1. Introduction
In recent years, the focus of the industrial landscape in China has gradually shifted from manufacturing to services, and research on user needs has become crucial for positioning product and service functionality [
1]. Enterprise demand for better user experience (UX) has created a need for UX education [
2,
3]. Although analyzing user needs is essential to UX research, it is also highly challenging [
4]. With the UX industry gaining popularity, many beginners with diverse professional backgrounds are stepping into the field [
5]. Their lack of industry experience and insight makes it difficult to classify or prioritize user needs and determine the direction of product or service development. Current methods, such as affinity diagrams, while valuable, often require extensive resources and expertise, limiting their accessibility to beginners and educational settings. Therefore, this study bridges this gap by introducing an innovative tool integrating the Kano model with deep learning. Theoretically, it advances our understanding of how AI can be effectively employed in UX research. Practically, it offers a user-friendly solution for beginners in UX design, making the complex process of user needs classification more approachable and less resource intensive.
1.1. Background and Significance
This study draws inspiration from the UX Foundation course. The course organically integrates design thinking and strategies from Stanford University, teaching a project-based approach to the entire product development process, from user research to prototype design [
6,
7]. Traditionally, user needs have been collected and classified using questionnaire surveys, interviews (or focus groups), and user journey maps according to specific scenarios or goals [
8,
9]. However, in the current era of big data and the Industry 4.0 trend, researchers have begun utilizing web crawlers to capture user comments from various forums or social media platforms to extract user needs [
10,
11]. Moreover, different types of deep learning models have been shown to perform well in Chinese text classification tasks and have been used for user needs classification [
12,
13]. Compared to traditional methods, deep learning-based approaches are more efficient and can guide decision making for novice practitioners in UX. However, developing or running complex code presents a significant challenge to design teams and hinders the usability of these classification tools. Therefore, enabling UX beginners to easily use text analysis methods to classify user needs is critical.
1.2. Research Objectives
This study aims to develop a user-friendly tool with a graphic user interface (GUI) that utilizes deep learning techniques to classify user needs according to the Kano model. The tool is intended to benefit individuals who are new to UX research. Moreover, the current study compares this tool with a traditional affinity diagram method to evaluate its usability and effectiveness in achieving UX beginners’ goals, reducing their workload and improving UX. The primary motivation behind this study is to facilitate beginners in user experience (UX) design to better analyze and interpret user needs. By recognizing the challenges that novices face, this research aims to provide an intuitive and practical approach to categorizing user needs. By integrating deep learning techniques with the Kano model, this study endeavors to simplify and clarify the process of user needs classification. This approach not only intends to make the UX design process more accessible to beginners, but also to instill a foundational understanding of how advanced analytical tools like deep learning can be harmoniously combined with established UX frameworks like the Kano model. Ultimately, this research seeks to empower beginners with the tools and knowledge necessary to contribute to the UX design field effectively.
3. Materials and Methods
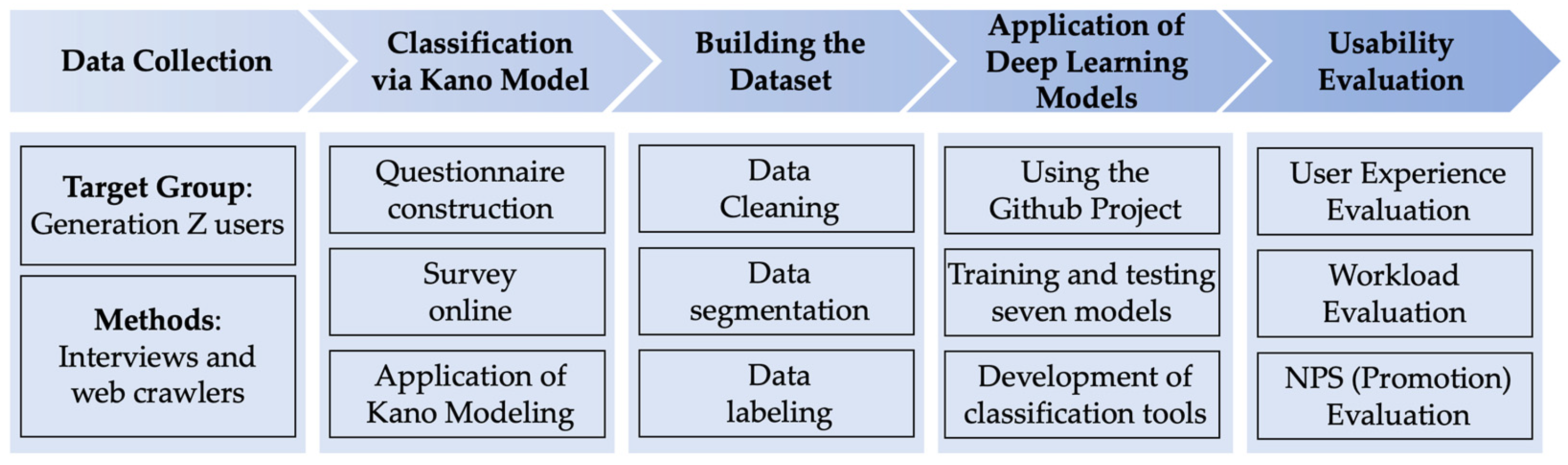
The workflow shown in
Figure 2 delineates the steps of our research methodology, including data collection, classification via the Kano Model, building the dataset, the application of deep learning models, and usability evaluation. In the relevant section, each step meticulously details the tools and methods employed, ensuring the transparency and reproducibility of the research. The purpose of this flowchart is to provide a clear visual guide for readers, aiding in the comprehension of the entire research process.
