Abstract
For chemical measurements, calibration is typically conducted by regression analysis. In many cases, generalized approaches are required to account for a complex-structured variance–covariance matrix of (in)dependent variables. However, in the particular case of highly correlated independent variables, the ordinary least squares (OLS) method can play a rational role with an approximated propagation of uncertainties of the correlated independent variables into that of a calibrated value for a particular case in which standard deviation of fit residuals are close to the uncertainties along the ordinate of calibration data. This proposed method aids in bypassing an iterative solver for the minimization of the implicit form of the squared residuals. This further allows us to derive the explicit expression of budgeted uncertainties corresponding to a regression uncertainty, the measurement uncertainty of the calibration target, and correlated independent variables. Explicit analytical expressions for the calibrated value and associated uncertainties are given for straight-line and second-order polynomial fit models for the highly correlated independent variables.
1. Introduction
For calibration purposes, regression analysis wherein (in)dependent variables with a complex uncertainty structure has been intensively studied to yield the best estimates of the regression coefficient and associated uncertainties [1,2,3,4,5,6,7,8,9,10,11,12,13]. In particular, the uncertainty propagation of measured scalar responses toward the final calibrated value is a critical issue for ensuring the compatibility of inter- and intra-laboratory measurement results [14]. In the case of non-zero covariances among responses (dependent variables) and stimuli (independent variables), generalized least squares (GLS) regression is required to solve for the matrix form of squared residuals (SR), which is weighted against the variance–covariance matrix of calibration data vectors [15]. The weighted SR matrix is then minimized by an iterative solver. When the uncertainties of independent variables and covariances among dependent and independent variables are nonexistent, the GLS regression can be reduced to the weighted least squares (WLS) regression [1,2,3,4,5,6,7,8,16]. As the off-diagonal elements of the SR matrix are zero, the analytical expression for the fitted parameters of the regression model can be analytically derived.
In the metrological field, several research papers [17,18,19,20,21,22,23,24] and standards [25,26,27] have been published on regression analysis, and relevant softwares have been developed [28,29,30,31,32]. Analytical formulations of GLS are available from NPL and INRiM [18,20]. INRiM’s software, CCC (v2.0), works for linear and nonlinear regression problems with a full covariance matrix, excluding covariance between independent and dependent variables [28]. However, NPL’s software, XLGENLINE (v1.1), implemented in EXCEL by calling FORTRAN DLL, can work only for linear regression problems with up to fourth-order polynomials and diagonal covariance matrices [29]. In contrast, XGENLINE (v8.1) [30], which is a MATLAB version of XLGENLINE, uses a representation in terms of the Chebyshev polynomials to obtain better numerical conditioning than the general polynomials [17]. ISO/TS 28037:2010(E) [26] and the relevant software B_LEAST [30] can address the case of correlation among dependent and independent variables, but only when considering a straight-line model. B_LEAST can work with different types of regression models, including power and exponential models, but it requires diagonal covariance matrices only [32].
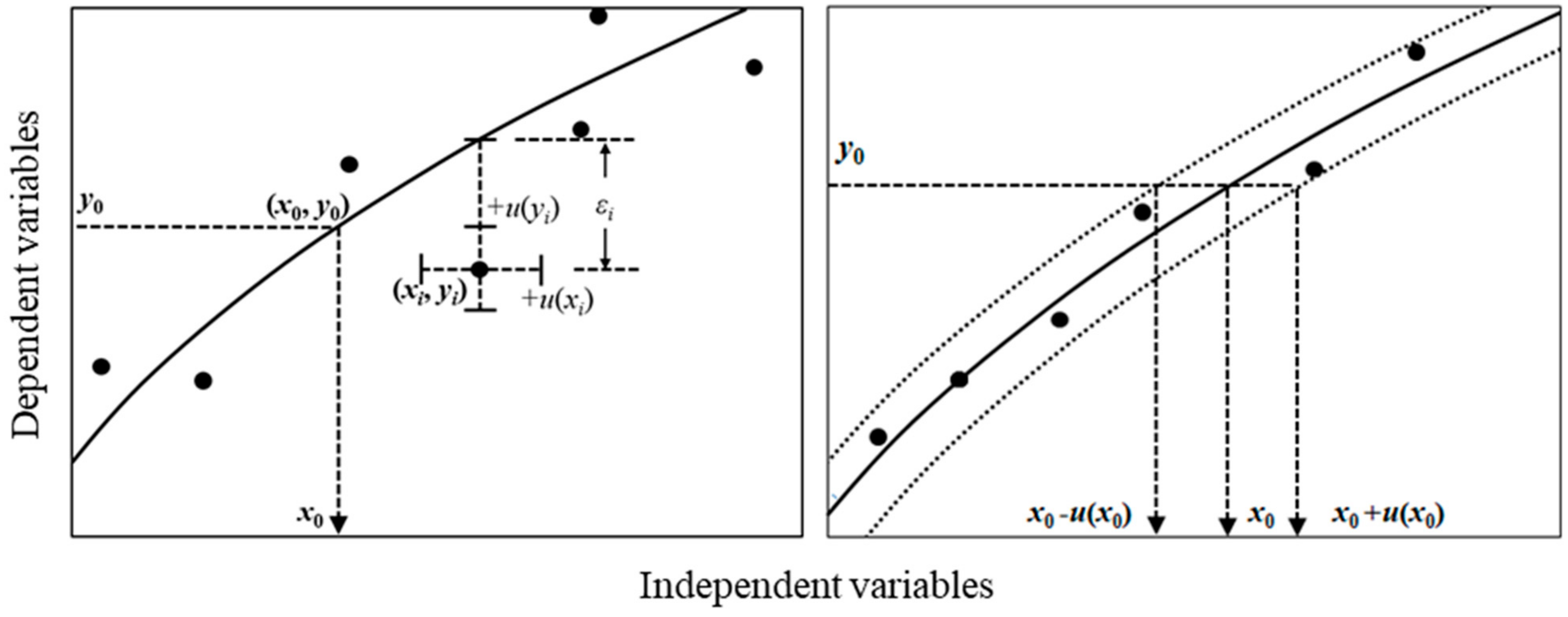
Following the Guide to the Expression of Uncertainty in Measurement (GUM), a common text for the metrological determination of the measurement value [33], the uncertainty of the calibration target can be evaluated by applying the (linear) law of propagation of uncertainty (LPU) to the abscissa. Therefore, for a generalized approach with the non-diagonalized SR matrix, an analytical process to derive the variance–covariance matrix of regression coefficients has been demonstrated only for particular cases wherein the correlation between variables does not disturb the derivation of the explicit variance–covariance formulae [33]. For chemical or biological RMs prepared from the same mother material, one may reasonably assume a strong correlation between these uncertainties [34]. For instance, a batch of chemical mixtures in various amount-fractions are typically blended using the same raw materials or mother mixture in the same facility and perhaps even by the same worker. Therefore, their variances may be correlated to some extent. Here, we attempt to derive an explicit expression of the uncertainty of the calibrated value which was propagated from measurement uncertainties of references and calibration targets using the ordinary least squares (OLS) estimator according to LPU. The calibration result using the proposed method is compared to the Monte Carlo simulation, complementing the validity of the proposed method. In addition, depicted in the right panel of Figure 1, a dataset in which the uncertainties of yi are equivalent to the sum of squared residuals (SSR) and the uncertainties of xi are highly correlated (Figure 1) was considered using LPU.
