2. Materials and Methods: Vector Spaces over
We form a
vector space using
by using columns of 0 s and 1 s as the
vectors. For instance,
is the 3-dimensional vector space of column vectors such as
. The column vectors add together component-wise, i.e., each of the first, second, or third components adds to the corresponding component of the other vector modulo 2, e.g.,
One very useful way to interpret these 3-dimensional column vectors is to see each component as the presence or absence of an element of a three-element set such as
. Thus, we have:
Then the above addition would be
. This addition operation on sets is called the
symmetric difference; it is performed by taking the union of the sets and then taking away the overlap or intersection of the sets. For instance, the union of
and
is
and then taking way the intersection
gives
. We will henceforth use this set-interpretation of
or, in general,
for the
n-dimensional case of QM/Sets.
In the vector space
, there are 8 vectors since each of the three components can be 0 or 1 so there are
possible vectors with the special vector with all zeros is the zero vector. When we interpret the vectors as sets, then each vector corresponds to a certain subset. The set of all possible subsets of a set
is its
power set (set of all subsets) which has the eight members in correspondence to the eight vectors where the empty set ∅ corresponds to the zero vector:
If we pair the subsets in
with the vectors in
by
(the superscript
t indicates the transpose, interchanging rows and columns) being paired with
,
with
, and so forth, then there is an isomorphism of vector spaces:
.
The choice of 3-dimensions or a 3-element universe set was only illustrative. The corresponding operations extend to n-dimensional vectors or n-element universes .
In the quantum interpretation, the single-element or singleton subsets represent definite-states or eigen-states of a quantum particle, and the multiple-element subsets represent indefinite-states or superposition states of the (always quantum) particle. The zero vector or empty set does not represent a state.
The definite states like
,
, or
form a
basis for the vector space in the sense that all the other subsets (=states) can be obtained by sums of them. But there are other basis sets so that all the other subsets can be obtained as sums of them. For instance, consider
where
,
, and
. This is easily seen by showing how to obtain the
U-basis from them:
It should be noted that whether a state is a definite eigenstate or a superposition state depends on the basis in which it is represented. For instance, the state
is a superposition state in the
-basis but a definite state in the
U-basis. In fact, there are many different basis sets for
(28 in all); four of them are listed in
Table 1.
It is useful to consider a vector abstracted from its representation in a certain basis and such abstract vectors, called
kets in QM and symbolized
in the Dirac notation, are identified as the rows in a
ket table like
Table 1 in the 3-dimensional case of
. Not all sets of three vectors in
form a basis. For instance,
,
, and
just cycle among themselves when added, e.g.,
, so they do not generate the whole space. A
subspace of a vector space is a set of vectors that are closed under addition (including the zero vector or empty set) so
is a subspace of
. Also, any subset
generates the subspace
.
In the ket notation, stands for the abstract vector (row in the ket table) that is in the U-basis. Operations in the vector space have the same outcome regardless of the basis used. For instance, (cancellation of ) but in the -basis, it is and .
In the Dirac notation of QM, there is also the bra so that the bra-ket or bracket is the inner product of and v. But there are no inner products in vector spaces over finite fields such as , so we have to look at the interpretation of the in QM. The inner product of normalized vectors in QM is interpreted as the overlap of the two states so that means no overlap, i.e., the vectors are orthogonal, and means complete overlap. In or , there is a natural notion of overlap, namely the cardinality of the intersection of two sets which takes values outside of in the natural numbers .
For two zero-one column vectors
, we can form the scalar product
(
is the transpose of
w into a row vector) taking values in
which computes the overlap of ones in the two vectors. Since the kets represent the abstract vector regardless of basis, the computation of the overlap as the size of the intersection of the two sets expressed in the same basis, we will make the bras basis-dependent as indicated by the subscript
so that for
, the bra-ket or bracket in QM/Sets is:
For basis vectors
,
where
is the characteristic function for the subset
such that
if
and 0 otherwise. The ket-bra
is an operator
that takes
to
. A
projection operator is an operator
P that is idempotent in the sense the
. Hence
is a projection operator:
since
. The sum of these projections over the basis is the identity operator
since:
Hence any bracket
can be resolved by inserting the identity operator:
In QM, the magnitude or norm of a vector
is often denoted as
. However, that conflicts with our notation
for cardinality, so we will use
for the norm in QM; the corresponding norm in QM/Sets is:
which takes values in the reals
.
In QM, a vector can be normalized at any time; in QM/Sets, the only normalization is in the calculation of probabilities. In QM, when a non-normalized state
is measured in the measurement basis of
, the probability of getting the outcome
is:
Hence the corresponding formula in QM/Sets is:
which is the conditional probability of outcome
given the event
S when the outcomes are equiprobable.
3. Results
3.1. Numerical Attributes as Observables
A (real-valued) numerical attribute (or observable) on is a function from U to the real numbers. It assigns a real number to each element of U. If it takes only the values of 0 and 1, then it is an attribute and is represented in the special notation as a characteristic function where , the set of elements taking on the value of 1. The set of real numbers that have an element of U mapped to them by f is the image or spectrum of f, denoted . Each number in the spectrum of f is a definite-value or eigenvalue of f. The inverse image subset of U is the set of elements of U mapped to an eigenvalue r, i.e., . That inverse image generates a subspace called the eigenspace associated with the eigenvaluer. Thus, if had and , then and is the eigenspace associated with the eigenvalue of 3. The non-zero vectors in the eigenspace for r are also called definite-states or eigenstates of f. All the non-empty subsets in are constant sets of f, i.e., subsets of U on which f has the same value of r.
A partition on U is a set of non-empty subsets , called the blocks of , such that the blocks are disjoint, i.e., for , and their union is all of U, i.e., . Each numerical attribute determines a partition on U called the inverse-image of f. Each block of the partition generates an eigenspace . The set of eigenspaces of f, form a direct-sum decomposition (DSD) of in the sense that every non-zero vector (i.e., every non-empty subset of U) can be uniquely represented as the sum of non-zero vectors from the subspaces in the DSD. For instance, in the example , the vector or subset is the sum of and . A DSD of a vector space is the vector space version of a partition on a set.
In QM, every observable or Hermitian operator
F has a set of eigenspaces
that form a direct-sum decomposition of the Hilbert space
V. In QM/Sets, the eigenspace for an eigenvalue
r of a numerical attribute
is
, which also form a DSD of
. In QM, different eigenspaces
and
for
are ‘disjoint’ is the sense that their intersection is the zero space. Similarly, for eigenvalues
, the intersection of
and
is only the empty set subspace
. In QM, the projections
to the eigenspaces
are complete in the sense that the sum of the projections is the identity operator:
. In QM/Sets, the corresponding projections are:
and the union of the images on any
is:
as illustrated in
Figure 1.
Since the sets in the union are disjoint, the union translates into a sum in the vector space [where the sum is ], so we have: .
To approach the probability calculus for numerical attributes
, the QM equation:
is expressed in QM/Sets as:
. Then we normalize to have probabilities that sum to one:
for
in QM, and
for
in QM/Sets. Then, when measuring
by the observable
F, the probability of getting the eigenvalue
is:
and the corresponding probability for getting the eigenvalue
r of the numerical attribute
f when conditioned by
S is:
These probabilities are for equiprobable outcomes; the machinery for the general case is developed below.
Table 2 starts building the connections or translation dictionary between the pedagogical model of QM/Sets and QM (where
is an orthonormal (ON) basis for
V and
is the complex conjugate of
).
3.2. The Yoga of Linearization
We have been implicitly using a bit of mathematical folklore that we will call the Yoga of Linearization. It connects set concepts with the corresponding vector space concepts. The idea is to first look at U as just a set to which a set concept may be applied (e.g., the notion of subset, numerical attribute, or partition on a set). Then take U to be a basis set of a vector space V (over a given field ) and the corresponding vector space notion is the notion generated by the set concept applied to the basis set. For instance, the notion of a subset S of a basis set generates the notion of a subspace generated by S, so the Yoga connects the notion of a subset and the notion of a subspace . If we apply a set partition to a basis set U, then each block in the partition of U generates a subspace, and the set of subspaces generated by the blocks of the partition form a direct-sum decomposition of the vector space, so the Yoga connects the set notion of a partition to the vector space notion of a DSD. A numerical attribute on a set defines a linear operator (assuming V is a vector space over a field containing the reals), which on the basis set U is given by where the are basis vectors and the definition of a linear operator on a basis set extends linearly to the whole space. Thus, the Yoga connects a real-valued numerical attribute with a linear operator on a vector space over a field containing the reals, e.g., the complex numbers, where the operator has real eigenvalues .
If the vector space such as is over a field not containing the reals, then the inverse image partition defines a DSD in the vector space, which may have many of the main properties of a linear operator (see next section). For a numerical attribute , let “” stand for the statement that f restricted to a subset S has the constant value r on that subset. The Yoga connects that equation to the eigenvalue/eigenvector equation . Then constant sets of a numerical attribute corresponds to eigenvectors of the linear operator defined on the basis set U by and the constant value r on a constant set corresponds to the eigenvalue of the eigenvector. When the numerical attribute is a characteristic function , then the corresponding linear operator defined by is the projection operator onto the subspace generated by . In the general case of defining , there is a ‘spectral decomposition’ of f in terms of the characteristic functions for , i.e., , that corresponds to the usual spectral decomposition of the linear operator F as .
In this manner, the Yoga builds up a translation dictionary of set concepts and the corresponding vector space concepts, as in
Table 3.
Our simplified model of QM is based on set notions and, where possible, the set notions connected by the Yoga to the vector spaces
over
. When the vector space
V is a finite-dimensional Hilbert vector space over
, then the Yoga shows how the machinery in the simplified model corresponds to the full-blown mathematical machinery of QM [
1]. But when
, then only a characteristic function
defines a linear operator
, but a general numerical attribute
still defines a partition
on
U and the DSD
of
. The same holds for any other basis set for
. For instance, for the
-basis of
Table 1, the numerical attribute
given by
and
, induces the partition
on
, and the DSD:
where the DSD expressed in terms of the
U-basis is not generated by a partition on
U.
As we will see in the next section, for many purposes, the important notion for an observable is not the Hermitian linear operator itself but its DSD of eigenspaces.
3.3. Commutativity and Conjugacy of Observables
In full-blown QM, the observables are represented by Hermitian linear operators on a Hilbert space over the complex numbers . One of the features of QM in contrast with classical mechanics is that these operators for different observables might commute, not commute, or even be conjugate like position and momentum. A linear operator is determined by its definition on a basis set; each basis vector is assigned a number in the base field, and in the case of Hermitian operators, those assigned values are always real numbers . But in our pedagogical model QM/Sets, the only linear operators are those that assign an element of the field to the elements of U, i.e., the characteristic functions .
Hence, the question arises: how can we represent commutativity, non-commutativity, and conjugacy in QM/Sets for numerical attributes ? The answer is that each Hermitian operator in QM determines the DSD of its eigenspaces, and the commutativity properties depend solely on the DSDs.
The first step in working this out is to notice that the notion of a subspace or a DSD of subspaces is basis-independent. In the previous example of , we had the eigenspace . But that subspace can be equally well expressed in the -basis as . Since a DSD is a certain type of collection of subspaces, it is also a basis-independent notion–even though it may be first defined using some particular basis. The point is that the commutativity properties can be defined in QM and in QM/Sets solely in terms of the DSDs of eigenspaces.
