Interactive Hesitation Synthesis: Modelling and Evaluation



Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
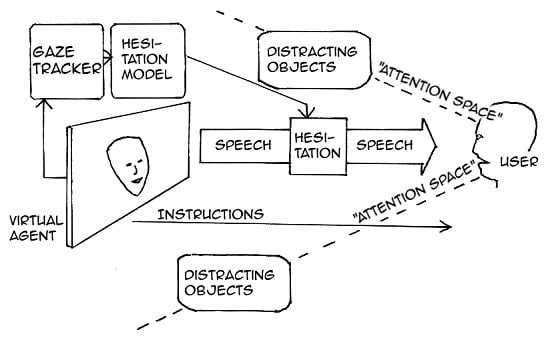
1. Introduction
1.1. Motivation and Aims of This Study
1.2. Scope of This Study
1.3. Structure of This Paper
2. Background and Related Work
2.1. Form and Function of Hesitations
2.2. Incremental Speech Production
- Anticipatory speech production errors. (e.g., “a cuff of coffee”) where parts of the utterance are produced in advance, or metathetically switched around, anticipating upcoming phonemes or syllables.
- Hesitation-lengthening form in English. (“Theee:” vs. “the”) The lengthened form has a different vowel quality (iː vs. ə), so the speaker must be aware of upcoming challenges in the speech plan (cf. [20]).
- Different types of fillers. (“uh” vs. “uhm”) The former appears to denote minor, the latter major problems in the speech plan, both requiring ahead planning [21].
- Hesitation occurrence probability. Hesitations are more likely to occur before longer utterances [22].
2.3. Dialogue Systems
3. Towards a Hesitation Synthesis Strategy for Incremental Spoken Dialogue Systems
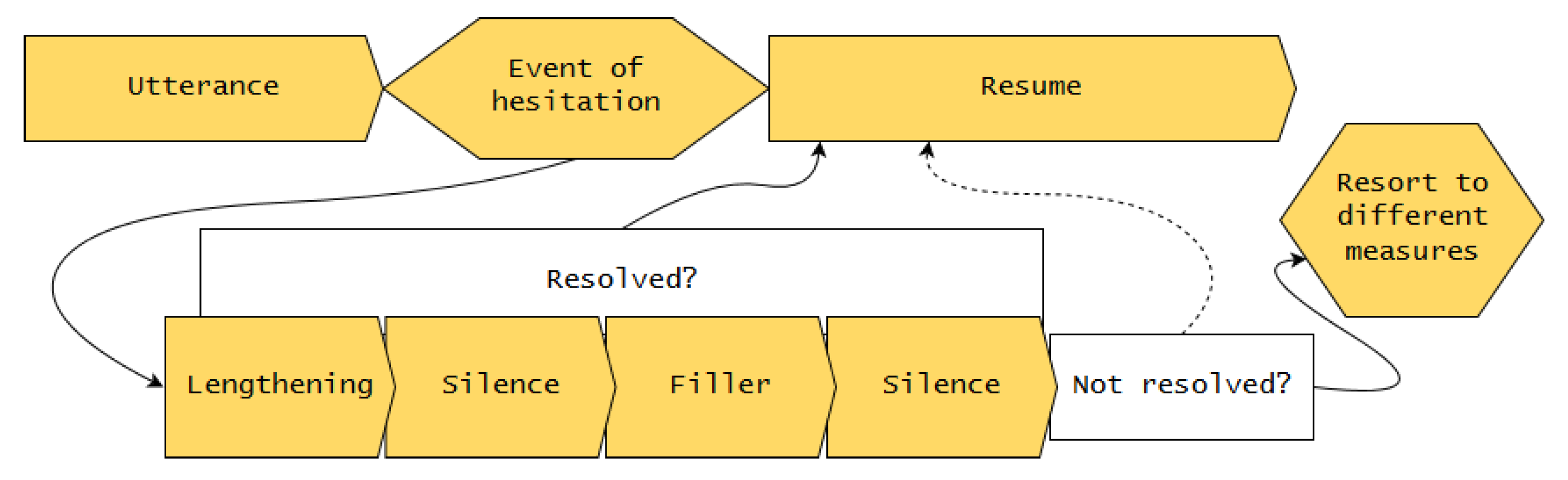
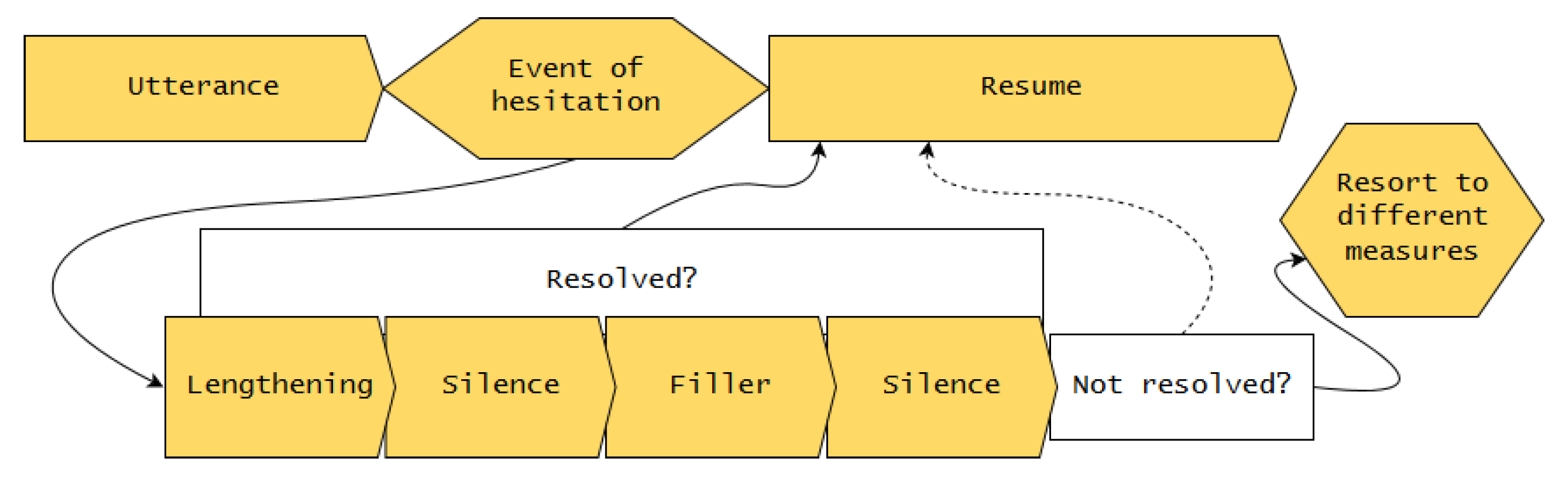
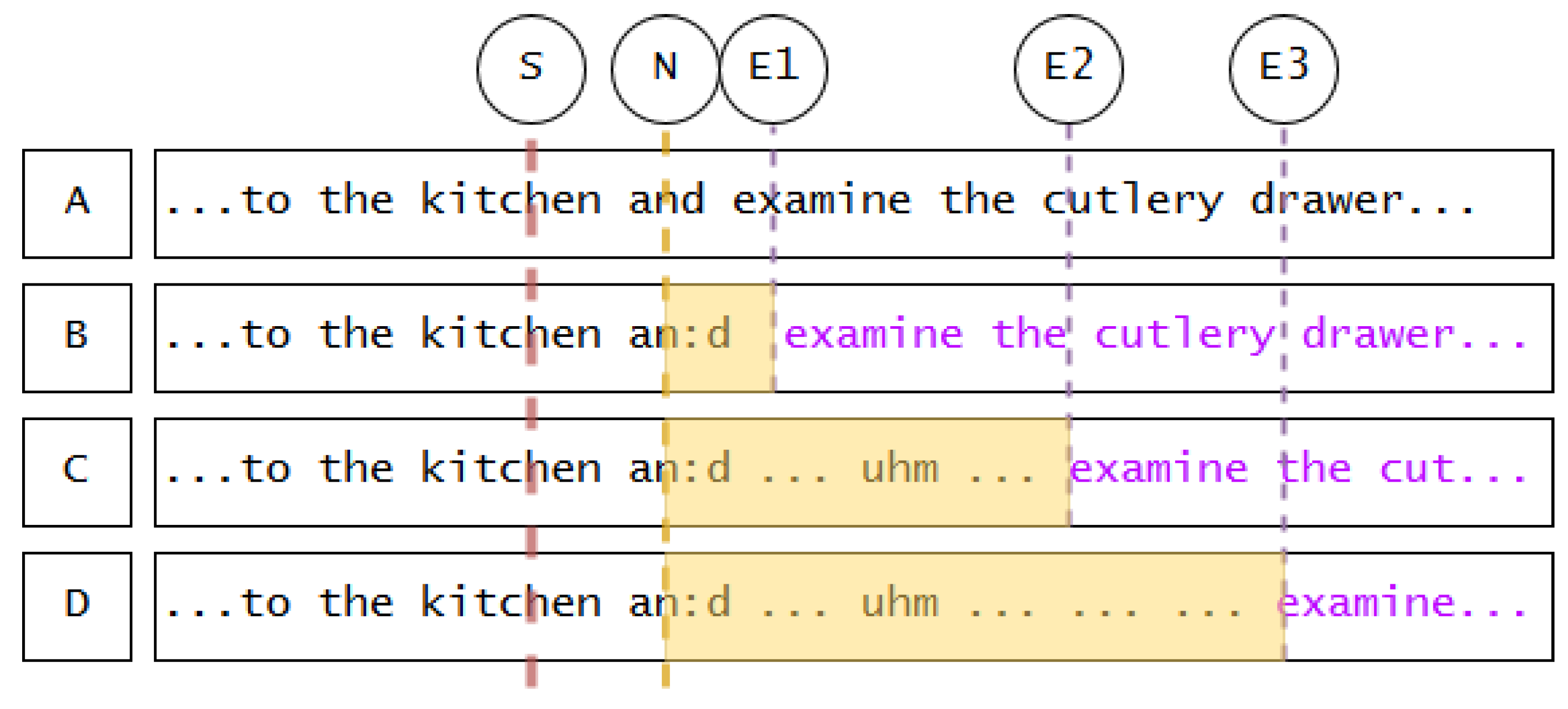
3.1. A Model for Hesitation Insertion in Incremental Spoken Dialogue Systems
- Apply lengthening to best target.
- Insert first silence.
- Insert filler.
- Insert second silence.
- Apply lengthening to best target. Hesitation lengthening does not occur arbitrarily. Given the concept of the articulatory buffer, speakers start hesitating as soon as possible, which means, at the next appropriate syllable. Several linguistic and phonetic factors determine which syllable that is, and how much that syllable can be stretched in duration. To summarize findings of Refs. [33,34]:
- Lengthening prefers closed-class (“function”) words.
