
How Close Is Existing C/C++ Code to a Safe Subset?


Abstract
:1. Introduction
- We summarize the existing work on safe C/C++ standards and the safe subsets of C/C++.
- We present a static analysis tool and methodology for identifying potentially problematic code constructs in the existing C/C++ code.
- We analyze the data from 5.8 million code samples in the Exebench benchmark suite, two C/C++ benchmark suites, and five modern C++ applications to determine how close existing C/C++ code is to conforming to a safe subset of C++.
2. Background
2.1. Memory Safety Errors in C/C++
2.2. Recent Arguments against C/C++
2.2.1. Executive Order (EO) 14028
2.2.2. NSA
2.2.3. NIST
2.3. ISO C++ Response
3. Safe C/C++ Standards
3.1. CPP Core Guidelines
3.2. MISRA C++
3.3. AUTOSAR C++
3.4. CERT
3.5. High Integrity C++
3.6. Joint Strike Fighter
3.7. Summary and Comparison
- C++ Core F.8: Prefer pure functions.
- CERT EXP54-CPP: Do not access an object outside its lifetime.
- JSF AV 70.1: An object shall not be improperly used before its lifetime begins or after its lifetime ends.
- AUTOSAR M5-2-5: An array or container shall not be accessed beyond its range.
- JSF AV 15: Provision shall be made for run-time checking (defensive programming).
- CERT STR53-CPP: Range check element access.
4. Safe Subsets of C/C++
4.1. SafeC
4.2. CCured
4.3. Cyclone
4.4. Ironclad C++
4.5. What Work Has Been Required to Translate to Previous Safe Subsets of C++?
4.6. Summary
5. Methodology
- (Q1)
- How often are raw pointers, void pointers, and smart pointers found in existing C/C++ code?
- (Q2)
- How often are “problematic” code constructs found in existing C/C++ code?
- (Q3)
- Is “modern” C++ code closer to a safe subset than C/C++ code at large?
5.1. Static Analysis Patterns
5.1.1. Pointers
- C++ Core ES.42: Keep use of pointers simple and straightforward.
- C++ Core ES.65: Do not dereference an invalid pointer.
- C++ Core R.3: A raw pointer is non-owning.
- C++ Core I.11: Never transfer ownership by a raw pointer (T*) or reference (T&).
5.1.2. Unsafe Functions
- C++ Core R.10: Avoid malloc() and free().
- AUTOSAR A18-5-1: Functions malloc, calloc, realloc, and free shall not be used.
- C++ Core SL.4: Use the standard library in a type-safe manner.
- HIC 17.2.1: Wrap the use of the C standard library.
- AUTOSAR A17-1-1: Use of the C standard library shall be encapsulated and isolated.
5.1.3. Casts
- C++ Core ES.48: Avoid casts.
- C++ Core ES.49: If you must use a cast, use a named cast.
- C++ Core C.146: Use dynamic_cast where class hierarchy navigation is unavoidable.
- HIC 5.4.1: Only use the casting forms static_cast (excl. void*), dynamic_cast, or explicit constructor call.
- AUTOSAR A5-2-2: Traditional C-style casts shall not be used.
- AUTOSAR A5-2-4: The reinterpret_cast shall not be used.
- MISRA 5-2-4: C-style casts (other than void casts) and functional notation casts (other than explicit constructor calls) shall not be used.
- C++ Core C.46: By default, declare single-argument constructors as explicit.
- C++ Core C.181: Avoid “naked” unions.
5.1.4. References
- C++ Core F.43: Never (directly or indirectly) return a pointer or reference to a local object.
- JSF AV 111: A function shall not return a pointer or reference to a non-static local object.
- MISRA 7-5-1: A function shall not return a reference or a pointer to an automatic variable (including parameters) defined within the function.
- MISRA 7-5-3: A function shall not return a reference or pointer to a parameter that is passed by reference or a const reference.
5.1.5. Arrays
- C++ Core I.13: Do not pass an array as a single pointer.
- C++ Core ES.27: Use std::array or stack_array for arrays on the stack.
- HIC 8.1.1: Do not use multiple levels of pointer indirection.
