
When Federated Learning Meets Watermarking: A Comprehensive Overview of Techniques for Intellectual Property Protection
 , , and
, , and
Abstract
:1. Introduction
1.1. Contributions
- We emphasize the foundational principle of secure federated learning and stress the importance of comprehensive security guarantees that align with the trust levels of the participants. This includes addressing various aspects such as training on non-Independently and Identically Distributed (non-I.I.D) data and ensuring robustness against poisoning and backdooring attacks.
- We conduct a comprehensive examination of the challenges concerning model watermarking in the context of federated learning.
- We expand upon the work presented in [16] by providing an in-depth analysis of nine currently available DNN watermarking schemes in the FL context along with their limitations.
- We bring attention to unresolved issues that necessitate further exploration.
1.2. Organization
2. Background
2.1. Federated Learning
- Setup:
- Central Server: A central server manages the overall training process and initiates model updates.
- Clients: These are the individual devices, such as smartphones, IoT devices, or computers, that participate in the training process. Each edge device has its local dataset that cannot be shared with the central server due to privacy concerns.
- Initialization:
- Initially, the central server initiates a global model (e.g., with random parameters) and distributes it to a subset of clients selected randomly at each round.
- Local Training:
- Each client trains the global model on its local dataset using its computational resources. The training is typically performed using gradient descent or a similar optimization algorithm.
- Model Update:
- After the local training is complete, the clients generate a model update (typically gradients) based on the locally processed data.
- Aggregation:
- The clients send their model updates back to the central server without sharing their raw data.
- The central server aggregates all received model updates to create a refined global model. This aggregation procedure can be completed in different ways [20,21,22,23,24]. To give an idea, the most common one is FedAvg [25] where the aggregation is completed by averaging the model weights (see Section 4.2).
- Iterative Process:
- Steps 3 to 5 are repeated for multiple rounds or epochs, allowing the global model to improve over time by leveraging knowledge from various clients.
- Centralized Model Deployment:
- Once the federated training process is complete, the final global model can be deployed from the central server to all clients for local inference.
2.2. DNN Watermarking
2.2.1. Requirements
- Pruning Attack: Setting the less useful weights of the model to zero.
- Fine-Tuning Attack: Re-training the model and updating its weights without decreasing accuracy.
- Overwriting Attack: Embedding a new watermark to replace the original one.
- Wang and Kerschbaum Attack: For static White-Box watermarking algorithms, it alters the weight distribution of the watermarked model, relying on visual inspection.
- Property Inference Attack: Training a discriminating model to distinguish watermarked from non-watermarked models, thereby detecting if a protected model is no longer watermarked.
- Another attack is the Ambiguity Attack, which forges a new watermark on a model, making it challenging for external entities, like legal authorities, to determine the legitimate watermark owner. This ambiguity prevents the legitimate owner from claiming the copyright of the intellectual property.
2.2.2. Related Works
- Initially, a target model M is considered, and a features extraction function is applied with a secret key . The features obtained can be a subset of the model weights, where indicates the indices of the selected weights. Alternatively, the features can be model activation maps for specific input data secretly chosen from a trigger set. These features are then utilized for watermark insertion and extraction.
- The embedding of a watermark message b involves regularizing M using a specific regularization term . This regularization term ensures that the projection function applied to the selected features encodes the watermark b in a predetermined watermark space, which depends on the secret key . The goal is to achieve the following after training:where is the watermarked version of the target model M. To achieve this, the watermarking regularization term relies on a distance measure d defined in the watermark space. For example, in the case of a binary watermark with a binary string of length l, i.e., , the distance measure could be the Hamming distance, Hinge distance, or Cross-Entropy. The regularization term is formulated as follows:To preserve the accuracy of the target model, the watermarked model is usually derived from M through a fine-tuning operation parameterized with the following loss function:where represents the original loss function of the network, which is essential to ensure good performance in the main task. is the regularization term added to facilitate proper watermark extraction, and is a parameter that adjusts the trade-off between the original loss term and the regularization term.
- The watermark retrieval process is relatively straightforward. It involves using both the features extraction function and the projection function as follows:where is the extracted message from the watermarked model .
- Content Watermarking: Incorporating meaningful content into images from the training dataset. The model should be activated by this content and provide the corresponding predefined label. In our example, the text “TEST” serves as the trigger for the model.
- Unrelated Watermarking: Images that are irrelevant from the main task of the model. Each image has an associated label (like in [75]) or each sample can have its specific output. In our example, some images from the MNIST dataset are used to trigger the model.
- Noise Watermarking: Adding a specific noise to images from the train set. Then, the model classifies any images with this specific noise as a predefined label. In our example, we add a small Gaussian noise to trigger the model.
- True adversaries: Samples that are misclassified by the model while being close to being well classified.
- False adversaries: Well-classified samples from which we add an adversarial perturbation without changing their classification.
3. Watermarking for Federated Learning
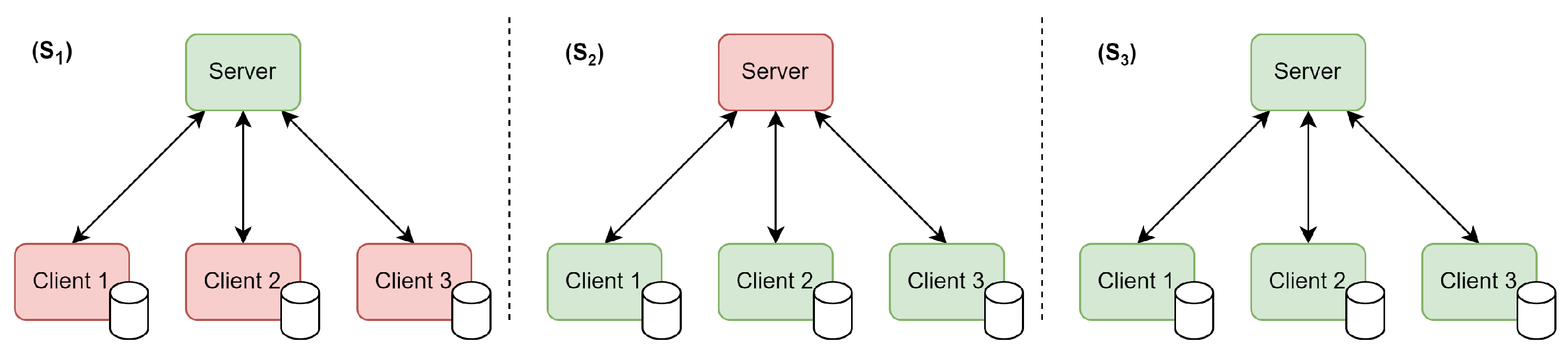
3.1. Definition
- (S1)
- Server: The server is in charge of watermarking the global model.
