1. Introduction
Biliary tract cancer (BTC) or cholangiocarcinomas (CCA) are malignancy tumors arising from biliary epithelia. They are categorized into intrahepatic (iCCA), perihilar (pCCA), and distal (dCCA) cholangiocarcinoma. The epithelial malignancies originate from transformed cholangiocytes [
1]. These cancers present in some specific areas with specific possible risk factors such as chronic cholangitis, liver fluke infection, and alcohol consumption [
2].
Alcohol has been classified as a class I carcinogen for several types of cancers [
3]. Excessive chronic alcohol consumption is a widely acknowledged possible risk factor for CCA. The carcinogenic effect of alcohol exposure on the cholangiocyte is sophisticated due to its effects on cholesterol metabolism, leading to a reduction of gallstone formation [
4,
5]. It has been shown that alcohol may inhibit DNA methylation, interaction with retinoid metabolism, and generation of reactive oxygen species (ROS), of which reactive free radicals from alcohol metabolism have the ability to form adducts with DNA, causing oxidative DNA damage [
6]. The one proposed mechanism of the putative oncogenic features of alcohol involves stimulation of cell proliferation and migration, which mediates increasing cyclin D 1 (CCND1) and matrix metalloproteinase 2 (MMP2) expression, respectively [
7]. Although several studies have reported positive associations between alcohol consumption and various cancers, the carcinogenicity of alcohol in epithelia of the biliary tract is still unclear [
8].
Next generation sequencing (NGS) techniques will certainly become a gold standard for understanding the molecular mechanisms of toxicity. RNA sequencing generates deep sequencing data for the direct quantification of transcripts. It also provides large expression data for comprehensive bioinformatics identification [
