3.1. Basic Notion
Let us consider the dataset , which contains examples. Each example is described using a fixed set of attributes and a special decision attribute . The form and interpretation of decision attributes can vary based on the type of problem specified. In this paper, we focus on three problem types: classification, regression, and survival analysis.
For the classification problem, each example could be assigned to a specific class based on the value of the decision attribute. In such a case, is a discrete class identifier . The task involves predicting the correct class value for a given example . In a regression problem, the decision attribute is a continuous variable: . Therefore, the task is to predict its value with minimal error, ideally zero. In survival analysis, the label attribute refers to the Boolean censoring status, indicating whether the example was subject to a certain event (e.g., patients who suffered a stroke). For such an analysis, an additional survival time attribute T is required. The attribute T specifies the time before the event occurs, if the event occurs, for a given example. Otherwise, it equals the overall observation time. For classification and regression data, each example from D is represented as a vector . For the survival problem, this vector must be extended by the variable .
Our main objective is to define (induce) a set of rules describing examples from the set D and enabling the prediction of the value of the attribute for new (unseen) examples. This set of rules is later referred to as a rule-based data model.
Let
R be a set of
rules. Each rule
takes the following form:
The rule premise is a conjunction of elementary conditions
(
).
If an example x fulfills the conditions of a rule r premise, we say that r covers x (x is covered by r).
The conclusion of a rule contains the decision part used during the prediction process. For classification and regression rules, a constant function is defined specifying a certain value of the decision attribute (e.g., a certain decision class).
For a survival rule
r,
represents the Kaplan–Meier [
62] estimator (i.e., the survival curve) defined based on all examples covered by
r.
A set of rules can be treated as a predictor. The prediction is made by evaluating the premise part of each rule for a given example x. Only the rules covering the example x participate in the prediction process. The predicted value is obtained based on the decision part of these rules. If all rules covering the example x have the same conclusion, the prediction is straightforward. The predicted value of the decision attribute of example x is taken from the conclusions of the rules.
For classification problems, if an example is covered by rules with different conclusions, a voting procedure is invoked. Each rule covering the given example votes for the predicted value from its conclusion, and each vote is multiplied by the so-called voting weight. Voting weights can be calculated in various ways, such as using rule quality measures [
8,
63].
In regression and survival problems, the final prediction is obtained by averaging the decisions of the rules covering the example. In particular, in survival analysis, the Kaplan–Meier estimators of all rules covering a given example are averaged to obtain the final prediction value.
Another scenario is applied to an example not covered by any rule. Such an example is usually predicted using the so-called default rule. The premise of the default rule is empty, ensuring that the default rule covers every example. The conclusion of the default rule is calculated for the entire set of training examples and specifies the majority class for classification problems, the median value of the decision attribute for regression problems, and the Kaplan–Meier estimator for survival data.
Most existing rule induction algorithms generate rules with simple elementary conditions. The simple elementary condition has one of the following forms: or or , where a is a conditional attribute, and v is one of its values. Such conditions may not always be optimal for describing datasets containing more complex relationships. In this paper, we focus on the induction of rules containing more complex conditions. We consider the following types of complex conditions.
Negated conditions: Represent negations of simple conditions (e.g., , and all complex conditions listed below (except Disjunctions).
Attribute Relations: This type of condition covers all examples for which a given relation exists between given attributes. They are generated only for attributes of the same type, either nominal or numeric. For nominal attributes, the possible relations are equality and inequality. For numeric ones, the relations of strict and weak inequalities are additionally analyzed. Examples of such conditions are presented below:
Internal Disjunctions: For nominal attributes, an elementary condition with internal disjunction is defined as follows:
For numeric attributes, the internal disjunction is represented as a disjunction of mutually disjoint intervals of values of the attribute
a:
where
<
<, …, <
are values of
a.
The above expression can be rewritten as an alternative of the simple elementary conditions , (
In this article, we propose a methodology that allows the induction of conditions known as M-of-N conditions. An M-of-N condition consists of
N conditions, which can be either simple or complex. In our study the M-of-N condition is satisfied if exactly
M or at least
M of its
N components are satisfied. Depending on the interpretation of the M-of-N condition, the sets of examples covering this condition may vary. In the experiments, we considered both interpretations of the M-of-N condition. An example of the M-of-N condition (2-of-3 condition) is presented below.