- Lengthening prefers, in this order, nasals, long vowels and diphthongs, short vowels, other non-plosive sounds. (The latter is language-specific. In some languages, plosives can be lengthened (e.g., Swedish) in others not (e.g., German).)
- The extent of the lengthening is governed by the elasticity of the phone in question.
The lengthening continues until the phone has been stretched to its maximum, or until hesitation mode ends, whichever occurs first. - Insert first silence. If the lengthening has not bought enough time to resolve the event of hesitation, silence can be added. Following the suggestion of a standard maximum silence of 1 s in conversation [35], this silence will continue for maximally 1000 ms, or until hesitation mode ends. For a more elaborate analysis of pauses and their duration, see [36].
- Insert filler. If the previous steps did not buy enough time, as a more severe measure of hesitation, fillers (“uhm”) can be added. Short fillers (“uh”) denote minor pauses and are thus not adequate for long hesitation loops [21].
- Insert second silence. If after the filler the hesitation mode is still not resolved, a second silence can be added to buy more time, with the same rules as the first silence. This is based on the observation that fillers are regularly followed by silent intervals: the authors of [12] suggested that the filler type (“uh” or “uhm”) predicts the extent of the following silence; this is challenged by the authors of [37] who found that post-filler silences vary arbitrarily in duration.
- Resort to different measures. Systems need a strategy to continue when the above steps do not suffice to buy enough time to resolve the event of hesitation. This strategy depends on the architecture. Some examples of how a system could proceed (see Section 6 for a detailed discussion of possible continuation strategies) are as follows:
- Wait for hesitation event to end.
- Re-enter the loop or parts of it to buy more time.
