Slant Removal Technique for Historical Document Images

1
Department Information and Communication Systems Engineering, University of the Aegean, Samos 83200, Greece
2
Institut Mines-Télécom/Télécom ParisTech, Université Paris-Saclay, 75013 Paris, France
*
Author to whom correspondence should be addressed.
J. Imaging 2018, 4(6), 80; https://doi.org/10.3390/jimaging4060080
Submission received: 14 May 2018
/
Revised: 1 June 2018
/
Accepted: 5 June 2018
/
Published: 12 June 2018
(This article belongs to the Special Issue Document Image Processing)
Abstract
:Slanted text has been demonstrated to be a salient feature of handwriting. Its estimation is a necessary preprocessing task in many document image processing systems in order to improve the required training. This paper describes and evaluates a new technique for removing the slant from historical document pages that avoids the segmentation procedure into text lines and words. The proposed technique first relies on slant angle detection from an accurate selection of fragments. Then, a slant removal technique is applied. However, the presented slant removal technique may be combined with any other slant detection algorithm. Experimental results are provided for four document image databases: two historical document databases, the TrigraphSlant database (the only database dedicated to slant removal), and a printed database in order to check the precision of the proposed technique.
1. Introduction
In handwriting, slant removal is a necessary component of the text normalization procedure in systems that perform recognition (e.g., optical character recognition (OCR) [1] or word-spotting [2]), in order to improve the training procedure (less samples, lower computational cost). Moreover, writer identification/verification systems also use slant estimation and/or detection [3]. After ideal slant removal processing, the text should appear with the vertical stokes parallel to the perpendicular axis of the page. Due to its importance, many researchers have already developed techniques for slant removal [4,5,6,7,8,9,10,11,12,13,14,15,16,17].
The available techniques may be divided into three categories:
Considering the application these techniques can handle, they can be further classified into:
Recently, Brink et al. [3] categorized the proposed techniques by angle-frequency and repeated-shearing approaches that are described as follows:
- Angle-frequency approach: Down-strokes are first located based on such criteria as the minimum vertical extent or velocity. Next, the angle of the local ink direction is measured at these locations and the resulting angles are agglomerated in a histogram. From this histogram, the slant angle is determined. This is a one-step procedure.
- Repeated-shearing approach: This method is based on the assumption that the projection of dark pixels is maximized along an axis parallel to the slant angle. The basic principle is to repeatedly shear images of individual text lines, varying the shear angle, and optimizing the vertical projection of dark pixels. This approach is clearly more time consuming, but proves more accurate, as indicated by its popularity.
The first category will be referred to here as ‘slant estimation’ (one-step procedure), and the second category is referred to as slant detection, since this method searches among many, for the most common angle. Slant estimation techniques are presented in [4,5,6,7], whereas a slant detection technique is presented in [9]. According to Brink et al. [3], the slant detection techniques are the most popular with the most precise results. The technique described in [9] is also used in that paper where extensive experiments over slant are performed. Last but not least, in the specific experiments, the pages were sheared entirely, since the alternative line or word segmentation is characterized as “less reliable and breaks ink traces at region boundaries” [3]. The proposed techniques up to now require line or word segmentation in order to be applied. In Figure 1, an example of the slant removal algorithm described in [9], is presented. The image is from the IAM Handwriting Database (IAM-DB), and the application of the algorithm requires image segmentation into text lines (Figure 1, horizontal stripes). For this example, text line segmentation could succeed since text lines are spaced enough. It is not the case for the document image shown in Figure 2 (17th century) which includes touching ascenders and descenders and noise in the inter-line space. Since all existing algorithms perform slant removal on word or text line level, a segmentation-free approach is desirable for difficult to segment documents. Moreover, avoiding the text-line segmentation processing is computationally less expensive.
A preliminary approach has been described in [17], while in this paper the parameter set up is considered and described in detail. Moreover, the approach is extensively evaluated on new databases. The proposed technique is appropriate for slant detection and removal from document images with homogenous slant. It does not require page segmentation into text lines or words. This makes the proposed technique appropriate for historical documents, especially formal ones, since they ensure a uniform slant over the entire page. Moreover, the segmentation into text lines would create more noise. Usually, formal historical documents are written by well-educated people with a standard writing style and fixed slant. On the other hand, the proposed methodology is inappropriate for document images containing unconstrained writing and several slant angles. Methodologies, such as the one described in [6], are more appropriate in such cases. Thus, experiments are performed on several databases:
- the TrigraphSlant database [18] (the only available database for slant estimation),
- a synthetic printed database where slants are fully determined.
The contribution of the current work consists of:
- To the best of our knowledge, this is the first time that a slant removal technique is proposed, able to be applied to the entire page, without requiring text line or word segmentation.
- It does not generate extra noise, due to line and/or word segmentation that would remain in the page after slant removal, which is accomplished by shifting the entire page uniformly and ensuring text homogeneity. Most of the existed techniques apply to ideal databases, like IAM-DB (Figure 1) that is appropriately made for line and word segmentation. In the case of historical documents (Figure 2), the final result would be full of dots and strokes because of the segmentation.
- Instructions are given over the best application to document page, after detailed results.
In Section 2.1, a short description of the elaborated slant detection algorithm [9] is presented. The proposed technique is described in detail in Section 2.2, where the parameters that are examined in detail are analyzed. The experimental results are presented and analyzed in Section 3 while the conclusions are discussed in Section 4.
2. Materials and Methods
2.1. Slant Detection Algorithm
As already mentioned, in the proposed technique, the slant detection algorithm that is presented in detail in [9] is used. The reason is that an algorithm for the detection is needed and this one has proved to be popular and successful [3].
This specific algorithm makes use of the difference between the ascenders and descenders. In case the text is vertical, the difference is larger (Figure 3). To detect that, it uses the Wigner Ville distribution (WVD) [21], a space-frequency distribution of Cohen’s class, which is given by the formula
where s the signal, f the frequency, z(s) represents the analytical signal associated with the discrete signal h(s), that in the paper [9] is the vertical projection profile of the word.
In more detail, the detection algorithm [9] consists of the steps:
- The word image is artificially slanted to both, left and right, under different slant detection angles. The maximum slant angle is approximately 45 degrees and the slant angle step depends on the height of the text image.
- For each of the extracted word images, the vertical projection profile is calculated.
- The WVD is calculated for all the above projected profiles.
- The curves of maximum intensity of the WVDs are extracted, just by keeping the maximum value of each curve of the space-frequency distribution, for the specific slant.
