
Why Do Tree Ensemble Approximators Not Outperform the Recursive-Rule eXtraction Algorithm?



Abstract
:1. Introduction
- 1.
- Introduction of a New Interpretability Metric: We propose a metric designed to evaluate and compare the interpretability of different types of rule sets. This metric addresses the gap in quantitative assessments of the interpretability of rule sets.
- 2.
- Comparative Analysis of Rule Sets: We provide an exhaustive comparison of decision list- and DT-based rule sets generated by the tree ensemble approximator. Our analysis provides new insights into the strengths and weaknesses of each type of rule set. Furthermore, we explain why categorical and numerical attributes should be treated separately.
- 3.
- Focus on the Interpretability of Categorical and Numerical Attributes: We explain the necessity of separating categorical and numerical attributes. This focus addresses a significant gap in current research as many existing methods overlook the distinction between categorical and numerical attributes.
2. Related Work
3. Materials and Methods
3.1. Datasets
3.2. Baseline
4. Proposed Methodology
4.1. Data Preprocessing
4.2. Interpretability Metrics
4.3. Model Evaluation and Hyperparameter Optimization
4.4. Summary of Evaluation Schemes for Each CV-Fold
| Algorithm 1 Evaluation scheme for each CV-fold |
Require: Training dataset , Validation dataset , Test dataset , Method M Ensure: The score set S for rule set
|
5. Results
5.1. Classification Results
5.2. Interpretability Results
5.3. Summary of Comparative Experiments
5.4. Two Examples
5.4.1. bank-marketing
5.4.2. german
6. Discussion
6.1. Why Should We Avoid a Mixture of Categorical and Numerical Attributes?
6.2. Optimal Selection of the Pareto Solutions
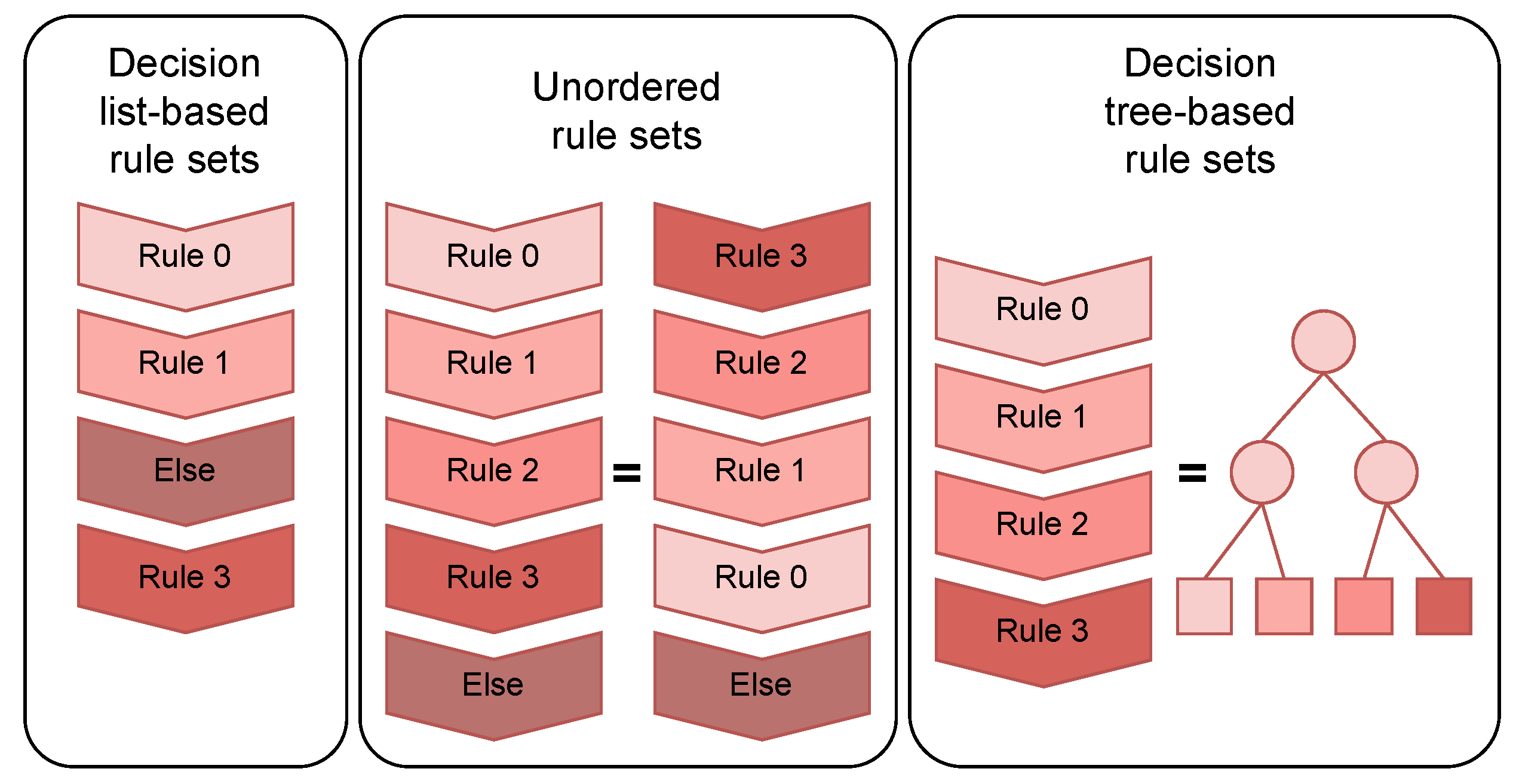
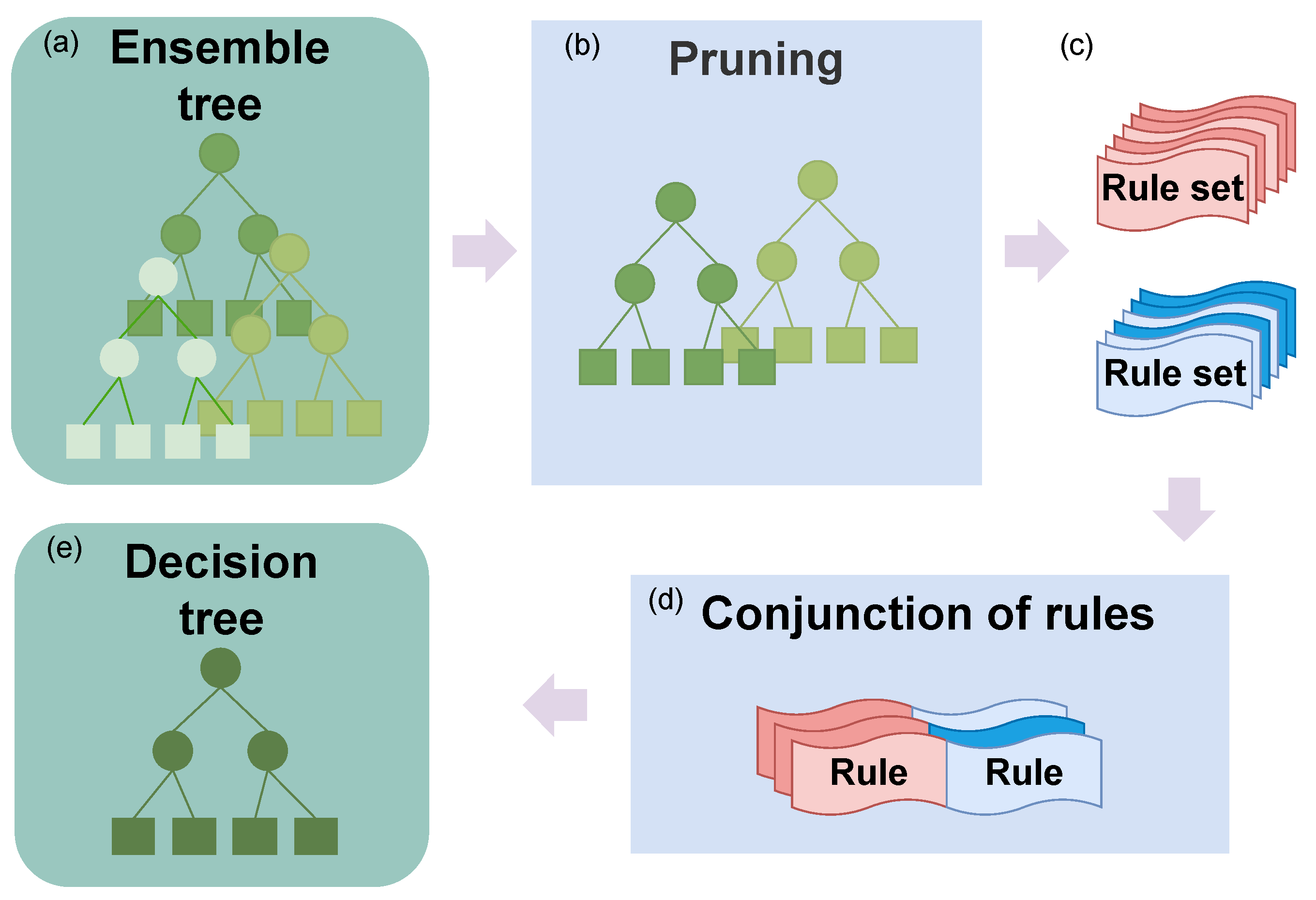
6.3. Decision Lists vs. Decision Trees
6.4. as a Metric of Interpretability
6.5. Limitations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Dataset Sources

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ID | URL |
|---|---|---|
| heart | 53 | https://archive.ics.uci.edu/dataset/145/statlog+heart (13 March 2024) |
| australian | 40981 | https://archive.ics.uci.edu/dataset/143/statlog+australian+credit+approval (13 March 2024) |