- (S2)
- Clients: One or multiple clients watermark their updates in order to watermark the global model.
- (S3)
- Server and clients: The server and the clients collaborate to watermark the global model together.
- Capacity: When multiple clients want to insert their own message , the watermarking technique needs to avoid possible conflict between the different inserted . The number of bits needs to be then enough.
- Generality: In a real FL scenario, many additional mechanisms are added for security and privacy such as robust aggregation functions (Section 4.2) or differential privacy [93] (Section 4.5). The watermarking technique must be applied independent of these mechanisms.
- Efficiency: The cost generated by the embedding process is more crucial in FL. For example, in a cross-device architecture, clients have low computation power and they cannot perform many operations. The watermarking techniques must take this parameter into account.
- Secrecy: If all parties are not enrolled in the watermarking process, the watermark should not be detected. In particular, if one or some clients are trying to watermark the global model, their updates need to be similar to benign updates. Otherwise, the server can use a defensive aggregation function to cancel the FL watermarking process (as described in Section 2.1).
- Robustness: Since the model can be redistributed for any clients or the server, the watermark must track who is the traitor. Traitor tracing is the fact that each actor of the federation has a unique watermark that can be used to uniquely identify the owner in addition to a global watermark.
3.2. Related Works
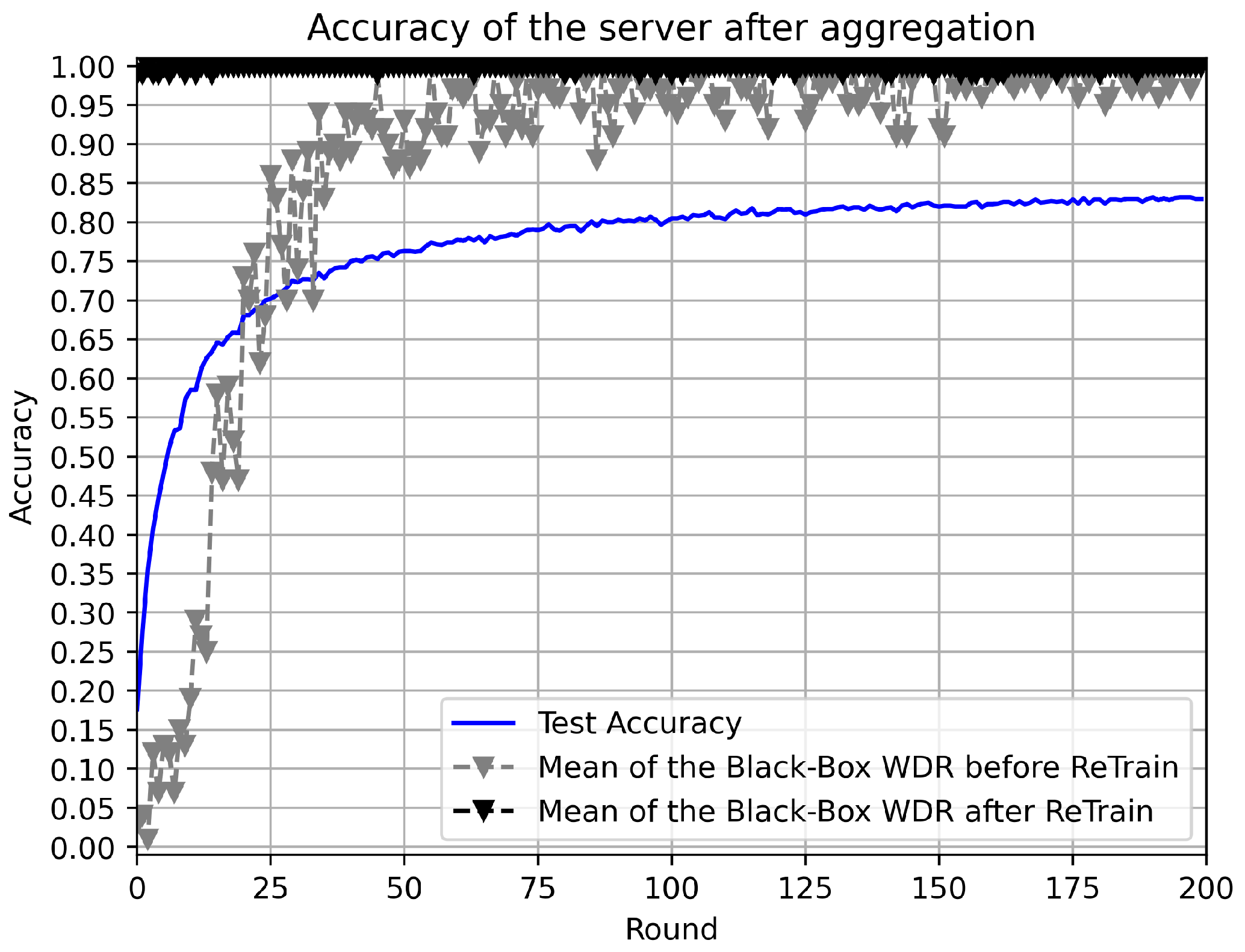
3.2.1. WAFFLE
- PreTrain: Train an initialized model with the trigger set until the model has good accuracy on this set.
- ReTrain: Fine-tune the model with the trigger set until the model has learned the watermark.
3.2.2. FedIPR
- Black-Box Watermark: Each client generates a trigger set using the Projected Gradient Descent technique in a small Convolutional Neural Network (CNN) trained with the local data.
- White-Box Watermark: Each client generates a random secret matrix and a location in the Batch-Normalization layers to embed its message.