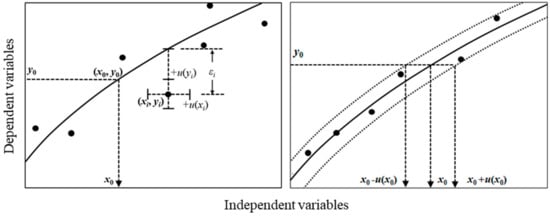
Figure 1.
(Left) Notation of uncertainties and errors addressed in this study. u(xi) and u(yi) denote input variances in the reference and corresponding response values, respectively. The residual error εi represents the deviation between its theoretical and input values along the ordinate. The measured response of the target is y0, which is calibrated to x0. (Right) Conceptual representation of linear dispersion of the calibrated value due to the fully correlated reference values. The tested dataset for the proposed calibration method is given in Table 1 in Section 2.5.
2. Theory
2.1. Least Squares Methods
Figure 1 illustrates the regression problem of the present study, presenting the measured data vector d, di = (xi, yi), where y corresponds to the response value and x the stimuli (typically, the value of the reference material (RM)), and reference values xi are fully correlated to each other. The minimization of regression variance for the data vector can be expressed as a generalized least squares (GLS) formulation as follows [13]:
where the unobservable true vector describing the fitted line is a constraint upon ), i = 1, ∙∙∙∙, n. of order 1 × (m + 1) denotes the input regression coefficient vector of the mth-order polynomial model function, and are auxiliary output quantities. Cd is the variance–covariance matrix of the measurement data vector d of order n × n, where Cd is assumed to have full rank. Equation (1) does not have a closed-form solution, and therefore, an iterative solving algorithm is required to derive the estimate that is a vector of maximum likelihood estimators under the normality assumption, that is, the Best Linear Unbiased Estimator (BLUE) [17]. Equation (1) can be reduced to yield the OLS estimator at the regression coefficient vector β in the case that the Cd is the identity matrix. The SSR at β is expressed as follows:
where , the design matrix X has n rows and m columns having elements of , and . The Gauss–Markov theorem allows the unobservable random error vector ε to have same variance σ2. The function S(b) is quadratic in with positive definite Hessian, and therefore, this function possesses a unique global minimum at = , which can be given by the explicit expression as follows:
Therefore, a BLUE estimator of regression coefficients in the OLS problem can be derived from Equation (3) by applying the inverse of the Gram matrix to both sides. The measurement uncertainty (errors-in-variable on abscissa of data vector d) can be considered identical to the standard deviation of fit residuals, and Equation (3) yields the OLS estimator that is the BLUE, satisfying the Gauss–Markov theorem as follows [35,36]:
Therefore, is an affine transformation of the response vector y onto a column space of the regression line by the orthogonal projection operator, [37]. The GLS method is required when there are errors in the independent variable (along the ordinate). However, the error propagation of the regression variance of the GLS method requires, in general, the linearization of the regression variance at the solution point of Equation (1). The following sections explore the explicit expressions for the uncertainty of fully correlated reference u(xi) propagated via .
