
Generating Up-to-Date Crop Maps Optimized for Sentinel-2 Imagery in Israel



Abstract
:
1. Introduction
2. Materials and Methods
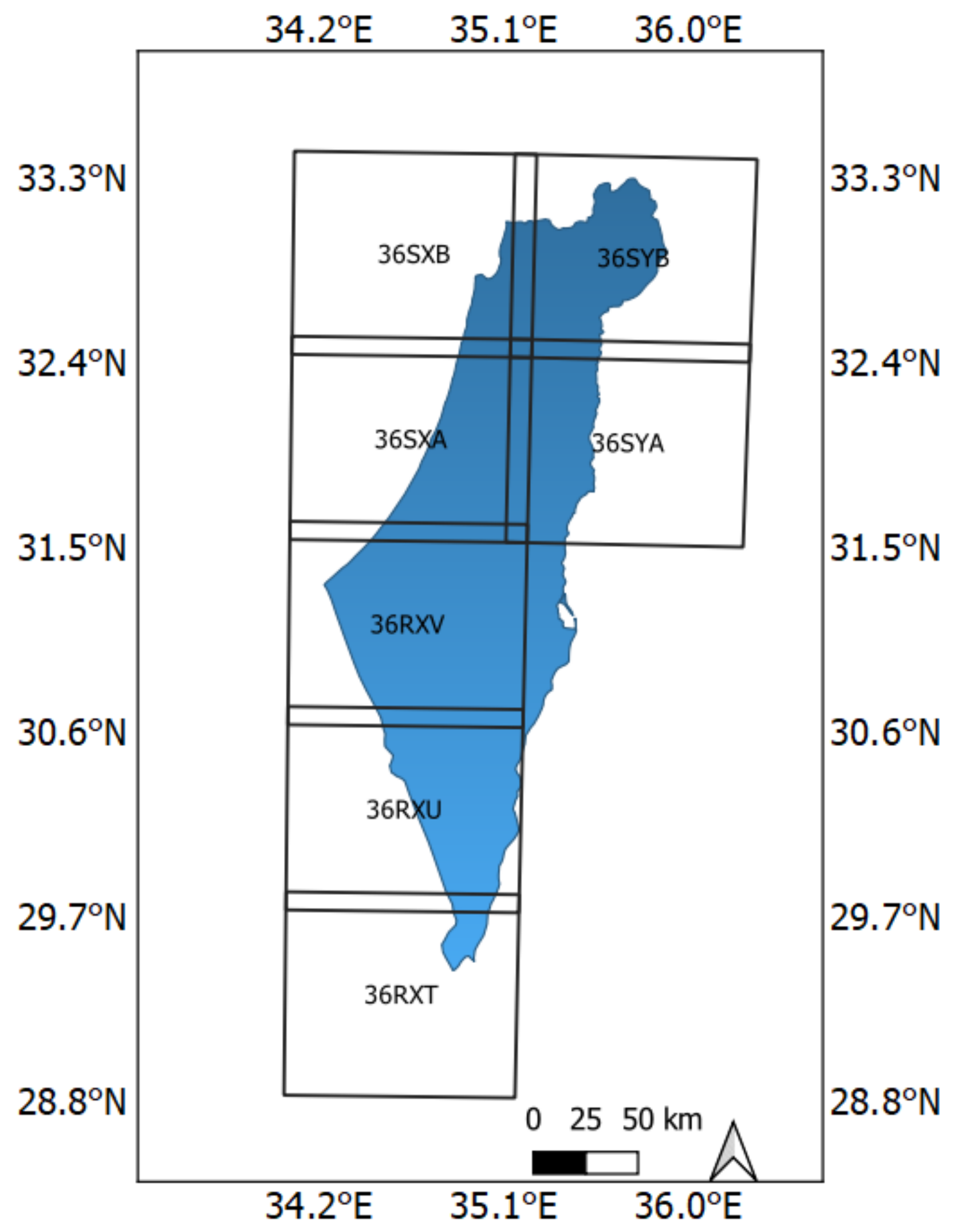
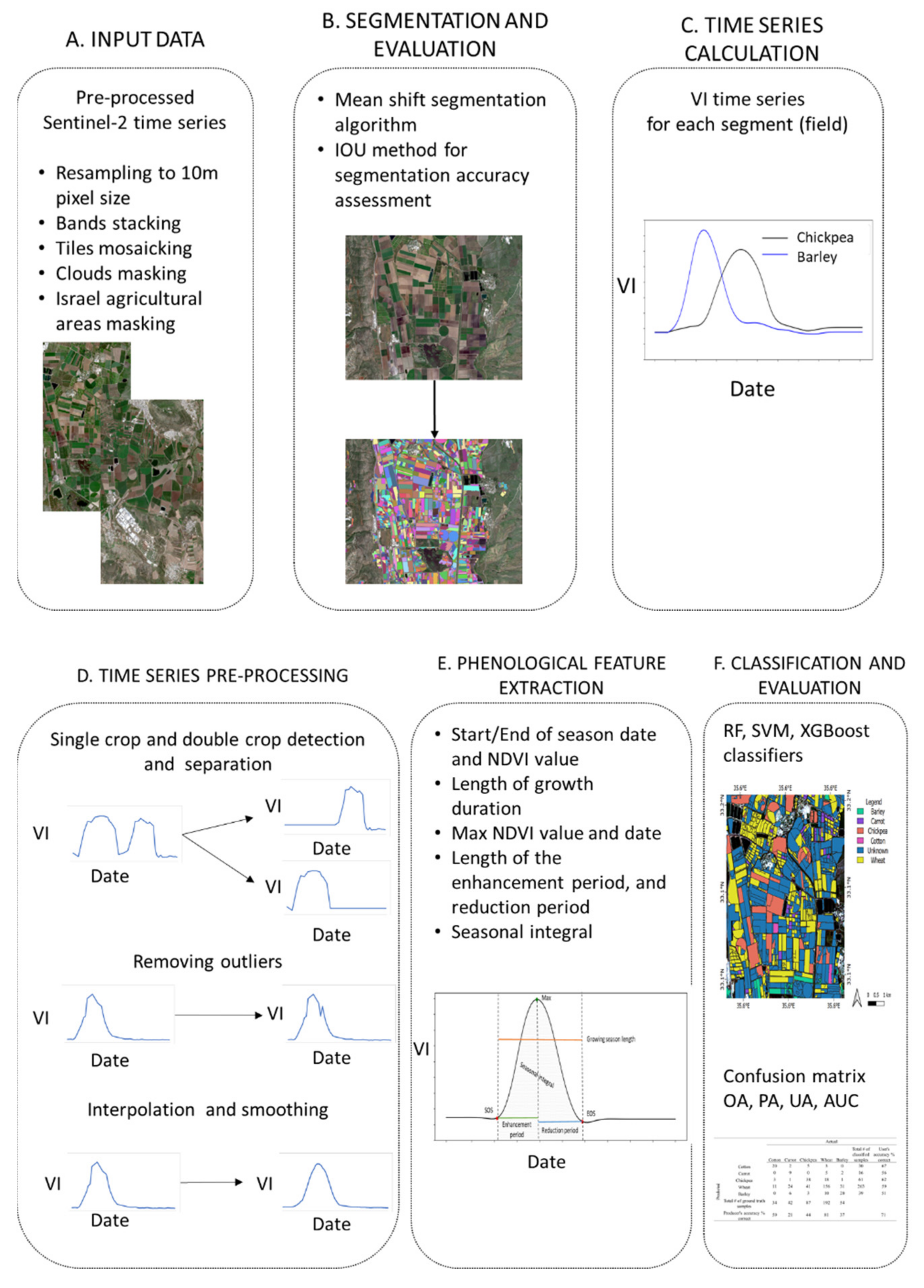