| mammographic | 45557 | https://archive.ics.uci.edu/dataset/161/mammographic+mass (13 March 2024) |
| tic-tac-toe | 50 | https://archive.ics.uci.edu/dataset/101/tic+tac+toe+endgame (13 March 2024) |
| german | 44096 | https://archive.ics.uci.edu/dataset/144/statlog+german+credit+data (13 March 2024) |
| biodeg | 1494 | https://archive.ics.uci.edu/dataset/254/qsar+biodegradation (13 March 2024) |
| banknote | 1462 | https://archive.ics.uci.edu/dataset/267/banknote+authentication (13 March 2024) |
| bank-marketing | 1558 | https://archive.ics.uci.edu/dataset/222/bank+marketing (13 March 2024) |
| spambase | 44 | https://archive.ics.uci.edu/dataset/94/spambase (13 March 2024) |
| occupancy | - | https://archive.ics.uci.edu/dataset/357/occupancy+detection (13 March 2024) |
Appendix B. Implementation Details and Hyperparameters
Appendix B.1. XGBoost
| Parameter | Space |
|---|---|
| UniformInt (1, 10) | |
| LogUniform (1 × 10−4,1.0) | |
| # Iterations | 50 |
Appendix B.2. FBTs
| Parameter | Space |
|---|---|
| UniformInt (1, 10) | |
| {auc, None} | |
| # Iterations | 50 |
Appendix B.3. RuleCOSI+
| Parameter | Space |
|---|---|
| Uniform (0.0, 0.95) | |
| Uniform (0.0, 0.5) | |
| c | Uniform (0.1, 0.5) |
| # Iterations | 50 |
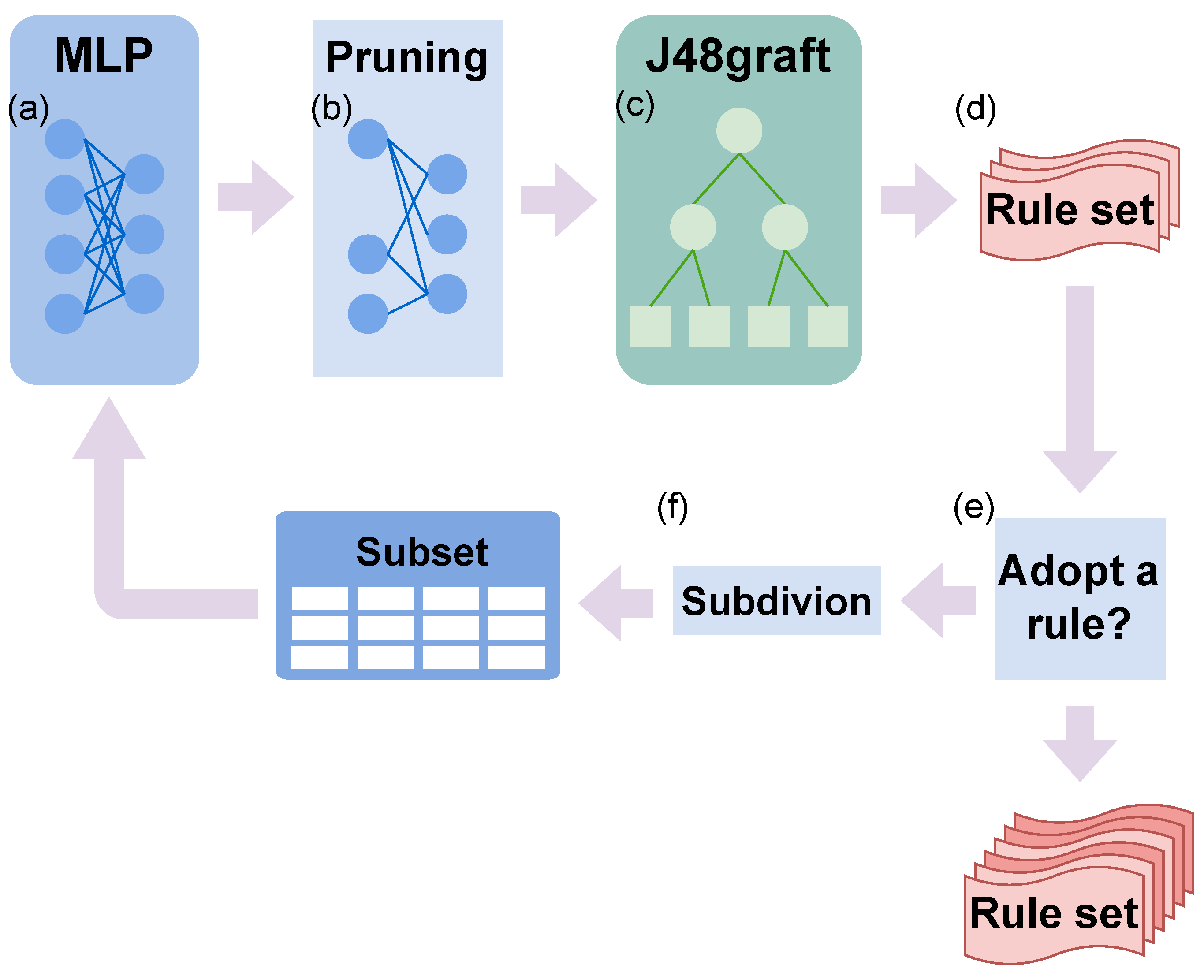
Appendix B.4. Re-RX with J48graft
- [59]
| Parameter | Space |
|---|---|
| UniformInt (1, 5) | |
| LogUniform (5 × 10−3, 0.1) | |
| LogUniform (1 × 10−6, 1 × 10−2) | |
| # Iterations | 50 |
| Parameter | Space |
|---|---|
| {2, 4, 8, …, 128} | |
| Uniform (0.1, 0.5) | |
| LogUniform (0.001, 0.25) | |
| Uniform (0.05, 0.4) | |
| Uniform (0.05, 0.4) | |
| # Iterations | 50 |
Appendix B.5. DT
| Parameter | Space |
|---|---|
| UniformInt (1, 10) | |
| Uniform (0.0, 0.5) | |
| Uniform (0.0, 0.5) | |
| # Iterations | 100 |
Appendix B.6. J48graft
| Parameter | Space |
|---|---|
| {2, 4, 8, …, 128} | |
| Uniform (0.1, 0.5) | |
| # Iterations | 100 |
Appendix C. Results for Other Metrics
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 4.0 | 2.1 | 2.5 | 4.1 | 2.3 |
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 2.8 | 3.3 | 3.3 | 2.5 | 3.1 |
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 2.9 | 1.1 | 3.9 | 3.8 | 3.0 |