2.2. Variance–Covariance Matrix of the Regression Coefficient
A full matrix expression of Equation (4) can be expanded as follows:
Then, the cost function matrix Q is expressed as Q = (q0, q1, ……, qm)T = 0 with coefficient vector β taken by the OLS estimator . Then, Equation (5) is reorganized to to have the implicit function vector elements qm, expressed as follows [38]:
Equation (6) does not require an estimation of the inverse matrix by organizing each element implicitly. The systematic equations of Equation (6) do not have an exact analytical solution. Instead, coefficient vector β fits the equation best in the sense of finding the minima of SSR as described above. According to DIN 1319-4, the uncertainty transformation matrix for accounting for variability in should be formed by the ordinate components of the regression coefficient vector β and the response vector y. To propagate the regression variance, an uncertainty propagation matrix requires the Jacobian matrices of the cost function matrix Q against coefficient vector β as an input quantity and response vector y as an output quantity. Jacobian matrices Qi and Qo, where the subscripts represent the input and output quantities, respectively, yield an uncertainty transformation matrix . To propagate the variances–covariances of the regression coefficients, the uncertainty propagation matrix requires Jacobian matrices of the cost function matrix Q against coefficient vector β and response vector y as input and output quantities, respectively. To obtain a positive definite, the uncertainty transformation matrix for estimating the OLS regression variance is negatively given as follows [23,39]:
where and are the Jacobian matrices of the Q matrix against the response vector y and the regression coefficient vector , respectively. These two matrices are given as follows:
The variance matrix of the regression coefficient is calculated as follows:
where Ω is the diagonal residual matrix with identical entries of s2 [2]. s2 is a variance of fit residual of the sampled data from the unobservable ‘true’ regression line, of which the regression coefficient vector is b. Notably, the statistical parameter for describing the extent of dispersion of an unobservable error ei ~ yi − q(xi,b) that has a constant variance σ2, in which the error vectors are normally distributed (zero mean and standard deviation equaling σ). The standard deviation of the fit residuals of the sampled data, s, can be expressed by the following:
where the degrees-of-freedom correction in the denominator is restricted by the polynomial order of the fitting model m and the number of data vectors n. allows the residual to be an observable estimate of the unobservable error ε. The probability distribution of the residual error converges to a normal distribution following the Gauss–Markov assumption. The variance–covariance matrix of the OLS estimator is expressed as follows:
where G is the Gram matrix of Equation (9). Each diagonal entry corresponds to the variance of the regression coefficient of each term, whereas the off-diagonal entries correspond to the covariance between regression coefficients.
2.3. Propagation of Variance–Covariance of the Regression Coefficients
For calibration, the measured response value of the target y0 is inversely evaluated to obtain the corresponding stimulus value x0, which can be numerically rooted by using Newton’s method. To propagate the measurement uncertainty of u(y0) onto u(x0), the inverse evaluation requires the estimated regression coefficient vector and estimated x0 as input and output quantities, respectively. The Jacobian matrix against the input and output quantities ( and , respectively) can then be expressed as follows:
Here, is the slope of the tangent of the determined regression line in the case of the second-order polynomial fit model at the target coordinate (x0, y0). This implies that the regression variance will be weighted by the slope of the tangent of the non-first-order calibration curve. The uncertainty transformation matrix for the regression variance toward the abscissa of the output quantity is then given as follows:
To transform the variance–covariance matrix of the OLS estimator with the mth-order polynomial model function (Equation (12)) onto the abscissa corresponding to the output quantity x0, the uncertainty propagation matrix (Equation (15)) is bracketed according to the LPU as follows:
where gij is an element of the inverse Gram matrix G−1. In this study, has only positive values. The propagated uncertainty of regression coefficients into the calibrated value x0 is given as follows:
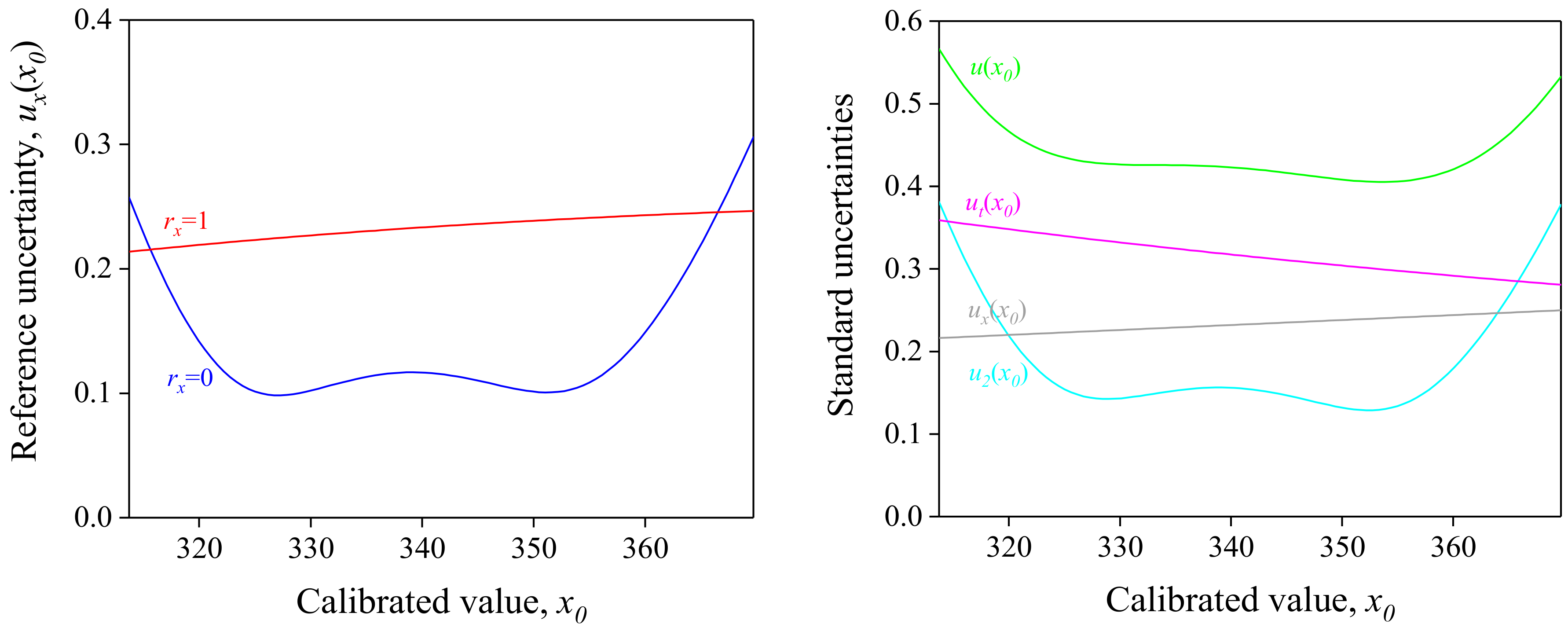
Because the highest-order element of the inverse Gram matrix is 2m order, for the second-order polynomial, u2(x0) is shown as a quartic curve, as shown in Figure 2. The variance of each component is estimated using the dataset in Table 1.