Suppose we have two different basis sets,
U and
for
and two numerical attributes,
and
, which then define two DSDs
and
. For two partitions
and
on the same set
U, their
join is the partition whose blocks are the non-empty intersections
of blocks from
and
. Since DSDs can be seen as the vector space versions of partitions, we would like to perform a join-like operation on two DSDs. Since a subspace can be represented on any basis, we need to represent the subspaces of two DSDs on the same basis before we can determine the intersection of the subspaces that serve as the blocks in the vector space partitions. Hence, instead of
and
, we abstractly consider two DSDs
and
(which could be the DSDs of eigenspaces of two observables in QM), and then perform a join-like operation to get the set
of non-zero subspaces (using the fact that the intersection of subspaces is a subspace). In terms of the original numerical attributes
and
, the non-zero vectors in an intersection
, e.g., in an intersection
(with subsets represented in the same basis), are eigenvectors (or constant sets) of both
f and
g, which are called “simultaneous eigenvectors” in QM. Then we take the sums of all those simultaneous eigenvectors to generate a subspace
of the space
. The commutativity properties of the observables in QM and the numerical attributes in QM/Sets can then be defined solely in terms of the DSDs of eigenspaces in both cases:
The join-like operation of taking all the non-zero subspaces
only creates another DSD in the commutative case when
or
, and it is only then that the operation is properly called the
join of DSDs. As Hermann Weyl put it when referring to the vector space partitions or DSDs as “gratings”, the “combination of two gratings presupposes commutability….” [
8] (p. 257).
Commutativity example: Any two numerical attributes defined on the same basis set will commute, but that is not necessary. Let
have
and
. On the
-basis of
Table 1, let
be defined by
,
, and
. Then the DSD defined by
f is
, and the DSD defined by
g is
. To consider the intersections of the subspaces in the DSDs, we need to express them both on the same basis. Taking the
U-basis as the ‘computational basis’, we have the two DSDs as:
Then taking all the possible intersections between the subspaces in the two DSDs, we see that the simultaneous eigenvectors are
,
, and
. These simultaneous eigenvectors form a basis, so they generate by their sums all the vectors or subsets in the whole space
so that those two DSDs commute.
Conjugacy example: Take
as
,
, and
, and take
as
,
, and
(
is as in
Table 1). Then the DSD determined by
f is
, and the DSD determined by
g is in the
-basis,
which translated into the
U-basis, gives the following two DSDs:
In this case, there are no simultaneous eigenvectors, so
, and thus those two DSDs are conjugate. Recalling that being a definite state (i.e., an eigenstate) or an indefinite state (i.e., a superposition state) depends on the basis, the key feature that determined conjugacy in this case is that all the definite states or eigenstates in one basis were indefinite states or superpositions in the other basis (see
Table 1) and both numerical attributes were assigned different numbers to different eigenstates. Hence, like the conjugate observables of position and momentum in QM, there is no non-zero vector that is a definite state or eigenstate of both numerical attributes. If any vector or state is an eigenstate or definite state of one numerical attribute, then it has to be a superposition or indefinite state for the other numerical attribute.
Since in all cases, the DSDs are determined by the numerical attributes, we may also say that those numerical attributes are commutative or conjugate as the case may be.
The join of the two inverse-image partitions
and
always exist if they are
compatible in the sense of being defined on the same universe set. That is the QM/Sets version of commuting observables in QM. The QM/Set version of Dirac’s complete set of commuting observables (CSCO) [
9] is easily constructed.
QM/Sets: Let be numerical attributes on U. They are said to be a complete Set of compatible attributes (CSCA) if the join of their (inverse-image) partitions is a partition with all subsets of cardinality one. Then each element can be uniquely characterized by the ordered set of values .
QM: Let be commuting observables on V. They are said to be a complete set of commuting observables (CSCO) if the join of their vector space partitions (DSDs) is a DSD with all subspaces of dimension one. Then each simultaneous eigenvector can be uniquely characterized by the ordered set of their eigenvalues. If is a basis of simultaneous eigenvectors and , ,…, are the eigenvalue functions assigning the eigenvalues to the simultaneous eigenvectors of the observables respectively, then the ordered set of eigenvalues that characterize the eigenvectors is .
This is a paradigm example of a translation or correlation dictionary between QM/Sets and full QM.
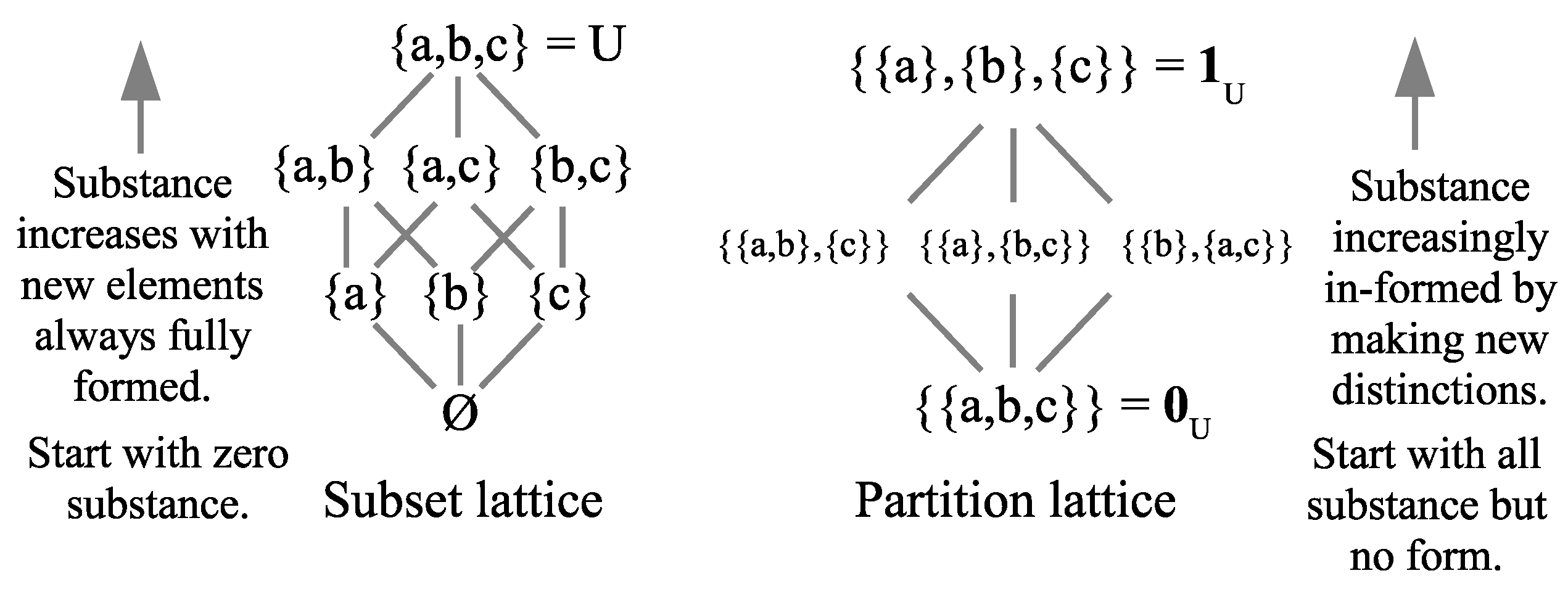
3.4. The Lattice of Partitions
Given a set U (), recall that a partition on is a set of non-empty subsets that are pairwise disjoint and jointly exhaustive of U. It is interesting to note that a partition can be given a DSD-type definition as a set of non-empty subsets so that any non-empty subset can be uniquely represented as the union of subsets of the blocks . If the blocks were not disjoint, say , then that non-empty subset S would have two representations as a subset of the blocks, so uniqueness fails. And if the blocks were not jointly exhaustive, then the non-empty subset would have no representation as a union of subsets of the blocks. The unique representation of S is given by the union of the projection operators , i.e., . Thus, a set partition is the set version of a vector space DSD. Moreover, when sets are treated as vectors in , then is a DSD of the vector space if is a partition of U.
An indistinction or indit of is an ordered pair of elements that in the same block of . The set of all indits is the indit set , which is the equivalence relation associated with the partition . A distinction or dit of is an ordered pair of elements in different blocks of , so the set of all dits, the ditset , is just the complement of the equivalence relation in .
Let be the set of all partitions on U. There is a partial order on given by the inclusion of ditsets. That is, for partitions and , the partial order is: if . This is also the equivalent refinement partial ordering where refines if for every block , there is a block such that . In the partial order on , there is a maximum or top partition, which is the discrete partition where all the blocks are the singletons of the elements . And there is a minimum or bottom partition which is the indiscrete partition, where there is only one block, which is all of U.
For , join operation gives the least upper bound on and in the refinement ordering. There is also a meet or greatest lower bound of two partitions and . When two blocks and have a non-empty intersection, they ‘blob’ together like two touching drops of water. Eventually, blobs will form of blocks from both partitions until they intersect no other blocks of the other partition. Those minimal unions of -blocks and -blocks are the blocks of the meet . The meet could also be defined as the partition formed from the equivalence relation that is the intersection of all equivalence relations containing the indit sets of and . The indiscrete partition is nicknamed “The Blob” since like in the Hollywood movie of the same name, it absorbs everything it meets: .
The join and meet operations on partitions were known in the nineteenth century (e.g., Richard Dedekind and Ernst Schröder) and they turn
into a
lattice (a partial order with joins and meets). The lattice of partitions on
is given in
Figure 2. The lines between partitions indicate refinement with no partitions in between.
3.5. Superposition Subsets and Density Matrices
Given a basis U for a vector space V, any vector has the form of a linear combination of the basis vectors where the are scalars from the field, e.g., in QM and in QM/Sets. The support of the vector is the set of basis vectors with non-zero coefficients . We can think of taking the support of a vector as ‘skeletionizing’ it to yield a set of basis vectors. If the support is a singleton, then the vector is a definite state or an eigenstate (perhaps not normalized), and if the support is a multiple-element subset of U, then the vector is a superposition or indefinite state. Hence, we need to mathematically distinguish between two types of subsets of U, the ordinary ‘discrete subsets’ where the elements are perfectly distinct from one another, and the ‘superposition subsets’, denoted , where the elements are blobbed or blurred together in an indefinite state, which represents the support of a superposition state in QM. An event in classical finite probability theory is a subset of the outcome space U. Then superposition subsets can be viewed as an extension of probability theory to include superposition events in addition to the usual discrete events where the outcomes are all distinct, i.e., not blobbed or blurred together.
One way to mathematically distinguish between these two types of subsets or events is to move from representing subsets as one-dimensional vectors to using two-dimensional matrices. We start by using incidence matrices of binary relations. A subset
is a
binary relation on
U, and it can be represented by the
incidence matrix , where each entry in the matrix is
if
and otherwise 0. Then for each subset
, we use the diagonal
as the binary relation to represent the discrete subset
S; we use the Cartesian product
as the binary relation to represent the superposition subset
. Then for
, the subset
gives the two incidence matrices:
The matrix
is always a diagonal matrix and represents the discrete event
, and
has the same diagonal but also has non-zero off-diagonal elements to indicate which elements of
U are blobbed, blurred, or cohered together in the superposition subset
. In the case of a singleton
, then the superposition set is the same as the discrete set since there are no multiple elements to blob together in an indefinite state, and, accordingly,
in the case of singletons.
The
inner product of a
row vector and a
column vector is a
scalar number, but the
outer product (reverse order) of a
column vector and a
row vector is a
matrix. A better way to construct the matrix representation
of the superposition set
is the outer product of the column vector representing
S (with column entries
) and its transpose row vector. For instance, for
in the example,
If the column vector representing
S is written as a ‘ket’
and its transpose as the ‘bra’
, then
.
To bring density matrices from QM into the pedagogical model, we allow the matrix entries to be real numbers. Then by dividing
through by its trace (=sum of the diagonal elements), we arrive at the density matrix representation
of
which in the example is:
Moreover, if we normalize
as
, then we obtain the important outer-product formula for the density matrix of superposition sets:
3.6. Probabilities and the Born Rule
The diagonal entries in a density matrix are always non-negative and sum to one so they should be seen as probabilities. Let the universe set have the (always positive) point probabilities . For a partition on U, the non-singleton blocks are always viewed as superposition sets so we can construct their density matrix (over the reals) from the normalized column vector whose ith entry is the ‘amplitude’ if and 0 otherwise.
