

Non-Destructive Detection of Soybean Storage Quality Using Hyperspectral Imaging Technology


Abstract
1. Introduction
2. Results and Discussion
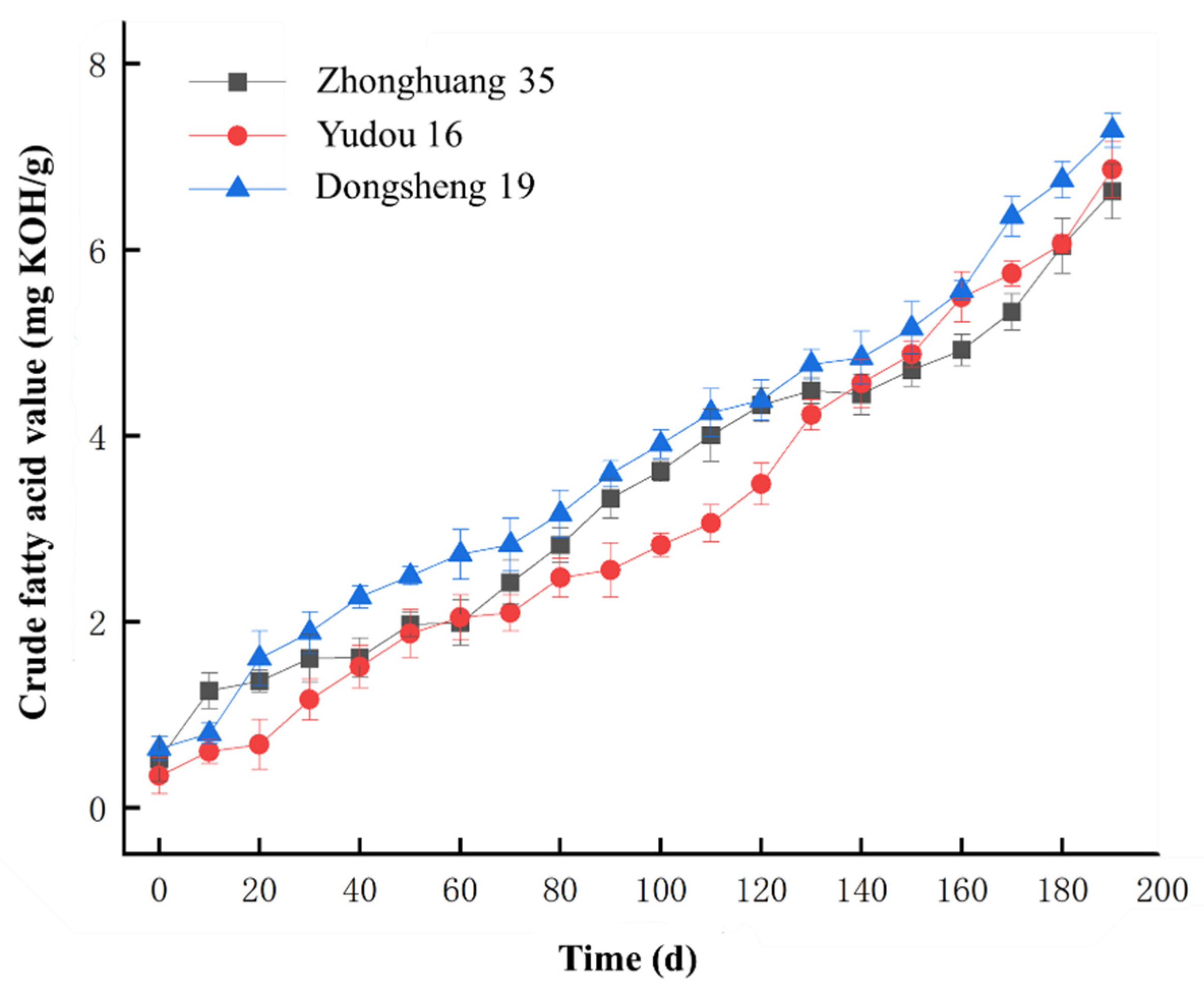
2.1. Changes in Crude Fatty Acid Values of Soybeans During Aging and Sample Set Partitioning
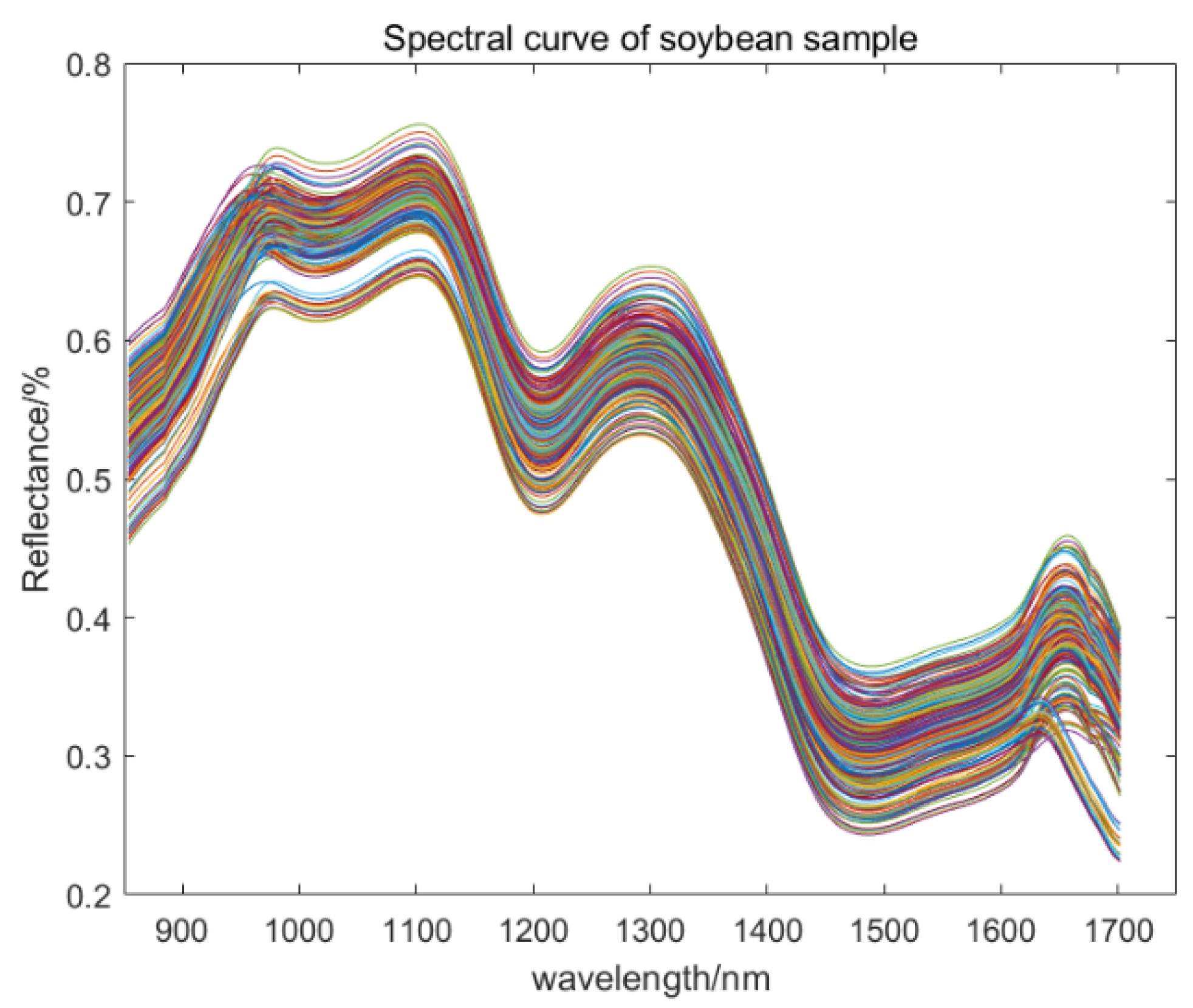
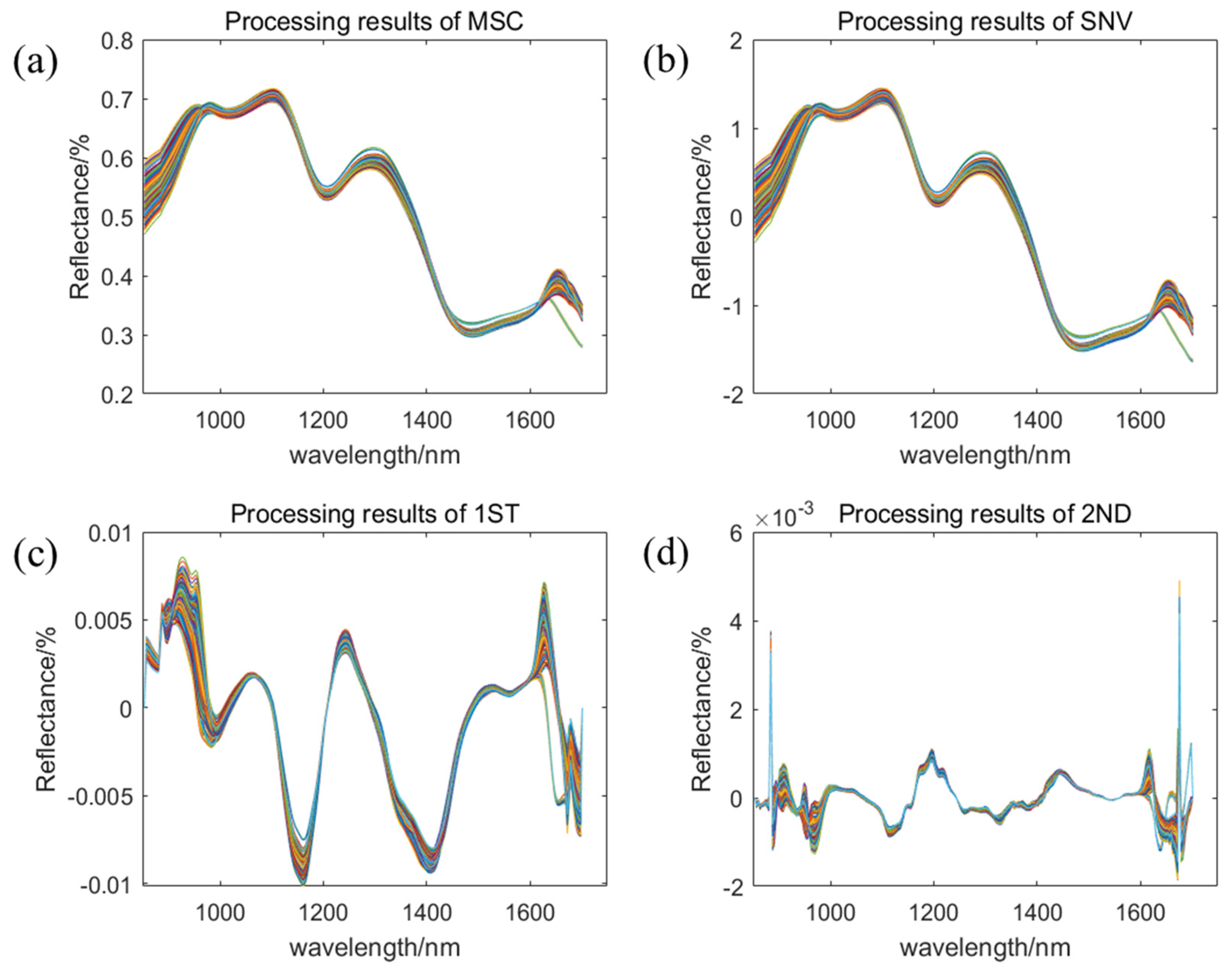
2.2. Data Extraction and Preprocessing
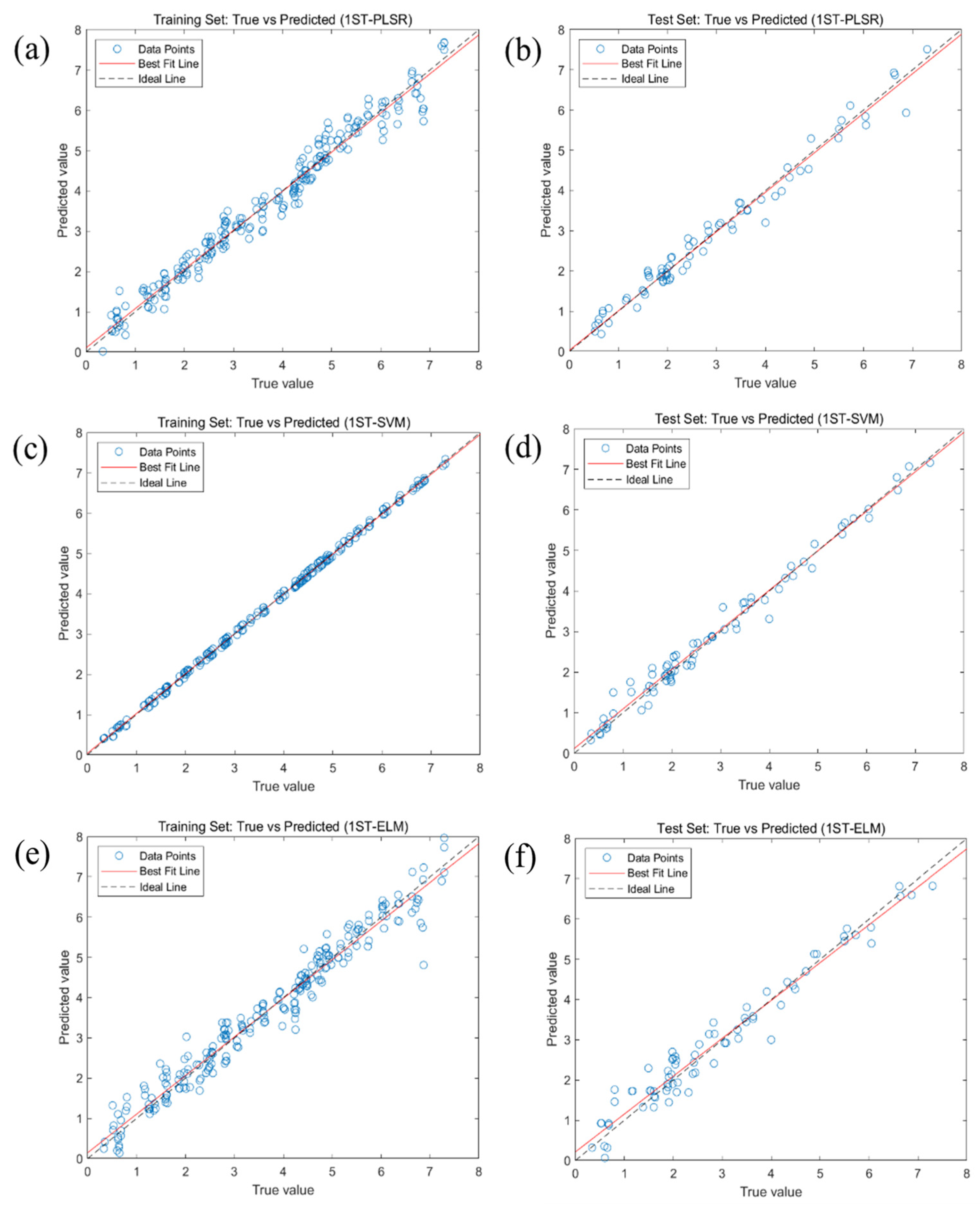