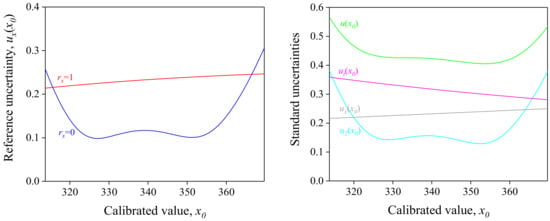
Figure 2.
(Left) Propagated reference variance corresponds to the calibrated value when there is no correlation, rx = 0 (blue); and correlation is unity, rx = 1 (red). (Right) Uncertainties propagated from the uncertainties of reference ux(x0) (gray); target measurement, ut(x0) (magenta); and regression, u2(x0) (cyan). The combined standard uncertainty u(x0) is represented by the green line. For detailed discussions of ux(x0) and ut(x0), see Section 2.4 and Section 2.5.
2.4. Propagation of the Measurement Uncertainty of the Calibration Target
To propagate the measurement uncertainty of the calibration target, its uncertainty value is treated as an input value of the reverse evaluation. The partial derivative of the cost function at y0 can be expressed as follows:
Then, the uncertainty transformation matrix for the measurement uncertainty of the unknown sample can then be obtained to obtain the positive definite as follows:
The propagation of the measurement uncertainty of the target u(y0) yields the target variance Vt as follows:
where s is the measurement uncertainty of the calibration target, which, in general, can be approximated to the same extent of sampling variance for the regression data vector, and p is the number of repetitions of the target measurement. The measurement variance s2 can be weighted by the number of repetitions p according to the central limit theorem. The target uncertainty can then be expressed as follows:
2.5. Propagation of Uncertainty of the Independent Variable
The uncertainty of the independent variable was propagated using same method for the estimation of the regression variance. To define an uncertainty transformation matrix toward the abscissa, if there are no correlations between xi and yi, the Jacobian matrix of the cost function against the stimulus xi is defined as follows:
The uncertainty transformation matrix of the reference uncertainty to the abscissa is given as follows:
where is given in Equation (9). As an analytical derivation of the above matrix is nontrivial. Then, the variances and covariances of the references are propagated back to the abscissa using following equation:
where the variance–covariance matrix of the reference is given as follows:
where is the correlation matrix in which the elements are rx, and is the diagonal matrix of the reference uncertainty. The uncertainty of the calibrated value of the target ux(x0) estimated from the OLS estimator is given as follows:
Unfortunately, the formulaic expression of the explicit form of ux(x0) is nontrivial for higher-order polynomials. In a condition of no correlation (rx = 0), a curvature of ux(x0) is quartically variated for the quadratic calibration function because of the nature of the regression variance–covariance matrix , of which the highest-order element is . (Figure 2).
As a quantitative investigation of the correlation coefficient is beyond the limitation of the realization in many cases, a conservative approach is required. In an extremely conservative case, for an all-ones correlation matrix (all ), the measurement uncertainty of the target along the abscissa is coherently dispersed, as presented below:
