
Prediction of Blood-Brain Barrier Penetration (BBBP) Based on Molecular Descriptors of the Free-Form and In-Blood-Form Datasets



Abstract
:1. Introduction
2. Results and Discussion
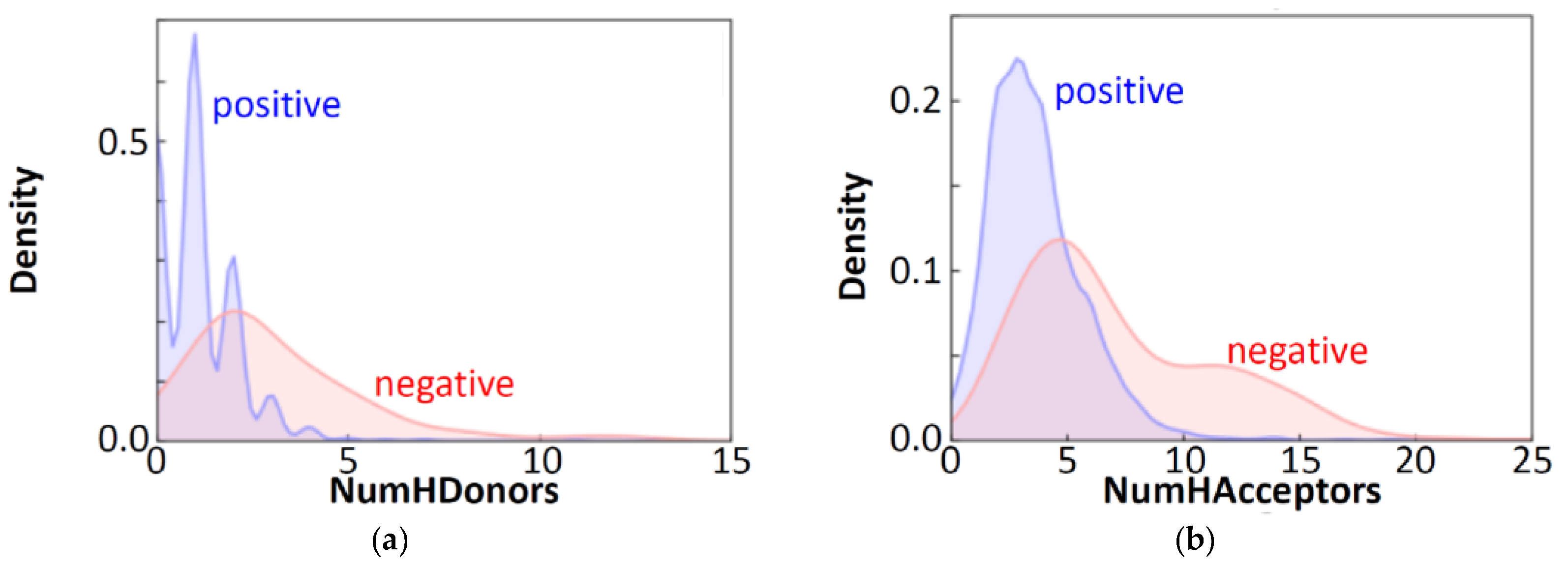
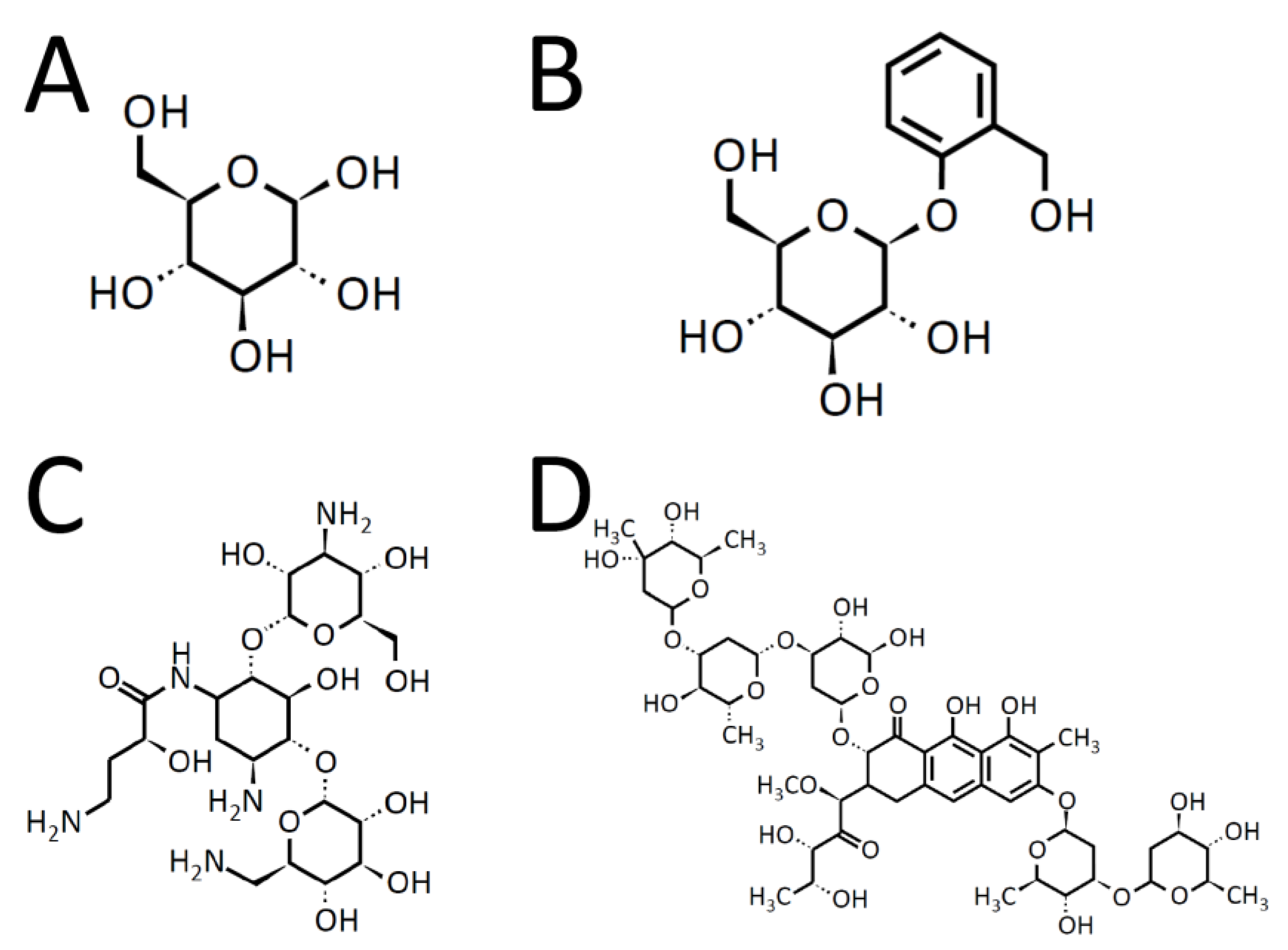
2.1. Free-Form and In-Blood-Form Datasets
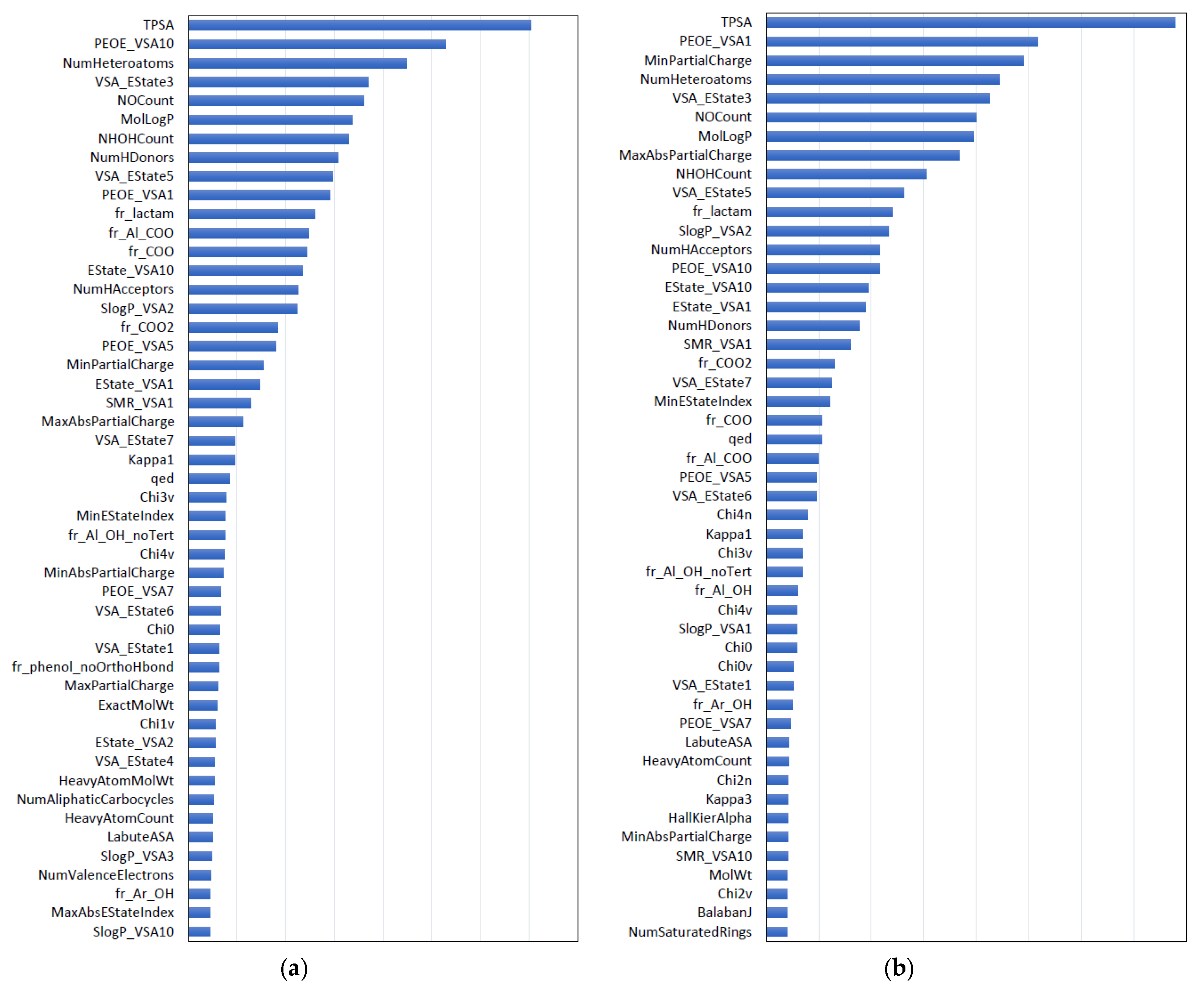
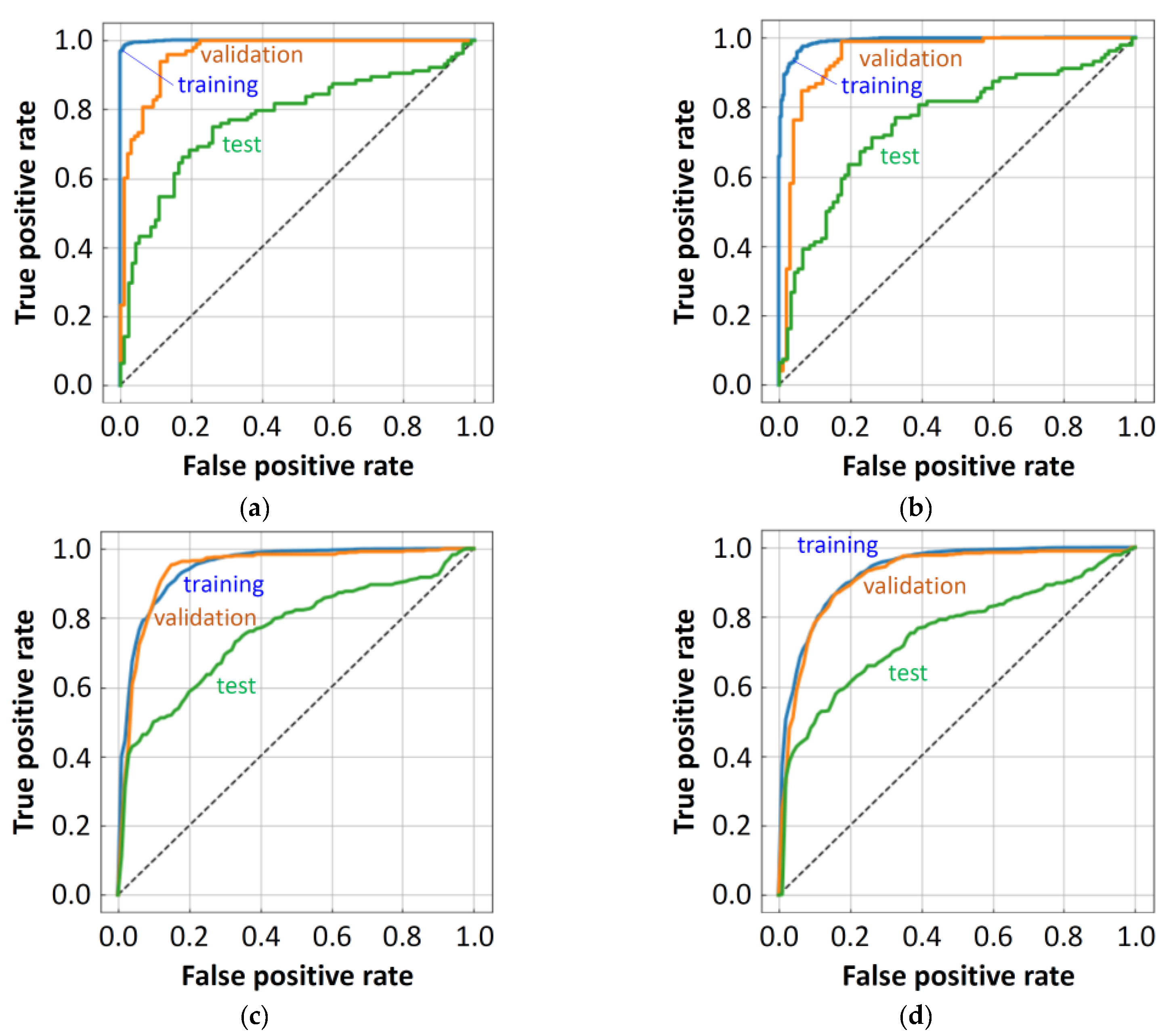
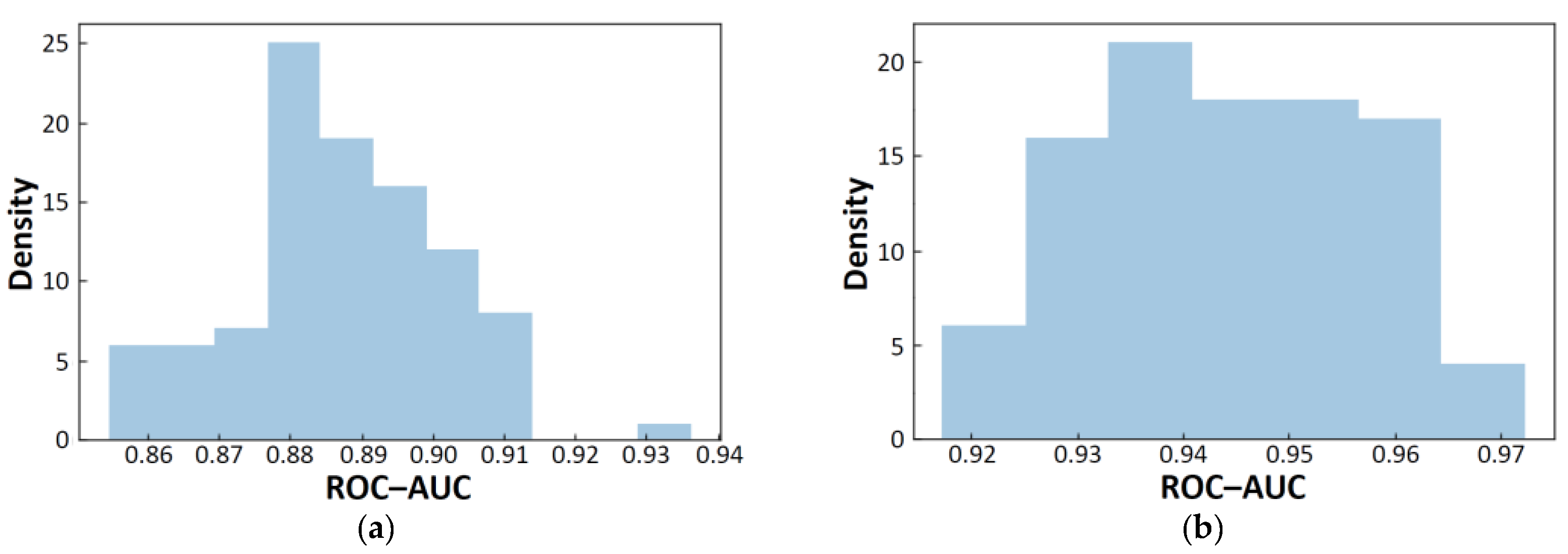
2.2. Forward Search for Molecular Descriptor Sets by DNN
2.3. BBBP Prediction by Some Other Models
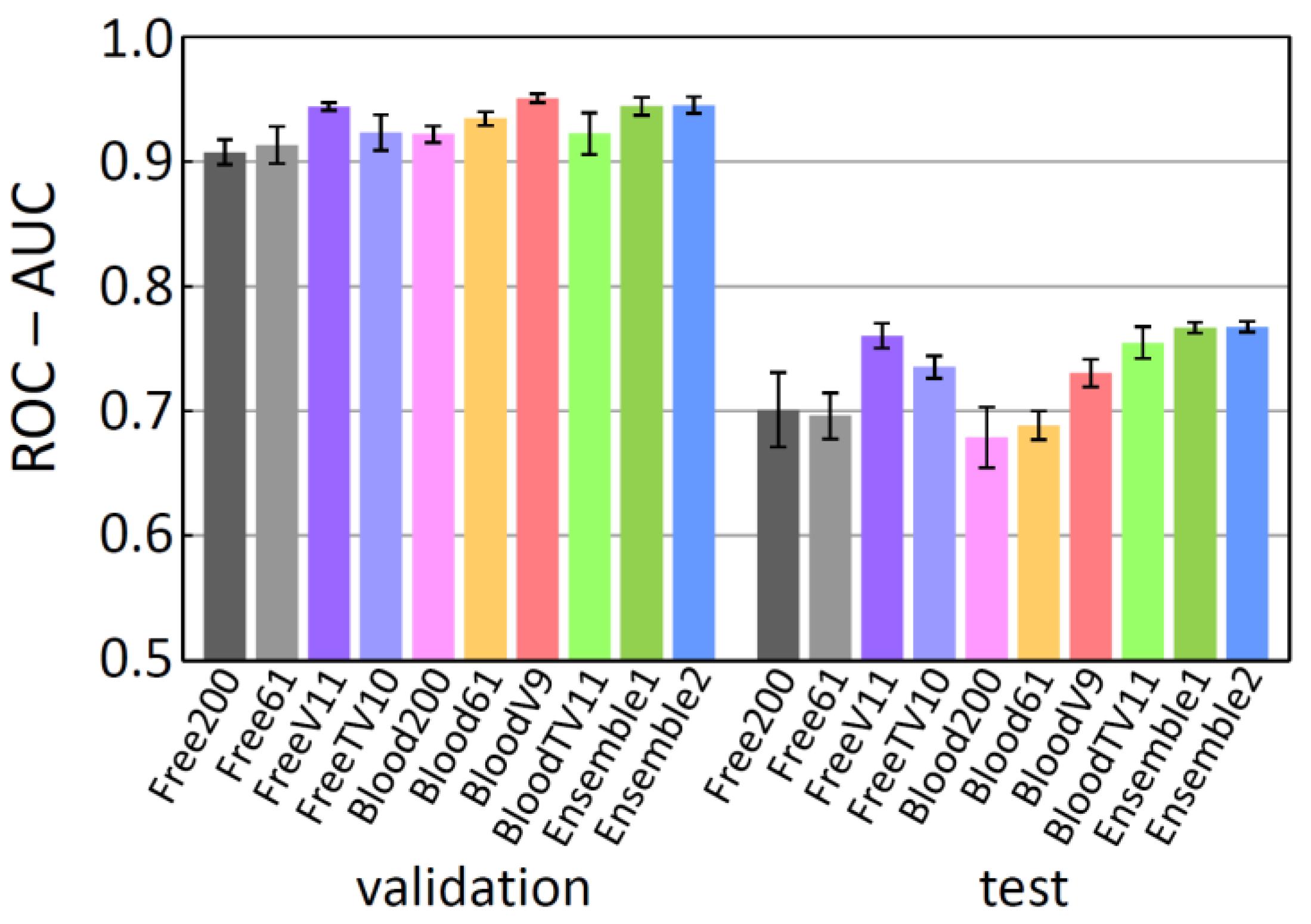
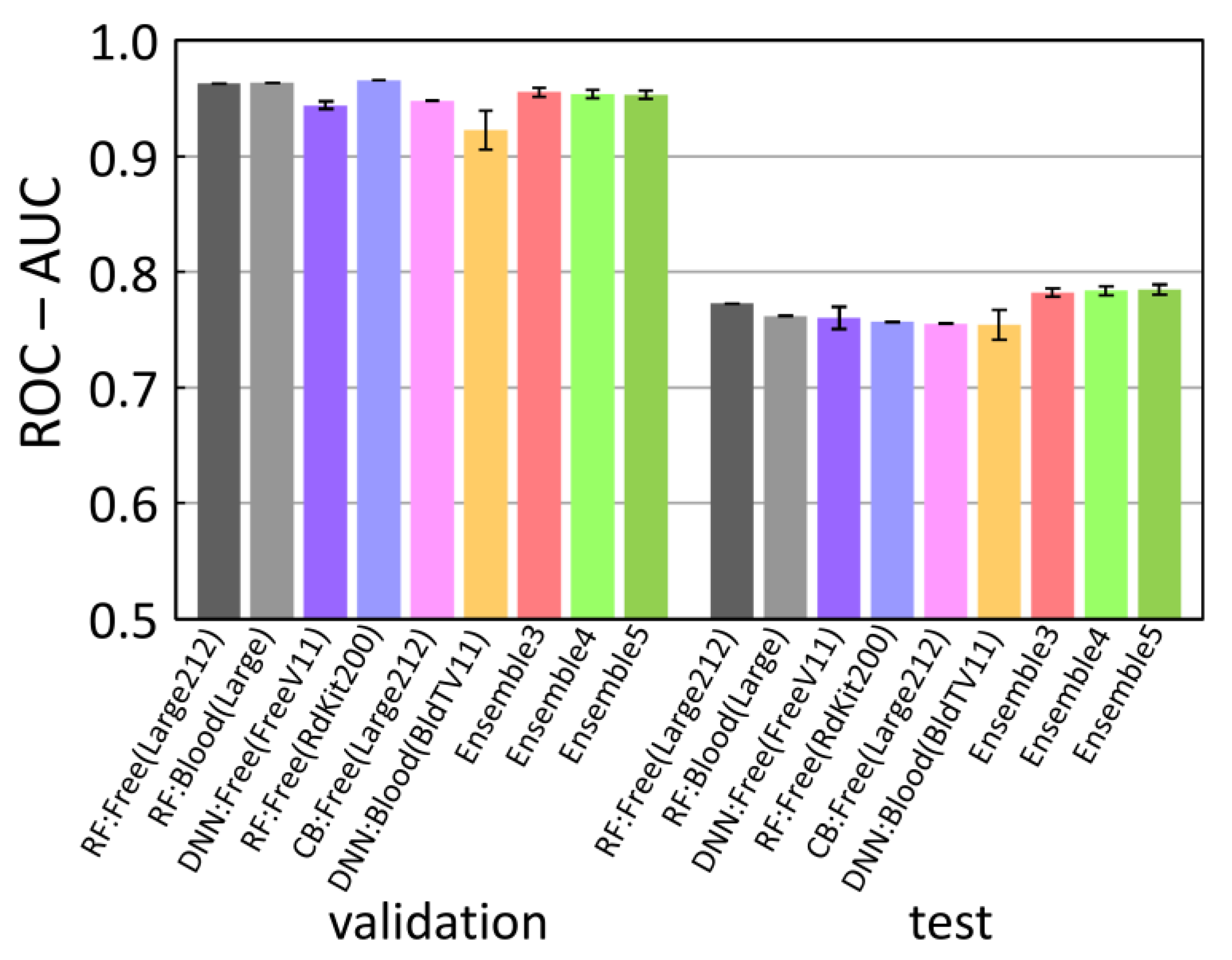
