
Mid-Air Gestural Interaction with a Large Fogscreen
 , , , , , , , and
, , , , , , , and
Abstract
:1. Introduction
2. Related Work
2.1. Particle Displays
2.2. Mid-Air Interaction with Large Conventional Screens
2.3. Mid-Air Interaction with Large Fogscreens
3. Interaction System Design
3.1. Screen and Projection
3.2. User Tracking
- 1.
- Initialize an empty buffer for 11 Kinect CameraSpacePoint.Position vectors;
- 2.
- Fill the buffer with vectors that are (a) “within” the fog (CameraSpacePoint.Position.Z < Threshold) and (b) far enough from the vector collected for the previous corner (except the first corner);
- 3.
- Compute medians of X and Y values of the vectors stored in the buffer—this will be the vector assigned to the corner being calibrated; and
- 4.
- Save the matrix of the four vectors into a file.
- 1.
- Read the calibration matrix [TL, TR, BL, BR] from the file (the first calibration point TL corresponding to the origin of the screen serves as an offset);
- 2.
- Compute the average distance between screen edges in Kinect coordinates:
- 3.
- Compute the X and Y scales as follows ():
- 4.
- For each point received from Kinect, compute the screen point as:
3.3. Haptic Device
3.4. Interaction Gestures and Feedback
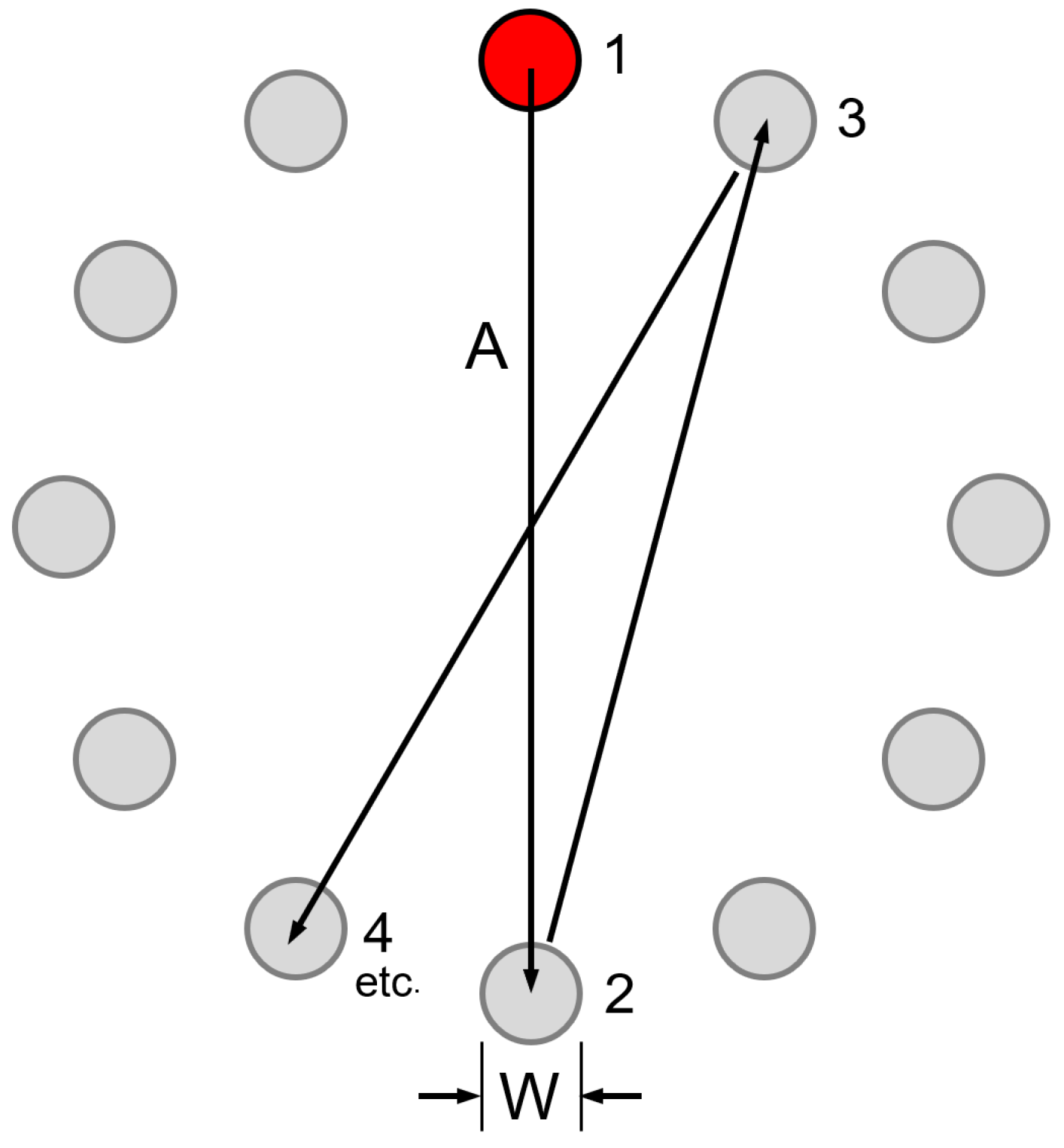
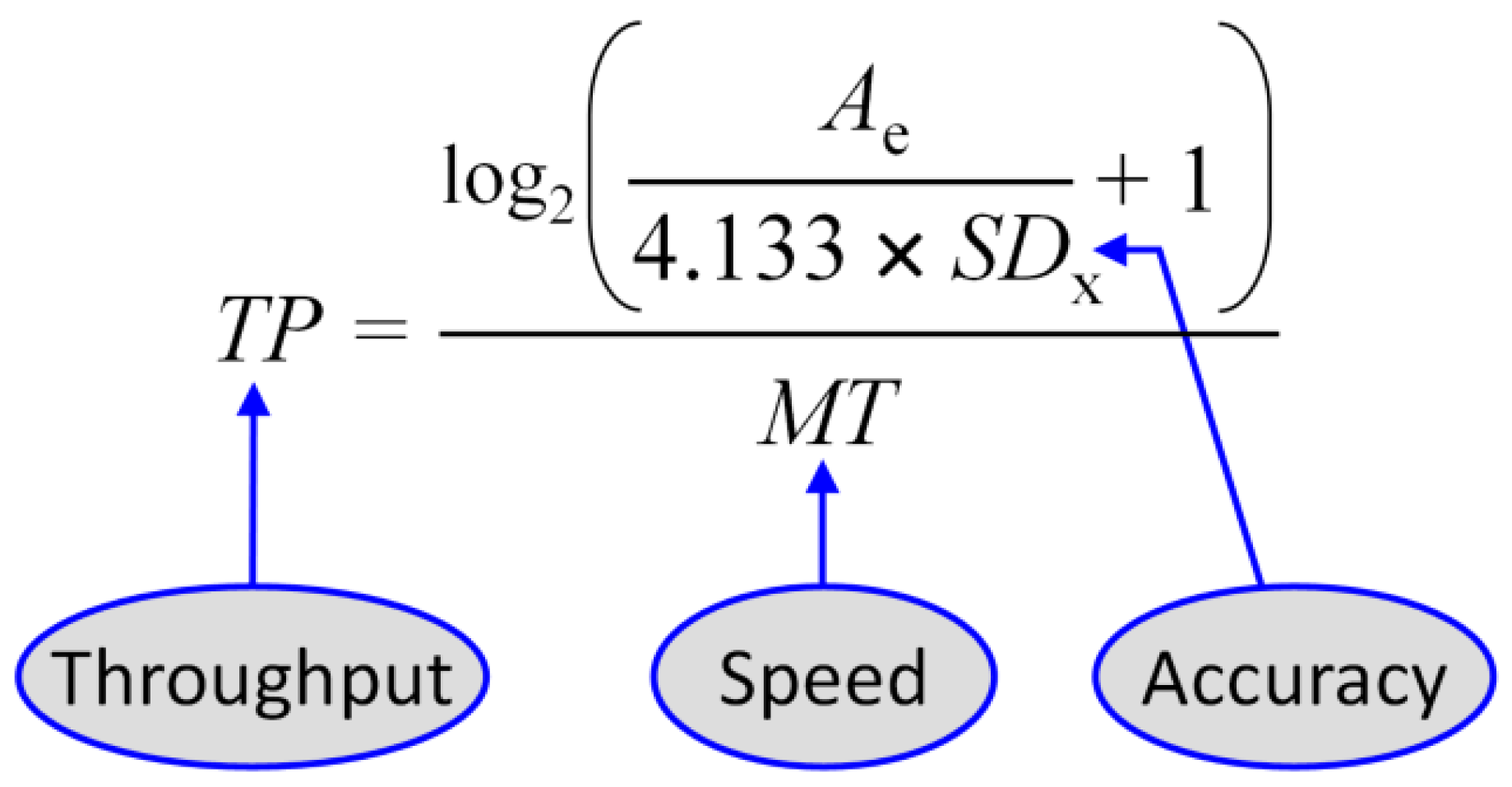
4. Evaluation Using Fitts’ Law
5. Methodology
5.1. Participants
5.2. Apparatus
5.3. Procedure
5.4. Design
5.5. Data Pre-Processing, Outlier Removal, and Data Analysis
6. Results
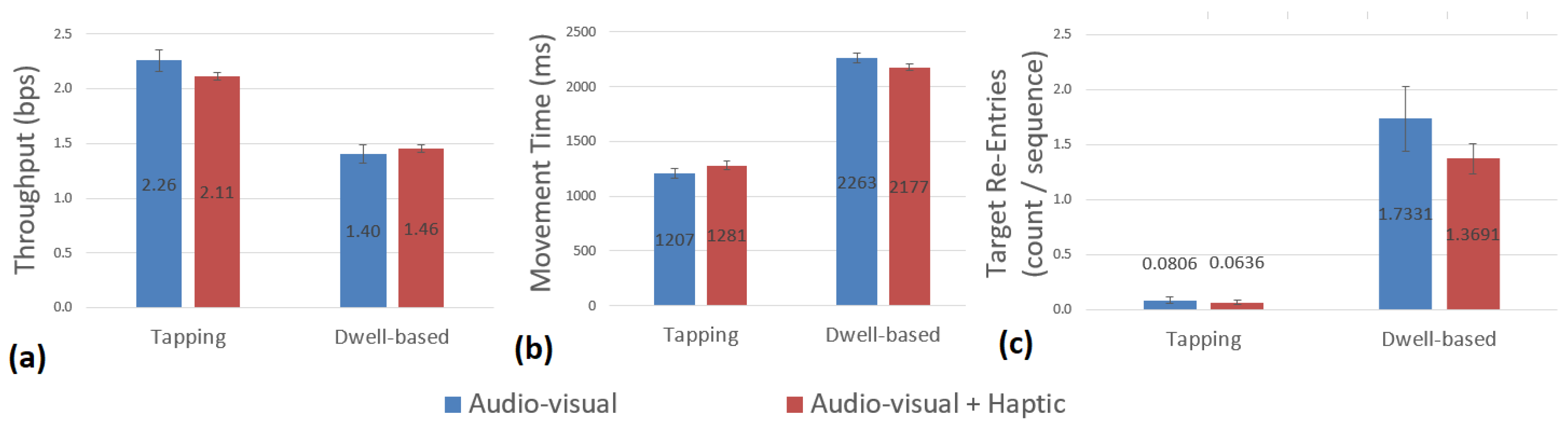
6.1. Throughput
6.2. Movement Time
6.3. Target Re-Entries
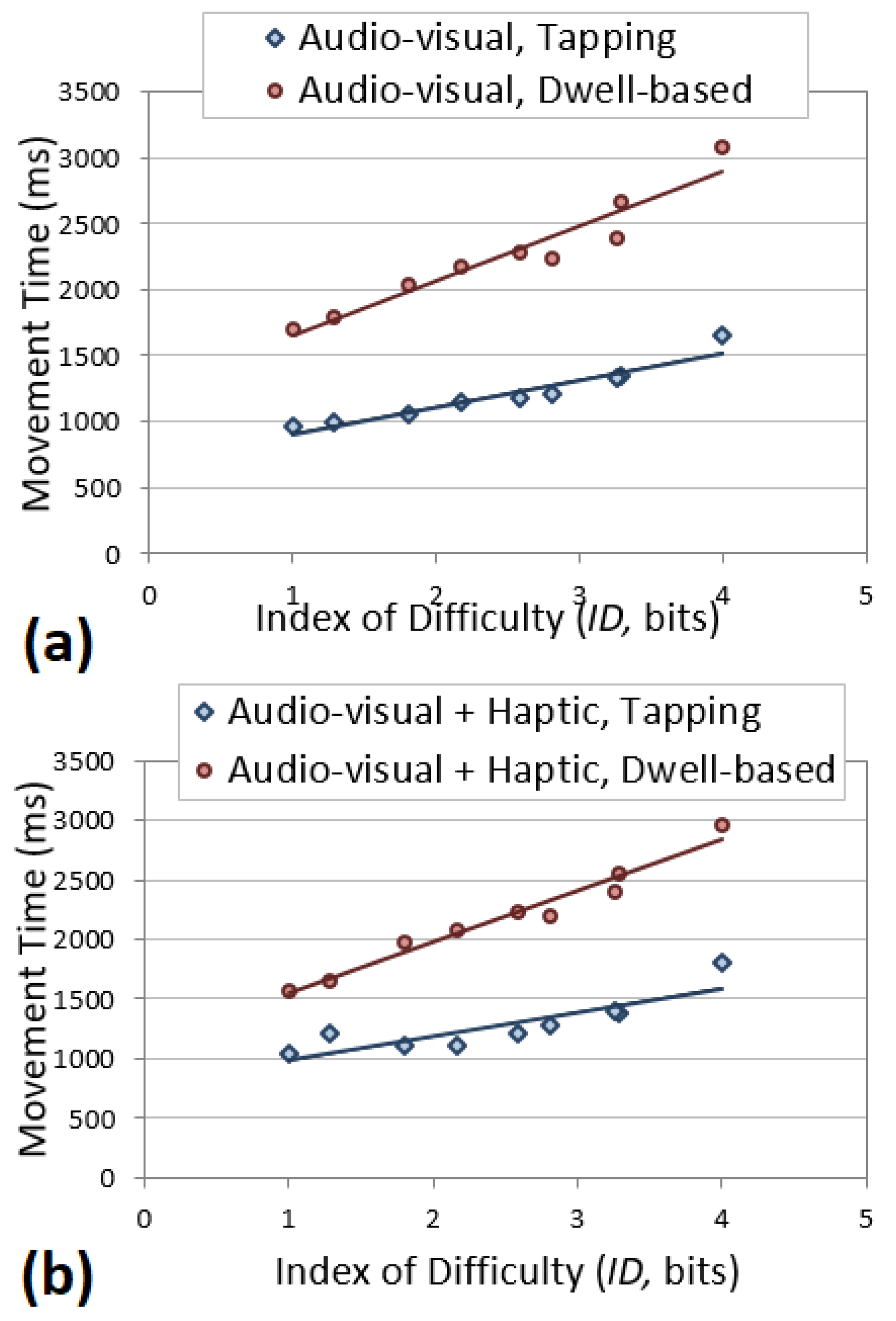
6.4. Fitts’ Law Models
6.5. Subjective Ratings
7. Discussion