3.1. Data Collection
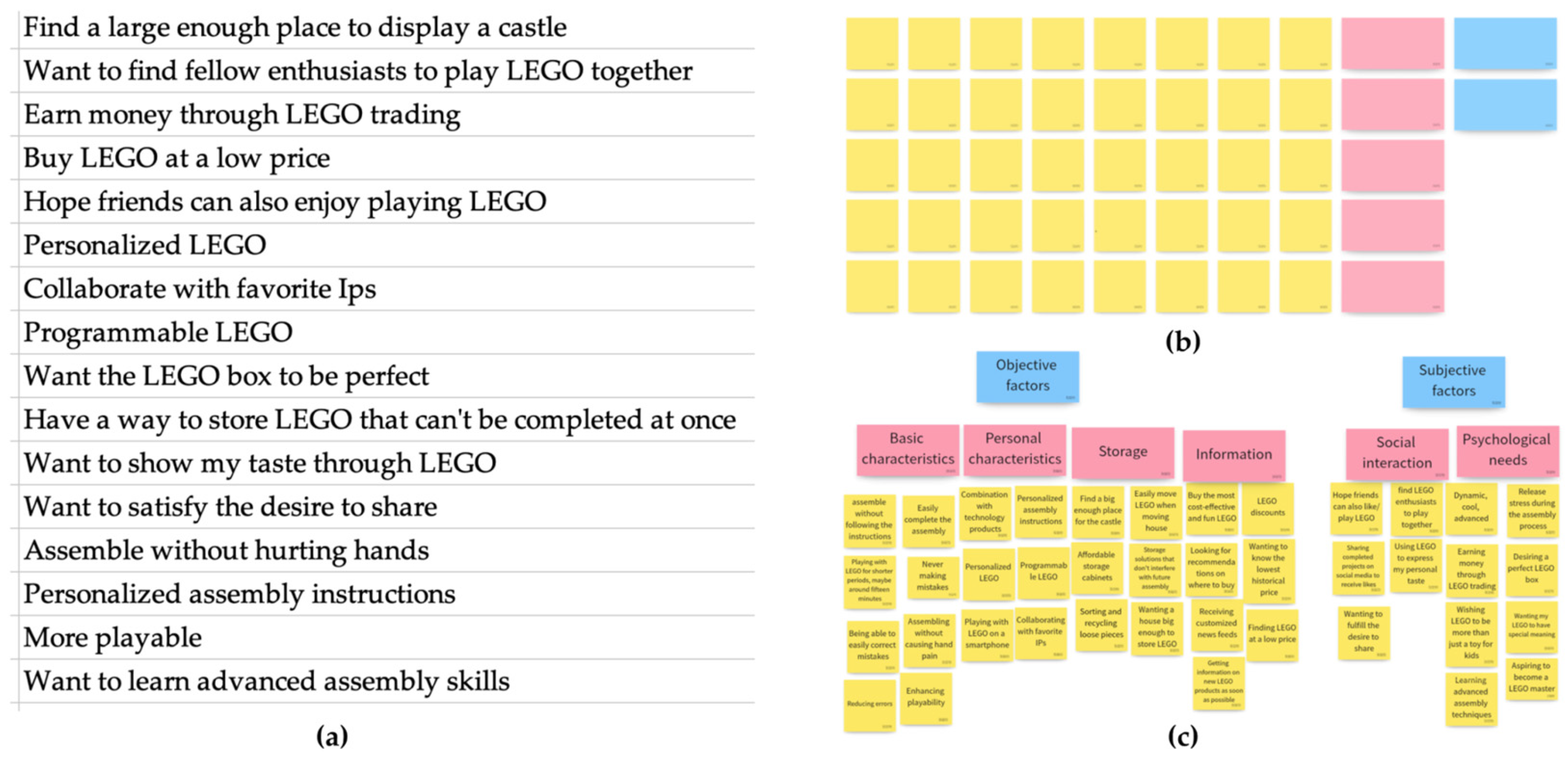
The first step of this study was to collect user needs as comprehensively as possible. With the support of a project in the UX Foundation course, this study focused on the needs of Generation Z (born between 1995 and 2009). A combination of interviews and web scraping methods were used for data collection. Twelve participants who had previously or were currently using the toys were interviewed individually, with each interview lasting about 30 min. The interviews aimed to gather basic information about the participants, including their understandings of the toys, preferences, UX, and expected features. Based on the interview results, 16 needs or expectations were identified and organized. In addition to the interviews, 3000 online reviews of LEGO toys (Billund, Denmark) were collected from JD.com using web scraping techniques. To ensure the data were mainly sourced from Generation Z, the products selected for data collection were suitable for ages 14 and above. The researchers extracted three additional needs from the online reviews that were not mentioned in the interviews.
In summary, this study collected 19 categories of demands from Generation Z through interviews and web scraping techniques. Additionally, we collected 3000 online comments about LEGO toys from JD.com.
3.2. Classification Based on the Kano Model
We surveyed the 19 user needs using a Kano model-based questionnaire and classified them according to the results. The study consisted of the following steps.
Firstly, we constructed a questionnaire consisting of two parts. The first part comprised demographic information of the participants, including age, gender, and whether they had purchased the LEGO toys. The second part consisted of a set of questions, each comprising a pair of positive and negative questions for each of the 19 identified user needs, as shown in
Table 1. It should be noted that since this study did not involve the ranking of needs, we did not use a question about the importance of each need.
Next, we released the online questionnaire and collected responses using the Credamo platform. One hundred and two valid participants (32 males and 70 females) with a mean age of 23.45 ± 2.25 were recruited for this study. All participants met the criteria of Generation Z. Among them, 90.20% (92 individuals) reported that they purchased the LEGO toys, indicating the sample’s high representativeness.