2.4. Best Single Models and Their Ensemble
2.5. Comparing the Predictive Ability with Other Works
2.6. Comparing the Results of Free-Form and In-Blood-Form Datasets
3. Materials and Methods
3.1. Computations
3.2. Dataset and Preprocessing
3.3. Molecular Descriptors
3.4. Models
3.5. Confidence Interval
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
References
- Bentivoglio, M.; Kristensson, K. Tryps and trips: Cell trafficking across the 100-year-old blood–brain barrier. Trends Neurosci. 2014, 37, 325–333. [Google Scholar] [CrossRef] [Green Version]
- Abbott, N.J.; Patabendige, A.A.K.; Dolman, D.E.M.; Yusof, S.R.; Begley, D.J. Structure and function of the blood–brain barrier. Neurobiol. Dis. 2010, 37, 13–25. [Google Scholar] [CrossRef] [PubMed]
- Graff, C.L.; Pollack, G.M. Drug transport at the blood–brain barrier and the choroid plexus. Curr. Drug Metab. 2004, 5, 95–108. [Google Scholar] [CrossRef] [PubMed]
- Golden, P.L.; Pollack, G.M. Blood–brain barrier efflux transport. Adv. Drug Deliv. Rev. 2003, 92, 1739–1753. [Google Scholar] [CrossRef]
- Abbott, N.J. Astrocyte–endothelial interactions and blood–brain barrier permeability. J. Anat. 2002, 200, 629–638. [Google Scholar] [CrossRef] [PubMed]