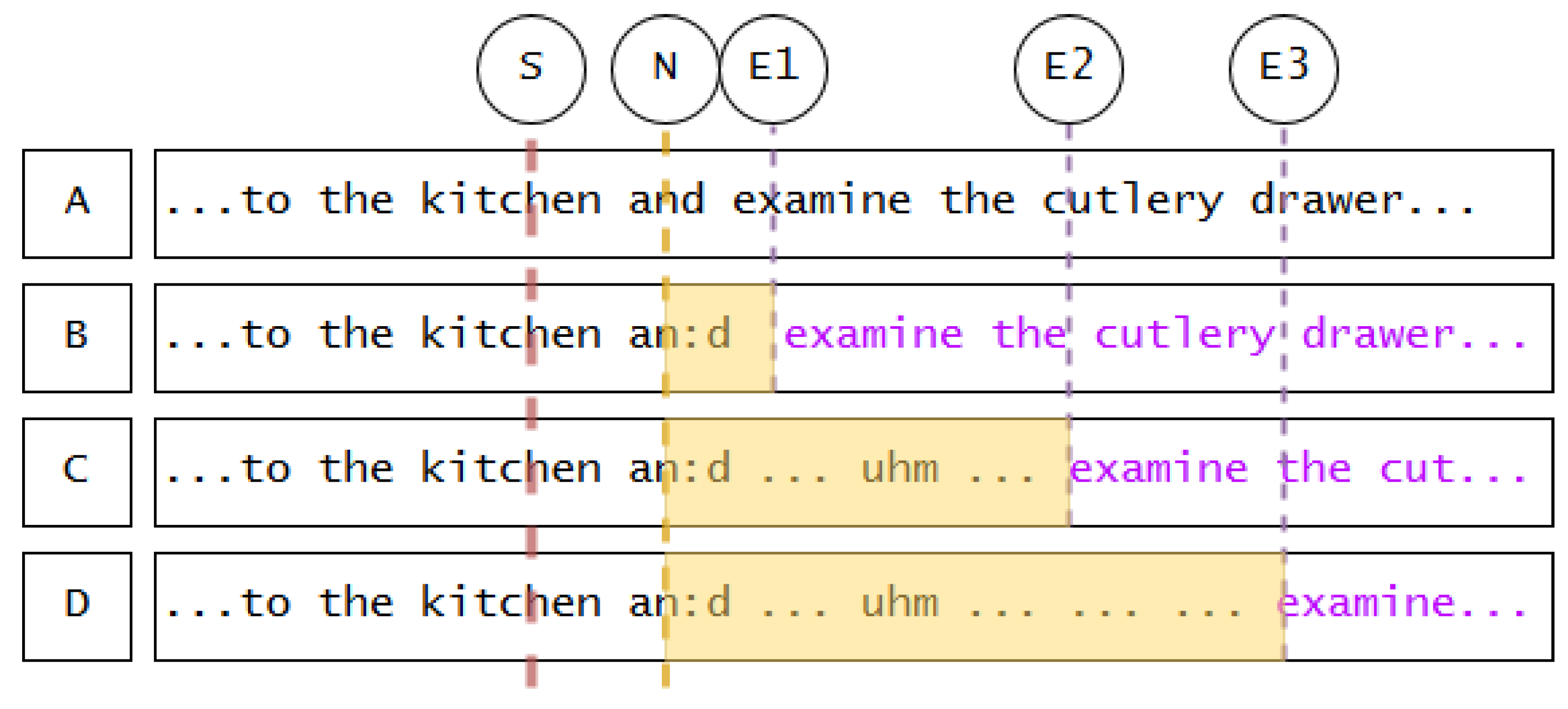
- Repeat parts of previously uttered speech to buy more time (cf. Example 1).
- Resume own speech plan if possible, despite the event of hesitation not being over.
3.2. Implementing the Algorithm
3.2.1. Event of Hesitation
3.2.2. Different Measures
3.2.3. Lengthening
3.2.4. Fillers
3.2.5. Silences
3.2.6. Reduced Hesitation Model
