
High-Resolution Mass Spectrometry and Chemometrics for the Detailed Characterization of Short Endogenous Peptides in Milk By-Products

 ,
, 
 , ,
, ,  ,
, 
Abstract
:1. Introduction
2. Results and Discussion
2.1. HRMS Data Acquisition and Short Peptide Identification
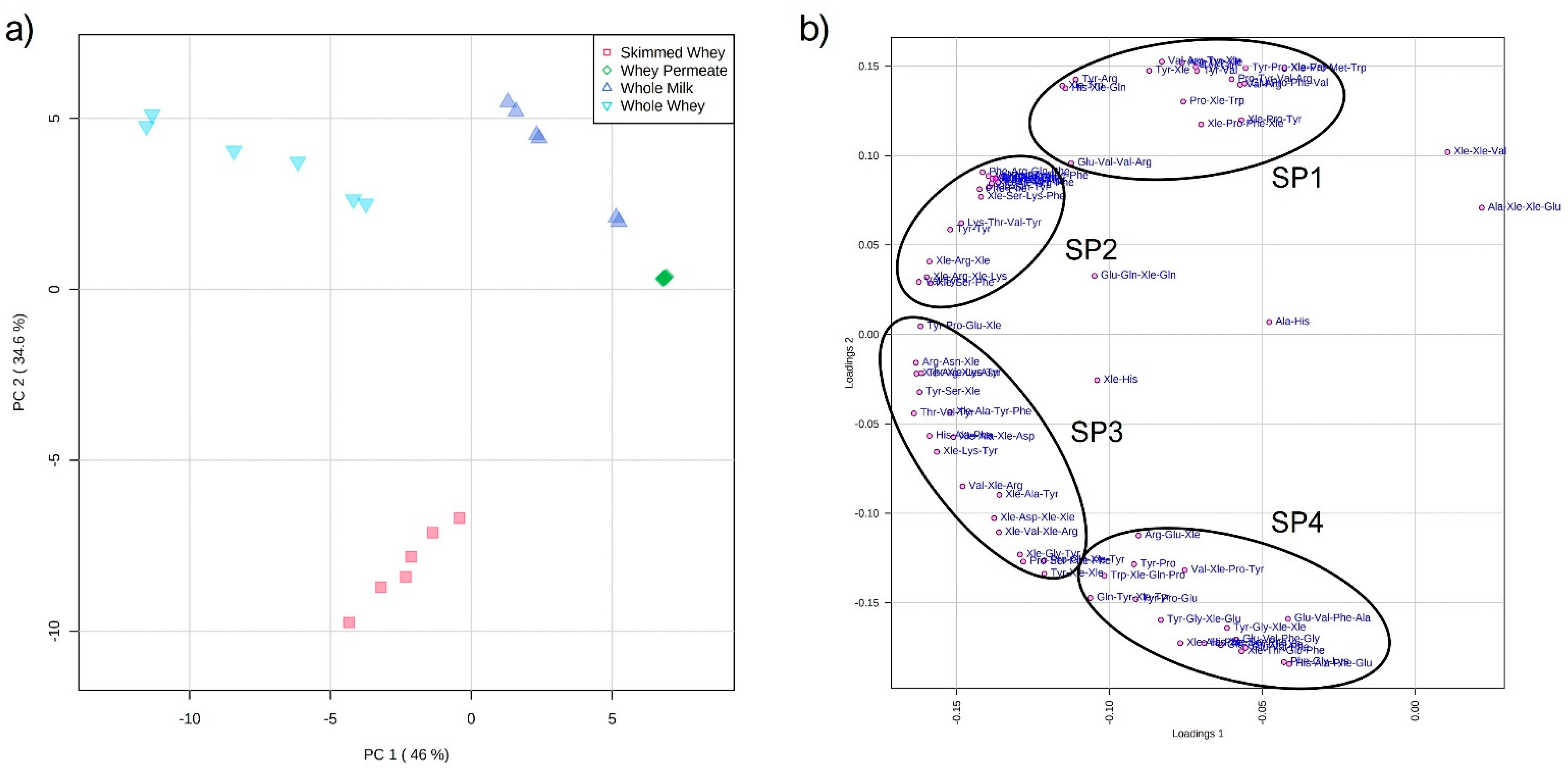
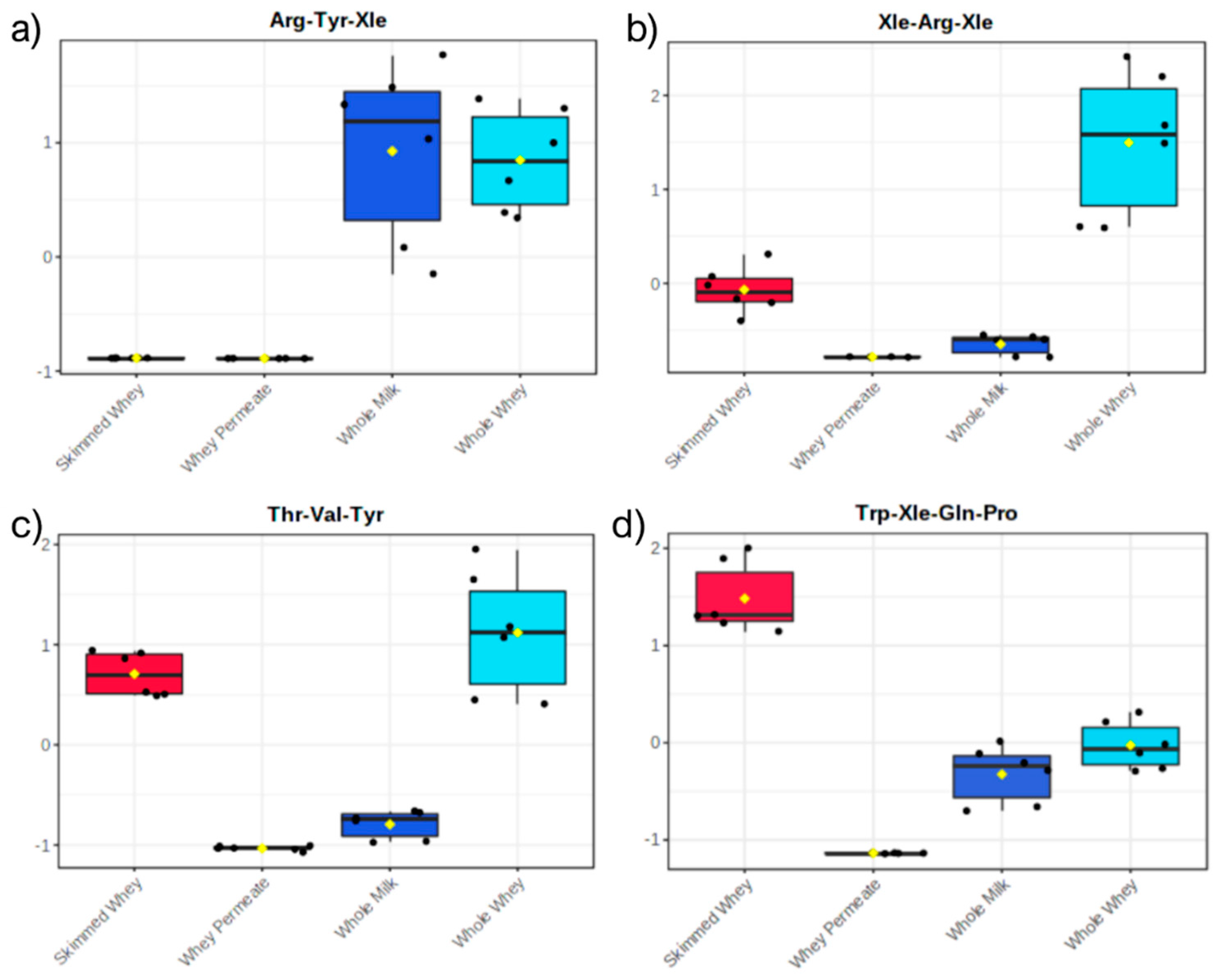
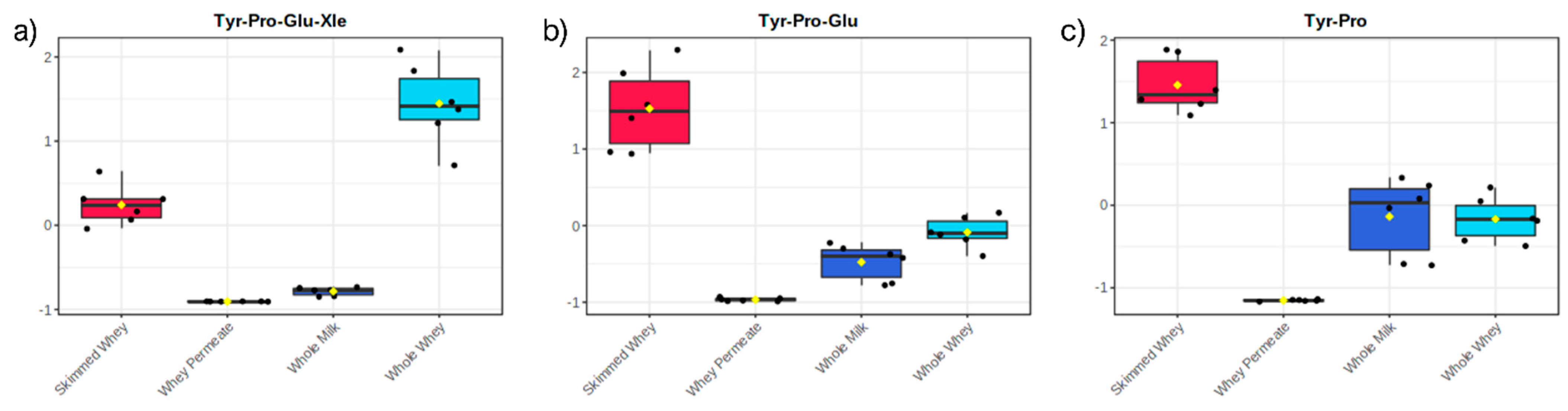
2.2. Principal Component Analysis of Datasets
3. Materials and Methods
3.1. Chemicals and Materials
3.2. Sample Collection
3.3. Sample Preparation
3.4. Liquid Chromatography–Mass Spectrometry Analysis
3.5. Short Peptide Identification
3.6. Statistical Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Salque, M.; Bogucki, P.I.; Pyzel, J.; Sobkowiak-Tabaka, I.; Grygiel, R.; Szmyt, M.; Evershed, R.P. Earliest evidence for cheese making in the sixth millennium bc in northern Europe. Nature 2013, 493, 522–525. [Google Scholar] [CrossRef]
- McGuffey, R.K.; Shirley, J.E. Introduction|History of Dairy Farming. In Encyclopedia of Dairy Sciences; Elsevier: Amsterdam, The Netherlands, 2011; pp. 2–11. [Google Scholar]
- Ahmad, T.; Aadil, R.M.; Ahmed, H.; ur Rahman, U.; Soares, B.C.V.; Souza, S.L.Q.; Pimentel, T.C.; Scudino, H.; Guimarães, J.T.; Esmerino, E.A.; et al. Treatment and utilization of dairy industrial waste: A review. Trends Food Sci. Technol. 2019, 88, 361–372. [Google Scholar] [CrossRef]
- Porwal, H.J.; Mane, A.V.; Velhal, S.G. Biodegradation of dairy effluent by using microbial isolates obtained from activated sludge. Water Resour. Ind. 2015, 9, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Carvalho, F.; Prazeres, A.R.; Rivas, J. Cheese whey wastewater: Characterization and treatment. Sci. Total Environ. 2013, 445–446, 385–396. [Google Scholar] [CrossRef] [PubMed]
- Kasmi, M. Biological Processes as Promoting Way for Both Treatment and Valorization of Dairy Industry Effluents. Waste Biomass Valorization 2018, 9, 195–209. [Google Scholar] [CrossRef]
- Tsermoula, P.; Khakimov, B.; Nielsen, J.H.; Engelsen, S.B. WHEY—The waste-stream that became more valuable than the food product. Trends Food Sci. Technol. 2021, 118, 230–241. [Google Scholar] [CrossRef]
- Haug, A.; Høstmark, A.T.; Harstad, O.M. Bovine milk in human nutrition—A review. Lipids Health Dis. 2007, 6, 25. [Google Scholar] [CrossRef] [Green Version]
- Corrochano, A.R.; Ferraretto, A.; Arranz, E.; Stuknytė, M.; Bottani, M.; O’Connor, P.M.; Kelly, P.M.; De Noni, I.; Buckin, V.; Giblin, L. Bovine whey peptides transit the intestinal barrier to reduce oxidative stress in muscle cells. Food Chem. 2019, 288, 306–314. [Google Scholar] [CrossRef] [Green Version]
- D’Souza, K.; Mercer, A.; Mawhinney, H.; Pulinilkunnil, T.; Udenigwe, C.C.; Kienesberger, P.C. Whey Peptides Stimulate Differentiation and Lipid Metabolism in Adipocytes and Ameliorate Lipotoxicity-Induced Insulin Resistance in Muscle Cells. Nutrients 2020, 12, 425. [Google Scholar] [CrossRef] [Green Version]
