

Classification of Mass Spectral Data to Assist in the Identification of Novel Synthetic Cannabinoids


Abstract
:1. Introduction
2. Results and Discussion
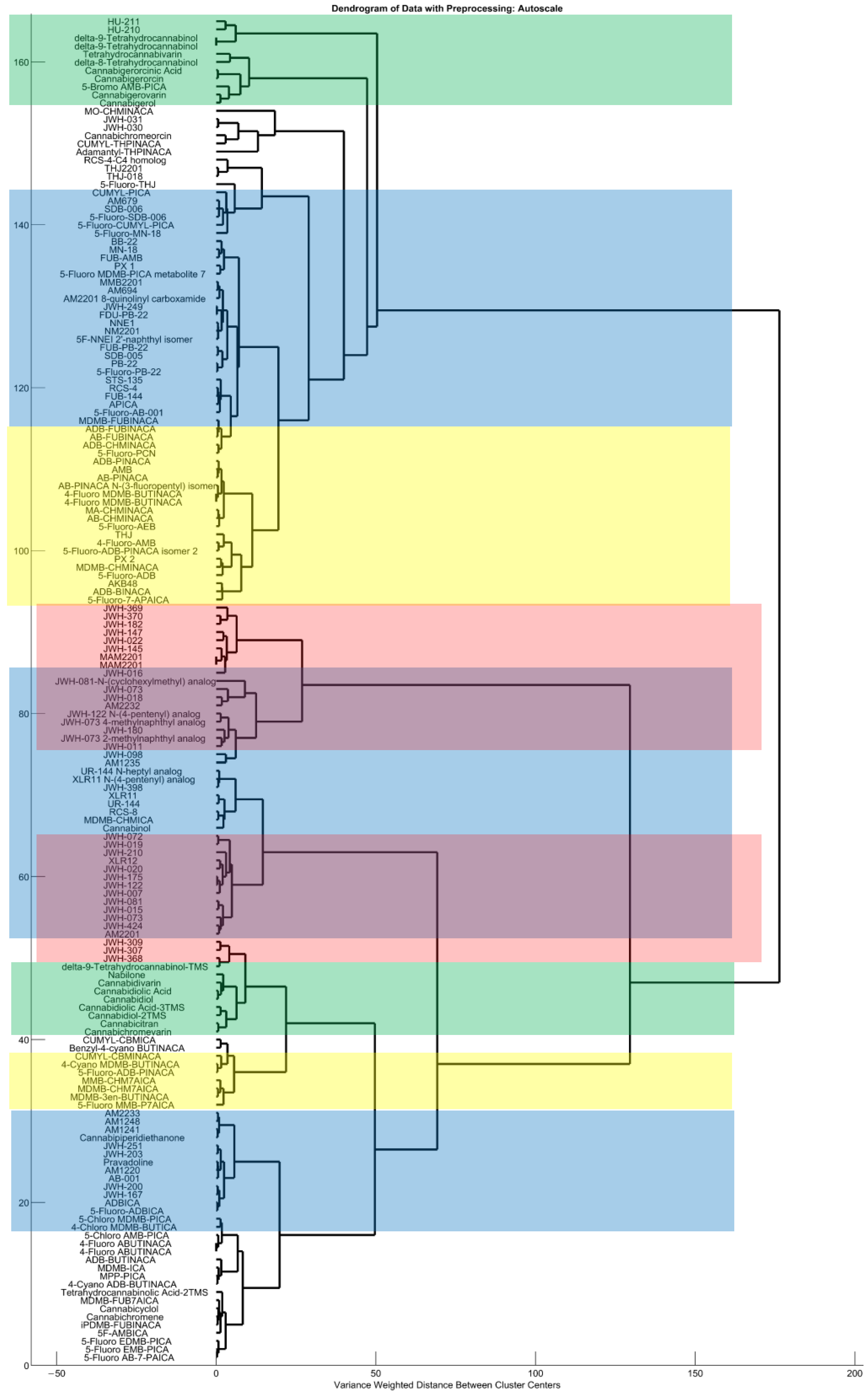
2.1. Preliminary Evaluation of Data
2.2. Partial Least Squares Discriminant Analysis