2.1. Sentinel-2 Data Acquisition, Preprocessing, and VIs Calculation
2.2. Segmentation
2.3. Time Series Analysis
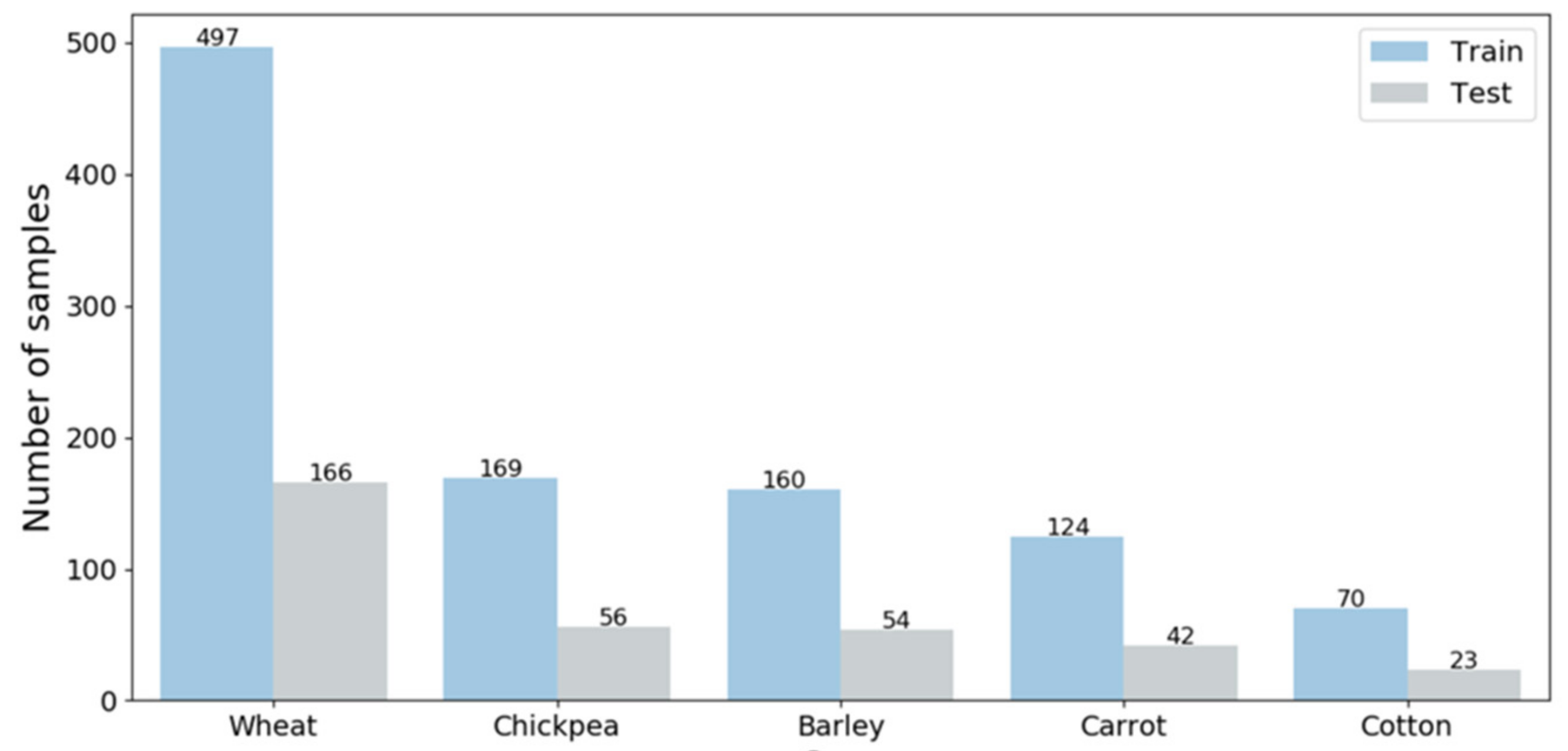
2.4. Classification and Accuracy Assessment
3. Results
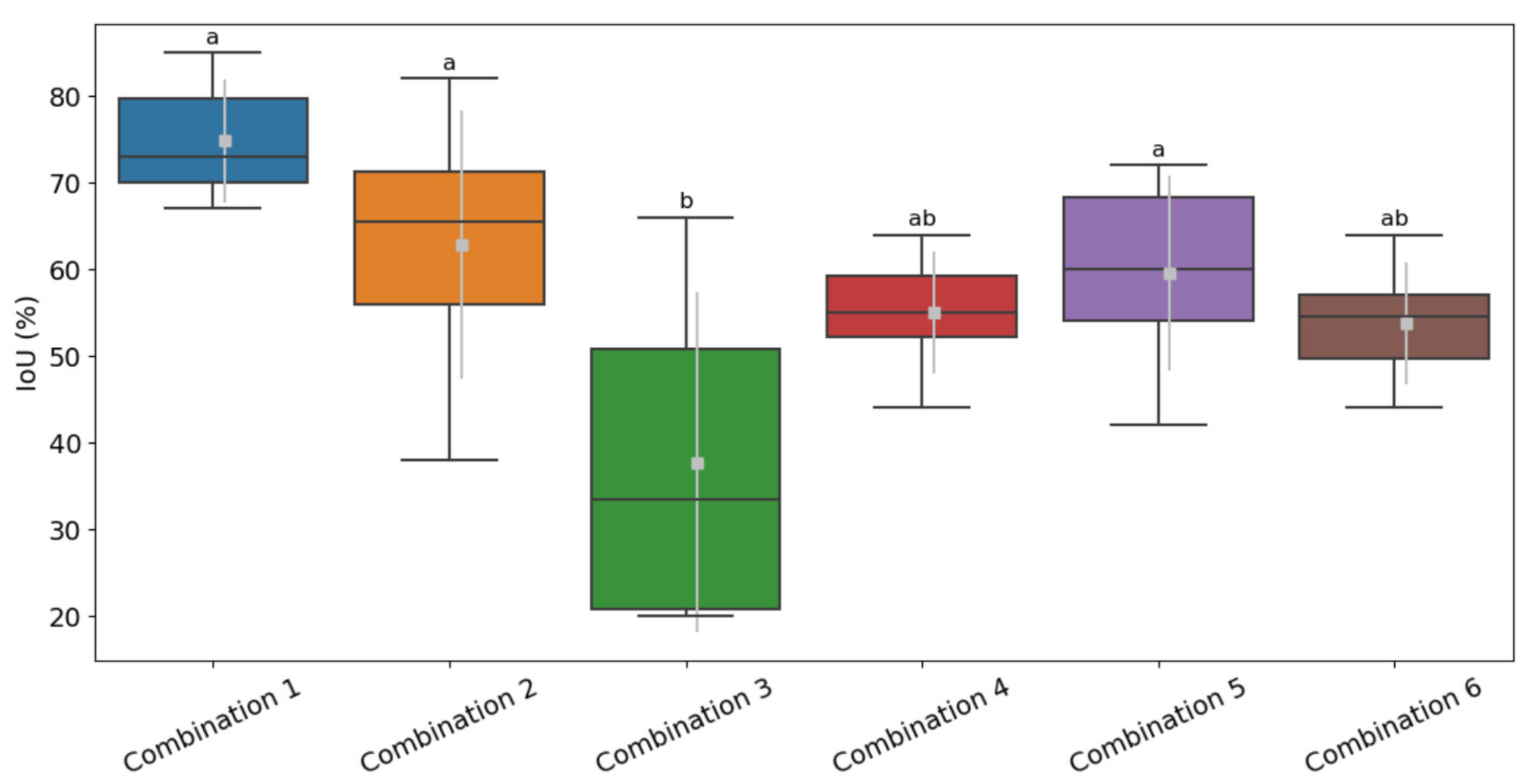