- Basilicata, M.G.; Pepe, G.; Sommella, E.; Ostacolo, C.; Manfra, M.; Sosto, G.; Pagano, G.; Novellino, E.; Campiglia, P. Peptidome profiles and bioactivity elucidation of buffalo-milk dairy products after gastrointestinal digestion. Food Res. Int. 2018, 105, 1003–1010. [Google Scholar] [CrossRef] [PubMed]
- Fajardo-Espinoza, F.S.; Ordaz-Pichardo, C.; Sankar, U.; Romero-Rojas, A.; Moreno-Eutimio, M.A.; Hernández-Sánchez, H. In vitro cytomodulatory and immunomodulatory effects of bovine colostrum whey protein hydrolysates. Int. J. Food Sci. Technol. 2021, 56, 2109–2121. [Google Scholar] [CrossRef]
- Luz, C.; Izzo, L.; Ritieni, A.; Mañes, J.; Meca, G. Antifungal and antimycotoxigenic activity of hydrolyzed goat whey on Penicillium spp: An application as biopreservation agent in pita bread. LWT 2020, 118, 108717. [Google Scholar] [CrossRef]
- Abdel-Hamid, M.; Romeih, E.; Saporito, P.; Osman, A.; Mateiu, R.V.; Mojsoska, B.; Jenssen, H. Camel milk whey hydrolysate inhibits growth and biofilm formation of Pseudomonas aeruginosa PAO1 and methicillin-resistant Staphylococcus aureus. Food Control 2020, 111, 107056. [Google Scholar] [CrossRef]
- Osman, A.; El-Hadary, A.; Korish, A.A.; AlNafea, H.M.; Alhakbany, M.A.; Awad, A.A.; Abdel-Hamid, M. Angiotensin-I Converting Enzyme Inhibition and Antioxidant Activity of Papain-Hydrolyzed Camel Whey Protein and Its Hepato-Renal Protective Effects in Thioacetamide-Induced Toxicity. Foods 2021, 10, 468. [Google Scholar] [CrossRef] [PubMed]
- Akan, E. An evaluation of the in vitro antioxidant and antidiabetic potentials of camel and donkey milk peptides released from casein and whey proteins. J. Food Sci. Technol. 2021, 58, 3743–3751. [Google Scholar] [CrossRef]
- Mazorra-Manzano, M.A.; Robles-Porchas, G.R.; González-Velázquez, D.A.; Torres-Llanez, M.J.; Martínez-Porchas, M.; García-Sifuentes, C.O.; González-Córdova, A.F.; Vallejo-Córdoba, B. Cheese Whey Fermentation by Its Native Microbiota: Proteolysis and Bioactive Peptides Release with ACE-Inhibitory Activity. Fermentation 2020, 6, 19. [Google Scholar] [CrossRef] [Green Version]
- Capriotti, A.L.; Cavaliere, C.; Piovesana, S.; Samperi, R.; Laganà, A. Recent trends in the analysis of bioactive peptides in milk and dairy products. Anal. Bioanal. Chem. 2016, 408, 2677–2685. [Google Scholar] [CrossRef]
- Baum, F.; Fedorova, M.; Ebner, J.; Hoffmann, R.; Pischetsrieder, M. Analysis of the Endogenous Peptide Profile of Milk: Identification of 248 Mainly Casein-Derived Peptides. J. Proteome Res. 2013, 12, 5447–5462. [Google Scholar] [CrossRef]