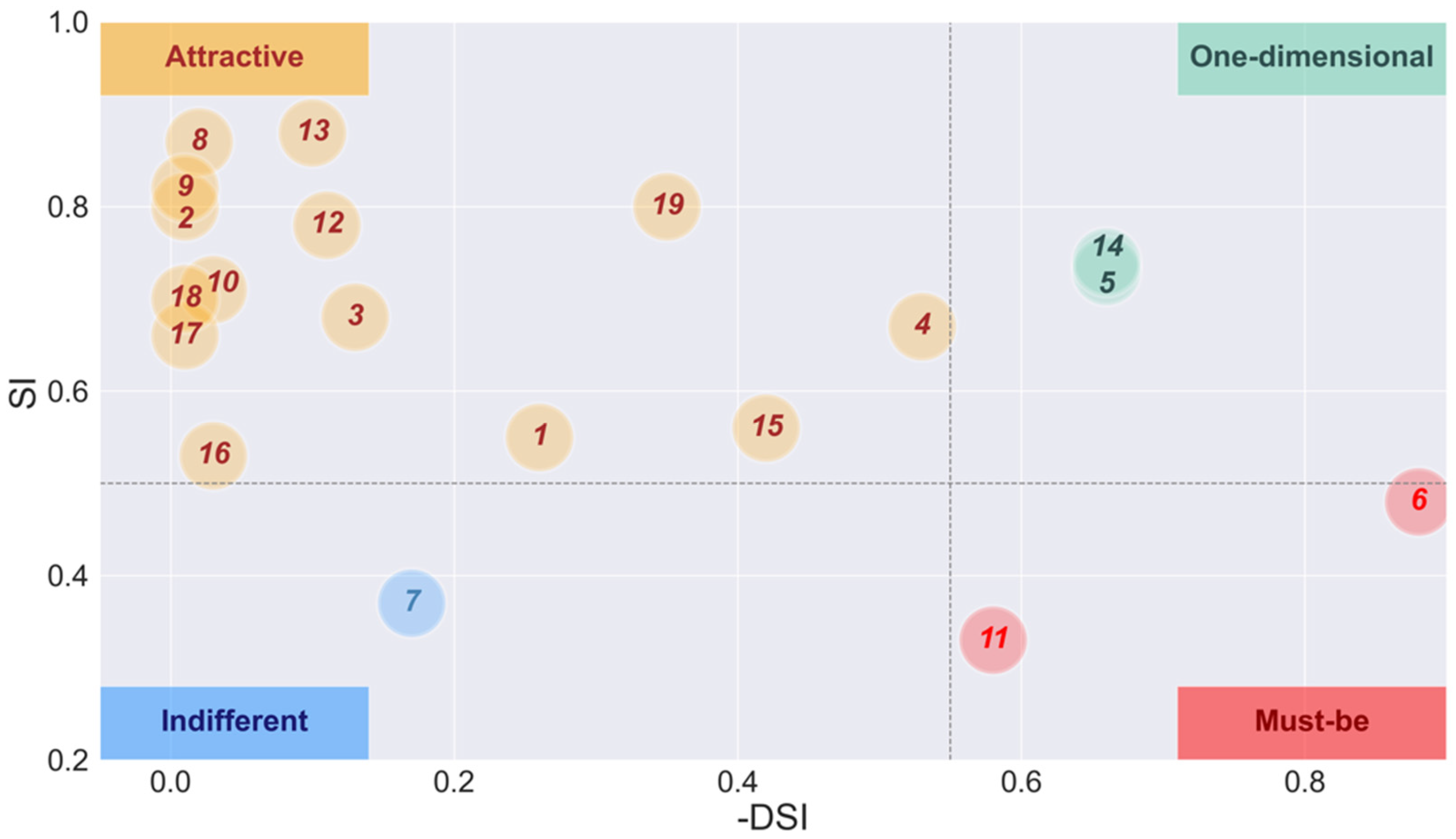
Subsequently, using the evaluation method shown in
Table 2, we obtained the A, O, M, I, R, and Q coefficients of the 19 user needs. The Kano model-based questionnaire analysis uses the A, O, M, I, R, and Q coefficients to categorize user needs. ‘A’ stands for attractive needs, ‘O’ stands for one-dimensional needs, ‘M’ stands for must-be needs, ‘I’ stands for indifferent needs, ‘R’ stands for reverse needs, and ‘Q’ stands for questionable or uncertain responses. These coefficients represent the categorizing of each user’s needs based on the participants’ responses to the functional and dysfunctional aspects of the products.
Table 2 illustrates the method used to determine these coefficients. The respondents’ answers to the pairs of positive and negative questions for each user need should yield different combinations corresponding to one of these coefficients. The category of each need is then determined by the highest frequency of responses aligning with these coefficients.
Finally, Satisfaction Influence (SI) coefficients and Dissatisfaction Influence (DSI) coefficients are calculated to visualize the analysis results on the coordinate axis [
28]. The SI and DSI coefficients are computed using better and worse values [
29].
3.3. Dataset Preprocessing and Labeling
In the manual labeling process, our primary objective was to annotate the dataset according to the distinct user needs categories as identified according to the Kano model. In this study, we applied four prominent types of user needs: attractive needs, one-dimensional needs, must-be needs, and indifferent needs. Consequently, our labeling incorporated this four-categorization label. This categorization was not arbitrary; in practical applications and academic research, user needs are expected to be classified into the four categories above. The incidence of other categories, such as reverse needs and questionable options, is relatively infrequent.
Firstly, we removed duplicated data in the reviews and eliminated useless characters (including English letters, numbers, emoticons, and punctuation marks). Then, using the Chinese word segmentation tool Jieba in Python to segment the text, we removed stop and low-frequency words (words with a frequency of less than 10 in all texts) to obtain the initial preprocessing file, reducing the data from 3760 to 2795 records. Finally, we labeled each text according to the Kano model. Moreover, we removed all of the text spaces in the dataset to generate another dataset. This work can provide more options for the deep learning model, which can be trained based on either words or characters.
After preprocessing and labeling the dataset, we obtained two versions, one with text spaces and one without. These two datasets will be used for model training.
3.4. Deep Learning Models for Text Classification