3.2.3. FedTracker
- Global Black-Box Watermark: A trigger set is generated using the WAFFLEPattern method [17].
- White-Box Watermark: The server generates a random secret matrix and a fingerprint for each client.
3.2.4. Scheme of Liu et al.
3.2.5. FedRight
3.2.6. FedCIP
3.2.7. Yang et al. Scheme
3.2.8. Merkle-Sign
3.2.9. FedZKP
4. Discussion
4.1. Trigger-Set-Based Watermarking on the Server Side
- Have access to its private dataset ;
- Train the model on both the main task dataset and its trigger set at the same time.
4.2. Aggregation Functions
4.3. Clients Selection
4.4. Cross-Device Setting
4.5. Differential Privacy and Homomorphic Encryption
4.6. Watermarking for Non-Client–Server Framework
4.7. Attacks from Clients and/or Server Sides
- Client-side solutions—None of these solutions have undergone testing with poisoning detection mechanisms such as anomaly detection, and only a few of them consider defensive aggregation functions like Krum and GeoMed.
- Server-side solutions—Black-Box watermarking is still challenging since the training data are not available for the server. And no watermarking algorithm has been found compatible with cryptographic tools like homomorphic encryption (HE).
- Other FL architectures—Only one method is compatible with peer-to-peer FL, and no solution is proposed for split learning. No solution has been tested with the cross-device setting, despite its importance in FL.
- Data distribution—Only a small portion of the proposed solutions have been tested in non-I.I.D scenarios, and none have been experimented with in vertical data distribution.
- FL framework—Despite the number of proposed FL watermarking solutions, no FL framework integrates such a tool as presented in Table 1.
5. Perspectives
- As mentioned by Boenisch [52], like most centralized watermarking techniques, FL watermarking is designed and tested for image classification tasks. FedIPR [18] is the only method that extends the experimental testing to Natural Language Processing (NLP) tasks. Thus, it is of interest to design new FL watermarking techniques for other tasks such as Object Detection [119], Semantic Segmentation [120], Regression [121], Conversational [122], and so on.
- It is worth noting that each state-of-the-art method has been experimented with non-standardized parameters, as illustrated in Table 3, Table 5, and Table 6. Furthermore, the majority of authors have not shared their source codes, making reproducibility and method comparison challenging. Table 6 summarizes the performance of each method. Given that they were tested with different datasets, model architectures, and parameters, making a fair comparison is inherently difficult. Nonetheless, it is evident that these methods have achieved commendable performance. As a final observation, it is worth mentioning that the tested models and datasets may not fully align with the realities of federated learning frameworks in domains such as health care [123] and IoT [124], as discussed in Section 4.4.
- Merkle-Sign [105] and FedZKP [88] are the only two proposals that present a rigorous ownership verification process based on cryptographic security. Such a verification protocol is also a research axis that needs to be investigated. This is of interest, for example, to counteract ambiguity and spoiling attacks or to enable traitor tracing.
- In Table 1, we have listed eleven open-source federated learning frameworks. Half of these frameworks are designed for research purposes, while the other half serve industrial purposes. Unfortunately, none of these solutions includes a watermarking feature or a pipeline to facilitate the integration and experimentation of such protection measures, as has been completed for differential privacy, homomorphic encryption, multi-party computation, and trusted execution environments [8,11,12,13,29,30]. Furthermore, as discussed in Section 4.5, it is worth noting that proposed federated learning watermarking solutions do not always account for the presence of these other security mechanisms within their frameworks.
6. Conclusions
Author Contributions
Funding

Data Availability Statement
Conflicts of Interest
References
- Singh, K.; Booma, P.; Eaganathan, U. E-commerce system for sale prediction using machine learning technique. Proc. J. Physics Conf. Ser. 2020, 1712, 012042. [Google Scholar] [CrossRef]
- Conze, P.h.; Daho, M.E.H.; Li, Y.; Brahim, I.; Le Boité, H.; Massin, P.; Tadayoni, R.; Cochener, B.; Quellec, G.; Lamard, M.; et al. Time-aware deep models for predicting diabetic retinopathy progression. Investig. Ophthalmol. Vis. Sci. 2023, 64, 246. [Google Scholar]
- Mallozzi, P.; Pelliccione, P.; Knauss, A.; Berger, C.; Mohammadiha, N. Autonomous vehicles: State of the art, future trends, and challenges. In Automotive Systems and Software Engineering: State of The Art and Future Trends; Springer: Berlin/Heidelberg, Germany, 2019; pp. 347–367. [Google Scholar]
- Regulation, P. General data protection regulation. Intouch 2018, 25, 1–5. [Google Scholar]
- Piper, D. Data Protection Laws of the World; DLA Piper: London, UK, 2019. [Google Scholar]
- Chen, J.; Sun, J. Understanding the chinese data security law. Int. Cybersecur. Law Rev. 2021, 2, 209–221. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Melbourne, VIC, Australia, 19–20 August 2017; pp. 1273–1282. [Google Scholar]
- Benaissa, A.; Retiat, B.; Cebere, B.; Belfedhal, A.E. TenSEAL: A library for encrypted tensor operations using homomorphic encryption. arXiv 2021, arXiv:2104.03152. [Google Scholar]
- Gehlhar, T.; Marx, F.; Schneider, T.; Suresh, A.; Wehrle, T.; Yalame, H. SAFEFL: MPC-friendly Framework for Private and Robust Federated Learning. Cryptol. Eprint Arch. 2023, 2023, 555. [Google Scholar]
- Chen, H.; Laine, K.; Rindal, P. Fast private set intersection from homomorphic encryption. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1243–1255. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Wei, K.; Li, J.; Ma, C.; Ding, M.; Chen, W.; Wu, J.; Tao, M.; Poor, H.V. Personalized Federated Learning with Differential Privacy and Convergence Guarantee. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4488–4503. [Google Scholar] [CrossRef]