- Dallas, D.C.; Weinborn, V.; de Moura Bell, J.M.L.N.; Wang, M.; Parker, E.A.; Guerrero, A.; Hettinga, K.A.; Lebrilla, C.B.; German, J.B.; Barile, D. Comprehensive peptidomic and glycomic evaluation reveals that sweet whey permeate from colostrum is a source of milk protein-derived peptides and oligosaccharides. Food Res. Int. 2014, 63, 203–209. [Google Scholar] [CrossRef] [Green Version]
- Webb, K.E.; Matthews, J.C.; DiRienzo, D.B. Peptide absorption: A review of current concepts and future perspectives. J. Anim. Sci. 1992, 70, 3248–3257. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Montone, C.M.; Capriotti, A.L.; Cerrato, A.; Antonelli, M.; La Barbera, G.; Piovesana, S.; Laganà, A.; Cavaliere, C. Identification of bioactive short peptides in cow milk by high-performance liquid chromatography on C18 and porous graphitic carbon coupled to high-resolution mass spectrometry. Anal. Bioanal. Chem. 2019, 411, 3395–3404. [Google Scholar] [CrossRef]
- Piovesana, S.; Capriotti, A.L.; Cavaliere, C.; La Barbera, G.; Montone, C.M.; Zenezini Chiozzi, R.; Laganà, A. Recent trends and analytical challenges in plant bioactive peptide separation, identification and validation. Anal. Bioanal. Chem. 2018, 410, 3425–3444. [Google Scholar] [CrossRef]
- Cerrato, A.; Aita, S.E.; Capriotti, A.L.; Cavaliere, C.; Montone, C.M.; Laganà, A.; Piovesana, S. A new opening for the tricky untargeted investigation of natural and modified short peptides. Talanta 2020, 219, 121262. [Google Scholar] [CrossRef]
- Piovesana, S.; Capriotti, A.L.A.L.; Cerrato, A.; Crescenzi, C.; La Barbera, G.; Laganà, A.; Montone, C.M.C.M.; Cavaliere, C. Graphitized Carbon Black Enrichment and UHPLC-MS/MS Allow to Meet the Challenge of Small Chain Peptidomics in Urine. Anal. Chem. 2019, 91, 11474–11481. [Google Scholar] [CrossRef] [PubMed]
- Xiao, Y.; Vecchi, M.M.; Wen, D. Distinguishing between Leucine and Isoleucine by Integrated LC–MS Analysis Using an Orbitrap Fusion Mass Spectrometer. Anal. Chem. 2016, 88, 10757–10766. [Google Scholar] [CrossRef] [PubMed]
- Dziuba, B.; Dziuba, M. New Milk Protein-Derived Peptides with Potential Antimicrobial Activity: An Approach Based on Bioinformatic Studies. Int. J. Mol. Sci. 2014, 15, 14531–14545. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Piovesana, S.; Capriotti, A.L.; Cavaliere, C.; La Barbera, G.; Samperi, R.; Zenezini Chiozzi, R.; Laganà, A. Peptidome characterization and bioactivity analysis of donkey milk. J. Proteom. 2015, 119, 21–29. [Google Scholar] [CrossRef]
- Torres-Fuentes, C.; del Mar Contreras, M.; Recio, I.; Alaiz, M.; Vioque, J. Identification and characterization of antioxidant peptides from chickpea protein hydrolysates. Food Chem. 2015, 180, 194–202. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, S.D.; Beverly, R.L.; Qu, Y.; Dallas, D.C. Milk bioactive peptide database: A comprehensive database of milk protein-derived bioactive peptides and novel visualization. Food Chem. 2017, 232, 673–682. [Google Scholar] [CrossRef]