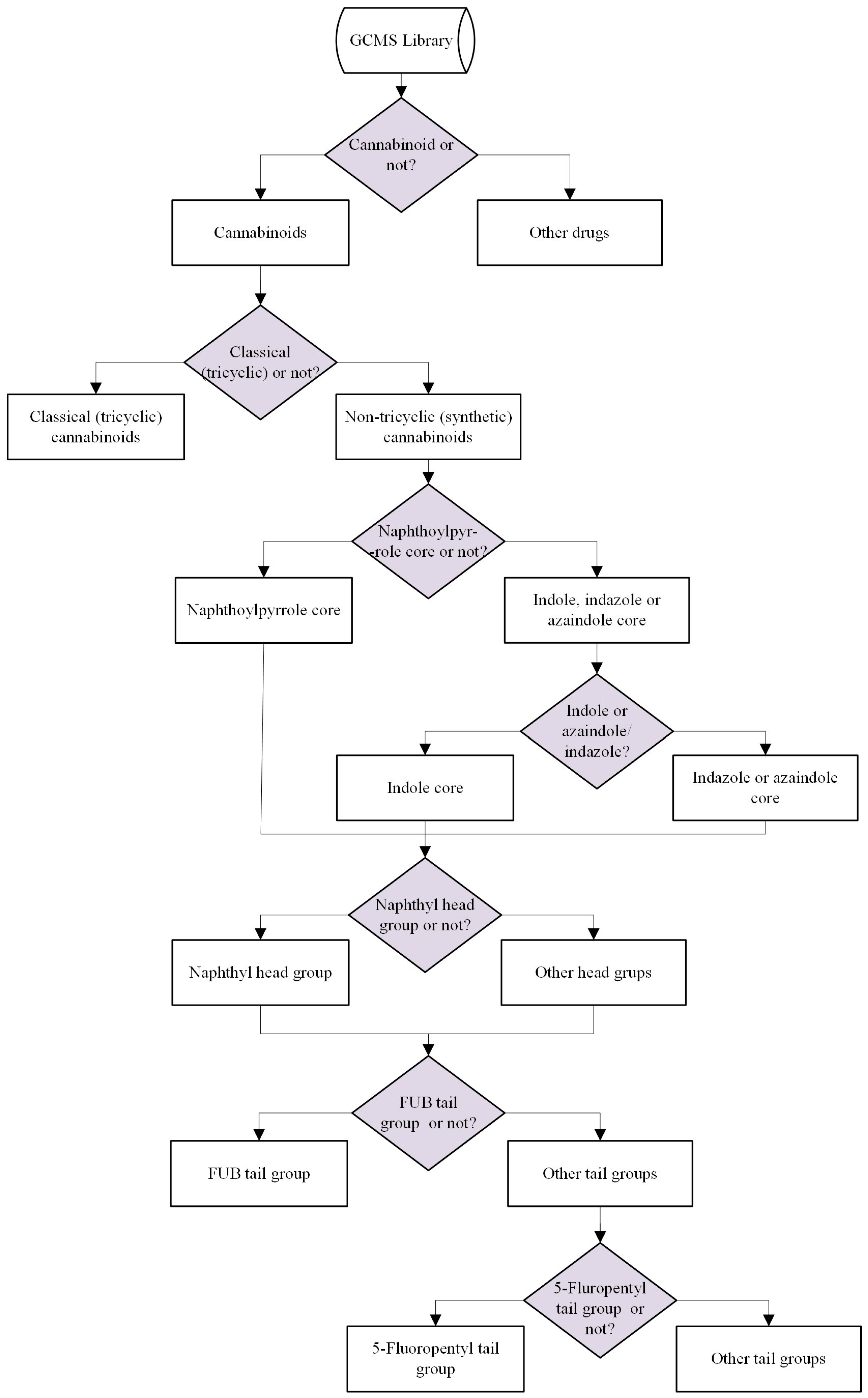
2.2.1. General Overview of the Binary Classification System
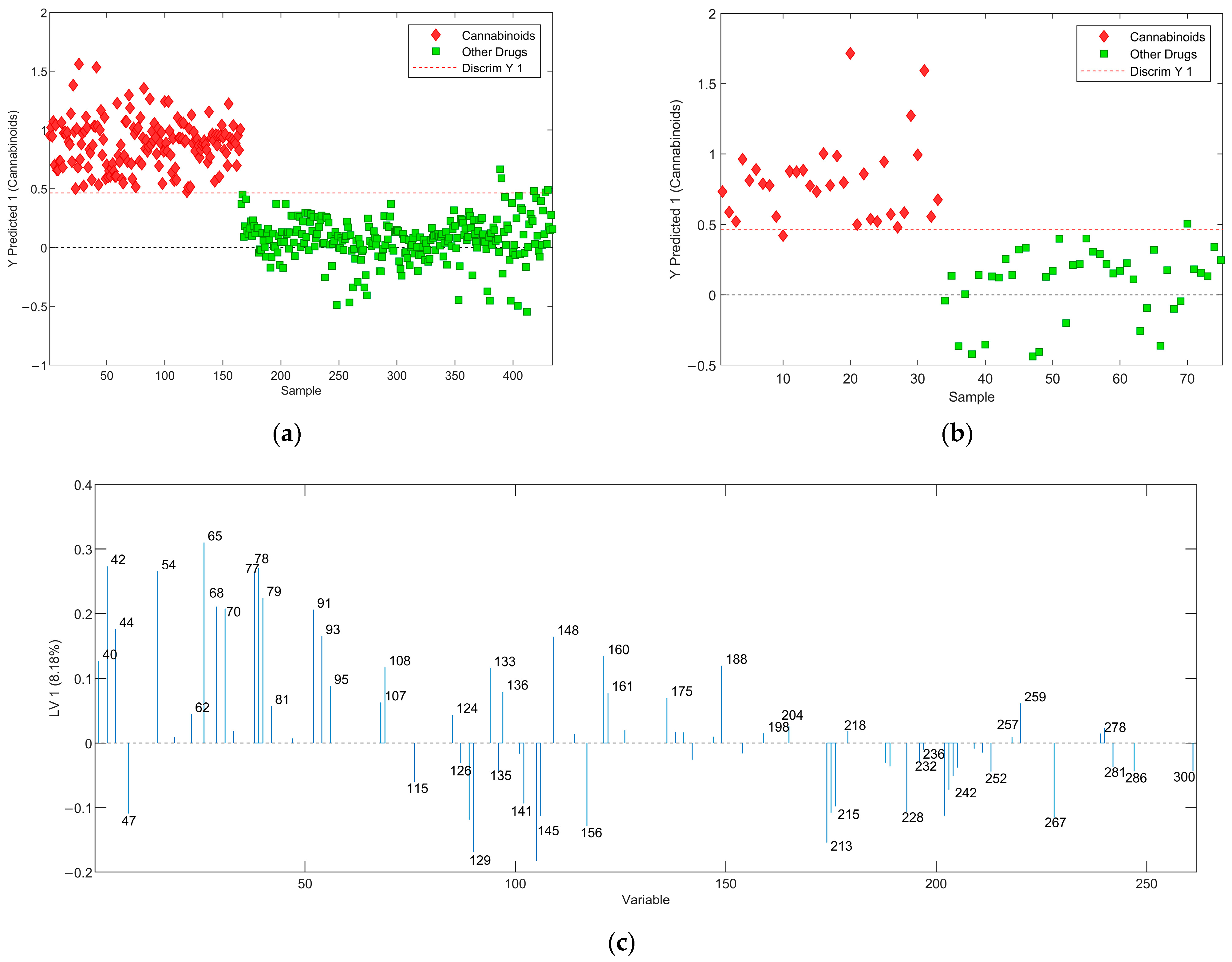
2.2.2. Cannabinoids versus Other Drugs
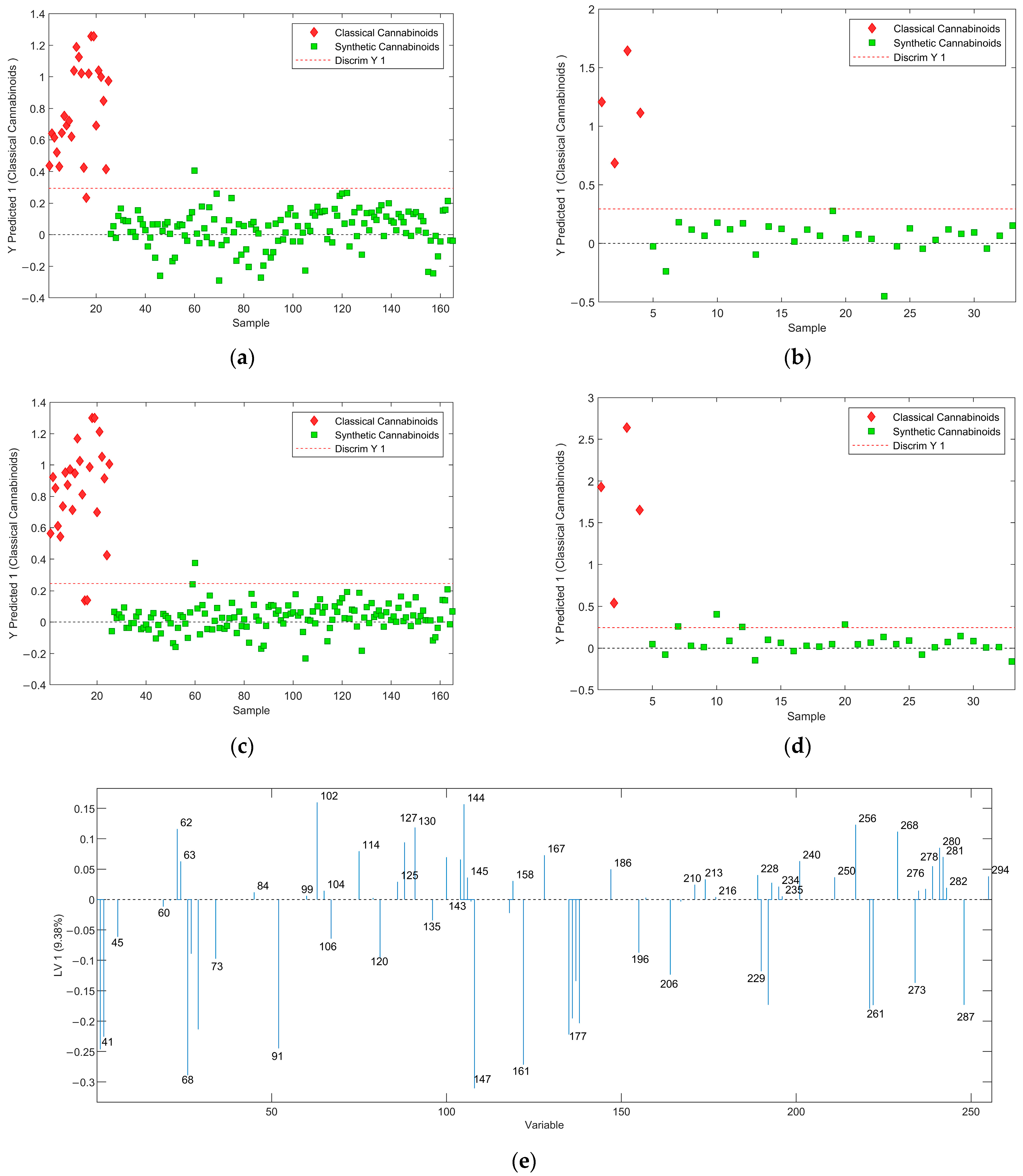
2.2.3. Classical Versus Synthetic Cannabinoids