There has been some controversy in QM about the origin of the Born rule; see [
10] and the references therein. Does it follow from other assumptions of QM, or must it be an extra postulate? We approach that question from a different and simpler angle by asking: What is the simplest mathematical extension of classical probability theory in which the Born rule appears? We have seen in QM/Sets that:
in the case of equal probabilities. In the general case of point probabilities, the conditional probability is
. Taking
, we have:
where the
ith entry of
is
and then we immediately have:
The square in the Born rule comes from taking the representation of a superposition set as the
two-dimensional matrix
obtained as the outer product
of the one-dimensional ‘amplitude’ vector
with its (conjugate) transpose
. Thus,
corresponds to the state vector
of amplitudes in QM such that the density matrix representation of that state vector is:
.
It might be said that this does not “account” for the Born rule since the square roots of the probabilities were built into the definition of . But if we start with a real density matrix that represents a superposition and is thus “pure” (defined below) as opposed to “mixed”, then it has one eigenvalue of 1 with the other eigenvalues being zeros, and the normalized eigenvector associated with that eigenvalue 1 is such that by the spectral decomposition of as a Hermitian matrix. This, of course, only accounts for the origin of the math of the Born rule in superposition; the interpretation of the math in terms of probabilities is empirical.
Tracing the origin of the Born rule back to the simplest example in QM/Sets (enriched with density matrices), we see that it arises out of superposition–which should be no surprise since “
superposition, with the attendant riddles of entanglement and reduction, remain
the central and generic interpretative problem of quantum theory” [
11] (p. 27). The thesis is that the Born rule is a feature of superposition. This is further corroborated by considering the case in QM/sets where there is no superposition, namely, the mixed state represented by the discrete partition
, which corresponds in full QM to the classical mixture of complete decomposed states (diagonal density matrix) where each state has only a probability associated with it, e.g., “the statistical mixture describing the state of a classical dice before the outcome of the throw” [
12] (p. 176). Then we are back in classical probability theory with no superposition and thus no Born rule.
Returning to
if
, and otherwise 0, the density matrix
for the partition
is the probabilistic sum of the
for the probabilities
:
Then
if
, and 0 otherwise. Thus, the non-zero entries of
represent the equivalence relation
and the zero entries represent the ditset
. Those non-zero off-diagonal entries represent the superposition of the corresponding diagonal entries and hence “the off-diagonal terms of a density matrix, …are often called
quantum coherences because they are responsible for the interference effects typical of quantum mechanics that are absent in classical dynamics”. [
12] (p. 177).
As in QM, in QM/Sets we say that a density matrix is a pure state if it is idempotent, i.e., , and otherwise a mixed state. All the density matrices represent pure states. The only partition as a whole in that represents a pure state is the indiscrete partition ; all the other partitions represent mixed states.
For example, consider
with the point probabilities
. Then for the partition
, the superposition state
is represented by the pure state density matrix
where
:
and
The indit set of
is
, which corresponds to the five non-zero entries in
and the ditset, is
, which corresponds to the four zeros in
.
In general for a partition on U, the diagonal entries are the point probabilities, and the eigenvalues of are the block probabilities and zeros, i.e., (with zeros).
3.7. Projective Measurement
By enriching the QM/Sets model with these density matrices over the reals, we can deal with any point probabilities on U and have simplified models of a broader range of results in QM such as projective measurement.
A measurement (always projective) in QM turns a pure state into a mixed state (or a mixed state into a more mixed state) according to the Lüders mixture operation ([
12] (p. 279); [
13]), and then one of the states in the mixture is realized according to their probabilities. We take
as the state being measured. The measurement observable is given by a numerical attribute
whose inverse-image partition is
. The
projection matrix
is the diagonal matrix with the diagonal entries
. Then the density matrix
being measured is pre- and post-multiplied by those projection matrices and then summed to give the post-measurement density matrix
:
Continuing the example, let
and
so that
. Then the Lüders calculation is:
In this case, the more-mixed state is the density matrix for the discrete partition
. This measurement operation is illustrated in
Figure 3 where the change from
to
is indicated by the arrow from
to
. That movement from an indefinite state to a more definite state, like the arrow in
Figure 3 is the skeletal representation of the infamous quantum jump in full QM.
It is easily shown in the general case, [
1], that:
namely, that in QM/Sets, the projective measurement operation is just the partition join, where one partition represents the state being measured, and the other partition represents the measurement that is observable or numerical attribute.
3.8. A New Information Measure: Logical Entropy
There is a natural notion of ‘classical’ and quantum entropy based on the notion of information as distinctions or distinguishings. As Charles Bennett, one of the founders of quantum information theory put it, “information really is a very useful abstraction. It is the notion of distinguishability abstracted away from what we are distinguishing, or from the carrier of information….” [
14] (p. 155) Ordinary logic is based on the Boolean logic of subsets (usually presented in the special case of propositional logic). The notion of a subset is category-theoretically dual to the notion of a partition, and there is a dual logic of partitions [
2]. The quantitative version of Boole’s logic of subsets started as finite ‘logical’ probability theory [
15] with equiprobable outcomes, i.e.,
, the normalized number of elements in a subset or event. In the duality between subsets and partitions,
distinctions of a partition are dual to
elements of a subset. Hence, the quantitative notion of a partition is the normalized number of distinctions, and that is the first definition of
logical entropy [
16,
17] with equiprobable outcomes:
where
in this equiprobable case. In the general case of point probabilities,
and
where the last equation holds since
.
The logical entropy has a natural interpretation; just as
is the probability that one random draw from
U will yield an element of
S, so
is the probability that two random draws from
U will yield a distinction of
. The information in a partition
is reproduced in the density matrix
, and the logical entropy can thus be calculated in terms of the density matrix:
i.e., as one minus the trace of the density matrix squared–which is the matrix version of
.
For our purposes at hand, the important thing is that logical entropy measures the increase in information-as-distinctions that takes place in projective measurement. In general, the ditset of a join is just the union of the ditsets of two partitions, i.e., . Thus, projective measurement will, in general, increase the logical entropy of the state being measured. And since logical entropy is based on information-as-distinctions, and the density matrix represents distinctions as the zero entries, the increase in logical entropy can be calculated directly from the new zero entries in the post-measurement density matrix compared to pre-measurement . The “measuring measurement theorem” in both the simplified pedagogical model of QM/Sets and in the full QM version is that the increase in logical entropy due to a projective measurement is the sum of the (absolute) squares of the non-zero entries (i.e., coherences) in the pre-measurement density matrix that are zeroed (i.e., decohered) in the post-measurement density matrix.
In the example, the two logical entropies are:
In the transition from
to
, only two entries of
were zeroed. The sum of their squares is
, and the increase in logical entropy is
. These results in QM/Sets enriched with density matrices are the simplified version of the corresponding results in full QM [
16] (p. 83).
3.9. Quantum Processes
John von Neumann famously divided quantum processes into two types [
18]. Type I was the process of measurement (state reduction), which we have seen involves the making of distinctions to transform an indefinite state into a more definite state. This is the quantum notion of “
becoming”. The Type II processes were the solutions to the time-dependent Schrödinger equation. But how might the Type II processes be characterized using the notion of information-as-distinctions? Since the Type I processes make distinctions, the simplest description of Type II processes would be ones that do not make distinctions. The extent to which two normalized states
and
in QM are distinguished is given by their inner product
; if
, they are maximally distinct (i.e., orthogonal), and if
, they are not distinguished. Hence the natural description of Type II processes is one that does not change the distinctness of quantum states, i.e., that preserve the inner product, which are the unitary transformations. The connection to the solutions of Schrödinger’s equation is given by Stone’s Theorem [
19].
One of the controversial aspects of the Type I measurement process is its indeterminancy. The Lüder mixture operation turns a pure (or mixed) state being measured into a mixed (or more mixed) state, and then one of the states in the mixture occurs, according to its probability. The transformation from the pre-measurement state to the post-measurement state is not unitary; it is a “state reduction”. It is known in misleading and archaic language as “collapse of the wave packet”. In the previous example in QM/Sets, measurement turned the mixed state into the more mixed state . There is no indeterminacy in ; the indeterminacy is in or .
This indeterminacy comes out clearly at the set level in the notion of a “choice function” [
20] (p. 60). In axiomatic set theory, the axiom of choice states that for any set of non-empty sets, there is a choice function for it. Given a set of non-empty sets, a
choice function takes each non-empty set to one of its elements. In QM, there is no indeterminacy in the measurement of an eigenstate in the measurement basis; the result is that eigenstate with probability one. Similarly, there is no indeterminacy in a choice function applied to a singleton, e.g.,
. The indeterminacy arises in set theory only when the choice is made out of a multiple-element set, e.g.,
. Similarly, the indeterminacy arises in QM only when the measurement is made of a state that is a superposition (in the measurement basis). Perhaps this is a case where the set version of a QM operation helps to remove some of the ‘mystery’, e.g., in what is called the “collapse postulate”.
What is the QM/Sets version of a unitary transformation since there are no inner products in vector spaces over finite fields like
? A unitary transformation can be defined as a linear transformation that takes an orthonormal basis to an orthonormal basis. Hence, the corresponding transformation for
would be a linear transformation that takes a basis set to a basis set–which is simply a non-singular linear transformation. For instance, using the
U-basis and the
-basis of
Table 1, the transformation defined by
,
, and
is a non-singular linear transformation that takes the
U-basis to the
-basis. It might be noted that such non-singular transformations do preserve the value of the brackets when we take into account their basis-dependency. For instance, if the sets
of
U-basis elements transform into the corresponding sets
in the
-basis, then
. Such non-singular linear transformations on
are the QM/Sets version of the Type II quantum processes.
The Type I processes of becoming were represented in a skeletal form on the left-hand side, and the Type II processes of evolution can be applied to pure or mixed states on the right-hand side in
Figure 4. The arrow on the right-hand side pictures the transformation of the mixed state
into the mixed state
.
The very important thing to notice about the Type II transformations is that they can operate on pure states or mixed states involving superpositions like
; they do not just operate on fully distinguished states like
like in classical physics. We see in
Figure 4 why there are two fundamental processes in QM: Type I (making an indefinite state
more definite) and Type II (transforming a state to another state at the
same level of indefiniteness).
Some quantum philosophers have questioned how there can be two fundamental processes in QM when there is only one in classical physics since “it seems unbelievable that there is a fundamental distinction between “measurement” and “non-measurement” processes. Somehow, the true fundamental theory should treat all processes in a consistent, uniform fashion” [
21] (p. 245). Our analysis gives an explanation why there is only one fundamental process (transforming definite states into definite states) in classical mechanics—in terms of the two processes in QM. When is the Type I process no longer possible? There can be no transformation of indefinite to more definite if the state is already fully definite, i.e., in a
classical mixed state represented by
. Then only the Type II process of transforming definite states into definite states is possible, as in classical mechanics.
As we will also see in the QM/Sets treatment of the double-slit experiment, that aspect is the key to understanding how a particle in the superposition state can evolve without first becoming the more-definite states of or , i.e., can evolve without going through Slit 1 or going through Slit 2. And it is that evolution of the superposition that involves the characteristic interference effects.
3.10. The Double-Slit Experiment in QM/Sets
We focus on the double-slit experiment since, according to Feynman, “it contains the
only mystery” and it illustrates “the basic peculiarities of quantum mechanics” [
22] (Section 1-1).