- Bickel, U.; Yoshikawa, T.; Pardridge, W.M. Delivery of peptides and proteins through the blood–brain barrier. Adv. Drug Deliv. Rev. 2001, 46, 247–279. [Google Scholar] [CrossRef]
- Pardridge, W.M. (Ed.) Introduction to the Blood–Brain Barrier: Methodology, Biology and Pathology; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Zhang, L.; Zhu, H.; Oprea, T.I.; Golbraikh, A.; Tropsha, A. QSAR modeling of the blood–brain barrier permeability for diverse organic compounds. Pharm. Res. 2008, 25, 1902. [Google Scholar] [CrossRef]
- Jónsdóttir, S.O.; Jørgensen, F.S.; Brunak, S. Prediction methods and databases within chemoinformatics: Emphasis on drugs and drug candidates. Bioinformatics 2005, 21, 2145–2160. [Google Scholar] [CrossRef]
- Martins, I.F.; Teixeira, A.L.; Pinheiro, L.; Falcao, A.O. A Bayesian approach to in silico blood–brain barrier penetration modeling. J. Chem. Inf. Model. 2012, 52, 1686–1697. [Google Scholar] [CrossRef]
- Wu, Z.; Ramsundar, B.; Feinberg, E.N.; Gomes, J.; Geniesse, C.; Pappu, A.S.; Leswingd, K.; Pande, V. MoleculeNet: A benchmark for molecular machine learning. Chem. Sci. 2018, 9, 513–530. [Google Scholar] [CrossRef] [Green Version]
- MoleculeNet. Available online: http://moleculenet.ai/ (accessed on 4 June 2021).
