [21] (fourth row), and the two-step algorithm by Niu2014 [17] (bottom row).

Figure 7.
Concentration of iodine (left), gadolinium (middle), and water (right) for the phantom shown in Figure 6 during the iteration.
Figure 7.
Concentration of iodine (left), gadolinium (middle), and water (right) for the phantom shown in Figure 6 during the iteration.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Prohaszka, T.; Neumann, L.; Haltmeier, M. Derivative-Free Iterative One-Step Reconstruction for Multispectral CT. J. Imaging 2024, 10, 98. https://doi.org/10.3390/jimaging10050098
AMA Style
Prohaszka T, Neumann L, Haltmeier M. Derivative-Free Iterative One-Step Reconstruction for Multispectral CT. Journal of Imaging. 2024; 10(5):98. https://doi.org/10.3390/jimaging10050098
Chicago/Turabian StyleProhaszka, Thomas, Lukas Neumann, and Markus Haltmeier. 2024. "Derivative-Free Iterative One-Step Reconstruction for Multispectral CT" Journal of Imaging 10, no. 5: 98. https://doi.org/10.3390/jimaging10050098
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.