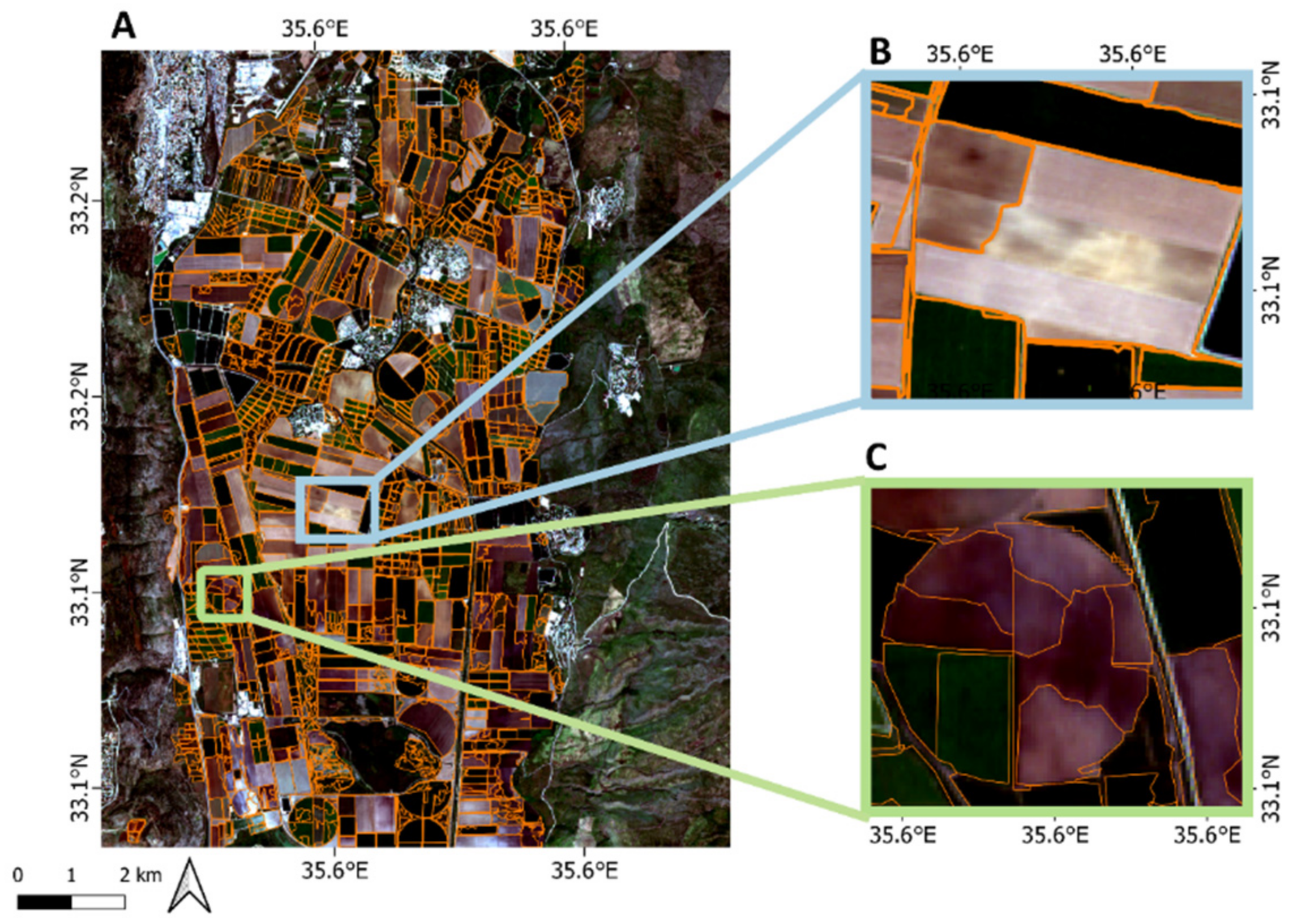
3.1. Segmentation
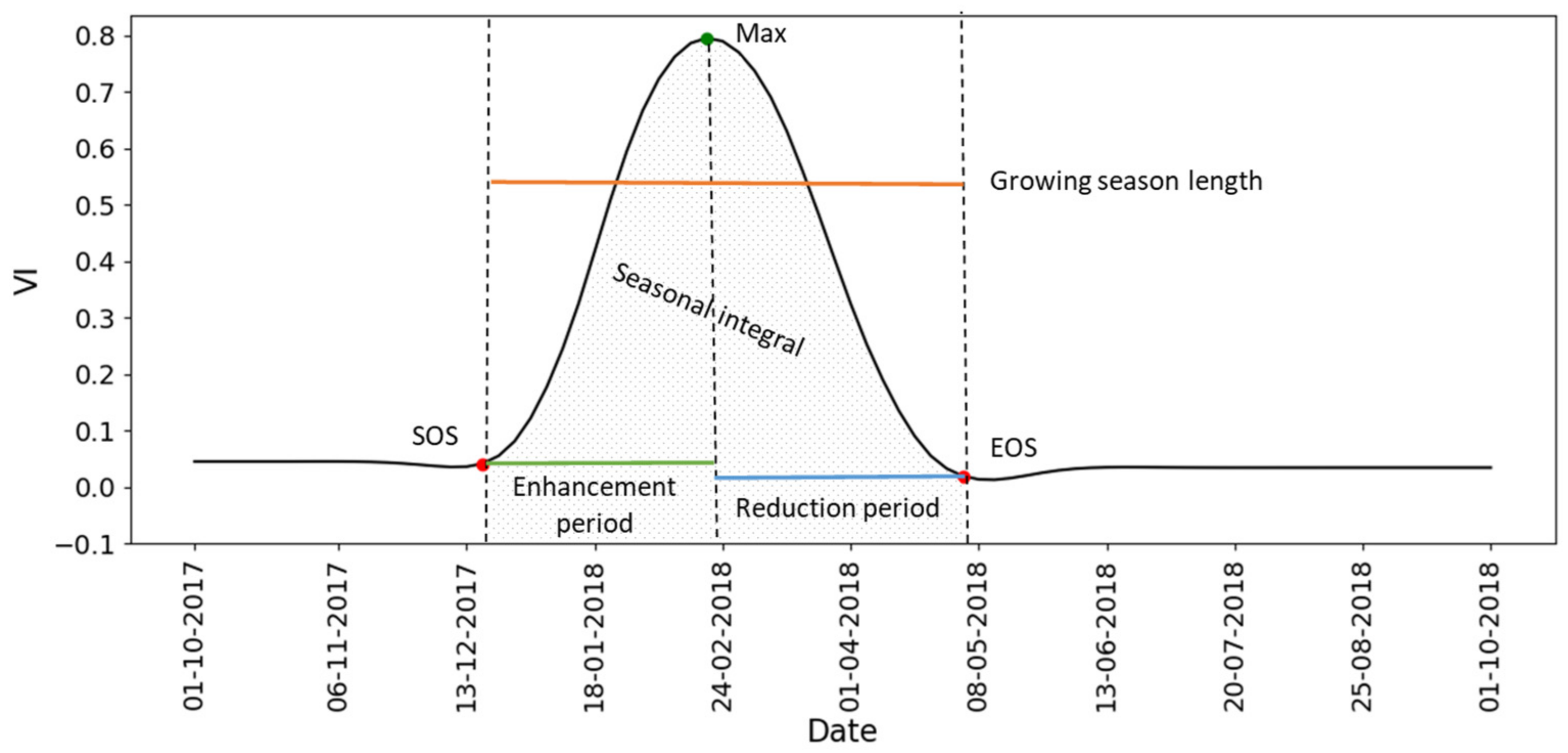
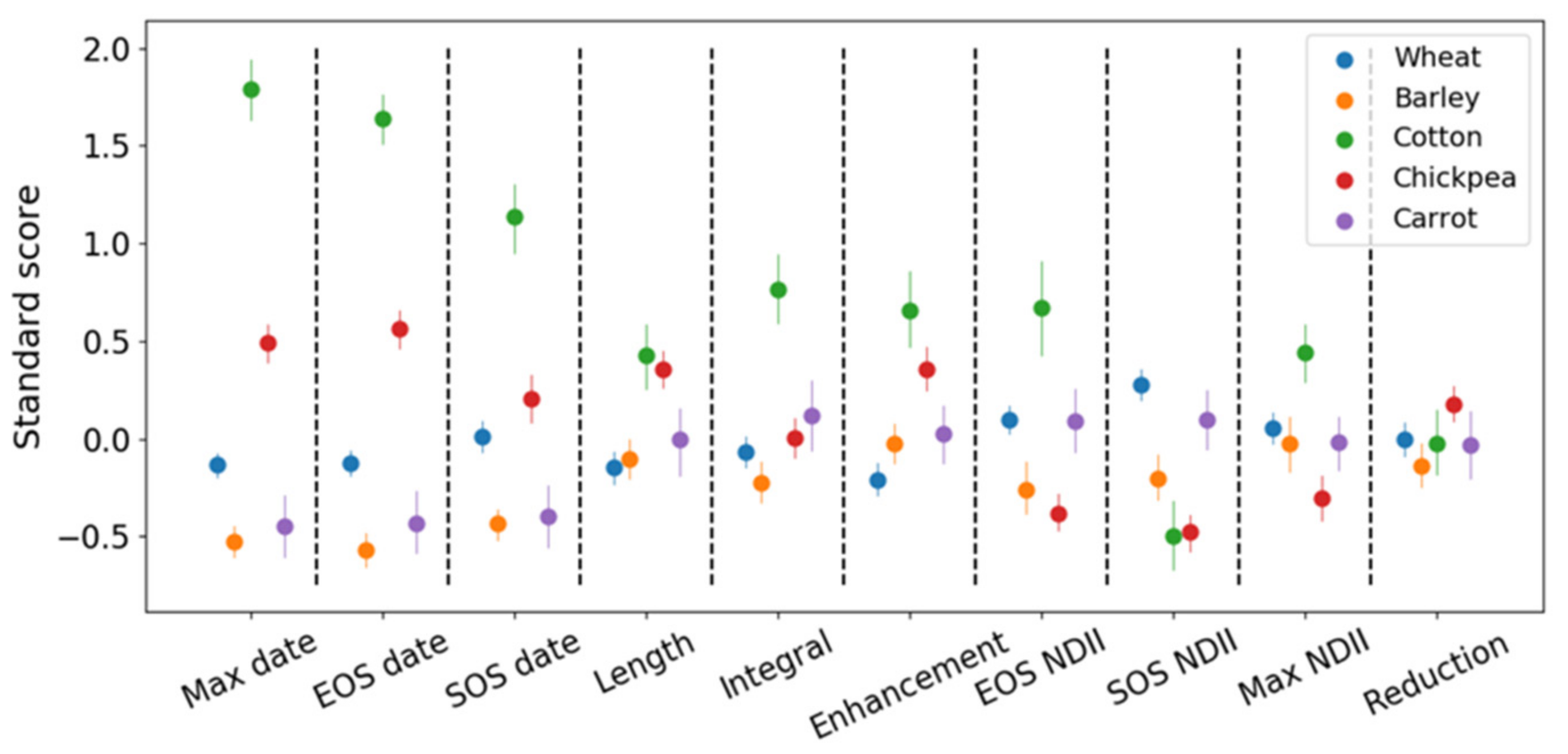
3.2. Phenology Features
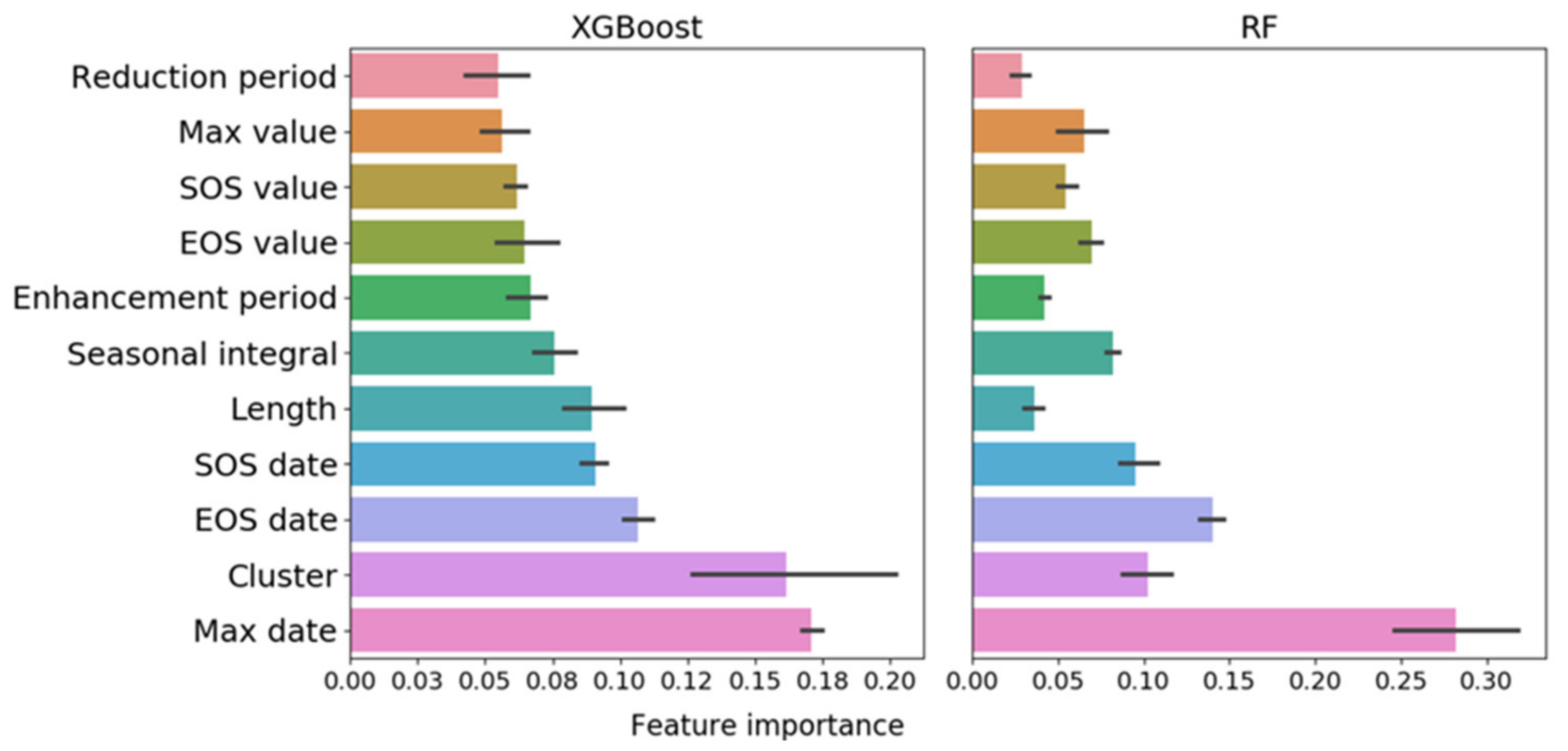
3.3. Classification Results
4. Discussion
4.1. Segmentation
4.2. Phenology Features
4.3. Classification
5. Conclusions
- High emphasis on the spectral and spatial characteristics is important when using the mean shift segmentation algorithm; nevertheless, the spectral parameter is more dominant.