- The curve of maximum intensity with the greatest peak, corresponding to the projected profile with the most intense alternations is selected.
- The corresponding word image is selected as the most non-slanted word.
The above procedure is repeated twice, once for a big step size of 10 degrees (BigStep) where the area around an ANGLE1 is selected closer to the slant and the second time for a smaller step size of 1 degree, where a more detailed detection is performed and a more exact area ANGLE2 is detected.
This way, the computational cost is reduced, since the first detection is performed between fewer possible angles in order to localize roughly the area ANGLE1, before a more accurate detection (ANGLE2) is performed in this specific area for a step size of one degree. A slant of less than one degree is not considered important enough to be examined. Finally, the detected angle (Detected_Slant) is given by
2.2. Proposed Slant Removal Technique
The proposed technique is based on the slant detection algorithm presented in Section 2.1, but in our case, it is applied to text fragments instead of words (Figure 4). It is based on the fact that in historical documents there is a uniform slant that extends throughout the entire document image. Since no segmentation is performed, fragments of text are used instead of words.
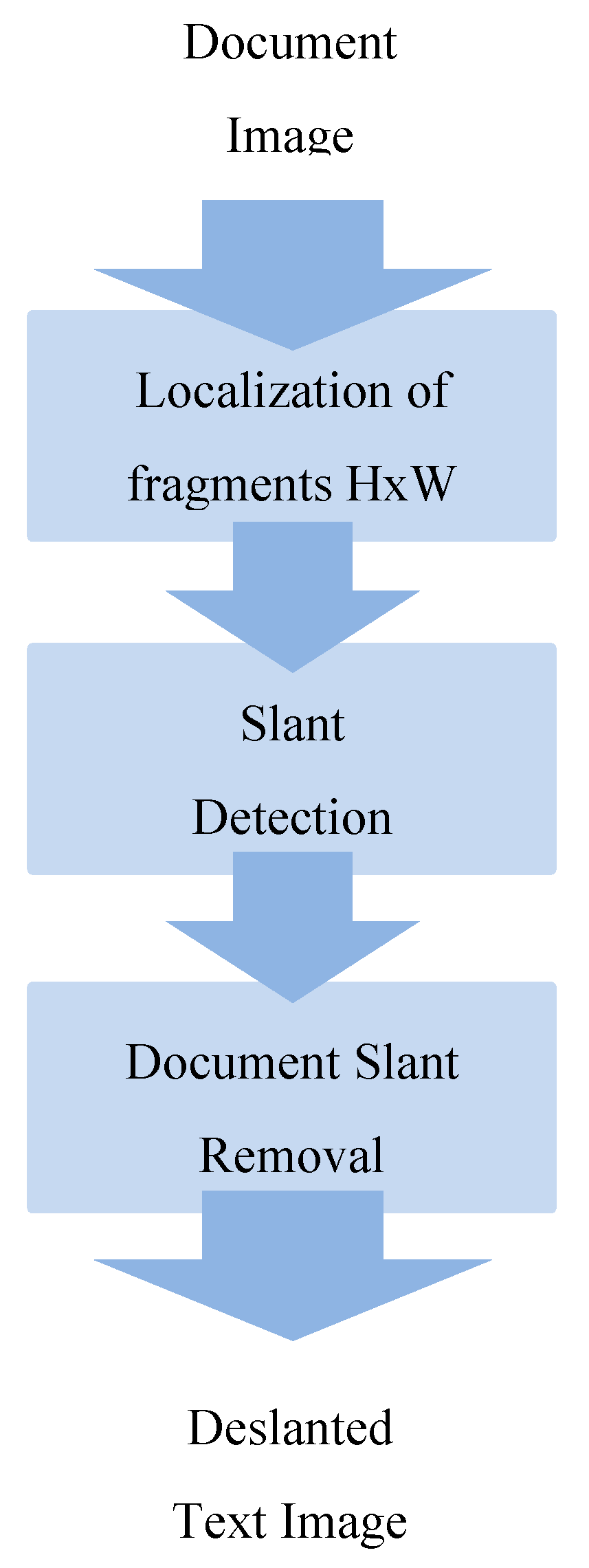
As previously mentioned, in the past, educated persons took special care when writing, resulting in a high degree of stability in the slant of their writing style. Thus, in order to detect the slant of the text in a historical document page, a few fragments of text are considered. Although one sample could theoretically be enough, several ones are in practice necessary to ensure coverage of pages with sparse text or special formatting, such as columns, arrays, etc. To localize appropriate fragments the following way is followed: a page is scanned from left to right, top to bottom using a window of size HxW (heightXwidth), starting from the pixel position (skip, skip) in order to skip scanning or other noise. Skip can be general e.g., 1/5 of document width (here), or be determined depending on the collection. All black pixels (black_pixels) inside the window are counted. The area inside the window is retained if Condition (3) is true and the scanning stops when the required number M of fragments is localized.
The Condition (3) requires the text in the window to take up more than R = 0.10 of the area. The size of the window in these experiments, HxW, was selected as H = 2 mb and W = 7 mb, where mb is the main character body size in the page (height of the character body excluding ascenders and descenders). In the current paper, the following metrics and parameters are set up:
- The text ratio R in the window;
- The amount M of the fragments in use;
- The height H of the window;
- The width W of the window.
However, the same techniques are considered for:
- The main body height detection [22], since it does not require line or word segmentation;
- The slant detection procedure. Once the M fragments have been selected (Figure 5), the slant detection algorithm [9], described in Section 2, is applied and the slant angles are detected, one per fragment. The maximum and minimum slant angles are ignored as possible outliers, while slant is defined as the detected slant of the page. The entire document page is then corrected according to the slant angle by shifting each pixel so thatwhere (x0, y0) defines the initial position of the pixel and (xf, yf) is the final pixel position.
3. Results
Since there is no previous similar work to compare with, a trial is made to perform an absolute evaluation in various ways. Thus, in order to perform our experiments and evaluate the parameters, four databases were used:
- The TrigraphSlant database (DB) [18], in order to perform tests on a renowned DB for slant. However, in this DB each writer was asked to write two pages of his natural slant and two of force slants. Only the natural slant documents were used here (see Experimental Results).
- The George Washington DB [19], in order to perform tests on a renowned DB of historical documents.
- The BH2M: the Barcelona Historical Handwritten Marriages database [20], in order to perform tests on a second DB of historical documents.
- The Print DB: printed documents with artificial slant, in order to check the accuracy of the technique. Moreover, since all the rest do not guarantee the existence of all the possible slants, special care was taken to include all possible slants, including 0 (no slant).