2.3. Predictive Modeling of Crude Fatty Acid Values Based on Full Band
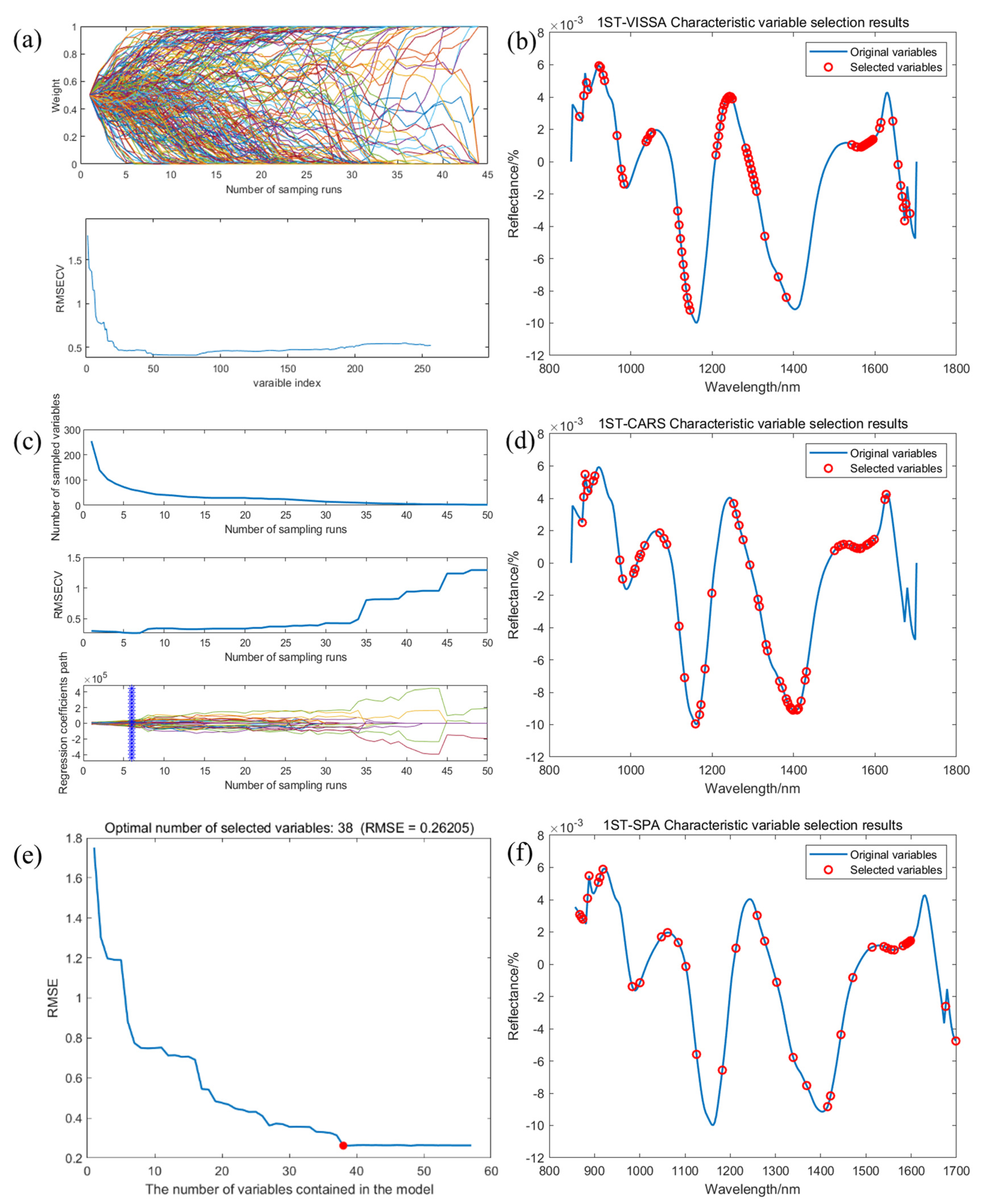
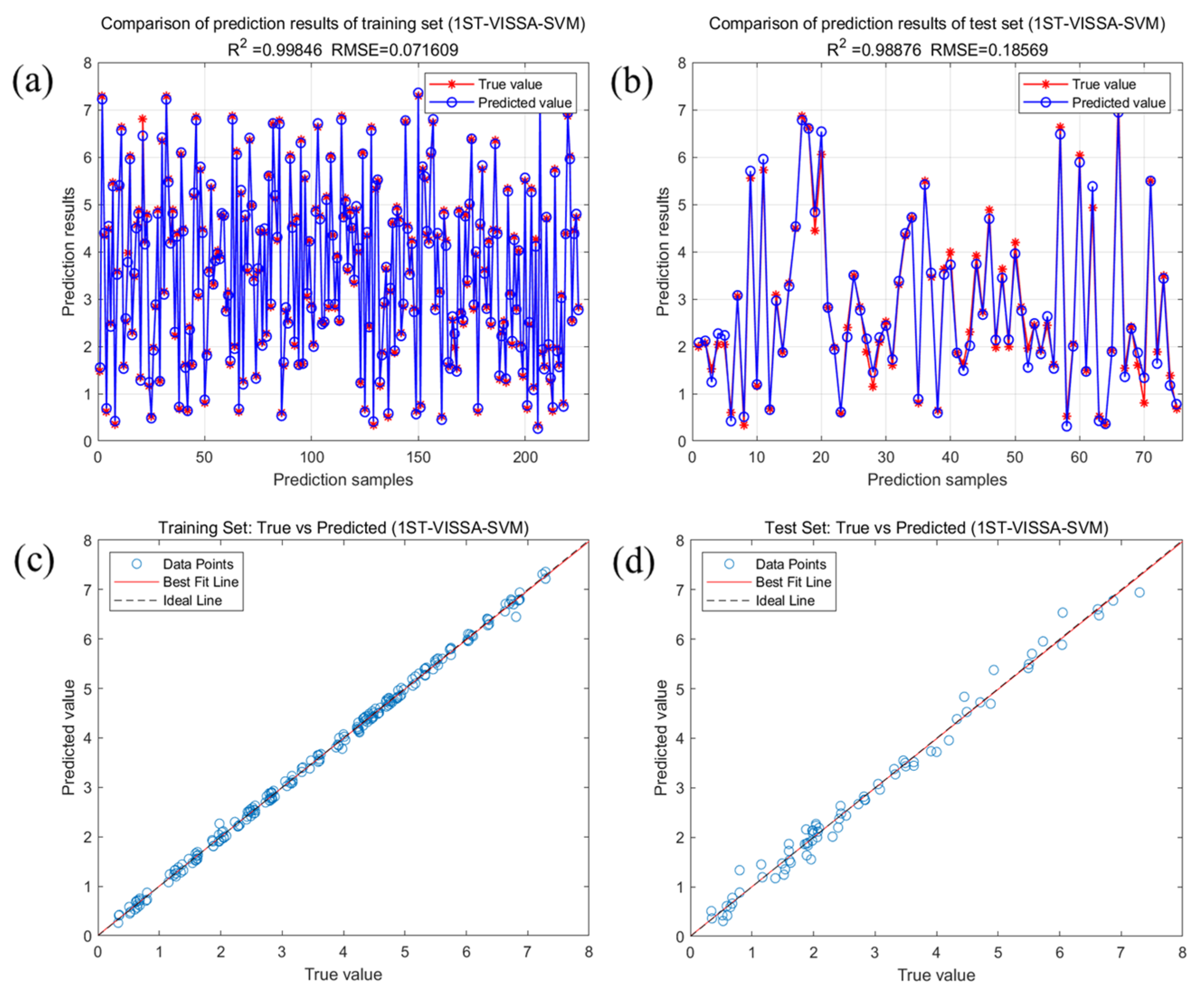
2.4. Predictive Modeling of Crude Fatty Acid Values Based on Feature Variables
2.5. Visualization of Crude Fatty Acid Values
3. Materials and Methods
3.1. Sample Processing
3.1.1. Sample Preparation
3.1.2. Packaging and Storage
3.1.3. Soybean Sampling