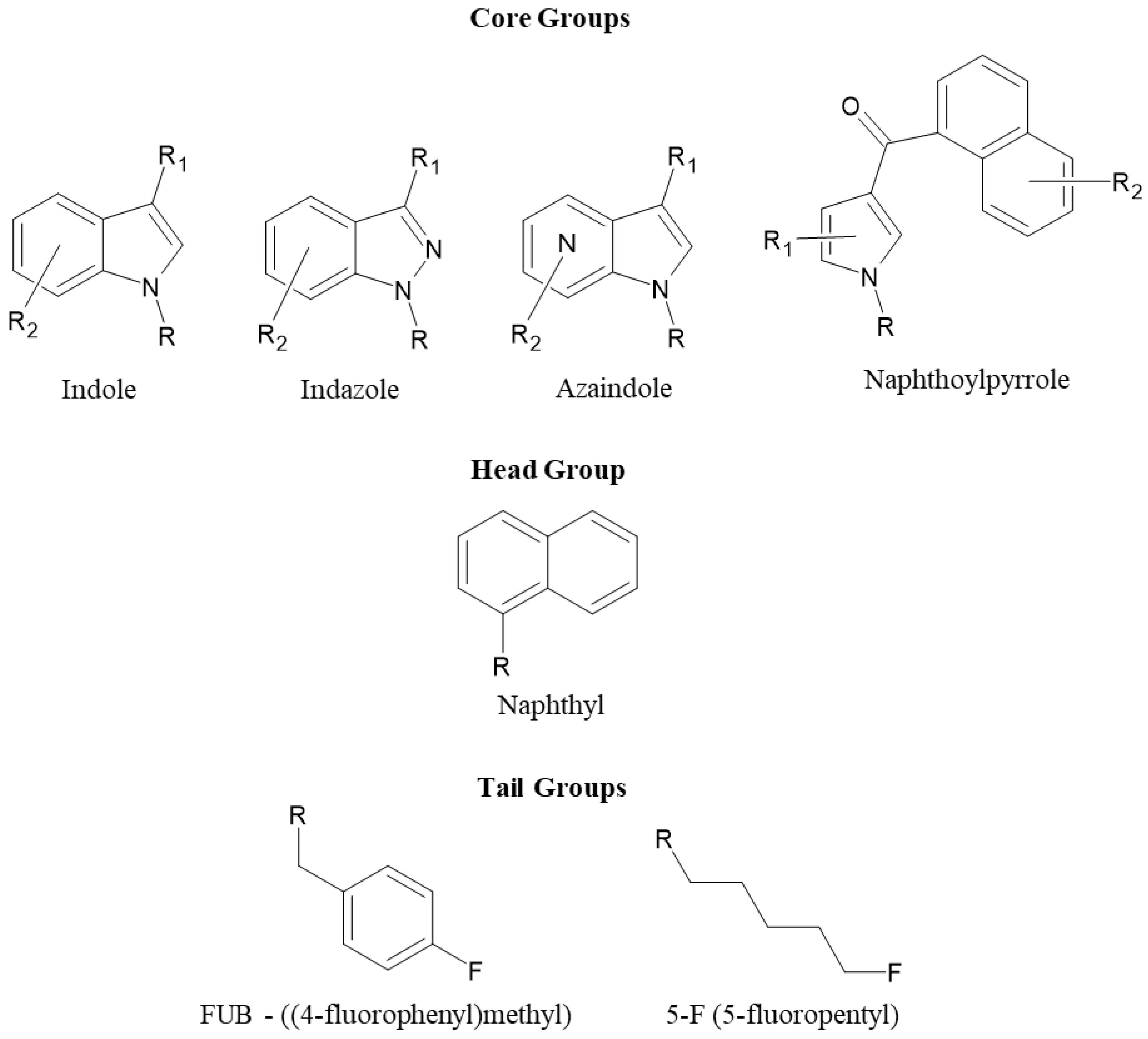
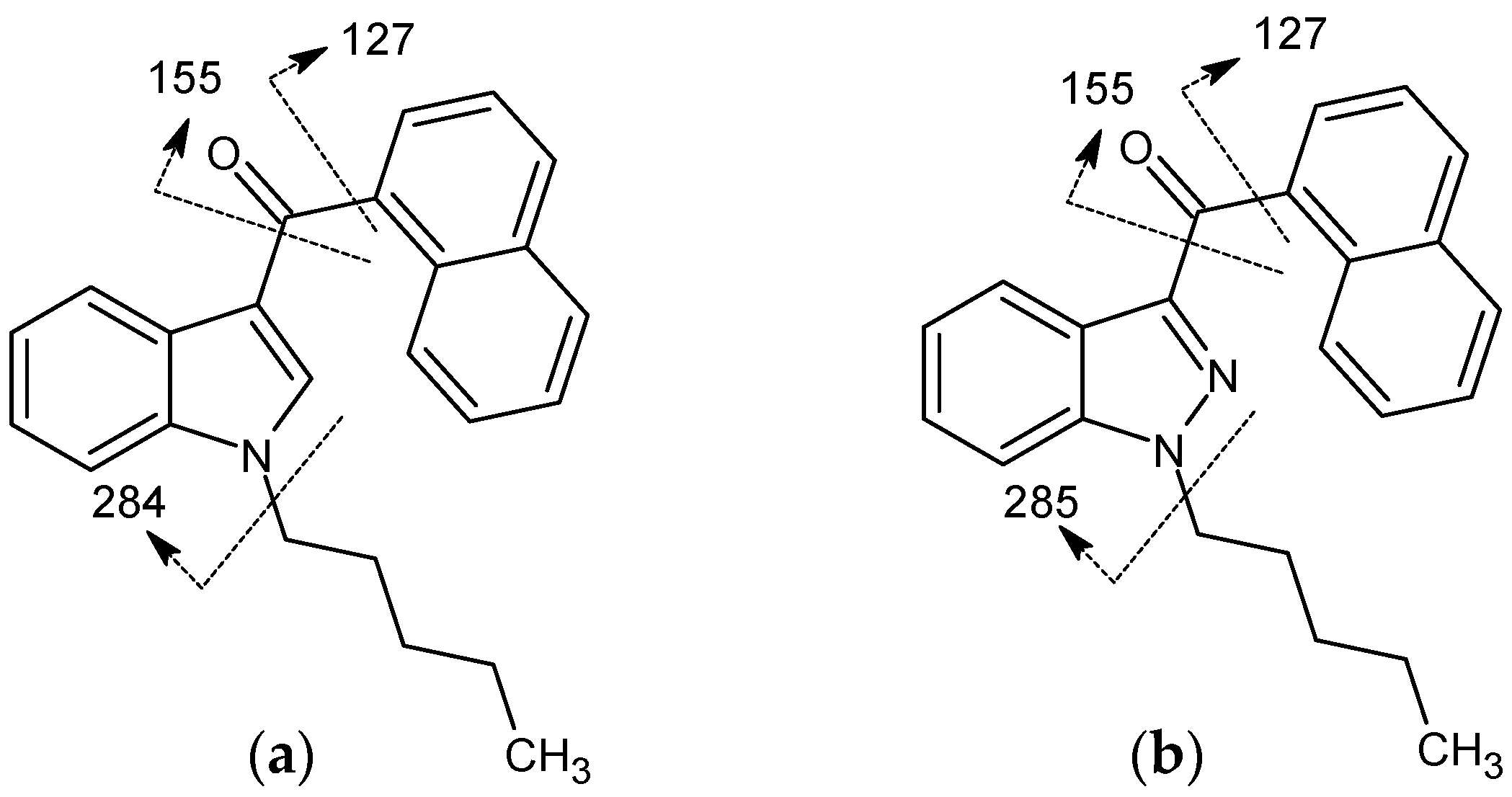
2.2.4. Core Group Analysis—Naphthoylpyrrole Versus Indole, Indazole, and Azaindole
2.2.5. Cannabinoids Containing Indole Core Group versus Indazole/Azaindole Core Groups
2.2.6. Cannabinoids Containing Naphthyl Head Group