A validation set and a test set were created. The validation set consists of 20 document images from the TrigraphSlant DB, 4 from the Washington DB, 4 from the BH2M DB, and 80 from the Print DB. The test set consists of 60 document images from the TrigraphSlant DB, 16 from the Washington DB, 16 from the BH2M DB, and 298 from the Print DB.
The measure used to evaluate the technique is the root-mean-square error (RMSE)
where Slantgr is the ground truth slant of document d and Slantes the slant estimated using the technique. This measure gives a comparative result that is independent of the right or left slant direction. N refers to the amount of documents. Next, a short description of the databases is given, while the setup on the parameters follows. As initial parameter values, the parameters used in [17] are used in our experiments, and as soon as the best parameter value is estimated, it is used further on. Finally, experimental results for the four databases are presented (see Section 3.9).
3.1. TrigraphSlant DB
The TrigraphSlant [18] database contains images of handwriting produced under normal and forced slant conditions. It includes 190 handwritten document images, written by 47 people. For each image, the slant has been estimated by two researchers (Axel and Rolland) from the average slant computed from 10 measurements on each document image. In Figure 6, an example of the TrigraphSlant database after the application of the proposed technique is shown.
3.2. George Washington DB
This archive contains a set of 20 page images from the George Washington collection [19] at the Library of Congress in the United States. A process similar to that used for the TrigraphSlant database was followed. Ten slants were measured by two humans on each page and the mean of these measurements was considered to be the page slant. Figure 7 shows an example of the George Washington DB after the application of the technique.
3.3. BH2M DB
The BH2M database [20] has been created under the EU ERC project Five Centuries of Marriages (5CofM). It includes the Archives of the Barcelona Cathedral: 244 books with information on approximately 550,000 marriages held between 1451 and 1905 in over 250 parishes. Each book was written by a different writer and contains information of the marriages during two years. Here pages for the 6th book are used. In Figure 8, an example of the BH2M DB is presented.
3.4. PrintDB
The PrintDB consists of five printed document images that are artificially slanted over a range from −45° to +45°, yielding a total of 455 slanted, printed document images. The exact slant is predetermined, making evaluation of the technique easier and more precise. The documents were made from parts of .pdf files to ensure precise slant values. The pages were selected to include different type of text types (including spare writing and single/double columns). All the text was slanted, keeping the original dimensions ((1/5) * A4_height * (1/2) * A4_width). Figure 9 shows an example of the PrintDB after the application of the technique.
3.5. Set-Up of the Text Ratio R Parameter
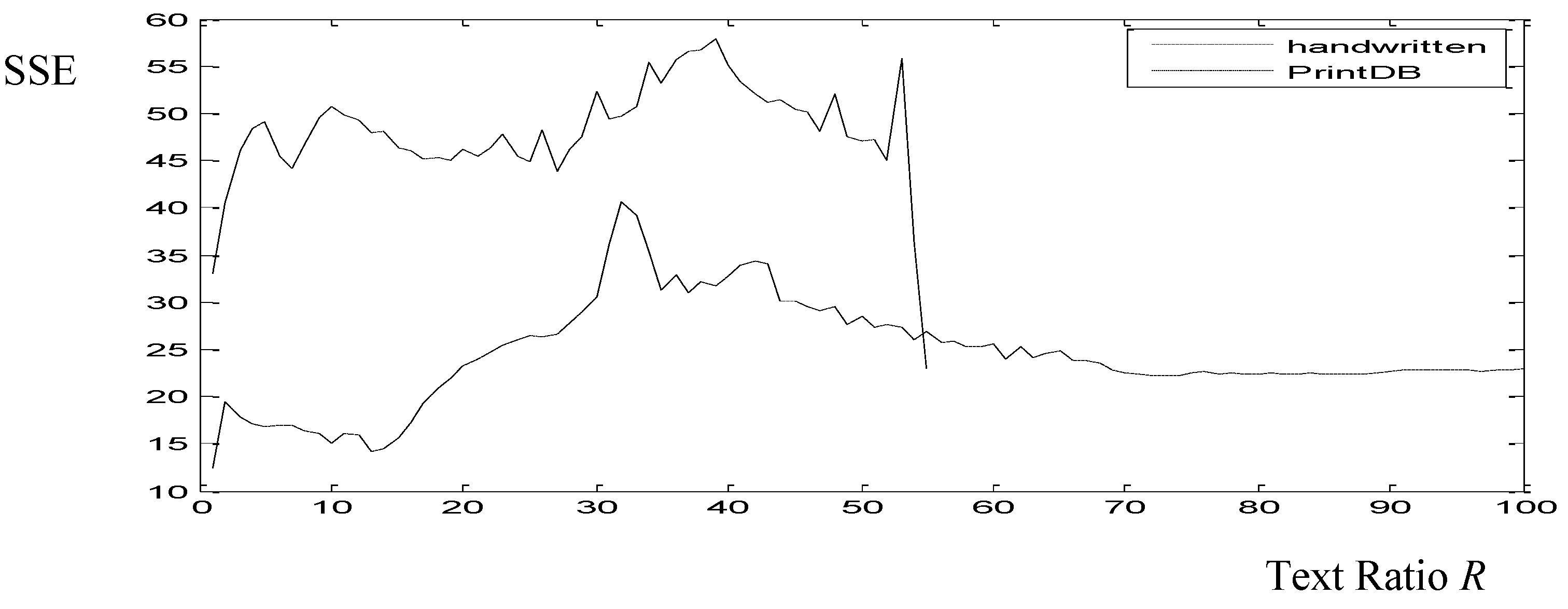
The amount of text in the window is very important in order to detect the slant angle. Little text includes very little information, while too much text would increase the computational cost. In [17], the rate of 10% was used as approved amount of text in the selected windows just by test and trial. Here, more detailed experiments are performed. The text ratio of each window is counted and compared to the slant detection error. The experiment was performed for every window on several images of the validation set: 5 document images from the TrigraphSlant DB, 1 from the Washington DB, 1 from the BH2M DB, and 20 from the Print DB. Since the handwritten images were of high resolution, the procedure was very time consuming and just few of them were used. On the other hand, the images of printed text were all used. In Figure 10, the curve of sum of slant square errors (SSE) with reference to the text ratio is presented for printed and handwritten text.