- Minkiewicz, P.; Iwaniak, A.; Darewicz, M. Darewicz BIOPEP-UWM Database of Bioactive Peptides: Current Opportunities. Int. J. Mol. Sci. 2019, 20, 5978. [Google Scholar] [CrossRef] [Green Version]
- Mooney, C.; Haslam, N.J.; Pollastri, G.; Shields, D.C. Towards the Improved Discovery and Design of Functional Peptides: Common Features of Diverse Classes Permit Generalized Prediction of Bioactivity. PLoS ONE 2012, 7, e45012. [Google Scholar] [CrossRef] [Green Version]
- Xue, L.; Yin, R.; Howell, K.; Zhang, P. Activity and bioavailability of food protein-derived angiotensin-I-converting enzyme–inhibitory peptides. Compr. Rev. Food Sci. Food Saf. 2021, 20, 1150–1187. [Google Scholar] [CrossRef]
- Kehinde, B.A.; Sharma, P. Recently isolated antidiabetic hydrolysates and peptides from multiple food sources: A review. Crit. Rev. Food Sci. Nutr. 2020, 60, 322–340. [Google Scholar] [CrossRef]
- Picod, A.; Deniau, B.; Vaittinada Ayar, P.; Genest, M.; Julian, N.; Azibani, F.; Mebazaa, A. Alteration of the Renin–Angiotensin–Aldosterone System in Shock: Role of the Dipeptidyl Peptidase 3. Am. J. Respir. Crit. Care Med. 2021, 203, 526–527. [Google Scholar] [CrossRef] [PubMed]
- Xia, J.; Wishart, D.S. Metabolomic Data Processing, Analysis, and Interpretation Using MetaboAnalyst. Curr. Protoc. Bioinforma. 2011, 34, 14.10.1–14.10.48. [Google Scholar] [CrossRef] [PubMed]
- Bro, R.; Smilde, A.K. Principal component analysis. Anal. Methods 2014, 6, 2812–2831. [Google Scholar] [CrossRef] [Green Version]
- Bikaki, M.; Shah, R.; Müller, A.; Kuhnert, N. Heat induced hydrolytic cleavage of the peptide bond in dietary peptides and proteins in food processing. Food Chem. 2021, 357, 129621. [Google Scholar] [CrossRef]
- Piovesana, S.; Montone, C.M.; Cavaliere, C.; Crescenzi, C.; La Barbera, G.; Laganà, A.; Capriotti, A.L. Sensitive untargeted identification of short hydrophilic peptides by high performance liquid chromatography on porous graphitic carbon coupled to high resolution mass spectrometry. J. Chromatogr. A 2019, 1590, 73–79. [Google Scholar] [CrossRef] [PubMed]
- Strohalm, M.; Kavan, D.; Novák, P.; Volný, M.; Havlíček, V. mMass 3: A Cross-Platform Software Environment for Precise Analysis of Mass Spectrometric Data. Anal. Chem. 2010, 82, 4648–4651. [Google Scholar] [CrossRef]
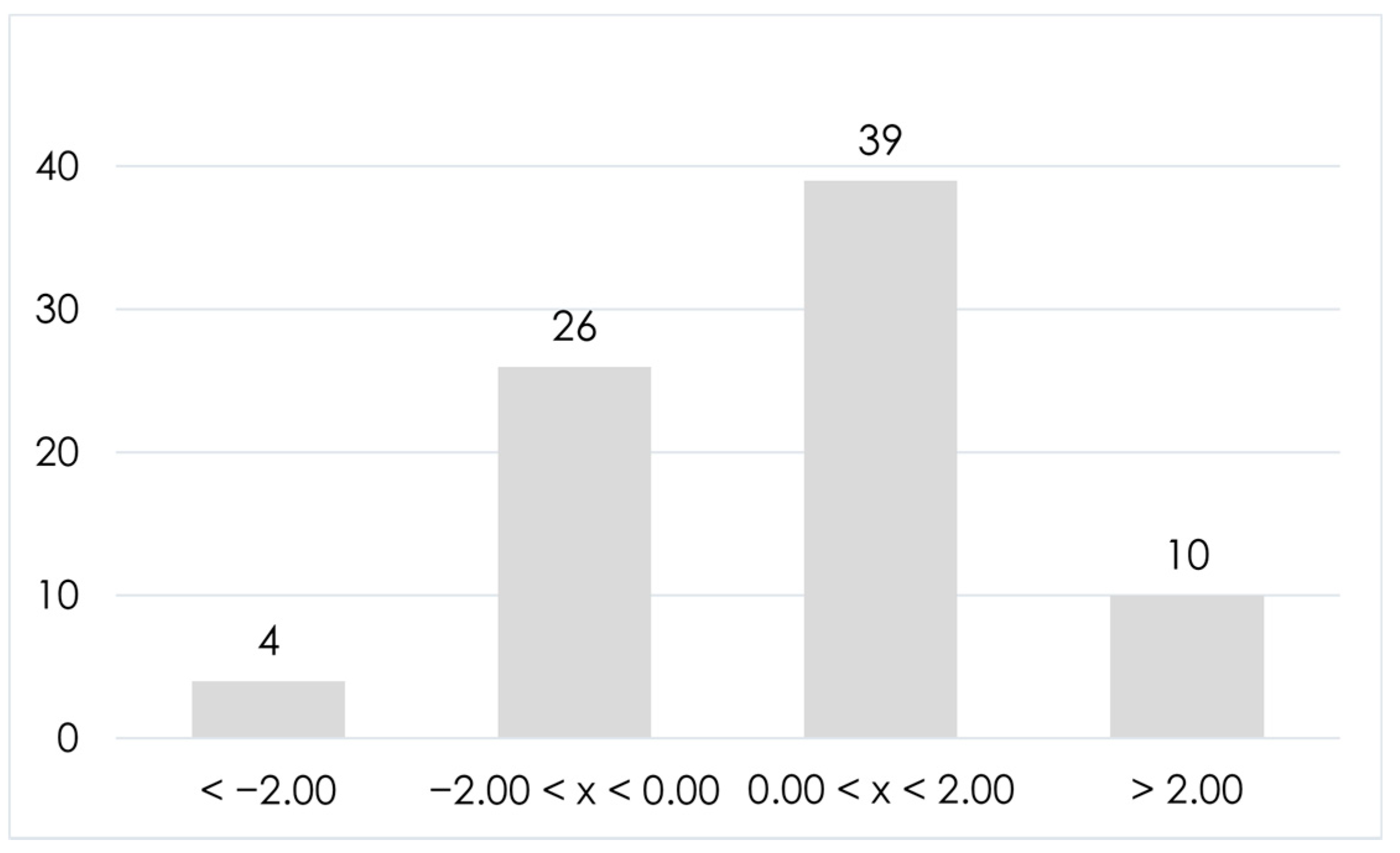
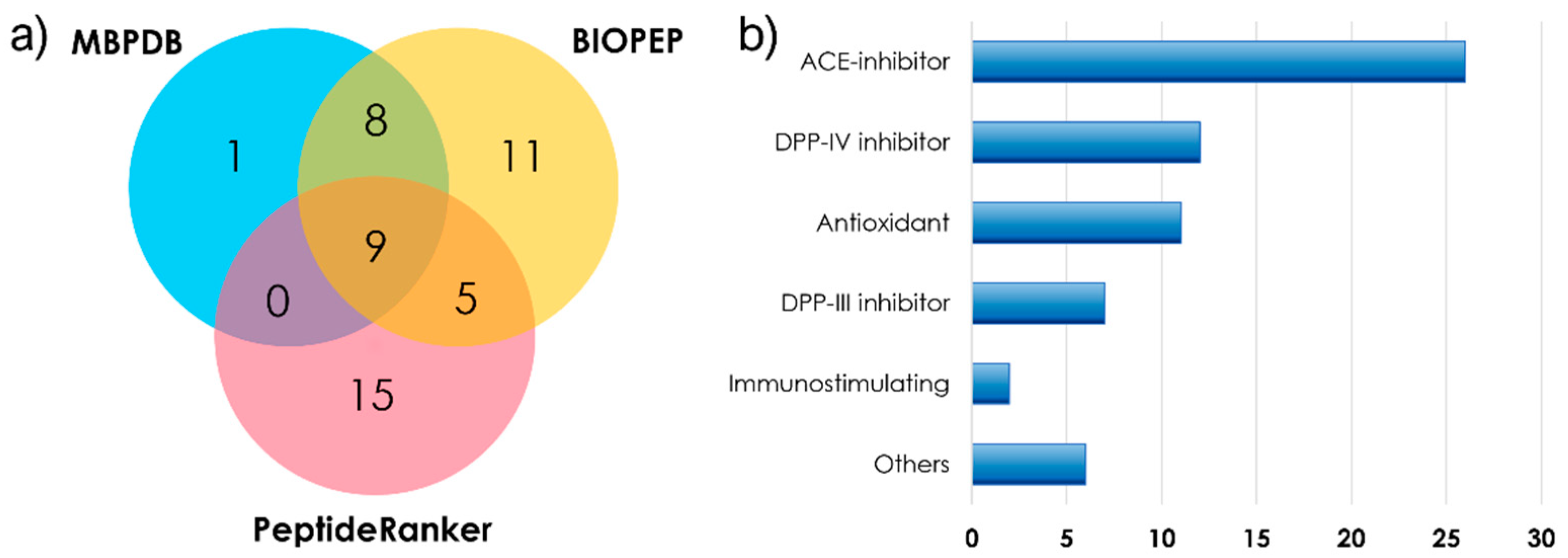




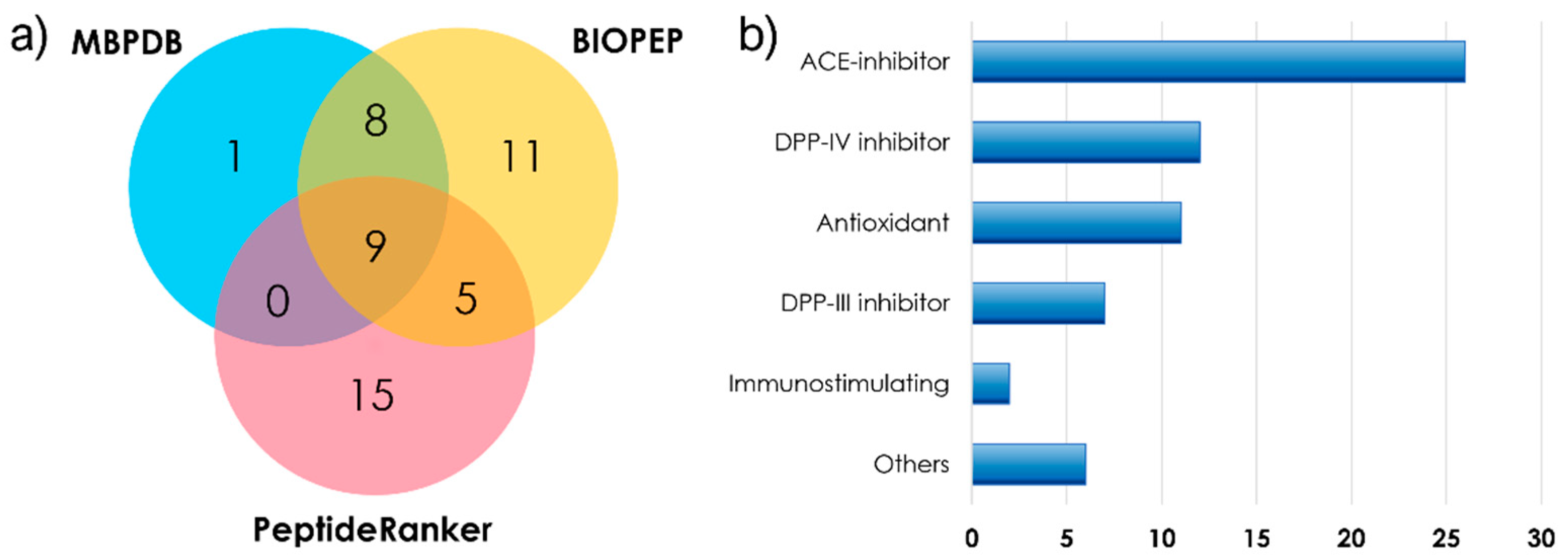
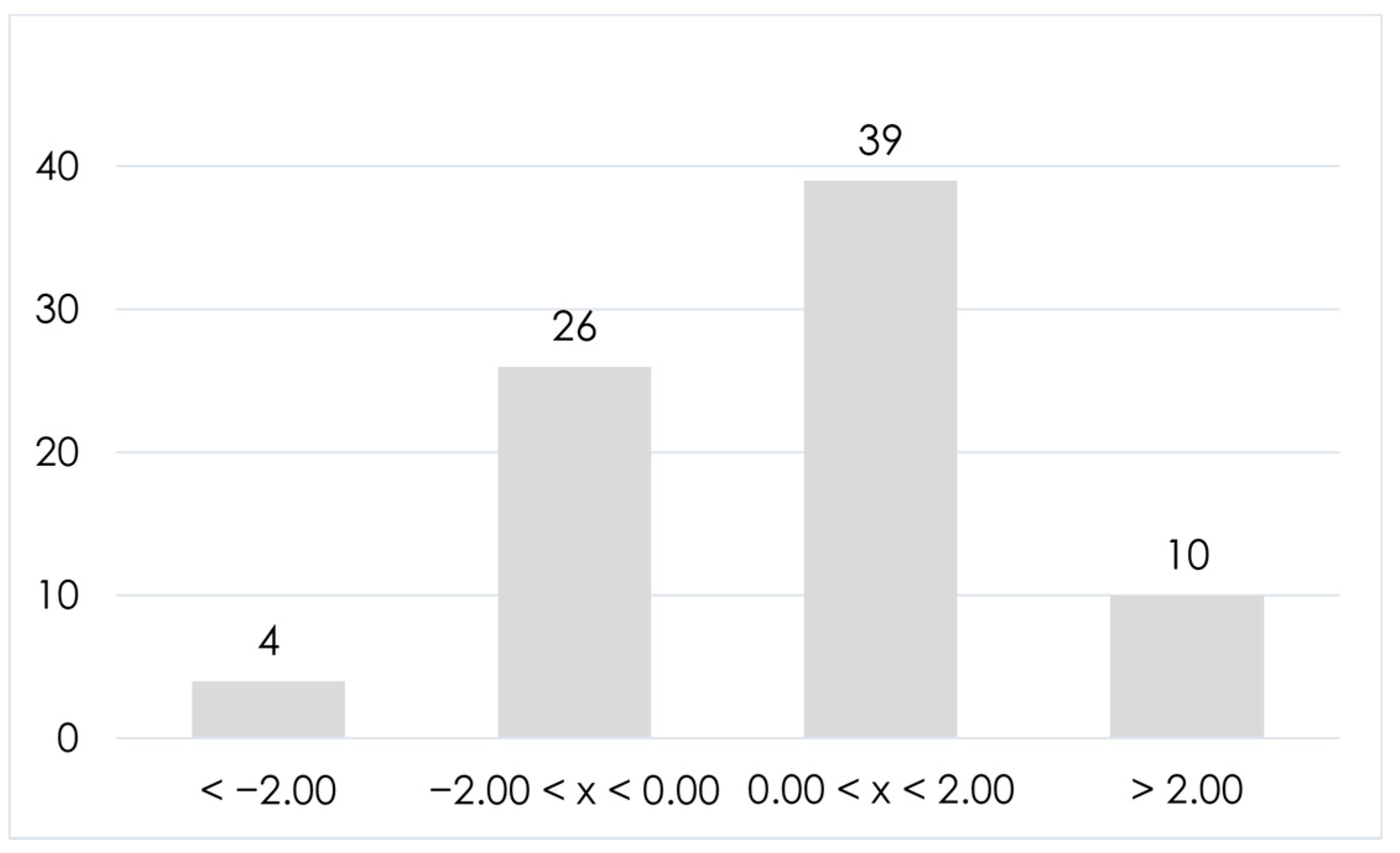{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Rt (min) | Proposed Formula | Exp. m/z | Δ (ppm) | Diagnostic Product Ions (m/z) |
|---|---|---|---|---|---|
| Dipeptides | |||||
| Ala-His | 0.8 | C9H14N4O3 | 227.1138 | −0.2 | 156.0768; 110.0712 |
| Val-Arg | 1.9 | C11H23N5O3 | 274.1873 | −0.1 | 274.1872; 257.160; 175.1186; 158.0923; 116.0704; 112.0866; 72.0807; 70.0651; 60.0558 |