- Date-based phenological features had the most influence on the classification models
- NDII with XGboost showed the highest classification results.
- RF and XGboost classified different types of crops with significantly greater success than did SVM. XGboost showed a better accuracy trend than did RF.
- The AUC was able to assess the significant differences between the classification algorithms in contrast to the OA.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Vegetation Index (VI) | VI Formula * | Reference |
| Normalized difference vegetation index (NDVI) | Rouse et al., 1974 [13] | |
| Optimized Soil Adjusted Vegetation Index (OSAVI) | Rondeaux, Steven, & Baret, 1996 [20] | |
| Normalized Difference Red Edge Index (NDRE) | Barnes et al., 2000 [25] | |
| Normalized Difference Infrared Index (NDII) | Hardisky et al., 1983 [28] | |
| VIs that were calculated from Sentinel-2 data and were employed in this study. * were NIR (band 8), RED (band 4), RED EDGE (band 5), and SWIR (band 12) are the spectral reflectance measurements acquired in the near-infrared band, the red band, the red edge band, and the short wave infrared band from MSI onboard Sentinel-2. | ||
References
- Hoekstra, A.Y.; Mekonnen, M.M. The water footprint of humanity. Proc. Natl. Acad. Sci. USA 2012, 109, 3232–3237. [Google Scholar] [CrossRef] [Green Version]
- Rozenstein, O.; Haymann, N.; Kaplan, G.; Tanny, J. Estimating cotton water consumption using a time series of Sentinel-2 imagery. Agric. Water Manag. 2018, 207, 44–52. [Google Scholar] [CrossRef]
- Rozenstein, O.; Haymann, N.; Kaplan, G.; Tanny, J. Validation of the cotton crop coefficient estimation model based on Sentinel-2 imagery and eddy covariance measurements. Agric. Water Manag. 2019, 223, 105715. [Google Scholar] [CrossRef]
- Manivasagam, V.S.; Rozenstein, O. Practices for upscaling crop simulation models from field scale to large regions. Comput. Electron. Agric. 2020, 175, 105554. [Google Scholar] [CrossRef]
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: A review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- Belgiu, M.; Csillik, O. Sentinel-2 cropland mapping using pixel-based and object-based time-weighted dynamic time warping analysis. Remote Sens. Environ. 2018, 204, 509–523. [Google Scholar] [CrossRef]
- Castillejo-González, I.L.; López-Granados, F.; García-Ferrer, A.; Peña-Barragán, J.M.; Jurado-Expósito, M.; de la Orden, M.S.; González-Audicana, M. Object-and pixel-based analysis for mapping crops and their agro-environmental associated measures using QuickBird imagery. Comput. Electron. Agric. 2009, 68, 207–215. [Google Scholar] [CrossRef]
- Peña-Barragán, J.M.; Ngugi, M.K.; Plant, R.E.; Six, J. Object-based crop identification using multiple vegetation indices, textural features and crop phenology. Remote Sens. Environ. 2011, 115, 1301–1316. [Google Scholar] [CrossRef]
- Rozenstein, O.; Karnieli, A. Comparison of methods for land-use classification incorporating remote sensing and GIS inputs. Appl. Geogr. 2011, 31, 533–544. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Serra, P.; Pons, X. Monitoring farmers’ decisions on Mediterranean irrigated crops using satellite image time series. Int. J. Remote Sens. 2008, 29, 2293–2316. [Google Scholar] [CrossRef]
- Belda, S.; Pipia, L.; Morcillo-Pallarés, P.; Rivera-Caicedo, J.P.; Amin, E.; De Grave, C.; Verrelst, J. DATimeS: A machine learning time series GUI toolbox for gap-filling and vegetation phenology trends detection. Environ. Model. Softw. 2020, 127, 104666. [Google Scholar] [CrossRef]
- Rouse, J.W.; Haas, R.H.; Schell, J.A.; Deering, D.W.; Harlan, J.C. Monitoring the Vernal Advancement and Retrogradation (Green Wave Effect) of Natural Vegetation; NASA/GSFC Type III Final Report, Greenbelt, Md, 371; Remote Sensing Center, Texas A & M University: College Station, TX, USA, 1974. [Google Scholar]
- Xue, J.; Su, B. Significant Remote Sensing Vegetation Indices: A Review of Developments and Applications. J. Sens. 2017, 2017, 1353691. [Google Scholar] [CrossRef] [Green Version]
- Herrmann, I.; Pimstein, A.; Karnieli, A.; Cohen, Y.; Alchanatis, V.; Bonfil, D. LAI assessment of wheat and potato crops by VENμS and Sentinel-2 bands. Remote Sens. Environ. 2011, 115, 2141–2151. [Google Scholar] [CrossRef]
- Conrad, C.; Colditz, R.R.; Dech, S.; Klein, D.; Vlek, P.L. Temporal segmentation of MODIS time series for improving crop classification in Central Asian irrigation systems. Int. J. Remote Sens. 2011, 32, 8763–8778. [Google Scholar] [CrossRef]
- Li, Q.; Wang, C.; Zhang, B.; Lu, L. Object-Based Crop Classification with Landsat-MODIS Enhanced Time-Series Data. Remote Sens. 2015, 7, 16091–16107. [Google Scholar] [CrossRef] [Green Version]
- Zheng, B.; Myint, S.W.; Thenkabail, P.S.; Aggarwal, R.M. A support vector machine to identify irrigated crop types using time-series Landsat NDVI data. Int. J. Appl. Earth Obs. Geoinf. 2015, 34, 103–112. [Google Scholar] [CrossRef]
- Hao, P.-Y.; Tang, H.-J.; Chen, Z.-X.; Meng, Q.-Y.; Kang, Y.-P. Early-season crop type mapping using 30-m reference time series. J. Integr. Agric. 2020, 19, 1897–1911. [Google Scholar] [CrossRef]
- Rondeaux, G.; Steven, M.; Baret, F. Optimization of soil-adjusted vegetation indices. Remote Sens. Environ. 1996, 55, 95–107. [Google Scholar] [CrossRef]
- Mercier, A.; Betbeder, J.; Rumiano, F.; Baudry, J.; Gond, V.; Blanc, L.; Bourgoin, C.; Cornu, G.; Ciudad, C.; Marchamalo, M.; et al. Evaluation of Sentinel-1 and 2 Time Series for Land Cover Classification of Forest–Agriculture Mosaics in Temperate and Tropical Landscapes. Remote Sens. 2019, 11, 979. [Google Scholar] [CrossRef] [Green Version]
- Palchowdhuri, Y.; Valcarce-Diñeiro, R.; King, P.; Sanabria-Soto, M. Classification of multi-temporal spectral indices for crop type mapping: A case study in Coalville, UK. J. Agric. Sci. 2018, 156, 24–36. [Google Scholar] [CrossRef]
- Sonobe, R.; Yamaya, Y.; Tani, H.; Wang, X.; Kobayashi, N.; Mochizuki, K.I. Crop classification from Senti-nel-2-derived vegetation indices using ensemble learning. J. Appl. Remote Sens. 2018, 12, 026019. [Google Scholar] [CrossRef] [Green Version]