5.2. Running Analysis on Exebench
5.3. Running Analysis on C/C++ Benchmark Suites and Modern C++ Programs
6. Results
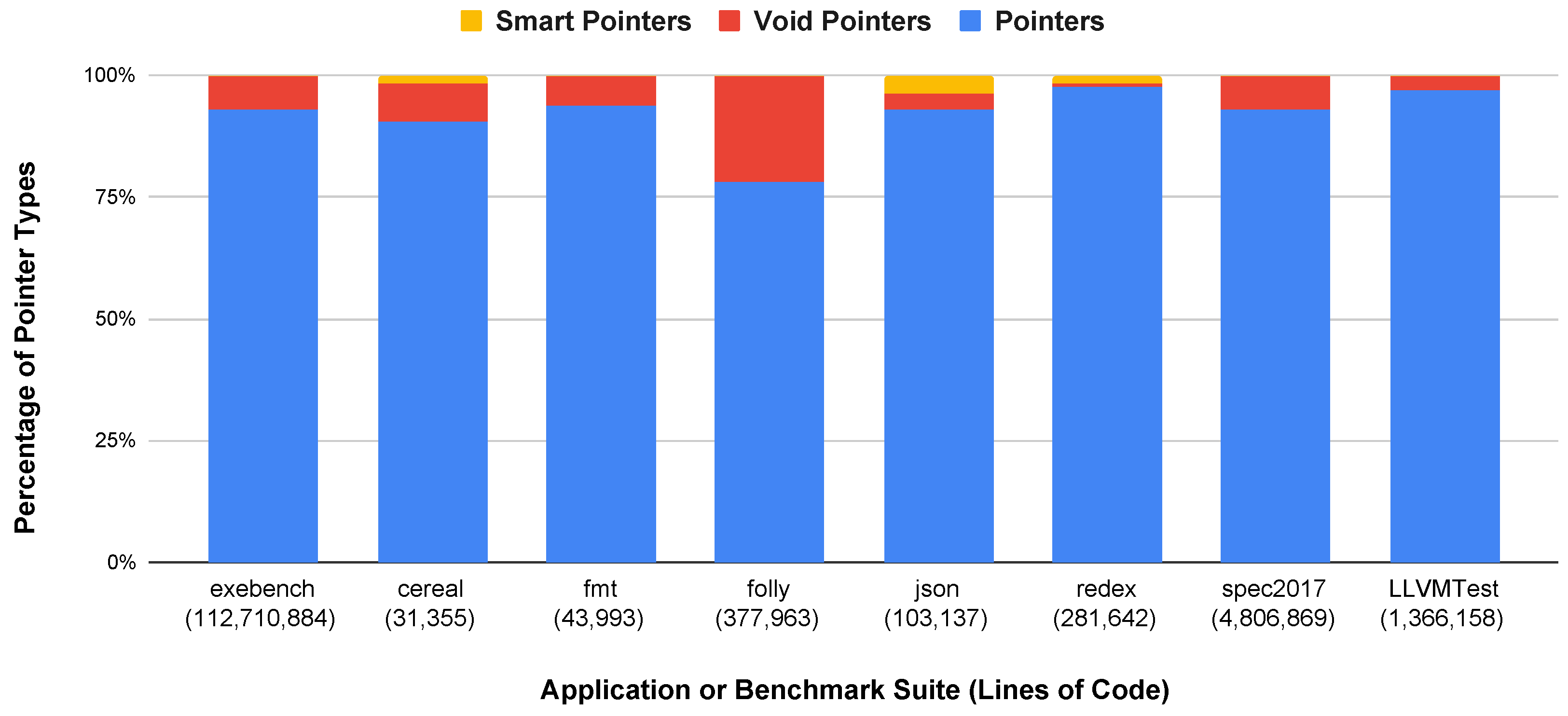
6.1. Pointers, Smart Pointers, and Void Pointers
6.2. Unsafe Functions
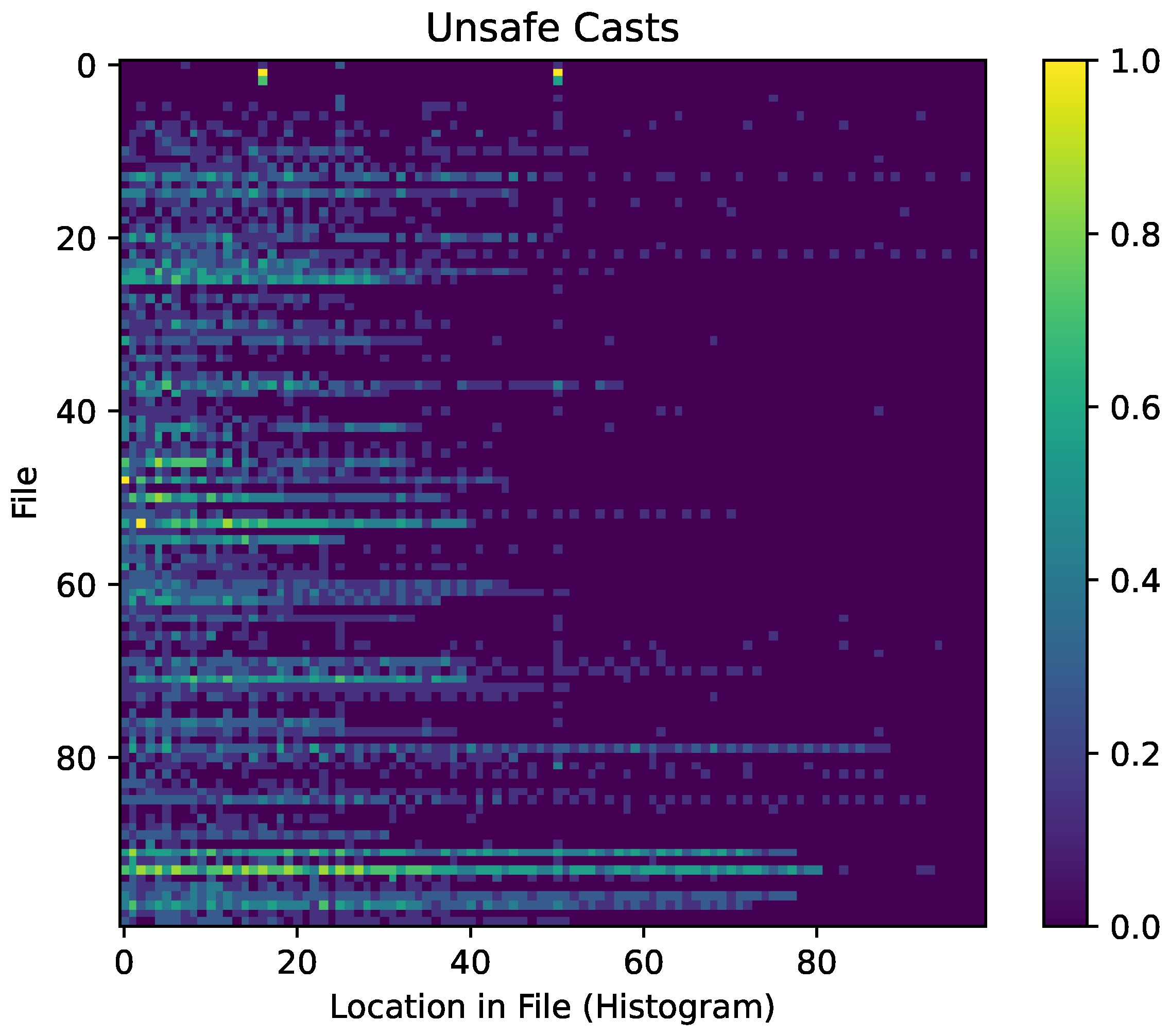
6.3. Casts and Unions
6.4. References
6.5. Arrays
6.6. Summary
7. Limitations and Future Work
8. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AST | Abstract Syntax Tree |
| AUTOSAR | Automotive Open System Architecture |
| CERT | Computer Emergency Response Team |
| HIC | High Integrity C++ |
| JSON | JavaScript Object Notation |
| MISRA | Motor Industry Software Reliability Association |
| JSF | Joint Strike Fighter |
| NSA | National Security Agency (United States) |
| NIST | National Institute for Standards and Technology (United States) |
References
- National Vulnerability Database CWE Over Time. Available online: https://nvd.nist.gov/general/visualizations/vulnerability-visualizations/cwe-over-time (accessed on 27 July 2023).