3.2. Determination of Crude Fatty Acid Values
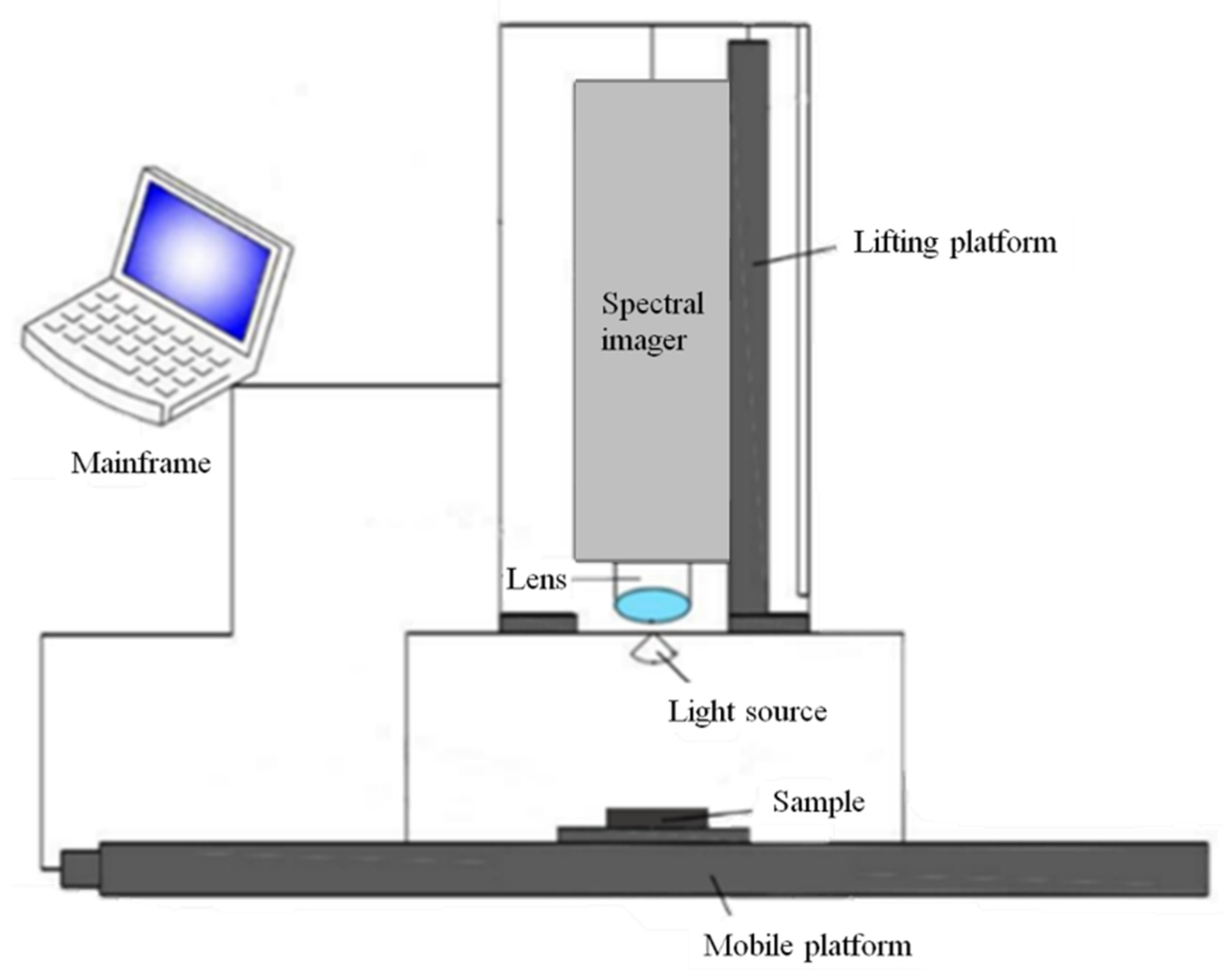
3.3. Acquisition and Correction of Hyperspectral Image Information
3.4. Data Analysis
3.5. Visualization of Crude Fatty Acid Values
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wijewardana, C.; Reddy, K.R.; Bellaloui, N. Soybean seed physiology, quality, and chemical composition under soil moisture stress. Food Chem. 2019, 278, 92–100. [Google Scholar] [CrossRef]
- Zhu, Z.; Chen, S.; Wu, X.; Xing, C.; Yuan, J. Determination of soybean routine quality parameters using near-infrared spectroscopy. Food Sci. Nutr. 2018, 6, 1109–1118. [Google Scholar] [CrossRef] [PubMed]
- Vergara, R.; Silva, R.N.O.D.; Nadal, A.P.; Gadotti, G.I.; Aumonde, T.Z.; Villela, F.A. Harvest delay, storage and physiological quality of soybean seeds. J. Seed Sci. 2019, 41, 506–513. [Google Scholar] [CrossRef]
- Weerasekara, I.; Sinniah, U.R.; Namasivayam, P.; Nazli, M.H.; Abdurahman, S.A.; Ghazali, M.N. The influence of seed production environment on seed development and quality of soybean (Glycine max (L.) Merrill). Agronomy 2021, 11, 1430. [Google Scholar] [CrossRef]
- GB/T 31785-2015; Guidelines for Evaluation of Soybean Storage Character. Standardization Administration of China: Beijing, China, 2015.