- Zheng, W.; Cao, Y.; Tan, H. Secure sharing of industrial IoT data based on distributed trust management and trusted execution environments: A federated learning approach. Neural Comput. Appl. 2023, 2023, 1–11. [Google Scholar] [CrossRef]
- Xu, Z.; Zhang, Y.; Andrew, G.; Choquette-Choo, C.A.; Kairouz, P.; McMahan, H.B.; Rosenstock, J.; Zhang, Y. Federated Learning of Gboard Language Models with Differential Privacy. arXiv 2023, arXiv:2305.18465. [Google Scholar]
- Uchida, Y.; Nagai, Y.; Sakazawa, S.; Satoh, S. Embedding watermarks into deep neural networks. In Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval, Bucharest, Romania, 6–9 June 2017; pp. 269–277. [Google Scholar]
- Yang, Q.; Huang, A.; Fan, L.; Chan, C.S.; Lim, J.H.; Ng, K.W.; Ong, D.S.; Li, B. Federated Learning with Privacy-preserving and Model IP-right-protection. Mach. Intell. Res. 2023, 20, 19–37. [Google Scholar] [CrossRef]
- Tekgul, B.G.; Xia, Y.; Marchal, S.; Asokan, N. WAFFLE: Watermarking in federated learning. In Proceedings of the 2021 40th International Symposium on Reliable Distributed Systems (SRDS), Chicago, IL, USA, 20–23 September 2021; pp. 310–320. [Google Scholar]
- Li, B.; Fan, L.; Gu, H.; Li, J.; Yang, Q. FedIPR: Ownership verification for federated deep neural network models. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4521–4536. [Google Scholar] [CrossRef] [PubMed]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Wang, J.; Liu, Q.; Liang, H.; Joshi, G.; Poor, H.V. Tackling the objective inconsistency problem in heterogeneous federated optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7611–7623. [Google Scholar]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.; Stich, S.; Suresh, A.T. Scaffold: Stochastic controlled averaging for federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 5132–5143. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 1. [Google Scholar]
- Guerraoui, R.; Rouault, S. The hidden vulnerability of distributed learning in byzantium. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3521–3530. [Google Scholar]
- Brendan McMahan, H.; Moore, E.; Ramage, D.; Hampson, S.; Agüera y Arcas, B. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602. [Google Scholar]
- Roy, A.G.; Siddiqui, S.; Pölsterl, S.; Navab, N.; Wachinger, C. Braintorrent: A peer-to-peer environment for decentralized federated learning. arXiv 2019, arXiv:1905.06731. [Google Scholar]
- Vepakomma, P.; Gupta, O.; Swedish, T.; Raskar, R. Split learning for health: Distributed deep learning without sharing raw patient data. arXiv 2018, arXiv:1812.00564. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Mo, F.; Shamsabadi, A.S.; Katevas, K.; Demetriou, S.; Leontiadis, I.; Cavallaro, A.; Haddadi, H. Darknetz: Towards model privacy at the edge using trusted execution environments. In Proceedings of the 18th International Conference on Mobile Systems, Applications, and Services, Florence, Italy, 18–22 May 2020; pp. 161–174. [Google Scholar]
- Kanagavelu, R.; Li, Z.; Samsudin, J.; Yang, Y.; Yang, F.; Goh, R.S.M.; Cheah, M.; Wiwatphonthana, P.; Akkarajitsakul, K.; Wang, S. Two-phase multi-party computation enabled privacy-preserving federated learning. In Proceedings of the 2020 20th IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGRID), Melbourne, VIC, Australia, 11–14 May 2020; pp. 410–419. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to {Byzantine-Robust} federated learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Virtual Evenet, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Shi, J.; Wan, W.; Hu, S.; Lu, J.; Zhang, L.Y. Challenges and approaches for mitigating byzantine attacks in federated learning. In Proceedings of the 2022 IEEE International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), Wuhan, China, 9–11 December 2022; pp. 139–146. [Google Scholar]
- Huang, A. Dynamic backdoor attacks against federated learning. arXiv 2020, arXiv:2011.07429. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.Y.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 16–21 June 2018; pp. 5650–5659. [Google Scholar]
- Anass, E.M.; Gouenou, C.; Reda, B. Poisoning-Attack Detection Using an Auto-encoder for Deep Learning Models. In Proceedings of the International Conference on Digital Forensics and Cyber Crime, Boston, MA, USA, 16–18 November 2022; pp. 368–384. [Google Scholar]
- Gu, Z.; Yang, Y. Detecting malicious model updates from federated learning on conditional variational autoencoder. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Portland, OR, USA, 17–21 May 2021; pp. 671–680. [Google Scholar]
- Li, S.; Cheng, Y.; Wang, W.; Liu, Y.; Chen, T. Learning to detect malicious clients for robust federated learning. arXiv 2020, arXiv:2002.00211. [Google Scholar]
- Cremonesi, F.; Vesin, M.; Cansiz, S.; Bouillard, Y.; Balelli, I.; Innocenti, L.; Silva, S.; Ayed, S.S.; Taiello, R.; Kameni, L.; et al. Fed-BioMed: Open, Transparent and Trusted Federated Learning for Real-world Healthcare Applications. arXiv 2023, arXiv:2304.12012. [Google Scholar]
- TensorFlow Federated: Machine Learning on Decentralized Data. Available online: https://www.tensorflow.org/ (accessed on 16 August 2023).
- Ziller, A.; Trask, A.; Lopardo, A.; Szymkow, B.; Wagner, B.; Bluemke, E.; Nounahon, J.M.; Passerat-Palmbach, J.; Prakash, K.; Rose, N.; et al. Pysyft: A library for easy federated learning. Fed. Learn. Syst. Towards-Next-Gener. AI 2021, 2021, 111–139. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Fernandez-Marques, J.; Gao, Y.; Sani, L.; Li, K.H.; Parcollet, T.; de Gusmão, P.P.B.; et al. Flower: A friendly federated learning research framework. arXiv 2020, arXiv:2007.14390. [Google Scholar]
- FATE: An Industrial Grade Federated Learning Framework. Available online: https://fate.fedai.org/ (accessed on 16 August 2023).