The text classification tool developed in this study was implemented with the help of an open-source Chinese text classification project based on the PyTorch framework, which can be found at github.com/649453932/Chinese-Text-Classification-Pytorch (accessed on 3 March 2023). This project achieved excellent results on a news headline classification dataset of 200,000 samples [
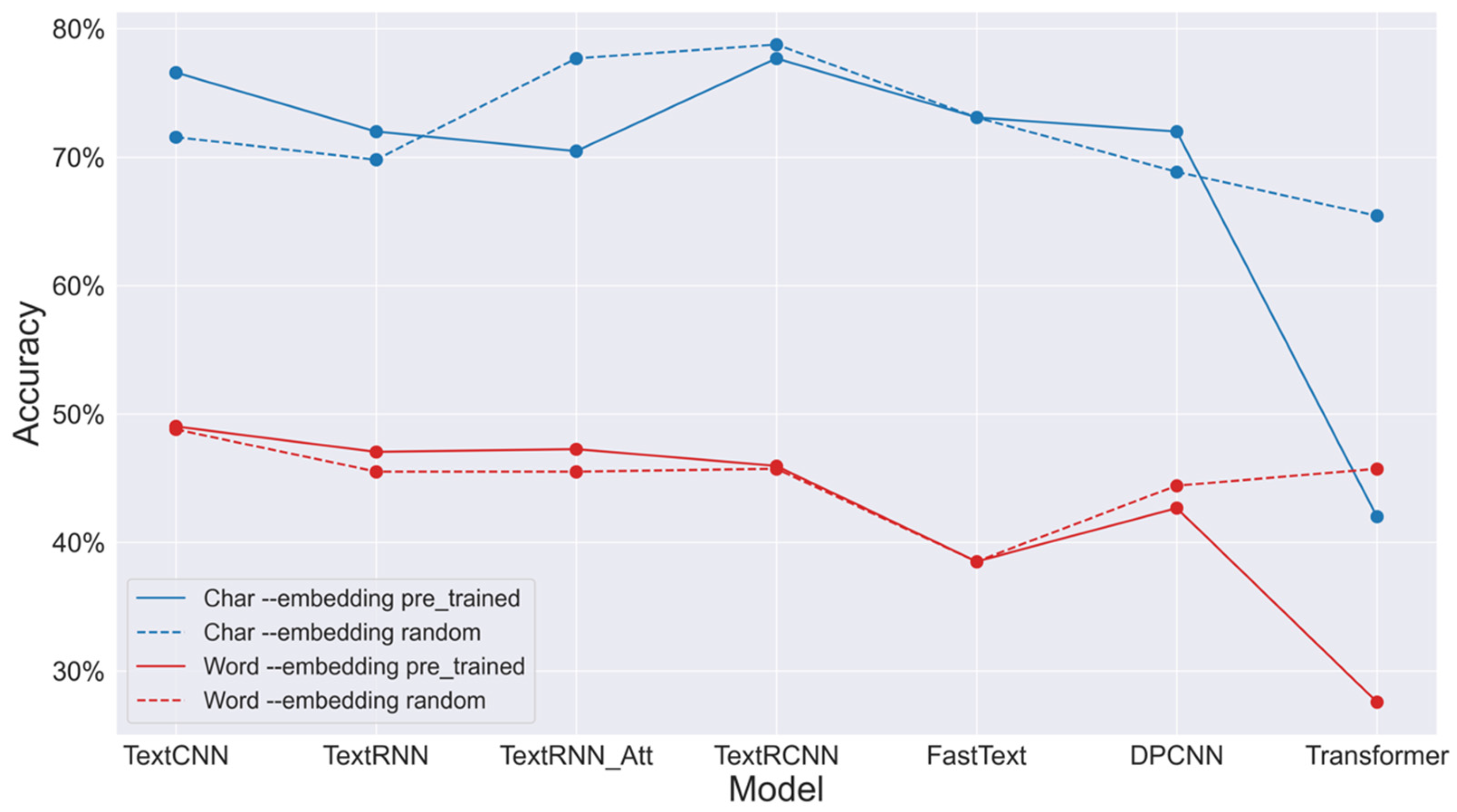
30]. In this study, we replaced the news headline dataset with two datasets obtained from the previous step of preprocessing and labeling. We trained and tested seven deep-learning models on these datasets, including TextCNN, TextRNN, TextRNN_Att, TextRCNN, FastText, DPCNN, and Transformer. Each model can be trained using either randomly initialized or pre-trained word embeddings. We obtained 28 (7 models × 2 datasets × 2 embeddings method) classification accuracies.
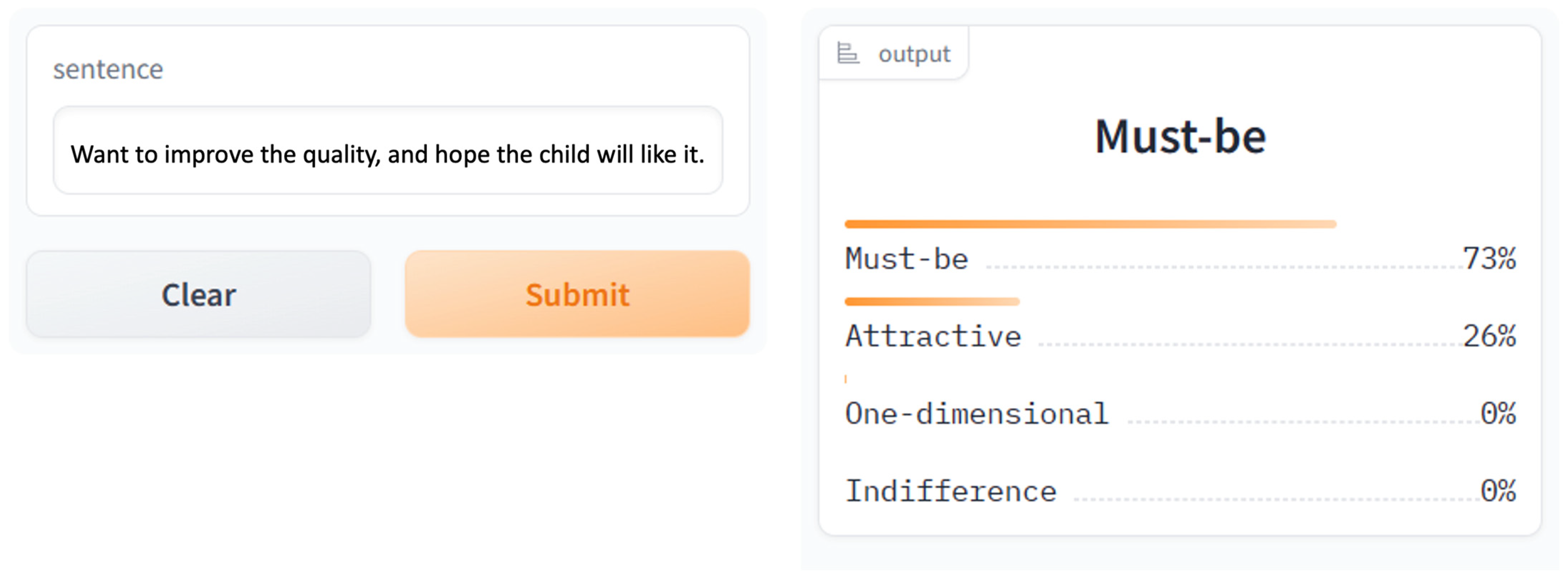
Based on the model and training mode with the highest accuracy, we developed a user-friendly text classification tool to assist novice users in automatically classifying user needs. While the existing Chinese-Text-Classification (CTC)-PyTorch tool is a general-purpose Chinese text classifier, our tool is fine-tuned to categorize text based on user needs, as defined in the Kano model. This includes custom-built categorizations namely must-be, attractive, one-dimensional, and indifferent needs, which are particularly relevant for UX research. When receiving a text representing user feedback or opinions about products, the tool displays the corresponding category of the user need and the probability for the four types.
3.5. Usability Evaluation
3.5.1. Participants
Forty participants (19 males and 21 females) with a mean age of 22.65 ± 3.08 were recruited for this study; they were undergraduate students in the “Design Thinking” course and graduate students in the “UX Foundation” course at our institute. All participants were beginners in UX and had no relevant work experience but had learned some classic user research methods. The 40 participants were randomly divided into eight groups of five people (the affinity diagram method is usually a team task). Four groups were randomly selected first to use the text classification tool and then apply the classic affinity diagram method for user needs classification. The remaining four groups first employed the affinity diagram method, followed by the text classification tool.
To prevent any confusion, it should be clarified that in this study, including the usability evaluation phase, the participants were recruited on three separate occasions: through interviews, online surveys, and usability evaluations. There was no overlap among the participants in these different occasions. Detailed information about the participants recruited for each of these three occasions is presented in
Table 3.