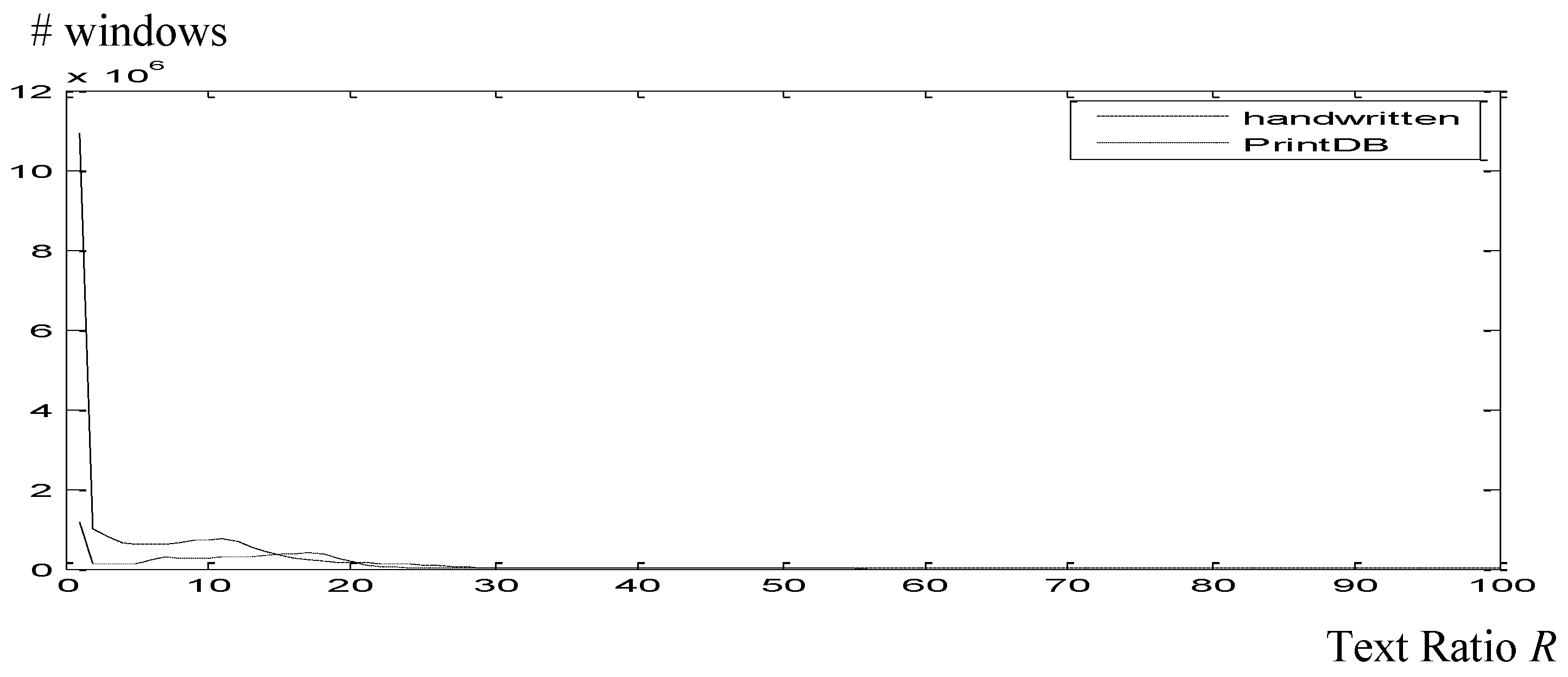
The main volume of windows, as it is shown in Figure 11, includes text up to 20%. Since the printed images with slant are an artificial database, the result derived from handwritten images were taken into account as a common R, that is 14% text in the image is the case of windows with minimum detection error. The majority of windows include text up to 20% (see Figure 11). Since the slanted printed images are an artificial database, the result derived from handwritten images were taken into account as a common R = 14% corresponding to the minimum detection error (see Figure 10).
3.6. Set-Up of the Height H of the Window
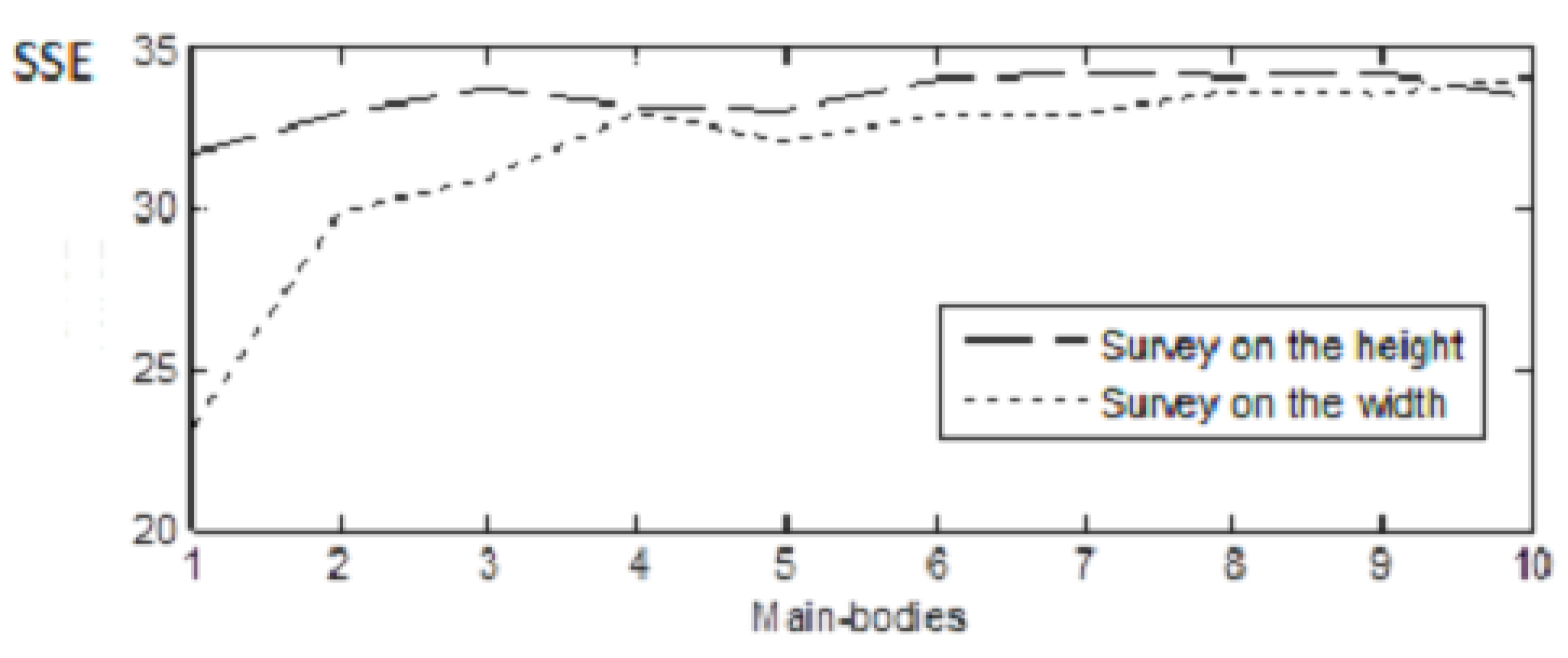
In order to estimate the best number for the window height, the whole validation set was used in our program with the ratio equal to 0.14, as derived by the previous experiment, for values of the height from 1 to 10 mb (main-bodies). The sum of square errors (SSE) was considered as evaluation measure. The results are shown in Figure 12. The SSE is higher than in Figure 10, as here, all the document images of the validation set were used, contrary to Figure 10 where just few of them were considered due to the computational cost of the corresponding experiment.