- Reina, G.A.; Gruzdev, A.; Foley, P.; Perepelkina, O.; Sharma, M.; Davidyuk, I.; Trushkin, I.; Radionov, M.; Mokrov, A.; Agapov, D.; et al. OpenFL: An open-source framework for Federated Learning. arXiv 2021, arXiv:2105.06413. [Google Scholar]
- Ludwig, H.; Baracaldo, N.; Thomas, G.; Zhou, Y.; Anwar, A.; Rajamoni, S.; Ong, Y.; Radhakrishnan, J.; Verma, A.; Sinn, M.; et al. Ibm federated learning: An enterprise framework white paper v0. 1. arXiv 2020, arXiv:2007.10987. [Google Scholar]
- Roth, H.R.; Cheng, Y.; Wen, Y.; Yang, I.; Xu, Z.; Hsieh, Y.T.; Kersten, K.; Harouni, A.; Zhao, C.; Lu, K.; et al. Nvidia flare: Federated learning from simulation to real-world. arXiv 2022, arXiv:2210.13291. [Google Scholar]
- Federated Learning powered by NVIDIA Clara. Available online: https://www.nvidia.com/fr-fr/clara/ (accessed on 16 August 2023).
- Xue, M.; Wang, J.; Liu, W. DNN intellectual property protection: Taxonomy, attacks and evaluations. In Proceedings of the 2021 on Great Lakes Symposium on VLSI, Virtual Conference and Exhibition, 22–25 June 2021; pp. 455–460. [Google Scholar]
- Lukas, N.; Jiang, E.; Li, X.; Kerschbaum, F. SoK: How robust is image classification deep neural network watermarking? In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; pp. 787–804. [Google Scholar]
- Li, Y.; Wang, H.; Barni, M. A survey of deep neural network watermarking techniques. Neurocomputing 2021, 461, 171–193. [Google Scholar] [CrossRef]
- Fkirin, A.; Attiya, G.; El-Sayed, A.; Shouman, M.A. Copyright protection of deep neural network models using digital watermarking: A comparative study. Multimed. Tools Appl. 2022, 81, 15961–15975. [Google Scholar] [CrossRef]
- Boenisch, F. A systematic review on model watermarking for neural networks. Front. Big Data 2021, 4, 729663. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, T.; Hu, P.; Liao, Q.; Ji, S.; Yu, N.; Guo, D.; Liu, L. Deep Intellectual Property: A Survey. arXiv 2023, arXiv:2304.14613. [Google Scholar]
- Bouslimi, D.; Bellafqira, R.; Coatrieux, G. Data hiding in homomorphically encrypted medical images for verifying their reliability in both encrypted and spatial domains. In Proceedings of the 2016 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Orlando, FL, USA, 16–20 August 2016; pp. 2496–2499. [Google Scholar]
- Ernawan, F.; Ariatmanto, D. A recent survey on image watermarking using scaling factor techniques for copyright protection. Multimed. Tools Appl. 2023, 2023, 1–41. [Google Scholar] [CrossRef]
- Pavan, A.; Somashekara, M. An Overview on Research Trends, Challenges, Applications and Future Direction in Digital Image Watermarking. Int. Res. J. Adv. Sci. Hub 2023, 5, 8–14. [Google Scholar]
- Niyitegeka, D.; Coatrieux, G.; Bellafqira, R.; Genin, E.; Franco-Contreras, J. Dynamic watermarking-based integrity protection of homomorphically encrypted databases—Application to outsourced genetic data. In Proceedings of the International Workshop on Digital Watermarking, Jeju Island, Republic of Korea, 22–24 October 2018; pp. 151–166. [Google Scholar]
- Hu, D.; Wang, Q.; Yan, S.; Liu, X.; Li, M.; Zheng, S. Reversible Database Watermarking Based on Order-preserving Encryption for Data Sharing. ACM Trans. Database Syst. 2023, 48, 1–25. [Google Scholar] [CrossRef]
- Song, C.; Ristenpart, T.; Shmatikov, V. Machine learning models that remember too much. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 587–601. [Google Scholar]
- Feng, L.; Zhang, X. Watermarking neural network with compensation mechanism. In Proceedings of the Knowledge Science, Engineering and Management: 13th International Conference, KSEM 2020, Hangzhou, China, August 28–30 2020; pp. 363–375. [Google Scholar]
- Li, Y.; Tondi, B.; Barni, M. Spread-Transform Dither Modulation Watermarking of Deep Neural Network. arXiv 2020, arXiv:2012.14171. [Google Scholar] [CrossRef]
- Tartaglione, E.; Grangetto, M.; Cavagnino, D.; Botta, M. Delving in the loss landscape to embed robust watermarks into neural networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1243–1250. [Google Scholar]
- Chen, H.; Rouhani, B.D.; Fu, C.; Zhao, J.; Koushanfar, F. Deepmarks: A secure fingerprinting framework for digital rights management of deep learning models. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 January 2019; pp. 105–113. [Google Scholar]
- Wang, J.; Wu, H.; Zhang, X.; Yao, Y. Watermarking in deep neural networks via error back-propagation. Electron. Imaging 2020, 2020, 1–22. [Google Scholar] [CrossRef]
- Rouhani, B.D.; Chen, H.; Koushanfar, F. Deepsigns: An end-to-end watermarking framework for protecting the ownership of deep neural networks. In Proceedings of the 24th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), ACM, Providence, RI, USA, 13–17 April 2019. [Google Scholar]