- Song, W.; Sun, S.; Wu, T.; Yang, R.; Tian, S.; Xu, C.; Jiang, B.; Yuan, S.; Hou, W.; Wu, C.; et al. Geographic distributions and the regionalization of soybean seed compositions across China. Food Res. Int. 2023, 164, 112364. [Google Scholar] [CrossRef]
- Fu, D.; Zhou, J.; Scaboo, A.M.; Niu, X. Nondestructive phenotyping fatty acid trait of single soybean seeds using reflective hyperspectral imagery. J. Food Process Eng. 2021, 44, e13759. [Google Scholar] [CrossRef]
- Oner, F.; Aykutlu, H.M. The effect of maize-soybean intercropping systems on a set of technological and physiological properties. Appl. Ecol. Environ. Res. 2019, 17, 2149–2165. [Google Scholar] [CrossRef]
- Aviara, N.A.; Liberty, J.T.; Olatunbosun, O.S.; Shoyombo, H.A.; Oyeniyi, S.K. Potential application of hyperspectral imaging in food grain quality inspection, evaluation and control during bulk storage. J. Agric. Food Res. 2022, 8, 100288. [Google Scholar] [CrossRef]
- An, D.; Zhang, L.; Liu, Z.; Liu, J.; Wei, Y. Advances in infrared spectroscopy and hyperspectral imaging combined with artificial intelligence for the detection of cereals quality. Crit. Rev. Food. Sci. Nutr. 2023, 63, 9766–9796. [Google Scholar] [CrossRef]
- Shi, T.; Gao, Y.; Song, J.; Ao, M.; Hu, X.; Yang, W.; Chen, W.; Liu, Y.; Feng, H. Using VIS-NIR hyperspectral imaging and deep learning for non-destructive high-throughput quantification and visualization of nutrients in wheat grains. Food Chem. 2024, 461, 140651. [Google Scholar] [CrossRef]
- Wu, J.; Zhang, Y.; Hu, P.; Wu, Y. A review of the application of hyperspectral imaging technology in agricultural crop economics. Coatings 2024, 14, 1285. [Google Scholar] [CrossRef]
- Wang, B.; Sun, J.; Xia, L.; Liu, J.; Wang, Z.; Li, P.; Guo, Y.; Sun, X. The applications of hyperspectral imaging technology for agricultural products quality analysis: A review. Food Res. Int. 2023, 39, 1043–1062. [Google Scholar] [CrossRef]
- Teet, S.E.; Hashim, N. Recent advances of application of optical imaging techniques for disease detection in fruits and vegetables: A review. Food Control 2023, 152, 109849. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, S.; Zhou, X.; Cheng, J. Study on rapid non-destructive detection method of corn freshness based on hyperspectral imaging technology. Molecules 2024, 29, 2968. [Google Scholar] [CrossRef]
- Lu, B.; Dao, P.D.; Liu, J.; He, Y.; Shang, J. Recent advances of hyperspectral imaging technology and applications in agriculture. Remote Sens. 2020, 12, 2659. [Google Scholar] [CrossRef]
- Nikzadfar, M.; Rashvand, M.; Zhang, H.; Shenfield, A.; Genovese, F.; Altieri, G.; Matera, A.; Tornese, I.; Laveglia, S.; Paterna, G.; et al. Hyperspectral imaging aiding artificial intelligence: A reliable approach for food qualification and safety. Appl. Sci. 2024, 14, 9821. [Google Scholar] [CrossRef]
- Pour, A.B.; Zoheir, B.; Pradhan, B.; Hashim, M. Editorial for the special issue: Multispectral and hyperspectral remote sensing data for mineral exploration and environmental monitoring of mined areas. Remote Sens. 2021, 13, 519. [Google Scholar] [CrossRef]
- Ram, B.G.; Oduor, P.; Igathinathane, C.; Howatt, K.; Sun, X. A systematic review of hyperspectral imaging in precision agriculture: Analysis of its current state and future prospects. Comput. Electron. Agric. 2024, 222, 109037. [Google Scholar] [CrossRef]
- Desta, K.T.; Hur, O.S.; Lee, S.; Yoon, H.; Shin, M.J.; Yi, J.; Lee, Y.; Ro, N.Y.; Wang, X.; Choi, Y.M. Origin and seed coat color differently affect the concentrations of metabolites and antioxidant activities in soybean (Glycine max (L.) Merrill) seeds. Food Chem. 2022, 381, 132249. [Google Scholar] [CrossRef]
- Abdelghany, A.M.; Zhang, S.; Azam, M.; Shaibu, A.S.; Feng, Y.; Li, Y.; Tian, Y.; Hong, H.; Li, B.; Sun, J. Profiling of seed fatty acid composition in 1025 Chinese soybean accessions from diverse ecoregions. Crop. J. 2020, 8, 635–644. [Google Scholar] [CrossRef]
- Li, Y.; Yu, Z.; Jin, J.; Zhang, Q.; Wang, G.; Liu, C.; Wu, J.; Wang, C.; Liu, X. Impact of elevated CO2 on seed quality of soybean at the fresh edible and mature stages. Front. Plant Sci. 2018, 9, 1413. [Google Scholar] [CrossRef]
- Ebone, L.A.; Caverzan, A.; Tagliari, A.; Chiomento, J.L.T.; Silveira, D.C.; Chavarria, G. Soybean seed vigor: Uniformity and growth as key factors to improve yield. Agronomy 2020, 10, 545. [Google Scholar] [CrossRef]
- Souza, A.; Santos, D.; Rodrigues, A.A.; Zuchi, J.; Vieira, M.C.; Sales, J.F. Physical and physiological soybean seed qualities stored under different environmental conditions and storage bag depths. Braz. J. Biol. 2023, 83, e277916. [Google Scholar] [CrossRef]
- Prabakaran, M.; Lee, K.; An, Y.; Kwon, C.; Kim, S.; Yang, Y.; Ahmad, A.; Kim, S.; Chung, I. Changes in soybean (Glycine max L.) flour fatty-acid content based on storage temperature and duration. Molecules 2018, 23, 2713. [Google Scholar] [CrossRef] [PubMed]