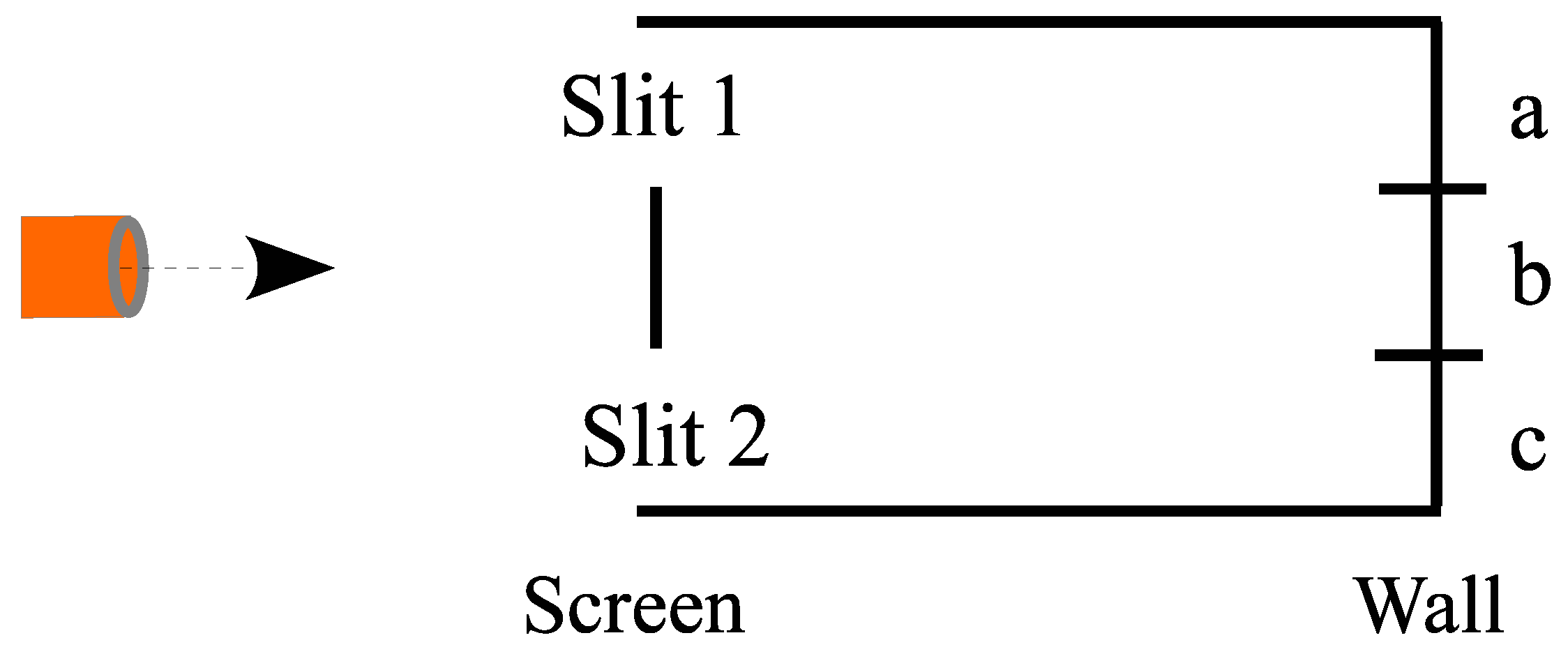
To model the essential aspects (and only those aspects), we consider the setup in
Figure 5 where the three states in
stand for vertical positions. A particle is sent from
towards a screen with two slits in it at positions
and
. The dynamics are the aforementioned transformations of the
U-basis into the
-basis each time period. One time period takes the particle to the screen, and the next time period takes the particle to the wall.
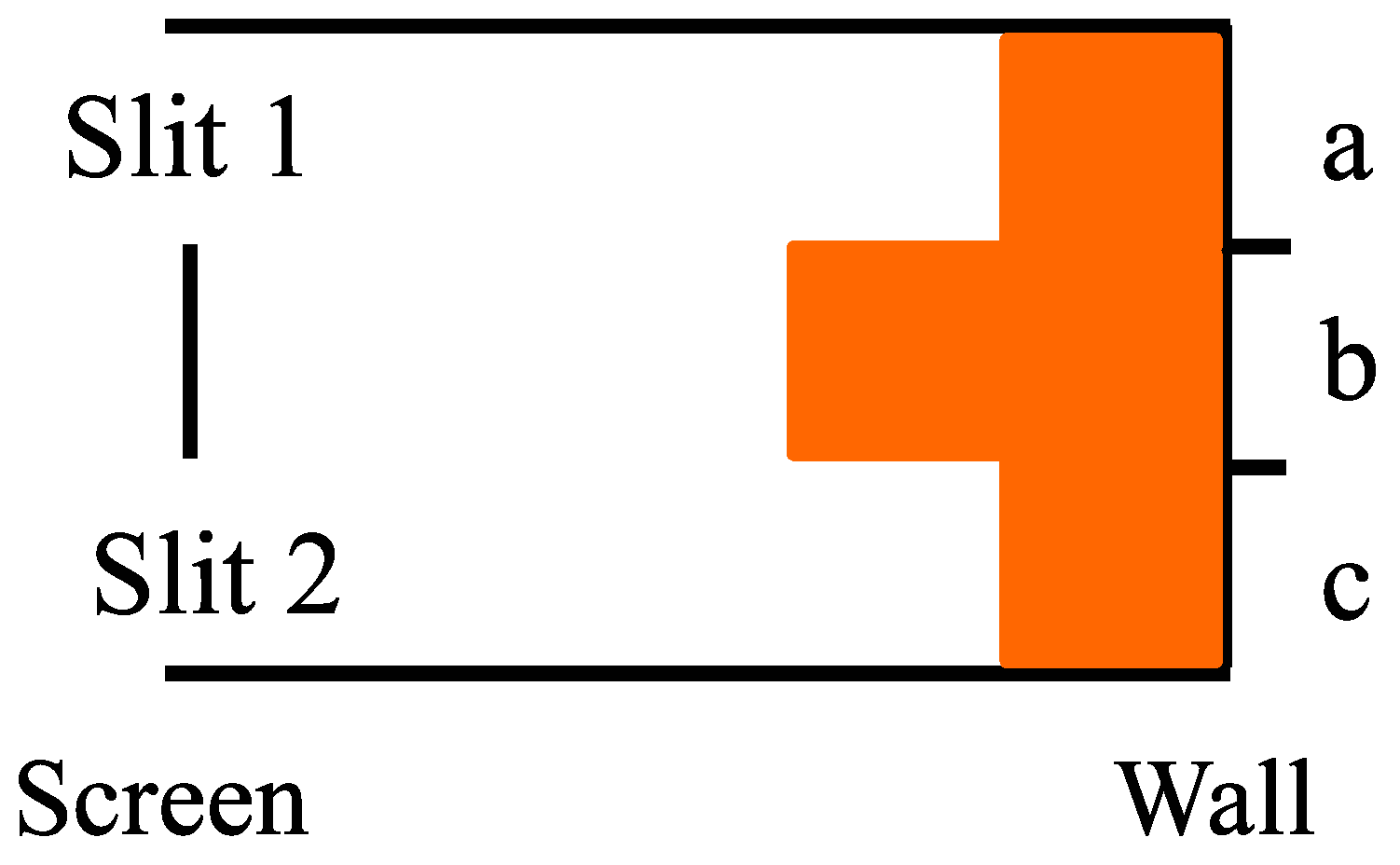
In the first time period, the particle evolves . One-third of the time the particle hits the barrier between the slits; we are concerned with the alternative case where the particle’s state is reduced to the superposition state , which in the model is . Then there are two cases to consider: Case 1 of detection at the slits, and Case 2 of no detection at the slits–both starting with at the screen.
Case 1. With detection at the slits, the superposition state
is reduced to
(i.e., going through Slit 1) with probability
or to
(i.e., going through Slit 2) with probability
so we have:
Then in the next time period, we have either
evolving to
and hitting the detection wall at
or
each with probability
, or similarly,
evolving to
and hitting the wall at
or
each with probability
. Then the computation of the probabilities to reach the three positions at the wall are as follows:
The resulting probability distribution is pictured in
Figure 6.
In Case 1, the detection at the slits forces the state reduction of
to either
(i.e., going through slit 1) or
(i.e., going through slit 2), and then one or the other evolves respectively to
or
. These state reductions and evolutions are (dashed arrows) illustrated in
Figure 7.
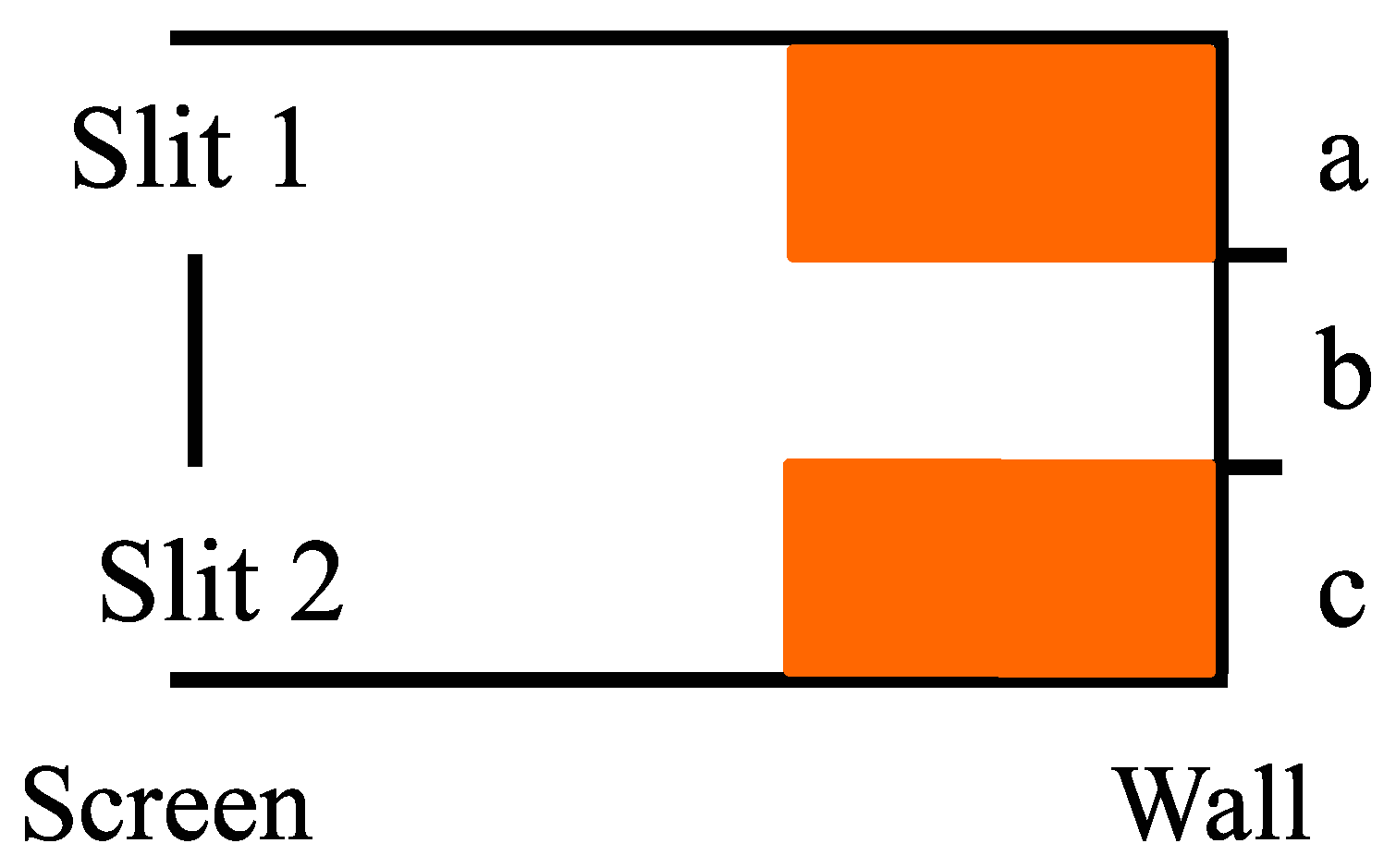
Case 2. With no detection at the slits, the superposition state
evolves as an indefinite or superposition state since there was no state reduction at the slits. Hence, the evolution is:
Then the probability distribution for the hits at the wall are as follows:
The resulting probability distribution is pictured in
Figure 8.