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 3.0 | 2.1 | 4.0 | 3.0 | 2.9 |
References
- Saeed, W.; Omlin, C. Explainable AI (XAI): A systematic meta-survey of current challenges and future opportunities. Knowl. Based Syst. 2023, 263, 110273. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Zhang, Y.; Tiňo, P.; Leonardis, A.; Tang, K. A Survey on Neural Network Interpretability. IEEE Trans. Emerg. Top Comput. Intell. 2021, 5, 726–742. [Google Scholar] [CrossRef]
- Demajo, L.M.; Vella, V.; Dingli, A. Explainable AI for Interpretable Credit Scoring. In Computer Science & Information Technology (CS & IT); AIRCC Publishing Corporation: Chennai, India, 2020. [Google Scholar] [CrossRef]
- Petch, J.; Di, S.; Nelson, W. Opening the Black Box: The Promise and Limitations of Explainable Machine Learning in Cardiology. Can. J. Cardiol. 2022, 38, 204–213. [Google Scholar] [CrossRef]
- Weber, L.; Lapuschkin, S.; Binder, A.; Samek, W. Beyond explaining: Opportunities and challenges of XAI-based model improvement. Inf. Fusion 2023, 92, 154–176. [Google Scholar] [CrossRef]
- Vilone, G.; Longo, L. Classification of Explainable Artificial Intelligence Methods through Their Output Formats. Mach. Learn. Knowl. Extr. 2021, 3, 615–661. [Google Scholar] [CrossRef]
- Cabitza, F.; Campagner, A.; Malgieri, G.; Natali, C.; Schneeberger, D.; Stoeger, K.; Holzinger, A. Quod erat demonstrandum?—Towards a typology of the concept of explanation for the design of explainable AI. Expert Syst. Appl. 2023, 213, 118888. [Google Scholar] [CrossRef]
- Deck, L.; Schoeffer, J.; De-Arteaga, M.; Kühl, N. A Critical Survey on Fairness Benefits of XAI. arXiv 2023. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mason, L.; Baxter, J.; Bartlett, P.; Frean, M. Boosting Algorithms as Gradient Descent. In Advances in Neural Information Processing Systems; Solla, S., Leen, T., Müller, K., Eds.; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the KDD ’16: 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; NIPS’17. pp. 3149–3157. [Google Scholar]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. arXiv 2019. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. WIREs Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- Longo, L.; Brcic, M.; Cabitza, F.; Choi, J.; Confalonieri, R.; Ser, J.D.; Guidotti, R.; Hayashi, Y.; Herrera, F.; Holzinger, A.; et al. Explainable Artificial Intelligence (XAI) 2.0: A manifesto of open challenges and interdisciplinary research directions. Inf. Fusion 2024, 106, 102301. [Google Scholar] [CrossRef]
