An Item–Item Collaborative Filtering Recommender System Using Trust and Genre to Address the Cold-Start Problem


Abstract
:1. Introduction
1.1. Motivation
1.2. Paper Contribution
- A single asymmetric similarity method has been proposed by taking account of items’ genre with the reliability between them which defines the direct asymmetric similar relation of items.
- Another new similarity method has been defined by identifying the correlations of items based on the transitive relations of reliability between them.
- A prediction algorithm is proposed to increase the accuracy of recommendation.
- A detailed experiment is done to prove our statement that the proposed methodology outperforms existing methods.
2. Related Works
3. Proposed Method
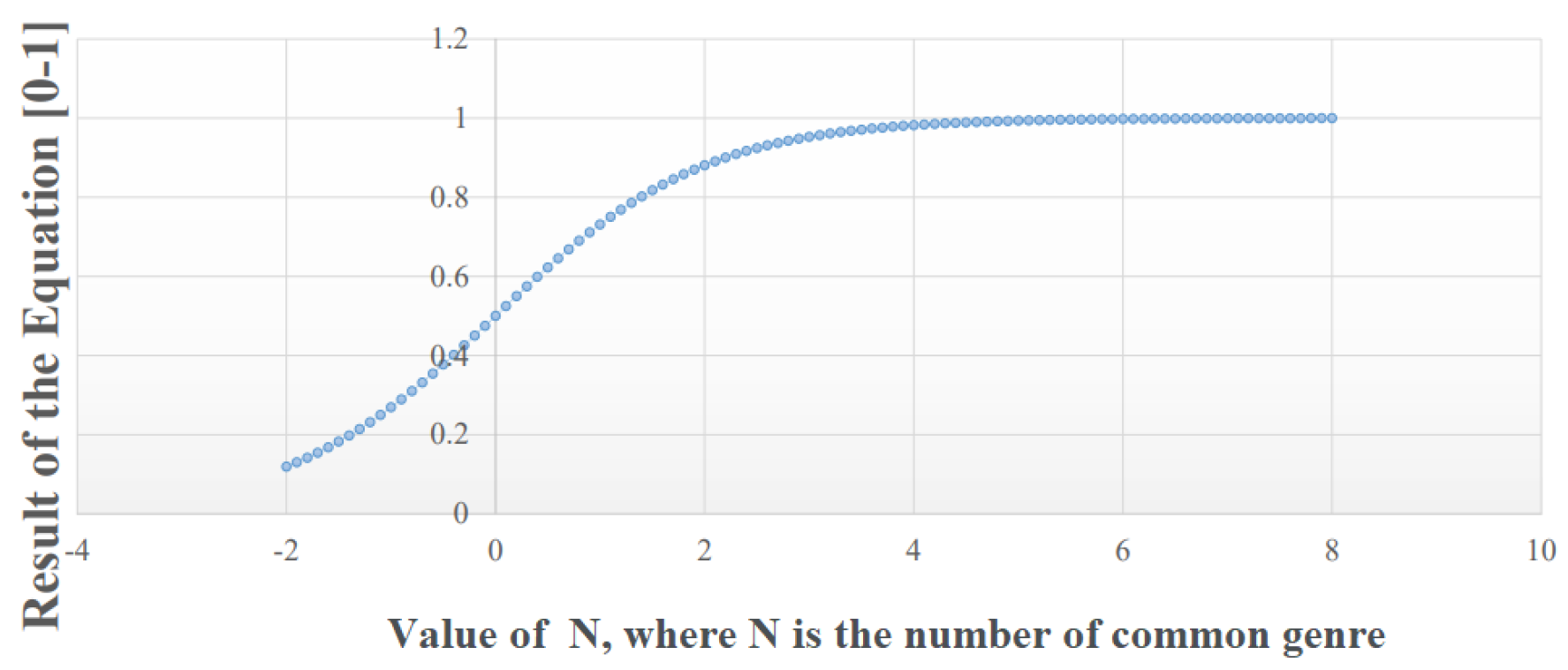
3.1. Genre Based Correlation Determination
3.2. Confidence with Laplace Correction
3.3. Direct Inter-Connectivity Detection: Genre Based Item–Item Asymmetric Similarity
3.4. Relative Inter-Connectivity Detection: Inferring Transitivity of Reliable Correlation of Items
3.5. Proposed Prediction Algorithm
| Algorithm 1: Enhanced Prediction Algorithm |
| Input: A list of users, and items, and similarity values of items, Output: A list of predicted ratings
|
4. Experimental Setup and Evaluations
4.1. Dataset
4.2. Evolution Metrics
4.2.1. Mean Absolute Error
4.2.2. Precision
4.2.3. Recall
4.2.4. F-Measures
4.2.5. Mean Reciprocal Rank
5. Results and Discussion
5.1. Prediction Accuracy
5.1.1. Performance Evaluation: Movielens DataSet
5.1.2. Performance Evaluation: MovieTweets DataSet
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Melville, P.; Sindhwani, V. Recommender systems. In Encyclopedia of Machine Learning and Data Mining; Springer: Berlin, Germany, 2017; pp. 1056–1066. [Google Scholar]
- Tarus, J.K.; Niu, Z.; Mustafa, G. Knowledge-based recommendation: A review of ontology-based recommender systems for e-learning. Artif. Intell. Rev. 2018, 50, 21–48. [Google Scholar] [CrossRef]
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Nobahari, V.; Jalali, M.; Mahdavi, S.J.S. ISoTrustSeq: A social recommender system based on implicit interest, trust and sequential behaviors of users using matrix factorization. J. Intell. Inf. Syst. 2019, 52, 239–268. [Google Scholar] [CrossRef]
- Barkan, O.; Koenigstein, N. Item2vec: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing (MLSP), Vietri sul Mare, Italy, 13–16 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning based recommendation system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; ACM: New York, NY, USA, 2008; pp. 426–434. [Google Scholar]
- Gantner, Z.; Drumond, L.; Freudenthaler, C.; Rendle, S.; Schmidt-Thieme, L. Learning attribute-to-feature mappings for cold-start recommendations. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 176–185. [Google Scholar]
- Menon, A.K.; Elkan, C. Predicting labels for dyadic data. Data Min. Knowl. Discov. 2010, 21, 327–343. [Google Scholar] [CrossRef] [Green Version]
- Hwang, C.S.; Chen, Y.P. Using trust in collaborative filtering recommendation. In Proceedings of the International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems, Kyoto, Japan, 26–29 June 2007; Springer: Berlin, Germany, 2007; pp. 1052–1060. [Google Scholar]
- Gao, Q.; Gao, L.; Fan, J.; Ren, J. A preference elicitation method based on bipartite graphical correlation and implicit trust. Neurocomputing 2017, 237, 92–100. [Google Scholar] [CrossRef] [Green Version]