where q is the cost function of the fitted model of the OLS estimator and u(x) is the averaged uncertainty of u(xi). It was assumed that the uncertainty values of references are close to each other, as shown in Table 1 and Figure 3. The fitted line spans out in the positive and negative directions by the extent of the width of the normal distribution, of which uncertainty is u(x) (Figure 1). As expected, ux(x0) is smoothly variated as a function of x0 when all correlations are fully positive (i.e., rx = 1) based on the assumption that u(x0) is constant with respect to x0 (Figure 2). The variation rate is lower at large values of x0 because the slope of the tangent for the used dataset is higher at such values. In the case that x0 is centered within the reference scale, Equation (26) can be simplified as follows:
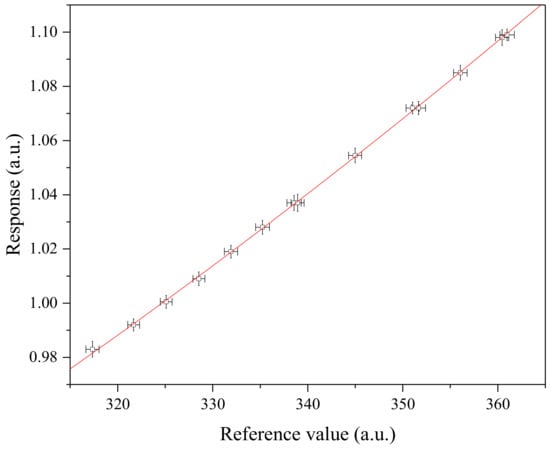
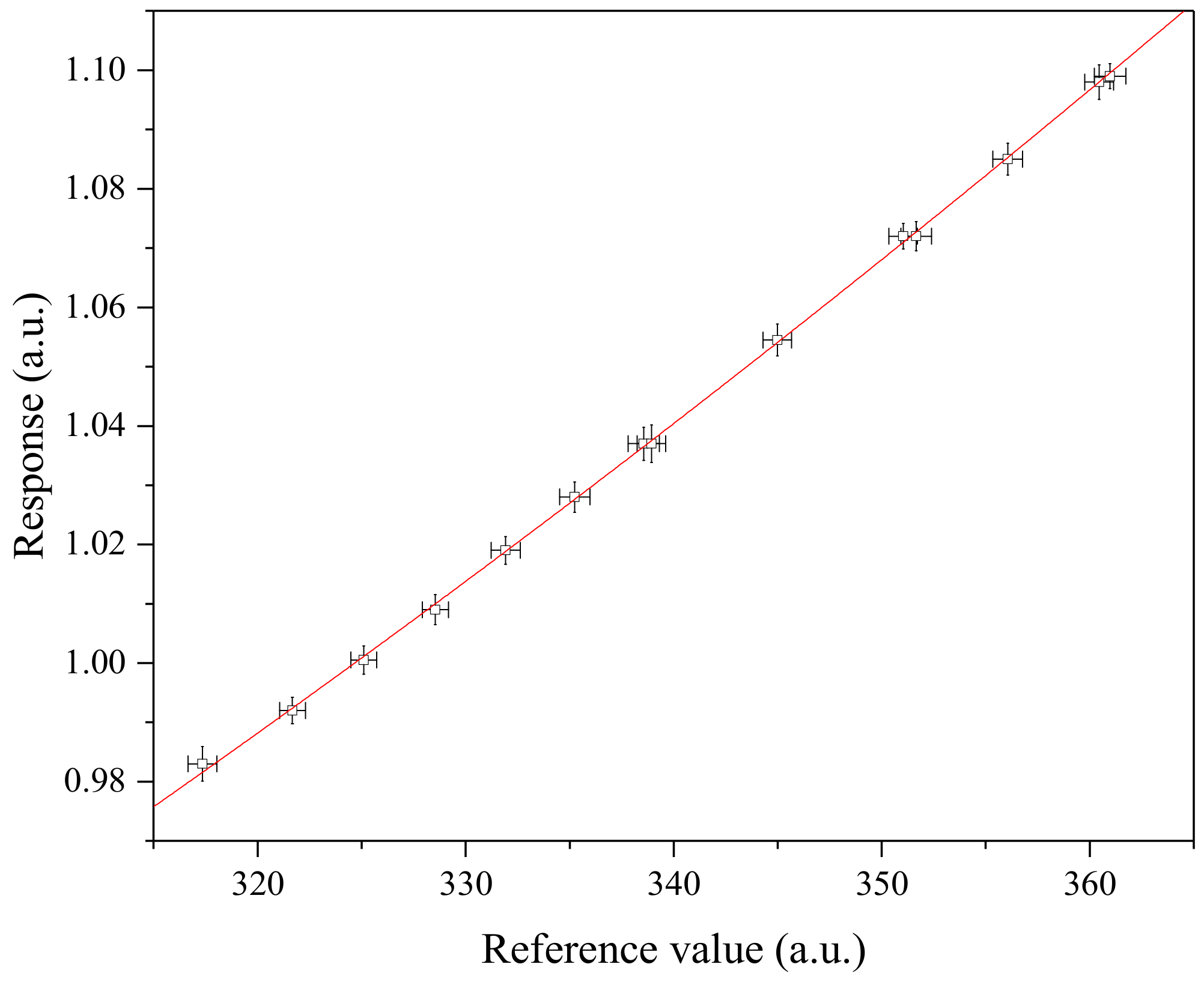
Figure 3.
Graphical representation of the artificial dataset A given in Table 1. Note that the uncertainties of reference values and responses are amplified three times to be seen. The uncertainties of reference values were assumed to be fully correlated with each other.

Table 1.
Datasets to test the proposed method in this study. Note that all u(yi) values are close to the standard deviation of the fit residual of the corresponding dataset. The uncertainties of reference values were assumed to be fully correlated with each other.
Table 1.
Datasets to test the proposed method in this study. Note that all u(yi) values are close to the standard deviation of the fit residual of the corresponding dataset. The uncertainties of reference values were assumed to be fully correlated with each other.
| Reference (xi) | u (xi) | Response | u(yi) | ||
|---|---|---|---|---|---|
| Set A | Set B | Set C | |||
| 317.35 | 0.231 | 0.983 | 0.00098 | 0.00098 | |
| 321.68 | 0.206 | 0.992 | 0.00074 | 0.00074 | 0.00041 |
| 325.11 | 0.208 | 1.001 | 0.00080 | ||
| 328.54 | 0.209 | 1.009 | 0.00085 | 0.00085 | |
| 331.92 | 0.233 | 1.019 | 0.00077 | 0.00077 | 0.00042 |
| 335.24 | 0.243 | 1.028 | 0.00085 | ||
| 338.56 | 0.252 | 1.037 | 0.00093 | 0.00093 | |
| 338.93 | 0.231 | 1.037 | 0.00106 | 0.00106 | 0.00058 |
| 344.98 | 0.230 | 1.055 | 0.00089 | ||
| 351.03 | 0.229 | 1.072 | 0.00072 | 0.00072 | |
| 351.66 | 0.246 | 1.072 | 0.00082 | 0.00082 | 0.00045 |
| 356.06 | 0.239 | 1.085 | 0.00090 | ||
| 360.45 | 0.232 | 1.098 | 0.00098 | 0.00098 | |
| 360.97 | 0.253 | 1.099 | 0.00069 | 0.00069 | 0.00038 |
| 364.85 | 0.241 | 1.111 | 0.00085 | ||
| Target | (p = 1) | 1.003 | n = 15 | n = 10 | n = 5 |
3. Discussions
Artificial datasets mimicking the measurements of ambient-level N2O using a gas chromatograph with an electron capture detector (GC-ECD) were utilized to evaluate the uncertainty of calibrated value x0 (Table 1). The artificial data are dispersed along the ordinate to have uncertainties, u(yi), which are closely set to the standard deviation of fit residuals s = 0.00073, 0.00085, and 0.00041, respectively, for dataset A, B, and C. This aspect implies that u(yi) are considered as the sampling uncertainties from the which was modeled by the OLS estimator. It should be noted that the OLS and the WLS methods yield similar results in the regression variance, where the variance–covariance matrix of the WLS estimator was computed by the equation of , where W is the weighting matrix and its elements are inversed u(yi) [5]. The ux(x0) curves for rx = 1 and rx = 0 cross outside of the range of the reference scale, implying that a conservative approach can be achieved by considering the correlation effect of reference values within the reference scale (Figure 2). The post-evaluation of the correlation factors among reference values is hard to achieve; one may assume rx = 1 to avoid underestimating the calibration uncertainty due to uncertainties of reference values.