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jumisko-Pyykkö, S.; Weitzel, M.; Rakkolainen, I. Biting, whirling, crawling: Children’s embodied interaction with walk-through displays. In Human–Computer Interaction—INTERACT 2009. INTERACT 2009; Gross, T., Al, E., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5726, pp. 123–136. [Google Scholar]
- Palovuori, K.; Rakkolainen, I. Improved virtual reality for mid-air projection screen technology. In Proceedings of the Third International Symposium on Communicability, Computer Graphics and Innovative Design for Interactive Systems (CCGIDIS 2013), Venice, Italy, 23–24 April 2013; Blue Herons Edition. Springer: Berlin/Heidelberg, Germany, 2013; pp. 25–33. [Google Scholar]
- Palovuori, K.; Rakkolainen, I. Improved Interaction for Mid-Air Projection Screen Technology. In Handbook of Research on Interactive Information Quality in Expanding Social Network Communications; Cipolla-Ficarra, F., Ed.; IGI Global: Hershey, PA, USA, 2015; pp. 87–107. [Google Scholar]
- Rakkolainen, I.; Palovuori, K. A walk-thru screen. In Projection Displays VIII; SPIE: San Jose, CA, USA, 2002; pp. 17–22. [Google Scholar]
- Rakkolainen, I.; Sand, A.; Palovuori, K. Midair user interfaces employing particle screens. IEEE Comput. Graph. Appl. 2015, 35, 96–102. [Google Scholar] [CrossRef] [PubMed]
- Sand, A.; Rakkolainen, I.; Isokoski, P.; Raisamo, R.; Palovuori, K. Light-weight immaterial particle displays with mid-air tactile feedback. In Proceedings of the 2015 IEEE International Symposium on Haptic, Audio and Visual Environments and Games (HAVE 2015), Ottawa, ON, Canada, 11 October 2015; IEEE: New York, NY, USA, 2015. [Google Scholar]
- Just, P.C. Ornamental Fountain. U.S. Patent No. 620592, 7 March 1899. [Google Scholar]
- Blundell, B.G. 3D Displays and Spatial Interaction: Exploring the Science, Art, Evolution and Use of 3D Technologies; Walker & Wood Ltd.: Nashville, TN, USA, 2011.