As it is obvious in Figure 12, the value of two main bodies seems to give the best results (smaller SSE) as (the 1: one main body) was considered extremely small in case of low resolution.
3.7. Set-Up of the Width W of the Window
In order to estimate the best number for the window width, the whole validation set was also used in our program with the ratio R = 0.14 and H = 2 mbs, for values of the width from 1 to 10 main-bodies. Sum of square errors (SSE) was considered as evaluation measure. The results are shown in Figure 12. The SSE is much higher than in Figure 10, as here, all the document images of the validation set were used, contrary to Figure 10 where just few of them were considered due to the computational cost of the corresponding experiment.
As it is obvious in Figure 12, the value of just five main-bodies seems to give significantly better results (smaller SSE) which is far smaller than seven, initially used in [17]. The values of 1 and 2 that give very low error proved very low in the case of low resolution, while more characters could confuse the system.
3.8. Set-Up of the Number M of Fragments to Use
In order to estimate the best number for the window width, the whole validation set was also used in our program with the ratio R = 0.14, H = 2 mbs, and W = 5 mbs, for values of the amount of the fragments M of 4 and 5. More fragments could be used, however it is a problem in the case of small images or images of low resolution. The sum of square errors (SSE) was considered as evaluation measure for the scenarios:
- Four fragments, mean of the fragments: SSE on the evaluation set 563
- Five fragments, mean of the fragments: SSE on the evaluation set 513
- Five fragments, median of the fragments: SSE on the evaluation set 509
Obviously, the median was finally selected as the best case.
3.9. Experimental Results on the Databases
Having specified the parameters above, several experiments were conducted for the four databases, on each test set. In order to demonstrate the flexibility of the proposed technique, two more slant detection techniques were also used for the slant detection part, using the parameters that were specified by the use of our technique [9]. The technique [23] detects the slant by using the main part of the text having removed the horizontal parts, ascenders, and descenders. The technique [24] estimates the slant by using the peaks of the slanted words.
The experimental results for all databases are given in Table 1 through RMSE. For the TrigraphSlantDB: the RMSE is given only for the normal slants (between −45 and +45 degrees) but for the both estimators (Axel & Rolland). In the TrigraphSlant, each writer was asked to force different slants in two of the four documents, these are not presented since the results were strange due to unnatural slant >45 degrees.
There were several significant differences in the RMSE values between the various DBs. Several reasons for this are:
- In the TrigraphSlant, the writing is modern and not as uniform as in the historical documents. When examined by human estimators, a standard deviation of 2.45 was observed.
- George Washington DB of historical documents is more uniform.
- BH2M presents more density which made our character main body size algorithm fail more times.
- PrintDB includes printed text that is artificially slanted, and therefore is uniform.
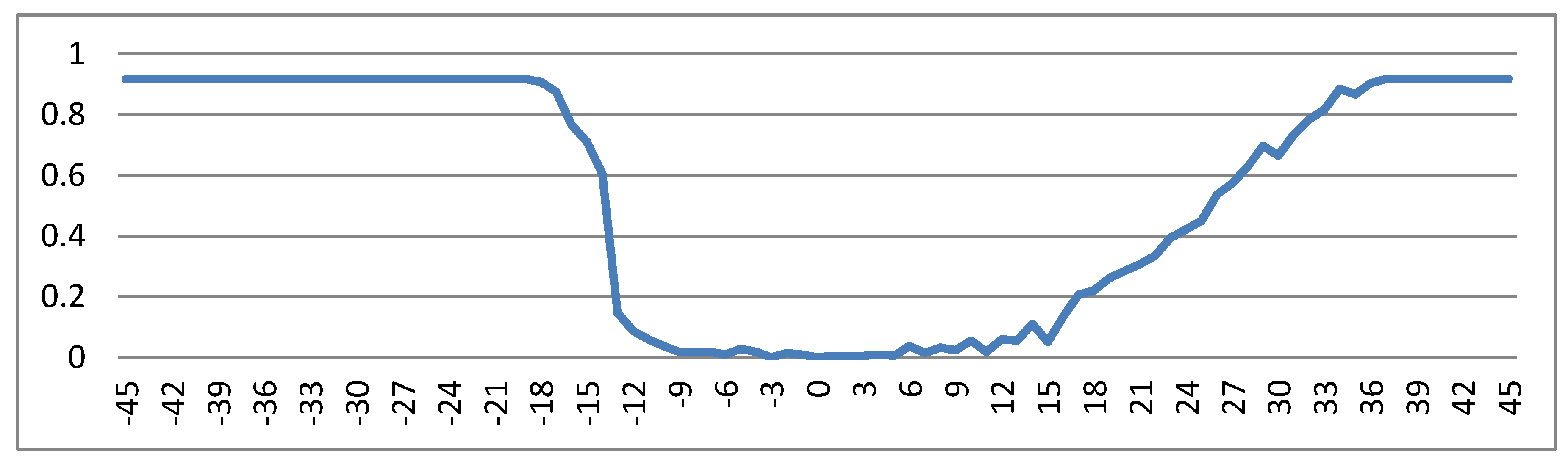
- We present in the following experiments in order to evaluate the improvement brought by our slant detection and removal technique on document analysis and recognition tasks. We thus conduct recognition experiments on printed documents with an OCR, and word spotting experiments on handwritten documents, before and after slant removal. The recognition results for the handwriting of our databases were a failure, due to having historical documents or/and languages other than English. For the PrintDB database, in Figure 13, the character error rate vs. the artificial slant are shown, as obtained by a commercial OCR system (Adobe Acrobat).