- Fan, L.; Ng, K.W.; Chan, C.S. Rethinking deep neural network ownership verification: Embedding passports to defeat ambiguity attacks. Adv. Neural Inf. Process. Syst. 2019, 32, 1. [Google Scholar]
- Li, F.; Wang, S. Secure watermark for deep neural networks with multi-task learning. arXiv 2021, arXiv:2103.10021. [Google Scholar]
- Bellafqira, R.; Coatrieux, G. DICTION: DynamIC robusT whIte bOx watermarkiNg scheme. arXiv 2022, arXiv:2210.15745. [Google Scholar]
- Kuribayashi, M.; Yasui, T.; Malik, A. White Box Watermarking for Convolution Layers in Fine-Tuning Model Using the Constant Weight Code. J. Imaging 2023, 9, 117. [Google Scholar] [CrossRef]
- Lv, P.; Li, P.; Zhang, S.; Chen, K.; Liang, R.; Ma, H.; Zhao, Y.; Li, Y. A Robustness-Assured White-Box Watermark in Neural Networks. IEEE Trans. Dependable Secur. Comput. (TDSC) 2023, 1–14. [Google Scholar] [CrossRef]
- Rodriguez-Lois, E.; Perez-Gonzalez, F. Towards Traitor Tracing in Black-and-White-Box DNN Watermarking with Tardos-based Codes. arXiv 2023, arXiv:2307.06695. [Google Scholar]
- Chen, H.; Rouhani, B.D.; Koushanfar, F. BlackMarks: Blackbox Multibit Watermarking for Deep Neural Networks. arXiv 2019, arXiv:1904.00344. [Google Scholar]
- Vybornova, Y. Method for copyright protection of deep neural networks using digital watermarking. In Proceedings of the Fourteenth International Conference on Machine Vision (ICMV 2021), Rome, Italy, 8–12 November 2022; Volume 12084, pp. 297–304. [Google Scholar]
- Zhang, J.; Gu, Z.; Jang, J.; Wu, H.; Stoecklin, M.P.; Huang, H.; Molloy, I. Protecting intellectual property of deep neural networks with watermarking. In Proceedings of the 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4–8 June 2018; pp. 159–172. [Google Scholar]
- Adi, Y.; Baum, C.; Cisse, M.; Pinkas, B.; Keshet, J. Turning your weakness into a strength: Watermarking deep neural networks by backdooring. In Proceedings of the 27th USENIX Security Symposium, Baltimore, MD, USA, 14 May 2018; pp. 1615–1631. [Google Scholar]
- Guo, J.; Potkonjak, M. Watermarking deep neural networks for embedded systems. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Diego, CA, USA, 5–8 November 2018; pp. 1–8. [Google Scholar]
- Le Merrer, E.; Perez, P.; Trédan, G. Adversarial frontier stitching for remote neural network watermarking. Neural Comput. Appl. 2020, 32, 9233–9244. [Google Scholar] [CrossRef]
- Namba, R.; Sakuma, J. Robust watermarking of neural network with exponential weighting. In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security, Auckland, New Zealand, 7–12 July 2019; pp. 228–240. [Google Scholar]
- Li, Z.; Hu, C.; Zhang, Y.; Guo, S. How to prove your model belongs to you: A blind-watermark based framework to protect intellectual property of DNN. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 126–137. [Google Scholar]
- Kapusta, K.; Thouvenot, V.; Bettan, O. Watermarking at the service of intellectual property rights of ML models. In Proceedings of the Actes de la conférence CAID 2020, Paris, France, 24–26 April 2020; p. 75. [Google Scholar]
- Lounici, S.; Önen, M.; Ermis, O.; Trabelsi, S. Blindspot: Watermarking through fairness. In Proceedings of the 2022 ACM Workshop on Information Hiding and Multimedia Security, Chicago, IL, USA, 28–30 June 2022; pp. 39–50. [Google Scholar]
- Kallas, K.; Furon, T. RoSe: A RObust and SEcure Black-Box DNN Watermarking. In Proceedings of the IEEE Workshop on Information Forensics and Security, Online, 12–16 December 2022. [Google Scholar]
- Qiao, T.; Ma, Y.; Zheng, N.; Wu, H.; Chen, Y.; Xu, M.; Luo, X. A novel model watermarking for protecting generative adversarial network. Comput. Secur. 2023, 127, 103102. [Google Scholar] [CrossRef]
- Kallas, K.; Furon, T. Mixer: DNN Watermarking using Image Mixup. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Hua, G.; Teoh, A.B.J.; Xiang, Y.; Jiang, H. Unambiguous and High-Fidelity Backdoor Watermarking for Deep Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Wang, T.; Kerschbaum, F. RIGA: Covert and Robust White-Box Watermarking of Deep Neural Networks. arXiv 2019, arXiv:1910.14268. [Google Scholar]
- Zhang, J.; Chen, D.; Liao, J.; Zhang, W.; Hua, G.; Yu, N. Passport-aware normalization for deep model protection. Adv. Neural Inf. Process. Syst. 2020, 33, 22619–22628. [Google Scholar]
- Yang, W.; Yin, Y.; Zhu, G.; Gu, H.; Fan, L.; Cao, X.; Yang, Q. FedZKP: Federated Model Ownership Verification with Zero-knowledge Proof. arXiv 2023, arXiv:2305.04507. [Google Scholar]
- Rosasco, L.; De Vito, E.; Caponnetto, A.; Piana, M.; Verri, A. Are loss functions all the same? Neural Comput. 2004, 16, 1063–1076. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Technical Report. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 16 August 2023).