3.2.7. Technical Implementation
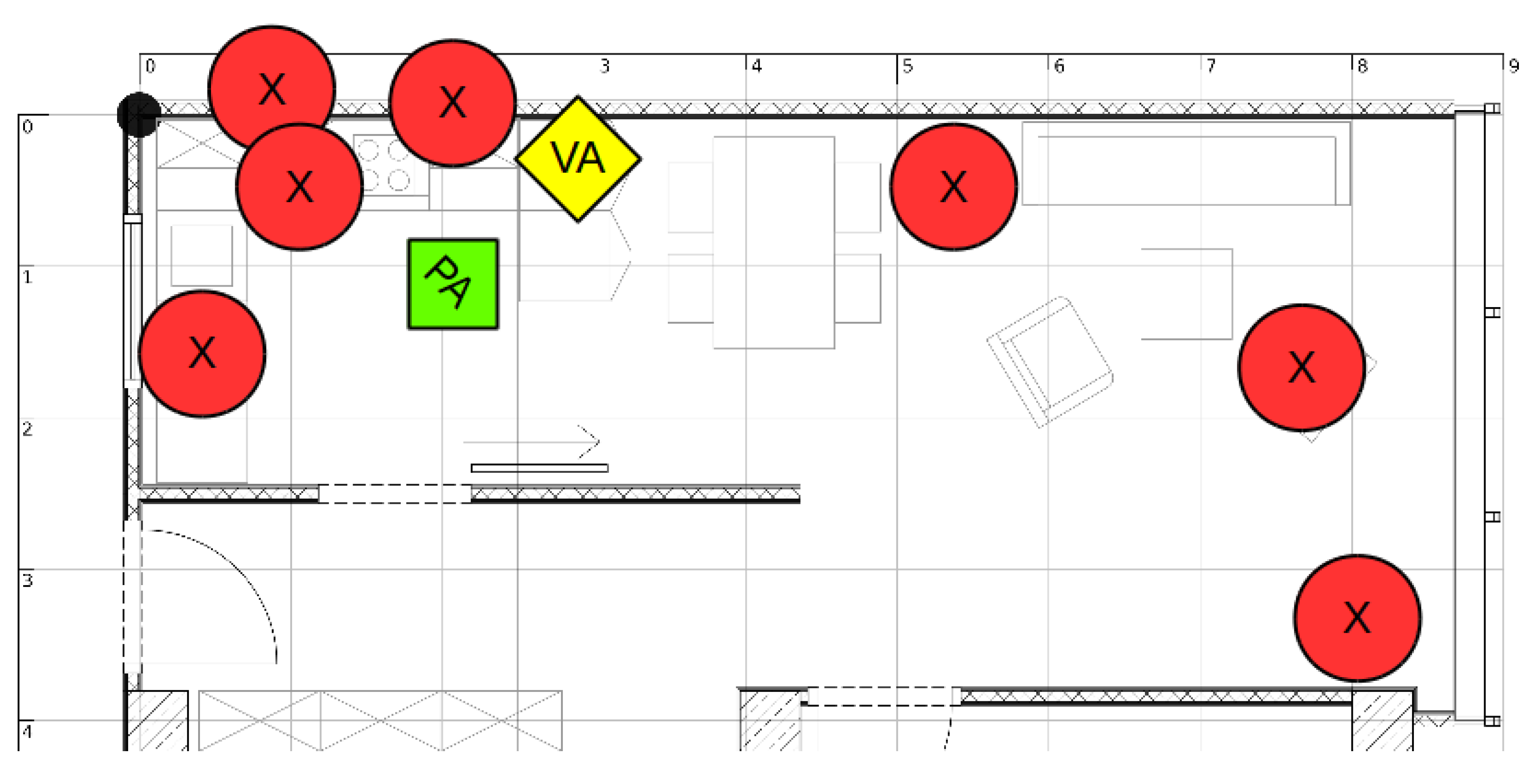
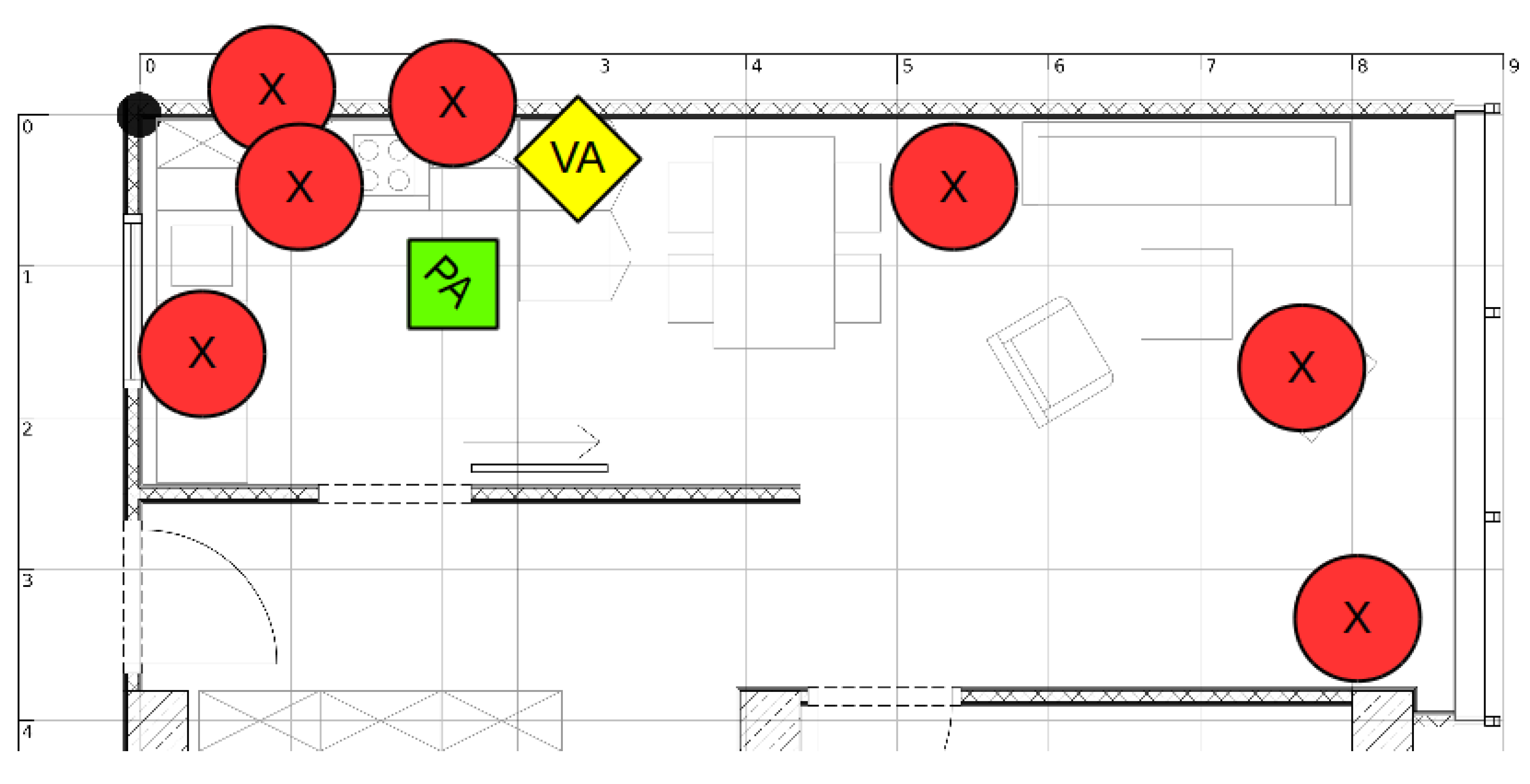
4. Experiment 1: Interaction Study
- We expect memory task performance to benefit from the presence of hesitations.
- We expect that presence of hesitations influences user ratings of perceived synthesis quality (undirected)