- Zihni, E.; Madai, V.I.; Livne, M.; Galinovic, I.; Khalil, A.A.; Fiebach, J.B.; Frey, D. Opening the black box of artificial intelligence for clinical decision support: A study predicting stroke outcome. PLoS ONE 2020, 15, e0231166. [Google Scholar] [CrossRef]
- Yang, C.C. Explainable Artificial Intelligence for Predictive Modeling in Healthcare. J. Healthc. Inform. Res. 2022, 6, 228–239. [Google Scholar] [CrossRef]
- Carmona, P.; Dwekat, A.; Mardawi, Z. No more black boxes! Explaining the predictions of a machine learning XGBoost classifier algorithm in business failure. Res. Int. Bus. Financ. 2022, 61, 101649. [Google Scholar] [CrossRef]
- Lipton, Z.C. The Mythos of Model Interpretability. arXiv 2017. [Google Scholar] [CrossRef]
- Qian, H.; Ma, P.; Gao, S.; Song, Y. Soft reordering one-dimensional convolutional neural network for credit scoring. Knowl. Based Syst. 2023, 266, 110414. [Google Scholar] [CrossRef]
- Mahbooba, B.; Timilsina, M.; Sahal, R.; Serrano, M. Explainable artificial intelligence (XAI) to enhance trust management in intrusion detection systems using decision tree model. Complexity 2021, 2021, 6634811. [Google Scholar] [CrossRef]
- Shulman, E.; Wolf, L. Meta Decision Trees for Explainable Recommendation Systems. In Proceedings of the AIES ’20: AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–9 February 2020; pp. 365–371. [Google Scholar] [CrossRef]
- Blanco-Justicia, A.; Domingo-Ferrer, J.; Martínez, S.; Sánchez, D. Machine learning explainability via microaggregation and shallow decision trees. Knowl. Based Syst. 2020, 194, 105532. [Google Scholar] [CrossRef]
- Sachan, S.; Yang, J.B.; Xu, D.L.; Benavides, D.E.; Li, Y. An explainable AI decision-support-system to automate loan underwriting. Expert Syst. Appl. 2020, 144, 113100. [Google Scholar] [CrossRef]