| Tyr-Gln | 2.5 | C14H19N3O5 | 310.1397 | 0.0 | 147.0764; 137.0757; 130.0499; 101.0709; 84.0443 |
| Tyr-Arg | 5.3 | C15H23N5O4 | 338.1821 | −0.5 | 338.1817; 321.1553; 175.1190; 158.0926; 136.0759; 116.0706; 112.0868; 70.0651 |
| Xle-His | 5.4 | C12H20N4O3 | 269.1607 | −0.5 | 132.1016; 110.0712; 86.0963 |
| Val-Tyr | 6.3 | C14H20N2O4 | 281.1495 | −0.5 | 182.0813; 165.0548; 136.0759; 72.0808 |
| Tyr-Val | 6.5 | C14H20N2O4 | 281.1495 | −0.3 | 136.0757; 118.0862; 72.0807 |
| Tyr-Pro | 6.9 | C14H18N2O4 | 279.1339 | −0.3 | 136.0756; 116.0705; 70.0651 |
| Tyr-Tyr | 7.6 | C18H20N2O5 | 345.1445 | 0.0 | 182.0813; 165.0548; 136.0759 |
| Arg-Phe | 7.9 | C15H23N5O3 | 322.1873 | −0.1 | 322.1870; 305.1603; 175.1189; 166.0864; 120.0807; 112.0869; 70.0651 |
| Tyr-Xle | 9.5 | C15H22N2O4 | 295.1651 | −0.4 | 136.0757; 132.1019; 86.0963 |
| Xle-Trp | 12.8 | C17H23N3O3 | 318.1811 | −0.3 | 205.0971; 188.0705; 159.0917; 146.0600; 86.0964 |
| Phe-Phe | 13.2 | C18H20N2O3 | 313.1545 | −0.6 | 166.0863; 120.0807 |
| Tripeptides | |||||
| Arg-Tyr-Gln | 4.6 | C20H31N7O6 | 466.2409 | 0.2 | 449.2143; 303.1452; 292.1768; 275.1503; 157.1084; 147.0763; 136.0757; 130.0499; 112.0868; 70.0651 |
| His-Xle-Gln | 4.9 | C17H28N6O5 | 397.2194 | −0.1 | 251.1503; 223.1552; 147.0763; 138.0662; 130.0499; 110.0713; 86.0964 |
| Tyr-Pro-Glu | 7.1 | C19H25N3O7 | 408.1764 | −0.4 | 245.1130; 148.0601; 136.0756; 70.0651 |
| Arg-Glu-Xle | 7.7 | C17H32N6O6 | 417.2455 | −0.3 | 304.1613; 287.1348; 269.1242; 258.1558; 243.1338; 241.1293; 157.1084; 132.1019; 112.0869; 102.0549; 86.0964; 84.0444; 70.0652 |
| Thr-Val-Tyr | 7.9 | C18H27N3O6 | 382.1972 | −0.1 | 201.1234; 173.1285; 155.1179; 136.0757; 101.0709; 74.0600; 72.0808 |
| Val-Arg-Tyr | 8.4 | C20H32N6O5 | 437.2506 | −0.2 | 321.1556; 274.1873; 239.1502; 175.1190; 136.0757; 112.0869;72.0808; 70.0651 |
| Xle-Xle-Arg | 8.5 | C18H36N6O4 | 401.2870 | −0.2 | 271.1862; 199.1805; 175.1190; 158.0926; 116.0705; 86.0964; 70.0651 |
| His-Ala-Phe | 8.7 | C18H23N5O4 | 374.1822 | −0.2 | 209.1033; 181.1084; 166.0863; 120.0808; 110.0713 |
| Phe-Gly-Lys | 9.5 | C17H26N4O4 | 351.2025 | −0.5 | 205.0971; 204.1343; 187.1077; 177.1022; 147.1128; 130.0863; 120.0808; 101.1073; 84.0808 |
| Xle-Lys-Tyr | 9.5 | C21H34N4O5 | 423.2600 | −0.5 | 310.1761; 182.0812; 165.0545; 131.1179; 101.1073; 86.0964; 84.0808 |
| Xle-Gly-Tyr | 9.7 | C17H25N3O5 | 352.1866 | −0.3 | 239.1022; 182.0812; 171.1126; 165.0547; 143.1178; 136.0757; 86.0963 |
| Xle-Gln-Tyr | 9.8 | C20H30N4O6 | 423.2238 | −0.1 | 225.1233; 208.0968; 182.0812; 165.0546; 136.0757; 131.1179; 101.0709; 86.0964; 84.0443 |
| Xle-Ala-Tyr | 10.0 | C18H27N3O5 | 366.2022 | −0.4 | 253.1187; 185.1285; 182.0812; 165.0546; 157.1335; 136.0757; 86.0963 |
| Arg-Asn-Xle | 10.0 | C16H31N7O5 | 402.2458 | −0.4 | 289.1617; 272.1351; 246.1450; 229.1186; 226.1297; 157.1084; 140.0819; 112.0869; 86.0963; 70.0651 |