Figure 8 shows the stripes characteristic of the interference pattern, i.e.,
, resulting from no detection at the slits.
The hardest point to understand is that our classical intuitions ‘insist’ that the particle has to go through Slit 1 or Slit 2 (which would yield the
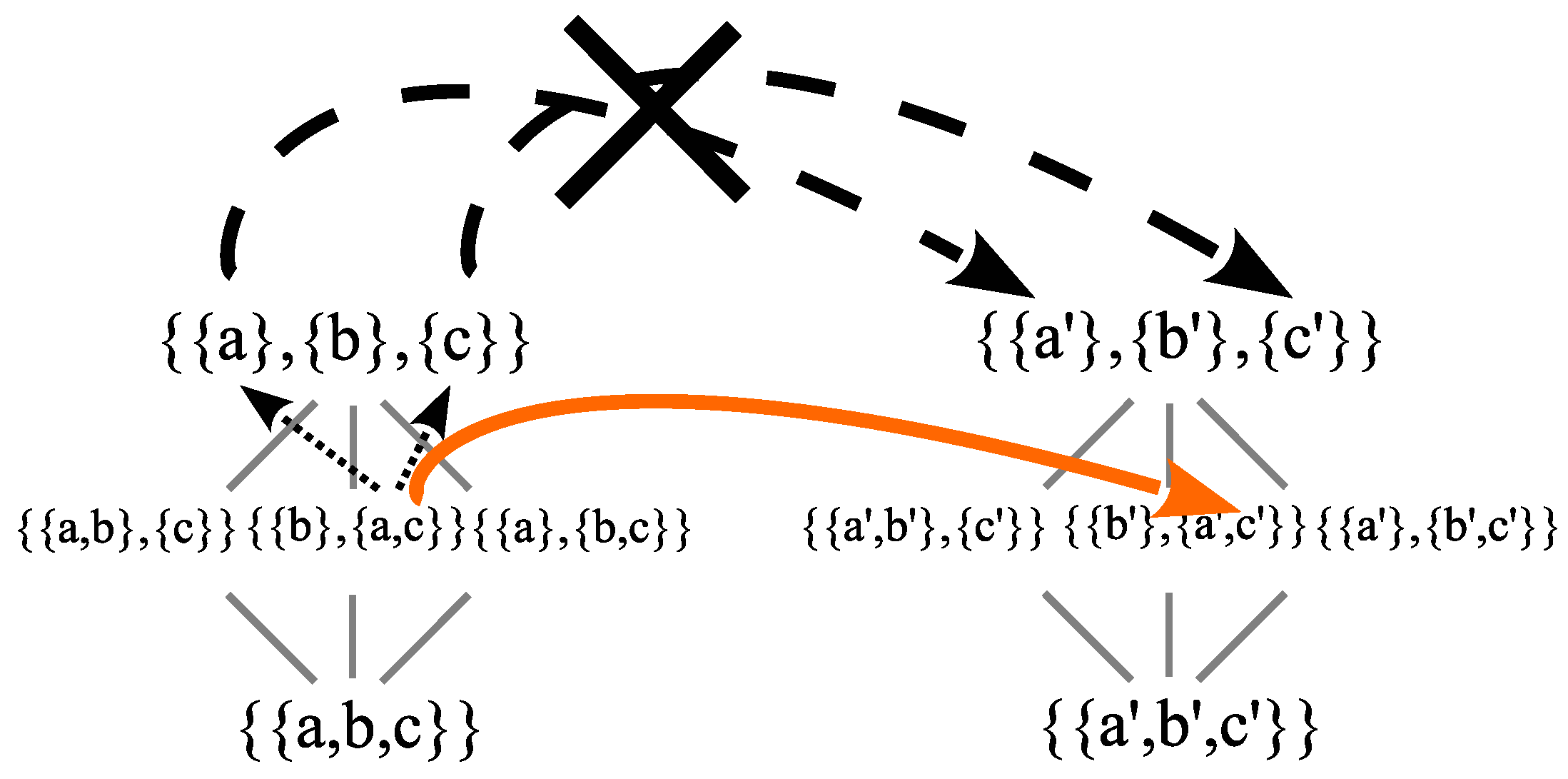
Figure 6 distribution of hits), but the distribution is as in
Figure 8 showing the stripes resulting from interference. The problem with our classical intuitions is that they operate at the classical level of all states being distinguished from each other (i.e., no superpositions), so one or the other of the
distinguished states “going through Slit 1” and “going through Slit 2” has to occur. In the quantum notion of becoming, states are constructed from below, as it were, by making distinctions to go from indefinite to more definite states. But the indefinite state
was not distinguished in Case 2. The classical level evolution of the distinguished states that do
not occur in Case 2 is marked with an
X in
Figure 9. As Richard Feynman put it: “We must conclude that when both holes are open, it is
not true that the particle goes through one hole or the other” [
23] (p. 536).
But with no distinction at the slits in Case 2, it is the non-classical superposition state
, or
in the model that evolves, which incurs the cancellation in the linear non-singular transformation resulting in the interference stripes of
Figure 8:
That is how the particle can ultimately hit the wall
without going through one of the slits, i.e., without the state reductions
(going through slit 1) or
(going through slit 2). Distinguishing between the alternatives in an interaction involving a superposition will wipe out any interference effects, i.e., will give Case 1 instead of Case 2.
Any determination of the alternative taken by a process capable of following more than one alternative destroys the interference between alternatives.
The lattice of partitions gives a skeletal representation of the rising levels of definiteness going from the bottom to the top. The top represents the fully definite or distinguished states. In Case 2, the evolution takes place at a
lower level, a level of indefiniteness where those states
are not distinguished. In classical physics, all states are distinguished, so classical evolution always takes definite states to definite states (as in the evolution marked by
X in
Figure 9). Here we see, in terms of the simplified model, the answer to the key question: “How does the particle get to the detection wall without passing through slit 1 or slit 2?”.
3.11. The Feynman Rules
3.11.1. The Fundamental Role of Distinguishability
The formulation of QM that shows the fundamental role of distinctions or distinguishings was developed by Richard Feynman [
24] who encapsulated the rules for working with amplitudes in the “Feynman rules” ([
6,
25] (pp. 314–315)) such as the one involved in analyzing the double-slit experiment.
The probability of an event (in an ideal experiment where there are no uncertain external disturbances) is the absolute square of a complex quantity called the probability amplitude. When the event can occur in several alternative ways, the probability amplitude is the sum of the probability amplitude for each alternative considered separately…. If an experiment capable of determining which alternative is actually taken is performed, the interference is lost and the probability becomes the sum of the probability for each alternative.
John Stachel gives the application to the double-slit experiment.
Feynman’s approach is based on the contrast between processes that are distinguishable within a given physical context and those that are indistinguishable within that context. A process is distinguishable if some record of whether or not it has been realized results from the process in question; if no record results, the process is indistinguishable from alternative processes leading to the same end result. In my terminology, a registration of the realization of a process must exist for it to be a distinguishable alternative. In the two-slit experiment, for example, passage through one slit or the other is only a distinguishable alternative if a counter is placed behind one of the slits; without such a counter, these are indistinguishable alternatives. Classical probability rules apply to distinguishable processes. Nonclassical probability amplitude rules apply to indistinguishable processes.
In QM/Sets, the ‘amplitudes’ are given by the vectors in the vector space over
where the cancellations occur, e.g.,
, in the non-distinguished Case 2, and then the probabilities are computed from the resulting amplitudes by the Born rule. In the distinguished Case 1, the probabilities from the distinct alternatives are added, e.g., the probabilities of the two distinct ways of
at the screen eventually resulting in
at the wall are added:
By following the Feynman rules, probabilities can be computed without “being confused by things such as the ‘reduction of a wave packet’ and similar magic” [
26] (p. 76). Using the rules to calculate probabilities, of course, does not eliminate state reductions since “a registration of the realization of a process must exist for it to be a distinguishable alternative” [
25] (p. 314). The point is what causes the state reduction, namely the distinguishability of the previously superposed alternatives undergoing an interaction.
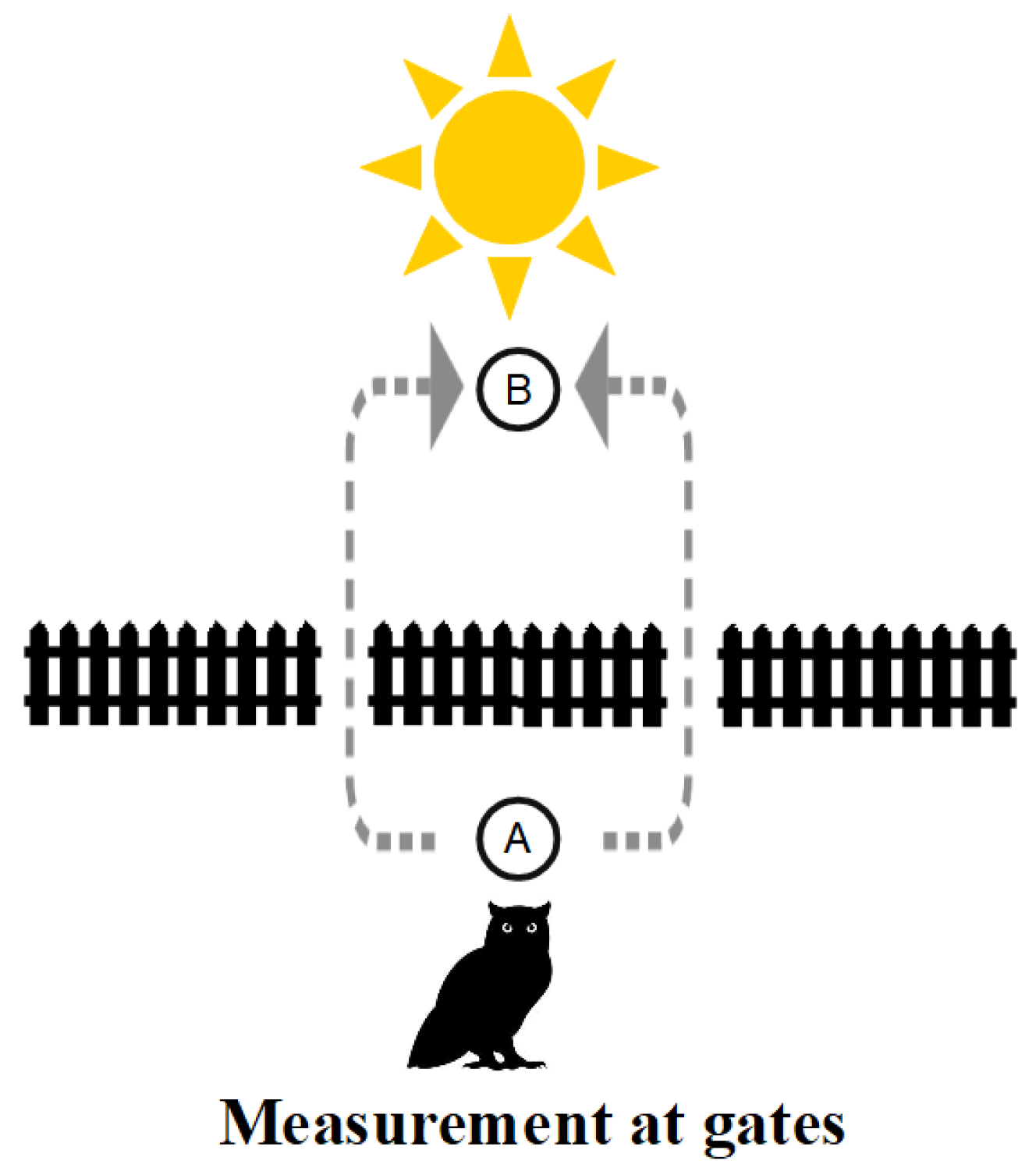
3.11.2. Weyl’s Use of the Yoga
In his popular writing about QM, Arthur Eddington used the notion of a sieve.