- Yang, L.H.; Liu, J.; Ye, F.F.; Wang, Y.M.; Nugent, C.; Wang, H.; Martinez, L. Highly explainable cumulative belief rule-based system with effective rule-base modeling and inference scheme. Knowl. Based Syst. 2022, 240, 107805. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Zhang, S.; Song, Y.; Qu, H. KG4Vis: A Knowledge Graph-Based Approach for Visualization Recommendation. IEEE Trans. Vis. Comput. Graph. 2022, 28, 195–205. [Google Scholar] [CrossRef]
- Setiono, R.; Baesens, B.; Mues, C. Recursive Neural Network Rule Extraction for Data With Mixed Attributes. IEEE Trans. Neural Netw. 2008, 19, 299–307. [Google Scholar] [CrossRef] [PubMed]
- Hayashi, Y.; Nakano, S. Use of a Recursive-Rule eXtraction algorithm with J48graft to achieve highly accurate and concise rule extraction from a large breast cancer dataset. Inform. Med. Unlocked 2015, 1, 9–16. [Google Scholar] [CrossRef]
- Friedman, J.H.; Popescu, B.E. Predictive learning via rule ensembles. Ann. Appl. Stat. 2008, 2, 916–954. [Google Scholar] [CrossRef]
- Deng, H. Interpreting tree ensembles with inTrees. Int. J. Data Sci. Anal. 2019, 7, 277–287. [Google Scholar] [CrossRef]
- Hara, S.; Hayashi, K. Making Tree Ensembles Interpretable: A Bayesian Model Selection Approach. In Proceedings of the Twenty-First International Conference on Artificial Intelligence and Statistics, Playa Blanca, Spain, 9–11 April 2018; Volume 84, pp. 77–85. [Google Scholar]
- Sagi, O.; Rokach, L. Explainable decision forest: Transforming a decision forest into an interpretable tree. Inf. Fusion 2020, 61, 124–138. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Approximating XGBoost with an interpretable decision tree. Inf. Sci. 2021, 572, 522–542. [Google Scholar] [CrossRef]
- Obregon, J.; Kim, A.; Jung, J.Y. RuleCOSI: Combination and simplification of production rules from boosted decision trees for imbalanced classification. Expert Syst. Appl. 2019, 126, 64–82. [Google Scholar] [CrossRef]
- Obregon, J.; Jung, J.Y. RuleCOSI+: Rule extraction for interpreting classification tree ensembles. Inf. Fusion 2023, 89, 355–381. [Google Scholar] [CrossRef]
- Nauck, D.D. Measuring interpretability in rule-based classification systems. In Proceedings of the 12th IEEE International Conference on Fuzzy Systems, FUZZ’03, St. Louis, MO, USA, 25–28 May 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 1, pp. 196–201. [Google Scholar]