- National Security Agency Cybersecurity Information Sheet. Available online: https://media.defense.gov/2022/Nov/10/\2003112742/-1/-1/0/CSI_SOFTWARE_MEMORY_SAFETY.PDF (accessed on 27 July 2023).
- Biden, J. Executive Order on Improving the Nation’s Cybersecurity. The White House. 12 May 2021. Available online: https://www.whitehouse.gov/briefing-room/presidential-actions/2021/05/12/executive-order-on-improving-the-nations-cybersecurity/ (accessed on 6 October 2023).
- Hinnant, R.; Orr, R.; Stroustrup, B.; Vandevoorde, D.; Wong, M. DG Opinion on Safety for ISO C++. In The C++ Standards Committee; JTC1, SC22, WG21; ISO: Geneva, Switzerland, 2023; Document Number P2759R0. [Google Scholar]
- Austin, T.M.; Breach, S.E.; Sohi, G.S. Efficient detection of all pointer and array access errors. In Proceedings of the ACM SIGPLAN 1994 Conference on Programming Language Design and Implementation (PLDI ’94), Orlando, FL, USA, 20–24 June 1994; Association for Computing Machinery: New York, NY, USA, 1994; pp. 290–301. [Google Scholar] [CrossRef]
- Necula, G.C.; Condit, J.; Harren, M.; McPeak, S.; Weimer, W. CCured: Type-safe retrofitting of legacy software. ACM Trans. Program. Lang. Syst. 2005, 27, 477–526. [Google Scholar] [CrossRef]
- Jim, T.; Morrisett, J.G.; Grossman, D.; Hicks, M.W.; Cheney, J.; Wang, Y. Cyclone: A Safe Dialect of C. In Proceedings of the General Track of the Annual Conference on USENIX Annual Technical Conference (ATEC ’02), Berkeley, CA, USA, 10–15 June 2002; USENIX Association: Berkeley, CA, USA, 2002; pp. 275–288. [Google Scholar]
- DeLozier, C.; Eisenberg, R.; Nagarakatte, S.; Osera, P.M.; Martin, M.M.; Zdancewic, S. Ironclad C++: A library-augmented type-safe subset of C++. In Proceedings of the 2013 ACM SIGPLAN International Conference on Object Oriented Programming Systems Languages and Applications (OOPSLA ’13), Indianopolis, IN, USA, 29–31 October 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 287–304. [Google Scholar] [CrossRef]
- Armengol-Estape, J.; Woodruff, J.; Brauckmann, A.; Magalhaes, J.; De Souza, W.; O’Boyle, M. Exebench: An ML-Scale Dataset of Executable C Functions. In Proceedings of the MAPS 2022 6th ACM SIGPLAN International Symposium on Machine Learning, San Diego, CA, USA, 13 June 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 50–59. [Google Scholar]
- LLVM Test Suite. Available online: https://github.com/llvm/llvm-test-suite (accessed on 24 November 2023).
- SPEC Benchmark Suite 2017. Available online: https://www.spec.org/cpu2017/ (accessed on 24 November 2023).
- Cereal—A C++ library for Serialization. Available online: https://uscilab.github.io/cereal/ (accessed on 24 November 2023).
- fmt. Available online: https://github.com/fmtlib/fmt (accessed on 24 November 2023).
- Folly: Facebook Open-Source Library. Available online: https://github.com/facebook/folly (accessed on 24 November 2023).
- JSON for Modern C++. Available online: https://github.com/nlohmann/json (accessed on 24 November 2023).
- ReDex: An Android Bytecode Optimizer. Available online: https://github.com/facebook/redex (accessed on 24 November 2023).
- SSH CRC32 Attack Detection Code Contains Remote Integer Overflow. Available online: https://www.kb.cert.org/vuls/id/945216 (accessed on 30 October 2023).