9]. Bioinformatics and computational analysis have been usefully applied in studies of various cancers and have been confirmed to provide efficient and reliable biomarkers for cancer diagnosis and therapeutic targets [
10]. In this study, integrative transcriptome analysis was designed to characterize all transcriptional activity in immortalized human cholangiocyte MMNK-1 cell line with chronic alcohol exposure. To study the association between chronic alcohol exposure and cholangiocarcinogenesis, the Differentially Expressed Genes (DEGs) from in vitro RNA-Seq were, through the use of bioinformatics analysis, merged with the DEGs of in silico CCA transcriptomics Gene Expression Omnibus (GEO) datasets.
The aims of the present study were to investigate (a) the transcriptomics alteration profile triggered by chronic alcohol exposure associated with CCA, (b) the early molecular biomarker associated with pathogenesis in CCA patients by using expression profile database, and (c) the possible oncogenic features of chronic alcohol exposure in immortalized normal human cholangiocytes.
3. Discussion
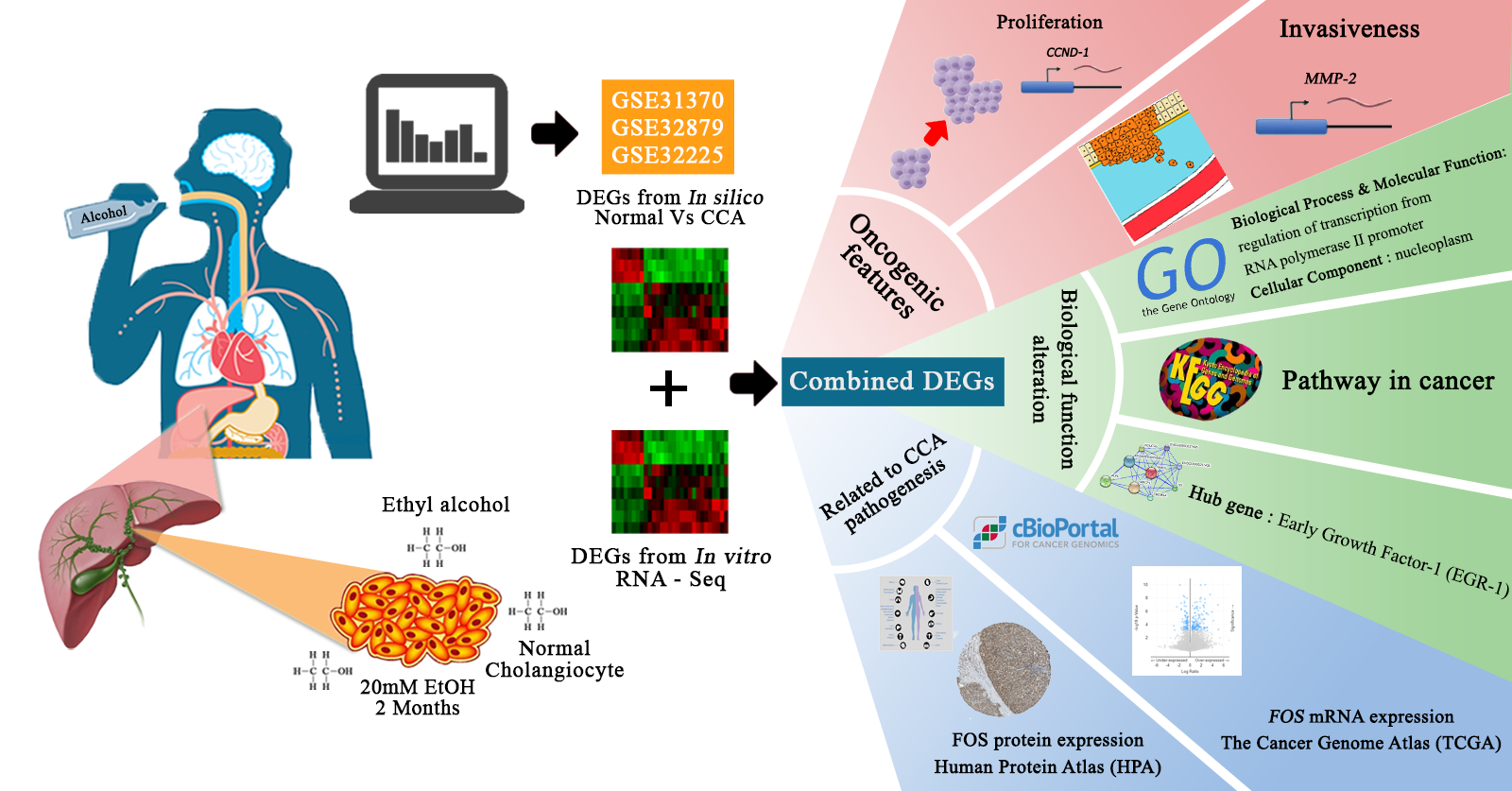
The negative lifestyle for CCA could be consumption of raw freshwater fish infected with liver fluke
Opisthorchis viverrini, beef sausage, alcohol, and tobacco use. These established possible risk factors for the CCA are very heterogeneous. The mutational landscape, the cellular origins and the carcinogenesis of the different CCA subtypes are still unclear [
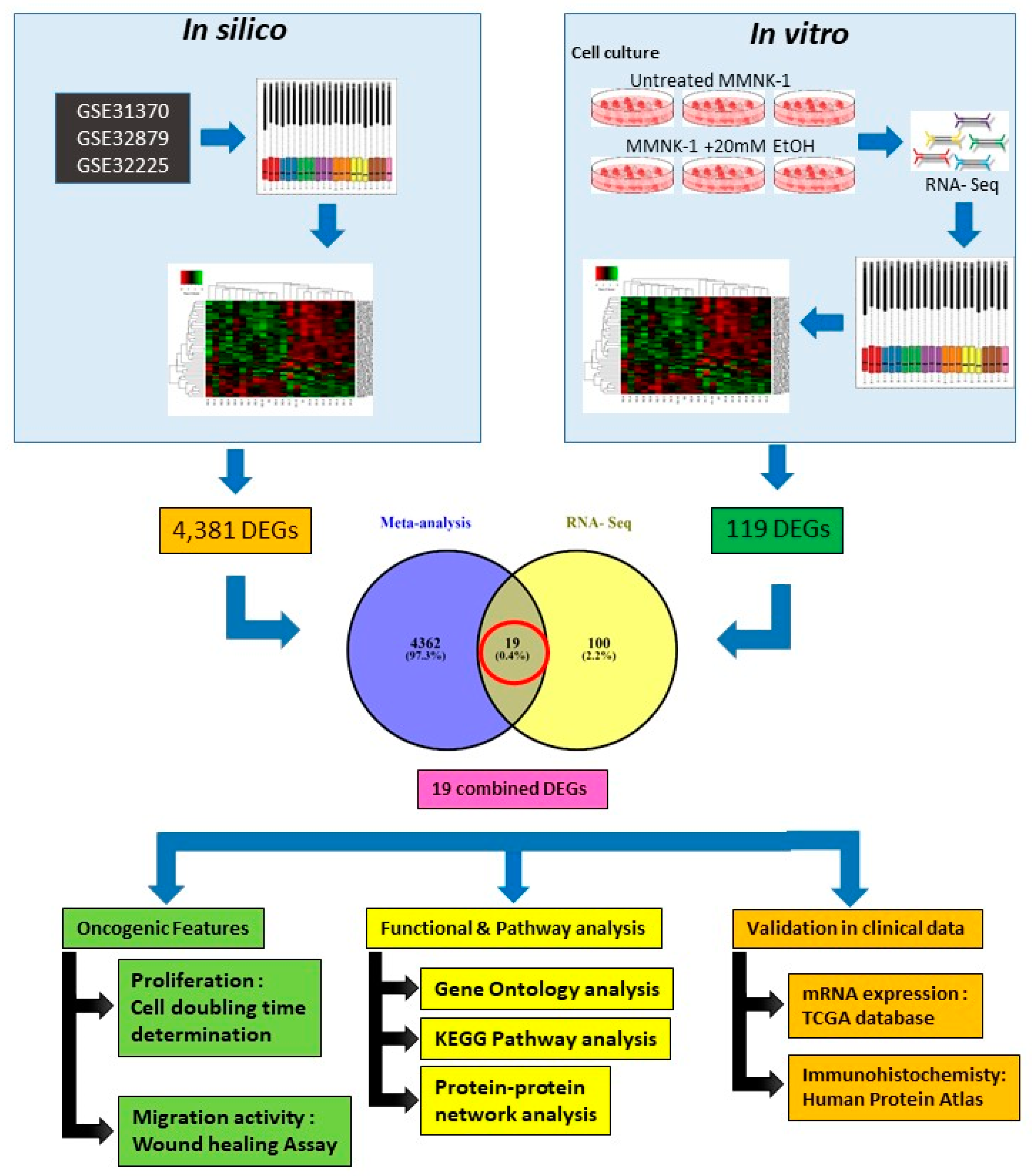
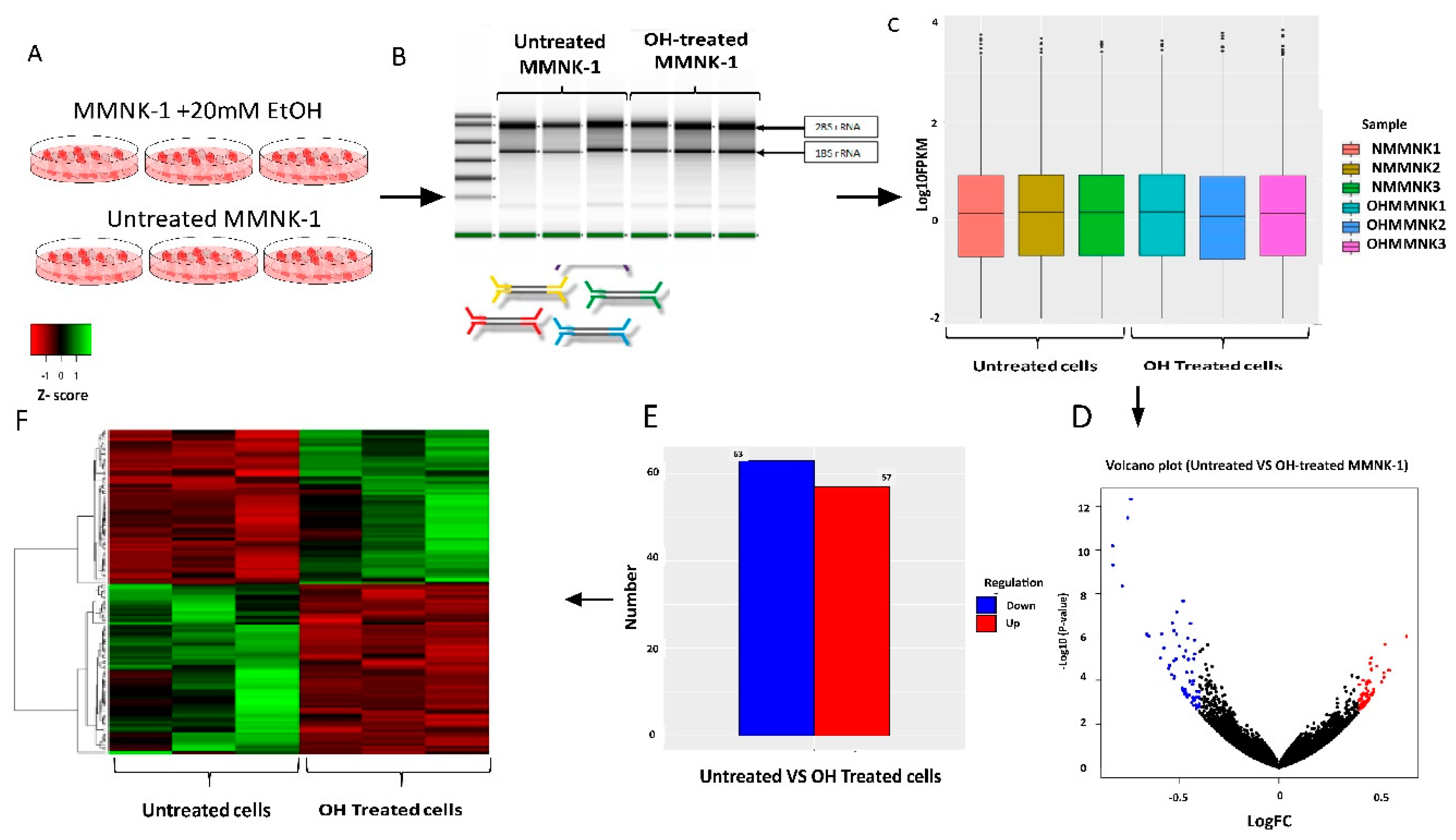
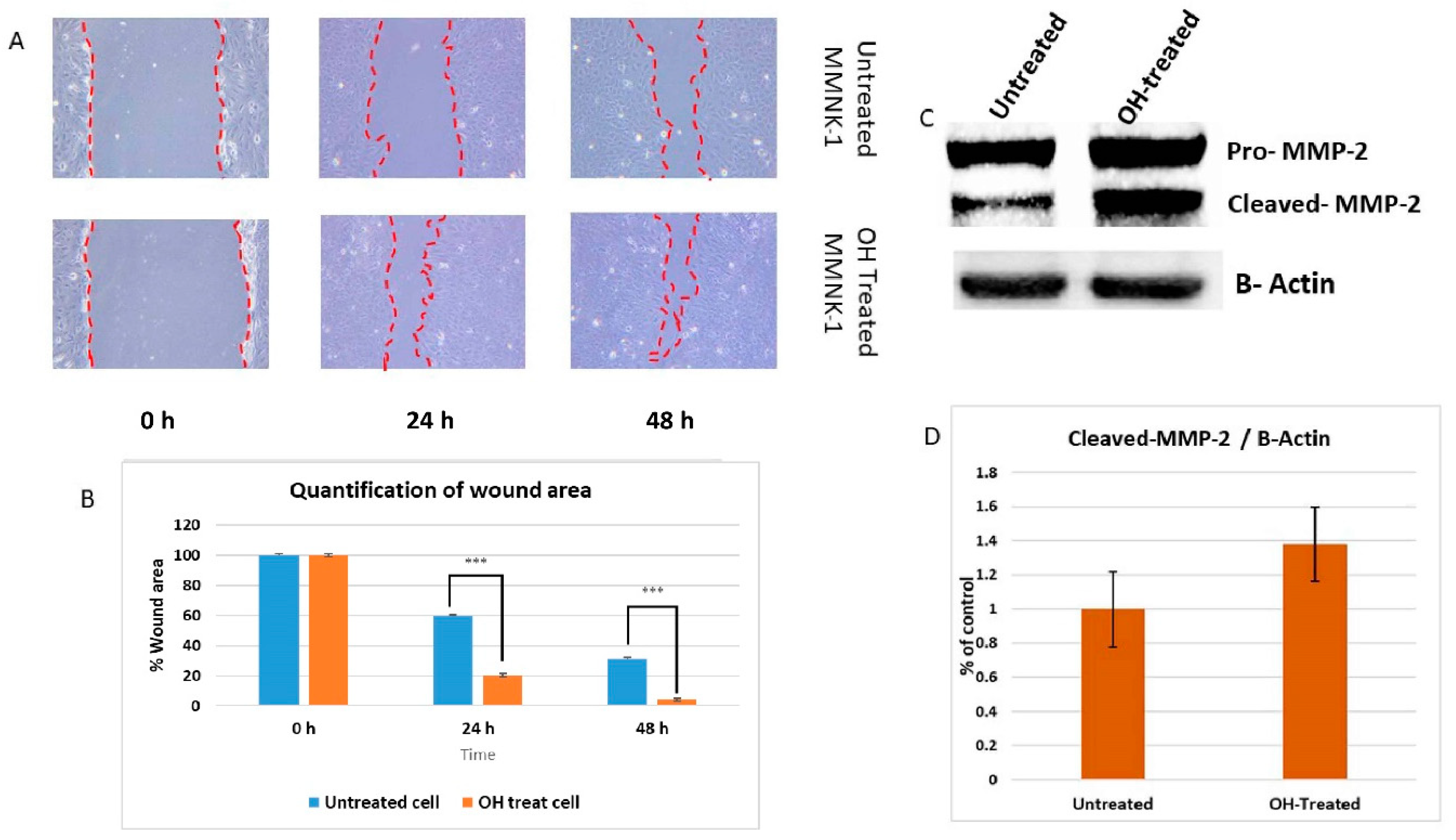
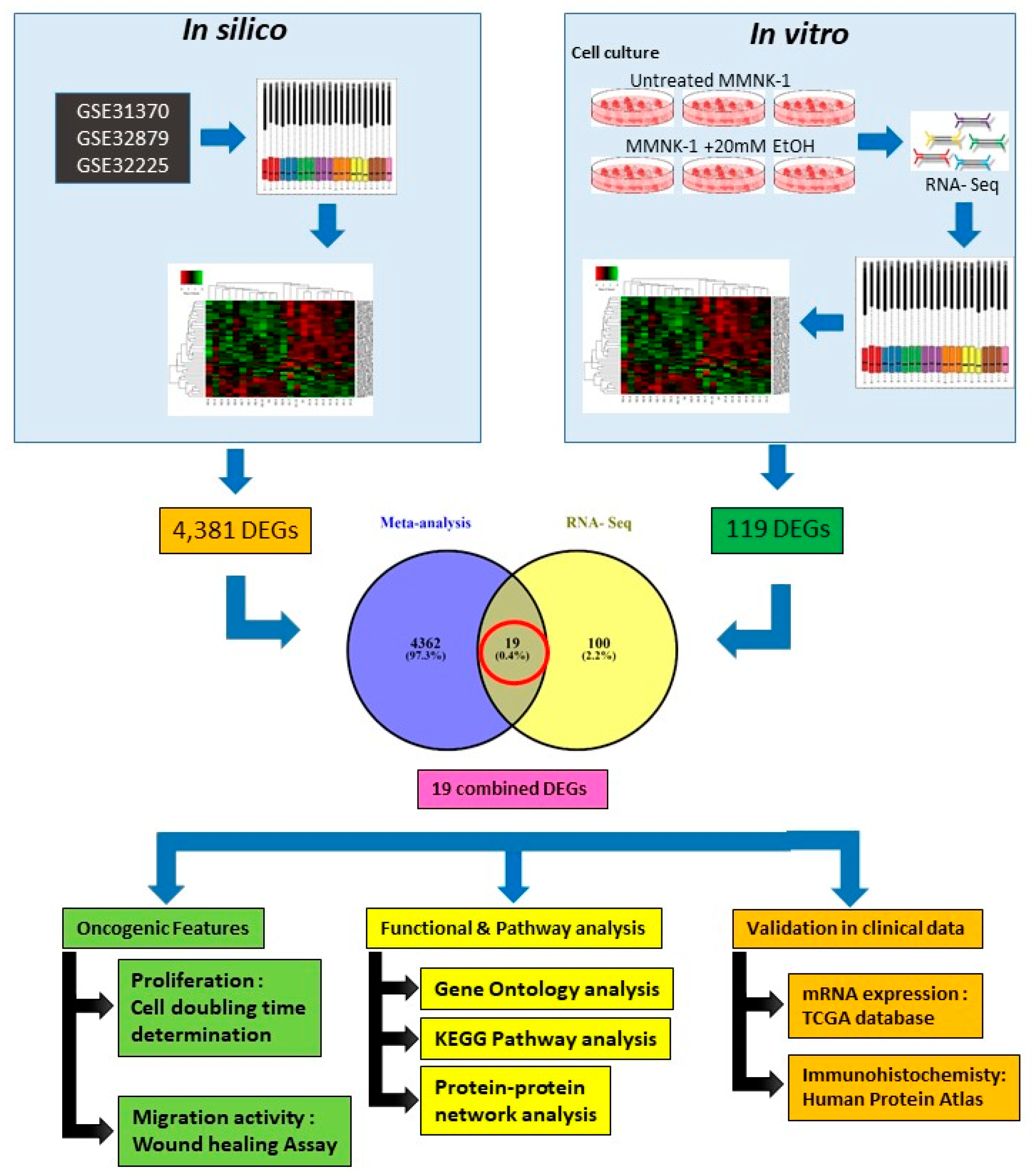
11]. The current knowledge of alcohol toxicity causing several cancers is well known. Here, as shown in