- Roy, F.; Sarwar, S.M.; Hasan, M. User similarity computation for collaborative filtering using dynamic implicit trust. In Proceedings of the International Conference on Analysis of Images, Social Networks and Texts, Yekaterinburg, Russia, 9–11 April 2015; Springer: Berlin, Germany, 2015; pp. 224–235. [Google Scholar]
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation systems: Principles, methods and evaluation. Egypt. Inf. J. 2015, 16, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Duricic, T.; Lacic, E.; Kowald, D.; Lex, E. Trust-based collaborative filtering: Tackling the cold start problem using regular equivalence. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2 October 2018; ACM: New York, NY, USA, 2018; pp. 446–450. [Google Scholar]
- Logesh, R.; Subramaniyaswamy, V. A reliable point of interest recommendation based on trust relevancy between users. Wirel. Pers. Commun. 2017, 97, 2751–2780. [Google Scholar] [CrossRef]
- Ma, X.; Ma, J.; Li, H.; Jiang, Q.; Gao, S. ARMOR: A trust-based privacy-preserving framework for decentralized friend recommendation in online social networks. Future Gener. Comput. Syst. 2018, 79, 82–94. [Google Scholar] [CrossRef]
- Berkhim, P.; Xu, Z.; Mao, J.; Rose, D.E.; Taha, A.; Maghoul, F. Trust Propagation through Both Explicit and Implicit Social Networks. U.S. Patent 9,576,029, 21 February 2017. [Google Scholar]
- Portugal, I.; Alencar, P.; Cowan, D. The use of machine learning algorithms in recommender systems: A systematic review. Expert Syst. Appl. 2018, 97, 205–227. [Google Scholar] [CrossRef] [Green Version]
- Dascalu, M.I.; Bodea, C.N.; Moldoveanu, A.; Mohora, A.; Lytras, M.; de Pablos, P.O. A recommender agent based on learning styles for better virtual collaborative learning experiences. Comput. Hum. Behav. 2015, 45, 243–253. [Google Scholar] [CrossRef]
- Pu, P.; Chen, L. Trust building with explanation interfaces. In Proceedings of the 11th International Conference on Intelligent User Interfaces, Sydney, Australia, 29 January–1 February 2006; ACM: New York, NY, USA, 2006; pp. 93–100. [Google Scholar] [Green Version]
- Goldberg, D.; Nichols, D.; Oki, B.M.; Terry, D. Using collaborative filtering to weave an information tapestry. Commun. ACM 1992, 35, 61–70. [Google Scholar] [CrossRef]
- Parvin, H.; Moradi, P.; Esmaeili, S. A collaborative filtering method based on genetic algorithm and trust statements. In Proceedings of the 2018 6th Iranian Joint Congress on Fuzzy and Intelligent Systems (CFIS), Kerman, Iran, 28 February–2 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 13–16. [Google Scholar]
- Cinicioglu, E.N.; Shenoy, P.P. A new heuristic for learning Bayesian networks from limited datasets: A real-time recommendation system application with RFID systems in grocery stores. Ann. Oper. Res. 2016, 244, 385–405. [Google Scholar] [CrossRef]
- Covington, P.; Adams, J.; Sargin, E. Deep neural networks for youtube recommendations. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; ACM: New York, NY, USA, 2016; pp. 191–198. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Analysis of recommendation algorithms for e-commerce. In Proceedings of the 2nd ACM Conference on Electronic Commerce, Minneapolis, MN, USA, 17–20 October 2000; ACM: New York, NY, USA, 2000; pp. 158–167. [Google Scholar]
- Liu, H.; Hu, Z.; Mian, A.; Tian, H.; Zhu, X. A new user similarity model to improve the accuracy of collaborative filtering. Knowl.-Based Syst. 2014, 56, 156–166. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; ACM: New York, NY, USA, 2001; pp. 285–295. [Google Scholar] [Green Version]