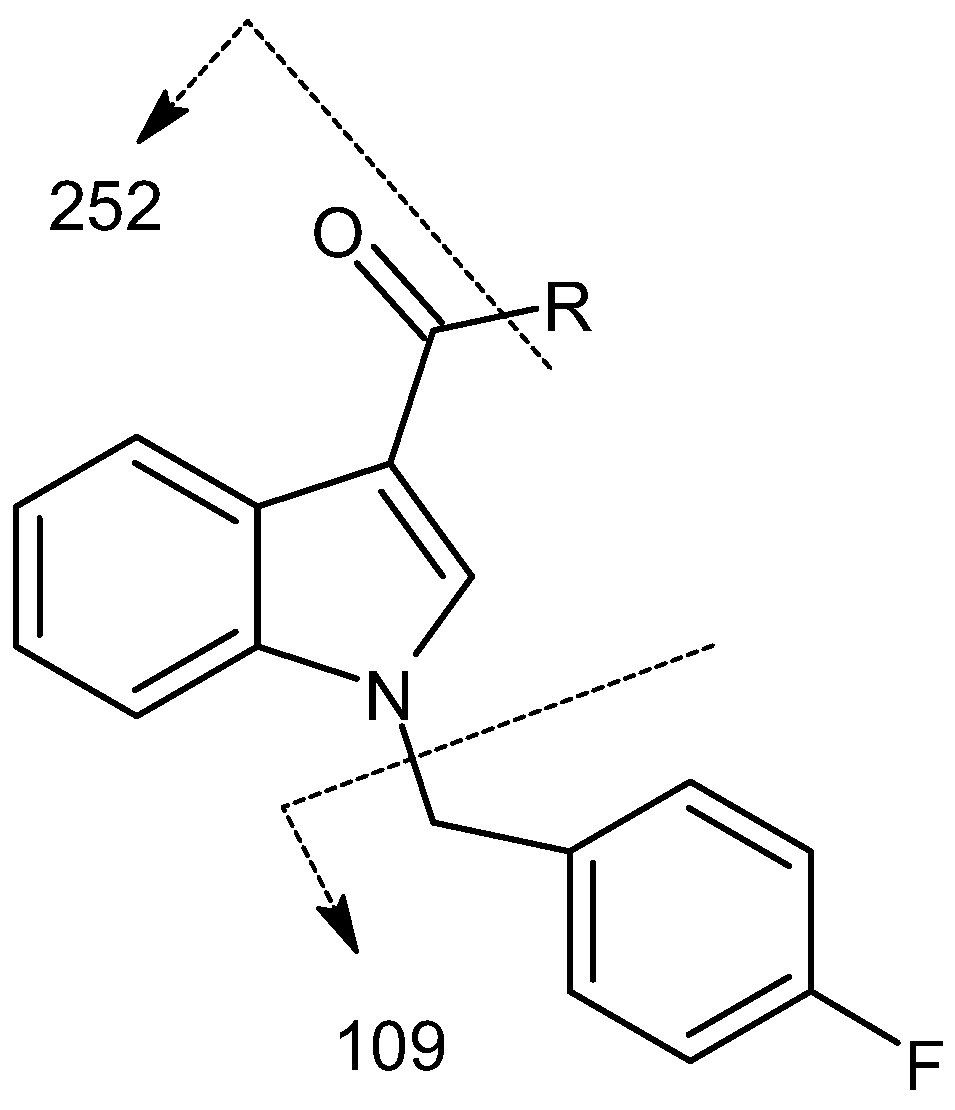
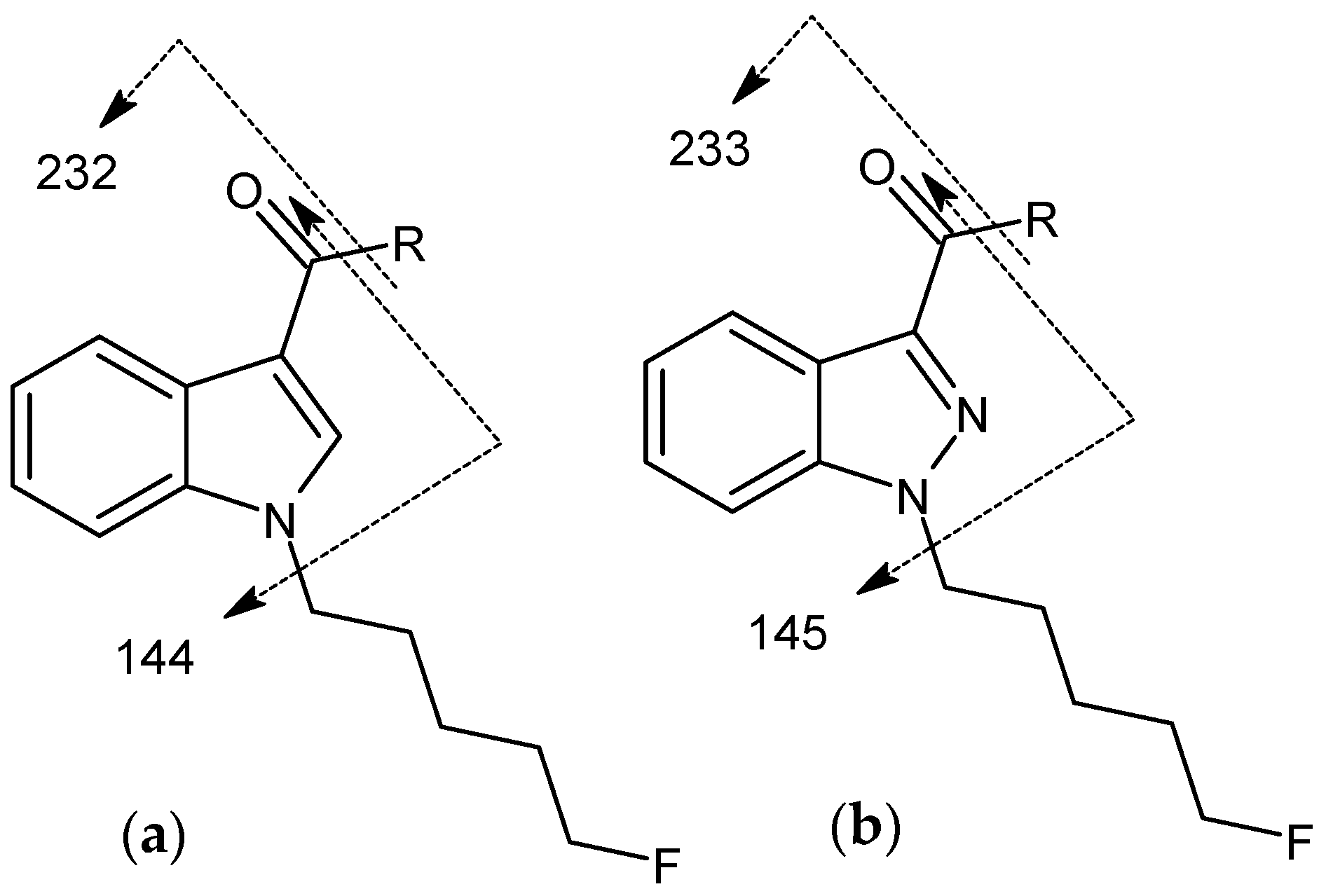
2.2.7. Cannabinoids Containing 4-Fluorobenzyl (FUB) Tail Group
2.2.8. Cannabinoids Containing 5-Fluoropentyl (5F-Pentyl) Tail Group
3. Materials and Methods
3.1. Mass Spectral Data
3.2. Software
3.3. Data Processing and Analysis
3.4. Evaluation of Classification Models
- Accuracy—proportion of cases correctly allocated,
- Sensitivity (TPR)—proportion of positive cases that were correctly identified,
- Specificity (TNR)—proportion of negative cases that were classified correctly
- F-1 score—can be interpreted as a harmonic mean of the precision and sensitivity.
- Matthew’s Correlation Coefficient (MCC)—measures the correlation between real and predicted values and reported as the best evaluator for binary classification models [21].