We can say that an M-of-N condition represents a compressed form of the DNF formula consisting of N disjunctions, each of which has M literals.
To simplify the notation, we denote all
N conditions that are part of M-of-N by
. In the case of our example,
. Using such a notation, the DNF form of our example condition, for the “at least M-of-N” interpretation, is as follows:
For the “exactly M-of-N” interpretation, the DNF form of our example is as follows:
3.2. Learning Rules with Simple Conditions
To induce rules with simple conditions, our approach employs the sequential covering rule induction algorithm. This algorithm makes it possible to induce classification, regression, and survival rules. The source code for the algorithm is available on GitHub [
8] as the RuleKit library. In this subsection, we provide a concise explanation of RuleKit for all three types of rules. For a comprehensive understanding of how the RuleKit algorithm works, refer to [
6,
7] and the library documentation [
64].
The algorithm starts with an empty ruleset and iteratively learns a single rule to induce a ruleset that covers the entire set of training examples, or until the number of uncovered examples remains below some fixed (algorithm’s parameter) value. After the induction of a rule, all examples covered by the rule are removed from the training set, and the algorithm proceeds to induce the next rule, which covers some of the remaining examples.
Inducing a new rule involves two phases: rule growing and rule pruning. In the growing phase (Algorithm 1), elementary conditions are added to the initially empty premise. When extending the premise, the algorithm considers all possible conditions built upon all attributes (line 5: GETALLCONDITIONS function call) and selects those leading to the rule with the highest quality. The algorithm enables the use of any well-known rule quality measures [
63] or a user-defined rule quality measure. These measures guide the rule induction process, favoring rules that cover as many positive and few negative examples as possible. Using the rule quality measure, the algorithm aims to maximize the number of positive examples while minimizing the number of negative ones covered by the induced rules.
In the simplest version of the algorithm, the function GETALLCONDITIONS generates a set of all possible simple elementary conditions. For nominal attributes, conditions in the form for all values from the attribute domain are considered. Regarding continuous attributes, values present in the observations covered by the rule are sorted. Subsequently, potential split points are determined as the arithmetic means of subsequent values, and conditions and are evaluated. If multiple conditions yield identical results, the one covering more examples is chosen. Rule pruning can be considered the opposite of rule growing. It iteratively removes conditions from the premise, systematically making eliminations that lead to the most substantial improvement in rule quality. The procedure stops when no conditions can be deleted without diminishing the rule’s quality or when the rule contains only one condition. RuleKit uses the hill climbing strategy for both rule growth and pruning. The process of searching for the best conditions is illustrated in Algorithm 2.
In the classification problem, the algorithm systematically iterates over all decision classes (class labels). In regression and survival analysis problems, the algorithm is executed once on the entire set of training examples. In the case of a regression problem, RuleKit transforms it into a binary classification problem, following the proposal in [
65]. The conclusion of a regression rule
r indicates a specific value of the decision attribute
. This value is calculated as the median
of the decision attribute values of the examples that cover
r. All training examples with a value
within a range
represent the positive decision class, while the remaining examples represent the negative one. It is important to note that changing the premise of an induced rule dynamically affects the class membership of the covered examples. For survival analysis, RuleKit, instead of relying on rule quality measures, uses the log-rank test [
66] to evaluate a rule during the growth and pruning phases. This test compares the differences between two Kaplan–Meier estimators: one fitted to the examples covered by the rule and the other fitted to the remaining examples.
3.3. Rules with Complex Conditions
The induction of rules with complex conditions (excluding M-of-N) is very similar to to the induction of rules containing only simple conditions.
When inducing rules with complex conditions, the set of all possible conditions (GETALLCONDITIONS line 5) includes not only simple conditions but in addition all possible attribute relations, internal disjunctions for symbolic attributes, and negated conditions.
The algorithm considers all possible attribute relations for attributes of the same type. For a symbolic attribute, the set of internal disjunctions corresponds to the power set of the attribute values.
To avoid nonsensical comparisons for a given dataset and to reduce computational complexity, the algorithm utilizes a list of attributes that should not be compared and limits the number of values that an internal alternative can contain.