| Xle-Glu-Tyr | 10.2 | C20H29N3O7 | 424.2078 | −0.1 | 293.1132; 215.1390; 182.0812; 136.0758; 102.0550; 86.0964; 84.0444 |
| Tyr-Val-Tyr | 10.2 | C23H29N3O6 | 444.2128 | −0.2 | 235.1443; 182.0812; 165.0545; 136.0757; 72.0808 |
| Val-Xle-Arg | 10.5 | C17H34N6O4 | 387.2712 | −0.5 | 288.2030; 271.1765; 185.1651; 175.1189; 158.0924; 116.0707; 112.0870; 86.0964; 72.0808; 70.0652 |
| Xle-Pro-Tyr | 10.5 | C20H29N3O5 | 392.2179 | −0.3 | 279.1337; 183.0493; 182.0814; 165.0545; 136.0758; 86.0963; 70.0651 |
| Glu-Val-Phe | 11.1 | C19H27N3O6 | 394.1971 | −0.4 | 265.1547; 229.1183; 201.1234; 183.1128; 166.0863; 120.0808; 102.0550; 84.0444; 72.0808 |
| Tyr-Ser-Xle | 11.2 | C18H27N3O6 | 382.1971 | −0.5 | 251.1026; 233.0921; 223.1077; 219.1339; 201.1234; 136.0757; 132.1019; 86.0964; 60.0445 |
| Xle-Xle-Val | 12.0 | C17H33N3O4 | 344.2543 | −0.2 | 231.1702; 199.1805; 118.0862; 86.0964; 72.0808 |
| Arg-Tyr-Xle | 12.1 | C21H34N6O5 | 451.2661 | −0.5 | 338.1821; 321.1556; 295.1651; 292.1762; 275.1500; 175.1189; 157.1084; 140.0818; 136.0757; 112.0869; 86.0964 |
| Xle-Arg-Xle | 12.5 | C18H36N6O4 | 401.2869 | −0.5 | 288.2028; 271.1760; 253.1658; 175.1189; 131.1178; 112.0869; 86.0964 |
| Xle-Xle-Tyr | 12.7 | C21H33N3O5 | 408.2491 | −0.4 | 199.1803; 182.0813; 165.0545; 136.0757; 86.0964 |
| Xle-Ser-Phe | 13.0 | C18H27N3O5 | 366.2023 | −0.2 | 253.1187; 235.1074; 173.1285; 166.0862; 155.1180; 120.0807; 86.0964; 60.0446 |
| Xle-Arg-Phe | 13.1 | C21H34N6O4 | 435.2713 | −0.4 | 322.1870; 305.1604; 288.2026; 253.1659; 175.1188; 166.0863; 131.1179; 120.0808; 86.0964; 70.0651 |
| Xle-Ala-Phe | 13.1 | C18H27N3O4 | 350.2072 | −0.6 | 237.1231; 185.1283; 166.0862; 157.1335; 120.0807; 86.0964 |
| Xle-Ser-Phe | 13.4 | C18H27N3O5 | 366.2022 | −0.5 | 253.1187; 235.1074; 173.1285; 166.0862; 155.1180; 120.0807; 86.0964; 60.0446 |
| Tyr-Xle-Xle | 14.5 | C21H33N3O5 | 408.2492 | −0.2 | 249.1596; 245.1858; 136.0757; 132.1021; 86.0964 |
| Pro-Xle-Trp | 15.1 | C22H30N4O4 | 415.2338 | −0.3 | 205.0972; 188.0705; 183.1492; 159.0917; 86.0964; 70.0651 |
| Phe-Arg-Phe | 16.9 | C24H32N6O4 | 469.2556 | −0.3 | 452.2290; 322.1873; 305.1606; 276.1816; 259.1552; 166.0863; 120.0808; 112.0869; 70.0652 |
| Tetrapeptides | |||||
| Glu-Gln-Xle-Gln | 6.1 | C21H36N6O9 | 517.2617 | 0.1 | 258.1084; 243.1339; 230.1135; 147.0764; 129.0659; 102.0550; 86.0964 |
| Glu-Val-Val-Arg | 6.6 | C21H39N7O7 | 502.2983 | −0.1 | 502.2984; 373.2558; 257.1602; 229.1179; 201.1233; 199.1440; 183.1126; 175.1189; 158.0923; 116.0704; 84.0444; 72.0807; 70.0651 |
| His-Ala-Phe-Glu | 8.1 | C23H30N6O7 | 503.2249 | 0.0 | 209.1033; 181.1084; 148.0608; 120.0808; 110.0713 |
| Lys-Thr-Val-Tyr | 8.3 | C24H39N5O7 | 510.2922 | −0.1 | 281.1496; 230.1499; 212.1394; 182.0812; 173.1285; 129.1022; 101.1073; 84.0808; 74.0600; 72.0808; 56.0495 |