For a page slant of less than −19 or greater than 37 degrees, it is very difficult to find a correspondence between the characters of the image and the OCR result. The corrected version is very well handled (0 degrees, English). Moreover, the OCR software handles right-slanted characters better than left-slanted characters. This is likely due to extra training for italics in the commercial software.
The computational cost is less than 5 s for a historical document image of size a little bigger than A4 and resolution 600 dpi in a computer with processor Intel(R) Core(TM) i5-4210U CPU @ 1.70GHz 2.40 GHz.
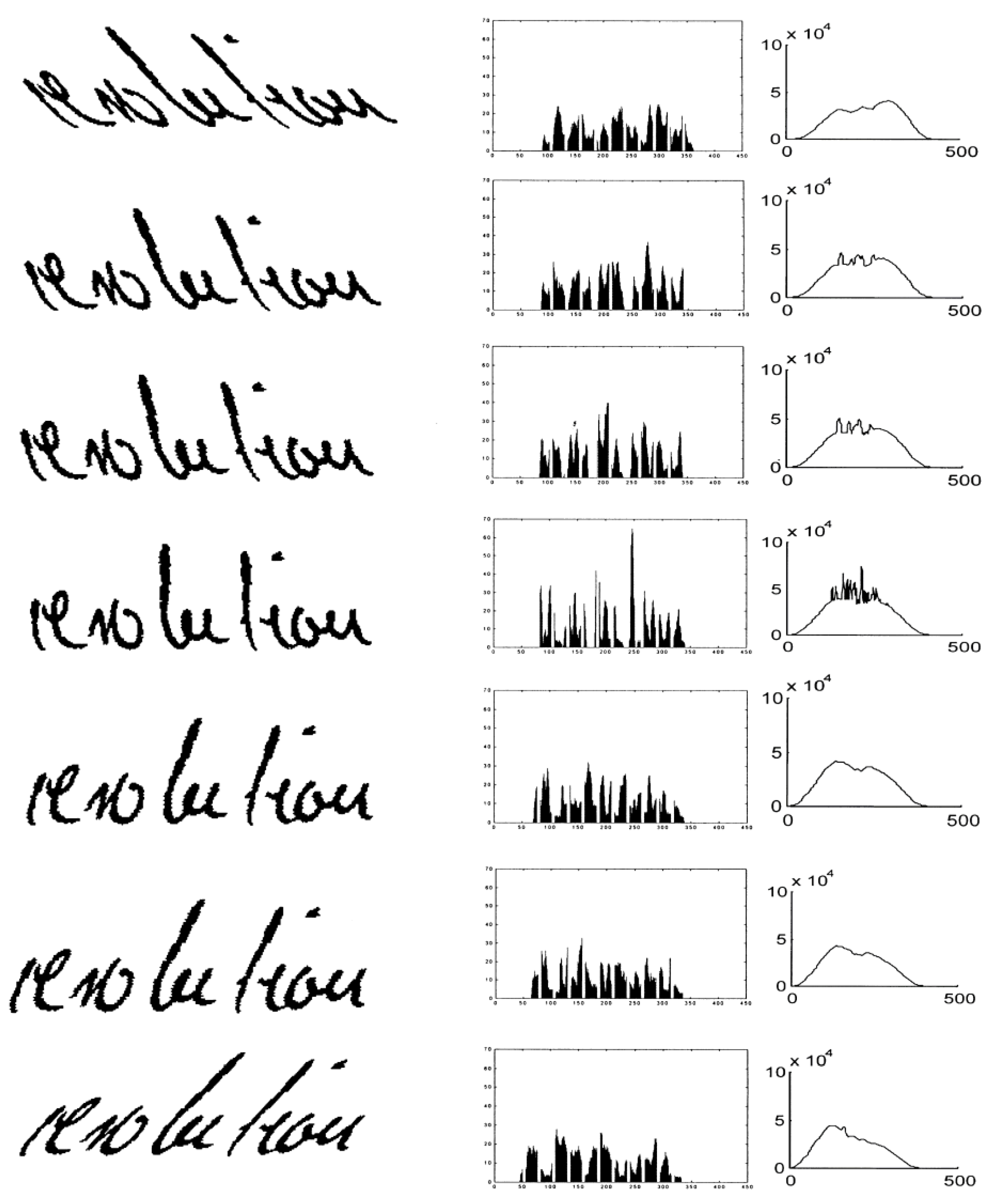
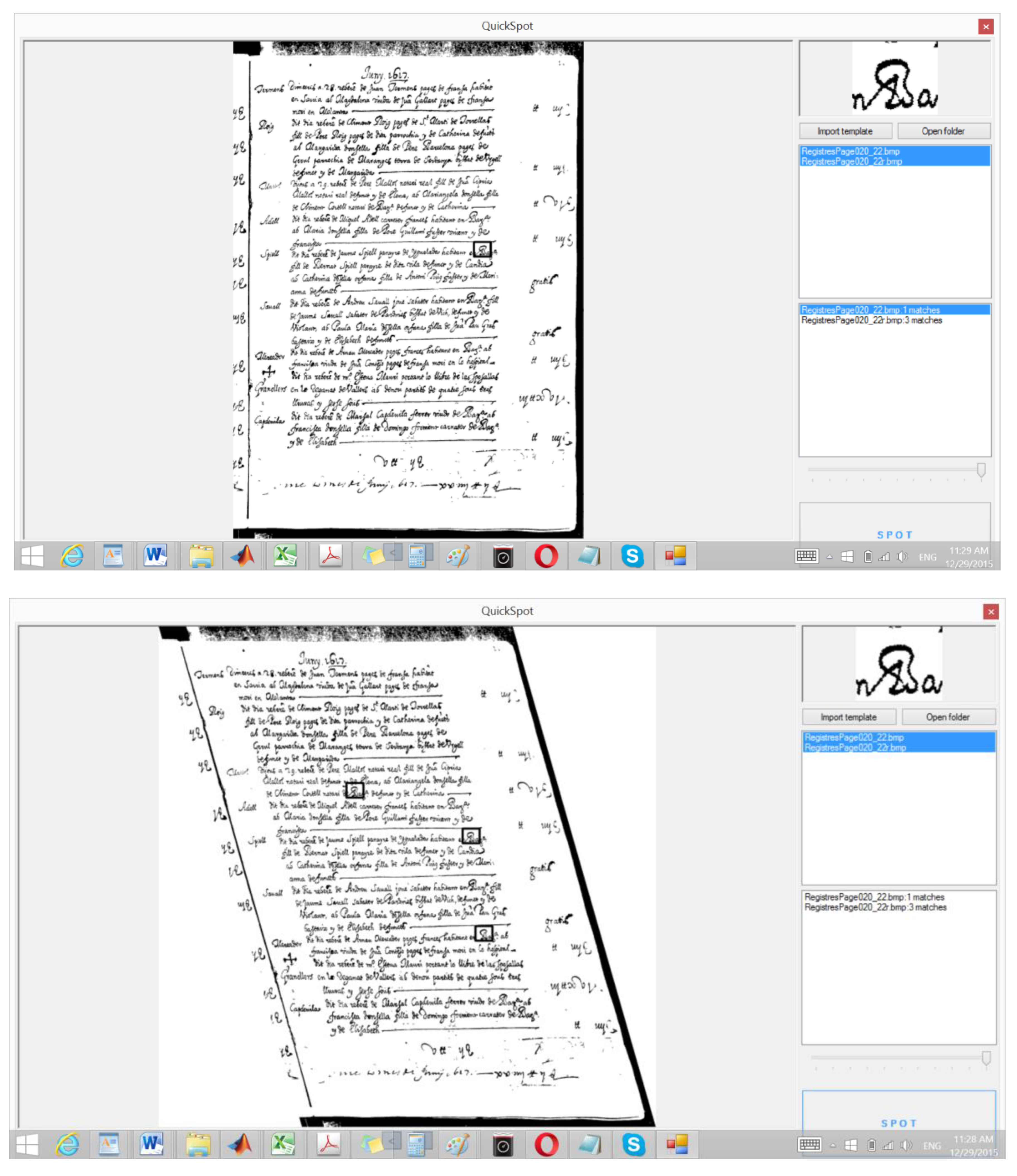
Since the proposed system was built in order to help our free-segmentation word-spotting system [25], we provide an example of word spotting task on handwritten documents. It is worth mentioning that an improvement of the recall of at least 20% is observed (Figure 14) for the 20 document images of George Washington DB and 100 queries. The improvement appears extremely high, which may be a result of the query being a part of the same page or collection. However, for slanted characters, the slant degree is not always fixed and in many cases, the slanted characters overlap with other characters.
4. Conclusions
In this paper, a technique was presented for slant estimation and removal for the entire document page, without requiring line or word segmentation. The proposed technique is recommended for historical document images that include homogenous slant throughout the page. This segmentation-free technique guarantees the minimization of extra noise that could be introduced since the segmentation procedure, in historical document images, where the text is very dense, would leave behind small strokes and other kind of noise (points, lines).
Experimental results were provided for four databases: PrintDB, which contains artificially slanted printed text to prove the accuracy of the technique; TrigraphSlant, a known DB of slant text; and the BH2M DB and the Washington DB to prove the application’s utility on historical documents. The results proved quite satisfactory with a RMSE of less than three for the PrintDB, less than four for the Washington DB, less than five for BH2M, and less than eight for the normal slanted documents of the TrigraphSlant. The improvement in our word-spotting system for difficult historical documents was impressive.
The technique fails if the character main body size detection is not correct. Thus, a good main body size detection algorithm is required. Moreover, the proposed technique is appropriate only if the slant is homogenous throughout the entire document image. However, more slant removal algorithms could be used in combination with the proposed technique. This is among our future plans.
Author Contributions
The mentioned authors, E.K., L.L.-S. and N.V. have contributed to all stages of the work.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Parvez, T.M.; Sabri, A.M. Arabic handwriting recognition using structural and syntactic pattern attributes. Pattern Recognit. 2013, 46, 141–154. [Google Scholar] [CrossRef]
- José, A.R.-S.; Perronnin, F. Handwritten word-spotting using hidden Markov models and universal vocabularies. Pattern Recognit. 2009, 42, 2106–2116. [Google Scholar]