- Clevers, J.G.P.W.; Kooistra, L.; Van den Brande, M.M. Using Sentinel-2 Data for Retrieving LAI and Leaf and Canopy Chlorophyll Content of a Potato Crop. Remote Sens. 2017, 9, 405. [Google Scholar] [CrossRef] [Green Version]
- Barnes, E.M.; Clarke, T.R.; Richards, S.E.; Colaizzi, P.D.; Haberland, J.; Kostrzewski, M.; Moran, M.S. Coincident detection of crop water stress, nitrogen status and canopy density using ground based multispectral data. In Proceedings of the Fifth International Conference on Precision Agriculture, Bloomington, MN, USA, 16–19 July 2000; Volume 1619. [Google Scholar]
- Eitel, J.U.H.; Vierling, L.A.; Litvak, M.E.; Long, D.S.; Schulthess, U.; Ager, A.A.; Krofcheck, D.J.; Stoscheck, L. Broadband, red-edge information from satellites improves early stress detection in a New Mexico conifer woodland. Remote Sens. Environ. 2011, 115, 3640–3646. [Google Scholar] [CrossRef]
- Ustuner, M.; Sanli, F.B.; Abdikan, S.; Esetlili, M.T.; Kurucu, Y. Crop Type Classification Using Vegetation Indices of RapidEye Imagery. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, XL-7, 195–198. [Google Scholar] [CrossRef] [Green Version]
- Hardisky, M.A.; Klemas, V.; Smart, R.M. The influence of soil salinity, growth form, and leaf moisture on the spectral radiance of Spartina alterniflora canopies, Photogram. Eng. Remote Sens. 1983, 49, 77–83. [Google Scholar]
- Xu, C.; Zhu, X.; Pan, Y.; Zhu, W.; Lei, Y. Comparison study on NDII and NDVI based on rice extraction from rice and ginkgo mixed area. In IGARSS 2008—2008 IEEE International Geoscience and Remote Sensing Symposium; IEEE: Piscataway, NJ, USA, 2008; Volume 3. [Google Scholar] [CrossRef]
- Van Niel, T.G.; McVicar, T.R.; Fang, H.; Liang, S.; Van Niel, T. Calculating environmental moisture for per-field discrimination of rice crops. Int. J. Remote Sens. 2003, 24, 885–890. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First Experience with Sentinel-2 Data for Crop and Tree Species Classifications in Central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Asgarian, A.; Soffianian, A.; Pourmanafi, S. Crop type mapping in a highly fragmented and heterogeneous agri-cultural landscape: A case of central Iran using multi-temporal Landsat 8 imagery. Comput. Electron. Agric. 2016, 127, 531–540. [Google Scholar] [CrossRef]
- Chen, Y.; Lu, D.; Moran, E.; Batistella, M.; Dutra, L.V.; Sanches, I.D.; da Silva, R.F.B.; Huang, J.; Luiz, A.J.B.; de Oliveira, M.A.F. Mapping croplands, cropping patterns, and crop types using MODIS time-series data. Int. J. Appl. Earth Obs. Geoinf. 2018, 69, 133–147. [Google Scholar] [CrossRef]
- Devadas, R.; Denham, R.J.; Pringle, M. Support vector machine classification of object-based data for crop mapping, using multi-temporal Landsat imagery. ISPAR 2012, 39, 185–190. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Lawrence, R.L.; Greenwood, M.C.; Marshall, L.; Miller, P.R. Object-oriented crop classification using multitemporal ETM+ SLC-off imagery and random forest. GISci. Remote Sens. 2013, 50, 418–436. [Google Scholar] [CrossRef]
- Ghazaryan, G.; Dubovyk, O.; Löw, F.; Lavreniuk, M.; Kolotii, A.; Schellberg, J.; Kussul, N. A rule-based approach for crop identification using multi-temporal and multi-sensor phenological metrics. Eur. J. Remote Sens. 2018, 51, 511–524. [Google Scholar] [CrossRef]
- Wang, S.; Azzari, G.; Lobell, D.B. Crop type mapping without field-level labels: Random forest transfer and unsupervised clustering techniques. Remote Sens. Environ. 2019, 222, 303–317. [Google Scholar] [CrossRef]
- Vuolo, F.; Neuwirth, M.; Immitzer, M.; Atzberger, C.; Ng, W.-T. How much does multi-temporal Sentinel-2 data improve crop type classification? Int. J. Appl. Earth Obs. Geoinf. 2018, 72, 122–130. [Google Scholar] [CrossRef]
- Ministry of Agriculture and Rural Development. 2019. Available online: https://moag.maps.arcgis.com/apps/webappviewer/index.html?id=deb443ad1b1f44a2baa74a4880d0ec27 (accessed on 1 September 2021).
- Fukunaga, K.; Hostetler, L. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Trans. Inf. Theory 1975, 21, 32–40. [Google Scholar] [CrossRef] [Green Version]
- Jaccard, P. Étude comparative de la distribution florale dans une portion des Alpes et du Jura. Bull. Soc. Vaudoise Sci. Nat. 1901, 37, 547–579. [Google Scholar] [CrossRef]
- Fisher, R.A. Statistical methods for research workers. In Breakthroughs in Statistics; Springer: New York, NY, USA, 1992; pp. 66–70. [Google Scholar]
- Tukey, J.W. The Problem of Multiple Comparisons; Princeton University: Princeton, NJ, USA, 1953. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28–30 June 2010; Volume 57, p. 61. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar]
- Whittaker, E.T. On a New Method of Graduation. Proc. Edinb. Math. Soc. 1922, 41, 63–75. [Google Scholar] [CrossRef] [Green Version]
- RStudio Team. RStudio: Integrated Development for R. RStudio; PBC: Boston, MA, USA, 2020; Available online: http://www.rstudio.com/ (accessed on 1 September 2021).
- Reed, B.C.; Brown, J.F.; VanderZee, D.; Loveland, T.R.; Merchant, J.W.; Ohlen, D.O. Measuring phenological variability from satellite imagery. J. Veg. Sci. 1994, 5, 703–714. [Google Scholar] [CrossRef]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-Means Clustering Algorithm. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 100. [Google Scholar] [CrossRef]
- Bentley, J.L. Multidimensional binary search trees used for associative searching. Commun. ACM 1975, 18, 509–517. [Google Scholar] [CrossRef]
- Gautheron, L.; Habrard, A.; Morvant, E.; Sebban, M. Metric Learning from Imbalanced Data. In Proceedings of the 2019 IEEE 31st International Conference on Tools with Artificial Intelligence (ICTAI), Portland, OR, USA, 4–6 November 2019; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2019; pp. 923–930. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Landgrebe, T.C.; Duin, R.P. Approximating the multiclass ROC by pairwise analysis. Pattern Recognit. Lett. 2007, 28, 1747–1758. [Google Scholar] [CrossRef]
- Tharwat, A. Classification assessment methods. Appl. Comput. Inform. 2021, 17, 168–192. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Environmental Systems Research Institute. Available online: https://pro.arcgis.com/en/pro-app/2.7/help/analysis/raster-functions/segment-mean-shift-function.htm (accessed on 1 September 2021).