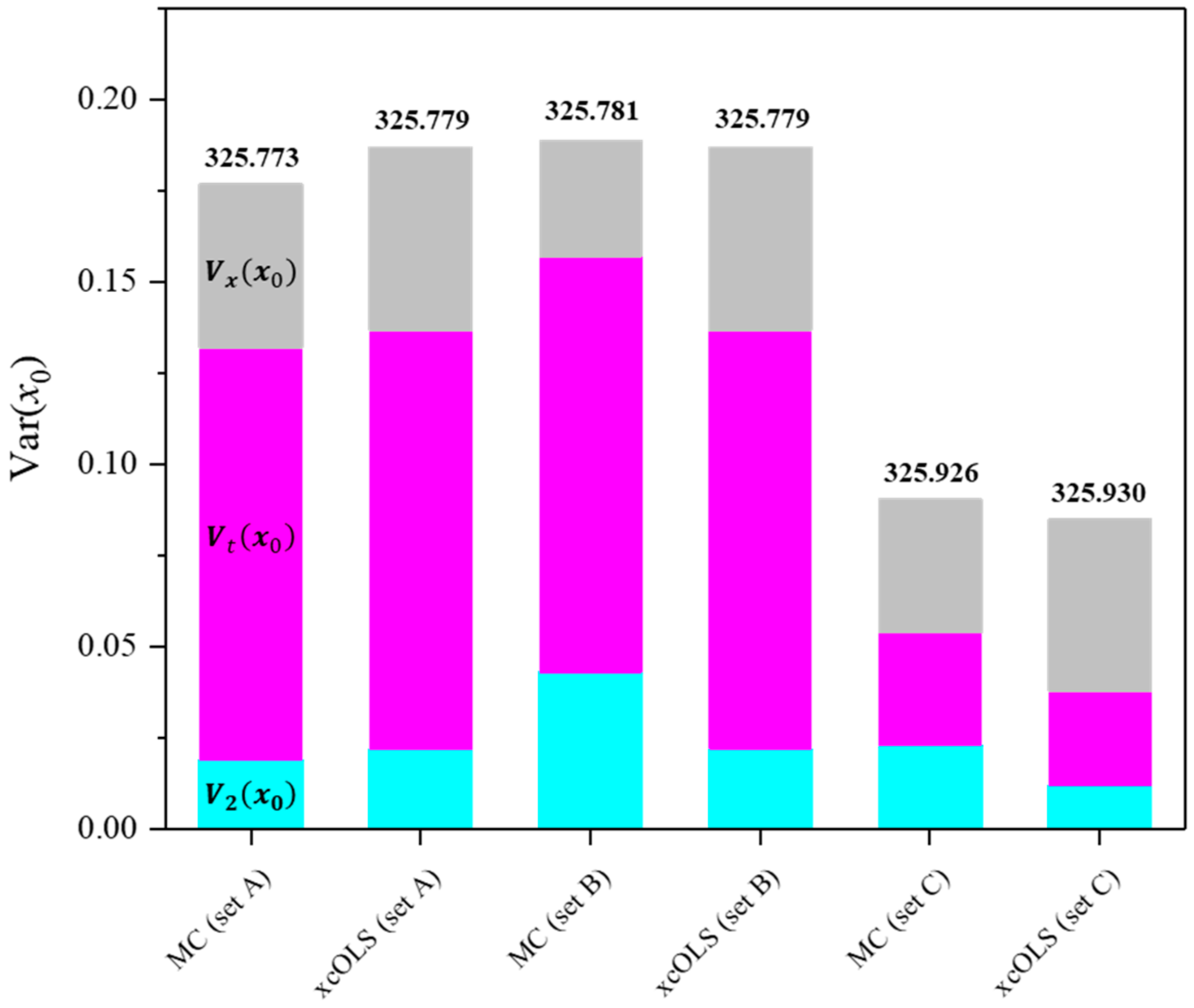
To verify the derived explicit equation of each uncertainty value, the Monte Carlo (MC) simulation was conducted employing identical datasets. In the MC method, individual data points were randomly sampled from normally distributed reference values (xi), which were fully correlated to each other (all ), and normally distributed response values (yi). The uncertainties of both xi and yi, denoted as u(xi) and u(yi), respectively, for each dataset are detailed in Table 1. A total of 10,500 di = (xi, yi) were randomly sampled from the population to compute the uncertainty value of the calibration target. Running the OLS estimator on each sampled data vector yielded the single regression coefficient vector β and calibrated value x0. An average and standard deviation of each parameter resulted in the corresponding value and its uncertainty. Because it is a valid assumption that a result by the MC simulation will be in close proximity to the unbiased limit of variance of the resulting distribution [40], a comparison between the x-correlated OLS method (xcOLS) and the MC method allowed us to test the reliability of the xcOLS method (Figure 4). With LPU, it is hard to handle the GLS problem in which the SR matrix cannot be reduced to the implicit model equations [33]. Therefore, approximating the uncertainties according to the LPU is prevalent in many cases. The uncertainties u2(x0), ut(x0), and ux(x0) from both the xcOLS and MC methods exhibit a high degree of agreement for various datasets in ranges of variance of fit residuals s2. Covariances stemming from the coherent dispersion of reference values were observed to be minor, as seen in the comparison between the MC and xcOLS methods in the datasets (Table 2 and Table 3 and Figure 4).
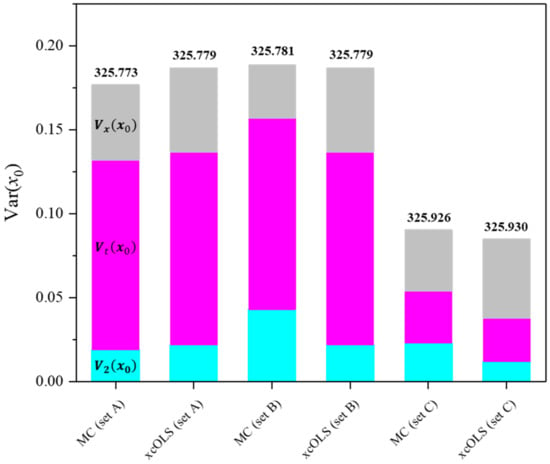
Figure 4.