Compared to the standard version of the RuleKit algorithm, the rule-growing phase differs only when internal disjunctions based on numeric attributes are added to the rule premise. The main modification involves introducing additional steps (see lines 8–10) into Algorithm 1. These additional steps occur only if the best-selected condition found earlier (line 6) is based on the numeric attribute. The GETDISJUNTIONS procedure extends this condition with pairs of mutually disjoint intervals.
The rule pruning phase remains the same as in the original version of the RuleKit algorithm. In both phases, there is a change in the selection of the best condition when several conditions achieve the same quality.
| Algorithm 1 Rule growing |
Require:
D—training dataset, —uncovered set of examples, —examples covered by r, T—list of condition types to induce. Ensure: r—rule.
- 1:
function Grow(D,, T) - 2:
- 3:
repeat - 4:
Covered(r, D) - 5:
GetAllConditions(T, D, , ) - 6:
GetBestCondition(C, r, D) - 7:
▹ induce internal disjunctions for numeric attributes - 8:
if T includes INTERNAL_DISJUNCTIONS then - 9:
GetDisjunctions(, D, , ) - 10:
GetBestCondition(, r, D) - 11:
if then - 12:
- 13:
until - 14:
return r
|
To compare the quality of elementary conditions, a lexicographic order is used. Let us suppose that a condition c is given and a rule r contains c in its premise, then the condition c is evaluated according to the following criteria (see Algorithm 2):
The quality of r—line 6;
The number of positive examples covered by r—line 9;
The number of unique attributes included in c—line 11;
Comprehensibility, complexity of c—line 15.
The last criterion reflects our subjective assessment of the comprehensibility of elementary conditions. Each type of elementary condition is assigned a weight that reflects its comprehensibility:
The higher the weight value, the more comprehensible the condition. It should be emphasized that the last criterion is invoked only when the conditions being compared achieve the same evaluation for the remaining criteria.
| Algorithm 2 Finding the best condition |
| Require:
C—set of conditions, r—rule, D—training dataset. Ensure: —best condition.
- 1:
function GetBestCondition(C,r,D) - 2:
, ▹ best condition and its quality - 3:
for do - 4:
▹ add condition to the rule - 5:
CalculateQuality(, D) - 6:
▹ compare quality - 7:
if then - 8:
▹ prefer conditions with a higher coverage - 9:
(CoveredCount(c, D) > CoveredCount(, D)) - 10:
if then - 11:
▹ prefer conditions with a smaller number of attributes - 12:
(AttributesCount(c) < AttributesCount()) - 13:
if then - 14:
▹ prefer conditions types with a higher weight - 15:
(TypeWeight(c) > TypeWeight()) - 16:
if then - 17:
, - 18:
return
|
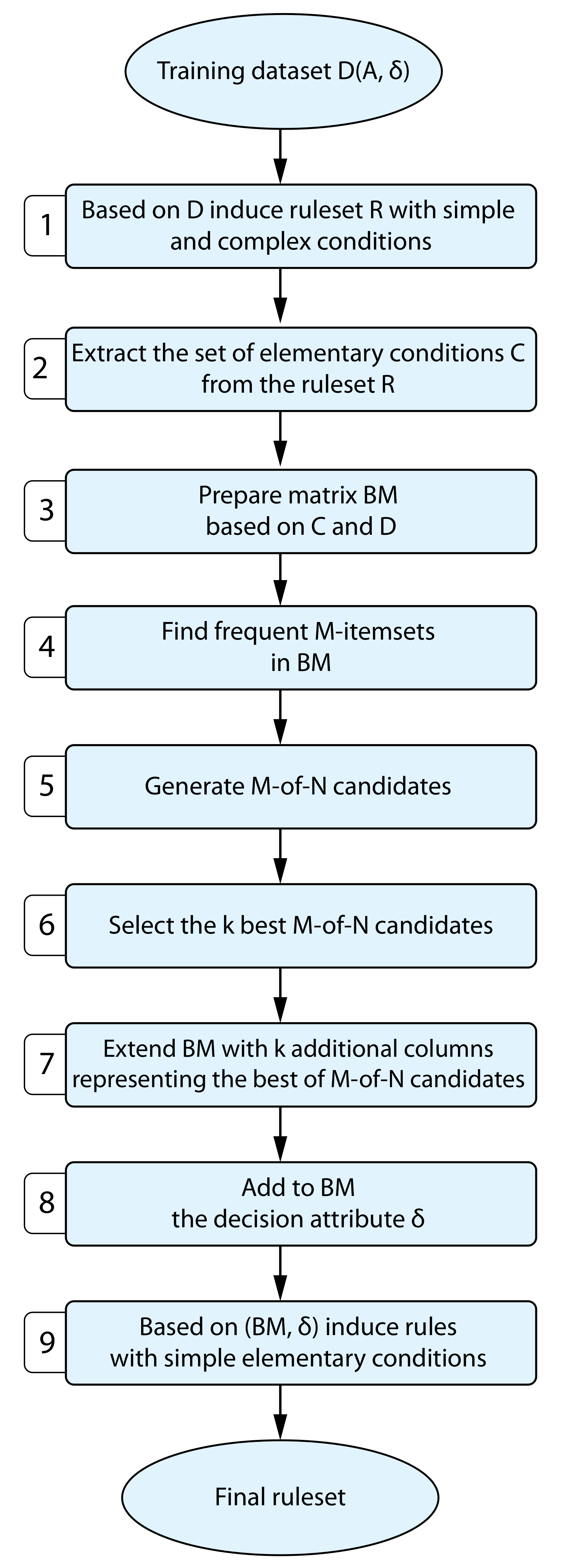
3.4. Learning Rulesets with M-of-n Conditions
The method for inducing rules with M-of-N conditions assumes that these conditions are constructed based on an already-induced set of rules (