- Lakkaraju, H.; Bach, S.H.; Leskovec, J. Interpretable decision sets: A joint framework for description and prediction. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1675–1684. [Google Scholar]
- Souza, V.F.; Cicalese, F.; Laber, E.; Molinaro, M. Decisiont Trees with Short Explainable Rules. In Advances in Neural Information Processing Systems; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; lCurran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 12365–12379. [Google Scholar]
- Margot, V.; Luta, G. A New Method to Compare the Interpretability of Rule-Based Algorithms. AI 2021, 2, 621–635. [Google Scholar] [CrossRef]
- Hayashi, Y. Synergy effects between grafting and subdivision in Re-RX with J48graft for the diagnosis of thyroid disease. Knowl. Based Syst. 2017, 131, 170–182. [Google Scholar] [CrossRef]
- Hayashi, Y.; Oishi, T. High accuracy-priority rule extraction for reconciling accuracy and interpretability in credit scoring. New Gener. Comput. 2018, 36, 393–418. [Google Scholar] [CrossRef]
- Chakraborty, M.; Biswas, S.K.; Purkayastha, B. Recursive Rule Extraction from NN using Reverse Engineering Technique. New Gener. Comput. 2018, 36, 119–142. [Google Scholar] [CrossRef]
- Hayashi, Y. Neural network rule extraction by a new ensemble concept and its theoretical and historical background: A review. Int. J. Comput. Intell. Appl. 2013, 12, 1340006. [Google Scholar] [CrossRef]
- Hayashi, Y. Application of a rule extraction algorithm family based on the Re-RX algorithm to financial credit risk assessment from a Pareto optimal perspective. Oper. Res. Perspect. 2016, 3, 32–42. [Google Scholar] [CrossRef]
- Hayashi, Y.; Takano, N. One-Dimensional Convolutional Neural Networks with Feature Selection for Highly Concise Rule Extraction from Credit Scoring Datasets with Heterogeneous Attributes. Electronics 2020, 9, 1318. [Google Scholar] [CrossRef]
- Hayashi, Y. Does Deep Learning Work Well for Categorical Datasets with Mainly Nominal Attributes? Electronics 2020, 9, 1966. [Google Scholar] [CrossRef]
- Kelly, M.; Longjohn, R.; Nottingham, K. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu (accessed on 13 March 2024).