A comparison of the variance values corresponding to the reference, (gray); the target measurement, (magenta); and regression, (cyan). Note that the number of target measurement repetitions p is 1. Calibrated values obtained through each method are indicated on top of the respective bars.
Table 2.
Estimated regression coefficients for each dataset. Associated uncertainties are given in the parentheses.
Table 3.
The combined standard uncertainty of the determined value of the calibration target under the assumption of unitive correlation of the reference values. β1 is the slope of a fitted straight line, and is the mean of the reference value. The measurement uncertainty of the target is assumed to be at a level similar to the measurement uncertainty of the reference. The unitive correlation among the reference variances is approximated to .
4. Conclusions
In the field of chemical and biological analysis, the OLS method is a prevalent choice for calibration tasks involving highly accurate RMs, particularly when the negligible uncertainty of references obviates the need for their consideration in the regression analysis. However, numerous scenarios, such as those encountered in graphite furnace atomic absorption spectroscopy, X-ray fluorescence spectroscopy, and spark emission spectroscopy, deviate from the simplicity of the OLS approach due to the presence of considerable variance–covariance in the independent variables, namely reference values. To address this challenge, an approximated propagation method for the variance–covariance of the data matrix becomes imperative. This study addresses a specific calibration scenario wherein the independent variables exhibit high correlation, and uncertainties along the ordinate are equivalent to the standard deviation of the fit residuals. If the uncertainties of the independent variables are deemed negligible, this scenario aligns with the traditional OLS case. Conceptually illustrated in Figure 1, the uncertainties of fully correlated independent variables were dispersed orthogonally along the abscissa. The validity of this concept is substantiated through the step-by-step derivation of explicit equations. This study meticulously budgets the contributions of variances arising from regression coefficients, target measurements, and references, offering an analytical framework for comprehending uncertainty propagation for the calibration scenario. The calibration task employing the xcOLS and the MC methods was exemplified using artificial datasets, with standard deviations of fit residuals s being 0.00073, 0.00085, and 0.00041. The resulting uncertainty values, as a metric for comparing results, were estimated by the xcOLS and the MC methods to show good agreement. This good agreement underscores the validity of the proposed approach in propagating uncertainties associated with highly correlated independent variables using the OLS estimator.
Author Contributions
J.S.L.: Formal Analysis, Investigation, Resources, Validation, Visualization, Writing—Original Draft, Review, and Editing, Funding Acquisition, Project Administration, Y.D.K.: Data Curation, Formal Analysis, J.-C.W.: Conceptualization, Methodology, Data Curation, Formal Analysis, Validation, Investigation, Supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Korea Research Institute of Standards under the basic project of the establishment of the measurement standard of a climate watch based on molecular spectroscopy (23011081) and by the Ministry of Trade, Industry & Energy (MOTIE, Republic of Korea) under the following project: the industrial strategic technology development program (RS-2023-00265582, development of monitoring and analysis technologies for greenhouse gases in the semiconductor manufacturing etching process).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors thank Sangil Lee for the discussions in the initial stage of this study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Tellinghuisen, J. Least squares methods for treating problems with uncertainty in x and y. Anal. Chem. 2020, 92, 10863–10871. [Google Scholar] [CrossRef] [PubMed]
- Tellinghuisen, J. Calibration: Detection, quantification, and confidence limits are (almost) exact when the data variance function is known. Anal. Chem. 2019, 91, 8715–8722. [Google Scholar] [CrossRef] [PubMed]
- Riu, J.; Ruis, F.X. Assessing the accuracy of analytical methods using linear regression with errors in both axes. Anal. Chem. 1996, 68, 1851–1857. [Google Scholar] [CrossRef]
- Tellinghuisen, J. A simple, All-purpose nonlinear algorithm for univariate calibration. Analyst 2000, 125, 1045–1048. [Google Scholar] [CrossRef]
- Tellinghuisen, J. Weighted least-squares in calibration: What difference does it make? Analyst 2007, 132, 536–543. [Google Scholar] [CrossRef] [PubMed]
- Tellinghuisen, J. Least squares in calibration: Dealing with uncertainty in x. Analyst 2010, 135, 1961–1969. [Google Scholar] [CrossRef]
- Tellinghuisen, J. Least-squares analysis of data with uncertainty in x and y: A Monte Carlo methods comparison. Chem. Int. Lab. Syst. 2010, 103, 160–169. [Google Scholar] [CrossRef]
- Francios, N.; Govaerts, B.; Boulanger, B. Optimal designs for inverse prediction in univariate nonlinear calibration models. Chem. Int. Lab. Syst. 2004, 74, 283–292. [Google Scholar] [CrossRef]
- Tellinghuisen, J. Simple algorithms for nonlinear calibration by the classical and standard additions methods. Analyst. 2005, 130, 370–378. [Google Scholar] [CrossRef]