- We expect no negative impact of the presence or absence of hesitation on the system’s likability.
4.1. Methods
4.2. Results and Discussion
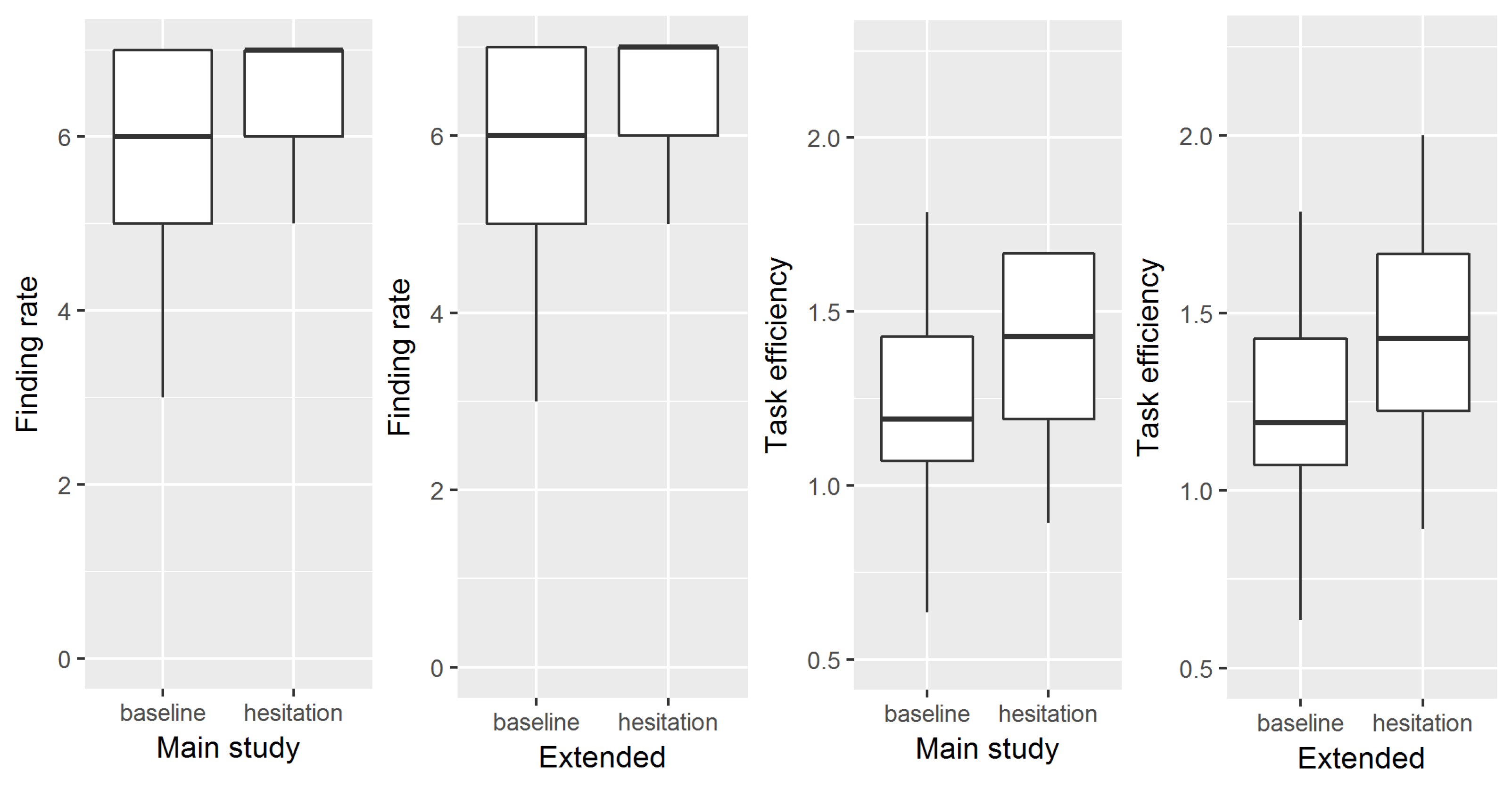
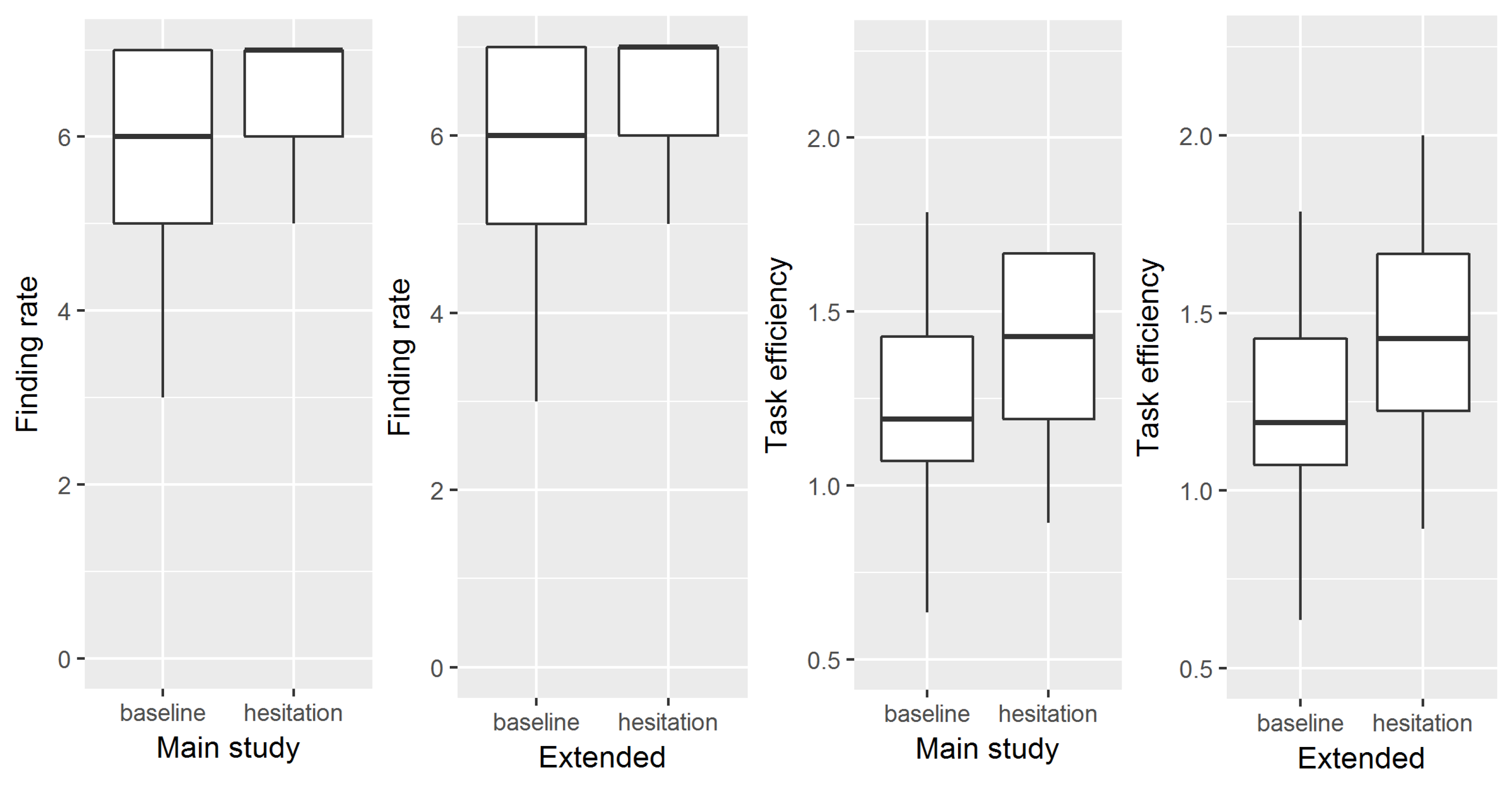
4.2.1. Finding Rate
4.2.2. Efficiency
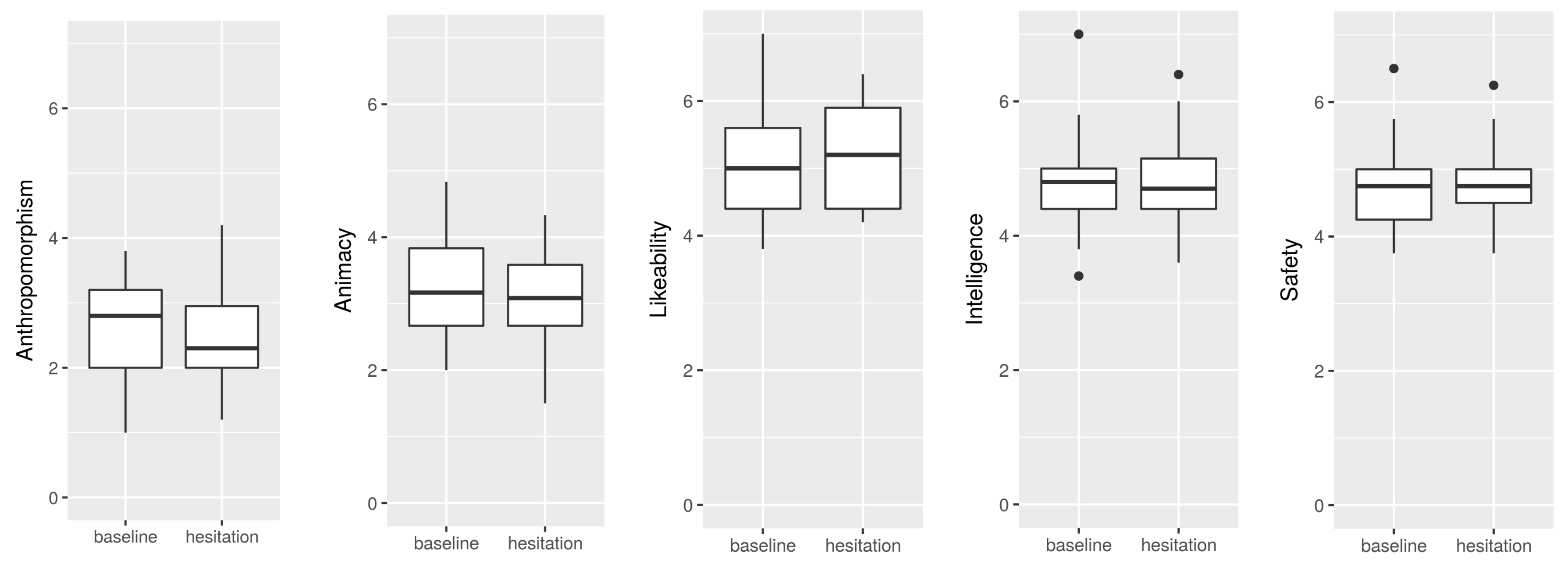
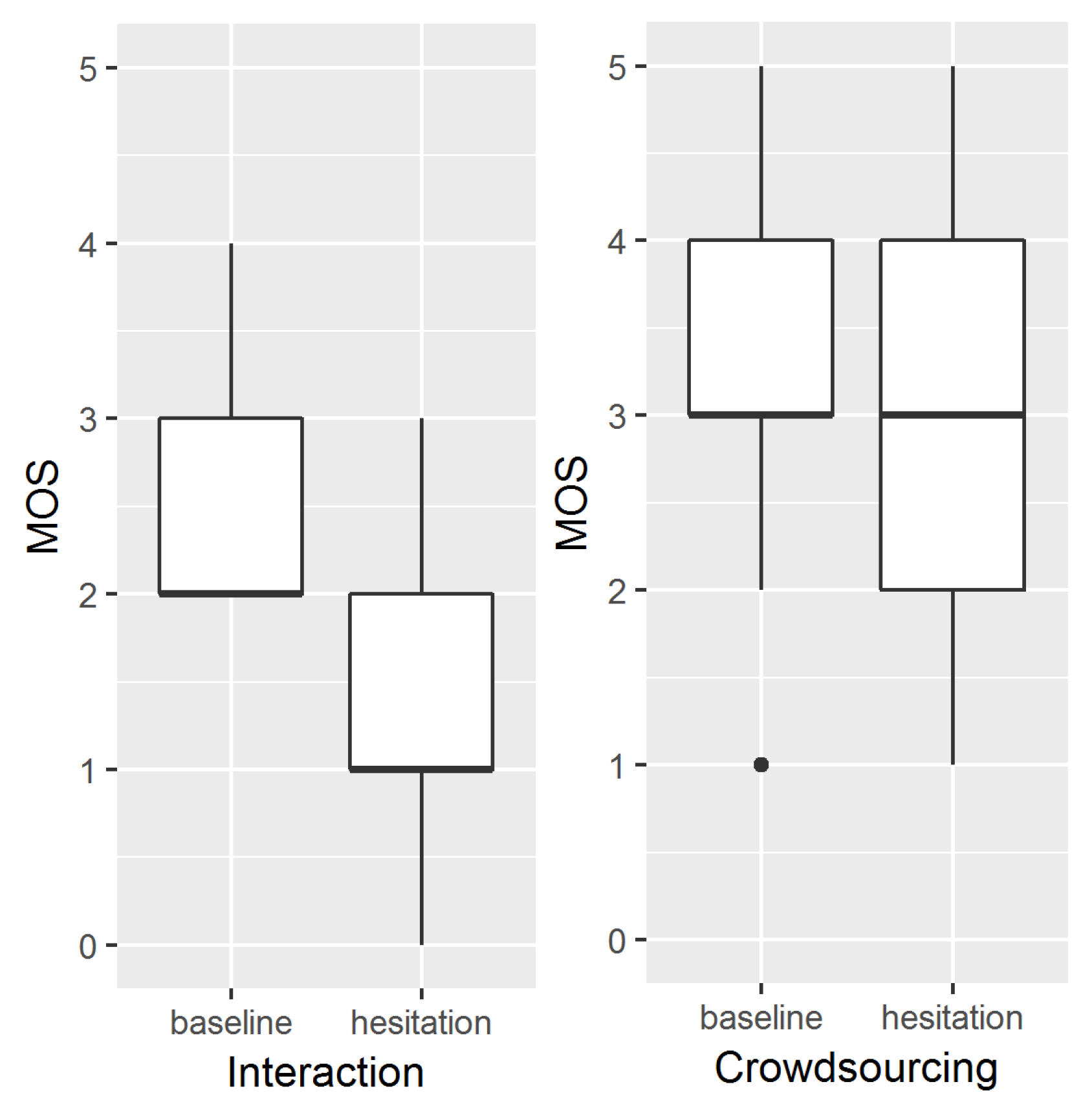
4.2.3. Subjective Speech Synthesis Quality
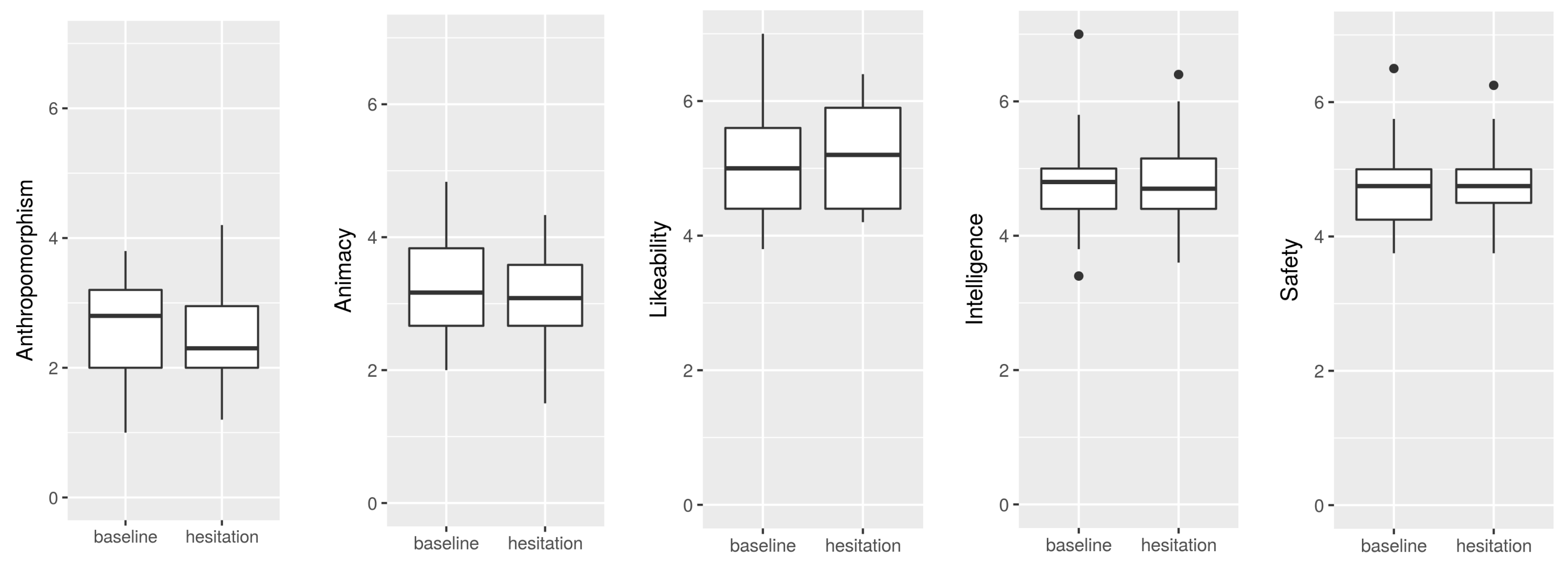
4.2.4. Subjective Rating of the Agent
4.2.5. Exploratory Extension of Analysis
4.2.6. Summary
5. Experiment 2: Crowdsourcing-Based Evaluation of Hesitation Synthesis
5.1. Methods
5.2. Results and Discussion
6. General Discussion
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Stimuli for Crowdsourcing Study
- “Hallo, schön, dass du an: (1.0) dieser Studie teilnimmst.”