- Sand, A.; Rakkolainen, I.; Surakka, V.; Raisamo, R.; Brewster, S. Touchless Tactile Interaction with Unconventional Permeable Displays. In Ultrasound Mid-Air Haptics for Touchless Interfaces; Human—Computer Interaction Series; Georgiou, O., Frier, W., Freeman, E., Pacchierotti, C., Hoshi, T., Eds.; Springer: Cham, Switzerland, 2022. [Google Scholar] [CrossRef]
- Sand, A.; Remizova, V.; MacKenzie, I.S.; Spakov, O.; Nieminen, K.; Rakkolainen, I.; Kylliäinen, A.; Surakka, V.; Kuosmanen, J. Tactile feedback on mid-air gestural interaction with a large fogscreen. In Proceedings of the 23rd International Conference on Academic Mindtrek, Tampere, Finland, 29–30 January 2020; pp. 161–164. [Google Scholar]
- Gong, J.; Sun, J.; Chu, M.; Wang, X.; Luo, M.; Lu, Y.; Zhang, L.; Wu, Y.; Wang, Q.; Liu, C. Side-by-Side vs. Face-to-Face: Evaluating Colocated Collaboration via a Transparent Wall-sized Display. arXiv 2023, arXiv:2301.07262. [Google Scholar] [CrossRef]
- Erazo, O.; Vicuña, A.; Pico, R.; Oviedo, B. Analyzing mid-air hand gestures to confirm selections on displays. In Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2018; pp. 341–352. [Google Scholar]
- Hespanhol, L.; Tomitsch, M.; Grace, K.; Collins, A.; Kay, J. Investigating intuitiveness and effectiveness of gestures for freespatial interaction with large displays. In Proceedings of the 2012 International Symposium on Pervasive Displays, PerDis ’12, Porto, Portugal, 12–14 June 2012; ACM: New York, NY, USA; pp. 6:1–6:6. [Google Scholar]
- Walter, R.; Bailly, G.; Valkanova, N.; Müller, J. Cuenesics: Using mid-air gestures to select items on interactive public displays. In Proceedings of the MobileHCI 14 16th International Conference on Human–Computer Interactions with Mobile Devices and Services, Toronto, ON, Canada, 23–26 September 2014; ACM: New York, NY, USA, 2014; pp. 299–308. [Google Scholar]
- Dube, T.; Ren, Y.; Limerick, H.; MacKenzie, I.S.; Arif, A. Push, Tap, Dwell, and Pinch: Evaluation of Four Mid-air Selection Methods Augmented with Ultrasonic Haptic Feedback. In Proceedings of the ACM on Human–Computer Interaction, New Orleans, LA, USA, 30 April–5 May 2022; Volume 6, pp. 207–225. [Google Scholar]
- Panger, G. Kinect in the kitchen: Testing depth camera interactions inpractical home environments. In Proceedings of the CHI’12 Extended Abstracts on Human Factors in ComputingSystems, Austin, TX, USA, 5–10 May 2012; ACM: New York, NY, USA, 2012; pp. 1985–1990. [Google Scholar]
- Yoo, S.; Parker, C.; Kay, J.; Tomitsch, M. To dwell or not to dwell: An evaluation of mid-air gestures for large information displays. In Proceedings of the OzCHI ’15 the Annual Meeting of the Australian Special Interest Group for Computer Human Interaction, Parkville, VIC, Australia, 7–10 December 2015; ACM: New York, NY, USA, 2015; pp. 187–191. [Google Scholar]
- Pino, A.; Tzemis, E.; Ioannou, N.; Kouroupetroglou, G. Using kinect for 2D and 3D pointing tasks: Performance evaluation. In Human-Computer Interaction. Interaction Modalities and Techniques, Proceedings of the 15th International Conference, HCI International 2013, Las Vegas, NV, USA, 21–26 July 2013, Proceedings, Part IV 15; Lecture Notes in Computer Science; Kurosu, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8007, pp. 358–367. [Google Scholar]
- Burno, R.A.; Wu, B.; Doherty, R.; Colett, H.; Elnaggar, R. Applying Fitts’ law to gesture based computer interactions. Procedia Manuf. 2015, 3, 4342–4349. [Google Scholar] [CrossRef]
- Freeman, E.; Brewster, S.; Lantz, V. Tactile feedback for above-device gesture interfaces. In Proceedings of the ICMI ’14- Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; ACM: New York, NY, USA, 2014; pp. 419–426. [Google Scholar]
- Schwaller, M.; Lalanne, D. Pointing in the air: Measuring the effect of hand selections trategies on performance and effort. In Human Factors in Computing and Informatics—First International Conference, SouthCHI 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7946, pp. 732–747. [Google Scholar]
- Wang, Y.; MacKenzie, C.L. The role of contextual haptic and visual constraints on object manipulation in virtual environments. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI ’00, Hague, The Netherlands, 1–6 April 2000; ACM: New York, NY, USA, 2000; pp. 532–539. [Google Scholar]
- Vogel, D.; Balakrishnan, R. Distant freehand pointing and clicking on very large, high resolution displays. In Proceedings of the UIST05: The 18th Annual ACM Symposium on User Interface Software and Technology, Seattle, WA, USA, 23–26 October 2005; ACM: New York, NY, USA, 2005; pp. 33–42. [Google Scholar]
- Kjeldsen, R.; Hartman, J. Design issues for vision-based computer interaction systems. In Proceedings of the 2001 Workshop on Perceptive User Interfaces, Orlando, FL, USA, 15–16 November 2001; pp. 1–8. [Google Scholar]
- Plasencia, D.M.; Joyce, E.; Subramanian, S. Mistable: Reach-through personal screens for tabletops. In Proceedings of the CHI ’14 the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; ACM: New York, NY, USA, 2014; pp. 3493–3502. [Google Scholar]
- Aglioti, S.; Tomaiuolo, F. Spatial stimulus-response compatibility and coding of tactile motor events: Influence of distance between stimulated and responding body parts, spatial complexity of the task and sex of subject. Percept. Mot. Ski. 2000, 91, 3–14. [Google Scholar] [CrossRef] [PubMed]
- Brewster, S.; Brown, L.M. Tactons: Structured tactile messages for non-visual information display. In Proceedings of the AUIC ’04 Australasian User Interface Conference 2004, Dunedin, New Zealand, 18–22 January 2004; Australian Computer Society, Inc.: Darlinghurst, Australia; Volume 28, pp. 15–23. [Google Scholar]
- Goldstein, E.B. Sensation and Perception; Brooks/Cole Publishing: Pacific Grove, CA, USA, 1999. [Google Scholar]
- Jones, L.A.; Sarter, N.B. Tactile displays: Guidance for their design and application. Hum. Factors J. Hum. Factors Ergon. Soc. 2008, 50, 90–111. [Google Scholar] [CrossRef] [PubMed]
- ISO/TC 159/SC4/WG3 N147; Ergonomic Requirements for Office Work with Visual Display Terminals (vdts)—Part 9: Requirements for Non-Keyboard Input Devices (ISO 9241-9). Technical Report; International Organization for Standardization (ISO): Geneva, Switzerland, 2000.