- Ming, D.; Li, J.; Wang, J.; Zhang, M. Scale parameter selection by spatial statistics for GeOBIA: Using mean-shift based multi-scale segmentation as an example. ISPRS J. Photogramm. Remote Sens. 2015, 106, 28–41. [Google Scholar] [CrossRef]
- Inglada, J.; Arias, M.; Tardy, B.; Hagolle, O.; Valero, S.; Morin, D.; Dedieu, G.; Sepulcre, G.; Bontemps, S.; Defourny, P.; et al. Assessment of an Operational System for Crop Type Map Production Using High Temporal and Spatial Resolution Satellite Optical Imagery. Remote Sens. 2015, 7, 12356–12379. [Google Scholar] [CrossRef] [Green Version]
- Peterson, J.J.; Yahyah, M.; Lief, K.; Hodnett, N. Predictive Distributions for Constructing the ICH Q8 Design Space. In Comprehensive Quality by Design for Pharmaceutical Product Development and Manufacture; Wiley: Hoboken, NJ, USA, 2017; pp. 55–70. [Google Scholar]
- Zhong, L.; Hu, L.; Zhou, H. Deep learning based multi-temporal crop classification. Remote Sens. Environ. 2019, 221, 430–443. [Google Scholar] [CrossRef]
- Saini, R.; Ghosh, S.K. Crop Classification on Single Date Sentinel-2 Imagery Using Random Forest and Suppor Vector Machine. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, XLII-5, 683–688. [Google Scholar] [CrossRef] [Green Version]
- Ling, C.X.; Huang, J.; Zhang, H. AUC: A Better Measure than Accuracy in Comparing Learning Algorithms. In Proceedings of the Canadian Society for Computational Studies of Intelligence; Springer International Publishing: Berlin/Heidelberg, Germany, 2003; pp. 329–341. [Google Scholar]
- Ghulam, A.; Li, Z.L.; Qin, Q.; Yimit, H.; Wang, J. Estimating crop water stress with ETM+ NIR and SWIR data. Agric. For. Meteorol. 2008, 148, 1679–1695. [Google Scholar] [CrossRef]
- Herrmann, I.; Karnieli, A.; Bonfil, D.J.; Cohen, Y.; Alchanatis, V. SWIR-based spectral indices for assessing nitrogen content in potato fields. Int. J. Remote Sens. 2010, 31, 5127–5143. [Google Scholar] [CrossRef]
- Roberts, D.; Smith, M.; Adams, J. Green vegetation, nonphotosynthetic vegetation, and soils in AVIRIS data. Remote Sens. Environ. 1993, 44, 255–269. [Google Scholar] [CrossRef]
- Bargiel, D. A new method for crop classification combining time series of radar images and crop phenology information. Remote Sens. Environ. 2017, 198, 369–383. [Google Scholar] [CrossRef]
- Chakhar, A.; Ortega-Terol, D.; Hernández-López, D.; Ballesteros, R.; Ortega, J.F.; Moreno, M.A. Assessing the Accuracy of Multiple Classification Algorithms for Crop Classification Using Landsat-8 and Sentinel-2 Data. Remote Sens. 2020, 12, 1735. [Google Scholar] [CrossRef]
- Htitiou, A.; Boudhar, A.; Lebrini, Y.; Hadria, R.; Lionboui, H.; Benabdelouahab, T. A comparative analysis of dif-ferent phenological information retrieved from Sentinel-2 time series images to improve crop classification: A machine learning approach. Geocarto Int. 2020, 1–24. [Google Scholar] [CrossRef]
- Zhang, H.; Kang, J.; Xu, X.; Zhang, L. Accessing the temporal and spectral features in crop type mapping using multi-temporal Sentinel-2 imagery: A case study of Yi’an County, Heilongjiang province, China. Comput. Electron. Agric. 2020, 176, 105618. [Google Scholar] [CrossRef]
- Van Tricht, K.; Gobin, A.; Gilliams, S.; Piccard, I. Synergistic Use of Radar Sentinel-1 and Optical Sentinel-2 Imagery for Crop Mapping: A Case Study for Belgium. Remote Sens. 2018, 10, 1642. [Google Scholar] [CrossRef] [Green Version]
- Arvor, D.; Jonathan, M.; Meirelles, M.S.P.; Dubreuil, V.; Durieux, L. Classification of MODIS EVI time series for crop mapping in the state of Mato Grosso, Brazil. Int. J. Remote Sens. 2011, 32, 7847–7871. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combination Number | Input Bands\Index | Spectral Characteristic Importance | Spatial Characteristic Importance |
|---|---|---|---|
| 1 | Green, Red, NIR | High (18) | High (18) |
| 2 | Green, Red, NIR | High (18) | Low (6) |
| 3 | Green, Red, NIR | Low (6) | High (18) |
| 4 | NDVI | High (18) | High (18) |
| 5 | NDVI | High (18) | Low (6) |
| 6 | NDVI | Low (6) | High (18) |
| OA (%) | AUC (%) | ||||||
|---|---|---|---|---|---|---|---|
| Algorithm | VI | Train | Validation | Cross Validation | Train | Validation | Cross Validation |
| RF | NDVI | 76 | 66 | 64 | 95 | 87 | 86 |
| OSAVI | 72 | 65 | 64 | 93 | 85 | 86 | |
| NDRE | 82 | 70 | 67 | 96 | 87 | 87 | |
| NDII | 76 | 66 | 69 | 96 | 87 | 87 | |
| SVM | NDVI | 72 | 65 | 58 | 91 | 80 | 79 |
| OSAVI | 72 | 61 | 59 | 91 | 79 | 79 | |
| NDRE | 68 | 62 | 63 | 89 | 81 | 82 | |
| NDII | 74 | 66 | 63 | 92 | 82 | 82 | |
| XGBoost | NDVI | 72 | 67 | 65 | 93 | 86 | 86 |
| OSAVI | 74 | 65 | 65 | 93 | 84 | 84 | |
| NDRE | 78 | 69 | 66 | 95 | 88 | 87 | |
| NDII | 75 | 68 | 68 | 95 | 88 | 88 |
| UA (%) | PA (%) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Carrot | Cotton | Barley | Wheat | Chickpea | Carrot | Cotton | Barley | Wheat | Chickpea | ||
| RF | NDVI | 60 | 73 | 64 | 67 | 63 | 21 | 70 | 43 | 89 | 55 |
| OSAVI | 50 | 67 | 60 | 68 | 63 | 19 | 61 | 46 | 88 | 54 | |
| NDRE | 58 | 74 | 60 | 73 | 67 | 26 | 61 | 44 | 87 | 77 | |
| NDII | 58 | 48 | 56 | 72 | 61 | 17 | 48 | 41 | 91 | 63 | |
| SVM | NDVI | 50 | 65 | 48 | 68 | 71 | 19 | 74 | 41 | 86 | 57 |
| OSAVI | 57 | 54 | 40 | 67 | 65 | 19 | 57 | 39 | 81 | 57 | |
| NDRE | 54 | 49 | 54 | 67 | 61 | 17 | 70 | 35 | 84 | 55 | |
| NDII | 56 | 47 | 46 | 73 | 71 | 21 | 61 | 44 | 87 | 57 | |
| XGBoost | NDVI | 60 | 70 | 67 | 69 | 61 | 21 | 70 | 48 | 87 | 59 |
| OSAVI | 61 | 71 | 67 | 68 | 55 | 26 | 52 | 41 | 87 | 59 | |
| NDRE | 67 | 63 | 62 | 73 | 66 | 29 | 65 | 52 | 84 | 75 | |
| NDII | 82 | 52 | 55 | 71 | 69 | 21 | 48 | 44 | 90 | 66 | |