Figure 11, we examined the effects of prolonged exposure to alcohol on human normal cholangiocytes and extracted out the total RNA for RNA sequencing as in vitro transcriptomics model. On the other hand, we performed an in silico computational bioinformatics analysis between healthy subjects and CCA patients by using GEO datasets from our selection criteria. To observe low alcohol induces the development of CCA, the DEGs from in vitro and in silico were merged and presented in the combined DEGs. We further analyzed the GO and KEGG pathways for identification of biological function by using combined DEGs. The results demonstrated that pathways involving in cancer were the most significant pathways. From KEGG results, oncogenic features including proliferation and migration were proved by our in vitro experiments. In addition, the transcriptomics alterations presented some genes that were related to clinical data with CCA. The candidate genes were validated by using TCGA and HPA and could be used as potential biomarkers for early CCA. This study is the first report of a transcriptomics analysis on normal human cholangiocytes involving continuous exposure for 2 months with low concentration of alcohol (20 mM). We found that even relatively low doses of alcohol contribute (a) alterations in global transcription activity, (b) the oncogenic features, including proliferation and migration mediated through CCND-1 and MMP-2 expression and (c) a potential early biomarker for CCA patients.
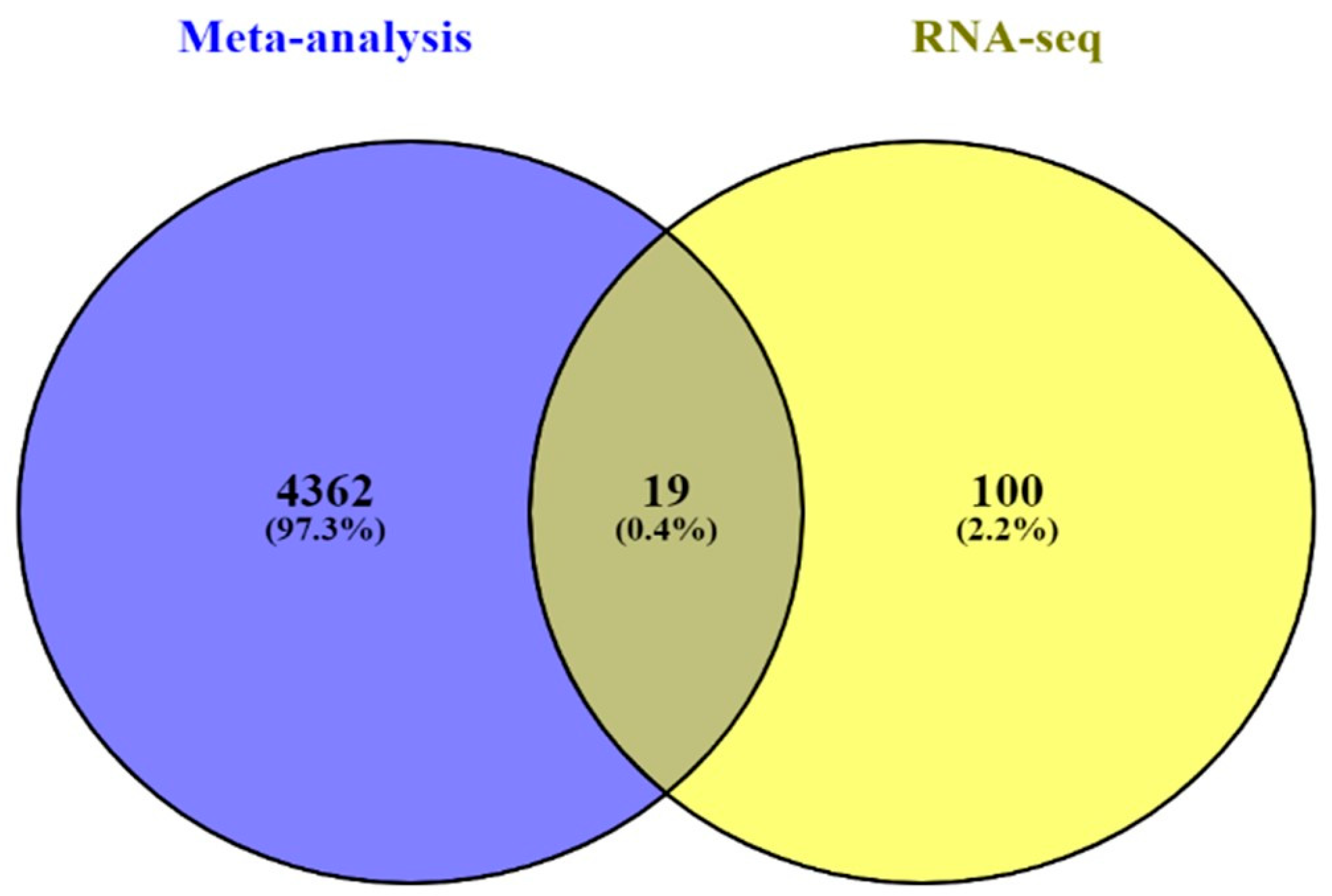
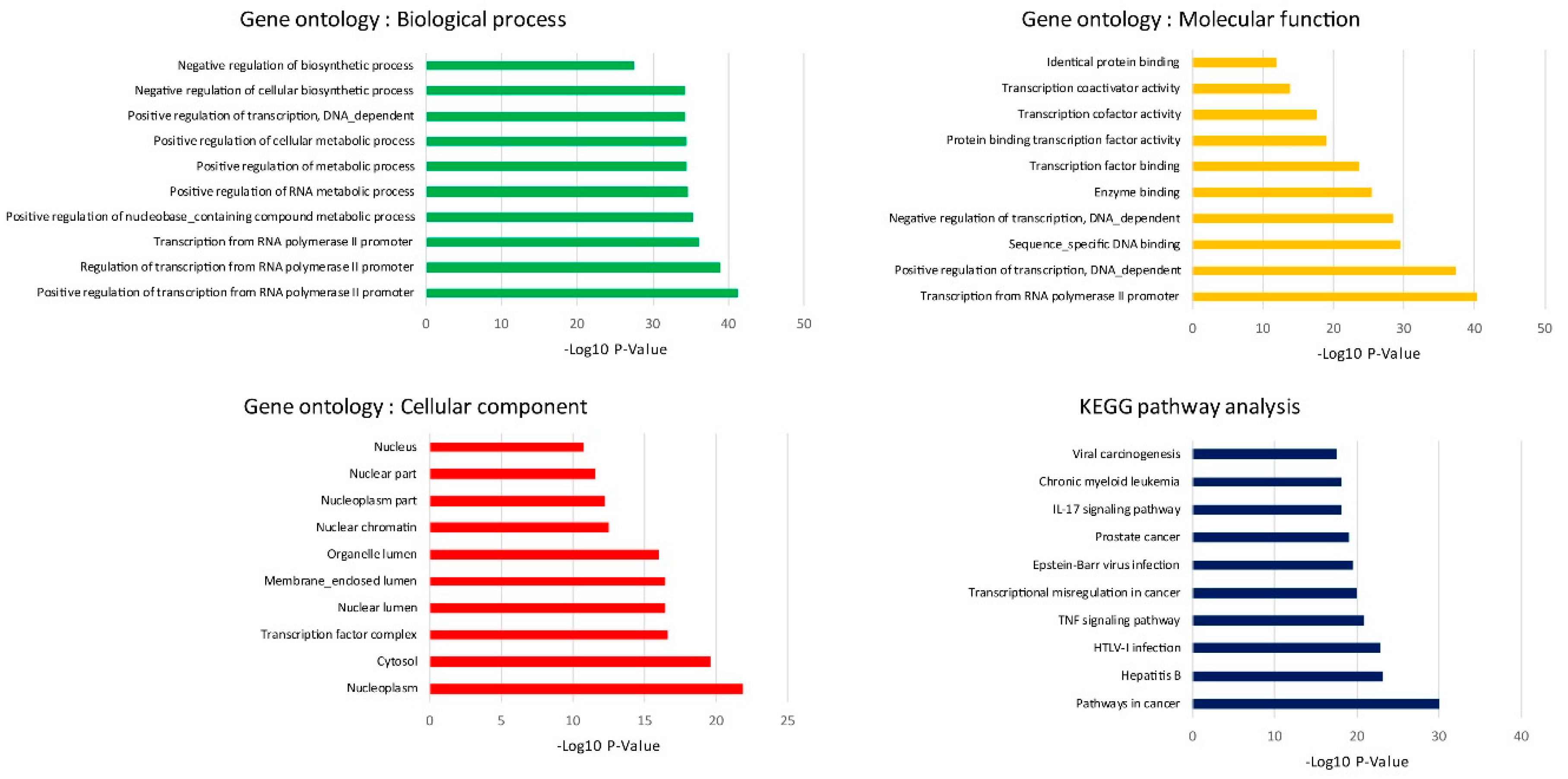
In silico and in vitro transcriptome data could offer accurate genome and transcription information especially in revealing affected biological pathways and processes that have previously not been considered. We identified 119 genes from in vitro (RNA-Seq) and 4381 genes from in silico experiments. There was a combined showing total of 19 genes. The enormous changes reflect not only cancer induction, but also many genes that are involved in the infection, transcription factor induction, and inflammatory responses. This is similar to previous reports showing that alcohol triggers oncogenicity, inflammation induction, and susceptibility to infection.