- MacKenzie, I.S. Fitts’ law. In Handbook of Human–Computer Interaction; Norman, K.L., Kirakowski, J., Eds.; Wiley: Hoboken, NJ, USA, 2018; pp. 349–370. [Google Scholar]
- Hart, S.G. Nasa-task load index (NASA-TLX); 20 years later. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, San Diego, CA, USA, 30 September–4 October 2006; SAGE Publications: Los Angeles, CA, USA, 2006; Volume 50, pp. 904–908. [Google Scholar]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Bachynskyi, M.; Palmas, G.; Oulasvirta, A.; Steimle, J.; Weinkauf, T. Performance and ergonomics of touch surfaces: A comparative study using biomechanical simulation. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; ACM: New York, NY, USA, 2015; pp. 1817–1826. [Google Scholar]
- List, C.; Kipp, M. Is bigger better? A Fitts’ Law Study on the impact of display size on touch performance. In Proceedings of the IFIP Conference on Human–Computer Interaction, Paphos, Cyprus, 2–6 September 2019; Springer: Cham, Switzerland, 2019; pp. 669–678. [Google Scholar]
- van de Camp, F.; Schick, A.; Stiefelhagen, R. How to click in mid-air. In Proceedings of the Distributed, Ambient, and Pervasive Interactions: First International Conference, DAPI 2013, Las Vegas, NV, USA, 21–26 July 2013; Stephanidis, C., Ed.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8028, pp. 78–86. [Google Scholar]
- Köpsel, A.; Majaranta, P.; Isokoski, P.; Huckauf, A. Effects of auditory, haptic and visual feedback on performing gestures by gaze or by hand. Behav. Inf. Technol. 2016, 35, 1044–1062. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Interaction Gestures * | Throughput ** (bps) | Results | Technology | Application Domain |
|---|---|---|---|---|---|
| Dube et al. [15] | Dwell-based (800 ms) | 1.73 | Dwell-based gesture was slowest, but the most accurate and the least physically and cognitive demanding. | Leap Motion Controller | Desktop |