- Webb, G.I. Decision Tree Grafting from the All-Tests-but-One Partition. In Proceedings of the IJCAI’99: 16th International Joint Conference on Artificial Intelligence, San Francisco, CA, USA, 31 July–6 August 1999; Volume 2, pp. 702–707. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: Burlington, MA, USA, 1993. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- Welch, B. The generalization of students problem when several different population variances are involved. Biometrika 1947, 34, 28–35. [Google Scholar] [CrossRef] [PubMed]
- Feurer, M.; van Rijn, J.N.; Kadra, A.; Gijsbers, P.; Mallik, N.; Ravi, S.; Müller, A.; Vanschoren, J.; Hutter, F. OpenML-Python: An extensible Python API for OpenML. J. Mach. Learn. Res. 2021, 22, 1–5. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]





| Metrics | Description |
|---|---|
| Number of rules | This metric is the total number of rules. |
| Number of conditions | This metric is the sum of the total or average number of conditions. |
| Complexity [40] | This metric relates the complexity, namely the number of conditions, to the number of classes. |
| Fraction uncover [41] | This metric measures the proportion of data points covered by at least one rule in the rule set. |
| Fraction overlap [41] | This metric calculates the degree to which rules in the rule set redundantly cover the same data points. |
| Uniq [39] | This metric quantifies the amount of non-redundant conditions contained in the rule set. |
| [42] | This metric is the weighted sum of the number of different attributes, based on the coverage of each rule. |
| Weighted sum of predictivity, stability, and simplicity [43] | This metric combines three critical aspects: predictivity, which assesses accuracy; stability, gauged through the Dice–Sorensen index comparing rule sets; and simplicity, measured by rule length sum, into a comprehensive weighted sum. |
| Dataset | #Instances | #Features | #Cate | #Cont | Major Class Ratio |
|---|---|---|---|---|---|
| heart | 270 | 13 | 7 | 6 | 0.55 |
| australian | 690 | 14 | 6 | 8 | 0.555 |
| mammographic | 831 | 4 | 2 | 2 | 0.52 |
| tic-tac-toe | 958 | 9 | 9 | 0 | 0.65 |
| german | 1000 | 20 | 7 | 13 | 0.70 |
| biodeg | 1055 | 41 | 0 | 41 | 0.66 |