In Einstein’s theory of relativity, the observer is a man who sets out in quest of truth, armed with a measuring rod. In quantum theory, he sets out armed with a sieve.
Hermann Weyl quotes Eddington about the idea of a sieve, which Weyl calls a “grating” [
8] (p. 255). Weyl then, in effect, uses the Yoga of linearization to develop the idea of a grating both as a set partition (or equivalence relation) and as a vector space direct-sum decomposition (DSD) [
8] (pp. 255–257). He starts with a numerical attribute, e.g.,
, which defines a partition on a set or “aggregate [which] is used in the sense of ‘set of elements with equivalence relation’” [
8] (p. 239). Then he goes to the quantum case where the “aggregate of
n states has to be replaced by an
n-dimensional Euclidean vector space” [
8] (p. 256. “Euclidean” is older terminology for an inner product space). He describes the vector space notion of a grating as the “splitting of the total vector space into mutually orthogonal subspaces” so that “each vector
splits into
r component vectors lying in the several subspaces” [
8] (p. 256), i.e., a direct-sum decomposition of the space. Finally, Weyl notes that “Measurement means application of a sieve or grating” [
8] (p. 259). In
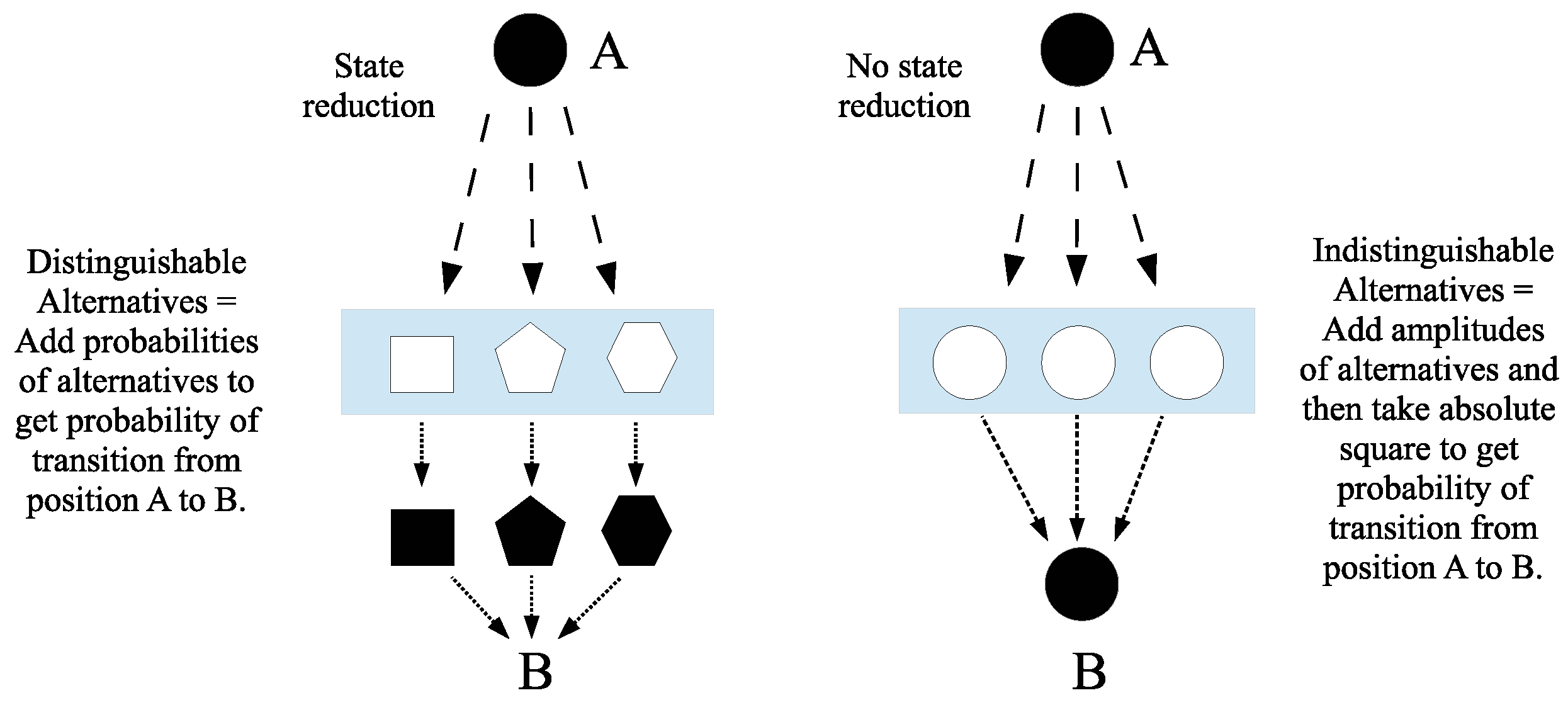
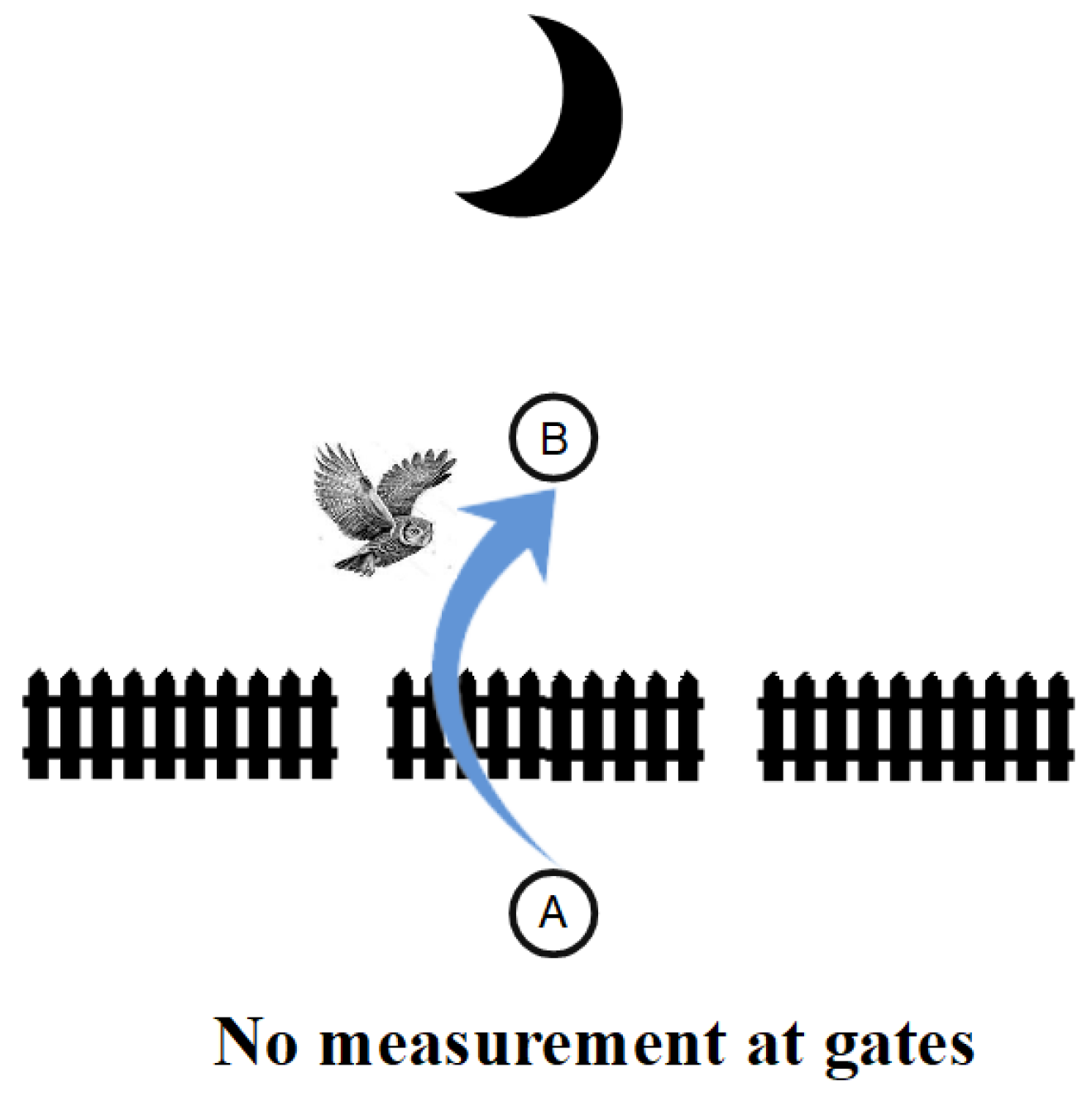
Figure 10, this idea of measurement as a superposition state passing through a grating or sieve is illustrated (on the left side) along with a similar image (on the right side) where no distinctions or distinguishings take place, so there is no measurement.
The doughball-shaped figure at position A visually illustrates the superposition of the definite shapes in the left-side grating. As the doughball falls through one of the holes, it “collapses” or reduces from its indefinite or superposition state to one of the definite eigenstates. To get the total probability of going from A to B, one has to add the three probabilities of each distinguishable path from A to B. On the right side of
Figure 10, no distinctions are made at a ‘null-grating’ so the amplitudes to go from A to B are added, and the (absolute) square gives the probability.
5. Conclusions: Ontological Intimations
The simplified model (QM/Sets with density matrices) is “Exhibit A” in the thesis [
1] that the distinctive mathematics of QM is the Hilbert space version of the mathematics of partitions–with the Yoga of Linearization providing the main bridge from partition math to QM math. We are ‘cutting at the joints’ between the math and the physics of QM. The physics of QM involves Planck’s constant, which accordingly has no role in QM/Sets based on the distinctive
mathematics of QM. The century-old problem with quantum mechanics is seeing the nature of the quantum-level reality that the theory seems to describe so well. Yet we know what the mathematical notion of a partition or equivalence relation describes, namely, what is described in different vocabularies as:
distinctions or inequivalences (ordered pairs of elements in different partition blocks or in different equivalence classes) versus indistinctions or equivalences (ordered pairs of elements in the same block or in the same equivalence class),
definiteness (singleton block or equivalence class) versus indefiniteness (multiple element block), and
distinguishability versus indistinguishability (e.g., of paths from A to B).
These concepts are not thought up to jury-rig another interpretation of QM; they are logical concepts based on the logic of partitions dual to the classical Boolean logic of subsets. These concepts start at the logical level, move through being quantified by logical entropy, and end up in the Feynman rules applying to quantum interactions. The simplified model using partition math implies that quantum reality is characterized by the presence of indistinctions, indefiniteness, and indistinguishability, i.e., superpositions.
One way to see this is to consider the various metaphysical characterizations of the world of classical physics. That classical world is seen to be ‘definite all the way down’ in the sense that by digging deep enough (i.e., by taking more and more joins of partitions), there is always some attribute to distinguish different entities (i.e., the different entities end up in different blocks of a partition). If there was no attribute to distinguish two seemingly different entities, then they were the same entity. This was expressed in Leibniz’s Principle of Identity of Indistinguishables (PII) ([
34], Fourth letter, p. 22).