- Luo, W.; Zhang, J.; Liu, S.; Huang, H.; Zhan, B.; Fan, G.; Zhang, H. Prediction of soluble solid content in Nanfeng mandarin by combining hyperspectral imaging and effective wavelength selection. J. Food Compos. Anal. 2024, 126, 105939. [Google Scholar] [CrossRef]
- Shao, Y.; Liu, Y.; Xuan, G.; Shi, Y.; Li, Q.; Hu, Z. Detection and analysis of sweet potato defects based on hyperspectral imaging technology. Infrared Phys. Technol. 2022, 127, 104403. [Google Scholar] [CrossRef]
- Zhang, Y.; Lu, G.; Zhou, X.; Cheng, J.H. Non-destructive hyperspectral imaging for rapid determination of catalase activity and ageing visualization of wheat stored for different durations. Molecules 2022, 27, 8648. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ou, X.; He, H.J.; Kamruzzaman, M. Advancements, limitations and challenges in hyperspectral imaging for comprehensive assessment of wheat quality: An up-to-date review. Food Chem. X 2024, 21, 101235. [Google Scholar] [CrossRef]
- Jiang, X.; Bu, Y.; Han, L.; Tian, J.; Hu, X.; Zhang, X.; Huang, D.; Luo, H. Rapid nondestructive detecting of wheat varieties and mixing ratio by combining hyperspectral imaging and ensemble learning. Food Control 2023, 150, 109740. [Google Scholar] [CrossRef]
- Dashti, A.; Mueller-Maatsch, J.; Roetgerink, E.; Wijtten, M.; Weesepoel, Y.; Parastar, H.; Yazdanpanah, H. Comparison of a portable VIS-NIR hyperspectral imaging and a snapscan SWIR hyperspectral imaging for evaluation of meat authenticity. Food Chem. X 2023, 18, 100667. [Google Scholar] [CrossRef]
- Ram, B.G.; Zhang, Y.; Costa, C.; Ahmed, M.R.; Peters, T.; Jhala, A.; Howatt, K.; Sun, X. Palmer amaranth identification using hyperspectral imaging and machine learning technologies in soybean field. Comput. Electron. Agric. 2023, 215, 108444. [Google Scholar] [CrossRef]
- Cozzolino, D.; Williams, P.J.; Hoffman, L.C. An overview of pre-processing methods available for hyperspectral imaging applications. Microchem. J. 2023, 193, 109129. [Google Scholar] [CrossRef]
- Dai, Y.; Yan, B.; Xiong, F.; Bai, R.; Wang, S.; Guo, L.; Yang, J. Tanshinone content prediction and geographical origin classification of Salvia miltiorrhiza by combining hyperspectral imaging with chemometrics. Foods 2024, 13, 3673. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Lei, Y.; He, L.; Hu, X.; Tian, J.; Chen, M.; Huang, D.; Luo, H. The rapid detection of the tannin content of grains based on hyperspectral imaging technology and chemometrics. J. Food Compos. Anal. 2023, 123, 105604. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, Y.; Yuan, Y.; Zhao, Y.; Nie, J.; Nan, T.; Huang, L.; Yang, J. Nutrient content prediction and geographical origin identification of red raspberry fruits by combining hyperspectral imaging with chemometrics. Front. Nutr. 2022, 9, 980095. [Google Scholar] [CrossRef]
- Song, Y.; Cao, S.; Chu, X.; Zhou, Y.; Xu, Y.; Sun, T.; Zhou, G.; Liu, X. Non-destructive detection of moisture and fatty acid content in rice using hyperspectral imaging and chemometrics. J. Food Compos. Anal. 2023, 121, 105397. [Google Scholar] [CrossRef]
- Aulia, R.; Amanah, H.Z.Z.; Lee, H.; Kim, M.S.S.; Baek, I.; Qin, J.; Cho, B. Protein and lipid content estimation in soybeans using Raman hyperspectral imaging. Front. Plant Sci. 2023, 14, 1167139. [Google Scholar] [CrossRef]
- Zaaboul, F.; Zhao, Q.; Xu, Y.; Liu, Y. Soybean oil bodies: A review on composition, properties, food applications, and future research aspects. Food Hydrocoll. 2022, 124, 107296. [Google Scholar] [CrossRef]
- Jo, H.; Noy, N.; Song, J.T.; Lee, J. Selection of soybean accessions with seed storability test under accelerated aging conditions. Plant Breed. Biotechnol. 2023, 11, 263–270. [Google Scholar] [CrossRef]
- GB/T 14488.1-2008; Oilseeds: Determination of Oil Content. Standardization Administration of China: Beijing, China, 2008.
- GB 5009.229-2016; National Food Safety Standard: Determination of Acid Value in Food. Standardization Administration of China: Beijing, China, 2016.
- Zhu, J.; Li, H.; Rao, Z.; Ji, H. Identification of slightly sprouted wheat kernels using hyperspectral imaging technology and different deep convolutional neural networks. Food Control 2023, 143, 109291. [Google Scholar] [CrossRef]
- Zuo, J.; Peng, Y.; Li, Y.; Zou, W.; Chen, Y.; Huo, D.; Chao, K. Nondestructive detection of nutritional parameters of pork based on NIR hyperspectral imaging technique. Meat Sci. 2023, 202, 109204. [Google Scholar] [CrossRef] [PubMed]
- Femenias, A.; Gatius, F.; Ramos, A.J.; Sanchis, V.; Marin, S. Near-infrared hyperspectral imaging for deoxynivalenol and ergosterol estimation in wheat samples. Food Chem. 2021, 341, 128206. [Google Scholar] [CrossRef] [PubMed]