R). The set
R contains rules with both simple and complex conditions (Block 1—
Figure 1). Following rule induction, a set
C containing all elementary conditions present in ruleset
R is determined (Block 2,
Figure 1). In the subsequent step, a table—binary matrix (
)—is constructed, with each column (
k) representing an elementary condition from
C (Block 3,
Figure 1). The matrix
contains |
C| columns and |
D| rows, each row representing one training example. For a given training example
and column
,
if and only if
x is covered by an elementary condition represented by column
k; otherwise,
. In
, frequent sets fulfilling the minimum support condition (algorithm’s parameter) are mined. Specifically, for all allowed values of M, all frequent M-itemsets are mined. For instance, if the analysis aims to extend the set of elementary conditions with 2-of-3 and 3-of-4 conditions, both frequent 2-itemsets and 3-itemsets are sought. In the proposed method, the FP-growth algorithm [
67] is applied to mining frequent itemsets. Following frequent itemset mining, the procedure to generate candidates for M-of-N conditions is initiated (Block 4,
Figure 1). A candidate for the M-of-N condition comprises N frequent M-itemsets (see Example). To constrain the number of candidates in further calculations, the average support is calculated for each M-of-N candidate. The average support of an M-of-N condition is the average value of supports of all N frequent M-itemsets defining this condition. The top
l (algorithm’s parameter) candidates with the highest support are selected for further processing. In the penultimate step, the binary matrix
is extended with
l candidate M-of-N conditions (Block 5,
Figure 1). To the extended
matrix, a decision column identical to the one in the training set
D is added (Block 6,
Figure 1). Finally, the rule induction is performed on (
,
), but this time the rule induction algorithm induces rules only with simple elementary conditions (i.e.,
or
). Note that column
k in the extended
matrix may represent a simple, complex (created in Block 2,
Figure 1) or M-of-N condition (created in Block 4,
Figure 1).
The proposed method has an additional advantage: if an induced rule contains a condition , and for example, k corresponds to the M-of-N condition, this means that the rule contains the negation of M-of-N.
Example
Let us assume that D contains a nominal attribute a and two numeric attributes b and c. The ruleset induced in the first step contains the following conditions: , , , , , , . The matrix BM contains 7 columns. Moreover, let us assume that 2-of-3 conditions are induced and the FP-growth algorithm found the following frequent 2-itemsets, fulfilling the minimal support requirement:
;
;
.
These itemsets may define a single 2-of-3 condition candidate:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}