- Linden, G.; Smith, B.; York, J. Amazon. com recommendations: Item-to-item collaborative filtering. IEEE Internet Comput. 2003, 1, 76–80. [Google Scholar] [CrossRef]
- Davidson, J.; Liebald, B.; Liu, J.; Nandy, P.; Van Vleet, T.; Gargi, U.; Gupta, S.; He, Y.; Lambert, M.; Livingston, B.; et al. The YouTube video recommendation system. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; ACM: New York, NY, USA, 2010; pp. 293–296. [Google Scholar] [Green Version]
- Li, D.; Chen, C.; Lv, Q.; Shang, L.; Zhao, Y.; Lu, T.; Gu, N. An algorithm for efficient privacy-preserving item-based collaborative filtering. Future Gener. Comput. Syst. 2016, 55, 311–320. [Google Scholar] [CrossRef]
- Dakhel, A.M.; Malazi, H.T.; Mahdavi, M. A social recommender system using item asymmetric correlation. Appl. Intell. 2018, 48, 527–540. [Google Scholar] [CrossRef]
- Papagelis, M.; Plexousakis, D.; Kutsuras, T. Alleviating the sparsity problem of collaborative filtering using trust inferences. In Proceedings of the International Conference on Trust Management, Paris, France, 23–26 May 2005; Springer: Berlin, Germany, 2005; pp. 224–239. [Google Scholar]
- Zhang, Z.; Liu, Y.; Jin, Z.; Zhang, R. A dynamic trust based two-layer neighbor selection scheme towards online recommender systems. Neurocomputing 2018, 285, 94–103. [Google Scholar] [CrossRef]
- Parvin, H.; Moradi, P.; Esmaeili, S. TCFACO: Trust-aware collaborative filtering method based on ant colony optimization. Expert Syst. Appl. 2019, 118, 152–168. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Liu, J.; Li, W. Social collaborative filtering by trust. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1633–1647. [Google Scholar] [CrossRef]
- Linda, S.; Bharadwaj, K.K. A fuzzy trust enhanced collaborative filtering for effective context-aware recommender systems. In Proceedings of the First, International Conference on Information and Communication Technology for Intelligent Systems, Ahmedabad, India, 28–29 November 2015; Springer: Cham, Switzerland, 2016; Volume 2, pp. 227–237. [Google Scholar]
- Yera, R.; Martinez, L. Fuzzy tools in recommender systems: A survey. Int. J. Comput. Intell. Syst. 2017, 10, 776–803. [Google Scholar] [CrossRef]
- Ebesu, T.; Fang, Y. Neural Semantic Personalized Ranking for item cold-start recommendation. Inf. Retr. J. 2017, 20, 109–131. [Google Scholar] [CrossRef]
- Barjasteh, I.; Forsati, R.; Masrour, F.; Esfahanian, A.H.; Radha, H. Cold-start item and user recommendation with decoupled completion and transduction. In Proceedings of the 9th ACM Conference on Recommender Systems, Vienna, Austria, 16–20 September 2015; ACM: New York, NY, USA, 2015; pp. 91–98. [Google Scholar]
- Blerina, L.; Kostas, K.; Stathes, H. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar]
- Beel, J.; Genzmehr, M.; Langer, S.; Nürnberger, A.; Gipp, B. A comparative analysis of offline and online evaluations and discussion of research paper recommender system evaluation. In Proceedings of the International Workshop on Reproducibility and Replication in Recommender Systems Evaluation, Hong Kong, China, 12 October 2013; ACM: New York, NY, USA, 2013; pp. 7–14. [Google Scholar] [Green Version]
- Dooms, S.; De Pessemier, T.; Martens, L. Movietweetings: A movie rating dataset collected from twitter. In Proceedings of the Workshop on Crowdsourcing and Human Computation for Recommender Systems, held in conjunction with the 7th ACM Conference on Recommender Systems, Hong Kong, China, 12 October 2013; ACM: New York, NY, USA, 2013; Volume 2013, p. 43. Available online: https://biblio.ugent.be/publication/4284240 (accessed on 10 December 2018).