The biological process of GO analysis showed that the regulation of transcription from RNA polymerase II promoter was most significant. The RNA polymerase II core promoter is defined as a sequence that controls transcription initiation and epigenetics regulation. Previous reports have pointed out that chronic alcohol exposure in neurons resulted in the decrease CpG island methylation, resulting in reduced DNA methylation and relaxation of nucleosome packing [
12]. KEGG analysis has shown that pathways in cancer were the most enriched, and that they were followed by infection and inflammatory regulation. To our best knowledge, chronic alcohol consumption is an important risk factor in the development of different types of cancers. We also extended the oncogenic features investigation to prove the hypothesis from our KEGG analysis that even low concentrations of alcohol in repeated exposure stimulates oncogenesis. Similar to previous in vitro studies, 25 mM ethanol in MCF-12A cells induced growth and oncogenic effects and also caused transcriptional signature alterations [
13]. Moreover, multiple mechanisms have been identified as underlying the immunosuppressive effects of alcohol. These include a host of defensive systems in the respiratory and gastrointestinal tract, as well as all of the essential components of the immune system which is compromised by both direct effects of alcohol and alcohol-related dysregulation [
14]. Previous reports have demonstrated that, chronic alcohol exposure in utero interferes with normal T-cell and B-cell development which may increase the risk of multiple infections during childhood and adulthood. Alcohol’s impact on T cells and B cells also increases the risk of infections such as pneumonia, HIV infection, hepatitis C viral infections and tuberculosis. It also impairs responses to vaccinations against infections, exacerbates cancer risk, and interferes with delayed-type hypersensitivity [
15]. However, the molecular mechanisms underlying ethanol negative impact on the immune system remain poorly understood and further in vivo study is needed to prove this concept.
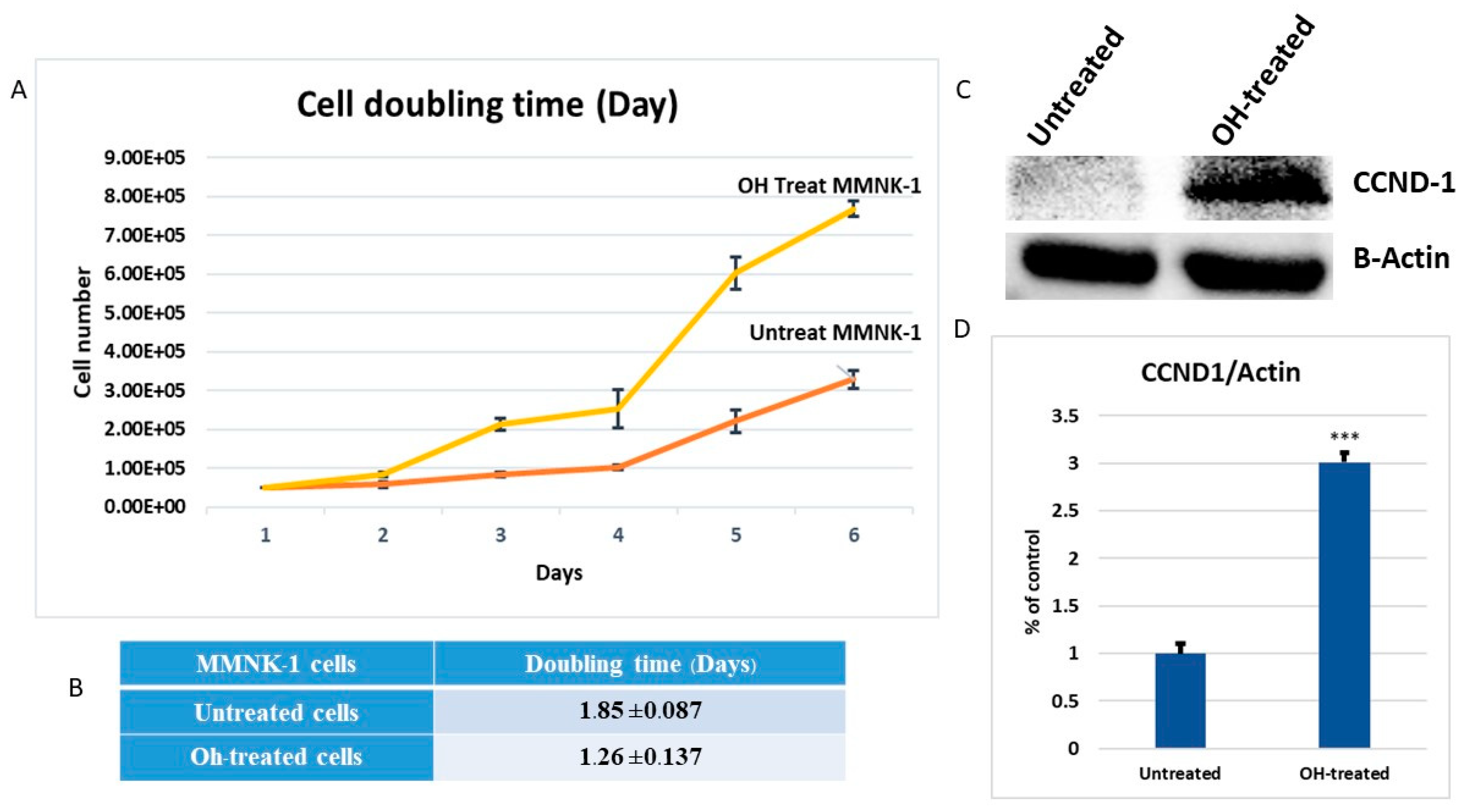
In a previous study, long-term alcohol exposure in low concentrations showed oncogenic features and global transcriptional changes in normal breast epithelial cells and normal human pancreatic ductal epithelial cells [
13,
16]. According to our study, results showed that the MMNK-1 cells with chronic alcohol exposure reduced their doubling time. They exhibited a strong proliferative effect and mediated through CCND-1 up-regulation. Long-term alcohol exposure also showed an induction of cell migration and cell motility enhancement effects via MMP-2 expression. CCND-1 interacts with cyclin-dependent kinase 4 (CDK4) or CDK6 to induce cell cycle progression from the G1 to S phase, promoting cell division or transformation. Aberrant expression of CCND-1 may cause an imbalance of the cell cycle, resulting in tumorigenesis [
17]. High expression of matrix metalloproteinase-2 (MMP-2) was found to be correlated with tumor progression and poor prognosis in a variety of carcinomas. In a previous study, up-regulations of MMP-2 were found to be a marker for increased tumorigenesis of human intrahepatic CCA [
18]. Invasion assay should be performed to support the effect of alcohol on MMP-2-associated invasiveness induction. However, our data suggests that low dose, chronic alcohol exposure contributes to oncogenic features that tend toward the development of cholangiocarcinoma. In addition, the expression of CCND1 and MMP-2 could be used as possible candidate molecular markers for early alcohol enhanced cell transformation. However, further studies should be done to confirm their contributions.
With protein-protein network interaction, the most 10 hub-genes were identified. They showed that Early growth factor-1 (
EGR-
1) was the highest centrality.