- Bemis, G.W.; Murcko, M.A. The properties of known drugs. 1. Molecular frameworks. J. Med. Chem. 1996, 39, 2887–2893. [Google Scholar] [CrossRef]
- Miao, R.; Xia, L.-Y.; Chen, H.-H.; Huang, H.-H.; Liang, Y. Improved classification of blood–brain-barrier drugs using deep learning. Sci. Rep. 2019, 9, 8802. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Wang, S.; Li, Z.; Zhang, S.; Jiang, M.; Wang, X.; Wei, Z. Molecular property prediction based on a multichannel substructure graph. IEEE Access 2020, 8, 18601–18614. [Google Scholar] [CrossRef]
- Weininger, D.; Weininger, A.; Weininger, J.L. SMILES. 2. Algorithm for generation of unique SMILES notation. J. Chem. Inf. Comput. Sci. 1989, 29, 97–101. [Google Scholar] [CrossRef]
- RDKit: Open-Source Cheminformatics Software. Available online: http://www.rdkit.org/ (accessed on 5 January 2021).
- Moriwaki, H.; Tian, Y.-S.; Kawashita, N.; Takagi, T. Mordred: A molecular descriptor calculator. J. Cheminform. 2018, 10, 4. [Google Scholar] [CrossRef] [Green Version]
- Lipinski, C.A.; Lombardo, F.; Dominy, B.W.; Feeney, P.J. Experimental and computational approaches to estimate solubility and permeability in drug discovery and development settings. Adv. Drug Deliv. Rev. 1997, 23, 3–25. [Google Scholar] [CrossRef]
- Wildman, S.A.; Crippen, G.M. Prediction of physicochemical parameters by atomic contributions. J. Chem. Inf. Comput. Sci. 1999, 39, 868–873. [Google Scholar] [CrossRef]
- Pajouhesh, H.; Lenz, G.R. Medicinal chemical properties of successful central nervous system drugs. NeuroRx 2005, 2, 541–553. [Google Scholar] [CrossRef] [Green Version]
- Rankovic, Z. CNS drug design: Balancing physicochemical properties for optimal brain exposure. J. Med. Chem. 2015, 58, 2584–2608. [Google Scholar] [CrossRef]
- Daina, A.; Zoete, V. A BOILED-egg to predict gastrointestinal absorption and brain penetration of small molecules. ChemMedChem 2016, 11, 1117–1121. [Google Scholar] [CrossRef] [Green Version]
- Mergenthaler, P.; Lindauer, U.; Dienel, G.A.; Meisel, A. Sugar for the brain: The role of glucose in physiological and pathological brain function. Trends Neurosci. 2013, 36, 587–597. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, D.; Xu, C.; Sun, P.; Wu, J.; Yan, C.; Hu, M.; Yan, N. Crystal structure of the human glucose transporter GLUT1. Nature 2014, 510, 121–125. [Google Scholar] [CrossRef]
- Rasio, E. Slimming | Metabolic consequences of slimming diets and weight maintenance. In Encyclopedia of Food Sciences and Nutrition, 2nd ed.; Caballero, B., Finglas, P., Toldrá, F., Eds.; Academic Press: Cambridge, MA, USA, 2003; pp. 5291–5296. [Google Scholar]
- CatBoost. Available online: https://catboost.ai/ (accessed on 13 January 2021).