- “Ich werde dir heute ein wenig über dieses Apartment erzählen, un:d (1.0) dann habe ich eine kleine Aufgabe für dich.”
- “Du könntest mir nämlich beim Suchen helfen. Hier sind eben ein paa:r (1.0) Sachen verloren gegangen.”
- “Einige Handwerker waren hier im Apartment un:d (1.0) haben die Küche umgebaut.”
- “Ich konnte wegen des Staubs leider nicht genau erkennen, wo die: (1.0) Sachen versteckt wurden.”
- “Jemand hat die Waschmaschine bedient un:d (2.0) das Waschpulverfach geöffnet.”
- “Und ich habe gesehen, wie jemand zur Pflanze im Wohnzimmer gegangen ist, un:d (2.0) etwas am Blumentopf gemacht hat.”
- “Danach hat jemand die Beschteckschublade geöffnet un:d (2.0) hat dort rumgewühlt.”
- “Und dann habe ich beobachtet dass jemand den Schrank über der: (2.0) Mikrowelle aufgemacht hat.”
- “Dann wurde einer der Stühle im: (2.0) Wohnzimmer bewegt.”
- “Irgend etwas ist mit den Kaffeetassen auf dem Tisch im: (2.0) Wohnzimmer passiert.”
- “Zu guter Letzt war noch jemand am Beschteckfach der: (2.0) Spülmaschine.”
- “Schau in beliebiger Reihenfolge an: (1.0) den Orten nach, die ich dir genannt habe.”
References
- Carlmeyer, B.; Schlangen, D.; Wrede, B. Exploring self-interruptions as a strategy for regaining the attention of distracted users. In Proceedings of the 1st Workshop on Embodied Interaction with Smart Environments-EISE ’16, Tokyo, Japan, 16 November 2016; Association for Computing Machinery (ACM): New York, NY, USA, 2016. [Google Scholar]
- Carlmeyer, B.; Schlangen, D.; Wrede, B. “Look at Me!”: Self-Interruptions as Attention Booster? In Proceedings of the Fourth International Conference on Human Agent Interaction-HAI ’16, Singapore, 4–7 October 2016; Association for Computing Machinery (ACM): New York, NY, USA, 2016. [Google Scholar]
- Chafe, W. Some reasons for hesitating. In Temporal Variables in Speech: Studies in Honour of Frieda Goldman-Eisler; Walter de Gruyter: Berlin, Germany, 1980; pp. 169–180. [Google Scholar]
- Skantze, G.; Hjalmarsson, A. Towards incremental speech generation in conversational systems. Comput. Speech Lang. 2013, 27, 243–262. [Google Scholar] [CrossRef]
- King, S. What speech synthesis can do for you (and what you can do for speech synthesis). In Proceedings of the 18th International Congress of thePhonetic Sciences (ICPhS 2015), Glasgow, UK, 10–14 August 2015. [Google Scholar]
- Mendelson, J.; Aylett, M. Beyond the Listening Test: An Interactive Approach to TTS Evaluation. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech 2017), Stockholm, Sweden, 20–24 August 2017; pp. 249–253. [Google Scholar]
- Rosenberg, A.; Ramabhadran, B. Bias and Statistical Significance in Evaluating Speech Synthesis with Mean Opinion Scores. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech 2017), Stockholm, Sweden, 20–24 August 2017; pp. 3976–3980. [Google Scholar]
- Wester, M.; Braude, D.A.; Potard, B.; Aylett, M.; Shaw, F. Real-Time Reactive Speech Synthesis: Incorporating Interruptions. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech 2017), Stockholm, Sweden, 20–24 August 2017; pp. 3996–4000. [Google Scholar]
- Wagner, P.; Betz, S. Speech Synthesis Evaluation—Realizing a Social Turn. In Proceedings of the Tagungsband Elektronische Sprachsignalverarbeitung (ESSV), Saarbrücken, Germany, 15–17 March 2017; pp. 167–172. [Google Scholar]
- Eklund, R. Disfluency in Swedish Human-Human and Human-Machine Travel Booking Dialogues. Ph.D. Thesis, Linköping University Electronic Press, Linköping, Sweden, 2004. [Google Scholar]
- Shriberg, E. Preliminaries to a Theory of Speech Disfluencies. Ph.D. Thesis, University of California, Berkeley, CA, USA, 1994. [Google Scholar]
- Clark, H.H.; Tree, J.E.F. Using uh and um in spontaneous speaking. Cognition 2002, 84, 73–111. [Google Scholar] [CrossRef]
- Goodwin, C. Conversational Organization: Interaction between Speakers and Hearers; Academic Press: Cambridge, MA, USA, 1981. [Google Scholar]
- Tree, J.E.F. Listeners’ uses ofum anduh in speech comprehension. Mem. Cognit. 2001, 29, 320–326. [Google Scholar] [CrossRef]
- Collard, P. Disfluency and Listeners’ Attention: An Investigation of The Immediate and Lasting Effects of Hesitations in Speech. Ph.D. Thesis, University of Edinburgh, Edinburgh, UK, 2009. [Google Scholar]
- Corley, M.; Stewart, O.W. Hesitation disfluencies in spontaneous speech: The meaning of um. Lang. Linguist. Compass 2008, 2, 589–602. [Google Scholar] [CrossRef]
- Betz, S.; Zarrieß, S.; Wagner, P. Synthesized lengthening of function words—The fuzzy boundary between fluency and disfluency. In Proceedings of the International Conference Fluency and Disfluency, Louvain-la-Neuve, Belgium, 15–17 February 2017. [Google Scholar]
- Kempen, G.; Hoenkamp, E. Incremental sentence generation: Implications for the structure of a syntactic processor. In Proceedings of the 9th Conference on Computational Linguistics-Volume 1, Prague, Czechoslovakia, 5–10 July 1982; Academia Praha: Praha, Czech Republic, 1982; pp. 151–156. [Google Scholar]
- Levelt, W.J.M. Speaking: From Intention to Articulation; MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Shriberg, E. To ‘errrr’ is human: Ecology and acoustics of speech disfluencies. J. Int. Phon. Assoc. 2001, 31, 153–169. [Google Scholar] [CrossRef]
- Clark, H. Speaking in Time. Speech Commun. 2002, 36, 5–13. [Google Scholar] [CrossRef]
- Shriberg, E. Disfluencies in switchboard. In Proceedings of the International Conference on Spoken Language Processing, Philadelphia, PA, USA, 3–6 October 1996; Volume 96, pp. 11–14. [Google Scholar]
- Li, J.; Tilsen, S. Phonetic evidence for two types of disfluency. In Proceedings of the ICPhS, Glasgow, UK, 10–14 August 2015. [Google Scholar]
- Sacks, H.; Schegloff, E.A.; Jefferson, G. A simplest systematics for the organization of turn-taking for conversation. Language 1974, 50, 696–735. [Google Scholar] [CrossRef]
- Heldner, M.; Edlund, J. Pauses, gaps and overlaps in conversations. J. Phon. 2010, 38, 555–568. [Google Scholar] [CrossRef]