EGR-
1 (also known as nerve growth factor induced-A) is a zinc-finger transcription factor responsible for regulation of cell growth and proliferation.
EGR-
1, an immediate early gene, is rapidly and transiently induced. It responds to various stimuli, including cytokines and growth factors, as well as to environmental stress, chemical exposure and tissue damage [
19]. Our results demonstrate that
EGR-
1 mRNA was up-regulated after prolonged alcohol exposure to human normal cholangiocytes (
supplementary data). Similar previous reports indicate that early-life exposure to arsenic causes hypomethylation of
EGR-
1 promoter and also increases mRNA expression [
20].
EGR-
1 overexpression links to alcohol-induced liver disease and related to CCA may be used as a potential target for alcoholic liver disease diagnosis [
21]. Interestingly,
EGR-
1 alterations may have a key role in responsive alcohol exposure mechanisms, which provides an important strategy for the development of a new molecular therapy for the treatment of CCA.
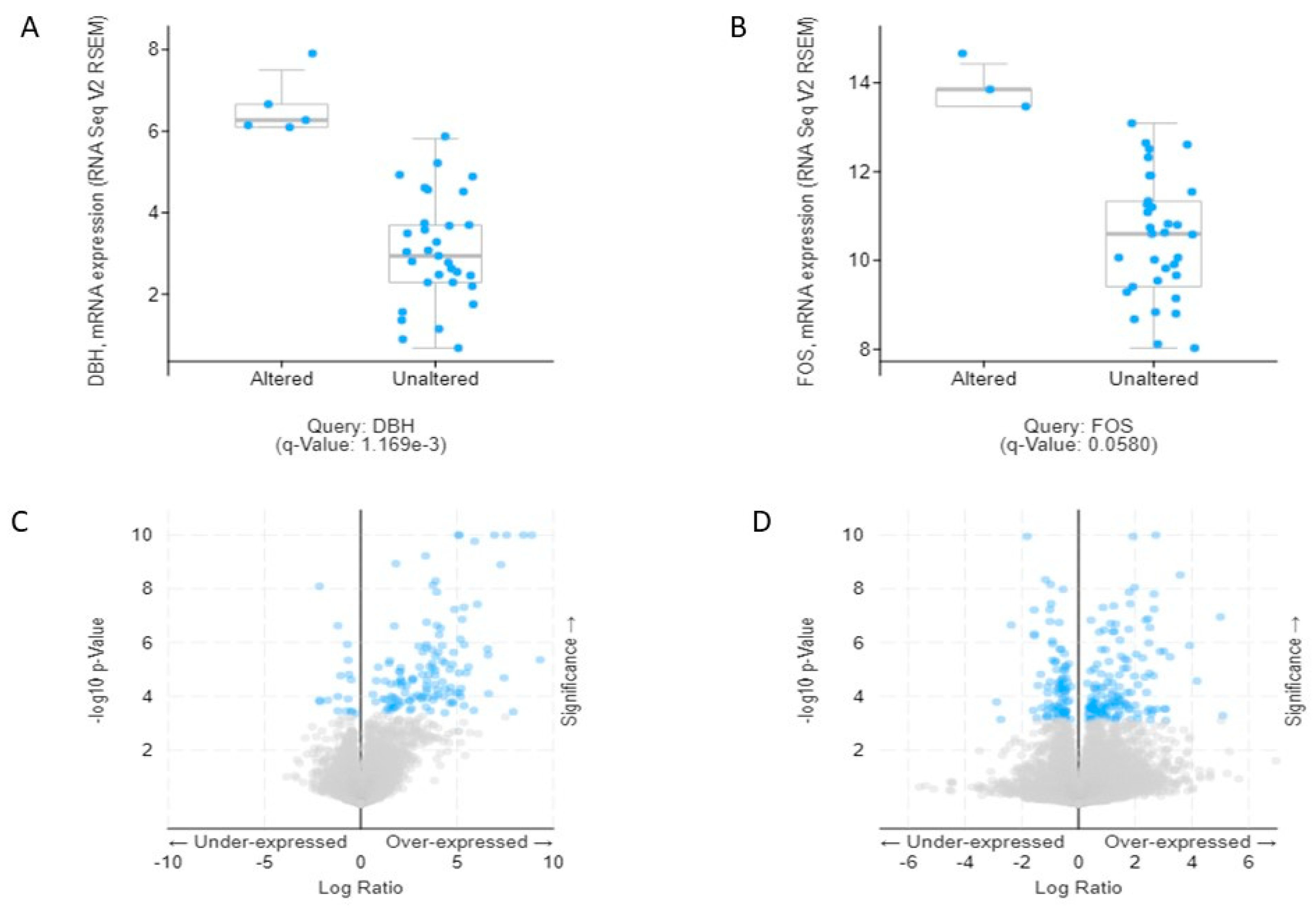
To observe the association of alcohol-induced CCA, we validated the 19 combined genes in The Cancer Genome Atlas (TCGA) database. These efforts made it clear that mRNA expression of
DBH and
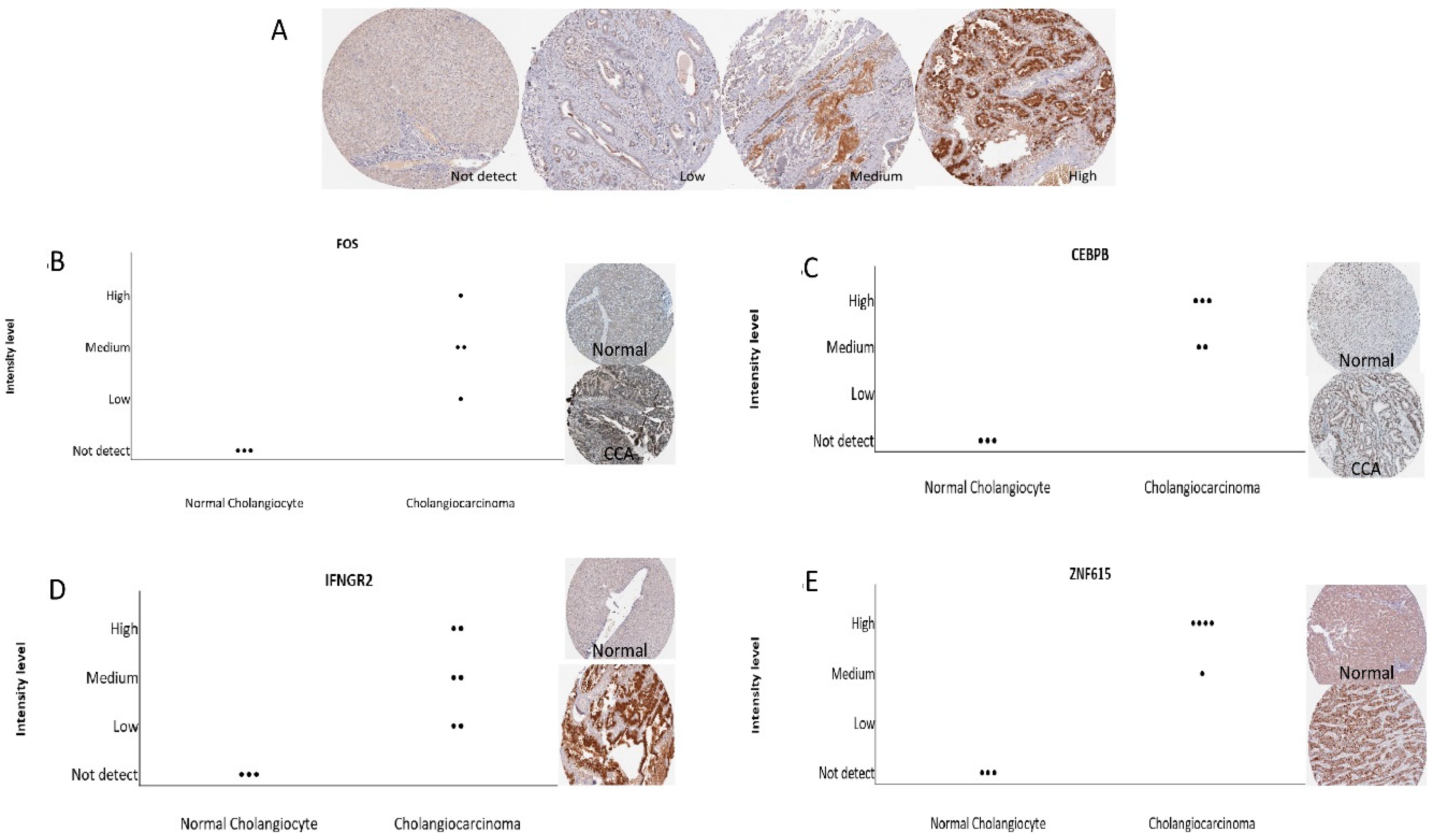
FOS are significantly associated and may play a crucial role in the aggressiveness of CCA. Additionally, we also verified combined genes in the Human Protein Atlas (HPA) database, which identifies of candidates for relevant biomarkers. Our immunohistochemistry results showed that
FOS,
INFGR2,
CEBPB, and
ANF615 expression are associated with the pathogenesis of CCA.
FOS is surprisingly associated with CCA pathogenesis in both databases.