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Shao, S.; Yang, W.; Gu, H.; Lou, J.; Qin, Z.; Fan, L.; Yang, Q.; Ren, K. FedTracker: Furnishing Ownership Verification and Traceability for Federated Learning Model. arXiv 2022, arXiv:2211.07160. [Google Scholar]
- Liu, X.; Shao, S.; Yang, Y.; Wu, K.; Yang, W.; Fang, H. Secure federated learning model verification: A client-side backdoor triggered watermarking scheme. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, VIC, Australia, 17–20 October 2021; pp. 2414–2419. [Google Scholar]
- Liang, J.; Wang, R. FedCIP: Federated Client Intellectual Property Protection with Traitor Tracking. arXiv 2023, arXiv:2306.01356. [Google Scholar]
- Chen, J.; Li, M.; Zheng, H. FedRight: An Effective Model Copyright Protection for Federated Learning. arXiv 2023, arXiv:2303.10399. [Google Scholar] [CrossRef]
- Yang, W.; Shao, S.; Yang, Y.; Liu, X.; Xia, Z.; Schaefer, G.; Fang, H. Watermarking in Secure Federated Learning: A Verification Framework Based on Client-Side Backdooring. arXiv 2022, arXiv:2211.07138. [Google Scholar]
- Li, F.Q.; Wang, S.L.; Liew, A.W.C. Towards practical watermark for deep neural networks in federated learning. arXiv 2021, arXiv:2105.03167. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wahba, G. Support vector machines, reproducing kernel Hilbert spaces and the randomized GACV. Adv. Kernel-Methods-Support Vector Learn. 1999, 6, 69–87. [Google Scholar]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3366–3385. [Google Scholar]
- Cao, X.; Jia, J.; Gong, N.Z. IPGuard: Protecting intellectual property of deep neural networks via fingerprinting the classification boundary. In Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security, Virtual Event, 7–11 June 2021; pp. 14–25. [Google Scholar]
- Becker, G. Merkle Signature Schemes, Merkle Trees and Their Cryptanalysis; Techical Report; Ruhr-University Bochum: Bochum, Germany, 2008; Volume 12, p. 19. [Google Scholar]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. arXiv 2020, arXiv:2003.05991. [Google Scholar]
- Jain, A.; Krenn, S.; Pietrzak, K.; Tentes, A. Commitments and efficient zero-knowledge proofs from learning parity with noise. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Beijing, China, 2–6 December 2012; pp. 663–680. [Google Scholar]
- Zheng, X.; Dong, Q.; Fu, A. WMDefense: Using Watermark to Defense Byzantine Attacks in Federated Learning. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), New York, NY, USA, 2–5 May 2022; pp. 1–6. [Google Scholar]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef] [PubMed]
- Hitaj, D.; Mancini, L.V. Have you stolen my model? evasion attacks against deep neural network watermarking techniques. arXiv 2018, arXiv:1809.00615. [Google Scholar]
- Yang, J.; Zhou, K.; Li, Y.; Liu, Z. Generalized out-of-distribution detection: A survey. arXiv 2021, arXiv:2110.11334. [Google Scholar]
- Melis, L.; Song, C.; De Cristofaro, E.; Shmatikov, V. Exploiting unintended feature leakage in collaborative learning. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 13–23 May 2019; pp. 691–706. [Google Scholar]
- Wang, B.; Chen, Y.; Jiang, H.; Zhao, Z. PPeFL: Privacy-Preserving Edge Federated Learning with Local Differential Privacy. IEEE Internet Things J. 2023, 10, 15488–15500. [Google Scholar] [CrossRef]
- Bellafqira, R.; Coatrieux, G.; Genin, E.; Cozic, M. Secure multilayer perceptron based on homomorphic encryption. In Proceedings of the Digital Forensics and Watermarking: 17th International Workshop, IWDW 2018, Jeju Island, Republic of Korea, 22–24 October 2018; pp. 322–336. [Google Scholar]
- Ma, J.; Naas, S.A.; Sigg, S.; Lyu, X. Privacy-preserving federated learning based on multi-key homomorphic encryption. Int. J. Intell. Syst. 2022, 37, 5880–5901. [Google Scholar] [CrossRef]
- Jin, W.; Yao, Y.; Han, S.; Joe-Wong, C.; Ravi, S.; Avestimehr, S.; He, C. FedML-HE: An Efficient Homomorphic-Encryption-Based Privacy-Preserving Federated Learning System. arXiv 2023, arXiv:2303.10837. [Google Scholar]
- Tolpegin, V.; Truex, S.; Gursoy, M.E.; Liu, L. Data poisoning attacks against federated learning systems. In Proceedings of the Computer Security–ESORICS 2020: 25th European Symposium on Research in Computer Security, ESORICS 2020, Guildford, UK, 14–18 September 2020; pp. 480–501. [Google Scholar]
- Xi, B.; Li, S.; Li, J.; Liu, H.; Liu, H.; Zhu, H. Batfl: Backdoor detection on federated learning in e-health. In Proceedings of the 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), Tokyo, Japan, 25–28 June 2021; pp. 1–10. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A brief survey on semantic segmentation with deep learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Sirsat, M.S.; Cernadas, E.; Alawadi, S.; Barro, S.; Febrero-Bande, M. An extensive experimental survey of regression methods. Neural Netw. 2019, 111, 11–34. [Google Scholar] [CrossRef]
- Fu, T.; Gao, S.; Zhao, X.; Wen, J.r.; Yan, R. Learning towards conversational AI: A survey. AI Open 2022, 3, 14–28. [Google Scholar] [CrossRef]
- Rieke, N.; Hancox, J.; Li, W.; Milletari, F.; Roth, H.R.; Albarqouni, S.; Bakas, S.; Galtier, M.N.; Landman, B.A.; Maier-Hein, K.; et al. The future of digital health with federated learning. NPJ Digit. Med. 2020, 3, 119. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutorials 2021, 23, 1622–1658. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| FL Frameworks | Developed by | Purpose | Security Protocols Provided |
|---|---|---|---|
| Fed-BioMed [39] | INRIA | Research | DP, HE |
| TensorFlow Federated [40] | Research | DP | |
| PySyft [41] | OpenMined | Research | MPC, DP, HE, PSI |
| Flower [42] | Flower Labs GmbH | Industrial | DP |