| banknote | 1372 | 4 | 0 | 4 | 0.55 |
| bank-marketing | 4521 | 16 | 9 | 7 | 0.89 |
| spambase | 4601 | 57 | 0 | 57 | 0.60 |
| occupancy | 8143 | 5 | 0 | 5 | 0.79 |
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 2.9 | 2.1 | 4.0 | 3.2 | 2.8 |
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 4.5 | 1.6 | 3.3 | 3.8 | 1.8 |
| Dataset | FBTs | RuleCOSI+ | Re-RX with J48graft | J48graft | DT |
|---|---|---|---|---|---|
| heart | |||||
| australian | |||||
| mammographic | |||||
| tic-tac-toe | |||||
| german | |||||
| biodeg | |||||
| banknote | |||||
| bank-marketing | |||||
| spambase | |||||
| occupancy | |||||
| ranking | 3.5 | 4.7 | 1.5 | 3.1 | 2.2 |
| Method | |||
|---|---|---|---|
| FBTs | |||
| RuleCOSI+ | |||
| Re-RX with J48graft | |||
| J48graft | |||
| DT |
| RuleCOSI+ | Coverage | |
| 0.744 | ||
| 0.148 | ||
| 0.109 | ||
| Re-RX with J48graft | Coverage | |
| 0.820 | ||
| 0.108 | ||
| 0.044 | ||
| 0.0 | ||
| 0.029 | ||
| DT | Coverage | |
| 0.891 | ||
| 0.025 | ||
| 0.084 |
| Re-RX with J48graft | Coverage | |
| 0.971 | ||
| 0.0 | ||
| 0.029 |
| RuleCOSI+ | Coverage | |
| 0.329 | ||
| 0.283 | ||
| 0.388 | ||
| Re-RX with J48graft | Coverage | |
| 0.394 | ||
| 0.063 | ||
| 0.16 | ||
| 0.067 | ||
| 0.013 | ||
| 0.022 | ||
| 0.012 | ||
| 0.19 | ||
| 0.079 | ||
| DT | Coverage | |
| 0.394 | ||
| 0.325 | ||
| 0.281 |
| Re-RX with J48graft | Coverage | |
| 0.394 | ||
| 0.063 | ||
| 0.067 | ||
| 0.207 | ||
| 0.19 | ||
| 0.079 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Onishi, S.; Nishimura, M.; Fujimura, R.; Hayashi, Y. Why Do Tree Ensemble Approximators Not Outperform the Recursive-Rule eXtraction Algorithm? Mach. Learn. Knowl. Extr. 2024, 6, 658-678. https://doi.org/10.3390/make6010031
Onishi S, Nishimura M, Fujimura R, Hayashi Y. Why Do Tree Ensemble Approximators Not Outperform the Recursive-Rule eXtraction Algorithm? Machine Learning and Knowledge Extraction. 2024; 6(1):658-678. https://doi.org/10.3390/make6010031
Chicago/Turabian StyleOnishi, Soma, Masahiro Nishimura, Ryota Fujimura, and Yoichi Hayashi. 2024. "Why Do Tree Ensemble Approximators Not Outperform the Recursive-Rule eXtraction Algorithm?" Machine Learning and Knowledge Extraction 6, no. 1: 658-678. https://doi.org/10.3390/make6010031