| Dwell-based (800 ms) + haptic | 1.74 | ||||
| Tapping | 1.75 | ||||
| Tapping + haptic | 2.07 | ||||
| Pino et al. [18] | Gesture + voice | 2.1 | Gesture interaction was slower and harder compared to using a mouse. | Microsoft Kinect Sensor | Desktop |
| Schwaller and Lalanne [21] | Dwell-based (500 ms) | 1.9 | The performance of dwell-based gesture was lower than that of pinching, but dwell-based was more accurate. | Microsoft Kinect Sensor | Large screen |
| Hespanhol et al. [13] | Dwell-based | – | Dwell-based was the most intuitive gesture for selection; tapping was a common gesture in other digital interfaces. | Microsoft Kinect Sensor | Large screen |
| Tapping | – | ||||
| Burno et al. [19] | Gesture S + button | 1.9 | Gesture interaction had lower throughput compared to using a mouse and a touchscreen. | Leap Motion Controller | Desktop |
| Gesture M + button | 1.9 | Creative Senz3D Camera | Desktop | ||
| Gesture L + button | 2.25 | PrimeSense Carmine 1.09 3D Camera | Desktop | ||
| Erazo et al. [12] | Tapping | – | Dwell-based gesture was the most intuitive and accurate for selection. | Microsoft Kinect Sensor | Large screen |
| Dwell-based (500 ms) | – |
| Selection Mode | Haptic Feedback | a (Intercept) | b (Slope) | Correl (r) |
|---|---|---|---|---|
| Tapping | no | 205.53 | 700.29 | 0.9142 |
| Dwell-based | no | 411.08 | 1248.8 | 0.9229 |
| Tapping | yes | 200.13 | 787.87 | 0.7434 |
| Dwell-based | yes | 429.71 | 1117.1 | 0.9664 |
| Tapping | Dwell-Based | Tapping + Haptic | Dwell-Based + Haptic | Significance, p | |
|---|---|---|---|---|---|
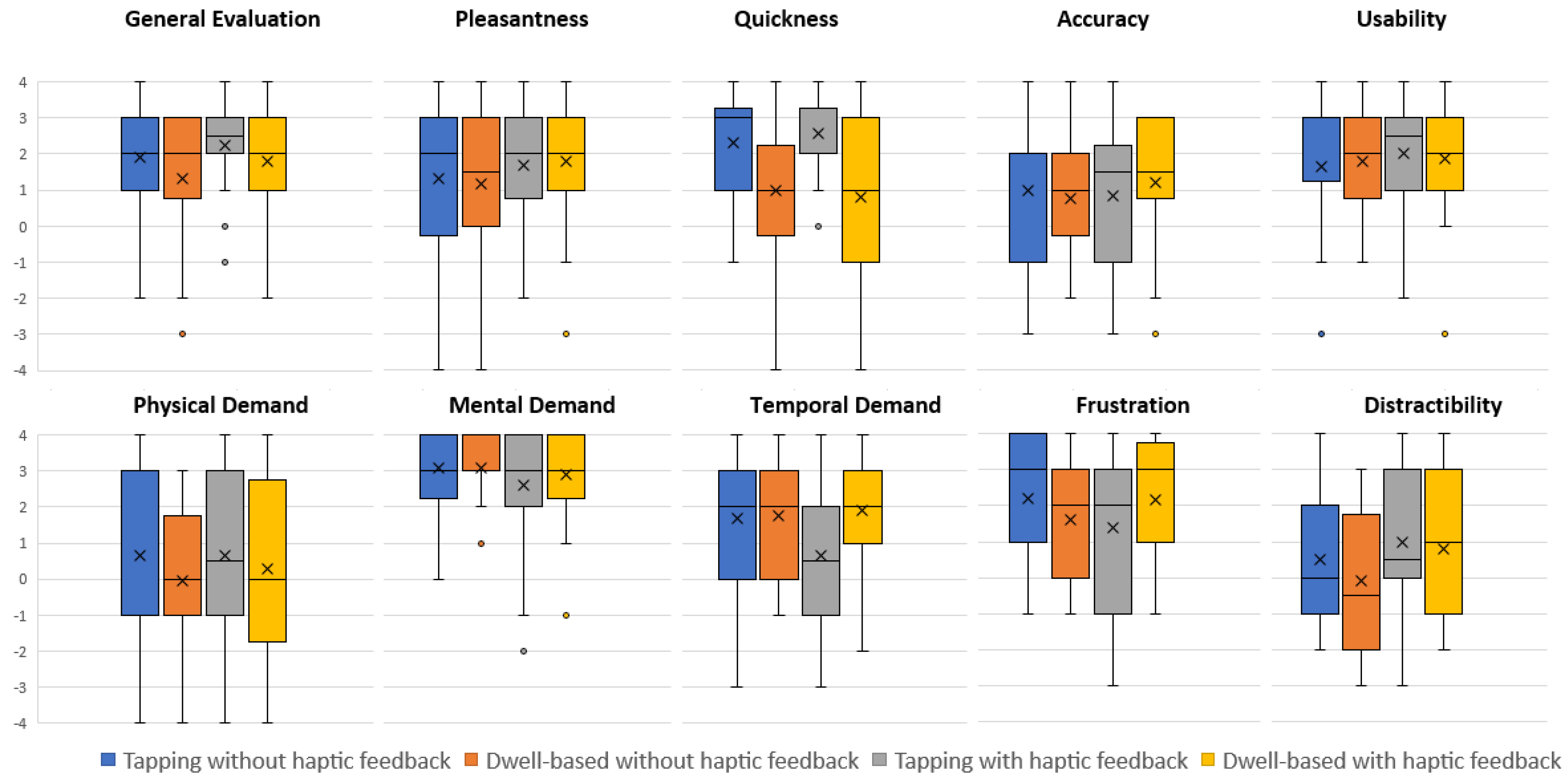
| General evaluation | 2.45 | 2.00 | 2.95 | 2.60 | <0.05 |
| Pleasantness | 2.40 | 2.25 | 2.68 | 2.68 | ns |
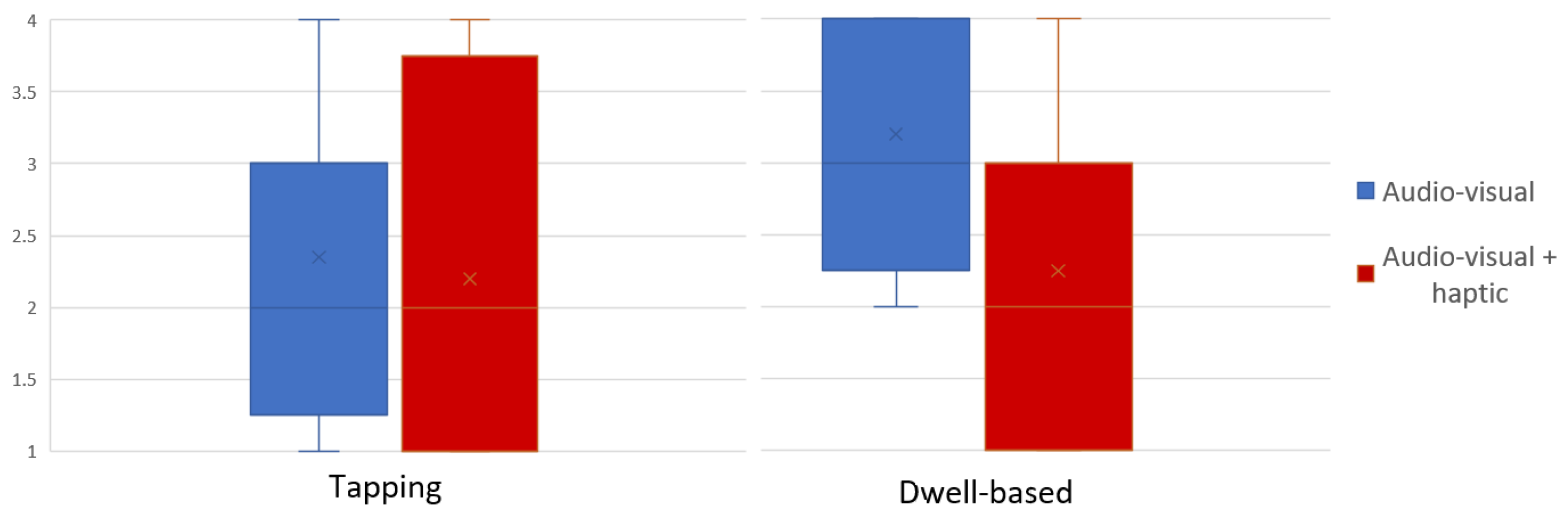
| Quickness | 2.93 | 2.05 | 3.18 | 1.85 | <0.001 |
| Accuracy | 2.45 | 2.15 | 2.68 | 2.73 | ns |