| Xle-Arg-Xle-Lys | 10.0 | C24H48N8O5 | 529.3820 | 0.0 | 529.3820; 416.2980; 270.1925; 260.1969; 253.1659; 225.1710; 147.1128; 86.0964; 84.0808 |
| Tyr-Gly-Xle-Glu | 10.0 | C22H32N4O8 | 481.2293 | 0.0 | 261.1439; 221.0915; 193.0971; 148.0604; 136.0756; 102.0548; 86.0963; 84.0443 |
| Xle-Arg-Xle-Asn | 10.0 | C22H42N8O6 | 515.3299 | −0.2 | 515.3300; 402.2459; 385.2194; 270.1925; 253.1659; 229.1183; 131.1179; 112.0869; 87.0553; 86.0964 |
| Thr-Xle-Lys-Tyr | 10.1 | C25H41N5O7 | 524.3078 | −0.2 | 310.1761; 293.1496; 242.1863; 187.1441; 182.0812; 169.1335; 165.0550; 136.0757; 101.0709; 86.0964; 84.0808; 74.0600; 56.0495 |
| Glu-Val-Phe-Gly | 10.2 | C21H30N4O7 | 451.2187 | 0.0 | 229.1183; 223.1076; 219.1492; 201.1234; 183.1128; 120.0808; 102.0443; 84.0443; 72.0808 |
| Xle-Val-Xle-Arg | 10.5 | C23H45N7O5 | 500.3555 | −0.1 | 387.2722; 271.1763; 213.1597; 185.1648; 175.1190; 158.0925; 86.0964; 72.0807 |
| Pro-Gln-Xle-Tyr | 10.9 | C25H37N5O7 | 520.2767 | 0.2 | 226.1186; 198.1237; 182.0812; 136.0757; 115.0866; 101.0709; 86.0964; 84.0444; 70.0651 |
| Xle-Ala-Xle-Asp | 11.0 | C19H34N4O7 | 431.2499 | −0.3 | 247.1291; 199.1808; 185.1284; 157.1335; 86.0964 |
| Gln-Tyr-Xle-Tyr | 11.7 | C29H39N5O8 | 586.2869 | −0.3 | 292.1292; 247.1077; 182.0812; 165.0545; 136.0757; 101.0709; 86.0964 |
| Pro-Tyr-Val-Arg | 11.8 | C25H39N7O6 | 534.3035 | 0.1 | 274.1870; 261.1234; 257.1608; 235.1441; 233.1285; 175.1190; 136.0757;72.0808; 70.0651 |
| Glu-Val-Phe-Ala | 12.0 | C22H32N4O7 | 465.2343 | −0.1 | 237.1234; 229.1182; 201.1234; 183.1128; 120.0808; 102.0549; 84.0444; 72.0808 |
| Phe-Arg-Gln-Phe | 12.0 | C29H40N8O6 | 597.3143 | −0.2 | 450.2459; 287.1503; 240.1455; 166.0863; 120.0808; 101.0709; 84.0444 |
| Val-Xle-Pro-Tyr | 12.1 | C25H38N4O6 | 491.2865 | 0.2 | 279.1339; 185.1648; 182.0913; 86.0964; 72.0808; 70.0651 |
| Val-Arg-Tyr-Xle | 12.1 | C26H43N7O6 | 550.3346 | −0.3 | 550.3348; 434.2398; 402.2136; 391.2452; 303.1452; 295.1652; 256.1768; 239.1503; 211.1553; 136.0757; 132.1019; 117.1022; 112.0869; 86.0964; 72.0808 |
| Xle-Thr-Glu-Phe | 12.3 | C24H36N4O8 | 509.2606 | 0.0 | 277.1183; 213.0870; 203.1026; 197.1285; 185.0921; 166.0863; 120.0808; 102.0550; 86.0964; 84.0444: 74.0600; 56.0495 |
| Glu-Asn-Xle-Xle | 12.6 | C21H37N5O8 | 488.2714 | −0.1 | 244.0925; 227.0663; 226.0821; 199.0712; 132.1018; 129.0659; 102.0549; 86.0964; 84.0444 |
| Trp-Xle-Gln-Pro | 13.0 | C27H38N6O6 | 543.2926 | 0.0 | 272.1757; 255.1490; 226.1184; 187.0865; 159.0916; 116.0706; 101.0709; 86.0964; 84.0444; 70.0651 |
| Tyr-Pro-Glu-Xle | 13.0 | C25H36N4O8 | 521.2605 | −0.1 | 358.1973; 243.1339; 227.1026; 199.1077; 136.0757; 102.0550; 86.0964; 84.0444; 70.0651 |
| Ala-Xle-Xle-Glu | 13.1 | C20H36N4O7 | 445.2656 | −0.1 | 199.1801; 185.1286; 157.1335; 148.0602; 102.0550; 86.0964 |
| His-Xle-Ser-Phe | 13.3 | C24H34N6O6 | 503.2611 | −0.3 | 251.1501; 223.1552; 110.073; 86.0964 |