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Drug Type | SWGDRUG Database | Cayman Chemical Company Database |
|---|---|---|
| (Training Set) | (Prediction Set) | |
| Cannabinoids | 165 | 33 |
| Fentanyl | 173 | 11 |
| Opioids | 27 | 8 |
| Cathinones | 48 | 10 |
| Tryptamines | 7 | 8 |
| Phenylethylamines | 14 | 5 |
| Total | 434 | 75 |
| Model | Number of LVs Used | Class | Training Set | Prediction Set |
|---|---|---|---|---|
| Cannabinoids vs. other drugs | 3 | Cannabinoids | 165 | 33 |
| Other drugs | 269 | 42 | ||
| Classical vs. synthetic cannabinoids | 2 | Classical cannabinoids | 25 | 4 |
| Synthetic cannabinoids | 140 | 29 | ||
| Naphthoylpyrrole vs. other core groups | 3 | Naphthoylpyrrole | 11 | 2 |
| Other core groups | 129 | 27 | ||
| Azaindole/Indazole vs. Indole | 2 | Indole core | 48 | 16 |
| Azaindole/Indazole core | 81 | 11 | ||
| Naphthyl vs. other head groups | 2 | Naphthyl head group | 44 | 2 |
| Other head groups | 96 | 27 | ||
| FUB vs. other tail groups | 1 | FUB tail group | 9 | 9 |
| Other tail groups | 131 | 20 | ||
| 5-Fluoropentyl vs. other tail groups | 3 | 5-Fluoropentyl tail group | 33 | 1 |
| Other tail groups | 107 | 28 |
References
- Feeney, W.; Moorthy, A.S.; Sisco, E. Spectral Trends in GC-EI-MS Data Obtained from the SWGDRUG Mass Spectral Library and Literature: A Resource for the Identification of Unknown Compounds. Forensic Chem. 2022, 31, 100459. [Google Scholar] [CrossRef] [PubMed]
- Strano Rossi, S.; Odoardi, S.; Gregori, A.; Peluso, G.; Ripani, L.; Ortar, G.; Serpelloni, G.; Romolo, F.S. An Analytical Approach to the Forensic Identification of Different Classes of New Psychoactive Substances (NPSs) in Seized Materials. Rapid Commun. Mass Spectrom. 2014, 28, 1904–1916. [Google Scholar] [CrossRef]
- Winokur, A.D.; Kaufman, L.M.; Almirall, J.R. Differentiation and Identification of Fentanyl Analogues Using GC-IRD. Forensic Chem. 2020, 20, 100255. [Google Scholar] [CrossRef]
- United Nations Office of Drugs and Crime. Current NPS Threats, Volume V; United Nations Office of Drugs and Crime: Vienna, Austria, 2022. [Google Scholar]
- Mohr, A.L.A.; Logan, B.K.; Fogarty, M.F.; Krotulski, A.J.; Papsun, D.M.; Kacinko, S.L.; Huestis, M.A.; Ropero-Miller, J.D. Reports of Adverse Events Associated with Use of Novel Psychoactive Substances, 2017–2020: A Review. J. Anal. Toxicol. 2022, 46, e116–e185. [Google Scholar] [CrossRef] [PubMed]
- Scientific Working Group for the Analysis of Seized Drugs. SWGDRUG Mass Spectral Library, Virsion 3.11. Available online: https://www.swgdrug.org/ms.htm (accessed on 30 January 2020).
- Gilbert, N.; Mewis, R.E.; Sutcliffe, O.B. Classification of Fentanyl Analogues through Principal Component Analysis (PCA) and Hierarchical Clustering of GC–MS Data. Forensic Chem. 2020, 21, 100287. [Google Scholar] [CrossRef]
- Levitas, M.P.; Andrews, E.; Lurie, I.; Marginean, I. Discrimination of Synthetic Cathinones by GC–MS and GC–MS/MS Using Cold Electron Ionization. Forensic Sci. Int. 2018, 288, 107–114. [Google Scholar] [CrossRef]
- Koshute, P.; Hagan, N.; Jameson, N.J. Machine Learning Model for Detecting Fentanyl Analogs from Mass Spectra. Forensic Chem. 2022, 27, 100379. [Google Scholar] [CrossRef]
- Wong, S.L.; Ng, L.T.; Tan, J.; Pan, J. Screening Unknown Novel Psychoactive Substances Using GC–MS Based Machine Learning. Forensic Chem. 2023, 34, 100499. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, D.; Hua, Z.; Xu, P.; Wang, Y.; Di, B.; Liao, J.; Su, M. Machine Learning-Assisted Rapid Screening of Four Types of New Psychoactive Substances in Drug Seizures. J. Chem. Inf. Model. 2023, 63, 815–825. [Google Scholar] [CrossRef]
- Andrews, R.; Jorge, R.; Christie, R.; Gallegos, A. From JWH-018 to OXIZIDS: Structural Evolution of Synthetic Cannabinoids in the European Union from 2008 to Present Day. Drug Test. Anal. 2023, 15, 378–387. [Google Scholar] [CrossRef]
- Bell, S. Forensic Chemistry, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2022; ISBN 978-0-429-44091-5. [Google Scholar]
- Cayman Chemical Company Cayman Spectral Library. Available online: https://www.caymanchem.com/forensics/publications/csl (accessed on 16 September 2022).