- Miller, M. Trends, Challnges, and Strategic Shifts in the Software Vulnerability Mitigation Landscape. BlueHat IL. 7 February 2019. Available online: https://github.com/Microsoft/MSRC-Security-Research/blob/master/presentations/2019_02_BlueHatIL/2019_01%20-%20BlueHatIL%20-%20Trends%2C%20challenge%2C%20and%20shifts%20in%20software%20vulnerability\%20mitigation.pdf (accessed on 4 October 2023).
- Taylor, A.; Whalley, A.; Jansens, D.; Nasko, O. An update on Memory Safety in Chrome. Google Security Blog. 21 September 2021. Available online: https://security.googleblog.com/2021/09/an-update-on-memory-safety-in-chrome.html (accessed on 4 October 2023).
- Akritidis, P.; Costa, M.; Castro, M.; Hand, S. Baggy bounds checking: An efficient and backwards-compatible defense against out-of-bounds errors. In Proceedings of the 18th Conference on USENIX Security Symposium (SSYM’09), Montreal, QC, Canada, 10–14 August 2009; USENIX Association: Berkeley, CA, USA, 2009; pp. 51–66. [Google Scholar]
- Zhou, J.; Criswell, J.; Hicks, M. Fat Pointers for Temporal Memory Safety in C. Proc. Acm Program. Lang. 2023, 7, 316–347. [Google Scholar] [CrossRef]
- Nagarakatte, S.; Zhao, J.; Martin, M.M.; Zdancewic, S. SoftBound: Highly compatible and complete spatial memory safety for C. ACM Sigplan Not. 2009, 44, 245–258. [Google Scholar] [CrossRef]
- C++ Core Guidelines. Available online: https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines.html (accessed on 29 October 2023).
- MISRA Publications. Available online: https://misra.org.uk/publications/ (accessed on 1 October 2023).
- AUTOSAR Guidelines for the Use of the C++14 Language in Critical and SafetyRelated Systems. Available online: https://www.autosar.org/fileadmin/standards/R22-11/AP/AUTOSAR_RS_CPP14Guidelines.pdf. (accessed on 29 October 2023).
- SEI CERT C++ Coding Standard. Available online: https://wiki.sei.cmu.edu/confluence/pages/viewpage.action?\pageId=88046682 (accessed on 29 October 2023).
- High Integrity C++ Standard. Available online: https://www.perforce.com/resources/qac/high-integrity-cpp-coding-standard (accessed on 27 October 2023).
- Joint Strike Fighter Air Vehicle C++ Coding Standards. Available online: https://www.stroustrup.com/JSF-AV-rules.pdf (accessed on 29 October 2023).
- Condit, J.; Harren, M.; McPeak, S.; Necula, G.C.; Weimer, W. CCured in the real world. In Proceedings of the ACM SIGPLAN 2003 Conference on Programming Language Design and Implementation (PLDI ’03), San Diego, CA, USA, 9–11 June 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 232–244. [Google Scholar] [CrossRef]
- SaferCPlusPlus. Hardened C++ for the Internet Age. Available online: http://duneroadrunner.github.io/SaferCPlusPlus/ (accessed on 25 October 2023).
- ISO/IEC 14882:2020; Programming Languages—C++. International Organization for Standards: Geneva, Switzerland, 2020.
- AST Matcher Reference. Available online: https://clang.llvm.org/docs/LibASTMatchersReference.html (accessed on 30 October 2023).
- Da Silva, A.F.; Kind, B.C.; de Souza Magalhães, J.W.; Rocha, J.N.; Guimaraes, B.C.F.; Pereira, F.M.Q. Anghabench: A suite with one million compilable C benchmarks for code-size reduction. In Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 27 February–3 March 2021; pp. 378–390. [Google Scholar] [CrossRef]
- Gousios, G.; Vasilescu, B.; Serebrenik, A.; Zaidman, A. Lean GHTorrent: Github data on demand. In Proceedings of the MSR 2014: Proceedings of the 11th Working Conference on Mining Software Repositories, Hyderbad, India, 31 May–1 June 2014. [Google Scholar] [CrossRef]
- Count Lines of Code. Available online: https://github.com/AlDanial/cloc (accessed on 24 November 2023).