- Brink, A.A.; Niels, R.M.J.; van Batenburg, R.A.; van den Heuvel, C.E.; Schomaker, L.R.B. Towards robust writer verification by correcting unnatural slant. Pattern Recognit. Lett. 2011, 32, 449–457. [Google Scholar] [CrossRef]
- Bozinovic, R.; Srihari, S. Off-line cursive script word recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 68–83. [Google Scholar] [CrossRef]
- Kim, G.; Govindaraju, V. A lexicon driven approach to handwritten word recognition for real-time applications. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 366–379. [Google Scholar] [Green Version]
- Shridar, M.; Kimura, F. Handwritten address interpretation using word recognition with and without lexicon. In Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, Vancouver, BC, Canada, 22–25 October 1995; Volume 3, pp. 2341–2346. [Google Scholar]
- Papandreou, A.; Gatos, B. Word slant estimation using non-horizontal character parts and core-region information. In Proceedings of the 10th IAPR International Workshop on Document Analysis Systems (DAS 2012), Gold Coast, QLD, Australia, 27–29 March 2012; pp. 307–311. [Google Scholar]
- Alessandro, V.; Luettin, J. A new normalization technique for cursive handwritten words. Pattern Recognit. Lett. 2001, 22, 1043–1050. [Google Scholar] [Green Version]
- Kavallieratou, E.; Fakotakis, N.; Kokkinakis, G. Slant estimation algorithm for OCR systems. Pattern Recognit. 2001, 34, 2515–2522. [Google Scholar] [CrossRef]
- Britto, A., Jr.; Sabourin, R.; Lethelier, E.; Bortolozzi, F.; Suen, C. Improvement handwritten numeral string recognition by slant normalization and contextual information. In Proceedings of the 7th International Workshop on Frontiers in Handwriting Recognition, Amsterdam, The Netherlands, 11–13 September 2000; pp. 323–332. [Google Scholar]
- Ding, Y.; Kimura, F.; Miyake, Y.; Shridhar, M. Accuracy improvement of slant estimation for handwritten words. In Proceedings of the International Conference on Pattern Recognition, Barcelona, Spain, 3–7 September 2000; Volume 4, pp. 527–530. [Google Scholar]
- Ding, Y.; Ohyama, W.; Kimura, F.; Shridhar, M. Local slant estimation for handwritten English words. In Proceedings of the 9th International Workshop on Frontiers in Handwriting Recognition (IWFHR), Kokubunji, Tokyo, Japan, 26–29 October 2004; pp. 328–333. [Google Scholar]
- Bertolami, R.; Uchida, S.; Zimmermann, M.; Bunke, H. Non-uniform slant correction for handwritten text line recognition. In Proceedings of the 9th International Conference on Document Analysis and Recognition, Parana, Brazil, 23–26 September 2007; pp. 18–22. [Google Scholar]
- Taira, E.; Uchida, S.; Sakoe, H. Non-uniform slant correction for handwritten word recognition. IEICE Trans. Inf. Syst. 2004, E87-D, 1247–1253. [Google Scholar]
- Seiichi, U.; Eiji, T.; Hiroaki, S. Non uniform slant correction using dynamic programming. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Seattle, WA, USA, 10–13 September 2001. [Google Scholar]
- Ziaratban, M.; Faez, K. Non-uniform slant estimation and correction for Farsi/Arabic handwritten words. Int. J. Doc. Anal. Recognit. (IJDAR) 2009, 12, 249–267. [Google Scholar] [CrossRef]
- Kavallieratou, E. A slant removal technique for document page. In Proceedings of the IS&T/SPIE Electronic Imaging, San Francisco, CA, USA, 3–6 February 2013. [Google Scholar]
- Available online:. Available online: http://www.unipen.org/trigraphslant.html (accessed on 14 May 2018).