- Mulholland, M.; Hibbert, D.B. Linearity and the limitations of least squares calibration. J. Chrom. A. 1997, 762, 73–82. [Google Scholar] [CrossRef]
- Rehman, Z.; Zhang, S. Three-dimensional elasto-plastic damage model for gravelly soil-structure interface considering the shear coupling effect. Comput. Geotech. 2021, 129, 103868. [Google Scholar] [CrossRef]
- Rehman, Z.; Khalid, U.; Ijaz, N.; Mujtaba, H.; Haider, A.; Farooq, K.; Ijaz, Z. Machine learning-based intelligent modeling of hydraulic conductivity of sandy soils considering a wide range of grain sizes. Eng. Geol. 2022, 311, 106899. [Google Scholar] [CrossRef]
- Ni, Y.; Wang, H.; Hu, S. Linear Fitting of Time-Varying Signals in Static Noble Gas Mass Spectrometry Should Be Avoided. Anal. Chem. 2023, 95, 3917–3921. [Google Scholar] [CrossRef] [PubMed]
- Bremser, W.; Viallon, J.; Wielgosz, R.I. Influence of correlation on the assessment of measurement result compatibility over a dynamic range. Metrologia 2007, 44, 495–504. [Google Scholar] [CrossRef]
- Cox, M.G.; Jones, H.M. An algorithm for least-squares circle fitting to data with specified uncertainty ellipses. IMA J. Numer. Anal. 1981, 1, 3–22. [Google Scholar] [CrossRef]
- Tellinghuisen, J. Goodness-of-Fit Tests in Calibration: Are They Any Good for Selecting Least-Squares weighting formula. Anal. Chem. 2022, 94, 15997–16005. [Google Scholar] [CrossRef]
- Milton, M.J.T.; Harris, P.M.; Smith, I.M.; Brown, A.S.; Goody, B.A. Implementation of a generalized least-squares method for determining calibration curves from data with general uncertainty structures. Metrologia 2006, 43, S291–S298. [Google Scholar] [CrossRef]
- Markovsky, I.; Van Huffel, S. Overview of total least-squares methods. Signal Process 2007, 87, 2283–2302. [Google Scholar] [CrossRef]
- Malengo, A.; Pennecchi, F. A weighted total least-squares algorithm for any fitting model with correlated variables. Metrologia 2013, 50, 654–662. [Google Scholar] [CrossRef]
- Krystek, M.; Anton, M. A weighted total least-squares algorithm for fitting a straight line. Meas. Sci. Technol. 2007, 18, 3438–3442. [Google Scholar] [CrossRef]
- Amiri-Simkooei, A.R.; Zangeneh-Nejad, F.; Asgari, J. On the covariance matrix of weighted total least-squares estimates. J. Surv. Eng. 2016, 142, 04015014. [Google Scholar] [CrossRef]
- Krystek, M.; Anton, M. A least-squares algorithm for fitting data points with mutually correlated coordinates to a straight line. Meas. Sci. Technol. 2011, 22, 035101. [Google Scholar] [CrossRef]
- Bremser, W.; Hasselbarth, W. Controlling uncertainty in calibration. Anal. Chim. Acta 1997, 348, 61–69. [Google Scholar] [CrossRef]
- Forbes, A.B. Generalised regression problems in metrology. Numer. Algorithms 1993, 5, 523–534. [Google Scholar] [CrossRef]
- ISO 6143:2001(E); Gas Analysis—Comparison Methods for Determining and Checking the Composition of Calibration Gas Mixtures, 2nd ed. ISO: Geneva, Switzerland, 2001.
- ISO/TS 28037:2010(E); Determination and Use of Straight Line Calibration Functions, 1st ed. ISO: Geneva, Switzerland, 2010.
- DIN 1319-4 1985; Basic Concepts of Measurements; Treatment of Uncertainties in the Evaluation of Measurements. DIN: Berlin, Germany, 1985.
- Malengo, A.; Pennecchi, F.; Spazzini, P.G. Calibration Curve Computing (CCC) software v2.0: A new release of the INRIM regression tool. Meas. Sci. Technol. 2015, 31, 114004. [Google Scholar] [CrossRef]
- Smith, I.M.; Onakunle, F.O. XLGENLINE, Software for Generalized Least Squares Fitting. 2007. Available online: https://www.npl.co.uk/resources/software/xlgenline-and-xgenline (accessed on 27 February 2024).
- XGENLINE. Software for Generalized Least Squares Fitting. Available online: https://www.npl.co.uk/resources/software/xgenline (accessed on 27 February 2024).
- Software to Support ISO/TS 28037:2010(E). Available online: https://www.npl.co.uk/resources/software/iso-ts-28037-2010e (accessed on 27 February 2024).
- Bremser, W. Calibration Tool B LEAST Software Supporting Implementation of ISO Standard 6143. 2001. Available online: https://www.iso.org/obp/ui/es/#iso:std:iso:6143:dis:ed-3:v1:en:sec:C (accessed on 27 February 2024).
- Klauenberg, K.; Martens, S.; Bošnjaković, A.; Cox, M.G.; van der Veen, A.M.H.; Elster, C. The GUM perspective on straight-line errors-in-variables regression. Measurement 2022, 187, 110340. [Google Scholar] [CrossRef]
- Khalid, U.; Rehman, Z.; Liao, C.; Farooq, K.; Mujtaba, H. Compressibility of Compacted Clays Mixed with a Wide Range of Bentonite for Engineered Barriers. Arab. J. Sci. Eng. 2019, 44, 5027–5042. [Google Scholar] [CrossRef]
- Johnson, R.A.; Wichern, D.W. Applied Multivariate Statistical Analysis, 6th ed.; Pearson: London, UK, 2002; Chapter 7; pp. 360–538. [Google Scholar]
- Hill, C.; Griffiths, W.E.; Lim, G.C. Principles of Econometrics, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 1971; pp. 119–124. [Google Scholar]
- Rao, C.R.; Toutenburg, H.; Shalabh; Heumann, C. Linear Models and Generalizations, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 36–38. [Google Scholar]
- Walpole, R.E.; Myers, R.H.; Myers, S.L.; Ye, K.E. Probability and Statistics for Engineers and Scientists, 9th ed.; Pearson: London, UK, 2014; 501p. [Google Scholar]
- DIN 1319-4:1999-02; Fundamentals of Metrology: Part 4. Evaluation of Measurements; Uncertainty of Measurement. DIN: Berlin, Germany, 1999.
- ISO/IEC Guide 98-3:2008/Suppl.1:2008; Propagation of Distributions Using a Monte Carlo Method. ISO: Geneva, Switzerland, 2008.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).