- Yoshida, H.; Leardi, R.; Funatsu, K.; Varmuza, K. Feature Selection by Genetic Algorithms for Mass Spectral Classifiers. Anal. Chim. Acta 2001, 446, 483–492. [Google Scholar] [CrossRef]
- Namera, A.; Kawamura, M.; Nakamoto, A.; Saito, T.; Nagao, M. Comprehensive Review of the Detection Methods for Synthetic Cannabinoids and Cathinones. Forensic Toxicol. 2015, 33, 175–194. [Google Scholar] [CrossRef]
- Shao, W.; Liao, P.; Zhang, X.; Fan, B.; Chen, R.; Chen, X.; Zhao, X.; Liu, W. Syntheses of Cannabinoid Metabolites: Ajulemic Acid and HU-210. Molecules 2024, 29, 526. [Google Scholar] [CrossRef]
- Harvey, D.J. Mass Spectrometry of the Cannabinoids and Their Metabolites. Mass Spectrom. Rev. 1987, 6, 135–229. [Google Scholar] [CrossRef]
- Moosmann, B.; Kneisel, S.; Girreser, U.; Brecht, V.; Westphal, F.; Auwärter, V. Separation and Structural Characterization of the Synthetic Cannabinoids JWH-412 and 1-[(5-Fluoropentyl)-1H-Indol-3yl]-(4-Methylnaphthalen-1-Yl)Methanone Using GC–MS, NMR Analysis and a Flash Chromatography System. Forensic Sci. Int. 2012, 220, e17–e22. [Google Scholar] [CrossRef] [PubMed]
- Bijlsma, L.; Ibáñez, M.; Miserez, B.; Ma, S.T.F.; Shine, T.; Ramsey, J.; Hernández, F. Mass Spectrometric Identification and Structural Analysis of the Third-Generation Synthetic Cannabinoids on the UK Market since the 2013 Legislative Ban. Forensic Toxicol. 2017, 35, 376–388. [Google Scholar] [CrossRef]
- Abdel-Hay, K.M.; DeRuiter, J.; Smith, F.; Belal, T.S.; Clark, C.R. GC–MS Analysis of the Regioisomeric Methoxy- and Methyl-Benzoyl-1-Pentylindoles: Isomeric Synthetic Cannabinoids. Sci. Justice 2015, 55, 291–298. [Google Scholar] [CrossRef]
- Shevyrin, V.; Melkozerov, V.; Nevero, A.; Eltsov, O.; Shafran, Y.; Morzherin, Y.; Lebedev, A.T. Identification and Analytical Characteristics of Synthetic Cannabinoids with an Indazole-3-Carboxamide Structure Bearing a N-1-Methoxycarbonylalkyl Group. Anal. Bioanal. Chem. 2015, 407, 6301–6315. [Google Scholar] [CrossRef]
- Wurita, A.; Hasegawa, K.; Minakata, K.; Gonmori, K.; Nozawa, H.; Yamagishi, I.; Watanabe, K.; Suzuki, O. Identification and Quantitation of 5-Fluoro-ADB-PINACA and MAB-CHMINACA in Dubious Herbal Products. Forensic Toxicol. 2015, 33, 213–220. [Google Scholar] [CrossRef]
- Alves, V.L.; Gonçalves, J.L.; Aguiar, J.; Caldeira, M.J.; Teixeira, H.M.; Câmara, J.S. Highly Sensitive Screening and Analytical Characterization of Synthetic Cannabinoids in Nine Different Herbal Mixtures. Anal. Bioanal. Chem. 2021, 413, 2257–2273. [Google Scholar] [CrossRef]
- Castaneto, M.S.; Wohlfarth, A.; Pang, S.; Zhu, M.; Scheidweiler, K.B.; Kronstrand, R.; Huestis, M.A. Identification of AB-FUBINACA Metabolites in Human Hepatocytes and Urine Using High-Resolution Mass Spectrometry. Forensic Toxicol. 2015, 33, 295–310. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The Advantages of the Matthews Correlation Coefficient (MCC) over F1 Score and Accuracy in Binary Classification Evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef]
- Foody, G.M. Challenges in the Real World Use of Classification Accuracy Metrics: From Recall and Precision to the Matthews Correlation Coefficient. PLoS ONE 2023, 18, e0291908. [Google Scholar] [CrossRef]


| Model | Accuracy | TPR * | TNR ** | F1 Score | MCC *** |
|---|---|---|---|---|---|
| Cannabinoids vs. other drugs | |||||
| Calibration | 0.9885 | 1.0000 | 0.9814 | 0.9851 | 0.9760 |
| Cross Validation | 0.9816 | 0.9939 | 0.9740 | 0.9762 | 0.9620 |
| External validation | 0.9733 | 0.9697 | 0.9762 | 0.9697 | 0.9460 |
| Classical vs. synthetic cannabinoids | |||||
| Calibration | 0.9886 | 0.9200 | 0.9929 | 0.9388 | 0.9280 |
| Cross-validation | 0.9697 | 0.9200 | 0.9786 | 0.9020 | 0.8840 |
| External validation | 0.8788 | 1.0000 | 0.8620 | 0.6667 | 0.6570 |
| Naphthoylpyrrole vs. other core groups | |||||
| Calibration | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Cross-validation | 0.9690 | 1.0000 | 0.9457 | 0.9843 | 0.8430 |
| External validation | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Azaindole/Indazole vs. Indole | |||||
| Calibration | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Cross-validation | 0.9845 | 1.0000 | 0.9753 | 0.9796 | 0.9680 |
| External validation | 0.9253 | 0.8750 | 1.0000 | 0.9333 | 0.8600 |
| Naphthyl vs. other head groups | |||||
| Calibration | 0.9714 | 0.9318 | 0.9896 | 0.9535 | 0.9330 |
| Cross-validation | 0.9714 | 0.9318 | 0.9896 | 0.9535 | 0.9330 |
| External validation | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| FUB vs. other tail groups | |||||
| Calibration | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| Cross-validation | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| External validation | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| 5-Fluoropentyl vs. other tail groups | |||||
| Calibration | 0.9643 | 0.9394 | 0.9720 | 0.9254 | 0.9020 |
| Cross-validation | 0.9571 | 0.9394 | 0.9626 | 0.9118 | 0.8840 |
| External validation | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Evans-Newman, K.C.; Schneider, G.L.; Perera, N.T. Classification of Mass Spectral Data to Assist in the Identification of Novel Synthetic Cannabinoids. Molecules 2024, 29, 4646. https://doi.org/10.3390/molecules29194646
Evans-Newman KC, Schneider GL, Perera NT. Classification of Mass Spectral Data to Assist in the Identification of Novel Synthetic Cannabinoids. Molecules. 2024; 29(19):4646. https://doi.org/10.3390/molecules29194646
Chicago/Turabian StyleEvans-Newman, Kristopher C., Garion L. Schneider, and Nuwan T. Perera. 2024. "Classification of Mass Spectral Data to Assist in the Identification of Novel Synthetic Cannabinoids" Molecules 29, no. 19: 4646. https://doi.org/10.3390/molecules29194646