FOS (
c-
fos) is an important proto-oncogene that has been shown encoding for growth factors, cell surface receptors, membrane proteins, phosphokinases, and nuclear proteins. The
c-
Fos protein forms a heterodimer complex. With the transcription factor
c-
Jun/
AP-
1 and
Fos/
Jun complex,
c-
Fos has the ability to bind to the regulatory elements of other genes. Chronic alcohol consumption leads to decrease retinoic acid by acceleration of retinoic acid metabolism, resulting in overexpression of the Activator protein 1 (
AP1) gene associated with an increase in their proteins
c-
jun and
c-
fos [
22]. Eventually, alcohol leads to increased CCND-1 expression, which is associated with hyperproliferation in the liver [
23]. Thus, retinoic acid deficiency due to chronic alcohol exposure is associated with acceleration of carcinogenesis [
24]. In a previous in vivo study,
c-
Fos overexpression appeared to be associated with high cellular proliferating activity and cell transformation in hamster cholangiocarcinogenesis [
25]. In addition, a previous report showed that decreased expression levels of
IFNGR2 are a risk factor for tumorigenesis in humans and may involve IFN-γ dependent cancer immunosurveillance [
26]. Meanwhile, there is no current publication which shows the important role of
DBH,
CEBPB and
ZNF615 in CCA. However, the
FOS expression may be used as a potential early biomarker in alcohol induced CCA. However, further experimental in vivo studies are needed to verify our in vitro and in silico results.
4. Materials and Methods
4.1. Selection and Identification of Gene Expression Dataset for Meta-Analysis
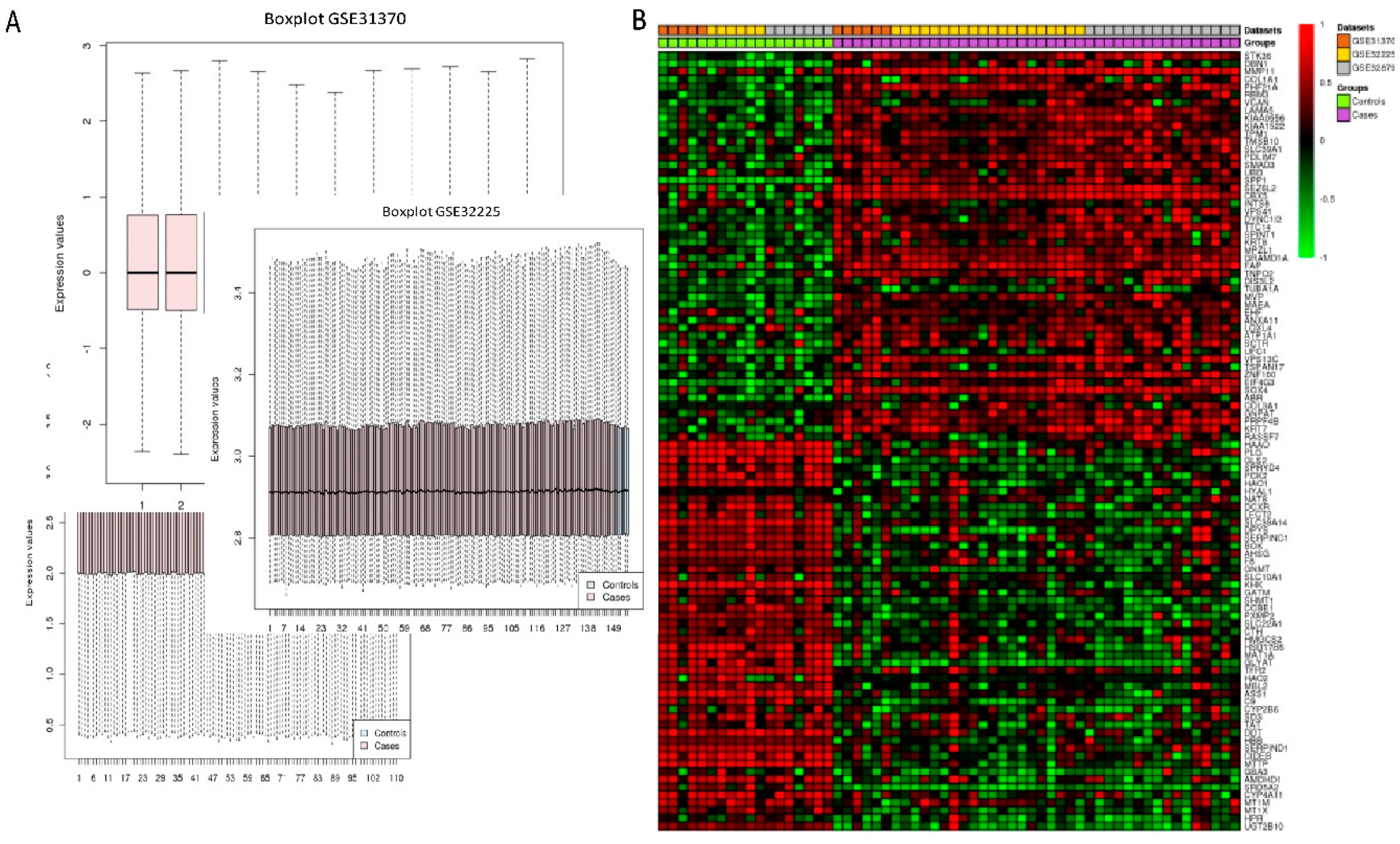
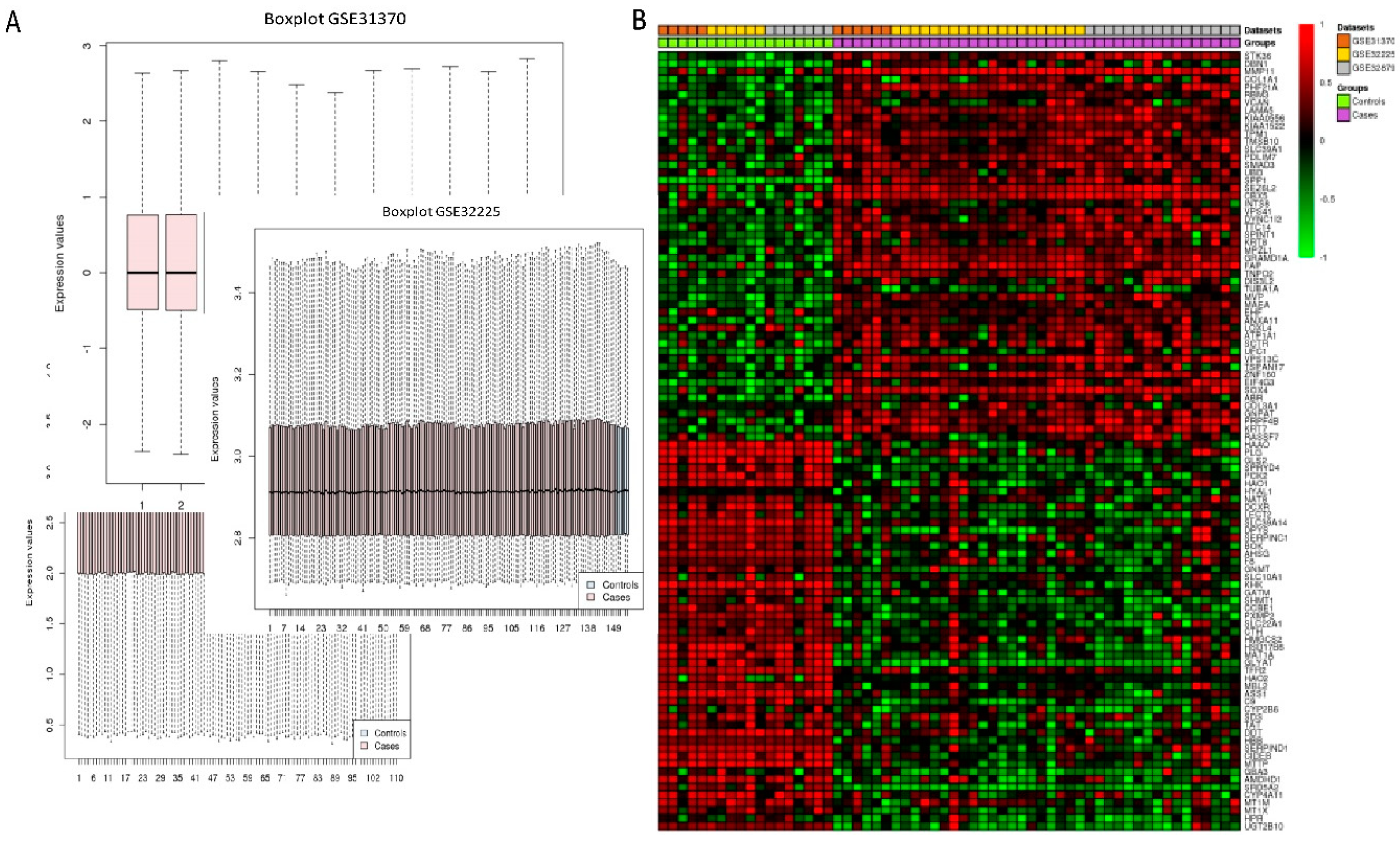
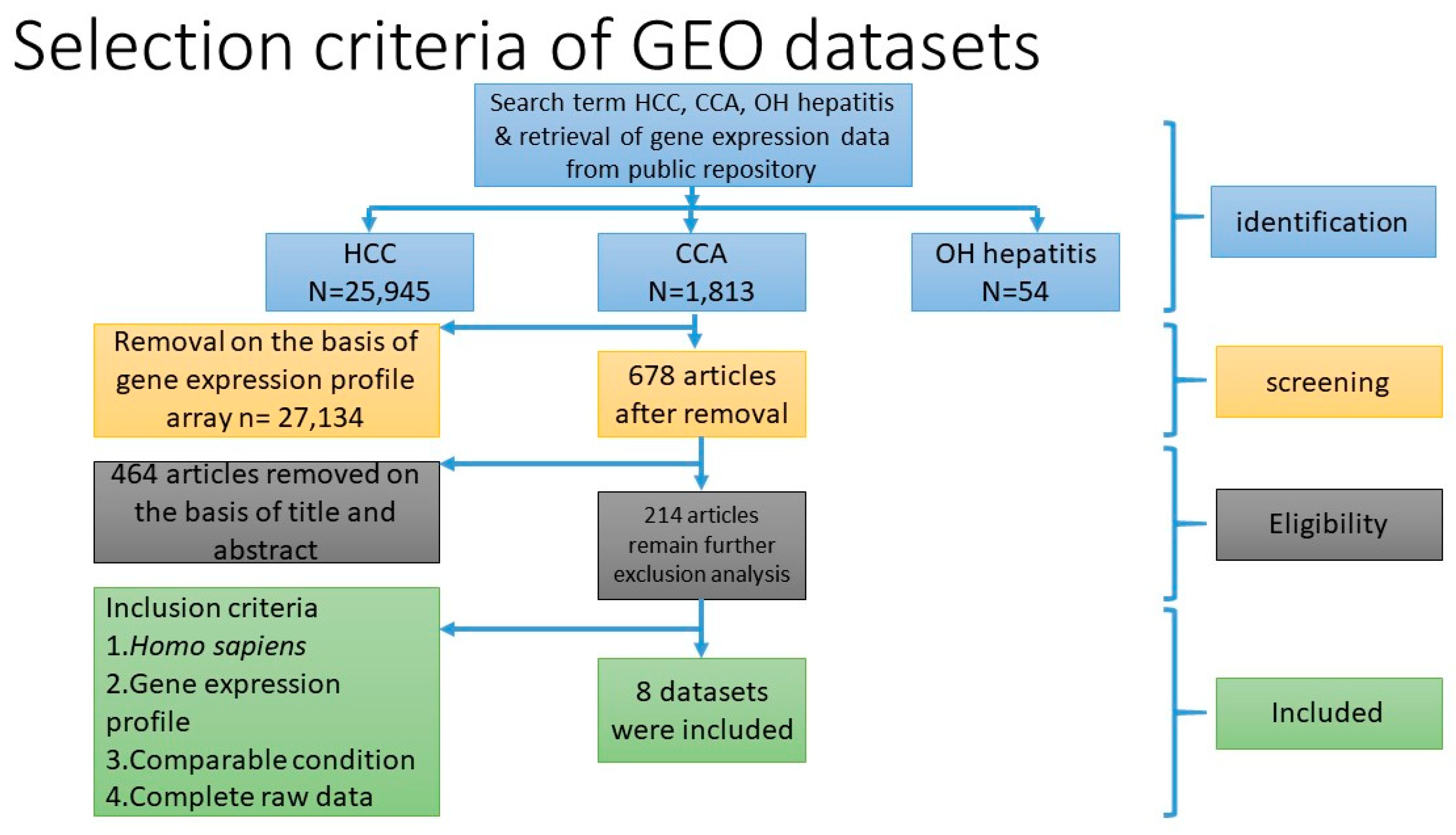
Three microarray datasets available on Pubmed database were selected according to our selection criteria. The key word used was “cholangiocarcinoma”. Gene Expression Omnibus (GEO): GSE31370, GSE32879, and GSE32225 were analyzed in this study. Information was extracted from each study, including accession number, disease, microarray platform, number of cases, and controls and references. Inclusion criteria were set and strictly identified for selection of dataset, i.e., human case and control study, gene expression profile, comparative condition, and complete raw data as shown in
Figure 12. Quality controls from three studies were performed with R package, using ImaGEO online tool [
27]. The results showed the distribution of expression values in boxplots and the missing values for each dataset.
4.2. DEGs Identification from In Silico Bioinformatics Meta-Analysis
Three microarray data sets of the diseases were selected for gene expression analysis using ImaGEO, a web interface, to integrate and perform meta-analysis. Data was retrieved and loaded by GEO IDs and processed by using GEO query package. As shown in