The simplified model provides a ‘skeletal’ model of both classical and quantum reality in the partition lattice (e.g.,
Figure 2,
Figure 3 and
Figure 4,
Figure 7 and
Figure 9). Using an iceberg metaphor, the tip of the iceberg ([
35], p. 3) above the water represents the classical world with the unseen quantum world under the water. In the lattice of partitions, that “tip of the iceberg” is the top of the lattice, the discrete partition
, with only singleton blocks and thus fully distinguished or classical states with no superposition. Accordingly, the discrete partition gives the partition logic version of the PII as the characteristic of classicality:
That is, if
u and
in
U are indistinguishable by the discrete partition, then they are the same element of
U. Mathematically, this is trivial since
. Every other partition
has some multiple-element block, so PII fails for it, indicating its quantum nature as a mixed or pure state containing at least one superposition state. In terms of density matrices, the classical states are represented by diagonal density matrices with no non-zero off-diagonal elements, i.e., no coherences representing superpositions.
In quantum physics, reality is not definite all the way down, so even when a definite state is maximally specified by a CSCO, there is no further specification to distinguish quantum particles (bosons) that have the same state.
In quantum mechanics, however, identical particles are truly indistinguishable. This is because we cannot specify more than a complete set of commuting observables for each of the particles; in particular, we cannot label the particle by coloring it blue.
Heisenberg [
3], Shimony [
37], Kastner [
35], Jaeger [
6], and many others have described a quantum-level world in terms of real potentialities, and Margenau [
38] and Hughes [
5] have described such a world in terms of latencies. In both cases, the potentialities and latencies are realized by the actual outcome of a measurement. And in all the cases, the other characteristic of the potentiality-latency view of the quantum world is the indefiniteness of superpositions. Even the non-philosophical practicing quantum physicist recognizes that a superposition in the measurement basis does not have a definite value prior to measurement. The potentiality-latency approach reformulated in terms of indefiniteness–plus the widespread recognition of superpositions having indefinite values prior to measurement–point to the dominant characteristic of the quantum world, objective indefiniteness.