| Physical demand | 2.65 | 2.38 | 2.83 | 2.15 | ns |
| Mental demand | 2.65 | 2.58 | 2.45 | 2.33 | ns |
| Temporal demand | 2.80 | 2.50 | 1.98 | 2.73 | ns |
| Frustration | 2.78 | 2.38 | 2.20 | 2.65 | ns |
| Distractibility | 2.45 | 2.00 | 2.80 | 2.75 | ns |
| Usability/applicability | 2.58 | 2.35 | 2.75 | 2.33 | ns |
| Interaction by tapping gesture | ‘It was not so fatiguing;’ ‘it was the easiest and most comfortable;’ ‘I was not getting tired;’ ‘it was more natural and fast;’ ‘I felt much like with iPad’ |
| Interaction by dwell-based gesture | ‘It was too slow;’ ‘it was unpleasant;’ ‘it took too much time’ |
| Haptic feedback | ‘Haptic feedback gave me some support;’ ‘haptic in tapping distracted;’ ‘good-to-have;’ ‘dwell-based gesture improved feedback;’ ‘more fun and exciting’ |
| Interaction with the fogscreen | ‘Continued trials meant my finger got cold;’ ‘bottom targets were difficult to see and touch when crouching down;’ ‘the experience felt exciting’ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Remizova, V.; Sand, A.; MacKenzie, I.S.; Špakov, O.; Nyyssönen, K.; Rakkolainen, I.; Kylliäinen, A.; Surakka, V.; Gizatdinova, Y. Mid-Air Gestural Interaction with a Large Fogscreen. Multimodal Technol. Interact. 2023, 7, 63. https://doi.org/10.3390/mti7070063
Remizova V, Sand A, MacKenzie IS, Špakov O, Nyyssönen K, Rakkolainen I, Kylliäinen A, Surakka V, Gizatdinova Y. Mid-Air Gestural Interaction with a Large Fogscreen. Multimodal Technologies and Interaction. 2023; 7(7):63. https://doi.org/10.3390/mti7070063
Chicago/Turabian StyleRemizova, Vera, Antti Sand, I. Scott MacKenzie, Oleg Špakov, Katariina Nyyssönen, Ismo Rakkolainen, Anneli Kylliäinen, Veikko Surakka, and Yulia Gizatdinova. 2023. "Mid-Air Gestural Interaction with a Large Fogscreen" Multimodal Technologies and Interaction 7, no. 7: 63. https://doi.org/10.3390/mti7070063