3.5.2. Materials and Tools
The materials and tools used in this experiment can be divided into three main parts:
3.5.3. Experimental Design
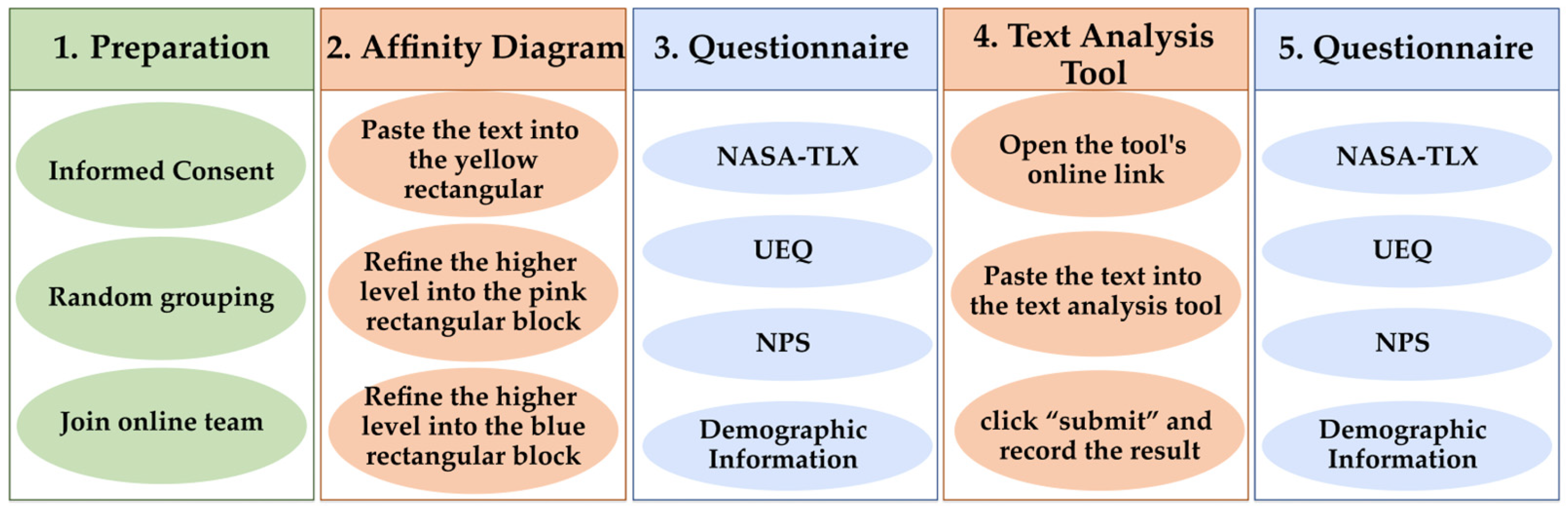
In this study, a single-factor, two-level, within-subjects design was utilized to evaluate and compare the performance of the text classification tool developed in previous stages with the conventional user needs classification method—the affinity diagram. The usability test procedure is presented in
Figure 3. The sequencing of the second (affinity diagram) and fourth steps (text analysis tool) may vary across groups to counterbalance potential order effects.
Taking the sequence in
Figure 2 as an example, the following detailed description of the experimental procedure is used.
During the preparation phase, after every 40 participants read and signed the informed consent form, they were randomly assigned to eight groups. The grouping method was introduced in the previous section, “
Section 3.5.1 Participants”. We established a WeChat group chat for each team to distribute the experimental materials to the participants efficiently and effectively.
After the preparation phase was completed, four group participants were invited to use the affinity diagram method for classification first. They utilized the pre-prepared online whiteboard tool, Boardmix, for the experiment. This task can be broken down into three parts: first, the participants were required to paste the text from the Excel file into yellow rectangular blocks; then, they grouped these yellow rectangles based on structural or content similarity and wrote their shared needs in pink rectangles; finally, they further refined these pink rectangles and recorded their commonalities in blue rectangles.
After completing the classification task using the affinity diagram, each participant was asked to complete an online questionnaire.
After sufficient rest, the participants were asked to use the text analysis tool for classification. This task could also be divided into three parts. First, the participants needed to open a webpage link to access the classification tool we developed. Then, they pasted the texts of user needs from the Excel file into the tool. Finally, they clicked “submit” and recorded the resulting categories in the Excel file.
Following this task, the participants were asked to complete the same online questionnaire.
There are three additional points to note. First, the other four groups of participants performed the two tasks in a different sequence, using the text analysis tool before the online affinity diagram to balance the order effects in the within-subjects design. Second, both tasks used the same set of 40 needs texts, which were placed in an Excel document and sent to the participants via WeChat group chats. Third, the groups used the text classification tool to classify the needs separately as individual tasks. In contrast, the groups used the affinity diagram as a team task.
Figure 4 illustrates the implementation of the 2 methods.