- Herlocker, J.L.; Konstan, J.A.; Terveen, L.G.; Riedl, J.T. Evaluating collaborative filtering recommender systems. ACM Trans. Inf. Syst. (TOIS) 2004, 22, 5–53. [Google Scholar] [CrossRef]
- Craswell, N. Mean Reciprocal Rank; Liu, L., ÖZsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; p. 1703. [Google Scholar] [CrossRef]
- Roberts, D.R.; Bahn, V.; Ciuti, S.; Boyce, M.S.; Elith, J.; Guillera-Arroita, G.; Hauenstein, S.; Lahoz-Monfort, J.J.; Schröder, B.; Thuiller, W.; et al. Cross-validation strategies for data with temporal, spatial, hierarchical, or phylogenetic structure. Ecography 2017, 40, 913–929. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Movie/Genre | Action | Romantic | Horror | Adventure |
|---|---|---|---|---|
| Stardust | - | 1 | - | 1 |
| Mr. and Mrs. Smith | 1 | 1 | - | - |
| Wolf Girl | - | 1 | 1 | 1 |
| Constantine | 1 | - | 1 | - |
| Wrong Turn | - | - | 1 | - |
| Stardust | Mr. and Mrs. Smith | Wolf Girl | Constantine | Wrong Turn | |
|---|---|---|---|---|---|
| Stardust | - | 0.250 | 0.165 | 0.000 | 0.000 |
| Mr. and Mrs. Smith | - | - | 0.165 | 0.250 | 0.000 |
| Wolf Girl | - | - | - | 0.165 | 0.330 |
| Constantine | - | - | - | - | 0.500 |
| Item1 | Item2 | Item3 | Item4 | Item5 | |
|---|---|---|---|---|---|
| Item1 | - | 0.52 | 0.00 | 0.33 | 0.25 |
| Item2 | 0.40 | - | 0.65 | 0.00 | 0.00 |
| Item3 | 0.00 | 0.25 | - | 0.16 | 0.33 |
| Item4 | 0.81 | 0.00 | 0.30 | - | 0.50 |
| Item5 | 0.10 | 0.00 | 0.41 | 0.65 | - |
| Item1 | Item2 | Item3 | Item4 | Item5 | |
|---|---|---|---|---|---|
| Item1 | - | 0.52 | 0.41 | 0.33 | 0.25 |
| Item2 | 0.40 | - | 0.65 | 0.38 | 0.41 |
| Item3 | 0.35 | 0.25 | - | 0.16 | 0.33 |
| Item4 | 0.81 | 0.66 | 0.30 | - | 0.50 |
| Item5 | 0.10 | 0.31 | 0.41 | 0.65 | - |
| Datasets | Users | Items | Rating Range | Genre |
|---|---|---|---|---|
| Movielens | 6040 | 3952 | 1–5 | 19 |
| MovieTweets | 43,357 | 25,193 | 1–10 | 28+ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, M.; Roy, F. An Item–Item Collaborative Filtering Recommender System Using Trust and Genre to Address the Cold-Start Problem. Big Data Cogn. Comput. 2019, 3, 39. https://doi.org/10.3390/bdcc3030039
Hasan M, Roy F. An Item–Item Collaborative Filtering Recommender System Using Trust and Genre to Address the Cold-Start Problem. Big Data and Cognitive Computing. 2019; 3(3):39. https://doi.org/10.3390/bdcc3030039
Chicago/Turabian StyleHasan, Mahamudul, and Falguni Roy. 2019. "An Item–Item Collaborative Filtering Recommender System Using Trust and Genre to Address the Cold-Start Problem" Big Data and Cognitive Computing 3, no. 3: 39. https://doi.org/10.3390/bdcc3030039
APA StyleHasan, M., & Roy, F. (2019). An Item–Item Collaborative Filtering Recommender System Using Trust and Genre to Address the Cold-Start Problem. Big Data and Cognitive Computing, 3(3), 39. https://doi.org/10.3390/bdcc3030039