Table 3, meta-analysis containing three studies were performed in Meta DE R package; they were effect size (EF), Fisher’s test, and adjusted
p-value. The results are displayed in an interactive table with the significant genes, gene symbol, gene name,
p-value, adjusted
p-value, and fold change value.
4.3. Cell Culture and Treatment
Immortalized normal human cholangiocyte MMNK-1 cells were purchased from the Japan Collection of Research Bioscience (JCRB) cell bank, Osaka, Japan. MMNK-1 cells were cultured in Dulbecco’s Modified Eagle’s Medium (DMEM) containing 10% fetal bovine serum (JR scientific, Inc, Woodland, CA, USA), 2 mM
l-Glutamine, 100 U/mL penicillin and 100 µg/mL streptomycin (Gibco, Carlsbad, CA, USA), and maintained at 37 °C in 5% CO
2 humidified atmosphere. For alcohol exposure, MMNK-1 cells were treated with alcohol in fresh medium 24 h after initial seeding. We chose alcohol treatment concentration at 20 mM to represent chronic alcohol exposure, as a previous study described where the chronic alcohol treatment at 20 mM for nine days could alter cellular functionality of rat astrocyte cell culture [
28]. For information, the 20 mM in vitro alcohol concentration approximates a 100 mg/dL blood alcohol level, which is achieved in vivo after a dose of moderate drink and is the upper range of blood alcohol concentration in most U.S. jurisdictions [
29]. The media with ethanol were replaced every 24 h with fresh media containing the 20 mM ethanol concentration. The cells were treated for 60 days (2 months) and trypsinized 80% twice weekly when archived. The duration of long-term alcohol exposure for 60 days was referred from previous established long-term alcohol exposure model [
30].
4.4. Cell Viability Assay
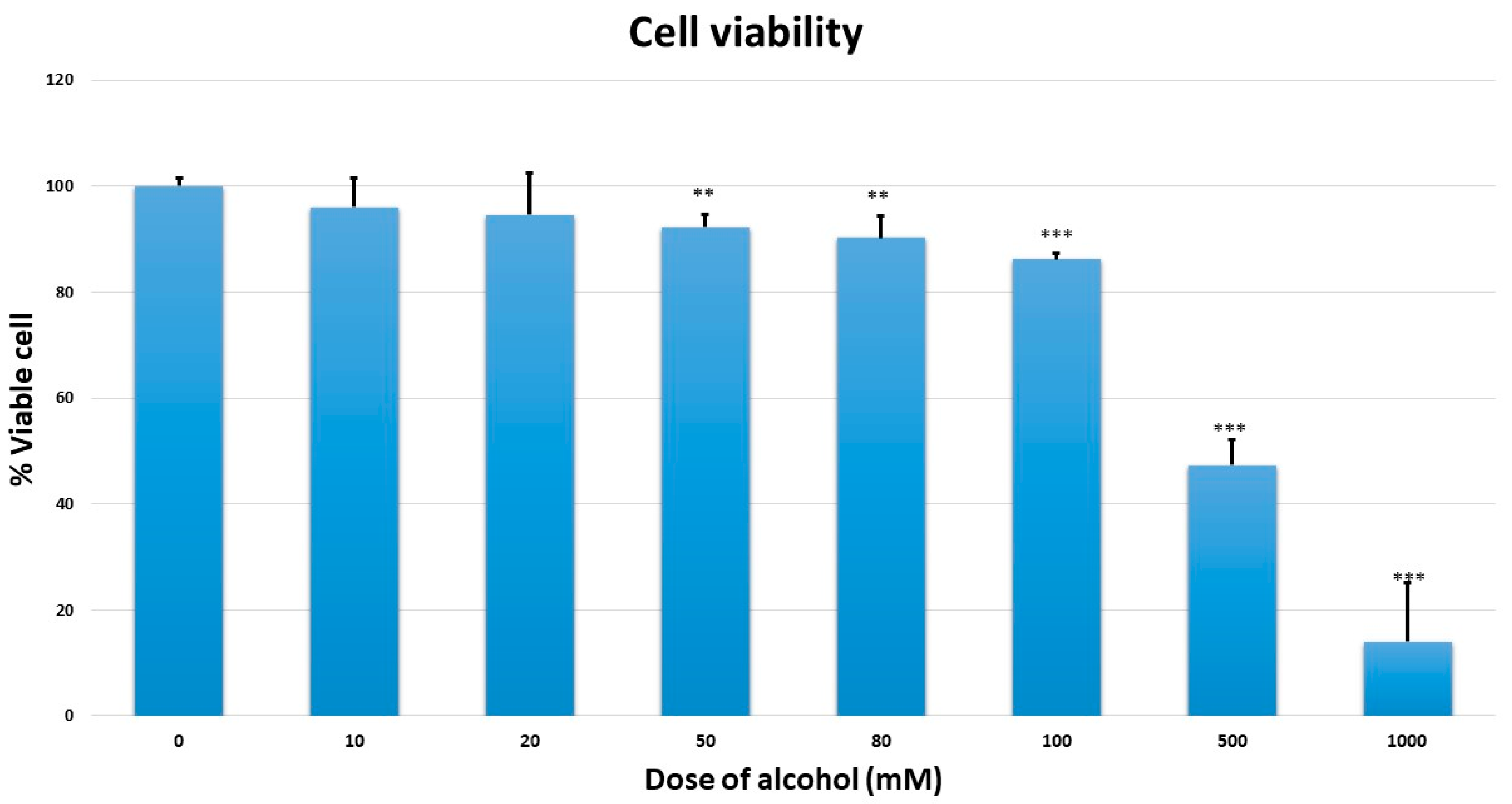
Cell viability assay was measured by a quantitative colorimetric assay (MTT) (1-(4,5-Dimethylthiazol-2-yl)-3,5 diphenyl (formazan) (Sigma-Aldrich, St. Louis, MO, USA) showing the mitochondrial activity of living cells. MMNK-1 cells were seeded in 96-well plates (1 × 103 cells/well) and cultured overnight for cell attachment. The cells were exposed to 0, 10, 20, 50, 80, 100, 500, and 1000 mM ethanol for seven days. The medium, with and without ethanol, was changed every day. At the end of incubation time, the medium was removed. MTT stock solution was prepared as 5 mg/mL in phosphate buffer saline (PBS). MTT working solution in complete medium (final concentration 0.5 mg/mL) at 100 µL was added to each well and cells were incubated in an atmosphere humidified at 5%, with CO2 at 37 °C. After incubation for 4 h, the supernatant was removed, the dark blue of formazan crystal was dissolved in 100 µL dimethyl sulfoxide (DMSO; Sigma-Aldrich, St. Louis, MO, USA), and the plates were shaken for five minutes. The optical density of dissolved formazan crystal was read at 570 nm, with reference wavelength at 650 nm, using a SpectroMax M3 microplate reader (Molecular Devices, Sunnyvale, CA, USA).