3.5.4. Data Analysis
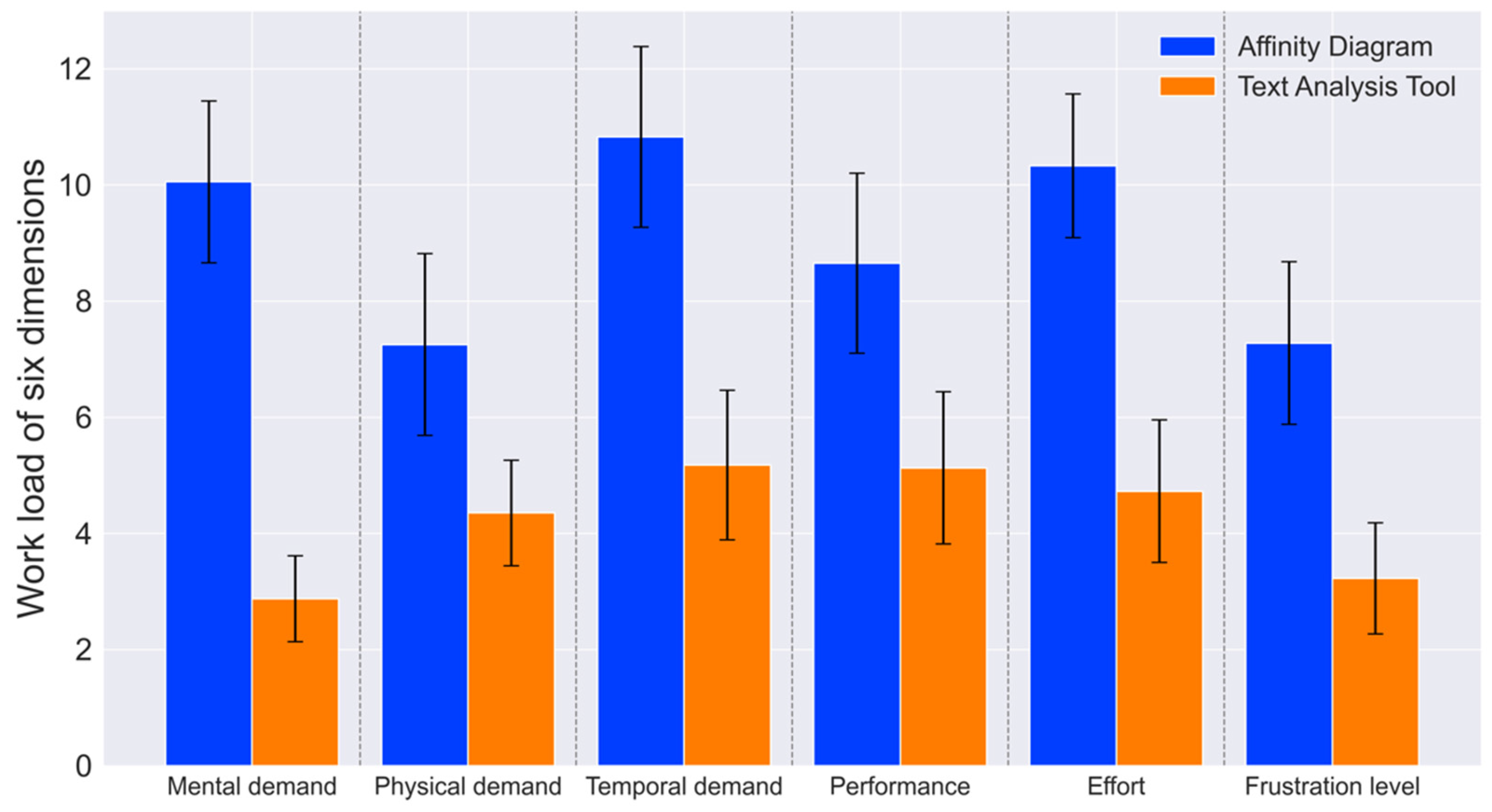
A paired-samples t-test was utilized to determine whether significant differences exist between the two methods based on the data collected from the NASA-TLX and UEQ.
5. Discussion
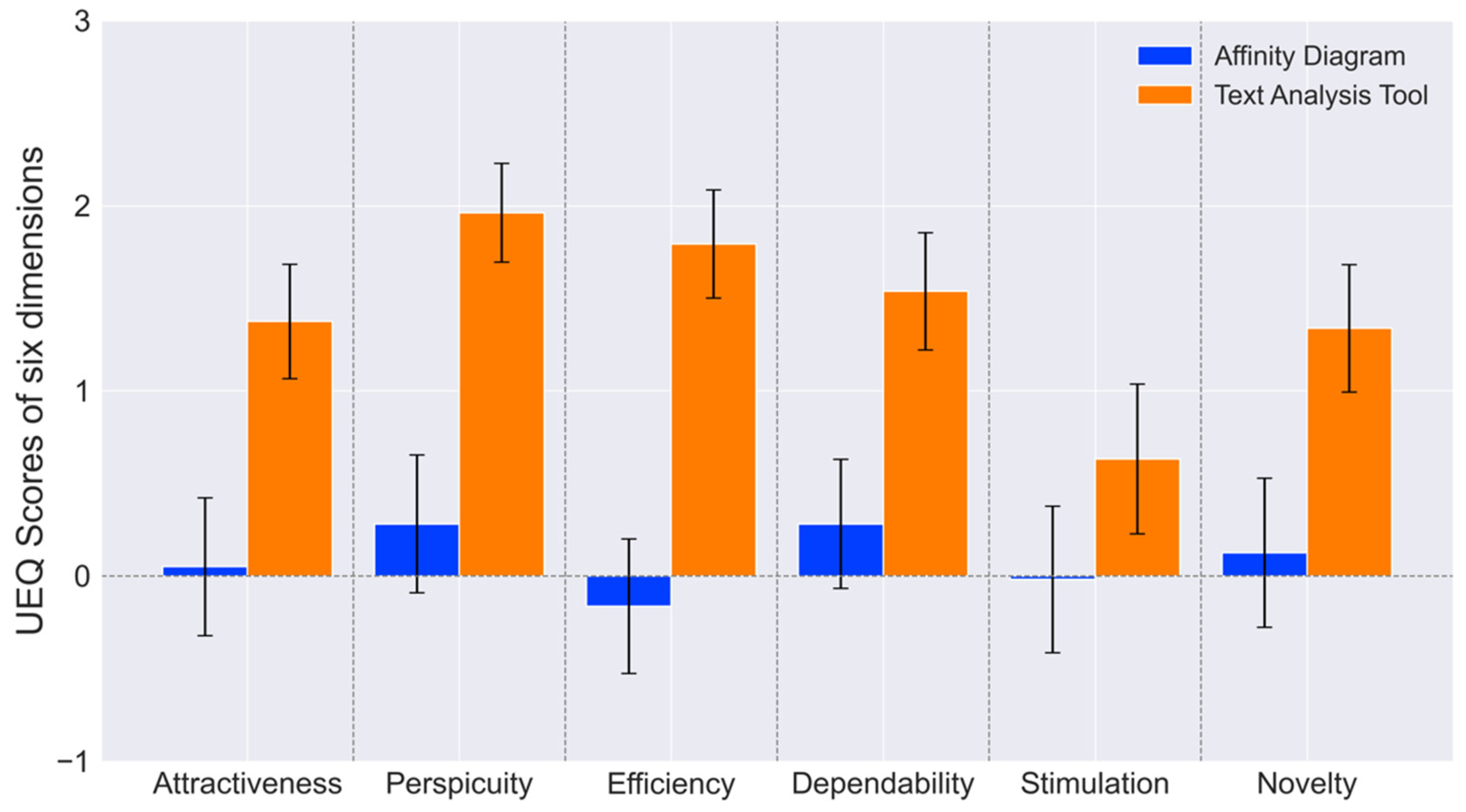
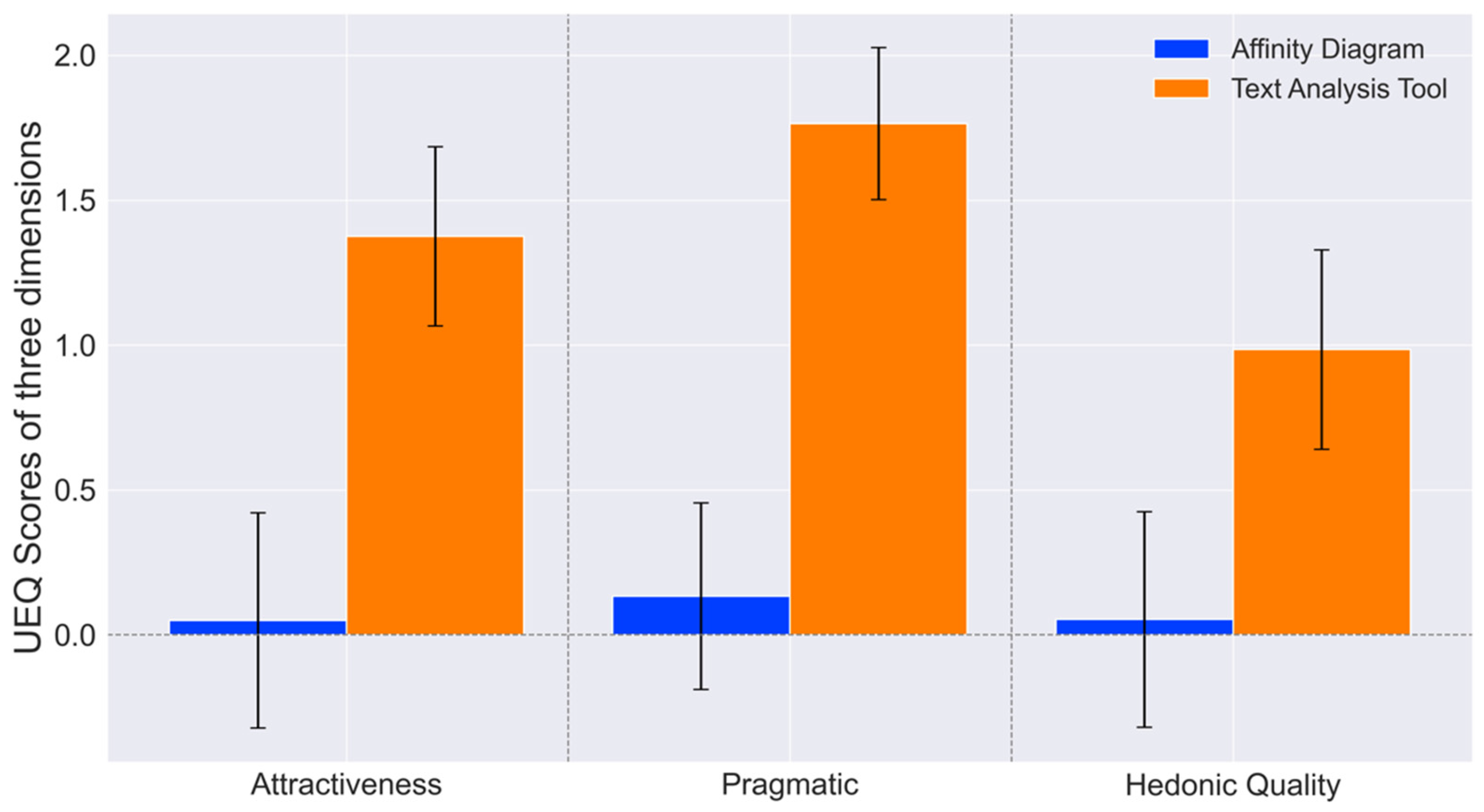
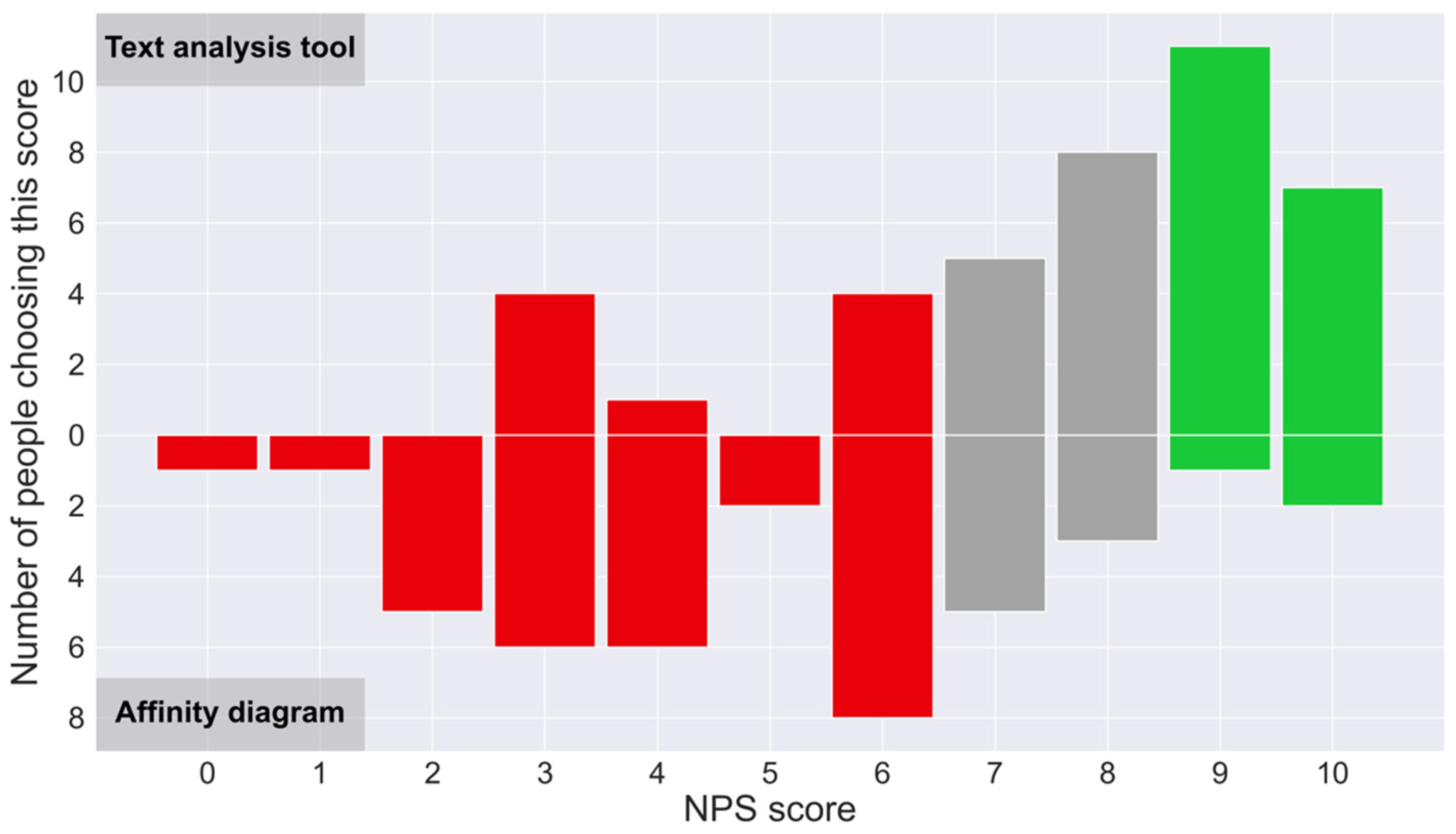
This study contributes to two key areas. Firstly, it introduces a novel text classification tool that utilizes the Kano model and deep-learning technology to categorize user needs efficiently, with potential applications in education. This study collected 19 user needs from Generation Z users of LEGO toys through interviews and web crawling. Subsequently, the researchers classified these needs into four categories, comprising two must-be needs, two one-dimensional needs, thirteen attractive needs, and one indifferent need, using a Kano model-based questionnaire. Based on the classification results, a dataset was generated through preprocessing and labeling over 3000 online reviews. The researchers then employed seven deep-learning models to train and predict the data, with the RCNN model being identified as the most effective. Using this model, the researchers developed a graphical text classification tool that accurately outputs the corresponding category and probability of user input text according to the Kano model. By integrating this tool into UX design curricula, educators can facilitate the learning process for students, helping them understand the importance of user needs classification and providing them with a practical, efficient method for applying the Kano model in their projects. Secondly, the study conducted a usability test on the developed tool, highlighting its potential as an educational resource for UX design courses. The results demonstrated that the tool performed better than the traditional affinity diagram method in six dimensions and in three qualities of the UEQ, indicating a superior UX. Additionally, the study used the NASA-TLX to measure the task load. The results showed that the tool had lower levels of mental demand, physical demand, temporal demand, performance, effort, and frustration than the affinity diagram, indicating a smaller workload. Furthermore, the NPS score of 23 showed the participants’ overall positive attitude toward the method. These findings suggest that the developed tool has the potential to be a valuable addition to text classification tools and can facilitate the efficient categorization of user needs with a superior UX for educational purposes.