| FATE [43] | WeBank | Industrial | HE, DP, MPC |
| OpenFL [44] | Intel | Industrial | TEE |
| IBM Federated Learning [45] | IBM | Industrial | DP, MPC |
| NvFlare [46] | Nvidia | Industrial | HE, DP, PSI |
| Clara [47] | Nvidia | Industrial | DP, HE, TEE |
| Property | Description |
|---|---|
| Fidelity | The watermarked model needs to have performances as close as possible compared to the model without watermark. |
| Capacity | The capacity of a technique to embed multiple watermarks. |
| Reliability | Demonstrate a low false negative rate, enabling legitimate users to accurately identify their intellectual property with a high level of certainty. |
| Integrity | Demonstrate a low false positive rate, preventing unjustly accusing honest parties with similar models of intellectual property theft. |
| Generality | The capacity of a watermarking technique to be applied independently of the architecture of the model. |
| Efficiency | The performance cost generated by the embedding and verification process of the watermarking. |
| Robustness | The capacity to resist against attacks aiming at removing the watermark. |
| Secrecy | The watermark should be secret and undetectable. |
| Existing Works | Verification | Watermarks Embedding | Security Tools Compatibility | Clients Selection | Poisoning Defense | ||||
|---|---|---|---|---|---|---|---|---|---|
| DP | HE | MPC | TEE | Aggregation | Anomaly Detector | ||||
| WAFFLE [17] | Black-Box | Server | ◐ | - | ◐ | ◐ | ◐ | ◐ | ◐ |
| FedIPR [18] | White-Box and Black-Box | Client(s) | ⬤ | ◐ | ◐ | ◐ | ⬤ | ⬤ | ◐ |
| FedTracker [94] | White-Box and Black-Box | Server | ◐ | - | ◐ | ◐ | ◐ | ◐ | ◐ |
| Liu et al. [95] | Black-Box | Client | ◐ | ⬤ | ◐ | ◐ | ◐ | - | - |
| FedCIP [96] | White-Box | Client(s) | ◐ | ◐ | ◐ | ◐ | ⬤ | ◐ | ◐ |
| FedRight [97] | White-Box | Server | ◐ | - | ◐ | ◐ | ◐ | ◐ | ◐ |
| Yang et al. [98] | Black-Box | Client | ◐ | ⬤ | ◐ | ◐ | ◐ | - | - |
| FedZKP [96] | White-Box | Client(s) | ◐ | ◐ | ◐ | ◐ | ◐ | ◐ | ◐ |
| Merkle-Sign [99] | White-Box and Black-Box | Server | ◐ | - | ◐ | ◐ | ◐ | ◐ | ◐ |
| Existing Works | Watermarks Embedding | Trigger Set | Evasion Attack | Backdoor Detection [100] |
|---|---|---|---|---|
| WAFFLE [17] | Server | Noise | ⬤ | ⬤ |
| Merkle-Sign [105] | Server | Generated by Auto-Encoder | - | - |
| FedTracker [94] | Server | Noise | ⬤ | ⬤ |
| FedIPR [18] | Client(s) | Adversarial Examples | - | - |
| Liu et al. [95] | Client | Noise | - | - |
| Yang et al. [98] | Client | Noise | - | - |
| Existing Works | Framework | Task | Maximum Number of Clients | Aggregation Function | Non-I.I.D Repartition of Training Set |
|---|---|---|---|---|---|
| WAFFLE [17] | PySyft, Pytorch | Image Classification | 100 | FedAvg | ⬤ |
| FedIPR [18] | Pytorch | Image Classification, NLP | 100 | FedAvg, Trim-Mean, Bulyan, Multi-Krum | ⬤ |
| FedTracker [94] | - | Image Classification | 50 | FedAvg | ⬤ |
| Liu et al. [95] | - | Image Classification | 100 | FedAvg | - |
| FedCIP [96] | - | Image Classification | 10 | FedAvg | ⬤ |
| FedRight [97] | - | Image Classification | 100 | FedAvg | - |
| Yang et al. [98] | - | Image Classification | 100 | FedAvg | - |
| FedZKP [96] | - | Image Classification | 50 | FedAvg | - |
| Merkle-Sign [99] | - | Image Classification | 200 | Gradient Average [105] | - |
| Existing Works | Model Used | Dataset | Baseline | Fine Tuning | Pruning |
|---|---|---|---|---|---|
| Acc. (WDR) | Acc. (WDR) | Acc. (WDR) | |||
| WAFFLE [17] | VGG | CIFAR10 | 85.8 (99.0) | 85.6 (96.2) | 85.0 (47.0) |
| MNIST | 98.9 (100.0) | 98.7 (98.0) | 97.0 (47.0) | ||
| FedIPR [18] | AlexNet | CIFAR10 | 91.7 (99.0) | 91.7 (98.0) | 78.0 (99.0) |
| ResNet | CIFAR100 | 76.9 (99.0) | - (-) | - (-) | |
| FedTracker [94] | VGG | CIFAR10 | 88.6 (99.1) | - (99.1) | 83.0 (84.5) |
| AlexNet | CIFAR10 | 84.3 (82.6) | - (82.6) | 73.0 (52.4) | |
| Liu et al. [95] | VGG | CIFAR10 | 84.2 (100.0) | - (87.0) | 78.0 (71.0) |
| LeNet | MNIST | 99.3 (100.0) | - (97.5) | 98.4 (100.0) | |
| FedCIP [96] | ResNet | CIFAR10 | 82.0 (100.0) | - (100.0) | - (92.0) |
| FedRight [97] | VGG | CIFAR10 | 86.0 (100.0) | - (87.0) | 85.13 (62.85) |
| LetNet | MNIST | 96.0 (100.0) | - (100.0) | 93.5 (58.1) | |
| Yang et al. [98] | VGG | CIFAR10 | 82.4 (99.7) | - (99.7) | 68.3 (87.9) |
| LeNet | MNIST | 99.2 (99.2) | - (99.2) | 99.2 (100.0) | |
| FedZKP [96] | AlexNet | CIFAR10 | 91.5 (100.0) | 91.5 (99.0) | - (-) |
| ResNet | CIFAR100 | 77.2 (100.0) | - (-) | 51.0 (100.0) | |
| Merkle-Sign [99] | ResNet | CIFAR10 | 89.1 (100.0) | - (-) | - (-) |
| CIFAR100 | 62.5 (100.0) | - (-) | - (-) | ||
| MNIST | 99.6 (100.0) | - (-) | - (-) | ||
| Fashion | 93.8 (100.0) | - (-) | - (-) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lansari, M.; Bellafqira, R.; Kapusta, K.; Thouvenot, V.; Bettan, O.; Coatrieux, G. When Federated Learning Meets Watermarking: A Comprehensive Overview of Techniques for Intellectual Property Protection. Mach. Learn. Knowl. Extr. 2023, 5, 1382-1406. https://doi.org/10.3390/make5040070
Lansari M, Bellafqira R, Kapusta K, Thouvenot V, Bettan O, Coatrieux G. When Federated Learning Meets Watermarking: A Comprehensive Overview of Techniques for Intellectual Property Protection. Machine Learning and Knowledge Extraction. 2023; 5(4):1382-1406. https://doi.org/10.3390/make5040070
Chicago/Turabian StyleLansari, Mohammed, Reda Bellafqira, Katarzyna Kapusta, Vincent Thouvenot, Olivier Bettan, and Gouenou Coatrieux. 2023. "When Federated Learning Meets Watermarking: A Comprehensive Overview of Techniques for Intellectual Property Protection" Machine Learning and Knowledge Extraction 5, no. 4: 1382-1406. https://doi.org/10.3390/make5040070