4.5. RNA Extraction
The total RNA of each sample was extracted using RNeasy® PlusMini kit (Qiagent, Hilden, Germany), and was qualified and quantified by Agilent 2100 Bioanalyzer (Agilent Technologies, Palo Alto, CA, USA), NanoDrop 2000 (Thermo Fisher Scientific Inc., Waltham, MA, USA) and 1% agarose gel. Total RNA at 1 µg with a RIN (RNA Integrity Number) value above seven was used for the following library preparation.
4.6. RNA Sequencing and Quality Control
Next generation sequencing library preparations were constructed according to the manufacturer’s protocol (NEBNext®UltraTM RNA Library Prep Kit for Illumina®). The poly(A) mRNA isolation was performed using NEBNext Poly(A) mRNA Magnetic Isolation Module (NEB)or Ribo-Zero rRNA removal Kit (Illumina, San Diego, CA, USA). The mRNA fragmentation and priming were then performed by using NEBNext First Strand Synthesis Reaction Buffer and NEBNext Random Primers. First strand cDNA was synthesized using ProtoScript II Reverse Transcriptase, and the second-strand cDNA were synthesized using Second Strand Synthesis Enzyme Mix. The purified double-stranded cDNA by AxyPrep Mag PCR Clean-up (Axygen Biosciences, Central Avenue, Union City, CA, USA) was then treated with End Prep Enzyme Mix to repair both ends and to add a dA-tailing in one reaction, followed by a T-A ligation to add adaptors to both ends. The size selection of Adaptor-ligated DNA was then operated by using the AxyPrep Mag PCR Clean-up (Axygen Biosciences, Central Avenue, Union City, CA, USA), and fragments of ~360 bp (with the approximate insert size of 300 bp) were recovered. Each sample was then amplified by PCR for 11 cycles, using P5 and P7 primers, with both primers carrying sequences which can anneal with flow cell to perform bridge PCR, and P7 primer, carrying a six-bases index allowing for multiplexing. The PCR products were cleaned up using AxyPrep Mag PCR Clean-up (Axygen Biosciences, Central Avenue, Union City, CA, USA), and validated using an Agilent 2100 Bioanalyzer (Agilent Technologies, Palo Alto, CA, USA), and quantified by Qubit 2.0 Fluorometer (Invitrogen, Carlsbad, CA, USA). Then, libraries with different indices were multiplexed and loaded on an Illumina HiSeq instrument according to manufacturer′s instruction (Illumina, San Diego, CA, USA). Sequencing was carried out using a 2 × 150 bp paired-end (PE) configuration; image analysis and base calling were conducted by the HiSeq Control Software (HCS) + OLB + GAPipeline-1.6 (Illumina, San Diego, CA, USA) on the HiSeq instrument. The sequences were processed and analyzed by Vishuo Biomedical, Singapore. In order to remove technical sequences, including adapters, polymerase chain reaction (PCR) primers, or fragments thereof, and quality of bases lower than 20, pass filter data of fasta format will be processed by Trimmomatic (v0.30) to obtain high quality clean data.
4.7. DEGs Identification from RNA-Seq
In the beginning, transcripts in fasta format were converted from known gff annotation files and indexed properly. Then, with the file as a reference gene file, HTSeq (v0.6.1) was estimated gene and isoform expression levels from the pair-end clean data. Differential expression analysis was conducted by using the DESeq Bioconductor package, a model based on the negative binomial distribution. After adjusted by Benjamini and Hochberg′s approach for controlling the false discovery rate, the
p-value of genes was set at <0.05 to detect differential expressed genes [
31]
4.8. Functional and Pathway Analysis
The DEGs from in silico and in vitro were combined and used for further integrated biological function analysis by using Venn diagram viewer. To investigate enriched functionally associated significant genes, Gene ontology (GO) analyses, including biological functions, molecular processes and cellular components, were performed using the Database for Annotation, Visualization and Integrated Discovery (DAVID;
https://david.ncifcrf.gov/) version 6.8 [
32]. The Kyoto Encyclopedia of Genes and Genomes (KEGG;
http://www.genome.jp/kegg/) pathway analysis is an integrative data mining tool for the biological pathway interpretation of genome sequences and other high-throughput data. The pathway analysis was performed for enriched significant pathway [
33]. A
p-value <0.05 was set as the cut-off criterion.
4.9. Protein-Protein Interaction Network and Hub-Gene Identification
To explore proteins interaction networks of Differentially Expressed Genes (DEGs), a protein network was constructed by using NetworkAnalyst. NetworkAnalyst is an integrative online tool which is designed to support integrative gene expression analysis (
https://www.networkanalyst.ca) [
34]. The lists of DEGs were uploaded into the web-based server of NetworkAnalyst. Network construction was strictly set to contain only the original seed proteins. NetworkAnalyst provided betweenness centrality to measure the number through of node and node. The highest betweenness represents the critical point of the protein network.
4.10. TCGA Validation Using Combined DEGs
The mRNA expression of CCA (TCGA Provisional) was selected from biliary tract cancer (
https://www.cbioportal.org/). Data were available for 51 samples. The total combined DEGs were applied for mRNA enrichment. The
p-value cut-off was set at <0.05. The frequency dot plot was summarized by using cBioportal [
35].
4.11. Immunohistochemistry Human Protein Atlas Validation Using Combined DEGs
The Human Protein Atlas contributes a large amount data on transcriptomics and proteomics in specific human tissue organs. The database is composed of a tissue atlas, a cell atlas and a pathology atlas (
https://www.proteinatlas.org/) [
36]. The combined DEGs and the differences in antibody-staining levels of cancer tissue samples and normal samples (cholangiocarcinoma VS. normal) were assessed, based on the available immunohistochemistry based staining levels in the HPA project.
4.12. Immunoblotting
At the end of chronic alcoholic treatment, the cells were lysed in lysis buffer containing 10 mM Tris (pH 7.4), 150 mM NaCl, 1% Triton X-100, 1 mM PMSF, 1 mM Na3VO4, 20 mM NaF and 1× protease inhibitor cocktail set I (Calbiochem, Germany). The cell lysates were then sonicated and incubated for 30 min at 4 °C before centrifuged 16,000× g for 15 min at 4 °C. The concentration of total protein was determined by using Bradford reagent (Bio-rad, Hercules, CA, USA). The 50 µg of protein was run onto a 7.5% SDS-polyacrylamide gel in a Mini-Protein II system (Bio-rad, Hercules, CA, USA). The separated protein was transferred onto nitrocellulose membrane using a Bio-rad mini Trans-Blot cell. The nitrocellulose membrane was incubated with blocking buffer containing 5% non-fat dry milk in a TBST buffer (10 mM Tris-HCl pH 8.0, 150 mM NaCl and 0.05% Tween-20) for 1 h at room temperature and followed by overnight incubation with primary antibodies at 4 °C. The antibodies against Cyclin D-1 (1:1000), β-actin (1:20,000) and MMP-2 (1:1500) were purchased from Cell Signaling Technology Inc. The membrane was washed three times with TBST for 10 min, and incubated with secondary antibodies conjugated with horseradish peroxidase (HRP) for 2 h. HRP conjugated secondary antibodies were as follow anti-rabbit IgG from Cell Signaling Technology Inc., anti-goat IgG from R&D system Inc, or anti-mouse IgG from Bio-Rad Laboratories, Inc. The protein bands were visualized using enhanced chemiluminescence (ECL) (GE Healthcare, UK). The intensity of bands was quantified by Image Quant TL software (GE Healthcare, UK).
4.13. Cell Doubling Time Determination
After chronic exposure to alcohol, the cells were seeded at 3 × 103 cells on 6 wells plate culture dishes. After cell adherences, the cells were counted every 24 h for 6 days. The cells were trypsinized and stained with trypan blue. The viable cells were counted using Countess® II FL Automated Cell counter (Thermo Fisher Scientific, UK). The doubling time was calculated from the cell group curve over 6 days using the following equation: Doubling time = (Final time − initial time) × (Log2/ log (final cell number) − log (initial cell number))
4.14. Wound Healing Assay
The motility of MMNK-1 after 60 days treatment with alcohol was assessed by using wound healing assay. The cells were seeded in 6 wells plate and grown to confluence. After 24 h, the complete medium was removed and replaced with serum-free medium to reduce the proliferative effect. Each well was scratched with a sterile pipette tip. After the incubation time at 0, 24, or 48 h, the serum-free medium was removed and washed suspended cells by PBS. The width of the denuded areas were measured. Wound closure was calculated as the percentage of the closed area of the initial width.
4.15. Statistical Analysis
Descriptive statistical analysis was generated for quantitative data and presented as mean ±SD. The mean ±SD. was calculated from 3 triplicates per sample. The difference between the 2 groups was determined by Student’s T test and p-value < 0.05, was considered significant.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}