When analyzing the reasons for these results, we found that our tool’s higher attractiveness, compared to traditional affinity diagram methods, could be attributed to its user-friendly interface and the integration of trending technologies related to AI and text analysis. Its higher clarity, efficiency, and reliability might stem from its ability to provide clear, quick, and consistent categorization and probability outputs. In contrast, the affinity diagram method, which relies on clustering rather than categorization, lacks clear decision-making support, potentially leading to lower clarity, efficiency, and reliability. These factors contribute to our tool’s superior practicality. Additionally, our tool’s higher stimulation and novelty could be due to its innovative combination of the Kano model with text analysis methodologies, which brings a fresh perspective to users. These factors contribute to our tool’s superior quality of pleasure. From the NASA-TLX perspective, the tool’s lower mental and physical demands and effort are likely due to its straightforward input mechanism, leading to immediate results, compared to the more cognitively demanding process of clustering and refining needs using affinity diagrams. Unlike the subjective and varying results of affinity diagrams, the tool’s lower self-performance (lower values indicate better performance) could be attributed to its definitive and reliable results. Finally, the tool’s lower frustration level could be due to its consistent ability to classify needs, avoiding the ambiguity that can occur with affinity diagrams. The higher NPS for our tool can be explained by its superior user experience and lower task load compared to affinity diagrams.
However, the current study has several limitations. Firstly, our study involved manually labeling online comments for a specific period, which is time-sensitive and labor-intensive. Secondly, the features of the tool we developed are relatively limited. Thus, we plan to add more features in the future, such as the automatic recording of input text and output categories in a table or allowing users to provide feedback as a basis for reinforcement learning.
Although the tool is still in the early stages of development, it has proven to be usable and well received. Artificial intelligence profoundly impacts our daily lives, ranging from ChatGPT [
36] to midjourney [
37]. Simultaneously, researchers, from Scratch [
38] to CNN Explainer [
39], have emphasized the significance of providing user-friendly, graphical, and interactive tools to disseminate research findings to a broader audience, especially novices or learners, thus enabling more individuals to benefit from these research results. Recent studies highlight the growing significance of deep learning-based automated classification tools. For instance, the Deep-PR method in mobile-edge networks offers improved POI recommendations by refining feature spaces [
40]. In the IoT domain, DeepClassifier efficiently classifies NOMA signatures, reducing the computational complexity by 90% [
41]. Similarly, a new traffic forecasting model combines deep and graph embeddings in the green Internet of Vehicles, enhancing the prediction reliability by up to 25% [