- Tian, P.; Meng, Q.; Wu, Z.; Lin, J.; Huang, X.; Zhu, H.; Zhou, X.; Qiu, Z.; Huang, Y.; Li, Y. Detection of mango soluble solid content using hyperspectral imaging technology. Infrared Phys. Technol. 2023, 129, 104576. [Google Scholar] [CrossRef]
- Zhang, L.; Sun, J.; Zhou, X.; Nirere, A.; Wu, X.; Dai, R. Classification detection of saccharin jujube based on hyperspectral imaging technology. J. Food Process Preserv. 2020, 44, e14591. [Google Scholar] [CrossRef]
- Feng, Z.; Wang, L.; Yang, Z.; Zhang, Y.; Li, X.; Song, L.; He, L.; Duan, J.; Feng, W. Hyperspectral monitoring of powdery mildew disease severity in wheat based on machine learning. Front. Plant Sci. 2022, 13, 828454. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, Y.; Wei, Y.; An, D. Near-infrared hyperspectral imaging technology combined with deep convolutional generative adversarial network to predict oil content of single maize kernel. Food Chem. 2022, 370, 131047. [Google Scholar] [CrossRef]
- Zhu, H.; Chu, B.; Zhang, C.; Liu, F.; Jiang, L.; He, Y. Hyperspectral imaging for presymptomatic detection of tobacco disease with successive projections algorithm and machine-learning classifiers. Sci. Rep. 2017, 7, 4125. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Sample Size | Crude Fatty Acid Value (mg KOH/g) | |||
|---|---|---|---|---|---|
| Maximum | Minimum | Average Value | Standard Deviation | ||
| Training set | 225 | 7.30 | 0.33 | 3.62 | 1.83 |
| Test set | 75 | 7.29 | 0.34 | 2.81 | 1.76 |
| Model | Pretreatment | Training Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | MAPE | R2 | RMSE | MAE | MAPE | ||
| PLSR | RAW | 0.9615 | 0.3579 | 0.2769 | 0.1270 | 0.9626 | 0.3385 | 0.2581 | 0.1704 |
| MSC | 0.9623 | 0.2731 | 0.3541 | 0.1219 | 0.9522 | 0.3828 | 0.2933 | 0.2076 | |
| SNV | 0.9611 | 0.2823 | 0.3600 | 0.1303 | 0.9505 | 0.3899 | 0.2996 | 0.2130 | |
| 1ST | 0.9712 | 0.2403 | 0.3095 | 0.1073 | 0.9748 | 0.2778 | 0.2205 | 0.1467 | |
| 2ND | 0.9882 | 0.1535 | 0.1986 | 0.0759 | 0.9716 | 0.2953 | 0.2525 | 0.1553 | |
| SVM | RAW | 0.9905 | 0.1780 | 0.0978 | 0.0402 | 0.9442 | 0.4138 | 0.3310 | 0.2094 |
| MSC | 0.9987 | 0.0644 | 0.0662 | 0.0288 | 0.9838 | 0.2230 | 0.1612 | 0.0987 | |
| SNV | 0.9987 | 0.0648 | 0.0664 | 0.0287 | 0.9738 | 0.2838 | 0.1936 | 0.1020 | |
| 1ST | 0.9988 | 0.0614 | 0.0642 | 0.0283 | 0.9826 | 0.2310 | 0.1714 | 0.0973 | |
| 2ND | 0.9987 | 0.0630 | 0.0653 | 0.0286 | 0.9802 | 0.2463 | 0.1782 | 0.1105 | |
| ELM | RAW | 0.9134 | 0.5368 | 0.4121 | 0.2086 | 0.8365 | 0.7084 | 0.4874 | 0.3889 |
| MSC | 0.9376 | 0.3741 | 0.4555 | 0.1895 | 0.9251 | 0.4792 | 0.3904 | 0.2911 | |
| SNV | 0.9661 | 0.2554 | 0.3359 | 0.1195 | 0.9438 | 0.4154 | 0.3205 | 0.2195 | |
| 1ST | 0.9599 | 0.2750 | 0.3651 | 0.1241 | 0.9558 | 0.3680 | 0.2921 | 0.1947 | |
| 2ND | 0.9216 | 0.3963 | 0.5107 | 0.1954 | 0.9062 | 0.5364 | 0.4035 | 0.2610 | |
| Model | Feature Extraction | Training Set | Test Set | ||||||
|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE | MAE | MAPE | R2 | RMSE | MAE | MAPE | ||
| PLSR | None | 0.9712 | 0.3095 | 0.1073 | 0.2403 | 0.9748 | 0.2778 | 0.1467 | 0.2205 |
| VISSA | 0.9648 | 0.3422 | 0.2617 | 0.1229 | 0.9643 | 0.3311 | 0.2530 | 0.1673 | |
| SPA | 0.9739 | 0.2947 | 0.2323 | 0.1048 | 0.9699 | 0.3040 | 0.2424 | 0.1602 | |
| CARS | 0.9772 | 0.2757 | 0.2173 | 0.1078 | 0.9729 | 0.2883 | 0.2311 | 0.1620 | |
| SVM | None | 0.9988 | 0.0642 | 0.0283 | 0.0614 | 0.9826 | 0.2310 | 0.0973 | 0.1714 |
| VISSA | 0.9985 | 0.0716 | 0.0631 | 0.0281 | 0.9888 | 0.1857 | 0.1409 | 0.0805 | |
| SPA | 0.9970 | 0.0996 | 0.0759 | 0.0342 | 0.9881 | 0.1908 | 0.1423 | 0.0864 | |
| CARS | 0.9980 | 0.0806 | 0.0681 | 0.0290 | 0.9847 | 0.2167 | 0.1686 | 0.0928 | |
| ELM | None | 0.9599 | 0.3651 | 0.1241 | 0.2750 | 0.9558 | 0.3680 | 0.1947 | 0.2921 |
| VISSA | 0.9899 | 0.1836 | 0.1466 | 0.0664 | 0.9790 | 0.2537 | 0.1953 | 0.1075 | |
| SPA | 0.9928 | 0.1545 | 0.1200 | 0.0564 | 0.9830 | 0.2286 | 0.1744 | 0.1166 | |
| CARS | 0.9898 | 0.1839 | 0.1392 | 0.0558 | 0.9770 | 0.2655 | 0.2046 | 0.1158 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Wu, W.; Zhou, X.; Cheng, J.-H. Non-Destructive Detection of Soybean Storage Quality Using Hyperspectral Imaging Technology. Molecules 2025, 30, 1357. https://doi.org/10.3390/molecules30061357
Zhang Y, Wu W, Zhou X, Cheng J-H. Non-Destructive Detection of Soybean Storage Quality Using Hyperspectral Imaging Technology. Molecules. 2025; 30(6):1357. https://doi.org/10.3390/molecules30061357
Chicago/Turabian StyleZhang, Yurong, Wenliang Wu, Xianqing Zhou, and Jun-Hu Cheng. 2025. "Non-Destructive Detection of Soybean Storage Quality Using Hyperspectral Imaging Technology" Molecules 30, no. 6: 1357. https://doi.org/10.3390/molecules30061357
APA StyleZhang, Y., Wu, W., Zhou, X., & Cheng, J.-H. (2025). Non-Destructive Detection of Soybean Storage Quality Using Hyperspectral Imaging Technology. Molecules, 30(6), 1357. https://doi.org/10.3390/molecules30061357