{kind=link}
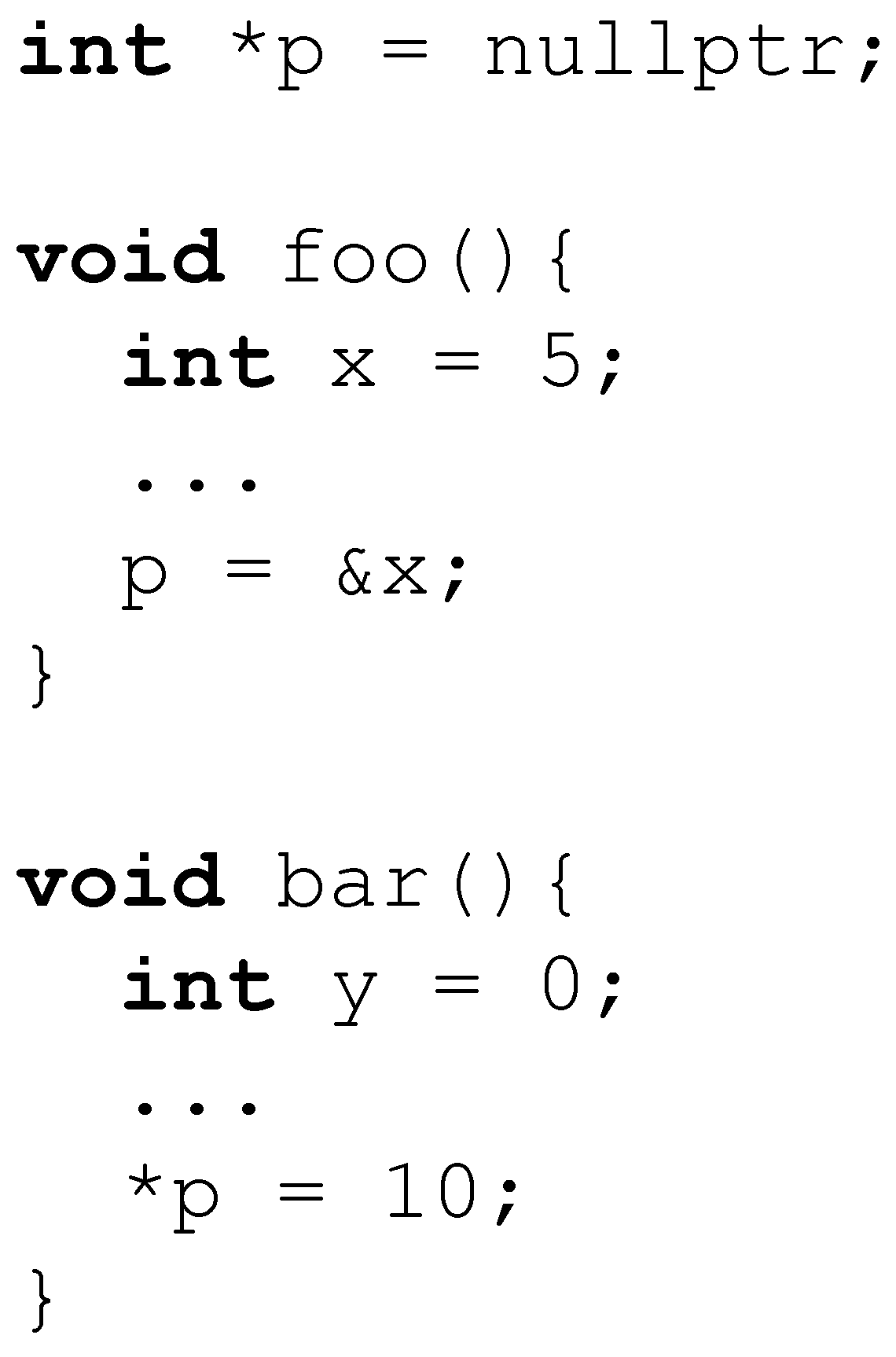{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Safe C/C++ Standard | Initialization | Spatial | Lifetime | Type |
|---|---|---|---|---|
| Core guidelines [23] | I.12, F.60, F.22, F.23, ES.20, ES.22 | I.13, C.90, C.152, R.14, ES.27, ES.42, ES.55, ES.71, ES.103 | I.11, F.7, F.26, F.27, F.42, F.43, F.44, F.45, F.53, C.21, C.31, C.33, C.49, C.82, C.127, C.149, R.1, R.3, R.4, R.5, R.10, R.11, R.36, ES.61, ES.65 | I.4, F.55, C.46, C.146, C.164, C.181, C.182, C.183, ES.34, ES.48, ES.49, SL.4 |
| MISRA [24] | 0-3-1, 8-5-1 | 0-3-1, 3-1-3, 5-0-15, 5-2-12, 18-0-5, 27-0-1 | 0-3-1, 7-5-1, 7-5-2, 7-5-3, 15-0-2, 18-4-1 | 5-2-2, 5-2-4, 5-2-6, 5-2-7, 5-2-8, 9-5-1 |
| Autosar [25] | A3-3-2, A5-3-2, A8-5-0, A12-6-1 | M5-0-15, M5-2-5, M5-2-12, A17-1-1, M18-0-5, A18-1-1, A27-0-4, A27-0-2 | A3-8-1, A5-1-4, A5-3-3, M7-5-1, M7-5-2, A7-5-1, A8-4-11, A8-4-12, A8-4-13, A18-1-4, A18-5-1, A18-5-3, A18-5-8, A20-8-1 | M5-2-2, A5-2-1, A5-2-2, A5-2-4, M5-2-6, M5-2-8, M5-2-9, A9-5-1, A13-5-2, A13-5-3 |
| CERT [26] | EXP53 | CNTR50, CTR53, CTR55, STR50, STR53 | EXP51, EXP54, EXP61 | DCL50, EXP58, INT50, MEM50, MEM51, MEM56 |
| HIC [27] | 8.4.1 | 4.1.1, 6.2.1, 17.2.1 | 3.4.1, 3.4.2, 8.1.1 | 3.5.1, 5.4.1, 5.4.3, 12.1.1 |