- Yang, K.; Swanson, K.; Jin, W.; Coley, C.; Eiden, P.; Gao, H.; Guzman-Perez, A.; Hopper, T.; Kelley, B.; Mathea, M.; et al. Analyzing learned molecular representations for property prediction. J. Chem. Inf. Model. 2019, 59, 3370–3388. [Google Scholar] [CrossRef] [Green Version]
- Shaker, B.; Yu, M.-S.; Song, J.S.; Ahn, S.; Ryu, J.Y.; Oh, K.-S.; Na, D. LightBBB: Computational prediction model of blood–brain-barrier penetration based on LightGBM. Bioinformatics 2021, 37, 1135–1139. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, L.; Feng, H.; Li, S.; Liu, M.; Zhao, J.; Liu, H. Prediction of the blood−brain barrier (BBB) permeability of chemicals based on machine-learning and ensemble methods. Chem. Res. Toxicol. 2021, 34, 1456–1467. [Google Scholar] [CrossRef]
- Li, X.; Fourches, D. Inductive transfer learning for molecular activity prediction: Next-Gen QSAR Models with MolPMoFiT. J. Cheminform. 2020, 12, 27. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, H.; Wu, Z.; Wang, T.; Li, W.; Tang, Y.; Liu, G. In silico prediction of blood–brain barrier permeability of compounds by machine learning and resampling methods. Chem. Med. Chem. 2018, 13, 2189–2201. [Google Scholar] [CrossRef] [PubMed]
- Python. Available online: https://www.python.org/ (accessed on 13 June 2021).
- Anaconda. Available online: https://www.anaconda.com/ (accessed on 20 May 2021).
- Project Jupyter. Available online: https://jupyter.org/ (accessed on 20 May 2021).
- Iyer, M.; Mishra, R.; Han, Y.; Hopfinger, A.J. Predicting blood–brain barrier partitioning of organic molecules using membrane-interaction QSAR analysis. Pharm. Res. 2002, 19, 1611–1621. [Google Scholar] [CrossRef] [PubMed]
- LightBBB. Available online: http://ssbio.cau.ac.kr/software/bbb/ (accessed on 17 November 2021).
- TensorFlow. Available online: https://www.tensorflow.org/ (accessed on 13 January 2021).
- Keras. Available online: https://keras.io/ (accessed on 13 January 2021).
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. NIPS’17. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 972–981. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Scikit-Learn. Available online: https://scikit-learn.org/stable/ (accessed on 13 January 2021).
- SciPy. Available online: https://scipy.org/ (accessed on 26 November 2021).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Molecular Descriptor | Meaning 1 |
|---|---|
| NumHeteroatoms | the number of heteroatoms |
| NOCount | the number of nitrogen and oxygen atoms |
| MolLogP | Wildman-Crippen LogP value [21] |
| NHOHCount | the number of NH and OH bonds |
| NumHDonors | the number of hydrogen bond donors |
| fr_lactam | the number of β-lactams |
| NumHAcceptors | the number of hydrogen bond acceptors |
| fr_COO2 and fr_COO | the number of carboxylic acids |
| fr_Al_OH_noTert | the number of aliphatic hydroxyl groups excluding tert-OH |
| Name of Descriptor Set | Molecular Descriptors |
|---|---|
| FreeV11 | NumHeteroatoms, NumHDonors, NHOHCount, NumHAcceptors, NumSaturatedHeterocycles, fr_Al_OH_noTert, NumAliphaticHeterocycles, nH, NOCount, qed, nO |
| FreeTV10 | NumHDonors, NumSaturatedHeterocycles, nO, NumAliphaticRings, MolWt, MolLogP, nN, fr_Al_OH, fr_SH, fr_ketone |
| BloodV9 | NumHeteroatoms, MaxAbsPartialCharge, NOCount, NumHDonors, NumAliphaticHeterocycles, nS, fr_C_S, fr_unbrch_alkane, fr_ester |
| BloodTV11 | NOCount, MaxAbsPartialCharge, NumHDonors, NumAliphaticHeterocycles, nO, MolWt, NumHeteroatoms, qed, NumHAcceptors, HeavyAtomCount, nN |
| RDKit61 (Free61, Blood61) | MaxEStateIndex, MinEStateIndex, MinAbsEStateIndex, qed, MolWt, MinPartialCharge, MaxAbsPartialCharge, FpDensityMorgan1, BalabanJ, BertzCT, Chi0, HallKierAlpha, LabuteASA, PEOE_VSA1, PEOE_VSA10, PEOE_VSA11, PEOE_VSA12, PEOE_VSA13, PEOE_VSA14, PEOE_VSA2, PEOE_VSA3, PEOE_VSA4, PEOE_VSA5, PEOE_VSA6, PEOE_VSA7, PEOE_VSA8, PEOE_VSA9, SMR_VSA1, SMR_VSA10, SMR_VSA2, SMR_VSA3, SMR_VSA4, SMR_VSA5, SMR_VSA6, SMR_VSA7, SMR_VSA9, TPSA, EState_VSA1, EState_VSA10, EState_VSA11, EState_VSA2, EState_VSA3, EState_VSA4, EState_VSA5, EState_VSA6, EState_VSA7, EState_VSA8, EState_VSA9, VSA_EState1, VSA_EState10, VSA_EState2, VSA_EState3, VSA_EState4, VSA_EState5, VSA_EState6, VSA_EState7, VSA_EState8, VSA_EState9, FractionCSP3, MolLogP, MolMR |