42]. These advancements demonstrate the pivotal role of deep learning tools in enhancing efficiency and technological capabilities across various sectors.
It is important to emphasize that we do not intend to suggest that the traditional affinity diagram method is not helpful. In contrast, it is an effective research method. On the one hand, the affinity diagram method refines user needs twice, which reflects human creativity. While deep learning methods make predictions (classify) based on existing data, design teams using the affinity diagram method may generate unprecedented ideas that cannot be classified into pre-existing categories [
43]. On the other hand, the scope of application of the affinity diagram method is not limited to user needs classification. Many researchers have produced excellent research results using the affinity diagram method, including public administration [
44] and software development [
45]. Furthermore, automated classification cannot replace user researchers or designers with rich experience. Although it may extract industry experience or user characteristics from a large amount of data, it still lacks human empathy and creativity, which is crucial in UCD [
46,
47,
48].
6. Conclusions
The usability evaluation results indicate that beginner UX designers found the user-need classification tool to significantly outperform the affinity diagram method regarding attractiveness, perspicuity, efficiency, dependability, stimulation, and novelty. Furthermore, the tool demonstrated significantly lower scores in mental demand, physical demand, temporary demand, performance, effort, and frustration levels compared to the affinity diagram method. Additionally, the tool achieved a higher Net Promoter Score (NPS). These results compellingly demonstrate the superiority of the automated tool over the affinity diagram method, emphasizing the importance of providing novice UX designers with an effective user needs classification tool. The automated tool, with its enhanced user experience and reduced workload, emerges as a promising educational resource in UX design. It simplifies the understanding of the Kano model and text analysis, particularly benefiting beginners. Its efficient, user-friendly interface and the positive reception indicated by the NPS highlight its potential for UX education.
Our fundamental point is that researchers must foster a more harmonious relationship between artificial intelligence and users, making AI achievements more accessible to different fields. A simple interactive interface can enhance UX (attractiveness, usefulness, and hedonic value) and reduce workload. In the future, improving UX while coexisting with artificial intelligence presents both a challenge and an opportunity.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}