From these two basic ideas alone–indefiniteness and the superposition principle–it should be clear already that quantum mechanics conflicts sharply with common sense. If the quantum state of a system is a complete description of the system, then a quantity that has an indefinite value in that quantum state is objectively indefinite; its value is not merely unknown by the scientist who seeks to describe the system. Furthermore, since the outcome of a measurement of an objectively indefinite quantity is not determined by the quantum state, and yet the quantum state is the complete bearer of information about the system, the outcome is strictly a matter of objective chance–not just a matter of chance in the sense of unpredictability by the scientist. Finally, the probability of each possible outcome of the measurement is an objective probability. Classical physics did not conflict with common sense in these fundamental ways.
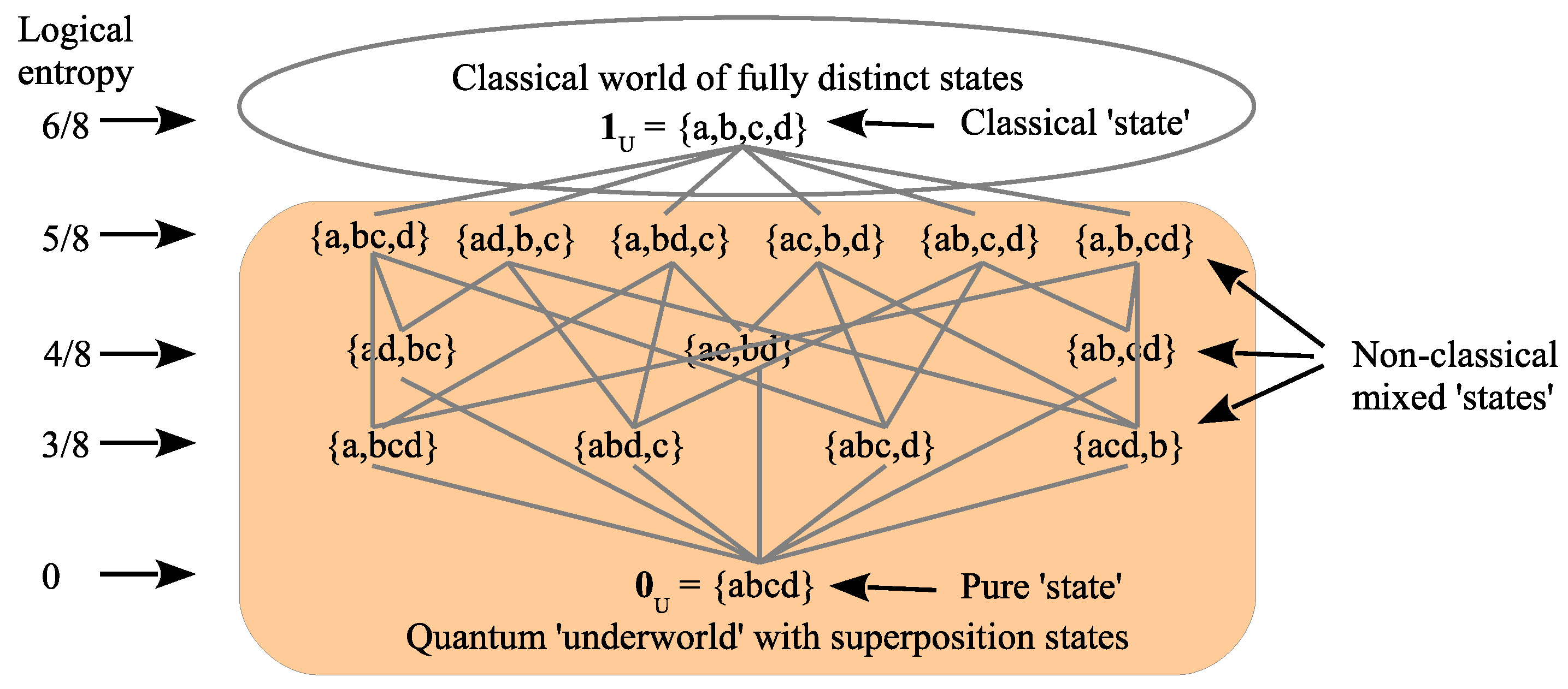
The simplified pedagogical model allows us to use the lattice of partitions to attach an intuitive image to the classical world of fully distinguished states and the quantum ‘underworld’ of indefinite states–as in
Figure 14. This model uses the lattice of partitions on the four state universe
. The logical entropies are for the equiprobable case and show how logical entropy, as the measurement of information-as-distinctions, increases as more distinctions are made moving up in the lattice.
The fact that the model ‘works’ (as a pedagogical model) is corroboration for the thesis that the mathematical machinery of full QM is the Hilbert space version of the mathematics of partitions that is expressed in the model. That view of the quantum world as ‘Indefinite World’ (not ‘Wave World’) might be described as the objective indefiniteness interpretation of quantum mechanics.


















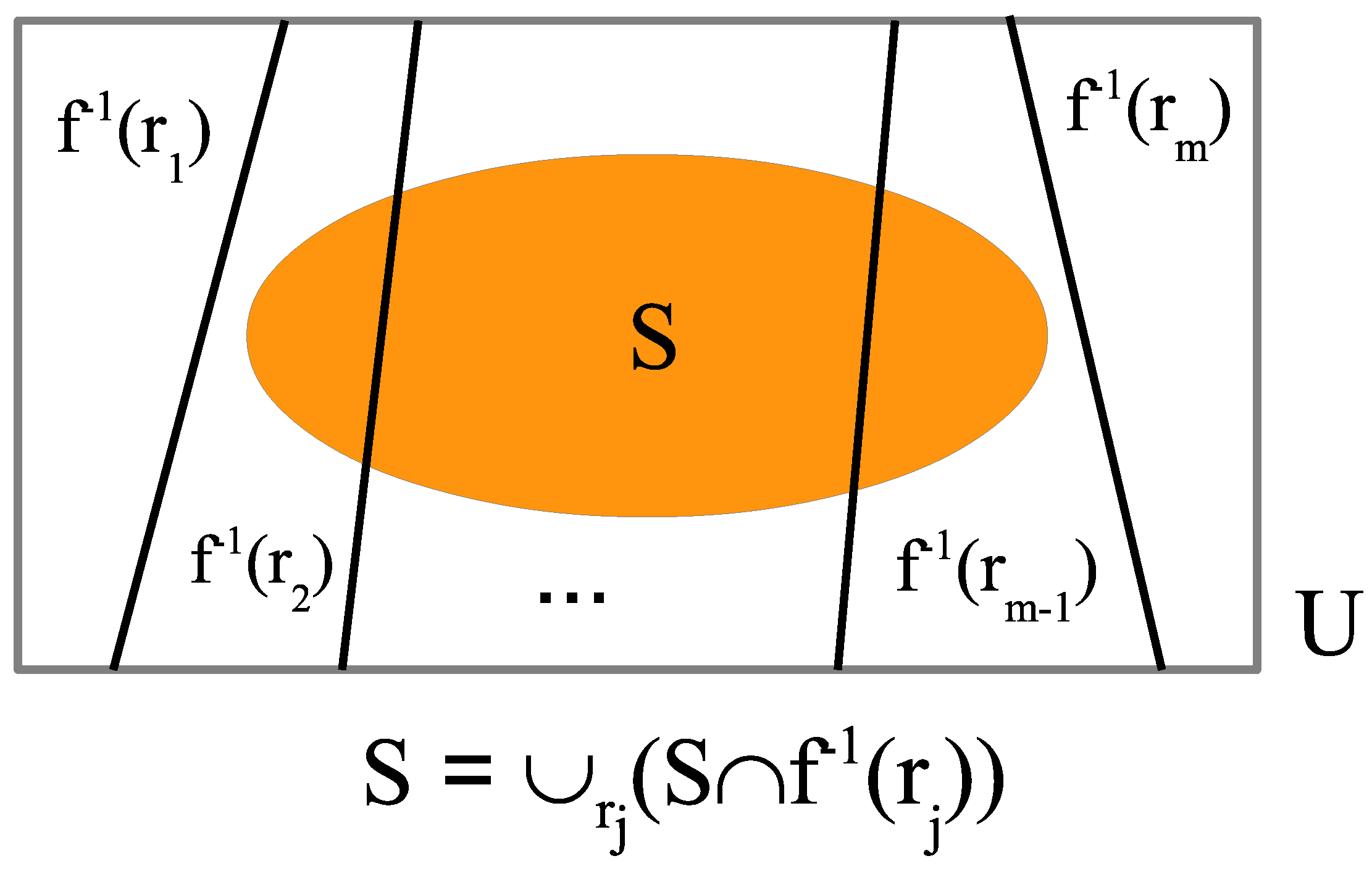{kind=link}
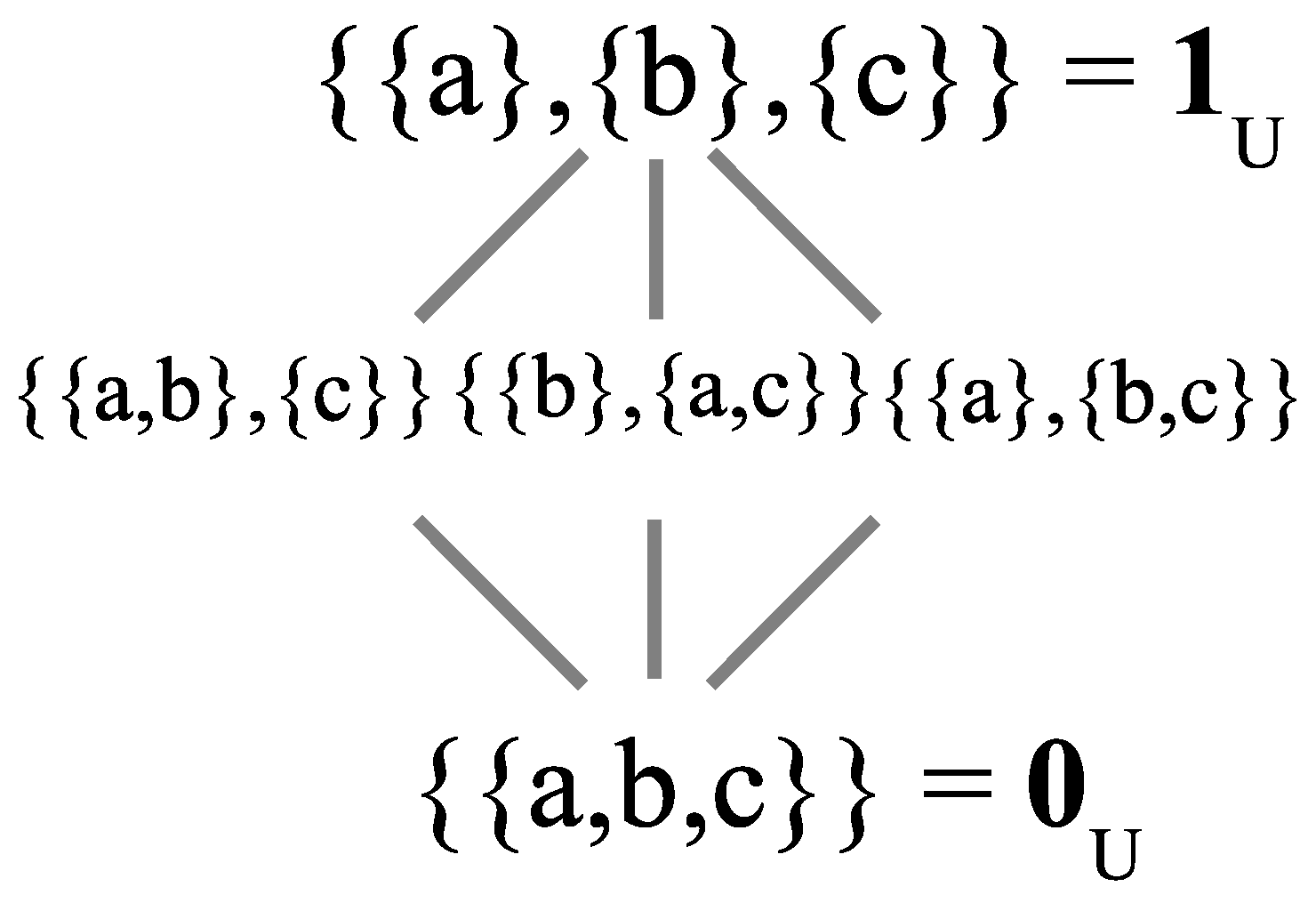{kind=link}
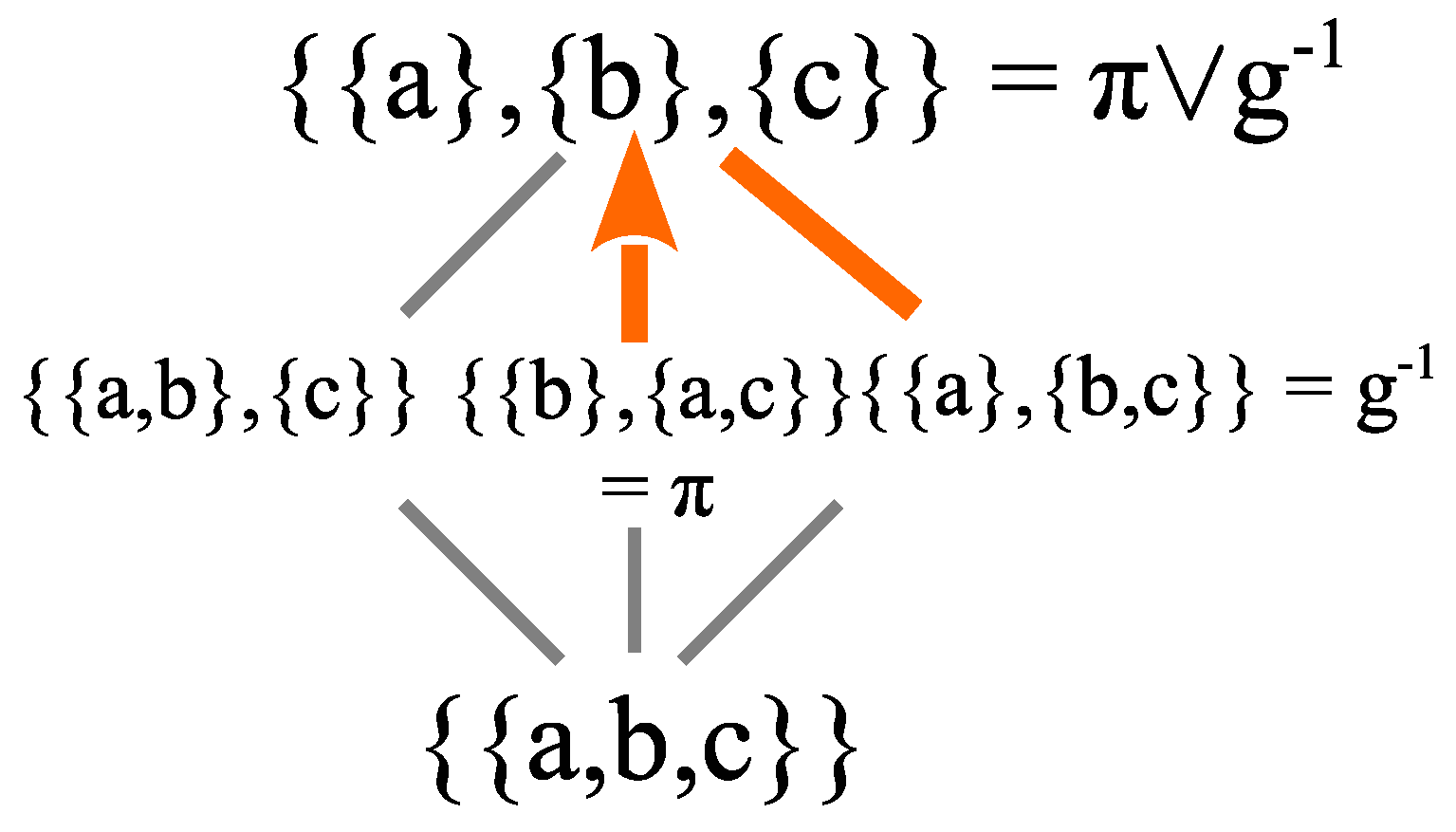{kind=link}
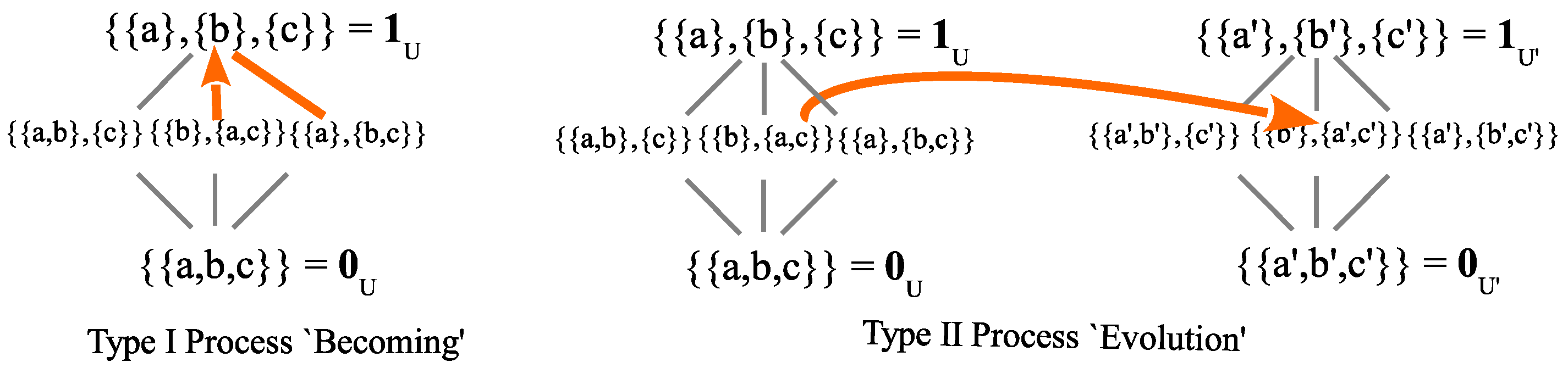{kind=link}
{kind=link}
{kind=link}
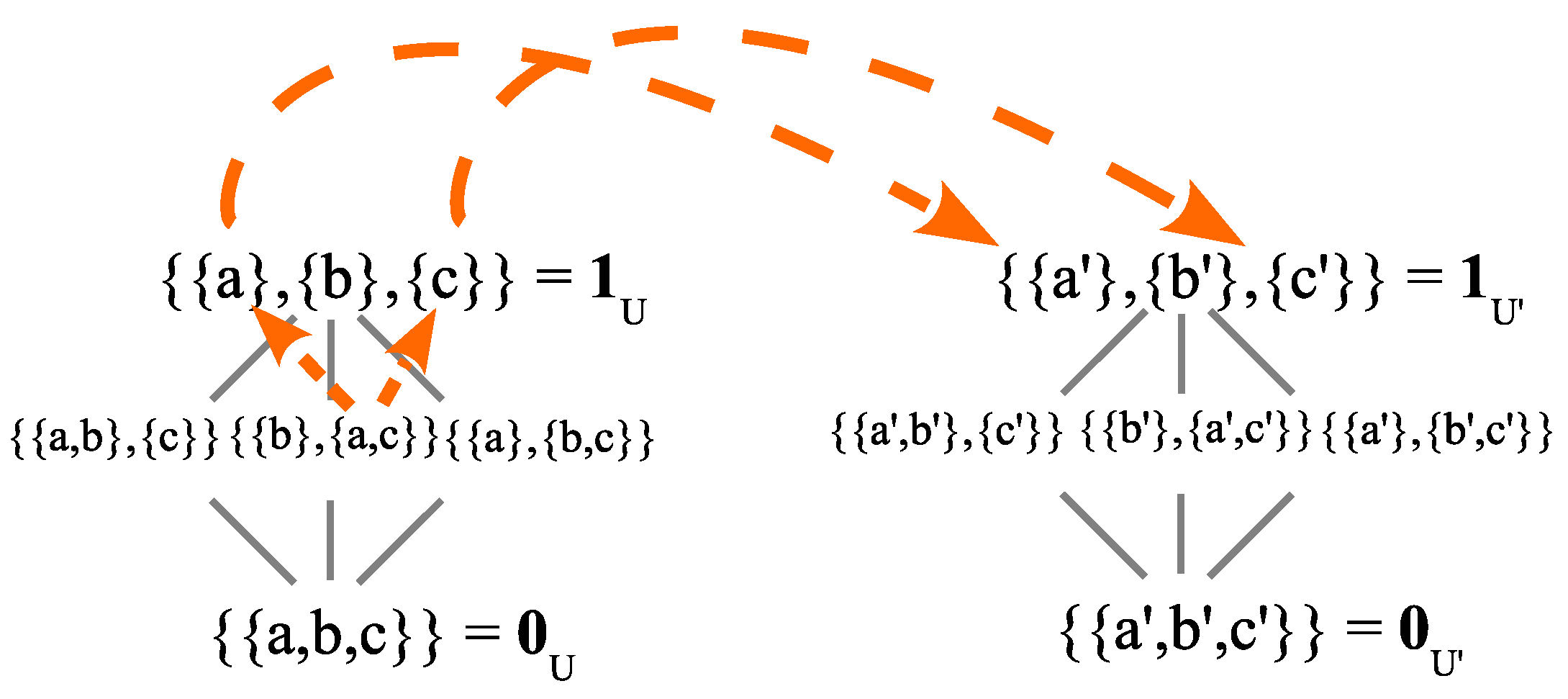{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}