- Skantze, G.; Schlangen, D. Incremental Dialogue Processing in a Micro-Domain. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2009), Athens, Greece, 30 March–3 April 2009; pp. 745–753. [Google Scholar]
- Schlangen, D.; Skantze, G. A General, Abstract Model of Incremental Dialogue Processing. Dialogue Discourse 2011, 2, 83–111. [Google Scholar] [CrossRef]
- Kousidis, S.; Kennington, C.; Baumann, T.; Buschmeier, H.; Kopp, S.; Schlangen, D. Situationally Aware In-Car Information Presentation Using Incremental Speech Generation: Safer, and More Effective. In Proceedings of the EACL 2014 Workshop on Dialogue in Motion, Gothenburg, Sweden, 26–27 April 2014; pp. 68–72. [Google Scholar]
- Bohus, D.; Horvitz, E. Managing Human-Robot Engagement with Forecasts and... Um... Hesitations. In Proceeding of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; ACM: New York, NY, USA, 2014; pp. 2–9. [Google Scholar]
- Chromik, M.; Carlmeyer, B.; Wrede, B. Ready for the Next Step: Investigating the Effect of Incremental Information Presentation in an Object Fetching Task. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction-HRI’17, Vienna, Austria, 6–9 March 2017; Association for Computing Machinery (ACM): New York, NY, USA, 2017. [Google Scholar]
- Betz, S.; Wagner, P.; Schlangen, D. Micro-Structure of Disfluencies: Basics for Conversational Speech Synthesis. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (Interspeech 2015), Dresden, Germany, 6–10 September 2015; pp. 2222–2226. [Google Scholar]
- Betz, S.; Voße, J.; Zarrieß, S.; Wagner, P. Increasing Recall of Lengthening Detection via Semi-Automatic Classification. In Proceedings of the 18th Annual Conference of the International Speech Communication Association (Interspeech 2017), Stockholm, Sweden, 20–24 August 2017; pp. 1084–1088. [Google Scholar]
- Betz, S.; Wagner, P.; Vosse, J. Deriving a strategy for synthesizing lengthening disfluencies based on spontaneous conversational speech data. In Proceedings of the Phonetik und Phonologie, München, Germany, 26–28 May 2016. [Google Scholar]
- Betz, S.; Voße, J.; Wagner, P. Phone Elasticity in Disfluent Contexts. In Proceedings of the Fortschritte der Akustik-DAGA, Kiel, Germany, 6–9 March 2017. [Google Scholar]
- Jefferson, G. Preliminary notes on a possible metric which provides for a “standard maximum” silence of approximately one second in conversation. In Conversation: An Interdisciplinary Perspective; Roger, D., Bull, P., Eds.; Multilingual Matters: Bristol, UK, 1989. [Google Scholar]
- Lundholm Fors, K. Production and Perception of Pauses in Speech. Ph.D. Thesis, University of Gothenburg, Gothenburg, Sweden, 2015. [Google Scholar]
- O’Connell, D.C.; Kowal, S. Uh and um revisited: Are they interjections for signaling delay? J. Psycholinguist. Res. 2005, 34, 555–576. [Google Scholar]
- Carlmeyer, B.; Schlangen, D.; Wrede, B. Towards Closed Feedback Loops in HRI: Integrating InproTK and PaMini. In Proceedings of the 2014 Workshop on Multimodal, Multi-Party, Real-World Human-Robot Interaction, Istanbul, Turkey, 16 November 2014; ACM: New York, NY, USA, 2014; pp. 1–6. [Google Scholar]
- Baumann, T.; Schlangen, D. The InproTK 2012 Release. In Proceedings of the NAACL-HLT Workshop on Future Directions and Needs in the Spoken Dialog Community: Tools and Data, Montreal, QC, Canada, 7 June 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 29–32. [Google Scholar]
- Schroeder, M.; Trouvain, J. The German text-to-speech synthesis system MARY: A tool for research, development and teaching. Int. J. Speech Technol. 2003, 6, 365–377. [Google Scholar] [CrossRef]
- Wrede, S.; Leichsenring, C.; Holthaus, P.; Hermann, T.; Wachsmuth, S. The Cognitive Service Robotics Apartment: A Versatile Environment for Human-Machine Interaction Research. Kuenstliche Intell. 2017, 31, 299–304. [Google Scholar] [CrossRef]
- Lütkebohle, I.; Hegel, F.; Schulz, S.; Hackel, M.; Wrede, B.; Wachsmuth, S.; Sagerer, G. The Bielefeld Anthropomorphic Robot Head “Flobi”. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 3384–3391. [Google Scholar]
- Schillingmann, L.; Nagai, Y. Yet another gaze detector: An embodied calibration free system for the iCub robot. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 8–13. [Google Scholar]
- Bartneck, C.; Kulić, D.; Croft, E.; Zoghbi, S. Measurement Instruments for the Anthropomorphism, Animacy, Likeability, Perceived Intelligence, and Perceived Safety of Robots. Int. J. Soc. Robot. 2009, 1, 71–81. [Google Scholar] [CrossRef]
- Holthaus, P.; Leichsenring, C.; Bernotat, J.; Richter, V.; Pohling, M.; Carlmeyer, B.; Köster, N.; Zu Borgsen, S.M.; Zorn, R.; Schiffhauer, B.; et al. How to Address Smart Homes with a Social Robot? A Multi-modal Corpus of User Interactions with an Intelligent Environment. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portoroz, Slovenia, 24 May 2016; European Language Resources Association: Paris, France, 2016. [Google Scholar]
- Draxler, C. Online Experiments with the Percy Software Framework—Experiences and some Early Results. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; Chair, N.C.C., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., Moreno, A., Odijk, J., Piperidis, S., Eds.; European Language Resources Association (ELRA): Reykjavik, Iceland, 2014. [Google Scholar]

© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Betz, S.; Carlmeyer, B.; Wagner, P.; Wrede, B. Interactive Hesitation Synthesis: Modelling and Evaluation. Multimodal Technol. Interact. 2018, 2, 9. https://doi.org/10.3390/mti2010009
Betz S, Carlmeyer B, Wagner P, Wrede B. Interactive Hesitation Synthesis: Modelling and Evaluation. Multimodal Technologies and Interaction. 2018; 2(1):9. https://doi.org/10.3390/mti2010009
Chicago/Turabian StyleBetz, Simon, Birte Carlmeyer, Petra Wagner, and Britta Wrede. 2018. "Interactive Hesitation Synthesis: Modelling and Evaluation" Multimodal Technologies and Interaction 2, no. 1: 9. https://doi.org/10.3390/mti2010009
APA StyleBetz, S., Carlmeyer, B., Wagner, P., & Wrede, B. (2018). Interactive Hesitation Synthesis: Modelling and Evaluation. Multimodal Technologies and Interaction, 2(1), 9. https://doi.org/10.3390/mti2010009