| Average | 59 | 61 | 57 | 70 | 64 | 21 | 61 | 43 | 87 | 61 |
| Actual | ||||||||
|---|---|---|---|---|---|---|---|---|
| Carrot | Cotton | Barley | Wheat | Chickpea | Total # of Classified Samples | User’s Accuracy % Correct | ||
| Predicted | Carrot | 9 | 0 | 2 | 3 | 1 | 15 | 60 |
| Cotton | 2 | 16 | 0 | 2 | 3 | 23 | 70 | |
| Barley | 4 | 0 | 26 | 7 | 2 | 39 | 67 | |
| Wheat | 25 | 3 | 21 | 144 | 17 | 210 | 69 | |
| Chickpea | 2 | 4 | 5 | 10 | 33 | 54 | 61 | |
| Total # of reference data samples | 42 | 23 | 54 | 166 | 56 | |||
| Producer’s accuracy % correct | 21 | 70 | 48 | 87 | 59 | OA = 68 | ||
| Number of Classes | Crop Type | Area | Object/Pixel-Based | Satellite | Classifier | Accuracy | Reference |
|---|---|---|---|---|---|---|---|
| 4 | Cotton, spring maize, winter wheat and summer maize, tree. | China, 5710 km2 | Pixel-based | Landsat and Sentinel-2 | Artificial Immune Network | OA: 97% | [19] |
| 8 | Citrus, sugar beet, fallow, cereals, urban, pomegranate, olive, alfalfa. | Morocco, 970 km2 | Pixel-based | Sentinel-2A | RF | OA: 88% | [68] |
| 8 | Rice, corn, water, soybean, potato, beet, building, forest. | China, 3685 km2 | Pixel-based | Sentinel-2 | RF | OA: 97.8% | [69] |
| SVM | OA: 97.2% | ||||||
| Decision Tree | OA: 95.9% | ||||||
| 6 | Winter cereal, maize, soybean, winter rapeseed, sunflower. | Ukraine 1184km2 | Pixel-based | Landsat 8 and Sentinel-1 | SVM + RF fusion | OA: 88% | [36] |
| SVM | OA: 75% | ||||||
| RF | OA: 81.4% | ||||||
| 6 | Been, beet root, grass, maize, potato, wheat | Japan, over 200 km2 | Pixel-based | Sentinel-2 | SVM | OA: 90.6% | [23] |
| RF | OA: 89% | ||||||
| Ensemble machine learning method | OA: 91.6% | ||||||
| 16 | Barley (spring + winter), beet, linseed, maize, wheat (spring + winter), potato, oats, oilseed, fallow, field beans (spring + winter), peas, grassland (permanent + temporary) | UK, 400 km2 | Object-based | WorldView-3, Sentinel-2 | RF and Decision Tree fusion | OA: 91% | [22] |
| 4 | Soy, cotton, maize, others | Brazil, over 90,000 km2 | Pixel-based | MODIS | Decision Tree | OA: 86% | [33] |
| 3 | Corn and soybean, others. | United States, 2585 km2 | Object-based | Landsat 5/7/8 | Machine learning model based on deep neural network | OA: 96% | [10] |
| 6 | Wheat, maize, rice, sunflower, forest, water. | Romania, 638.77 km2 | Pixel-based | Sentinel-2 | RF | OA: 97% | [6] |
| Time-Weighted Dynamic Time Warping | OA: 95% | ||||||
| Object-based | RF | OA: 98% | |||||
| Time-Weighted Dynamic Time Warping | OA: 96% | ||||||
| 6 | Forage, forest, maize, water, cereal, double cropping. | Italy, 242.56 km2 | Pixel-based | RF | OA: 87% | ||
| Time-Weighted Dynamic Time Warping | OA: 87% | ||||||
| Object-based | RF | OA: 86% | |||||
| Time-Weighted Dynamic Time Warping | OA: 90% | ||||||
| 7 | Wheat, alfalfa, hay, sugar beets, onions, fallow, lettuce. | California, USA 588.9 km2 | Pixel-based | RF | OA: 89% | ||
| Time-Weighted Dynamic Time Warping | OA: 75% | ||||||
| Object-based | RF | OA: 88% | |||||
| Time-Weighted Dynamic Time Warping | OA: 78% | ||||||
| 12 | Wheat, barley, rapeseed, maize, potatoes, beets, flax, grassland, forest, built-up, water, other | Belgium, 13,414.87 km2 | Pixel-based | Sentinel-1 and Sentinel-2 | Hierarchical RF | OA: 82% | [70] |
| 7 | Carrots, maize, onions, soya, sugar beet, sunflower, winter crops | Austria, 600 km2 | Pixel-based | Sentinel-2 | RF | OA: 83% | [31] |
| Object-based | OA: 77% | ||||||
| 9 | Alfalfa, cotton, corn, wheat, barley, potatoes barley-cotton, wheat-sorghum, and wheat-cotton | Arizona, USA, 1338 km2 | Pixel-based | Landsat 5/7 | SVM | OA: 90% | [18] |
| 10 | First crop corn, second crop corn, well-developed cotton, moderately developed cotton, weakly developed cotton, wet soil, moist soil, dry soil, and water surface | Turkey, 17.3 km2 | Pixel-based | RapidEye | SVM | OA: 87% | [27] |
| 3 | Cereal, pulse, other | Montana, USA, approximately 13,778 km2 | Object-based | Landsat ETM+ | RF | OA: 85% | [35] |
| Pixel-based | OA: 85% | ||||||
| 6 | Cotton, fallow, other crops, pasture, sorghum, woody | Australia, 1.7 million km2 | Object-based | Landsat TM | SVM | OA: 78% | [34] |
| 5 | Soybean, soybean + noncommercial crop, soybean + maize, soybean + cotton, cotton. | Brazil, 906000 km2 | Pixel-based classification and object-based post-classification | MODIS | Maximum Likelihood | OA: 74% | [71] |
| 13 | Alfalfa, vineyard, almond, walnut, corn, rice, safflower, sunflower, tomato, oat, rye, wheat and meadow. | California, USA, 2649 km2 | Object-based | ASTER | Decision Tree | OA: 79% | [8] |
| 5 | Wheat, cotton, chickpea, barley, carrot. | Israel, approximately 220 km2 | Object-based | Sentinel-2 | FR | OA: 69% | This study |
| SVM | OA: 63% | ||||||
| XGBoost | OA: 68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goldberg, K.; Herrmann, I.; Hochberg, U.; Rozenstein, O. Generating Up-to-Date Crop Maps Optimized for Sentinel-2 Imagery in Israel. Remote Sens. 2021, 13, 3488. https://doi.org/10.3390/rs13173488
Goldberg K, Herrmann I, Hochberg U, Rozenstein O. Generating Up-to-Date Crop Maps Optimized for Sentinel-2 Imagery in Israel. Remote Sensing. 2021; 13(17):3488. https://doi.org/10.3390/rs13173488
Chicago/Turabian StyleGoldberg, Keren, Ittai Herrmann, Uri Hochberg, and Offer Rozenstein. 2021. "Generating Up-to-Date Crop Maps Optimized for Sentinel-2 Imagery in Israel" Remote Sensing 13, no. 17: 3488. https://doi.org/10.3390/rs13173488
APA StyleGoldberg, K., Herrmann, I., Hochberg, U., & Rozenstein, O. (2021). Generating Up-to-Date Crop Maps Optimized for Sentinel-2 Imagery in Israel. Remote Sensing, 13(17), 3488. https://doi.org/10.3390/rs13173488