| JSF [28] | 71, 71.1, 117, 118, 142, 143, 174 | 15, 20–25, 96, 97, 215 | 70.1, 111, 173, 206 | 153, 178, 179, 182, 183, 185 |
| Application/Suite | Description | Language | Lines of Code |
|---|---|---|---|
| Cereal [12] | Serialization Library | C++ | 31,355 |
| Fmt [13] | Formatting library alternative | C++ | 43,993 |
| Folly [14] | Facebook core library components | C++ | 377,963 |
| Json [15] | JSON support for modern C++ | C++ | 103,137 |
| Redex [16] | Bytecode optimizer for Android | C++ | 281,642 |
| Exebench [9] | Exebench code samples | C | 112,710,884 |
| LLVM Test Suite [10] | LLVM Code Samples | C/C++ | 1,366,158 |
| SPEC CPU 2017 [11] | SPEC 2017 Benchmarks | C/C++ | 4,806,869 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
DeLozier, C. How Close Is Existing C/C++ Code to a Safe Subset? J. Cybersecur. Priv. 2024, 4, 1-22. https://doi.org/10.3390/jcp4010001
DeLozier C. How Close Is Existing C/C++ Code to a Safe Subset? Journal of Cybersecurity and Privacy. 2024; 4(1):1-22. https://doi.org/10.3390/jcp4010001
Chicago/Turabian StyleDeLozier, Christian. 2024. "How Close Is Existing C/C++ Code to a Safe Subset?" Journal of Cybersecurity and Privacy 4, no. 1: 1-22. https://doi.org/10.3390/jcp4010001
APA StyleDeLozier, C. (2024). How Close Is Existing C/C++ Code to a Safe Subset? Journal of Cybersecurity and Privacy, 4(1), 1-22. https://doi.org/10.3390/jcp4010001