| Glu-Pro-Phe-Val | 13.4 | C24H34N4O7 | 491.2500 | 0.0 | 245.1287; 227.1025; 217.1335; 199.1076; 120.0807; 102.0550; 84.0443; 70.0651 |
| Tyr-Pro-Xle-Val | 13.6 | C25H38N4O6 | 491.2864 | −0.1 | 261.1231; 233.1282; 211.1439; 183.1491; 136.0756; 118.0963; 86.0963; 70.0651 |
| Tyr-Gly-Xle-Xle | 14.0 | C23H36N4O6 | 465.2707 | −0.1 | 193.0972; 171.1128; 136.0757; 86.0964 |
| Xle-Ala-Tyr-Phe | 15.1 | C27H36N4O6 | 513.2708 | 0.0 | 207.1127; 157.1335; 136.0757; 86.0964 |
| Xle-Xle-Arg-Phe | 15.4 | C27H45N7O5 | 548.3553 | −0.3 | 548.3555; 435.2714; 366.2500; 355.2816; 322.1874; 305.1608; 253.1659; 227.1754; 199.1805; 166.0863; 120.0808; 112.0869; 86.0964 |
| Pro-Ser-Phe-Phe | 15.5 | C26H32N4O6 | 497.2393 | −0.4 | 207.1126; 167.0815; 166.0865; 157.0972; 120.0807; 70.0651 |
| Xle-Ser-Lys-Phe | 15.5 | C24H39N5O6 | 494.2971 | −0.4 | 329.2175; 294.1809; 216.1343; 201.1234; 198.1238; 173.1284; 170.1288; 166.0862; 155.1179; 129.1022; 120.0808; 101.1073; 86.0964; 84.0807; 60.0444 |
| Xle-Asp-Xle-Xle | 15.9 | C22H40N4O7 | 473.2970 | 0.0 | 229.1179; 201.1233; 183.1129; 86.0964 |
| Xle-Arg-Phe-Phe | 16.9 | C30H43N7O5 | 582.3396 | −0.4 | 452.2291; 400.2356; 389.2660; 270.1925; 259.1553; 253.1659; 166.0963; 131.1179; 120.0808; 112.0869; 86.0964 |
| Xle-Pro-Met-Trp | 17.2 | C27H39N5O5S | 546.2746 | 0.2 | 342.1846; 229.1005; 211.1441; 205.0972; 188.0706; 183.1492; 159.0917; 104.0528; 86.0964; 70.0651 |
| Xle-Pro-Phe-Xle | 17.5 | C26H40N4O5 | 489.3071 | −0.1 | 245.1280; 217.1333; 211.1443; 183.1491; 120.0809; 86.0964; 70.0652 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Montone, C.M.; Aita, S.E.; Cavaliere, C.; Cerrato, A.; Laganà, A.; Piovesana, S.; Capriotti, A.L. High-Resolution Mass Spectrometry and Chemometrics for the Detailed Characterization of Short Endogenous Peptides in Milk By-Products. Molecules 2021, 26, 6472. https://doi.org/10.3390/molecules26216472
Montone CM, Aita SE, Cavaliere C, Cerrato A, Laganà A, Piovesana S, Capriotti AL. High-Resolution Mass Spectrometry and Chemometrics for the Detailed Characterization of Short Endogenous Peptides in Milk By-Products. Molecules. 2021; 26(21):6472. https://doi.org/10.3390/molecules26216472
Chicago/Turabian StyleMontone, Carmela Maria, Sara Elsa Aita, Chiara Cavaliere, Andrea Cerrato, Aldo Laganà, Susy Piovesana, and Anna Laura Capriotti. 2021. "High-Resolution Mass Spectrometry and Chemometrics for the Detailed Characterization of Short Endogenous Peptides in Milk By-Products" Molecules 26, no. 21: 6472. https://doi.org/10.3390/molecules26216472
APA StyleMontone, C. M., Aita, S. E., Cavaliere, C., Cerrato, A., Laganà, A., Piovesana, S., & Capriotti, A. L. (2021). High-Resolution Mass Spectrometry and Chemometrics for the Detailed Characterization of Short Endogenous Peptides in Milk By-Products. Molecules, 26(21), 6472. https://doi.org/10.3390/molecules26216472