- Lavrenko, V.; Rath, T.M.; Manmatha, R. Holistic word recognition for handwritten historical documents. In Proceedings of the International Workshop on Document Image Analysis for Libraries (DIAL), Palo Alto, CA, USA, 23–24 January 2004; pp. 278–287. [Google Scholar]
- Fernández-Mota, D.; Almazán, J.; Cirera, N.; Fornés, A.; Lladós, J. Bh2m: The barcelona historical, handwritten marriages database. In Proceedings of the 2014 22nd International Conference on Pattern Recognition (ICPR), Stockholm, Sweden, 24–28 August 2014; pp. 256–261. [Google Scholar]
- Claasen, T.A.; Mecklenbrauker, W.F. The Wigner distribution: A tool for time-frequency signal analysis. Phillips J. Res 1980, 35(Pts 1, 2 and 3), 217–250, 276–300, 372–389. [Google Scholar]
- Diamantatos, P.; Verras, V.; Kavallieratou, E. Detecting main body size in document images. In Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), Washington, DC, USA, 25–28 August 2013; pp. 1160–1164. [Google Scholar]
- Zeeuw, F. Slant Correction Using Histograms. Ph.D. Thesis, Artifical Intelligence, University of Groningen, Groningen, The Netherlands, 2006. [Google Scholar]
- Papandreou, A.; Gatos, B. Slant estimation and core-region detection for handwritten Latin words. Pattern Recognit. Lett. 2014, 35, 16–22. [Google Scholar]
- Vasilopoulos;N.;Kavallieratou, E. A classification-free word-spotting system. In Proceedings of the IS&T/SPIE Electronic Imaging. International Society for Optics and Photonics, San Francisco, CA, USA, 3–6 February 2013. [Google Scholar]
Figure 1.
An example of a slant removal application resulting from the detection algorithm described in [9]. Text-line segmentation is required prior to slant estimation.
Figure 1.
An example of a slant removal application resulting from the detection algorithm described in [9]. Text-line segmentation is required prior to slant estimation.

Figure 2.
A document from the Barcelona historical, handwritten marriages database (BH2M) [20].
Figure 2.
A document from the Barcelona historical, handwritten marriages database (BH2M) [20].

Figure 3.
From left to right: slanted words, corresponding histograms and maximum intensity curves of WVD (Wigner–Ville distribution).
Figure 3.
From left to right: slanted words, corresponding histograms and maximum intensity curves of WVD (Wigner–Ville distribution).

Figure 4.
The proposed slant removal technique applied to fragments of text corrects the entire page without segmentation.
Figure 4.
The proposed slant removal technique applied to fragments of text corrects the entire page without segmentation.

Figure 5.
Possible localization of appropriate fragments on the page. The required number of fragments is M = 5.
Figure 5.
Possible localization of appropriate fragments on the page. The required number of fragments is M = 5.

Figure 6.
Application of the technique on a sample from the TrigraphSlant database (left); corrected by +28 degrees (right).
Figure 6.
Application of the technique on a sample from the TrigraphSlant database (left); corrected by +28 degrees (right).

Figure 7.
Application of our slant removal technique on a sample from the George Washington DB (left); corrected by −42.5° (right).
Figure 7.
Application of our slant removal technique on a sample from the George Washington DB (left); corrected by −42.5° (right).

Figure 8.
Application of our slant removal technique on sample from BH2M DB (left); corrected by −17° (right).
Figure 8.
Application of our slant removal technique on sample from BH2M DB (left); corrected by −17° (right).

Figure 9.
Application of our slant removal technique on sample of PrintDB (left); corrected by 35° (right).
Figure 9.
Application of our slant removal technique on sample of PrintDB (left); corrected by 35° (right).

Figure 10.
Sum of square errors according to text ratio R for the printed db (dotted line) and the three handwritten databases (broken line).
Figure 10.
Sum of square errors according to text ratio R for the printed db (dotted line) and the three handwritten databases (broken line).

Figure 11.
Number of windows according to text ratio in the window. The large amount close to zero corresponds to almost empty windows (background).
Figure 11.
Number of windows according to text ratio in the window. The large amount close to zero corresponds to almost empty windows (background).

Figure 12.
Sum of square errors for various widths and heights of the detected windows. The best choice is five.
Figure 12.
Sum of square errors for various widths and heights of the detected windows. The best choice is five.

Figure 13.
Character error rate vs. the degree of page slant as performed by a commercial OCR system.
Figure 13.
Character error rate vs. the degree of page slant as performed by a commercial OCR system.

Figure 14.
Application of the word-spotting system [25], before (above) and after (below) slant correction.
Figure 14.
Application of the word-spotting system [25], before (above) and after (below) slant correction.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Kavallieratou, E.; Likforman-Sulem, L.; Vasilopoulos, N. Slant Removal Technique for Historical Document Images. J. Imaging 2018, 4, 80. https://doi.org/10.3390/jimaging4060080
AMA Style
Kavallieratou E, Likforman-Sulem L, Vasilopoulos N. Slant Removal Technique for Historical Document Images. Journal of Imaging. 2018; 4(6):80. https://doi.org/10.3390/jimaging4060080
Chicago/Turabian StyleKavallieratou, Ergina, Laurence Likforman-Sulem, and Nikos Vasilopoulos. 2018. "Slant Removal Technique for Historical Document Images" Journal of Imaging 4, no. 6: 80. https://doi.org/10.3390/jimaging4060080
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.