| RDKit200 | 200 RDKit descriptors [18] |
| Large | RDKit200 + {nH, nC, nN, nO, nS, nP, nF, nCl, nBr, nI, nX} from Mordred [19] |
| Large212 | RDKit200 + {nH, nB, nC, nN, nO, nS, nP, nF, nCl, nBr, nI, nX} from Mordred [19] |
| No | Method | Dataset | Descriptor Set | ROC-AUC(Training) | ROC-AUC(Validation) | ROC-AUC(Test) |
|---|---|---|---|---|---|---|
| 1 | RF | Free-form | Large212 | 0.999(0) | 0.963(0) | 0.773(0) |
| 2 | RF | In-blood-form | Large | 0.999(0) | 0.964(0) | 0.762(0) |
| 3 | DNN | Free-form | FreeV11 | 0.948(4) | 0.944(3) | 0.760(10) |
| 4 | RF | Free-form | RdKit200 | 0.999(0) | 0.966(0) | 0.757(0) |
| 5 | CB | Free-form | Large212 | 0.990(0) | 0.948(0) | 0.755(0) |
| 6 | DNN | In-blood-form | BloodTV11 | 0.934(14) | 0.923(17) | 0.755(13) |
| Category | Removed Items |
|---|---|
| One of each two-identical-compound set (60 sets, 60 items) | ‘63’ (=‘73’), ‘154’ (=‘129’), ‘312’ (=‘97’), ‘337’ (=‘29’), ‘384’ (=‘62’), ‘388’ (=‘96’), ‘394’ (=‘70’), ‘415’ (=‘3’), ‘422’ (=‘105’), ‘435’ (=‘13’), ‘453’ (=‘87’), ‘457’ (=‘52’), ‘468’ (=‘467’), ‘488’ (=‘46’), ‘489’ (=‘56’), ‘508’ (=‘50’), ‘533’ (=‘34’), ‘535’ (=‘75’), ‘562’ (=‘140’), ‘591’ (=‘72’), ‘593’ (=‘2’), ‘607’ (=‘490’), ‘616’ (=‘62’), ‘619’ (=‘567’), ‘644’ (=‘26’), ‘646’ (=‘60’), ‘649’ (=‘40’), ‘650’ (=‘58’), ‘651’ (=‘393’), ‘667’ (=‘4’), ‘668’ (=‘33’), ‘669’ (=‘93’), ‘670’ (=‘89’), ‘671’ (=‘69’), ‘672’ (=‘79’), ‘673’ (=‘23’), ‘690’ (=‘55’), ‘959’ (=‘450’), ‘966’ (=‘691’), ‘1073’ (=‘523’), ‘1085’ (=‘564’), ‘1086’ (=‘1741’), ‘1111’ (=‘555’), ‘1388’ (=‘296’), ‘1462’ (=‘139’), ‘1471’ (=‘585’), ‘1508’ (=‘191’), ‘1567’ (=‘344’), ‘1583’ (=‘654’), ‘1597’ (=‘219’), ‘1662’ (=‘437’), ‘1782’ (=‘45’), ‘1882’ (=‘700’), ‘1906’ (=‘15’), ‘1947’ (=‘101’), ‘1961’ (=‘142’), ‘1971’ (=‘664’), ‘1979’ (=‘189’), ‘2031’ (=‘245’), and ‘2045’ (=‘252’) |
| Two of each three-identical-compound set (6 sets, 12 items) | ‘269’ (=‘83’ =‘569’), ‘435’ (=‘13’ =‘1161’), ‘534’ (=‘85’ =‘1541’), ‘565’ (=‘59’ =‘617’), ‘566’ (=‘49’ =‘618’), ‘569’ (=‘269’ =‘569’), ‘617’ (=‘59’ =‘565’), ‘618’ (=‘49’ =‘566’), ‘713’ (=‘315’ =‘1916’), ‘1161’ (=‘13’ =‘435’), ‘1541’ (=‘85’ =‘534’), and ‘1916’ (=‘315’ =‘713’) |
| Inconsistent pair (12 pairs, 24 items) (Note: The number “1” represents penetrating, and “0” non-penetrating properties.) | (‘1’ [1], ‘380’ [0]), (‘17’ [1], ‘552’ [0]), (‘53’ [1], ‘648’ [0]), (‘102’ [0], ‘1009’ [1]), (‘128’ [0], ‘1701’ [1]), (‘176’ [0], ‘1645’ [1]), (‘267’ [0], ‘1314’ [1]), (‘284’ [0], ‘1881’ [1]), (‘305’ [0], ‘1361’ [1]), (‘325’ [0], ‘1910’ [1]), (‘326’ [0], ‘1381’ [1]), and (‘571’ [0], ‘1338’ [1]) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sakiyama, H.; Fukuda, M.; Okuno, T. Prediction of Blood-Brain Barrier Penetration (BBBP) Based on Molecular Descriptors of the Free-Form and In-Blood-Form Datasets. Molecules 2021, 26, 7428. https://doi.org/10.3390/molecules26247428
Sakiyama H, Fukuda M, Okuno T. Prediction of Blood-Brain Barrier Penetration (BBBP) Based on Molecular Descriptors of the Free-Form and In-Blood-Form Datasets. Molecules. 2021; 26(24):7428. https://doi.org/10.3390/molecules26247428
Chicago/Turabian StyleSakiyama, Hiroshi, Motohisa Fukuda, and Takashi Okuno. 2021. "Prediction of Blood-Brain Barrier Penetration (BBBP) Based on Molecular Descriptors of the Free-Form and In-Blood-Form Datasets" Molecules 26, no. 24: 7428. https://doi.org/10.3390/molecules26247428
APA StyleSakiyama, H., Fukuda, M., & Okuno, T. (2021). Prediction of Blood-Brain Barrier Penetration (BBBP) Based on Molecular Descriptors of the Free-Form and In-Blood-Form Datasets. Molecules, 26(24), 7428. https://doi.org/10.3390/molecules26247428